
Abstract
We consider Gaussian graphical tree models in discriminant analysis for two populations. Both the parameters and the structure of the graph are assumed to be unknown. For the estimation of the parameters maximum likelihood is used, and for the estimation of the structure of the tree graph we propose three methods; in these, the function to be optimized is the J-divergence for one and the empirical log-likelihood ratio for the two others. The main contribution of this paper is the introduction of these three computationally efficient methods. We show that the optimization problem of each proposed method is equivalent to one of finding a minimum weight spanning tree, which can be solved efficiently even if the number of variables is large. This property together with the existence of the maximum likelihood estimators for small group sample sizes is the main advantage of the proposed methods. A numerical comparison of the classification performance of discriminant analysis using these methods, as well as three other existing ones, is presented. This comparison is based on the estimated error rates of the corresponding plug-in allocation rules obtained from real and simulated data. Diagonal discriminant analysis is considered as a benchmark, as well as quadratic and linear discriminant analysis whenever the sample size is sufficient. The results show that discriminant analysis with Gaussian tree models, using these methods for selecting the graph structure, is competitive with diagonal discriminant analysis in high-dimensional settings.







Similar content being viewed by others
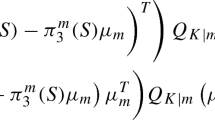
References
Anderson, T.W.: Estimation of covariance matrices which are linear combinations or whose inverses are linear combinations of given matrices. In: Bose, R.C., Chakravarti, I.M., Mahalanobis, P.C., Rao, C.R., Smith, K.J.C. (eds.) Essays in Probability and Statistics, pp. 1–24. Univ North Carolina Press, Chapel Hill (1970)
Bartlett, M.S., Please, N.W.: Discrimination in the case of zero mean differences. Biometrika 50, 17–21 (1963)
Bickel, P., Levina, E.: Some theory for Fisher’s linear discriminant function, naive Bayes, and some alternatives when there are many more variables than observations. Bernoulli 10, 989–1010 (1995)
Chow, C., Liu, C.: An approach to structure adaptation in pattern recognition. IEEE Trans. Syst. Sci. Cybern. 2, 73–80 (1966)
Chow, C., Liu, C.: Approximating discrete probability distributions with dependence trees. IEEE Trans. Inf. Theory 14, 462–467 (1968)
Danaher, P., Wang, P., Witten, D.: The joint graphical lasso for inverse covariance estimation across multiple classes. J. R. Stat. Soc. Ser. B Stat. Methodol. 76, 373–397 (2014)
Dethlefsen, C., Højsgaard, S.: A common platform for graphical models in R: the gRbase package. J. Stat. Softw. 14, 1–12 (2005)
Edwards, D., Abreu, G., Labouriau, R.: Selecting high-dimensional mixed graphical models using minimal AIC or BIC forests. BMC Bioinformatics 11, 18 (2010)
Friedman, N., Geiger, D., Goldszmidt, M.: Bayesian network classifiers. Mach. Learn. 29, 131–163 (1997)
Friedman, N., Goldszmidt, M., Lee, T.: Bayesian Network Classification with Continuous Attributes: Getting the Best of Both Discretization and Parametric Fitting. In: Proceedings of the Fifteenth International Conference on Machine Learning (ICML 1998), pp. 179–187 (1998)
Højsgaard, S., Lauritzen, S.L., Edwards, D.: Graphical Models with R. Springer, New York (2012)
Højsgaard, S., Lauritzen, S.L.: Graphical Gaussian models with edge and vertex symetries. J. R. Stat. Soc. Ser. B 70, 1005–1027 (2008)
Kim, J.: Estimating classification error rate: repeated cross-validation, repeated hold-out and bootstrap. Comput. Stat. Data. Anal. 53, 3735–3745 (2009)
Kruskal, J.B.: On the shortest spanning subtree of a graph and the traveling salesman problem. Proc. Am. Math. Soc. 7, 48–50 (1956)
Kullback, S., Leibler, R.A.: On information and sufficiency. Ann. Math. Stat. 22, 79–86 (1951)
Lauritzen, S.L.: Graphical Models. Clarendon Press, Oxford (1996)
Lauritzen, S.L.: Elements of Graphical Models. Lectures from the XXXVIth International Probability Summer School in Saint-Flour, France, 2006. Unpublished manuscript, electronic version (2011)
Meilă, M., Jordan, M.: Learning with mixtures of trees. J. Mach. Learn. Res. 1, 1–48 (2000)
Miller, L.D., Smeds, J., George, J., Vega, V., Vergara, L., Pawitan, Y., Hall, P., Klaar, S., Liu, E., Bergh, J.: An expression signature for p53 status in human breast cancer predicts mutation status, transcriptional effects, and patient survival. Proc. Natl. Acad. Sci. PNAS 102, 13550–13555 (2005)
Prim, R.C.: Shortest connection networks and some generalizations. Bell Syst. Technol. J. 36, 1389–1401 (1957)
Speed, T.P., Kiiveri, H.T.: Gaussian Markov distributions over finite graphs. Ann. Stat. 14, 138–150 (1986)
Sturmfels, B., Uhler, C.: Multivariate Gaussians, semidefinite matrix completion and convex algebraic geometry. Ann. Inst. Stat. Math. 62, 603–638 (2010)
Tan, V.Y.F., Sanghavi, S., Fisher, J.W., Willsky, A.S.: Learning graphical models for hypothesis testing and classification. IEEE Trans. Signal Process. 58, 5481–5495 (2010)
Acknowledgments
The Mexican National Council for Science and Technology (CONACYT) provided financial support to Gonzalo Perez de la Cruz through a doctoral scholarship.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
1.1 A.1 Proofs
The following properties for Gaussian graphical models with tree graph \(\tau =(V,E_{\tau })\) and distribution \(N(\varvec{\mu }, \varvec{{\Sigma }}_{\tau })\) are used in the proofs of Propositions 1, 2, and Corollary 1, some of which can be found in Lauritzen (2011). Let \(\widehat{\varvec{{\Sigma }}}_{\tau }=\widehat{\mathbf {K}}_{\tau }^{-1}\), where \(\widehat{\mathbf {K}}_{\tau }\) is the MLE of \(\mathbf {K}_{\tau }\).
- A.1 :
-
\( f_{\tau }(x_1,\ldots ,x_{p})=\left. \prod _{i=1}^{p}f(x_i)\right. \left. \prod _{\begin{array}{c} i < j\\ (i,j)\in E_{\tau } \end{array}}\dfrac{f(x_i,x_j)}{f(x_i) \ f(x_j)}\right. .\)
- A.2 :
-
\( \widehat{\varvec{{\Sigma }}}_{\tau }(\tau )=\mathbf {W}(\tau ),\) with \( \mathbf {W}=\sum _{j=1}^{n}({ \mathbf {x}_j-\overline{\mathbf {x}}})({ \mathbf {x}_j-\overline{\mathbf {x}}})^t/n \) for a sample \(\mathbf {x}_1, \ldots , \mathbf {x}_{n}\), and where for any square matrix \(\mathbf {A}\), \(\mathbf {A}(\tau )\) is the square matrix such that
\((\mathbf {A}(\tau ))_{ij}=\left\{ \begin{array}{l@{\quad }l} (\mathbf {A})_{ij} &{} \text{ if } i=j \; \text{ or } \; (i,j)\in E_{\tau }, \\ 0 &{} \text{ otherwise }. \end{array} \right. \)
- A.3 :
-
For any square matrix \(\mathbf {A}\), \(tr(\mathbf {K}_{\tau }\mathbf {A})=tr(\mathbf {K}_{\tau }\mathbf {A}(\tau )).\) Moreover, if \(\widehat{\mathbf {K}}_{\tau }\) exists, then \(tr(\widehat{\mathbf {K}}_{\tau }\mathbf {A})=tr(\widehat{\mathbf {K}}_{\tau }\mathbf {A}(\tau )).\)
- A.4 :
-
$$\begin{aligned} \widehat{\mathbf {K}}_{\tau }= & {} \sum _{\mathcal {C} \in \mathscr {C}}[\mathbf {W}^{-1}_\mathcal {C}]^{p}-\sum _{\mathcal {S} \in \mathscr {S}}v(\mathcal {S})[\mathbf {W}^{-1}_\mathcal {S}]^{p}\nonumber \\= & {} \sum _{\begin{array}{c} i < j \\ (i,j) \in E_{\tau } \end{array}}\left( [\mathbf {W}^{-1}_{(i,j)}]^{p}-[\mathbf {W}^{-1}_{(i)}]^{p}-[\mathbf {W}^{-1}_{(j)}]^{p}\right) +\sum _{j=1}^{p}\left( [\mathbf {W}^{-1}_{(j)}]^{p}\right) . \end{aligned}$$
- A.5 :
-
\(\widehat{f}_{{\tau }}(x_1,\ldots ,x_{p})=\left. \prod _{i=1}^{p}\widehat{f}(x_i)\right. \left. \prod _{\begin{array}{c} i < j \\ (i,j) \in E_{\tau } \end{array}}\dfrac{\widehat{f}(x_i,x_j)}{\widehat{f}(x_i) \ \widehat{f}(x_j)}\right. ,\) where \(\widehat{f}_{{\tau }}\) is the density of \(N(\widehat{\varvec{\mu }}, \widehat{\mathbf {K}}_{{\tau }}^{-1})\).
- A.6 :
-
$$\begin{aligned} \ln \dfrac{\widehat{f}(x_i,x_j)}{\widehat{f}(x_i) \widehat{f}(x_j)}= & {} -\frac{1}{2}\ln (1-\widehat{\rho }_{ij}^2)-\dfrac{\widehat{\rho }_{ij}^2}{2(1-\widehat{\rho }_{ij}^2)}\left\{ \dfrac{(x_i-\overline{x}_i)^2}{w_{ii}}+\dfrac{(x_j-\overline{x}_j)^2}{w_{jj}}\right. \\&\left. -\,\dfrac{2(x_i-\overline{x}_i)(x_j-\overline{x}_j)}{w_{ij}}\right\} , \end{aligned}$$
where \(\left. \widehat{\rho }_{ij}\right. =w_{ij}/\sqrt{w_{ii}w_{jj}}\).
Proof of Proposition 1
We note that for a given tree graph \(\tau =(V,E_{\tau })\) with p nodes
where \(\lambda (\tau )=\sum _{\begin{array}{c} i < j \\ (i,j)\in E_{\tau } \end{array}}\lambda (i,j)\) is the total weight of \(\tau \), \(\mathbf {D}=(\overline{\mathbf {x}}_1-\overline{\mathbf {x}}_2)(\overline{\mathbf {x}}_1-\overline{\mathbf {x}}_2)^t\), \(\widehat{\varvec{{\Sigma }}}_{c_{\tau }}=\widehat{\mathbf {K}}_{c_{\tau }}^{-1}\), \(c=1,2\), C is a constant, and
Since \(-\lambda (\tau )\) is the only term in \(J(\widehat{f}_{1_{\tau }},\widehat{f}_{2_{\tau }})\) that varies depending on \(\tau \), the problem of maximizing \(J(\widehat{f}_{1_{\tau }},\widehat{f}_{2_{\tau }})\) over \(T_p\) in (18) is equivalent to the problem of finding a MWST for the complete graph with p nodes and weights given in (24) for each edge (i, j). We note that weights in (24) are equal to those in (19). \(\square \)
Proof of Proposition 2
The problem in (20) can be expressed as finding \(\tau _1^*\) and \(\tau _2^*\) such that
Considering the problem for \(\tau _1^*\) in (25), we note that for a given tree \(\tau =(V,E_{\tau })\) with p nodes
where
Since \(-\sum _{\begin{array}{c} i < j \\ (i,j)\in E_{\tau } \end{array}}\lambda (i,j)\) is the only term that varies depending on \(\tau \), the problem of maximizing \({\sum }_{l=1}^{n_1}\ln {\widehat{f}_{1_{\tau }}(\mathbf {x}_l)}- \sum _{l=n_1+1}^{n_1+n_2}\ln {{\widehat{f}_{1_{\tau }}(\mathbf {x}_l)}}\) over \(T_p\) is equivalent to the problem of finding a MWST for the complete graph with p nodes and weights given in (27) for each edge (i, j). Using property A.6 in (27) we can obtain the weights given in (21) for \(c=1\). A similar procedure can be done for the problem for \(\tau _2^*\) in (26). \(\square \)
Proof of Corollary 1
We note that for a given tree \(\tau =(V,E_{\tau })\) with p nodes
The rest can be obtained using simultaneously the two procedures given in the proof of Proposition 2 for (25) and (26). \(\square \)
1.2 A.2 Random concentration matrix
Let \(p_k\) be the fraction of vertices in the graph that have degree k. A power law network is a graph with \(p_k\propto k^{-\alpha }\), where \(\alpha \) is the power parameter. We consider \(\alpha =2.3\) and simulate the two networks with graphs presented in Fig. 2. Given a specific network with graph \(G=(V,E)\), we use the following procedure to specify the associated covariance matrix. Let \(\mathbf {A}\) be a matrix with entries
where \(u_{ij}\) is a random number from a uniform distribution U(D). Then the diagonal elements of \(\mathbf {A}\) are defined such that the final matrix is a diagonally dominant matrix, i.e., \(a_{ii}=R \times \sum _{j\ne i}|a_{ij}|, \; i= 1, \ldots , p,\) where \(R>1\). The covariance matrix \(\varvec{{\Sigma }}\) is then determined by \(\sigma _{ij}=a^{ij}/\sqrt{a^{ii}a^{jj}},\) where \(a^{ij}\) is the entry ij of the matrix \(\mathbf {A}^{-1}\).
For the numerical study, the RAND models associated with a power law network use \(R=1.01\) and graph given in Fig. 2a with \(D= (-1,-0.5) \cup (0.5,1)\), and graph given in Fig. 2b with \(D=(-0.5, 0.5)\).
1.3 A.3 Asymptotic error rates of LDA and DLDA
When a common concentration matrix is assumed for both populations, \(N(\varvec{\mu }_1, \varvec{{\Sigma }})\) and \(N(\varvec{\mu }_2, \varvec{{\Sigma }})\), the error rate of the optimal allocation rule given in (4) with \(\pi _1=\pi _2\) is
This corresponds to the asymptotic error rate of LDA. On the other hand, the asymptotic error rate of DLDA when \(\pi _1=\pi _2=1/2\), that is, the error rate for the allocation rule: \(\mathbf {x}\) is assigned to \({\varPi }_1\) when
and otherwise to \({\varPi }_2\), is given by
where \(\mathbf {D}=\text{ diag }(\varvec{{\Sigma }})\).
Let \(\{{\mathbf {v}}_1,\ldots ,\mathbf {v}_p\}\) and \(\{l_1,\ldots ,l_p\}\) be the set of orthonormal eigenvectors and eigenvalues of \(\varvec{{\Sigma }}\), respectively. The asymptotic error rates for LDA and DLDA are the same under the following conditions: (a) \(\varvec{{\Sigma }}\) with its diagonal elements all equal to a constant value, (b) \(\pi _1=\pi _2\), and (c) the pair of mean vectors is \(\{{\varvec{\mu }}_1=a_1\mathbf {v}_j, \; \varvec{\mu }_2=a_2{\mathbf {v}}_j\}\); with \(a_i \in \mathbb {R}\), \(i=1,2\), and \(\mathbf {v}_j \in \{{\mathbf {v}}_1,\ldots ,{\mathbf {v}}_p\}\). To verify this, we write \(\varvec{{\Sigma }}\) and \(\mathbf {K}\) as
Then the probability of misclassification in (28) is given by
and (29) is
where \(a=|a_1-a_2|\). In particular, this is true for \(a_1=0\), \(\mathbf {v}_j=\mathbf {v}_\mathrm{max}\) or \(\mathbf {v}_j=\mathbf {v}_\mathrm{min}\).
Rights and permissions
About this article

Cite this article
Perez-de-la-Cruz, G., Eslava-Gomez, G. Discriminant analysis with Gaussian graphical tree models. AStA Adv Stat Anal 100, 161–187 (2016). https://doi.org/10.1007/s10182-015-0256-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10182-015-0256-6