
Abstract
In this study, I describe the song of the Cinnamon-breasted Bunting (Emberiza tahapisi)—a common and widespread species in sub-Saharan Africa. Several aspects of song behaviour were addressed based on recordings of 58 males in the Bamenda Highlands (NW Cameroon). The song of the Cinnamon-breasted Bunting is discontinuous and consists of short (1.2 s on average), relatively broadband (range 2.5–9.2 kHz) strophes repeated at a highly variable rate (2–14 strophes per minute). Each male sang a single song type consisting of 4–9 different syllable types. Syllable types differed in acoustic structure, and I describe a total of 40 discrete types. At the song type level, only 8 different song types were found. Males from local groups tended to have slightly more similar songs than strangers separated by a distance of more than 500 m. However, males with shared song types clearly did not aggregate. All males within the studied population shared a characteristic final whistle syllable, which resemble some other buntings. The birds sang from locations elevated above the surrounding vegetation, usually from trees or rocks. I found no significant relationship between song rate, time after sunrise, time of season and song post height.
Zusammenfassung
In dieser Arbeit beschreibe ich den Gesang der Bergammer, einer in den Ländern südlich der Sahara häufigen und weit verbreiteten Art. Anhand der Aufnahmen von 58 Männchen aus dem Bamenda-Hochland (NW-Kamerun) werden die Aspekte ihres Sing-Verhaltens untersucht. Der Gesang dieser Art ist nicht zusammenhängend, sondern besteht aus kurzen, im Schnitt 1,2 Sekunden dauernden, relativ breitbandigen (2,5–9,2 kHz) Strophen, die mit einer hohen Variabilitätsrate wiederholt werden (2–14 Strophen pro Minute). Jedes einzelne Männchen sang einen einzigen Gesangs-Typ aus 4–9 unterschiedlichen Silben-Typen, die sich in ihrem akustischen Aufbau unterschieden; ich beschreibe 40 eigene derartige Typen. Bei den Gesangs-Typen konnten nur 8 Typen gefunden werden. Männchen innerhalb lokaler Gruppen zeigten etwas ähnlichere Gesänge als fremde Männchen in Entfernungen von mehr als 500 Metern; aber Männchen mit gemeinsamen Gesangs-Typen kamen nicht unbedingt zusammen vor. Alle Männchen der untersuchten Population hatten eine Pfeif-Silbe am Schluss gemeinsam, die an einige andere Ammern-Arten erinnerte. Die Vögel sangen an Stellen, die höher als die umgebende Vegetation lagen, in der Regel Felsen oder Bäume. Ich fand keinen signifikanten Zusammenhang zwischen der Gesangs-Rate, der seit Sonnenaufgang verstrichenen Zeit, der Jahreszeit und der Höhe des Gesangsplatzes.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Song is a sexually selected trait that plays a crucial role in mate attraction and resource defence in birds (Catchpole and Slater 2008). Therefore, it has attracted the attention of biologists for decades and is probably one of the most thoroughly studied models of socially transmitted behaviour. Impressive progress has been made in the science of bird songs in the last 50 years in terms of mechanisms of song production, learning and its neurobiological background and detailed analyses of song variation patterns in time and space (Slater 2003). This growth of knowledge has a double effect: we know more about song behaviour, but we can also determine the most important gaps in our knowledge that hinder our understanding of song evolution and ecology. One issue is the amount and uneven distribution of data on song behaviour. We know a lot about the song of a very few species that have become intensively studied models, whereas we only have rudimentary data for hundreds of other species. A special case is birds from the tropics. The majority of modern bird species live in tropical or subtropical areas. The tropics were also localised centres of bird evolution. Therefore, the early evolution of song also occurred in the tropics. However, the majority of the studies on bird song have been conducted in temperate areas, although some tropical song phenomena as (e.g. duetting) have been recognised relatively recently (Hall 2009). Bird songs from tropical Africa are the least studied, and there is still a paucity of data for most of the species, including common and widespread ones. This problem also concerns birds which started large radiation in open habitats in the temperate zone and then colonised the tropics. Here, the genus Emberiza is a good example (Klicka et al. 2003; Alström et al. 2008), as our knowledge is heavily biased towards temperate zone species. An interspecific comparison in such a taxon gives good opportunities to track changes in song behaviour, which likely appeared after colonisation of the areas with different climatic conditions and habitats.
Emberizidae (sparrows, buntings and their relatives) are among the most diverse families in terms of number of species among birds. Emberizids are found on all continents except Australia and Antarctica and have the highest diversity in the western hemisphere Byers et al. (1995). The genus Emberiza consists of about 40 living species inhabiting the different, typically open habitats of Eurasia. Only a few species have limited distribution in Africa. The acoustic communication of some Emberiza species has been intensively studied. Most of these descriptive studies have focussed on different aspects of song variation in space (Møller 1982; Hansen 1985; McGregor 1986; Glaubrecht 1989, 1991; Matessi et al. 2000a; Osiejuk and Ratyńska 2003; Caro et al. 2009; Wonke and Wallschläger 2009). Other experimental studies have addressed questions related to dialect function and mechanisms of dialect recognition (Pellerin 1983; Hansen 1984; Baker et al. 1987; Osiejuk et al. 2007a). The other aspects of song behaviour that have been investigated are territorial defence (Kreutzer & Güttinger 1991; Nemeth 1996; Osiejuk et al. 2007b; Suter et al. 2009, neighbour-stranger recognition (Hansen 1984; Osiejuk et al. 2007a, b; Skierczyński et al. 2007; Skierczyński and Osiejuk 2010) and male–female communication (Nemeth 1994; Wingelmaier et al. 2007). However, in these studies, ornithologists have focussed on just five common European species: Corn Buntings, E. calandra; Ortolan Buntings, E. hortulana; Yellowhammers, E. citrinella; Cirl Buntings, E. cirlus; and Reed Buntings, E. schoeniclus. For the rest of the Emberiza species, we have only rudimentary data that hinders the possibility of comparative studies on song evolution in Emberiza and their relatives. The particularly understudied species are those limited to eastern Asia and all African species (Byers et al. 1995).
Here, I describe song structure, syllable repertoire variation and singing behaviour of the Cinnamon-breasted Bunting, Emberiza tahapisi goslingi. To my knowledge, this is the first study on the song behaviour of this species, despite it being one of the most common and widespread of the African buntings (Byers et al. 1995). This study is the first step to a better understanding of changes in song behaviour, which likely occurred during and after colonisation of Afrotropics in Emberizids.
Methods
Study area
The study was conducted in November and December of 2008 (the beginning of the dry season) approximately 6 km southeast of Big Babanki village in the Bamenda Highlands, Northwest Region, Cameroon. The study area was spread between 6°5′8″–6°6′40″N and 10°17′45″–0°19′77″E (altitude range 1,928–2,358 m a.s.l., average altitude 2,178 m a.s.l., area surveyed ca. 6 km2). The Bamenda Highlands are one of the most important hotspots of bird diversity and endemism in Africa (Orme et al. 2005). However, intensive logging has reduced formerly continuous forests to isolated patches in recent decades (ICBP 1992). At present, the vegetation covering the study area consists of mosaics of montane forest patches, shrubby corridors, grasslands and vegetable plantations (at a lower altitude than the study site).
The Cinnamon-breasted Bunting prefers intensively grazed pastures dominated by grasslands and rocky grasslands and, to some extent, also inhabits gentle rocky slopes with bare soil available (Byers et al. 1995; Sedlácek et al. 2007; personal observation). There is no systematically collected data available on the occurrence of the Cinnamon-breasted Bunting in this region, but it is likely that forest fragmentation in the Bamenda Highlands has increased the habitat area preferred by this species. In a recent survey of birds in the same study area, Sedlácek et al. (2007) found that the Cinnamon-breasted Bunting is a common species (with a category of abundance of 3–4 according to the classification of Stuart and Jensen 1986) that is resident to the area. The peak of its breeding is most likely at the beginning of the dry season.
Recording of birds
Birds were recorded between 16 November and 14 December 2008, preferably during the morning (0600–1200 hours) and evening (1600–1800 hours). However, singing birds were observed at almost every time of the day. Furthermore, on cloudy days with lower temperature some birds were also recorded at 1200 hours and 1600 hours. During the study, the area was surveyed each day for 8–10 h. Although I was not focused only on the detection of Cinnamon-breasted Buntings, I tried to survey each habitat patch that seemed to be suitable for that species. Patches were chosen based on aerial photos and visual inspection of the area from surrounding hills.
Birds were recorded using a Marantz PMD660 solid-state recorder with a Sennheiser ME 67 shotgun microphone (K6 powering unit and MZW67PRO windscreen). All recordings were mono-linear PCM WAV of 48-kHz sampling frequency and 16-bit resolution. Geographic coordinates and a.s.l. height of all males were measured using a Garmin GPSMap 76 CSx receiver. In sites with a higher density of males, recordings were preceded by the intensive observation of all males and preparation of sketch maps of their song posts, including information about the location of simultaneously singing males. Then, all birds were recorded on 1 day, and special attention was paid to the location of song posts of all neighbours during recording. This ensured the identification of different males. Besides the location of the subject male, each recording was given a unique number and the following data were recorded: time, behaviour of the subject (song, calls, etc.), context (counter-singing, solo singing) and song post characteristics (type and height as well as height of surrounding vegetation). In some cases, it was not possible to collect all data. Therefore, sample size differed for analyses of particular variables.
Sound analysis and bioacoustics terms
Sonograms of songs were analysed using Avisoft SASLab Pro 4.52 software (Specht 2002) with the following set of parameters: 512 FFT-length, frame (%) = 75, window = hamming and temporal overlap = 75%. This provided a sonogram of 162-Hz bandwidth with 94-Hz frequency and 2.67-ms time resolution.
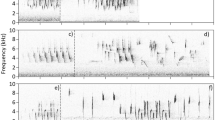
Preliminary analysis revealed that Cinnamon-breasted Buntings sing short, simple song phrases, repeated in a very stereotyped manner for each male. Because the acoustic character of sounds forming the songs was similar to the intensively studied White-crowned Sparrow, Zonotrichia leucophrys, I applied a similar terminology to describe the song structure and its variation (e.g. Nelson 2000). I defined a “note” as a continuous tracing on a sonogram separated from other notes by at least 3 ms of silence. Single notes or group of notes always occurring together built minimal units of sound production called “syllables”. Syllables were comparable both between performances of each male and between different males, regardless of their occurrence as single syllables or a repeated sequence (e.g. a trill) (Fig. 1).

Sonograms of the Cinnamon-breasted Bunting, Emberiza tahapisi goslingi, songs with terms used to describe acoustic song structure and syllable type diversity
Each recognised syllable type was analysed in detail and categorised to a particular type of sound from an acoustic perspective (see Fig. 1). A “whistle” was defined as a single note with one dominant frequency and no amplitude modulation (i.e., pure whistle). A “buzz” was considered to be a complicated note or group of notes that always clearly contained an amplitude modulated whistle. A “complex syllable” was defined as a group of short whistle notes of different frequency in a time domain that always occurred together as a group separated from other syllables. Some types of whistles and complex syllables occurred exclusively in groups forming characteristic trills, while others always occurred as single syllables. Therefore, I used the following terms and abbreviations: whistle (W), buzz (B), complex syllable (C) and trill (T) (Fig. 1). For example, a typical song could be built with a sequence of T-T-B-B-B-C-W, meaning that the song started with two different trills followed by three different buzzes and finished with a complex syllable and a single whistle. This acoustic description allowed me to present results on song structure to describe the song syntax of Cinnamon-breasted Buntings.
Songs of Cinnamon-breasted Buntings consisted of several different syllable types belonging to the acoustic categories mentioned above. To describe songs in a way that allowed for the comparison of syllable repertoires, I used syllables as minimal units of song production and divided each song into a sequence of different syllable types (as in Osiejuk et al. 2003 for the Ortolan Bunting). Each syllable on a sonogram recognised as a new type received its own symbolic representation as a letter or a letter with number subscript. For example, a song described as a-b-c-d-e–f-g consisted of seven different syllable types that occurred exactly in that order within the song phrase (Fig. 1). Syllables were clearly separated by gaps and occurred as single examples or in series of the same kind (trills).
The initial inspection of sonograms revealed that each male was almost always singing songs consisting of exactly the same sequence of syllables. The only within-individual variation in song structure concerned omitting some syllables and thereby shortening the song. In the majority of cases, males omitted some initial syllables or trills or ceased singing in the middle of the song phrase. Shortening of the song was common but not very frequent with respect to the number of all songs recorded. It was also clear that some males shared the majority of syllable sequences regardless of shortening songs from time to time, and that the shortened versions should not be counted as separate song types. The shortening was either caused by the observer effect or might reflect aggressive interactions with a rival. Therefore, I primarily tried to identify different song types (defined as a group of songs that consisted of the same syllables arranged in the same order) based on the most complete versions of the song performed by particular males. For example, several males sang full songs with a sequence of syllables of a-b-c-d-e–f-g but also occasionally produced songs that consisted of the following sequences: b-c-d-e–f-g, a-b-c-d-e–f or b-c-d-e–f. Such songs were treated as belonging to the same type with the unchangeable “core” sequence indicated by brackets around the core syllables, e.g. [b-c-d-e–f].
Microgeographic song variation
I analysed microgeographic song variation at two levels. In the first approach, I used distinguished song types as discrete units based on shared core syllable sequences. Because each male sang only a single song type, the song type similarity between males had binary character. In other words, any two males shared (similarity = 1) or did not share (similarity = 0) their syllable repertoires. In the second approach, I used the Jaccard index to compare the similarity of songs performed by pairs of males in detail. The data on the song structure of individual males were used to construct the similarity matrix using the Jaccard similarity coefficient (J), which covered song similarity between males with respect to the syllable types of their songs. The Jaccard coefficient was calculated as J = M11/(M01+M10+M11), where M11 represents the total number of shared syllables of the respective song types between a given pair of males and M01 and M10 represent syllables unique to each of the two males. The coefficient values ranged from 0 to 1, with J = 0 indicating that the songs of compared males did not contain any shared syllables and J = 1 indicating that all syllables were shared between the two males.
In both analyses, I used 58 males with known song structure and known geographical position to generate randomly 1,000 pairs of males without repetitions. Binary song type sharing (1 = sharing, 0 = no sharing) and the Jaccard index of song similarity (0–1) were calculated for each pair. Additionally, I calculated the corresponding matrices of geographic distances between the song posts of males (between 10 and 4,070 m).
To illustrate the degree of song sharing in relation to the distance between males, I compared measures of binary song type sharing and the Jaccard index of similarity for three types of pairs: pairs within hearing range (≤250 m), i.e. familiar neighbours; pairs within a particular habitat patch (excluding pairs from the first group), i.e. local groups; and pairs consisting of males from distant patches, i.e. strangers (separated by >500 m). The hearing range distance of 250 m was based on measurements of distances from which it was possible to hear singing males. The distance of 500 m for distinguishing between local groups and strangers was based on the direct measurement of distances between territories. The statistical methods used in the song sharing analyses are provided below.
Statistical analyses
Before each statistical analysis, the distribution of tested variables was assessed, and then appropriate parametric or nonparametric tests were applied. Correlations between binary song sharing patterns and the Jaccard index of similarity with distance between pairs of males were analysed with 1,000 bootstrap samples and a Mersene Twister random number generator. The specific hypotheses on binary song type sharing and song similarity between neighbours, males from local groups and strangers were tested using the Monte Carlo permutation procedure (Manly 1997). All tests were performed using PASW Statistics 18.
Material
The study was based on 101 recordings of 58 different males. I recorded approximately 1,100 songs in total, but not all of them were of high enough quality for subsequent analyses. Once I realised that males sang only one song type, I strived to record all males within a particular locality rather than collecting recordings that were as long as possible. Irrespective of this recording strategy, I still collected enough recordings that were long enough to characterise temporal song variation.
Results
Song structure and repertoire
Songs of the Cinnamon-breasted Bunting were short and rarely exceeded 2 s (Table 1). Songs typically covered wide frequency bands between 2.5 and 9.2 kHz (Table 1). The analysis of all recorded songs revealed that they consisted of 40 different syllable types in total. These different syllable types were classified as whistles (4), buzzes (15), and complex syllables (21). Ten of these 40 syllable types always occurred as trills. In nine cases, these trills were built of repeated complex syllables, and in one case the trill was a repeated whistle. Songs were built of 4–9 different syllable types (mean ± SE = 6.5 ± 0.17). The majority of the songs contained all described acoustical structures (i.e. whistle, buzz, complex syllable and trill). Complete songs always began with 1–3 trills that were followed by a sequence of different buzzes, complex syllables and in some cases a single trill before the terminal whistle. Each song, except for some shortened performances, was finished with the same characteristic terminal whistle of declining frequency. This terminal whistle was described as the “g-whistle” syllable (Fig. 2). Within a song phrase, each syllable type occurred only in one place in the sequence of syllable types, but some syllables were repeated and formed trills.

Sonograms of the eight different song types described in the studied population of the Cinnamon-breasted Bunting from the Bamenda Highlands. Song types are ordered from a to h with decreasing frequency as they were found in the repertoires of 58 males (i.e., song type a was sung by 13 males, type b was sung by 11 males, etc.)
Each male sang basically a single song type, and succeeding songs were identical in most cases. The only observed within-male variations in song structure concerned deletion of one or more initial syllables, deletion of the final whistle (very rarely) or insertion/deletion of single syllables in the middle of the song. In the last case, the deleted or inserted syllables were always very short. Such variations did not change the hearing impression of the songs. Based on the most complete songs of each male, I classified all songs into eight different song types, each of which shared the same core sequence of syllables (Fig. 2). Seven song types were shared by 13, 11, 10, 8, 6, 4 and 4 males, and one song type was unique to a single male.
Microgeographic song variation
To analyse the spatial pattern of song type sharing between males, I compared syllable repertoires and distances for pairs of males with the randomisation procedure described in “Methods”. Binary song type sharing decreased with distance (Fig. 3), but the relationship was weak and insignificant (1,000 bootstraps, r s = 0.03, P = 0.325). The probability of shared song types for males within hearing distance (≤250 m) was relatively low (approximately 0.2) (Fig. 3). The comparison of song structure similarity between males with the Jaccard index of similarity revealed analogous but significant results (1,000 bootstraps, r = −0.11, P = 0.001; Fig. 4).

Binary song type sharing among pairs of males (1,000 bootstraps) belonging to three categories: neighbours, local group and strangers

Song type similarity measured by the Jaccard index among pairs of males (1,000 bootstraps) belonging to three categories: neighbours, local group and strangers
To test more specific hypotheses, I conducted two self-designed randomisation tests with the Monte Carlo permutation procedure. First, I tested differences in binary song type sharing among pairs of males being neighbours, belonging to the same local group and being strangers (i.e., belonging to different groups). I found significant differences in binary song type sharing between these three categories (Fig. 3; Kruskal–Wallis, χ 22 = 6.19, P = 0.046). Similarly, I found significant differences between the same three categories with the Jaccard similarity Index (ANOVA, F 2,997 = 13.925, P < 0.001). The Bonferroni post hoc test revealed significant differences between song similarity of neighbours and strangers (P < 0.001) and males belonging to a local group and strangers (P = 0.004), while there was no significant difference between neighbours and males within a local group (P = 1). Regardless of the statistical significance of differences, average differences between all groups were small, and birds within local groups did not share syllable repertoires as a whole (Figs. 3, 4). However, all recorded males shared the final g-whistle.
Song posts and rate of singing
I collected partial data for song post characteristics of 68 recordings (no more than 2 per male). Most birds sang from exposed places on trees, shrubs or rocks (Table 2). Trees and shrubs used as song posts were often dead (34%, n = 38). Song post height varied between 0 and 19 m (average ± SE = 4.3 ± 0.59 m and n = 53). Song posts were located significantly higher (Wilcoxon signed-rank test, Z = −4.501, n = 48, p < 0.001) than the surrounding vegetation (0–8 m, 1.7 ± 0.33 m, n = 48). Males singing from high trees did not tend to sing from the highest possible place. Rather, they sang from places slightly above the level of surrounding vegetation (1–3 m).
Cinnamon-breasted Bunting males were quite agile and often changed singing locations or sang when walking and foraging on the ground. Such behaviour was not a result of the observer effect because birds that were observed from a distance through binoculars were equally mobile. Moreover, the song rate calculated for all recordings of acceptable quality (n = 86) had a highly skewed distribution (K–S test, Z = 2.45, p < 0.001) and correlated significantly with the recording duration (r = −0.30, n = 86, p = 0.005). Therefore, I only extracted song rates from recordings exceeding one minute in duration, during which birds were clearly concentrated on singing. Song rates measured for these recordings were normally distributed (K–S test, Z = 0.485, p = 0.973) and did not correlate significantly with the duration of the recordings (r = −0.18, n = 47, p = 0.213). The measured song rate varied between 2.8 and 14.2 songs per minute (average ± SE = 7.4 ± 0.34 songs per minute).
I found no significant relationships between song rate, day of the season, time after sunrise, or song post height (all p for Spearman’s rho between 0.222 and 0.740). Likewise, I did not find any significant relationships in a linear regression model including all three variables (F 3,17 = 0.025, p = 0.994).
Discussion
Song structure and repertoire size
The songs of birds in the genus Emberiza are not among the most elaborate songs known. The majority of species are discontinuous singers with short song phrases and small repertoires. Thus, the Cinnamon-breasted Rock Bunting seems to be a typical Emberiza singer. The song phrase complexity in Emberiza species is quite variable. There are species such as the Cirl Bunting, whose songs consist of a trill as a repetition of a single syllable type, thus representing the lowest level of phrase versatility (Kreutzer and Güttinger 1991). In contrast, the Corn Bunting has highly complex song phrases that sometimes consist of dozens of different elements produced very rapidly in time (McGregor 1986; Osiejuk and Ratyńska 2003). The Cinnamon-breasted Rock Bunting has 4–9 different syllable types occurring only once (as a trill or single syllable) within a song phrase and thus forms songs of quite high complexity (the ratio between number of different syllables and the total number of syllables within a song strophe).
My results clearly indicate that the song type repertoire of the Cinnamon-breasted Bunting is extremely small, as all males sang only one single song type. However, I observed some differences between successive performances of songs in particular males. The differences were always small modifications (e.g. omitting a single syllable or shortening the song) and should not be regarded as separate song types. Similar small variations have been observed in other species with single song type repertoires (e.g. treecreepers Certhia sp.; Thielcke 1992; Osiejuk and Kuczyński 2003).
Microgeographic song variation
Two characteristic findings were related to microgeographic song variation in Cinnamon-breasted Buntings. First, all males within the studied population shared the same final syllable of song. This final syllable was a very characteristic whistle (g-whistle) that has the longest duration among all 40 syllables described (Figs. 1 and 2). Such a pattern is very similar to those found for several other bunting species, because buntings often share a specific song structure over larger areas. For example, Yellowhammer males share specific final whistles within dialect areas (Møller 1982; Hansen 1985; Glaubrecht 1989, 1991; Rutkowska-Guz and Osiejuk 2004; Caro et al. 2009; Wonke and Wallschläger 2009). It has been shown that these regional song differences affect the sexual response of females (Baker et al. 1987). Similarly, Ortolan Bunting males share final parts of the song, but these elements may have different acoustical structures (usually they are low frequency, narrowband trills) in different populations. In the majority of the populations studied thus far, all males within a local dialect area have a single version of the final structure (review in Cramp and Perrins 1994; Osiejuk et al. 2003). Thus, because Cinnamon-breasted Bunting songs have a more variable initial song and a fully shared stereotyped whistle at the end of the song, this finding seems to reflect the same geographical pattern as other bunting species (i.e. with local dialect and an easy to detect “dialect cue” in a form of the final whistle). However, the term “dialect” is quite vague. For example, depending on the form of the final whistle one may distinguish only two large dialect areas in Europe for the Yellowhammer (Cramp and Perrins 1994). However, it is possible to detect some specific differences at a smaller scale (e.g. Hansen 1985; Caro et al. 2009; Wonke and Wallschläger 2009). In Ortolan Buntings, dialects usually cover smaller areas of hundreds of square kilometres. However, under some specific ecological conditions, this characteristic pattern may completely disappear, as found in the isolated and patchy population at the border of the species range in Norway (Osiejuk et al. 2003). In such a population, the final song structures do not act as dialect cues (Osiejuk et al. 2007a). It is not known whether the final g-whistle is shared only among Cinnamon-breasted Bunting males in the studied population or if it is typical for males from larger areas. Unfortunately, there is a paucity of data, which hinders further discussion. I did not find such a final whistle in my own recordings from Lesotho in 1998 (a few males of subspecies E. t. tahapisi recorded, unpublished data). There is also no such whistle in songs recorded from Zimbabwe (Macaulay Library recording #79983, Ethiopia, spp. tahapisi; after J. del Hoyo 2005, http://ibc.lynxeds.com/video/cinnamon-breasted-bunting-emberiza-tahapisi/bird-rock-singing) or Yemen (Poul Hansen, personal communication). On the other hand, I was able to detect final g-whistles in songs of males at a distance of up to 7 km from the study area and at the altitude of around 1,000 m a.s.l., which suggests that the g-whistle dialect probably is spread over 100 km2 or more. Additionally, such whistles are clearly present in recordings of males from the same subspecies in NW Nigeria (Chappuis 2000). These comparisons suggest that the characteristic whistle is widespread among E. t. goslingi populations. The differences in dialect formation between subspecies may not only be caused by variations in learning patterns and dispersal strategies (Catchpole and Slater 2008) but may also be due to genetic differences (Matessi et al. 2000b ).
However, the Cinnamon-breasted Bunting clearly differed from species in which all males within a local dialect share the same single song type, like the White-crowned Sparrow (Nelson 2000), or a few song types, such as the Corn Bunting (McGregor 1980, 1986; Osiejuk and Ratyńska 2003).
According to the second aspect of spatial song variation, I found a tendency for males from local groups (within a radius of ≤500 m) to sing more similar song types than strangers. If young males learn song during the first months after hatching, which is typical (Beecher and Brenowitz 2005), the observed song distribution in space could be due to the dispersal pattern of males being slightly biased towards settlement within the patch where they hatched. Alternatively, the same result could be obtained if males tend to settle after dispersal within a group where other males sing similarly. Whatever the relationship between learning and dispersal is, it should be stressed that the observed sharing is weak among neighbours within hearing range and within local groups as a whole. Males sharing the same song type did not aggregate in clusters as in the Corn Bunting or the White-crowned Sparrow (McGregor 1980; Osiejuk and Ratyńska 2003; Nelson 2000).
Song post and song rate
Cinnamon-breasted Bunting males seemed to be opportunists in the choice of song posts. They tended to sing from places slightly above the surrounding vegetation but often did not choose very exposed places. It seems that the males maximised sound transmission but simultaneously avoided being exposed to others (e.g. conspecifics or predators). This is quite similar to the behaviour of the Ortolan Bunting (Tryjanowski 2001). However, it is different from the behaviour of Corn Bunting males that clearly choose the highest possible place (probably because of interactions with other males; Olinkiewicz and Osiejuk 2003) or the Yellowhammer males that expose yellow feathers during singing as a signal of quality to females (Sundberg 1995).
Cinnamon-breasted Bunting males had quite variable singing rates with mean values and maxima exceeding those reported for other buntings (e.g. mean = 6.3 (2–12.4) songs per minute in the Yellowhammer; Rutkowska-Guz and Osiejuk 2004; mean = 4.9 (1.4–10.4) in the Ortolan Bunting and mean = 6.2 (3.2–11.1) in the Corn Bunting; Olinkiewicz and Osiejuk 2003). Thus, the song rate seems to be an important signal in the Cinnamon-breasted Bunting, as it is the main song character that may be modulated during performance.
In summary, the song of the Cinnamon-breasted Bunting seems to be an extremely good model for a large-scale survey due to its moderate structural complexity, short song duration and single song type per male. It is relatively easy to obtain recordings of many individuals in a short time. The species is divided into five clear subspecies, and their populations are fragmented with variable patterns across Africa (Byers et al. 1995). Therefore, the Cinnamon-breasted Bunting seems to be a good model species for the study of interactions between ecology and cultural transmission of song (Laiolo and Tella 2006).
References
Alström P, Olsson U, Lei F, Wang H-t, Ga W, Sundberg P (2008) Phylogeny and classification of the Old World Emberizini (Aves, Passeriformes). Mol Phyl Evol 47:960–973
Baker MC, Bjerke TK, Lampe HU, Espmark YO (1987) Sexual response of female yellowhammers to differences in regional song dialects and repertoire sizes. Anim Behav 35:395–401
Beecher MD, Brenowitz EA (2005) Functional aspects of song learning in songbirds. Trends Ecol Evol 20:143–149
Byers C, Olsson U, Curson J (1995) Buntings and Sparrows. A guide to the Buntings and North American Sparrows. Pica, Sussex, UK
Caro SP, Keulen C, Poncin P (2009) Song repertoires in a western European population of yellowhammers Emberiza citrinella. Acta Ornithol 44:9–16
Catchpole CK, Slater PJB (2008) Bird song. Biological themes and variations, 2nd edn. Cambridge University Press, Cambridge
Chappuis C (2000) African bird sounds birds of north, west and central Africa. 15-CD set with the collaboration of the British Library National Sound Archive (London). Société d’Études Ornitholgiques de France, Paris, France
Cramp S, Perrins CM (1994) Birds of the western palearctic, vol. 9. Oxford University Press, Oxford
Glaubrecht M (1989) Geographische Variabilität des Gesangs der Goldammer, Emberiza citrinella, im norddeutschen Dialekt-Grenzgebiet. J Ornithol 130:277–292
Glaubrecht M (1991) Gesangsvariation der Goldammer (Emberiza citrinella) in Norddeutschland und auf den dänischen Inseln. J Ornithol 132:441–445
Hall ML (2009) A review of vocal duetting in birds. Adv Study Behav 40:67–121
Hansen P (1984) Neighbour-stranger song discrimination in territorial Yellowhammer Emberiza citrinella males, and a comparison with responses to own and alien song dialects. Ornis Scand 15:240–247
Hansen P (1985) Geographic song variation in the Yellowhammer (Emberiza citronella). Natura Jutlandica 21:209–219
ICBP (1992) Putting biodiversity on the map: priority areas for global conservation. International Council for Bird Preservation, Cambridge
Klicka J, Zink RM, Winker K (2003) Longspurs and snow buntings: phylogeny and biogeography of a high-latitude clade (Calcarius). Mol Phyl Evol 26:165–175
Kreutzer M, Güttinger HR (1991) Species-specificity and individual variation of songs and song responses in the cirl bunting (Emberiza cirlus)—does ecological competition modulate the behavioural-response to songs. J Ornithol 132:165–177
Laiolo P, Tella JL (2006) Landscape bioacoustics allows detection of the effects of habitat patchiness on population structure. Ecology 87:1203–1214
Manly BFJ (1997) Randomization. Bootstrap and Monte Carlo methods in biology. Chapman & Hall, London
Matessi G, Pilastro A, Marin G (2000a) Variation in quantitative properties of song among European populations of reed bunting (Emberiza schoeniclus) with respect to bill morphology. Can J Zool 78:428–437
Matessi G, Dabelsteen T, Pilastro A (2000b) Responses to playback of different subspecies song in the reed bunting Emberiza schoeniclus. J.Avian Biol 31:96–101
McGregor PK (1980) Song dialects in the corn bunting (Emberiza calandra). Z Tierpsychol 54:285–297
McGregor PK (1986) Song types in the corn bunting Emberiza calandra—matching and discrimination. J Ornithol 127:37–42
Møller AP (1982) Song dialects in a population of yellowhammers Emberiza citrinella in Denmark. Ornis Scand 13:239–246
Nelson DA (2000) Song overproduction, selective attrition and song dialects in the white-crowned sparrow. Anim Behav 60:887–898
Nemeth E (1994) Individuelles Erkennen des Gesangs durch die Weibchen und Gesangsaktivität der Männchen bei der Rohrammer (Emberiza schoeniclus). J Ornithol 135:217–222
Nemeth E (1996) Different singing styles in mated and unmated reed buntings Emberiza schoeniclus. Ibis 138:172–176
Olinkiewicz A, Osiejuk TS (2003) Effect of time of season and neighbours on singing activity in the corn bunting Miliaria calandra. Acta Ornithol 38:117–122
Orme CDL, Davies RG, Burgess M, Eigenbrod F, Pickup N, Olson VA, Webster AJ, Ding TS, Rasmussen PC, Stattersfield AJ, Bennett PM, Blackburn TM, Gaston KJ, Owens IPF (2005) Global hotspots of species richness are not congruent with endemism or threat. Nature 436:1016–1019
Osiejuk TS, Kuczyński L (2003) Response to typical, mixed and shortened song versions in Eurasian treecreepers, Certhia familiaris. Biologia 58:985–989
Osiejuk TS, Ratyńska K (2003) Song repertoire and microgeographic variation in song types distribution in the corn bunting Miliaria calandra from Poland. Folia Zool 52:275–286
Osiejuk TS, Ratyńska K, Cygan JP, Dale S (2003) Song structure and repertoire variation in ortolan bunting (Emberiza hortulana L.) from an isolated Norwegian population. Ann Zool Fenn 40:3–16
Osiejuk TS, Ratyńska K, Dale S (2007a) What makes a ‘local song’ in a population of ortolan bunting without common dialect? Anim Behav 74:121–130
Osiejuk TS, Łosak K, Dale S (2007b) Cautious response of inexperienced birds to conventional signal of stronger threat. J Avian Biol 38:644–649
Pellerin M (1983) Variability of response of the corn bunting, Emberiza calandra, to songs of different dialects. Behav Process 8:157–163
Rutkowska-Guz JM, Osiejuk TS (2004) Song structure and variation in yellowhammers Emberiza citrinella from western Poland. Pol J Ecol 52:333–345
Sedláček O, Reif J, Hořák D, Riegert J, Pešata M, Klvaňa P (2007) The birds of a montane forest mosaic in Big Babanki area, Bamenda Highlands, Cameroon. Malimbus 29:89–100
Skierczyński M, Osiejuk TS (2010) Sharing songs within a local dialect does not hinder neighbour-stranger discrimination in ortolan bunting (Emberiza hortulana) males. Behaviour 147:333–351
Skierczyński M, Czarnecka KM, Osiejuk TS (2007) Neighbour-stranger song discrimination in territorial ortolan bunting Emberiza hortulana males. J Avian Biol 38:415–420
Slater PJB (2003) Fifty years of bird song research: a case study in animal behaviour. Anim Behav 65:633–639
Specht R (2002) Avisoft-saslab pro: sound analysis and synthesis laboratory. Avisoft Bioacoustics, Berlin
Stuart SN, Jensen FP (1986) The status and ecology of montane forest bird species in Western Cameroon. In: Stuart SN (ed) Conservation of Cameroon montane forests. International Council of Bird Preservation, UK, pp 38–105
Sundberg J (1995) Female yellowhammers (Emberiza citrinella) prefer yellower males—a laboratory experiment. Behav Ecol Sociobiol 37:275–282
Suter SM, Ermacora D, Rieille N, Meyer DR (2009) A distinct reed bunting dawn song and its relation to extrapair paternity. Anim Behav 77:473–480
Thielcke G (1992) Stability or changes in dialects and dialect borders of the short-toed treecreeper (Certhia brachydactyla). J Ornithol 133:43–59
Tryjanowski P (2001) Song sites of buntings Emberiza citrinella, E. hortulana and Miliaria calandra in farmland: microhabitat differences. In: Tryjanowski P, Osiejuk TS, Kupczyk M (eds) Bunting studies in Europe. Bogucki Wyd Nauk, Poznań, pp 25–31
Wingelmaier K, Winkler H, Nemeth E (2007) Reed bunting (Emberiza schoeniclus) males sing an ‘all=clear’ signal to their incubating females. Behaviour 144:195–206
Wonke G, Wallschläger D (2009) Song dialects in the yellowhammer Emberiza citrinella: bioacoustic variation between and within dialects. J Ornithol 150:117–126
Acknowledgments
I would like to thank Marcin Antczak, Jan Riegert, Vunan Ernest Amohlon for their help and all Kedjom-Keku people from the Big Babanki village for allowing me to study birds on their land and for the friendly atmosphere during my stay there. Poul Hansen, Henrik Brumm and Jan Riegert provided their own recordings or helped with finding recordings for comparison. Marcin Antczak, Michał Skierczyński and Poul Hansen provided helpful comments that improved the manuscript. The study was supported by the Adam Mickiewicz University and GAAV (IAA601410709).
Open Access
This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Jon Fjeldså.
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License (https://creativecommons.org/licenses/by-nc/2.0), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
Osiejuk, T.S. The song of the Cinnamon-breasted Bunting, Emberiza tahapisi, in the Bamenda Highlands (NW Cameroon). J Ornithol 152, 651–659 (2011). https://doi.org/10.1007/s10336-010-0626-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10336-010-0626-5