
Abstract
A pandemic poses particular challenges to decision-making because of the need to continuously adapt decisions to rapidly changing evidence and available data. For example, which countermeasures are appropriate at a particular stage of the pandemic? How can the severity of the pandemic be measured? What is the effect of vaccination in the population and which groups should be vaccinated first? The process of decision-making starts with data collection and modeling and continues to the dissemination of results and the subsequent decisions taken. The goal of this paper is to give an overview of this process and to provide recommendations for the different steps from a statistical perspective. In particular, we discuss a range of modeling techniques including mathematical, statistical and decision-analytic models along with their applications in the COVID-19 context. With this overview, we aim to foster the understanding of the goals of these modeling approaches and the specific data requirements that are essential for the interpretation of results and for successful interdisciplinary collaborations. A special focus is on the role played by data in these different models, and we incorporate into the discussion the importance of statistical literacy and of effective dissemination and communication of findings.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In December 2019, the first cases of coronavirus disease 2019 (COVID-19) were reported in Wuhan, China (Zhou et al. 2020; Wu et al. 2020) and the outbreak of severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) was declared a pandemic in March 2020 by the World Health Organization. In order to control the spread of the virus and limit the negative consequences of the pandemic, important decisions had and still have to be made. These concern the spread of the disease, its impact on health, the utilization of health care resources or potential effects of counter measures and vaccination strategies, to name some examples. Statistical modeling plays an important role in different fields of COVID-19 research. This starts with the collection of adequate data and the preprocessing of this data, a complex sequence of steps, where input is required from the data users, taking into account their questions and information needs. After this preprocessing, examples of statistical models range from characterizing the disease (Küchenhoff et al. 2021; Roy et al. 2021; Luo et al. 2021), investigating comorbidities (Gross et al. 2021; Hadzibegovic et al. 2021; Evangelou et al. 2021), evaluating new treatments and vaccines with respect to efficacy and safety (Horby et al. 2020; RECOVERY Collaborative Group 2020; Shinde et al. 2021; Flaxman et al. 2020) as well as planning corresponding trials (Mütze and Friede 2020; Stallard et al. 2020; Beyersmann et al. 2021), assessing the spread of the disease in potential scenarios—such as comparing lockdown or vaccination strategies (Nussbaumer-Streit et al. 2020; Van Pelt et al. 2021; Jahn et al. 2021)—and evaluating the impact of the pandemic on clinical trials (Kunz et al. 2020; Anker et al. 2020). One important aspect in the special situation of a pandemic with a novel pathogen is the incorporation of sequential inference, that is, continuously updating the research as new data become available.
In the course of the pandemic, the availability and quality of data, the varying interpretations of modeling results, as well as apparently contradicting statements by scientists, have caused confusion and fostered intense debate. The role, use and misuse of modeling for infectious disease policy making have been critically discussed (James et al. 2021; Holmdahl and Buckee 2020). Furthermore, the CODAG reports (COVID-19 Data Analysis Group 2021) clarify why models can lead to conflicting conclusions and discuss the purposes of modeling and the validity of the results. For instance, policies to contain the pandemic were—in the beginning—mainly guided by 7-day incidence. Measures such as curfews, limited numbers of guests at events and restricted opening hours of stores were driven by this figure. However, considering the 7-day incidence alone does not provide a meaningful view of the overall picture as discussed by Küchenhoff et al. (2021). As mentioned in the series “Unstatistik” (RWI – Leibniz-Institut für Wirtschaftsforschung 2020), a value of 50 cases per 100,000 inhabitants in October 2020 in Germany had an entirely different meaning than six months earlier due to changes in testing strategies and improved treatments among other factors. Concerning the expected number of intensive care patients and deaths, a value of approximately 50 in October 2020 is likely to correspond to a value of 15 to 20 in April 2020, possibly even less (RWI – Leibniz-Institut für Wirtschaftsforschung 2020). Recently, the hospitalization and ICU incidences have been considered as additional measures. While this provides a more reliable picture of the severity of the situation and is less affected by differing testing strategies, it is not without shortcomings. For example, under-reporting and time-lags lead to large differences between reported and actual numbers. Moreover, as the severity of COVID infections dropped with the Omicron variant and prevalence increased, a new discussion of hospitalization “with” or “because of” COVID-19 emerged. These examples highlight the need to use statistical methods such as nowcasting (Günther et al. 2021; Schneble et al. 2021; Salas 2021; Altmejd et al. 2020) for more precise estimations.
As known from the field of evidence-based medicine and health data and decision science, decisions should be underpinned by the best available evidence. For evidence-based decision making, three components are important: a) data, b) statistical, mathematical and decision-analytic models (which reduce the amount and the complexity of the data to meaningful indices, visualizations and/or predictions), and c) a set of available decisions, interventions or strategies with their consequences described through a utility or loss function (decision-making framework) and the related tradeoffs. General international guidance on these assessments and decision analysis is implemented in a country-specific manner, mainly by Health Technology Assessment (HTA) organisations (Drummond et al. 2008; Gandjour 2020). COVID-19 examples include the evaluation of vaccination strategies (Kohli et al. 2021; Debrabant et al. 2021; Reddy et al. 2021) or treatment (Sheinson et al. 2021). Scientists of the German Network for Evidence-based Medicine raised the question on “COVID-19: Where is the evidence?” (EbM-Netzwerk 2020) which motivated a discussion about the need of randomized controlled trials to investigate the effectiveness of preventive measures, feasibility of such studies and longitudinal, representative data generation.
In the pandemic, a multitude of models has been used but the systematic comparison across different classes of models is lacking. The goal of this paper is to provide an overview of the process from data collection (primary and secondary) and modeling, up to communication and decision making and to provide recommendations related to these areas. We discuss a range of modeling techniques including mathematical, statistical and decision-analytic models along with their application in the COVID-19 context. With this overview, we aim to foster the understanding of the goals of these modeling approaches, and the specific data requirements that are essential for the interpretation of results and a successful interdisciplinary collaboration. Model types less known to statisticians, such as decision-analytic models, still require statistical thinking. In particular, functional relationships and input parameters for these models are often provided by statisticians and epidemiologists. Our target audience, therefore, is broad. It includes data scientists—such as statisticians—mathematicians, physicists, epidemiologists, economists, social and computer scientists and decision scientists.
The paper is organized as follows. In Sect. 2, we give a short overview of modeling purposes and approaches with a special focus on differences between disciplines. In Sect. 3, we discuss requirements of data quality and why this is fundamental for the entire process. We then move on to modeling, with Sect. 4 dealing with the different purposes of modeling. In Sect. 5, we explain how decisions can be informed based on these models. We discuss aspects of the reporting and communication of results in Sect. 6 , provide recommendations in Sect. 7 and a discussion in Sect. 8.
2 Overview of modeling approaches and their purposes
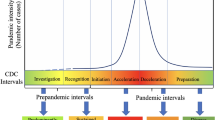
As a statistician, the process of gaining knowledge starts with a research question and continues with the acquisition of data, which then enters into the statistical model—see Figure 1 in Friedrich et al. (2021) for an illustration. Data acquisition here might refer either to the design of an adequate experiment or observation, or to the use of so-called secondary data, which has been collected for a different purpose. Statistical principles of design are relevant, even when using secondary data (Rubin 2008). In Bayesian statistics, other information can be incorporated as a priori information (e.g., O’Hagan 2004). This might stem from previous studies or might be based on expert opinions. The prior information combined with the data (likelihood) then results in a posterior distribution. In modeling contexts outside statistics, data and/or information is used in different ways. Simulation models use prior information (again based either on data or on other sources such as expert opinion or beliefs) to determine the parameters of interest and are usually validated on a data set. The formal representation of the mathematical or decision-analytic model makes assumptions about the system that generates the data (Roberts et al. 2012), and the (mis)match between data and model then provides insights that can be used as basis for decisions. In contrast to statistical models, the order of data and modeling is thus reversed. An illustration is depicted in Fig. 1. For the purpose of illustration, Fig. 1 depicts the process as a sequence of steps. As the pandemic progresses, however, some steps such as data capturing and modeling might be iterated.
From a mathematical perspective, a statistic f is a quantity or function defined on the sampling space. Note that the term statistic is used both for the function f as well as for the value \(f(\mathbf{x})\) of the function on a given data set \(\mathbf{x}\) (DeGroot and Schervish 2014; Licker 2003). Choices of f include very simple preprocessing steps, e.g., taking the mean where \(f(x_1, \dots , x_n)= \frac{1}{n}\sum _{i=1}^n x_i\), as well as estimates obtained from complex statistical models, such as hierarchical Bayesian models used for nowcasting (Günther et al. 2021) or sophisticated regression models for prediction (Iwendi et al. 2020). Thus, the input to a statistical model might either be ‘raw data’ or might have undergone some previous steps, like scaling or transformation applied to variables before entering them in a regression model. These previous steps are often referred to as preprocessing (especially in the context of machine learning) and examples include descriptive statistics and exploratory data analysis, see also Friedrich et al. (2021) and the references cited therein. It should be noted, however, that data can often not be analyzed directly, but is the product of a complex sequence of processing steps. In particular, Desrosières (2010) separates three aspects of statistics, namely “(1) that of quantification properly speaking, the making of numbers, (2) that of the uses of numbers as variables, and finally, (3) the prospective inscription of variables in more complex constructions, models”. Throughout this paper, we refer to the model input parameters as ‘data’ irrespective of whether some preprocessing took place or not. Official statistics, for instance, usually refer to crude observations when talking about ‘data’, while the information obtained by (pre-)processing this data is called statistics. For this paper, however, we adapt a slightly different view on the same aspect and do not distinguish between crude and preprocessed data. In this sense, the measures of quality and trustworthiness discussed in Sect. 3 similarly extend to preprocessing, descriptive statistics and exploratory data analysis (Friedrich et al. 2021).

For evidence-based decision making, a complex process is often necessary. In both statistical and mathematical/decision-analytic modeling, the path starts with a research question and ends in guidance for decision making. In statistics (upper path), using data as the basis for modeling is common. In mathematical and decision-analytic modeling (lower path), models are based on subject matter knowledge and validated or calibrated using data sets. For the purpose of illustration, the process is depicted as a sequence of steps here. In reality, however, these are more likely to be cyclic, iterating steps such as data capturing and modeling and informing new questions based on previous results
As mentioned above, modeling is an integral part of evidence-based decision making. Here, we distinguish three purposes of modeling, which are summarized in Table 1. The first category contains models which aim to explain patterns and trends in the data. The second category aims to predict the present (so-called now-casting) or the future (forecasting). Finally, decision-analytic models aim to inform decision makers by simulating the consequences of interventions and their related tradeoffs (e.g., benefit-harm tradeoff, cost-effectiveness tradeoff).
In medical decision making and health economics, this leads to a formal decision framework, which relates to statistical decision theory (Siebert 2003, 2005). In this framework, (Parmigiani and Inoue 2009) the decision maker has to choose among a set of different actions. The consequences of these actions depend on an unknown “state of the world”. The basis for decision making depends on the quantitative assessment of these uncertain consequences. To this end, a loss or utility function must be defined which allows the quantification of benefits, risk, cost or other consequences of different actions. Minimizing the loss function (or maximizing the utility function) then leads to optimal decisions.
3 Data availability and quality
An essential basis for research and for evidence-based policy is high quality data. The mere presence of data is not enough, as the process of data definition, collection and processing determines the quality of the data in reflecting the phenomena on which to provide evidence. Poor definition of data concepts and variables as well as bad choices in their collection and processing can lead to misleading data, that is data with severe bias, or to an unacceptably large remaining level of uncertainty about the phenomena of interest, so that any results generated with that data form an inadequate basis for decision making. Below, we describe which quality characteristics have to be considered when planning a data collection or when assessing the quality of already existing data for a task at hand. The underlying concepts are general and well-known. Despite this, they are regretfully often neglected, and thus, we summarize them as eight characteristics in the context of policy making.
-
1.
Suitability for a target: Data in itself are neither good nor bad, but only more or less suitable for achieving a certain goal. In order to assess data, it is first necessary to understand, agree on, and describe the goal that the data are supposed to support.
-
2.
Relevance: Data must provide relevant information to achieve the goal. To do this, the data must measure the characteristics needed (e.g., how to measure population immunity?) on the right individuals (e.g., representative sample for generalization, or high-resolution data for local action?).
-
3.
Transparency: The data collection process must be transparent in terms of origin, time of data collection and nature of the data. Transparency is a requirement for peer-review processes to ensure correctness of results and for an adequate modeling of uncertainties.
-
4.
Quality standards: Data are well suited for policy making requiring general overviews and spatio-temporal trends if local data collection follows a clear and uniform definition of what is recorded and how it has been recorded. Standardization includes, for example, the harmonization of data processes, adequate training of the persons involved in the collection, and monitoring of the processes.
-
5.
Trustworthiness: To place trust in the data, these must be collected and processed independently, impartially and objectively. In particular, conflicts of interest should be avoided in order not to jeopardize their credibility.
-
6.
Sources of error: Most data contain errors, such as measurement errors, input errors, transmission errors or errors that occur due to non-response. With a good description of data collection and data processing (see ‘Transparency’ above), possible sources of error can be assessed and incorporated into the modeling for the quantification of uncertainty and the interpretation of results.
-
7.
Timeliness and accuracy: Ideally, data used for policy-making should meet all quality criteria. However, information derived from data must additionally be up-to-date, and some decisions (e.g., contact restrictions) cannot be postponed to wait until standardized processes have been defined and implemented, and optimal data have been collected. The greater uncertainty in the data associated with this must be met with transparency and with great care in its interpretation.
-
8.
Access to data for science: In order to achieve the overall goal of evidence-based policy making, it is important to make good data available as a resource to a wide scientific public. This allows for the data to be analyzed in different contexts and with different methods and enables the data to be interpreted from the perspective of different social groups and scientific disciplines.
These eight aspects are included in the European Statistics Code of Practice (European Statistics Code of Practice 2017). This Code of Practice, however, goes beyond the above mentioned points by covering further aspects of statistical processes and statistical outputs as well as an additional section on the institutional environment. The aim is to provide a common quality framework of the European Statistical System.
The items presented above mainly refer to a primary data generating process, that is, when the data are directly generated to provide information on a pre-defined target. Especially in the context of COVID-19, information from available sources often has to be considered, where the data generation does not necessarily coincide with the aim of the study. One prominent example is the number of infections, which are gathered by the local health authorities, but are used for comparing regional incidences which are the basis of several policy decisions. Particular attention in this case has to be paid to selection bias. One way to assess (and thus address) selection bias would come from accompanying information on asymptomatically infected persons gained through representative studies. Other information to mitigate selection bias comes from the number of tests and the reasons for testing, but these are not appropriately reported in Germany. Both problems yield biased regional incidences. Hence, modeling based on these data may cause misleading results and has to be considered carefully. Additionally, the data generating process may be subject to informative sampling (Pfeffermann and Sverchkov 2009).
The above aspects always have to be seen in light of the research question. Incidences and infection patterns need highly different data. Available data are often inappropriate, or must be accompanied by additional data sources. Due to the highly volatile character of COVID-19 infections, data gathering—especially via additional samples—must be very carefully planned to foster the necessary quality to provide the foundation for policy actions (Rendtel et al. 2021).
Representativity implies drawing adequate conclusions from the sample on the population or parameters of the population. To achieve this, known inclusion probabilities on a complete list of elements must be given in order to allow statistical inference. Nowadays, the term representativity is generalized to cover regional smaller granularity, as well as in accordance with the time scale. Further details, especially for subgroup representativity, can be drawn from Gabler and Quatember (2013). In household or business surveys, the term representativity has to be seen in the context of non-response and its compensation (Schnell 2019). In practice, the term representativity is often recognized as a sufficiently high quality sample. This is entirely misleading. Indeed, statistical properties, and especially accuracy, have to be additionally considered (Münnich 2020). Finally, it has to be pointed out that these aspects have to be separately considered for each variable or target of interest.
4 From data to insights: the purposes of modeling
Data and decisions are often linked using statistical models or simulations. As noted in Sect. 2, we refer to data as the input to statistical models irrespective of any preprocessing steps. As such, data preparation, descriptive statistics and preprocessing are not the focus of this paper and are thus not discussed in detail. Nonetheless, they are an essential step in any statistical analysis and especially in a situation such as the COVID-19 pandemic, where data are, in particular in the early stages of a pandemic, sparse and often disorganized. Exploratory data analysis is an important step to check data quality and discover potential anomalies in the data. An important aspect, however, is to keep in mind that data are a product of a complex sequence of steps. Here, transparency concerning the origin of the data and the whole process of data preparation is important and should be included as meta-data. As outlined in the Sect. 2, modeling can serve three purposes. Each of them can be approached from either a statistical or a mathematical modeling perspective. In these models, data can play different roles: while statistical models use data as the basis for the model itself, simulations are based on parameters according to prior information and predictions based on the simulation can be checked against real data to assess the precision and validity of the constructed model.
An important aspect is handling and communicating uncertainty. In statistical models, different types of uncertainty occur: sampling variation, model uncertainty, incomplete data, applicability of information and confounding are common examples (e.g., Altman and Bland 2014; Abadie et al. 2020; Chatfield 1995). In mathematical and decision-analytic models, there are usually alternative approaches to determine the values for key parameters used in simulations. For decision-making purposes, therefore, it is important to compare different methods for determining the indicators. Consequently, in most cases, not a single number but an interval or distribution has to be considered. In the following, we will consider the three purposes of modeling in more detail. For each of them, we provide some mathematical background, explain the difference between statistical models and mathematical or decision-analytic models and give some examples of how these approaches were applied in the COVID-19 pandemic.
4.1 Modeling for explanation
The main goal of these models is to explain patterns, trends or interactions. Statistical models for this purpose include, for example, regression models (Fahrmeir et al. 2007) as well as factor, cluster or contingency analyses (e.g., Fabrigar and Wegener 2011; Duran and Odell 2013). In this context, associations are often misinterpreted as causal relationships. The discovery of correlations and associations, however, cannot be equated to establishing causal claims. In statistics and clinical epidemiology, for example, the Bradford Hill criteria (Hill 1965) can be used to define a causal effect.
From a statistical perspective, there are two possibilities to tackle this issue. The gold standard is to design a randomized experiment, which enables causal conclusions. In the context of the SARS-CoV-2 pandemic, randomized controlled trials were used for assessment of COVID-19 treatments including the RECOVERY platform trial leading to publications such as Horby et al. (2020); Abani et al. (2021); RECOVERY Collaborative Group (2020). In the development of vaccines, too, randomized controlled trials (RCT) played a vital role (e.g., Baden et al. 2021; Shinde et al. 2021). However, randomized experiments are not always feasible due to ethical considerations, cost constraints and other reasons. Moreover, RCTs have been criticised for a number of problems including their lack of external validity (Rothwell 2005) or the Hawthorne effect (Mayo 2004).
Where randomized experiments are not possible and observational data is used instead, causal conclusions are harder to draw. In order to get valid estimates in this situation, a common approach is the counterfactual framework by Rubin (1974). For simplicity, assume that we are interested in the effect of a binary “treatment” \(A \in \{0, 1\}\) (this could be an “ immediate lockdown” vs. “no immediate lockdown”, for example) on some outcome Y (e.g., number of infections with COVID-19). Then we denote \(Y^{a=1}\) as the outcome that would have been observed under treatment \(a=1\), and \(Y^{a=0}\) the outcome that would have been observed under no treatment (\(a=0\)). A causal effect of A on Y is now present, if \(Y^{a=1} \ne Y^{a=0}\) for an individual. In practice, however, only one outcome can be observed for each individual. Thus, it is only possible to estimate an average causal effect, i.e., \(E(Y^{a=1})-E(Y^{a=0})\) (Hernán and Robins 2020). Different possibilities for estimating a causal effect have been proposed, for example, propensity score methods (Cochran and Rubin 1973), the parametric g-formula (Robins et al. 2004), marginal structural models (Robins et al. 2000), structural nested models (Robins 1998) and graphical models (Didelez 2007). Recent works have shown that these methods have difficulties when it comes to small sample studies as in the context of COVID-19 (Friedrich and Friede 2020). Note that the methods explained here can also be applied to more complex situations such as non-binary treatments. In the pandemic, for example, it might be relevant to compare different time points for starting the lockdown, i.e., to include a time dimension in the considerations above. Furthermore, the methods can also be extended to more complicated outcome variables, e.g., time-to-event data.
Mathematical models and simulations can also be used to understand and explain dynamic patterns. Examples are simulation studies for public health interventions such as lockdown and exit strategies, where general consequences of different measures can be compared. Seemingly simple simulation models have played an important role in communicating the dynamics during a pandemic. In these models, assumptions about the system that generates the data and (causal) relationships are made. The (mis)match between data and model then provides insights that can be used as basis for decisions. However, this procedure does not establish causal relationships in the statistical sense described above.
The main challenge in modeling for explanation is good communication, irrespective of whether the model is based on statistical or mathematical approaches. Therefore, we consider standards for good communication in detail in Sect. 6. Anticipating the human bias for interpreting results causally, clear statements need to be made to which extent (from “not at all” to “plausible”) specific detected associations allow some causal interpretation and why. The two extreme interpretations—on the one hand, the simple disclaimer that “correlation is not causation”, on the other, blanket and unqualified causal interpretations—do a disservice to the complexity of the problem as outlined by the methods above.
4.2 Modeling for prediction
In statistical prediction models, the modeler can choose from large toolboxes in (spatio)-time-series analysis as well as statistics and machine learning (ML). Examples cover simple but interpretable ARIMA models (Benvenuto et al. 2020; Roy et al. 2021), support vector machines (Rustam et al. 2020), joint hierarchical Bayes approaches (Flaxman et al. 2020) or state-of-the art ML methods, such as long short-term memory (LSTM) or extreme gradient boosting (XGBoost) (Luo et al. 2021). A comprehensive overview is also given by Kristjanpoller et al. (2021).
For predictions based on such models, one can distinguish different aims: now-casting and forecasting. For now-casting, information up to the current date and state are used to estimate or predict key figures, like the R value, for example, which estimates during a pandemic how many people an infected person infects on average. In forecasting, spatio-temporal predictions or simulations are used to look ahead in time, as in a weather forecast, or to estimate the required number of ICU beds. An important aspect in this situation is that the behavior of people influences the process that is being modeled. To be concrete, policy decisions are based on the predictions of a statistical or mathematical model and by introducing certain counter-measures, the original predictions of the model never come true. Thus, these models are not prediction models in a classical sense but more like projections, i.e., scenarios of what would happen if no intervention was taken. A thorough discussion of this topic can be found in Hellewell (2021). In forecasting models, a causal relationship between the predictors and the outcome may be required, while now-casting can also be achieved with predictive variables that do not necessarily have a causal effect on the outcome. Several statistical models have been proposed for now-casting, for example hierarchical Bayesian models (Günther et al. 2021) or trend regression models (Küchenhoff et al. 2021). Related approaches are discussed in Altmejd et al. (2020), Schneble et al. (2021), Salas (2021).
Dynamic Models/Time-variant Dynamics A unique feature of pandemic assessment is the dynamic nature of the event. By this, we not only refer to the explosive (exponential) growth that may occur but the fact that the properties of the processes that describe spatio-temporal changes are a function of time themselves. This is due to the fact that the behavior of the people continuously changes the properties of the system that we are trying to understand and make predictions for. This contrasts with other natural systems, like the current weather, and most systems in the engineering and physical sciences.
Simple infectious disease compartmental models can be described by the stock of susceptible S, infected I, and removed population R (either by death or recovery), the contact rate \(\kappa\), the infection probability \(\beta\), the recovery rate \(\gamma\), the death rate \(\mu\) and the birth rate \(\varLambda\) (Kermack and McKendrick 1927; Hethcote 2000; Andersson and Britton 2012; Grassly and Fraser 2008). Here,
where t denotes the time point, and N is the total number of individuals in the population, i.e., \(N=I + S + R\).
Assuming that the susceptible individual first goes through a latent period after infection before becoming infectious E, adapted models such as SEI, SEIR or SEIRS, depending on whether the acquired immunity is permanent or not can be applied (Jit and Brisson 2011). Modeling the COVID-19 pandemic, applications include further approaches such as SIR-X accounting for the removal (quarantine) of symptomatic infected individuals and various other extensions and applications (Dehning et al. 2020; Dings et al. 2021) including prediction of the impact of vaccination (Bubar et al. 2021).
In this deterministic compartment model, predictions are determined entirely by their initial conditions, the set of underlying equations, and the input parameter values. Deterministic compartmental models have the advantage of being conceptually simple and easy to implement, but they lack for example stochasticity inherent in infectious disease transmission. In stochastic compartment models, the occurrence of events like transmission of infection or recovery is determined by probability distributions. Therefore, the chain of events (like an outbreak) is not exactly predictable. However, there are many possible types of stochastic epidemic models (Britton 2010; Kretzschmar et al. 2020).
Agent-based models (ABM) Agent-based modeling as an alternative approach uses individual-level simulation (Karnon et al. 2012). ABMs have been used to model biological processes, ecological systems, traffic management, customer flow management or stock markets, and in recent years increasingly for decision analysis as discussed later (Marshall et al. 2015; Bonabeau 2002; Macal and North 2008). ABMs represent complex systems in which individual ‘agents’ act autonomously and are capable of interactions (Miksch et al. 2019). These agents can represent the heterogeneity of individuals, and the behavior of individuals can be described by simple rules. Such rules include how agents interact, move between geographical zones, form households or consume resources (Chhatwal and He 2015; Bruch and Atwell 2015; Hunter et al. 2017). ABMs are often applied to study “emergent behavior” as a result of these predefined rules. In infectious disease modeling, agent behaviors combined with transmission patterns and disease progression lead to population-wide dynamics, such as disease outbreaks (Macal and North 2010). In agent-based models, either all affected individuals are simulated individually, or specific networks of individuals are integrated into the simulation.
Discrete Event Simulation (DES) Discrete event simulation is an individual-level simulation (Pidd 2004; Karnon et al. 2012; Jun et al. 1999; Zhang 2018). The core concepts of DES are entities (e.g., patients), attributes (e.g., patient characteristics), events, resources (i.e., physical resources such as medical staff and medical equipment), queues and time (Pidd 2004; Banks et al. 2005; Jahn et al. 2010). In addition to health outcomes, performance measures such as resource use or waiting times can be calculated, as physical resources (e.g., hospital beds) can be explicitly modeled (Jahn et al. 2010). The term discrete refers to the fact that DES moves forward in time at discrete intervals (i.e., the model jumps from the time of one event to the time of the next) and that events are discrete (mutually exclusive) (Karnon et al. 2012).
Microsimulation Microsimulation methods, introduced by Orcutt (1957), are used to simulate policy actions on real populations. Li and O’Donoghue (2013) describe microsimulations as “a tool to generate synthetic micro-unit-based data, which can then be used to answer many “what-if” questions that, otherwise, cannot be answered”. The main difficulty for microsimulation is considered to be the choice of an appropriate data source on which these simulations can be conducted. Often, survey data are used. Nowadays, the first step in microsimulation is the realistic generation of data in the necessary geographic depth (e.g., Li and O’Donoghue 2013). A full-population approach is described in Münnich et al. (2021). Thereafter, the scenario-based microsimulation analysis yields the necessary information for building conclusions for policy support. In microsimulation methods, we distinguish between static and dynamic models. The latter can be divided into time-continuous and time-discrete models. An overview of microsimulation methods is given in Li and O’Donoghue (2013) and the references therein. For modeling COVID-19, dynamic models have to be considered. Bock et al. (2020) presents a continuous time SIR microsimulation approach as an example for a dynamic transmission model. In contrast to ABM, other microsimulations are often based on survey data, or on realistic but synthetically extended survey data. The above-mentioned cohort simulations are usually deterministic simulations, in which an initial cohort of interest is followed over different paths over time, and thus leading to a distribution of outcomes after the analytic-time horizon. Recently, the dividing line between these methods and the related terminology has become blurred, Which method is ultimately used often depends on the background of the research team.
A key objective of forecasting in this context is to obtain numerically precise predictions, for variables such as the number of ICU beds. With this goal in mind, the reliability or accuracy of the predictions highly depends on the availability and quality of the data used to estimate the values of the parameters in the underlying mathematical or statistical models.
It should be noted that these models are highly sensitive to context in the following sense: changes in the underlying system in variables that are not part of the model can lead to changes in the relationship between the selected predictors and the predictions, rendering the predictions and their assumed uncertainty meaningless.
While it is widely appreciated that, for example, weather forecasts are only reliable for a couple of days, forecasting during a pandemic is even more complicated since the behavior of people influences the process that is being modeled. Forecasting during pandemics is, therefore, itself a continuous process with time-varying parameters. For this reason, such modeling effort is a complex undertaking requiring a range of data and expertise. Such activities should, therefore, be realized and coordinated through cross-disciplinary teams. To account for regional differences, one would expect a collective of modeling groups that support decision making for different parts of a country.
4.3 Decision-analytic modeling
Depending on the research question, different modeling approaches are used for decision-analytic modeling and development of computer simulations (IQWiG 2020; Roberts et al. 2012; Stiko 2016). These include decision tree models, state-transition models, discrete event simulation models, agent-based models and dynamic transmission models. Some of them have been introduced already since they are also commonly used for prediction. Models introduced in this section are predominantly used for decision analysis but could potentially be used for other purposes as well (Table 1).
The selection of the model type depends on the decision problem and the disease. In general, decision trees are applied for simple problems, without time-dependent parameters and with a fixed and comparatively short time horizon. If the decision problem requires the evaluation over a longer time period and if parameters are time or age dependent, a state-transition cohort (Markov) models (STM) could be applied. STMs allow for the modeling of different health states and transitions between these states and thus also for repeated events. They are applied when time to event is important. If the decision problem can be represented in an STM “with a manageable number of health states that incorporate all characteristics relevant to the decision problem, including the relevant history, a cohort simulation should be chosen because of its transparency, efficiency, ease of debugging and ability to conduct specific value of information analyses.” (Siebert et al. 2012). If the representation of the decision problem would lead to an unmanageable number of states, then an individual-level state-transition model is recommended (Siebert et al. 2012). Especially in situations where interactions of individuals among each other or the health-care system need to be considered, that is, when we are confronted with scarce physical resources, queuing problems and waiting lines (e.g., limited testing capacities), discrete event simulation (DES) would be an appropriate modeling technique. DES allows the modeler to incorporate time-to-event data (e.g., time to progression), and physical resources are explicitly defined (Karnon et al. 2012). Modeling types such as differential equation systems, agent-based models and system dynamics account for the specific features of infectious diseases such as the transmissibility from infected to susceptible individuals and the uncertainties arising from complex natural history and epidemiology (Pitman et al. 2012; Grassly and Fraser 2008; Jit and Brisson 2011).
Decision tree models In a decision-tree model, the consequences of alternative interventions or health technologies are described by possible paths. Decision trees start with decision nodes, followed by alternative choices (interventions, technologies, etc.) of the decision maker. For each alternative, the patients’ paths, which are determined by chance and that are outside the decision maker’s control, are then described by chance nodes. At the end of the paths, the respective consequences of each path are shown. Consequences or outcomes may include symptoms, survival, quality of life, number of deaths or costs. Finally, the expected outcomes of each alternative choice are calculated by taking a weighted average over all pathways (Hunink et al. 2001; Rochau et al. 2015), such as in the evaluation of COVID-19 testing strategies for university campuses in a decision-tree analysis (Van Pelt et al. 2021).
State-transition models A state-transition model is conceptualized in terms of a set of (health) states and transitions between these states. Time is represented in time intervals. Transition probabilities, time cycle length, state values (“rewards”) and termination criteria are defined in advance. During the simulations, individuals can only be in one state in each cycle. Paths of individuals determined by events during a cycle are modeled with a Markov cycle tree that uses a set of random nodes. The average number of cycles in which individuals are in each state can be used in conjunction with the rewards (e.g., life years, health-related quality of life or costs) to estimate the consequences in terms of life expectancy, quality-adjusted life expectancy, and the expected costs of alternative interventions or health technologies. There are two common types of analyses of state-transition models: Cohort models (“Markov”) (Beck and Pauker 1983; Sonnenberg and Beck 1993) and individual-level models (“first order Monte Carlo” models) (Spielauer 2007; Groot Koerkamp et al. 2010; Weinstein 2006). Simple cohort models are defined in mathematical literature as discrete-time Markov chains. A discrete-time Markov chain is a sequence of random variables \({\displaystyle X_{0},X_{1},X_{2},\ldots }\) representing health states with the Markov property, namely that the probability of moving to the next health state depends only on the present state and not on the previous states:
Generalized models such as continuous time Markov chains with finite or infinite state space are not commonly applied in health decision science. Applications of state-transition models in the pandemic include evaluation of treatments (Sheinson et al. 2021) and vaccination strategies (Kohli et al. 2021). We also find hybrid models including the combination of decision trees and STMs (see Fig. 2).

Example: a cost-effectiveness framework for COVID-19 treatments for hospitalized patients in the United States, (Sheinson et al. 2021)
Discrete Event Simulation (DES) Similar to decision trees and state-transition models, health outcomes and costs of alternative health technologies can be assessed. In addition to these outcomes, as mentioned earlier, performance measures can be calculated as additional information for decision makers, and the impact of scarce resources on costs and health outcomes can be evaluated (Jahn et al. 2010). The increased use of DES to support decision making under uncertainty is shown in the review of Zhang (2018). Model applications in COVID-19 include optimizations of processes with scarce resources such as bed capacities (Melman et al. 2021) or testing stations (Saidani et al. 2021) and laboratory processes (Gralla 2020).
Dynamic Models/Time-variant Dynamics The dynamic SIR type models explained in Sect. 4.2 can also be used in the context of decision-analytic modeling (e.g., vaccination allocation, ECDC 2020a; Sandmann et al. 2021) . This model type can be extended by further compartments such as Death (D) and other states (X), reflecting, for example, quarantine or other states relevant to the research question. Such SIRDX models have been used frequently to model non-pharmaceutical intervention effects during the COVID-19 pandemics (Nussbaumer-Streit et al. 2020). As in Markov state-transition models, a deterministic cohort simulation approach is used to model the distribution of compartments over time. Deterministic compartment models are useful for modeling the average behavior of disease epidemics in larger populations. When stochastic effects (e.g., the extinction of disease in smaller populations), more complex interactions between disease and individual behavior or distinctly nonrandom mixing patterns (e.g., the spread of the disease in different networks) are relevant, stochastic agent-based approaches can be used (see next section).
Agent-based models (ABM) Agent-based models as introduced earlier, have been used for decision analysis, for example for cost-effectiveness analyses in health care in the recent years (Marshall et al. 2015; Chhatwal and He 2015). ABMs are also used in public health studies to model noncommunicable diseases (Nianogo and Arah 2015). A comparison of ABM, DES and system dynamics can be found in Marshall et al. (2015), Marshall et al. (2015) and Pitman et al. (2012). ABMs are increasingly applied for COVID-19 evaluations including decision support for vaccination allocation accounting explicitly for network structure and contact behavior (Bicher et al. 2021; Jahn et al. 2021).
Microsimulation Microsimulation as a modeling approach based on survey data and combining characteristics of above mentioned modeling approaches is used for prediction and decision analysis in various fields, especially for policy support using scenarios. Recently, MSM are also used for modeling diseases (Hennessy et al. 2015) including infectious diseases.
Table 2 provides a short comparative overview of these commonly applied modeling approaches with example applications for COVID-19 research, in addition to our general comparison at the beginning of the section. Further guidance on model selection for a given problem at hand exists (IQWiG 2020; Roberts et al. 2012; Siebert et al. 2012; Marshall et al. 2015).
5 Decision analysis
The models described in Sect. 4 are built to inform decision making. Therefore, the so-called decision analysis framework is used. Decision analysis aims to support decisions under uncertainty by means of systematic, explicit and quantitative methods. In particular, computer simulations and prediction models as described above are used to calculate the short-term and long-term benefits and harms (as well as the costs) of alternative interventions, technologies or measures in health care (Schöffski and Schulenburg 2011; Richardson and Spiegelhalter 2021). The decision-analytic framework includes, among other things, the relevant health states and events considered to describe possible disease trajectories, the type of analysis (e.g., benefit-harm, cost-benefit, budget-impact analyses (Drummond et al. 2005)) and the simulation method (cohort- or individual-based). In addition to base-case analysis (using the most likely parameters), scenario and sensitivity analyses (Briggs et al. 2012) should be performed to show the robustness or uncertainty of the results. Value of information analysis can be applied to assess the value of future research to reduce uncertainty (Fenwick et al. 2020; Siebert et al. 2013).
5.1 Decision tradeoffs
A central idea in decision analysis is that tradeoffs in outcomes of alternative choices are formalized and, if possible, quantified. In addition, the tradeoff between such outcomes is explicitly expressed, usually in the form of an incremental tradeoff ratio. In the context of a benefit-harm analysis, for example, this relates to quantifying the benefits of COVID-19 vaccination in terms of (incremental) deaths avoided and the harms of vaccination in terms of (incremental) potential side effects.Alternatively, the tradeoff of different school closure strategies in a pandemic (e.g., according to incidence level) weighting benefits in terms of (incremental) deaths or hospitalisations avoided and lost education time should be considered. In general, two or more interventions can be compared in a stepwise incremental fashion (Keeney and Raiffa 1976). Benefit-harm analyses are often applied in screening evaluations (Mandelblatt et al. 2016; Sroczynski et al. 2020). To detect efficient strategies, so-called strongly dominated strategies are first excluded. These are strategies that result in higher harms (e.g., due to testing or invasive diagnostic work-up) and lower benefits (e.g., cancer-cases avoided, life-years gained) than other strategies. Second, weakly dominated strategies are excluded, that is strategies that result in higher harms per additional benefit compared with the next most harmful strategy, or in other words, strategies that are strongly dominated by a linear combination of any two other strategies. Third, the incremental harm-benefit ratios (IHBRs) are calculated for the non-dominated strategies.
There is no general benchmark for how much additional harm individuals are willing to accept per unit of additional benefit. Strategies are explored as a function of willingness-to-accept thresholds, and they are displayed as harm-benefit acceptability curves on the efficiency frontier (Neumann et al. 2016).
In this context, the choice of measures that are presented and discussed also influences decision behavior (Ariely and Jones 2008). The same applies to changes in decision-making due to alternatives that are presented. Regarding optimization of vaccination interventions, temporal aspects of availability and effectiveness of vaccinations can be considered. Alternative strategies can be evaluated, like in the comparison of immediate vaccination with lower vaccine protection, against later vaccination with expected higher effectiveness but risk of intermediate infection. Further non-pharmaceutical measures like school-closure strategies can be evaluated depending on incidence level but also accounting for additional measures to reduce the spread of the disease.
5.2 Statistical decision theory
As a more general framework, statistical decision theory can help to make decisions on a formal basis. In this framework, the decision maker has to choose among a set of different actions a by quantitatively assessing the consequences of these actions. To this end, we consider a loss function \(L(\theta , a)\), where the unknown parameter \(\theta\) refers to the “state of the world”. The interesting question for the statistician is how to use the data in order to make optimal decisions. Assume we observe an experimental outcome x with possible values in a set \(\mathcal {X}\), which depends on the unknown parameter \(\theta\). Furthermore, let \(f(x | \theta )\) be the corresponding likelihood function. Then, we define a decision function \(\delta (x)\) which turns data into actions (Parmigiani and Inoue 2009). To choose between decision functions, we measure their performance by a risk function
These can be approached from either a frequentist perspective (e.g., the minimax decision rule) or a Bayesian perspective, where the risk is associated with a prior distribution \(\pi (\theta )\). For a more thorough treatment of these concepts, we refer to Parmigiani and Inoue (2009).
Examples for loss functions in the context of COVID-19 include the number of avoided deaths (Bubar et al. 2021), negative reward functions in Markovian decision models (Eftekhari et al. 2020) or the social loss function as proposed in a recent discussion paper of the European Commission (Buelens et al. 2021).
6 Reporting and communication
For data analysis and modeling to have an impact as a component of decision making, appropriate reporting and communication is key. There are numerous standards and guidelines for study planning and statistical reporting in the numerous application areas, such as the ESS standard for quality reporting, the CONSORT, PRISMA, CHEERs guidelines and others (see https://equator-network.org). These standards are based on commonly accepted core quality principles and values such as accuracy, relevance, timeliness, clarity, coherence and reproducibility. For measures to restrain and overcome an epidemic effectively, communication among experts that follows highest professional and ethical standards is not sufficient. In a democratic society, policy measures can only be implemented if they are accepted by the wider population. This puts high demand on skills associated with communicating statistical evidence on the side of scientists, governments and media, and a citizenry able to understand statistical messages.
In recent decades, there have been numerous publications, initiatives, and ideas to improve the communication of quantitative and statistical information, see Hoffrage et al. (2000), Tufte (2001), Rosling and Zhang (2011), Otava and Mylona (2020), to name only a few. Data journalism has recently taken off as an innovative component of news publishing, and COVID-19 provides numerous excellent examples, often using an interactive visual format on the Internet, such as dashboards. A fundamental problem in assessing probabilities, for example, lies in the intuitive conflation of subjective risks (“how likely am I to become infected”) and general risks (“how likely is it that some person will become infected”). Another issue is that of equating sensitivity of a diagnostic test and the positive predictive value (Eddy 1982; Gigerenzer et al. 2007; McDowell et al. 2019; Binder et al. 2020). In particular, the prevalence (or base rate) is often neglected leading to this confusion. Fact boxes combined with icon arrays are recommended for the presentation of test results. Both representations are based on natural frequencies (Gigerenzer 2011; Krauss et al. 2020) and present case numbers as simply and concretely as possible. Many scientific studies show that icon arrays help people understand numbers and risks more easily (e.g., McDowell et al. 2019). The Harding Center for Risk Literacy shows many other examples of transparent communication of risks, including COVID-19Footnote 1 and a collection of misleading or wrong communication of statistics, such as for vaccination effects (“Unstatistik”).
When communicating the results of an analysis to policy makers or the general public, the following aspects must also be kept in mind. While human thinking tends towards pattern simplification and political communication also prefers a simple cause-effect relationship, real phenomena are often multivariate. Thus, when studying COVID-19 and predicting its spread, it is important to consider its symptomatology, the incidence and geographic distribution of diseases, population behavior patterns, government policies and impacts on the economy, on schools, on people in nursing homes and on social life as a whole. However, it is also crucial to integrate these into data analyses and to communicate results clearly and transparently; for example, it might be important to state that associations observed in the data could be caused by other, omitted variables (confounders). In addition, much of the data comes from observational studies, which usually makes a robust causal attribution problematic. As many of these phenomena cannot be studied other than by observation (for ethical and feasibility reasons), causal attribution might be achieved as a scientific consensus opinion among scientists from the relevant disciplines that understand the complexity of the models and the subject matter studied. Visual representations take a central position in public communication and aim to represent the corresponding dynamics and contents in a quickly understandable way. Usually either time-dependent parameters or data with a spatial reference are visualized. For spatially distributed data, choropleth maps are predominantly used, in which administrative regions defined by the responsible health authorities are colored according to the distribution density of the infection figures or variables derived from them (see Fig. 3). Their visual perception problems—such as the visual dominance of the area of administrative regulatory frameworks that have no direct relation to infection events—are well known but the effects of such problems are still widespread. In addition, the use of ordinance thresholds as the basis for color scaling is often at odds with color schemes that emphasize real spatial distributional differences.

Choropleth map of the incidence figures on 2021-02-12 for Germany by district. Source: Robert-Koch-Institute https://app.23degrees.io/export/oCRP768wQ3mCswE7-choro-corona-faelle-pro-100-000/image
For time-dependent parameters, different variants of time series diagrams are used, predominantly line and column diagrams. The use of logarithmic scales in time series diagrams should be evaluated with caution (Romano et al. 2020). On the one hand, they tempt superficial readers to underestimate dynamic growth processes; on the other hand, they increase the demands on the mathematical and statistical literacy of the readership without corresponding advantages of visual representation. Figure 4 shows the time course of the 7-day incidence per 100,000 people between 24 January and 4 February 2021 for some selected countries. While the differences appear relatively small on the logarithmic scale, the linear scale shows considerable differences.

The 7-day incidence for different countries over time. On the logarithmic scale (top graphic), differences appear small. The linear scale (bottom graphic), however, shows considerable differences. Source: Our World in Data, https://ourworldindata.org/covid-cases?country=INDUSAGBRCANDEUFRA, accessed 2022-02-22
7 Recommendations
Reaching a decision based on data requires several steps, which we have illustrated in this paper: Data provide the basis for different kinds of models, which can be used for prediction, explanation and decision making. This forms the basis for making decisions within a formal framework. The results of these models must be communicated to non-scientists in order to gain acceptance of and adherence to policy decisions. Each of these steps comes with its own caveats and requires sound statistical knowledge.
Data: Lessons learned from the current pandemic about data, variables and information that should be obtained are critically discussed for specific countries (Grossmann et al. 2022; The Royal Statistical Society 2021; Rendtel et al. 2021) and on a European and international level (Kucharski et al. 2021; ECDC 2020b), (Dean 2022; Mathieu 2022). Examples include establishing new vaccination registries, extending coronavirus registries with further socio-demographic parameters and data sharing. We recommend the implementation of standards (European Statistics Code of Practice 2017) and processes for data collection on a national and international level, especially within Europe. These standards need to be refined, meeting the requirements of relevance, transparency, truthfulness, timeliness and accuracy to improve the handling of epidemics and pandemics in the coming years. National and international strategies and systematic collection and sharing of data allowing researchers to access the information that is important to build comparable statistical and decision-analytic models.
Modeling Methods: Depending on the modeling approach, the model can be fit to one data set (e.g., regression model) or data from different sources with different levels of evidence can be used to populate the model (e.g., decision-analytic models). In addition, several modeling approaches may be applicable for one research question (e.g., differential equation model or ABM for the prognosis of COVID-19 spread and consequences). We recommend clear communication about 1) the purpose of the model, 2) how the model uses data, 3) the database or additional assumptions and their evidence basis, and 4) risks and uncertainties. If applicable, several modeling approaches should be applied. As a result, the model best fitting the data would be selected or different modeling approaches could provide insights into uncertainty, like in national forecasting consortia (e.g., as in the Austrian COVID Prognosis Consortium (CPK 2021)) and nowcast/forecast ensembles. The infrastructure of comprehensive population or microsimulation models—including population, disease and flexible intervention or policy modules—needs to be established and maintained beyond the current crisis.
Data Aquisition: Models require data from various sources, and different modeling approaches allow data transformation and synthesis from different sources. Data aquisition for scientific evaluations requires a further improved infrastructure to speed up model development and to parameterize models with high level evidence including vaccine effectiveness in real time. We recommend the creation of a central national DataLab, collecting data in a unified way and linking data from different sources as well as enabling accessibility for experienced users. With regard to data sharing, it is important that this is manageable from a practical point of view in terms of the time frame and resources needed.
Transparency: In the wake of the COVID-19 pandemic, reporting of infection numbers and derived epidemiological indicators boomed, demonstrating with dramatic clarity the knowledge gap between experts, policymakers and the public. To increase the acceptance of decisions and associated measures, all steps in the decision-making process must be disclosed. We recommend a transparent decision-making process and communication of this process starting with the data, continuing with the choice of models, relevant perspectives, outcomes or metrics for several outcomes and an explicit discussion of considered tradeoffs (see, e.g., Gigerenzer et al. 2007; Gigerenzer and Edwards 2003; Richardson and Spiegelhalter 2021). In this context, the media also play a crucial role.
Interdisciplinary cooperation: A pandemic poses particular challenges to society as a whole. In order to tackle these as efficiently as possible, interdisciplinary cooperation, such as that fostered by the DAGStat, is essential. We recommend that experts act as a specialist group rather than as individuals, broadly positioned and media-sensitive. These interdisciplinary collaborations should consist of data scientists including statisticians, epidemiologists, experts in public health, social sciences and ethics, as well as decision and communication scientists. The DAGStat as an umbrella organization of various professional societies, the Competence Network Public Health COVID-19 or the Society for Medical Decision Making (SMDM) are examples for existing networks that can be built upon.
Statistical Literacy / Data Literacy: The COVID-19 crisis brought into the general public’s awareness that our social interaction and political decisions are essentially based on data, modeling, the weighing of risks and benefits, and thus on probability estimates, expected values and incremental harm-benefit ratios. Clearly, we need additional efforts to promote statistical or data literacy at all levels of society. The ability to critically evaluate and interpret data and to critically reflect on model outcomes serves to promote maturity in a modern digitized world. We recommend promotion of statistical literacy to be intensified at all levels of education (school/vocational education/training) following the Data Literacy Charta (Schüller et al. 2021) and including risk competency (Ball et al. 2020; Loss et al. 2021). Therefore, collaboration between statisticians and all stakeholders involved in statistical literacy is necessary.
8 Discussion
In our paper, we discussed all steps starting from data capturing to statistics, modeling, decision making and communication which are important aspects in the context of evidence-based decision making. The current pandemic has shown that, in particular in Germany, we are still far from such an evidence-based decision-making process. Aims of this process include the following: First, it should result in the best possible decision given the available evidence, and it is necessary to explicitly consider the tradeoffs involved with certain interventions. Second, gaining the public’s acceptance of the decisions is fundamental. In order to achieve these goals, we need reliable data, careful interpretation of the results and a clear communication, especially concerning uncertainty, see, for instance, WHO (2020).
It is important to note that the considerations described in our paper not only apply to the current pandemic, but also extend to future pandemicsFootnote 2 and other (public or political) challenges such as the climate change debate (Ritchie 2021).
Our paper has several limitations. First, we refer to data as the input to the statistical models irrespective of possible preprocessing steps. An upcoming publication on data and data infrastructure in Germany will include more details on data preparation, building upon the DAGStat white paper (Deutsche Arbeitsgemeinschaft Statistik 2021). Second, our overview of modeling techniques does not provide a detailed discussion of all modeling approaches and their advantages and limitations but it should foster interdisciplinary collaboration among data scientists. References on guidance papers provide valuable further readings. Third, the decision-making process involves a variety of stakeholders, including politicians, government agencies and health authorities, health care providers, citizens, patients and their relatives, scientists, and they all take different perspectives. We have not discussed this aspect in detail in our paper, but the original white paper included a paragraph on political decision making (Deutsche Arbeitsgemeinschaft Statistik 2021).
The German Consortium in Statistics (DAGStat), a network of 13 statistical associations and the German Federal Office of StatisticsFootnote 3 and the Society for Medical Decision Making (SMDM), initiated a collaboration of scientists with backgrounds in all areas of statistics as well as epidemiology, decision analysis and political sciences to critically discuss the role of data and statistics as a basis for decision-making motivated by the COVID-19 pandemic. We found that similar concepts are often considered in different areas, but different notation and wording can hinder transferability. In this sense, this paper also aims to bridge the gaps between disciplines and to broaden the research focus of statistical disciplines to prepare for future pandemics.
References
Abadie, A., Athey, S., Imbens, G.W., Wooldridge, J.M.: Sampling-based versus design-based uncertainty in regression analysis. Econometrica 88(1), 265–296 (2020)
Abani, O., Abbas, A., Abbas, F., Abbas, M., Abbasi, S., Abbass, H., Abbott, A., Abdallah, N., Abdelaziz, A., Abdelfattah, M., et al.: Convalescent plasma in patients admitted to hospital with COVID-19 (RECOVERY): a randomised controlled, open-label, platform trial. The Lancet 397(10289), 2049–2059 (2021)
Altman, D.G., Bland, J.M.: Uncertainty beyond sampling error. BMJ 349, g7065 (2014)
Altmejd, A., Rocklöv, J., Wallin, J.: Nowcasting Covid-19 statistics reported with delay: a case-study of Sweden. (2020). arXiv:2006.06840
Andersson, H., Britton, T.: Stochastic Epidemic Models and Their Statistical Analysis, vol. 151. Springer, Berlin (2012)
Anker, S.D., Butler, J., Khan, M.S., Abraham, W.T., Bauersachs, J., Bocchi, E., Bozkurt, B., Braunwald, E., Chopra, V.K., Cleland, J.G., Ezekowitz, J., Filippatos, G., Friede, T., Hernandez, A.F., Lam, C.S.P., Lindenfeld, J., McMurray, J.J.V., Mehra, M., Metra, M., Packer, M., Pieske, B., Pocock, S.J., Ponikowski, P., Rosano, G.M.C., Teerlink, J.R., Tsutsui, H., Van Veldhuisen, D.J., Verma, S., Voors, A.A., Wittes, J., Zannad, F., Zhang, J., Seferovic, P., Coats, A.J.S.: Conducting clinical trials in heart failure during (and after) the COVID-19 pandemic: an Expert Consensus Position Paper from the Heart Failure Association (HFA) of the European Society of Cardiology (ESC). Eur. Heart J. 41(22), 2109–2117 (2020)
Ariely, D., Jones, S.: Predictably Irrational. Harper Audio, New York (2008)
Baden, L.R., El Sahly, H.M., Essink, B., Kotloff, K., Frey, S., Novak, R., Diemert, D., Spector, S.A., Rouphael, N., Creech, C.B., McGettigan, J., Khetan, S., Segall, N., Solis, J., Brosz, A., Fierro, C., Schwartz, H., Neuzil, K., Corey, L., Gilbert, P., Janes, H., Follmann, D., Marovich, M., Mascola, J., Polakowski, L., Ledgerwood, J., Graham, B.S., Bennett, H., Pajon, R., Knightly, C., Leav, B., Deng, W., Zhou, H., Han, S., Ivarsson, M., Miller, J., Zaks, T.: Efficacy and safety of the mRNA-1273 SARS-CoV-2 Vaccine. N. Engl. J. Med. 384(5), 403–416 (2021)
Ball, D., Humpherson, E., Johnson, B., McDowell, M., Ng, R., Radaelli, C., Renn, O., Seedhouse, D., Spiegelhalter, D., Uhl, A., Watt, J.: Improving Society’s Management of Risks—a statement of principles. Collaboration to explore new avenues to improve public understanding and management of risk (CAPUR). Atomium, EISMD (2020)
Banks, J., Carson, J.S., Nelson, B.L., Nicol, D.M.: Discrete Event System Simulation. Pearson Education India, New Delhi (2005)
Beck, J.R., Pauker, S.G.: The Markov process in medical prognosis. Med. Decis. Mak. 3(4), 419–458 (1983)
Benvenuto, D., Giovanetti, M., Vassallo, L., Angeletti, S., Ciccozzi, M.: Application of the ARIMA model on the COVID-2019 epidemic dataset. Data Brief 29, 105340 (2020)
Beyersmann, J., Friede, T., Schmoor, C.: Design aspects of COVID-19 treatment trials: improving probability and time of favorable events. Biometr. J. (2021)
Bicher, M., Rippinger, C., Urach, C., Brunmeir, D., Siebert, U., Popper, N.: Evaluation of Contact-Tracing Policies against the Spread of SARS-CoV-2 in Austria: An Agent-Based Simulation. Medical decision making : an international Journal of the Society for Medical Decision Making pp. 1–16 (2021)
Binder, K., Krauss, S., Wiesner, P.: A new visualization for probabilistic situations containing two binary events: the frequency net. Front. Psychol. 11, 750 (2020)
Bock, W., Adamik, B., Bawiec, M., Bezborodov, V., Bodych, M., Burgard, J.P., Goetz, T., Krueger, T., Migalska, A., Pabjan, B., et al.: Mitigation and herd immunity strategy for COVID-19 is likely to fail. medRxiv (2020)
Bonabeau, E.: Agent-based modeling: Methods and techniques for simulating human systems. Proc. Natl. Acad. Sci. 99(suppl 3), 7280–7287 (2002)
Briggs, A.H., Weinstein, M.C., Fenwick, E.A.L., Karnon, J., Sculpher, M.J., Paltiel, A.D.: Model Parameter Estimation and Uncertainty Analysis: A Report of the ISPOR-SMDM Modeling Good Research Practices Task Force Working Group-6. Med. Decis. Making 32(5), 722–732 (2012)
Britton, T.: Stochastic epidemic models: A survey. Math. Biosci. 225(1), 24–35 (2010)
Bruch, E., Atwell, J.: Agent-based models in empirical social research. Sociological Methods & Research 44(2), 186–221 (2015)
Bubar, K.M., Reinholt, K., Kissler, S.M., Lipsitch, M., Cobey, S., Grad, Y.H., Larremore, D.B.: Model-informed COVID-19 vaccine prioritization strategies by age and serostatus. Science 371(6532), 916–921 (2021). https://doi.org/10.1126/science.abe6959,https://www.science.org/doi/abs/10.1126/science.abe6959
Buelens C, et al. (2021) Lockdown policy choices, outcomes and the value of preparation time - a stylised model. Tech. rep., Directorate General Economic and Financial Affairs (DG ECFIN), European Commission
Chatfield, C.: Model uncertainty, data mining and statistical inference. J. R. Stat. Soc. A. Stat. Soc. 158(3), 419–444 (1995)
Chhatwal, J., He, T.: Economic evaluations with agent-based modelling: an introduction. Pharmacoeconomics 33(5), 423–433 (2015)
Cochran, W.G., Rubin, D.B.: Controlling bias in observational studies: A review. Sankhyā: The Indian Journal of Statistics, Series A pp. 417–446 (1973)
COVID-19 Data Analysis Group: CODAG Berichte. (2021). https://www.covid19.statistik.uni-muenchen.de/newsletter/index.html
CPK: Covid-prognose-konsortium. (2021). https://www.sozialministerium.at/Informationen-zum-Coronavirus/Neuartiges-Coronavirus-(2019-nCov)/COVID-Prognose-Konsortium.html
Dean, N.: Tracking COVID-19 infections: time for change. Nature 602(7896), 185 (2022). https://doi.org/10.1038/d41586-022-00336-8
Debrabant, K., Grønbæk, L., Kronborg, C.: The cost-effectiveness of a covid-19 vaccine in a danish context. Clin. Drug Investig. 41, 975–988 (2021)
DeGroot, M.H., Schervish, M.J.: Probability and Statistics. Pearson Education Limited, New Delhi (2014)
Dehning, J., Zierenberg, J., Spitzner, F.P., Wibral, M., Neto, J.P., Wilczek, M., Priesemann, V.: Inferring change points in the spread of COVID-19 reveals the effectiveness of interventions. Science 369(6500), (2020)
Desrosières, A.: A politics of knowledge-tools: The case of statistics. Between Enlightenment and Disaster: Dimensions of the Political Use of Knowledge, Brussels: Peter Lang pp 111–129 (2010)
Deutsche Arbeitsgemeinschaft Statistik: Stellungnahme der DAGStat. Daten und Statistik als Grundlage für Entscheidungen: Eine Diskussion am Beispiel der Corona-Pandemie. (2021). https://www.dagstat.de/fileadmin/dagstat/documents/DAGStat_Covid_Stellungnahme.pdf
Didelez, V.: Graphical models for composable finite Markov processes. Scand. J. Stat. 34(1), 169–185 (2007)
Dings, C., Götz, K., Och, K., Sihinevich, I., Selzer, D., Werthner, Q., Kovar, L., Marok, F., Schräpel, C., Fuhr, L., Türk, D., Britz, H., Smola, S., Volk, T., Kreuer, S., Rissland, J., Lehr, T.: COVID-19 Simulator. (2021). https://covid-simulator.com/en
Drummond, M., Sculpher, M., Torrance, G., O’Brien, B., Stoddart, G.: Methods for the economic evaluation of health care programmes, 3rd edn, Oxford University Press, New York, USA, chap Chapter 2: Basic types of economic evaluation, pp. 6–33 (2005)
Drummond, M.F., Schwartz, J.S., Jönsson, B., Luce, B.R., Neumann, P.J., Siebert, U., Sullivan, S.D.: Key principles for the improved conduct of health technology assessments for resource allocation decisions. Int. J. Technol. Assess. Health Care 24, 244–258 (2008)
Duran, B.S., Odell, P.L.: Cluster analysis: a survey, vol. 100. Springer, Berlin (2013)
EbM-Netzwerk: COVID-19: Wo ist die Evidenz? (2020). https://www.ebm-netzwerk.de/de/veroeffentlichungen/stellungnahmen-pressemitteilungen
ECDC: Covid-19 vaccination and prioritisation strategies in theeu/eea. (2020a). https://www.ecdc.europa.eu/sites/default/files/documents/COVID-19-vaccination-and-prioritisation-strategies.pdf
ECDC: Strategic andperformance analysisof ecdc response tothe covid-19 pandemic. (2020b). https://www.ecdc.europa.eu/sites/default/files/documents/ECDC_report_on_response_Covid-19.pdf
Eddy, D.M.: Probabilistic reasoning in clinical medicine: Problems and opportunities. In: Kahneman, D., Slovic, P., Tversky, A. (eds.) Judgment under Uncertainty: Heuristics and Biases, pp. 249–267. Cambridge University Press, Cambridge (1982)
Eftekhari, H., Mukherjee, D., Banerjee, M., Ritov, Y.: Markovian And Non-Markovian Processes with Active Decision Making Strategies For Addressing The COVID-19 Pandemic. (2020). arXiv preprint arXiv:200800375
European Statistics Code of Practice (2017). URL europa.eu
Evangelou, N,. Garjani, A., dasNair, R., Hunter, R., Tuite-Dalton, K.A., Craig, E.M., Rodgers, W.J., Coles, A., Dobson, R., Duddy, M., Ford, D.V., Hughes, S., Pearson, O., Middleton, L.A., Rog, D., Tallantyre, E.C., Friede, T., Middleton, R.M., Nicholas, R.: Self-diagnosed covid-19 in people with multiple sclerosis: a community-based cohort of the uk ms register. Journal of Neurology, Neurosurgery & Psychiatry 92(1),107–109 (2021). https://jnnp.bmj.com/content/92/1/107
Fabrigar, L.R., Wegener, D.T.: Exploratory factor analysis. Oxford University Press, Oxford (2011)
Fahrmeir, L., Kneib, T., Lang, S., Marx, B.: Regression. Springer, Berlin (2007)
Fenwick, E., Steuten, L., Knies, S., Ghabri, S., Basu, A., Murray, J.F., Koffijberg, H.E., Strong, M., Sanders Schmidler, G.D., Rothery, C.: Value of Information Analysis for Research Decisions-An Introduction: Report 1 of the ISPOR Value of Information Analysis Emerging Good Practices Task Force. Value in health : the Journal of the International Society for Pharmacoeconomics and Outcomes Research 23, 139–150 (2020)
Flaxman, S., Mishra, S., Gandy, A., Unwin, H.J.T., Mellan, T.A., Coupland, H., Whittaker, C., Zhu, H., Berah, T., Eaton, J.W., et al.: Estimating the effects of non-pharmaceutical interventions on COVID-19 in Europe. Nature 584(7820), 257–261 (2020)
Friedrich, S., Friede, T.: Causal inference methods for small non-randomized studies: Methods and an application in COVID-19. Contemp. Clin. Trials 99, 106213 (2020)
Friedrich, S., Antes, G., Behr, S., Binder, H., Brannath, W., Dumpert, F., Ickstadt, K., Kestler, H.A., Lederer, J., Leitgöb, H., Pauly, M., Steland, A., Wilhelm, A., Friede, T.: Is there a role for statistics in artificial intelligence? Advances in Data Analysis and Classification pp. 1–24 (2021)
Gabler, S., Quatember, A.: Repräsentativität von Subgruppen bei geschichteten Zufallsstichproben. AStA Wirtschafts-und Sozialstatistisches Archiv 7(3–4), 105–119 (2013)
Gandjour, A.: Willingness to pay for new medicines: a step towards narrowing the gap between NICE and IQWiG. BMC Health Services Research 20, (2020)
Gigerenzer, G.: What are natural frequencies? BMJ 343, d6386 (2011)
Gigerenzer, G., Edwards, A.: Simple tools for understanding risks: from innumeracy to insight. BMJ 327(7417), 741–744 (2003)
Gigerenzer, G., Gaissmaier, W., Kurz-Milcke, E., Schwartz, L.M., Woloshin, S.: Helping doctors and patients make sense of health statistics. Psychological Science in the Public Interest 8(2), 53–96 (2007)
Gralla, E.: Discrete Event Simulation for COVID-19 Testing: Identifying Bottlenecks and Supporting Scale-Up. In: 42nd Annual Meeting of the Society for Medical Decision Making, SMDM (2020)
Grassly, N.C., Fraser, C.: Mathematical models of infectious disease transmission. Nat. Rev. Microbiol. 6, 477–487 (2008)
Groot Koerkamp, B., Weinstein, M.C., Stijnen, T., Heijenbrok-Kal, M.H., Hunink, M.M.: Uncertainty and patient heterogeneity in medical decision models. Med. Decis. Making 30(2), 194–205 (2010). (publisher: SAGE Publications Sage CA: Los Angeles, CA)
Gross, O., Moerer, O., Rauen, T., Böckhaus, J., Hoxha, E., Jörres, A., Kamm, M., Elfanish, A., Windisch, W., Dreher, M., Floege, J., Kluge, S., Schmidt-Lauber, C., Turner, J.E., Huber, S., Addo, M.M., Scheithauer, S., Friede, T., Braun, G.S., Huber, T.B., Blaschke, S.: Validation of a Prospective Urinalysis-Based Prediction Model for ICU Resources and Outcome of COVID-19 Disease: A Multicenter Cohort Study. Journal of Clinical Medicine 10(14), (2021)
Grossmann, W., Hackl, P., Richter, J.: Corona: Concepts for an improved statistical database. Austrian Journal of Statistics 51(3), 1–26 (2022). https://ajs.or.at/index.php/ajs/article/view/1350
Günther, F., Bender, A., Katz, K., Küchenhoff, H., Höhle, M.: Nowcasting the COVID-19 pandemic in Bavaria. Biom. J. 63(3), 490–502 (2021)
Hadzibegovic, S., Lena, A., Churchill, T.W., Ho, J.E., Potthoff, S., Denecke, C., Rösnick, L., Heim, K.M., Kleinschmidt, M., Sander, L.E., Witzenrath, M., Suttorp, N., Krannich, A., Porthun, J., Friede, T., Butler, J., Wilkenshoff, U., Pieske, B., Landmesser, U., Anker, S.D., Lewis, G.D., Tschöpe, C., Anker, M.S.: Heart failure with preserved ejection fraction according to the HFA-PEFF score in COVID-19 patients: clinical correlates and echocardiographic findings. Eur. J. Heart Fail. 23(11), 1891–1902 (2021)
Hellewell, J.: Is COVID-19 forecasting bad, or are you just projecting? (2021). https://jhellewell14.github.io/2021/11/16/forecasting-projecting.html
Hennessy, D.A., Flanagan, W.M., Tanuseputro, P., Bennett, C., Tuna, M., Kopec, J., Wolfson, M.C., Manuel, D.G.: The population health model (pohem): an overview of rationale, methods and applications. Popul. Health Metrics 13, 24 (2015). https://doi.org/10.1186/s12963-015-0057-x
Hernán, M.A., Robins, J.M.: Causal Inference: What If. Chapman & Hall/ CRC, Boca Raton (2020)
Hethcote, H.W.: The mathematics of infectious diseases. SIAM Rev. 42(4), 599–653 (2000)
Hill, A.B.: The environment and disease: association or causation? Proc. R. Soc. Med. 58(5), 295–300 (1965)
Hoffrage, U., Lindsey, S., Hertwig, R., Gigerenzer, G.: Communicating statistical information. Science 290(5500), 2261–2262 (2000)
Holmdahl, I., Buckee, C.: Wrong but useful - what Covid-19 epidemiologic models can and cannot tell us. N. Engl. J. Med. 383(4), 303–305 (2020)
Horby, P.W., Mafham, M., Bell, J.L., Linsell, L., Staplin, N., Emberson, J., Palfreeman, A., Raw, J., Elmahi, E., Prudon, B., et al.: Lopinavir-ritonavir in patients admitted to hospital with COVID-19 (RECOVERY): a randomised, controlled, open-label, platform trial. The Lancet 396(10259), 1345–1352 (2020)
Hunink, M., Glasziou, P., Siegel, J., Weeks, J., Pliskin, J., Elstein, A., Weinstein, M.: Managing uncertainty. Decision Making in Health and Medicine: Integrating Evidence and Values. Cambridge University Press, New York, USA, (2001). https://ebm.bmj.com/content/10/1/30
Hunter, E., Mac Namee, B., Kelleher, J.D.: A taxonomy for agent-based models in human infectious disease epidemiology. Journal of Artificial Societies and Social Simulation 20(3), (2017)
IQWiG: IQWiG: Allgemeine Methoden. Version 6.0 vom 05.11.2020. Institut für Qualität und Wirtschaftlichkeit im Gesundheitswesen (2020), https://www.iqwig.de/methoden/allgemeine-methoden_version-6-0.pdf?rev=180500
Iwendi, C., Bashir, A.K., Peshkar, A., Sujatha, R., Chatterjee, J.M., Pasupuleti, S., Mishra, R., Pillai, S., Jo, O.: COVID-19 patient health prediction using boosted random forest algorithm. Front. Public Health 8, 357 (2020)
Jahn, B., Pfeiffer, K.P., Theurl, E., Tarride, J.E., Goeree, R.: Capacity Constraints and Cost-Effectiveness: A Discrete Event Simulation for Drug-Eluting Stents. Med. Decis. Making 30(1), 16–28 (2010)
Jahn, B., Theurl, E., Siebert, U., Pfeiffer, K.P.: Tutorial in medical decision modeling incorporating waiting lines and queues using discrete event simulation. Value in Health 13(4), 501–506 (2010)
Jahn, B., Sroczynski, G., Bicher, M., Rippinger, C., Mühlberger, N., Santamaria, J., Urach, C., Schomaker, M., Stojkov, I., Schmid, D., Weiss, G., Wiedermann, U., Redlberger-Fritz, M., Druml, C., Kretzschmar, M., Paulke-Korinek, M., Ostermann, H., Czasch, C., Endel, G., Bock, W., Popper, N., Siebert, U.: Targeted COVID-19 Vaccination (TAV-COVID) Considering Limited Vaccination Capacities-An Agent-Based Modeling Evaluation. Vaccines 9(5), 434 (2021)
James, L.P., Salomon, J.A., Buckee, C.O., Menzies, N.A.: The use and misuse of mathematical modeling for infectious disease Policymaking: lessons for the COVID-19 pandemic. Med. Decis. Making 41(4), 379–385 (2021)
Jit, M., Brisson, M.: Modelling the epidemiology of infectious diseases for decision analysis. Pharmacoeconomics 29(5), 371–386 (2011)
Jun, J.B., Jacobson, S.H., Swisher, J.R.: Application of discrete-event simulation in health care clinics: A survey. Journal of the Operational Research Society 50(2), 109–123 (1999). (publisher: Springer)
Karnon, J., Stahl, J., Brennan, A., Caro, J.J., Mar, J., Möller, J.: Modeling Using Discrete Event Simulation: A Report of the ISPOR-SMDM Modeling Good Research Practices Task Force–4. Med. Decis. Making 32(5), 701–711 (2012). (publisher: SAGE Publications Inc STM)
Keeney, R.L., Raiffa, H.: Decision analysis with multiple conflicting objectives. Wiley & Sons, New York (1976)
Kermack, W.O., McKendrick, A.G.: A contribution to the mathematical theory of epidemics. Proceedings of the Royal Society of London Series A, Containing papers of a mathematical and physical character 115(772), 700–721 (1927)
Kohli, M., Maschio, M., Becker, D., Weinstein, M.C.: The potential public health and economic value of a hypothetical COVID-19 vaccine in the United States: Use of cost-effectiveness modeling to inform vaccination prioritization. Vaccine 39, 1157–1164 (2021)
Krauss, S., Weber, P., Binder, K., Bruckmaier, G.: Natürliche Häufigkeiten als numerische Darstellungsart von Anteilen und Unsicherheit-Forschungsdesiderate und einige Antworten. J. Math.-Didakt. 41(2), 485–521 (2020)
Kretzschmar, M.E., Rozhnova, G., Bootsma, M.C.J., van Boven, M., van de Wijgert, J.H.H.M., Bonten, M.J.M.: Impact of delays on effectiveness of contact tracing strategies for COVID-19: a modelling study. The Lancet Public health 5, e452–e459 (2020)
Kristjanpoller, W., Michell, K., Minutolo, M.C.: A causal framework to determine the effectiveness of dynamic quarantine policy to mitigate COVID-19. Appl. Soft Comput. 104, 107241 (2021)
Kucharski, A.J., Hodcroft, E.B., Kraemer, M.U.G.: Sharing, synthesis and sustainability of data analysis for epidemic preparedness in europe. The Lancet Regional Health - Europe, 9,100215 (2021), https://www.sciencedirect.com/science/article/pii/S2666776221001927
Küchenhoff, H., Günther, F., Höhle, M., Bender, A.: Analysis of the early COVID-19 epidemic curve in Germany by regression models with change points. Epidemiology & Infection, 149, (2021)
Kunz, C.U., Jörgens, S., Bretz, F., Stallard, N., Lancker, K.V., Xi, D., Zohar, S., Gerlinger, C., Friede, T.: Clinical Trials Impacted by the COVID-19 Pandemic: Adaptive Designs to the Rescue? Statistics in Biopharmaceutical Research 12(4), 461–477 (2020)
Küchenhoff, H., Antes, G., Berger, U., Hoyer, A., Brinks, R., Kauermann, G.: CODAG Bericht Nr. 18. Informationen zur Pandemiesteuerung: Welche Daten benötigen wir? (2021). https://www.covid19.statistik.uni-muenchen.de/newsletter/index.html
Li, J., O’Donoghue, C.: A survey of dynamic microsimulation models: uses, model structure and methodology. International Journal of Microsimulation 6(2), 3–55 (2013)
Licker, M.D. (ed): McGraw-Hill dictionary of mathematics. McGraw-Hill Companies, Inc (2003)
Loss, J., Boklage, E., Jordan, S., Jenny, M.A., Weishaar, H., El Bcheraoui, C.: Risikokommunikation bei der Eindämmung der COVID-19-Pandemie: Herausforderungen und Erfolg versprechende Ansätze. Bundesgesundheitsblatt - Gesundheitsforschung - Gesundheitsschutz 64(3), 294–303 (2021)
Luo, J., Zhang, Z., Fu, Y., Rao, F.: Time series prediction of COVID-19 transmission in America using LSTM and XGBoost algorithms. Results in Physics p 104462 (2021)
Macal, C.M., North, M.J.: Agent-based modeling and simulation: ABMS examples. In: 2008 Winter Simulation Conference, IEEE, pp. 101–112 (2008)
Macal, C.M., North, M.J.: Tutorial on agent-based modelling and simulation. Journal of Simulation 4(3), 151–162 (2010)
Mandelblatt, J.S., Stout, N.K., Schechter, C.B., van den Broek, J.J., Miglioretti, D.L., Krapcho, M., Trentham-Dietz, A., Munoz, D., Lee, S.J., Berry, D.A., van Ravesteyn, N.T., Alagoz, O., Kerlikowske, K., Tosteson, A.N.A., Near, A.M., Hoeffken, A., Chang, Y., Heijnsdijk, E.A., Chisholm, G., Huang, X., Huang, H., Ergun, M.A., Gangnon, R., Sprague, B.L., Plevritis, S., Feuer, E., de Koning, H.J., Cronin, K.A.: Collaborative Modeling of the Benefits and Harms Associated With Different U.S. Breast Cancer Screening Strategies. Ann. Intern. Med. 164, 215–225 (2016)
Marshall, D.A., Burgos-Liz, L., IJzerman, M.J., Crown, W., Padula, W.V., Wong, P.K., Pasupathy, K.S., Higashi, M.K., Osgood, N.D.: Selecting a dynamic simulation modeling method for health care delivery research-Part 2: Report of the ISPOR Dynamic Simulation Modeling Emerging Good Practices Task Force. Value in Health 18(2), 147–160 (2015)
Marshall, D.A., Burgos-Liz, L., IJzerman MJ, Osgood ND, Padula WV, Higashi MK, Wong PK, Pasupathy KS, Crown W,: Applying dynamic simulation modeling methods in health care delivery research-the SIMULATE checklist: report of the ISPOR simulation modeling emerging good practices task force. Value in Health 18(1), 5–16 (2015)
Mathieu, E.: Commit to transparent COVID data until the WHO declares the pandemic is over. Nature 602(7898), 549–549 (2022). https://doi.org/10.1038/d41586-022-00424-9
Mayo, E.: The human problems of an industrial civilization. Routledge, Abingdon (2004)
McDowell, M., Gigerenzer, G., Wegwarth, O., Rebitschek, F.G.: Effect of tabular and icon fact box formats on comprehension of benefits and harms of prostate cancer screening: a randomized trial. Med. Decis. Making 39(1), 41–56 (2019)
Melman, G., Parlikad, A., Cameron, E.: Balancing scarce hospital resources during the COVID-19 pandemic using discrete-event simulation. Health Care Management Science pp. 1–19 (2021)
Miksch, F., Jahn, B., Espinosa, K.J., Chhatwal, J., Siebert, U., Popper, N.: Why should we apply ABM for decision analysis for infectious diseases?-An example for dengue interventions. PLoS ONE 14(8), e0221564 (2019)
Münnich, R.: Qualität der regionalen Armutsmessung–vom Design zum Modell. In: Qualität bei zusammengeführten Daten, Springer, pp. 7–25 (2020)
Münnich, R., Schnell, R., Brenzel, H., Dieckmann, H., Dräger, S., Emmenegger, J., Höcker, P., Kopp, J., Merkle, H., Neufang, K., Obersneider, M., Reinhold, J., Schaller, J., Schmaus, S., Stein, P.: A Population Based Regional Dynamic Microsimulation of Germany: The MikroSim Model. Methods, Data, Analyses, 15(2), 241–264 (2021), https://mda.gesis.org/index.php/mda/article/view/2021.03
Mütze, T., Friede, T.: Data monitoring committees for clinical trials evaluating treatments of COVID-19. Contemp. Clin. Trials 98, 106154 (2020)
Neumann, P.J., Sanders, G.D., Russell, L.B., Siegel, J.E., Ganiats, T.G.: Cost-Effectiveness in Health and Medicine. Oxford University Press, Oxford (2016)
Nianogo, R.A., Arah, O.A.: Agent-based modeling of noncommunicable diseases: a systematic review. Am. J. Public Health 105(3), e20–e31 (2015)
Nussbaumer-Streit, B., Mayr, V., Dobrescu, A.I., Chapman, A., Persad, E., Klerings, I., Wagner, G., Siebert, U., Ledinger, D., Zachariah, C., et al.: Quarantine alone or in combination with other public health measures to control covid-19: a rapid review. Cochrane Database Syst. Rev. 4(4), CD013574 (2020). (update in: Cochrane Database Syst Rev. 2020; 15;9:CD013574)
Orcutt, G.H.: A new type of socio-economic system. Rev. Econ. Stat. 39(2), 116–123 (1957)
Otava, M., Mylona, K.: Communicating statistical conclusions of experiments to scientists. Qual. Reliab. Eng. Int. 36(8), 2688–2698 (2020)
O’Hagan, A.: Bayesian statistics: principles and benefits. Frontis pp. 31–45 (2004)
Parmigiani, G., Inoue, L.: Decision theory: Principles and approaches, vol. 812. Wiley, Hoboken (2009)
Pfeffermann, D., Sverchkov, M.: Inference under informative sampling. In: Handbook of Statistics, vol 29, Elsevier, pp. 455–487 (2009)
Pidd, M.: Computer simulation in management science, 5th edn. Wiley, Hoboken (2004)
Pitman, R., Fisman, D., Zaric, G.S., Postma, M., Kretzschmar, M., Edmunds, J., Brisson, M.: Dynamic transmission modeling: a report of the ISPOR-SMDM Modeling Good Research Practices Task Force Working Group-5. Med. Decis. Making 32(5), 712–721 (2012)
RECOVERY Collaborative Group: Effect of hydroxychloroquine in hospitalized patients with Covid-19. New England Journal of Medicine 383(21), 2030–2040 (2020)
Reddy, K.P., Fitzmaurice, K.P., Scott, J.A., Harling, G., Lessells, R.J., Panella, C., Shebl, F.M., Freedberg, K.A., Siedner, M.J.: Clinical outcomes and cost-effectiveness of covid-19 vaccination in south africa. Nat. Commun. 12, 6238 (2021)
Rendtel, U., Liebig, S., Meister, R., Wagner, G.G., Zinn, S.: Die erforschung der dynamik der corona-pandemie in deutschland: Survey-konzepte und eine exemplarische umsetzung mit dem sozio-oekonomischen panel (soep). AStA Wirtschafts-und Sozialstatistisches Archiv pp. 1–42 (2021)
Richardson, S., Spiegelhalter, D.: How ideas from decision theory can help guide our actions. (2021). https://rss.org.uk/news-publication/news-publications/2021/general-news/how-ideas-from-decision-theory-can-help-guide-our/
Ritchie, H.: COVID’s lessons for climate, sustainability and more from our world in data. Nature 598(7879), 9–9 (2021). https://doi.org/10.1038/d41586-021-02691-4
Roberts, M., Russell, L.B., Paltiel, A.D., Chambers, M., McEwan, P., Krahn, M., Force, I.: Conceptualizing a model: a report of the ISPOR-SMDM Modeling Good Research Practices Task Force-2. Medical decision making : an international Journal of the Society for Medical Decision Making 32, 678–689 (2012)
Robins, J.M.: Structural nested failure time models. Encyclopedia of Biostatistics 6, 4372–4389 (1998)
Robins, J.M., Hernán, M.A., Brumback, B.: Marginal structural models and causal inference in epidemiology. Epidemiology 11(5), 550–560 (2000)
Robins, J.M., Hernán, M.A., Siebert, U.: Estimations of the effects of multiple interventions. In: Ezzati, M., Lopez, A., Rodgers, A., Murray, C. (eds.) Comparative Quantification of Health Risks: Global and Regional Burden of Disease Attributable to Selected Major Risk Factors, vol. 1, pp. 2191–2230. World Health Organization, Geneva (2004)
Rochau, U., Jahn, B., Qerimi, V., Burger, E.A., Kurzthaler, C., Kluibenschaedl, M., Willenbacher, E., Gastl, G., Willenbacher, W., Siebert, U.: Decision-analytic modeling studies: An overview for clinicians using multiple myeloma as an example. Crit. Rev. Oncol. Hematol. 94(2), 164–178 (2015)
Romano, A., Sotis, C., Dominioni, G., Guidi, S.: The scale of covid-19 graphs affects understanding, attitudes, and policy preferences. Health Econ. 29(11), 1482–1494 (2020)
Rosling, H., Zhang, Z.: Health advocacy with gapminder animated statistics. Journal of Epidemiology and Global Health 1, 11–14 (2011)
Rothwell, P.M.: External validity of randomised controlled trials:“to whom do the results of this trial apply?’’. The Lancet 365(9453), 82–93 (2005)
Roy, S., Bhunia, G.S., Shit, P.K.: Spatial prediction of COVID-19 epidemic using ARIMA techniques in India. Modeling Earth Systems and Environment 7(2), 1385–1391 (2021)
Rubin, D.B.: Estimating causal effects of treatments in randomized and nonrandomized studies. J. Educ. Psychol. 66(5), 688 (1974)
Rubin, D.B.: For objective causal inference, design trumps analysis. The Annals of Applied Statistics 2(3), 808–840 (2008)
Rustam, F., Reshi, A.A., Mehmood, A., Ullah, S., On, B.W., Aslam, W., Choi, G.S.: COVID-19 future forecasting using supervised machine learning models. IEEE access 8, 101489–101499 (2020)
RWI – Leibniz-Institut für Wirtschaftsforschung: Anti-corona measures - don’t just look at new infections. (2020). https://www.rwi-essen.de/unstatistik/108/
Saidani, M., Kim, H., Kim, J.: Designing optimal COVID-19 testing stations locally: A discrete event simulation model applied on a university campus. PLoS ONE 16(6), e0253869 (2021)
Salas, J.: Improving the estimation of the COVID-19 effective reproduction number using nowcasting. Statistical Methods in Medical Research p 09622802211008939 (2021)
Sandmann, F.G., Davies, N.G., Vassall, A., Edmunds, W.J., Jit, M., for the Mathematical Modelling of Infectious Diseases COVID-19 working group C,: The potential health and economic value of sars-cov-2 vaccination alongside physical distancing in the uk: a transmission model-based future scenario analysis and economic evaluation. The Lancet Infectious diseases 21, 962–974 (2021). https://doi.org/10.1016/S1473-3099(21)00079-7
Schneble, M., De Nicola, G., Kauermann, G., Berger, U.: Nowcasting fatal COVID-19 infections on a regional level in Germany. Biom. J. 63(3), 471–489 (2021)
Schnell, R.: Survey-Interviews: Methoden standardisierter Befragungen, 2nd edn. Springer VS, Berlin (2019)
Schöffski, O., Schulenburg, J.M.G.: Gesundheitsökonomische Evaluationen. Springer, Berlin Heidelberg (2011)
Schüller, K., Koch, H., Rampelt, F.: Data Literacy Charta. (2021). https://www.stifterverband.org/data-literacy-charter, accessed Dec 21, 2021
Sheinson, D., Dang, J., Shah, A., Meng, Y., Elsea, D., Kowal, S.: A Cost-Effectiveness Framework for COVID-19 Treatments for Hospitalized Patients in the United States. Adv. Ther. 38, 1811–1831 (2021)
Shinde, V., Bhikha, S., Hoosain, Z., Archary, M., Bhorat, Q., Fairlie, L., Lalloo, U., Masilela, M.S., Moodley, D., Hanley, S., Fouche, L., Louw, C., Tameris, M., Singh, N., Goga, A., Dheda, K., Grobbelaar, C., Kruger, G., Carrim-Ganey, N., Baillie, V., de Oliveira, T., Lombard Koen, A., Lombaard, J.J., Mngqibisa, R., Bhorat, A.E., Benadé, G., Lalloo, N., Pitsi, A., Vollgraaff, P.L., Luabeya, A., Esmail, A., Petrick, F.G., Oommen-Jose, A., Foulkes, S., Ahmed, K., Thombrayil, A., Fries, L., Cloney-Clark, S., Zhu, M., Bennett, C., Albert, G., Faust, E., Plested, J.S., Robertson, A., Neal, S., Cho, I., Glenn, G.M., Dubovsky, F., Madhi, S.A.: Efficacy of NVX-CoV2373 Covid-19 Vaccine against the B.1.351 Variant. N. Engl. J. Med. 384(20), 1899–1909 (2021)
Siebert, U.: When should decision-analytic modeling be used in the economic evaluation of health care? Eur. J. Health Econ. 4, 143–150 (2003)
Siebert, U.: Using decision-analytic modelling to transfer international evidence from health technology assessment to the context of the german health care system. GMS Health Technol Assess 1(Doc03), 1 (2005)
Siebert, U., Alagoz, O., Bayoumi, A.M., Jahn, B., Owens, D.K., Cohen, D.J., Kuntz, K.M.: State-transition modeling: a report of the ISPOR-SMDM Modeling Good Research Practices Task Force-3. Medical decision making : an international journal of the Society for Medical Decision Making 32, 690–700 (2012)
Siebert, U., Rochau, U., Claxton, K.: When is enough evidence enough?-Using systematic decision analysis and value-of-information analysis to determine the need for further evidence. Z. Evid. Fortbild. Qual. Gesundhwes. 107(9–10), 575–584 (2013)
Sonnenberg, F.A., Beck, J.R.: Markov models in medical decision making: a practical guide. Med. Decis. Making 13(4), 322–338 (1993). (publisher: Sage Publications Sage CA: Thousand Oaks, CA)
Spielauer, M.: Dynamic microsimulation of health care demand, health care finance and the economic impact of health behaviours: survey and review. International Journal of Microsimulation 1(1), 35–53 (2007). (publisher: International Microsimulation Association)
Sroczynski, G., Esteban, E., Widschwendter, A., Oberaigner, W., Borena, W., von Laer, D., Hackl, M., Endel, G., Siebert, U.: Reducing overtreatment associated with overdiagnosis in cervical cancer screening–a model-based benefit-harm analysis for austria. Int. J. Cancer 147(4), 1131–1142 (2020). https://doi.org/10.1002/ijc.32849
Stallard, N., Hampson, L., Benda, N., Brannath, W., Burnett, T., Friede, T., Kimani, P.K., Koenig, F., Krisam, J., Mozgunov, P., Posch, M., Wason, J., Wassmer, G., Whitehead, J., Williamson, S.F., Zohar, S., Jaki, T.: Efficient Adaptive Designs for Clinical Trials of Interventions for COVID-19. Statistics in Biopharmaceutical Research 12(4), 483–497 (2020)
STIKO: Stiko (2016) methoden zur durchführung und berücksichtigung von modellierungen zur vorhersage epidemiologischer und gesundheitsökonomischer effekte von impfungen für die ständige impfkommission, version 1.0 (stand: 16.03.2016), berlin. (2016). https://www.rki.de/DE/Content/Kommissionen/STIKO/Aufgaben_Methoden/Methoden_Modellierung.pdf?__blob=publicationFile
The Royal Statistical Society: Statistics, Data and Covid - “Ten statistical lessons the government can learn from the past year. (2021). https://rss.org.uk/policy-campaigns/policy/covid-19-task-force/statistics,-data-and-covid/
Tufte, E.R.: The Visual Display of Quantitative Information, 2nd edn. Graphics Press, Cheshire, CT (2001)
Van Pelt, A., Glick, H.A., Yang, W., Rubin, D., Feldman, M., Kimmel, S.E.: Evaluation of COVID-19 testing strategies for repopulating college and university campuses: a decision tree analysis. J. Adolesc. Health 68(1), 28–34 (2021)
Weinstein, M.C.: Recent developments in decision-analytic modelling for economic evaluation. Pharmacoeconomics 24(11), 1043–1053 (2006). (publisher: Springer)
WHO: Communicating and Managing Uncertainty in the COVID-19 Pandemic: A quick guide. (2020). https://cdn.who.int/media/docs/default-source/searo/whe/coronavirus19/managing-uncertainty-in-covid-19-a-quick-guide.pdf
Wu, F., Zhao, S., Yu, B., Chen, Y.M., Wang, W., Song, Z.G., Hu, Y., Tao, Z.W., Tian, J.H., Pei, Y.Y., et al.: A new coronavirus associated with human respiratory disease in China. Nature 579(7798), 265–269 (2020)
Zhang, X.: Application of discrete event simulation in health care: a systematic review. BMC Health Serv. Res. 18(1), 1–11 (2018)
Zhou, P., Yang, X.L., Wang, X.G., Hu, B., Zhang, L., Zhang, W., Si, H.R., Zhu, Y., Li, B., Huang, C.L., et al.: A pneumonia outbreak associated with a new coronavirus of probable bat origin. Nature 579(7798), 270–273 (2020)
Acknowledgements
We thank Lyndon James (Harvard T.H. Chan School of Public Health) for proofreading and language editing.
Funding
Open Access funding enabled and organized by Projekt DEAL. Tim Friede and Markus Pauly are grateful for support by the Volkswagen Foundation (“Bayesian and Nonparametric Statistics—Teaming up two opposing theories for the benefit of prognostic studies in Covid-19”). Research by Beate Jahn and Uwe Siebert was also funded in part by the Austrian Federal Ministry for Digital and Economic Affairs BMDW and handled by the Austrian Research Promotion Agency (FFG) within the Emergency Call for research into COVID-19 in response to the SARS-CoV-2 outbreak (CIDS-Concurrent Infectious Disease Simulation) (881665) and by the Gordon and Betty Moore Foundation through Grant (GBMF9634) to Johns Hopkins University to support the work of the Society for Medical Decision Making COVID-19 Decision Modeling Initiative.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jahn, B., Friedrich, S., Behnke, J. et al. On the role of data, statistics and decisions in a pandemic. AStA Adv Stat Anal 106, 349–382 (2022). https://doi.org/10.1007/s10182-022-00439-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10182-022-00439-7