
Abstract
We propose and study a class of novel algorithms that aim at solving bilinear and quadratic inverse problems. Using a convex relaxation based on tensorial lifting, and applying first-order proximal algorithms, these problems could be solved numerically by singular value thresholding methods. However, a direct realization of these algorithms for, e.g., image recovery problems is often impracticable, since computations have to be performed on the tensor-product space, whose dimension is usually tremendous. To overcome this limitation, we derive tensor-free versions of common singular value thresholding methods by exploiting low-rank representations and incorporating an augmented Lanczos process. Using a novel reweighting technique, we further improve the convergence behavior and rank evolution of the iterative algorithms. Applying the method to the two-dimensional masked Fourier phase retrieval problem, we obtain an efficient recovery method. Moreover, the tensor-free algorithms are flexible enough to incorporate a priori smoothness constraints that greatly improve the recovery results.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The theory of inverse problems is nowadays one of the main tools to deal with recovery problems in medicine, engineering, and life sciences. The real-world applications of this theory embrace for instance computed tomography, magnetic resonance imaging, and deconvolution problems in microscopy, see [8, 48, 49, 59, 65, 66]. Besides these recent monographs, which are only a small selection, there exist many further publications about applications, regularization, and numerical solvers. In particular, the modern theory of inverse problems studies the regularization of ill-posed problems, i.e., strategies to overcome instability of the solution with respect to noisy data [24]. Among the various available regularization strategies, Tikhonov regularization [61,62,63] or, more generally, variational regularization, i.e., the stabilization of an inverse problem by solving suitable optimization problems, enjoys great attention within the literature. In particular, the latter allows to incorporate a priori assumptions on the sought solutions and to exploit problem structure. Further, variational regularization commonly allows the utilization of optimization algorithms for the numerical solution and thus inherently provides, in many cases, also approaches to solve given inverse problems in practice [34, 68].
In this paper, we consider the subclass of bilinear and quadratic inverse problems and propose dedicated solution algorithms based on specific variational regularization approaches. Problem formulations of these kinds originate from real-world applications in imaging and physics [56] like blind deconvolution [12, 36], deautoconvolution [1, 26, 29], phase retrieval [22, 47, 57], parallel imaging in MRI [9], and parameter identification in EIT [48]. Being nonlinear, bilinear and quadratic inverse problems can be studied with general techniques from nonlinear inverse problems [24, 64]. Recently, however, dedicated approaches have started to emerge, firstly for quadratic problems [25]. One of these approaches for both bilinear and quadratic inverse problems is the exploitation of so-called tensorial liftings. This allows, in particular, to generalize the linear regularization theory to show well-posedness and to derive convergence rates for the solutions of the regularized problems in a common treatment [5]. The question of how to exploit the specific structure of bilinear and quadratic inverse problems to solve these problems numerically with a common approach however has remained open.
In the recent years, PhaseLift [14, 17] has become increasingly popular to solve phase retrieval formulations of the form
for the measurement vectors \(\varvec{a}_m \in \mathbb {R}^M\). The main idea of PhaseLift is to rewrite (1) into
Relaxing the rank by the trace or nuclear norm, we here obtain a semi-definite program, which can be solved by interior point methods, projected subgradient methods, or non-convex low-rank parametrizations [51, 67]. Because of the squared number of unknown of the lifted problem, solving the semi-definite program becomes tremendously challenging for high-dimensional instances since the matrix \(\varvec{U} \in \mathbb {R}^{N\times N}\) cannot be hold in memory. From the theoretical side, one has proved that the solution of the relaxed problem has rank one with high probability and thus yields a solution of the original phase retrieval problem [15, 17]. The close relation to linear matrix equation and matrix completion yield several further recovery guarantees for generic phase retrieval [23, 37, 51].
Noticing that the lifted and relaxed phase retrieval formulation is a convex minimization problem, one can replace the semi-definite programming solvers by convex optimization methods like forward-backward splitting [21, 44], the fast iterative shrinkage-thresholding algorithm (FISTA) [3], the alternating direction method of multiplies (ADMM) [10], or the proximal primal-dual methods [18, 19] to name a few examples. All of these methods have been intensively studied in the literature. Unfortunately, these methods usually have the same problems as semi-definite solvers because, again, of the dimension of the lifted formulation.
Methodology One central idea of this paper is to employ tensorial liftings to lift the bilinear/quadratic structure of the considered problems into a linear using the universal property of the tensor product; so we transfer the idea behind PhaseLift for generic phase retrieval to arbitrary bilinear/quadratic inverse problems. In fact, the lifting allows us to rewrite the bilinear/quadratic inverse problem into a linear one with rank-one constraint. Similarly to PhaseLift or matrix completion, we then relax the lifted problem to obtain a convex variational formulation on the tensor product. If the dimension of the problem is large like in image recovery problems, then the dimension of the tensor product literally explodes such that the required operations on the tensor product for most convex solver usually become intractable. The main focus of this work is to show that for some specific solvers like primal-dual [18] or FISTA [3], the required operations can be performed in a tensor-free manner, which has significantly less memory requirements and makes the lifted problem computationally tractable.
Main contributions The main goal of this paper is to develop tensor-free numerical methods capable of solving general bilinear/quadratic inverse problems on the high-dimensional tensor product in a common manner. For this purpose, we combine the lifting ideas behind PhaseLift with convex optimization methods as well as algorithms from numerical linear algebra. Our main contributions consist in the following points:
-
We show that the structure of the primal-dual method [19] and FISTA [3] can be exploited to derive tensor-free implementations for the solution of lifted bilinear/quadratic problems, which are efficient and memory-saving since they are based on a low-rank representation of the tensorial iteration variable. Moreover, our approaches allow an explicit evaluation of the proximal methods, the lifted operator, and its adjoint. The proposed methods can be used in real-world applications like imaging in masked phase retrieval as shown in the numerical examples.
-
Throughout the paper, we generalize the classical nuclear norm heuristic that is based on the Euclidean setting to nuclear norms deduced from arbitrary Hilbert norms. In this manner, each argument of the bilinear forward operator may be regularized differently with respect to the bilinear/quadratic structure, and the nuclear norm remains computable. This allows us to incorporate a priori information like smoothness of one or both components directly into the nuclear norm regularizer to improve the convergence of the algorithm.
-
We give detailed information on how the tensor-free methods, which turn out to be an iterative singular value thresholding, can be implemented with respect to the generalized nuclear norm heuristic based on arbitrary Hilbert spaces. For this, we generalize the restarted Lanczos process [2] and the orthogonal iteration [60] to compute the required partial singular value decompositions directly with respect to the actual inner products.
-
To improve the convergence and solution behavior, we additionally propose a novel reweighting technique that reduces the rank of the iteration variables.
Road map The paper is organized as follows: In Sect. 2, we introduce the considered bilinear inverse problems in more detail. The focus here lies on the bilinear setting since quadratic formulations are based on underlying bilinear structures. Based on the universal property of bilinear mappings and the nuclear norm heuristic, we then derive a relaxed convex minimization problem with linear lifted forward operator. To stabilize the lifted problem regarding noise and measurement errors, we additionally consider a Tikhonov approach.
In Sect. 3, we first develop a proximal solver based on the first-order primal-dual method of Chambolle and Pock [18] to solve the lifted problem numerically. The primal-dual iteration is here only one explicit example and can be replaced by other proximal methods. In particular, we show an adaption to FISTA. In so doing, we obtain a singular value thresholding depending on the actual Hilbert spaces building the domain of the original problem. Although the tensorial lifting allows us to apply linear methods, the dimension of the relaxed minimization problem becomes tremendous.
To overcome this issue, we derive a tensor-free representation of the suggested algorithm. The efficient computation of the required singular value thresholding is here ensured by exploiting an orthogonal power iteration or, alternatively, an augmented Lanczos process, see Sect. 4. Moreover, in Sect. 5, we introduce a novel Hilbert space reweighting to promote low-rank iterations and solutions. The effect of the slightly different structure of quadratic problems instead of bilinear problems is discussed in Sect. 6. We complete the paper with a numerical study, where we consider generic Gaussian bilinear inverse problems and the masked Fourier phase retrieval; see Sects. 7 and 8.
2 Convex Liftings of Bilinear Inverse Problems
Bilinear problem formulations arise in a wide range of applications in imaging and physics [56] like blind deconvolution [12, 36], parallel imaging in MRI [9], and parameter identification in EIT [48]. Since we are mainly interested in computing a numerical solution, we restrict ourselves to finite-dimensional bilinear problems of the form
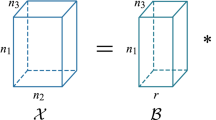
where \(\mathcal {B}\) is a bilinear operator from \(\mathbb {R}^{N_1} \times \mathbb {R}^{N_2}\) into \(\mathbb {R}^{M}\). In the following, we write \(\varvec{u} \in \mathbb {R}^{N_1}\) in the form \(\varvec{u} := (u_n)_{n=0}^{N_1-1}\). To incorporate a priori conditions, we equip each vector space with its own inner product and norm. In the finite-dimensional setting, every inner product corresponds to a unique symmetric, positive definite matrix \(\varvec{H}\) and can be written as \(\langle \cdot ,\cdot \rangle _{\varvec{H}} := \langle \varvec{H} \, \cdot ,\cdot \rangle = \langle \cdot ,\varvec{H} \, \cdot \rangle \), where the inner products on the right-hand side denote the usual Euclidean inner product \(\left\langle \varvec{u},\varvec{v}\right\rangle := \varvec{v}^* \varvec{u}\). Here \(\cdot ^*\) labels the transposition of a vector or matrix. The corresponding norm is denoted by \(||\cdot ||_{\varvec{H}}\). In the following, we denote the associate matrices of the spaces \(\mathbb {R}^{N_1}\), \(\mathbb {R}^{N_2}\), \(\mathbb {R}^M\) by \(\varvec{H}_1\), \(\varvec{H}_2\), \(\varvec{K}\) respectively. The associated matrix of the Euclidean inner product is the identity \(\varvec{I}_N \in \mathbb {R}^{N \times N}\).
Although we restrict ourselves to the real-valued setting, all following algorithms and statements remain valid for the complex-valued setting, where one considers sesquilinear mappings \(\mathcal {B} :{\mathbb {C}}^{N_1} \times {\mathbb {C}}^{N_2} \rightarrow {\mathbb {C}}^M\). Replacing the property ‘symmetric’ by ‘Hermitian,’ and using the real part of the inner products, i.e. \(\left\langle \varvec{u},\varvec{v}\right\rangle = \mathfrak {R}[ \varvec{v}^* \varvec{u}]\), where \(\cdot ^*\) is the transposition and conjugation, all considerations translate one to one. In the complex case, the associate matrices \(\varvec{H}\) may be complex-valued, Hermitian, and positive definite.
Inspired by PhaseLift [14, 17], which exploits the solution strategy developed for matrix completion problems [13, 46], we suggest to tackle the general bilinear problem (\({\mathfrak {B}}\)) by convex liftings and relaxations. Our approach is here based on the so-called universal property of the tensor product with respect to bilinear mappings; see, for instance, [35, 54, 55]. In the finite-dimensional setting, the lifting may be stated as follows.
Definition 1
(Universal property) For every bilinear mapping \(\mathcal {B} :\mathbb {R}^{N_1} \times \mathbb {R}^{N_2} \rightarrow \mathbb {R}^{M}\), there exists a unique linear mapping \(\breve{\mathcal {B}} :\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2} \rightarrow \mathbb {R}^{M}\) such that \(\breve{\mathcal {B}}(\varvec{u} \otimes \varvec{v}) = \mathcal {B}(\varvec{u}, \varvec{v})\).
Notice that the universal property uniquely defines the tensor product \(\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\) in an abstract sense [35, 54]. The other way round, one can also first define the tensor product and then deduce the universal property or the bilinear lifting [55]. In the finite-dimensional setting considered by us, the tensor product \(\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\) can be identified with the matrix space \(\mathbb {R}^{N_2 \times N_1}\), where the rank-one tensor \(\varvec{u} \otimes \varvec{v}\) corresponds to the matrix \(\varvec{v} \varvec{u}^* = (v_{n_2} u_{n_1})_{n_2=0,n_1=0}^{N_2-1,N_1-1}\).
Due to the uniqueness of the lifting, the bilinear inverse problem (\({\mathfrak {B}}\)) is equivalent to the linear inverse problems
The central benefit of these reformulations is the shift of the nonlinearity of the forward operator into the rank-one constraint. Although the problem is now linear, we have to deal with an additional non-convex side condition.
In order to eliminate the nonlinear constraint, we first rewrite (\({\breve{\mathfrak {B}}}\)) into the rank minimization problem
and then relax the non-convex objective function by replacing it with the nuclear or projective norm \(||\cdot ||_{\pi ( \varvec{H}_1, \varvec{H}_2)}\) of the tensor \(\varvec{w}\). Depending on the norms \(||\cdot ||_{\varvec{H}_1}\) and \(||\cdot ||_{\varvec{H}_2}\), this norm is defined by
where the infimum is taken over all finite representations of the tensor \(\varvec{w}\). In so doing, we finally obtain the convex minimization problem

with linear constraints.
Since the considered norm are induced by inner products, the nuclear norm here coincides with the trace class norm or with the Schatten one-norm; so the nuclear norm is the sum of the corresponding singular values of the matrix \(\varvec{w} \in \mathbb {R}^{N_2 \times N_1}\) with respect to the chosen inner products, cf. for instance [69, Satz VI.5.5].
Lemma 1
(Projective norm, [69]) For \(\varvec{w} \in \mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\), the projective norm is given by \(||\varvec{w}||_{\pi (\varvec{H}_1, \varvec{H}_2)} = \sum _{n=0}^{R-1} \sigma _n\), where \(\sigma _n\) denotes the nth singular value and R the rank of \(\varvec{w}\).
The main idea behind the nuclear norm heuristic is that the projective norm is the convex envelope of the rank on the unit ball with respect to the spectral norm. Since we have restricted ourselves to the finite-dimensional setting, each bilinear operator \(\mathcal {B} :\mathbb {R}^{N_1} \times \mathbb {R}^{N_2} \rightarrow \mathbb {R}^{M}\) may be written as
with appropriate matrices \(\varvec{A}_k \in \mathbb {R}^{N_2 \times N_1}\). In general, we cannot expect that the solution of the lifted and relaxed problem (\({\mathfrak {B}_{0}}\)) is rank-one and thus yields a meaningful solution of the original inverse problem (\({\mathfrak {B}}\)). The lifting of the bilinear inverse problem is here a linear matrix equation. More precisely, the lifting can be written as
where \({\cdot }\) is the columnwise vectorization; so the minimum-rank guarantees in [51] are applicable. Therefore, if the matrices \(\varvec{A}_k\) are, for instance, randomly generated with respect to the Gaussian or symmetric Bernoulli distribution, i.e.
the situation changes from the ground up. Combining [51, Thm. 3.3] and [51, Thm. 4.2], we obtain the following recovery guarantee.
Theorem 1
(Recht–Fazel–Parrilo) Let \(\mathcal {B}\) be a bilinear operator randomly generated as in (2). Then there exist positive constants \(c_0\) and \(c_1\) such that the solutions of (\({\mathfrak {B}}\)) and (\({\mathfrak {B}_{0}}\)) coincide with probability at least \(1 - \mathrm {e}^{-c_1 p}\) whenever \(p \ge c_0(N_1+N_2) \log (N_1 N_2)\).
Remark 1
Note that the random bilinear operators in (2) are only two examples of nearly isometrically distributed random variables considered in [51]. Therefore, Theorem 1 is only a special case of the theory presented in [51], which means that many other classes of randomly generated bilinear operators guarantee the recovery of the wanted solution with high probability using tensorial lifting and convex relaxation.
Further, recovery guarantees that directly apply to the lifted bilinear problem can be found in [20, 23, 37]. For instance, [23, Thm. 2.2] ensures the recovery of the wanted rank-one solution tensor for Gaussian operators (left-hand side of (2)) almost surely.
Theorem 2
(Eldar–Needell–Plan) Let \(\mathcal {B} :\mathbb {R}^N \times \mathbb {R}^N \rightarrow \mathbb {R}^M\) with \(M \ge 2N\) be a bilinear Gaussian operator. Then the solutions of (\({\mathfrak {B}}\)) and (\({\mathfrak {B}_{0}}\)) coincide almost surely.
Up to this point, the given data \(\varvec{g}^\dagger \) have been known exactly. A first approach to incorporate noisy measurements into the inverse problems (\({\mathfrak {B}}\)) could be to extend the subspace of exact solutions with respect to a supposed error level. More precisely, one may consider the minimization problems
In other words, we minimize over all solutions that approximate the given noisy data \(\varvec{g}^\epsilon \) with \(||\varvec{g} - \varvec{g}^\epsilon ||_{\varvec{K}} \le \epsilon \) up to the error level \(\epsilon \). Another approach is to incorporate the data fidelity of the possible solutions directly into the objective function. Following this approach, we may minimize a Tikhonov functional with projective norm regularization to solve (\({\mathfrak {B}}\)). In more detail, we consider the problems
For the Euclidean setting, the stability of the lifted and relaxed problem (\({\mathfrak {B}_{\epsilon }}\)) has been well studied, see for instance [20, 37]. If the corresponding matrices \(\varvec{A}_k\) are again realizations of certain random variables or fulfil a restricted isometry property, then the solutions of (\({\mathfrak {B}_{\epsilon }}\)) yield a good approximation of the true rank-one solution \(\varvec{u}^\dagger \otimes \varvec{v}^\dagger \) of (\({\mathfrak {B}}\)). More precisely, one can show that
with high probability, where \(\varvec{w}^\dagger \) denotes a minimizer of (\({\mathfrak {B}_{\epsilon }}\)), and where C is an appropriate constant. For a bilinear Gaussian operator, the relaxed problem (\({\mathfrak {B}_{\epsilon }}\)) guarantees a stable solution as follows, which is a consequence of [37, Thm. 2].
Theorem 3
(Kabanava–Kueng–Rauhut–Terstiege) Let \(\mathcal {B} :\mathbb {R}^{N_1 \times N_2} \rightarrow \mathbb {R}^M\) with \(M \ge c_1 \rho ^{-2} (N_1 + N_2)\), where \(0< \rho < 1\), be a bilinear Gaussian operator. Then with probability at least \(1 - \mathrm {e}^{-c_2 M}\), the solution \(\varvec{w}^\dagger \) of (\({\mathfrak {B}_{\epsilon }}\)) approximates the solution \(\varvec{u}^\dagger \otimes \varvec{v}^\dagger \) of (\({\mathfrak {B}}\)) with
where \(c_1\), \(c_2\), \(c_3\) are positive constants.
For small noise, we thus expect that the solution \(\varvec{w}^\dagger \) is nearly rank-one, i.e., the leading singular value is large compared with the remaining, and that the projection to the rank-one tensors yield a good approximation of \(\varvec{u} \otimes \varvec{v}\). More precisely, on the basis of the Lidskii–Mirsky–Wielandt theorem, see for instance [41], the difference between the singular values is here bounded by
where \(\sigma _n\) are the singular values in decreasing order, and where R is the rank of \(\varvec{w}^\dagger \).
3 Proximal Algorithms for the Lifted Problem
To exploit the nuclear norm heuristic, we have to solve the minimization problem (\({\mathfrak {B}_{0}}\)), (\({\mathfrak {B}_{\epsilon }}\)), and (\({\mathfrak {B}_\alpha }\)) in an efficient manner. Looking back at the comprehensive literature about matrix completion [13, 16, 46], low-rank solutions of matrix equations [51], and PhaseLift [14, 17], there exists several numerical methods like interior-point methods for semi-definite programming, fixed point iterations, singular value thresholding algorithm, projected subgradient methods, and low-rank parametrization approaches.
In order to solve the lifted bilinear inverse problems, we follow another approach. Let us first consider the actual structure of the three derived minimization problems in Sect. 2, which is given by
where \(\mathcal {A} :\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2} \rightarrow \mathbb {R}^{M}\) denotes the lifted bilinear forward operator, \(F :\mathbb {R}^{M} \rightarrow \overline{\mathbb {R}}\) with \(\overline{\mathbb {R}}:= \mathbb {R}\cup \{-\infty , +\infty \}\) describes the data fidelity, and \(G :\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2} \rightarrow \overline{\mathbb {R}}\) is the projective norm. Since the regularization mapping G and, in some circumstances, the data fidelity mapping F are non-smooth but convex functions, we may apply proximal first-order methods like the forward-backward splitting, the primal-dual method by Chambolle–Pock, the alternating directions method of multipliers (ADMM), the Douglas–Rachford splitting, and several variants of these and other algorithms, see for instance [19].
Theoretically, we can apply any of these algorithms to solve the lifted variational problems. In many applications, the dimension of the tensor product, however, explodes literally such that the required tensorial operations cannot be computed efficiently. With respect to this problematic, we exemplarily consider the primal-dual method [18, Alg. 1]
with fixed parameters \(\tau , \sigma > 0\) and \(\theta \in [0,1]\) and FISTA (fast iterative shrinkage-thresholding algorithm) [3, Sect. 4]
with fixed parameter \(\tau > 0\). The details of these methods are given below. The main reason for this restriction is that both algorithms can be implemented in a tensor-free fashion. For further methods, which, for instance, require implicit steps on the tensor product, the efficient implementation on the tensor product is a non-trivial task.
First, the primal-dual method and FISTA are originally defined for linear forward operators between finite-dimensional Hilbert spaces; so we have to equip the tensor product \(\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\) with a corresponding structure. In the following, we always assume that this structure arises from the inner product defined by
see for instance [38, Sect. 2.6]. Using the matrices \(\varvec{H}_1\) and \(\varvec{H}_2\) defining the inner products, we can write the resulting Hilbertian inner product for \(\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\) in the form
where the inner products on the right-hand side denote the Hilbert–Schmidt inner product for matrices. Notice that the Hilbertian inner product is related to the Kronecker product \(\varvec{H}_1 \otimes \varvec{H}_2\) due to
where we recall that \({\cdot }\) denotes the column-wise vectorization. Further, the defined inner product introduces the norm \(||\cdot ||_{\varvec{H}_1 \otimes \varvec{H}_2}\), which differ from the projective norm \(||\cdot ||_{\pi (\varvec{H}_1,\varvec{H}_2)}\). Similarly, the Hilbertian norm may be computed using the singular values with respect to the equipped inner products. Here we have
thus \(||\cdot ||_{\varvec{H}_1 \otimes \varvec{H}_2}\) corresponds to the Schatten two-norm whereas \(||\cdot ||_{\pi (\varvec{H}_1,\varvec{H}_2)}\) corresponds to the Schatten one-norm.
Next, the above stated methods are mainly based on concepts from convex analysis, which is reflected in the presuppositions; so the data fidelity mapping F and, similarly, the regularization mapping G have to be convex and lower semicontinuous. Commonly, a function \(f :\mathbb {R}^{N} \rightarrow \overline{\mathbb {R}}\) is called convex when
for all \(\varvec{x}_1, \varvec{x}_2 \in \mathbb {R}^{N}\) and all \(t \in [0,1]\), and lower semicontinuous when
for all sequences \((\varvec{x}_n)_{n\in \mathbb {N}}\) in \(\mathbb {R}^{N}\) with \(\varvec{x}_n \rightarrow \varvec{x}\). Since F and G in the relaxed minimization problems of Sect. 2 represent norms or indicator functions on closed convex sets, here the assumptions for the primal-dual method are always fulfilled. The forward-backward splitting additionally requires a differentiable data fidelity F with Lipschitz-continuous derivative; so this method can only be applied to the Tikhonov relaxations.
For the primal-dual iteration (4), the first proximity operator \(\text {prox}_{\sigma F^*}\) is computed with respect to the Legendre–Fenchel conjugate \(F^*\). For any function \(f :\mathbb {R}^{N} \rightarrow \overline{\mathbb {R}}\), where \(\mathbb {R}^{N}\) is equipped with the inner product associated to \(\varvec{H}\), the Legendre–Fenchel conjugate \(f^* :\mathbb {R}^{N} \rightarrow \overline{\mathbb {R}}\) is defined by
and is always convex and lower semicontinuous; see [52]. If the function \(f :\mathbb {R}^{N} \rightarrow \overline{\mathbb {R}}\) is lower semicontinuous and convex, the subdifferential \(\partial f\) at a certain point \(\varvec{x} \in \mathbb {R}^{N}\) is given by
and figuratively consists of all linear minorants, see [52]. Finally, the proximation or proximity operator \(\text {prox}_{f}\) of a lower semicontinuous, convex function \(f :\mathbb {R}^{N} \rightarrow \overline{\mathbb {R}}\) is defined as the unique minimizer
Using the subdifferential calculus, one can show that the proximation coincides with the resolvent, i.e.
The most crucial step in the primal-dual iteration (4) and FISTA (5) is the application of the proximal projective norm \(\text {prox}_{\tau ||\cdot ||_{\pi (\varvec{H}_1, \varvec{H}_2)}}\), whereas the computation of proximal conjugated data fidelity \(\text {prox}_{\sigma F^*}\) is usually much simpler. To determine the proximal projective norm explicitly, we exploit the singular value decomposition of the argument with respect to the underlying inner products, which can be derived by an adaption of the classical singular value decomposition for matrices with respect to the Euclidean inner product.
Lemma 2
(Singular value decomposition) Let \(\varvec{w}\) be a tensor in \(\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\). The singular value decomposition of \(\varvec{w}\) with respect to the associate matrices \(\varvec{H}_1\) and \(\varvec{H}_2\) is given by
where \(\sum _{n=0}^{R-1} \sigma _n \, (\varvec{u}_n \otimes \varvec{v}_n)\) is the classical singular value decomposition of \(\varvec{H}_2^{\nicefrac 12} \varvec{w} \, (\varvec{H}_1^{\nicefrac 12})^*\) with respect to the Euclidean inner product.
Remark 2
Unless stated otherwise, the square roots \(\varvec{H}_1^{\nicefrac 12} \in \mathbb {R}^{N_1 \times N_1}\) and \(\varvec{H}_2^{\nicefrac 12} \in \mathbb {R}^{N_2 \times N_2}\) are taken with respect to the factorizations
Allowing also non-symmetric but invertible factorizations, the root \(\varvec{H}_1^{\nicefrac 12}\) and \(\varvec{H}_2^{\nicefrac 12}\) are here non-unique. Possible candidates are the symmetric positive definite square root or the Cholesky decomposition of \(\varvec{H}_1\) and \(\varvec{H}_2\). In the following, the roots are solely required to derive the proximal projective norm mathematically. Their actual computation is not necessary in the final tensor-free algorithm.
Proof of of Lemma 2
By assumption the possibly non-symmetric square roots \(\varvec{H}_1^{\nicefrac 12}\) and \(\varvec{H}_2^{\nicefrac 12}\) are invertible. Considering the classical Euclidean singular value decomposition of the matrix \(\varvec{H}_2^{\nicefrac 12} \varvec{w} \, (\varvec{H}_1^{\nicefrac 12})^*\), we immediately obtain
The last arrangement may be easily validated by using the matrix notation \(\varvec{v}_n \varvec{u}_n^*\) of the rank-one tensor \(\varvec{u}_n \otimes \varvec{v}_n\). Due to the identity
for all \(n,m \in \{0, \dots , R-1\}\), the singular vectors \(\{\tilde{\varvec{u}}_n : n=0,\dots ,R-1\}\) form an orthonormal system with respect to \(\varvec{H}_1\) as well as their counterparts \(\{\tilde{\varvec{v}}_n : n=0,\dots , R-1\}\) with respect to \(\varvec{H}_2\). \(\square \)
Remark 3
The singular value decomposition can also be interpreted as a matrix factorization of the tensor \(\varvec{w}\). In this case, we have the factorization
where \(\varvec{V} \varvec{\Sigma } \varvec{U}^*\) is the classical Euclidean singular value decomposition of \(\varvec{H}_2^{\nicefrac 12} \varvec{w} \, (\varvec{H}_1^{\nicefrac 12})^*\) with the left singular vectors \(\varvec{V} := [\varvec{v}_0, \dots , \varvec{v}_{R-1}]\), the right singular vectors \(\varvec{U} := [\varvec{u}_0, \dots , \varvec{u}_{R-1}]\), and the singular values \(\varvec{\Sigma } := \text {diag}(\sigma _0, \dots , \sigma _{R-1})\).
With the adaption in Lemma 2, we can apply any numerical singular value method to compute the singular value decomposition of a given tensor. The next ingredient is the subdifferential of the nuclear norm based on \(\varvec{H}_1\) and \(\varvec{H}_2\) with respect to Hilbertian inner product on \(\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\) associated to \(\varvec{H}_1 \otimes \varvec{H}_2\). In the following, the set-valued signum function \({\text {sgn}}\) is defined by
Lemma 3
(Subdifferential) Let \(\varvec{w}\) be a tensor in \(\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\). Then the subdifferential of the projective norm \(||\cdot ||_{\pi (\varvec{H}_1, \varvec{H}_2)}\) at \(\varvec{w}\) with respect to \(\varvec{H}_1 \otimes \varvec{H}_2\) is given by
where \(\varvec{w} = \sum _{n=0}^{R-1} \sigma _n \, (\tilde{\varvec{u}}_n \otimes \tilde{\varvec{v}}_n)\) is a valid singular value decomposition of \(\varvec{w}\) with respect to \(\varvec{H}_1\) and \(\varvec{H}_2\).
Proof
The central idea to compute the subdifferential is to rely on the corresponding statement for the Euclidean setting in [39]. More precisely, if \(\mathbb {R}^{N_1}\) and \(\mathbb {R}^{N_2}\) are equipped with the Euclidean inner product, then the subdifferential \(\partial _{\mathcal {H\!S}}\) with respect to the Hilbert–Schmidt inner product on \(\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\) is given by
where \(\varvec{w} = \sum _{n=0}^{R-1} \sigma _n \, (\varvec{u}_n \otimes \varvec{v}_n)\) is an Euclidean singular value decomposition of \(\varvec{w}\), see [39, Cor. 2.5]. The upper bound R is here some number less than or equal to \(\min \{N_1, N_2\}\), and the singular value decomposition of \(\varvec{w}\) may contain zero as singular value.
Next, we adapt this result to our specific case. Therefore, we exploit that the projective norm is the sum of the singular values. Using Lemma 2, we notice that the generalized projective norm of a tensor \(\varvec{w}\) is given by
where the norm on the right-hand side is the usual projective norm with respect to the Euclidean inner product. In order to consider the Hilbertian inner product associated to \(\varvec{H}_1 \otimes \varvec{H}_2\) in the subdifferential, we exploit that
if and only if
where the inner product on the right-hand side is the usual Hilbert–Schmidt scalar product for matrices; see (6). Thus, the subdifferential with respect to the \(\varvec{H}_1 \otimes \varvec{H}_2\) scalar product can be expressed in terms of \(\partial _{\mathcal {H\!S}}\) by
Plugging (8) into (9), and using the chain rule, we obtain the assertion. \(\square \)
With the characterization of the subdifferential, we are ready to determine the proximity operator for the projective norm with respect to \(\varvec{H}_1\) and \(\varvec{H}_2\). In the following, the soft-thresholding operator with respect to the level \(\tau \) is defined by
Theorem 4
(Proximal projective norm) Let \(\varvec{w}\) be a tensor in \(\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\). The proximation of the projective norm is given by
where \(\sum _{n=0}^{R-1} \sigma _n \, (\tilde{\varvec{u}}_n \otimes \tilde{\varvec{v}}_n)\) is a singular value decomposition of \(\varvec{w}\) with respect to \(\varvec{H}_1\) and \(\varvec{H}_2\).
Proof
In order to establish the statement, we only have to convince ourselves that \(\breve{\varvec{w}} := \sum _{n=0}^{R-1} S_\tau (\sigma _n) \, (\tilde{\varvec{u}}_n \otimes \tilde{\varvec{v}}_n)\) is the resolvent for the given \(\varvec{w}\), i.e. \(\varvec{w} \in (I + \tau \, \partial ||\cdot ||_{\pi (\varvec{H}_1, \varvec{H}_2)})(\breve{\varvec{w}})\). Since \(\breve{\varvec{w}}\) is already represented by its singular value decomposition, Lemma 3 implies
If \(\sigma _n > \tau \), the related summand becomes \(\sigma _n \, (\tilde{\varvec{u}}_n \otimes \tilde{\varvec{v}}_n)\). Otherwise, the summand is \(\mu _n \, (\tilde{\varvec{u}}_n \otimes \tilde{\varvec{v}}_n)\) with \(\mu \in [-\tau , \tau ]\). Since the singular value decomposition of \(\varvec{w}\) obviously has this form, the proof is completed. \(\square \)
Remark 4
(Singular value thresholding) The proximation of the projective norm with respect to \(\varvec{H}_1\) and \(\varvec{H}_2\) is a soft thresholding of the corresponding singular values. In the following, we denote the matrix-valued operation
as (soft) singular value thresholding \(\mathcal {S}_\tau \).
Knowing the proximation of the (modified) projective norm, we are now able to perform proximal algorithms to solve the minimization problem in Sect. 2. Although we can use any of the mentioned method, here we restrict ourselves the primal-dual iteration (4). First, we consider the bilinear minimization problems (\({\mathfrak {B}_{0}}\)), (\({\mathfrak {B}_{\epsilon }}\)), and (\({\mathfrak {B}_\alpha }\)).
For exactly given data \(\varvec{g}^\dagger \) corresponding to the minimization problem (\({\mathfrak {B}_{0}}\)), the data fidelity functional corresponds to \(F :\mathbb {R}^M \rightarrow \overline{\mathbb {R}}\) with \(F(\varvec{y}) := \chi _{\{0\}}(\varvec{y} - \varvec{g}^\dagger )\). Here and in the following, the indicator function \(\chi _C\) is equal to 0 for arguments in the set C and \(+\infty \) otherwise. A simple computation shows that the conjugate \(F^*\) is given by \(F^*(\varvec{y}') := \langle \varvec{y}',\varvec{g}^\dagger \rangle _{\varvec{K}}\) and the associated proximal mapping by
Thus, we obtain the following algorithm.
Algorithm 1
(Primal-dual for exact data)
-
(i)
Initiation: Fix the parameters \(\tau , \sigma > 0\) and \(\theta \in [0,1]\). Choose an arbitrary start value \((\varvec{w}^{(0)}, \varvec{y}^{(0)})\) in \((\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}) \times \mathbb {R}^M\), and set \(\breve{\varvec{w}}^{(0)}\) to \(\varvec{w}^{(0)}\).
-
(ii)
Iteration: For \(n>0\), update \(\varvec{w}^{(n)}\), \(\breve{\varvec{w}}^{(n)}\), and \(\varvec{y}^{(n)}\) by
$$\begin{aligned} \varvec{y}^{(n+1)}:= & {} \varvec{y}^{(n)} + \sigma \, (\breve{\mathcal {B}}(\breve{\varvec{w}}^{(n)}) - \varvec{g}^\dagger )\\ \varvec{w}^{(n+1)}:= & {} \mathcal {S}_{\tau }\bigl (\varvec{w}^{(n)} - \tau \,\breve{\mathcal {B}}^* (\varvec{y}^{(n+1)})\bigr )\\ \breve{\varvec{w}}^{(n+1)}:= & {} \varvec{w}^{(n+1)} + \theta \, ( \varvec{w}^{(n+1)} - \varvec{w}^{(n)}). \end{aligned}$$
Remark 5
If the projective norm in (\({\mathfrak {B}_{0}}\)) is weighed with a parameter \(\alpha > 0\) in order to control the influence of the data fidelity and the regularization, cf. (\({\mathfrak {B}_\alpha }\)), then the iteration in Algorithm 1 changes slightly. More precisely, one has to replace \(\mathcal {S}_\tau \) by \(\mathcal {S}_{\alpha \tau }\).
For inexact data \(\varvec{g}^\epsilon \), we first consider the Tikhonov minimization (\({\mathfrak {B}_\alpha }\)), whose data fidelity corresponds to \(F(\varvec{y}) := \nicefrac 12 \, ||\varvec{y} - \varvec{g}^\epsilon ||_{\varvec{K}}^2\). Here the conjugate \(F^*\) is given by \(F^*(\varvec{y}') = \nicefrac 12 \, ||\varvec{y}'||_{\varvec{K}}^2 + \left\langle \varvec{y}',\varvec{g}^\epsilon \right\rangle _{\varvec{K}}\) with subdifferential \(\partial F^*(\varvec{y}') = \{\varvec{y}' + \varvec{g}^\epsilon \}\). Again a simple computation leads to the proximation
which yields the following algorithm.
Algorithm 2
(Tikhonov regularization)
-
(i)
Initiation: Fix the parameters \(\tau , \sigma > 0\) and \(\theta \in [0,1]\). Choose an arbitrary start value \((\varvec{w}^{(0)}, \varvec{y}^{(0)})\) in \((\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}) \times \mathbb {R}^M\), and set \(\breve{\varvec{w}}^{(0)}\) to \(\varvec{w}^{(0)}\).
-
(ii)
Iteration: For \(n>0\), update \(\varvec{w}^{(n)}\), \(\breve{\varvec{w}}^{(n)}\), and \(\varvec{y}^{(n)}\) by
$$\begin{aligned} \varvec{y}^{(n+1)}:= & {} \tfrac{1}{\sigma + 1} \bigl (\varvec{y}^{(n)} + \sigma \, (\breve{\mathcal {B}}(\breve{\varvec{w}}^{(n)}) -\varvec{g}^\epsilon ) \bigr ) \\ \varvec{w}^{(n+1)}:= & {} \mathcal {S}_{\tau \alpha }\bigl (\varvec{w}^{(n)} - \tau \,\breve{\mathcal {B}}^* (\varvec{y}^{(n+1)})\bigr ) \\ \breve{\varvec{w}}^{(n+1)}:= & {} \varvec{w}^{(n+1)} + \theta \, ( \varvec{w}^{(n+1)} - \varvec{w}^{(n)}). \end{aligned}$$
Remark 6
Since the data fidelity F for the Tikhonov functional is differentiable, one may here apply FISTA as an alternative for the primal-dual iteration. In so doing, the whole iteration in Algorithm 2.ii becomes
where \(\breve{\varvec{w}}^{(0)} := \varvec{w}^{(0)}\) and \(t_0 := 1\).
If we incorporate the measurement errors by extending the solution space as in (\({\mathfrak {B}_{\epsilon }}\)), then the data fidelity is chosen by \(F(\varvec{y}) := \chi _{\epsilon \mathbb {B}_{\varvec{K}}}(\varvec{y} - \varvec{g}^\epsilon )\), where \(\mathbb {B}_{\varvec{K}}\) denotes the closed unit ball with respect to the norm induced by \(\varvec{K}\), and \(\chi _{\epsilon \mathbb {B}_{\varvec{K}}}\) is the indicator functional of the closed \(\epsilon \)-ball, i.e., \(\chi _{\epsilon \mathbb {B}_{\varvec{K}}}(\varvec{y}) = 0\) if \(||\varvec{y}||_{\varvec{K}} \le \epsilon \) and \(\infty \) otherwise. Since the conjugation of the unit ball yields the corresponding norm, we obtain \(F^*(\varvec{y}') = \epsilon \, ||\varvec{y}'||_{\varvec{K}} + \left\langle \varvec{y}',\varvec{g}^\epsilon \right\rangle \) with subdifferential
cf. [53, Ex. 8.27]. Since the proximation is not as simple as in the previous cases, we give a more detailed computation.
Lemma 4
(Proximity operator) Let the functional \(F :\mathbb {R}^M \rightarrow \overline{\mathbb {R}}\) be defined by \(F(\varvec{y}) := \chi _{\epsilon \mathbb {B}_{\varvec{K}}}(\varvec{y} - \varvec{g}^\epsilon )\). The proximation of \(F^*\) is then given by
Proof
The vector \(\breve{\varvec{y}}\) is the resolvent \((I + \sigma \, \partial F^*)^{-1}(\varvec{y})\) if and only if
which is an immediate consequence of (10). Bringing \(\sigma \varvec{g}^\epsilon \) to the left-hand side, we are looking for a \(\breve{\varvec{y}}\) such that
For \(||\varvec{y} - \sigma \varvec{g}^\epsilon ||_{\varvec{K}} \le \sigma \epsilon \), the last condition is fulfilled for \(\breve{\varvec{y}} = \varvec{0}\). Otherwise, it follows that \(\breve{\varvec{y}} = \gamma \, (\varvec{y} - \sigma \varvec{g}^\epsilon )\) for some \(\gamma > 0\). With the notation \(\varvec{z} := \varvec{y} - \sigma \varvec{g}^\epsilon \), the first condition becomes
Since \(||\varvec{z}||_{\varvec{K}} > \sigma \epsilon \), we obtain \(\gamma = 1 - \nicefrac {(\sigma \epsilon )}{||\varvec{z}||_{\varvec{K}}}\), and consequently, the assertion. \(\square \)
Remark 7
The central part of the resolvent in Lemma 4 is given by the operator \(\mathcal {P}_\gamma :\mathbb {R}^M \rightarrow \mathbb {R}^M\) with
Pictorially, this operator may be interpreted as shrinkage or contraction around the origin.
After this small digression to compute the proximation of the conjugated data fidelity, the minimization problem (\({\mathfrak {B}_{\epsilon }}\)) may be solved by the following primal-dual iteration.
Algorithm 3
(Primal-dual for inexact data)
-
(i)
Initiation: Fix the parameters \(\tau , \sigma , \epsilon > 0\) and \(\theta \in [0,1]\). Choose an arbitrary start value \((\varvec{w}^{(0)}, \varvec{y}^{(0)})\) in \((\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}) \times \mathbb {R}^M\), and set \(\breve{\varvec{w}}^{(0)}\) to \(\varvec{w}^{(0)}\).
-
(ii)
Iteration: For \(n>0\), update \(\varvec{w}^{(n)}\), \(\breve{\varvec{w}}^{(n)}\), and \(\varvec{y}^{(n)}\) by
$$\begin{aligned} \varvec{y}^{(n+1)}:= & {} \mathcal {P}_{\sigma \epsilon }\bigl ( \varvec{y}^{(n)} + \sigma \, ( \breve{\mathcal {B}}(\breve{\varvec{w}}^{(n)}) - \varvec{g}^\epsilon )\bigr ) \\ \varvec{w}^{(n+1)}:= & {} \mathcal {S}_{\tau }\bigl (\varvec{w}^{(n)} - \tau \, \breve{\mathcal {B}}^* (\varvec{y}^{(n+1)})\bigr ) \\ \breve{\varvec{w}}^{(n+1)}:= & {} \varvec{w}^{(n+1)} + \theta \, ( \varvec{w}^{(n+1)} - \varvec{w}^{(n)}). \end{aligned}$$
The weighing between data fidelity and regularization in Remark 5 analogously holds for Algorithm 3.
The central differences between the primal-dual iterations in Algorithms 1, 2, and 3 for the minimization problems (\({\mathfrak {B}_{0}}\)), (\({\mathfrak {B}_\alpha }\)), and (\({\mathfrak {B}_{\epsilon }}\)) are contained in the dual update of \(\varvec{y}^{(n+1)}\). If the parameter \(\sigma \) is chosen close to zero, the three iterations nearly coincide. Thus, all three iterations should yield similar results; so Algorithm 1 should also be able to deal with noisy measurements.
4 Tensor-Free Singular Value Thresholding
Each of the proposed methods solving bilinear inverse problems is based on a singular value thresholding on the tensor product \(\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\) . If the dimension of the original space \(\mathbb {R}^{N_1} \times \mathbb {R}^{N_2}\) is already enormous, then the dimension of the tensor product literally explodes, which makes the computation of the required singular value decomposition impracticable. This difficulty occurs for nearly all bilinear image recovery problems. However, since the tensor \(\varvec{w}^{(n)}\) is generated by a singular value thresholding, the iterates \(\varvec{w}^{(n)}\) usually possesses a very low rank. Hence, the involved tensors can be stored in an efficient and storage-saving manner. In order to determine this low-rank representation, we only compute a partial singular value decomposition of the argument \(\varvec{w}\) of \(\mathcal {S}_\tau \) by deriving iterative algorithms only requiring the left- and right-hand actions of \(\varvec{w}\).
Our first algorithm is based on the orthogonal iteration with Ritz acceleration, see [28, 60]. In order to compute the leading \(\ell \) singular values, the main idea is here a joint power iteration over two \(\ell \)-dimensional subspaces \(\tilde{\mathcal {U}}_n \subset \mathbb {R}^{N_1}\) and \(\tilde{\mathcal {V}}_n \subset \mathbb {R}^{N_2}\) alternately generated by \(\tilde{\mathcal {U}}_n := \varvec{w}^* \varvec{H}_2 \tilde{\mathcal {V}}_{n-1}\) and \(\tilde{\mathcal {V}}_n := \varvec{w} \varvec{H}_1 \tilde{\mathcal {U}}_{n}\). These subspaces are represented by orthonormal bases \(\tilde{\varvec{U}}_n := [\tilde{\varvec{u}}_0^{(n)}, \dots , \tilde{\varvec{u}}_{\ell -1}^{(n)}]\) and \(\tilde{\varvec{V}}_n := [\tilde{\varvec{v}}_0^{(n)}, \dots , \tilde{\varvec{v}}_{\ell -1}^{(n)}]\) with respect to the inner products associated with \(\varvec{H}_1\) and \(\varvec{H}_2\).
Algorithm 4
(Subspace iteration)
Input: \(\varvec{w} \in \mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\), \(\ell > 0\), \(\delta > 0\).
-
(i)
Choose \(\tilde{\varvec{V}}_0 \in \mathbb {R}^{N_2 \times \ell }\), whose columns are orthonormal with respect to \(\varvec{H}_2\).
-
(ii)
For \(n>0\), repeat:
-
(a)
Compute \(\tilde{\varvec{E}}_n := \varvec{w}^* \varvec{H}_2 \tilde{\varvec{V}}_{n-1}\), and reorthonormalize the columns regarding \(\varvec{H}_1\).
-
(b)
Compute \(\tilde{\varvec{F}}_n := \varvec{w} \varvec{H}_1 \tilde{\varvec{E}}_{n}\), and reorthonormalize the columns regarding \(\varvec{H}_2\).
-
(c)
Determine the Euclidean singular value decomposition
$$\begin{aligned} \tilde{\varvec{F}}_n^* \varvec{H}_2 \varvec{w} \varvec{H}_1 \tilde{\varvec{E}}_n = \varvec{Y}_n \varvec{\Sigma }_n \varvec{Z}_n^*, \end{aligned}$$and set \(\tilde{\varvec{U}}_n := \tilde{\varvec{E}}_n \varvec{Z}_n\) and \(\tilde{\varvec{V}}_n := \tilde{\varvec{F}}_n \varvec{Y}_n\).
until \(\ell \) singular vectors have converged, which means
$$\begin{aligned} \left| \left| \varvec{w}^* \varvec{H}_2 \tilde{\varvec{v}}_m^{(n)} - \sigma _m^{(n)} \tilde{\varvec{u}}_m^{(n)}\right| \right| _{\varvec{H}_1} \le \delta \, ||\varvec{w}||_{\mathcal {L}(\varvec{H}_1, \varvec{H}_2)} \qquad \text {for}\qquad 0 \le m < \ell , \end{aligned}$$where \(||\cdot ||_{\mathcal {L}(\varvec{H}_1, \varvec{H}_2)}\) denotes the operator norm with respect to norms induced by \(\varvec{H}_1\) and \(\varvec{H}_2\), which may be estimated by \(\sigma _0^{(n)}\).
-
(a)
Output: \(\tilde{\varvec{U}}_n \in \mathbb {R}^{N_1 \times \ell }\), \(\tilde{\varvec{V}}_n \in \mathbb {R}^{N_2 \times \ell }\), \(\varvec{\Sigma }_n \in \mathbb {R}^{\ell \times \ell }\) with \(\tilde{\varvec{V}}_n^* \varvec{H}_2 \varvec{w} \varvec{H}_1 \tilde{\varvec{U}}_n = \varvec{\Sigma }_n\).
Here, reorthonormalization means that for each applicable m, the span of the first m columns of the matrix and its reorthonormalization coincide, and that the reorthonormalized matrix has orthonormal columns. This can, for instance, be achieved by the well-known Gram–Schmidt procedure.
Under mild conditions on the subspace associated with \(\tilde{\varvec{V}}_0\), the matrices \(\tilde{\varvec{U}}_n\), \(\tilde{\varvec{V}}_n\), and \(\varvec{\Sigma }_n := \text {diag}(\sigma _0^{(n)}, \dots , \sigma _{\ell -1}^{(n)})\) converge to leading singular vectors as well as to the leading singular values of a singular value decomposition \(\varvec{w} = \sum _{n=0}^{R-1} \sigma _n \, (\tilde{\varvec{u}}_n \otimes \tilde{\varvec{v}}_n)\).
Theorem 5
(Subspace iteration) If none of the basis vectors in \(\tilde{\varvec{V}}_0\) is orthogonal to the \(\ell \) leading singular vectors \(\tilde{\varvec{v}}_0, \dots , \tilde{\varvec{v}}_{\ell -1}\), and if \(\sigma _{\ell -1} > \sigma _\ell \), then the singular values \(\sigma _0^{(n)} \ge \cdots \ge \sigma _{\ell -1}^{(n)}\) in Algorithm 4 converge to \(\sigma _0 \ge \cdots \ge \sigma _{\ell -1}\) with a rate of
Proof
By the construction in steps (a) and (b), the columns in \(\tilde{\varvec{E}}_n\) and \(\tilde{\varvec{F}}_n\) form orthonormal systems with respect to \(\varvec{H}_1\) and \(\varvec{H}_2\). In this proof, we denote the corresponding subspaces by \(\tilde{\mathcal {E}}_n\) and \(\tilde{\mathcal {F}}_n\), which are related by \(\tilde{\mathcal {E}}_n = \varvec{w}^* \varvec{H}_2 \tilde{\mathcal {F}}_{n-1}\) and \(\tilde{\mathcal {F}}_n = \varvec{w} \varvec{H}_1 \tilde{\mathcal {E}}_n\). Due to the basis transformation in (c), the columns of \(\tilde{\varvec{U}}_n\) and \(\tilde{\varvec{V}}_n\) also form orthonormal bases of \(\tilde{\mathcal {E}}_n\) and \(\tilde{\mathcal {F}}_n\). Next, we exploit that the projection \(\varvec{P}_n := \tilde{\varvec{V}}_n \tilde{\varvec{V}}_n^* \varvec{H}_2\) onto \(\tilde{\mathcal {F}}_n\) acts as identity on \(\varvec{w} \varvec{H}_1 \tilde{\mathcal {E}}_n\) by construction. Since \(\tilde{\varvec{U}}_n\) is a basis of \(\tilde{\mathcal {E}}_n\), and since \(\tilde{\varvec{V}}_n^* \varvec{H}_2 \varvec{w} \varvec{H}_1 \tilde{\varvec{U}}_n = \varvec{\Sigma }_n\) by the singular value decomposition in step (c), we have
and \(\tilde{\varvec{U}}_n\) diagonalizes \(\varvec{H}_1 \varvec{w}^* \varvec{H}_2 \varvec{w} \varvec{H}_1\) on the subspace \(\tilde{\mathcal {E}}_n\).
Using the substitutions
as well as
we notice that the iteration in Algorithm 4 is composed of two main steps. First, in (a) and (b), we compute an orthonormal basis \(\varvec{E}_n\) of
Secondly, (11) implies that we determine an Euclidean eigenvalue decomposition on the subspace \(\mathcal {E}_n\) by
and \(\varvec{U}_n := \varvec{E}_n \varvec{Z}_n\).
This two-step iteration exactly coincides with the orthogonal iteration with Ritz acceleration for the matrix \( (\varvec{H}_1^{\nicefrac 12} \varvec{w}^* (\varvec{H}_2^{\nicefrac 12})^* ) (\varvec{H}_2^{\nicefrac 12} \varvec{w} \, (\varvec{H}_1^{\nicefrac 12} )^*)\), see [28, 60]. Under the given assumptions, this iteration converges to the \(\ell \) leading eigenvalues and eigenvectors with the asserted rates. In view of Lemma 2, the columns in \(\tilde{\varvec{U}}_n\) and \(\tilde{\varvec{V}}_n\) together with \(\varvec{\Sigma }_n\) converge to the leading components of the singular value decomposition of \(\varvec{w}\) with respect to \(\varvec{H}_1\) and \(\varvec{H}_2\). \(\square \)
Considering the subspace iteration (Algorithm 4), notice that the algorithm does not need an explicit representation of its argument \(\varvec{w}\) but the left- and right-hand actions of \(\varvec{w}\) as a matrix-vector multiplication. We may thus use the subspace iteration to compute the singular value thresholding \(\mathcal {S}_\tau (\varvec{w})\) without a tensor representation of \(\varvec{w}\).
Algorithm 5
(Tensor-free singular value thresholding)
Input: \(\varvec{w} \in \mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\), \(\tau > 0\), \(\ell > 0\), \(\delta > 0\).
-
(i)
Apply Algorithm 4 with the following modifications:
-
If \(\sigma _m^{(n)} > \tau \) for all \(0 \le m < \ell \), increase \(\ell \) and extend \(\tilde{\varvec{V}}_n\) by further orthonormal columns, unless \(\ell = {\text {rank}}\varvec{w}\), i.e., when the columns of \(\tilde{\varvec{E}}_n\) would become linearly dependent.
-
Additionally, stop the subspace iterations when the first \(\ell ' + 1\) singular values with \(\ell ' < \ell \) have converged and \(\sigma _{\ell '+1}^{(n)} < \tau \). Otherwise, continue the iteration until all nonzero singular values converge and set \(\ell ' = \ell \).
-
-
(ii)
Set \(\tilde{\varvec{U}}' := [\tilde{\varvec{u}}_0, \dots , \tilde{\varvec{u}}_{\ell '-1}]\), \(\tilde{\varvec{V}}' := [\tilde{\varvec{v}}_0, \dots , \tilde{\varvec{v}}_{\ell '-1}]\), and
$$\begin{aligned} \varvec{\Sigma }' := \text {diag}\bigl (S_\tau \bigl (\sigma _0^{(n)}\bigr ), \dots , S_\tau \bigl (\sigma _{\ell '}^{(n)}\bigr )\bigr ). \end{aligned}$$
Output: \(\tilde{\varvec{U}}' \in \mathbb {R}^{N_1 \times \ell '}\), \(\tilde{\varvec{V}}' \in \mathbb {R}^{N_2 \times \ell '}\), \(\varvec{\Sigma }' \in \mathbb {R}^{\ell ' \times \ell '}\) with \(\tilde{\varvec{V}}' \varvec{\Sigma }' (\tilde{\varvec{U}}')^* = \mathcal {S}_\tau (\varvec{w})\).
Corollary 1
(Exact singular value thresholding) If the nonzero singular values of \(\varvec{w}\) are distinct, and if none of the columns in \(\tilde{\varvec{V}}_n\) is orthogonal to the singular vectors with \(\sigma _n > \tau \), then Algorithm 5 computes the low-rank representation of \(\mathcal {S}_\tau (\varvec{w})\).
Although Algorithm 5 for generic start values always yields the singular value thresholding, the convergence of the subspace iteration is rather slow. Therefore, we now derive an algorithm that is based on the Lanczos-based bidiagonalization method proposed by Golub and Kahan in [27] and the Ritz approximation in [28]. This method again only require the left-hand and right-hand action of \(\varvec{w}\) with respect to a given vector. For simplifying the following considerations, we initially present the employed Lanczos process with respect to the Euclidean singular value decomposition.
The central idea is here to construct, for fixed k, orthonormal matrices \(\varvec{F}_k = [\varvec{f}_0, \dots , \varvec{f}_{k-1}] \in \mathbb {R}^{N_2 \times k}\) and \(\varvec{E}_k = [\varvec{e}_0, \dots , \varvec{e}_{k-1}] \in \mathbb {R}^{N_1 \times k}\) such that the transformed matrix
is bidiagonal, and then to compute the singular value decomposition of \(\varvec{B}_k\) by determining orthogonal matrices \(\varvec{Y}_k\), \(\varvec{Z}_k\), and \(\varvec{\Sigma }_k\) in \(\mathbb {R}^{k \times k}\) such that
Defining \(\varvec{U}_k \in \mathbb {R}^{N_1 \times k}\) and \(\varvec{V}_k \in \mathbb {R}^{N_2 \times k}\) as
we finally obtain a set of approximate right-hand and left-hand singular vectors, see [2, 27, 28].
The values \(\beta _n\) and \(\gamma _n\) of the bidiagonal matrix \(\varvec{B}_k\) and the related vectors \(\varvec{e}_n\) and \(\varvec{f}_n\) can be determined by the following iterative procedure [27]: Choose an arbitrary unit vector \(\varvec{p}_{-1} \in \mathbb {R}^{N_1}\) with respect to the Euclidean norm, and compute
For the first iteration, we set \(\gamma _{-1} := 1\) and \(\varvec{f}_{-1} := \varvec{0}\). If \(\gamma _{m+1}\) vanishes, then we stop the Lanczos process since we have found an invariant Krylov subspace such that the computed singular values become exact.
In order to compute an approximate singular value decomposition with respect to \(\varvec{H}_1\) and \(\varvec{H}_2\), we exploit Lemma 2 and perform the Lanczos bidiagonalization regarding the transformed matrix \(\varvec{H}_2^{\nicefrac 12} \varvec{w} \, (\varvec{H}_1^{\nicefrac 12})^*\). Moreover, we incorporate the back transformation in Lemma 2 with the aid of the substitutions
In this manner, the square roots \(\varvec{H}_1^{\nicefrac 12}\) and \(\varvec{H}_2^{\nicefrac 12}\) and their inverses cancel out, and we obtain the following algorithm, which only relies on the original matrices \(\varvec{H}_1\) and \(\varvec{H}_2\).
Algorithm 6
(Lanczos bidiagonalization)
Input: \(\varvec{w} \in \mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\), \(k>0\).
-
(i)
Initiation: Set \(\gamma _{-1} := 1\) and \(\tilde{\varvec{f}}_{-1} := \varvec{0}\). Choose a unit vector \(\tilde{\varvec{p}}_{-1}\) with respect to \(\varvec{H}_1\).
-
(ii)
Lanczos bidiagonalization: For \(m = -1, \dots , k-2\) while \(\gamma _m \ne 0\), repeat:
-
(a)
Compute \(\tilde{\varvec{e}}_{m+1} := \gamma _m^{-1} \, \tilde{\varvec{p}}_m\), and reorthogonalize with \(\tilde{\varvec{e}}_0, \dots , \tilde{\varvec{e}}_m\) as to \(\varvec{H}_1\).
-
(b)
Determine \(\tilde{\varvec{q}}_{m+1} := \varvec{w} \varvec{H}_1 \tilde{\varvec{e}}_{m+1} - \gamma _m \tilde{\varvec{f}}_m\), and set \(\beta _{m+1} := ||\tilde{\varvec{q}}_{m+1}||_{\varvec{H}_2}\). Compute \(\tilde{\varvec{f}}_{m+1} := \beta _{m+1}^{-1} \tilde{\varvec{q}}_{m+1}\) and reorthogonalize with \(\tilde{\varvec{f}}_0, \dots , \tilde{\varvec{f}}_m\) as to \(\varvec{H}_2\).
-
(c)
Determine \(\tilde{\varvec{p}}_{m+1} := \varvec{w}^* \varvec{H}_2 \tilde{\varvec{f}}_{m+1} - \beta _{m+1} \tilde{\varvec{e}}_{m+1}\), and set \(\gamma _{m+1} := ||\tilde{\varvec{p}}_{m+1}||\).
-
(a)
-
(iii)
Compute the Euclidean singular value decomposition of \(\varvec{B}_k\) according to (12), i.e. \(\varvec{B}_k = \varvec{Y}_k \varvec{\Sigma }_k \varvec{Z}_{k}^*\), and set \(\tilde{\varvec{U}}_k := \tilde{\varvec{E}}_k \varvec{Z}_k\) and \(\tilde{\varvec{V}}_k := \tilde{\varvec{F}}_k \varvec{Y}_k\).
Output: \(\tilde{\varvec{U}}_k \in \mathbb {R}^{N_1 \times k}\), \(\tilde{\varvec{V}}_k \in \mathbb {R}^{N_2 \times k}\), \(\varvec{\Sigma }_k \in \mathbb {R}^{k \times k}\) with \(\tilde{\varvec{V}}_{k}^* \varvec{H}_2 \varvec{w} \varvec{H}_1 \tilde{\varvec{U}}_k = \varvec{\Sigma }_k\).
Remark 8
The bidiagonalization by Golub and Kahan is based on a Lanczos-type process, which is numerically unstable in the computation of \(\tilde{\varvec{e}}_n\) and \(\tilde{\varvec{f}}_n\). For this reason, we have to reorthogonalize all newly generated vectors \(\tilde{\varvec{e}}_n\) and \(\tilde{\varvec{f}}_n\) with the previously generated vectors, see [27]. This amounts to projecting \(\tilde{\varvec{e}}_{m+1}\) to the orthogonal complement of the span of \(\{\tilde{\varvec{e}}_{0}, \ldots , \tilde{\varvec{e}}_{m} \}\) and the analog for \(\tilde{\varvec{f}}_{m+1}\), for instance, via the Gram–Schmidt procedure.
Remark 9
The computation of the last \(\tilde{\varvec{p}}_{k-1}\) seems to be superfluous since it is not needed for the determination of the matrix \(\varvec{B}_k\). On the other side, this vector represents the residuals of the approximate singular value decomposition. More precisely, we have
for \(m = 0, \dots , k-1\), see [2]. Here the vectors \(\tilde{\varvec{u}}_m\), \(\tilde{\varvec{v}}_m\), and \(\varvec{y}_m\) denote the columns of the matrices \(\tilde{\varvec{U}}_k = [\tilde{\varvec{u}}_0, \dots , \tilde{\varvec{u}}_{k-1}]\), \(\tilde{\varvec{V}}_k = [\tilde{\varvec{v}}_0, \dots , \tilde{\varvec{v}}_{k-1}]\), and \(\varvec{Y}_k = [\varvec{y}_0, \dots , \varvec{y}_{k-1}]\) respectively; the singular values \(\sigma _m\) of \(\varvec{B}_k\) are given by \(\varvec{\Sigma }_k = \text {diag}(\sigma _0, \dots , \sigma _{k-1})\); the vector \(\varvec{\eta }_{k-1} \in \mathbb {R}^k\) represents the last unit vector \((0, \dots , 0, 1)^*\).
Since the bidiagonalization method by Golub and Kahan is based on the Lanczos process for symmetric matrices, one can apply the related convergence theory to show that the approximate singular values and singular vectors – for increasing k – converge to the wanted singular value decomposition of \(\varvec{w}\), see [28]. Since we are only interested in the leading singular values and singular vectors, and since we want to choose the matrix \(\varvec{B}_k\) as small as possible, this convergence theory does not apply to our setting.
In order to improve the quality of the approximate singular value decomposition computed by Algorithm 6, we here use a restarting technique proposed by Baglama and Reichel [2]. The central idea is to adapt the Lanczos bidiagonalization such that the method can be restarted by a set of \(\ell \) previously computed Ritz vectors. For this purpose, Baglama and Reichel suggest a modified bidiagonalization of the form
where the first \(\ell \) columns of the orthonormal matrices
are predefined by the Ritz vectors of the previous iteration. For the computation of the first \(\ell < k\) leading singular values and singular vectors, we employ the following algorithm [2], which has been adapted to our setting by incorporating Lemma 2 and the substitution (14).
Algorithm 7
(Augmented Lanczos Bidiagonalization)
Input: \(\varvec{w} \in \mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\), \(\ell > 0\) \(k> \ell \), \(\delta >0\).
-
(i)
Apply Algorithm 6 to compute an approximate singular value decomposition \(\tilde{\varvec{V}}_{k,0}^* \varvec{H}_2 \varvec{w} \varvec{H}_1 \tilde{\varvec{U}}_{k,0} = \varvec{\Sigma }_{k,0}\).
-
(ii)
For \(n > 0\), until \(\ell \) singular vectors have converged, which means
$$\begin{aligned} \gamma _{k-1}^{(n-1)} |\varvec{\eta }_{k-1}^* \varvec{y}_m^{(n-1)}| \le \delta ||\varvec{w}||_{\mathcal {L}(\varvec{H}_1, \varvec{H}_2)} \qquad \text {for}\qquad 0 \le m < \ell , \end{aligned}$$where \(||\cdot ||_{\mathcal {L}(\varvec{H}_1, \varvec{H}_2)}\) denotes the operator norm with respect to the norms induced by \(\varvec{H}_1\) and \(\varvec{H}_2\), which may be estimated by \(\sigma _0^{(n-1)}\), repeat:
-
(a)
Initialize the new iteration by setting \(\tilde{\varvec{e}}_m^{(n)} := \tilde{\varvec{u}}_m^{(n-1)}\) and \(\tilde{\varvec{f}}_m^{(n)} := \tilde{\varvec{v}}_m^{(n-1)}\) for \(m = 0, \dots , \ell - 1\). Further, set \(\tilde{\varvec{p}}_{\ell - 1}^{(n)} := \tilde{\varvec{p}}_{k-1}^{(n-1)}\) and \(\gamma _{\ell - 1}^{(n)} := ||\tilde{\varvec{p}}_{\ell - 1}^{(n)}||_{\varvec{H}_1}\).
-
(b)
Compute \(\tilde{\varvec{e}}_\ell ^{(n)} := (\gamma _{\ell - 1}^{(n)})^{-1} \, \tilde{\varvec{p}}_{\ell - 1}^{(n)}\), and reorthogonalize with \(\tilde{\varvec{e}}_0^{(n)}, \dots , \tilde{\varvec{e}}_{\ell - 1}^{(n)}\) as to \(\varvec{H}_1\).
-
(c)
Determine \(\tilde{\varvec{q}}_{\ell }^{(n)} := \varvec{w} \varvec{H}_1 \tilde{\varvec{e}}_\ell ^{(n)}\), compute the inner products \(\rho _m^{(n)} := \langle \tilde{\varvec{f}}_m^{(n)},\tilde{\varvec{q}}_\ell ^{(n)}\rangle _{\varvec{H}_2}\) for \(m = 0, \dots , \ell - 1\), and reorthogonalize \(\tilde{\varvec{q}}_\ell ^{(n)}\) as to \(\varvec{H}_2\) by
$$\begin{aligned} \tilde{\varvec{q}}_\ell ^{(n)} := \tilde{\varvec{q}}_\ell ^{(n)} - \sum _{m=0}^{\ell - 1} \rho _m^{(n)} \tilde{\varvec{f}}_m^{(n)} . \end{aligned}$$ -
(d)
Set \(\beta _\ell ^{(n)} := ||\tilde{\varvec{q}}_\ell ^{(n)}||_{\varvec{H}_2}\) and \(\tilde{\varvec{f}}_\ell ^{(n)} := (\beta _\ell ^{(n)})^{-1} \, \tilde{\varvec{q}}_\ell ^{(n)}\).
-
(e)
Determine \(\tilde{\varvec{p}}_\ell ^{(n)} := \varvec{w}^* \varvec{H}_2 \tilde{\varvec{f}}_\ell ^{(n)} - \beta _\ell ^{(n)} \tilde{\varvec{e}}_\ell ^{(n)}\), and set \(\gamma _\ell ^{(n)} := ||\tilde{\varvec{p}}_\ell ^{(n)}||_{\varvec{H}_1}\).
-
(f)
Calculate the remaining values of \(\varvec{B}_{k,n}\) by applying step (ii) of Algorithm 6 with \(m = \ell , \dots , k - 2\).
-
(g)
Compute the Euclidean singular value decomposition of \(\varvec{B}_{k,n}\) in (15), i.e. \(\varvec{B}_{k,n} = \varvec{Y}_{k,n} \varvec{\Sigma }_{k,n} \varvec{Z}_{k,n}^*\), and set \(\tilde{\varvec{U}}_{k,n} := \tilde{\varvec{E}}_{k,n} \varvec{Z}_{k,n}\) and \(\tilde{\varvec{V}}_{k,n} := \tilde{\varvec{F}}_{k,n} \varvec{Y}_{k,n}\).
-
(a)
-
(iii)
Set \(\tilde{\varvec{U}} := [\tilde{\varvec{u}}_0^{(n)}, \dots , \tilde{\varvec{u}}_{\ell -1}^{(n)}]\), \(\tilde{\varvec{V}} :=[\tilde{\varvec{v}}_0^{(n)}, \dots , \tilde{\varvec{v}}_{\ell -1}^{(n)}]\), and \(\varvec{\Sigma } := \text {diag}(\sigma _0^{(n)}, \dots , \sigma _{\ell -1}^{(n)})\).
Output: \(\tilde{\varvec{U}} \in \mathbb {R}^{N_1 \times \ell }\), \(\tilde{\varvec{V}} \in \mathbb {R}^{N_2 \times \ell }\), \(\varvec{\Sigma } \in \mathbb {R}^{\ell \times \ell }\) with \(\tilde{\varvec{V}}^* \varvec{H}_2 \varvec{w} \varvec{H}_1 \tilde{\varvec{U}} = \varvec{\Sigma }\).
Remark 10
The stopping criterion in step (ii) originates from the error representation in (14). For the operator norm \(||\tilde{\varvec{w}}||_{\mathcal {L}(\varvec{H}_1, \varvec{H}_2)}\), one may use the maximal leading singular values of the former iterations, which usually gives a sufficiently good approximation, see [2].
Although the numerical effort of the restarted augmented Lanczos process is enormously reduced compared with the subspace iteration, we are unfortunately not aware of a convergence and error analysis for this specific variant of Lanczos-type method. Nevertheless, we can employ the obtained partial singular value decomposition to determine the singular value thresholding.
Algorithm 8
(Tensor-free singular value thresholding)
Input: \(\varvec{w} \in \mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\), \(\tau > 0\), \(\ell > 0\), \(k>\ell \), \(\delta > 0\).
-
(i)
Apply Algorithm 7 with the following modifications:
-
If \(\sigma _m^{(n)} > \tau \) for all \(0 \le m < \ell \), increase \(\ell \) and k with \(\ell < k\), unless \(k = {\text {rank}}\varvec{w}\), i.e., when \(\gamma _{k}^{(n)}\) in Algorithm 6 vanishes.
-
Additionally, stop the augmented Lanczos method when the first \(\ell ' + 1\) singular values with \(\ell ' < \ell \) have converged and \(\sigma _{\ell '+1}^{(n)} < \tau \). Otherwise, continue the iteration until all nonzero singular values converge and set \(\ell ' = \ell \).
-
-
(ii)
Set \(\tilde{\varvec{U}}' := [\tilde{\varvec{u}}_0^{(n)}, \dots , \tilde{\varvec{u}}_{\ell '-1}^{(n)}]\), \(\tilde{\varvec{V}}' := [\tilde{\varvec{v}}_0^{(n)}, \dots , \tilde{\varvec{v}}_{\ell '-1}^{(n)}]\), and
$$\begin{aligned} \varvec{\Sigma }' := \text {diag}\bigl (S_\tau \bigl (\sigma _0^{(n)}\bigr ), \dots , S_\tau \bigl (\sigma _{\ell '}^{(n)}\bigr )\bigr ). \end{aligned}$$
Output: \(\tilde{\varvec{U}}' \in \mathbb {R}^{N_1 \times \ell '}\), \(\tilde{\varvec{V}}' \in \mathbb {R}^{N_2 \times \ell '}\), \(\varvec{\Sigma }' \in \mathbb {R}^{\ell ' \times \ell '}\) with \(\tilde{\varvec{V}}' \varvec{\Sigma }' (\tilde{\varvec{U}}')^* = \mathcal {S}_\tau (\varvec{w})\).
Besides the singular value thresholding, the proximal methods in Sect. 3 to solve the lifted and relaxed bilinear problems in Sect. 2 require the application of the lifted operators \(\breve{\mathcal {B}}\) well as its adjoints \(\breve{\mathcal {B}}^*\). Both operations can be computed in a tensor-free manner. Assuming that \(\varvec{w}\) has a low rank, one may compute the lifted bilinear forward operator with the aid of the universal property in Definition 1.
Corollary 2
(Tensor-free bilinear lifting) Let \(\mathcal {B} :\mathbb {R}^{N_1} \times \mathbb {R}^{N_2} \rightarrow \mathbb {R}^{M}\) be a bilinear mapping. If \(\varvec{w} \in \mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\) has the representation \(\varvec{w} = \tilde{\varvec{V}} \varvec{\Sigma } \tilde{\varvec{U}}^*\) with \(\tilde{\varvec{U}} := [\tilde{\varvec{u}}_0, \dots , \tilde{\varvec{u}}_{\ell -1}]\), \(\varvec{\Sigma } := \text {diag}(\sigma _0, \dots , \sigma _{\ell -1})\), and \(\tilde{\varvec{V}} := [\tilde{\varvec{v}}_0, \dots , \tilde{\varvec{v}}_{\ell -1}]\), then the lifted forward operator \(\breve{\mathcal {B}}\) acts by
Considering the proximal methods, we see that the adjoint lifting only occurs in the argument of the singular value thresholding. If one applies the subspace iteration or the augmented Lanczos process, it is hence enough to study the left-hand and right-hand actions of the adjoint liftings. These actions can be expressed by the left-hand or right-hand adjoint of the original bilinear mapping \(\mathcal {B}\).
Lemma 5
(Tensor-free adjoint bilinear lifting) Let \(\mathcal {B} :\mathbb {R}^{N_1} \times \mathbb {R}^{N_2} \rightarrow \mathbb {R}^{M}\) be a bilinear mapping. The left-hand and right-hand actions of the adjoint lifting \(\breve{\mathcal {B}}^*(\varvec{y}) \in \mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\) with \(\varvec{y} \in \mathbb {R}^M\) are given by
for \(\varvec{e} \in \mathbb {R}^{N_1}\) and \(\varvec{f} \in \mathbb {R}^{N_2}\).
Proof
Testing the right-hand action of the image \(\breve{\mathcal {B}}^*(\varvec{y})\) on \(\varvec{e} \in \mathbb {R}^{N_1}\) with an arbitrary vector \(\varvec{f} \in \mathbb {R}^{N_2}\), we obtain
The left-hand action follows analogously. \(\square \)
Remark 11
(Composed tensor-free adjoint lifting) Since the left-hand and right-hand actions of the tensor \(\varvec{w}^{(n)} = \sum _{k=0}^{R-1} \sigma _{k}^{(n)} \, (\tilde{\varvec{u}}_{k}^{(n)} \otimes \tilde{\varvec{v}}_{k}^{(n)})\) are given by
and
the right-hand action of the singular value thresholding argument \(\varvec{w} = \varvec{w}^{(n)} - \tau \, \breve{\mathcal {B}}^*(\varvec{y}^{(n+1)})\) within the proximal methods in Sect. 3 is given by
and the left-hand action by
where \(\varvec{w}^{(n)} = \sum _{k=0}^{R-1} \sigma _{k}^{(n)} \, (\tilde{\varvec{u}}_{k}^{(n)} \otimes \tilde{\varvec{v}}_{k}^{(n)})\).
Now we are ready to rewrite the proximal methods in Sect. 3 into tensor-free variants. Exemplarily, we consider the primal-dual method for bilinear operators and exact data, see Algorithm 1.
Algorithm 9
(Tensor-free primal-dual for exact data)
-
(i)
Initiation: Fix the parameters \(\tau , \sigma > 0\) and \(\theta \in [0,1]\). Choose the start value \((\varvec{w}^{(0)}, \varvec{y}^{(0)}) = (\varvec{0} \otimes \varvec{0}, \varvec{0})\) in \((\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}) \times \mathbb {R}^M\), and set \(\varvec{w}^{(-1)}\) to \(\varvec{w}^{(0)}\).
-
(ii)
Iteration: For \(n \ge 0\), update \(\varvec{w}^{(n)}\) and \(\varvec{y}^{(n)}\):
-
(a)
Using the tensor-free computations in Corollary 2, determine
$$\begin{aligned} \varvec{y}^{(n+1)} := \varvec{y}^{(n)} + \sigma \, \bigl ( (1 + \theta ) \; \breve{\mathcal {B}}(\varvec{w}^{(n)}) - \theta \; \breve{\mathcal {B}}(\varvec{w}^{(n-1)}) - \varvec{g}^\dagger \bigr ). \end{aligned}$$ -
(b)
Compute a low-rank representation \(\varvec{w}^{(n+1)} = \tilde{\varvec{V}}^{(n+1)} \varvec{\Sigma }^{(n+1)} \tilde{\varvec{U}}^{(n+1)}\) of the singular value threshold
$$\begin{aligned} \mathcal {S}_\tau ( \varvec{w}^{(n)} - \tau \, \breve{\mathcal {B}}^*(\varvec{y}^{(n+1)})) \end{aligned}$$with Algorithms 8 (or 5). The required actions are given in (18) and (19).
-
(a)
Remark 12
As starting value for the augmented Lanczos bidiagonalization according to Algorithm 8 required for step (ii.b) of Algorithm 9, we suggest a linear combination of the right-hand singular vectors of the previous iteration \(\varvec{w}^{(n)}\) in the hope that they are good approximations of the new singular vectors.
Using the above tensor-free computation methods, we immediately obtain a tensor-free variant for FISTA in Remark 6 since this iteration scheme is also based on the singular value thresholding, the lifted operator, and the action of its adjoint as well. Exploiting the universal property and Lemma 5, we can compute the actions of \(\breve{\varvec{w}}^{(n)} - \tau \breve{\mathcal {B}}^*(\breve{\mathcal {B}} \breve{\varvec{w}}^{(n)} - \varvec{g}^\epsilon )\) by setting \(\beta _{n+1} := \nicefrac {(t_n - 1)}{t_{n+1}}\) and
The right-hand and left-hand actions are now given by
and
where \(\varvec{w}^{(n)} = \sum _{k=0}^{R^{(n)}-1} \sigma _{k}^{(n)} \, (\tilde{\varvec{u}}_{k}^{(n)} \otimes \tilde{\varvec{v}}_{k}^{(n)})\). These lead us to the following tensor-free algorithm.
Algorithm 10
(Tensor-free FISTA for Tikhonov)
-
(i)
Initiation: Fix the parameters \(\alpha , \tau > 0\). Choose the start value \((\varvec{w}^{(0)}) = (\varvec{0} \otimes \varvec{0})\) in \((\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2})\), and set \(\varvec{w}^{(-1)}\) to \(\varvec{w}^{(0)}\) as well as \(t_0 := 1\) and \(\beta _0 := 0\).
-
(ii)
Iteration: For \(n \ge 0\), update \(\varvec{w}^{(n)}\), \(t_n\) and \(\beta _n\):
-
(a)
Determine \(\varvec{y}^{(n)}\) in (20).
-
(b)
Compute a low-rank representation \(\varvec{w}^{(n+1)} = \tilde{\varvec{V}}^{(n+1)} \varvec{\Sigma }^{(n+1)} \tilde{\varvec{U}}^{(n+1)}\) of the singular value threshold
$$\begin{aligned} \mathcal {S}_{\tau \alpha } ( (1+\beta _n) \varvec{w}^{(n)} - \beta _n \varvec{w}^{(n-1)}- \tau \, \breve{\mathcal {B}}^*(\varvec{y}^{(n)})) \end{aligned}$$with Algorithms 8 (or 5). The required actions are given in (21) and (22).
-
(c)
Set
$$\begin{aligned} t_{n+1} := \frac{1 + \sqrt{1 + 4 t_n^2}}{2} \qquad \text {and}\qquad \beta _{n+1} := \frac{t_n - 1}{t_{n+1}}. \end{aligned}$$
-
(a)
Since FISTA as well as the primal-dual method require two times the evaluation of the lifted operator and one time the singular value thresholding in every iteration, the numerical complexity of both algorithms is comparable.
Adapting the computation of \(\varvec{y}^{(n+1)}\), one may analogously apply Algorithms 2 and 3 in a completely tensor-free manner. Because the singular value thresholding can be computed with arbitrary high accuracy, the convergence results for the primal-dual algorithm translates to our setting. The convergence analysis [18, Thm. 1] yields the following convergence guarantee, where the norm of the bilinear operator \(\mathcal {B}\) is defined by
Theorem 6
(Convergence—exact primal-dual) Under the parameter choice rule \(\theta = 1\) and \(\tau \sigma ||\mathcal {B}||^2 < 1\), the iteration \((\varvec{w}^{(n)}, \varvec{y}^{(n)})\) in Algorithm 9 converges to a minimizer \((\varvec{w}^\dagger , \varvec{y}^\dagger )\) of the lifted and relaxed problem (\({\mathfrak {B}_{0}}\)).
Proof
For the general minimization problem (3), the related saddle-point problem is given by
cf. [18]. Hence, the bilinear relaxation with exact data (\({\mathfrak {B}_{0}}\)) corresponds to the primal-dual formulation
Due to [52, Thm. 28.3], the first components \(\tilde{\varvec{w}}\) of the saddle-points \((\tilde{\varvec{w}}, \tilde{\varvec{y}})\) of (24) are solutions of (\({\mathfrak {B}_{0}}\)). Vice versa, [52, Cor. 28.2.2] implies that the solutions \(\tilde{\varvec{w}}\) of (\({\mathfrak {B}_{0}}\)) are saddle-points of (24). In particular, the saddle-point problem (24) has at least one solution since the given data are exact.
Now, [18, Thm. 1] yields the convergence \((\varvec{w}^{(n)}, \varvec{y}^{(n)}) \rightarrow (\varvec{w}^\dagger , \varvec{y}^\dagger )\) of the primal-dual iteration in Algorithm 9, where the limit \((\varvec{w}^\dagger , \varvec{y}^\dagger )\) denotes a saddle point of (24), and \(\varvec{w}^\dagger \) thus a solution of (\({\mathfrak {B}_{0}}\)). \(\square \)
The employed subspace iteration and augmented Lanczos bidiagonalization are iterative schemes, which only calculate an approximation of the required singular value decomposition. How does this errors affect the convergence of the tensor-free primal-dual method? Using the subspace iteration, we may theoretically calculate the required singular values and vectors arbitrarily precise, which allows us to control the approximation error
between the exact thresholding \(\varvec{w}^{(n)}\) and the approximated \(\tilde{\varvec{w}}^{(n)}\). If the made errors \(E_n\) are square-root summable, the primal-dual method converges nevertheless to the wanted solution.
Theorem 7
(Convergence – inexact primal-dual) Let \(\theta = 1\) and \(\tau \sigma ||\mathcal {B}||^2 < 1\). If the series \(\sum _{n = 1}^\infty E_n^{\nicefrac 12}\) converges, then the iteration \((\varvec{w}^{(n)}, \varvec{y}^{(n)})\) in Algorithm 9 converges to a point \((\varvec{w}^\dagger , \varvec{y}^\dagger )\), where \(\varvec{w}^\dagger \) is a minimizer of the lifted and relaxed problem (\({\mathfrak {B}_{0}}\)).
Proof
Without loss of generality, we assume that the approximations errors are bounded by \(E_n \le 1\). Next, we compare the objective of the proximation function in (7) at the minimizer \(\varvec{w}^{(n)} := \mathcal {S}_\tau (\varvec{w})\) and its approximation \(\tilde{\varvec{w}}^{(n)}\), where \(\varvec{w}\) is the argument of the singular value thresholding in the nth iteration. Exploiting that the projective (Schatten-one) norm is bounded by the Hilbertian (Schatten-two) norm, we here have
with \(S := \min \{N_1,N_2\}\) and with an appropriate constant \(C > 0\). Since \(\tilde{\varvec{w}}^{(n)}\) approximates the minimum of the proximal function with precision \(C E_n\), the calculated \(\tilde{\varvec{w}}^{(n)}\) is a so-called type-one approximation of the proximal point \(\varvec{w}^{(n)} := \mathcal {S}_\tau (\varvec{w})\) with precision \(C E_n\), see [50, p. 385]. Since the precisions \((C E_n)^{\nicefrac 12}\) are summable, [50, Thm. 2] guarantees the convergence of the inexact primal-dual method to a saddle-point \((\varvec{w}^\dagger , \varvec{y}^\dagger )\). As in the proof of Theorem 6, the first component \(\varvec{w}^\dagger \) is a solution of the lifted problem (\({\mathfrak {B}_{0}}\)). \(\square \)
Similar convergence guarantees can be obtained for the bilinear relaxations (\({\mathfrak {B}_{\epsilon }}\)) and (\({\mathfrak {B}_\alpha }\)). Depending on the considered problem—the bilinear forward operator—and on the applied proximal algorithm, one may even obtain explicit convergence rates. Recalling the recovery guarantee in Theorem 1 exemplarily, then Algorithm 9 moreover converges to a rank-one tensor and thus to a solution of the bilinear inverse problem (\({\mathfrak {B}}\)) with high probability. Analogous convergence results apply for other recovery guarantees for noise-free and noisy measurements.
Corollary 3
(Recovery guarantee) Let \(\mathcal {B}\) be a bilinear operator randomly generated as in (2). Then, there exist positive constants \(c_0\) and \(c_1\) such that the Algorithm 9 converges to a solution of (\({\mathfrak {B}}\)) with probability at least \(1 - \mathrm {e}^{-c_1 p}\) whenever \(p \ge c_0(N_1+N_2) \log (N_1 N_2)\).
5 Reducing Rank by Hilbert Space Reweighting
As motivated in Sect. 2, the proposed tensor-free primal-dual methods converges with high probability to the rank-one tensor \(\varvec{u}^\dagger \otimes \varvec{v}^\dagger \), where \((\varvec{u}^\dagger , \varvec{v}^\dagger )\) is a solution of the original problem (\({\mathfrak {B}}\)). In the case of noise, we only obtain a low-rank approximation of \(\varvec{u}^\dagger \otimes \varvec{v}^\dagger \), and a numerical solution of (\({\mathfrak {B}}\)) may be extracted by the rank-one projection \(\sigma _0^{(n)}\,(\tilde{\varvec{u}}_0^{(n)} \otimes \tilde{\varvec{v}}_0^{(n)})\) of the last iteration \(\varvec{w}^{(n)}\). However, this projection causes an additional error. Instead of projecting, we suggest to reweight the employed nuclear norm and restart the algorithm. Starting from the last iteration \(\varvec{w}^{(n)}\), we lower the weight of the singular vectors \(\tilde{\varvec{u}}_{k}^{(n)}\) and \(\tilde{\varvec{v}}_{k}^{(n)}\) in \(\mathbb {R}^{N_1}\) and \(\mathbb {R}^{N_2}\). In this manner, the resulting nuclear norm promotes the directions \(\tilde{\varvec{u}}_{k}^{(n)} \otimes \tilde{\varvec{v}}_{k}^{(n)}\). Lowering the weights proportional to the corresponding singular values, the restarted minimization process avoid the small singular values because these directions become more expensive. Heuristically, the reweighting thus lowers all singular values besides the leading one, which reduces the error due to the final rank-one projection.
More generally, we initially reweight the norms associated to \(\varvec{H}_1\) and \(\varvec{H}_2\) with respect to some orthonormal bases. In the following, we only consider the reweighting of \(\mathbb {R}^{N_1}\) whose inner product is related to \(\varvec{H}_1\). The reweighting of \(\mathbb {R}^{N_2}\) can be done completely analogously. If \(\varvec{\Phi } := [\varvec{\phi }_0, \dots , \varvec{\phi }_{N_1-1}]\) denotes an arbitrary orthonormal basis of \(\mathbb {R}^{N_1}\) with respect to \(\varvec{H}_1\), then Parseval’s identity states
In other words, the matrix \(\varvec{H}_1\) corresponding to the inner product on \(\mathbb {R}^{N_1}\) can be written in the form \(\varvec{H}_1 = \varvec{H}_1 \varvec{\Phi } \varvec{\Phi }^* \varvec{H}_1\), which incidentally shows \(\varvec{\Phi } \varvec{\Phi }^* = \varvec{H}_1^{-1}\). To reweight the \(\varvec{H}_1\)-norm (25) with respect to the basis \(\varvec{\Phi }\), we introduce the weights \(\varvec{\Xi } := \text {diag}(\xi _0, \dots , \xi _{N_1-1})\) and the adapted norm \(||\cdot ||_{\varvec{H}_1(\varvec{\Xi })}\) defined by
In so doing, we obtain the updated inner product matrix \(\varvec{H}_1(\varvec{\Xi }) = \varvec{H}_1 \varvec{\Phi } \varvec{\Xi } \varvec{\Phi }^* \varvec{H}_1\) with inverse \( \varvec{H}_1^{-1}(\varvec{\Xi }) = \varvec{\Phi } \varvec{\Xi }^{-1} \varvec{\Phi }^*\). Depending on the weights, some directions are more promoted or penalized than others.
Unfortunately, for large-scale bilinear inverse problems, the proposed approach is impractical since we have to store a complete orthonormal basis. Remember that we however only want to lower the weight for the right-hand side singular vectors of \(\varvec{w}^{(n)}\); so we choose the weights as \(\xi _n = 1 - \lambda _n\) with \(\lambda _n \in (0,1)\) for \(n=0, \dots , S-1\) and \(\lambda _n = 0\) otherwise, where S is the rank of \(\varvec{w}^{(n)}\). We thus make the approach
with \(\tilde{\varvec{\phi }}_n := \varvec{H}_1 \varvec{\phi }_n\). The inverse is here given by
Hence, to update the inner product matrices, we only require the original matrices \(\varvec{H}_1\) and \(\varvec{H}_1^{-1}\), the (transformed) promoted vectors \(\varvec{\phi }_n\) and \(\tilde{\varvec{\phi }}_n\), and the weights \(\lambda _n\). For the second space \(\mathbb {R}^{N_2}\), we proceed completely analogously.
The reweighting of the Hilbert spaces has consequences for the proposed algorithms. On the one hand, notice that the adjoint of the lifted operator \(\breve{\mathcal {B}}\) directly depends on the actual associate matrices \(\varvec{H}_1\) and \(\varvec{H}_2\). In order to update the adjoint, we first determine the standardized adjoint \(\breve{\mathcal {B}}^*_{\mathcal {H\!S, E}}\) with respect to the Hilbert-Schmidt and Euclidean inner product. Afterward, we transform this adjoint to the actual spaces by the following lemma.
Lemma 6
(Adjoint operator) The adjoint operator \(\breve{\mathcal {B}}^*_{\varvec{H}_1 \otimes \varvec{H}_2, \varvec{K}}\) with respect to the associate matrices \(\varvec{H}_1 \otimes \varvec{H}_2\) and \(\varvec{K}\) is given by
where \(\breve{\mathcal {B}}^*_{\mathcal {H\!S}, \mathcal {E}}\) denotes the adjoint with respect to Hilbert–Schmidt and Euclidean inner product.
Proof
The assertion immediately follows from
for all \(\varvec{w} \in \mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}\) and all \(\varvec{y} \in \mathbb {R}^M\). \(\square \)
On the one side, Lemma 6 allows us to transform the adjoint \(\breve{\mathcal {B}}^*_{\mathcal {H\!S}, \mathcal {E}}\), which can usually be determined more easily, to the inner products related to \(\varvec{H}_1\), \(\varvec{H}_2\), and \(\varvec{K}\). On the other side and more generally, we may transform the adjoint lifted operator between arbitrary Hilbert space structures. For our specific setting in (27) and (28), for instance, we obtain the following transformation rule, where \(\varvec{T}_1(\varvec{\Xi })\) denotes the transformation matrix
with the identity \(\varvec{I}\). The transformation \(\varvec{T}_2(\varvec{\Xi })\) is defined analogously.
Corollary 4
(Adjoint operator) The adjoint operator \(\breve{\mathcal {B}}^*_{\varvec{H}_1(\varvec{\Xi }) \otimes \varvec{H}_2 (\varvec{\Xi }), \varvec{K}}\) with respect to the inner products related to \(\varvec{H}_1(\varvec{\Xi }) \otimes \varvec{H}_2(\varvec{\Xi })\) and \(\varvec{K}\) is given by
Proof
Apply Lemma 6 two times to transform the adjoint firstly from the inner products regarding \(\varvec{H}_1 \otimes \varvec{H}_2\) and \(\varvec{K}\) to Hilbert–Schmidt and Euclidean and, secondly, from Hilbert–Schmidt and Euclidean to the inner products associated with \(\varvec{H}_1(\varvec{\Xi }) \otimes \varvec{H}_2(\varvec{\Xi })\) and \(\varvec{K}\). \(\square \)
The main benefit of Corollary 4 compared with Lemma 6 is that the transformation can be done without involving inverse matrices. On the other side, one relies on an efficient and direct implementation of \(\breve{\mathcal {B}}^*_{\varvec{H}_1 \otimes \varvec{H}_2, \varvec{K}}\) for the unweighted spaces. Remember that this adjoint may be determined by Lemma 5. The required actions to compute the singular value threshold regarding the reweighted spaces then have the following form.
Corollary 5
(Tensor-free adjoint bilinear lifting) The left-hand and right-hand actions of the reweighted adjoint \(\breve{\mathcal {B}}^*_{\varvec{H}_1(\varvec{\Xi }) \otimes \varvec{H}_2 (\varvec{\Xi }), \varvec{K}}( \varvec{y})\) with \(\varvec{y} \in \mathbb {R}^M\) are given by
and
for \(\varvec{e} \in \mathbb {R}^{N_1}\) and \(\varvec{f} \in \mathbb {R}^{N_2}\).
Proof
The assertion follows from Theorem 4 and Eq. (29) by
The second identity follows completely analogously. \(\square \)
Thanks to the above transformations, we can expand the tensor-free primal-dual iteration for exact data in Algorithm 9 by an efficient reweighting step, which we perform every \((n_{\mathrm {rew}})\)th iteration. If the set of promoted directions \(\varvec{\Phi }\) and \(\varvec{\Psi }\) for \(\mathbb {R}^{N_1}\) and \(\mathbb {R}^{N_2}\) is empty, we perform the unweighted algorithm with \(\varvec{\Xi } = \varvec{I}\) and hence \(\varvec{H}_1(\varvec{\Xi }) = \varvec{H}_1\) as well as \(\varvec{H}_2(\varvec{\Xi }) = \varvec{H}_2\).
In order to avoid a recursive reweighting, we always reweight the original Hilbert spaces. Thus, if we want to promote the leading singular vectors of \(\varvec{w}^{(n)}\), we first have to compute the singular value decomposition \(\varvec{w}^{(n)} = \sum _{k=0}^{S-1} \sigma _k' \, (\tilde{\varvec{u}}_k' \otimes \tilde{\varvec{v}}_k')\) with respect to original associate matrices \(\varvec{H}_1\) and \(\varvec{H}_2\). Based on the tensor-free characterization \(\varvec{w}^{(n)} = \sum _{k=0}^{R-1} \sigma _{k}^{(n)} \, (\tilde{\varvec{u}}_{k}^{(n)} \otimes \tilde{\varvec{v}}_{k}^{(n)})\) obtained from the (weighted) singular value thresholding, this decomposition can be computed by Algorithms 4 or 7, where the required actions are given by (16) and (17). Note that the involved inner products are here again the unweighted versions.
After a reweighting step, the singular value thresholding must be computed with respect to the new weight. For this purpose, we adapt the actions in (18) and (19) by Corollary 5. In so doing, for \(\varvec{w} = \varvec{w}^{(n)} - \tau \, \breve{\mathcal {B}}^*_{\varvec{H}_1(\varvec{\Xi }) \otimes \varvec{H}_2(\varvec{\Xi }), \varvec{K}}(\varvec{y}^{(n+1)})\), we obtain the right-hand action
and the left-hand action
The definition of the transformations \(\varvec{T}_1(\varvec{\Xi })\) and \(\varvec{T}_2(\varvec{\Xi })\) is given in (29). The associated matrix \(\varvec{H}_1(\varvec{\Xi })\) in (27) leads to the inner product
where S is the number of promoted directions. For \(\langle \cdot ,\cdot \rangle _{\varvec{H}_2(\varvec{\Xi })}\), we obtain a similar representation.
Algorithm 11
(reweighted tensor-free primal-dual for exact data)
-
(i)
Initiation: Fix the parameters \(\tau , \sigma > 0\), \(\theta \in [0,1]\), \(\lambda \in [0,1)\), and \(n_{\mathrm {rew}} > 0\). Choose the start value \((\varvec{w}^{(0)}, \varvec{y}^{(0)}) = (\varvec{0} \otimes \varvec{0}, \varvec{0})\) in \((\mathbb {R}^{N_1} \otimes \mathbb {R}^{N_2}) \times \mathbb {R}^M\), and set \(\varvec{w}^{(-1)}\) to \(\varvec{w}^{(0)}\). Starting without weights, i.e. \(\varvec{\Phi } = []\) and \(\varvec{\Psi } = []\).
-
(ii)
Iteration: For \(n \ge 0\), update \(\varvec{w}^{(n)}\) and \(\varvec{y}^{(n)}\):
-
(a)
Using the tensor-free computations in Corollary 2, determine
$$\begin{aligned} \varvec{y}^{(n+1)} := \varvec{y}^{(n)} + \sigma \, \bigl ( (1 + \theta ) \; \breve{\mathcal {B}}(\varvec{w}^{(n)}) - \theta \; \breve{\mathcal {B}}(\varvec{w}^{(n-1)}) - \varvec{g}^\dagger \bigr ). \end{aligned}$$ -
(b)
Compute a low-rank representation \(\varvec{w}^{(n+1)} = \tilde{\varvec{V}}^{(n+1)} \varvec{\Sigma }^{(n+1)} \tilde{\varvec{U}}^{(n+1)}\) of the singular value threshold
$$\begin{aligned} \mathcal {S}_\tau ( \varvec{w}^{(n)} - \tau \, \breve{\mathcal {B}}^*_{\varvec{H}_1(\varvec{\Xi }) \otimes \varvec{H}_2(\varvec{\Xi }), \varvec{K}}(\varvec{y}^{(n+1)})) \end{aligned}$$with Algorithm 8. The required actions are given by (30) and (31).
-
(c)
Every \(n_{\mathrm {rew}}\) iteration, re-weight the Hilbert spaces:
-
When \(\varvec{w}^{(n+1)} = \varvec{0}\), set \(\varvec{\Phi } = []\) and \(\varvec{\Psi } = []\).
-
Otherwise, use Algorithm 7 to compute the (unweighted) singular value decomposition \(\varvec{w}^{(n+1)} = \sum _{k=0}^{S-1} \sigma '_k \, (\varvec{u}'_k \otimes \varvec{v}'_k)\), i.e., with respect to \(\varvec{H}_1 \otimes \varvec{H}_2\), where the needed actions are given in (30) and (31). Set \(\lambda _k := \nicefrac {\lambda \sigma '_k}{\sigma '_0}\) for \(k=0,\ldots , S-1\), and \(\varvec{\Phi } := [\varvec{u}'_0, \dots , \varvec{u}'_{S-1}]\) as well as \(\varvec{\Psi } := [\varvec{v}'_0, \dots , \varvec{v}'_{S-1}]\).
-
-
(a)
Analogously, one can apply the reweighting technique in Algorithm 11.ii.c to Algorithms 2 and 3.
6 Convex Liftings of Quadratic Inverse Problems
In general, the bilinear inverse problem considered so far covers all quadratic inverse problems like deautoconvolution [1, 26, 29], phase retrieval [22, 47, 57] as special case. More precisely, every finite-dimensional quadratic problems can be written in the form
where the quadratic operator \(\mathcal {Q} :\mathbb {R}^N \rightarrow \mathbb {R}^M\) is the restriction of the associate bilinear operator \(\mathcal {B}_{\mathcal {Q}} : \mathbb {R}^N \times \mathbb {R}^N \rightarrow \mathbb {R}^M\) to its diagonal and is thus given by \(\mathcal {Q}(\varvec{u}) := \mathcal {B}_{\mathcal {Q}}(\varvec{u}, \varvec{u})\). Therefore, one can directly apply the proposed tensor-free methods. On the other hand, the quadratic problem possesses, due to the symmetry of the solution, more structure than the bilinear problem. Without loss of generality, one can assume that \(\mathcal {B}_{\mathcal {Q}}\) is symmetric, i.e. \(\mathcal {B}_{\mathcal {Q}} (\varvec{u}, \varvec{v}) = \mathcal {B}_{\mathcal {Q}} (\varvec{v}, \varvec{u})\) for all \(\varvec{u}\), \(\varvec{v} \in \mathbb {R}^N\). In this section, we briefly discuss how the additional constraints can be incorporated.
Since the wanted rank-one solution \(\varvec{u} \otimes \varvec{u}\) is symmetric and positive semi-definite, the quadratic problem \(({\mathfrak {Q}})\) is equivalent to the lifted problem
where the domain of \(\breve{\mathcal {Q}}\) is the subset \(\mathbb {R}^N \otimes _{\mathrm {sym}} \mathbb {R}^N\) of symmetric tensors. Because the singular values \(\sigma _n\) of a symmetric tensor \(\varvec{w}\) coincide with the absolute value of its eigenvalues \(\lambda _n\), the positive semi-definiteness can be incorporated into the projective norm by
so \(||\cdot ||_{\pi (\varvec{H}, \varvec{H})}^+\) sums up the nonnegative eigenvalues for positive semi-definite tensors and is infinity otherwise.
To solve the quadratic inverse problem \(({\mathfrak {Q}})\) numerically, we consider the relaxation
Similarly, we adapt the bilinear relaxations (\({\mathfrak {B}_{\epsilon }}\)) and (\({\mathfrak {B}_\alpha }\)) by replacing \(||\cdot ||_{\pi (\varvec{H}_1, \varvec{H}_2)}\) by \(||\cdot ||_{\pi (\varvec{H}, \varvec{H})}^+\). On the basis of the singular value decomposition \(\tilde{\varvec{V}}_n^* \varvec{H} \varvec{w} \varvec{H} \tilde{\varvec{U}}_n = \varvec{\Sigma }_n\), the required eigenvalue decomposition is given by \(\tilde{\varvec{U}}_n^* \varvec{H} \varvec{w} \varvec{H} \tilde{\varvec{U}}_n = \varvec{\Lambda }_n\), where \(\varvec{\Lambda }_n := \text {diag}(\lambda _0, \dots , \lambda _{\ell -1})\) with \(\lambda _m := \sigma _m \left\langle \tilde{\varvec{u}}_m,\tilde{\varvec{v}}_m\right\rangle \).
In order to compute the proximation \(\text {prox}_{\tau ||\cdot ||_{\pi (\varvec{H}, \varvec{H})}^+}\), we determine the subdifferential of the modified norm with respect to the symmetric Hilbertian tensor product. In a nutshell, we have to replace the set-valued signum function by the modified signum \({\text {sgn}}^+\) defined by
Lemma 7
(Subdifferential) Let \(\varvec{w}\) be a positive semi-definite tensor in \(\mathbb {R}^N \otimes _{\mathrm {sym}} \mathbb {R}^N\). The subdifferential of the modified projective norm \(||\cdot ||^+_{\pi (\varvec{H}, \varvec{H})}\) at \(\varvec{w}\) with respect to \(\varvec{H} \otimes \varvec{H}\) on \(\mathbb {R}^N \otimes _{\mathrm {sym}} \mathbb {R}^N\) is given by
where \(\varvec{w} = \sum _{n=0}^{R-1} \lambda _n \, (\tilde{\varvec{u}}_n \otimes \tilde{\varvec{u}}_n)\) is an eigenvalue decomposition of \(\varvec{w}\) with respect to \(\varvec{H}\). If \(\varvec{w}\) is not positive semi-definite, then the subdifferential is empty.
Proof
Similarly to Lemma 3, we rely on the corresponding statement for the Euclidean setting in [40]. If we endow \(\mathbb {R}^N\) with the Euclidean inner product, then the subdifferential of the modified projective norm is determined by
where \(\varvec{w} = \sum _{n=0}^{R-1} \lambda _n \, ({\varvec{u}}_n \otimes {\varvec{u}}_n)\) is a eigenvalue decomposition of \(\varvec{w}\), see [40, Thm. 6]. The transformation to an arbitrary inner product related to \(\varvec{H}\) works exactly as in the proof of Lemma 3. \(\square \)
Together with the positive soft-thresholding operator \(S^+_\tau \) defined by
the computed subdifferential leads us to the following proximity operator.
Theorem 8
(Proximal projective norm) Let \(\varvec{w}\) be a tensor in \(\mathbb {R}^N \otimes _{\mathrm {sym}} \mathbb {R}^N\). Then the proximation of the modified projective norm is given by
where \(\sum _{n=0}^{R-1} \lambda _n \, (\tilde{\varvec{u}}_n \otimes \tilde{\varvec{u}}_n)\) is an eigenvalue decomposition of \(\varvec{w}\) with respect to \(\varvec{H}\).
Proof
The assertion follows similarly to Theorem 4 by replacing the subdifferential in Lemma 3 by Lemma 7 and the singular value decomposition by an eigenvalue decomposition. \(\square \)
Since we have assumed that the underlying bilinear operator \(\mathcal {B}_{\mathcal {Q}}\) is symmetric, one can show that the adjoint \(\breve{B}^*_{\mathcal {Q}}\) maps to the symmetric tensor product \(\mathbb {R}^N \otimes _{\mathrm {sym}} \mathbb {R}^N\). More precisely, the adjoint of the quadratic lifting can be computed as follows.
Lemma 8
(Tensor-free adjoint quadratic lifting) Let \(\mathcal {Q} :\mathbb {R}^N \rightarrow \mathbb {R}^M\) denote a quadratic mapping. The action of the (symmetric) adjoint lifting \(\breve{\mathcal {Q}}^*(\varvec{y}) \in \mathbb {R}^N \otimes _{\mathrm {sym}} \mathbb {R}^N\) with \(\varvec{y} \in \mathbb {R}^M\) is given by
for \(\varvec{e} \in \mathbb {R}^N\).
Proof
Similarly to the bilinear setting, we test the action of the image \(\breve{\mathcal {Q}}^*(\varvec{y})\) on \(\varvec{e} \in \mathbb {R}^N\) with an arbitrary vector \(\varvec{f} \in \mathbb {R}^N\). Exploiting the symmetry, we obtain
\(\square \)
All in all, the symmetry and positive semi-definiteness in the quadratic setting can be incorporated by replacing the singular value thresholding by the positive eigenvalue thresholding in Theorem 8.
7 Application for Gaussian Bilinear Inverse Problems
For the first numerical simulations, we consider the Gaussian bilinear inverse problem with forward operator \(\mathcal {B} :\mathbb {R}^N \times \mathbb {R}^N \rightarrow \mathbb {R}^M\) given by
If the number of measurements is high enough, the solutions of (\({\mathfrak {B}}\)) and (\({\mathfrak {B}_{0}}\)) will almost surely coincide by Theorem 2. In the case of noise, the solutions of (\({\mathfrak {B}_{\epsilon }}\)) or, equivalently, (\({\mathfrak {B}_\alpha }\)) will be good approximations with high probability. In order to apply our tensor-free methods, we need the adjoint of the lifted forward operator, which is here given by
The left-hand and right-hand actions of the adjoint are thus matrix-vector multiplications with the measurement matrices.

Performance of the primal-dual method and FISTA for Gaussian bilinear inverse problems. The regularization parameter corresponds to \(\alpha =30\), \(\alpha =50\), and \(\alpha =100\) from dark to bright lines
In this first numerical example, we want to compare the performance of the primal-dual method (Algorithm 9) with FISTA (Algorithm 10). Since the numerical complexity of both algorithms is comparable, we study the decrease of the objective functional with respect to the computation time. For all simulations in this paper, the proposed methods have been implemented in MATLAB® (R2017a, 64-bit) and are performed using an Intel© Core™ i7-4790 CPU (4\(\times \)3.60 GHz) and 32 GiB main memory. Now, we employ both algorithms to recover the unknown signals \(\varvec{u} \in \mathbb {R}^{100}\) and \(\varvec{v} \in \mathbb {R}^{100}\) from 1000 measurements. The inner products are chosen as Euclidean. Since FISTA can only be used to solve (\({\mathfrak {B}_\alpha }\)), we add 5% white noise to the given data, i.e. \(||\varvec{g}^\dagger - \varvec{g}^\epsilon || = 0.05 \, ||\varvec{g}^\dagger ||\). Because of the effect of the regularization parameter \(\alpha \) to the rank evolution and thus to the performance, we compare FISTA and the primal-dual method for \(\alpha =30\), \(\alpha =50\), and \(\alpha =100\). The results are shown in Figs. 1 and 2.
We observe that the objective is initially decreasing much faster for FISTA but finally the primal-dual method here overtakes FISTA and converges much earlier. The reason for this behavior is the different rank evolution of both methods. Where the tensors generated by FISTA have a high rank over a long period of time, the primal-dual method keeps the rank nearly at one. Since the lower rank results in a speed-up during the partial singular value decomposition, the primal-dual method here outruns FISTA. Considering the parameters \(\sigma = \tau = 10^{-2}\) for primal-dual and \(\tau = 2 \cdot 10^{-4}\) for FISTA, we notice that the primal-dual method allows a stronger singular value threshold. To achieve a similar threshold for FISTA, one may increase the regularization parameter \(\alpha \), which however results in a complete over-regularization, which can already be noticed for \(\alpha =100\).

Performance of the primal–dual method and FISTA for Gaussian bilinear inverse problems
Secondly, we use this experiment to study the influence of the approximate singular value thresholding calculated with an iterative algorithm. Using the same setup as before, however, without noise, we consider the data fidelity of (\({\mathfrak {B}_{0}}\)) for different accuracies \(\delta \) for the augmented Lanczos bidiagonalization in Algorithm 7. Already with an accuracy of \(\delta = 10^{-6}\), the error of the thresholding carries no weight compared with the remaining calculation errors; the overall performance cannot be improved by decreasing \(\delta \) further. For very small accuracies (\(\delta = 10^{-2}\)), the overall accuracy of the reconstruction is slightly decreased, see Fig. 3.

Influence of the stopping criterion of the iterative singular value thresholding with respect to the overall performance of the tensor-free primal-dual method. The parameter \(\delta \) in Algorithm 8 has been chosen as \(10^{-2}\), \(10^{-6}\), and \(10^{-14}\)
8 Masked Fourier Phase Retrieval
In this section, we apply the developed algorithm to the phase retrieval problem. Generally, the phase retrieval problem consists in the recovery of an unknown signal from its Fourier intensity. Problems of this kind occur, for instance, in crystallography [31, 47], astronomy [11, 22], and laser optics [57, 58]. To be more precise, in the following, we consider the two-dimensional masked Fourier phase retrieval problem [14, 15, 17, 30, 45], where the true signal \(\varvec{u} \in {\mathbb {C}}^{N_2 \times N_1}\) is firstly pointwise multiplied with a set of known masks \(\varvec{d}_\ell \in {\mathbb {C}}^{N_2 \times N_1}\) and afterward transformed by the two-dimensional \(M_2 \times M_1\)-point Fourier transform \(\mathop {\mathcal {F}}\nolimits _{M_2 \times M_1}\) defined by
Denoting by \(\odot \) the Hadamard (or pointwise) product, the masked Fourier phase retrieval problem can be stated as follows.
Problem 1
(Masked Fourier phase retrieval) Recover the unknown complex-valued image \(\varvec{u} \in {\mathbb {C}}^{N_2 \times N_1}\) from the masked Fourier intensities \(|\mathop {\mathcal {F}}\nolimits _{M_2 \times M_1}[\varvec{d}_\ell \odot \varvec{u}]|\) with \(d = 0, \dots , L-1\).
In general, phase retrieval problems are ill-posed due to the loss of the phase information in the frequency domain. In one dimension, the problem usually possesses an enormous set of non-trivial solutions, which heavily differ from the true signal; see, for instance, [6] and references therein. In the two-dimensional setting considered by us, the situation changes dramatically since here almost every signal can be uniquely recovered up to a global phase and up to reflection and conjugation, see [7, 32, 33].
Before considering some numerical simulations, we study the quadratic nature of the masked Fourier phase retrieval problem, where we employ the complex notation as mentioned in the introduction of Sect. 2. For this purpose, we interpret both, the domain \({\mathbb {C}}^{N_2 \times N_1}\) and the image \({\mathbb {C}}^{L \times M_2 \times M_1}\) of the measurement operator in Problem 1, as real Hilbert spaces. To simplify the notation, we vectorize the unknown image \(\varvec{u} \in {\mathbb {C}}^{N_2 \times N_1}\) and the given Fourier intensities \(|\mathop {\mathcal {F}}\nolimits _{M_2 \times M_1}[\varvec{d}_\ell \odot \varvec{u}]| \in {\mathbb {C}}^{M_2 \times M_1}\) for a fixed mask columnwise. Henceforth, the vectorized variables are labeled with \({\cdot }\). On the Fourier side, we additionally attach the measurements for different masks to each other. Thus, the domain of the measurement operator in Problem 1 becomes \({\mathbb {C}}^{N_2 N_1}\) and the image \({\mathbb {C}}^{L M_2 M_1}\). At the moment, the endowed real inner product is not specified in detail.
In order to derive an explicit representation of the (vectorized) forward operator, we write the two-dimensional \((M_2 \times M_1)\)-point Fourier transform as
with the Fourier matrices
where \(\otimes \) denotes the Kronecker product of two matrices. For the vectorized version of the Fourier transform \(\mathop {\mathcal {F}}\nolimits _{M_2 \times M_1}\), we henceforth use the notation \(\varvec{F}_{M_2 \times M_1} := \varvec{F}_{M_2} \otimes \varvec{F}_{M_1}\).
In the same manner, we write the pointwise multiplication \(\varvec{d}_\ell \odot \varvec{u}\) as matrix vector multiplication \(\text {diag}(\varvec{d}_\ell ) \, {\varvec{u}}\), where \(\text {diag}(\varvec{d}_\ell )\) denotes the matrix with diagonal \(\varvec{d}_\ell \). Combining the interference with the given masks into one operator, we define the matrix
The action \(\varvec{D}_L {\varvec{u}}\) thus attaches the single masked signals to each other.
Composing the two operations, and squaring the measurements, we notice that Problem 1 is equivalent to
where \(\varvec{I}_L \in {\mathbb {C}}^{L \times L}\) denotes the identity matrix, and \(\varvec{g}^\dagger \in \mathbb {R}^{L M_2 M_1}\) the vectorized exact squared, masked Fourier intensities of the looked-for signal. The associate bilinear operator \(\mathcal {B}_{\mathfrak {F}}\) of the quadratic forward operator \(\mathcal {Q}_{\mathfrak {F}}\) in \(({\mathfrak {F}})\) is now given by
where the function \(\text {diag}\) extracts the diagonal of a matrix. Since the last right-hand side is linear in \({\varvec{v}} {\varvec{u}}{}{^*}\) or linear in \({\varvec{u}} {\varvec{u}}{}{^*}\) for \({\varvec{v}} = {\varvec{u}}\), the quadratic lifting \(\breve{\mathcal {Q}}_{\mathfrak {F}} :{\mathbb {C}}^{N_2N_1} \otimes _{\mathrm {sym}} {\mathbb {C}}^{N_2N_1} \rightarrow {\mathbb {C}}^{L M_2M_1}\) has to be
The last missing ingredient in order to apply our proximal algorithms is the action of the adjoint \(\breve{\mathcal {Q}}_{\mathfrak {F}}^*({\varvec{y}})\) for a fixed \({\varvec{y}} \in {\mathbb {C}}^{LM_2M_1}\).
Lemma 9
(Tensor-free adjoint lifting) If the Hilbert spaces \({\mathbb {C}}^{N_2N_1}\) and \({\mathbb {C}}^{LM_2M_1}\) are endowed with the real Euclidean inner product, i.e. \(\varvec{H} = \varvec{I}_{N_2N_1}\) and \(\varvec{K} = \varvec{I}_{LM_2M_1}\), then the action of the adjoint operator \(\breve{\mathcal {Q}}_{\mathfrak {F}}^*({\varvec{y}})\) with fixed \({\varvec{y}} \in {\mathbb {C}}^{LM_2M_1}\) is given by
for \({\varvec{e}} \in {\mathbb {C}}^{N_2N_1}\).
Proof
We compute the action of the adjoint operator with the aid of Lemma 8. For this purpose, we first determine the left adjoint of \(\mathcal {B}_{\mathfrak {F}}\) by considering
for all \({\varvec{f}} \in {\mathbb {C}}^{N_2N_1}\) and fixed \({\varvec{e}} \in {\mathbb {C}}^{N_2N_1}\). For the right adjoint, we analogously obtain
where diagonal in the middle is not conjugated. Summation of the left and right adjoint as in Lemma 8 yields the assertion. \(\square \)
Remark 13
Using Lemma 6, we can now transform the actions of the Euclidean adjoint to our actual Hilbert spaces. More precisely, we have
One of the central reasons to choose the masked Fourier phase retrieval problem as application of the proposed algorithms and heuristics is that the phase retrieval problem \(({\mathfrak {F}})\), although severely ill posed, behaves nicely under convex relaxation. More precisely, one can show that under certain conditions the solution of the convex relaxed problem
is unique and coincides with the true lifted solution \({\varvec{u}} {\varvec{u}}{}{^*}\) with high probability, see [14, 15, 17, 30]. Therefore, we expect that the proposed tensor-free proximal algorithms converge to a unique rank-one solution.
8.1 Effects of Bidiagonalization and Reweighting
In the first numerical example, we want to study the effect of the applied augmented Lanczos bidiagonalization and of the reweighting heuristic to the computation time and the convergence behavior. The employed true two-dimensional signal consists in a synthetic image referring to transmission electron microscopy experiments with nanoparticles. The test image \(\varvec{u}\) is rather small and is composed of \(16 \times 16\) pixels. The corresponding tensor \(\varvec{w} := {\varvec{u}} {\varvec{u}}{^*}\) is already of dimension 256.
Based on the true image, we compute synthetic and noise-free data by applying the masked Fourier transform. The entries of the eight employed masks have been randomly generated with respect to independent Rademacher random variables. More precisely, the entries of the masks are distributed with respect to the model
Masks of this kind have been studied in [15, 30] in order to de-randomize the generic phase retrieval problem considered in [14, 17]. In our experiment, we employ the \(32 \times 32\)-point Fourier transform such that the complete autocorrelation of the masked signals is encoded in the given Fourier intensities. A first reconstruction of the true signal based on Algorithm 1 is shown in Fig. 4, where we compute the singular value threshold with the aid of a full singular value decomposition of the tensor \(\varvec{w}^{(n)}\). For the involved inner products on \({\mathbb {C}}^{N_2N_1}\) and \({\mathbb {C}}^{LM_2M_1}\), we choose the corresponding Euclidean spaces. In other words, we employ the Hilbert–Schmidt inner product for the (vectorized) matrices in \({\mathbb {C}}^{N_2 N_1}\).

Masked phase retrieval based on Algorithm 1 with 1000 iterations and without any modification. The eight masks have been chosen with respect to a Rademacher distribution. Each pixel is covered by at least one mask
Although the reconstruction is quite accurate, the main drawbacks of a direct application of Algorithm 1 are the computation time and memory requirements. For 1000 iterations, we need about 6.38 minutes to recover the true signal. Next, we employ the tensor-free variant of the primal-dual iteration in Algorithm 9, where we apply the augmented Lanczos bidiagonalization to determine the singular value thresholding (Algorithm 8). Using this modification, we merely need about 58 seconds to perform the reconstruction. Since we can control the accuracy of the partial singular value decomposition, the performed iteration essentially coincides with the original iteration.
The influence of the augmented Lanczos bidiagonalization on the computation time is presented in Table 1. The parameter k here describes the maximal size of the bidiagonal matrix \(\varvec{B}_k\). Further, \(\ell \) denotes the number of fixed Ritz pairs in the augmented restarting procedure. Since the approximation property of the incomplete Lanczos method becomes worse for small k, we require more restarts in order to observe an accurate partial singular value decomposition. For higher-dimensional input images, the time-saving aspect becomes much more important.
Considering the evolution of the nonzero singular values of \(\varvec{w}^{(n)}\) during the iteration, see Table 2, we observe that the projective norm heuristic here enforces a very low rank. After 500 iterations, we nearly obtain a rank-one tensor such that the additional reconstruction error caused by the rank-one projection of \(\varvec{w}^{(n)}\) to extract the recovered image becomes negligible. After 2000 iterations, the tensor \(\varvec{w}^{(n)}\) has converged to a rank-one tensor.
In order to promote the rank-one solutions of the masked Fourier phase retrieval problem even further, we next exploit the reweighting approach proposed in Sect. 5. For our current simulation, this means that we replace the inner product matrices \(\varvec{H} = \varvec{I}\) by the modified matrices \(\varvec{H}(\varvec{\Xi })\) defined in (27), where we build up the basis \(\{\varvec{\phi }_{k}\}\) from the singular value decomposition of \(\varvec{w}^{(n)}\). In the Euclidean setting considered in this simulation, the transformed directions \(\tilde{\varvec{\phi }}_k\) coincide with \(\varvec{\phi }_{k}\). The reweighting is here applied every ten iterations with relative weight \(\lambda := \nicefrac 12\).

Masked phase retrieval based on Algorithm 11 incorporating the augmented Lanczos process and the reweighting heuristic. The algorithm is terminated after 1000 iterations, the reweighting is repeated every 10 iterations with \(\lambda := \nicefrac 12\)
The results of the tensor-free masked Fourier phase retrieval with augmented Lanczos process and Hilbert space reweighting (Algorithm 11) are shown in Fig. 5. Although the reconstruction looks comparable, we want to point out that the absolute errors are several magnitudes smaller. If we compare the evolution of the ranks, see Fig. 6, we can see that the proposed reweighting heuristic reduces the rank quite efficiently. More precisely, most of the iterations have rank one. Due to this reduction, the reweighting has also a positive effect on the computation time and the average number of restarts of the Lanczos process, see Table 1. Moreover, we may notice that the data fidelity term \(||\breve{\mathcal {Q}_{\mathfrak {F}}}(\varvec{w}^{(n)}) - \varvec{g}^\dagger ||\) decreases with a higher rate. Here the convergences stops after about 650 iterations due to numerical reasons.

Since we employ Euclidean inner products, in this example, the minimization problem (36) coincides with PhaseLift, the state-of-the-art approach to tackle general and masked phase retrieval problems. To solve this positive semi-definite program numerically, Candes et al. [14, 17] employ the TFOCS toolbox [4], which is implemented in MATLAB®. Here, we apply the smooth SDP solver of TFOCS to solve the smoothened problem
where \(\Vert \cdot \Vert _\mathrm {F}\) is the Frobenius norm, and where the smoothing parameter is chosen as \(\mu := 0{.}01\). As predicted by the theory, the iterative SDP solver converges to a rank-one solution. The results are shown in Fig. 7 and are comparable to our algorithm without reweighting in Fig. 4. In order to recover the unknown image, the SDP solver need around 21,62 minutes and is thus much slower than our tensor-free method. Note that we have applied the smooth SDP solver as a black box without further optimizations. Further, this SDP solver can only be applied to low-dimensional instances of (36).

Masked phase retrieval based on PhaseLift using TFOCS [4]
8.2 Incorporating Smoothness Properties
One of the central difference between our tensor-free reweighting algorithm and PhaseLift [14, 17] consists in the modeling of the domain and image space of the phase retrieval problem. Where PhaseLift is based on the standard Euclidean setting, we rely on arbitrary discrete Hilbert spaces. In particular, in two-dimensional phase retrieval, we may thus exploit relationships between neighbored pixels like finite differences. More precisely, we here study the influence of the a priori smoothness property formulated in terms of the two-dimensional discretized Sobolev norm.
In order to discretize the (weighted) Sobolev space \(W^{1,2}\), we employ the forward differences
and
to approximate the first partial derivatives. The associate linear mappings for the vectorized image \({\varvec{u}}\) are here denoted by \(\varvec{D}_1\) and \(\varvec{D}_2\). Thus the weighted Sobolev space \( W^{1,2}_{\varvec{\mu }}\) with weights \(\varvec{\mu } := (\mu _{\varvec{I}}, \mu _{\varvec{D}_1}, \mu _{\varvec{D}_2})^*\) corresponds to the matrix
In comparison, the discretized \(L^2\)-norm corresponds to the standard Euclidean setting associated with the identity matrix.

The Fourier data for the second experiment (\(256 \times 256\) pixels) have been created on the basis of the TEM micrograph of gold nanoparticles [42, Fig. 6C]. The employed masks have again been chosen with respect to the Rademacher distribution. In this instance, about a sixteenth of all pixels are blocked in each of the four masks
The masked Fourier intensities of the second example has been created on the basis of a transmission electron microscopy (TEM) reconstruction in [42]. The image has a dimension of \(256 \times 256\) pixels such that the related tensor possesses \(2^{32}\) complex-valued entries and requires 64 GiB memory (double precision complex numbers). Further, we apply four random masks of Rademacher-type (35). Since the masks are generated entirely random, about a one-sixteenth of the pixel are blocked by all masks. The test image together with the number of masks covering a certain pixel are shown in Fig. 8.
To solve the corresponding masked phase retrieval problem, we apply Algorithm 11, where we reweight the Hilbert spaces every 10 steps with the relative weight \(\lambda := \nicefrac 12\). Since the algorithm tends to higher-rank tensors in the starting phase, we only compute a partial singular value decomposition with at most five leading singular values using ten Lanczos vectors \(\varvec{e}_n\) and \(\varvec{f}_n\). Hence, we perform Algorithm 9 in an inexact manner. After a few iterations the rank of \(\varvec{w}^{(n)}\) decreases such that the method becomes again exact, and that the convergence is ensured.
The reconstructions for the Euclidean and Sobolev setting are presented in Figs. 9 and 10, respectively. Due to the small number of four masks, the convergence of the algorithm using the discretized \(L^2\)-norm is very problematic. Although the method converges for the chosen parameters, the convergence rate is very low. Moreover, pixels that are not covered by any masks cannot be recovered and cause reconstruction defects characterized by black holes. Using instead the discretized Sobolev norm with weight \(\varvec{\mu } := (\nicefrac 14,1,1)\) and the same parameters, we obtain a much faster convergence and rank reduction, see Fig. 11. Further, the required number of dual updates in order to produce a nonzero primal update is reduced. A small drawback is that the Sobolev norm tends to smooth out the edges of the particles in the reconstruction. One the other side, the a priori smoothness condition allows us to recover pixels not covered by the given data.

Masked phase retrieval based on Algorithm 11. The pre-image space \({\mathbb {C}}^{N_2 N_1}\) is equipped with the discrete \(L^2\) inner product. The reconstruction is terminated after 100 iterations. In order to compare the retrieval with the true signal, the pixels are presented in the same range as the true image, resulting in the truncation of higher intensities

Masked phase retrieval based on Algorithm 11. The pre-image space \({\mathbb {C}}^{N_2 N_1}\) is equipped with the discrete Sobolev inner product based on the weight \(\varvec{\mu } = (0.25, 1.00, 1.00)^*\). The reconstruction is terminated after 100 iterations

Evolution of the rank and data fidelity term during the masked phase retrieval based on Algorithm 11. Both terms are compared for the discrete \(L^2\) norm (Euclid) and the discrete Sobolev norm with weight \(\varvec{\mu } = (0.25, 1.00, 1.00)^*\)
8.3 Phase Retrieval for Large-Scale Images
Using the proposed reweighting heuristic to reduce the rank of the iteration \(\varvec{w}^{(n)}\), we are able to perform Algorithm 11 for much larger test images. In this numerical experiment, we consider an \(1024 \times 1024\) pixel image, whose Fourier data are again based on a TEM micrograph of gold nanoparticles [42]. The lifted image here already requires 16 TiB memory in order to hold the \(2^{40}\) complex-valued entries with double precision. Differently from the previous examples, we here apply eight Gaussian masks following the standard normal distribution
The recovered signal for the Euclidean inner product is shown in Fig. 12 together with the evolution of the rank and data fidelity in Fig. 13. Analogously to the above experiments, the inner product of \({\mathbb {C}}^{N_2N_1}\) is reweighted every ten iterations with a relative weight \(\lambda := \nicefrac 12\).


Evolution of the rank and data fidelity term during the masked phase retrieval problem based on Algorithm 11 using eight Gaussian masks and terminating after 1000 iterations
8.4 Corruption by Noise
In the last numerical example, we study the influence of noise to the proposed tensor-free primal-dual algorithm. For simplicity, we only study the behavior of the proposed method with respect to white or Gaussian noise of the form \(\varvec{g}^\epsilon := \varvec{g}^\dagger + \varvec{\zeta }\) where \(\varvec{\zeta }\) is a normal distributed random vector. For the noise level \(\epsilon := ||\varvec{g}^\dagger - \varvec{g}^\epsilon ||\), we consider different percentages of the norm \(||\varvec{g}^\dagger ||\). Similarly to the first numerical examples, we again apply four Rademacher-type masks of the form (35). The synthetic data \(\varvec{g}^\dagger \) for the \(256 \times 256\) test image are again based on a TEM reconstruction of gold nanoparticles [43, Fig. S1B] and the \(512 \times 512\)-point Fourier transform. The domain \({\mathbb {C}}^{N_2N_1}\) is again equipped with the discretized Sobolev norm with weight \(\varvec{\mu } := (\nicefrac 14, 1, 1)^*\). Due to the noise, we have adapted Algorithm 11 to the Tikhonov regularization in Algorithm 2, which means that we have to multiply \(\varvec{y}^{(n+1)}\) in step (ii.a) with \(\nicefrac {1}{\sigma +1}\) additionally and to scale the threshold in step (ii.b) to \(\mathcal {S}_{\tau \alpha }\). Since \(\alpha \) affects the influence of the projective norm heuristic, this parameter has to be chosen relatively large. In this brief test run with noisy measurements, we chose \(\alpha := 10^3\) independent of the noise level. Surely, the results can be improved by more sophisticated parameter choice rules.


Evolution of the rank and data fidelity term during masked phase retrieval for noisy measurements. The noise level is given with respect to the norm \(||\varvec{g}^\dagger ||\) of the noise-free measurements
The recovered signals and the evolution of the rank and data fidelity are shown in Figs. 14 and 15, respectively. Due to the noise, we cannot ensure that the recovered tensor has rank one and corresponds to a meaningful approximation of the true signal. If we endow the domain \({\mathbb {C}}^{N_2N_1}\) with the Euclidean inner product in analogy to classical PhaseLift, then we observed that the rank of the iteration \(\varvec{w}^{(n)}\) increases uncontrollably, and the proposed algorithm diverges because of the limited data provided by only four masks. Using instead the weighted Sobolev norm and the Hilbert space reweighting, the rank becomes one after a short starting phase, where the maximal rank is restricted by five. Because of the same starting value and the same regularization parameter, the primal-dual iteration initially performs nearly identical for the three considered noise levels such that the rank evolutions coincide. Further, for all three cases, we here obtain reasonable reconstructions. Moreover, the pixels not covered by any mask are filled up, and the influence of the noise to the reconstruction is smoothed out. Further numerical experiments suggest that Algorithm 11 in combination with a priori smoothness properties recovers the unknown signal in a stable manner.
9 Conclusion
In this paper, we developed novel proximal algorithms to solve bilinear and quadratic inverse problems. The basic idea was to exploit the universal property to lift the considered problem to linear inverse problems on the tensor product. In order to deal with the rank-one constraint, we applied a nuclear or projective norm heuristic, which is known to produce low-rank solutions. The relaxation of the lifted problem yields a constrained minimization problem, which we numerically solve by applying the first-order primal-dual algorithm proposed by Chambolle and Pock [18] and FISTA [3]. We showed that both algorithms can be performed in a tensor-free manner. In the moment, it is an open question whether further convex solvers like ADMM or the Douglas–Rachford splitting can be rewritten in a tensor-free manner. Considering there iterative updates on the tensorial variable, both methods seem to produce full-rank tensors.
The flexibility to adapt the domain of the bilinear or quadratic operator allows us to incorporate smoothness assumptions or neighborhood relations. As demonstrated for the masked Fourier phase retrieval problem, this freedom enables us to recover pixels that are blocked by the applied masks such that they do not contribute to the given measurements. Further, the smoothing properties of the discretized Sobolev norm greatly improve the numerical observed convergence rates. Moreover, one can exploit this flexibility to reweight the pre-image spaces in order to promote low-rank solutions. In the moment, we rely on a projective norm based on the corresponding Hilbert norms. Here, the question arises if one can employ nuclear “norms” based on semi-norms like the total variation or total generalized variation.
For the masked Fourier phase retrieval problem, we have shown that the developed algorithms can approximate the unknown solution in the presence of noise. More precisely, we have studied the influence of white noise, which can be treated by choosing the squared Euclidean or discretized \(L^2\)-norm as data fidelity term of the Tikhonov functional in (\({\mathfrak {B}_\alpha }\)). In order to incorporate more realistic noise models like Poisson noise into phase retrieval, one can, for instance, replace the data fidelity by the Kullback–Leibler divergence. In so doing, one only has to update the proximal mapping to compute the dual variable.
References
Anzengruber, S.W., Bürger, S., Hofmann, B., Steinmeyer, G.: Variational regularization of complex deautoconvolution and phase retrieval in ultrashort laser pulse characterization. Inverse Probl 32(3), 035002(27) (2016)
Baglama, J., Reichel, L.: Augmented implicitly restarted Lanczos bidiagonalization methods. SIAM J Sci Comput 27(1), 19–42 (2005)
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J Imaging Sci 2(1), 183–202 (2009)
Becker, S., Candès, E.J., Grant, M.: Templates for convex cone problems with applications to sparse signal recovery. Math Prog Comp 3(3), 165–218 (2011). http://tfocs.stanford.edu
Beinert, R., Bredies, K.: Non-convex regularization of bilinear and quadratic inverse problems by tensorial lifting. Inverse Probl 35(1), 015002 (2018)
Beinert, R., Plonka, G.: Ambiguities in one-dimensional discrete phase retrieval from Fourier magnitudes. J Math Anal Appl 21(6), 1169–1198 (2015)
Bendory, T., Beinert, R., Eldar, Y.C.: Fourier phase retrieval: uniqueness and algorithms. In: H. Boche, G. Caire, R. Calderbank, M. März, G. Kutyniok, R. Mathar (eds.) Compressed Sensing and its Applications, Applied and Numerical Harmonic Analysis, chap. 2, pp. 55–91. Birkhäuser, Cham (2017)
Bertero, M., Boccacci, P.: Introduction to Inverse Problems in Imaging. Institute of Physics Publishing, Bristol (1998)
Blaimer, M., Breuer, F., Mueller, M., Heidemann, R.M., Griswold, M.A., Jakob, P.M.: SMASH, SENSE, PILS, GRAPPA: how to choose the optimal method. Top Magn Reson Imaging 15(4), 233–236 (2004)
Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Found Trends Mach Learn 3(1), 1–122 (2011)
Bruck, Y.M., Sodin, L.G.: On the ambiguity of the image reconstruction problem. Opt Commun 30(3), 304–308 (1979)
Burger, M., Scherzer, O.: Regularization methods for blind deconvolution and blind source separation problems. Math Control Signals Systems 14(4), 358–383 (2001)
Cai, J.F., Candès, E.J., Shen, Z.: A singular value thresholding algorithm for matrix completion. SIAM J Optim 20(4), 1956–1982 (2010)
Candès, E.J., Eldar, Y.C., Strohmer, T., Voroninski, V.: Phase retrieval via matrix completion. SIAM J Imaging Sci 6(1), 199–225 (2013)
Candès, E.J., Li, X., Soltanolkotabi, M.: Phase retrieval from coded diffation patterns. Appl Comput Harmon Anal 39(2), 277–299 (2015)
Candès, E.J., Recht, B.: Exact matrix completion via convex optimization. Found Comput Math 9(6), 717–772 (2009)
Candès, E.J., Strohmer, T., Voroninski, V.: Phaselift: exact and stable signal recovery from magnitude measurements via convex programming. Comm Pure Appl Math 66(8), 1241–1274 (2013)
Chambolle, A., Pock, T.: A first-order primal-dual algorithm for convex problems with applications to imaging. J Math Imaging Vis 40(1), 120–145 (2011)
Chambolle, A., Pock, T.: An introduction to continuous optimization for imaging. Acta Numerica 25, 161–319 (2016)
Chen, W., Li, Y.: Stable recovery of low-rank matrix via nonconvex Schatten \(p\)-minimization. Sci. China Math. 58(12), 2643–2654 (2015)
Combettes, P.L., Wajs, V.R.: Signal recovery by proximal forward-backward splitting. Multiscale Model. Simul. 4(4), 1168–1200 (2005)
Dainty, J.C., Fienup, J.R.: Phase retrieval and image reconstruction for astronomy. In: H. Stark (ed.) Image Recovery : Theory and Application, chap. 7, pp. 231–275. Academic Press, Orlando (Florida) (1987)
Eldar, Y.C., Needell, D., Plan, Y.: Uniqueness conditions for low-rank matrix recovery. Appl Comput Harmon Anal 33(2), 309–314 (2012)
Engl, H.W., Hanke, M., Neubauer, A.: Regularization of Inverse Problems, Mathematics and Its Applications, vol. 375. Kluwer Academic Publishers, Dortrecht (1996)
Flemming, J.: Regularization of autoconvolution and other ill-posed quadratic equations by decomposition. J Inverse Ill-Posed Probl 22(4), 551–567 (2014)
Gerth, D., Hofmann, B., Birkholz, S., Koke, S., Steinmeyer, G.: Regularization of an autoconvolution problem in ultrashort laser pulse characterization. Inverse Probl Sci Eng 22(2), 245–266 (2014)
Golub, G., Kahan, W.: Calculating the singular values and pseudo-inverse of a matrix. J Soc Indust Appl Math Ser B Numer Anal 2(2), 205–224 (1965)
Golub, G.H., Van Loan, C.F.: Matrix Computations, 4th edn. Johns Hopkins Studies in the Mathematical Sciences. The John Hopkins University Press, Baltimore (2013)
Gorenflo, R., Hofmann, B.: On autoconvolution and regularization. Inverse Probl 10(2), 353–373 (1994)
Gross, D., Krahmer, F., Kueng, R.: Improved recovery guarantees for phase retrieval form coded diffraction patterns. Appl Comput Harmon Anal 42(1), 37–64 (2017)
Hauptman, H.A.: The phase problem of x-ray crystallography. Rep Prog Phys 54(11), 1427–1454 (1991)
Hayes, M.H.: The reconstruction of a multidimensional sequence from the phase or magnitude of its Fourier transform. IEEE Trans Acoust Speech Signal Process ASSP-30(2), 140–154 (1982)
Hayes, M.H., McClellan, J.H.: Reducible polynomials in more than one variable. Proc IEEE 70(2), 197–198 (1982)
Ito, K., Jin, B.: Inverse Problems : Tikhonov Theory and Algorithms, Series on Applied Mathematics, vol. 22. World Scientific, New Jersey (2015)
Jacobson, N.: Basic algebra. II, 2nd edn. W. H. Freeman and Company, New York (1989)
Justen, L., Ramlau, R.: A non-iterative regularization approach to blind deconvolution. Inverse Probl 22(3), 771–800 (2006)
Kabanava, M., Kueng, R., Rauhut, H., Terstiege, U.: Stable low-rank matrix recovery via null space properties. Inf. Inference 5(4), 405–441 (2016)
Kadison, R.V., Ringrose, J.R.: Elementary Theory, Fundamentals of the Theory of Operator Algebras, vol. I. Academic Press, New York (1983)
Lewis, A.S.: The convex analysis of unitarily invariant matrix functions. J Convex Anal 2(1/2), 173–183 (1995)
Lewis, A.S.: Nonsmooth analysis of eigenvalues. Math Program 84(1), 1–14 (1999)
Li, C.K., Mathias, R.: The Lidskii–Mirsky–Wielandt theorem – additive and multiplicative versions. Numer Math 81, 377–413 (1999)
Liebig, F., Sarhan, R.M., Prietzel, C., Reinecke, A., Koetz, J.: ‘Green’ gold nanotriangles: synthesis, purification by polyelectrolyte/micelle depletion flocculation and performance in surface-enhanced Raman scattering. RSC Adv 6, 33561–33568 (2016). Open Access Article licensed under a Creative Commons Attribution 3.0 Unported Licence
Liebig, F., Sarhan, R.M., Prietzel, C., Reinecke, A., Koetz, J.: ‘Green’ gold nanotriangles: synthesis, purification by polyelectrolyte/micelle depletion flocculation and performance in surface-enhanced Raman scattering – Supplementary part. RSC Adv 6, 33561–33568 (2016). Open Access Article licensed under a Creative Commons Attribution 3.0 Unported Licence
Lions, P.L., Mercier, B.: Splitting algorithms for the sum of two nonlinear operators. SIAM J Numer Anal 16(6), 964–979 (1979)
Liu, Y.J., Chen, B., Li, E.R., Wang, J.Y., Marcelli, A., Wilkins, S.W., Ming, H., Tian, Y.C., Nugent, K.A., Zhu, P.P., Wu, Z.Y.: Phase retrieval in x-ray imaging based on using structured illumination. Phys Rev A 78(2), 023817(5) (2008)
Ma, S., Goldfarb, D., Chen, L.: Fixed point and Bregman iterative methods for matrix rank minimization. Math Program 128(1–2), 321–353 (2011)
Millane, R.P.: Phase retrieval in crystallography and optics. J Opt Soc Am A 7(3), 394–411 (1990)
Mueller, J.L., Siltanen, S.: Linear and Nonlinear Inverse Problems with Practical Applications. Computational Science & Engineering. SIAM, Philadelphia (2012)
Ramm, A.G.: Inverse problems. Mathematical and Analytical Techniques with Applications to Engineering. Springer, Springer (2005)
Rasch, J., Chambolle, A.: Inexact first-order primal-dual algorithms. Comput Optim Appl 76(2), 381–430 (2020)
Recht, B., Fazel, M., Parrilo, P.A.: Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization. SIAM Rev 52(3), 471–501 (2010)
Rockafellar, R.: Convex Analysis. No. 28 in Princeton Mathematical Series. Princeton University Press, Princeton (New Jersey) (1970)
Rockafellar, R., Wets, R.J.B.: Variational Analysis. No. 317 in Grundlehren der mathematischen Wissenschaften. A Series of Comprehensive Studies in Mathematics. Springer, Dortrecht (2009)
Rotman, J.J.: An Introduction to Homological Algebra, 2nd edn. Universitext. Springer, New York (2009)
Ryan, R.A.: Introduction to Tensor Products of Banach Spaces. Springer Monographs in Mathematics. Springer, London (2002)
Scherzer, O., Grasmair, M., Grossauer, H., Haltmeier, M., Lenzen, F.: Variational Methods in Imaging. Springer, New York (2009)
Seifert, B., Stolz, H., Donatelli, M., Langemann, D., Tasche, M.: Multilevel Gauss-Newton methods for phase retrieval problems. J Phys A: Math Gen 39(16), 4191–4206 (2006)
Seifert, B., Stolz, H., Tasche, M.: Nontrivial ambiguities for blind frequency-resolved optical gating and the problem of uniqueness. J Opt Soc Am B 21(5), 1089–1097 (2004)
Seo, J.K., Woo, E.J.: Nonlinear Inverse Problems in Imaging. John Wiley & Sons, Chichester (2013)
Stewart, G.W.: Accelerating the orthogonal iteration for the eigenvectors of a Hermitian matrix. Numer Math 13(4), 362–376 (1969)
Tikhonov, A.N.: Regularization of incorrectly posed problems. Sov Math, Dokl 4, 1624–1627 (1963). Translation from Doklady Akademii Nauk SSSR 153, 49–52 (1963)
Tikhonov, A.N.: Solution of incorrectly formulated problems and the regularization method. Sov Math, Dokl 4, 1035–1038 (1963). Translation from Doklady Akademii Nauk SSSR 151, 501–504 (1963)
Tikhonov, A.N., Arsenin, V.: Solutions of Ill-Posed Problems. Scripta Series in Mathematics. John Wiley & Sons, New York (1977)
Tikhonov, A.N., Leonov, A.S., Yagola, A.G.: Nonlinear ill-posed problems. Vol. 1, 2. No. 14 in Applied Mathematics and Mathematical Computation. Chapman & Hall, London (1998)
Uhlmann, G. (ed.): Inside Out: Inverse Problems and Applications, Mathematical Sciences Research Institute Publications, vol. 47. Cambridge University Press, Cambridge (2003)
Uhlmann, G. (ed.): Inverse Problems and applications: Inside Out II, Mathematical Sciences Research Institute Publications, vol. 60. Cambridge University Press, Cambridge (2013)
Vandenberge, L., Boyd, S.: Semidefinite programming. SIAM Review 38(1), 49–95 (1996)
Vogel, C.R.: Computational methods for inverse problems. Frontiers in Applied Mathematics. Society for Industrial and Applied Mathematics (SIAM), Philadelphia (2002)
Werner, D.: Funktionalanalysis, 4th edn. Springer-Lehrbuch. Springer, Berlin (2002)
Acknowledgements
We would like to thank the unknown reviewers for there valuable comments and suggestions to improve this manuscript. Further, we gratefully acknowledge the funding of this work by the Austrian Science Fund (FWF) within the project P28858. The Institute of Mathematics and Scientific Computing of the University of Graz, with which the authors are affiliated, is a member of NAWI Graz (https://www.nawigraz.at/).
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Thomas Strohmer.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
R. Beinert and K. Bredies were supported by the Austrian Science Fund (FWF) Grant P28858.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Beinert, R., Bredies, K. Tensor-Free Proximal Methods for Lifted Bilinear/Quadratic Inverse Problems with Applications to Phase Retrieval. Found Comput Math 21, 1181–1232 (2021). https://doi.org/10.1007/s10208-020-09479-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10208-020-09479-4
Keywords
- Tensor-free proximal methods
- Tensorial lifting
- Nuclear norm relaxation
- Reweighting techniques
- Bilinear inverse problem
- Quadratic inverse problem
- Masked Fourier phase retrieval