
Abstract
Examining otoscopic images for ear diseases is necessary when the clinical diagnosis of ear diseases extracted from the knowledge of otolaryngologists is limited. Improved diagnosis approaches based on otoscopic image processing are urgently needed. Recently, convolutional neural networks (CNNs) have been carried out for medical diagnosis to obtain higher accuracy than standard machine learning algorithms and specialists' expertise. Therefore, the proposed approach involves using the Bayesian hyperparameter optimization with the CNN architecture for automatic diagnosis of ear imagery database including four classes: normal, myringosclerosis, earwax plug, and chronic otitis media (COM). The suggested approach was trained using 616 otoscopic images, and the performance of this approach was assessed using 264 testing images. In this paper, the performance of ear disease classification was compared in terms of accuracy, sensitivity, specificity, and positive predictive value (PPV). The results produced a classification accuracy of 98.10%, a sensitivity of 98.11%, a specificity of 99.36%, and a PPV of 98.10%. Finally, the suggested approach demonstrates how to locate optimal CNN hyperparameters for accurate diagnosis of ear diseases while taking time into account. As a result, the usefulness and dependability of the suggested approach will lead to the establishment of an automated tool for better categorization and prediction of different ear diseases.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Previously, biometric recognition systems used ear shapes which figured prominently for person identification in forensic, security, and building monitoring applications [1]. Currently, a challenge that becomes increasingly difficult when working with image recognition of various ear diseases to alleviate auditory loss [2]. In the context of otolaryngology, the otoscopic examination is a clinical ear test to assess its function and improve the diagnosis [3]. Accordingly, otoscopic images occupy a great niche in diagnosing diseases of the external and middle ear [4]. The common ear disease is called acute otitis media (AOM) that infects the middle ear, particularly in children [5]. There are some types of ear diseases including otitis media with effusion (OME), chronic otitis media with effusion (COME), chronic suppurative otitis media (CSOM), earwax plug, myringosclerosis, and serous otitis media (SOM). OME is defined as middle ear enlargement and fluid accumulation without bacterial infection. COME is defined as fluid staying in the middle ear and coming back without a bacterial infection that causes the hearing problem. CSOM is defined as a severe infection that has resisted conventional treatment and causes perforation of the eardrum. CSOM is one of the most prevalent infectious disorders affecting children. Earwax plug is defined as a buildup of earwax in the ear, which usually leads to hearing loss. Myringosclerosis is defined as a buildup of calcium in the eardrum without any symptoms. SOM is defined as a retracted and dull tympanic membrane. All these ear diseases are interrelated and may lead to serious developmental symptoms that are life-threatening [4]. The risk factors for ear diseases are based on the immune system, frequent colds, seasonal allergies, air pollution, gene mutation, and speech delays [6].
Based on WHO statistics [7] for ear disorders, nearly 2.5 billion patients suffer from different levels of ear disorders and at least 700 million will require hearing rehabilitation in 2050. It was noted that five out of six children develop otitis media by the time they reach the age of three. The good treatment of otitis media in children can be carried out by accurate diagnostic tools. Especially in developing countries, the inexperience of pediatricians leads to the wrong treatment and disability caused by ear diseases [8].
Portable otoscopy [9] is a standard test for ear inspection. This test is insufficient due to the resulting limited diagnostic accuracy. Besides, the common diagnostic tools for ear diseases mainly depend on head mirror, auriscope, otomicroscope, and video-endoscope [10]. An auriscope has a diagnostic accuracy than a head mirror, and it is insufficient to identify pathological structures of the ear. The otoscope is not suitable for a narrow ear canal due to limitations imposed by the size of the speculum. The best diagnostic tool is a portable otoscope with video-endoscope compared to other tools for determining the external ear canal, tympanic membrane, and normal or unusual constructions at these sites.
With the appearance of endoscopic ear surgery [11], many otolaryngologists began to use it in private clinics because of the high image quality and ideal illumination of this instrument to reach accurate inspection. However, the time and cost of this procedure are a disadvantage compared to manual otoscopy. From this point of view, early detection and appropriate treatment require new algorithms for ear image diagnosis to avoid the unavailability of otolaryngologists and low diagnostic accuracy at a lower time cost than the previous works [12]. In a clinical test, the correct diagnosis of OME achieved an accuracy of 43–52% [13], and the correct diagnosis of AOM achieved an accuracy of 62–78% [14].
Artificial intelligence screening systems for ear diseases could be used by healthcare workers in developing areas where there is a shortage of otolaryngologists. It could also reduce the number of clinicians by assigning a nurse to perform the first evaluation of individuals with ear complaints, which are exploited by automated diagnostic models. The automated diagnostic models based on machine and deep learning studies exist relatively in otology for the automated diagnosis of otoscope images as follows.
In terms of machine learning algorithms, Myburgh et al. [15] used an automatic system to diagnose five types of otitis media by applying it to a proprietary database including 389 ear images extracted from the video-endoscope. The diagnostic accuracy of this approach reached 81%-58% using a decision tree, and 86%-84% using the neural network method. Also, Vizcaino et al. [16] used a public database including 880 ear images by support vector machine (SVM) algorithm for classifying between four ear categories with an accuracy of 93.9%. Livingstone et al. [17] employed machine learning algorithms on 724 ear images with an accuracy of 89% using 14 classes. Sandström et al. [18] demonstrated good examination for ear diseases using machine learning algorithms on ear images detected by an expert panel.
In terms of deep learning algorithms, CNN models are applied to detect ear images as in Cha et al. [19] based on 10,544 private samples for six categories with an accuracy of 93.67%.
Zeng et al. [20] implemented 20,542 endoscopic images extracted from six categories to train nine CNN models with an accuracy of 95.59%.
Khan et al. [21] reported an accuracy of 95% using CNN models on 2,484 otoendoscopic images to distinguish them into three categories. Lee et al. [22] proposed the class activation map as feature extraction with CNN models on 1338 ear images to classify two types with an accuracy of 91 %. Zafer [23] proposed a combined approach extracted from CNN as feature extraction and machine model to classify 857 ear images with an accuracy of 99.47%. Moreover, this research suffered from a biased model and insufficient ear dataset. Recently, the classification of the public ear database used by Viscanio et al. [16] adopted the CNN-LSTM with good performance rather than CNN only [24]. This recent study confirmed that Bayesian optimization is a highly effective optimization technique because it is able to detect better hyperparameters in less time than other evolutionary techniques [24].
There are some limitations of previous works on ear diagnostic systems. It was observed that the number of ear images used in the machine learning algorithms was less than the images used in CNN models. As far as know, deep algorithms are more accurate for ear image detection due to their multilayered but have a high computational cost during model training [25]. Most ear detection systems are not executed in real-time diagnostics of the ear in clinics [20].
Therefore, the objective of this work is based on the optimized CNN approach based on four selected hyperparameters for providing an accurate otologic diagnosis with less time.
The primary feature of the propounded approach is applied to the available dataset which provides a large number of images used in [16] to classify four ear categories. Also, the proposed approach supported ear detection using CNN-based Bayesian optimization [26] as a supplement, but not as a replacement for the otoscope, which remains the typical screening tool among non-specialized physicians.
Materials and Methods
Proposed Framework
The basic target of the study is to include an accurate approach for classifying four ear conditions by Bayesian optimization [26] based on tuning the hyperparameters of a CNN architecture. Also, this proposed approach is used to minimize the training time of CNN without influencing the approach performance. This optimizer's advantage is its ability to identify the appropriate hyperparameters to obtain the best accuracy on the testing dataset.
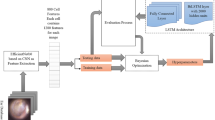
Figure 1 designs the proposed framework for the classification of ear diseases. The following contributions were adopted in the proposed approach.
-
1-
Using Bayesian optimization can determine the optimal hyperparameter values in a shorter time.
-
2-
Using the CNN architecture that contains convolutional layers followed by a fully connected layer to obtain a more accurate classification model.
-
3-
Using the performance appraisal to compute the optimal indicators of 30 and 100 iterations. Also, a comparison with the previous methods is conducted.
-
4-
Using the feedback structure to duplicate all aforementioned procedures for 30 and 100 iterations to determine the optimal outcomes.

A proposed framework based on Bayesian optimization with the CNN for ear imagery classification
Database Acquisition
In this study, the ear imagery database [16] consists of 880 otoscopic images obtained from physicians in the Clinical Hospital of Universidad de Chile. These images were extracted from 180 patients and evaluated by an otolaryngologist according to four types including earwax plug, myringosclerosis, COM, and normal. Each type has 220 otoscopy images.
The otoscopic images are collected from 90 video images at 20 frames per second at a resolution of 640 x 480 for each case and the experts check the good frames identified by the jamming method from each of those video images. Then, it was found that the best-selected images were resized to 420 × 380 pixels. Fig.2 presents otoscopy images of four diagnostic classes of ear diseases in the ear image dataset.

Otoscopy images for four diagnostic classes of ear diseases: A normal ear, B myringosclerosis, C earwax plug, D chronic otitis media (COM).
In this paper, the database is indiscriminately partitioned into 70% for training data and 30% for testing data. It means that 880 images are divided into 616 training images and 264 testing images. For the implementation of the proposed approach, each class has 154 training images and 66 testing images. All images in the database were transformed to resized images with 32 × 32 pixels resolution for preprocessing data. The reason for resizing images to 32*32 is compatibility with proposed layers in deep learning methods, e.g., CNN. Also, resized images help in reducing the training time during the CNN method.
Bayesian Optimization
To reduce computing costs and benefit from reliable CNN design, Bayesian optimization [27] is a potent technique for hyperparameter optimization. To choose the appropriate hyperparameters for the estimate process, this optimizer takes into account prior discoveries. When the data are complex, this optimizer is successfully employed to improve classification [28]. Hyperparameters are often a set of values employed in the learning process and are made up of an integer or variable that has values ranging from lower to higher bounds. Given the training duration, the best hyperparameters ought to have a low-loss function and excellent algorithmic accuracy. The selection of hyperparameters varies depending on the algorithm's goal.
The Bayes Theorem [29], which comprises prior knowledge of the goal function and updates posterior knowledge to reduce loss and improve classification precision, is a key component of the optimization process. The objective function's previous outcomes are updated using the posterior distribution, which is dependent on the Gaussian process [29]. Additionally, the acquisition function [26] is used to set a balance between exploring modern regions of the objective space and taking advantage of regions where suitable values are already known to exist. Depending on model Z and observation Y, Eq. (1) is Bayes' Theorem.
where P(Z|Y) is the posterior probability of Z given Y, P(Y|Z) is the likelihood of Y given Z, and P(Y) is the prior probability of Y.
The Bayesian hyperparameter optimization is generated by Eq. (2) as in previous work [26].
Y is a set of hyperparameters in the domain, and f(y) is an objective score to minimize the error rate in the learning process. The Bayesian optimization is constructed to locate the minimal function f(y) on a bounded set Y.
Hyperparameters
In this study, the selected hyperparameters are learning rate, momentum, regularization, and network depth as used in [26]. These four hyperparameters had previously produced good optimization results for images [31] as follows.
-
Depending on the gradient loss function error, the learning rate (α) is utilized to identify the extensive patterns in images. Important patterns may inadvertently be left out if the learning rate is low.
-
By updating the prior gradients, the momentum (δ) is used to adjust the entire image without losing significant components. To eliminate vertical oscillations and reroute a decent path to local optimums with lower iterations than the random gradient, the momentum value's goal is to facilitate the gradient descent processes.
-
To get better forecasts without overfitting the database, regularization (λ) allows for good generalizability. To prevent the model complexity, the regularization is based on reducing the weight by a tiny amount known as weight decay. In this study, the loss function (L).-based computation of the squares of all the feature weights is employed to implement ridge regularization.
-
The network depth is used to recognize the good features of the images by the accurate setting of the network.
The equations (Eqs. 3–5) for the hyperparameters are shown as the following:
The primary benefit of employing momentum is to smooth down the gradient descent steps, which reduces vertical oscillations and provides a smoother path to the local optimum with fewer iterations than the stochastic gradient. The gradient descent is made more efficient and produces better estimates by adding momentum [26].
where Δw is defined as the gradient change, Vt is defined as the momentum variation according to the weight, and L (W, Z, y) is the loss function of weight (W), model (Z), and hyperparameters (y).
In Eq. (6), the loss function L is employed as an index for regularization (λ).
where θi is the feature vector and y, z are the input parameters for the ith iteration.
In this paper, Table 1 displays the chosen hyperparameters for Bayesian optimization. Table 2 displays the ideal hyperparameters for five iterations using solely Bayesian optimization. The four chosen hyperparameters had an impact on the CNN computational time, as given in Table 3. Table 3 displays the best feasible locations for the hyperparameters tested with 30 and 100 iterations.
CNN Architecture
The CNN architecture [32] successfully used medical image classification because it is based on the learning of features to achieve adequate realization without detailed information. For each iteration, the CNN consists of repeated three layers, including a convolutional layer, batch normalization layer, and a rectified linear unit (RELU) layer accompanied by a fully connected layer represented by the SoftMax classifier in the output layer.
In this paper, the max-pooling layer keeps the upper pixel values with its locative arranging to reduce the number of parameters over the training process. Hence, the function of a max-pooling layer is to gradually minimize the spatial size of the pattern to obtain fewer parameters and less time computation in the architecture.
Bayesian Optimization for CNN Architecture
Some studies [33, 34] were performed to determine the amount of hyperparameters' influence on CNN design. There is a difference in the significance of the different hyperparameters. It has been observed that utilizing the incorrect hyperparameters increases both the time cost and classification error.
A good configuration of hyperparameters, such as learning rate, momentum, regularization, and network depth, was necessary for the CNN architecture to function well. It should be highlighted that the propounded network cannot be used to adjust the size and number of layers. The architecture and connectivity of the structure are taken into account as a sequential choice issue for this reason. The use of simple CNN architecture relied on tedious hyperparameter tuning and had a low degree of precision.
The optimizer's job is to use training samples to quickly identify the optimum hyperparameters. These techniques are addressed by the trial-and-error principle which is unsuccessful in selecting hyperparameters when compared to classic optimization methods [34]. Therefore, Bayesian optimization is appropriate for adjusting hyperparameters.
In this study, the fully connected layer and convolutional layers' hyperparameters for CNN architecture are tuned using the Bayesian optimization approach. The training and testing databases were inputs used by the Bayesian optimizer to generate the objective function. The objective function returned the classification error on the testing set after training a CNN architecture.
Four hyperparameters that were taken from the Bayesian optimization and training dataset were used as the input for the CNN architecture during implementation. The testing dataset and CNN architecture output are mixed to assess the classification process.
As seen in Fig. 3, the following steps outline the Bayesian optimization of CNN architecture:

Flow chart of CNN-Bayesian optimization approach for ear imagery classification
Step 1: Choose the initial hyperparameters for optimization from the images.
Step 2: Use an acquisition function to assess the objective function [30].
Step 3: Execute 30 and 100 iterations to determine the suitable iterations achieved in less time.
Step 4: Choose the most optimal values.
Step 5: Make use of the test database's optimized hyperparameters.
Optimization Setup
In this paper, the implementation of the proposed approach is performed on a laptop with 5 GB RAM GPU under the MATLAB 2020 program. The experiments are evaluated on otoscopy images for classifying ear diseases acquired from [16]. This work contains a total of 880 otoscopy images. To assess the model performance, the ear disease detection approach is employed on these images by using four common criteria: accuracy, sensitivity, specificity, and PPV, as used in former work [16]. Also, the receiver operating characteristic (ROC) curve is widely applied to compare the model performance in various classifiers [36].
The overall efficiency of a classifier is its accuracy. Specificity is used to correctly identify the samples free of illnesses, whereas sensitivity is utilized to prevent false negative samples. To determine the accurately categorized samples based on the total number of classified samples, PPV is employed as a precision parameter. For each criterion, the best performance is represented by the maximum of these percentages [37].
Experimental Results
The limited confidence during otoscopy examination to detect ear is adequate to warrant a new strategy for diagnosing various ear diseases [38]. Considering some previous studies regarding the diagnosis of ear diseases, the automated diagnosis based on otoscopy image classification models can perform better than otolaryngologists, as this classification contributes to the early diagnosis of ear diseases, especially for clinical suspicion. Interestingly, this proposed approach suggested that automatic ear detection by CNN models should be an addition to, rather than a replacement for, otoscopes in ear disease diagnostic methods.
In this research, a total of 880 otoscopy images were applied to train two CNN models and CNN-Bayesian optimization by four hyperparameters to select the best model. The performance of three architectures on the ear imagery dataset containing normal, myringosclerosis, earwax plug, and COM is evaluated in terms of four criteria [37].
Performance Analysis
In the first stage, the two CNN frameworks used DarkNet-19 [39] and inception-v3 [40] on the four ear diseases for the classification task. Inception-v3 [40] and DarkNet-19 [39] were originally designed for different applications, and these architectures are fundamentally sound for image classification tasks. In our study, we chose to use Inception-v3 and DarkNet-19 as reference classifiers due to their well-established performance in image classification tasks, although they have no application to ear disease diagnosis.
In the second stage, the CNN framework employed Bayesian optimization using four hyperparameters, including learning rate, momentum, regularization, and network depth, during the development and testing of the suggested methodology for the autonomous diagnosis of four ear disorders. The layers are used to quickly optimize the hyperparameters, and the testing dataset is used for extensive optimization.
In this study, the CNN framework was exploited to recognize the four groups obtained from the ear imagery dataset [16] which every image has a dimension of 32 × 32. The total ear database occupied 880 images which have 616 images for training and 264 images for testing. We tested the proposed framework with 264 test images that were not used in the training process for the diagnosis task. The sum of convolutional layers is 3 stacks. Each stack consists of a convolutional layer, batch normalization layer, and RELU layer. The image volume is 32 × 32 × 3, where 3 indicates the image depth. The minimum batch size is 128. The first number of filters is round (16/√ (Ov × network depth)), where Ov is the optimizing value applied to retain the same training values. The filter size along layers is 32 × 32, 16 × 16, and 8 × 8, respectively.
According to Table 3, the CNN-Bayesian optimization approach is applied to the best values of hyperparameters for two iterations including 30 and 100. To reduce the generalization error and improve classification accuracy, the optimal hyperparameter values are used for iterations. Using the testing set (30%), the acquired results for the CNN-Bayesian optimization approach were reported accuracy of 98.10%, sensitivity of 98.11%, specificity of 99.36%, and PPV of 98.10%, for 30 iterations as shown in Table 4.
On the other hand, the classification tests using the validation set (10%) and testing set (20%) showed that the CNN-Bayesian optimization approach reported an accuracy of 96.5%, sensitivity of 96.5%, and specificity of 98.8% for 30 iterations. Moreover, the results showed that the CNN-Bayesian optimization approach using training and testing sets was superior to the CNN-Bayesian optimization approach using a validation set.
The confusion matrix represented the classifier's accuracy tool that depended on the relationship between the correctly predicted images in the diagonal of the matrix and the incorrectly categorized images outside of the diagonal.
In this paper, a confusion matrix for four ear categories using CNN-Bayesian optimization with 264 testing images is superior to the previous works, as shown in Fig. 4.

Confusion matrix for four ear classes using CNN-Bayesian optimization with 264 testing images
The images taken from the acquisition function are approximated over the objective function for each iteration. Through a feedback system, the images are introduced to the data to refresh its posterior. The posterior distribution is motivated by the objective function using a Gaussian process. By using CNN-Bayesian optimization. Figure 5 demonstrates the relationship between the minimal target attained after 30 iterations and the quantity of function evaluations. Figure 6 depicts the relationship between the minimal target attained after 100 iterations and the quantity of function evaluations.

Minimum objective and number of function evaluations by using CNN- Bayesian optimization for 30 iterations

Minimum objective and number of function evaluations by using CNN-Bayesian optimization for 100 iterations
Training Time Analysis
The training time for detecting the ear imagery dataset for 30 iterations is 3136.9 seconds and the time of objective function evaluation is 3138.7 seconds, as shown in Table 5. On the other hand, the training time for detecting the ear imagery dataset for 100 iterations is 5608.2 seconds and the time of objective function evaluation is 5374.9 seconds, as shown in Table 5. It means that the CNN-Bayesian optimization approach with 30 iterations achieved a lower training time for the detection of the ear imagery dataset when compared to the proposed approach with 100 iterations.
In this paper, two CNN approaches (DarkNet-19 [39] and inception-v3 [40]) are used and compared the performance between the proposed approach and these two approaches on the same database [16]. The appropriate parameters for Darknet-19 and inception-v3 applied on the ear imagery database for one iteration are presented in Table 6. The ROC curves [36] for ear imagery classification using Darknet-19 and inception-v3 approaches are illustrated in Fig.7. It means that the inception-v3 approach achieved a higher result than the Darknet-19 approach as illustrated in Table 4. As inferred from Table 4, the experimental findings confirmed that this proposed approach is more accurate and effective for ear condition classification than CNN's previous works [39, 40]. For one iteration, the training time on Darknet-19, Inception-v3, and CNN-Bayesian optimization networks is 5580 seconds, 44880 seconds, and 80 seconds, respectively. After investigating three different networks, our results showed that the CNN-Bayesian optimization is the optimal network for detecting four imaging patterns of ear diseases with less training time for one iteration, as shown in Table 7. Therefore, using the CNN approach only is not efficient for the accurate diagnosis of ear diseases. Also, it was observed that ear detection by CNN models required a longer time.

ROC Curve for ear diseases classification using two approaches a Inception-v3, b Darknet-19
Discussion
Instead, an otoscopy image is merely a screening tool for ear pathologies. This study focused on a second opinion for estimating the diagnostic performance of otoscope images [41].
The propounded approach helps in diagnosing ear diseases mainly depends on otoscopy images and physicians’ practice. For otology, ear disease detection by otolaryngologists is not easy [42].
Many researchers adopted both accessible and inaccessible databases of image detection techniques for ear diseases. Due to the variations in the samples, classes, and applied procedures, it was highlighted that there is no way to effectively compare earlier works of ear disease diagnosis. The significance of this work is to achieve the rapid and accurate classification of images of ear ailments such as normal, myringosclerosis, earwax plug, and COM.
The suggested approach took advantage of a modern public database, specifically the dataset of 880 ear images [16] that had previously been implemented to machine learning algorithms with an accuracy of 93.9%, a sensitivity of 87.8, a specificity of 95.9%, and a PPV of 87.7%.
Besides, the private dataset of 389 images was used with 86.8% accuracy by machine learning algorithms [15]. This indicates that the dataset for the ear with big images is more useful for enhancing the classification procedure. The lack of large sample sizes in the otolaryngology sector imposed numerous limitations on CNN design.
Among the three multi-classification models, CNN-Bayesian optimization achieved higher yield estimation accuracy relative to Inception-v3 and Darknet-19 models. In the proposed research, the optimized CNN architecture is applied to differentiate ear classes in the ear imagery dataset and obtained an accuracy of 98.10%, a sensitivity of 98.11%, a specificity of 99.36%, and a PPV of 98.10%. When the suggested approach was tested, the test error rate was 1.9%, indicating a reduced rate. These results performed better than what is stated in the literature [16]. Once it had reached the maximum optimized values, the Bayesian optimization automatically halted.
The Bayesian optimization for CNN architecture produced 616 training images (154 per class) to create the optimal hyperparameters that support the multi-class classification procedure. The multi-class classification procedure produced 264 testing images (66 per class) to track how well the approach performed according to the four metrics that were considered. We notice that the best results of the proposed approach were achieved by performing a classification stage without a validation set, using the training and testing sets.
The comparison between the Inception-v3, Darknet-19, and CNN-Bayesian optimization approach concerning four criteria is shown in Table 4. Also, it was found that the performance of the proposed approach for 30 iterations was the same as for the proposed approach for 100 iterations. However, the proposed approach for 30 iterations could be a useful time-saving tool for screening ear diseases, and this is especially true in areas where there is a shortage of otolaryngologists. From experimental outcomes, the combination of CNN with Bayesian optimization is an effective tool in ear diagnosis where human experience is inadequate to improve classification accuracy. The limitation of this study depends on a recent ear database and fewer studies dealing with ear image databases.
Furthermore, this is the first survey to use a CNN schema with Bayesian hyperparameter optimization to classify otoscopy images into four diagnostic categories using a total of 880 images. This study is a good choice whether the otoscopy images were taken by otolaryngologists or non-otolaryngologists. The main issues handled in this study are minimizing the dependence on large training images and reducing the time when the CNN is used.
Considering some limitations of the current study, this proposed approach did not consider external factors for patients with ear complaints such as age, fever, ear fullness, and environmental changes in the diagnostic process. There is no correlation between clinical information and the current classifier's results based on otoscopy images.
Regarding the implications of the obtained results, the current study suggested the demand for a sufficient database for ear diseases. In future, the accurate diagnostic coverage in the proposed approach will be beneficial for physicians with less experience; thus, it may reduce the growing number of hearing-impaired patients.
Conclusion and Future Trends
In the era of ear disorders, it is difficult for an otolaryngologist to reach a precise diagnosis, which can have negative implications for treatment decisions. This field has been plagued by issues in otologic diagnosis related to limited consciousness, false detection, and a paucity of ear databases. This proposed approach could address these issues with CNN based on Bayesian hyperparameter optimization to provide an automatic diagnosis for patients with ear diseases who have otoscopic images. It was observed that the proposed approach is excellent analytical for multi-classification through four ear diseases. Ultimately, otology image processing will improve otolaryngology patient care, and ongoing work will boost the understanding of prediction models for rare specialized illnesses.
Data Availability
Data are available upon request.
References
Raveane, W., P. L. Galdámez, and M. A. González Arrieta. Ear detection and localization with convolutional neural networks in natural images and videos. Processes. 7:457, 2019.
Block, S. L., E. Mandel, S. Mclinn, M. E. Pichichero, S. Bernstein, S. Kimball, and J. Kozikowski. Spectral gradient acoustic reflectometry for the detection of middle ear effusion by pediatricians and parents. Pediatr. Infect. Dis. J. 17:560–564, 1998.
Wang, X., T. A. Valdez, and J. Bi. Detecting tympanostomy tubes from otoscopic images via offline and online training. Comput Biol Med. 61:107–118, 2015.
Lieberthal, A. S., A. E. Carroll, T. Chonmaitree, T. G. Ganiats, A. Hoberman, M. A. Jackson, M. D. Joffe, D. T. Miller, R. M. Rosenfeld, X. D. Sevilla, and R. H. Schwartz. The diagnosis and management of acute otitis media. Pediatrics. 131(3):e964–e999, 2013.
Harnsberger, H. R. The temporal bone: external, middle and inner ear segments. In: Handbook of Head and Neck Imaging, edited by S. M. Gay. St. Louis: Mosby, 1995, pp. 426–458.
Trojanowska, A., A. Drop, P. Trojanowski, K. Rosińska-Bogusiewicz, J. Klatka, and B. Bobek-Billewicz. External and middle ear diseases: radiological diagnosis based on clinical signs and symptoms. Insights Imaging. 3:33–48, 2012.
Pichichero, M. E., and M. D. Poole. Comparison of performance by otolaryngologists, paediatricians, and general practitioners on an otoendoscopic diagnostic video examination. Int. J. Pediatr. Otorhinolaryngol. 69:361–366, 2005.
Bassiouni, M., D. G. Ahmed, S. I. Zabaneh, S. Dommerich, H. Olze, P. Arens, and K. Stölzel. Endoscopic ear examination improves self-reported confidence in ear examination skills among undergraduate medical students compared with handheld otoscopy. GMS J. Med. Educ. 39(1):doc 3, 2022.
Shiao, A. S., and G. Yaun-Ching. A comparison assessment of videotelescopy for diagnosis of paediatric otitis media with effusion. Int. J. Pediatr. Otorhinolaryngol. 69:1497–1502, 2005.
Yong, M., T. Mijovic, and J. Lea. Endoscopic ear surgery in Canada: a cross-sectional study. J. Otolaryngol. Head Neck Surg. 45:4, 2016.
Pichichero, M. E., and M. D. Poole. Assessing diagnostic accuracy and tympanocentesis skills in the management of otitis media. Arch. Pediatr. Adolesc. Med. 155:1137–1142, 2001.
Buchanan, C. M., and D. D. Pothier. Recognition of paediatric otopathology by General Practitioners. Int. J. Pediatr. Otorhinolaryngol. 72:669–673, 2008.
Asher, E., E. Leibovitz, J. Press, D. Greenberg, N. Bilenko, and H. Reuveni. Accuracy of acute otitis media diagnosis in community and hospital settings. Acta Paediatr. 94:423–428, 2007.
Myburgh, H. C., S. Jose, D. W. Swanepoel, and C. Laurent. Towards low cost automated smartphone- and cloud-based otitis media diagnosis. Biomed. Signal Process Control. 39:34–52, 2018.
Viscaino, M., J. C. Maass, P. H. Delano, M. Torrente, C. Stott, and F. A. Cheein. Computer-aided diagnosis of external and middle ear conditions: a machine learning approach. PLoS ONE. 15:e0229226, 2020.
Livingstone, D., and J. Chau. Otoscopic diagnosis using computer vision: an automated machine learning approach. Laryngoscope. 130:1408–1413, 2019.
Sandström, J., H. Myburgh, C. Laurent, D. W. Swanepoel, and T. Lundberg. A machine learning approach to screen for otitis media using digital otoscope images labelled by an expert panel. Diagnostics. 12:1318, 2022.
Cha, D., C. Pae, S.-B. Seong, J. Y. Choi, and H.-J. Park. Automated diagnosis of ear disease using ensemble deep learning with a big otoendoscopy image database. EBioMedicine. 45:606–614, 2019.
Zeng, X., Z. Jiang, W. Luo, et al. Efficient and accurate identification of ear diseases using an ensemble deep learning model. Sci Rep. 11:10839, 2021.
Khan, M. A., S. Kwon, J. Choo, S. M. Hong, S. H. Kang, I. H. Park, S. K. Kim, and S. J. Hong. Automatic detection of tympanic membrane and middle ear infection from oto-endoscopic images via convolutional neural networks. Neural Netw. 126:384–94, 2020.
Lee, J. Y., S. H. Choi, and J. W. Chung. Automated classification of the tympanic membrane using a convolutional neural network. Appl. Sci. 9:1827, 2019.
Zafer, C. Fusing fine-tuned deep features for recognizing different tympanic membranes. Biocybernetics Biomed. Eng. 40(1):40–51, 2020.
Mohammed, K. K., A. E. Hassanien, and H. M. Afify. Classification of ear imagery database using Bayesian optimization based on CNN-LSTM architecture. J. Digit. Imaging. 35:947–961, 2022.
Prakash, N., A. Manconi, and S. Loew. Mapping landslides on EO data: performance of deep learning models vs traditional machine learning. Models. Remote Sens. 12:346, 2020.
Victoria, A. H., and G. Maragatham. Automatic tuning of hyperparameters using Bayesian optimization. Evol. Syst. 12:217–223, 2021.
Shahriari, Bobak, Swersky, Kevin, Wang, Ziyu, Adams, Ryan P., and de Freitas, Nando. Taking the human out of the loop: A review of bayesian optimization. Technical report, Universities of Harvard, Oxford, Toronto, and Google DeepMind, Proceedings of the IEEE 104.1 (2015): 148-175.
Kochanski G, Golovin D, Karro J, Solnik B, Moitra S, Sculley D. Bayesian optimization for a better dessert. In: 31st conference on neural information processing systems (NIPS) Long Beach, CA, USA, pp.1-10, 2017.
Kramer, O., D. E. Ciaurri, and S. Koziel. Derivative-free optimization. In: Computational Optimization, Methods and Algorithms, edited by C. E. Rasmussen, and C. K. I. Williams. Berlin: Springer, 2011, pp. 61–83.
Rasmussen, C. E. and Williams, C. K. I. Gaussian Processes for Machine Learning. In summer school on machine learning, Springer, Berlin, Heidelberg, pp. 63-71, 2006.
Joy TT, Rana S, Gupta S, Venkatesh S. Hyperparameter tuning for big data using Bayesian optimisation. 23rd International Conference on Pattern Recognition (ICPR) Cancún Center, Cancún, México, pp.2575- 2580, December 4-8, 2016.
Le Cun, Y., B. Yoshua, and G. Hinton. Deep learning. Nature. 521(7553):436–444, 2015.
Koutsoukas, A., K. J. Monaghan, X. Li, and J. Huan. Deep-learning: investigating deep neural networks hyper-parameters and comparison of performance to shallow methods for modeling bioactivity data. J. Cheminformat. 9(42):1–13, 2017.
Yoo, Y. Hyperparameter optimization of deep neural network using univariate dynamic encoding algorithm for searches. Knowl. Based Syst. 17:74–83, 2019.
S.R. Young, D.C. Rose, T.P. Karnowski, S. Lim, R.M. Patton, Optimizing deep learning hyper-parameters through an evolutionary algorithm, in Proceedings of the Workshop on Machine Learning in High-Performance Computing Environments (MLHPC 2015), ACM, Austin, Texas, 2015, pp. 1–5.
Davis J, Goadrich M. The relationship between Precision-Recall and ROC curves. Proceedings of the 23rd international conference on Machine learning. 2006 June 25-29; Pittsburgh USA; 2006, 233- 240.
Hossin, M., and M. Sulaiman. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process. 5(2):1, 2015.
Niermeyer, W. L., R. H. W. Philips, G. F. Essig, and A. C. Moberly. Diagnostic accuracy and confidence for otoscopy: are medical students receiving sufficient training? Laryngoscope. 129(8):1891–1897, 2019.
Ahuja, S., B. K. Panigrahi, and T. K. Gandhi. Enhanced performance of Dark-Nets for brain tumor classification and segmentation using colormap-based superpixel techniques. Mach. Learn. Appl. 7:100212, 2022.
Rajasekar, V., M. P. Vaishnnave, S. Premkumar, V. Sarveshwaran, and V. Rangaraaj. Lung cancer disease prediction with CT scan and histopathological images feature analysis using deep learning techniques. Results Eng. 18:101111, 2023.
Senaras C, Moberly AC, Teknos T, Essig G, Elmaraghy C, Taj-Schaal N, et al. detection of eardrum abnormalities using ensemble deep learning approaches. Proceeding in medical imaging 2018: Computer-Aided Diagnosis. 2018 February 27; Houston USA; 10575, pp.105751A.
Huang YK, Huang CP. A depth-first search algorithm based otoscope application for real-time otitis media image interpretation. Parallel Distrib Comput Appl Technol PDCAT Proc 2018; 2017(Decem):170–5.
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
HMA contributed to writing- reviewing and editing, conceptualization, and methodology. KKM contributed to software, validation, and data curation. AEH contributed to supervision.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no conflict of interest.
Additional information
Associate Editor Joel Stitzel oversaw the review of this article.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Afify, H.M., Mohammed, K.K. & Hassanien, A.E. Insight into Automatic Image Diagnosis of Ear Conditions Based on Optimized Deep Learning Approach. Ann Biomed Eng 52, 865–876 (2024). https://doi.org/10.1007/s10439-023-03422-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10439-023-03422-8