
Abstract
Assessing carbon (C) capture and storage potential by the agroforestry practice of windbreaks has been limited. This is due, in part, to a lack of suitable data and associated models for estimating tree biomass and C for species growing under more open-grown conditions such as windbreaks in the Central Plains region of the United States (U.S.). We evaluated 15 allometric models using destructively sampled Pinus ponderosa (Lawson & C. Lawson) data from field windbreaks in Nebraska and Montana. Several goodness-of-fit metrics were used to select the optimal model. The Jenkins’ et al. model was then used to estimate biomass for 16 tree species in windbreaks projected over a 50 year time horizon in nine continental U.S. regions. Carbon storage potential in the windbreak scenarios ranged from 1.07 ± 0.21 to 3.84 ± 0.04 Mg C ha−1 year−1 for conifer species and from 0.99 ± 0.16 to 13.6 ± 7.72 Mg C ha−1 year−1 for broadleaved deciduous species during the 50 year period. Estimated mean C storage potentials across species and regions were 2.45 ± 0.42 and 4.39 ± 1.74 Mg C ha−1 year−1 for conifer and broadleaved deciduous species, respectively. Such information enhances our capacity to better predict the C sequestration potential of windbreaks associated with whole farm/ranch operations in the U.S.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Agroforestry systems represent an appealing management strategy to increase the ecological and environmental services obtained from agricultural lands (Rani et al. 2008). Included in these services are the capacity of these practices to mitigate greenhouse gases (GHGs) by sequestering carbon (C) while providing climate adaptation services that may add resiliency to our food systems and agricultural lands (FAO 2010; Schoeneberger et al. 2012).
In agroforestry systems, trees and shrubs can increase the amount of C stored above- and belowground within agricultural operations compared to a monoculture crop field or pasture (Sharrow and Ismail 2004; Kumar and Nair 2011). These systems may contribute to reducing atmospheric carbon dioxide (CO2) while maintaining and potentially increasing soil productivity (Nair et al. 2009). From these systems, windbreaks planted on just 3–5 % of agricultural lands, may reduce the emissions of CO2 and nitrate (NO3) from farming (Brandle et al. 1992) while increasing crop yields (Kort 1988). Owing to the characteristics of this agroforestry practice to adapt to and mitigate climate change, windbreaks have been included as one of the tools in the Climate Smart Agriculture Approach (FAO 2010).
Designing field windbreaks to address the various issues from crop and livestock protection to GHG mitigation and other services is relatively straightforward. The resulting biological, structural, spatial and environmental characteristics of their components, however, generate high levels of complexity that make assessments of actual and potential functions difficult (Raintree 1986). Extrapolation of results across individual plantings, settings and regions can be misleading (Nair 2011). Likewise, the lack of reliable biomass data from agroforestry systems (Jose et al. 2004) makes it difficult to approximate windbreak contributions in C budgets. Currently, there are several efforts to develop consistent approaches to estimate C contributions of different management activities in agricultural operations. They range from compilation of accepted methodologies (Ogle et al. 2014) to incorporation into tools like COMET-Farm (http://cometfarm.nrel.colostate.edu/), a voluntary C reporting tool. Inclusion of agroforestry practices, like windbreaks, in these efforts requires that consistent and valid methods be developed that estimate the C storage potential of windbreaks.
The Forest Inventory and Analysis (FIA) program of the U.S. Department of Agriculture, Forest Service (www.fia.fs.fed.us) provides an extensive and publicly available database (http://apps.fs.fed.us/fiadb-downloads/datamart.html) for use in determining the extent, condition, volume, and growth of forestlands in the U.S. (USDA-FS 2014). This inventory may serve as a baseline to obtain above- and belowground biomass and C storage potential for windbreak tree species. The main objectives of this study were to: (1) assess the suitability of various allometric models for estimating tree biomass under the more open-grown conditions associated with windbreaks and (2) develop a methodology for estimating the C storage potential of windbreaks on agricultural lands in the U.S.
Materials and methods
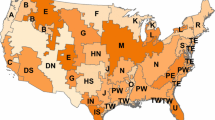
This study was carried out using inventory data from the FIA program, peer-reviewed literature and relevant allometric models for the major U.S. ecoregions (McNab et al. 2005) (Fig. 1) where windbreak use was applicable. We selected 23 states of the continental U.S. and grouped them into nine regions (Fig. 2) based on three main criteria: (1) located in almost identical Major Land Resource Areas (MLRA) (USDA-NRCS 2006), (2) sharing the same ecoregions (Bailey 1995; USDA-FS 2014), and (3) having trees periodically re-measured in the FIA data set (USDA-FS 2015).

Major ecoregions encompassing different sampled states

Distribution of ecoregions within regions selected for estimating carbon storage potential for windbreaks in the United States. The regions without color (hollow) were not studied
Forest inventory data
We selected 16 tree species as suitable for windbreaks in the different regions and grouped them into two categories: conifer and broadleaved deciduous (Table 1). These tree species were queried in the FIA database (FIADB version 5.1) dataset. The FIA inventory design, description of variables, field data collection, subsequent manipulation, uncertainties and the FIADB are available at http://fia.fs.fed.us/library/database-documentation/ (USDA-FS 2015). This dataset included 276,849 tree records from 30,095 plots for the selected tree species in the identified ecoregions.
Tree and site specific variables included in this study were current and previous diameter at breast height (dbh), 1.30 m, tree height (ht), and stand age as a proxy for tree age. These data were used to obtain the mean annual increment in diameter (MAID) as
where t.dia symbolizes current tree diameter, t.prevdia denotes the previous tree diameter, and ds.remper signifies the number of years between measurements. The resulting datasets were used to predict biomass stored in the respective tree species. The dataset was then randomly subsampled once within the tree age range of 10–50 years.
Estimation of the tree biomass
The tree MAIDs were converted into biomass using species-specific allometric models. The models were selected according to the approximate age of the trees, diameter range, and component measured. In some cases, when a specific model did not estimate belowground biomass, the ratio (2) from Jenkins et al. (2003) was used
where ratio refers to the ratio of root component to total aboveground biomass (dry weight) for trees 2.5 cm dbh and larger and β 0 and β 1 identify the regression coefficients.
Case study with Pinus ponderosa
Eighteen P. ponderosa were destructively sampled from windbreaks located in Montana and Nebraska. Based on stem diameter distribution, trees of different dbh and representative for the mean of their diameter classes and covering a range of heights were selected for the destructive study of aboveground biomass. Samples taken from the stem at different lengths (dbh, mid-stem, crown base) and branches (base, mid and top) were weighed, labelled and packed for transport. Dry mass of these components were determined after oven-drying all samples at 65 °C, to a constant weight. Tree biomass was recorded as the summed dry weight of each tree component.
Twelve generic models from Spurr (1965), Prodan (1968) and Loetsch et al. (1973), two new models (one based on dbh and the other on dbh and height) and Jenkins’ et al. coefficients for pines (Table 2) were used to fit the relationships between biomass and diameter/height of the P. ponderosa samples.
Although dbh is currently used for most local or regional biomass estimations, some researchers have suggested that both dbh and height should be included for larger-scale application (e.g., Honer 1971; Crow 1978; Domke et al. 2012). As such, we included height in our analysis of estimating biomass in these open-grown trees. The new models used in this study were called “this study model 1” and “this study model 2” based on dbh and dbh and height, respectively. When models with a log-transformed response variable were present, predicted outputs were back-transformed with a correction factor (Eq. 3) following Sprugel (1983):
where CF denotes correction factor, e indicates natural logarithm base equal to 2.718282 and SEE corresponds to standard error of the estimate. The CF corrects for bias when log biomass estimates are back transformed to the original arithmetic units.
Statistical analysis
To detect differences in tree growth, MAIDs per tree species were compared among ecoregions within geographic regions using one-way ANOVA and the adjusted Tukey test. When significant differences appeared among ecoregions, we selected the ecoregion with the “mid-point” value for each species to avoid under- and overestimation. The MAIDs were converted to biomass by using generic allometric models. The statistical analysis used SAS 9.3 (SAS Institute Inc. 2014).
The biomass observations from the 18 destructively sampled P. ponderosa trees (Table 3) were evaluated against the biomass predictions from the 15 models using the Model Selection Analysis (MSA) procedure (Kutner et al. 2004). All models were fit in their basic form and plotted to provide a visual assessment of the relationships between biomass and the independent variables. Least-square regression models were developed for individual variables, such as dbh and height, using several curve forms, including simple linear, second-order polynomial, and logarithmic models. These regression models were tested for significance on the basis of a “t” statistic (p < 0.05), linearity, homoscedasticity, normality and outliers (Kutner et al. 2004; Chatterjee and Hadi 2006). Constant variance was tested using a Breusch–Pagan test (BP) (Kutner et al. 2004). Finally, a Box-Cox transformation was applied to determine the power of variable response transformation for each regression model (Box and Cox 1964). The regression analysis used R 3.11 (CRAN 2014).
Allometric models: dbh-height based
Power functions (Eq. 4) were used for the log-transformed variables (Fahey and Knapp 2007):
where Y is oven-dry mass (kg), X is a tree dimension variable (dbh or ht), a, and b are parameters and ε is a random normally distributed additive error term with constant variance (Picard et al. 2012). The power function was derived as log-model (Eq. 5) and used in some generic models:
where bm is the response variable of the total aboveground biomass, dbh is the explanatory variables for dbh and a and b are the parameters of the model.
The models were evaluated with Akaike’s information criterion (AIC), predicted residual sum of squares (PRESS), adjusted R2, and variance inflation factor (VIF). The Furnival index (FI) (Furnival 1961) model (Eq. 6) was used to compare models with different response variables following Parresol (1999):
where f′ (Y) is the first derivative of the transformation function with respect to Y; the square bracket ([·]) is the geometric mean and MSE is the mean square error of the fitted model.
The type of transformation required for different cases of the response variable are displayed in Table 4. Models with lower AIC, RSE, PRESS, VIF and FI and higher adjusted R2 values were selected for further evaluation. These information criteria prevented us from under- and over-fitting models (Nakamura et al. 2005) while variable transformation allowed us to adjust the residuals for normality, linearity and homoscedasticity, and to choose the most parsimonious model (Kutner et al. 2004). Generally, the information criteria analyzed selected the models with best fit which were further validated.
Validation process
This process was based on an approach by Dietz and Kuyah (2011) to develop allometric models using the 18 P. ponderosa trees. The models were developed as follows: from the 18 trees, one tree was randomly selected and pulled out, the remaining 17 trees were used to develop the coefficients for each model. This process was repeated six times with different selections such that the six trees in the sample were used once for validation with all models. The final coefficients for each model were the average of the coefficients from the different runs. To determine the predictive accuracy of these models, the error between the predicted biomass and the true biomass measured for each tree was calculated according to Chave et al. (2005):
From these validation procedures, the Jenkins’s et al. model was the model with the lowest error in the estimates (best fit) for predicting biomass of P. ponderosa.
After evaluating these models, we chose the Jenkins et al. (2003) model and coefficients to estimate biomass and C storage for the different species of pines in this study. The agreement between Jenkins et al. (2003) predictions and the observations in this study indicate that these coefficients are the best available at this time to develop biomass estimates for pines used in windbreaks. In this study, we used the coefficients developed for broadleaved trees by Jenkins et al. and estimated the potential of these trees for storing C in the continental U.S.
These biomass estimates were converted to C by using conversion factors of 0.48 and 0.51, for broadleaved deciduous and conifer trees respectively (Lamlom and Savidge 2003). These trees were grouped into broadleaved deciduous and coniferous tree species by region. Finally, these values were expanded to a per-unit-area (ha) basis by using a one-row windbreak with a width of 3 m (USDA-NRCS 2009). This windbreak was monospecific, 1111 conifers, or 2525 small conifers (Juniperus virginiana L.), trees per ha, respectively.
Sources of error
There are several potential sources of error inherent in estimating forest biomass at large scales using published biomass equations. Measurement, sampling, model parameter, and model selection errors are all potential sources of uncertainty that must be considered when developing new biomass models or using existing models. Furthermore, published models are often used to predict biomass for trees outside the range (e.g., diameter, species or species-group, geographic) of the original data used to develop the model. This extrapolation may represent an additional source of uncertainty that must be considered when applying biomass models from the literature.
Results
Suitability of allometric models for estimating biomass
Comparing different allometric models using data from the destructively sampled ponderosa pine in NE and MT, five models fit the data reasonably well (Table 5). The models of Berkhout and Husch (n.d.) (Model #10), Schumacher and Hall (1933) (Model #12), “This study model 1” (Model #13), and “This study model 2” (Model #14) had the best fits. Although the Brenac (n.d.) (Model #11) fit well, it was excluded from the next step because it had high VIF. An elevated value of VIF (>10) indicates that the predictor variables being considered in the regression model are highly correlated among themselves (Kutner et al. 2004).
The next step consisted of evaluating four models (#10, #12, #13 and #14 in Table 5) which had the highest adjusted R2 and lowest RSE, AIC, PRESS, VIF, and FI criterion. The selected models included a square root response variable with and without height as explanatory variables and a log transformed response variable. Among these information criteria FI (Furnival 1961; Parresol 1999; Schreuder and Williams 1998) was preferred because it allows comparing models with different response variables and reduces the usual estimate of the standard error about the curve when the dependent variable is biomass (Parresol 1999). Finally, to define the accuracy of these models for predicting biomass, a validation test was carried out according to Picard et al. (2012) and Kutner et al. (2004).
In the validation process (Table 4), Jenkins’ et al. generalized model (Model #15) was included to test the relationship between the overestimation reported for forest stands (Zhou and Hemstrom 2009; Domke et al. 2012; Chojnacky et al. 2014) and the biomass estimates for open-grown trees.
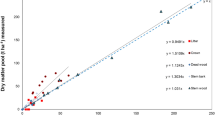
The models validated included log- and square root-transformed response variables with and without height. Figure 3 displays the predicted values of all five competing models. These results suggest that all these models are good estimators of the P. ponderosa biomass. However, in the validation process (Table 6), Jenkins’ et al. model showed the lowest percentage of error (0.45 %) and higher adjusted R2 (98.7 %).

Allometric equations fit from the relationships of total above-ground biomass (kg) against dbh
The models #13, #14 and Jenkins et al. (#15) were evaluated again, including the adjustment made by Chojnacky et al. (2014) to Jenkins et al., using data from FIA and destructively sampled P. ponderosa, in NE, MT, ecoregions 331, and 332, projected to 50 years. These biomass estimates were consistent with predictions from models #13, #14 and Jenkins et al. (Table 7). However, when compared to the adjusted Jenkins’ et l. models proposed by Chojnacky et al. (2014) the differences were substantial, especially for trees with specific gravity greater than 0.40. There were notable differences when comparing these predictions between states and ecoregions, this may be attributed to larger diameter P. ponderosa trees in Nebraska than in other states. These differences between the estimates could have been a result of the way these trees were selected and the performance of these trees in different ecoregions. Trees in NE showed a dbh ranging from 15.09 to 41.72 cm, which is higher when compared to MT (13.57–27.00 cm), ecoregion 331 (19.81–29.21 cm), and ecoregion 332 (16.76–25.91 cm).
Carbon storage potential for windbreaks trees in different regions
Carbon storage potential for windbreak trees as determined by the different allometric models showed high variability across regions. The Jenkins’ et al. coefficients gave the most consistent estimates in this research. For this reason, we decided to use only Jenkins’ et al. coefficients to report estimates of C storage for all species. The mean estimated C storage potentials across the regions were 4.39 ± 1.7 Mg C ha−1 year−1 for broadleaved deciduous species and 2.45 ± 0.4 Mg C ha−1 year−1 for conifers (Table 8). Both broadleaved deciduous and conifer species displayed the highest C storage potential, 13.6 ± 7.72 and 3.84 ± 0.04 Mg C ha−1 year−1 respectively, in the Southern Plains region, over a 50 year period. The estimate for broadleaved deciduous trees was high because the data set includes cottonwood, a much larger species than any of the others in the study.
Discussion
The low variability of the trees’ MAIDs among ecoregions indicated that most species are growing within their natural range (Wells 1964; Burns and Honkala 1990; USDA-NRCS 2015) and that the ecoregions are commonly occupied by trees growing naturally (USDA-NRCS 2015). The variations in some MAIDs were due to extreme climatic conditions and soil types within regions (e.g., ecoregions 315 and 231 in southern Plains).
Tree growth in forests, fields, or otherwise is not linear (Lutz 2011). Instead, their cumulative growth curves (CGC) are commonly sigmoidal in that they generally grow rapidly during early stages of development and eventually reach a growth maximum which is dependent on species traits and growing conditions. Stephenson et al. (2014) questioned the leveling-off conclusion for individual trees and proposed that tree biomass accumulation continuously increased with tree size, and that old growth trees can store more biomass than young trees. Oliver and Rycker (1990) indicated the same trend for P. ponderosa, which still increased its biomass after 200 years. Therefore, the MAIDs projection to 50 years was a reliable and conservative timeframe for windbreak tree biomass estimates given their lifespan and their growth curves (Spears 2000).
Biomass and the potential C storage obtained from these MAIDs in windbreaks were affected by their location even within relatively small geographic areas. These results are corroborated by the diversity of locations and climatic conditions where these species persist (USDA-NRCS 2006; Birdsey 1992; Kirby and Potvin 2007). Brown et al. (1999), Ketterings et al. (2001), Montagnini and Nair (2004) affirmed that these changes could occur in areas smaller than the ecoregions used throughout this study.
The different biomass models directly influenced the estimates of C in this study. These differences in the relationship between MAIDs and biomass/C potential could be due to various reasons: (1) the method for developing the allometric models and the coefficients used in those models, (2) the species, condition and location of the trees used to fit the allometric models, (3) the location effect (Arcano 2005; McHale et al. 2009), (4) wood-specific gravity (Jenkins et al. 2003), (5) site index (Balboa-Murias et al. 2006), (6) stand density (Litton et al. 2004), and (7) back-transformation correction factors.
Our analysis found that four of the models evaluated fit the observations. Two of the proposed published models (Berkhout & Husch, Schumacher & Hall) and the two new models developed in this study (This study 1 and This study 2) showed the best agreement with observations so they were used to estimate total aboveground tree biomass for P. ponderosa in Nebraska and Montana and in ecoregions 331 and 332. Surprisingly, coefficients for pines presented by Jenkins reported the highest accuracy for predicting tree biomass in the validation process. These results indicate that the Jenkins’ et al. coefficients for pines may be used as a first approximation for developing estimates of biomass and C storage potential for open-grown trees.
The biomass estimates for all U.S. tree species compiled by the FIA program can serve as a valuable resource for comparisons based on predictions from locally developed models. However, the coefficients of Jenkins et al. (2003) as modified by Chojnacky et al. (2014) did not necessarily produce values consistent with those from the destructively sampled data. Our study results indicate that the original Jenkins et al. model coefficients result in better predictions of biomass in windbreak trees.
Regarding stand-level estimates, most authors have reported an overestimation when using Jenkins et al. (2003). Domke et al. (2012) reported the Jenkins et al. (2003) model overestimated biomass for the most abundant tree species in the FIA inventory. The same trend was reported by Zhou and Hemstrom (2009) when estimating aboveground tree biomass on forest land in the Pacific Northwest. Conversely, Zhou et al. (2015) found these forest-derived models underestimated biomass in more open-grown windbreak trees.
In this study, the aforementioned overestimations agreed with the estimates for open-grown P. ponderosa trees in NE and MT, ecoregions 331 and 332, indicating a need for applying this same exercise to other regions to evaluate model predictions. Although the relatively small sample size of 18 trees (12 trees for NE and 6 for MT), are not likely to be representative of all windbreaks with P. ponderosa, these results can be used locally (Picard et al. 2012). A much larger sample would be required to account for regional variability (Weiskittel et al. 2015) (Table 9).
This study highlights how predictions from different models, when extrapolated to more open-grown trees growing in various regions, will produce varying results when trying to predict field windbreak tree biomass or C storage potential. The standardization of the methodologies, the implementation of averaged models across sites (Miles and Smith 2009), and the development of geographic weighted regression models (Brunsdon et al. 1996) could be a potential solution for reducing the current variability.
The above- to belowground biomass ratios reported by Jenkins et al. (2003), when applied to this study, resulted in estimates consistent with other studies. For example, the belowground ratio for P. contorta ranged from 20 to 28 % (Comeau and Kimmins 1989) and 26 % for P. sylvestris (Xiao and Ceulemans (2004). On the other hand, Douglas fir (Pseudotsuga menziesii (Mirb). Franco) was found to have proportionately more root biomass on sites with low-productivity than on a highly productivity sites (Keyes and Grier 1981). For the same species, belowground production represented a greater proportion to total production in two xeric sites compared to two mesic sites (Comeau and Kimmins 1989).
Estimates of C storage potentials per-unit-area were difficult to compare with the data reported by other authors because of their different approaches. However, the assessments carried out suggest a partial agreement among reported estimates. The estimates from Brandle et al. (1992), Nair et al. (2009), Schoeneberger (2009), and this study fit in the generalized range of 0.29–15.21 Mg C ha−1 year−1. To avoid most uncertainties and make results more usable, standardized experimental procedures and data-gathering protocols for all regions are required so that data can be compared on a wider basis (Udawatta and Jose 2011).
The findings in this study suggest that the C storage potential for windbreaks over 50 years range from 1.07 ± 0.21 to 3.84 ± 0.04 Mg C ha−1 year−1 for conifer species and 0.99 ± 0.16 to 13.6 ± 7.72 Mg C ha−1 year−1 for broadleaved deciduous species. Because the magnitude of the differences in the estimates from P. ponderosa suggested a good agreement with the Jenkins et al. model predictions, this analysis may provide the foundation for making a comprehensive assessment of the coefficients used by Jenkins et al. to estimate biomass for other open grown tree species.
While much uncertainty exists in C estimation in agroforestry systems first approximations are necessary to move the state of the science forward. Much of the uncertainty that exists is due to a dearth of data available for trees growing outside of forests. More research on C storage potential for windbreaks, using local models, and analyzing variables such as site index, tree densities, C accumulation in soils, and future climates will greatly improve our understanding of the carbon dynamics in these systems (Mbow et al. 2014). These uncertainties raise questions on which trees and management options will be suitable in future climates and how to best minimize negative climate change impacts on agriculture (Nguyen et al. 2013). Although these uncertainties limit our ability to definitively estimate the carbon storage potential of windbreaks and other agroforestry practices, substantial potential clearly exists. These uncertainties should be addressed in future research.
Conclusions
The purpose of our study was to better approximate C estimates of windbreak trees by determining which of the readily available models were the best predictors, and then use that information to develop regional estimates to provide a basis for evaluating the use of windbreaks within and across regions in the U.S. Tree form in regards to model selection for estimating tree C is important (Melson et al. 2011) and, as demonstrated by Zhou et al. (2015) and this study, is especially true for more open-grown windbreak trees. Based on our study, we recommend the use of the Jenkins et al. (2003) biomass model and associated coefficients specifically for pines. As more information becomes available, particularly on the different species and greater range of diameters, newer equations can be generated that will further reduce the uncertainty in estimating the C stores in agroforestry.
A better understanding of how trees impact agricultural lands, especially windbreaks and how these impacts may in turn be affected by climate change are essential as we develop management strategies (Gockowski et al. 2001). Depending on tree species, location and windbreak arrangement, the C storage potential can vary from one region to another and will most likely vary even more under climate change. Having scientifically sound and readily available means to generate regional estimates of windbreak tree biomass and C stocks will lead to a better understanding of the dynamics of these agroforestry systems in contributing to the global C cycle and national C budgets.
References
Alder D (1980) Forest volume and prediction of the production focused on the tropics. Roma, IT, FAO: Montes 22(2):80
Arcano R (2005) Allometric model development, biomass allocation patterns, and nitrogen use efficiency of lodge pole pine in the Greater Yellowstone ecosystem. Thesis, University of Wyoming
Bailey RG (1995) Description of the ecoregions of the United States, 2nd edn. (map). Miscellaneous. US Department of Agriculture, US Forest Service, Publication No. 1391, Washington DC
Balboa-Murias MA, Rodríguez-Soalleiro R, Merino A, Álvarez-González JG (2006) Temporal variations and distribution of carbon stocks in aboveground biomass of radiata pine and maritime pine pure stands under different silvicultural alternatives. For Ecol Manag 237:29–38
Birdsey RA (1992) Carbon storage and accumulation in United States forest ecosystems. USDA General Technical Report. http://www.nrs.fs.fed.us/pubs/gtr/gtr_wo059.pdf. Accessed 9 July 2015
Box GEP, Cox DR (1964) An analysis of transformations. J R Stat Soc Ser B 26:211–234
Brandle JR, Wardle TD, Bratton GF (1992) Opportunities to increase tree planting in shelterbelts and the potential impacts on carbon storage and conservation. In: Sampson RN, Hair D (eds) Forests and global change, opportunities for increasing forest cover, vol 1. American Forests, Washington, pp 157–176
Brown SL, Schroeder P, Kern JS (1999) Spatial distribution of biomass in forests of the eastern USA. For Ecol Manag 123:81–90
Brunsdon C, Fotheringham AS, Charlton M (1996) Geographically weighted regression: a method for exploring spatial non-stationarity. Geogr Anal 28(4):281–298
Burns RM, Honkala BH (Tech. Coords.) (1990) Silvics of North America: deciduous, vol 2. Agriculture Handbook 654, US Department of Agriculture, Forest Service, Washington DC
Chatterjee S, Hadi AS (2006) Regression analysis by example. Wiley, New Jersey
Chave J, Andalo C, Brown S, Cairns MA, Chambers JQ, Eamus D, Fölster H et al (2005) Tree allometry and improved estimation of carbon stocks and balance in tropical forests. Oecologia 145:87–99
Chojnacky DC, Heath LS, Jenkins CJ (2014) Updated generalized biomass equations for North American tree species. Forestry 87:129–151
Comeau PG, Kimmins JP (1989) Above- and belowground biomass and production of lodgepole pine on sites with differing soil moisture regimes. Can J For Res 19(4):447–454
CRAN (The Comprehensive R Archive Network) (2014) R. http://cran.r-project.org/. Accessed 4 July 2015
Crow TR (1978) Biomass and production in three contiguous forests in northern Wisconsin. Ecology 59:265–273
Dietz J, Kuyah S (2011) Guidelines for establishing regional allometric equations for biomass estimation through destructive sampling. Document Version 1.0. http://www.goes.msu.edu/cbp/allometry.pdf. Accessed 12 July 2014
Domke GM, Woodall CW, Smith JE, Westfall JA, McRoberts RE (2012) Consequences of alternative tree-level biomass estimation procedures on U.S. forest carbon stock estimates. For Ecol Manag 270:108–116
Fahey TJ, Knapp AK (2007) Principles and standards for measuring primary production. Oxford University Press, Oxford
FAO (Food and Agriculture Organization of the United Nations) (2010) “Climate-Smart” Agriculture policies, practices and financing for food security, adaptation and mitigation. http://www.fao.org/docrep/013/i1881e/i1881e00.pdf. Accessed 19 July 2015
Furnival GM (1961) An index for comparing equations used in constructing volume tables. For Sci 7:337–341
Gockowski J, Nkamleu GB, Wendt J (2001) Implications of resource-use intensification for the environment and sustainable technology systems in the Central African Rainforest. In: Lee DR, Barrett CB (eds) Tradeoffs or synergies? Agricultural intensification, economic development and the environment. CAB International, Wallingford
Honer T (1971) Weight relationships in open- and forest-grown balsam fir trees. In: Young H (ed) Forest biomass studies, IUFRO working group on forest biomass studies. University of Maine College of Life Science and Agriculture, Orono
Jenkins JC, Chojnacky DC, Heat LS, Birdsey RA (2003) Comprehensive database of diameter-based biomass regressions for North American tree species. Forest Service, General Technical Report NE-319
Jose S, Gillespie AR, Pallardy SG (2004) Interspecific interactions in temperate agroforestry. Agrofor Syst 61:237–255
Ketterings QM, Coe R, van Noordwijk M et al (2001) Reducing uncertainty in the use of allometric biomass equations for predicting above-ground tree biomass in mixed secondary forests. For Ecol Manag 146:199–209
Keyes MR, Grier CC (1981) Above- and below-ground net production in 40-year-old Douglas fir stands on low and high productivity sites. Can J For Res 11:599–605
Kirby KR, Potvin C (2007) Variation in carbon storage among tree species: implications for the management of a small-scale carbon sink project. For Ecol Manag 246:208–221
Kort J (1988) Benefits of windbreaks to field and forage crops. Agri Ecosyst Environ 22–23:165–190
Kumar BM, Nair PKR (eds) (2011) Carbon sequestration potential of agroforestry systems: opportunities and challenges. Advances in Agroforestry. Springer, Dordrecht
Kutner MH, Nachtsheim CJ, Neter J (2004) Applied linear regression models, 4th edn. Irwin Inc., New York
Lamlom SH, Savidge RA (2003) A reassessment of carbon content in wood: variation within and between 41 North American species. Biomass Bioenerg 25:381–388
Litton CM, Ryan MG, Knight DH (2004) Effects of tree density and stand age on carbon allocation patterns in post-fire lodge pole pine. Ecol Appl 14(2):460–475
Loetsch F, Zohrer F, Haller KE (1973) Forest inventory. BLV Verlagsgesellschaft, Munchen
Lutz J (2011) How trees grow. http://www.forestresearchgroup.com/Newsletters/V8No2.pdf. Accessed 19 July 2015
Mbow C, Smith P, Skole D, Duguma L, Bustamante M (2014) Achieving mitigation and adaptation to climate change through sustainable agroforestry practices in Africa. Curr Opin Environ Sustain 6:8–14
McHale MR, Burke IC, Lefsky MA, Peper PJ, McPherson EG (2009) To use allometric relationships developed specifically for urban trees. Urban Ecosyst 12:95–113
McNab WH, Cleland DT, Freeouf JA, Keys JE, Nowacki GJ, Carpenter CA (2005) Description of ecological subregions: sections of the conterminous United States, First approximation. http://na.fs.fed.us/sustainability/ecomap/section_descriptions.pdf. Accessed 17 Oct 2015
Melson SL, Harmon ME, Fried JS, Domingo JB (2011) Estimates of live-tree carbon stores in the Pacific Northwest are sensitive to model selection. Carbon Balance Manag 6:2
Miles PD, Smith WD (2009) Specific gravity and other properties of wood and bark for 156 tree species found in North America. USDA Forest Service Research Note NRS-38
Montagnini F, Nair PKR (2004) Carbon sequestration: an underexploited environmental benefit of agroforestry systems. Agrofor Syst 61:281–295
Nair PKR (2011) Carbon sequestration studies in agroforestry systems: a reality-check. Agrofor Syst 86:243–253
Nair PKR, Nair VD, Kumar BM, Haile SG (2009) Soil carbon sequestration in tropical agroforestry systems: a feasibility appraisal. Environ Sci Policy 12(8):1099–1111
Nakamura T, Judd K, Mess MI, Small M (2005) A comparative study of information criteria for model selection. http://staffhome.ecm.uwa.edu.au/~00027830/pdf/IJBC16-2.pdf. Accessed 1 July 2015
Nguyen Q, Hoang MH, Öborn I, van Noordwijk M (2013) Multipurpose agroforestry as a climate change resiliency option for farmers: an example of local adaptation in Vietnam. Clim Change 117:241–257
Ogle SM, Adler PR, Breidt FJ et al (2014) Quantifying greenhouse gas sources and sinks in cropland and grazing land systems. In: Marlen E et al (eds) Quantifying greenhouse gas fluxes in agriculture and forestry: methods for entity-scale inventory. Office of the Chief Economist, U.S. Department of agriculture, Washington DC. Technical Bulletin No. 1939
Oliver WW, Rycker RA (1990) Ponderosa pine. In: Russell M, Honkala BH (Tech. Coords.) Silvics of North America: conifers. Agriculture Handbook 654. U.S. Department of Agriculture, Forest Service, Washington
Parresol BR (1999) Assessing tree and stand biomass: a review with examples and critical comparisons. For Sci 45(4):573–593
Picard N, Saint-Andre L, Henry M (2012) Manual for building tree volume and biomass allometric equations: from field measurement to prediction. Food and Agricultural Organization of the United Nations, Rome, and Centre de Coopération Internationale en Recherche Agronomique pour le Développement, Montpellier. http://www.fao.org/docrep/018/i3058e/i3058e.pdf. Accessed 30 Oct 2015
Prodan M (1968) Forest Biometrics, English edn. Pergamon Press, Oxford
Raintree JB (1986) An introduction to agroforestry diagnosis and designs. ICRAF
Rani BD, Kumar KR, Jose S, Pal HS (2008) Ecological basis of agroforestry. CRC Press, Taylor & Francis Group, Boca Raton
SAS Institute Inc. (2014) SAS 9.3 for windows. SAS Institute Inc., Cary
Schoeneberger MM (2009) Agroforestry: working trees for sequestering carbon on agricultural lands. Agrofor Syst 75:23–27
Schoeneberger MM, Bentrup G, de Gooijer H, Soolanayakanahally R, Sauer T, Brandle J, Zhou X, Current D (2012) Branching out: agroforestry as a climate change mitigation and adaptation tool for agriculture. Soil Water Conserv 67(5):128–136
Schreuder HT, Williams MS (1998) Weighted linear regression using D2H and D2 as the independent variables. Research Paper RMRS-RP-6. U.S. Department of Agriculture, Forest Service, Rocky Mountain Research Station, Fort Collins
Schumacher FX, Hall FS (1933) Logarithmic expression of timber-tree volume. Agric Res 47:719–734
Segura C, Andrade J (2008) How to build allometric models of volume, biomass or carbon from woody species?. Agrofor Am, No 46
Sharrow SH, Ismail S (2004) Carbon and nitrogen storage in agroforests, tree plantations, and pastures in western Oregon, USA. Agrofor Syst 60:123–130
Spears S (2000) Calculation of the mean annual increment by forest type and reconciling with expected management plan yields mean annual increment. http://www.fundymodelforest.net/pdfs/publications/management/Management_2000_Spears_%20Calculation%20of%20Mean%20Annual%20increment.pdf. Accessed 12 July 2015
Sprugel DG (1983) Correcting for bias in long-transformed allometric equations. Ecology 64:209–210
Spurr SH (1965) Forest associations of the Harvard Forest. Ecol Monogr 26:245–262
Stephenson NL, Das AJ, Condit R (2014) Rate of tree carbon accumulation increases continuously with tree size. Nature 507:90–101
Udawatta RP, Jose S (2011) Carbon sequestration potential of agroforestry practices in temperate North America. In: Kumar BM, Nair PKR (2011) Carbon sequestration potential of agroforestry systems: opportunities and challenges. Adv Agrofor 17, pp 17–42
USDA-FS (Forest Service) (2014) Ecoregions of the United States. http://www.fs.fed.us/rm/ecoregions/products/map-ecoregions-united-states/. Accessed 9 July 2015
USDA-FS (Forest Service) (2015) Forest Inventory and Analysis National Program, FIA Library, Database Documentation, Washington DC. http://fia.fs.fed.us/library/database-documentation/. Accessed 8 July 2015
USDA-NRCS (USDA Natural Resource Conservation Service) (2006) Land resource regions and major land resource areas of the United States, the Caribbean, and the Pacific basin. U.S. Department of Agriculture Handbook
USDA-NRCS (USDA Natural Resource Conservation Service) (2009) Conservation practice standard: windbreak/shelterbelt establishment (Feet) Code 380. http://efotg.sc.egov.usda.gov/references/public/MN/380mn.pdf. Verified 9 July 2015
USDA-NRCS (USDA Natural Resource Conservation Service) (2015) Plants database. http://www.plants.usda.gov/java/. Accessed 9 July 2015
Weiskittel AR, MacFarlane DW, Radtke PJ, Affleck DR, Temesgen H, Woodall CW, Westfall JA, Coulston JW (2015) A call to compare methods for estimating tree biomass for regional and national assessments.http://www.ingentaconnect.com/content/saf/jof/pre-prints/content-jof14091. Accessed 8 July 2015
Wells OO (1964) Geographical variation in ponderosa pine: the ecotypes and their distribution. Silvae Genet 13:89–103
Xiao CW, Ceulemans R (2004) Allometric relationships for below- and aboveground biomass of young Scots pines. For Ecol Manag 203:177–186
Zhou X, Hemstrom MA (2009) Estimating aboveground tree biomass on forestland in the Pacific Northwest: a comparison of approaches. Research Paper PNW-RP-584. U.S. Department of Agriculture, Forest Service, Pacific Northwest Research Station, Portland
Zhou X, Schoeneberger MM, Brandle RJ, Awada TN, Chu J, Derrel LM, Li J, Li Y, Mize CW (2015) Analyzing the uncertainties in use of forest-derived biomass equations for open-grown trees in agricultural lands. For Sci 15:144–161
Acknowledgments
The authors would like to acknowledge financial support through the Institute of International Education (IIE)—Fulbright, Colombia; U.S. Forest Service Agreement #11-JV-11330152-115; and the Nebraska Agricultural Experiment Station with funding from the McIntire-Stennis Cooperative Forestry program (Accession Number 230910) from the USDA National Institute of Food and Agriculture.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Possu, W.B., Brandle, J.R., Domke, G.M. et al. Estimating carbon storage in windbreak trees on U.S. agricultural lands. Agroforest Syst 90, 889–904 (2016). https://doi.org/10.1007/s10457-016-9896-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10457-016-9896-0