
Abstract
Optimization problems in software engineering typically deal with structures as they occur in the design and maintenance of software systems. In model-driven optimization (MDO), domain-specific models are used to represent these structures while evolutionary algorithms are often used to solve optimization problems. However, designing appropriate models and evolutionary algorithms to represent and evolve structures is not always straightforward. Domain experts often need deep knowledge of how to configure an evolutionary algorithm. This makes the use of model-driven meta-heuristic search difficult and expensive. We present a graph-based framework for MDO that identifies and clarifies core concepts and relies on mutation operators to specify evolutionary change. This framework is intended to help domain experts develop and study evolutionary algorithms based on domain-specific models and operators. In addition, it can help in clarifying the critical factors for conducting reproducible experiments in MDO. Based on the framework, we are able to take a first step toward identifying and studying important properties of evolutionary operators in the context of MDO. As a showcase, we investigate the impact of soundness and completeness at the level of mutation operator sets on the effectiveness and efficiency of evolutionary algorithms.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Various software engineering problems, such as software modularization [13], software testing [62], and release planning [8], can be viewed as optimization problems. Search-based software engineering (SBSE) [34] explores the application of meta-heuristic techniques to such problems. One of the widely used approaches to efficiently explore a search space is the application of evolutionary algorithms [35]. In this approach, elements of the search space are generated from existing elements using evolutionary operators such as mutation operators. However, the proper application of SBSE techniques is often not an easy task. As pointed out in [66], “the problem domains in software engineering are too complex to be effectively captured with traditional representations as they are typically used in search-based systems.” Compared to traditional encodings, e.g., by vectors, domain-specific models allow to more easily capture structural information about the problem and solution domains. Thus, their use can facilitate the exploratory search for solutions using evolutionary operators, especially for structural software engineering problems.
Model-driven engineering (MDE) [58] aims to represent domain knowledge in models and solve problems through model transformations. MDE can be used in the context of SBSE to minimize the expertise required of users of SBSE techniques. This combination of SBSE and MDE is referred to in the literature as model-based or model-driven optimization (MDO) [38, 66]. Two main approaches have emerged in MDO: The model-based approach [18, 66] performs optimization directly on the models, while the rule-based approach [2, 11, 31] searches for optimized model transformation sequences. In this paper, we focus on the model-based approach to MDO and refer to it as MDO for short. Problem instances and solutions are represented as models and the search space is explored by model transformations.
With reference to [30, 66], the definition of an evolutionary algorithm requires a representation of problem instances and search space elements (i.e., solutions). It also includes a formulated optimization problem that clarifies which of the solutions are feasible (i.e., satisfy all constraints of the optimization problem) and best satisfy the objectives. The key ingredients of an evolutionary algorithm are a procedure for generating an initial population of solutions, a mechanism for generating new solutions from existing ones (in this case, by mutation), a selection mechanism that typically implements the evolutionary concept of survival of the fittest, and a condition for stopping evolutionary computations. Selecting these ingredients so that an evolutionary algorithm is effective and efficient is a challenge.
Using MDO the application of search-based techniques in software engineering can be simplified since the search space consists of models evolved with model transformations. However, this does not prevent us from creating suboptimal specifications of evolutionary operators. For example, a particular set of mutation operators may not be complete, i.e., it may not reach all regions of the search space, so an optimum or a good enough solution may be missed. For optimization, however, it can be quite advantageous if the entire search space is reachable with a given set of evolutionary operators. Furthermore, too many of the possible mutations can lead to infeasible solutions, so that it may be advantageous if the given set of operators is sound in the sense that mutating a feasible solution yields a feasible solution again. In [15, 38, 59], several sets of mutation operators were evaluated for their effectiveness, i.e., ability to produce good results, and for their efficiency, i.e., low computational cost. In particular, the results in [15] suggest that feasibility-preserving (i.e., sound) mutation operators can be advantageous. To clarify what soundness and completeness can mean in the first place, and what implications they can have for evolutionary computation, we need a formal basis.
According to Harman et al. [35], the initial excitement about SBSE is over; it is now time for consolidation, i.e., “to develop a deeper understanding and scientific basis for the results obtained so far.” This statement has motivated us to develop a formal framework for MDO that will hopefully lead to a deeper understanding of MDO, which combines SBSE with MDE. Our contributions are as follows:
-
(1)
We present a graph-based framework for (the model-based approach to) MDO using mutation operators and evolutionary algorithms, and exemplify an instantiation based on the well-known NSGA-II algorithm [24]. We use the theory of graph transformation [26] to define model-driven optimizations since graphs are a natural means to encode models of different types. Mutations of models can be formally defined as graph transformations. Our framework precisely defines all the relevant components of MDO and is intended to assist the developer in using MDO to solve optimization problems.
-
(2)
We identify and define soundness and completeness as interesting properties of mutation operator sets. We select these properties because previous evaluations suggest that they may play a role and because these properties can be analyzed statically for certain types of mutation operator sets.
-
(3)
In an evaluation, we investigate the impact of soundness and completeness on the effectiveness and efficiency of evolutionary algorithms. We use the framework to clarify all critical factors for conducting a reproducible experiment. In the experiment conducted, we stick to three state-of-the-art evolutionary algorithms (NSGA-II [24], PESA-II [21], and SPEA2 [64]) and we study different sets of mutation operators for three optimization problems: the Class Responsibility Assignment problem (CRA case) [13, 15, 32, 38, 47], the problem of Scrum Planning [15], and the Next Release Problem [8, 15]. The experiment is based on the tools MDEOptimiser [15] and Henshin [4].
In the next section, the model-based approach to MDO is presented using an example. Section 3 considers the state of the art of MDO and other work related to our framework. Then, in Sect. 4, we present our graph-based framework for MDO. Soundness and completeness of evolutionary operators are defined in Sect. 5. To enable comparison of evolutionary algorithms, we define their effectiveness and efficiency with respect to our framework in Sect. 6. The evaluation is presented in Sect. 7. We conclude in Sect. 8. All proofs and additional material for the evaluation can be found in Appendices A and B.
2 Running example
Since the CRA case [13] is a structural optimization problem in software engineering and has become one of the most well-known cases when considering MDO, we use it to recall the core concepts of MDO, illustrate our formalization, and conduct a set of experiments. The CRA case aims to provide a high-level design for object-oriented systems. Given a class model with features (i.e., attributes and methods) and their usage relationships as the problem instance, each partial assignment of features to classes forms a solution. What is sought is a complete assignment of features to classes such that coupling between classes is low and cohesion within classes is high.
Meta-modeling is used to define what kind of domain models are considered for optimization. A suitable meta-model for the CRA case is presented in [32] and a slightly adapted version is reproduced in Fig. 1. Since the CRA case is a structural problem, we neglect all meta-attributes (which are attributes of meta-model classes) such as class and feature names to keep the running example as simple as possible. The meta-model specifies class models that contain features (i.e., attributes and methods) and prescribes the possible usage relationships. While methods can use attributes and methods, attributes are used only by methods. To represent solutions, a class model may contain classes to encapsulate features. A solution model is considered to be feasible if each feature is assigned to exactly one class (the feasibility constraint).
To assess the quality of a class design, two quality aspects are important: cohesion and coupling. While cohesion confirms that dependent features are within a single class, coupling refers to the dependencies of features between different classes. Good solutions exhibit a class design with high cohesion and low coupling because it is considered easy to understand and maintain. Cohesion and coupling are measured by the CohesionRatio and CouplingRatio presented in [32], respectively.

Meta-model of the CRA case as in [32], slightly adapted. White solid elements are invariant problem parts, the colored, dashed class element and its incoming and outgoing references are solution-related
3 Related work
Recently, several papers have been published on MDO optimizing models or rule-based model transformation sequences. We consider related work on both approaches below. Since our main contribution is a graph-based framework for MDO, we also consider related work on evolving graphs and other frameworks for (evolutionary) optimization.
3.1 The rule-based approach to MDO
Early approaches combining SBSE with MDE seek optimized model transformation sequences [2, 11, 31]. More precisely, a solution is a sequence of rule calls that is to be applied to a given input model. The successful application of such a sequence then yields a solution model. The sequences are optimized using local search algorithms and evolutionary algorithms. While a mutation operator can change sequence slots, a crossover operator splits sequences into parts and recombines them in a different order. The behavior of these operators is largely similar to the operation of traditional variants for sequential encoding. As sequences of rule calls do not per se satisfy consistency constraints, they can easily become inapplicable to the input model after mutation or crossover has taken place. Thus, a disruptive repair step (e.g., truncation of a sequence) is typically needed to regain applicable sequences.
To our knowledge, soundness and completeness have not yet been formally defined in the rule-based approach. In addition, the effects of soundness and completeness on the effectiveness and efficiency of evolutionary algorithms have not been investigated in the rule-based approach.
A comparison of the rule-based approach with the model-based approach [38] revealed that the model-based approach tends to be more effective than the rule-based approach. For that reason, we decided to first develop a framework for the model-based approach to MDO and plan to extend the framework toward the rule-based approach in future work.
3.2 The model-based approach to MDO
Since our framework follows the model-based approach to MDO, we consider related work in more detail. We selected the following papers on the model-based approach to MDO that have been published in journals, at conferences, and at workshops on modeling and SBSE: [15, 17, 18, 37, 38, 40, 59, 66]. We investigate which core concepts of MDO were considered. In addition, we compare MDO approaches by describing how they account for the soundness and completeness of mutation operators.
An early work proposing an MDE-based framework to facilitate the application of SBSE to MDE problems is given in [40]. A generic meta-model for encoding is presented that can be extended for specific optimization problems. However, only preliminary ideas are presented for how to specify an evolutionary algorithm based on that encoding.
Generally, early papers such as [17, 18, 40] mainly discuss the representation of a problem and the search space. The computation space is specified with meta-models that cover the representation of problems and solutions. A distinction between problem and solution models was introduced in [17, 18]. Feasibility constraints and objectives for comparing search space elements are not explicitly distinguished in the early papers. In [40, 66], the authors consider objectives and fitness functions and suggest that, for example, a Java implementation can be used to measure the quality of solutions.
Almost all papers on model-based MDO propose to define mutations of solution models as model transformations. Later works such as [15, 38, 59, 66] go into more details and define as well as evaluate concrete mutation operators. Models are selected according to how well they meet the objectives or by giving preference to feasible solutions [15, 38, 59]. To terminate an evolutionary computation, various forms of termination conditions were presented in [15, 37, 38]: Simple conditions limit the number of evolutionary iterations performed in an evolutionary computation or the total runtime of these computations. Alternatively, the computation can be terminated if a certain number of iterations does not yield a sufficient improvement regarding the quality of solutions.
In [15, 38, 59] several groups of mutation operators are compared with respect to effectiveness and efficiency. In [59], mutation operators are generated by higher-order transformations and compared to manually constructed operators. Since the higher-order transformations generate larger rules than the manually constructed ones, the evolutions can be shortened, resulting in higher efficiency. In [38], the effects of destructive mutation operators were studied. Evolutionary computations using these rules were faster but resulted in models of less quality. In [15], the generation of consistency-preserving (i.e., sound) mutation operators with regard to multiplicity constraints is presented. The generated operators were compared to manually designed operators; some effects on effectiveness and efficiency were noted. In [37], the authors use techniques from model-based MDO to tackle the problem of optimal configuration of product lines. Concretely, from a feature model with basic constraints they derive consistency-preserving configuration operators that transform valid configurations into valid configurations, i.e., they also construct sound operators. These are used as mutation operators in a genetic algorithm to search for optimal configurations. In an evaluation, in particular, concerning effectiveness, their approach outperforms other approaches that do not use sound mutation operators but rely on repair techniques instead. They mention that their technique might not result in a complete set of operators. Generally, the completeness of operator sets has not yet been explicitly investigated.
In summary, related approaches to MDO consider several evolutionary operators and compare them in experiments with respect to their effects on the effectiveness and efficiency of evolutionary algorithms. The understanding of the core concepts of MDO remains implicit or problem-specific. In contrast, we will present a graph-based framework for MDO that concisely defines the core concepts. It will help clarify the critical factors for conducting experiments in MDO and increase the reproducibility of experiments. In particular, the soundness and completeness of mutation operators have only been roughly discussed. We will precisely define these properties with the help of our framework and investigate whether they have an impact on the effectiveness and efficiency of evolutionary algorithms.
3.3 Evolving graphs
Since our framework is based on graphs and graph transformation, a closely related approach is Evolving Graphs by Graph Programming (EGGP) by Atkinson et al. [5,6,7]. The general motivation is to increase the effectiveness of evolutionary algorithms that operate on graph-like structures by operating directly on graphs as genotypes (as opposed to a linear encoding of graphs). In EGGP, so-called function graphs serve as genotypes, and graph programs based on graph transformation rules serve as mutation operators. The mutations are designed to respect certain constraints, namely acyclicity, the arity of nodes (since a node represents a function of a certain arity), and the maximal depth. No other constraints are discussed, and the effects of unsound mutations are not measured. Our framework does not generally restrict the type of constraints used to specify feasibility, but we propose to stick with graph constraints [33] since the soundness of mutation operators for graphs can be statically shown for this kind of constraints. In this sense, we consider a more general form of soundness than that shown for EGGP. To our knowledge, the completeness of operator sets has not yet been considered for EGGP.
3.4 Other formal frameworks
While MOMoT [11] and MDEOptimiser [16] are tooling frameworks for combining search-based optimization and model transformations, we are developing a formal framework for the model-based approach to MDO. While we are the first to develop a formal framework for this particular area, there are other formal frameworks for evolutionary computation or processes. Two such frameworks are discussed below as examples.
The first approach, which encompasses a large class of evolutionary (and other randomized search) algorithms, regards population-based algorithms as algorithms that generate a new population at each iteration such that each individual is selected from the pool of all possible individuals according to a probability distribution that depends on the current population [22]. This highly abstract view on evolutionary computation allows the development of common formal techniques that can be applied to analyze different kinds of evolutionary algorithms on different problems (see, e.g., the results in [19, 22, 23]). However, this framework is too abstract for our purposes; it does not provide support for determining the ingredients of an evolutionary algorithm for which we need to find model-based implementations. Furthermore, this framework does not capture elitism or methods used to preserve the diversity of a population during evolutionary computation.
The most recent theoretical framework for evolutionary processes that we are aware of is [52]; we also refer the reader to this paper for an overview of attempts to develop such frameworks. In this work, the authors define in modular terms the parts that make up evolutionary processes, namely, selection and variation operators. To show the adequacy of their framework, they demonstrate how various evolutionary models from the domain of population genetics and various evolutionary algorithms can be instantiated within it. While soundness is not discussed in [52], completeness (in our terminology) serves as the defining property that a mutation operator should have. They deal with recombination operators, a topic we leave for future work, and do not yet cover multi-objective problems that MDO regularly addresses.
Because the existing frameworks do not adequately fit our purposes, we develop our own framework in the following instead of presenting our framework as an instantiation of an existing one.
4 A graph-based framework for model-driven optimization
MDO has been used in the literature to solve a variety of optimization problems [15, 18, 32, 37, 38, 66] and the key ideas of the evolutionary algorithms presented are similar. To clarify the design space of MDO problems and evolutionary algorithms that solve them, we present a framework for model-driven optimization below. The definition of the framework is deliberately generic since we want to include the existing variants (of the model-based approach to MDO) into the framework. The framework is also intended to be formal to allow for formal reasoning on MDO. In particular, we want to facilitate impact analysis of important properties of evolutionary operators since domain experts can easily specify suboptimal operators. In Sect. 5, we define two properties of mutation operator sets, soundness and completeness, and in Sect. 7 we study their impact on effectiveness and efficiency of evolutionary algorithms.
We will present the framework in two steps: First, the key concepts of the framework are presented using a meta-model. It represents these key concepts as interface classes and captures their structure and relations.
In a second step, all the key concepts identified in the meta-model are defined. The definitions capture various requirements that have to be met when using the framework to define concrete MDO problems, develop appropriate evolutionary algorithms, and design suitable experiments in MDO. Since models in general have a graph structure and evolutionary operators generate new models, it is natural to define the framework based on graph transformation theory.
The presentation of the formal framework is accompanied by a discussion of the characteristics of each key concept and examples of how the concept can be instantiated. The nature of instantiation varies depending on the concept: while the underlying computation space determines the type of models we work with, an instantiation of the term “optimization problem” is primarily concerned with an appropriate formulation of constraints and objectives. When instantiating the term “evolutionary algorithm,” we must specify how to generate an initial population, which evolutionary operators are to be applied, how they are applied, and when to terminate.
4.1 Meta-model for MDO
Figure 2 presents a meta-model that contains the core concepts of MDO and their interrelationships. We use this meta-model to remind us what evolutionary optimization is and to facilitate the understanding of our framework, which defines each of the concepts appearing in this meta-model.

Meta-model for MDO
To formulate an optimization problem, we encode it in terms of a computation space that defines all computation models that can occur in the context of the optimization problem. A problem instance spans a search space that contains only those computation models that represent solutions to this problem instance, the solution models. In addition, there are objective relations (which may be realized by functions) to evaluate how well the solution models satisfy the optimization objectives. Also, there may be feasibility constraints; a solution model that satisfies all feasibility constraints is said to be feasible. A problem instance is itself considered a (potentially infeasible) solution model. A population is a finite multi-set of solution models over a common search space; a sequence of populations is called evolutionary sequence.
To solve an optimization problem with respect to a particular problem instance, an evolutionary algorithm iteratively evolves a population. A population generator first creates an initial population for a given problem instance. Given a set of evolutionary operators, the evolution is performed following a computation specification that dictates how the evolutionary operators are applied in each iteration. An evolutionary computation of an evolutionary algorithm is represented as an evolutionary sequence which can be generated by that specific algorithm. While element mutation operators are used to perform changes on computation models, a population mutation operator organizes at the population level how a new population is created by applying element mutation operators. Survival selection operators decide which elements from a population survive and are candidates for further evolution. Evolutionary operators usually make decisions based on the given objective relations and constraints. Finally, an evolution is terminated when a given termination condition is met.
4.2 Computation space
A computation space for MDO forms the basis for encoding and solving an optimization problem (see Fig. 2). Basically, it defines a domain-specific modeling language to specify both optimization problems and their solutions. In evolutionary computing, phenotypes, which represent elements externally, are distinguished from genotypes, which represent their internal encodings. In MDO, we do not consider this distinction when formulating an evolutionary algorithm. Problem instances and search space elements are all domain-specific models. It is the task of future work to compare the efficiency of model-based encodings with traditional encodings and to translate models into more efficient encodings as needed. (An example where models are translated to bit strings is given in [37].)
However, to show formal properties and implement evolutionary computation, we choose appropriate formal representations such as typed graphs for formalizing models (see below) and Ecore models for implementing them (in Sect. 7). Since there are several modeling languages used in software engineering, we are looking for a formalization that is generic such that it is not restricted to models of a particular type. Graph-like structures are a natural way to formalize models of different types.
In MDO, computation spaces are defined based on modeling languages, typically specified with meta-models. Several MDO approaches in the literature [15, 38, 66] have chosen to represent problem instances by models and solutions by models with dedicated problem models. This means that each model of a computation space has a particular part, the problem model, which represents important information of the given problem instance and is invariant throughout evolutionary computations. Typical examples of such encoding are the CRA case [15, 38, 59], the NRP case [15], and the SCRUM case [15]. Accordingly, the meta-model for a computation space, called computation meta-model, contains a dedicated problem meta-model. All solution models must conform to the computation meta-model. A problem model is a solution model that is fully typed over the problem meta-model.
A meta-model contains typing information as well as multiplicities and optionally other constraints. We distinguish constraints that restrict the language (called language constraints) from constraints that specify the feasibility of solutions (called feasibility constraints). The problem meta-model induces a subset of the language constraints as problem constraints, namely the constraints that affect only the problem elements. Feasibility constraints specify properties that are expected to be satisfied by reasonable solutions, i.e., they constitute side conditions for the optimization. In contrast, language constraints serve to exclude instances that would not constitute a well-posed optimization problem, or to exclude instances for technical reasons. We distinguish problem constraints because, as will be shown in Proposition 1, they are particularly easy to use in optimization. In the context of graph transformation, constraints are formalized with nested graph constraints [33].
A computation model is given by an instance model that conforms to a computation meta-model. Its problem model and solution part are fully specified by the types in the computation meta-model. This basic structuring is reflected in the following definitions and is shown in Fig. 3. It is based on graphs typed over type graphs; a type graph contains a node for each node type and an edge for each edge type. The parallels to the structural part of meta-models are therefore striking. Typed graphs are presented in [26] (and recalled in the appendix). For simplicity reasons, we neglect the handling of attributes here.
Appendix A presents a generalized form of computation space based on category theory. A generalized computation space can have various instantiations. For example, it allows to define models as typed, attributed graphs using type inheritance and model changes as typed, attributed graph transformations. All the propositions presented in this section are proven in the appendix based on category theory.

Computation models and cm-morphism
Definition 1
(Computation space). A computation meta-model is a pair \( MM = (\subseteq : TG _{\textrm{P}}\hookrightarrow TG , LC )\) where \(\subseteq \) is an inclusion between type graphs \( TG _{\textrm{P}}\) and \( TG \), and \( LC \) is a set of graph constraints typed over \( TG \), called language constraints. The set \( PC \subseteq LC \), called problem constraints, is the subset of constraints that can be considered as being already typed over \( TG _{\textrm{P}}\). \(( TG _{\textrm{P}}, PC )\) is called problem meta-model. A computation element or computation model \((E, type _E)\) over \( MM \) is a graph E together with a graph morphism \( type _E: E \rightarrow TG \) such that \(E \models LC \). The computation space over \( MM \) is
Given a computation model \((E, type _E)\) over \( MM \), the model \((E_{\textrm{P}}, type _{E_{\textrm{P}}})\) where
is the problem model and \(E \setminus E_{\textrm{P}}\) is the solution part of \((E, type _E)\).
A computation-model morphism, short cm-morphism, m between computation models \((E, type _E)\) and \((F, type _F)\) is a graph morphism \(m: E \rightarrow F\) such that m is compatible with typing, i.e., \( type _F \circ m = type _E\) (Fig. 3). A cm-morphism m is problem-invariant if \(m_{\textrm{P}}\), the restriction of m to the problem model of E, is an isomorphism between \(E_{\textrm{P}}\) and \(F_{\textrm{P}}\).
Characteristics. The definition of a computation model reflects the core idea that it consists of a problem model (which specifies a problem) and a solution part (which contains information about the solution). The problem model should stay invariant during evolution (which must be ensured); the solution part is developed during an evolutionary computation. A special case is an empty problem model (and problem meta-model). A computation model (meta-model) would be a simple model (meta-model) in this case.
A meta-model may contain constraints to specify the well-formedness of the modeling language it defines. For example, certain elements of the solution part must always occur together or the number of instantiations of a certain problem type must be restricted. The latter would even be a problem constraint since it applies only to the problem model. Language constraints impose hard constraints that any computation model must satisfy at any point in an evolutionary computation.
Example 1
(Computation space). The meta-model underlying the computation space for the CRA case is shown in Fig. 1. We consider the presence of exactly one class model as a problem constraint. Additionally, representing a dependency between two features by multiple edges is not useful. Parallel edges are thus forbidden by further language constraints; avoiding parallel edges between features can actually be realized by problem constraints.
For simplicity, the graph TG in Fig. 4 focuses on the core structural part and shows the computation meta-model for the CRA case without abstract types and names of edge types. Edge types are still distinguishable by the types of their source and target nodes. As there will always be one class model, we also neglect the node type ClassModel and its containment-edges shown in Fig. 1. As for type inheritance, the graph TG shows a flattened version where all inherited edges are shown. (For details on the flattening construction, see [43].) The black part of TG indicates the node and edge types of the problem meta-model TG\(_{P}\), while the red, dashed part with filled node rectangles indicates the components of the solution part of computation models. Note that the solution part itself is usually not a graph.

Computation models as typed graphs
Figure 4 also shows two computation models E and S. They are both typed over TG and use the same color coding as TG. The type within each node indicates how it maps to the corresponding node in TG. S shows only a part of the problem model of E along with its solution part. It can be included in E; the inclusion morphism from S to E is indicated by numbers. Each node of S is mapped to the node in E with the same number. The mapping of edges is not shown explicitly but can be inferred from the node mapping. All morphisms between the graphs E and S and to the type graph TG are shown by arrows between the graphs in Fig. 4. Note that due to the definition of cm-morphisms, the red and black parts are mapped separately. Problem-invariant morphisms will be used for the definition of element mutation operators in Def. 4.
Remark 1
In the remainder of this paper, we assume that every computation model E and every cm-morphism is typed over a graph \( TG \), even if this is not explicitly stated. For simplicity, we omit the definition of type inheritance in Sect. 4, but use it in the evaluation. The interested reader can find a suitable definition of type graphs with inheritance in [44]. The meta-model in Fig. 1 is an example of a type graph with inheritance. Class models and classes can refer to features, which can be attributes or methods. In that case, morphisms between computation models are allowed to map objects with compatible types. This means that objects in the image model may have more concrete types than their origins. For example, a Feature object may be mapped to an Attribute object. We explain and prove our formal results for type graphs without inheritance. However, all results can be applied to the case with inheritance as long as inheritance hierarchies are limited to either the problem or the solution part introduced in Def. 1 (i.e., problem elements cannot inherit from solution elements and vice versa). The inheritance hierarchy in Fig. 1, for example, is limited to the problem meta-model. When we prove our results in Appendix A, we also explain why the results are transferable in this way.
4.3 Optimization problem
To formulate an optimization problem, we need a computation space that contains problem instances, solutions, and any other models we need to perform evolutionary computations. As in the literature on evolutionary algorithms, we define an optimization problem in MDO as containing both a set of feasibility constraints and a set of objective relations (see Fig. 2), so that it belongs to the category of Constrained Optimization Problems [30]. Unlike the language constraints, feasibility constraints can be violated by a model, and that model remains an element of the modeling language and the search space. However, a reasonable solution must not violate feasibility constraints. For each optimization objective, there is a corresponding relation that allows to compare solutions in terms of how well they satisfy the respective objective. Ultimately, the extent to which each of the objectives is met determines the perceived quality of a solution. A concrete problem to be optimized is given by a problem instance; it defines its search space within the computation space. This search space includes all models that have the same problem model as the given problem instance.
Definition 2
(Optimization problem. Search space). Let a computation space \(\textit{CS}\) over a meta-model \( MM = (\subseteq : TG _{\textrm{P}}\hookrightarrow TG , LC )\) be given. An optimization problem \(\mathscr {P} = ( FC ,\le _{\textrm{O}})\) over \(\textit{CS}\) consists of
-
a set \( FC \) of graph constraints typed over \( TG \), called feasibility constraint set, which defines
$$\begin{aligned} FE (\textit{CS}, FC ):=\{ E \in \textit{CS}\mid E \models FC \}, \end{aligned}$$the set of feasible elements of \(\textit{CS}\), and
-
a finite set \(\le _{\textrm{O}}\) of total preorders \(\le _j \, \subseteq \textit{CS}\times \textit{CS}\) for \(j \in J\), where J indexes \(\le _{\textrm{O}}\), which are called objective relations.
A problem instance \( PI \) for \(\mathscr {P}\) is a computation model in \(\textit{CS}\). It defines the search space
Each element of a search space is called solution model for \( PI \). A solution model E with \(E \models FC \) is called feasible; we also write \(E \in FE (S( PI ), FC )\).
Characteristics. There are two special cases for an optimization problem, both of which are covered by the definition: If \( FC \) is empty, it is an unconstrained optimization problem. All computation models are then automatically feasible, i.e., \( FE (\textit{CS},\emptyset ) = \textit{CS}\). If \(\le _{\textrm{O}}\) is empty (but \( FC \) is not), we get a classical constraint satisfaction problem that only looks for a feasible element in the computation space.
When \(|\le _{\textrm{O}}| = 1\), we have a single-objective problem. An objective is often given as a function and is referred to as an objective function or fitness function in the literature. A metric that measures the ratio of coupling and cohesion can be defined as an objective function in the CRA case. We use objective relations instead of functions because they are more general. We also avoid the term “fitness function” because it is used variously in the literature.
For \(|\le _{\textrm{O}}| > 1\), a multi-objective problem is defined. In this case, it can happen that the objectives are contradictory. This means that a solution may be better than another with respect to one objective but at the same time worse with respect to another objective. As stated in [65] by Zitzler et al., “we consider the most general case, in which all objectives are considered equally important – no additional knowledge about the problem is available.” Thus, to compare two elements with regard to multiple objectives, we can use the dominance relation. We say that a solution model E dominates a model F if it is as good as the other in all defined objective relations and, in addition, E is better in at least one of these relations. Formally this means that, if \(E \le _j F\) for all \(j \in J\) and there is at least one \(k \in J\) with \(F \not \le _k E\), then E dominates F. A solution model that is not dominated by any other model is called Pareto optimum. The set of all Pareto optima of a search space forms the Pareto front. The set of non-dominated solutions of a population is called approximation set.
Example 2
(CRA problem). In the CRA case, each feature must be assigned to exactly one class, which represents two feasibility constraints, an assignment to at least one class and at most one class. For each constraint, the extent of its violation in a solution can be determined by counting the number of features that violate the constraint.
Two computation models are compared using two metrics for coupling and cohesion. Combining both metrics into a single one (which is called CRA Index in [47]), the CRA case can be considered as single-objective problem. These metrics can also be used to define two objective relations, which would then lead to a multi-objective problem. Class models can then easily become incomparable because one model has better coupling and another model has better cohesion. Only if both the coupling and cohesion of model A are better than those of model B, does A dominate B, so B is likely to be discarded.
A problem instance is given by a class model that contains a set of features that can use each other (and usually no class is given). It conforms to the type graph in Fig. 4. The problem models of the two computation models S and E shown in Fig. 4 can be used as problem instances. All the models in this figure formalize feasible solutions (albeit for different problem instances) because they provide a single class assignment for each of their features, implying that the feasibility constraints are satisfied.
The following lemma states that the validity of problem constraints only depends on the problem model of a computation model. For arbitrary constraints (typed over the entire given meta-model), an analogous statement is obviously false; their validity depends on the entire computation model, not just its problem part. This result especially means that, only depending on the problem model of a problem instance \( PI \), either every element of its search space \(S( PI )\) satisfies the problem constraints or none of it does.
Lemma 1
Given a computation meta-model \( MM = (\subseteq : TG _{\textrm{P}}\hookrightarrow TG , LC )\) with a set of problem constraints \( PC \subseteq LC \), a typed graph \((E, type _E)\) satisfies the problem constraints from \( PC \) if and only if \((E_{\textrm{P}}, type _{E_{\textrm{P}}})\) satisfies them.
Later, in order to think about the quality of evolutionary computations, we need the notion of an evolutionary sequence for a given problem instance. Evolutionary sequences are computed by evolutionary algorithms (see Def. 7).
Definition 3
(Population. Evolutionary sequence). Given an optimization problem \(\mathscr {P}\) over \(\textit{CS}\) and a problem instance \( PI \) for \(\mathscr {P}\), a finite multi-set over \(S( PI )\) is called a population for \( PI \). \(\mathscr {Q}( PI )\) denotes the set of all populations for \( PI \). An evolutionary sequence for \( PI \) is a sequence of populations \(Q_0 Q_1Q_2 \ldots \) with \(Q_j \in \mathscr {Q}( PI )\) for \(j = 0, 1, 2, \ldots \) The set \(\mathscr {E}( PI )\) consists of all evolutionary sequences for \( PI \).
4.4 Evolutionary operators
One of the most important configuration parameters of an evolutionary algorithm are the evolutionary operators. These can be divided into change (or variation) operators and selection operators. Evolutionary operators control the evolution with the goal of finding solutions of ever better quality. In order to not leave the search space of a problem instance, evolutionary operators need to be problem-invariant, i.e., they may not change the problem model of solutions.
In this paper, we stick to mutation operators as the only kind of change operators; crossover operators will be studied in the future. Mutations are usually considered as local changes of search space elements. Therefore, in the context of MDO, it is natural to define so-called element mutations as model transformations, as done in the literature [15, 38, 66].
We specify an element mutation operator for computation models as a model transformation rule with a pre-condition (L) and a post-condition (R). Nodes and edges of \(L \setminus R\) are deleted, while nodes and edges of \(R \setminus L\) are created. In addition, the application of a rule can be prohibited by negative application conditions (NACs). A NAC N is an extension of L and the pattern \(N \setminus L\) is forbidden to occur. A concrete mutation of a computation model is realized as a rule application.
In the formal specification of element mutations, we follow the algebraic approach to graph transformation, which takes a transformation rule with a match and performs a transformation step on a graph representing a solution model. In the following, we give a set-theoretic definition (omitting many details) and stick to simple application conditions for mutation operators. A generalized form of transformation that allows more complex forms of application conditions is defined in the appendix. A detailed definition of graph transformation based on set and category theory can be found, for example, in [26]. All models and their relations used to define an element mutation are shown in Fig. 5.

Mutation of element E to element F
Definition 4
(Element mutation operator. Element mutation). Given a computation space \(\textit{CS}\) over a meta-model \( MM = (\subseteq : TG _{\textrm{P}}\hookrightarrow TG , LC )\) including problem constraints \(PC \subseteq LC\), an (element) mutation operator mo is defined by \(mo = (L {\mathop {\hookleftarrow }\limits ^{ le }} I {\mathop {\hookrightarrow }\limits ^{ ri }} R, \mathscr {N})\), where L, I, and R are typed graphs over \( TG \) with \( le \) and \( ri \) being injective, typed morphisms. \(\mathscr {N}\) is a set of negative application conditions defined by injective, typed morphisms \(n_j: L \hookrightarrow N_j\) with \(j \in J\) (where J enumerates the elements of \(\mathscr {N}\)).
Given a computation model E, an element mutation operator mo is applicable at an injective cm-morphism \(m: L \rightarrow E\) if the dangling condition holds: A node \(n \in E\) must not be deleted if there is an edge \(e \in E \setminus m(L)\) which would dangle afterward. In addition, there must not be a cm-morphism \(q_j:N_j \hookrightarrow E\) with \(q_j \circ n_j = m\) for a \(j \in J\); m is then called match. An element mutation \(E \Longrightarrow _{mo} F\) using mo at match m is defined as follows: If mo is applicable at m, construct graph \(C = E \setminus m(L \setminus le (I))\). Then, \(F = C \dot{\cup }(R \setminus ri (I))\), i.e., a new copy of \(R \setminus ri (I)\) is added disjointly to graph C, so that the dangling edges of \(R \setminus ri (I)\) are connected to the nodes in C as prescribed by their preimages in I (see Fig. 5).
An element mutation \(E \Longrightarrow _{mo} F\) is called pc-preserving if \(E \models PC \) implies \(F \models PC \). An element mutation \(E \Longrightarrow _{mo} F\) is called lc-preserving if \(E \models LC \) implies \(F \models LC \). An element mutation \(E \Longrightarrow _{mo} F\) is called problem-invariant if \(E_{\textrm{P}}\cong F_{\textrm{P}}\). An element mutation operator mo is called pc-preserving (lc-preserving) if every element mutation \(E \Longrightarrow _{mo} F\) with \(E \models PC \) (\(E \models LC \)) is pc-preserving (lc-preserving). An element mutation operator mo is called problem-invariant if every element mutation \(E \Longrightarrow _{mo} F\) is problem-invariant.
A sequence \(E = E_0 \Longrightarrow _{mo_1} E_1 \Longrightarrow _{mo_2} \ldots E_n = F\) of element mutations (where mutation operators \(mo_i\) and \(mo_j\) are allowed to coincide for \(1 \le i \ne j \le n\)) is denoted by \(E \Longrightarrow ^*_{M} F\), where M is a set containing all mutation operators that occur. For \(n = 0\), we have \(E = F\).
Remark 2
Element mutation operators must not change the types of nodes or edges. This also applies to node types in type hierarchies. Any nodes that are newly created must not have abstract types (such as Feature) since these types must not be instantiated. However, abstract types are useful in the pre-condition of a mutation operator, or in its NACs. For example, in the CRA case, the moving of a method or attribute from one class to another can be specified with only one operator if the abstract type Feature is used. Otherwise, two operators would be required, one for moving a method and one for moving an attribute. When applying a mutation operator, a node can be mapped to a node with a more concrete type if they are compatible with related edge types.
Characteristics. In order to not leave the computation space, element mutations must be lc-preserving. In principle, this condition can be satisfied in two ways: Either the system checks after each mutation whether the resulting model satisfies LC if the input model does and retracts the mutation result if it does not, or the modeler ensures that the underlying element mutation operator is designed to be lc-preserving.
We will see below that preservation of problem constraints PC can be easily ensured by not creating, deleting or changing elements that are typed over the problem meta-model. In this case, the resulting computation model F has the same problem model as E and if E satisfies PC, so does F. Proposition 1 states that problem invariance of mutation operators can be statically characterized by problem-invariant morphisms \( le \) and \( ri \) in the mutation operator. Hence, Proposition 1 provides a static analysis check that can be easily performed.
However, preserving PC still does not ensure that an element mutation remains in the computation space. For this, one must additionally ensure that an element mutation operator cannot introduce violations of the remaining language constraints, i.e., for constraints from \( LC \setminus PC \). There are several approaches to (semi-)automatically check whether a transformation rule preserves a given graph constraint [9, 41, 50, 51, 53]. If a constraint is first-order, it can be expressed as a nested graph constraint and then ensured by integrating it as an application condition into a transformation rule [33, 54]; the resulting rule forms an element mutation operator that preserves the given constraint. This constraint integration was automated in the tool OCL2AC by Nassar et al. [50, 51]. However, the resulting element mutation operator is more restricted than the original one since it is only applicable if the mutations do not violate the integrated constraints. Consequently, it may not or hardly be applicable to a computation model anymore. When checking a computed application condition, it may be subsumed by an already existing application condition of the respective operator or it may cover a case that is known to not occur in solutions at all (such as multiple class models in the CRA case). In these cases, the integration of the computed application condition is not necessary.
Example 3
(Element mutation). As a concrete example, we consider the element mutation operator moveFeatureToExClass in Fig. 6; it moves a feature from one existing class to another. Given the computation model E in Fig. 4 and applying moveFeatureToExClass to 3:Attribute (an instance of the abstract type Feature), 5:Class, and 6:Class and the included edge, we get model F in Fig. 7 as a result. Note that it represents a computation model with the same problem model as E. Based on model E, four different element mutations can be performed with moveFeatureToExClass: either 1:Method, 2:Method, 3:Attribute, or 4:Attribute can change their encapsulating class.
Operator moveFeatureToExClass is problem-invariant since \(L_{\textrm{P}}\cong R_{\textrm{P}}\) and therefore, is pc-preserving (as shown below). However, it can introduce a language constraint violation by introducing a parallel edge between the nodes matched by f:Feature and c2:Class. This can happen in infeasible solution models where a feature is contained in more than one class. To preserve the language constraint, the operator can be extended with a negative application condition that checks whether f:Feature is already assigned to c2:Class.

Element mutation operator moveFeatureToExClass

Result of an element mutation of solution model E in Fig. 4
The next proposition ensures that an element mutation \(E \Longrightarrow _{mo} F\) returns a computation model F that has the same problem model as E (formally: there exists an isomorphism between \(E_{\textrm{P}}\) and \(F_{\textrm{P}}\)) if operator mo is problem-invariant. This is not obvious in MDO, since unrestricted element mutations can easily change the problem model.
Proposition 1
Let \(mo = (L {\mathop {\hookleftarrow }\limits ^{ le }} I {\mathop {\hookrightarrow }\limits ^{ ri }} R, \mathscr {N})\) be an element mutation operator, and let \(E, F \in \textit{CS}\) be computation models such that there is an element mutation \(E \Longrightarrow _{mo} F\) (compare Fig. 5). Then the operator mo is problem-invariant if the morphisms \( le \) and \( ri \) in mo are problem-invariant.
Together with Lemma 1, the above proposition clarifies that problem constraints are trivial to treat in optimization: If the given problem instance \( PI \) (or equivalently, its problem model \( PI _{\textrm{P}}\)) satisfies the problem constraints, Lemma 1 ensures that each computation model E of the search space \(S( PI )\) does. Proposition 1 then ensures that this also holds for any computation model F obtained by an element mutation \(E \Longrightarrow _{mo} F\). Thus, one only needs to verify (i) that a given problem instance satisfies the problem constraints (otherwise it specifies an ill-posed optimization problem) and (ii) that the morphisms used to specify the element mutation operators are indeed problem-invariant (an easy condition to verify).
Next, we consider mutations of populations. Normally, not the entire population is mutated, but a so-called parent selection decides whether and how often an element is mutated. A parent selection can be considered as the first step of mutating a population. After the selection of elements to be mutated, the actual mutations take place, which are primarily element mutations but can also be sequences of element mutations. Since there are innumerable variations in the literature on how populations can be mutated, especially how parents can be selected, the following definition is deliberately generic.
Definition 5
(Population mutation. Population mutation operator). Let a problem instance \( PI \) for an optimization problem \(\mathscr {P}\) over the computation space \(\textit{CS}\) and a set of element mutation operators M be given. A population mutation operator \( MO \) is a binary relation over \(\mathscr {Q}( PI )\) with \(Q \subseteq Q'\) for each \((Q,Q')\in MO \). For each \(F \in Q'\) there is a (possibly empty) finite sequence of element mutations \(E \Longrightarrow _{M}^* F\) with \(E \in Q\). Each \((Q,Q') \in MO \) is called a population mutation of Q to \(Q^{\prime }\) via \( MO \).
Characteristics. Usually, it is not desired that each element of a population is evolved to an offspring solution. A parent selection decides whether an element is evolved once, several times or not at all. In addition, population mutations can differ in how many offspring solutions they generate and which and how many element mutations they apply to evolve an existing solution, i.e., what the finite transformation sequences that produce offspring are. The framework leaves open how these sequences are specified. In particular, such a sequence might be a complex programmed graph transformation sequence.
All of these decisions can be based on the fitness of solutions, which is usually determined by the objective relations (e.g., considering the dominance relation) and the satisfaction of the feasibility constraints. However, meta-information about the population can also be taken into account. Due to its generality, our definition supports all these variants.
Example 4
(Population mutation). In addition to the element mutation operator moveFeatureToExClass shown in Ex. 3, other element mutation operators can be addUnassignedFeatureToNewClass, which creates a class and assigns an unassigned feature to it, addUnassignedFeatureToExClass, to assign an unassigned feature to an existing class, and deleteEmptyClass to remove an empty class from the model. Apart from their names, which were chosen for clarity, these mutation operators are analogous to those in [14, 15]. All the element mutation operators presented form the set \( M \).
For parent selection, the NSGA-II algorithm [24] uses, for example, binary tournament selection, which we reproduce below: Let a population mutation operator CraMutation rely on n binary tournament selections (where n is the size of the population) to decide which solutions to evolve. In each tournament, two randomly chosen elements of the input population compete with regard to the following fitness specification: (1) Given two feasible solutions (assigning each feature to exactly one class), a solution that dominates the other in terms of the coupling and cohesion metrics is considered fitter. (2) A feasible solution is automatically fitter than a non-feasible one. (3) If two infeasible solutions are compared, the one with a lower degree of constraint violations is the fitter one. The extent to which a constraint is violated can be determined by the number of violations of the constraint. Alternatively, if a constraint is defined by attribute values, the extent to which a desired value is missed can also be considered. The degree of violation of a constraint can be calculated by summing up the extent of violation of each constraint.
For the CRA case, if two infeasible solutions are equal in terms of the degree of constraint violations, the solution that dominates the other in terms of the coupling and cohesion metrics is the fitter solution. Solutions of equal fitness with respect to the aforementioned rules can be further distinguished by their crowding distance [24]. The crowding distance estimates the proximity of a solution to other solutions in a population. To maintain diversity in a population, solutions with a high crowding distance are considered fitter. (For more details, we refer to [24].) The solution with the higher fitness wins the tournament. It is cloned, and the clone is mutated with an arbitrarily chosen applicable element mutation operator of \( M \). If none of the element mutation operators is applicable, the clone remains unchanged. When n tournaments have been run, all clones are merged with the elements of the input population to form the output population.
In a population, not all its elements are required or desired to form the next generation. A survival selection filters the next generation from a population according to certain criteria. The following definition is also deliberately generic, as we do not want to exclude certain implementations from our framework.
Definition 6
(Survival selection. Survival selection operator). Given a problem instance \( PI \) for an optimization problem \(\mathscr {P}\), a survival selection operator SO is a binary relation over \(\mathscr {Q}( PI )\) such that for all \((Q,Q^{\prime }{}) \in SO\) holds: \(Q^{\prime }{} \subseteq Q \in \mathscr {Q}( PI )\). Each \((Q,Q^{\prime }{}) \in SO\) is called a survival selection that selects \(Q^{\prime }{}\) from Q.
Characteristics. Following nature’s example, survival selection is used to realize the concept of survival of the fittest. The concept of fitness often coincides with that used in parent selection of population mutation; the objective relations and feasibility constraints are the most influencing criteria for defining fitness. However, fitness in survival selection can also be viewed from a different perspective. Factors such as the age of solutions, i.e., how many generations they have survived, or the diversity of the resulting next generation can be considered. To avoid losing the most valuable solutions achieved so far, survival selection typically employs elitism, i.e., the fittest solutions are (partially) preserved for the next generation. On the other hand, survival of less optimal or even infeasible solutions may allow broader exploration of the search space. As with population mutation, there are many ways to implement survival selection.
Example 5
(CRA survival selection). A survival selection operator corresponding to the one used in the NSGA-II algorithm can be based on the notion of fitness presented in Ex. 4. First, the three rules that take the constraints and objectives into account are used to create a preorder (rank) of population elements, i.e., each rank contains solutions that have the same overall constraint violation and do not dominate each other. Beginning with the rank of best solutions, all solutions from subsequent ranks are selected until the selection of the entire next rank would exceed the number of desired solutions in the output population. At this point, solutions from the next rank are selected, taking their crowding distance (introduced in Ex. 4) into account, until the desired size of the output population is reached.
4.5 Evolutionary algorithm
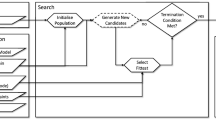
A given instance of an optimization problem is solved using an evolutionary algorithm. Since MDO has been performed with several evolutionary algorithms and there are many more variants of evolutionary algorithms in the literature, we want to keep the definition of evolutionary algorithm deliberately generic. Actually, we define a skeleton of an evolutionary algorithm as shown in the pseudo code in Algorithm 1. The minimal set of parameters for an evolutionary algorithm includes a problem instance and a set of evolutionary operators. Concrete evolutionary algorithms may have further parameters, such as an initial population. If the algorithm does not receive the initial population as input, it first generates an initial population for the given problem instance PI. Then it iteratively applies operators from the given set \( OP \) of evolutionary operators to evolve this population. To this end, the computation specification C specifies how the operators of \( OP \) are orchestrated over the course of an iteration. After each iteration, a termination condition t determines whether further iterations are performed. Algorithm 1 leaves G, C, and t completely generic since the framework is intended to support all kinds of evolutionary algorithms. In the following, we define such a generic algorithm and its semantics.

Definition 7
(Evolutionary algorithm and its semantics). Given a problem instance \( PI \) for an optimization problem \(\mathscr {P}\) and a set of evolutionary operators \( OP \) for \(\mathscr {P}\), let \(\rightarrow _{ OP } \subseteq \mathscr {Q}( PI ) \times \mathscr {Q}( PI )\) be defined as
An evolutionary algorithm \(\mathscr {A}( PI , OP ) = (G,C,t)\) consists of a population generator G to generate a starting population \(Q_0\) based on \( PI \), a computation specification C based on \( OP \), and a termination condition t.
The semantics Sem(C) of C is a subset of the binary relation \(\rightarrow _{ OP }^*\). The termination condition t is a predicate over \(\mathscr {E}( PI )\), the set of evolutionary sequences for \( PI \). An evolutionary computation of \(\mathscr {A}( PI , OP )\) is an evolutionary sequence \(Q_0 Q_1 Q_2 \ldots \) \(\in \mathscr {E}( PI )\) with \((Q_{j},Q_{j+1}) \in Sem(C)\) for \(j = 0,1, \ldots \). Each \((Q_{j},Q_{j+1})\) is called an iteration. The semantics \(Sem(\mathscr {A}( PI , OP ))\) of \(\mathscr {A}( PI , OP )\) is the set of all its evolutionary computations satisfying t. An execution of \(\mathscr {A}( PI , OP )\) results in an evolutionary computation of \(Sem(\mathscr {A}( PI , OP ))\). A set of executions of \(\mathscr {A}( PI , OP )\), called execution batch of \(\mathscr {A}( PI , OP )\), yields a batch result, a multi-set of evolutionary computations of \(Sem(\mathscr {A}( PI , OP ))\).
Characteristics. In general, evolutionary algorithms are non- deterministic since the generator for initial populations, the computation specification, and the evolutionary operators can introduce probabilistic behavior. Therefore, an evolutionary algorithm generally determines a set of possible evolutionary computations. When experimenting with an evolutionary algorithm, it is executed a certain number of times. Each execution of the algorithm results in an evolutionary computation being part of its semantics. An experiment usually includes a whole batch of executions. It may happen that the same computation is obtained several times in one experiment. Therefore, an execution batch may result in a multi-set of evolutionary computations. As a special case, algorithms with deterministic behavior (leading to a single computation) are also included.
The generator G, the computation specification C and the termination condition t can be instantiated by familiar patterns for existing evolutionary algorithms, adapted to MDO. In most cases, a random initialization procedure is used to generate an initial population from a given problem instance. Properties such as feasibility or diversity of elements in the initial population can affect the efficiency and effectiveness of an evolutionary algorithm. Ideally, the entire search space should be reachable from an initial population. However, depending on the problem, specifying diversity, implementing an efficient generator, and analyzing reachability can be challenges in themselves. Traditionally, the set of operators consists of at least one population change operator and a survival selection; the computation specification combines them by first applying the change operators sequentially, followed by the survival selection to choose the population for the next iteration. More sophisticated concepts (such as self-adaptive evolutionary algorithms [30]) can also be expressed using our framework but may require the implementation of more complex computation specifications.
Example 6
(CRA evolutionary algorithm). For the CRA case, consider an example evolutionary algorithm with an initial population of 100 models, all equal to the given problem instance. The set \( OP \) contains the population mutation operator CraMutation introduced in Example 4. Also, \( OP \) contains the selection operator presented in Example 5. The computation specification C prescribes that both operators in \( OP \) are applied alternately, starting with the mutation of a population, followed by the selection of a population for the next iteration.
An example termination condition t is the following: It monitors the progress of an evolutionary computation with respect to the improvement of the approximation set. The improvement between the approximation sets \(A_1, A_2\) of the populations of two iterations is measured by the Euclidean distance of the solution vectors of their solutions. For each solution E, its solution vector \(v_{\textrm{S}}(E)\) consists of the values of the cohesion and coupling metrics and two values reflecting the extent to which the two feasibility constraints are violated. For \(E_2 \in A_2\), let \(d^{A_1}_{\textrm{min}}(E_2)\) be the minimum Euclidean distance of \(v_{\textrm{S}}(E_2)\) to the solution vectors of all solutions in \(A_1\). The distance between \(A_1\) and \(A_2\) is then defined as
Let a finite evolutionary computation \(Q_0 Q_1 \ldots Q_k\) and a corresponding sequence of approximation sets \(A_0 A_1 \ldots A_k\) be given. Furthermore, let a sequence of progression indices \(x_1 x_2 \ldots x_i\) be defined with \(1 \le x_j \le k\) for all \(1 \le j \le i\) as follows. The first progression index \(x_1\) represents the iteration at which the approximation set changed for the first time. Further progression indices represent iterations where the approximation set has improved by at least 3 percent compared to the approximation set of the iteration represented by the previous progression index. Thus, for any progression index \(x_j\) with \(1 < j \le i\), it holds that
Let the sequence of progression indices be complete, i.e.,
hold for all m, n with \(x_{j-1}< m < x_j\) and \(x_i < n \le k\). The termination condition t is satisfied if \(k - x_i = 100\).
5 Soundness and completeness
Evolutionary algorithms aim at finding optimal solutions or at least approximating them. The operators chosen determine the effectiveness and efficiency of the search. In this section, we will consider two fundamental properties of sets of element mutation operators that can affect the effectiveness and efficiency of evolutionary algorithms: soundness and completeness. Soundness refers to preserving the feasibility of solutions and completeness refers to preserving the reachability of all feasible solutions. Investigating whether properties such as soundness and completeness actually have an impact on the effectiveness and efficiency of evolutionary search is of particular interest in the context of MDO. One of its promises is that domain knowledge can be integrated into problem-specific search operators, thereby improving evolutionary search. Determining general properties that operator sets should have provides guidelines and limits for constructing problem-specific operators.
While evolutionary algorithms typically operate on populations, in this paper we first introduce our notions at the level of element operators. There are two reasons for this: First, we deliberately introduced the population mutation operators in general terms. At the level of element operators, it is still clear what soundness and completeness should mean. At the level of population operators, it becomes more complex; we think that it might be more promising to look for appropriate definitions for more concrete (classes of) population operators. Second, we also develop our definitions from the point of view of analyzability. The properties we define can be analyzed statically since they are based on element operators. Analyzing comparable properties at the level of population operators would likely be more difficult and costly. The fact that an element operator has a particular property with respect to all or certain classes of solutions needs to be checked only once. At the level of population operators, runtime verification might be required to obtain a particular property. We will outline the possibilities for static analysis after the respective definitions and give some hints on how to define the respective properties for the more general level of population operators.
We consider an element mutation operator sound if it ensures the feasibility of all generated solution models under the assumption that the input models are already feasible.
Definition 8
(Soundness of element mutation (operator sets)). Let \(\mathscr {P} = ( FC ,\le _{\textrm{O}})\) be an optimization problem for a computation space CS. Assuming \(E \in FE (\textit{CS}, FC )\), an element mutation \(E \Longrightarrow _{mo} F\) is sound, where mo is an element mutation operator, if \(F \in FE (\textit{CS}, FC )\).
An element mutation operator mo is sound if every element mutation \(E \Longrightarrow _{mo} F\) via mo with \(E \in FE (\textit{CS}, FC )\) is sound. A set of element mutation operators is sound if each of its operators is sound.
Note that a population mutation that starts with feasible solutions can lead to a population with only feasible solutions, even if the element mutation operators are not sound. This is because the soundness of the element mutation operators is a sufficient condition for preserving the feasibility of solutions but not a necessary condition.
Example 7
(CRA soundness). In the CRA case, the element mutation operator moveFeatureToExClass in Fig. 6 is sound because it reassigns a feature to another class, i.e., the feature is neither left without a class assignment nor given a second one. In contrast, an operator that simply removes a feature from a class is obviously unsound.
Static analysis. In the formal framework developed so far, element mutation operators are not generally sound. It is up to the modeler to prove that concrete element mutation operators are sound. We discussed above (after Def. 4) which approaches exist in the literature to (semi-)automatically check whether a transformation rule preserves a given graph constraint. Since feasibility constraints are also specified as graph constraints, these approaches can also be used for checking soundness. In principle, it is also possible to check at runtime whether unsound operators preserve feasibility (and if not, to undo their application), but this would require additional computational effort at runtime.
Outlook on population operators and runtime verification. Since feasibility is a property of an individual solution, it is not immediately obvious how soundness should be defined for population mutation or survival selection (operators). One might think about requiring that at least the proportion of feasible solutions be preserved in a population. Preserving the proportion of feasible solutions (while allowing enough newly computed solutions to be selected for the next population) might require sophisticated control of the selection of solutions and element mutation operators used during population mutation to ensure that enough feasible offspring are computed. Note that the probability for this could be increased by the use of sound element mutation operators (without further control): In (most) evolutionary algorithms, feasible solutions are preferred over infeasible ones in both selection for reproduction (here: for mutation) and survival selection.
In our evaluation, we investigate whether the use of sound element mutation operators supports the finding of optimal solutions more efficiently and effectively.
Next, we consider the completeness of a set of element mutation operators. It is satisfied if, for a given problem instance, all feasible solutions of its search space can be generated at each point of an optimization.
Definition 9
(Completeness of element mutation operator sets). Let \(\mathscr {P} = ( FC ,\le _{\textrm{O}})\) be an optimization problem, \( PI \) a problem instance for \(\mathscr {P}\), and M a set of element mutation operators. The set \( M \) is complete if, for every solution model \(E \in S( PI )\) and every feasible solution model \(F \in FE (S( PI ), FC )\), there exists a finite sequence of element mutations \(E \Longrightarrow _{M}^* F\).
Only considering element mutations based on a set of mutation operators, the completeness of that set is a sufficient (but not a necessary) condition for the reachability of all optimal solutions. It should be noted that the evolutionary algorithm may still miss these optimal solutions since it further constrains which element mutations are actually applied. Therefore, the completeness of a set of element mutation operators does not imply that an evolutionary algorithm using that set definitely reaches all optimal solutions. Conversely, an evolutionary algorithm that uses an incomplete set of element mutation operators can, in principle, still find optimal solutions. However, using an incomplete set of element mutation operators bares the risk of completely truncating regions of the search space that contain optimal solutions. Knowing whether a set of element mutation operators is complete or not allows the developer to make an informed decision about it.
Example 8
(CRA completeness). The set of element mutation operators discussed in Ex. 4 is not complete since no new classes can be created after all features are assigned. To obtain a complete set of element mutation operators, we make a small change. We add an additional element mutation operator moveFeatureToNewClass that can move an already assigned feature to a new class. The resulting set of element mutation operators is complete since any computation model (feasible or not) can be converted into a feasible model with one class using the operators addUnassignedFeatureToNewClass at most once, the operator addUnassignedFeatureToExClass as often as possible, and operators moveFeatureToExClass and deleteEmptyClass as often as needed. This feasible model with one class can then be transformed into any feasible model using the operators moveFeatureToExClass and moveFeatureToNewClass. Summarizing, every feasible model is reachable from any model. Note that this argumentation (implicitly) uses the fact that computation models satisfy the language constraints of the CRA case: General graphs that are typed over the meta-model of the CRA case could contain more than one class model or classes that are not contained in a class model. In such situations, we could, for example, not assign two features that are contained in different class models to the same class. Hence, our (extended) set of operators is not complete for general graphs.
Static analysis. We are not aware of any formal approach that automatically checks the completeness of sets of element mutation operators as defined above. Basically, the problem is a reachability problem that can be analyzed for a single model using model checking for graph transformation [56]. However, we do not ask about the reachability of a single model from a single model but about the reachability of a (possibly infinite) set of models from each possible model. Maybe surprisingly, in all three example cases of our evaluation the same simple technique can be used to manually prove completeness of a set of element mutation operators. As sketched for the CRA case in the example above, one looks for one model for which one can argue that it can be transformed (via the given element mutation operators) into any feasible model, and that any model can be transformed into it. This (manual) analysis is still static in the sense that it only needs to be done once for a given set of element mutation operators. Since we selected our case studies before developing operator sets for them, for which we then proved completeness, and the same simple proof technique worked in all cases, we are confident that proving completeness manually will be feasible also in other cases.
Outlook on population operators and runtime verification. If a chosen set of element mutation operators is complete, we can be sure that in principle all optimal feasible solutions can be found using these operators. However, much weaker forms of completeness suffice to obtain this property. It is sufficient that during an evolutionary computation every feasible solution remains reachable from one element of the current population, but it need not be reachable from all elements. Defining such a population as complete, a survival selection operator would be completeness-preserving if it transforms complete populations to complete populations. Note that completeness of a set of element mutation operators, as introduced above, ensures this milder notion and, as mentioned above, can be argued statically.
Note also that the completeness of element mutation operator sets we introduced also allows a more free choice of initial populations. While an initial population can still affect the search, a complete set of element mutation operators ensures that, in principle, every feasible element can be reached, regardless of the initial population chosen.
In our evaluation, we investigate whether the use of a complete set of element mutation operators supports finding optimal solutions more efficiently and effectively. While we believe that soundness and completeness are interesting properties, they also serve to show that the formal framework we developed in the previous section allows one to define and reason about such properties.
6 Effective and efficient algorithms
A major concern in the configuration of evolutionary algorithms is to make them solve optimization problems effectively and efficiently. To that end, we want to investigate how the choice of sound and/or complete sets of element mutation operators affects the effectiveness and efficiency of evolutionary algorithms. To compare evolutionary algorithms in this regard, we start with the definition of quality relations based on our formal framework. Due to their probabilistic nature, evolutionary algorithms cannot be directly compared regarding our definition of their semantics. Instead, we compare execution batches that represent evolutionary computations that result from conducting experiments.
Definition 10
(Quality relation). Given a problem instance PI for an optimization problem \(\mathscr {P}\), a quality relation \(\le _{\textrm{Q}}\) is a total preorder over multi-sets over \(\mathscr {E}(PI)\). Let further two evolutionary algorithms \({\mathscr {A}}_i\) for PI and two corresponding execution batches \( EB _i\), with \(i = 1,2\), be given. Then algorithm \({\mathscr {A}}_1\) has a better or equal quality than \({\mathscr {A}}_2\) w.r.t \(\le _{\textrm{Q}}\) and the considered execution batches if \( EB _2 \le _{\textrm{Q}} EB _1\).
In the following, we show examples for quality relations. To make statements about the effectiveness and efficiency of evolutionary computations, evolutionary computations are compared with respect to a so-called quality indicator, which relates populations according to their quality.
Definition 11
(Quality indicator). Given an optimization problem \(\mathscr {P}\), a problem instance PI for \(\mathscr {P}\), and a set T endowed with a total order <, the quality indicator \(I: \mathscr {Q}(PI) \rightarrow T\) is a function that assigns a value I(Q) in T to each population \(Q \in \mathscr {Q}(PI)\).
In a multi-objective setting, a quality indicator should be Pareto-compliant such that it does not contradict the order induced by the dominance relation. Pareto compliance means the following: For two populations \(Q_1\) and \(Q_2\), if \(E_1\) dominates \(E_2\) and \(E_2\) does not dominate \(E_1\) for all search space elements \(E_1 \in Q_1\) and \(E_2 \in Q_2\), then \(I(Q_1) < I(Q_2)\). Typically, the hypervolume indicator is used as quality indicator; it is known to be Pareto-compliant [63].
In practice, algorithms often need to be compared by performing a limited number of optimizations; one uses statistical methods to validate conclusions drawn from the generated execution batches. Consequently, as in the following examples, quality relations can be restricted to execution batches that are non-empty, finite, of equal size, and contain only finite evolutionary computations.
Example 9
(Effectiveness as quality relation). The effectiveness of an algorithm can be considered in each iteration of an evolutionary computation, with the last iteration usually being the most interesting. To capture the effect of outliers, non-robust measures (e.g., mean) may be specifically favored over robust ones (e.g., median) when aggregating quality indicator values from multiple populations. In this case, it may also be useful to consider the standard deviation of quality indicator values. Low deviations indicate greater robustness of the computations than higher deviations.
For a problem instance of a multi-objective optimization problem, we use a normalized hypervolume indicator \(h: \mathscr {Q}(PI) \rightarrow [0,1]\) to determine the quality of a population. Two vectors are used for its calculation. A vector consisting of the worst values found for each objective (also known as nadir point). And an artificial Pareto optimum consisting of the best values found for each objective (called ideal point). While the nadir point, which is degraded by a fixed value of 1 for each objective, is used as the reference point for calculating the area of the search space dominated by a solution, the ideal point is used to normalize the results. For the construction of both vectors, the approximation sets of the populations of the last iterations of all evolutionary computations generated by all evolutionary algorithms for this specific problem instance are considered.
Let \({{\,\textrm{mean}\,}}\) and \({{\,\textrm{sd}\,}}\) be functions that compute the mean and standard deviation of a set of real values, respectively. Given \(h_{\textrm{last}}(Q_0Q_1\ldots Q_k) = h(Q_k)\) for \(Q_0Q_1\ldots Q_k \in \mathscr {E}(PI)\) and \(h_{n}(Q_0Q_1\ldots Q_n \ldots Q_k)= h(Q_{n})\) for \(0 \le n \le k\), \(h_{\textrm{last}}(Q_0Q_1\ldots Q_k)\) otherwise (i.e., given projections onto the hypervolume of the last or the n-th population of a finite evolutionary sequence), we define three quality relations to compare the effectiveness of two algorithms \({\mathscr {A}}_1(PI,OP)\) and \({\mathscr {A}}_2(PI,OP)\) regarding two execution batches \( EB _1\) of \({\mathscr {A}}_1\) and \( EB _2\) of \({\mathscr {A}}_2\) with \( EB _1, EB _2 \subseteq \mathscr {E}(PI)\).
-
The mean-effectiveness \(\le _{\textrm{mean}}\) with \( EB _2 \le _{\textrm{mean}} EB _1\) if\({{\,\textrm{mean}\,}}\{h_{\textrm{last}}(e_2) \mid e_2\in EB _2\} \le {{\,\textrm{mean}\,}}\{h_{\textrm{last}}(e_1)\mid e_1\in EB _1\}\),
-
the mean-n-effectiveness \(\le _{\textrm{mean},n}\) with \( EB _2 \le _{\textrm{mean},n} EB _1\) if \({{\,\textrm{mean}\,}}\{h_{n}(e_2) \mid e_2\in EB _2\} \le {{\,\textrm{mean}\,}}\{h_{n}(e_1) \mid e_1\in EB _1\}\) for \(n>0\), and
-
the sd-effectiveness \(\le _{\textrm{sd}}\) with \( EB _2 \le _{\textrm{sd}} EB _1\) if\({{\,\textrm{sd}\,}}\{h_{\textrm{last}}(e_2) \mid e_2\in EB _2\} \le {{\,\textrm{sd}\,}}\{h_{\textrm{last}}(e_1) \mid e_1\in EB _1\}\).
Example 10
(Efficiency as quality relation). With respect to the efficiency of evolutionary computations, the length of evolutionary sequences, i.e., the number of iterations needed to satisfy the termination condition, and the mean runtime of these iterations are of interest. For the latter, let a runtime function \(rt:\mathscr {E}(PI)\rightarrow \mathbb {R}\) be given which computes the mean runtime in ms per iteration for an evolutionary sequence. Analogously to Ex. 9 we define two quality relations to compare efficiency of two algorithms \({\mathscr {A}}_1(PI, OP )\) and \({\mathscr {A}}_2(PI, OP )\) regarding two execution batches \( EB _1\) of \({\mathscr {A}}_1\) and \( EB _2\) of \({\mathscr {A}}_2\) with \( EB _1, EB _2 \subseteq \mathscr {E}(PI)\).
-
The iteration-efficiency \(\le _{\textrm{it}}\) with \( EB _2 \le _{\textrm{it}} EB _1\) if\({{\,\textrm{mean}\,}}\{{{\,\textrm{length}\,}}(e_1) \mid e_1\in EB _1\} \le {{\,\textrm{mean}\,}}\{{{\,\textrm{length}\,}}(e_2) \mid e_2\in EB _2\}\),
-
and the runtime efficiency \(\le _{\textrm{rt}}\) with \( EB _2 \le _{\textrm{rt}} EB _1\) if\({{\,\textrm{mean}\,}}\{{{\,\textrm{rt}\,}}(e_1) \mid e_1 \in EB _1\} \le {{\,\textrm{mean}\,}}\{{{\,\textrm{rt}\,}}(e_2) \mid e_2 \ldots \in EB _2\}.\)
7 Evaluation
In Sect. 5, we briefly discussed how sound and complete operator sets may influence evolutionary computations. Consequently, we also expect these operator sets to have an impact on the outcome of optimizations in quantitative evaluations. To investigate this assumption, we conduct experiments focusing on the following two research questions:
-
RQ1
Does the soundness of element mutation operators have an impact on the effectiveness or efficiency of evolutionary algorithms?
-
RQ2
Does the completeness of the set of element mutation operators have an impact on the effectiveness or efficiency of evolutionary algorithms?
In the following, we first introduce the context and use cases of the evaluation according to the structure presented in our framework. Then, we present the evaluation setup and results. All evaluation data can be found at [1]. They include the results of our experiments and all artifacts needed to reproduce them.
7.1 Implementation of the framework
To conduct the experiments, we use MDEOptimiser [16, 48], a tool that implements the framework presented. It allows users to configure, instantiate, and run evolutionary algorithms as defined in our framework. MDEOptimiser relies on the MOEAFramework [49] to provide a selection of evolutionary algorithms from which users can choose. The algorithm implementations provide the computation specification and the selection operators. They also predefine most parts of the population mutation operators. However, the user can choose between different variants of how to apply element mutation operators when a solution needs to be evolved. These variants differ, for example, in how they select which element mutation operators to apply and how many element mutations to use. Furthermore, the set of element mutation operators used by the population mutation operators can be specified.
The realization of the computation space is based on the Eclipse Modeling Framework (EMF) [25]. Accordingly, the computation meta-models and problem instances are implemented as EMF Ecore and instance models, respectively. By default, an initial population is created by first replicating the provided problem instance. Each replica is then modified by two applications of the specified population mutation operator (ignoring parent selection). Alternatively, a user can provide an initialization procedure implemented in Java to generate a user-defined initial population. Feasibility constraints and objective relations are induced from constraint functions and objective functions implemented in OCL or Java. The user must specify a set of element mutation operators as rules or units of the Henshin model transformation language [4]. Henshin units allow complex transformations to be composed of multiple rules using control flow elements. Regarding the termination condition, the user can choose between predefined variants.
7.2 Optimization problems selected
The evaluation considers three multi-objective problems: the Class Responsibility Assignment [13, 15, 32, 38, 47] problem (CRA), the problem of Scrum Planning [15] (SCRUM), and the Next Release Problem [8, 15] (NRP). The reasons for this choice are twofold. First, these use cases cover different aspects that might be relevant for optimization problems in MDO since they differ in their structural complexity, the number and kind of their feasibility constraints (more structural or more attribute-oriented), and the number and complexity of element mutation operators needed to perform meaningful optimizations. Second, the number and complexity of the required element mutation operators is low enough to allow for their (partially manual) analysis with regard to soundness and completeness. In the absence of real-world examples, all problem instances of the chosen use cases were generated.
The same use cases were already considered by Burdusel et al. [15]. However, some adjustments to the objectives and constraints were necessary to allow comparison of operator sets implementing different degrees of soundness and completeness. Therefore, the evaluation results are not directly comparable to those in [15].
The computation space of each of the optimization problems is defined by an EMF meta-model. The meta-model of the running example is shown in Fig. 1. The meta-models of the other optimization problems can be found in Appendix B. Since the experiments are based on EMF as the underlying modeling framework, EMF-specific language constraints apply to all of the following optimization problems: Each computation model has exactly one root node that (transitively) contains all other nodes, each node is contained in at most one container, there are no containment cycles, and there are no parallel edges of the same type between two objects. In our use cases, the root node is always part of the problem model. Thus, its unique existence is even a problem constraint. The SCRUM and NRP cases demand further language constraints. Here, we will only discuss constraints stemming from the semantics of the respective optimization problem. For a discussion of constraints tightly connected to the design of the meta-model please also refer to Appendix B.
CRA. Our running example (Sect. 2), the CRA case, also serves as the initial use case for the experiments. In summary, in this case, a unique class model serves as the root node to which classes can be added. The assignment of interdependent features to classes must be done in compliance with two feasibility constraints: each feature must be assigned to one class and must not be assigned to more than one class. The objectives are to minimize the coupling between classes and maximize their cohesion. In the experiments, problem instances range from 9 features and 14 dependencies (Model A) to 160 features and 600 dependencies (Model E), as introduced in [32]. All problem instances are infeasible because none of their features are initially assigned.
SCRUM. Scrum [57] is an agile software development technique. In Scrum, a software product is defined by a set of work items each representing a feature desired by one of the project stakeholders. The work items of all stakeholders are collected in a backlog. Work items can be of varying importance to their stakeholder and can also differ in the estimated effort required to implement them. In order to partition the development of all features into manageable units, the work items are assigned to so-called sprints. Sprints represent timed iterations and are implemented one after the other.
The SCRUM case goes back to the idea of using Scrum to manage maintenance tasks for existing projects. In this scenario, sprints are not decided on in an ad hoc basis. Instead, an optimal plan for distributing the work items across the sprints must be found. Two objectives are considered when evaluating the quality of a solution. First, the total effort of all work items should be distributed evenly across sprints by minimizing effort variance. Second, the requirements of each stakeholder should be distributed evenly across the sprints in terms of their importance. For each stakeholder, the variance in the sum of the importance of their work items in each sprint is considered. The objective is implemented by minimizing the average of this deviation across all stakeholders. Each work item must be assigned to exactly one sprint (a feasibility constraint similar to class assignment in the CRA case). Additionally, a sprint should neither be too easy nor too complex. Thus, the plan must respect a minimum and maximum number of desired sprints for each problem instance. These limits are expressed via additional feasibility constraints. For reasonable problem instances, the minimum and maximum must be at least zero and must not be greater than the number of available work items. Additionally, the minimum must be less than or equal to the maximum. These requirements are formulated as problem constraints.
In the experiments, we consider two problem instances: Model A with 5 stakeholders and 119 work items and Model B with 10 stakeholders and 254 work items.
NRP. When planning the next release of a software system, customer satisfaction must be weighed against the costs associated with developing new software artifacts. This struggle is known as the Next Release Problem [8]. In the formulation considered here, requirements may be abstract and depend on other requirements. By assigning a value to a requirement, customers can specify how important a requirement is for them. A requirement can be satisfied to varying degrees by different sets of software artifacts. In addition, some customers may be more important to the software development company than others. Ultimately, software artifacts may depend on each other and complex dependency hierarchies may even emerge. Each software artifact has a development cost associated with it. The cost of the next release is determined by the sum of the costs of all artifacts selected for that release.
The goal of the NRP case is to select a set of software artifacts while considering two conflicting objectives: minimizing the total development cost of the selection while maximizing customer satisfaction by satisfying the requirements. The dependency hierarchy between software artifacts imposes a structural feasibility constraint; an artifact can only be selected for the next release if all of its (transitive) dependencies are also selected. In addition, a predefined budget limits the cost allowed for a feasible solution. In reasonable problem instances no cyclic dependencies may occur in the dependency structure of requirements or software artifacts. Additionally, the values assigned to requirements, the costs associated with software artifacts, the degrees to which sets of software artifacts satisfy requirements, and the importance of customers need to be positive. These requirements constitute problem constraints of the NRP case.
Experiments are conducted with three models that differ in size and complexity of the underlying dependency hierarchy. Model A contains 25 customers, 25 requirements, and 200 software artifacts with a median of 11 (transitive) dependencies per artifact. Model B has twice as many requirements and a slightly higher median of 15 (transitive) dependencies per artifact. Also, Model C contains twice as many artifacts (25 customers, 50 requirement, 400 software artifacts) and a median of 16 (transitive) dependencies per artifact.
7.3 Evolutionary operators
In MDEOptimiser the selection operators and most parts of the population mutation operators are given by the choice of the evolutionary algorithm used to perform an optimization (as described in Sect. 7.1). Therefore, we will discuss this choice in the next section. However, regardless of the used evolutionary algorithm, in our experiments the evolution of a solution is always performed as presented in Ex. 4. A single arbitrarily chosen applicable element mutation operator from is applied. If none of the available element mutation operators is applicable, the solution remains unchanged. In the following, we present the sets of element mutation operators used by the population mutation operators.
For each use case, we consider three variants of sets of element mutation operators: a set SC that is sound and complete, a set SIC that is sound but incomplete, and a set UC that is unsound but complete. We checked each set for soundness and completeness. Since all the element mutation operators are formalized as transformation rules in Henshin, we used the tool OCL2AC [50, 51] to support the soundness checks for all three cases. With regard to the common EMF-specific language constraints, we designed our rules according to the guidelines developed in [10], which were proven there to be sufficient conditions to preserve these constraints. Additionally, the implementation of the transformation language Henshin does not support parallel edges of the same type, i.e., attempts to introduce a parallel edge are ignored. Therefore, we do not need additional negative application conditions (as proposed in Ex. 3) for our element mutation operators to preserve the respective language constraint. As the root nodes are part of the problem model in all use cases, Proposition 1 and Lemma 1 guarantee their unique existence in all solutions throughout the evolutionary computations. Overall, all of the following element mutation operators are lc-preserving with regard to the EMF-specific language constraints.
The operator sets used in the experiments are discussed in detail using the CRA case as example. For the other use cases, please refer to Appendix B for more illustrations and details regarding their preservation of further language constraints, their soundness, and their completeness.
CRA. Figure 8 shows the element mutation operators considered in the CRA case as Henshin rules in graphical syntax. Nodes and edges are preserved, deleted, created, or forbidden as annotated (and encoded via a color scheme). Apart from the EMF-specific language constraints no language constraints are specified for the CRA case. Therefore, all operators are lc-preserving.
The SC variant includes five operators. The operators 8a and 8c can only add an assignment to a feature. To prevent features from being assigned to multiple classes, application conditions ensure that only features that have not yet been assigned are considered. If a feature is already assigned to a class, the operators 8e (introduced in Ex.4) and 8f can move it to another class. The new assignment replaces the existing one in each case. In doing so, features cannot be assigned to more than one class, nor can they remain unassigned. Since the last operator (8h) only deletes empty classes and does not change assignments, all operators in the set are sound. For a given solution model, any feature assignment can be reached as argued in Ex. 8. Consequently, the set SC is complete.
The operator set SIC largely coincides with the SC variant, but the designer forgot to implement the operator 8f, which moves a feature to a new class. Since this is a subset of SC, the set is also sound. However, once all features have been assigned to classes, no new classes can be created. Therefore, the set is not complete.
UC shares with its competitors only the deletion operator. Unlike their SC counterparts (8a and 8c), the operators responsible for adding assignments (8b and 8d) do not check if a feature is already assigned. Their application may result in features being assigned to multiple classes. The operator 8g can be used to unassign a feature which may result in unassigned features. Since both feasibility constraints can be violated, the set UC is not sound. By removing an assignment of a feature and reassigning it to another class, both move rules of the SC variant can be mimicked. As the operators for adding assignments are also more general than in the SC variant, the argumentation for completeness presented in Ex. 8 can also be adapted to the UC variant. Thus, the set is complete.

The set of all element mutation operators used for the CRA case. The operator set variants to which an operator belongs are given in parenthesis
SCRUM. Conceptually, the SCRUM and CRA cases are similar: Certain objects (work items/features) must be assigned to containers (sprints/classes). Therefore, it is not surprising that the operator sets also have similarities. The operator set for SCRUM is shown in Fig. 18. The SC variant of the SCRUM case contains two operators for adding unassigned work items to new or existing sprints. Two other operators move work items from one sprint to another (existing or new) sprint. Empty sprints can be deleted by the last operator. The reasoning about completeness and soundness, at least with respect to the feasibility constraints related to the assignment of work items, is analogous to the CRA case. In addition, rules that create/delete new sprints are only applied when the maximum/minimum number of allowed sprints has not yet been reached.
In the SIC variant, we again simulate a designer who forgot to design an operator (as in the CRA case). Unlike the CRA case, where at some point no new containers (i.e., classes) could be created, the rule for deleting containers (i.e., sprints) is completely missing. Otherwise, the set is equal to SC. Obviously, this set is not complete. For example, if all solutions in the population have reached the maximum number of sprints allowed, there is no way to create new solutions with fewer sprints.
The set UC is similar to the SC variant. However, the operators that create or delete sprints do so regardless of the current number of sprints in a solution.
NRP. Each of the operator set variants in the NRP case (in Fig. 19) contains two element mutation operators, one for adding an artifact to a release and one for removing an artifact. To not violate the constraints on the dependency hierarchy of artifacts, the SC variant follows a bottom-up construction of a release. Starting from artifacts without dependencies, artifacts are added only if all their dependencies are already part of the release. Complementarily, artifacts are removed in a top-down manner.
SIC. shares the bottom-up approach for adding artifacts. However, important artifacts (representing a dependency for three or more other artifacts) are never removed once they are in the release. Compared to SC, the rules in SIC are more restrictive and therefore this set is still sound. However, it is not complete. If an important artifact is added, feasible solutions without that artifact can no longer be reached.
The UC variant randomly adds and removes artifacts, regardless of their dependency structure. Randomly, all feasible and infeasible solutions can be reached at any time.
7.4 Evolutionary algorithms
We consider three common evolutionary algorithms: NSGA-II [24], PESA-II [21], and SPEA2 [64]. NSGA-II is most commonly used in the MDO literature and is also well represented in the literature combining SBSE and MDE [12]. Therefore, we already used it to exemplify our framework in Sect. 4. It uses the population mutation operator explained in Ex. 4 and the survival selection operator discussed in Ex. 5. Its computation specification is described in Ex. 6. For details on PESA-II and SPEA2, we refer the reader to [21] and [64], respectively. All algorithms are used with the population size and termination condition of Ex. 6. The initial population is always generated by mutating replicas of the problem instance twice, the standard initialization procedure of MDEOptimiser.
For PESA-II, two additional parameters must be specified: the size of an archive of non-dominated solutions and the number of regions into which the search space is partitioned when selecting parents. In agreement with [21], we use an archive of 100 elements and 32 regions. For SPEA2, an additional factor k (to estimate the uniqueness of solutions) must be specified. For performance reasons and in accordance with a recommendation of the MOEA framework, we set \(k=1\).
For each use case, each evolutionary algorithm is run in three configurations depending on the operator sets used: an SC, SIC, and UC variant. According to Def. 7, we denote each of these configurations by \({\mathscr {A}}( PI _{\mathscr {P}}, OP _{\mathscr {P}})\), where \({\mathscr {A}}\) is the name of the evolutionary algorithm, \( PI _{\mathscr {P}}\) indicates a problem instance of the optimization problem \({\mathscr {P}}\), and \( OP _{\mathscr {P}}\) uniquely identifies the set of evolutionary operators. Although each set of evolutionary operators contains not only mutation operators but also a selection operator, we name the set of operators only after the mutation operators since the selection operator is always the same. For ease of reading, the name of the algorithm is given by its initial letter only. For example, \(N(A_{\textrm{CRA}}, SC _{\textrm{CRA}})\) represents NSGA-II applied to model A of the CRA case using the sound and complete operator set for the CRA case. For each of our use cases, we run an execution batch of 30 executions for each combination of problem instance and operator set.
7.5 Effectiveness and efficiency
For each evolutionary algorithm separately, we compare the variants of the mutation operator sets with respect to the quality relations presented in Examples 9 and 10. This means that we do not compare the results between different evolutionary algorithms; for example, we do not compare an algorithm configuration based on NSGA-II with a configuration based on PESA-II or SPEA2. This allows us to attribute the differences in results to a single parameter: the differences in mutation operator sets. Using the hypervolume [63] as a quality indicator for each algorithm configuration and problem instance, we recorded the mean-effectiveness of the last population, the standard deviation from this mean, the mean length of evolutionary computations performed, and the mean runtime per iteration. Table 1 summarizes the measurements for all configurations based on NSGA-II. Since the results for the other algorithms are very similar, we will not list them explicitly here, but will discuss the observed differences.
In general, the results of optimization algorithms cannot be assumed to be normally distributed. Therefore, pairwise Mann-Whitney U tests [46] on the mean-effectiveness of the last populations are performed to test the significance (with \({\text {p-value}} < 0.05\)) of the differences between two algorithm configurations. We analyze the effect size of the observed differences using Cliff’s delta [20], which takes values between 0.0 (no effect at all) and \(\pm 1.0\) (the hypervolume of each evolutionary computation of one algorithm configuration is larger than the hypervolumes of all evolutionary computations of the other). We will use only positive values and rely on context to clarify which algorithm configuration is the dominating one.
To discuss the mean-n-effectiveness, for NSGA-II based configurations, Figures 9 to 11 show the development of the mean hypervolume for the smallest and largest problem instance of each use case, respectively. Consistent with Ex. 9, the mean hypervolume of each iteration of an algorithm configuration is computed with regard to all populations generated in that iteration in all evolutionary computations of the respective configuration. Figure 12 illustrates, as an example, the cumulative approximation sets achieved by each NSGA-II-based algorithm configuration for Model E of the CRA case and Model A of the NRP case. A cumulative approximation set is formed by combining the approximation sets of the last populations of all evolutionary computations of an algorithm configuration into one set of non-dominated solutions. Note that the diagrams in Figure 12 depict objective values along the axis and not the normalized values used for the hypervolume calculation. Also, note that the cumulative approximation sets shown in no way reflect how many evolutionary computations of an algorithm configuration yielded a particular solution.

Development of the mean hypervolume (defined in Sect. 7.5) for all NSGA-II based algorithm configurations for problem instances A and E of the CRA case

Development of the mean hypervolume (defined in Sect. 7.5) for all NSGA-II based algorithm configurations for problem instances A and B of the SCRUM case

Development of the mean hypervolume (defined in Sect. 7.5) for all NSGA-II based algorithm configurations for problem instances A and C of the NRP case

Cumulative approximation sets (defined in Sect. 7.5) for all NSGA-II based algorithm configurations for model E of the CRA case and model A of the NRP case, respectively
7.6 Results
In the following, we compare the UC and SIC variants of all evolutionary algorithms with their respective SC variant for all cases.
UC effectiveness. Regardless of the evolutionary algorithm, the UC variant turns out to be less effective than its two sound counterparts in terms of mean-effectiveness in almost all cases. Model B of the NRP case seems to be a special case, as UC is almost on par with SC and SIC here. Only the configurations \(N(B_{\textrm{NRP}}, UC _{\textrm{NRP}})\), \(P(A_{\textrm{NRP}}, UC _{\textrm{NRP}})\), \(P(B_{\textrm{NRP}}, UC _{\textrm{NRP}})\), and \(P(C_{\textrm{NRP}}, UC _{\textrm{NRP}})\) are better than their respective SIC variants. The differences between a UC variant and its corresponding SC and SIC variants are significant with a few exceptions. These are the SC variants \(P(A_{\textrm{NRP}}\), \( SC _{\textrm{NRP}})\), \(P(B_{\textrm{NRP}}, SC _{\textrm{NRP}})\), and \(S(A_{\textrm{NRP}}, SC _{\textrm{NRP}})\) as well as the SIC variant \(S(B_{\textrm{NRP}},\) \( SIC _{\textrm{NRP}})\).
Apart from the few insignificant differences, high effect sizes can be observed. For all problem instances of the CRA case, the highest possible effect size of 1.0 is achieved regardless of the algorithm used.
Apart from the NRP case where UC eventually surpasses SIC when PESA-II is used, UC always shows the lowest mean-n-effectiveness. For larger models of the CRA case, UC stands out with a low standard deviation. However, considering the poor quality of the solutions found, the robustness indicated by the low standard deviation can hardly be considered an advantage.
UC efficiency. In the CRA case, UC trades effectiveness for efficiency and requires far fewer iterations than the other variants (clearly seen in Fig. 9b). The iterations are also performed faster. In the NRP and SCRUM cases, UC requires more iterations than its competitors and its runtime efficiency is closer to (in some PESA-II and SPEA2 cases even worse than) that of SC and SIC. In general, UC converges more slowly than the other variants, i.e., the hypervolume improves in smaller steps (most evident in Fig. 11b).
SIC effectiveness. Comparing the incomplete variant SIC with its complete counterpart SC, the situation is not as clear as for UC. The result differs between the use cases and even between problem instances of the same use case. In terms of mean-effectiveness, SC is significantly better than SIC for models B, C, and D of the CRA case regardless of the evolutionary algorithm used. Effect sizes for models B and C lie between 0.55 and 0.96; for model D they range from 0.33 with SPEA2 to 0.55 with NSGA-II. For models A and E of the CRA case, the differences are not significant regarding NSGA-II and PESA-II; however, \(S(E_{\textrm{CRA}}, SIC _{\textrm{CRA}})\) outperforms its SC counterpart significantly.
For both models of the SCRUM case, SC outperforms SIC. However, the differences are only significant for NSGA-II and SPEA2. In the NRP case, the differences between SC and SIC are significant except for \(S(C_{\textrm{NRP}}, SIC _{\textrm{NRP}})\). SC performs slightly better than SIC in most cases (with effect sizes up to 1.0 for PESA-II and medium effect sizes for NSGA-II and SPEA2). However, \(N(A_{\textrm{NRP}}, SIC _{\textrm{NRP}})\) and \(S(A_{\textrm{NRP}}, SIC _{\textrm{NRP}})\) surpass their respective SC variants with effect sizes close to 1.0.
Looking at the standard deviation, SC produces slightly more consistent results in most cases. Regarding the mean-n-effectiveness, SIC performs better than SC at the beginning of an optimization in the CRA and NRP cases. For the SCRUM case, both variants behave nearly identically.
SIC efficiency. Most of the time SIC requires fewer iterations than SC to terminate. Only when using PESA-2 to solve the NRP case, it is the other way around. Although this result is not well reflected in Table 1, there is no clear winner in terms of runtime; the winner depends heavily on the algorithm considered and the problem instance.
7.7 Discussion
UC Since unsound operators allow the introduction of constraint violations, their effect on optimization depends heavily on the constraint handling mechanisms of the underlying evolutionary algorithm. As described in Ex. 5, the selection operator of NSGA-II discriminates hard against infeasible solutions. The same holds for PESA-II and SPEA2. As a result, infeasible solutions in the population are discarded as soon as a feasible substitute is found. Especially in scenarios where the optimization starts from a population containing feasible or nearly feasible solutions (as in the NRP case), the introduction of constraint violations caused by unsound operators usually wastes evolution steps. The resulting infeasible solutions are replaced early on by newly found or existing feasible solutions. This behavior cannot only slow down the optimization process (as seen in Fig. 11) but also increases the probability of getting stuck in local optima (see Fig. 9).
The extent to which negative effects of an unsound operator become apparent depends on other factors: (1) how often and at which stage of an optimization it is applicable, (2) whether it necessarily produces infeasible solutions, and (3) whether other operators are given a chance to counteract its negative effects. In the CRA case, the unsound operators addFeatureToNewClass, addFeatureToExClass, and removeFeatureFromExClass are all applicable to the vast majority of solutions. At the beginning of an optimization, only a few features have a chance to be assigned to a class (most of them to exactly one class). Therefore, an application of removeFeatureFromExClass is likely to leave a feature unassigned. The more features are assigned, the more likely multi-assignments will occur when addFeatureToNewClass or addFeatureToExClass are applied. Although removeFeatureFromExClass can potentially resolve multi-assignments, the corresponding solutions are often discarded before such a resolution can occur due to the constraint handling used by the considered evolutionary algorithms. Since the combination of the discussed operators repeatedly leads to constraint violations in the course of an optimization, their negative effects are clearly reflected in the observed effectiveness of the UC variant. In contrast, in the SCRUM case, the negative effects of the unsound operators are less noticeable. The unsound operators for creating/deleting sprints do not necessarily lead to constraint violations as long as the maximum/minimum number of allowed sprints is not exceeded after their application. Furthermore, the effect of creating a sprint can be neutralized by subsequent deletion of a sprint and vice versa, before the respective limit is reached. Finally, one of the unsound operators that creates sprints can no longer be applied once all work items have been assigned.
In cases were UC is nearly as effective as its competitors, more iterations are required to compensate for the wasted mutations caused by unsound operators. On the other hand, UC also reaches the termination condition when it gets stuck in local optima. Therefore, fewer iterations are required than for the other variants. Checking the application condition of an operator and finding a match of the operator in the solution model can be a time-consuming task. Unsound operators restrict their applicability less than their sound counterparts. Consequently, UC is often the fastest variant in terms of time required per iteration.
SIC. The performance of the SIC variant depends largely on which part of the search space becomes unreachable due to the incompleteness of the operator set. When (near) optimal solutions become unavailable, the mean-effectiveness of SIC likely suffers (as for the CRA case in Table 1). Comparing the cumulative approximation sets generated by the NSGA-II variants for models C, D, and E of the CRA case, we found that SC generated solutions with high cohesion and high coupling that SIC could not find (e.g., Fig. 12a). We attribute this to the inability of the SIC variant to create new classes once all features are assigned. Obviously, SIC was unable to maintain solutions with the number of classes necessary to induce such a high coupling. However, ignoring certain parts of the search space during the course of an optimization can also serve to take shortcuts, speed up the optimization process, or even overcome local optima. With NSGA-II, this can clearly be observed for model A of the NRP case (see Fig. 12b). While complete variants get stuck at solutions of low satisfaction, SIC manages to explore a much larger portion of the search space. For some reason, however, the same set of operators is less successful in SPEA2 and even worse than the other variants in PESA-II.
Note that the impact of an incomplete operator set may depend on the problem instance at hand. While SIC performs better than SC on model A of the NRP case, it is the opposite for the other problem instances. Moreover, small changes in the introduced incompleteness can have large effects. In the SIC variant of the NRP case, we do not allow an artifact to be removed if it serves as a dependency for \(x=3\) other artifacts. Choosing other values for x (e.g., 2 or 4), we found that the aforementioned superiority of SIC for Model A disappears completely.
Summary. In summary, we observe that the use of unsound operator sets in our experiments has a mostly negative impact on optimization (RQ1). While they are sometimes more efficient than their sound counterparts, their lack of effectiveness outweighs this advantage. An effect on the optimization was also observed for the completeness of operator sets (RQ2). In our use cases, the incomplete variants were slightly more efficient than the sound and complete variants, but less effective in most cases. However, in a few cases, they managed to perform significantly better than their competitors regarding effectiveness.
7.8 Threats to validity
Although the selected use cases already differ in various aspects covering a range of problems relevant in practice, they represent only a small part of the broad spectrum of optimization problems in software engineering. While the problem models of the considered cases have rather complex structures, the complexity of the solution parts is rather limited. Consequently, the complexity of changes made by element mutation operators is also limited; a fact that allows us to reason about the soundness and completeness of the operator sets in the first place. Unfortunately, only a relatively small number of use cases have been prepared for MDO so far, i.e., with problem instances formalized over meta-models and element mutation operators implemented as model transformations; elaborating a suitable use case is a non-trivial task. Other optimization problems, including those that allow for more complex mutations, will need to be addressed in the future.
While the use cases considered reflect practical software engineering problems, all problem instances were generated. The extent to which these are representative of real-world cases remains unknown. We have attempted to address this problem by considering problem instances of varying sizes and complexity for each use case.
We attribute the observed behavior of the mutation operator sets to their soundness and completeness. However, there may also be hidden side effects on the optimization caused by other differences in the implementation of the mutation operators. Due to the simplicity of the use cases mentioned above, we attempted to mitigate this risk by keeping the changes between operator sets as small as possible and maintaining a similar granularity of model changes made by the mutation operators.
Finding the best parametrization of an evolutionary algorithm (e.g., the initial population, the operators, and the termination criterion) can be considered as an optimization problem in its own right. We chose the size and generation process of the population based on our experience from previous experiments [15, 38]. By design, our termination criterion allows a fair comparison as all evolutionary computations converge in same way. However, in the experiments for each evolutionary algorithm, we kept all variation points constant except for the mutation operator sets. This allows us to attribute differences to a single independent variable, but neglects possible synergies between specific parameters and variants of mutation operator sets. Like NSGA-II, the selection mechanisms of PESA-II and SPEA2 also discriminate infeasible solutions (see Ex. 5). Other selection and constraint handling mechanisms may lead to different observations and need to be investigated. However, since NSGA-II, PESA-II, and SPEA2 can be considered state of the art, we believe that our results are very relevant.
8 Conclusion
Developing effective and efficient algorithms in MDO requires not only domain expertise but also in-depth knowledge of evolutionary algorithm design. We have presented a graph-based framework that identifies and clarifies the core concepts of MDO. It is intended to assist the domain expert in using MDO to solve optimization problems. It can also help in clarifying the critical factors for conducting reproducible experiments in MDO. We have used this framework to conduct a series of experiments on optimizing software modularization and release planning using the CRA, SCRUM, and NRP cases.
In particular, since our formal framework puts the focus on the specification of mutation operators, it facilitates impact analysis of the properties of operators. As a showcase, we consider the soundness and completeness of element mutation operator sets. Our experiments provide a first insight into the effects of these properties on the effectiveness and efficiency of evolutionary algorithms in MDO. We found that for a selection operator that strictly discriminates infeasible solutions, unsound mutation operators can slow down the optimization process as infeasible solutions are generated and discarded; moreover, unsound operators increase the probability of getting stuck in local optima. The performance of a set of incomplete mutation operators depends largely on which part of the search space becomes unreachable due to the incompleteness of the operator set. When (near) optimal solutions become unreachable, the effectiveness of the corresponding algorithm may suffer. On the other hand, ignoring parts of a search space that do not contain interesting solutions can speed up the optimization process. Since a search space also depends on the given problem instance, the effect of completeness may vary from instance to instance of the same optimization problem. Therefore, it can be very important to make an informed decision about the soundness and completeness of change operators.
To confirm our observations, the task of future work is to consider other optimization problems and further vary the determining factors. More tool support for analyzing soundness and completeness would facilitate further experimentation. Investigating runtime verification techniques for analyzing soundness and completeness on the population level is also part of future work.
In addition, it is interesting to consider crossover (or breeding) operators for MDO and investigate the effects of soundness and completeness for these as well. In [60], we have taken a first step in this direction by defining a crossover operator for graph-like structures. It forms the formal basis for a crossover operator for EMF models; we present a first draft and implementation in [39]. Furthermore, in [61], we develop a (not yet implemented) approach to crossover on graphs that is sound with respect to multiplicity constraints. We intend to use these works to extend our framework to crossover operators and to extend our impact analysis of soundness and completeness also to evolutionary algorithms that use both mutation and crossover operators.
A fundamental design decision of our framework is to distinguish problem and solution parts in models: it can be advantageously used in the CRA, NRP, and SCRUM optimization problems that we have considered throughout the paper. There may also be optimization problems where the separation of problem and solution parts in models is not clear. For example, the Refactoring case [42, 55] starts from a class model and searches for an optimal refactoring sequence for that model; during evolution, all parts of the class model may change. This case would be specified in our framework with empty problem models. It is left to future work to investigate the consequences of this design decision.
Our graph-based framework is deliberately generic in terms of modeling languages and specification options for evolutionary algorithms. It is incumbent on future work to investigate how it relates to other existing optimization approaches based on graphs or models. This is particularly true for the evolution of graphs through graph programs by Atkinson et al. [5,6,7] and the rule-based approach to MDO [2, 11, 31].
Our long-term goal is to consolidate MDO so that it is well-suited for optimizations in complex problem domains such as those encountered in search-based software engineering and beyond.
References
Evaluation data: Results and artifacts. https://github.com/Leative/SoSyM22-MDO-framework-evaluation. Accessed: 2022-12-19
Abdeen, H., Varró, D., Sahraoui, H.A., Nagy, A.S., Debreceni, C., Hegedüs, Á., Horváth, Á.: Multi-objective optimization in rule-based design space exploration. In: I. Crnkovic, M. Chechik, P. Grünbacher (eds.) ACM/IEEE International Conference on Automated Software Engineering, ASE ’14, Vasteras, Sweden – September 15–19, 2014, pp. 289–300. ACM (2014). https://doi.org/10.1145/2642937.2643005
Adámek, J., Herrlich, H., Strecker, G.E.: Abstract and Concrete Categories. Wiley-Interscience, The Joy of Cats (1990)
Arendt, T., Biermann, E., Jurack, S., Krause, C., Taentzer, G.: Henshin: Advanced concepts and tools for in-place EMF model transformations. In: D.C. Petriu, N. Rouquette, Ø. Haugen (eds.) Model Driven Engineering Languages and Systems – 13th International Conference, MODELS 2010, Oslo, Norway, October 3–8, 2010, Proceedings, Part I, Lecture Notes in Computer Science, vol. 6394, pp. 121–135. Springer (2010). https://doi.org/10.1007/978-3-642-16145-2_9
Atkinson, T., Plump, D., Stepney, S.: Evolving graphs by graph programming. In: M. Castelli, L. Sekanina, M. Zhang, S. Cagnoni, P. García-Sánchez (eds.) Genetic Programming – 21st European Conference, EuroGP 2018, Parma, Italy, April 4–6, 2018, Proceedings, Lecture Notes in Computer Science, vol. 10781, pp. 35–51. Springer (2018). https://doi.org/10.1007/978-3-319-77553-1_3
Atkinson, T., Plump, D., Stepney, S.: Horizontal gene transfer for recombining graphs. Genet. Program. Evolvable Mach. 21(3), 321–347 (2020). https://doi.org/10.1007/s10710-020-09378-1
Atkinson, T., Plump, D., Stepney, S.: Evolving graphs with semantic neutral drift. Nat. Comput. 20(1), 127–143 (2021). https://doi.org/10.1007/s11047-019-09772-4
Bagnall, A.J., Rayward-Smith, V.J., Whittley, I.M.: The next release problem. Inf. Softw. Technol. 43(14), 883–890 (2001). https://doi.org/10.1016/S0950-5849(01)00194-X
Becker, B., Lambers, L., Dyck, J., Birth, S., Giese, H.: Iterative development of consistency-preserving rule-based refactorings. In: J. Cabot, E. Visser (eds.) Theory and Practice of Model Transformations – 4th International Conference, ICMT@TOOLS 2011, Zurich, Switzerland, June 27–28, 2011. Proceedings, Lecture Notes in Computer Science, vol. 6707, pp. 123–137. Springer (2011). https://doi.org/10.1007/978-3-642-21732-6_9
Biermann, E., Ermel, C., Taentzer, G.: Formal foundation of consistent EMF model transformations by algebraic graph transformation. Softw. Syst. Model. 11(2), 227–250 (2012). https://doi.org/10.1007/s10270-011-0199-7
Bill, R., Fleck, M., Troya, J., Mayerhofer, T., Wimmer, M.: A local and global tour on MOMoT. Softw. Syst. Model. 18(2), 1017–1046 (2019). https://doi.org/10.1007/s10270-017-0644-3
Boussaïd, I., Siarry, P., Ahmed-Nacer, M.: A survey on search-based model-driven engineering. Autom. Softw. Eng. 24(2), 233–294 (2017). https://doi.org/10.1007/s10515-017-0215-4
Bowman, M., Briand, L.C., Labiche, Y.: Solving the class responsibility assignment problem in object-oriented analysis with multi-objective genetic algorithms. IEEE Trans. Software Eng. 36(6), 817–837 (2010). https://doi.org/10.1109/TSE.2010.70
Burdusel, A., Zschaler, S.: Model optimisation for feature class allocation using MDEOptimiser: A TTC 2016 submission. In: A. García-Domínguez, F. Krikava, L.M. Rose (eds.) Proceedings of the 9th Transformation Tool Contest, co-located with the 2016 Software Technologies: Applications and Foundations (STAF 2016), Vienna, Austria, July 8, 2016, CEUR Workshop Proceedings, vol. 1758, pp. 33–38. CEUR-WS.org (2016). http://ceur-ws.org/Vol-1758/paper6.pdf
Burdusel, A., Zschaler, S., John, S.: Automatic generation of atomic multiplicity-preserving search operators for search-based model engineering. Softw. Syst. Model. 20(6), 1857–1887 (2021). https://doi.org/10.1007/s10270-021-00914-w
Burdusel, A., Zschaler, S., Strüber, D.: MDEOptimiser: A Search Based Model Engineering Tool. In: Ö. Babur, D. Strüber, S. Abrahão, L. Burgueño, M. Gogolla, J. Greenyer, S. Kokaly, D.S. Kolovos, T. Mayerhofer, M. Zahedi (eds.) Proceedings of the 21st ACM/IEEE International Conference on Model Driven Engineering Languages and Systems: Companion Proceedings, MODELS 2018, Copenhagen, Denmark, October 14–19, 2018, pp. 12–16. ACM (2018). https://doi.org/10.1145/3270112.3270130
Burton, F.R., Paige, R.F., Rose, L.M., Kolovos, D.S., Poulding, S.M., Smith, S.: Solving acquisition problems using model-driven engineering. In: A. Vallecillo, J. Tolvanen, E. Kindler, H. Störrle, D.S. Kolovos (eds.) Modelling Foundations and Applications – 8th European Conference, ECMFA 2012, Kongens Lyngby, Denmark, July 2–5, 2012. Proceedings, Lecture Notes in Computer Science, vol. 7349, pp. 428–443. Springer (2012). https://doi.org/10.1007/978-3-642-31491-9_32
Burton, F.R., Poulding, S.M.: Complementing metaheuristic search with higher abstraction techniques. In: R.F. Paige, M. Harman, J.R. Williams (eds.) 1st International Workshop on Combining Modelling and Search-Based Software Engineering, CMSBSE@ICSE 2013, San Francisco, CA, USA, May 20, 2013, pp. 45–48. IEEE Computer Society (2013). https://doi.org/10.1109/CMSBSE.2013.6604436
Case, B., Lehre, P.K.: Self-adaptation in nonelitist evolutionary algorithms on discrete problems with unknown structure. IEEE Trans. Evol. Comput. 24(4), 650–663 (2020). https://doi.org/10.1109/TEVC.2020.2985450
Cliff, N.: Dominance statistics: Ordinal analyses to answer ordinal questions. Psychological Bulletin 114(3), 494–509 (1993). https://doi.org/10.1037/0033-2909.114.3.494.psycnet.apa.org/record/1994-08169-001
Corne, D.W., Jerram, N.R., Knowles, J.D., Oates, M.J.: PESA-II: Region-based selection in evolutionary multiobjective optimization. In: Proceedings of the 3rd Annual Conference on Genetic and Evolutionary Computation, GECCO’01, pp. 283–290. Morgan Kaufmann Publishers Inc. (2001)
Corus, D., Dang, D., Eremeev, A.V., Lehre, P.K.: Level-based analysis of genetic algorithms and other search processes. IEEE Trans. Evol. Comput. 22(5), 707–719 (2018). https://doi.org/10.1109/TEVC.2017.2753538
Dang, D., Lehre, P.K., Nguyen, P.T.H.: Level-based analysis of the univariate marginal distribution algorithm. Algorithmica 81(2), 668–702 (2019). https://doi.org/10.1007/s00453-018-0507-5
Deb, K., Agrawal, S., Pratap, A., Meyarivan, T.: A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 6(2), 182–197 (2002). https://doi.org/10.1109/4235.996017
Eclipse: Eclipse Modeling Framework (EMF). http://www.eclipse.org/emf. Accessed: 2022-12-07
Ehrig, H., Ehrig, K., Prange, U., Taentzer, G.: Fundamentals of Algebraic Graph Transformation. Monographs in Theoretical Computer Science. Springer (2006). https://doi.org/10.1007/3-540-31188-2
Ehrig, H., Ermel, C., Golas, U., Hermann, F.: Graph and Model Transformation – General Framework and Applications. Monographs in Theoretical Computer Science. An EATCS Series. Springer (2015). https://doi.org/10.1007/978-3-662-47980-3
Ehrig, H., Golas, U., Habel, A., Lambers, L., Orejas, F.: \(\cal{M}\)-adhesive transformation systems with nested application conditions. Part 2: Embedding, critical pairs and local confluence. Fundam. Informaticae 118(1-2), 35–63 (2012). https://doi.org/10.3233/FI-2012-705
Ehrig, H., Golas, U., Habel, A., Lambers, L., Orejas, F.: \(\cal{M}\)-adhesive transformation systems with nested application conditions. Part 1: Parallelism, concurrency and amalgamation. Math. Struct. Comput. Sci. 24(4) (2014). https://doi.org/10.1017/S0960129512000357
Eiben, A.E., Smith, J.E.: Introduction to Evolutionary Computing, 2nd edn. Natural Computing Series. Springer (2015). https://doi.org/10.1007/978-3-662-44874-8
Fleck, M., Troya, J., Wimmer, M.: Marrying search-based optimization and model transformation technology. In: Proceedings of the First North American Search Based Software Engineering Symposium. Elsevier (2015). http://publik.tuwien.ac.at/files/PubDat_237899.pdf. Accessed: 2022-12-07
Fleck, M., Troya, J., Wimmer, M.: The Class Responsibility Assignment Case. In: A. García-Domínguez, F. Krikava, L.M. Rose (eds.) Proceedings of the 9th Transformation Tool Contest, co-located with the 2016 Software Technologies: Applications and Foundations (STAF 2016), Vienna, Austria, July 8, 2016, CEUR Workshop Proceedings, vol. 1758, pp. 1–8. CEUR-WS.org (2016). http://ceur-ws.org/Vol-1758/paper1.pdf
Habel, A., Pennemann, K.: Correctness of high-level transformation systems relative to nested conditions. Math. Struct. Comput. Sci. 19(2), 245–296 (2009). https://doi.org/10.1017/S0960129508007202
Harman, M., Jones, B.F.: Search-based software engineering. Inf. Softw. Technol. 43(14), 833–839 (2001). https://doi.org/10.1016/S0950-5849(01)00189-6
Harman, M., Mansouri, S.A., Zhang, Y.: Search-based software engineering: Trends, techniques and applications. ACM Comput. Surv. 45(1), 11:1-11:61 (2012). https://doi.org/10.1145/2379776.2379787
Hermann, F., Ehrig, H., Golas, U., Orejas, F.: Formal analysis of model transformations based on triple graph grammars. Math. Struct. Comput. Sci. 24(4) (2014). https://doi.org/10.1017/S0960129512000370
Horcas, J.M., Strüber, D., Burdusel, A., Martinez, J., Zschaler, S.: We’re not gonna break it! Consistency-preserving operators for efficient product line configuration. IEEE Trans. Software Eng. (2022). https://doi.org/10.1109/TSE.2022.3171404
John, S., Burdusel, A., Bill, R., Strüber, D., Taentzer, G., Zschaler, S., Wimmer, M.: Searching for optimal models: Comparing two encoding approaches. J. Object Technol. 18(3), 6:1-22 (2019). https://doi.org/10.5381/jot.2019.18.3.a6
John, S., Kosiol, J., Taentzer, G.: Towards a configurable crossover operator for model-driven optimization. In: T. Kühn, V. Sousa (eds.) Proceedings of the 25th International Conference on Model Driven Engineering Languages and Systems: Companion Proceedings, MODELS 2022, Montreal, Quebec, Canada, October 23–28, 2022, pp. 388–395. ACM (2022). https://doi.org/10.1145/3550356.3561603
Kessentini, M., Langer, P., Wimmer, M.: Searching models, modeling search: On the synergies of SBSE and MDE. In: R.F. Paige, M. Harman, J.R. Williams (eds.) 1st International Workshop on Combining Modelling and Search-Based Software Engineering, CMSBSE@ICSE 2013, San Francisco, CA, USA, May 20, 2013, pp. 51–54. IEEE Computer Society (2013). https://doi.org/10.1109/CMSBSE.2013.6604438
Kosiol, J., Strüber, D., Taentzer, G., Zschaler, S.: Sustaining and improving graduated graph consistency: A static analysis of graph transformations. Sci. Comput. Program. 214, 102,729 (2022). https://doi.org/10.1016/j.scico.2021.102729
Lano, K., Rahimi, S.K.: Case study: Class diagram restructuring. In: P.V. Gorp, L.M. Rose, C. Krause (eds.) Proceedings Sixth Transformation Tool Contest, TTC 2013, Budapest, Hungary, 19–20 June, 2013, EPTCS, vol. 135, pp. 8–15 (2013). https://doi.org/10.4204/EPTCS.135.2
de Lara, J., Bardohl, R., Ehrig, H., Ehrig, K., Prange, U., Taentzer, G.: Attributed graph transformation with node type inheritance. Theor. Comput. Sci. 376(3), 139–163 (2007). https://doi.org/10.1016/j.tcs.2007.02.001
Löwe, M., König, H., Schulz, C., Schultchen, M.: Algebraic graph transformations with inheritance and abstraction. Sci. Comput. Program. 107–108, 2–18 (2015). https://doi.org/10.1016/j.scico.2015.02.004
MacLane, S.: Categories for the Working Mathematician, Graduate Texts in Mathematics, vol. 5. Springer-Verlag, New York (1971)
Mann, H.B., Whitney, D.R.: On a test of whether one of two random variables is stochastically larger than the other. The Annals of Mathematical Statistics 18(1), 50–60 (1947)
Masoud, H., Jalili, S.: A clustering-based model for class responsibility assignment problem in object-oriented analysis. J. Syst. Softw. 93, 110–131 (2014). https://doi.org/10.1016/j.jss.2014.02.053
MDEOptimiser. http://mde-optimiser.github.io. Accessed: 2022-12-07
Moea framework. http://moeaframework.org. Accessed: 2022-12-07
Nassar, N., Kosiol, J., Arendt, T., Taentzer, G.: OCL2AC: Automatic translation of OCL constraints to graph constraints and application conditions for transformation rules. In: L. Lambers, J.H. Weber (eds.) Graph Transformation – 11th International Conference, ICGT 2018, Held as Part of STAF 2018, Toulouse, France, June 25–26, 2018, Proceedings, Lecture Notes in Computer Science, vol. 10887, pp. 171–177. Springer (2018). https://doi.org/10.1007/978-3-319-92991-0_11
Nassar, N., Kosiol, J., Arendt, T., Taentzer, G.: Constructing optimized constraint-preserving application conditions for model transformation rules. J. Log. Algebraic Methods Program. 114, 100,564 (2020). https://doi.org/10.1016/j.jlamp.2020.100564
Paixão, T., Badkobeh, G., Barton, N., Çörüş, D., Dang, D.C., Friedrich, T., Lehre, P.K., Sudholt, D., Sutton, A.M., Trubenová, B.: Toward a unifying framework for evolutionary processes. J. Theoret. Biol. 383, 28–43 (2015). https://doi.org/10.1016/j.jtbi.2015.07.011
Pennemann, K.: Development of correct graph transformation systems. Ph.D. thesis, University of Oldenburg, Germany (2009). https://nbn-resolving.org/urn:nbn:de:gbv:715-oops-9483. Accessed: 2022-12-07
Radke, H., Arendt, T., Becker, J.S., Habel, A., Taentzer, G.: Translating essential OCL invariants to nested graph constraints for generating instances of meta-models. Sci. Comput. Program. 152, 38–62 (2018). https://doi.org/10.1016/j.scico.2017.08.006
Rahimi, S.K., Lano, K., Pillay, S., Troya, J., Gorp, P.V.: Evaluation of model transformation approaches for model refactoring. Sci. Comput. Program. 85, 5–40 (2014). https://doi.org/10.1016/j.scico.2013.07.013
Rensink, A., Schmidt, Á., Varró, D.: Model checking graph transformations: A comparison of two approaches. In: H. Ehrig, G. Engels, F. Parisi-Presicce, G. Rozenberg (eds.) Graph Transformations, Second International Conference, ICGT 2004, Rome, Italy, September 28 - October 2, 2004, Proceedings, Lecture Notes in Computer Science, vol. 3256, pp. 226–241. Springer (2004). https://doi.org/10.1007/978-3-540-30203-2_17
Rubin, K.S.: Essential Scrum. Addison-Wesley, A Practical Guide to the Most Popular Agile Process (2012)
Schmidt, D.C.: Guest editor’s introduction: Model-driven engineering. Computer 39(2), 25–31 (2006). https://doi.org/10.1109/MC.2006.58
Strüber, D.: Generating efficient mutation operators for search-based model-driven engineering. In: E. Guerra, M. van den Brand (eds.) Theory and Practice of Model Transformation – 10th International Conference, ICMT 2017, Held as Part of STAF 2017, Marburg, Germany, July 17–18, 2017, Proceedings, Lecture Notes in Computer Science, vol. 10374, pp. 121–137. Springer (2017). https://doi.org/10.1007/978-3-319-61473-1_9
Taentzer, G., John, S., Kosiol, J.: A generic construction for crossovers of graph-like structures. In: N. Behr, D. Strüber (eds.) Graph Transformation – 15th International Conference, ICGT 2022, Held as Part of STAF 2022, Nantes, France, July 7–8, 2022, Proceedings, Lecture Notes in Computer Science, vol. 13349, pp. 97–117. Springer (2022). https://doi.org/10.1007/978-3-031-09843-7_6
Thölke, H., Kosiol, J.: A multiplicity-preserving crossover operator on graphs. In: T. Kühn, V. Sousa (eds.) Proceedings of the 25th International Conference on Model Driven Engineering Languages and Systems: Companion Proceedings, MODELS 2022, Montreal, Quebec, Canada, October 23–28, 2022, pp. 588–597. ACM (2022). https://doi.org/10.1145/3550356.3561587. https://doi.org/10.1145/3550356.3561587
Wappler, S., Lammermann, F.: Using evolutionary algorithms for the unit testing of object-oriented software. In: H. Beyer, U. O’Reilly (eds.) Genetic and Evolutionary Computation Conference, GECCO 2005, Proceedings, Washington DC, USA, June 25–29, 2005, pp. 1053–1060. ACM (2005). https://doi.org/10.1145/1068009.1068187
Zitzler, E., Brockhoff, D., Thiele, L.: The hypervolume indicator revisited: On the design of pareto-compliant indicators via weighted integration. In: S. Obayashi, K. Deb, C. Poloni, T. Hiroyasu, T. Murata (eds.) Evolutionary Multi-Criterion Optimization, 4th International Conference, EMO 2007, Matsushima, Japan, March 5–8, 2007, Proceedings, Lecture Notes in Computer Science, vol. 4403, pp. 862–876. Springer (2007). https://doi.org/10.1007/978-3-540-70928-2_64
Zitzler, E., Laumanns, M., Thiele, L.: SPEA2: Improving the strength pareto evolutionary algorithm. TIK-Report 103, ETH Zürich (2001). https://doi.org/10.3929/ETHZ-A-004284029
Zitzler, E., Thiele, L., Laumanns, M., Fonseca, C.M., da Fonseca, V.G.: Performance assessment of multiobjective optimizers: An analysis and review. IEEE Trans. Evol. Comput. 7(2), 117–132 (2003). https://doi.org/10.1109/TEVC.2003.810758
Zschaler, S., Mandow, L.: Towards model-based optimisation: Using domain knowledge explicitly. In: P. Milazzo, D. Varró, M. Wimmer (eds.) Software Technologies: Applications and Foundations – STAF 2016 Collocated Workshops: DataMod, GCM, HOFM, MELO, SEMS, VeryComp, Vienna, Austria, July 4–8, 2016, Revised Selected Papers, Lecture Notes in Computer Science, vol. 9946, pp. 317–329. Springer (2016). https://doi.org/10.1007/978-3-319-50230-4_24
Funding
Open Access funding enabled and organized by Projekt DEAL. This work has been partially supported by the German Research Foundation (DFG), grants TA 294/17-1 and TA 294/19-1.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Dimitris Kolovos.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
A Additional formal preliminaries and proofs
1.1 A.1 Formal preliminaries
Graphs. We first recall the definitions of graphs and typed graphs and their morphisms.
Definition 12
(Graph) A graph \(G = (G_V, G_E, src _G, tgt _G)\) consists of a set \(G_V\) of vertices (or nodes), a set \(G_E\) of edges, and two maps \( src _G, tgt _G:G_E \rightarrow G_V\) assigning the source and target to each edge, respectively. By \(e:x \rightarrow y\) we denote an edge \(e \in G_E\) with \( src _G(e) = x\) and \( tgt _G(e) = y\).
Definition 13
(Graph morphism) A graph morphism \(f:G \rightarrow H\) consists of a pair of functions \(f_V:G_V \rightarrow H_V\), \(f_E:G_E \rightarrow H_E\) preserving the graph structure: For each edge \(e:x \rightarrow y\) in \(G_E\) it holds that \(f_E(e):f_V(x) \rightarrow f_V(y)\) in H, i.e., we have \(f_V \circ src _G = src _H \circ f_E \) and \(f_V \circ tgt _G = tgt _H \circ f_E\). Morphism f is injective if \(f_V\) and \(f_E\) are injective.
A typed graph is a graph that is mapped to a given type graph. A mapping between two typed graphs over one and the same type graph has to be type-conformant.
Definition 14
(Type graph, typed graph and typed morphism) A type graph is a distinguished graph \( TG = ( TG _V, TG _E, src _{ TG }, tgt _{ TG })\). A typed graph \((G, type _G:G \rightarrow TG )\) which is typed by \( TG \) is a graph G together with a graph morphism \( type _G\) from G to \( TG \). A typed graph G is also called instance graph of graph \( TG \) and the morphism \( type _G\) is called typing morphism.
Given a type graph \( TG \), a typed graph morphism \(f :G \rightarrow H\) between typed graphs \((G, type _G)\) and \((H, type _H)\) is a graph morphism \(f:G \rightarrow H\) such that \( type _G = type _H \circ f\).
Categories. In this section, we give a short and semi-formal introduction into all those notions of category theory we need for our approach. For more details see, e.g., [45, 3, 29], and [28].
A category C is a mathematical structure that has objects collected in \(Ob_C\) and morphisms \( Mor _C(A,B)\) relating pairs of objects \(A,B \in Ob_C\) in some way. There needs to be a composition operation \(\circ \) for morphisms \(f \in Mor _C(A,B)\) and \(g \in Mor _C(B,D)\) as well as an identity morphism \(id_A\) for each object \(A \in Ob_C\). The composition \(\circ \) has to be associative and composition with identities has to be neutral.
Examples are the category Set of all sets and functions, the category Poset of all partially ordered sets and order-preserving mappings, and the category Graph of all graphs and graph morphisms.
There are special types of morphisms: An isomorphism is a morphism to which an inverse morphism exists, i.e., composing them in either order leads to identities. Objects related by an isomorphism exhibit exactly the same structure and can thus be considered as equal in many contexts. If we have \(m \circ f = m \circ g \implies f = g\) for any two morphisms f and g such that the composition is defined, m is called monomorphism. In the category Set, isomorphisms are the bijective functions and monomorphisms are the injective ones.
Pushouts and pullbacks. A pushout can be considered as a kind of union of two objects over a common one. Given two morphisms \(g:A \rightarrow B\) and \(h:A \rightarrow C\), a pushout, if it exists, consists of an object D and two morphisms \(k:B \rightarrow D\) and \(l:C \rightarrow D\) such that (1) \(k \circ g = l \circ h\) and (2) the following universal property holds: If there are morphisms \(k^{\prime }:B \rightarrow X\) and \(l^{\prime }:C \rightarrow X\) with \(k^{\prime } \circ g = l^{\prime } \circ h\), then there is a unique morphism \(x:D \rightarrow X\) with \(x \circ k = k^{\prime }\) and \(x \circ l = l^{\prime }\) (see the left diagram in Fig. 13).

A schematic depiction of a pushout (left) and a pullback (right)
Reversing the direction of all morphisms, a pullback can be seen as a generalized intersection of two objects over a common object. Given two morphisms \(k:B \rightarrow D\) and \(l:C \rightarrow D\), a pullback consists of an object A and morphisms \(g :A \rightarrow B\) and \(h:A \rightarrow C\) such that \(k \circ g = l \circ h\) and the following universal property holds: If there are morphisms \(g^{\prime }:Y \rightarrow B\) and \(h^{\prime }:Y \rightarrow C\) with \(k \circ g^{\prime } = l \circ h^{\prime }\), then there is a unique morphism \(a:Y \rightarrow A\) with \(g \circ a = g^{\prime }\) and \(h \circ a = h^{\prime }\) (see the right diagram in Fig. 13).
In the category Set, if a morphism g is injective, the pushout object is \(D = C \cup (B - g(A))\). Since a pushout is unique up to isomorphism, any set isomorphic to D would also be a pushout object. A pullback object, for l being injective, is constructed by \(A = k(B) \cap l(C)\). In the category Graph, pushouts and pullbacks can be constructed componentwise on node and edge sets. For these, and more general computations, compare, e.g., [26, Fact 2.17, Fact 2.23, and Remark 2.24].
\(\mathscr {M}\)-adhesive categories. We will prove our statements in a quite abstract setting, namely the one of \(\mathscr {M}\)-adhesive categories [28, 29]. These are categories where pushouts along monomorphisms interact in a particularly nice way with pullbacks and encompass the categories of sets, of graphs, and many graph-like structures, including typed attributed graphs. A category C with a morphism class \(\mathscr {M}\) is an \(\mathscr {M}\)-adhesive category if the following properties hold:
-
\(\mathscr {M}\) is a class of monomorphisms closed under isomorphisms (f isomorphism implies that \(f \in \mathscr {M}\)), composition (\(f,g \in \mathscr {M}\) implies \(g \circ f \in \mathscr {M}\)), and decomposition (\(g \circ f, g \in \mathscr {M}\) implies \(f \in \mathscr {M}\)).
-
C has pushouts and pullbacks along \(\mathscr {M}\)-morphisms, i.e., pushouts and pullbacks, where at least one of the given morphisms is in \(\mathscr {M}\), and \(\mathscr {M}\)-morphisms are closed under pushouts and pullbacks, i.e., given a pushout like the left diagram in Fig. 14, \(m \in \mathscr {M}\) implies \(n \in \mathscr {M}\) and, given a pullback (1), \(n \in \mathscr {M}\) implies \(m \in \mathscr {M}\).
-
Pushouts in C along \(\mathscr {M}\)-morphisms are so-called vertical weak van Kampen squares, i.e., for any commutative cube in C where we have the pushout with \(m \in \mathscr {M}\) in the bottom, \(b,c,d \in \mathscr {M}\), and pullbacks as back faces, the top is a pushout if and only if the front faces are pullbacks.

A schematic depiction of an \(\mathscr {M}\)-VK square
Examples for categories that are \(\mathscr {M}\)-adhesive are sets with injective functions, graphs with injective graph morphisms and several variants of graphs with special forms of injective graph morphisms. In particular, typed attributed graphs constitute an \(\mathscr {M}\)-adhesive category (where the class \(\mathscr {M}\) consists of injective morphisms where the attribute part is an isomorphism).
The definition of element mutation operators (i.e., rules) can easily be lifted to this more general setting: An element mutation operator then is a span of \(\mathscr {M}\)-morphisms and a NAC is an \(\mathscr {M}\)-morphism with domain L. The application of such an element mutation operator is defined via the diagram depicted in Fig. 5, requiring that both squares are pushouts. For details and, in particular, a proof that the set-theoretic approach from Definition 4 coincides with the here discussed category-theoretic one, we refer to [26].
Next, we introduce a logic in \(\mathscr {M}\)-adhesive categories that allows to reason about objects as well as about morphisms in it. In the category of graphs, this logic turns out to be expressively equivalent to the ordinary first-order logic on graphs [33]. Nested conditions express properties of morphisms; the definition of nested constraints is based on these and allows to express properties of objects. Constraints and conditions are defined recursively as trees of morphisms. For the definition of constraints, we assume the existence of an initial object \(\emptyset \) in the given category, i.e., of an object \(\emptyset \) such that for every object A of the given category there is a unique morphism \(i_A:\emptyset \rightarrow A\). In the category of graphs, this is just the empty graph.
Definition 15
((Nested) conditions and constraints) Let \(\mathscr {C}\) be an \(\mathscr {M}\)-adhesive category with initial object \(\emptyset \). Given an object P, a (nested) condition over P is defined recursively as follows: true is a condition over P. If \(a:P \rightarrow C\) is a morphism and d is a condition over C, \(\exists \, (a:P \rightarrow C, d)\) is a condition over P again. Moreover, Boolean combinations of conditions over P are conditions over P. A (nested) constraint is a condition over the initial object \(\emptyset \).
Satisfaction. of a nested condition c over P for a morphism \(g:P \rightarrow G\), denoted as \(g \models c\), is defined as follows: Every morphism satisfies true. The morphism g satisfies a condition of the form \(c = \exists \, (a:P \rightarrow C, d)\) if there exists an \(\mathscr {M}\)-morphism \(q:C \hookrightarrow G\) such that \(g = q \circ a\) and \(q \models d\). For Boolean operators, satisfaction is defined as usual. An object G satisfies a constraint c, denoted as \(G \models c\), if the initial morphism to G does so.
Remark 3
When considering typed graphs with inheritance, the definition of satisfaction of a nested condition should be adapted. The category of typed graphs with inheritance is \(\mathscr {M}\)-adhesive with \(\mathscr {M}\) being the class of injective, type-strict morphisms [44]. When simultaneously matches are not required to be type-strict – as is usually the case in applications – evaluating conditions via type-strict morphisms leads to an undesired semantics. Therefore, the semantics of conditions should be defined using the same class of morphisms that is used as matches, e.g., via injective morphisms (that are allowed to be down-typing). Alternatively, instead of interpreting an application condition as a single application condition, one could interpret it as representing all of its flattened versions and check the validity of every flattened version via a type-strict morphism. The same suggestions to deal with the semantics of conditions (i.e., adapting the class of morphisms that defines their semantics to be the class of morphisms that is also used for matches or interpreting a condition as a class of conditions) have been made and formalized for attributed structures [27, 36]. In the following proofs, we will always remark why our result remains true in case one considers typed graphs with inheritance and defines the satisfaction of conditions via injective morphisms (that are allowed to be down-typing).
1.2 A.2 Proofs
We now present the proofs of the statements in the paper. We do so in the more general setting of \(\mathscr {M}\)-adhesive categories. This means, we obtain our results in greater generality as stated in the paper above. In particular, the case of typed attributed graphs is covered by our proofs. For this, we first need to generalize the notion of computation space to arbitrary \(\mathscr {M}\)-adhesive categories.
Definition 16
(Generalized computation space (cf. Definition 1)) Let \(\mathscr {C}\) be any \(\mathscr {M}\)-adhesive category. A computation meta-model in \(\mathscr {C}\) is a pair \( MM = (\subseteq : TG _{\textrm{P}}\hookrightarrow TG , LC )\) where \(\subseteq \) is an \(\mathscr {M}\)-morphism from \( TG _{\textrm{P}}\) to \( TG \), and \( LC \) is a set of nested constraints typed over \( TG \), called language constraints. The set \( PC \subseteq LC \), called problem constraints, is the subset of constraints that can be considered as already typed over \( TG _{\textrm{P}}\). \(( TG _{\textrm{P}}, PC )\) is called problem meta-model. A computation element or computation model \((E, type _E)\) over \( MM \) is an object E together with a morphism \( type _E:E \rightarrow TG \) such that \(E \models LC \). The computation space over \( MM \) is
Given a computation model \((E, type _E)\) over \( MM \), the model \((E_{\textrm{P}}, type _{E_{\textrm{P}}})\) where \( type _{E_{\textrm{P}}}:E_{\textrm{P}}\rightarrow TG _{\textrm{P}}\) and \(\subseteq _E:E_{\textrm{P}}\hookrightarrow E\) are obtained by pulling back \( type _E\) along \(\subseteq \) is the problem model and \(E \setminus E_{\textrm{P}}\) (if defined) is the solution part of \((E, type _E)\) (where initial pushouts [26] can be used to lift the definition of the set-theoretic difference operator \(\setminus \) to the categorical level).
A computation-model morphism, short cm-morphism, m between computation models \((E, type _E)\) and \((F, type _F)\) is a morphism \(m:E \rightarrow F\) such that m is compatible with typing, i.e., \( type _F \circ m = type _E\). A cm-morphism m is problem-invariant if \(m_{\textrm{P}}\), the restriction of m to the problem model of E, is an isomorphism between \(E_{\textrm{P}}\) and \(F_{\textrm{P}}\).
By the above description of pullbacks, since \(\subseteq : TG _{\textrm{P}}\hookrightarrow TG \) is an inclusion, the definition of \(E_{\textrm{P}}\) as \(E \cap type ^{-1}_E( TG _{\textrm{P}})\) and of \( type _{E_{\textrm{P}}}\) via restriction ensures that the typing morphism of a computation model (considered as a pair of morphisms) constitutes a pullback square. In particular, the above definition indeed generalizes the set-theoretic Definition 1. One important observation for the following proof of Proposition 1 is that, therefore, cm-morphisms between computation models constitute pullback squares, as well (compare Fig. 3): Since both typing morphisms are pullbacks, pullback decomposition [26, Fact 2.27] implies that a cm-morphism is a pullback square. This means, all squares depicted in Fig. 3 are pullbacks. Another important observation is that the morphism \(\subseteq _E:E_{\textrm{P}}\hookrightarrow E\) is always an \(\mathscr {M}\)-morphism as it arises by pullback along one.
We first prove that validity of the problem constraints only depends on the problem part of a computation model.
Lemma 2
In any \(\mathscr {M}\)-adhesive category \(\mathscr {C}\), given a computation meta-model \( MM = (\subseteq : TG _{\textrm{P}}\hookrightarrow TG , LC )\) in \(\mathscr {C}\) with a set of problem constraints \( PC \subseteq LC \), a typed object \((E, type _E)\) satisfies the problem constraints from \( PC \) if and only if \((E_P, type _{E_{\textrm{P}}})\) satisfies them.
Proof
We show more generally that the corresponding statement holds for conditions, not only for constraints. For this, let c be a nested condition over a computation model \((X, type _X)\) where c is typed over \( TG _{\textrm{P}}\). In particular, \( type _X\) can be considered to already have codomain \( TG _{\textrm{P}}\). First, it is easy to check that this implies that \(\subseteq _X:X_{\textrm{P}} \hookrightarrow X\) is an isomorphism. Without loss of generality, we assume it to be the identity of X in the following; in particular \(X_{\textrm{P}} = X\). The same holds for any other model occurring in the condition c.
This implies that, for every model \((E, type _E)\), there is a one-to-one correspondence between cm-morphisms \(g:X \rightarrow E\) and typed morphisms \(g_{\textrm{P}}:X_{\textrm{P}} \rightarrow E_{\textrm{P}}\) between the problem parts: Given g, \(g_{\textrm{P}}\) is obtained by pulling back g along \(\subseteq _E:E_{\textrm{P}}\rightarrow E\). Given a morphism \(g_{\textrm{P}}:X_{\textrm{P}} \rightarrow E_{\textrm{P}}\), \(g :=\subseteq _E \circ g_{\textrm{P}}:X_{\textrm{P}} \rightarrow E\) defines a cm-morphism from X to E since \(X_{\textrm{P}} = X\) (checking the induced square to constitute a pullback square is routine). We show, via structural induction, for any cm-morphism \(g:X \rightarrow E\) that \(g \models c\) if and only if \(g_{\textrm{P}} \models c\) where \(g_{\textrm{P}}:X_{\textrm{P}} \rightarrow E_{\textrm{P}}\) is the restriction of g to the problem model.
The induction basis is trivial as every morphism satisfies true. In particular, \(g \models \textsf {true}\) if and only if \(g_{\textrm{P}} \models \textsf {true}\).
Assume that the statement holds for conditions \(d_1,d_2,d\). For the induction step, first let \(c :=d_1 \wedge d_2\). Then
Similarly, for \(c :=\lnot d\)
Finally, for \(c :=\exists (a:X \rightarrow Y, d)\)
where the second equivalence holds by the above explained correspondence of morphisms and the third by monotonicity of \(\subseteq _E\) and the induction hypothesis. \(\square \)
Proof of Lemma 1
Just instantiate Lemma 2 to typed graphs noting that graph inclusions are \(\mathscr {M}\)-morphisms. \(\square \)
Remark 4
The central ingredient for the proof of Lemma 2 is the one-to-one correspondence between cm-morphisms and morphisms starting at the problem part (as used in the last induction step). While in the context of a type graph with inheritance this cannot any longer be argued for in the same way, the statement is still true as long as no solution element inherits from a problem element. Therefore, the lemma also holds for typed graphs with inheritance under the assumption of separate inheritance hierarchies for problem and solution elements.
Definition 17
(Generalized element mutation operator. Generalized element mutation (cf. Definition 4)) Given a computation space \(\textit{CS}\) over a meta-model \( MM = (\subseteq : TG _{\textrm{P}}\hookrightarrow TG , LC )\), a generalized element mutation operator \( mo \) is defined by \( mo = (L {\mathop {\hookleftarrow }\limits ^{ le }} I {\mathop {\hookrightarrow }\limits ^{ ri }} R, ac )\), where L, I, and R are objects typed over \( TG \), \( le \) and \( ri \) are \(\mathscr {M}\)-morphisms, and \( ac \) is a (nested) condition over L.
A generalized element mutation \(E \Longrightarrow _{ mo } F\) using \( mo \) at match m is defined as in the diagram of Fig. 5 such that both squares are pushouts and m satisfies \( ac \).
A sequence \(E = E_0 \Longrightarrow _{mo_1} E_1 \Longrightarrow _{mo_2} \ldots E_n = F\) of generalized element mutations (where mutation operators \(mo_i\) and \(mo_j\) are allowed to coincide for \(1 \le i \ne j \le n\)) is denoted by \(E \Longrightarrow ^*_{M} F\), where M is a set containing all generalized mutation operators that occur. For \(n = 0\), we have \(E = F\).
Instead of proving Proposition 1 as stated in the paper, we present a more precise statement in the general setting of \(\mathscr {M}\)-adhesive categories below.

Mutation of solution model E to solution model F explicitly showing the problem model
Proposition 2
Let \(\mathscr {C}\) be an \(\mathscr {M}\)-adhesive category and \( MM \) a computation meta-model in \(\mathscr {C}\). Let \( mo = (L {\mathop {\hookleftarrow }\limits ^{ le }} I {\mathop {\hookrightarrow }\limits ^{ ri }} R, ac )\) be a generalized element mutation operator, and let \(E, F \in \textit{CS}\) be computation models such that there is a generalized element mutation \(E \Longrightarrow _{ mo } F\) (compare Fig. 15). Then the morphisms \( le ^{\prime }\) and \( ri ^{\prime }\) in Fig. 15 are cm-morphisms, and the operator \( mo \) is problem-invariant if the morphisms \( le \) and \( ri \) defining the operator \( mo \) are problem-invariant.
Proof
We have to show that (i) \( le ^{\prime }\) and \( ri ^{\prime }\) are cm-morphisms and (ii) the stated equivalence. To prove both (i) and (ii) compare Fig. 15: The front of the diagram is basically the same as in Fig. 5; we just omit the application condition as we already assume the rule to be applicable at match m. The typing morphisms to \( TG \) are added; the ones for L, I, R are given by composition. The typing morphism \( type _C\) is obtained by composition of \( le ^{\prime }\) with \( type _E\); \( type _F:F \rightarrow TG \) is obtained by the universal property of F as a pushout object (using \( type _C\) and \( type _R\) as comparison morphisms). The back of Fig. 15 is then induced by pulling back the front diagram along \(\subseteq : TG _{\textrm{P}}\hookrightarrow TG \). In particular, this makes both the squares \((C_{\textrm{P}},E_{\textrm{P}},C,E)\) and \((C_{\textrm{P}},C,F_{\textrm{P}},F)\) to pullback squares. This shows \( le ^{\prime }\) and \( ri ^{\prime }\) to be typed morphisms, i.e., (i) holds.
Concerning (ii), if we show both squares in the back to be pushouts as well as pullbacks, this implies (ii): Both pushouts and pullbacks of isomorphisms result in isomorphisms again. For this, observe that both front squares are pushouts by assumption. Moreover, since cm-morphisms constitute pullback squares, the further squares (except for the two in the back) are pullbacks. This implies, by the weak vertical van Kampen property of the front squares, that the squares in the back are pushouts as well. Furthermore, because the top squares are pullbacks, \( le , ri \in \mathscr {M}\) implies that also \( le _{\textrm{P}}, ri _{\textrm{P}} \in \mathscr {M}\). Therefore, as pushouts along \(\mathscr {M}\)-morphisms in an \(\mathscr {M}\)-adhesive category, the squares in the back are also pullbacks. Summarizing, \( le _{\textrm{P}}\) and \( ri _{\textrm{P}}\) are isomorphisms if and only if \( le ^{\prime }_{\textrm{P}}\) and \( ri ^{\prime }_{\textrm{P}}\) are isomorphisms. \(\square \)
Proof of Proposition1
Again, proving Proposition 1 just amounts to instantiating Proposition 2 to the category of typed graphs noting that the inclusion of graphs is an \(\mathscr {M}\)-morphism. Also, every negative application condition is a nested condition. \(\square \)
Remark 5
The short category-theoretical proof we gave for Proposition 2 does not carry over to the setting of a type graph with inheritance. The reason is that cm-morphisms between typed graphs with inheritance do not constitute pullback squares anymore (compare the discussion before Lemma 2). But the claim of Proposition 2 can still be proved elementary in that setting by excluding every way in which it would be possible for a rule (defined via problem-invariant morphisms) to alter the problem model. To exclude the deletion of problem elements, however, it is necessary to assume that problem elements cannot inherit from solution elements. Otherwise, a rule could specify the deletion of a solution element but be applied to a problem element (via down-typing).
B Evaluation: Details of optimization problems SCRUM and NRP
In the following, we first present the meta-models of both optimization problems SCRUM and NRP. Thereafter, we present the language constraints for SCRUM and present the change operators, first for SCRUM and then for NRP. Figures 18 and 19 show the element mutation operators used in both use cases. Explanations of the operators can be found in Sec. 7.3. We will then argue how the proposed operators preserve the language constraints of their respective use case and discuss their soundness and completeness. An argumentation for the preservation of language constraints shared by all use cases can be found in Sec. 7.3.
Metamodels. Figures 16 and 17 show the meta-models of the SCRUM and NRP use cases. In the SCRUM case, the type Sprint (along with its incoming and outgoing edges) and the attribute currentSprints are part of the solution. All other elements are part of the problem meta-model. Similarly, the solution part of the NRP case comprises only the edge between Solution and SoftwareArtifact as well as the attribute totalCosts.

Meta-model of the SCRUM use case

Meta-model of the NRP use case

The set of element mutation operators used for the SCRUM case. The algorithm variants to which an operator belongs are given in parenthesis

The set of element mutation operators used for the NRP case. The algorithm variants to which an operator belongs are given in parenthesis
Preservation of language constraints in the SCRUM case. In addition to the EMF-specific language constraints common to all use cases (with Plan being the root node), we consider the following language constraints specific to the SCRUM case: The attributes minSprints and maxSprints require several problem constraints. Their values must be between zero to the number of work items, and minSprints must be less than (or equal to) maxSprints. Since the edges of the solution part are unbound, only problem constraints arise from the multiplicities of the meta-model (we will not enumerate all of them here). To save computation time, the current number of sprints is recorded in the attribute currentSprints. A language constraint requires that this attribute always reflects the correct number of sprints currently available.
All element mutation operators, including those belonging to the set UC, preserve the validity of these language constraints. With respect to the correct value of currentSprints, we see that every operator that creates or deletes a Sprint increments or decrements currentSprints accordingly; the other operators do not change its value. Since all other constraints are problem constraints, Proposition 1 and Lemma 1 ensure their preservation.
Soundness for SCRUM case. In the SCRUM case, there are four feasibility constraints. First, two structural constraints require that each WorkItem is assigned to exactly one Sprint (this is a lower and an upper bound). Furthermore, it is required that the total number of sprints is between a minimum and a maximum value; this is expressed as an attribute constraint via a counter. The structural constraints of the SCRUM case have exactly the same structure as the feasibility constraints of the CRA case, where it is required that each feature is assigned to exactly one class. Moreover, each rule of the SCRUM case that belongs to the set SC and/or SIC structurally corresponds to such a rule in the CRA case (namely, addUnassignedWorkItemToNewSprintRespectingMax to addUnassignedFeatureToNewClass, deleteEmptySprintRespectingMin to deleteEmptyClass, moveWorkItemToNewSprintRespectingMax to moveFeatureToNewClass, addUnassignedWorkItemToExSprint to addUnassignedFeatureToExClass, and moveWorkItemToExSprint to moveFeatureToExClass). Since the rules for the CRA case are sound, the rules for the SCRUM case are also sound with regard to the structural constraints.
With respect to the attribute constraints, it is sufficient to note that each rule in the sets SC and SIC that creates or deletes a sprint has an application condition that ensures that the number of sprints does not exceed the maximum and does not fall below the minimum. Therefore, these rules also cannot transform a model with a correct number of sprints to one with a number that violates the minimum or maximum number of sprints allowed. Overall, the rules for the SCRUM case that belong to the sets SC and/or SIC are sound with respect to all constraints.
In the case of UC, it is obvious that there are rules that can create computation models with too few or too many sprints, even if they start from feasible solutions. Hence, the set is unsound.
Completeness for SCRUM case. In the SCRUM use case, completeness can be argued for almost in the same way as in the CRA case. We just need to additionally consider the given minimum and maximum number of sprints. First, for any instance, we can use the rules addUnassignedWorkItemToNewSprintRespectingMax (or addUnassignedWorkItemToNewSprint in case of UC), moveWorkItemToNewSprintRespectingMax (or moveWorkItemToNewSprint in case of UC), moveWorkItemToExSprint, and deleteEmptySprintRespectingMin (or deleteEmptySprint in case of UC) to transform any computation model (feasible or not) into the model that contains the minimal number of sprints and in which all WorkItems are assigned to the same Sprint. Using the rules moveWorkItemToNewSprintRespectingMax (or moveWorkItemToNewSprint in case of UC) and moveWorkItemToExSprint, this model can then be transformed into any feasible model. Therefore, both sets SC and UC are complete.
In case of SIC, there is no rule to delete a sprint. Therefore, no instance can be transformed into an instance with fewer sprints, making the rule set incomplete.
Preservation of language constraints in the NRP case. In addition to the EMF-specific language constraints common to all use cases (with NRP being the root node), we consider the following language constraints specific to the NRP case: Neither the dependency hierarchies of requirements nor of software artifacts may contain cycles. Furthermore, the attributes value, amount, percentage, and importance must be greater than zero. All of these requirements are problem constraints. Again, only problem constraints arise from the multiplicities of the meta-model. To save computations, similar to the SCRUM case, the attribute totalCosts is used to capture the sum of the costs of all selected software artifacts. A language constraint must guarantee the correctness of its value.
All element mutation operators, including those belonging to the set UC, preserve the validity of these language constraints. With respect to the correct value of totalCosts, all operators (de-)select a SoftwareArtifact, but also recompute totalCosts accordingly. Finally, Proposition 1 and Lemma 1 again guarantee that all problem constraints are preserved.
Soundness for NRP case. In the NRP case, we consider two feasibility constraints. A structural constraint states that a solution that contains a SoftwareArtifact also contains all SoftwareArtifacts that this SoftwareArtifact (transitively) requires. An additional attribute constraint expresses that the total cost of a feasible solution does not exceed the budget. Since the depth of a requires-hierarchy can be arbitrary, the structural constraint is not first-order in this case. Therefore, we cannot use the tool OCL2AC and instead perform a manual analysis.
Let us assume that a feasible solution for the NRP case is given (for any problem instance). This means that for each selected SoftwareArtifact, all (transitively) required SoftwareArtifacts are also selected. The rules from SC and SIC that deselect SoftwareArtifacts (removeArtifactRespectingHierarchy resp. removeArtifactRespectingHierarchyAndDependents) both have a NAC that ensures that the rule is only applicable if no other selected SoftwareArtifacts require the one to be deleted. Therefore, only “leafs” of the requires-hierarchy can be deleted, resulting in offspring that again satisfies the constraint. For the rule that selects new SoftwareArtifacts (addArtifactRespectingHierarchyAndBudget), the first application condition (annotated with forbid#1) prohibits the SoftwareArtifact to be selected to require another SoftwareArtifact that is not already selected. (Note that the second part of this application condition has no counterpart in the visual representation of the rule in Fig. 19a. However, it is present in the programmed rule.) This means that only SoftwareArtifacts that do not require other SoftwareArtifacts or for which all directly required SoftwareArtifacts are already selected can be selected. However, for feasible solutions, all SoftwareArtifacts required by them are also already selected (by feasibility), which means that the overall result of applying addArtifactRespectingHierarchyAndBudget to a feasible solution yields a solution where the structural constraints are satisfied.
With regard to the attribute constraint, addArtifactRespectingHierarchyAndBudget prohibits the selection of a SoftwareArtifact that would result in a budget overrun. In summary, both sets SC and SIC are sound.
In addition, the set UC is obviously unsound. Both addRandomArtifact and removeRandomArtifact can destroy an intact requires-hierarchy of the selected artifacts. Moreover, addRandomArtifact may lead to budget violations.
Completeness for NRP case. Both sets SC and UC are complete. First, with rule removeArtifactRespectingHierarchy resp. removeRandomArtifact, each computation model can be transformed to the instance where no SoftwareArtifact is selected at all. In the first case, this must be done from top to bottom along the requires-hierarchy; in the second case, the order can be arbitrary. Subsequently, the rule addArtifactRespectingHierarchyAndBudget resp. addRandomArtifact can be used to create any feasible instance by selecting the appropriate SoftwareArtifacts. Again, in the first case this must be done in a definite order, here from bottom to top, while in the second case, the order can be arbitrary.
With respect to the set SIC, it is not possible to deselect a SoftwareArtifact from an instance if it is required by at least three other SoftwareArtifacts (cf. the NAC annotated with forbid#2 in rule removeArtifactRespectingHierarchyAndDependents). In general, therefore, an instance in which such a SoftwareArtifact is selected cannot be transformed to every feasible solution using this rule set.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
John, S., Kosiol, J., Lambers, L. et al. A graph-based framework for model-driven optimization facilitating impact analysis of mutation operator properties. Softw Syst Model 22, 1281–1318 (2023). https://doi.org/10.1007/s10270-022-01078-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10270-022-01078-x