
Abstract
The object of this paper is to study the relationship between the border effect and the geographic concentration of production. We explain this relationship through the home market effect and test the robustness of this explanation by using an analysis that considers the European single market. A sectoral gravity equation is estimated with different econometric estimators; in particular, we discuss a recently suggested estimator for log-linear CES models. Overall, our findings suggest a steady relationship between the border effect and the concentration of production. Furthermore, the analysis of concentration through a synthetic index provides us with valuable insights into the structure of the European industry.





Similar content being viewed by others

Notes
In the extreme case in which there are no border-related trade costs, a BE can still emerge when nationals are biased towards domestic products (high elasticity of substitution). In this case, the BE functions more as an indicator of home-biased preferences than an indicator of trade integration with respect to border-related trade costs. In empirical analyses, however, it is difficult to assess the relevance of the elasticity of substitution; more on this phenomenon can be found in Hummels (2001).
We improve Chen’s (2004) analysis as follows: (i) we employ a concentration index computed using European employment data, whereas Chen uses an index (Ellison and Glaeser 1997) computed with American industrial data to explain trade patterns within the EU; (ii) we use a more appropriate estimator for the gravity equation considered. In addition to what Chen does, we explain why the relationship between the BE and concentration emerges and develop a study of concentration functional to the analysis.
As Wooldridge (2002) explains, the censoring of the dependent variable can be either a recording problem of the data or derive from the solution of an optimisation process. In the second case, we might imagine that for some agents the optimal choice is the corner solution y = 0; Wooldridge calls this kind of response variable “corner solution outcome” (p. 518).
Usually, the percentage of zero observations in Tobit estimations is higher than 30%; for example, see Tobin (1958).
See Cafiso (2008) Section IV.A for further discussion.
In the case of “exporter/sector/year + partner/sector/year” fixed-effects, we need to include 3,952 dummies. It was not possible to generate any estimation output with this pattern of fixed-effects, so we preferred “exporter/year + partner/year” fixed-effects. Nonetheless, we attempted the use of “exporter/sector/year + partner/sector/year” fixed-effects in a smaller sample (only 5 sectors, from 27,725 to 6,860 observations) in order to compare the estimation output. The estimation output is alike, our results are therefore robust regardless of the the fixed-effects pattern used. A possible explanation is that there is no so much heterogeneity in the real data even if theoretically the MRTs need to vary by each dimension.
In the Tobit estimation, normality is tested through a conditional moment test, and the null hypothesis is that the disturbances have a normal distribution.
Reasons in favour of the PPML estimator: (1) the likely bias of the Tobit due to non-normally distributed residuals (as from the test) and Silva–Tenreyro’s critique, (2) the bias of OLS given the occurrence of zero-trade observations and Silva–Tenreyro’s critique, (3) the outcome of the RESET test.
An anonymous referee pointed out that the inclusion of two non-manufacturing sectors (“Mining and Quarrying” and “Electricity, Gas and Water supply”) could bias the estimation of the BE for the manufacturing sectors. To address this issue, we ran the estimations in Table 2 by ruling out the two non-manufacturing sectors. The BE estimates and ranking remain unchanged, thus confirming that the two non-manufacturing sectors do not introduce any bias but enrich our analysis.
In the group of concentration indices, the EG delivers a higher degree of accuracy because it controls for differences in the sizes of plants and for differences in the sizes of geographic areas. However, this accuracy is at a cost because the EG index requires computation of the Herfindahl index of plant shares (Ellison and Glaeser 1997, p. 899). Then, if the activity variable used is employment, data on the number of plants and on employment in each plant must be available (Ellison and Glaeser 1997, p. 906).
We computed the correlation between the theil index for the EU and the Ellison–Glaeser index for the US. This is 0.09, a very low value which signals no correlation. Such low value is likely to depend on the aggregation of the sectors in Ellison and Glaeser (1997) to match our sectors (from 459 to 20 sectors); for the scope of our analysis we use simple averaging. Moreover, Ellison and Glaeser use employment figures dated 1987 while we use 1995–2003 figures.
The Theil index does not control for the distribution of plants’ size as the EG does, thus delivering a different description of the concentration pattern. Several concentration indices can be used to account for agglomeration. Good reviews of these indices (with applications to Europe) are Aiginger and Davies (2004), Cutrini (2006). Combes and Overman (2004) list seven properties which concentration indices should satisfy. They acknowledge that no measure meets all those criteria simultaneously and that the choice of one index implies neglecting some criteria.
If \( \alpha = 1 \), we obtain the theil index, whereas if \( \alpha = 2 \), we get the half square coefficient of variation. The more positive the sensitivity parameter is, the more sensitive the index is to activity differences at the top of the distribution; the less positive the sensitivity parameter, the more sensitive the index at the bottom of the distribution. The index has a different formula for calculating relative concentration, see Cafiso (2009).
The within component is calculated as the index itself but restricted to observations only within the group.
The use of employment figures may bias concentration values when there are relevant productivity differences across regions and sectors; this is why some authors prefer using value-added figures (Behrens et al. 2005). In our analysis, we preferred employment because this was available at the Nuts-2 regional level (necessary for the between/within decomposition of the Theil index) for the sectors, countries and years to match with the trade data. Besides, we reckon that such differences are not particularly relevant in our analysis since we consider a homogenous set of countries such as the EU-15 group.
The employment figures used are an average of the yearly observations within the period.
When the within contribution is higher than the between, concentration mainly depends on an unequal distribution within countries, while the across-countries distribution is relatively more equal. To wit, if a sector was located unevenly among countries but equally spread among the regions of each country, then concentration would be caused exclusively by across-country diversity.
The bootstrap is based on 5,000 replications. Because the bootstrap distribution is not normal for some sectors, rejection areas are defined through the Bias Corrected and Accelerated Confidence Interval.
As regards manufacturing, this finding also emerges in Brulhart and Traeger (2005; p. 614).
We tested the relationship further by using relative concentration; the premise holds, but slightly less conclusively. Results are available upon request.
The predicted values are valid under a ceteris paribus condition. Indeed, the estimated BE values (those in Table 3) are different because other conditions differ across sectors (e.g., technical barriers to trade, internationalisation costs).
To compute the CD index as accurately as done for CP in Section 4, we need domestic absorption figures at the Nuts-2 level. However, export and import figures are available only at the country level. Then, we have generated Nuts-2 level observations by splitting the national figures through regional weights. We compute the weights using the number of local units at the basis of the employment data set (used to compute concentration of production). This process could artificially boost correlation between CP and CD, unfortunately, no alternative was available. More information about the data generating process is in the “Appendix”.
The results in this section are only for the 1-period analysis. Construction of domestic absorption figures for two different periods requires an even deeper data manipulation while the 2-period analysis itself does not provide any additional insight.
Proof of the link between CP and CD which goes beyond correlation can be found in Haaland et al. (1999).
Data for Belgium and Luxembourg are recorded together for the so-called Belgium-Luxembourg Economic Union (BLEU).
For more information about the measurement of distance and how it can affect the estimation of BEs, see Head and Mayer (2002).
This is the ratio between the weight in kilos and the value in currency units of a certain trade flow which reflects the diversity in trade costs borne by different goods; diversity which we deem wrong to neglect.
CIF is the abbreviation for “Cost of Insurance and Freight” while FOB means “Free On Board”. Hummels and Lugovskyy (2006) study the accuracy of these ratios as indicators of trade costs. They affirm that “since data on transportation costs are difficult to obtain, in their absence many researchers have turned to indirect measures of transportation costs constructed using matched partner CIF/FOB ratios” (page 69). Their overall conclusion is that those ratios are poor indicators of trade costs but that, in absence of any other alternative “the matched partner data may be useful as a rough control variable for aggregate bilateral transportation costs” (page 84). We therefore decided to use them.
It was not possible to compute any CIF/FOB ratio for the national trade observations, then we set the ratio equal to 1 for those observations.
In the Eurostat’s Regio database, the local units are the firms where the number of employees is recorded. Then, the number of local units is the number of firms in a specific Nuts-2 region.
References
Aiginger, K., & Davies, S. (2004). Industrial specialisation and geographic concentration: Two sides of the same coin? Not for the European Union. Journal of Applied Economics, 7(2), 231–248.
Anderson, J. E., & van Wincoop, E. (2003). Gravity with gravitas: A solution to the border puzzle. American Economic Review, 93(1), 170–192.
Baldwin, R., Forslid, R., Martin, P., Ottaviano, G., & Robert-Nicoud, F. (2005). Economic geography and public policy. Princeton (NJ): Princeton University Press.
Baldwin, R., & Taglioni, D. (2006). Gravity for dummies and dummies for gravity equations (Discussion Paper 5850). London: Centre for Economic Policy Research.
Behrens, K., Ottaviano, G. I., Lamorgese, A. R., & Tabuchi, T. (2005). Testing the home market effect in a multi-country World (Working Paper 2005/55). Louvain: Centre for Operations Research and Econometrics.
Biewen, M. (2002). Bootstrap inference for inequality, mobility and poverty measurement. Journal of Econometrics, 108(2), 317–342.
Brulhart, M., & Traeger, R. (2005). An account of geographic concentration patterns in Europe. Regional Science and Urban Economics, 35(6), 597–624.
Cafiso, G. (2008). The Euro’s influence upon trade: Rose effect versus border effect (Working Paper 941) Frankfurt am Main: European Central Bank.
Cafiso, G. (2009). Sectorial border effects in the European single market: An explanation through industrial concentration (Working Paper 1116). Frankfurt am Main: European Central Bank.
Cameron, A., & Trivedi, P. (2005). Microeconometrics: Methods and applications. Cambridge (UK): Cambridge University Press.
Chen, N. (2004). Intra-national versus international trade in the European Union: Why do national borders matter? Journal of International Economics, 63(1), 93–118.
Combes, P., & Overman, H. (2004). The spatial distribution of economic activities in the European Union. In J. V. Henderson & J. F. Thisse (Eds.), Handbook of regional and urban economics (vol. 4). Amsterdam: Elsevier.
Cutrini, E. (2006). The Balassa index meets the dissimilarity Theil index: A decomposition methodology for location studies. (Working Paper 274). Ancona: Università Politecnica delle Marche.
Drukker, D. (2002). Bootstrapping a conditional moments test for normality after Tobit estimation. Stata Journal, 2(2), 125–139.
Ellison, G., & Glaeser, E. (1997). Geographic concentration in US manufacturing industries: A dartboard approach. Journal of political economy, 105(5), 889–927.
Evans, C. (2003). The economic significance of national border effects. American Economic Review, 93(4), 1291–1312.
Goldberger, A. (1981). Linear regression after selection. Journal of Econometrics, 15(3), 357–366.
Haaland, J., Kind, H., Knarvik, K., & Torstensson, J. (1999). What determines the economic geography of Europe? (Discussion Paper 2072). London: Centre for Economic Policy Research.
Head, K., & Mayer, T. (2000). Non-Europe: The magnitude and causes of market fragmentation in the EU. Review of World Economics/Weltwirtschaftliches Archiv, 136(2), 284–314.
Head, K., & Mayer, T. (2002). Illusory border effects: Distance mismeasurement inflates estimates of home bias in trade (Working Paper 2002–01). Paris: Centré d’ Études Prospectives et d’Informationes Internationales.
Helpman, E., & Krugman, P. (1985). Market structure and foreign trade. Cambridge (MA): MIT Press.
Hummels, D. (2001). Toward a geography of trade costs (Working Paper). West Lafayette (IN): Purdue University.
Hummels, D., & Lugovskyy, V. (2006). Are matched partner trade statistics a usable measure of transportation costs? Review of International Economics, 14(1), 69–86.
Krugman, P. (1980). Scale economies, product differentiation, and the pattern of trade. The American Economic Review, 70(5), 950–959.
Mayer, T., & Zignago, S. (2006). Notes on CEPII’s distances measures. Paris: Centré d’ Études Prospectives et d’Informationes Internationales.
McCallum, J. (1995). National borders matter: Canada-US regional trade patterns. American Economic Review, 85(3), 615–623.
Nitsch, V. (2000). National borders and international trade: Evidence from the European Union. Canadian Journal of Economics, 33(4), 1091–1105.
Ottaviano, G., & Thisse, J. F. (2004). Agglomeration and economic geography. In J. V. Henderson & J. F. Thisse (Eds.), Handbook of regional and urban economics (vol. 4). Amsterdam: Elsevier.
Pagan, A., & Vella, F. (1989). Diagnostic tests for models based on individual data: A survey. Journal of Applied Econometrics, 4(S1), S29–S59.
Ramsey, J. (1969). Tests for specification errors in classical linear least-squares regression analysis. Journal of the Royal Statistical Society. Series B (Methodological), 31(2), 350–371.
Ruud, P. (1986). Consistent estimation of limited dependent variable models despite misspecification of distribution. Journal of Econometrics, 32(1), 157–187.
Silva, S., & Tenreyro, S. (2006). The log of gravity. Review of Economics and Statistics, 88(4), 641–658.
Tobin, J. (1958). Estimation of relationships for limited dependent variables. Econometrica: Journal of the Econometric Society, 26(1), 24–36.
Wooldridge, J. (2002). Econometric analysis of cross section and panel data. Cambridge (MA): MIT Press.
Acknowledgments
This work is partially drawn from my PhD thesis at the University of Pavia. I thank Paolo Epifani and Rodolfo Helg for their guidance and useful comments. I acknowledge financial support from the Italian Ministry of Education and Research by way of a PhD scholarship.
Author information
Authors and Affiliations
Corresponding author
Appendix: Data description
Appendix: Data description
1.1 Trade data for the estimation of the border effect
The analysis comprises twenty sectors of activity organised according to ISIC rev. 3/NACE 1.1, these sectors are: 1—the aggregate for “Mining and Quarrying” (NACE: C, ISIC: 10–14), 2—the aggregate for “Electricity, Gas and Water Supply” (NACE: E, ISIC: 40–41), 3–18 subgroups of manufacture as partitions of the “Total Manufacturing” aggregate (NACE: D, ISIC: 15–37; see Table 1 for the list of all the sectors considered). The time range is 1995–2003 for both a data availability issue and to correctly match the trade data with the employment data available for the concentration index. The countries considered are Austria, Belgium-Luxembourg, Denmark, Finland, France, Germany, Greece, Ireland, Italy, the Netherlands, Portugal, Spain, Sweden and the United Kingdom.Footnote 26
Bilateral exports among the 15 European countries considered (needed for the gravity equation) are extracted from the OECD Stan database (Bilateral Trade Flows section). These data are integrated with the national trade (NT) observations for every country-sector-year combination (the NT observations are for the estimation of the BE) and they amount to sectoral production less total sectoral export (to wit, the amount of sectoral production consumed within the country). Sectoral production and total sectoral export are extracted from the OECD Stan database as well (Industrial Analysis section). GDPs in purchasing power parities (regressor in the gravity equation) are extracted from the Penn World Table 6.2. All trade and production figures in current US dollars are converted in real terms by using the producer price index from the OECD Economic Outlook 2007. Weighted distances between and within countries are from the CEPII Distance database (Mayer and Zignago 2006).Footnote 27
Since our benchmark paper is Chen (2004), we wanted to estimate a gravity equation as close as possible to hers. However, her equation includes a variable named weight-to-value (wv k ) which was not possible to reproduce for our sample.Footnote 28 Instead of the weight-to-value ratios, we use the CIF/FOB ratios to account for different trade costs across industrial goods and pairs.Footnote 29 We compute the ratios by matching export and import figures by sector. We follow Hummels and Lugovskyy (2006) in ruling out the ratios higher than 2.Footnote 30 An original interpretation of the CIF/FOB ratios used in this paper is in Cafiso (2009), Appendix II .
1.2 Data for the concentration of production index
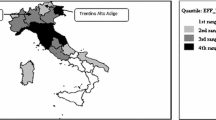
Concentration of production is computed by using employment figures which have the sectoral and geographic dimension (for the list of sectors see Table 1). These data come from the Eurostat’s Regio database (Structural Business Statistics section). The Data are at the Nuts-2 level for the period 1995–2003. Observations were available from 1995 to 2006, but we limited extraction to 2003 to select a sample which matches the trade data used for the BE estimation. We started with 207 Nuts-2 regions.: Austria, 9 regions; Belgium, 10 regions; Germany, 38 regions; Denmark, 5 regions (5 deleted); Spain, 19 regions (8 deleted); Finland, 5 regions (1 deleted); France, 22 regions; Greece, 13 regions (1 deleted); Ireland, 2 regions; Italy, 21 regions; Luxembourg, 1 region (1 deleted); the Netherlands, 12 regions; Portugal, 5 regions; Sweden, 8 regions; the United Kingdom, 37 regions.
This data set is characterized by the high occurrence of missing values. A correct computation of absolute concentration would require a balanced-panel of data (namely, the same number of geo-units for every sector). To get as close as possible to a balanced data set, we fill up the missing values through the following actions:
-
1.
Cubic Spline Interpolation over the annual observations.
-
2.
Computation of unique values through the average of the within period observations. For the 1-period analysis, the value comes from averaging the yearly observations for the entire 1995–2003 period. For the 2-period analysis, the first-period value comes from averaging the yearly observations for 1995–1998, while the second-period value comes from averaging the yearly observations for 2000–2003.
-
3.
If the higher-level geo-unit employment figure is available (i.e. employment for the Nuts-1 units), we split this for the within subunits (i.e. the Nuts-2 regions whose values we need) by using as weight the number of local units for each Nuts-2 region over the Nuts-1 total.Footnote 31
-
4.
Deletion of those Nuts-2 regions for which the missing value could not be filled-in (see values in brackets above).
1.3 Data for the concentration of demand index
Concentration of demand is computed using domestic absorption (DA). DA is generated as “Production less Export plus Import”. To make concentration of demand comparable to concentration of production, we needed production, export and import data by Nuts-2 region, ISIC rev. 3 sector and year. However, export and import figures are available only at the national level. We therefore constructed DA figures at the Nuts-2 level by dividing national DA through regional weights. National production, export and import in US dollars are extracted from the OECD Stan database.
We use the amount of local units in each Nuts-2 region (as reported in the Eurostat’s Regio database) to generate weights; no alternatives were available because of the sectoral dimension. As already mentioned, the local units in the Eurostat’s Regio database are the firms where the number of employees is recorded. Then, the number of local units is the number of firms in a specific Nuts-2 region. We acknowledge that this process might boost correlation between CD and CP, however, this was the only way to generate regional DA figures. It is to notice that the correlation between the two is hampered anyway: (i) employment does not depend only upon the number of firms but also upon the size of each firm; (ii) the distribution of national DA by sector is different from the distribution of national employment by sector.
About this article
Cite this article
Cafiso, G. Sectoral border effects and the geographic concentration of production. Rev World Econ 147, 543–566 (2011). https://doi.org/10.1007/s10290-011-0091-0
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10290-011-0091-0