
Abstract
When attempting to solve a problem, humans call upon cognitive resources. These resources are limited, and the degree of their utilisation is described as cognitive load. While the number of parameters to be taken into account and to be processed by modern-day knowledge workers increases, their cognitive resources do not. Research shows that too high a load can increase stress and failure rates and decrease the work satisfaction and performance of employees. It is thus in the interest of organisations to reduce the cognitive load of their employees and keep it at a moderate level. One way to achieve this may be the application of virtual assistants (VAs), software programs, that can be addressed via voice or text commands and respond to the users’ input. This study uses a laboratory experiment with N = 91 participants comparing two groups in their ability to solve a task. One group was able to make use of a VA while the other could not. Besides task performance, the cognitive load of the participants was measured. Results show that (a) cognitive load is negatively related to task performance, (b) the group using the VA performed better at the task and (c) the group using the VA had a lower cognitive load. These findings show that VAs are a viable way to support employees and can increase their performance. It adds to the growing field of IS research on VAs by expanding the field for the concept of cognitive load.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
1 Introduction
The working memory plays an important role in learning and processing of information. As its capacity is limited so is the amount of information that can be processed at the same time. The amount of working memory used during this processing is called cognitive load (Sweller 1988). The concept of cognitive load originates in behavioural psychology and the realm of learning but has since been transferred to research on other disciplines, amongst others to Information Systems (IS) (e.g. Hu et al. 2017). Studies have also transferred the concept to the working context and could, for example, show that work-related well-being was decreased when the cognitive load was too high (Pace et al. 2019). Even more severely, findings also indicate that task performance of employees seem to suffer under too high a load (Altaf and Awan 2011). Taken together with the digitalisation that takes place in almost all industries and poses challenges to both employers and employees who need to adapt to new and complex processes (Matt et al. 2015) it is increasingly important to control the cognitive load experienced by employees in order to ensure their well-being and in turn the performance of the employer.
However, the digitalisation does not only pose challenges but also offers opportunities to reduce the workload, for example in the form of virtual assistants (VAs). These computer-based support systems are projected to be used by at least a quarter of digital workers within the next two years (Maedche et al. 2019). It follows that research has looked at the application of this technology in the working context from several angles, e.g. its potential for support in customer service (Cui et al. 2017) or internal communication (Stöckli et al. 2018). Furthermore, introducing VAs in organisations aims at reducing the workload of employees by assisting in the execution of work-related tasks (Norman 2017). Research on whether support through computer-based systems may be able to reduce the workload yields ambiguous results (Moreno et al. 2001). On the one hand, studies show that learning is promoted (e.g. Moreno et al. 2001; Schmuntzsch et al. 2012) and superior results are achievable (Mechling et al. 2010). On the other hand, the learning process is not always facilitated (Schnotz and Rasch 2005) and work performances can be impacted negatively (Chandler and Sweller 1991). However, to our knowledge, the potential of VAs to reduce cognitive load, or the question whether they even interfere when performing tasks, has not yet been addressed sufficiently. If these systems are actually to become widely-used within a few years and they furthermore hold the potential to reduce the workload, they could be a feasible way to relieve employees, thus supporting their well-being and performance, and they could therefore be of great value to enterprises. However, to make informed assumptions on this topic, more research is needed as it is currently inconclusive, which is why more clarification is necessary. The aim of this paper is thus to shed light on these aspects, especially on the ambiguity regarding the in- or decrease in cognitive load through technology and thus to answer the following questions:
RQ1
To what extent do virtual assistants influence the perceived workload during the solution of a task?
RQ2
How do participants supported by virtual assistants compare to those without support regarding their performance at a task?.
To address this shortcoming, we conducted an experiment with N = 91 participants in two groups that had to solve a work-related task and where one group was supported by a VA. We then measured and compared the cognitive load of the participants in the two groups and their actual task performance. The paper presents the findings and aims to shed light on the potential of VAs to positively influence the cognitive load of their users. It first presents current literature on cognitive load and VAs before detailing the chosen methodological approach. Afterwards the results are described and discussed, followed by the conclusion as to what extent VAs are feasible to influence the cognitive load of employees.
2 Theoretical background
2.1 Cognitive load
Cognitive load theory explains how factors such as task difficulty and people’s available mental resources influence their success in learning to solve problems effectively (Sweller 1988). It originates in educational psychology. An underlying assumption is that a learner has limited cognitive capacity that he or she can make use of when attempting to solve a problem. Effective learning takes place when the learner develops the ability to recognise that the task belongs to a category of problems, and knows which steps are normally required to solve such problems. This process is referred to as schema acquisition (Sweller 1988). It can only take place when enough cognitive capacity is available for categorising and systematising knowledge (germane cognitive load). If it is taken up by the task’s inherent cognitive load demands (intrinsic load) and by additional cognitive load that is unnecessarily imposed, for example, by poor instructional design (extraneous cognitive load), then learning cannot take place (Paas et al. 2003). This implies that, counterintuitively, if all of one’s cognitive capacity is devoted to achieving a specific goal set by the instructor, learning can actually suffer, and a goal-free approach might be better (Sweller 1988). The psychological resistance to stress or difficult situations, known as resilience (Neyer and Asendorpf 2017), might further impact the cognitive load in addition to task difficulty and people’s available mental resources. The term resilience is defined as “positive psychological capacity to rebound, to ‘bounce back’ from adversity, uncertainty, conflict, failure or even positive change, progress and increased responsibility” (Luthans 2002). Resilience is related to satisfaction or commitment of employees at the workplace (Youssef and Luthans 2007) and changes when known behaviour and common procedures vary. Cognitive load theory has obvious implications for instructional design. An overloaded or underloaded learner will acquire problem-solving skills less effectively. An appropriate instructional procedure should therefore encourage learners to use their cognitive resources in a way that furthers learning, while at the same time avoid demanding cognitive resources unnecessarily.
Cognitive load theory also has implications for management. In an organisational setting, the concept of learning how to solve a problem by attempting to solve it is commonplace, if not as a result of deliberate instructional design, then as a practical consequence of business demands. In an age of frequent technological and organisational change, Galy et al. (2012) argue, managing workload is an important part of ensuring employees’ wellbeing and safety. Exorbitant cognitive load can have negative implications on business decisions: for example, managers under high cognitive load may face difficulties in evaluating job candidates appropriately (Nordstrom et al. 1996).
2.2 Virtual assistants in organisations
The deployment of virtual assistants in organisations seems reasonable for managing employees’ workload, facilitating tasks and improving business decisions. Various synonyms for VAs exist which are used interchangeably (Luger and Sellen 2016). Terms that can be found in research and practice are, for example, voice assistants (Diao et al. 2014; Alepis and Patsakis 2017; Hoy 2018), personal assistants (Moorthy and Vu 2015; Sangyeal and Heetae 2018), cognitive assistants (Siddike and Kohda 2018; Siddike et al. 2018) or conversational agents (Saffarizadeh et al. 2017). Similar to the variety of words, there is no consensus on a precise definition. Researchers and practitioners explain VAs from different perspectives such as their primary mode of communication or their main purpose (Gnewuch et al. 2017) as well as by their tasks and system characteristics (Strohmann et al. 2018). The explicit classification of VAs in one of these categories is simply not possible due to overlaps. Text-based VAs might use speech-to-text modules to convert human language into text (Gnewuch et al. 2017). VAs might also be further developed and customised to adapt features to individual needs or specific tasks (Chung et al. 2017). However, VAs can generally be described as systems interacting with users by simulating the behaviour of human beings and using natural language (Luger and Sellen 2016; McTear et al. 2016; Diederich et al. 2019) to assist in the execution of work-related tasks or even have them fulfilled entirely (Norman 2017). In the current context, the definition used by Stieglitz et al. (2018) to define the term VA seems to fit best for our purpose: “software programs that can be addressed via voice or text and that can respond to the user’s input (i.e. assist) with sought-after information” (p. 3).
Research has recently gained an interest in the interaction with VAs (Gnewuch et al. 2017) since building systems with the help of artificial intelligence and machine learning algorithms has become more practical to assist users in a wide variety of tasks (Knijnenburg and Willemsen 2016). VAs are particularly helpful in tackling repetitive tasks that require the fast retrieval and processing of digital data as well as the understanding of complex interdependencies (Dellermann et al. 2019). By tailoring systems to the users’ needs, better assistance and added value can be generated (Maedche et al. 2016). Due to the fact that numerous benefits are generated, especially regarding competitive advantage, organisations are heavily investing in VAs (Schuetzler et al. 2018). Applied in organisations, for example in banking, insurance or retail, VAs aim at the prospect of generating additional revenue or cost savings (Quarteroni 2018) and positively influencing the customer’s satisfaction (Verhagen et al. 2014). VAs can be used for the direct interaction with customers. When assisting while shopping online, VAs provide advice to find suitable products and thus reduce information overload (Benbasat and Wang 2005; Qiu and Benbasat 2009). Moreover, users are supported when having inquiries regarding the company’s services (Quarteroni 2018). In addition, VAs also have the potential to enhance processes within organisations. Systems are utilised in human resource departments to facilitate the onboarding process of new employees by providing a question-and-answer assistant (Shamekhi et al. 2018). Further, VAs are applied in customer service (e.g. (e.g. Gnewuch et al. 2017; Hu et al. 2018) to reduce the workload of call centre agents. By supporting the handling of customer enquiries with VAs (McTear et al. 2016), a solution for users can be proposed immediately (Frick et al. 2019) as requests can be handled without additional overhead (Stieglitz et al. 2018).
2.3 Virtual assistants and cognitive load
Research has already taken several attempts to validate if the cognitive load can be reduced through the deployment of various technologies. Moreno et al. (2001) showed that students interacting with an animated pedagogical agent via natural language outperform students not using an agent when learning. Another study could show that VAs, embodied by an animated character, help to focus on relevant information and facilitate learning thus supporting users performing physical tasks (Schmuntzsch et al. 2012). However, a VA could also interfere with successful learning. Interacting with it requires the participant to exert cognitive resources. Cognitive load theory has long recognised that this additional, extraneous cognitive load may eliminate the benefit from the additional instruction (Tarmizi and Sweller 1988). Seemingly useful material can negatively impact performance if it is not essential to solving the task (Chandler and Sweller 1991). Schnotz and Rasch (2005) found that facilitating learning is not always beneficial as users are prevented from performing relevant cognitive processes on their own. Lohse et al. (2014) examined robot gestures and report that a higher human–robot interaction increases user performance and decreased cognitive load for difficult tasks but not for easy tasks. Regarding virtual agents, Moreno et al. (2001) make a similar argument, and refer to the constructivist hypothesis (that agents help learning) and the interference hypothesis (that they hinder it).
The application of VAs in organisations seems beneficial to facilitate internal processes and to gain competitive advantage in that it supports workers in better completing their tasks (Morana et al. 2017). As studies indicate that increased cognitive load at the workplace hinders employees from reaching their full potential (Altaf and Awan 2011), it should be in the interest of organisations to keep this load at a moderate level. The utilisation of VAs aims at doing exactly that: reducing the cognitive load when enhancing humans in work-related tasks for further performance improvements. This might create significant benefits for the applying organisation itself and further for its customers. Studies have already shown that, under certain circumstances, cognitive load can be reduced through the use of technology, increasing the user performance. For example, Mechling et al. (2010) could show that groups instructed by a digital assistant showed better results than groups without that support. Likewise, cognitive load might be enlarged when dealing with additional instructions or different tasks. Until now there has not yet been any research giving evidence if VAs are able to reduce the cognitive load or if they even interfere when performing tasks. To test this, we conducted an experiment with two groups which had to solve a task and where the experimental group could use a virtual assistant to solve the task while the control group could not. In the following section we will describe the structure of the experiment, the task that was to be solved as well as the measures that were collected.
3 Method
3.1 Participants
The experiment was conducted at a German University between 28 May and 18 June 2019. The university’s students were invited to participate on a voluntary basis. In this timespan, 91 people participated in the study. We then randomly assigned the participants into two groups, resulting in a well-balanced sample of 46 participants in the control group without a virtual assistant and 45 in the experimental group using a virtual assistant. Overall, 54.9% of the participants were female (N = 50), and their age ranged from 18 to 31 (M = 22.01, SD = 3.02), indicating a rather young sample. Furthermore, 80% of the participants had passed their A-levels while 14% held a Bachelor's degree. Together with the young age and in accordance with the mode of acquisition of the sample this shows a typical undergraduate student sample.
3.2 Materials
3.2.1 NASA task load index (NASA-TLX)
Concepts related to cognitive load are frequently measured using self-report rating scales (Paas et al. 2003). This approach assumes that learners are able to report the amount of mental effort that they experienced while attempting to solve a task. It is worth noting that self-report rating scales do not typically distinguish between the three types of cognitive load (intrinsic, extraneous, germane) but rather measure the overall load experienced.
A commonly used scale to quantify the perceived workload of a participant is the NASA Task Load Index (Galy et al. 2012). The National Aeronautics and Space Administration (NASA) developed the NASA-TLX in order to measure the perceived workload of a task (Hart and Staveland 1988). This measurement was successfully used in several contexts such as in both laboratory and field studies (Rubio et al. 2004; Noyes and Bruneau 2007; Cao et al. 2009). The index itself contains six subjective subscales forming the NASA-TLX score: (1) Mental Demand, (2) Physical Demand, (3) Temporal Demand, (4) Performance, (5) Effort, and (6) Frustration. These clusters of variables were chosen to cover the “range of opinions and apply the same label to very different aspects of their experience” (Hart 2006, p. 904). Due to the subjective experience of conducting a specific task, the NASA-TLX was developed to consider the perception of a variety of activities such as simple laboratory task or flying an aircraft. While (1) describes how much mental and perceptual activity was required, (2) shows the perceived amount of required physical activity. Besides the perceived mental and physical efforts, the NASA-TLX also covers the perception of time pressure (3) during a task. Furthermore, the subscales (4) to (6) ask about the perception of the results of the given tasks. Therefore, (4) describes the personal performance perception – i. e. the perceived success reaching the given goals of the tasks and (5) asks to what extent the participants had to work to reach the achieved level of performance. As people sometimes feel frustrated when a given task is perceived as too difficult, subscale (6) asks the participants about the level of frustration during the task (Hart 2006). In our experiment, all subscales had high reliability (Cronbach’s α = 0.89).
3.2.2 Resilience scale (RS-11)
According to the appraisal theory, stress emerges when a task at hand exceeds one’s own resources and abilities (Smith et al. 2011). Following, an increasing level of stress might impact the participant’s task performance as well as the perception of the work and its outcome. In order to avoid undetected distortion towards the task performance, we consider the psychological resistance to stress or difficult situations, known as resilience (Neyer and Asendorpf 2017). We use the Resilience Scale (RS-11) as a short scale for assessing the resilience of a human (Schumacher et al. 2005). The RS-11 is a self-report scale containing eleven items which are divided into two sub-scales: (1) personal competence and (2) acceptance of the self and life. The subscales had a high reliability, all Cronbach’s α = 0.90.
3.2.3 Virtual assistant
In order to investigate the impact of a text-based VA on decreasing the cognitive load during task-solving, we made use of Google’s cloud platform DialogFlow.Footnote 1 This platform is widely used for developing natural and rich conversational experiences based on Google’s machine learning (Canonico and De Russis 2018). Furthermore, the implementation is based on four general concepts (Muñoz et al. 2018). First, Agents transform natural user language into actionable data when a user input matches one of the intents. Second, Intents represent a mapping between what the user says and what action is taken. Third, Entities represent concepts and serve as a tool for extracting parameter values from natural language inputs. Finally, Contexts are designed for passing on information from previous conversations or external sources. To reduce the degree of complexity caused by the interaction with the VA, we focused on establishing a disembodied VA with a messaging-based interface (Araujo 2018).
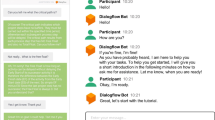
As VAs exhibit social and conversational dialogue (Hung et al. 2009), our VA is implemented to make a simple conversation at the beginning of the interaction. Participants can interact with the VA via a web-based interface, similar to contemporary instant messengers such as Telegram or WhatsApp, using a keyboard and a computer screen. This interaction could be a request for the participant’s name and feelings. Furthermore, the applied VA is text-based to avoid additional influential factors which may evolve by voice interactions or embodied avatars. Figure 1 shows a translated example of a dialogue with the VA.

Example of a dialogue with the Virtual Assistant
To support the participants during the task, the assistant simulates intelligence by selecting a prefabricated answer based on distinct keywords used in the participant’s input. We defined 25 Intents to match the user input. The intents belonged into roughly 3 groups: Introduction, Tutorial and Task Support. The Intents in the Introduction Group mostly revolved around welcoming the users, asking for their well-being and readiness to start the task. The tutorial intents were designed to increase the users’ familiarity with the VA and the capabilities of the VA. Most of the intents revolved around Task support where users could ask for help solving the task, for example by asking what certain parameters meant or how they were calculated. We also used the standard „sys.given-name “ entity provided by DialogFlow as an Entity. The VA’s feedback includes a question-answering component (Morrissey and Kirakowski 2013; Lamontagne et al. 2014) that can be queried by the user to gain information, support and instruction about the specific task. In this context, the VA only provides helpful hints which support the participants solving the task. However, the VA does not deliver the actual solution to the current task.
3.2.4 Task performance and pre-study
Task performance was measured with a score ranging from 0 to 28 that captures how well participants did at a critical path method (CPM) task. A higher value represents a better performance in the execution of the task. The goal of this task was to use this method to plan a research project for the market research unit of a large organisation.
The task was determined in a pre-study to ensure that it is sophisticated and involves a potentially high perceived workload in the experiment. The sample of 10 participants (6 female, 4 male) consists of randomly selected students at the University. In this context, a good fitting task challenges the participants on decent level, and therefore causes an increased cognitive load score. A task which overwhelms the participants may prevent sustained learning effects due to less available cognitive resources (Paas et al. 2003). To this end, a text-based task (TBT) and CPM were compared. On the one hand, the TBT required the participants to read three texts about medieval ages, a topic which does not rely on previous knowledge of the participants. On the other hand, the CPM was implemented with a scenario that puts the participants in a working context. In detail, the participants had to organise a marketing study using the CPM. The time limit for each of the tasks was 10 min.
Each task was given to five participants and the perceived workload was measured by the NASA-TLX. The age ranged from 22 to 31 (M = 25). On average, participants given the CPM task engaged in higher NASA-TLX scores (M = 12.5, SD = 3.85) than the TBT group (M = 6.36, SD = 4.06). This difference of 6.13 was significant (95% CI [0.35, 11.91], t(8) = 2.44, p = 0.040. Furthermore, it represents a large-sized effect, d = 0.98. Following, the CPM task has the potential to increase the cognitive load of the participants in a more effective way than the TBT does. Thus, due to its better potential to benefit from the use of a virtual assistant, the CPM was chosen for the main study.
3.3 Procedure
In order to investigate the influence of a VA on the perceived workload of a participant, the experiment used a between-subjects design. The independent variables were the resilience score (RS-11) and the usage of a VA (group variable) whereas the dependent variables were the perceived workload (NASA-TLX), the task-score as well as the time to finish the task. Analyses were conducted using the software SPSS Statistics (Version 25) and Jamovi (1.0.2.0).
The main study was conducted as a laboratory experiment at a German University in German language. A laboratory experiment was chosen to better control the surroundings, to ensure that the task performance was measured correctly and to ensure a steady and even experience with the virtual assistant. Furthermore, the investigators were present to assist the participants with questions should those arise. However, their assistance was not utilised by any of the subjects.
The participants were welcomed by the investigator and introduced to the study. They were then led to a computer to begin with the first questionnaire. First, the participants were presented with the RS-11 questionnaire to retrieve the resilience score.
Afterwards they were presented with an introduction to the CPM followed by an example. After reading through the briefing, participants were instructed to contact the investigator for the material needed. The goal was to use the CPM to plan a research project for the market research unit of a big organisation. Participants were given a list with unordered process steps (such as "literature research", "conducting the study" or "develop methodology"), the respective duration for each step as well as its dependencies on the other steps in the process. They were also handed an empty template for a CPM to fill out with the according parameters. Finally, the participants were informed of a virtual folder they were allowed to use which was located on the laboratory computer and included unordered text files explaining the CPM procedure and the calculation of the individual values.
Additionally, the participants in the experimental group were also presented with a sheet of paper which explained that they were allowed to use a text-based VA and that it was nested in a browser window in the computer. They were then explained how to use the VA properly such as using single sentences and that the VA did not have contextual knowledge. All subjects in the experimental group made use of the VA which provided the participants with the same information available in the folder to all groups but could be specifically asked for certain information, e.g. what certain parameters stood for or how they were calculated. Figure 2 depicts the steps a conversation with the VA consisted of. Except for the availability of the VA, the participants in the control and experimental group were presented the exact same task. Also, all participants had access to the same information for solving the task with the only difference that subjects in the control group could access the data via browsing through virtual folders on the computer whereas subjects in the experimental group could specifically access the information via dialogue with the VA.

Depiction of the interaction with the Virtual Assistant
Participants then had a time limit of 10 min to complete the task after which they had to stop solving the task even when they had not yet completed it. They were also instructed to give notice should they be finished before the time limit had run out. In the latter cases the investigator noted the time that was needed. After the participants either completed the task or the time ran out, they were re-referred to the computer to complete the remainder of the survey.
Following the task, the participants were presented with the NASA-TLX to assess their perceived workload immediately after solving the task. They were then asked whether they had already been familiar with the technique of CPM and the participants in the experimental condition were additionally asked whether they thought the support by VA was helpful.
Finally, all participants were asked for their gender, age, highest educational attainment and were debriefed, asked whether they had any further questions and then thanked for their time.Footnote 2
4 Results
4.1 Descriptive statistics
Overall, 95% of the participants who used the virtual assistant found it helpful and on average had 14 interactions with the chatbot (where one interaction is defined as one user input followed by one chatbot reply), 94.3% of which were matched (i.e. the chatbot was able to match the input with intent). Participants scored between 0 and 28 points in the task, with M = 16.68 (SD = 7.81, Med = 17) indicating that most of the participants achieved more than half of the 28 points possible. 14% reached the maximum score of 28 points. 70% of participants used the full 10 min to complete the task, 3.3% needed less than 5 min. Only 4 participants had already used CPM.
4.2 Relation between perceived workload and task performance
To check whether the perceived workload was connected to the performance of the participants, we conducted a bivariate correlation separate for each group (i.e. with assistant and without assistant). In both groups the NASA-TLX score showed a significant negative correlation with the performance score, indicating a better performance when the cognitive load was lower. The correlation r(46) = -0.673, p < 0.001 in the control-group without an assistant was larger than in the experimental group with the assistant r(45) = -0.462, p < 0.001. To assess whether this difference was meaningful, we calculated the z-scores, which showed that the correlation between NASA-TLX and task-score was not significantly different between the two groups (Z = 1.458, p = 0.072) which indicates that, regardless of the condition the participants were in, a higher cognitive load was connected to worse performance.
4.3 Resilience and perceived workload
A t-test was conducted to investigate possible differences between the groups in the participants’ resilience. To test whether the resilience of the participants influenced their perceived workload, the correlation between the two variables was calculated for each of the groups. To assess whether the strength of a possible relationship differed between the groups, a z-test was used to determine if the two correlations differed significantly.
The t-test for a difference in mean resilience score between the group with the assistant (M = 130, SD = 20.5) and the group without the assistant (M = 128, SD = 14.6) does not indicate a significant difference, t(89) = -0.52, p = 0.602, d = -0.110. In both groups, resilience and cognitive load correlated significantly with r(46) = -0.354 (p = 0.016) in the control group and r(45) = -0.380 (p = 0.010) in the experimental group. The correlation coefficients did not differ significantly between the groups (Z = 0.139, p = 0.445), indicating that the higher the participants’ resilience, the lower the perceived workload – regardless of the group.
4.4 Performance of the groups
To assess whether performance differences between the groups with and without an assistant exist, we calculated an independent t-test with a 95% confidence interval and with the task-score as independent variable and the groups as factor (Table 1). As Levene's Test for Equality of Variances was not significant (p = 0.767), equal variances were assumed. On average, participants who used an assistant performed better (M = 19.76, SD = 7.36) compared to participants in the group without an assistant (M = 13.67, SD = 7.09). This difference was significant t(89) = − 4.01, p < 0.001 and represents a large-sized effect (d = 0.84).
4.5 Difference between cognitive load of the groups
Next, to test whether participants using the assistant differed in their reported perceived workload, we conducted an independent t-test with a 95% confidence interval and with the NASA-TLX-score as independent variable and the groups as factor (Table 2). Levene's Test for Equality of Variances was not significant (p = 0.470). The mean of the group without the assistant was significantly (t(89) = 3.55, p < 0.001) higher (M = 10.28, SD = 4.52) than the mean of the group using an assistant (M = 7.17, SD = 3.79), indicating a higher perceived workload for the group without an assistant. The effect size was large (d = 0.75).
4.6 Time needed by the groups
An independent t-test with the groups as factor and the time needed to complete the task was calculated to check whether one group on average took less time than the other (Table 3). As Levene’s test for equality of variances was significant (p < 0.001), degrees of freedom were adjusted from 89 to 67. The control group without the VA needed significantly more time (M = 586 s, SD = 107) than the group with the assistant (M = 518 s, SD = 107), t(67.35) = 3.74, p < 0.001. d = 0.79 indicated a large effect size.
4.7 Difference in the personal performance perception of the groups
As subscale 4 of the NASA-TLX measured the perception of the participants own performance in completing the task it was used to assess whether this perception differed between the groups. A lower value on this scale indicates a better performance. An independent t-test with a 95% confidence interval was calculated. Levene’s test for equality of variances was significant (p = 0.045), and the degrees of freedom were reduced accordingly (from 89 to 86.74). The groups differed significantly (t(86.74) = 2.32, p = 0.023) with the participants in the control group without the VA having a higher mean (M = 10.1, SD = 6.86) than the participants in the experimental condition (M = 7.00, SD = 5.70) indicating that the former believed they did a worse job at completing the given task than the group using a VA believed of themselves (Table 4). The effect size was moderate (d = 0.486).
5 Discussion
5.1 Key findings and implications
One question this paper aimed to answer was how VAs influence cognitive load during the solution of a task, as previous literature presented inconclusive findings on this matter (e.g. Lohse et al. 2014). The current findings support the notion that VAs are suitable to decrease said load, indicating that the application of VAs also has an impact on the perceived workload of its users in that it reduces this workload as well. Prior findings were ambiguous, indicating that the application of technology supporting users may also hinder the users because of the additional effort needed to learn interacting with the supporting system (Tarmizi and Sweller 1988). In our study this was not the case, for which there are several possible explanations. VAs may be easy and intuitive to use. As the interaction with the VA applied in our study takes place in text form and natural language akin to a chat with a human, this concept may be familiar with participants, especially regarding the young age of the sample. Thus, there is no additional effort needed to first learn how to use the VA and it can solely help in supporting to reach the goal. Based on this assumption, one takeaway from the study is that a VA which is easy to use and whose usage is not connected to any extra effort is a good way to support people in fulfilling certain tasks. Then again, the VA used in the current study had a very special focus as did the participants while solving the task. It may be that specialised VAs are able to more easily help solve special goals while VAs with a broader skill set may be less effective. However, in practice it is not always feasible to provide several VAs for several tasks. On the one hand, that may drive up costs for an applying organisation; on the other hand, it may also be counterproductive in that it actually would require the users to always have to pick the right VA according to the task at hand but in turn increasing workload as additional mental resources are needed to make that decision. However, this was not the current studies’ scope but needs more elaboration in future studies.
From a learning perspective, the result that the group with virtual assistant perceived a lower mental workload, performed better on the task and also perceived their performance as better means that more resources could be available for germane cognitive load, which fosters schema acquisition and thereby improves learning (Paas et al. 2003). However, this process is not automatic. Depending on the design of the materials, people who are exposed to too little cognitive load could also be less likely to learn permanently how to solve the problem. In other words, the availability of a VA might have helped them perform their tasks better but at the same time made the task too easy for them to be able to later recall how they solved it. This effect could be detrimental to their performance especially if they will not always have the assistant available. Future studies should examine retention, and employers who consider supporting their knowledge workers with VAs should keep this point in mind to avoid an undesirable over-reliance on technology.
The current study furthermore examined the influence VAs could have on task performance. Here, the findings show that the application of VAs had a positive influence on the performance while solving a task. This is in line with findings from previous literature e.g. from the learning domain which reported that students which received support by a system akin to a VA performed better than those who did not have the support (Moreno et al. 2001; Mechling et al. 2010). However, the current study demonstrated this aspect on a domain rather related to the working environment. This finding supports assumptions made by other researches (e.g. Morana et al. 2017) and shows the importance that these systems may have in improving organisational performance (through its employees) which may also lead to a higher satisfaction of the latter. Furthermore, it demonstrates, that VAs are not only beneficial for organisations when applied in contact with its customers (cf. Quarteroni 2018) but also for its own employees. However, as we discuss in the limitations and outlook section, the current study was conducted as a laboratory experiment which means that its external validity (i.e. in a practical context) has to be shown in future studies. Nevertheless, these findings lay the groundwork for further evaluation of VAs in the working context. Aspects such as the applicability over various industries and for various tasks could be examined. Also, the acceptance by the users and the applicability for different tasks or categories of tasks need to be explored.
Connected to the aspects discussed before, the current findings also show that a reduced perceived workload is beneficial in reaching a higher score on task solution. The findings thus show that it is desirable to reduce the workload in order to improve performance. In context of a working environment and regardless of the application of VAs, employers should in general strive to support knowledge workers in eliminating any distraction. Processes in the way to reach a certain goal could be examined regarding unnecessary or outsourceable steps which could then be reduced to a minimum. Especially steps connected to repetitive or overhead (i.e. bureaucratic) activities seem to hold potential to be reduced as especially the latter have been found to be negatively related to the perception of work-related well-being (Pace et al. 2019).
One important finding is also that the personal predisposition in the form of resilience plays a role in the amount of perceived workload the participants felt. The higher the resilience of the participants, the lower their perceived workload – regardless of whether they used a VA or not. This means that, besides external support, personal predispositions do also play a role in the amount of workload people report. This is an important aspect that should not be overlooked as it indicates that a person can get all the help in the world and still have a high workload which may impede the performance in solving a task. Furthermore, different people may need different amounts of support in solving a task or reaching a goal, which is important to consider when evaluating any performance-related finding in regard to perceived workload. While this aspect is not at the focus of the current paper, it shows that individual predispositions should be taken into account and considered when conducting research and interpreting results on perceived workload and in turn cognitive load.
5.2 Limitations and future research
As with all research, several limitations to the findings apply. Our findings are based on a sample consisting mostly of undergraduate students. Because of their youth and thereby assumed familiarity with communication technology, the experimental group using the VA may have had less trouble operating the VA than an average adult that may be not as affine to modern communication technology. Furthermore, our paper aimed to research cognitive load and task performance in a working context, for which one may argue that students are not as feasible as actual employees with working experience. However, as Kretzer and Maedche put it “students are suitable subjects, and students may also tend to be less biased than experienced professionals due to their general relative youth and lack of work experience.” (2019, p. 1156). Still, future studies may take this aspect into account and aim to replicate the findings on different samples that may be older or have experience in a working environment.
Furthermore, the task chosen in the current context may not completely represent daily work processes as it is rather abstract. Still, with regard to the measurability of the performance outcome, the task chosen in the current paper is, in our eyes, a good compromise as it accomplishes two things: It simulates a task in a working environment (such as a process that needs to be planned in a short time span) and it ensures measurability and applicability in a laboratory research setting, which increases the validity of the results. Nevertheless, future studies may alter the task and, for example, conduct a case study in a real-world setting. Our research thus also adds to the emerging body of work considering the “Operator 4.0” – the worker who relies on increasing automation at the workplace for increased efficiency (Romero et al. 2020). As the technology becomes more capable and people become more familiar with it, this field of research is poised to grow.
Future studies may also deeper examine the relation of personal predispositions and the effect of a heightened perceived workload. In the current paper, resilience showed that it impacted the perceived workload of the participants. First, this connection could be further examined – is this true for other samples or for other tasks? As the resilience was correlated with the perceived workload – which in turn was based on the task to solve it would be interesting to see how this relation holds up if the task is changed, e.g. to be more complex or easier. Furthermore, different predispositions could also be taken into account like the involvement in a certain topic that is investigated with the task, the personality of participants or technological affinity and the likes. This would lead to better insights into what aspects play a role in in- or decreasing perceived workload in individuals.
As the cognitive load theory originates in educational psychology it would also be interesting to conduct time-series analyses. These could show the effect learning has on the task performance. This way, the effectivity of VAs over time may be shown, e.g. to be even greater, as participants get used to working with such systems, possibly reducing cognitive load that is initially needed to adapt to the system. While the aspect of adapting to a VA didn’t seem to play a role in the current study, future studies that alter the task or the VA could help shed light on this aspect. This may be especially interesting to test how the interaction with a VA evolves over its lifespan and to evaluate its long-term value, for example for organisations.
Future studies should also examine whether our findings hold true for alternate VA approaches. For example, in the current study, the response the participants in the experimental group got was instant—i.e. there was no delay between sending a question to the VA and getting feedback (in part due to the realisation via DialogFlow). However, current research indicates that artificial delays in the response time by a VA may lead to a more satisfying experience for the users (Gnewuch et al. 2018). Here, it could be interesting to see how such modulations influence task performance or the perceived workload as in situations where a user is under pressure it may be more beneficial to deliver fast answers.
In summary, there is much research to be done on the effectiveness of virtual assistants. Our study has shown that they are a viable option that is worth exploring. If they can succeed in reducing knowledge workers’ cognitive load in a variety of situations, then they might be able to help make the digitisation of the workplace something to be welcomed, and perhaps even enjoyed, by all.
Notes
The concrete wording as well as the items can be taken from the supplementary material in the electronic version of this article.
References
Alepis E, Patsakis C (2017) Monkey says, monkey does: security and privacy on voice assistants. IEEE Access 5:17841–17851. https://doi.org/10.1109/ACCESS.2017.2747626
Altaf A, Awan MA (2011) Moderating affect of workplace spirituality on the relationship of job overload and job satisfaction. J Bus Ethics 104:93–99. https://doi.org/10.1007/s10551-011-0891-0
Araujo T (2018) Living up to the chatbot hype: The influence of anthropomorphic design cues and communicative agency framing on conversational agent and company perceptions. Comput Human Behav 85:183–189. https://doi.org/10.1016/j.chb.2018.03.051
Benbasat I, Wang W (2005) Trust In and Adoption of Online Recommendation Agents. J Assoc Inf Syst 6:72–101. https://doi.org/10.17705/1jais.00065
Canonico M, De Russis L (2018) A comparison and critique of natural language understanding tools. In: CLOUD COMPUTING 2018: the ninth international conference on cloud computing, GRIDs, and virtualization, pp 110–115
Cao A, Chintamani KK, Pandya AK, Ellis RD (2009) NASA TLX: Software for assessing subjective mental workload. Behav Res Methods 41:113–117. https://doi.org/10.3758/BRM.41.1.113
Chandler P, Sweller J (1991) Cognitive load theory and the format of instruction. Cogn Instr 8:293–332. https://doi.org/10.1207/s1532690xci0804_2
Chung H, Lorga M, Voas J, Lee S (2017) Alexa, can I trust you? IEEE Comput Soc 50:100–104. https://doi.org/10.1109/MC.2017.3571053
Cui L, Huang S, Wei F, Tan C, Duan C, Zhou M (2017) SuperAgent: a customer service chatbot for E-commerce websites. In: Proceedings of ACL 2017, system demonstrations. association for computational linguistics, Vancouver, Canada, pp 97–102
Dellermann D, Ebel P, Söllner M, Leimeister JM (2019) Hybrid Intelligence. Bus Inf Syst Eng 61:637–643. https://doi.org/10.1007/s12599-019-00595-2
Diao W, Liu X, Zhou Z, Zhang K (2014) Your voice assistant is mine: how to abuse speakers to steal information and control your phone. In: Proceedings of the ACM conference on computer and communications security, pp 63–74
Diederich S, Brendel A, M Kolbe L (2019) On conversational agents in information systems research: analyzing the past to guide future work. In: Proceedings of 14th internatioanl conference on Wirtschaftsinformatik, pp 1550–1564
Frick N, Brünker F, Ross B, Stieglitz S (2019) The utilization of artificial intelligence for improving incident management. HMD 56:357–369. https://doi.org/10.1365/s40702-019-00505-w
Galy E, Cariou M, Mélan C (2012) What is the relationship between mental workload factors and cognitive load types? Int J Psychophysiol 83:269–275. https://doi.org/10.1016/j.ijpsycho.2011.09.023
Gnewuch U, Morana S, Adam MTP, Maedche A (2018) Faster is not always better: understanding the effect of dynamic response delays in human-chatbot interaction. In: 26th European conference on information systems
Gnewuch U, Morana S, Maedche A (2017) Towards designing cooperative and social conversational agents for customer service digital nudging view project designing chatbots. In: 38th international conference on information systems
Hart SG (2006) Nasa-Task Load Index (NASA-TLX); 20 years later. In: Proceedings of the human factors and ergonomics society annual meeting, pp 904–908
Hart SG, Staveland LE (1988) Development of NASA-TLX (Task Load Index): results of empirical and theoretical research. Adv Psychol 52:139–183. https://doi.org/10.1016/S0166-4115(08)62386-9
Hoy MB (2018) Alexa, Siri, Cortana, and more: an introduction to voice assistants. Med Ref Serv Q 37:81–88. https://doi.org/10.1080/02763869.2018.1404391
Hu PJ-H, Hu H-F, Fang X (2017) Examining the mediating roles of cognitive load and performance outcomes in user satisfaction with a website: a field quasi-experiment. MIS Q 41:975–987. https://doi.org/10.25300/MISQ/2017/41.3.14
Hu T, Xu A, Liu Z, You Q, Guo Y, Sinha V, Luo J, Akkiraju R (2018) touch your heart: a tone-aware chatbot for customer care on social media. In: Proceedings of the 2018 CHI conference on human factors in computing systems - CHI ’18
Hung V, Elvir M, Gonzalez A, DeMara R (2009) Towards a method for evaluating naturalness in conversational dialog systems. In: 2009 IEEE international conference on systems, man and cybernetics, pp 1236–1241
Knijnenburg B, Willemsen M (2016) Inferring capabilities of intelligent agents from their external traits. ACM Trans Interact Intell Syst 6:1–25. https://doi.org/10.1145/2963106
Kretzer M, Maedche A (2019) Designing social nudges for enterprise recommendation agents: an investigation in the business intelligence systems context. J Assoc Inf Syst 19:1145–1186. https://doi.org/10.17705/1jais.00523
Lamontagne L, Laviolette F, Khoury R, Bergeron-Guyard A (2014) A framework for building adaptive intelligent virtual assistants. In: Artificial intelligence and applications
Lohse M, Rothuis R, Gallego-Pérez J, Karreman DE, Evers V (2014) Robot gestures make difficult tasks easier. In: Proceedings of the SIGCHI conference on human factors in computing systems, pp 1459–1466
Luger E, Sellen A (2016) “Like having a really bad PA”: The gulf between user expectation and experience of conversational agents. In: CHI ’16 Proceedings of the 2016 CHI conference on human factors in computing systems, San Jose, CA, USA, pp 5286–5297
Luthans F (2002) The need for and meaning of positive organizational behavior. J Organ Behav 23:695–706. https://doi.org/10.1002/job.165
Maedche A, Legner C, Benlian A, Berger B, Gimpel H, Hess T, Hinz O, Morana S, Söllner M (2019) AI-based digital assistants. Bus Inf Syst Eng 61:535–544. https://doi.org/10.1007/s12599-019-00600-8
Maedche A, Morana S, Schacht S, Werth D, Krumeich J (2016) Advanced user assistance systems. Bus Inf Syst Eng 58:367–370. https://doi.org/10.1007/s12599-016-0444-2
Matt C, Hess T, Benlian A (2015) Digital transformation strategies. Bus Inf Syst Eng 57:339–343. https://doi.org/10.1007/s12599-015-0401-5
McTear M, Callejas Z, Griol D (2016) The conversational interface: talking to smart devices, 1st edn. Springer, Cham
Mechling LC, Gast DL, Seid NH (2010) Evaluation of a personal digital assistant as a self-prompting device for increasing multi-step task completion by students with moderate intellectual disabilities. Educ Train Autism Dev Disabil 45:422–439
Moorthy AE, Vu KP-L (2015) Privacy concerns for use of voice activated personal assistant in the public space. Int J Hum Comput Interact 31:307–335. https://doi.org/10.1080/10447318.2014.986642
Morana S, Friemel C, Gnewuch U, Maedche A, Pfeiffer J (2017) Interaktion mit smarten Systemen –- Aktueller Stand und zukünftige Entwicklungen im Bereich der Nutzerassistenz. Wirtschaftsinformatik Manag 9:42–51. https://doi.org/10.1007/s35764-017-0101-7
Moreno R, Mayer RE, Spires HA, Lester JC (2001) The case for social agency in computer-based teaching: Do students learn more deeply when they interact with animated pedagogical agents? Cogn Instr 19:177–213. https://doi.org/10.1207/S1532690XCI1902_02
Morrissey K, Kirakowski J (2013) “Realness” in chatbots: establishing quantifiable criteria. In: Kurosu M (ed) 5th international conference on human–computer interaction: interaction modalities and techniques - volume Part IV, pp 87–96
Muñoz S, Araque O, Llamas AF, Iglesias CA (2018) A cognitive agent for mining bugs reports, feature suggestions and sentiment in a mobile application store. In: 2018 4th international conference on Big Data innovations and applications (innovate-data), pp 17–24
Neyer FJ, Asendorpf JB (2017) Psychologie der Persönlichkeit, 6th edn. Springer-Verlag, Berlin Heidelberg
Nordstrom CR, Williams KB, LeBreton JM (1996) The effect of cognitive load on the processing of employment selection information. Basic Appl Soc Psych 18:305–318. https://doi.org/10.1207/s15324834basp1803_4
Norman D (2017) Design, business models, and human-technology teamwork. Res Manag 60:26–30. https://doi.org/10.1080/08956308.2017.1255051
Noyes JM, Bruneau DPJ (2007) A self-analysis of the NASA-TLX workload measure. Ergonomics 50:514–519. https://doi.org/10.1080/00140130701235232
Paas F, Tuovinen JE, Tabbers H, Van Gerven PWM (2003) Cognitive load measurement as a means to advance cognitive load theory. Educ Psychol 38:63–71. https://doi.org/10.1207/S15326985EP3801_8
Pace F, D’Urso G, Zappulla C, Pace U (2019) The relation between workload and personal well-being among university professors. Curr Psychol. https://doi.org/10.1007/s12144-019-00294-x
Qiu L, Benbasat I (2009) Evaluating anthropomorphic product recommendation agents: a social relationship perspective to designing information systems. J Manag Inf Syst 25:145–182. https://doi.org/10.2753/MIS0742-1222250405
Quarteroni S (2018) Natural language processing for industry: ELCA’s experience. Informatik-Spektrum 41:105–112. https://doi.org/10.1007/s00287-018-1094-1
Romero D, Stahre J, Taisch M (2020) The Operator 4.0: towards socially sustainable factories of the future. Comput Ind Eng 139:106128. https://doi.org/10.1016/j.cie.2019.106128
Rubio S, Díaz E, Martín J, Puente JM (2004) Evaluation of Subjective Mental Workload: A Comparison of SWAT, NASA-TLX, and Workload Profile Methods. Appl Psychol 53:61–86. https://doi.org/10.1111/j.1464-0597.2004.00161.x
Saffarizadeh K, Boodraj M, Alashoor TM (2017) Conversational assistants: investigating privacy concerns, trust, and self-disclosure. In: Thirty eighth international conference on information systems, South Korea
Sangyeal H, Heetae Y (2018) Understanding adoption of intelligent personal assistants. Ind Manag Data Syst 118:618–636. https://doi.org/10.1108/IMDS-05-2017-0214
Schmuntzsch U, Sturm C, Reichmuth R, Roetting M (2012) Virtual agent assistance for maintenance tasks in IPS2 - first results of a study. Adv Hum Factors/Ergonom 18:221–231. https://doi.org/10.1201/b12322-27
Schnotz W, Rasch T (2005) Enabling, facilitating, and inhibiting effects of animations in multimedia learning: why reduction of cognitive load can have negative results on learning. Educ Technol Res Dev 53:47–58. https://doi.org/10.1007/BF02504797
Schuetzler RM, Grimes GM, Giboney JS (2018) An Investigation of conversational agent relevance, presence, and engagement. In: Twenty-fourth Americas conference on information systems
Schumacher J, Leppert K, Gunzelmann T, Strauss B, Brahler E (2005) The resilience scale-A questionnaire to assess resilience as a personality characteristic. Zeitschrift für Klin Psychol Psychiatr und Psychother 53
Shamekhi A, Liao QV, Wang D, Bellamy RKE, Erickson T (2018) Face value? Exploring the effects of embodiment for a group facilitation agent. In: 2018 CHI Conference on human factors in computing systems
Siddike A, Kohda Y (2018) Towards a framework of trust determinants in people and cognitive assistants interactions. In: 51st Hawaii international conference on system sciences, pp 5394–5401
Siddike MAK, Spohrer J, Demirkan H, Kohda Y (2018) People’s interactions with cognitive assistants for enhanced performances. In: 51st Hawaii international conference on system sciences, pp 1640–1648
Smith C, Crook N, Dobnik S, Charlton D, Boye J, Pulman S, de la Camara RS, Turunen M, Benyon D, Bradley J, Gambäck B, Hansen P, Mival O, Webb N, Cavazza M (2011) Interaction strategies for an affective conversational agent. Presence Teleoperators Virtual Environ 20:395–411. https://doi.org/10.1162/PRES_a_00063
Stieglitz S, Brachten F, Kissmer T (2018) Defining bots in an enterprise context. In: Thirty ninth international conference on information systems
Stöckli E, Uebernickel F, Brenner W (2018) Exploring affordances of slack integrations and their actualization within enterprises? Towards an Understanding Of How Chatbots Create Value. In: 51th Hawaii international conference on system sciences
Strohmann T, Fischer S, Siemon D, Brachten F, Lattemann C, Robra-Bissantz S, Stieglitz S (2018) Virtual moderation assistance: creating design guidelines for virtual assistants supporting creative workshops. In: 22nd Pacific Asia conference on information systems, pp 3580–3594
Sweller J (1988) Cognitive load during problem solving: effects on learning. Cogn Sci 12:257–285. https://doi.org/10.1016/0364-0213(88)90023-7
Tarmizi RA, Sweller J (1988) Guidance during mathematical problem solving. J Educ Psychol 80:242–436. https://doi.org/10.1037/0022-0663.80.4.424
Verhagen T, van Nes J, Feldberg F, van Dolen W (2014) Virtual customer service agents: using social presence and personalization to shape online service encounters. J Comput Commun 19:529–545. https://doi.org/10.1111/jcc4.12066
Youssef CM, Luthans F (2007) Positive organizational behavior in the workplace: the impact of hope, optimism, and resilience. J Manage 33:774–800. https://doi.org/10.1177/0149206307305562
Acknowledgements
Open Access funding provided by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendix
Appendix
Structure and content of questionnaire.
-
Greeting of the participant
-
Measurement of resilience (RS-11)
-
Prompt to address the investigator regarding introduction to the task followed by the processing of the task
-
Measurement of task performance score
-
Measurement of time of processing the task
-
-
Measurement of perceived work-load (NASA-TLX)
-
Question whether CPM was known before the current study
-
Question whether VA was helpful (only experimental group)
-
Demographics
-
Gender
-
Age
-
Highest educational attainment
-
-
Debriefing
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Brachten, F., Brünker, F., Frick, N.R. et al. On the ability of virtual agents to decrease cognitive load: an experimental study. Inf Syst E-Bus Manage 18, 187–207 (2020). https://doi.org/10.1007/s10257-020-00471-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10257-020-00471-7