
Abstract
The purpose of this study was to assess the effect of using alternative types of forest inventory units (FIUs) in multi-objective forest planning. The research was carried out in a Mediterranean forest area in central Spain. The study area was divided, alternatively, into pixels (square cells) and segments of two different sizes (small and large), which represented the tested FIU types. Airborne laser scanning data (ALS) and field sample plots were combined using the area-based approach to estimate forest attributes for each FIU. Dynamic treatment units were created using cellular automaton optimization aiming at maximizing timber production during a 60-year plan with periodical even-flow cuttings both with and without the aim of creating aggregated harvest blocks. The hypothesis was that the use of segments would enhance the clustering of harvests, as compared to cells, and provide dynamic treatment units more suitable for forestry practice. The results showed that segment-based planning created compact harvest blocks even without the use of spatial objective variables in optimization. The spatial layout of the solution for large segments was the most efficient in the absence of spatial objective variables. The FIU type that performed the best in maximizing timber production was the small segments. For the three tested FIU types, the inclusion of spatial objective variables further improved the clustering of harvests, especially during the latter half of the 60-year planning period. Segmentation acted as a first-phase clustering that made spatial optimization easier and faster. In the case of square cells, the clustering of harvests was greatly improved by the inclusion of spatial goals. The forest planning system and the spatial optimization method proposed in this study maximize the utility of fine-grained ALS data.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The use of remote sensing data in forest inventory has considerably increased the efficiency of practical forestry operations (Maltamo and Packalen 2014). Airborne laser scanning (ALS), especially, is nowadays extensively used to predict stand-level forest attributes (Maltamo et al. 2014). The integration of remote sensing data into forest management planning can be highly valuable as ALS data provide spatially continuous and accurate information about canopy and underlying trees.
ALS can be also used to stratify a given forest area into homogenous inventory units (Mustonen et al. 2008). There are several methods and techniques for classifying and delineating forest inventory units (FIUs), ranging from traditional aerial photointerpretation to automatic unsupervised or supervised segmentation (Coburn and Roberts 2004). Good estimates of current stand attributes result in better projections of future stand conditions, which contributes to reducing uncertainty in forest planning (Eid 2000; Mäkinen et al. 2009). Segmentation methods are computationally more demanding than straightforward approaches based on a grid of cells when delineating FIUs (e.g., Næsset 1997), but this effort might be compensated for in later steps of forest planning as FIUs based on segments tend to be more homogenous than grid cells in terms of stand attributes, and follow better existing stand boundaries (Hyvönen et al. 2006). The use of the so-called nano-segments (Pippuri et al. 2013) as temporary interpretation units might enhance the performance of using segments in forest planning. Nano-segments enable reduced edge effect in the border of actual segments while keeping the mean size of prediction unit approximately the same as the size of field plots used in model fitting.
Size and shape of FIUs are important parameters to consider in modern forest management planning, which often combines spatial and non-spatial objectives (Pukkala et al. 2009). Previous studies have explored the use of dynamic treatment units (DTU) with different inventory units by integrating spatial goals in the formulation of optimization-based forest planning problems (Heinonen et al. 2007; Packalen et al. 2011; Pascual et al. 2016), so as to cluster harvesting activities as required in forestry practice (Öhman and Eriksson 2010). However, adding spatial objectives increases the complexity of optimization problems. Different shapes and sizes of inventory units have different neighborhood relationships, which may result in different optimal solutions for a given spatially explicit forest planning problem.
The aim of this study is to assess the impact of differences in size and shape of FIUs on the achievement of spatial and non-spatial forest management objectives. We compare three ALS-based alternative FIUs: segments of two different sizes (small and large) and square cells. Stand attributes at segment levels are computed from nano-segments for which attributes are predicted first. This reduces the issue caused by mixed cells in the border of the segments.
Material
Study area
The study area is the public forest MUP89 owned by the municipality of San Leonardo de Yagüe (41°51′N, 3°15′E, 1122 m–1243 m a.s.l.) and located in the Iberian System mountain range, in central Spain. The study area of 1059 hectares consists of Pinus nigra Arn. stands with scattered presence of Pinus pinaster Ait. as a secondary species. The MUP89 consists of two forest areas divided by a main road and secondary forest tracks. The southwestern limit is the Rio Lobos canyon where slopes steeper than 45° can be found. The landscape is a mosaic of heterogeneous patches of vegetation, typical of many Mediterranean forest areas, resulting in substantial variation in forest attributes throughout the study area. Forest management in the area is devoted to ensure sustained timber supply to local industries, important drivers of local economy.
Sample plots and ALS data
Systematic sampling was used to establish a network of 116 circular sample plots of 12.6 m radius. The plots were measured during autumn 2010 using satellite positioning system (Trimble R6 Global Navigation Satellite System) to precisely determine the locations of plot centers. On each plot, all trees with a diameter at breast height (dbh) > 7.5 cm were callipered and the heights (h) of all trees were measured using Vertex III hypsometer. Stand basal area (G) and number of trees per hectare (N) were computed from tree data, while age was estimated using tree-ring analysis of a dominant tree per plot. The maximum tree height measured in each plot was considered as the dominant height (H0) of the plot (Table 1).
The ALS data were collected in April 2010 using ALS60 II laser scanning system. The study area was scanned from an altitude of 1200 m above ground level, with a scan angle of ± 12°. This resulted in a nominal pulse density of 2 pulses m−2 and a footprint size of 26 cm (1/e2). An interpolated digital terrain model (DTM) of 1-m2 cell size was constructed by classifying echoes as ground and non-ground hits according to the approach described by Axelsson (2000). Heights above ground level were calculated by subtracting DTM from ALS echoes. The 1-m2 canopy height model (CHM) was interpolated by searching the highest ALS echo from the center of each pixel within a radius of 1.6 m. Empty pixels were filled by the average value of non-empty neighboring pixels (Fig. 1).

Delineation of the study area with the orthophotograph as background image on left and the canopy height model (CHM) on right
Methods
Estimation of stand-level attributes
Forecasting stand development under alternative management options based on forest growth and yield models (see further details in “Growth models and simulation rules” section) required the prediction of the current number of trees per hectare (N), stand basal area (G, m2 ha−1) and dominant height (H0, m) for each segment or cell. We relied on the area-based approach (Næsset 2002) to predict these stand attributes using ALS metrics and field sample plots. In this approach, the echoes within a given plot area are used to describe above-ground vegetation characteristics. An array of 41 ALS height and density metrics were computed for each plot (McGaughey 2015) and used as potential predictor variables for our regression models.
First we selected an initial set of predictor variables based on well-performing variables in our previous studies and with the help of the stepwise model construction procedure (Venables and Ripley 2002). In the second stage, square-root, logarithmic and quadratic transformation of the response and predictor variables were tested and final models were selected based on visual assessment of residuals. Statistical analyses were carried out in the R software (R Development Core Team 2016).
Definition of FIUs
Segments
Multiresolution segmentation implemented in Trimble eCognition program was used to create either small or large segments from the canopy height model (CHM) of 1-m cell size. Individual pixels (image objects of one-pixel-size) were first identified, and then merged into neighboring objects based on a homogeneity criterion, which was calculated as a combination of CHM and shape homogeneity (Trimble eCognition 2015). The CHM homogeneity was defined based on the standard deviation of the CHM values, and the shape homogeneity based on the deviation from a compact shape. By weighting these criteria and changing the scale parameter, the results of multiresolution segmentation can be customized. When larger objects are preferred, higher values for the scale parameter are used, and vice versa.
Different scales and weightings for CHM and shape were used to split the study area into segments of two different sizes. In both segmentations, an initial fine-grained segmentation was first made for the whole study area using multiresolution segmentation. Two sets of scale parameters were used to get two segmentations of different average sizes of segments. Then, the region-growing method of multiresolution segmentation was used to merge the smallest segments to their neighboring image objects. First, all image objects smaller than 500 m2 were merged, and then all objects smaller than 1000 m2 were merged to their neighbors if the scale and weightings enabled the merging of the objects. The average sizes for small and large segments were 1651 m2 and 3595 m2, respectively. The creation of segments took 37 and 22 min for small and large segments, respectively. As a final step, segment borders were slightly smoothed using the Chaikin’s Algorithm implemented in GRASS GIS (GRASS Development Team 2017).
Nano-segments
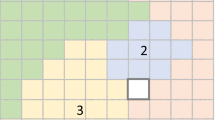
Segments were divided into sub-units (later referred to as nano-segments) using a grid of cells, as described in Pippuri et al. (2013), to obtain prediction units of about the same size as the field plots but without mixed cells in borders of segments. Grid cells were first intersected by segment borders. Then, the formed small parts of grid cells in the inner edge of the segment were merged to the neighboring cells (Fig. 2). As a result, nano-segments never crossed segment boundaries, which prevented the creation of mixed calculation units, i.e., units that included parts of two dissimilar stands. The resulting non-square cells were, on average, slightly larger than square cells (here 500 m2), but minor difference in size is not a serious issue in the area-based method (Table 2).

Delineation of large segments (red boundaries) and the corresponding nano-segments (yellow boundaries). The background shows the canopy height model (CHM). (Color figure online)
ALS metrics were computed and forest attributes predicted for nano-segments. Then, predicted nano-segment attributes were aggregated to obtain stand attributes for segments as follows: for stand basal area and number of trees, segment-level attributes were computed as area-weighted mean values; and the segment value of H0 was computed as the maximum dominant height among all nano-segments located within a given segment.
Square cells
Cell-based planning was implemented using a grid of square cells that were overlaid with the study area. The cell size was 500 m2 (side 22.36 m), i.e., equal to the area of the field sample plots. The ALS metrics were computed for the cells, and finally, stand attributes (N, G and H0) were predicted for every cell.
Growth models and simulation rules
To be able to use individual-tree growth models in simulation, diameter distribution models as used in Pascual et al. (2016) were fitted to our data and used to transform the predicted stand-level attributes into individual-tree level information.
Growth models were developed based on permanent plots from the 2nd and 3rd Spanish National Forest Inventory (NFI) (DGCN 1996, 2006). The model set (Eqs. 1–5) consisted of models for 10-year diameter increment (Id, cm), 10-year survival rate (s), height–diameter relationship (Hd, m), number of ingrowth trees during a 10-year period (Fin, trees ha−1) and the mean diameter of ingrowth (Din, cm). The models are as follows:
where d is dbh (cm), BAL is basal area of trees larger than the subject tree (m2 ha−1), BALthinned is basal area of the trees thinned during the past 10-year period (m2 ha−1), GI is growth index of the plot as defined in Trasobares and Pukkala (2004), A is altitude of the site in hundreds of meters, h is tree height (m), N is number of trees (trees ha−1), G is stand basal area (m2 ha−1), and Gspe is stand basal area of the species for which ingrowth is predicted (m2 ha−1). GI is a measure of site productivity. It is the ratio between the growth of the plot and the growth of a similar growing stock on average site (Trasobares and Pukkala 2004). The removed competing trees during the 10-year growth projection period (BALthinned) were always zero in our simulations. However, BALthinned was not always zero in the modeling dataset (NFI plot). Since BALthinned improved the models for diameter increment and survival, it was included as a predictor in these two models.
Simulation instructions for “nearly optimal” management were developed as follows: We used the stand dynamics models shown above to predict stand attributes from present state to 10 years ahead. We then calculated the predicted 10-year value increment and divided it by the stumpage value of the stand, to obtain relative value increment (RelVaInc). Then, a regression model showing RelVaInc as a function of stand-level attributes was used to develop instructions for thinning basal area and for the diameter at which final felling should be done assuming a 2% discount rate to find out when a stand was financially mature for thinning or final felling. The results of these calculations were used to develop simulation instructions as shown in Pascual et al. (2018).
Simulation of forest management alternatives
The set of growth and yield models (Eqs. 1–5) was used to predict stand dynamics for a 60-year planning period (divided into three 20-year periods). The simulation instructions were used as follows: If the stand mean diameter of a given FIU was higher than the final felling diameter of the instruction, seed tree cut was simulated followed by the removal of seed trees in the following period. Otherwise, stand basal area was compared to the thinning basal area, and a thinning treatment was simulated if the basal area was higher than in the instruction. In this case, three thinning intensities were simulated: light (20% reduction in stand basal area), intermediate (30%) and heavy thinning (40%). A total of 60,581 treatment schedules were simulated for large segments, 129,641 for small segments and 460,417 for cells. To create variation in the timing of cuttings, the basal area limit for thinning and the diameter limit for final felling were multiplied by 0.7, 1 and 1.3 and the simulation was repeated with all modifications of the simulation instructions.
Planning problems and spatial optimization
Forest planning aimed at maximizing timber production during the 60-year planning horizon (i.e., sum of harvested volumes and ending volume less initial volume) with even-flow of harvested timber every 20-year period. For each FIU type, two alternative planning problems were formulated, i.e., either without considering spatial objectives (NonSpatPlan), and by explicitly including spatial objectives (SpatPlan). As a result, six alternative forest plans (two per FIU type) were developed.
The following four non-spatial objective variables were used in both NonSpatPlan and SpatPlan: maximize growing stock volume at the end of the plan, i.e., after 60 years (Vtot), and harvest the same volume during all three 20-year periods (R1, R2 and R3, respectively). A harvesting target of 50,000 m3 per period was defined based on preliminary optimizations which showed that cutting 50,000 m3 during 20 years maintained the growing stock volume at the initial level. Therefore, we set the harvesting target as 50,000 m3 in all problems.
SpatPlan included four additional spatial objective variables with the aim of aggregating harvesting activities: maximization of the proportion of cut–cut borders of all adjacent FIUs (CC) and those treated with final felling (CCFF), and minimization of the proportion of cut–uncut borders of adjacent FIUs (CNC) and those treated with final felling (CNCFF). Objective variables CC and CNC were used to create compact treatment units for all cuttings, while CCFF and CNCFF did the same for final felling.
Numerical optimization methods were used to solve the afore-described forest planning problems using the utility theoretic approach, which has been successfully applied in multi-objective forest planning (Pukkala and Kangas 1993). The previous literature has explored the efficiency of heuristic methods in spatially explicit forest planning problems (Pukkala and Kurttila 2005). Among these heuristics algorithms, threshold accepting (TA) and simulated annealing (SA) have been proved to be good but very slow and inefficient when the planning problem includes a high number of calculation units (Pukkala et al. 2009). To overcome this shortcoming and after testing SA, we used cellular automaton (CA) (von Neumann 1966) based on its efficiency in solving large spatially explicit forest planning problems (Heinonen and Pukkala 2007; Mathey et al. 2007).
The CA method described in Heinonen and Pukkala (2007) was used to solve a two-phase optimization problem including FIU-level and neighborhood-related goals (local function), and global goals at study area level (global function). The initial solution was obtained by randomly assigning one of the simulated schedules to each FIU. Then, for each FIU, a random number is drawn from a uniform 0–1 distribution. A mutation took place if the random number was smaller than the current mutation probability (Heinonen and Pukkala 2007). Otherwise, innovation occurred if the random number was smaller than the current innovation probability. When innovation occurred, the schedule which maximized the following local objective function was selected for the cell or segment.
NonSpatPlan:
SpatPlan
where U is the objective function value and V is the ending volume of the FIU (m3 ha−1) and Vmax is the largest ending volume value after 60 years among all schedules of all FIUs (m3 ha−1). In SpatPlan, based on preliminary tests, the same weights were used with all FIU types giving high importance to CNC and CNCFF objectives in order to create compact harvest blocks.
When the local phase was completed, a global objective function (Eq. 8) was added to the local function to obtain a function that expressed both local and global objectives (Eq. 9). The global objective function expressed the 50,000 m3 periodical cutting targets (R1, R2 and R3) and maximized the total ending volume (Vtot, m3). Ending volume was included also in the global function as preliminary tests showed that this resulted in slightly better solutions than having the non-spatial objective only in the local objective function. The global priority function was:
where P is global priority. After the local optimization phase (maximizing Eqs. 6 or 7) was completed, the global phase started to use Eq. 9 as the objective function. The value of b was increased gradually so that the step size was proportional to the mean size of the FIU type. The starting value of b was zero. In every iteration, the value of b was increased by 0.072 when using large segments, 0.0022 when using small segments and 0.001 when using cells. When the global utility function (Eq. 8) reached a value which could not be improved, global optimization ended in all cases. At that point, the even-flow harvesting targets (R1, R2 and R3) were always met. The objective function maximized in the second phase was:
where OF is total priority, a is the area of the FIU, A is the total area of the study area, and b is the weight of the global priority function P. An example of the progress of an optimization run is shown in Fig. 3.

Example of the progress of the two-step CA run (spatially explicit optimization for cells); a local and global utility, b harvested volume and c spatial objective variables (total length of different boundaries). The arrows indicate the moment when the global priority function was added to the objective function
Assessment of cutting aggregation
The performance of different FIU types, and NonSpatPlan versus SpatPlan, was assessed in terms of timber production and aggregation of harvest blocks. The number and mean size of harvest blocks were computed for all problems. In addition, the area–perimeter ratio (AP) was computed to assess the spatial efficiency of segments and cells in creating harvest blocks considering all cuttings and specifically final felling. Solutions for cell-based plans were smoothed to eliminate the stair-type pattern caused by the square-shaped FIUs, to make cell- and segment-based harvest blocks comparable with respect to AP ratio. The smoothing was implemented with the PAEK procedure (Bodansky et al. 2002). In the PAEK, the magnitude of smoothing is controlled with the smoothing tolerance parameter. Its value was set to 23.3 m, which is slightly a larger value than the used cell size (22.4 m). In addition, the time needed for optimization was recorded for each problem.
Results
Regression models
The selected predictor variables for the number of trees per hectare (N) were the 60th percentile of height distribution of the echoes (ElevP60), forest cover computed from first echoes (FC1) and coefficient of variation of all echoes (ElevCV). In the stand basal area model (G), the predictor variables were the 20th percentile of height distribution (ElevP20) and forest cover including all echoes (FCALL). Finally, the 99th height percentile (ElevP99) was the predictor of dominant height. In this case, the square-root transformation of the response variable (H0) resulted in the best model (Table 3).
Prediction of current forest attributes
Stand attributes were predicted for each nano-segment using the previously presented regression models (Table 3) and then aggregated to obtain forest attributes for the FIUs. The mean values of N and H0 were higher for square cells than for segments. Predicted values of G were, on average, slightly lower for cells than for large segments, but higher for cells than for small segments (Table 4). The standard deviation of G between FIUs was the same for small and large segments, and slightly lower for cells. The total growing stock volume estimates were 253,016 m3 for large segments and 253,019 m3 for small segments, whereas for cells the growing stock volume was about 1.1% less (250,163 m3).
Timber production and computation time
Timber production was the highest when small segments were used (Table 5). In NonSpatPlan, timber production for large and small segments was 0.7 and 3.9% higher than in cell-based planning. In SpatPlan, the difference was 2.3% for large segments and 4.8% for small segments. The use of spatially explicit problem formulation decreased ending volume and, as a result, timber production. The difference in timber production between non-spatial and spatial formulation was 5.6% for large segments, 6.3% for small segments and 7.1% for cells.
The computational cost of using cells in SpatPlan was about 10 times higher than with small segments and 40 times higher than with large segments. The difference in time consumption decreased to 6.1-fold (cells vs. large segments) and 4.1-fold (cells vs. small segments) times when the time consumed for segmentation was added. The time for simulating alternative treatment schedules for the FIUs was directly proportional to the number of FIUs, i.e., 7.8 times longer for cells than large segments, 2.2 times longer for cells than small segments and 3.6 times longer for small segments than large segments.
Aggregation of cuttings
According to the AP values, the use of large segments aggregated all cuttings most efficiently (highest AP ratio) in NonSpatPlan, followed by small segments and cells (Fig. 4). The AP values increased 2.4-, 3.4- and 4.4-fold for large segments, small segments and cells, respectively, for SpatPlan formulation. Therefore, the benefit of using spatial optimization increased as FIUs decreased in size. As a result, the AP ratios of the spatial problems were of the same magnitude for all three FIU types. When only final felling was considered, the improvement in AP ratios was 2.1-, 2.5- and 3.7-fold, respectively, for large segments, small segments and cells. Final felling harvest blocks composed of large segments had the highest AP ratios in both problems.

Area–perimeter ratio (AP) in NonSpatPlan (non-spatial formulation) and SpatPlan (spatial formulation) for the three tested FIUs when considering all cuttings (left) and final felling (right). A high AP value implies good aggregation and high compactness in the harvest blocks
In NonSpatPlan, the size of harvest blocks was always the largest when using large segments. However, spatial optimization narrowed the gap between FIU types (Table 6). With large segments, the mean size of harvest blocks was 6.1 times larger in SpatPlan as compared to NonSpatPlan. The corresponding ratio was 8.9 for small segments and 22.8 for cells. In all cases for SpatPlan, the size of harvest blocks increased from the first period onward (Table 6, Fig. 6). The number of harvest blocks was clearly lower in SpatPlan than in NonSpatPlan (Table 6).
In NonSpatPlan, all plans had scattered harvest blocks, most when cells were used (Fig. 5). The plans started to differ more and more after the first 20-year period in the spatio-temporal allocation of treatments and also in terms of prescription type. Segment-based plans included more final felling, while cell-based plans relied more on thinning. In SpatPlan, the spatial layout and distribution of treatments were very similar for the three FIU types (Fig. 6).

Treatment units in NonSpatPlan (non-spatial)

Treatment units in SpatPlan (spatial)
Discussion
This study compared the use of segments of different sizes and square cells in forest planning. The outer boundary of nano-segments and segments followed the irregular boundary of forest patches, which is a clear advantage compared to cells, some of which are located in the transition zone between two forest patches of different characteristics, or between forest and non-forest area. The standard deviation of G between all the FIUs of the study area was higher for segments than for square cells. This is logical because segmentation reduced the variation in the values of ALS metrics within segments as compared to cells, leading to greater variability in stand attributes between segments than between cells. The standard deviation of G was exactly the same for small and large segments, which is indicative of the reliability of using nano-segments for upscaling stand-level information to different levels of spatial resolution.
In NonSpatPlan, the spatial arrangement of treatments was very scattered when cells were used. The dispersion of treatments was so high that it would be difficult to implement NonSpatPlan when using cells. This conclusion is in line with previous experiences on cell-based planning (Pascual et al. 2016). The spatial layout of segments in NonSpatPlan showed fewer isolated FIUs as compared to cells. This suggested that, opposite to using square cells, relying on ALS-based segmentation leads to some spatio-temporal clustering of forest treatments even without using spatial objective variables in optimization. Therefore, segmentation may be regarded as a method to conduct preliminary or first-stage aggregation of cuttings.
The inclusion of spatial goals improved the formation of compact harvest blocks by promoting the spatio-temporal clustering of similar forest treatments, which is in line with previous studies (Lu and Eriksson 2000; Rebain and McDill 2003; Tóth and McDill 2008). As numerically expressed by the AP ratios, spatial optimization yielded compact harvest blocks with all three FIU types but the gain in spatial goals was greater with smaller FIUs (cells and small segments). The ranking of the AP ratio of cells shifted from the last place to the first when all cuttings were considered. When the analyses were done for final felling, large segments had the highest AP ratio in both problems.
In this research, the same weights of objective variables were used with all FIU types to reveal the effect of the type and size of FIU on the layout of dynamic treatment units. Preliminary tests and sensitivity analysis were used to derive weights that ensured the achievement of harvesting targets (global optimization) while simultaneously clustering cuttings. These preliminary tests led to high weight for minimizing the length of adjacent FIUs both treated with final felling (CNCFF).
As expected, the inclusion of spatial objective variables in problem formulation decreased timber production (by 5.6–7.1%). Previous research has explored the effect of spatial formulations and spatial constraints on non-spatial objectives such as net present value or yield (Baskent and Keles 2005). For example, Daust and Nelson (1993) found 2–29% losses in yield due to the use of spatially explicit formulations in Monte Carlo integer programming.
Segment-based solutions for SpatPlan concentrated cuttings with a lower computational effort compared to cells. It might be interesting to compare the performance of alternative FIUs when adding additional spatial constraints to the problem formulation (Williams et al. 2005; Vielma et al. 2007) as the size and shape of FIUs might have an impact on the solution depending on the nature of the added spatial constraints (Murray and Weintraub 2002). For example, it might be possible to measure the contribution of segments to reduce the presence of undesirable edges (Ross and Tóth 2016) when composing the harvest blocks along the optimization process. In addition, it might also be worthwhile to evaluate spatial optimization by integrating fire risk minimization in problem formulation since wildfires are a major concern in the region.
Alternative optimization methods such as mixed integer programming and global meta-heuristics have been used to aggregate cuttings in spatial optimization (e.g., Pukkala and Kurttila 2005; McDill et al. 2016). In our case, during the preliminary tests with global meta-heuristics, we found that when SA was used with square cells in spatial optimization, the solution times were substantially longer than with CA, and the aggregation was poorer. The probable reason was the high number of square cells (22,879 cells with a total of 460,117 alternative treatment schedules), and therefore, global meta-heuristics became inefficient (Pukkala et al. 2009).
Conclusions
Our results show that spatial optimization improves the delineation of harvest blocks. Segmentation greatly decreased the computational cost of spatial problem formulations and substantially increased the aggregation of FIUs. The use of small segments maximized timber production in both non-spatial and spatial problem formulations. The compactness of harvest blocks composed of cells was greatly improved when spatial objective variables were included in problem formulation. The use of nano-segments made it possible to precisely upscale the prediction of attributes; the computed initial growing stock volume was the same for small and large segments. The findings of this study verified the capability of spatial optimization to create dynamic treatment units when using small calculation units resulted from ALS-based inventories. The spatial forest planning methods analyzed in this study increase the precision of prescriptions and help to maximize the utility that can be obtained by using fine-grained ALS data.
References
Axelsson P (2000) DEM generation from laser scanner data using adaptive TIN models. ISPRS 33:111–118
Baskent EZ, Keles S (2005) Spatial forest planning: a review. Ecol Model 188:145–173. https://doi.org/10.1016/j.ecolmodel.2005.01.059
Bodansky E, Gribov A, Morakot P (2002) Smoothing and compression of lines obtained by raster-to-vector conversion, LNCS 2390. Springer, Berlin, pp 256–265
Coburn CA, Roberts ACB (2004) A multiscale texture analysis procedure for improved forest stand classification. Int J Remote Sens 25(20):4287–4308. https://doi.org/10.1080/0143116042000192367
Daust DK, Nelson JD (1993) Spatial reduction factors for strata- based harvest schedules. For Sci 39(1):152–165
DGCN (1996) II Inventario Forestal Nacional 1986–1996, Dirección General de Conservación de la Naturaleza. Ministerio de Medio Ambiente, Madrid
DGCN (2006) III Inventario forestal nacional 1996–2006, Dirección General de Conservación de la Naturaleza. Ministerio de Medio Ambiente, Madrid
Eid T (2000) Use of uncertain inventory data in forestry scenario models and consequential incorrect harvest decisions. Silva Fenn 34:89–100
GRASS Development Team (2017) Geographic resources analysis support system (GRASS) software, version 7.2. Open source geospatial foundation. http://grass.osgeo.org
Heinonen T, Pukkala T (2007) The use of cellular automaton approach in forest planning. Can J For Res 37:2188–2200. https://doi.org/10.1139/X07-073
Heinonen T, Kurttila M, Pukkala T (2007) Possibilities to aggregate raster cells through spatial optimization in forest planning. Silva Fenn 41:89–103
Hyvönen P, Pekkarinen A, Tuominen S (2006) Segment-level stand inventory for forest management. Scand J For Res 20:75–84. https://doi.org/10.1080/02827580510008220
Lu F, Eriksson LO (2000) Formation of harvest units with genetic algorithms. For Ecol Manag 130:57–67
Mäkinen A, Holopainen M, Kangas A, Rasinmäki J (2009) Propagating the errors of initial forest variables through stand- and tree-level growth simulators. Eur J For Res 129:887–897
Maltamo M, Packalen P (2014) Species-specific management inventory in Finland. In: Maltamo M et al (eds) Forestry applications of airborne laser scanning: concepts and case studies, managing forest ecosystems 27. Springer, Dordrecht. https://doi.org/10.1007/978-94-017-8663-8_1
Maltamo M et al (eds) (2014) Forestry applications of airborne laser scanning: concepts and case studies, managing forest ecosystems 27. Springer, Dordrecht. https://doi.org/10.1007/978-94-017-8663-8_1
Mathey AH, Krcmar E, Tait D, Vertinsky I, Innes J (2007) Forest planning using co-evolutionary cellular automata. For Ecol Manag 239:45–56. https://doi.org/10.1016/j.foreco.2006.11.007
McDill ME, Tóth SF, John RS, Braze J, Rebain SA (2016) Comparing model I and model II formulations of spatially explicit harvest scheduling models with maximum area restrictions. For Sci 62:28–37
McGaughey RJ (2015) FUSION/LDV: software for LiDAR data analysis and visualization. Version 3.30. U.S. Department of Agriculture Forest Service, Pacific Northwest Research Station, University of Washington, Seattle, Wash. http://forsys.cfr.washington.edu/fusion/. FUSION_manual.pdf, Accessed October 2015
Murray AT, Weintraub A (2002) Scale and unit specification influences in harvest scheduling with maximum area restrictions. For Sci 48:779–789
Mustonen J, Packalen P, Kangas A (2008) Automatic segmentation of forest stands using a canopy height model and aerial photography. Scand J For Res 23:534–545. https://doi.org/10.1080/02827580802552446
Næsset E (1997) Determination of mean tree height of forest stands using airborne laser scanner data. ISPRS 52:49–56
Næsset E (2002) Predicting forest stand characteristics with airborne scanning laser using a practical two-stage procedure and field data. Remote Sens Environ 80:88–99
Öhman K, Eriksson LO (2010) Aggregating harvest activities in long term forest planning by minimizing harvest area perimeters. Silva Fenn 44:77–89
Packalen P, Heinonen T, Pukkala T, Vauhkonen J, Maltamo M (2011) Dynamic treatment units in eucalyptus plantation. For Sci 57:416–426
Pascual A, Pukkala T, Rodríguez F, de-Miguel S (2016) Using spatial optimization to create dynamic harvest blocks from LiDAR-based small interpretation units. Forests 7(10):220
Pascual A, Pukkala T, de-Miguel S (2018) Effects of plot positioning errors on the optimality of harvest prescriptions when spatial forest planning relies on ALS data. Forests 9(7):371. https://doi.org/10.3390/f9060371
Pippuri I, Maltamo M, Packalen P, Mäkitalo J (2013) Predicting species-specific basal areas in urban forests using airborne laser scanning and existing stand register data. Eur J For Res 132:999–1012
Pukkala T, Kangas J (1993) A heuristic optimization method for forest planning and decision-making. Scand J For Res 8:560–570
Pukkala T, Kurttila M (2005) Examining the performance of six heuristic optimisation techniques in different forest planning problems. Silva Fenn 39:67–80
Pukkala T, Heinonen T, Kurttila M (2009) An application of a reduced cost approach to spatial forest planning. For Sci 55:13–22
R Core Team (2016) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/
Rebain S, McDill ME (2003) A mixed-integer formulation of the minimum patch size problem. For Sci 49:608–618
Ross KL, Tóth SF (2016) A model for managing edge effects in harvest scheduling using spatial optimization. Scand J For Res 31:646–654
Tóth SF, McDill ME (2008) Promoting large, compact mature forest patches in harvest scheduling models. Environ Model Assess 13:1–15
Trasobares AT, Pukkala P (2004) Using past growth to improve individual-tree diameter growth models for uneven-aged mixtures of Pinus sylvestris L. and Pinus nigra Arn. in Catalonia, north-east Spain. Ann For Sci 61:409–417. https://doi.org/10.1051/forest:2004034
Trimble eCognition (2015) eCognition Developer 9.1 User Guide. pp 265
Venables WN, Ripley BD (2002) Modern applied statistics with S, 4th edn. Springer, New York
Vielma J, Murray A, Ryan D, Weintraub A (2007) Improving computational capabilities for addressing volume constraints in forest harvest scheduling problems. Eur J Oper Res 176(2):1246–1264
von Neumann J (1966) The theory of self-reproducing automata. In: Burks A (ed) Theory of Self- Producing Automata. University of Illinois Press, Urbana
Williams J, ReVelle C, Levin S (2005) Spatial attributes and reserve design models: a review. Environ Model Assess 10(3):163–181
Acknowledgements
Open access funding provided by University of Eastern Finland (UEF) including Kuopio University Hospital. This research was supported by the University of Eastern Finland, School of Forest Sciences and research consortium projects FORBIO (Proj. 14970) and ADAPT (Proj. 14907), funded by the Academy of Finland and led by Prof. Heli Peltola, at the School of Forest Sciences, University of Eastern Finland (UEF). Sergio de-Miguel was supported by the European Union’s Horizon 2020 MultiFUNGtionality Marie Sklodowska-Curie (IF-EF No 655815).
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Arne Nothdurft.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Pascual, A., Pukkala, T., de Miguel, S. et al. Influence of size and shape of forest inventory units on the layout of harvest blocks in numerical forest planning. Eur J Forest Res 138, 111–123 (2019). https://doi.org/10.1007/s10342-018-1157-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10342-018-1157-5