
Abstract
Automatic short answer grading (ASAG), a hot field of natural language understanding, is a research area within learning analytics. ASAG solutions are conceived to offload teachers and instructors, especially those in higher education, where classes with hundreds of students are the norm and the task of grading (short)answers to open-ended questionnaires becomes tougher. Their outcomes are precious both for the very grading and for providing students with “ad hoc” feedback. ASAG proposals have also enabled different intelligent tutoring systems. Over the years, a variety of ASAG solutions have been proposed, still there are a series of gaps in the literature that we fill in this paper. The present work proposes GradeAid, a framework for ASAG. It is based on the joint analysis of lexical and semantic features of the students’ answers through state-of-the-art regressors; differently from any other previous work, (i) it copes with non-English datasets, (ii) it has undergone a robust validation and benchmarking phase, and (iii) it has been tested on every dataset publicly available and on a new dataset (now available for researchers). GradeAid obtains performance comparable to the systems presented in the literature (root-mean-squared errors down to 0.25 based on the specific tuple \(\langle \)dataset-question\(\rangle \)). We argue it represents a strong baseline for further developments in the field.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In the past, there has been a growing number of students enrolled at universities worldwide.Footnote 1 Large courses have thousands of students participating, especially when using virtual classrooms. In introductory computer science and software engineering courses, classroom sizes with up to 1700 students are no longer an exception, with growth by factor five in the last ten years. The free Stanford Massive Open Online Course (MOOC) “Intro to Artificial Intelligence,”Footnote 2 is started in 2011, quickly reaching 160,000 students [1]. After witnessed a period of decline, MOOCs are coming back,Footnote 3 also due to the COVID-19 pandemic outbreak. As a result of COVID-19, higher education all over the world has moved to deliver courses online [2,3,4,5], facing issues similar to MOOCs.
Large lectures pose a problem for instructors when grading textual exercises, and the shifting of learning contexts from physical to virtual classrooms has made the evaluation of the students even more difficult. In addition, in [6] the authors highlighted the influence of favoritism and the emotional mindset on the assessment procedure. Therefore, automatic short answers grading (ASAG) systems have been introduced both in scientific research [7] and at the service of commercial solutions.Footnote 4 Moreover, automatically scoring short student answers is important for building intelligent tutoring systems. In general, computer-aided assessment systems are particularly useful because scoring by humans can become monotonous and tedious [8]. Automatic scoring systems can help teachers save lots of time from duplication of marking student’s homework.

Example of question and related reference answer, and the student’s answer
One of the primary challenge in ASAG—especially with closed-ended questions—is to deal with variations in surface representations of key concepts in student answer and reference answer pairs [9] In some cases, the student answers are syntactic and lexical variations of model answers. The answer pairs may contain synonyms, polysemous words and statements that are paraphrases of each other (see Fig. 1).
The problem of finding semantic similarity of a pair of strings has been well studied in NLP literature [10]. Consequently, a variety of such similarity measures have been used—when feasible, based on the type of questions/assignments—in different ASAG systems, e.g., [11, 12]. Other systems, e.g., [13], focused on questions with no reference answers (that often appear in reading comprehension assessments) providing a grade by integrating both domain-general and domain-specific information.
Limits
As we will see more in detail in Sect. 2, the literature on ASAG mainly shows the following limitations: (i) There are a few publicly available datasets on ASAG, and they are generally very limited in size, (ii) works available generally did not performed experiments on all the available datasets and in most cases just on a single one, (iii) there are no tools or software for end-users, hence no clues on how teachers and instructors could interact with such systems and on their user satisfaction, and (iv) experiment’s validation conducted in previous literature is limited because authors have generally not split the datasets by question (even if in the same subject, two questions may be totally different and requiring two completely diverse—lexically and semantically—answers) or have performed just straightforward strategies such as splitting between training and testing sets. Lastly, (v) there is no consensus on the metrics to use, the experiments to perform and the way they should be done.
The aim of the work
In this paper, we focus on developing an ASAG framework, namely GradeAid, to support (i) instructors in evaluating students questionnaires (see Fig. 2 for a sketch of our proposal), (ii) students’ learning by providing numerical feedback. Our attention is put toward making it usable and available to the potential stakeholders (students, instructors). On this page, we want to answer the following research questions:
-
What is the best approach for ASAG in GradeAid? In this respect, we aim to study which kind of features/text characteristics it should take into account and which machine learning method is most suitable for ASAG.
-
How does the solution perform in different scenarios (e.g., heterogeneous datasets)?
By answering these research questions, this paper aims to fill the gaps of the literature highlighted in the previous paragraph, and therefore offering to researchers in this field a new dataset for benchmarking, a methodological framework for experimenting and validating ASAG solutions as well as the code used so to ease other researchers in comparison with our tool. The code would serve as a “scaffold”, a basis to build and validate future ASAG systems. The impact foreseen is to ease the development of ASAG systems through offering more comparability and reproducibility to ASAG systems.

Visual abstract of our proposal. An instructor has to score the short answers (SAs) of students in a class. The answers are input to GradeAid that support the instructor providing a score
The proposed approach
Our idea is to exploit both lexical and semantic features of answers to provide a final grade. First, we have gathered different publicly available datasets for ASAG that are ASAP, SAG, SciEntBank, Cu-NLP which will be presented and discussed deeply in Sect. 3.1. For each dataset, we split the data into coherent subsets representing one question and the related students’ answers. The proposed approach integrates the traditional methodology of natural language processing tasks belonging to the bag-of-words approach, with the most modern technology based on state-of-the-art deep learning methodology involving the semantic of texts. Therefore, each answer is represented as the fusion between its semantic and lexical characteristics. The mixing of the two approaches has been useful (as seen in, e.g., [14] fusing lexical and embedding features) for feature augmentation and provided a richer feature matrix to be processed with machine learning approaches. Further details and motivation behind this implementation are available in Sect. 5. For the validation phase, given the size of the datasets, we employ the well-known leave-one-out cross-validation (LOO-CV). From the experiments carried out, we obtained that single regressors show better results than ensemble of them. Moreover, the best regressors where adaptive boosting, random forest and support vector regressor for all the datasets experimented, and we have obtained up to 0.25 root-mean-squared error (scores for students’ answers from 0 to 5).
Our method’s performance is comparable with (and sometimes better than) state-of-the-art ones. Furthermore, we have collected a new dataset for ASAG in Italian language and performed experiments with our method on this new dataset that proved its goodness achieving up to 0.42 root-mean-squared error. To give concreteness to our proposal, we embedded our method into GradeAid framework.
Methodological contributions
The primary contributions of our work can be summarized as follows:
-
We have provided GradeAid, a framework for ASAG whose python-like pseudo-code is available in Appendix B, and its full code will be available at in a GitHub repositoryFootnote 5 shortly;
-
GradeAid is novel because it jointly considers lexical features and semantic features of the short answers, where the lexical features are computed with TF-IDF method, and semantic features are computed with BERT Cross-Encoder and condensed in a similarity score. Words (and the exact choice of words by students) are very important in several HE subjects, and thus, we had to include lexical analysis in our GradeAid. Second, the similarity between students’ answers and reference answers is crucial for the overall assessment as well as for specific subjects. GradeAid, in this version, is our proposal bringing together both clues and provides the solution in a not computationally demanding fashion.
-
Compared to the literature, we have performed more robust experiments on ASAG with our method on all the datasets publicly available in the literature; the results show that our method’s performance is comparable with (and sometimes better than) state-of-the-art ones.
-
We have introduced a new dataset for ASAGFootnote 6 that has been used as testbed for our solution. The dataset will be published in the near future, for all researchers interested into.
Contribution to ASAG research field
We remark that, from the literature review, further expanded in Sect. 2, this research field lacks of standardized and well-defined approach in comparing the proposed methodologies performances: Researchers use different datasets and performance indicators to benchmark their methods and often do not share the code or pseudo-code or software to reproduce their tests. With this work, we intend to provide:
-
a standardized set of datasets (based of the most commonly used in the literature), available in a public repository, and open for further contributions from other authors;
-
a standard target of evaluation approach of ASAG solutions;
-
a standard indicators’ set to benchmark other ASAG solutions’ performance.
-
public repository for the proposed method, open to be improved by other researchers.
Therefore, the milestone of this paper is to lay the foundation for a developing more open, transparent and robust ASAG solutions.
Organization
The rest of the paper is structured as follows. Section 2 presents related works in the literature and a schematic comparison among such works with the one presented here. Section 3 offers an overview on methods and materials employed. Section 4 formulates and details the problem faced in this work. Section 5 presents GradeAid framework with its components and the methods evaluated. Section 6 shows obtained results and offers a throughout discussion about insights got. Finally, Sect. 7 concludes with final remarks and future developments.
2 Related work
In this section, we report and offer details about previous literature showing contact points with the work here presented.
The issue of ASAG has been studied for a long time; indeed, different reviews and surveys concerning ASAG are available in the literature. In the following, we briefly discuss about main goal and findings of such studies in chronological order (from older to newest).
In [7], the authors surveyed ASAG systems, analyzing 80 papers published between 1996 and 2014. They mainly focused on the advancement of methods and approaches. The authors found that statistical methods were the most used to tackle automatic grading, and natural language processing techniques were widely adopted for extracting lexical, morphological, semantic and syntactic features from data. Moreover, they observed that this body of works was emerging; still there were barriers in the advancement of the research due to the impossibility of publishing the datasets employed for privacy reasons. Later, the authors in [15] pushed forward the analysis, including 44 papers published between 2003 and 2016. They studied datasets employed, machine learning (ML) techniques adopted, commonly used features and quality of results. The authors found that the most used ML method was SVM (no deep learning methods were used) and answers are represented through bag of words and word2vec mainly.
In [16], the authors reviewed works on ASAG published before 2019. Their aim was understanding how they work, mainly with regard to features employed, and what challenges in education they face and address. One of the drawbacks found was related to features extraction: Vast majority of proposals rely on feature engineering that can be time-consuming, since features need to be carefully handcrafted and selected to fit the appropriate model.
More recently, the authors in [17,18,19] reviewing a narrower set of articles detected an increasing use of deep learning techniques in last years with quality results which could favor the real applications.
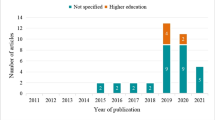
For the sake of clarity, here we zoom into recent articles on ASAG which we will compare to. In particular, using ScopusFootnote 7 and Web of ScienceFootnote 8 databases, we have downloaded the latest articles (from 2018). The query used is available in Appendix C. After applying the method proposed by [20], and the quality filtering proposed by [21], we gathered a total of 32 articles about automatic short answers (or essays) grading (or scoring). Such articles have all employed a dataset of answers written in English language.
In the following, we first describe each work highlighting key differences with the present one, and then, we will compare on different criteria such papers.
First of all, we can distinguish between works dealing with ASAG as classification problem, and other ones that faced a regression problem, like we do here. We will take out of the deeper analysis the work by De Clercq et al. [22]. In such a paper, the authors proposed an analysis of handcrafted features for ASAG and their correlation with the final score assigned to a student’s answer. They did not develop a new method, or experimented with ML models, and hence, they had a different focus with respect to all other articles here surveyed.
2.1 ASAG as classification problem
This section is devoted to present the works that have approached to ASAG as a classification problem.
Tay et al. [23] proposed a new method based on SKIPFLOW mechanism that models relationships between snapshots of the hidden representations of a LSTM network as it reads. Subsequently, the semantic relationships between multiple snapshots are used as additional features for scoring students answers. They obtained an average quadratic weighted Kappa (QWK)Footnote 9 = 0.764. They compared the solution with different models, also a commercial one, namely EASE. It is unclear if the solution is portable in real-world scenarios with many more parameters to tune than the other works. In fact, the authors compare the parameters’ impact, observing that small variations in training time and parameters of the LSTM lead to performance degradation (lower than competitors) on scoring. The solution proposed only works in the English language.
Cai et al. [24] proposed a RNN architecture trained on a fusion between word embedding features (via GloVe) and handcrafted features (spelling mistakes, article length, etc.) for scoring students’ answers. They evaluated different RNN models and measured the correlation of handcrafted features with final scores. They obtained a QWK up to 0.80. Surprisingly, the size of deep learning models did not significantly affect the results. Deeper RNNs might overfit the small training data and yield inferior results than shallower networks. RNN with 50 hidden neurons might be powerful enough to learn latent information and features for this ASAP dataset. Furthermore, the usage of both handcrafted and GloVe features improves QWK. The solution has not been compared with others in literature and only works in English.
Chen et al. [25] proposed a novel CNN with a final ordinal regression layer for scoring. The model is trained on one-hot encoding of answers’ words (after segmentation and tokenization tasks). They obtained a QWK of 0.826. With respect to using LSTM and CNN models alone, the accuracy of the proposed solution has been greatly improved when combining CNN and Ordinal Regression. However, it is unclear if the method can work with languages other than English.
Chimingyan et al. [26] fine-tuned word2vec model for the embedding of students’ answers and added handcrafted features (grammar errors, answer length, average words length, etc.) for the automatics scoring through LSTM network. They compared LSTM with logistic regression, obtaining an accuracy of 0.32 and QWK of 0.94. They found that LSTM performs much better than logistic regression (QWK = 0.65) in scoring students answers. They found that grammar errors profoundly affect the final score as they are the most important among the handcrafted features. The method developed works only with the English language. Furthermore, as for other related works, the researchers did not compare their solution against other methods in the literature.
Wiranto et al. [27] introduced a method based on transfer learning Siamese dependency tree-LSTM network for scoring students’ answers. The model is trained with GloVe embedded answers and relevant words thereof combined with their synonyms generated through autoencoders. The experimental phase foresees different tests with and without synonyms, deleting words, adding noisy words, with transfer learning and without transfer learning. They obtained a QWK and accuracy of 0.8574 and 70.80%, respectively. Furthermore, they found that the proposed method generally has the best evaluation QWK and accuracy with transfer learning and without data augmentation. However, the validation method is not precise.
Hussein et al. [28] developed a framework that scores students’ answers and essay traits (ideas, style, organization, conventions). They explored multiple deep learning models for the automatic essay scoring task. The authors obtained a QWK of 0.851. The results show that the prediction of the traits scores enhances the efficiency of the prediction of the overall score. However, the authors foresee the use of essay traits prediction for giving feedback to students, but such a scenario has not been evaluated. Moreover, other models compared are faster than the developed ones.
In [29], the authors collect and perform an experiment on, a small dataset of answers in the Slovenian language, which are graded into three labels. Experiments encompass two-label and three-label settings. Answers are represented with word2vec, and the final grade is given through a state-of-the-art neural network model. One of the limitations of this work is that they only performed experiments with neural networks (no other methods have been compared), and they adopted training and testing split only.
In [30], the authors developed a bi-LSTM inspired by [31] with a lexical attention mechanism to score students’ answers. The model is trained with word2vec embedded answers. The attention mechanism relies on a feature capture layer that computes the weights for each word in the essay [31]. The method scored a QWK of 0.83. Their method can show critical words and sentences that lead to the final assigned/predicted score; thus, it has more interpretability than other deep learning approaches found in the literature. The model has not been evaluated against others in the literature. It does not consider the sentiment of the essay (the attitude of the students toward the essay). The model has not been tested on other datasets.
For the ASAG task, some researchers started using the state-of-the-art method for natural language processing, BERT. In Lun et al. [32], the authors proposed a method involving the usage of BERT. In particular, they fine-tuned the BERT base model to classify the students’ answers. Besides, the authors adopted data augmentation strategies: back-translation, correct answer as reference answer and swap content. The performance achieved from this model is measured using the accuracy and F1 on the SciEntBank dataset. The performance shows a peak \(accuracy = 0.8277\) for the binary classification. The limitation of this method is that the score provided is just binary, not a more linear score of goodness to fit to the reference answer. Moreover, the fine-tuning of BERT model is a resource-intensive task. Similarly, in [33], the researchers used the SciEntBank dataset and BERT for automatic grading, by fine-tuning the model, in this case, with a softmax layer to provide the final score. In addition, the authors used XLNET (Extra Long Network) to compare performances. Here, the BERT approach provided better results over XLNET, with a MeanF1 score close to 80% for binary tasks. The authors only split the dataset one time randomly with 20% of data used for validation, therefore not performing a more robust testing with cross-validation. Also in [34], the authors proposed a method relying on the BERT model. In this case, the BERT basic model has been further trained using domain-specific knowledge of textbooks and further fine-tuned with questions-answer. The further training increased performance on test runs on proprietary and not publicly available datasets, achieving a MeanF1 = 83.95%. However, this approach is not directly reproducible since the dataset is not publicly available.
Lastly, an interesting approach was conceived in [35], where the authors represented the students’ answers and the reference ones as a graph. Each sentence is represented as a node, and it is connected with an edge to another type of node representing the uni-gram and bi-gram included in the very sentence. Then, the method used to grade the answer is based on a graph neural network that accounts for similarities between the reference answer’s graph and the student’s one. Furthermore, the authors provide a deep analysis of the graph features more correlated with the final grade. However, they have used only the ASAP dataset, and their experiments involve a straightforward approach of splitting the dataset into training and testing, then reserving 10% of the training set for validation purposes.
2.2 ASAG as regression problem
This group of works is closer to the one presented here because the problem of ASAG has been approached as a regression one. Therefore, to better highlight differences and similarities, we first describe each element found in this group, and then, we sketch and summarize significant points of each of them (and ours) in Table 1. The table focuses on the following aspects:
-
Dataset, i.e., the set of datasets employed;
-
Features, i.e., how text answers have been represented;
-
Method, i.e., how scores have been computed (regressors, similarity methods, and so on);
-
Validation, i.e., whether authors have only performed training and testing (TT) or cross-validation (CV), and/or split the dataset by question (QS), and/or cross-validation with nested features computation—as we did here—(CV-FC), or, lastly, validation not clear from the paper (NA);
-
Code, i.e., the availability of the code.
Hassan et al. [36] compared different embedding techniques for students’ answers, i.e., word2vec, GloVe, fasttext and Skip thoughts. The proposed model employs embedding on students’ answers and reference answers to generate vector representation of answers. Cosine similarity measure between vectors of students’ answers and reference answer is used as a feature vector to train ridge regression model for predicting students’ scores. The method achieved RMSE of 0.821. Paragraph embedding techniques resulted in being the most effective for short answers grading. The authors have not compared different regression methods for obtaining the final score. The proposal has not been evaluated on diverse datasets.
Prabhudesai et al. [14] proposed a method to score students’ answers based on (i) word embedding via GloVe combined with handcrafted features (e.g., number of words, length of answer, number of unique words, average word length, etc.) and (ii) customized LSTM that takes as input embeddings, handcrafted features and the reference/golden answer. Moreover, they compare several architectures for LSTM, like plain, deep and bidirectional (also with and without handcrafted features) to find the most suitable for the scoring problem. Lastly, authors compare their solution with those previously available in the literature. They obtained a MAE of 0.618 and a RMSE of 0.889. Their work shows how including handcrafted features improves results, especially with regard to MAE (of about 0.25). However, the approach not evaluated on other datasets (like ASAP).
Sahu et al. [37] faced the problem of scoring both as regression and classification task. They experiment a rich set of text similarity features, CBoW and TF-IDF to train machine learning regressors and classifiers whose output is then conveyed into a fusion model for the final scoring. The proposed method has also been evaluated on ASAP dataset. They achieved RMSE = 0.793 and F1 from 0.50 to 0.93. The stacked ensemble method exhibits better performance than single methods. Moreover, the alignment-based and lexical overlapping features in addition to the semantic similarity features employed in the proposed system contribute a lot toward enhancement in labeling performance as compared to previous systems in the literature. The paper does not compare further ensemble methods with the one proposed. Very short answers are not graded correctly, and in some cases, the system fails to capture sequence information of answers.
Gomaa et al. [38] propose ans2vec, a method based on skip-thought mechanism to perform students and reference answer embedding and measure their similarity. The proposed method has also been evaluated on SciEntBank dataset. They achieved a RMSE of 0.91 and a F1 score from 0.54 to 0.58. The result is comparable with others in the literature without using any handcrafted feature. The method is not applicable on languages other than English due to the dependency from ans2vec method.
Besesio et al. [39] proposed a series of experiments for ASAG on the ASAP datasets, but they have rescaled the scores to three integer values, i.e., 1, 2 and 3. The authors have performed experiments, using cross-validation, with word2vec, with handcrafted features and with a fine-tuned BERT model. They found that the combination of all three representations of answers (students’ and reference) minimizes the error on the regression. Differently from most related works, here the hyper-parameters of the BERT model are transparent to the research community, but the final method to provide the score is hard to get from the paper.
In [40], the authors proposed a novel fusion model which takes: (a) the string of the reference answer and the students answers to get the first output; (b) the string of the question and student answer to get the second output. Finally, the model feeds the two outputs obtained above into the a features fusion layer filtering out multiple facets of semantic features, followed by an output layer for generating the final score. The proposed method has also been evaluated on ASAP and SciEntBank datasets. The method achieved a RMSE of 0.678 and a F1 from 0.62 to 0.768. The proposed model overcome previous developed scoring systems on the datasets employed for the evaluation. The authors found that the proposed system performs poorly on long-tailed datasets. Lastly, the authors compare their solution with a narrow set of previous works, overlooking many contributions we have identified in the literature.
Tulu et al. [41] proposed an automatic scoring system based on SemSpace [42], a novel embedding approach to learn word vectors by weighting semantic relations, used to feed Manhattan LSTM network (which is precisely used for similarity tasks [43]). The proposed method has also been evaluated on CU-NLP dataset. It obtained RMSE = 0.040 on SAG dataset. The proposed method also showed its reliability and consistency with CU-NLP dataset. Authors show that their solution overcome previous ones in the literature (by at least 0.80). However, SemSpace cannot handle mis-spelled words or grammar errors.
Overall, as anticipated in the introduction of the paper, we remark that the literature on ASAG mainly shows the following limitations:
-
there are a few publicly available datasets on ASAG, and they are generally very limited in size. Besides those listed in Sect. 3.1, no other work has released the dataset employed;
-
works available generally did not performed experiments on all the (few) available datasets and in most cases just on a single one;
-
there are no tools or software for end-users, hence no clues on how teachers and instructors could interact with such systems and on their user satisfaction;
-
experiments’ settings are not uniform: Validation conducted in previous literature is limited because authors have generally not split the datasets by question or have performed just straightforward strategies such as splitting between training and testing sets.
3 Materials and methods
In this section, we provide basic and background knowledge useful to better understand the subsequent sections. In particular, we detail the datasets employed (Sect. 3.1), the techniques exploited to represent students answers (Sect. 3.2), the machine learning methods experimented (Sect. 3.3) and the metrics used to evaluate the performance of GradeAid (Sect. 3.4).
3.1 Dataset(s)
In this work, datasets reported in Table 2 have been exploited for building GradeAid framework. The table lists all datasets found by analyzing the related literature.
Each dataset is built differently from the others. The ASAP dataset provides scores by two annotators in the range \({\mathbb {R}}[0,3]\). We scaled such scores in the range \({\mathbb {R}}[0,5]\) as other datasets in Table 2 and computed the average between the two annotators scores. We remark the dataset ASAP is composed of short text answers that the official page refers as essays. We have used them as short answers, and we had to include the reference answers. To obtain such reference answers, our strategy implies to use the highest scored ones among those provided by students.
Within the SciEntBank dataset, we only found correct/not correct labels. Therefore, to uniform such dataset with the others in Table 2, we asked two experts in the field of science and chemistry to provide grades for the students’ short answers (as similarly done in ASAP dataset). We measured their agreement through the Cohen’s kappa [51], obtaining a value of \(k=0.642\), thus a substantial agreement. The scores are subsequently obtained by averaging the experts’ grades.
Lastly, we obtained the binary assessment of students’ answers, for all datasets missing it, as follows: Each answer whose score was greater or equal to 2.5 was put to “correct” class, otherwise “not correct” (Figs. 3, 4, 5, 6).

ASAP dataset distribution of scores (and their binary labels counterpart)

SAG dataset distribution of scores (and their binary labels counterpart)

CU-NLP dataset distribution of scores (and their binary labels counterpart)

SciEntBank dataset distribution of labels (and their scores counterpart)
3.2 Short answers representation
There are different ways to represent short answers: a lexical representation, and a semantic representation. For what concerns the lexical representation, one of the most used techniques is Term Frequency-Inverse Document Frequency (TF-IDF). This approach is a well-known approach to natural language processing (NLP) tasks that is part of techniques representing the textual data as bag of words (BoW). This name is derived to the concept of ignoring words order in documents, and focusing on the presence of the words in the specific document. Many NLP tasks showed to be managed with this simplification (e.g., email phishing detection [52], management research [53], fake news detection [54] and ASAG as well [55]). Not considering the words order, these methodologies usually have no benefit from grammar and generic words, such as “the”, “with”, “be” and “go”. The TF-IDF methodology creates a documents-terms matrix, where the documents are represented on the rows, and on the columns there is the vocabulary of all the words present in the corpus. Each cell in the matrix indicates the frequency of term in the document, multiplied for the inverse of the frequency of word across all the documents in the corpus. The first indicates is useful to manage documents of different lengths, and the second is useful to reduce the weight of words too common in the corpus, typical of stopwords.
Formally, let k be a term/keyword, d a document and D the set of all documents. We define \(TF(k) = \frac{{\texttt {count}}(k,d)}{{\texttt {wordcount}}(d)}\), i.e., the number of times k appears in d (count(k, d)) divided by the total number of words/terms in d (wordcount(d)). We define \(IDF(k)=\log _e\frac{|D|}{{\texttt {countDocs}}(D,k)}\), where countDocs(D, k) returns the number of documents containing k. Then, the TF-IDF is computed as follows: \(\texttt {{TF-IDF}}(k,d,D) = TF(k,d) \times IDF(k,D)\). Thus, d is then described as an array whose length is equal to all the keywords/terms in D, i.e., \(A_d=[{\texttt {TF-IDF}}(k_1),\ldots , {\texttt {TF-IDF}}(k_N)]\), where N is the total number of terms in D.
Concerning the semantic representation, in the NLP field there have been introduced several techniques to understand the meaning of words or sentences for purposes ranging from question answering [56] to opinion mining [57], cybersecurity studies [58] and law [59]. In the last years, word embedding has established itself as one of the most popular representation methods of document vocabulary [60]. Among its capabilities we can cite that of capturing the context of a word in a document, semantic and syntactic similarity, relation with other words. Word2vec [61, 62] is the most popular technique in this field. It uses the conditional probability P(w, c) to predict the target word w based on its context c. It has been used for a variety of tasks, e.g., finance-relating text mining [63], question answering [64], as well as ASAG systems [26, 44, 45, 50].
The success of neural networks-based methods for computing word embeddings has motivated the proposal of several methods for generating semantic embeddings of longer pieces of text, such as sentences, phrases or short paragraphs [65]. They are methods to embed a full sentence into a n-dimensional vector space. These sentence embeddings retain some properties, as they inherit features from their underlying word embeddings (e.g., semantic similarity).
The current state of the art for NLP tasks relies on the usage of BERT (Bidirectional Encoder Representations from Transformers) [66] and its related extensions, such as roBERTa [67]. BERT is designed to pre-train deep bidirectional representations from an unlabeled text by jointly conditioning on both left and right context in all layers [66]. BERT is a two-step framework. The first step is pre-training; during this step, the model is trained on unlabeled data over different pre-training tasks. The second step is fine-tuning; the BERT model is first initialized with the pre-trained parameters, and all of the parameters are fine-tuned using labeled data from the downstream task [66]. The pre-training phase works by jointly training the transformer network on two tasks: (i) predicting the masked words in the sentence (masked model language) and (ii) predicting the next sentence (next sentence prediction). Further details of BERT implementation are disserted in [66]. Once the pre-trained BERT model is achieved, it can be fine-tuned with additional output layers to create models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications [66]. For this research, we involved BERT cross-encoder: In this approach, two sentences are provided to the model, producing an output value between 0 and 1, indicating the semantic similarity between sentences.
3.3 Machine learning methods for ASAG
One of the main techniques used in ML consists in training a model through a supervised learning algorithm which analyzes training data (observed samples) and produces an inferred function which can be used for mapping new samples. ASAG systems in the literature—see Sect. 2—face the problem of giving a score to students answers in two different ways, i.e., regression task (approximating a mapping function from input variables to continuous output variables) or classification task (approximating a mapping function from input variables to discrete output variables). In our approach, GradeAid—through supervised learning—exploits regressors (mapping function) to map the model/reference answers and the students ones (input) in a suitable score for each specific students answer.
Several regression methods have been proposed in the literature. To build our system, we have considered the following: support vector regressor (SVR), random forest regressor (RF), ElasticNet (EN), ridge regression (RR) and adaptive boosting regressor (Ada). The choice of such methods is justified by their widespread usage in several studies and applications. All the methods are available in scikit-learn Python library.Footnote 10
3.4 Metrics for ASAG performance assessment
In this work, we adopt standard metrics used by previous ASAG systems, and, as we will see (Sect. 4), we model the ASAG problem as regression task. In the following, we report the metrics employed to measure the performance of GradeAid.
Regression. Let \(y_i\) be the target value (known score), \(\hat{y_i}\) be the model’s predicted value (predicted score), and N be the samples, to evaluate GradeAid in regression task, we use the following metrics:
-
Mean Squared Error (MSE): \(MSE=\frac{1}{N} \sum \nolimits _{i=1}^N (y_i - \hat{y_i})^2\) It measures the square of differences between predictions and target values and computes the mean of them.
-
Root-Mean-Squared Error (RMSE): \(RMSE = \sqrt{MSE}\) The use of RMSE is very common, and it is considered an excellent general-purpose error metric for numerical predictions.
-
Mean Absolute Error (MAE): \(MAE=\frac{1}{N} \sum \nolimits _{i=1}^N \vert y_i - \hat{y_i}\vert \) It is known as a scale-dependent accuracy and therefore cannot be used to make comparisons between series using different scales.
-
Normalized Root-Mean-Squared Error (NRMSE): \(NRMSE = \frac{RMSE}{{\overline{y}}}\) While RMSE provides an absolute error metric, this measure is strictly related to the absolute scale of the distribution. Therefore, it lacks the capability to directly show the performance of the proposed method on different dataset. The normalized version of this indicator scales the error based on the true mean of distribution. This index allows us to compare the performance of the method on different datasets and so the error made varying the dataset. MAE and MSE are dependent on the datasets where the regression is made.
4 Problem description
ASAG problem has been modeled as a supervised machine learning problem. Let \(Q=\{q_1,q_2,\ldots ,q_m\}\) be the set of questions posed to students. Let \(S=\{s_1,s_2,\ldots ,s_n\}\) be the set of students answers to the different questions in Q. \(A = \{a_1,a_2,\ldots , a_k\}\) represents the set of k responses such that a unique one-to-one mapping exists between Q, A and S. Lastly, let \(R=\{r_1,r_2,\ldots ,r_m\}\) be the set of reference/model answers to the questions such that \(r_i\) is the reference answer to \(q_i\). Furthermore, we define a set of grades \(G=\{g_1,g_2,\ldots ,g_h\}\) that are assigned to students answers. Thus, the ASAG problem is formulated with the following input and output specifications:
-
Input: A pair of short answers \((r_i, a_j)\) representing reference answer \(r_i\) to a question \(q_i\) and student answer \(a_j\) to \(q_i\);
-
Output: Assignment of score s to student answer (regression task) based on the extent of similarity between the student answer and the respective reference answer.
The problem of ASAG (regression task) can be mathematically formulated as follows:
-
the ASAG regression model is trained with a data set of \(<a_j, r_i, g_j>\) tuple. Therefore, we want to learn a regression model \(reg:(a_j,r_i)\rightarrow s\in {\mathbb {R}}\), i.e., \(s=w\cdot X\) where w refers to the regression coefficients, and X refers to the input feature vector obtained by processing \((a_j,r_i)\).
-
The scoring performance of the regression model is measured using the following evaluation metrics: RMSE, MSE, MAE and NRMSE (see Sect. 3.4).
5 GradeAid: our framework
The framework proposed in this research aims to provide numerical feedback to students for learning purposes. A graphical representation of the framework is available in Fig. 7. The main challenge for a real application of this methodology is usually related to the datasets’ size. There a no large training datasets available to properly train the model. Moreover, the framework, namely GradeAid, is meant to be applicable to different languages, minimizing the need of specific tuning.

GradeAid: the framework. It takes students’ answers and the reference answer (it translates the texts in English if needed), and it splits the dataset provided based on the questions. During a cross-validation, at the same time, it computes similarity between students’ answers and reference answer, and TF-IDF matrix. Finally, the lexical features (TF-IDF) and semantic features (similarity) are concatenated for the prediction of the score
GradeAid works creating a model specific for each open-ended question subject to evaluation. To proceed in the creation the model, the input is the training dataset of answers labeled with a score between 0 and 5, and the reference answer (that can be or the answer provided by the teacher or, if not available, the answer with the highest score).
For answers provided in language different from English, the first block of the framework implies the usage of the EasyNMT package, a state-of-the-art machine translator for more than 100 languages.Footnote 11 It is used to translate the corpus to English language.
The next block involves the construction the feature matrix from the corpus. This step consists of two different parallel operations: The well-established feature extraction method, TF-IDF, is applied to the dataset to build the matrix of words occurring in the documents; in parallel, a BERT Cross-Encoder with the pre-trained “cross-encoder/stsb-roberta-large” model is run, to build a the similarity scores between each student’s answer and the reference answer. BERT Cross-Encoder model, opposed to BoW methodologies, is trained to provide as output the semantic similarity score between a document (text) with another one. This implementation differs from bi-encoders implementations, where the sentences are passed separately to BERT to compute the embeddings (therefore used as extractor), with a final function that computes similarity. In this case, the sentences are passed to the model simultaneously that directly provides the similarity as output. This is more clear in Fig. 8. The similarity is expressed with a value between \(-1\) (opposite meaning) and 1 (same meaning). The details of the implementation of this BERT configuration are further explored by [67].

SBERT model used in this paper (left) vs BERT model as extractor through sentence embedding (right). Adapted from https://www.sbert.net/examples/applications/cross-encoder/README.html
The usage of these two methodologies for the features matrix construction relies on two relevant consideration about the evaluation of questionnaires: (i) The usage of specific words, coherent with the question, is usually a good indicator of the answer’s quality, and (ii) it is also relevant for the final evaluation and scoring that the sentences/answers of students are semantically correct and coherent with the reference answer.
The concatenation of the TF-IDF matrix with the similarity scores is the final feature matrix to be processed by regression methods. For the TF-IDF processing, the corpus is prepared with typical NLP preprocessing steps, lowercasing, stopwords removal (stopwords list got from the R Text Mining Solution projectFootnote 12) and not-alphabetic words removal. Instead, the processing with BERT Cross-Encoder is performed directly on the raw corpus. The feature matrix generated can be processed from every machine learning method. In the experiments, we compared several regression methods which can be found in Sect. 3.3. The final output is a score of the answer.
5.1 Experiment
Our experiments’ setting revolves around four significant points: (1) the split by question, (2) TF-IDF strategy used, (3) the cross-validation approach and (4) the combination thereof:
-
1.
Implementing an experimental strategy for this task presents some difficulties: Often, datasets have a small size, while in some cases, they are large. Thus, finding a strategy to make results effectively comparable is not straightforward. Moreover, the small size of datasets limits rigorous benchmarking. Considering the aim of the ASAG and specifically GradeAid, i.e., providing feedback to students for learning, we decided to implement a strategy to simulate the most realistic use case. We treat each question (and therefore students’ and model answers) in datasets as a separate dataset, even if some questions share the same domain/context. While some approaches could benefit from other questions fusion, our implementation would not benefit from it and, on the contrary, would be misled by the mixture.
-
2.
TF-IDF Algorithm builds the matrix and defines the number of columns in the matrix based on the vocabulary size extracted from the training dataset. Usually, each question has a specific typical dictionary for answers. Therefore, mixing answers would lead to the creation of a TF-IDF Matrix largely sparse (Fig. 9a). Instead, applying TF-IDF to a single question creates less sparse feature matrices (Fig. 10).
-
3.
For what concerns the validation, cross-validation is the primary approach we used to measure the performance of our methods. For large datasets, such as ASAP, we performed tenfold cross-validation, while for smaller datasets, SAG, SciEntBank and Cu-NLP we used the leave-one-out cross-validation (LOO-CV). In the former case, for each question, the answers are split into ten blocks (folds), and in ten iterations, nine blocks are used for training the model, and one is used to validate results. Finally, in the last case, the reduced size of the dataset suggested us to run as many iterations as the number of samples in the dataset, leaving one sample out for validation of the model in each iteration.
-
4.
Lastly, another significant point of our experiment methodology is as follows. In many cases of NLP, TF-IDF is performed before cross-validation. We decided to apply TF-IDF after the division between training and validation sets. This helps to simulate the actual use case, where the model is used to predict (totally) new answers of new students, with new words that have not been accounted for from the training TF-IDF. In this regard, Fig. 10 helps to describe the approach followed: Considering a dataset of \(N+M\) answers, this is split into two parts, i.e., the training with N documents and validation with M documents. The TF-IDF algorithm is applied to the training dataset, generating the feature matrix based on the dictionary of K words used in training. The dictionary and the IDF information are retained and used as a base to compute the feature matrix for the validation corpus, which will have the same number of column of the training (K), and the term frequencies are weighted with the IDF weight of the training dataset.
We ran 50 times the whole experiment for each dataset and for each parameters combination so to achieve more robust results.

How TF-IDF algorithm can be applied in ASAG problems

TF-IDF algorithm (this paper): split by question, dictionary resulting from training is used for applying the algorithm on the validation
5.2 Results
Tables 3, 5, 7, 9, and 13 show the results of the proposed framework, over all datasets described in Sect. 3.1. The tables report the MAE, RMSE and NRMSE achieved by all the regressors in Sect. 3.3 scoring every short answer (split by question) in each dataset. For MSE, please refer to Appendix D.
In the tables, lower values indicate better fit of the method. MAE, MSE and RMSE, however, are not absolute index of good fit, because their maximum value is dependent from the specific dataset, while NRMSE is scale independent and can be compared across datasets (see Sect. 3.4 for more details).
To increase the interpretability of the goodness of results, in the tables we provide, for each question, also the respective value of MAE, RMSE and NRMSE, for the middle regressor (Middle reg.), average regressor (Avg. reg.), and worst regressor (Worst reg.). These can be considered as “dummy regressors” and are useful as baseline to compare the performance of our methods. Worst reg. predicts always the worst value, i.e., the output for each answer is the further score possible from the true value. Therefore, its performance represents the worst that can be achieved from a regressor. Instead, Avg. reg. predicts always the average (mean) value of the answers for that questions. In this case, the value of MAE, MSE and RMSE of this regressor represents, respectively, the concept of average absolute deviation, variance and standard deviation. Lastly, Middle reg. always predicts the score in middle the minimum and maximum possible: In our case, the scores go from 0 to 5, and therefore, the middle score is 2.5.
The most evident insight is that the proposed method, with every regressor, always outperforms the dummy regressors. Considering the singular regressor methods, the best performing are SVR, RF and Ada. Poorer results are achieved from the ensemble of the selected methods. The goodness of results varies according to the dataset and questions. The best results are achieved on the ASAP dataset.
Tables 4, 6, 10, 14, and 8 show the comparison of performances of the proposed methods of this research with Avg. reg., since this dummy regressor was the best among such. This comparison allows us to directly compare the performance of the regressors. Values reported are given from the ratio between the regressor RMSE and the average regressor RMSE. The formula is
When PerformanceRatio is equal to 1.00, it means a full improvement of the regressor (i.e., the regressor has a \(RMSE = 0\)). Instead, when equal to 0.00 it indicates an “improvement” comparable to average regressor (\(NRMSE_{regressor} = NRMSE_{Avg.Reg.}\)). Lastly, values lower than 0.00 indicate the worsening of the regressor’s performance.
The best PerformanceRatio (the peak) is 0.59 for ASAP, and the two best performing regressors are SVR and RF. For Cu-NLP, RF performed very well and Ada outperformed the other regressors with a peak of 0.38. In SAG, RF outperformed the other regressors, with a peak of 0.47. It is very interesting to observe that the SVR regressor, in this case, performed worse than the baseline. Concerning the SciEntBank dataset, best performance has been achieved by RF as well, with a peak of 0.25.
In summary, the proposed methods are always able to perform ASAG with good results. However, these are not stable, and although there are two regressors with generally exciting results (SVR and RF), the performance tends to oscillate between questions and datasets. We expected ensemble could provide better results compared to single learners, but the table shows how some single learners have more potentials.
6 Discussion
In the following, we provide additional experiments to validate the proposed approach (Sect. 6.1). The discussion is split into two “Additional questions” paragraphs with related experiments. Next, further specifications and motivations regarding implementation choices are provided (Sects. 6.2–6.4).
6.1 Additional experiments
Additional question 1
Are there significant differences between the joint analysis of lexical and semantic features and only the one of lexical features?
Table 11 shows how the answer to this question is not straightforward. We have used for each dataset, the Shapiro–Wilk [68] test to assess the normality distribution of data, and then, based on its results, we have checked the statistical difference of the performance with the two approaches with the proper test. If we accept the null hypothesis \(H_0\) = “data are normally distributed”, the Student’s t test has been employed to check the difference [69]; otherwise, the Mann–Whitney U test [70] has been exploited (for not normally distributed data).
These tests confirm the significance of the better results in terms of MSE, using semantic features on datasets ASAP and Cu-NLP, while the difference is not significant for SAG and SciEntBank (illustrated also in Figs. 11, 12). However, Fig. 11 shows that on the SAG dataset, although the statistical difference is not significant, performance obtained by the joint exploitation of semantic and lexical features is always better (lowering the MSE in almost every condition) than those achieved with the only lexical ones. In summary, we can consider the semantic features effective in improving the scoring precision of the methods, also if the benefits are not always high for all datasets.

Difference of MSE obtained with and without semantic features with SVR on SAG dataset. On the x-axis, the graphic represents the questions in SAG, and on the y-axis the MSE is obtained by the SVR using different kinds of features. The blue line represents the MSE achieved with lexical and semantic features, while the red bars represent the MSE achieved with the only lexical features. Lower MSE values are better (color figure online)

Difference of MSE obtained with and without semantic features with best regressors on SciEntBank dataset. Lower MSE values are better
Additional question 2
How does GradeAid perform on non-English datasets?
To fully answer this research question, we have used an Italian dataset, namely STITA. The STITA dataset is made publicly available on GitHub (see Table 12). However, only the English translated versionFootnote 13 is publicly available for privacy reasons. For some preliminary information about this dataset, we refer the reader to Table 12 (where subject and number of samples are reported) and Fig. 13 (where we show the distribution of scores).
On STITA, we have performed the same experiments seen previously for other datasets (Sect. 5.1). As the results shown in Table 13, the performance of GradeAid is effective also on non-English datasets. The best regressor, in this case, is Ada with NRMSE from 0.54 to 0.17. This regressor shows an improvement with respect to the Avg. reg., of 0.17 for q5, 0.21 for q1, 0.41 for q2, 0.43 for q4 and 0.70 for q3 (best improvement). Another very promising regressor is RF, which overcomes Ada in q5, showing an improvement with respect to Avg. reg. of 0.45.
In addition, also for STITA dataset, we have performed an experiment with and without semantic features and we have employed, as for other datasets the same statistical tests. The result, in this case, is that there is a significant difference in the results obtained using the semantic features (\(p =.01511 <.05\)).
These results should be take carefully, as the test has been performed only on a dataset of a specific language, i.e., Italian, translated in English with an open machine learning translator and on a specific subject, i.e., statistics. More robust proofs would involve using datasets in different languages (e.g., Arabic, German, Brazilian, etc.)—which, to the best of our knowledge, are, to date, not available for researchers, as the performance of translator could vary. Moreover, different subjects could easily impact the results. Anyway, the strategy of translating the answers and process them showed to be successful in our experimental setting.

STITA’s dataset distribution of scores (and their grades counterpart)
6.2 Motivation for translation in STITA experiment
A transformation/translation step somehow adds a bias in the dataset. Anyway, the machine translation used in the experiments carried, i.e., EasyNMT, is the current state of the art among the non-commercial ones. We did not use a human translation, because we wanted to test our methodology also in this way, on datasets that are not in English. Whoever intended to use an ASAG systems, it is clearly not prone to manually translate answers if they are in another language. Therefore, it is realistic that future stakeholders will use a machine translation (commercial or non-commercial), paying the price of introducing an error in the evaluation. In addition, a translation step (manual or automatic) is often required since many languages have no sophisticated embedding models available.
6.3 Motivation for integrating lexical and semantic features
In the preliminary experiment phase we have carried out, by only using our semantic features, the performance of GradeAid was not promising on all datasets. Therefore, we have added lexical features that are mostly employed also in the literature of ASAG systems. Anyway, we have employed lexical features also to measure the kind of lexic is used by the student. As reported in the paper, and as also emerged from informal focus groups held with teachers and instructors from different education levels prior to the development, the exact choice of words by students is very important in several HE subjects, especially technical ones. Nonetheless, we are aware that hidden layers of BERT and other semantic models for embedding can be used to extract lexical representations. But, as highlighted by a recent EU Council’s white paper (COM(2021) 206), applications of artificial intelligence in education are considered high risk ones where the development should pursue more drillable and interpretable solutions ensuring human oversight. Therefore, since our objective was to support instructors and students, we cannot deliver a method whose outputs are hard to explain.
6.4 Motivation for keeping the datasets’ data distribution
We kept the distribution as it is for three reasons: (a) Related works did not change it. To compare against them in the best possible way, we have kept the datasets distributions as it were. (b) After a discussion with instructors and teachers (university, high schools, etc.), we assessed that the difference in the distribution of the scores was fair for our task. (c) The unbalanced score of the datasets is by itself a prior of the score of answers. Of course this effect may not be wished, but for our experiments, we decided to keep it. Further experiments, and in consideration of the specific application of GradeAid, may induce a different choice, and using a balanced dataset may become mandatory or at least more convenient. (i.e., when the training dataset is applied in a learning environment in a different context).
7 Conclusion
The presented research addresses two primary points of automatic short answer grading (ASAG) area: (i) a standardized pattern to benchmark the research progress and methods, and (ii) we proposed a new framework for ASAG, namely GradeAid, involving both semantic (from the BERT model) and lexical features (TF-IDF algorithm). Furthermore, differently from related works (see Sect. 2), to benchmark our performance, we experimented GradeAid on all the publicly available datasets in the ASAG literature. The proposed ASAG methodology mixes the traditional bag-of-words methodology with most recent progress of state-of-the-art NLP tasks. The inclusion of also semantic features, through BERT model, shows to be beneficial for all datasets accounted in this research, although in some case, the benefit has not been statistically significant.
Expected impact
Education and learning are the principal factors for innovation and drive wellness growth. Improvement and automation benefit the learning process and lower the costs for students education, making this more accessible also in developing countries. This research wants to be a cornerstone for ASAG by proposing a framework, a feasible standard methodology for benchmark, a new dataset and overview of the works in ASAG area. The results of this work are promising for ASAG, and the public availability of the used datasets and the code should lead to more fair and directly comparable benchmark for the proposal of new methods. In addition, it also acts as a base to be applied in production environment, overcoming the current gap in the ASAG literature.
Limitations and future steps of the project
Despite the promising results of GradeAid, the framework has some intrinsic limitations: The usage of regressors generates some paradoxes in the final scoring. Regressions are not capped, and thus, they can theoretically estimate values under the minimum (zero) and over the maximum score (five). Although a dummy solution is to manually cap the regressors’ output, this is something that would need attention in the near future. Virtually, the usage of some methods different from regressors, such as ordinal regressor, could help to address the issue and improve the quality of results: Humans do not score answers over a infinite number of scores, but across a limited set of values. Clearly, this could be addressed by rounding the output of the regressor to the nearest (integer) value. However, an ordinal regressor should be a more efficient and natural way to provide scores to students’ answers.
For the future, we aim to address these limitations by integrating our framework with other features and adopting newer datasets on specific subjects. In this research, we used both lexical and semantic features, the latter using the semantic similarity provided from a pre-trained BERT model. But such a model could be further trained with more domain-specific texts, so to improve its semantic evaluation, as performed, for example, in [34]. In addition, we are planning to experiment the latest transformer-based pre-trained models like XLM, XLM-Align, InfoXLM [71, 72]. Further directions would involve the development of a methodology able to provide comprehensibility of results following the guideline of human-centered AI [73,74,75,76,77,78]. Since the main aim of this study is to provide an automated system for feedback during learning, it is of paramount interest of learner to know what are the reasons of the score computed, to improve the quality of learning. This last point has spillovers on the cheating phenomenon [79]. On the one hand, the problem is severe, and clearly an extensive usage of automatic assessment tools like GradeAid could bring new challenges in facing such a problem. Currently, GradeAid is not intended to provide a final score for students’ answers, but as a supporting tool both for students and teachers. However, cheating is surely an aspect worth investigating for our research. To this end, before releasing GradeAid as a production tool we will take into consideration a series of user studies—involving students and teachers—in order to evaluate, among others, the cheating phenomenon.
For the next future, we have also planned to perform experiments with deep learning models for scoring and study advantages and disadvantages of such with respect to the current GradeAid.
Our ultimate goal for future is to embed GradeAid in a web application with an intuitive user interface. Indeed, we aim at experimenting an adaptation of GradeAid such that it provides contextual tags to the students’ answers. These tags are helpful for teachers and instructors to better comprehend the tool’s scores, thus enhancing the support for the final evaluation [80]. For example, an interesting evolution could be that of highlighting common keywords between students’ and reference answers.
Lastly, the hope of this paper is to nudge the research community to make more comparable, open and reproducible algorithms for ASAG.
Data availability
The datasets generated during and/or analyzed during the current study are available at https://github.com/edgresearch/dataset-automaticgrading-2022.
Notes
Peter Norvig and Sebastian Thrun, “Intro to Artificial Intelligence,” https://www.udacity.com/course/intro-to-artificial-intelligence-cs271.
QWK is a classification metric used when two or more raters labels (in this case, grades) are available.
Possible limitations to the translation: the usage of autocorrection steps of the corpus answer before processing may be helpful, considering that mistypes are likely to occur when students input the answer. The dataset STITA has been corrected using the python autocorrection package before to be translated.
References
Rodriguez CO (2012) Moocs and the AI-stanford like courses: two successful and distinct course formats for massive open online courses. Eur J Open Distance E-Learning
Ali W (2020) Online and remote learning in higher education institutes: a necessity in light of covid-19 pandemic. High Educ Stud 10(3):16–25
Daniel J (2020) Education and the covid-19 pandemic. Prospects 49(1):91–96
Hodges CB, Moore S, Lockee BB, Trust T, Bond MA (2020) The difference between emergency remote teaching and online learning
Murphy MP (2020) Covid-19 and emergency elearning: consequences of the securitization of higher education for post-pandemic pedagogy. Contemp Secur Policy 41(3):492–505
Prendergast C, Topel R (1993) Discretion and bias in performance evaluation. Eur Econ Rev 37(2–3):355–365
Burrows S, Gurevych I, Stein B (2015) The eras and trends of automatic short answer grading. Int J Artif Intell Educ 25(1):60–117. https://doi.org/10.1007/s40593-014-0026-8
Kumar S, Chakrabarti S, Roy S (2017) Earth mover’s distance pooling over siamese lstms for automatic short answer grading. In: IJCAI, pp 2046–2052
Sahu A, Bhowmick PK (2019) Feature engineering and ensemble-based approach for improving automatic short-answer grading performance. IEEE Trans Learn Technol 13(1):77–90
Pedersen T, Patwardhan S, Michelizzi J et al (2004) Wordnet: similarity-measuring the relatedness of concepts. AAAI 4:25–29
Mohler M, Mihalcea R (2009) Text-to-text semantic similarity for automatic short answer grading. In: Proceedings of the 12th conference of the European chapter of the ACL (EACL 2009), pp 567–575
Mohler M, Bunescu R, Mihalcea R (2011) Learning to grade short answer questions using semantic similarity measures and dependency graph alignments. In: Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies, pp 752–762
Zhang L, Huang Y, Yang X, Yu S, Zhuang F (2022) An automatic short-answer grading model for semi-open-ended questions. Interact Learn Environ 30(1):177–190. https://doi.org/10.1080/10494820.2019.1648300
Prabhudesai A, Duong TNB (2019) Automatic short answer grading using siamese bidirectional LSTM based regression. In: TALE 2019–2019 IEEE international conference on engineering, technology and education. https://doi.org/10.1109/TALE48000.2019.9226026
Galhardi LB, Brancher JD (2018) Machine learning approach for automatic short answer grading: a systematic review. In: Ibero-American conference on artificial intelligence, pp 380–391. Springer
Hussein MA, Hassan H, Nassef M (2019) Automated language essay scoring systems: a literature review. PeerJ Comput Sci 5:208
Prasain B, Bajaj SK (2020) Analysis of algorithms in automated marking in education: a proposed hybrid algorithm. In: CITISIA 2020—IEEE conference on innovative technologies in intelligent systems and industrial applications, proceedings. https://doi.org/10.1109/CITISIA50690.2020.9371783
Sychev O, Anikin A, Prokudin A (2020) Automatic grading and hinting in open-ended text questions. Cognit Syst Res 59:264–272. https://doi.org/10.1016/j.cogsys.2019.09.025
Ge S, Chen X (2020) The application of deep learning in automated essay evaluation vol 11984 LNCS, pp 310–318. https://doi.org/10.1007/978-3-030-38778-5_34
Kitchenham B, Charters S (2007) Guidelines for performing systematic literature reviews in software engineering
Roehrs A, Da Costa CA, da Rosa Righi R, De Oliveira KSF (2017) Personal health records: a systematic literature review. J Med Internet Res 19(1):13
de Clercq O, van Hoecke S (2020) An exploratory study into automated précis grading. In: LREC 2020—12th international conference on language resources and evaluation, conference proceedings, pp 397–404
Tay Y, Phan MC, Tuan LA, Hui SC (2018) SKIPFLOW: incorporating neural coherence features for end-to-end automatic text scoring. In: 32nd AAAI conference on artificial intelligence, AAAI 2018, pp 5948–5955
Cai C (2019) Automatic essay scoring with recurrent neural network. In: ACM international conference proceeding series, pp 1–7. https://doi.org/10.1145/3318265.3318296
Chen Z, Zhou Y (2019) Research on automatic essay scoring of composition based on CNN and OR. In: 2019 2nd international conference on artificial intelligence and big data, ICAIBD 2019, pp 13–18. https://doi.org/10.1109/ICAIBD.2019.8837007
Chimingyang H (2020) An automatic system for essay questions scoring based on LSTM and word embedding. In: Proceedings—2020 5th international conference on information science, computer technology and transportation, ISCTT 2020, pp 355–364. https://doi.org/10.1109/ISCTT51595.2020.00068
Wiratmo A, Fatichah C (2020) Assessment of Indonesian short essay using transfer learning siamese dependency tree-LSTM. In: ICICoS 2020—proceeding: 4th international conference on informatics and computational sciences. https://doi.org/10.1109/ICICoS51170.2020.9299044
Hussein MA, Hassan HA, Nassef M (2020) A trait-based deep learning automated essay scoring system with adaptive feedback. Int J Adv Comput Sci Appl 11(5):287–293. https://doi.org/10.14569/IJACSA.2020.0110538
Smith GG, Haworth R, Žitnik S (2020) Computer science meets education: natural language processing for automatic grading of open-ended questions in eBooks. J Educ Comput Res 58(7):1227–1255. https://doi.org/10.1177/0735633120927486
Wang Z, Liu J, Dong R (2018) Intelligent auto-grading system. In: Proceedings of 2018 5th IEEE international conference on cloud computing and intelligence systems (CCIS), pp 430–435. IEEE, 345 E 47th st, New York, NY 10017 USA. https://doi.org/10.1109/CCIS.2018.8691244. IEEE; IEEE Beijing Sect; Chinese Assoc Artificial Intelligence; Nanjing Univ Posts & Telecommunicat; Shanghai Univ; Jiangsu Engineering Lab Big Data Anal and Control Active Distribut Network; Nanjing Univ Sci and Technol; Swinburne Univ Technol; Shanghai K
Yang Z, Yang D, Dyer C, He X, Smola A, Hovy E (2016) Hierarchical attention networks for document classification. In: Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies, pp 1480–1489
Lun J, Zhu J, Tang Y, Yang M (2020) Multiple data augmentation strategies for improving performance on automatic short answer scoring. In: AAAI 2020—34th AAAI conference on artificial intelligence, pp 13446–13453
Ghavidel HA, Zouaq A, Desmarais MC (2020) Using BERT and XLNET for the automatic short answer grading task. In: CSEDU 2020—proceedings of the 12th international conference on computer supported education, vol 1, pp 58–67
Sung C, Ma T, Dhamecha TI, Reddy V, Saha S, Arora R (2020) Pre-training BERT on domain resources for short answer grading. In: EMNLP-IJCNLP 2019—2019 conference on empirical methods in natural language processing and 9th international joint conference on natural language processing, proceedings of the conference, pp 6071–6075
Tan H, Wang C, Duan Q, Lu Y, Zhang H, Li R (2020) Automatic short answer grading by encoding student responses via a graph convolutional network. Interact Learn Environ. https://doi.org/10.1080/10494820.2020.1855207
Hassan S, Fahmy AA, El-Ramly M (2018) Automatic short answer scoring based on paragraph embeddings. Int J Adv Comput Sci Appl 9(10):397–402. https://doi.org/10.14569/IJACSA.2018.091048
Sahu A, Bhowmick PK (2020) Feature engineering and ensemble-based approach for improving automatic short-answer grading performance. IEEE Trans Learn Technol 13(1):77–90. https://doi.org/10.1109/TLT.2019.2897997
Gomaa WH, Fahmy AA (2020) Ans2vec: a scoring system for short answers, vol. 921, pp 586–595. https://doi.org/10.1007/978-3-030-14118-9_59
Beseiso M, Alzahrani S (2020) An empirical analysis of BERT embedding for automated essay scoring. Int J Adv Comput Sci Appl 11(10):204–210. https://doi.org/10.14569/IJACSA.2020.0111027
Chen S, Li L (2021) Incorporating question information to enhance the performance of automatic short answer grading. In: Qiu H, Zhang C, Fei Z, Qiu M, Kung S (eds) Knowledge science, engineering and management, PT III. Lecture notes in artificial intelligence, vol 12817, pp 124–136. Springer AG, Gewerbestrasse 11, CHAM, CH-6330, SWITZERLAND. https://doi.org/10.1007/978-3-030-82153-1_11. Springer LNCS; Waseda Univ; N Amer Chinese Talents Assoc; Longxiang High Tech Grp Inc
Tulu CN, Ozkaya O, Orhan U (2021) Automatic Short Answer Grading with SemSpace Sense Vectors and MaLSTM. IEEE Access 9:19270–19280. https://doi.org/10.1109/ACCESS.2021.3054346
Orhan U, Tulu CN (2021) A novel embedding approach to learn word vectors by weighting semantic relations: Semspace. Expert Syst Appl 180:115146
Mueller J, Thyagarajan A (2016) Siamese recurrent architectures for learning sentence similarity. In: Proceedings of the AAAI conference on artificial intelligence, vol 30
Tashu TM, Horvath T (2018) Pair-wise: Automatic essay evaluation using Word Mover’s distance. In: CSEDU 2018—proceedings of the 10th international conference on computer supported education, vol 1, pp 59–66. https://doi.org/10.5220/0006679200590066
Tashu TM, Horváth T (2019) A layered approach to automatic essay evaluation using word-embedding 1022:77–94. https://doi.org/10.1007/978-3-030-21151-6_5
Tashu TM, Esclamado JP, Horvath T (2019) Intelligent on-line exam management and evaluation system vol 11528 LNCS, pp 105–111. https://doi.org/10.1007/978-3-030-22244-4_14
Gomaa WH, Fahmy AA (2019) Ans2vec: a scoring system for short answers. In: International conference on advanced machine learning technologies and applications. Springer, pp 586–595
Süzen N, Gorban AN, Levesley J, Mirkes EM (2020) Automatic short answer grading and feedback using text mining methods. Procedia Computer Science 169(2019):726–743. https://doi.org/10.1016/j.procs.2020.02.171. arXiv:1807.10543
Mathias S, Bhattacharyya P (2020) Can neural networks automatically score essay traits? In: Innovative use of NLP for building educational applications, pp 85–91. Assoc computational linguistics-ACL, 209 N eighth street, Stroudsburg, PA 18360 USA. Natl Board Med Examiners; ETS
Tashu TM (2020) Off-topic essay detection using C-BGRU siamese. In: Proceedings—14th IEEE international conference on semantic computing, ICSC 2020, pp 221–225. https://doi.org/10.1109/ICSC.2020.00046
McHugh ML (2012) Interrater reliability: the kappa statistic. Biochemia Medica 22(3):276–282
Salloum S, Gaber T, Vadera S, Sharan K (2022) A systematic literature review on phishing email detection using natural language processing techniques. IEEE Access
Kang Y, Cai Z, Tan C-W, Huang Q, Liu H (2020) Natural language processing (nlp) in management research: a literature review. J Manag Anal 7(2):139–172
Nirav Shah M, Ganatra A (2022) A systematic literature review and existing challenges toward fake news detection models. Soc Netw Anal Min 12(1):168
del Gobbo E, Guarino A, Cafarelli B, Grilli L, Limone P Automatic evaluation of open-ended questions for online learning. A systematic mapping. Studies in Educational Evaluation. Article currently in Press. Temporary https://doi.org/10.1016/j.stueduc.2023.101258
Liu Y, Zhang X, Huang F, Zhou Z, Zhao Z, Li Z (2020) Visual question answering via combining inferential attention and semantic space mapping. Knowl-Based Syst 207:106339
del Gobbo E, Fontanella S, Sarra A, Fontanella L (2021) Emerging topics in Brexit debate on twitter around the deadlines. Soc Indic Res 156(2):669–688. https://doi.org/10.1007/s11205-020-02442-4
Guarino A, Malandrino D, Zaccagnino R (2021) An automatic mechanism to provide privacy awareness and control over unwittingly dissemination of online private information. Comput Netw, 108614
Guarino A, Lettieri N, Malandrino D, Zaccagnino R (2021) A machine learning-based approach to identify unlawful practices in online terms of service: analysis, implementation and evaluation. Neural Comput Appl 33(24):17569–17587
Turian J, Ratinov L, Bengio Y (2010) Word representations: a simple and general method for semi-supervised learning. In: Proceedings of the 48th annual meeting of the association for computational linguistics. Association for Computational Linguistics, pp 384–394
Mikolov T, Chen K, Corrado G, Dean J (2013) Efficient estimation of word representations in vector space. In: Bengio Y, LeCun Y (eds) 1st International conference on learning representations, ICLR 2013, Scottsdale, Arizona, USA, May 2–4, 2013. Workshop Track Proceedings
Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J (2013) Distributed representations of words and phrases and their compositionality. In: Advances in neural information processing systems, pp 3111–3119
Wang C, Miao Z, Lin Y, Gao J (2019) User and topic hybrid context embedding for finance-related text data mining. In: 2019 International conference on data mining workshops (ICDMW), pp 751–760
Yang Z, Li L (2019) An online retrieval question answering system for featured snippets triggering. In: 2019 International conference on data mining workshops (ICDMW), pp 49–55. IEEE
Arora S, Liang Y, Ma T (2016) A simple but tough-to-beat baseline for sentence embeddings
Devlin J, Chang M-W, Lee K, Toutanova K (2018) BERT: pre-training of deep bidirectional transformers for language understanding. arXiv. arXiv:1810.04805
Reimers N, Gurevych I (2019) Sentence-BERT: sentence embeddings using siamese BERT-networks. arXiv arXiv:1908.10084
Shapiro SS, Wilk MB (1965) An analysis of variance test for normality (complete samples). Biometrika 52(3/4):591–611
Japkowicz N, Shah M (2011) Evaluating learning algorithms: a classification perspective. Cambridge University Press, Cambridge
McKnight PE, Najab J (2010): Mann-whitney u test. The Corsini encyclopedia of psychology, 1
Chi Z, Dong L, Wei F, Yang N, Singhal S, Wang W, Song X, Mao X-L, Huang H, Zhou M (2020) Infoxlm: an information-theoretic framework for cross-lingual language model pre-training. arXiv preprint arXiv:2007.07834
Chi Z, Dong L, Zheng B, Huang S, Mao X-L, Huang H, Wei F (2021) Improving pretrained cross-lingual language models via self-labeled word alignment. arXiv preprint arXiv:2106.06381
Licklider JC (1960) Man-computer symbiosis. IRE Trans Hum Factors Electron 1:4–11
Xu W (2019) Toward human-centered AI: a perspective from human-computer interaction. Interactions 26(4):42–46
Hohman F, Head A, Caruana R, DeLine R, Drucker SM (2019) Gamut: a design probe to understand how data scientists understand machine learning models. In: Proceedings of the 2019 CHI conference on human factors in computing systems, pp 1–13
Shneiderman B (2020) Bridging the gap between ethics and practice: guidelines for reliable, safe, and trustworthy human-centered AI systems. ACM Trans Interact Intell Syst 10(4):1–31
Weld DS, Bansal G (2019) The challenge of crafting intelligible intelligence. Commun ACM 62(6):70–79
Wenskovitch J, Zhou M, Collins C, Chang R, Dowling M, Endert A, Xu K (2020) Putting the “i” in interaction: interactive interfaces personalized to individuals. IEEE Comput Graphics Appl 40(3):73–82
Filighera A, Steuer T, Rensing C (2020) Fooling automatic short answer grading systems. In: Bittencourt II, Cukurova M, Muldner K, Luckin R, Millán E (eds) Artificial intelligence in education. Springer, Cham, pp 177–190
Mello RF, Neto R, Fiorentino G, Alves G, Arêdes V, Silva JVGF, Falcão TP, Gašević D (2022) Enhancing instructors’ capability to assess open-response using natural language processing and learning analytics. In: Hilliger I, Muñoz-Merino PJ, De Laet T, Ortega-Arranz A, Farrell T (eds) Educating for a new future: making sense of technology-enhanced learning adoption. Springer, Cham, pp 102–115
Funding
Open access funding provided by Università di Foggia within the CRUI-CARE Agreement. The authors did not receive financial support from any organization for the submitted work.
Author information
Authors and Affiliations
Contributions
E.D.G. and A.G. contributed to conceptualization; methodology; formal analysis and investigation; data curation; and writing original draft and provided software; L.G. was involved in project administration; and L.G. and B.C. contributed to writing reviewing and editing and supervision.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Hyper-parameters tuned for each regressor
In this section, and specifically in Table 15, we show, for each regressor evaluated, the hyper-parameters tuned with the range of values and the related step. The range of the best parameters found is available in Table 16.
Appendix B: Running the experiments: pseudo-code of GradeAid
In this section, we sketch the (python-like) pseudo-code of GradeAid for running the experiments presented in the core of the paper.
First, we open the dataset provided according to the template we designed, where there must be five columns, i.e., ID (identifier of the question), question (text of the question), reference_ans (reference answer provided by the instructor/teacher), student_ans (answer provided by a student), grade (the evaluation provided by the teacher/instructor, from 0 to 5). Next, the dataset is split by question (line 15). For each question available, we find the indexes of samples to include in the training and validation sets (function get_folds() at line 19). For each folds configuration, we compute the lexical features through TF-IDF (lines 23–24) and the similarity between each students’ answer and the reference one (lines 27–28). Then, features are merged (function fusion() at lines 31–32). Lastly, the regressor chosen is called and after the scoring, MAE, MSE, RMSE and NRMSE are computed (lines 34–38).

Appendix C: Query for searching previous literature on ASAG
In the following, we report the query used to search the articles in the related work (Sect. 2).
((automatic text based grading) OR (open ended questions automatic grading) OR (short answers automatic grading) OR (open ended questions automatic assessment) OR (short answers automatic assessment) OR (short answers automatic marking) OR (open ended questions automatic marking) OR (short answers automatic scoring) OR (open ended questions automatic scoring) OR (short answers machine learning grading) OR (natural language processing exam grading) OR (natural language processing exam scoring) OR (natural language processing exam marking) OR (natural language processing exam assessment) OR (nlp exam grading) OR (nlp exam scoring) OR (nlp exam marking) OR (text answers grading) OR (text answers marking) OR (essays automatic grading) OR (essays automatic scoring) OR (essays automatic marking) OR (essays automatic assessment) OR (descriptive answers automatic marking) OR (descriptive answers automatic grading ) OR (descriptive answers automatic assessment))

MSE achieved for each question in SAG dataset with SVR
Appendix D: Mean squared error obtained in the experiments
In this section, we report the MSE got for each experiment performed over the different datasets. In particular, Table 17 summarizes the MSE obtained by the different regression methods for the ASAP dataset as well as Table 18 does for Cu-NLP dataset. Likewise, Tables 19 and 20 provide the MSE achieved by the regression methods for SciEntBank and SAG datasets, respectively.
Lastly, we also provide the MSE achieved for every question in the SAG dataset by SVR method (see Fig. 14).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
del Gobbo, E., Guarino, A., Cafarelli, B. et al. GradeAid: a framework for automatic short answers grading in educational contexts—design, implementation and evaluation. Knowl Inf Syst 65, 4295–4334 (2023). https://doi.org/10.1007/s10115-023-01892-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10115-023-01892-9