
Abstract
Our contribution is twofold. Firstly, for a system of uncertain linear equations where the uncertainties are column-wise and reside in general convex sets, we derive convex representations for united and tolerable solution sets. Secondly, to obtain centered solutions for uncertain linear equations, we develop a new method based on adjustable robust optimization (ARO) techniques to compute the maximum size inscribed convex body (MCB) of the set of the solutions. In general, the obtained MCB is an inner approximation of the solution set, and its center is a potential solution to the system. We use recent results from ARO to characterize for which convex bodies the obtained MCB is optimal. We compare our method both theoretically and numerically with an existing method that minimizes the worst-case violation. Applications to the input–output model, Colley’s Matrix Rankings and Article Influence Scores demonstrate the advantages of the new method.
Similar content being viewed by others
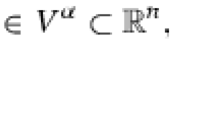
Avoid common mistakes on your manuscript.
1 Introduction
Systems of linear equations are of immense importance in mathematics and its applications in physics, economics, engineering, and many more fields. However, the presence of unavoidable errors (inaccuracies) in the specification of parameters in both the right- and left-hand sides introduces uncertainty in the sought solution. The uncertainties may be raised due to measurement/rounding errors in the data of the physical problems, estimation errors in the estimated parameters by using expert opinions and/or historical data, or numerical errors associated with finite representation of numbers by computer (see Ben-Tal et al. 2009).
A basic version of the problem that we consider is well known in the context of interval linear systems. For a given system of linear equations,
where the coefficient matrix \(A\in \mathbb {R}^{m \times n}\) and right-hand side \(\varvec{b} \in \mathbb {R}^{m}\) are uncertain and allowed to vary uniformly and independently of each other in the given intervals:
where \(\underline{a}_{ij}, \overline{a}_{ij}, \underline{b}_{i}, \overline{b}_{i} \in \mathbb {R}\), for all i, j, are the lower- and upper-bounds of the components in the matrix A and vector \(\varvec{b}\), respectively. Let  . There are three well known solution sets to the linear system (1), see, e.g., Kreinovich et al. (1998), Shary (2011), Popova (2012) and Hladík and Popova (2015):
. There are three well known solution sets to the linear system (1), see, e.g., Kreinovich et al. (1998), Shary (2011), Popova (2012) and Hladík and Popova (2015):
-
united solution set
$$\begin{aligned} \mathcal {X}=\left\{ \varvec{x}\in \mathbb {R}^{n}\,\, | \,\,\exists (A,\varvec{b})\in \mathcal {U} : A\varvec{x}=\varvec{b} \right\} , \end{aligned}$$ -
controllable solution set
$$\begin{aligned} \mathcal {X}^{con}=\left\{ \varvec{x}\in \mathbb {R}^{n}\,\, | \,\,\forall \varvec{b} \in \mathcal {B} ,\,\, \exists A \in \mathcal {A} : A\varvec{x}=\varvec{b} \right\} , \end{aligned}$$ -
tolerable solution set
$$\begin{aligned} \mathcal {X}^{tol}=\left\{ \varvec{x}\in \mathbb {R}^{n}\,\, | \,\,\forall A \in \mathcal {A},\,\, \exists \varvec{b} \in \mathcal {B} : A\varvec{x}=\varvec{b} \right\} . \end{aligned}$$
For a united solution set \(\mathcal {X}\), each of the possible \((A,\varvec{b}) \in \mathcal {U}\) has equal claim to be the true realization of the physical problem. Different parameters may produce different solutions for the system of linear equations. Since the pioneer work by Oettli and Prager (1964), much literature has been devoted to describe the ranges of the components of the solution \(\varvec{x} \in \mathcal {X}\) for interval linear systems, i.e.,
where \(x_i\) denotes the i-th element of vector \(\varvec{x}\). The main source of difficulties connected with obtaining ranges of \(x_i\) is the complicated structure of the solution set \(\mathcal {X}\). Although the intersection of the solution set and each orthant is a convex polyhedron, the union of those polyhedra, i.e., \(\mathcal {X}\), is generally non-convex. Oettli (1965) proposes to use a linear programming procedure in each orthant (i.e., \(2^n\) orthants in total) to determine \(\overline{x}_i\) and \(\underline{x}_i\), for all \(i\in [n]\). Rohn and Kreinovich (1995) show that, in general, determining the exact ranges for the components of \(\varvec{x}\in \mathcal {X}\) is an NP-hard problem. For a comprehensive treatment and for references to the literature on interval linear systems one may refer to the books Neumaier (1990), Kreinovich et al. (1998), Fiedler et al. (2006) and Moore et al. (2009). Due to the NP-hardness of solving (3) exactly, many ingenious methods have been developed to obtain sufficiently close outer estimates of the solution set, e.g., Hansen (1992), Jansson (1997), Ning and Kearfott (1997), Rump (2010), Hladík (2014), Popova (2004, 2014), Rohn (1981), Alefeld et al. (1998), Calafiore and Ghaoui (2004), Popova and Krämer (2007) and Hladík (2012) consider interval linear systems with dependent data. We refrain here from listing papers dedicated to computing enclosures since they are simply too many. Interval linear systems has been applied to many engineering problems described by systems of linear equations involving uncertainties. These problems include analysis of mechanical structures (see Smith et al. 2012; Muhanna and Erdolen 2006), electrical circuit designs (see Dreyer 2005; Kolev 1993) and chemical engineering (see Gau and Stadtherr 2002). For more applications we refer to the book Moore et al. (2009).
In this paper, we consider the system of uncertain linear equations:
where the coefficient matrix \(A:\mathbb {R}^{n_{\zeta }} \rightarrow \mathbb {R}^{m\times n}\) and right-hand side \(\varvec{b}:\mathbb {R}^{n_{\zeta }} \rightarrow \mathbb {R}^{m}\) are affine in \(\varvec{\zeta }\), and the uncertain parameters \(\varvec{\zeta } \in \mathbb {R}^{n_{\zeta }}\) reside in the uncertainty set \(\mathcal {U}\). Firstly, we focus on systems of linear equations with column-wise uncertainties. Let \(A(\varvec{\zeta })= [\varvec{a}_{\cdot 1} (\varvec{\zeta }_1)\,\, \varvec{a}_{\cdot 2}(\varvec{\zeta }_2) \cdots \varvec{a}_{\cdot n}(\varvec{\zeta }_n)]\), \(\varvec{b}(\varvec{\zeta }) = \varvec{b}(\varvec{\zeta }_0)\), and \(\varvec{\zeta }=[\varvec{\zeta }_0'\,\,\varvec{\zeta }_1'\,\, \cdots \,\, \varvec{\zeta }_n']'\). We represent the system (4) as follows:
where the vector function \(\varvec{a}_{\cdot j}\) is affine in \(\varvec{\zeta }_j \in \mathcal {U}_j\), the vector function \(\varvec{b}\) is affine in \(\varvec{\zeta }_0 \in \mathcal {U}_0\), and the set \(\mathcal {U}_j\) is convex, for all \(j\in [n] \cup \{0\}\). The corresponding united solution set \(\mathcal {X}\) is:
where  , and \(\varvec{\zeta } = [\varvec{\zeta }_0' \,\, \varvec{\zeta }_1' \,\, \cdots \,\, \varvec{\zeta }_n']' \in \mathbb {R}^{n_\zeta }\). Most of the existing literature consider (4) with independent interval uncertainties. Oettli (1965) shows that for a special class of (6), where uncertainties are component-wise and reside in independent intervals, i.e., (2), the intersection of the united solution set \(\mathcal {X}\) and any orthant of \(\mathbb {R}^{n}\) is a convex polyhedron. Popova (2014) devises a method to obtain close outer estimates of (4) with independent interval uncertainties. Popova (2015) characterize the solvability of (4) with independent interval uncertainties. Here, we consider uncertain linear systems with column-wise (dependent) uncertainties that reside in general convex sets, and derive convex representations of \(\mathcal {X}\) in an arbitrary orthant. Moreover, when \(\mathcal {U}_j\) are polyhedral, \(j\in [n]\cup \{0\}\), the set \(\mathcal {X}\) is also polyhedral; when \(\mathcal {U}_j\) are ellipsoidal, \(j\in [n]\cup \{0\}\), the set \(\mathcal {X}\) is conic quadratic representable.
, and \(\varvec{\zeta } = [\varvec{\zeta }_0' \,\, \varvec{\zeta }_1' \,\, \cdots \,\, \varvec{\zeta }_n']' \in \mathbb {R}^{n_\zeta }\). Most of the existing literature consider (4) with independent interval uncertainties. Oettli (1965) shows that for a special class of (6), where uncertainties are component-wise and reside in independent intervals, i.e., (2), the intersection of the united solution set \(\mathcal {X}\) and any orthant of \(\mathbb {R}^{n}\) is a convex polyhedron. Popova (2014) devises a method to obtain close outer estimates of (4) with independent interval uncertainties. Popova (2015) characterize the solvability of (4) with independent interval uncertainties. Here, we consider uncertain linear systems with column-wise (dependent) uncertainties that reside in general convex sets, and derive convex representations of \(\mathcal {X}\) in an arbitrary orthant. Moreover, when \(\mathcal {U}_j\) are polyhedral, \(j\in [n]\cup \{0\}\), the set \(\mathcal {X}\) is also polyhedral; when \(\mathcal {U}_j\) are ellipsoidal, \(j\in [n]\cup \{0\}\), the set \(\mathcal {X}\) is conic quadratic representable.
Moreover, via a convex representation technique and the techniques from (adjustable) robust optimization, we are able to derive convex representations of a special class of \(\mathcal {X}^{con}\). We further show that \(\mathcal {X}^{tol}\) can be interpreted as a solution set for a static robust optimization problem, which admits tractable reformulations for many important classes of \(\mathcal {A}\) and \(\mathcal {B}\).
We propose to compute the maximum size inscribed convex body (MCB) of the set of possible solutions for systems of uncertain linear equations. It is intuitively appealing to find a centered solution that is “far” from the boundaries of the solution set \(\mathcal {X}\) (i.e., infeasibility). The obtained MCB is an inner approximation of the solution set, and its center is a potential solution to the system. We extend the method developed in Zhen and den Hertog (2017) to compute the MCB of the solution set \(\mathcal {X}\). This method is independently developed in Zhang et al. (2017) and applied to optimal control problems. Furthermore, we use the recent results of Zhen et al. (2016) for adjustable robust optimization (ARO) to characterize for which convex bodies the obtained MCB is optimal.
We compare our new method both theoretically and numerically with an existing method. The conventional method of determining a robust solution for systems of uncertain linear equations first appears in the context of robust least-squares (RLS) problems Ghaoui and Lebret (1997). The RLS method finds the minimizer \(\varvec{x}_{RLS}\) of the worst-case 2-norm violation of the system:
The tractability of Problem (7) strongly relies on the choice of the uncertainty set \(\mathcal {U}\). Ben-Tal et al. (2009) show that Problem (7) under independent interval uncertainties can be reformulated into an SOCP problem. In Ghaoui and Lebret (1997), Beck and Eldar (2006) and Jeyakumar and Li (2014), authors derive an SOCP or a semidefinite programming (SDP) reformulation of Problem (7) under ellipsoidal uncertainties. Burer (2012) and Juditsky and Polyak (2012) solve (7) to find the robust rating vectors for Colley’s Matrix Ranking and Google’s PageRank, respectively.
The contributions of this paper may be summarized as follows:
-
1.
For column-wise (dependent) uncertainties that reside in convex sets, we show that the united solution set \(\mathcal {X}\) in any orthant is convex, and derive a convex representation of \(\mathcal {X}\). We then derive a convex representation of \(\mathcal {X}^{con}\) via robust optimization techniques, and further discuss the cases in which \(\mathcal {X}^{tol}\) can be reformulated into equivalent convex sets.
-
2.
Based on ARO techniques, we develop a new method to compute the MCB of the set of possible solutions for uncertain linear systems. Its center can be considered as a candidate. Furthermore, we use the recent results of Zhen et al. (2016) for ARO to characterize for which convex bodies the obtained MCB is optimal.
-
3.
We compare our new method both theoretically and numerically with the RLS method. We show that the solutions \(\varvec{x}_{RLS}\) are scale sensitive and may even be outside \(\mathcal {X}\). Applications to the input–output model, Colley’s Matrix Rankings, and Article Influence Scores demonstrate the advantages and disadvantages of the two methods.
The remainder of the paper is organized as follows. Section 2 discusses the properties of the solution sets, and derive equivalent convex representations of \(\mathcal {X}\) and \(\mathcal {X}^{con}\). The method for computing the MCB is discussed in Sect. 3. In Sect. 4, we compare our method with the RLS method theoretically, and Sect. 5 presents numerical results.
Notation We use [n], \(n \in \mathbb {N}\) to denote the set of running indices, \(\{1,\ldots ,n\}\). We use bold faced characters such as \(\varvec{x} \in \mathbb {R}^n\) to represent vectors. We use \(x_i\) to denote the i-th element of the vector \(\varvec{x}\). We denote \(\varvec{a}_{\cdot j}\) as the j-th column of the matrix A. We use normal and calligraphy capital letters such as \(A \in \mathbb {R}^{m\times n}\) and \(\mathcal {X}\) to represent matrices and sets, respectively. We denote \(\varvec{\zeta } \in \mathbb {R}^{n_\zeta }\) as the uncertain parameters.
2 Convexity and representation of the solution set
2.1 Convexity of united solution set
Let us consider system (5) of uncertain linear equations. We assume that the uncertainty set \(\mathcal {U}\) that \(\varvec{\zeta } = [\varvec{\zeta }_0' \,\, \varvec{\zeta }_1' \,\, \cdots \,\, \varvec{\zeta }_n']' \in \mathbb {R}^{n_\zeta }\) resides in, is bounded and defined as follows:

and the function \(f_{jk}\) is convex in \(\varvec{\zeta }_j\), \(j\in [n]\cup \{0\}\), \(k\in [n]\). The components of \( \varvec{\zeta }_j \in \mathcal {U}_j\) may be dependent. For \(i\ne j\), the components of \(\varvec{\zeta }_i \in \mathcal {U}_i\) and \(\varvec{\zeta }_j \in \mathcal {U}_j\) are independent. The uncertainties in the system (5) are indeed column-wise. Note that the dimensions of the uncertain parameters \(\varvec{\zeta }_i\) and \(\varvec{\zeta }_j\) are not necessarily the same for \(i \ne j\). For a given pair \(\mathcal {I}, \mathcal {J} \subseteq [n]\), where \(\mathcal {I}\cup \mathcal {J} = [n]\), and \(\mathcal {I} \cap \mathcal {J} =\emptyset \), the corresponding orthant is defined as
Lemma 1
The intersection of \(\mathcal {R}^{n}_{\mathcal {I}, \mathcal {J}}\) and the solution set \(\mathcal {X}\) with the uncertainty set \(\mathcal {U}\) defined in (5):
is convex.
Proof
Since this proof is almost identical to the proof for Blanc and Hertog (2008, Proposition 1), we omit it here. \(\square \)
Although Blanc and Hertog (2008, Proposition 1) only considers \(\varvec{x}\) in the nonnegative orthant with polyhedral uncertainties on the left hand side, their proof also holds for general convex uncertainties on both left and right hand side with \(\varvec{x}\) reside in any given orthant. Soyster (1973) shows that the nonnegative sum of a finite number of convex sets is convex, which is basically the result of Lemma 1. Examples 1 and 2 show that in order to preserve convexity of the solution set \(\mathcal {X}\) the two conditions are indeed necessary: (a) the feasible solutions \(\varvec{x} \in \mathcal {X}\) are within a particular orthant of \(\mathbb {R}^n\), and (b) the uncertainties in \(A(\varvec{\zeta })\) and \(\varvec{b}(\varvec{\zeta })\) are column-wise.
Example 1
The union of the solutions \(\varvec{x} \in \mathcal {X}\) in two orthants can be nonconvex. Let us consider the following solution set of an uncertain linear system
The solution set \(\mathcal {X}\) can be represented as:
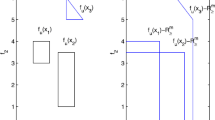
One can easily see that the intersection of the solution set \(\mathcal {X}\) and each orthant of \(\mathbb {R}^2\) is indeed convex. However, the set \(\mathcal {X}\) is nonconvex, see Fig. 1. This result is known in Oettli (1965).

The shaded region is the solution set \(\mathcal {X}\) in Example 1
Example 2
The solution set \(\mathcal {X}\) can be nonconvex when the uncertainties are not column-wise. Let us consider the following solution set of an uncertain linear system:
Note that the uncertainties of the system are not column-wise. The set can be represented as:
This set is nonempty only in the nonnegative orthant \(\mathbb {R}^2_+\), and clearly, the set \(\mathcal {X}\) is nonconvex. See Fig. 2. A similar observation is also made in, e.g., Tichatschke et al. (1989) and Popova and Krämer (2007).

The shaded region is the solution set \(\mathcal {X}\) in Example 2
2.2 Convex representation of united solution set
Given the uncertainty sets defined in (8), the intersection of the solution set \(\mathcal {X}\) and an arbitrary orthant \(\mathcal {R}^{n}_{\mathcal {I}, \mathcal {J}}\) can be compactly represented as follows:
where the components of the vector functions \(\varvec{a}_{\cdot j}\), \( \varvec{b}\) are affine in \(\varvec{\zeta }_j\), and \(f_{jk}\) is convex in \(\varvec{\zeta }_j\), for all j, k. Due to the presence of products of variables (e.g., \(\varvec{\zeta }_{j} x_j\) for some \(j \in [n]\)), the representation of set (9) is nonconvex.
Theorem 1
The set (9) admits the following convex representation
where \(0 \varvec{a}_{\cdot j} \left( \frac{\varvec{y}_j}{0}\right) = \lim _{x_j \rightarrow 0} x_j \varvec{a}_{\cdot j} \left( \frac{\varvec{y}_j}{x_j}\right) \) and \(0 f_{jk}\left( \frac{\varvec{y_j}}{0} \right) = \lim _{x_j \rightarrow 0} x_j f_{jk}\left( \frac{\varvec{y}_j}{x_j}\right) \) are the recession functions of \(\varvec{a}_{\cdot j}\) and \(f_{jk}\), respectively.
Proof
The set (10) is obtained by substituting \(\varvec{y}_j=x_j\varvec{\zeta }_{j} \) and multiply the inequality constraints containing \(\varvec{\zeta }_{j}\) with \(x_j\) in (9). Since the vector functions \(\varvec{a}_{\cdot j}(\cdot )\), \(j\in [n]\), and \(\varvec{b} (\cdot )\) are affine, the equalities \(\sum _{j=1}^{n} \varvec{a}_{\cdot j} \left( \frac{\varvec{y}_j}{x_j}\right) x_j =\varvec{b} (\varvec{\zeta }_0)\) are affine in \(\varvec{x}\), \(\varvec{\zeta }_0\) and \(\varvec{y}_j\), \(j\in [n]\). Dacorogna and Maréchal (2008) show that, for a convex function \(f:\mathbb {R}^n\rightarrow \mathbb {R}\), its perspective \(g(\varvec{y},x):= x f(\frac{\varvec{y}}{x})\) is convex on \(\mathbb {R}^n \times \mathbb {R}_+\setminus \{0\}\). Here is a short proof of the convexity of \(x f(\frac{\varvec{y}}{x})\) on \(\mathbb {R}^n \times \mathbb {R}_+\setminus \{0\}\) uses convex analysis (adopted from Gorissen et al. 2014):
from which it follows that \(g(\varvec{y},x)\) is jointly convex since it is the pointwise supremum of functions which are linear in x and \(\varvec{y}\). Hence, the functions \(x_i f_{ik}\left( \frac{\varvec{y}_i}{x_i}\right) \), \(i\in \mathcal {I}\), \(-x_j f_{jk}\left( \frac{\varvec{y}_j}{x_j}\right) \), \(j\in \mathcal {J}\), are jointly convex in \(\varvec{x}\) and \(\varvec{y}_k\), \(k\in [n]\). \(\square \)
Theorem 1 shows that for general convex functions \(f_{jk}\), for all j, k, the solution set \(\mathcal {X}\) in any orthant of \(\mathbb {R}^n\) is convex, which coincides with the findings in Lemma 1. Furthermore, for each \(j\in [n] \cup \{0\}, k\in [n]\), if \(f_{jk}\) is affine in \(\varvec{\zeta }_{ j}\), the set \(\mathcal {X}\) is polyhedral; if \(f_{jk}\) is quadratic in \(\varvec{\zeta }_{ j}\), the set \(\mathcal {X}\) is conic quadratic representable. Our result generalizes the results of Rohn (1981), where the author provides a convex representation of interval linear systems with prescribed column sums.
This transformation technique used in the proof of Theorem 1 is first proposed by Dantzig (1963) to solve Generalized LPs. In the field of disjunctive programming, Balas (1998) employs this technique to derive a convex representation of the union of polytopes. Grossmann and Lee (2003) use it to derive a convex representation of the convex hull of general convex sets. This technique is also applied to the dual of LPs with polyhedral uncertainty in Römer (2010). Gorissen et al. (2014) use it to derive tractable robust counterparts of a linear conic optimization problem. We illustrate this transformation by the following interval linear system example. This example is used throughout this paper.
Example 3
The convex representation of \(\mathcal {X} \cap \mathbb {R}_+^n\) with product of variables. Let us consider the solution set in non-negative orthant \(\mathcal {R}^{2}_{[2],\emptyset }= \mathbb {R}_+^2\):
where  , \(\mathcal {U}_0 = [0, \,\, 120] \times [60,\,\, 240]\), \(\mathcal {U}_1 = [0, \,\, 1] \times \{2\}\) and \(\mathcal {U}_2 = [2, \,\, 3] \times [1,\,\, 2]\). Substituting \(\varvec{\zeta }_1 = \frac{\varvec{y}_1}{x_1}\) and \( \varvec{\zeta }_2= \frac{\varvec{y}_2}{x_2}\), and multiplying the inequality constraints containing \(\varvec{\zeta }_{j}\) with \(x_j\), yields the following representation:
, \(\mathcal {U}_0 = [0, \,\, 120] \times [60,\,\, 240]\), \(\mathcal {U}_1 = [0, \,\, 1] \times \{2\}\) and \(\mathcal {U}_2 = [2, \,\, 3] \times [1,\,\, 2]\). Substituting \(\varvec{\zeta }_1 = \frac{\varvec{y}_1}{x_1}\) and \( \varvec{\zeta }_2= \frac{\varvec{y}_2}{x_2}\), and multiplying the inequality constraints containing \(\varvec{\zeta }_{j}\) with \(x_j\), yields the following representation:

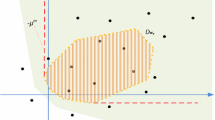
One can further simplify this set by eliminating the equality constraints. From Fig. 3, we observe that the set defined in (11) is a full-dimensional polytope.
For interval linear systems, Kreinovich et al. (1998) show that checking the boundedness of the solution set is NP-hard. If we only focus on the solution set in a specific orthant, the boundedness can simply be checked by maximizing \(\sum _{i\in \mathcal {I}} x_i - \sum _{j\in \mathcal {J}} x_j\) over \(\mathcal {X}\) in \(\mathcal {R}^{n}_{\mathcal {I}, \mathcal {J}}\).
2.3 Convex representations of controllable and tolerable solution sets
Let us first consider a controllable solution set in an arbitrary orthant with column-wise uncertainties:
where the uncertainty sets \(\mathcal {U}_j\), \(j\in [n]\cup \{0\}\), are defined in (8). Via the convex representation technique in Sect. 2.2, the set (12) can be reformulated as:
Let us now focus on a special class of (13), where \(f_{ik}\), \(i,k\in [n]\), are affine. The set (13) can be interpreted as a solution set of a two-stage robust linear optimization problem. Here, the auxiliary variables \(\varvec{y}_j\), \(j\in [n]\), can be seen as general functions of \(\varvec{\zeta }_0\). Ben-Tal et al. (2004) show that solving ARO problems is generally NP-hard, because the auxiliary variables (a.k.a., adjustable variables) are decision rules instead of finite vectors of decision variables. Zhen et al. (2016) show via Fourier–Motzkin elimination that the solution set of two-stage robust linear optimization problems can be reformulated into a convex set, e.g., the set (13) is a polyhedron if \(\mathcal {U}_0\) is polyhedral.
For computational tractability, we often restrict the adjustable variable \(\varvec{y}\) (for simplicity, here we drop the subscript of \(\varvec{y}_j\)) to linear decision rules, e.g., the decision rule \(\varvec{y}\) is linear in \(\varvec{\zeta }_0\):
where the coefficients \(\varvec{u}\in \mathbb {R}^{n_y}\) and \(V\in \mathbb {R}^{n_y \times n}\) will be optimization variables. Despite that linear functions may not be optimal, it appears that such a decision rule performs well in practice. For instance, Ben-Ameur et al. (2016) and Zhen et al. (2016) show that linear decision rules are optimal for adjustable robust linear optimization problems with a simplicial uncertainty set. Suppose \(\mathcal {U}_0 = \{ \varvec{\zeta }_0 \in \mathbb {R}^{n}_+ \,|\, \varvec{1}'\varvec{\zeta }_0 \le 1 \}\) is a standard simplex, then linear decision rules are optimal, and (13) can be reformulated into a polyhedron. For a general convex \(\mathcal {U}_0\), linear decision rules result in an inner approximation of (13).
In case of tolerable solution set, one can eliminate all the auxiliary variables \(\varvec{b}\), and obtain:
Note that here we do not restrict the solution set to be within a specific orthant. The set (15) can be seen as a solution set of a static robust optimization problem. If \(\mathcal {A}\) and \(\mathcal {B}\) are ellipsoidal, then the set (15) is SDP-representable; if \(\mathcal {B}\) is polyhedral, then (15) can be equivalently reformulated into a convex set via Fenchel duality (see Ben-Tal et al. 2015) for almost all convex \(\mathcal {A}\). For polyhedral \(\mathcal {A}\) and \(\mathcal {B}\), the set (15) can be reformulated into a convex polyhedron. This generalizes the result of Popova (2012), where the author shows that the tolerable solution set with interval uncertainties is a convex polyhedron.
3 Maximum size inscribed convex body of solution set
Firstly, in Sect. 3.1, we extend the method of Zhen and den Hertog (2017) to compute the maximum size inscribed convex body (MCB) of a polytopic projection. Since the obtained MCB is an under approximation of the optimal MCB, in Sect. 3.2, we briefly discuss a simple procedure that provides an upper approximation.
3.1 MCB of polytopic projection
It is well-known that for a general convex set, finding the MCB can be computationally intractable. In this subsection, we focus on polyhedral solution sets. For instance, the united solution set \( \mathcal {X} \cap \mathcal {R}^{n}_{\mathcal {I}, \mathcal {J}}\) defined in (10) is polyhedral if the functions \(f_{jk}\) and \(f_{0k}\) are affine, \(j,k \in [n]\):
for some scalar \(c_{jk}, c_{0k}\), and vectors \(\varvec{d}_{jk}, \varvec{d}_{0k}\). Similarly, the controllable and tolerable solution sets can also be reformulated (exactly or approximately via linear decision rules and robust optimization techniques) into polyhedral sets, and the method discussed in this section can also be directly applied. For clarity, we represent the (projected) polyhedral set (16) as follows:
where \(D \in \mathbb {R}^{m \times (n+n_y)}\), and \(\varvec{c}\in \mathbb {R}^{m}\). The auxiliary variable \(\varvec{y}\) in (17) represents the variables \(\varvec{y}_j\)’s and \(\varvec{\zeta }_0\) in (16). If the set \(\mathcal {H}\) is not full-dimensional, then there are (hidden) equality constraints in \(\mathcal {H}\). One can simply eliminate the equality constraints via Gaussian elimination. Without loss of generality, let us assume that the set \(\mathcal {H}\) is full-dimensional.
The set \(\mathcal {H}\) contains both variables \(\varvec{x}\) and \(\varvec{y}\), but it is desired to find the MCB only with respect to \(\varvec{x}\). Due to the existence of \(\varvec{y}\) in the description of \(\mathcal {H}\), finding the MCB in a polytopic projection is generally a non-convex optimization problem (see Zhen and den Hertog 2017). One can use elimination methods, e.g., Fourier–Motzkin elimination (see Fourier 1824; Motzkin 1936), to eliminate all \(\varvec{y}\) in \(\mathcal {H}\). This is equivalent to deriving a description of \(\mathcal {H}\) that does not contain \(\varvec{y}\). Tiwary (2008) shows that deriving an explicit description of a projected polytope is NP-hard. Alternatively, Zhen and den Hertog (2017) approximate the maximum volume inscribe ellipsoid (MVE) of \(\mathcal {H}\) via linear and quadratic decision rules.
We extend the method of Zhen and den Hertog (2017) to compute the MCB (and its center) of a polytopic projection by solving the following adjustable robust optimization problem:
where \(E\in \mathbb {S}^{n}\) with implicit constraint \(E \succ 0\), \( \mathbb {S}^{n}\) is the set of \(n \times n\) symmetric matrices, \(\varvec{x}\) are non-adjustable variables, the vector function \(\varvec{y}\) are called decision rules, and \(\Xi \subseteq \mathbb {R}^{n}\) is a compact convex body. By maximizing the concave function logdet(E) in Problem (18), the matrix E “stretches” (or “suppresses”) and “rotates” the convex body \(\Xi \) around \(\varvec{x}\) in \(\mathcal {H}\) to its maximum volume. If one would like to “stretch” (or “suppress”) the convex body along the \(\varvec{x}\)’s axes (i.e., without rotation), this can simply be done by restricting the non-diagonal entries of E to be 0, and maximizing \(\sum _{i\in [n]}\log E_{ii}\). When \(\mathcal {H}\) is unbounded, the volume of the MCB is also unbounded. The boundedness of \(\mathcal {H}\) can be checked via an LP problem.
Let us restrict the decision rule \(\varvec{y}\) to be linear in \(\varvec{\xi }\) as in (14), and substitute it in (18) to get the affinely adjustable robust formulation:
Problem (19) is a semi-infinite optimization problem that approximates the MCB and its center. For a broad class of convex bodies \(\Xi \), Problem (19) can be reformulated into an equivalent tractable reformulation (see Ben-Tal et al. 2015):
-
Maximum inscribed polytope For a polytope \(\Xi = \{ \varvec{\xi } \in \mathbb {R}^{n}_+ \,|\, P\varvec{\xi } \le \varvec{q} \}\), where \(P \in \mathbb {R}^{ m_{\xi } \times n}\) and \(\varvec{q} \in \mathbb {R}^{ m_{\xi }}\), the tractable counterpart of Problem (19) is as follows:
$$\begin{aligned} \max _{\varvec{x},\varvec{u}, V, E, \Delta } \left\{ \log \text {det} E \,\, \left| \,\, D \begin{bmatrix} \varvec{x} \\ \varvec{u} \end{bmatrix} + \Delta \varvec{q} \le \varvec{c},\,\, \Delta P \ge D\begin{bmatrix} E \\ V \end{bmatrix}, \,\, \Delta \ge \varvec{0} \right\} , \right. \end{aligned}$$(20)where \(\Delta \in \mathbb {R}^{m\times m_{\xi }}\). Let us consider two special polyhedral sets, i.e., \(\Xi \) is a box or simplex. Zhen et al. (2016) proves that linear and two-piecewise decision rules are optimal for two-stage robust linear optimization problems with simplex and box uncertainties, respectively. If \(\Xi = \{ \varvec{\xi } \in \mathbb {R}^{n}_+ \,|\, \varvec{1}'\varvec{\xi } \le 1 \}\) is a standard simplex, the solution of (20) gives a maximum inscribed simplex of \(\mathcal {H}\); if \(\Xi = \{ \varvec{\xi } \in \mathbb {R}^{n} \,|\, |\varvec{\xi }| \le \varvec{1} \}\) is a box, there exists two-piecewise affine decision rules that are optimal for (18), and the solutions of (20) are in general suboptimal. For tolerable solution sets with interval uncertainties, Hladík and Popova (2015) devise an exponential LP methods for computing maximal inner boxes exactly, and also propose a polynomial heuristic that yields an approximated maximal inner box. Furthermore, Ben-Tal et al. (2004) show that static decision rules are optimal for two-stage robust linear optimization problems with constraint-wise uncertainties. Hence, one can directly show that the solution of

gives a maximum inscribed box (without rotation) of \(\mathcal {H}\), where \(\varvec{d}'_{i\cdot }\) is the i-th row of D, and \( \varvec{y}_i \in \mathbb {R}^{n_y}, i\in [m]\).
-
Maximum inscribed ellipsoid For \(\Xi = \{ \varvec{\xi } \in \mathbb {R}^{n}\,|\, || \varvec{\xi }||_{2} \le 1 \}\), the tractable counterpart of Problem (19) is as follows:
$$\begin{aligned} \max _{\varvec{x},\varvec{u}, V,E} \left\{ \log \text {det} E \,\, \left| \,\, \varvec{d}_{i \cdot }' \begin{bmatrix} \varvec{x} \\ \varvec{u} \end{bmatrix} + \left| \left| \begin{bmatrix} E \\ V \end{bmatrix}' \varvec{d}_{i \cdot } \right| \right| _{2}\le c_i, \quad \forall i \in [m] \right\} ,\right. \end{aligned}$$(21)where \(\varvec{d}_{i \cdot } \in \mathbb {R}^n\) is the i-th row of the matrix D. Problem (21) approximates the MVE of \(\mathcal {H}\). A largest ball in \(\mathcal {H}\) can be determined by replacing the matrix E by \(eI \in \mathbb {R}^{n \times n}\) (i.e., a product of a scaler \(e \in \mathbb {R}_+\) and identity matrix) everywhere in (21). For the rest of this paper, we focus on MVE, i.e., \(\Xi = \{ \varvec{\xi } \in \mathbb {R}^{n}\,|\, || \varvec{\xi }||_{2} \le 1 \}\), because it possesses many appealing properties: (a) it is unique, invariant of the representation of the given convex body; (b) its center is a centralized (relative) interior point of the convex body; (c) it is a inner approximation of \(\mathcal {H}\) which admits a simple description (i.e., one inequality constraint). We denote \(\varvec{x}_{aMVE}\) as the approximated MVE center of \(\mathcal {H}\) obtained from the MVE method (21). In the following example, we solve (21) to compute \(\varvec{x}_{aMVE}\) of the solution set \(\mathcal {H}\).

Example 4
The maximum volume inscribed ellipsoid (Example 3 continued). From Fig. 3 we know that \(\mathcal {H}\) is full-dimensional. Since we are interested in the MVE center of \(\mathcal {H}\) only with respect to \(\varvec{x}\), we compute the \(\varvec{x}_{aMVE}\) of \(\mathcal {H}\) by solving (21), and obtain \(\varvec{x}_{aMVE}=(52.1,\,\,30.7)\). In order to evaluate the obtained solution, we derive an explicit description of \(\mathcal {H}\) with no auxiliary variables by using Fourier–Motzkin elimination, and obtain the optimal MVE center \(\varvec{x}_{MVE}\) at \((53.6,\,\, 30)\). Note that, in general, it is NP-hard to derive such a description. From Fig. 3, one can observe that \(\varvec{x}_{aMVE}\) is a close approximation of \(\varvec{x}_{MVE}\).
3.2 Upper bounding method of Hadjiyiannis et al. (2011)
Hadjiyiannis et al. (2011) propose to compute upper bounds on the optimal value of adjustable robust optimization problems by only considering a finite set of scenarios, which they call critical scenarios (CSs). The CSs are obtained by solving the auxiliary optimization problems:
where \(E^*\) and \(V^*\) denote the optimal solution from (19). If more than one CS is determined from the k-th constraint, an arbitrary CS is chosen and included in the CS set. The scenario counterpart of Problem (18) with respect to the CS set \(\widehat{\Xi }\), where \(\widehat{\Xi }= \{\varvec{\xi }^{1}, \ldots , \varvec{\xi }^{m} \}\), is given by the following optimization problem:
For each \(\varvec{\xi }^{k} \in \widehat{\Xi }\), \(k\in [m]\), we only need a feasible \(\varvec{y}^k \in \mathbb {R}^{n_y}\) to exist. Since \(\widehat{\Xi } \subset \Xi \), Problem (23) provides an upper bound of (18).
4 Comparison of solution methods
In this section, we compare the theoretical aspects of the robust least-square (RLS) method with our MVE method discussed in Sect. 3. Let us first consider an interval linear system where:

and \(\varvec{\zeta } = [\varvec{\zeta }_0' \,\, \varvec{\zeta }_1' \,\, \cdots \,\, \varvec{\zeta }_n']' \in \mathbb {R}^{n_\zeta }\). We further denote the nominal realization \(\varvec{\zeta }^{nom}\) as the median of the intervals, i.e., \(\varvec{\zeta }^{nom} = \frac{1}{2}(\overline{\varvec{\zeta } } + \underline{\varvec{\zeta } }) \in \mathbb {R}^{n_\zeta }\).
Lemma 2
Given \(A(\varvec{\zeta })\), \(\varvec{b}(\varvec{\zeta })\) and \(\mathcal {U}\) in (24), the solution \(\varvec{x}_{RLS}\) is optimal for (7) if and only if it is also optimal for the following SOCP problem with a unique \(\varvec{z}\in \mathbb {R}^m\):
where \(\varvec{\theta }_j = \overline{\varvec{\zeta }}_j - \varvec{\zeta }^{nom}_j \in \mathbb {R}^m, j\in [n]\cup \{0\}\).
Proof
This proof is adapted from Ben-Tal et al. (2009) [Chapter 6.2]:
\(\square \)
Note that in Lemma 2, the optimal solution \(\varvec{x}_{RLS}\) of (25) is not restricted to be within any specific orthant. The tractability of Problem (7) strongly relies on the choice of the uncertainty set \(\mathcal {U}\). For deriving tractable counterpart of (7) with ellipsoidal uncertainties in A and/or \(\varvec{b}\), we would like to refer to Ghaoui and Lebret (1997), Beck and Eldar (2006) and Jeyakumar and Li (2014). In the following example, we solve Problem (25) for the interval linear system in Example 3.
Example 5
The robust least-squares solution for an interval linear system. We apply the RLS method to the interval linear system in Example 3 and find the solution \(\varvec{x}_{RLS}\) is at (67.06, 10.59), which is denoted as \(\square \) in Fig. 3. The solution \(\varvec{x}_{RLS}\) coincides with the nominal solution \(\varvec{x}_{nom}\) (i.e., the solution obtained from the nominal realization) of the system.

The shaded region is the solution set \(\mathcal {X}\) in Example 3. The dashed ellipsoid is the MVE. The solutions from the MVE method and the RLS method are denoted as \(\varvec{x}_{aMVE}\) and \(\varvec{x}_{RLS}\), respectively. The solutions \(\varvec{x}_{nom}\) and \(\varvec{x}_{MVE}\) are the nominal solution and the optimal MVE center, respectively
The RLS method is in line with the philosophy of Robust Optimization (see Ben-Tal et al. 2009), i.e., minimizing the violation with respect to the worst-case scenario. Our method finds a centered solution of the solution set. In Sect. 5, we show that in many real-life problems that involve solving a system of linear equations, the uncertainties are often column-wise, i.e., the uncertainties within each column of \(A(\varvec{\zeta })\) and \(\varvec{b}(\varvec{\zeta })\) may be dependent, and the centered solution \(\varvec{x}_{aMVE}\) can be efficiently obtained. However, the choice of uncertainty sets for Problem (7) that admits a tractable counterpart is rather limited, e.g., for polyhedral uncertainties, Problem (7) is generally NP-hard.
One of the most fundamental properties of a system of (uncertain) linear equations is scale invariance. The nominal solution \(\varvec{x}_{nom}\) and centered solution \(\varvec{x}_{aMVE}\) are scale invariant, whereas, the solution \(\varvec{x}_{RLS}\) is not. In fact, \(\varvec{x}_{RLS}\) can be outside the solution set (see Example 6), and even if one restrict \(\varvec{x}_{RLS}\) to be within \(\mathcal {X}\), it may still be on the boundary of the solution set. As the feasibility of the solutions are not guaranteed, the solution \(\varvec{x}_{RLS}\) may be less appealing than \(\varvec{x}_{aMVE}\).

The shaded region is the solution set \(\mathcal {X}\) in Example 3. The dashed ellipsoid is the MVE. The solutions from the MVE method and the RLS method are denoted as \(\varvec{x}_{aMVE}\) and \(\varvec{x}_{RLS}\), respectively. The solutions \(\varvec{x}_{nom}\) and \(\varvec{x}_{MVE}\) are the nominal solution and the optimal MVE center, respectively
Example 6
Scale sensitivity of the solutions. Let us consider an adapted version of the interval linear system in Example 3 where the uncertainty sets are defined as:
The components of the first row of the interval linear system in Example 3 are now multiplied by a factor 30. Note that this operation does not alter the set \(\mathcal {X}\cap \mathbb {R}_+^2\). The solutions for this uncertain linear system are depicted in Fig. 4. The nominal and MVE solutions remain unchanged. The solution \(\varvec{x}_{RLS}\) is outside the solution set.
5 Numerical experiments
In this section, we conduct four experiments to evaluate the candidate solutions. The first experiment considers the interval linear system introduced in Example 3 and its adapted version in Example 6. The other three are input–output model, Colley’s Matrix Ranking and Article Influence Scores, respectively. A common feature of these problems is that their solutions are obtained by solving a system of linear equations. All the procedures are performed by using Mosek 8 (see MOSEK ApS 2017) within Matlab R2017a on an Intel Core i5-4590 CPU running at 3.3 GHz with 8 GB RAM under Windows 7 operating system.
5.1 A simple experiment
Firstly, we compute the candidate solutions for the interval linear system discussed in Example 3. Given a candidate solution \(\tilde{\varvec{x}}\), three measures are considered:
-
VOL the volume of the MVE centered at \(\tilde{\varvec{x}}\) within \(\mathcal {X}\)
-
WD the worst-case 2-norm deviations of \(A(\varvec{\zeta })\tilde{\varvec{x}}\) from \(\varvec{b}(\varvec{\zeta })\) (i.e., \(\max _{ \varvec{\zeta } \in \mathcal {U}} ||A(\varvec{\zeta })\tilde{\varvec{x}}- \varvec{b}(\varvec{\zeta })||_2\))
-
MD the mean 2-norm deviations of uniformly sampled solutions in \(\mathcal {X}\) (i.e., \(\frac{1}{n_s} \sum _{i\in [n_s]} ||\varvec{x}_i -\tilde{\varvec{x}}||_2\)), where \(\varvec{x}_i \in \mathcal {X}\), \(i\in [n_s]\), are obtained from the Hit-and-Run sampling (see Smith 1984).
For the interval linear system in Example 3, the nominal solution \(\varvec{x}_{nom}\) coincides with \(\varvec{x}_{RLS}\) (see Fig. 3). From Table 1, one can observe that \(\varvec{x}_{nom}\) and \(\varvec{x}_{RLS}\) are most robust against the worst-case deviations. The solutions \(\varvec{x}_{MVE}\) Footnote 1 and \(\varvec{x}_{aMVE}\) are centered solutions (see also the exact ranges of \(\varvec{x}\) in the last column of Table 1). The solution \(\varvec{x}_{MVE}\) has the largest inscribed ellipsoid and the least MD. The small difference in the VOLs and MDs of \(\varvec{x}_{MVE}\) and \(\varvec{x}_{aMVE}\) indicates that the solution \(\varvec{x}_{aMVE}\) is a very close approximation of \(\varvec{x}_{MVE}\).
In Table 2, we evaluate the solutions for the interval linear system in Example 6. Here, the nominal solution \(\varvec{x}_{nom}\) is no longer the same as \(\varvec{x}_{RLS}\), and \(\varvec{x}_{RLS}\) is outside the solution set (see Fig. 4). Therefore, the corresponding volume of the MVE is 0. The solutions \(\varvec{x}_{nom}\), \(\varvec{x}_{MVE}\) and \(\varvec{x}_{aMVE}\) are scale invariant.
5.2 Production vector for input–output model
Leontief’s Nobel prize-winning input–output model describes a simplified view of an economy. Its goal is to predict the proper level of production for each of several types of goods or service. We apply this to predict the production of different industries in the Netherlands. In Table 3, we present the data that are reported in Deloitte (2014). This is a simplified version of the consumption data of the Netherlands published by the Dutch statistics office. From Leontief (1986), the nominal input–output matrix is defined as:
where \(\varvec{w} \in \mathbb {R}^{5}\) is the total output vector, \(C \in \mathbb {R}^{5\times 5}\) is the consumption matrix from Table 3, and Diag\((\cdot )\) places its vector components into a diagonal matrix. The nominal production vector \(\varvec{x}_{nom}\) can be obtained by solving the following system of linear equations:
where \(\varvec{b}\) is the vector of the nominal external demands (see the last column of Table 3).
Suppose there are uncertainties in the system (26), and each component of \(A(\varvec{\zeta }) = [\varvec{\zeta }_1 \,\, \cdots \,\, \varvec{\zeta }_n]\) and \(\varvec{b}(\varvec{\zeta }) = \varvec{\zeta }_0\) resides in an independent interval, where \(\varvec{\zeta }=[\varvec{\zeta }_0'\,\,\varvec{\zeta }_1'\,\, \cdots \,\, \varvec{\zeta }_n']' \in \mathbb {R}^{n^2+n}\). We assume that the interval uncertainty sets \(\mathcal {U}_j\), \(j=[n]\cup \{0\}\), are as follows:
where \(\sigma \) is user specified, \(\varvec{a}_{\cdot j}\) is the j-th column of the nominal matrix A. Input–output models with interval data were also studied in, e.g., Rohn (1978) and Dymova et al. (2013). In Table 4, the computation time of the solution methods is positively correlated with its theoretical complexity. Since the problem size is relative small, all the solutions can be obtained within 2 s.
We again consider the three measures as in Sect. 5.1. From Table 5, we observe that the solution \(\varvec{x}_{aMVE}\) has the largest inscribed ellipsoid and the best (i.e., least) MD; \(\varvec{x}_{RLS}\) is the most robust solution with respect to WD, but geometrically, it is not centered. The nominal solution \(\varvec{x}_{nom}\) is the second best solution for all the three measures. For other values of \(\sigma \), or different \(\sigma _{ij}\)’s for each components of A and \(\varvec{b}\), the above observations remain valid. However, when \(\sigma \ge 25\%\), the RLS solutions are outside the solution set. Since \(\varvec{x}_{aMVE}\) is an approximation of the optimal MVE center, we apply the upper bounding method of Sect. 3.2. The upper bounding VOL is 44.4. The obtained inner approximation is 44.3, which implies that \(\varvec{x}_{aMVE}\) is very close to the optimal solution.
5.3 Colley’s matrix ranking
Colley’s bias free college football ranking method was first introduced by Colley (2001). This method became so successful that it is now one of the six computer rankings incorporated in the Bowl Championship Series method of ranking National Collegiate Athletic Association college football teams. The notation here is adapted from Burer (2012).
Colley Matrix Rankings require to solve a system of linear equations \(A\varvec{x}=\varvec{b}\). For n teams, the \(n\times n\) matrix W is defined as
In particular, \(W_{ij}=W_{ji}=0\) if i has not played against j, and \(W_{ii}=0\) for all i. Note that the ij-th entry of \(W+W'\) represents the number of times team i and team j has played against each other. Let \(\varvec{1}\) be the all-ones vector, then the i-th entry of \((W+W')\varvec{1}\) and \((W-W')\varvec{1}\) gives the total number of games played by team i, i.e., the schedule of the games, and its win–loss spread. The Colley matrix A and the vector \(\varvec{b}\) are defined via the schedule of the games and the win–loss spread vector respectively, i.e.,
where I is the identity matrix and Diag\((\cdot )\) places its vector components into a diagonal matrix. Since the schedule of the games is often predetermined, we only consider uncertainties in the vector \(\varvec{b}\). We empirically investigate the robust version of Colley Matrix ratings to modest changes in the win–loss outcomes of inconsequential games. A game is inconsequential if it has occurred between two bottom teams, i.e., teams win less than \(50\%\) of all the games they played. Suppose m inconsequential games has been played during the whole season. Let \(\varvec{\zeta }\in \mathbb {R}^m\) denote the perturbation of the games. The game j switches its outcome if \(\zeta _j=1\), and it remains unchanged if \(\zeta _j=0\). For all j, we have \(0 \le \zeta _j\le 1\). Then, we define a matrix \(\Delta \in \mathbb {R}^{n\times m}\), where
The vector \(\Delta \varvec{\zeta }\) represents the possible switches in the outcome of the games. The maximum number of inconsequential games that are allowed to switch their outcomes is less than \(L \in \mathbb {N}^0\), i.e., \(\sum _j \zeta _j \le L\). The polyhedral solution set is as follows:
where the matrix A and the vector \(\varvec{b}\) are nominal, conv\((\mathcal {X})\) denotes the convex hull of the set \(\mathcal {X}\), and \(\mathcal {U}= \left\{ \varvec{\zeta } : \varvec{\zeta } \in \{0,1\}^m, \,\, \sum _j \zeta _j \le L \right\} \). The uncertainty set \(\mathcal {U}\) contains all possible integral \(\varvec{\zeta }\)’s (i.e., scenarios). For \(\varvec{\zeta } = \varvec{0}\), the nominal rating vector \(\varvec{x}_{nom} = A^{-1} \varvec{b}\) is on the boundary of \(\mathcal {X}\). Note that the ratings of Colley’s Matrix Rankings are not necessarily nonnegative. Since negative ratings are rather rare and their values are marginal (often very close to zero), we restrict ourselves to the rating vectors that are nonnegative.
The data we use in this subsection are downloaded from the website Wolfe (2017). The data contains the outcomes of 4197 college football games played by \(n=760\) teams in 2016, US. There are \(m=112\) inconsequential games in total. We allow at most \(L=30\) inconsequential games to switch their outcomes. The total number of possible outcomes is \(|\mathcal {U}|=\sum _{i=1}^{30} \left( {\begin{array}{c}112\\ i\end{array}}\right) =2.4 \times 10^{27}\). The solution \(\varvec{x}_{aMVE}\) is defined as the approximated MVE center of the solution set conv\((\mathcal {X})\). For the polyhedral set conv\((\mathcal {X})\), the RLS method requires solving a 2-norm maximization problem which is NP-hard. Burer (2012) proposes a two-stage method to solve the following MINLP problem:
We denote the solution of Burer as \(\varvec{x}_{RLS}\). Due to the high dimension of the solutions (i.e., \(n=760\)), we do not report the obtained solutions, and the exact ranges of the components of \(\varvec{x}\) for this numerical experiment. Since the uncertainty set \(\mathcal {U}\) is discrete, the measures that we consider here are slightly different from those introduced in Sect. 5.1:
-
VOL the volume of the MVE centered at \(\tilde{\varvec{x}}\) within conv\((\mathcal {X})\)
-
WD the worst-case 2-norm deviations of \(A\tilde{\varvec{x}}\) from \(\varvec{b}+ \Delta \varvec{\zeta }\) with respect to \(10^5\) randomly sampled integer \(\varvec{\zeta } \in \mathcal {U}\) (i.e., \(\max _{\varvec{\zeta } \in \mathcal {U}} ||A \varvec{x}- \varvec{b}- \Delta \varvec{\zeta }||_2\))
-
MD the mean 2-norm deviations of \(10^5\) uniformly sampled solutions in conv(\(\mathcal {X}\)) (i.e., \(\frac{1}{n_s} \sum _{i\in [n_s]} ||\varvec{x}_i -\tilde{\varvec{x}}||_2\)), where \(\varvec{x}_i \in \mathcal {X}\), \(i\in [n_s]\), are obtained from the Hit-and-Run sampling (see Smith 1984)
-
MDD the mean 2-norm deviations of \(A\tilde{\varvec{x}}\) from \(\varvec{b}+ \Delta \varvec{\zeta }\) with respect to \(10^5\) randomly sampled discrete \(\varvec{\zeta } \in \mathcal {U}\).
From Table 6, it is readily obvious that the solution \(\varvec{x}_{aMVE}\) is the best for three out of four measures. Due to the problem definition, the effect of switching the result of the inconsequential games is not symmetric. The solution \(\varvec{x}_{nom}\) is on the boundary of \(\mathcal {X}\) and it is the least robust solution among all three solutions with respect to the considered measures. We again evaluate the quality of the approximation \(\varvec{x}_{aMVE}\) by computing its upper bounding volume. The obtained upper bounding volume is 0.18. The optimal volume lies between 0.06 and 0.18. The MINLP problem is solved with CPLEX 12.7 ILOG (2016). For larger sized problems, one can expect exponential growth in computation time for the RLS method, whereas the MVE method remains computationally tractable.
5.4 Article influence scores
Around 1996–1998, Larry Page and Sergey Brin, Ph.D. students at Stanford University, developed the PageRank algorithm for rating and ranking the importance of Web pages (see Brin and Page 1999). An adapted version of PageRank has recently been proposed to rank the importance of scientific journals as a replacement for the traditional impact factor (see Bergstrom et al. 2008).
Let us consider the following six prestigious journals in the field of Operations Research, i.e., Management Science (MS), Operations Research (OR), Mathematical Programming (MP), European Journal of Operational Research (EJOR), INFORMS Journal on Computing (IJC) and Mathematics of Operations Research (MOR). The journal citation network can be represented as an adjacency matrix H, where \(H_{ij}\) indicates the number of times that articles published in journal j during the census period cite articles in journal i published during the same period. The number of publications for journal i is denoted as the i-th component of \(\varvec{v}\). We consider the number of citations and publications of the six journals in 2013 and obtain the corresponding H and \(\varvec{v}\) from Thomson-Reuters Corp (2014):

There are some modifications that need to be done to H before the influence vector can be calculated. First, we set the diagonal elements of H to 0, so that journals do not receive credit for self-citation. Then, we normalize the columns of H. To do this, we divide each column of H by its sum. We normalize the vector \(\varvec{v}\) in the same fashion. The normalized H and \(\varvec{v}\) in (27) are as follows:

Finally, we construct the matrix A, a convex combination of S and a rank-one matrix, i.e.,
where \(\alpha \) is the damping factor and \(\varvec{w1}'\) is a \(n\times n\) matrix. The damping factor models the possibility that a searcher choose a random paper out of all papers. Therefore, the closer the \(\alpha \) gets to 1, the better the journal’s citation structure is represented by the matrix A. The influence vector \(\varvec{x}^*\) can be obtained by solving as follows:
From the Perron-Frobenius theorem, we know a unique rating vector \(\varvec{x}^*\) can be found. The Article Influence score of journal i can be calculated as follows:
In this subsection, we assume \(\alpha =90\%\). Let us consider the matrix S and vector \(\varvec{w}\) defined in (28) and denote the obtained matrix in (29) as the nominal matrix A. The nominal influence vector \(\varvec{x}_{nom}\) is obtained by solving the system of linear equations (30). Since the estimated probabilities are not exact, we take uncertainty in the matrix A into consideration. Let us consider the following column-wise 1-norm uncertainties in A:
where \(\varvec{\zeta }=[\varvec{\zeta }_1'\,\, \cdots \,\, \varvec{\zeta }_n']' \in \mathbb {R}^{n^2}\), \(\sigma =20\%\), \(\varvec{\zeta }_{j}\) and \(\varvec{a}_{ \cdot j}\) are the jth column of matrix \(A(\varvec{\zeta })\) and A, respectively. The uncertainties occur in the left-hand side of the system. Note that each column of the nonnegative matrix \(A(\varvec{\zeta })\) is a probability vector, i.e., \(\varvec{\zeta }_j' \varvec{1} = 1\) for all j. Hence, the uncertain parameters are dependent. Since 2-norm maximization over a polyhedron is an NP-hard problem, the RLS method is computationally intractable. We consider the tractable (upper-bound) approximation of the RLS proposed in Juditsky and Polyak (2012):
The solution of this approximation coincides with \(\varvec{x}_{nom}\). We refer to Polyak and Timonina (2011) for a fast algorithm that solves (JP) with high-dimensional A. Hence, in the remaining of this section, we do not distinguish the solution of (JP) from \(\varvec{x}_{nom}\). The resulting Article Influence Scores from the influence vectors are reported in Table 7. The exact ranges of the components of the solution and the AIS AI are reported. The difference between the nominal and MVE solution is marginal. The width of \([\underline{\varvec{x}}, \overline{\varvec{x}}]\) and \([\underline{AI}, \overline{AI}]\) indicates that the system (30) is sensitive to this type of uncertainties.
We again consider the measures VOL and MD. Besides these two measures, the mean 2-norm deviations of \(10^4\) uniformly sampled \((A, \varvec{b})\) in \(\mathcal {U}\) are also considered (i.e., \(MD_{A, \varvec{b}}\)). From Table 8, one can observe that the solution \(\varvec{x}_{aMVE}\) is slightly more robust than \(\varvec{x}_{nom}\) with respect to all three considered measures. Here, the nominal solution is robust against uncertainties. The obtained upper bounding volume of \(\varvec{x}_{aMVE}\) is 0.0739. The optimal MVE volume lies between 0.0313 and 0.0739. We further observe that for a smaller uncertainty \(\sigma \) or damping factor \(\alpha \), the difference between \(\varvec{x}_{nom}\) and \(\varvec{x}_{aMVE}\) is smaller.
6 Conclusion and future research
In this paper, we first generalize the results for interval linear systems. For a system of uncertain linear equations with column-wise uncertainties, we derive convex representations of the united solution set in a given orthant. The exact ranges of the components of the solutions can then be determined. Via a convex representation technique and the techniques from (adjustable) robust optimization, we show how to derive convex representations of a broad class of controllable and tolerable solution sets. We apply the MCB method for obtaining centered solutions of systems of uncertain linear equations, and compare our proposed method both theoretically and numerically with the RLS method. The solutions from the RLS method may even be outside the solution set. As a byproduct, the MCB method produce a simple inner approximation of the solution set. From the numerical experiments, we observe that, for column-wise dependent uncertainties, our proposed solutions are more centered than the RLS or nominal solutions.
Further research is needed to determine the usefulness the MCB method for many other real-life applications, e.g., analysis of mechanical structures, electrical circuit designs and chemical engineering.
Notes
The optimal MVE center \(\varvec{x}_{MVE}\) is obtained by first eliminating all the auxiliary variables via Fourier–Motzkin elimination, and then compute the MVE (only with respect to \(\varvec{x}\)). For a more detailed description, we refer to the paper of Zhen and den Hertog (2017).
References
Alefeld G, Kreinovich V, Mayer G (1998) The shape of the solution set for systems of interval linear equations with dependent coefficients. Math Nachr 192:23–36
Balas E (1998) Disjunctive programming: properties of the convex hull of feasible points. Discrete Appl Math 89:3–44
Beck A, Eldar Y (2006) Strong duality in nonconvex quadratic optimization with two quadratic constrains. SIAM J Optim 17(3):844–860
Ben-Ameur W, Wang G, Ouorou A, Źotkiewicz M (2016) Multipolar robust optimization. http://arxiv.org/pdf/1604.01813.pdf
Ben-Tal A, Goryashko A, Guslitzer E, Nemirovski A (2004) Adjustable robust solutions of uncertain linear programs. Math Program 99(2):351–376
Ben-Tal A, El Ghaoui L, Nemirovski A (2009) Robust Optimization. Princeton series in applied mathematics. Princeton University Press, Princeton
Ben-Tal A, den Hertog D, Vial J-Ph (2015) Deriving robust counterparts of nonlinear uncertain inequalities. Math Program 149(1):265–299
Bergstrom C, West J, Wiseman M (2008) The eigenfactor metrics. J Neurosci 28(45):11433–11434
Blanc H, den Hertog D (2008) On Markov chains with uncertain data. CentER Discussion Paper Series No. 2008-50
Brin S, Page L (1999) The pagerank citation ranking: bringing order to the web. Technical report 1999-0120, vol 21. Stanford University, pp 37–47
Burer S (2012) Robust rankings for college football. J Quant Anal Sports 8(2):1–22
Calafiore G, El Ghaoui L (2004) Ellipsoidal bounds for uncertain linear equations and dynamical systems. Automatica 40:773–787
Colley W (2001) Colley’s bias free college football ranking method: the colley matrix explained. http://www.colleyrankings.com
Dacorogna B, Maréchal P (2008) The role of perspective functions in convexity, polyconvexity, rank-one convexity and separate convexity. J Convex Anal 15(2):271–284
Dantzig G (1963) Linear programming and extensions. Princeton University Press, Princeton
Deloitte (2014) Mathematical sciences and their value for the Dutch economy. http://www.euro-math-soc.eu/system/files/uploads/DeloitteNL.pdf
Dreyer A (2005) Interval analysis of analog circuits with component tolerances. Ph.D. thesis, Shaker Verlag, Aachen, Germany, TU Kaiserslautern
Dymova L, Sevastjanov P, Pilarek M (2013) A method for solving systems of linear interval equations applied to the leontief input–output model of economics. Expert Syst Appl 40(1):222–230
El Ghaoui L, Lebret H (1997) Robust solutions to least-squares problems with uncertain data. SIAM J Matrix Anal Appl 18(4):1035–1064
Fiedler M, Ramik J, Rohn J, Zimmermann K (2006) Linear optimization problems with inexact data. Springer, New York
Fourier J (1824) Reported in: analyse des travaux de l’Académie royale des sciences, pendant l’année 1824, Partie mathématique (1827). Histoire de l’Academie Royale des Sciences de l’Institut de France, 7: 47–55
Gau C, Stadtherr M (2002) New interval methodologies for reliable chemical process modeling. Comput Chem Eng 26:827–840
Gorissen BL, Ben-Tal A, Blanc H, den Hertog D (2014) Deriving robust and globalized robust solutions of uncertain linear programs with general convex uncertainty sets. Oper Res 62(3):672–679
Grossmann I, Lee S (2003) Generalized convex disjunctive programming: nonlinear convex hull relaxation. Comput Optim Appl 26:83–100
Hadjiyiannis M, Goulart P, Kuhn D (2011) A scenario approach for estimating the suboptimality of linear decision rules in two-stage robust optimization. In: Proceedings IEEE conference on decision and control and European control conference (CDC-ECC), pp 7386–7391
Hansen E (1992) Bounding the solution of interval linear equations. SIAM J Numer Anal 29:1493–1503
Hladík M (2012) Enclosures for the solution set of parametric interval linear systems. Int J Appl Math Comput Sci 22(3):561–574
Hladík M (2014) New operator and method for solving real preconditioned interval linear equations. SIAM J Numer Anal 52(1):194–206
Hladík M, Popova E (2015) Maximal inner boxes in parametric ae-solution sets with linear shape. SIAM J Numer Anal 270:606–619
Inc ILOG (2016) ILOG CPLEX 12.7, User Manual
Jansson C (1997) Calculation of exact bounds for the solution set of linear interval systems. Linear Algebra Appl 251:321–340
Jeyakumar V, Li G (2014) Trust-region problems with linear inequality constrains: exact sdp relaxation, global optimality and robust optimization. Math Program Ser A 147:171–206
Juditsky A, Polyak B (2012) Robust eigenvector of a stochastic matrix with application to PageRank. In: Proceedings of 51th IEEE conference on decision and control, pp 3171–3176
Kolev L (1993) Interval methods for circuit analysis. World Scientific, Singapore
Kreinovich V, Lakeyev A, Rohn J, Kahl P (1998) Computational complexity and feasibility of data processing and interval computations. Kluwer Academic Publishers, Dordrecht
Leontief W (1986) Input–output economics, 2nd edn. Oxford University Press, New York
Moore R, Kearfott R, Cloud M (2009) Introduction to interval analysis. Society for Industrial and Applied Mathematics, Philadelphia
MOSEK ApS (2017) The MOSEK optimization toolbox for MATLAB manual. Version 8. http://docs.mosek.com/8.0/toolbox.pdf
Motzkin T (1936) Beiträge zur Theorie der linearen Ungleichungen. University Basel Dissertation, Jerusalem, Israel
Muhanna L, Erdolen A (2006) Geometric uncertainty in truss systems: an interval approach. In: Muhanna RL (ed) Proceedings of the NSF workshop on reliable engineering computing: modeling errors and uncertainty in engineering computations, Savannah, Georgia USA, 22–24 Feb, pp 239–247
Neumaier A (1990) Interval methods for systems of equations. Cambridge University Press, Cambridge
Ning S, Kearfott R (1997) A comparison of some methods for solving linear interval equations. SIAM J Numer Anal 34(4):1298–1305
Oettli W (1965) On the solution set of a linear system with inaccurate coefficients. SIAM J Numer Anal 2:115–118
Oettli W, Prager W (1964) Compatibility of approximate solution of linear equations with given error bounds for coefficients and right-hand sides. Numer Math 6:402–409
Polyak B, Timonina A (2011) Pagerank: new regularizations and simulation models. Preprints of the 18th IFAC World Congress, Milano, Italy
Popova E (2004) Parametric interval linear solver. Numer Algorithms 37(1–4):345–356
Popova E (2012) Explicit description of ae solution sets for parametric linear systems. SIAM J Matrix Anal Appl 33(4):1172–1189
Popova E (2014) Improved enclosure for some parametric solution sets with linear shape. J Comput Appl Math 68(9):994–1005
Popova E (2015) Solvability of parametric interval linear systems of equations and inequalities. SIAM J Matrix Anal Appl 36(2):615–633
Popova E, Krämer W (2007) Inner and outer bounds for the solution set of parametric linear systems. J Comput Appl Math 199(2):310–316
Rohn J (1978) Input–output planning with inexact data. Freiburger Intervall-Berichte 78/9. Albert-Ludwigs-Universität, Freiburg
Rohn J (1981) Interval linear systems with prescribed column sums. Linear Algebra Appl 39:143–148
Rohn J, Kreinovich V (1995) Computing exact componentwise bounds on solutions of lineary systems with interval data is NP-hard. SIAM J Matrix Anal Appl 16(2):415–420
Römer M (2010) Von der Komplexmethode zur robusten Optimierung und zurück. In: Beiträge Zum Festkolloquium “Angewandte Optimierung” Anlässlich Des 65. Geburtstags von Prof. Rolf Rogge. Diskussionsbeiträge Zu Wirtschaftsinformatik Und Operations Research, Nr 23, Halle (Saale), pp 38–61
Rump S (2010) Verification methods: Rigorous results using floating-point arithmetic. Acta Numer 19:287–449
Shary S (2011) Konechnomernyi interval’nyi analiz (finite-dimensional interval analysis). Novosibirsk. http://www.nsc.ru/interval/Library/InteBooks/
Smith R (1984) Efficient monte carlo procedures for generating points uniformly distributed over bounded regions. Oper Res 32:1296–1308
Smith A, Garloff J, Werkle H (2012) Verified solution for a statically determinate truss structure with uncertain node locations. J Civ Eng Archit 4(11):1–10
Soyster A (1973) Convex programming with set-inclusive constraints. Oper Res 21(5):1154–1157
Thomson-Reuters Corp (2014) Journal citation reports. Web of Science, Accessed 23 March 2015
Tichatschke R, Hettich R, Still G (1989) Connections between generalized, inexact and semi-infinite linear programming. Methods Models Oper Res 6:367–382
Tiwary H (2008) On computing the shadows and slices of polytopes. CoRR, abs/0804.4150. http://arxiv.org/abs/0804.4150
Wolfe P (2017) Peter Wolfe’s college football website. http://prwolfe.bol.ucla.edu/cfootball/. Accessed 10 July 2017
Zhang X, Kamgarpour M, Georghiou A, Goulart P, Lygeros J (2017) Robust optimal control with adjustable uncertainty sets. Automatica 75:249–259
Zhen J, den Hertog D (2017) Computing the maximum volume inscribed ellipsoid of a polytopic projection. INFORMS J Comput. http://www.optimization-online.org/DB_HTML/2015/01/4749.html (to appear)
Zhen J, den Hertog D, Sim M (2016) Adjustable robust optimization via fourier–motzkin elimination. http://www.optimization-online.org/DB_FILE/2016/07/5564.pdf
Acknowledgements
The authors would like to thank S. Burer for the insightful discussion and the Matlab code used in Sect. 5.3. We also thank B.L. Gorissen for his helpful comments on this manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Zhen, J., den Hertog, D. Centered solutions for uncertain linear equations. Comput Manag Sci 14, 585–610 (2017). https://doi.org/10.1007/s10287-017-0290-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10287-017-0290-9