
Abstract
We provide a comprehensive study of the convergence of the forward-backward algorithm under suitable geometric conditions, such as conditioning or Łojasiewicz properties. These geometrical notions are usually local by nature, and may fail to describe the fine geometry of objective functions relevant in inverse problems and signal processing, that have a nice behaviour on manifolds, or sets open with respect to a weak topology. Motivated by this observation, we revisit those geometric notions over arbitrary sets. In turn, this allows us to present several new results as well as collect in a unified view a variety of results scattered in the literature. Our contributions include the analysis of infinite dimensional convex minimization problems, showing the first Łojasiewicz inequality for a quadratic function associated to a compact operator, and the derivation of new linear rates for problems arising from inverse problems with low-complexity priors. Our approach allows to establish unexpected connections between geometry and a priori conditions in inverse problems, such as source conditions, or restricted isometry properties.

Similar content being viewed by others

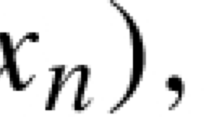
Notes
If we discard the “classic” strong convexity assumption.
Note that \( \mathrm{proj}(\varOmega ; \mathrm{argmin\,}f) \subset \varOmega \) holds when \(\varOmega ={\mathbb {B}}_X({\bar{x}},\delta ) \cap [f<r]\), for \({\bar{x}} \in \mathrm{{argmin}}f\), because \( \mathrm{proj}(\cdot ; \mathrm{argmin\,}f)\) is nonexpansive.
This can be defined through the power of the eigenvalues of the matrix.
References
Absil, P.-A., Mahony, R., Andrews, B.: Convergence of the iterates of descent methods for analytic cost functions. SIAM J. Optim. 16(2), 531–547 (2005)
Aragón Artacho, F.J., Geoffroy, M.H.: Characterization of metric regularity of subdifferentials. J. Convex Anal. 15(2), 365–380 (2008)
Attouch, H., Bolte, J.: On the convergence of the proximal algorithm for nonsmooth functions involving analytic features. Math. Program. 116(1–2), 5–16 (2009)
Attouch, H., Bolte, J., Redont, P., Soubeyran, A.: Proximal alternating minimization and projection methods for nonconvex problems. An approach based on the Kurdyka-Łojasiewicz inequality. Math. Oper. Res. 35(2), 438–457 (2010)
Attouch, H., Bolte, J., Svaiter, B.F.: Convergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward-backward splitting, and regularized Gauss-Seidel methods. Math. Program. 137(1–2), 91–129 (2013)
Attouch, H., Wets, R.: Quantitative stability of variational systems II, a framework for nonlinear conditioning. SIAM J. Optim. 3(2), 359–381 (1993)
Azé, D., Corvellec, J.-N.: Nonlinear local error bounds via a change of metric. J. Fixed Point Aheory Appl. 16(1), 351–372 (2014)
Baillon, J.-B.: Un exemple concernant le comportement asymptotique de la solution du problème \(du/dt + \partial \vartheta \ni 0\). J. Funct. Anal. 28(3), 369–376 (1978)
Bandeira, A.S., Dobriban, E., Mixon, D.G., Sawin, W.F.: Certifying the restricted isometry property is hard. IEEE Trans. Inf. Theory 59(6), 3448–3450 (2013)
Bauschke, H.H., Borwein, J.M.: On the convergence of von Neumann’s alternating projection algorithm for two sets. Set-Valued Anal. 1(2), 185–212 (1993)
Bauschke, H.H., Combettes, P.: Convex Analysis and Monotone Operator Theory, 2nd edn. Springer, New York (2017)
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imag. Sci. 2(1), 183–202 (2009)
Bégout, P., Bolte, J., Jendoubi, M.A.: On damped second-order gradient systems. J. Differ. Equ. 259(7), 3115–3143 (2015)
Bolte, J., Daniilidis, A., Lewis, A.: The Łojasiewicz inequality for nonsmooth subanalytic functions with applications to subgradient dynamical systems. SIAM J. Optim. 17(4), 1205–1223 (2007)
Bolte, J., Daniilidis, A., Lewis, A.S., Shiota, M.: Clarke subgradients of stratifiable functions. SIAM J. Optim. 18(2), 556–572 (2007)
Bolte, J., Daniilidis, A., Ley, O., Mazet, L.: Characterizations of Łojasiewicz inequalities: subgradient flows, talweg, convexity. Trans. Am. Math. Soc. 362, 3319–3363 (2010)
Bolte, J., Nguyen, T.P., Peypouquet, J., Suter, B.: From error bounds to the complexity of first-order descent methods for convex functions. Math. Program. 165(2), 471–507 (2017)
Bolte, J., Sabach, S., Teboulle, M.: Proximal alternating linearized minimization for nonconvex and nonsmooth problems. Math. Program. 146(1–2), 459–494 (2013)
Bonnans, J.F., Shapiro, A.: Perturbation Analysis of Optimization Problems. Springer, New York (2000)
Bredies, K., Lorenz, D.A.: Linear convergence of iterative soft-thresholding. J. Fourier Anal. Appl. 14(5–6), 813–837 (2008)
Brézis, H.: Opérateurs Maximaux Monotones et Semi-groupes de Contractions dans les Espaces de Hilbert. North-Holland/Elsevier, New-York (1973)
Brézis, H.: On a characterization of flow-invariant sets. Commun. Pure Appl. Math. 23(2), 261–263 (1970)
Burke, J., Ferris, M.C.: Weak Sharp Minima in Mathematical Programming. SIAM J. Control. Optim. 31(5), 1340–1359 (1993)
Calatroni, L., Garrigos, G., Rosasco, L., Villa, S.: Accelerated iterative regularization via dual diagonal descent. SIAM J. Optim. 31(1), 754–784 (2021)
Candès, E.J.: The restricted isometry property and its implications for compressed sensing. C.R. Math. 346(9–10), 589–592 (2008)
Chandrasekaran, V., Recht, B., Parillo, P.A., Willsky, A.S.: The convex geometry of linear inverse problems. Found. Comput. Math. 12(6), 805–849 (2012)
Chouzenoux, E., Pesquet, J.-C., Repetti, A.: A block coordinate variable metric forward-backward algorithm. J. Global Optim. 66(3), 457–485 (2016)
Combettes, P.L., Pesquet, J.-C.: Proximal Splitting Methods in Signal Processing, in Fixed-Point Algorithms for Inverse Problems in Science and Engineering. Springer, New York (2011)
Cornejo, O., Jourani, A., Zalinescu, C.: Conditioning and upper-lipschitz inverse subdifferentials in nonsmooth optimization problems. J. Optim. Theory Appl. 95(1), 127–148 (1997)
Crane, D.K., Gockenbach, M.: The singular value expansion for arbitrary bounded linear operators. Mathematics 8(8), 1258 (2020)
Daubechies, I., Defrise, M., De Mol, C.: An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Commun. Pure Appl. Math. 57(11), 1413–1457 (2004)
Davis, D., Yin, W.: Convergence rate analysis of several splitting schemes. In: Splitting Methods in Communication, Imaging, Science, and Engineering, Springer International Publishing (2014)
De Vito, E., Caponnetto, A., Rosasco, L.: Model selection for regularized least-squares algorithm in learning theory. Found. Comput. Math. 5(1), 59–85 (2005)
Yao, Y., Rosasco, L., Caponnetto, A.: On early stopping in gradient descent learning. Constr. Approx. 26(2), 289–315 (2007)
DeVore, R.: Approximation of functions. Approx. Theory Proc. Symp. Appl. Math. AMS 36, 1–20 (1986)
Dontchev, A.L., Lewis, A.S., Rockafellar, R.T.: The radius of metric regularity. Trans. Am. Math. Soc. 355(2), 493–517 (2003)
Dontchev, A., Rockafellar, T.: Implicit functions and Solution Mappings. Springer, New York (2009)
Dontchev, A., Zolezzi, T.: Well-Posed Optimization Problems. Springer, Berlin (1993)
Drusvyatskiy, D., Ioffe, A.D.: Quadratic growth and critical point stability of semi-algebraic functions. Math. Program. Ser. A 153(2), 635–653 (2015)
Drusvyatskiy, D., Lewis, A.D.: Error bounds, quadratic growth, and linear convergence of proximal methods. Math. Oper. Res. 43, 693–1050 (2018)
Drusvyatskiy, D., Mordukhovich, B.S., Nghia, T.T.A.: Second-order growth, tilt stability, and metric regularity of the subdifferential. J. Convex Anal. 21(4), 1165–1192 (2014)
Engl, H., Hanke, M., Neubauer, A.: Regularization of Inverse Problems. Kluwer, Dordrecht (1996)
Fadili, J., Malick, J., Peyré, G.: Sensitivity analysis for mirror-stratifiable convex functions. SIAM J. Optim. 28(4), 2975–3000 (2018)
Federer, H.: Curvature measures. Trans. Am. Math. Soc. 93(3), 418–491 (1959)
Ferris, M.C.: Finite termination of the proximal point algorithm. Math. Program. 50(1–3), 359–366 (1991)
Frankel, P., Garrigos, G., Peypouquet, J.: Splitting methods with variable metric for Kurdyka-Łojasiewicz functions and general convergence rates. J. Optim. Theory Appl. 165(3), 874–900 (2015)
Foucart, S., Rauhut, H.: A Mathematical Introduction to Compressive Sensing. Springer, New York (2013)
Garrigos, G.: Descent dynamical systems and algorithms for tame optimization and multi-objective problems, Ph.D. thesis (2015). https://tel.archives-ouvertes.fr/tel-01245406
Garrigos, G., Rosasco, L., Villa, S.: Thresholding gradient methods in Hilbert spaces: support identification and linear convergence. ESAIM Control Optim. Calc. Var. 26, 20 (2020)
Goldstein, A.A.: Cauchy’s method of minimization. Numerische Mathematik 4(1), 146–150 (1962)
Groetsch, C.W.: Generalized Inverses of Linear Operators: Representation and Approximation. Dekker, New York (1977)
Güler, O.: On the convergence of the proximal point algorithm for convex minimization. SIAM J. Control. Optim. 29(2), 403–419 (1991)
Haraux, A., Jendoubi, M.A.: The Łojasiewicz gradient inequality in the infinite dimensional Hilbert space framework. J. Funct. Anal. 260(9), 2826–2842 (2011)
Hare, W.L., Lewis, A.S.: Identifying active constraints via partial smoothness and prox-regularity. J. Convex Anal. 11(2), 251–266 (2004)
Hare, W.L., Lewis, A.S.: Identifying active manifolds. Algorithmic Oper. Res. 2(2), 75–82 (2007)
Helmberg, G.: Introduction to Spectral Theory in Hilbert Space. North Holland Publishing Company, Amsterdam (1969)
Hiriart-Urruty, J.-B., Lemaréchal, C.: Convex Analysis and Minimization Algorithms I: Fundamentals. Springer, New York (1993)
Hoffman, A.J.: On approximate solutions of systems of linear inequalities. J. Res. Natl. Bur. Stand. 49(4), 263–265 (1952)
Hohage, T.: Inverse Problems. University of Göttingen, Vorlesungskript (2002)
Hou, K., Zhou, Z., So, A.M.-C., Luo, Z.-Q.: On the Linear Convergence of the Proximal Gradient Method for Trace Norm Regularization. In: Advances in Neural Information Processing Systems, pp. 710–718 (2013)
Karimi, H., Nutini, J., Schmidt, M.: Linear Convergence of Gradient and Proximal-Gradient Methods Under the Polyak-Łojasiewicz Condition. In: Machine Learning and Knowledge Discovery in Databases (ECML PKDD). Lecture Notes in Computer Science, vol. 9851. Springer (2016)
Knyazev, A.V., Argentati, M.E.: On proximity of Rayleigh quotients for different vectors and Ritz values generated by different trial subspaces. Linear Algebra Appl. 415(1), 82–95 (2006)
Ladde, G.S., Lakshmikantham, V.: On flow-invariant sets. Pac. J. Math. 51(1), 215–220 (1974)
Lemaire, B.: About the convergence of the proximal method. Adv. Optim. Econ. Math. Syst. 382, 39–51 (1992)
Lemaire, B.: Stability of the iteration method for non expansive mappings. Serdica Math. J. 22(3), 331–340 (1996)
Lemaire, B.: Well-posedness, conditioning and regularization of minimization, inclusion and fixed-point problems. Pliska Studia Mathematica Bulgarica 12(1), 71–84 (1998)
Leventhal, D.: Metric subregularity and the proximal point method. J. Math. Anal. Appl. 360(2), 681–688 (2009)
Lewis, A.S.: Active sets, nonsmoothness, and sensitivity. SIAM J. Optim. 13(3), 702–725 (2002)
Lewis, A., Malick, J.: Alternating projections on manifolds. Math. Oper. Res. 33(1), 216–234 (2008)
Li, W.: Error bounds for piecewise convex quadratic programs and applications. SIAM J. Control. Optim. 33(5), 1510–1529 (1995)
Li, G.: Global error bounds for piecewise convex polynomials. Math. Program. Ser. A 137(1–2), 37–64 (2013)
Li, G., Mordukhovich, B.: Hölder metric subregularity with applications to proximal point method. SIAM J. Optim. 22(4), 1655–1684 (2012)
Li, G., Mordukhovich, B.S., Pham, T.S.: New fractional error bounds for polynomial systems with applications to Holderian stability in optimization and spectral theory of tensors. Math. Program. 153(2), 333–362 (2015)
Li, G., Pong, T.K.: Calculus of the exponent of Kurdika-Łojasiewicz inequality and its applications to linear convergence of first-order methods. Found. Comput. Math. 18, 1199–1232 (2018)
Liang, J., Fadili , J., Peyré, G.: Local linear convergence of Forward–Backward under partial smoothness. In: Advances in Neural Information Processing Systems, pp. 1970–1978 (2014)
Liang, J., Fadili, J., Peyré, G.: Activity identification and local linear convergence of Forward-Backward-type methods. SIAM J. Optim. 27(1), 408–437 (2017)
Liang, J., Fadili, J., Peyré, G.: A Multi-step Inertial Forward–Backward Splitting Method for Non-convex Optimization. In: Advances in Neural Information Processing Systems, pp. 4042–4050 (2016)
Liu, J., Wright, S.J., Ré, C., Bittorf, V., Sridhar, S.: An asynchronous parallel stochastic coordinate descent algorithm. J. Mach. Learn. Res. 16(1), 285–322 (2015)
Łojasiewicz, S.: Une propriété topologique des sous-ensembles analytiques réels. In: Les Équations aux Dérivées Partielles, Éditions du centre National de la Recherche Scientifique, Paris, pp. 87–89 (1963)
Luke, R.: Prox-regularity of rank constraint sets and implications for algorithms. J. Math. Imaging Vision 47(3), 231–238 (2013)
Luo, Z.Q., Tseng, P.: On the linear convergence of descent methods for convex essentially smooth minimization. SIAM J. Control. Optim. 30(2), 408–425 (1992)
Luo, Z.Q., Tseng, P.: Error bounds and convergence analysis of feasible descent methods: a general approach. Ann. Oper. Res. 46(1), 157–178 (1993)
Luque, F.: Asymptotic convergence analysis of the proximal point algorithm. SIAM J. Control. Optim. 22(2), 277–293 (1984)
Merlet, B., Pierre, M.: Convergence to equilibrium for the backward Euler scheme and applications. Commun. Pure Appl. Anal. 9(3), 685–702 (2010)
Mosci, S., Rosasco, L., Santoro, M., Verri, A., Villa, S.: Solving structured sparsity regularization with proximal methods. In: Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pp. 418–433. Springer, Berlin (2010)
Necoara, I., Nesterov, Y., Glineur, F.: Linear convergence of first order methods for non-strongly convex optimization. Math. Program. 175(1–2), 69–107 (2019)
Penot, J.-P.: Conditioning convex and nonconvex problems. J. Optim. Theory Appl. 93(3), 535–554 (1996)
Peypouquet, J.: Convex Optimization in Normed Spaces. In: Theory, Methods and Examples. Springer, New York (2015)
Poliquin, R.A., Rockafellar, R.T.: Prox-regular functions in variational analysis. Trans. Am. Math. Soc. 348(5), 1805–1838 (1996)
Polyak, B.T.: Gradient methods for minimizing functionals. Zhurnal Vychislitel’noi Matematiki i Matematicheskoi FizikiZh 3(4), 643–653 (1963)
Polyak, B.T.: Introduction to Optimization. Optimization Software, New York (1987)
Rockafellar, R.T.: Monotone operators and the proximal point algorithm. SIAM J. Control. Optim. 14(5), 877–898 (1976)
Rockafellar, R.T.: Convex Analysis. Princeton University Press, Princeton (1996)
Rockafellar, R.T.R.J.-B.: Wets Variational Analysis. Springer, New York (2009)
Salzo, S.: The variable metric forward-backward splitting algorithm under mild differentiability assumptions. SIAM J. Optim. 27(4), 2153–2181 (2017)
Schmidt, M., Le Roux, N., Bach, F.: Convergence Rates of Inexact Proximal-Gradient Methods for Convex Optimization. In Advances in neural information processing systems, pp. 1458–1466 (2011)
Spingarn, J.E.: Applications of the method of partial inverses to convex programming: decomposition. Math. Program. 32(2), 199–223 (1985)
Spingarn, J.E.: A projection method for least-squares solutions to overdetermined systems of linear inequalities. Linear Algebra Appl. 86, 211–236 (1987)
Vainberg, M.M.: Le problème de la minimisation des fonctionelles non linéaires. C.I.M.E, IV ciclo (1970)
Vaiter, S., Peyré, G., Fadili, J.M.: Model consistency of partly smooth regularizers. IEEE Trans. Inf. Theory 64(3), 1725–1737 (2018)
Wright, S.: Identifiable surfaces in constrained optimization. SIAM J. Control. Optim. 31(4), 1063–1079 (1993)
Zalinescu, C.: Convex Analysis in General Vector Spaces. World Scientific, Singapore (2002)
Zhang, R., Treiman, J.: Upper-Lipschitz multifunction and inverse subdifferentials. Nonlinear Anal. Theory Methods Appl. 24, 273–286 (1995)
Zhou, Z., So, A.M.-C.: A unified approach to error bounds for structured convex optimization problems. Math. Program. 165(2), 689–728 (2017)
Zhou, Z., Zhang, Q., So, A.M.-C.: \(\ell _{1, p}\)-Norm Regularization: Error Bounds and Convergence Rate Analysis of First-Order Methods. In: Proceedings of the 32nd International Conference on Machine Learning, pp. 1501–1510 (2015)
Zolezzi, T.: On equiwellset minimum problems. Appl. Math. Optim. 4(1), 209–223 (1978)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
L. Rosasco acknowledges the financial support of the Italian Ministry of Education, University and Research FIRB project RBFR12M3AC, the European Research Council (grant SLING 819789), the AFOSR project FA9550-18-1-7009 and FA9550-17-1-0390. (European Office of Aerospace Research and Development), the EU H2020-MSCA-RISE project NoMADS - DLV-777826, and the Center for Brains, Minds and Machines (CBMM), funded by NSF STC award CCF-1231216. S. Villa is supported by the INDAM GNAMPA research project 2020 “Processi evolutivi con memoria descrivibili tramite equazioni integro-differenziali" and the H2020-MSCA-ITN Project Trade-OPT 2019 funded under the Marie Skłodowska-Curie grant agreement No 861137; G. Garrigos realized most of this work during his postdoc at the Italian Institute of Technology.
A Appendix
A Appendix
1.1 A.1 Worst case analysis: proofs of Section 2
The following Lemma contains a detailed proof for the lower bound (7) in Remark 2.3, which can also be applied to (5) by using a symmetry argument.
Lemma A.1
(Lower bounds for the proximal algorithm). Let \(p \in ]-\infty ,0[ \cup ]2,+\infty [\), and let \(f_p \in \varGamma _0({\mathbb {R}})\) be the function defined by
If \(x_0 \in \mathop {\mathrm { dom}}f \setminus \mathrm{argmin\,}f\), and \(x_{n+1} = \text{ prox}_{\lambda f}(x_n)\), then for all \(n \ge 1\):
Proof
Note that \(\mathop {\mathrm { dom}}f_p\) is an open interval, and that \(f_p\) is infinitely differentiable there. We can then see that \(f_p\), \(f_p'\) and \(f_p''\) are non-negative. In particular, we deduce that \(f_p\) and \(f'_p\) are non-decreasing on \(\mathop {\mathrm { dom}}f\).
Let us now take some \(x_0 \in \mathop {\mathrm { dom}}f\setminus \mathrm{argmin\,}f\), and consider the following continuous trajectory
It is a simple exercise to verify that \(x(\cdot )\) is a solution of this differential equation:
The main step towards proving our lower bound is to show, by induction, that for every \(n \in {\mathbb {N}}\), \(x_n \ge x(n\lambda )\). This is clearly true for \(n=0\), so, let us assume now that this is true for \(n \in {\mathbb {N}}\), and show that this implies \(x_{n+1} \ge x((n+1)\lambda )\). Start by writing
On the one hand, \(f_p'\) is non-negative on \(\mathop {\mathrm { dom}}f\), and \(\dot{x}(t) = -f_p'(x(t))\), which means that \(x(\cdot )\) is non-increasing. On the other hand, \(-f_p'\) is non-increasing, which means that \((-f_p' \circ x)\) is non-decreasing. This fact, together with our induction assumption, allows us to write
Consider now the function \(\phi : \mathop {\mathrm { dom}}f_p \rightarrow ]0,+\infty [\) defined by \(\phi (t) = t+ \lambda f_p'(t)\). It is clearly increasing and bijective on its image, so its inverse \(\phi ^{-1}\) is also increasing. We observe moreover that, by definition, the proximal sequence satisfies \(x_{n+1} = \phi ^{-1}(x_n)\). This allows us to write
This ends the proof of the induction argument.
Observe that, given non-negative numbers \(a,b>0\), the following inequality holds
This means that, for all \(n \ge 1\),
Passing this inequality through \(f_p\) (which is non-decreasing) yields the desired result. \(\square \)
1.2 A.2 Proofs of Section 3
1.2.1 A.2.1. Invariant sets and proofs of Section 3.1
We provide here a result concerning the equivalence between all the notions in Definition 3.1, for a large class of sets \(\varOmega \subset X\). The sets \(\varOmega \) we will consider are directly related to the gradient flow induced by \(\partial \!f\). Given \(u_0 \in \mathop {\mathrm { dom}}f\), it is knownFootnote 5 that there exists a unique absolutely continuous trajectory noted \(u(\cdot ;u_0) : [0,+\infty [ \longrightarrow X\), called the steepest descent trajectory, which satisfies:
Following [21], we introduce the notion of invariant sets for the flow of \(\partial \!f\):
Definition A.2
A set \(\varOmega \subset X\) is \(\partial \!f\)-invariant if for any \(x \in \varOmega \cap \mathop {\mathrm { dom}}\partial \!f\) and a.e. \(t>0\), \(u(t;x) \in \varOmega \) holds.
In other words, \(\varOmega \) is said to be \(\partial f\)-invariant if any steepest descent trajectory starting in \(\varOmega \) remains therein. It is straightforward to see that the intersection of two \(\partial \!f\)-invariant sets is still \(\partial \!f\)-invariant.
Example A.3
An easy way to construct a \(\partial \!f\)-invariant set is to consider the sublevel set of a Lyapunov function \(\psi : X \rightarrow {\mathbb {R}}\cup \{+\infty \}\) for the gradient flow induced by \(\partial \!f\). A function is said to be Lyapunov if for any \(x \in \mathop {\mathrm { dom}}f\), \(\psi (u(\cdot ;x)) : [0, +\infty [ \rightarrow {\mathbb {R}}\) is decreasing. Classical examples of this kind are:
-
\(\varOmega =X\), which is \([\psi < 1]\) with \(\psi = 0\).
-
\(\varOmega = [f<r]\) for \(r >\inf f\), which is \([\psi <r]\) with \(\psi =f\) (see [21, Theorem 3.2.17]).
-
\(\varOmega = {\mathbb {B}}({\bar{x}}, \delta )\) for \({\bar{x}} \in \mathrm{argmin\,}f\), \(\delta >0\), which is \([\psi < \delta ]\) with \(\psi (x)=\Vert x-{\bar{x}} \Vert \) (see [21, Theorem 3.1.7]).
-
\(\varOmega = \{x \in X \ | \ \Vert \partial \!f(x) \Vert _\_ < M \}\) for \(M>0\), which is \([\psi < M]\) with \(\psi (x)=\Vert \partial \!f(x) \Vert _\_\) (see [21, Theorem 3.1.6]).
See [21, Section IV.4] for more details on the subject, as well as [22, 63]. It is also a good exercise to verify that the source sets considered in Proposition 5.12 are \(\partial \!f\)-invariant.
We next prove Proposition 3.3, stating the equivalence between conditioning, metric subregularity and Łojasiewicz on \(\partial \!f\)-invariant sets. The proof is based on an argument used in [17, Theorem 5], which relies essentially on the following convergence rate property for the continuous steepest descent dynamic (43).
Proof of Proposition 3.3
Convexity of f and the Cauchy-Schwartz inequality imply
and so i) \(\implies \)ii) \(\implies \) iii). Next, we just have to prove that the Łojasiewicz property implies the conditioning one. So let us assume that f is p-Łojasiewicz on \(\varOmega \), which is \(\partial f\)-invariant, and fix \(x \in \varOmega \cap \mathop {\mathrm { dom}}^* f\). Define, for all \(t \ge 0\), \(\varphi (t):=pc_{f,\varOmega }t^{1/p}\), which is differentiable on \(]0,+\infty [\), and for all \(u\in \mathop {\mathrm { dom}}f\), \(r(u)=f(u)-\inf f\). Let us lighten the notations by noting \(u(\cdot )\) instead of \(u(\cdot ;x)\), so that \(u(0)=x\). Because we will need to distinguish the case in which the trajectory converges in finite time, we introduce \(T:= \inf \{t \ge 0 \ | \ u(t) \in \mathrm{{argmin}}~f \} \in [0, + \infty ]\). Since \(x \in \mathop {\mathrm { dom}}^*\!\!f\) and \(u(\cdot )\) is continuous, we see that \(T >0\). For every \(t \in [0,T[\), we have \(u(t) \notin \mathrm{{argmin}}~f\), so \(u(t) \in \varOmega \cap \mathop {\mathrm { dom}}^* f\) and \(r(u(t)) \ne 0\). If \(T < + \infty \), we also have for every \(t > T\) that \(u(t)=u(T)\) and \(\dot{u}(t) =0\). Since \(u(0)=x \in \mathop {\mathrm { dom}}f\), we know that \(r \circ u\) is absolutely continuous on [0, t] for every \(t \in ]0,T[\) [21, Theorem 3.6]. So \(\varphi \circ r \circ u\) is also absolutely continuous on such intervals, and we can write:
But \(\frac{\mathrm{d}}{\mathrm{d}\tau } (r \circ u) (\tau ) =- \Vert \dot{u}(\tau ) \Vert ^2 = - \Vert \partial \!f(u(\tau )) \Vert _\_^2\) for a.e. \(t \in ]0,T[\) (see [21, Theorem 3.6 & Remark 3.9]), so the above inequality becomes
Since \(\varOmega \) is \(\partial \!f\)-invariant, we can apply the Łojasiewicz inequality at \(u(\tau ) \in \varOmega \cap \mathop {\mathrm { dom}}^* f\) for a.e. \(\tau \in ]0,t[\), which can be rewritten in this case as \(1 \le \varphi '(r(u(\tau ))) \Vert \partial \!f(u(\tau )) \Vert _\_.\) This applied to (45) gives us:
From (46) and the definition of T, we see that \(\int _0^{+ \infty } \Vert \dot{u}(\tau ) \Vert \ \mathrm{d}\tau \le \varphi (r(x)) < +\infty \), meaning that the trajectory \(u(\cdot )\) has finite length. As a consequence, it converges strongly to some \({\bar{u}}\) when t tends to T. Finally, we use on (46) the fact that \(\Vert u(0) - u(t) \Vert \le \int _0^t \Vert \dot{u}(\tau ) \Vert \ \mathrm{d}\tau \), together with the fact that \({\bar{u}} \in \mathrm{argmin\,}f\) (see [21, Theorem 3.11]) to conclude that
\(\square \)
Proof of Proposition 3.4
i): let \(S:= \mathrm{argmin\,}f \ne \emptyset \). Given \(\delta >0\), there exists \(M \in ]0, + \infty [\) such that
Since f is p-conditioned on \(\varOmega \), we deduce that:
meaning that f is \(p'\)-conditioned on \(\varOmega \cap \delta {\mathbb {B}}_X\). The proof relies on the same argument for the metric subregular case.
ii): Let \(p,p',r\) be as in the statement. If \(x \in \varOmega \cap [f<r] \cap \text{ dom}^* f\), we can use the fact that \(\frac{1}{p} \ge \frac{1}{p'}\) to write
The conclusion follows immediately from the p-Łojasiewicz property of f on \(\varOmega \). \(\square \)
Proof of Proposition 3.5
Assume by contradiction that there exists a sequence \((z^n)_{n\in {\mathbb {N}}} \subset \varOmega \) such that
Since \(\varOmega \) is weakly compact, we can assume without loss of generality that \(z^n\) weakly converges to some \(z^\infty \in \varOmega \) when \(n \rightarrow + \infty \). Then, it follows from (47), the boundedness of \((z^n)_{n\in {\mathbb {N}}}\subset \varOmega \) and the weak lower semi-continuity of f that \(f(z^\infty ) - \inf f \le 0\), meaning that \(z^\infty \in \mathrm{argmin\,}f\), contradicting \(\varOmega \cap \mathrm{argmin\,}f = \emptyset \). \(\square \)
Lemma A.4
Let \(p\ge 1\), let \(f \in \varGamma _0({\mathbb {R}}^N)\) with an open domain, and let \(\varOmega \subset {\mathbb {R}}^N\) be a bounded open set such that \(\varOmega \supset \mathrm{{argmin}}~f \ne \emptyset \). Then f is p-Łojasiewicz on \(\varOmega \) if and only if f is “classically” p-Łojasiewicz on \(\varOmega \), namely

Proof
\(\Rightarrow \): Let \({\bar{x}} \in \varOmega \). Since \(\varOmega \) is open, there exists \(\delta >0\) such that \({\mathbb {B}}({\bar{x}}, \delta ) \subset \varOmega \). So f is p-Łojasiewicz on \({\mathbb {B}}({\bar{x}}, \delta ) \cap [f({\bar{x}})< f < f({\bar{x}}) +r] \subset \varOmega \), for any \(r > 0\).
\(\Leftarrow \): by assumption, \(\mathrm{{argmin}}~f\) is compact, and f is “classically” Łojasiewicz on \(\mathrm{{argmin}}~f\). The arguments in [18, Lemma 6] imply that there exist \(\delta ,r >0\), such that f is p-Łojasiewicz on
Since \(\mathop {\mathrm { dom}}f\) is open, f is continuous on \(\mathop {\mathrm { dom}}f\) [11, Corollary 8.39], and we deduce that \({\hat{\varOmega }}\) is open. So \(( \mathrm{cl\,}\varOmega \setminus {\hat{\varOmega }})\) is closed, it is bounded because \(\varOmega \) is bounded, and it does not intersect \(\mathrm{{argmin}}~f \subset {\hat{\varOmega }}\). Propositions 3.5 and 3.3 applied to \(( \mathrm{cl\,}\varOmega \setminus {\hat{\varOmega }})\) imply that f is p-Łojasiewicz on \(( \mathrm{cl\,}\varOmega \setminus {\hat{\varOmega }})\). We conclude that f is p-Łojasiewicz on \(\varOmega \). \(\square \)
1.2.2 A.2.2 Proofs of Section 3.2
Lemma A.5
(The conditioning constant for uniformly convex functions). Let \(f \in \varGamma _0(X)\), let \(C \subset X\) be a closed convex set such that \(C \cap \mathrm{{argmin}}~f \ne \emptyset \), and \(p \ge 2\). Assume that f is p-uniformly convex on C, in the sense that (8) holds for all \(x,y \in C \cap \mathop {\mathrm { dom}}f\). Then f is p-conditioned on C, with \(\gamma _{f,C}\) being the constant \(\gamma \) in (8). In particular, p-uniformly convex functions are globally p-conditioned.
Proof
Let \(f_C := f + \delta _C \in \varGamma _0(X)\). Then \(\mathop {\mathrm { dom}}f_C=\mathop {\mathrm { dom}}f \cap C\) and \(f_C\) is uniformly convex on X. Let \({\bar{x}} \in \mathrm{{argmin}}~f \cap C\), and let \(x \in \mathop {\mathrm { dom}}f \cap C\). Using [102, Corollary 3.5.11.ii] with (8), we obtain that
where \(f_C'({\bar{x}} ; x- {\bar{x}} )\) is the directional derivative of \(f_C\) at \({\bar{x}}\) in the direction \(x - {\bar{x}}\) (see its definition in [102, Theorem 2.1.13]). Given that \({\bar{x}} \in \mathrm{{argmin}}~f\cap C\), it is easy to see that \(f_C'({\bar{x}} ; x- {\bar{x}} ) \ge 0\). Moreover, \(f_C\) coincides with f on C, and \( \mathrm{dist\,}(x,\mathrm{{argmin}}~f) \le \Vert x - {\bar{x}} \Vert \). We conclude then from (48) that f is p-conditioned on C with \(\gamma _{f,C}=\gamma \). In the case that f is uniformly convex, we take \(C=X\) and use the fact that \(\mathrm{{argmin}}~f \ne \emptyset \) [102, Proposition 3.5.8]. \(\square \)
Lemma A.6
(The Łojasiewicz constant for uniformly convex functions). Let \(p \ge 2\), and let \(f \in \varGamma _0(X)\) be p-uniformly convex, with constant \(\gamma \). Then f is p-Łojasiewicz on X, with \(c_{f,X}=(1-1/p)^{1-1/p} \gamma ^{-1/p}\).
Proof
By [102, Corollary 3.5.11.iii], for all \(x_1,x_2 \in \mathop {\mathrm { dom}}\partial \!f, x^*_1 \in \partial \!f(x_1)\):
Fix \(x \in \mathop {\mathrm { dom}}\partial \!f\) and \(x^* \in \partial \!f(x)\). The above inequality yields
The right hand side of the above inequality involves a strictly convex optimization problem, whose unique optimal value \({\bar{u}}\) can be determined by using Fermat’s rule:
Injecting this optimal value in (49) gives, after rearranging the terms,
and, since \(x^*\) is arbitrary in \(\partial \!f (x)\), the result follows after passing this inequality to the power \(1- 1/p\). \(\square \)
Proof of Example 3.10
ii). To prove the claim, it is enough to verify the three conditions of [40, Theorem 4.2]. The first condition (boundedness of \( \mathrm{argmin\,}f\)) is guaranteed by the fact that f is coercive. Indeed, h is strongly convex, therefore bounded from below, and g is itself coercive. The second condition (dual qualification conditions) follows immediately from the fact that both \(h^*\) and \(g^*\), and are continuously differentiable. To see this, observe that in this example \(g^*\) is (up to a constant) \(\Vert \cdot \Vert _q^q\), where q is the conjugate number of p: \((1/p) + (1/q) = 1\). Moreover, h being strongly convex means that \(h^*\) is also continuously differentiable, with \(\mathop {\mathrm { dom}}h^* = {\mathbb {R}}^M\). The third condition (firm convexity) is easy to check for h because it is strongly convex; for g the proof is left in the following Lemma. We can then apply [40, Theorem 4.2], which ensures that f is 2-conditioned on every compact set. Using again the fact that f is coercive, and therefore has bounded sublevel sets, we conclude that f is 2-conditioned on every sublevel set. \(\square \)
1.2.3 A.2.3 Proofs of Section 3.3
Lemma A.7
(p-powers are 2-tilt conditioned when \(\mathbf{{p}}\varvec{\in }{} \mathbf{]}{} \mathbf{{1,2}])}\). Let \(p \in ]1,2]\), \(u \in {\mathbb {R}}^N\), and \(f : {\mathbb {R}}^N \rightarrow {\mathbb {R}}\) be defined as \(f(x)=\frac{1}{p}\Vert x \Vert _p^p - \langle u,x \rangle \). Then f is 2-conditioned on every bounded subset of \({\mathbb {R}}^N\).
Proof
This function is a separable sum, so, without loss of generality, we can assume from here that \(N=1\) (see [40, Lemma 4.4]). Given a real \(t \in {\mathbb {R}}\), we will note its sign with s(t), which is equal to \(-1\) (resp. \(+1\)) if \(t<0\) (resp. \(t>0\)), or 0 if \(t=0\). Using the convexity, the differentiability of f, and the Fermat’s rule, we see that f admits a unique minimizer \({\bar{x}}\), defined by the relations
If \(u=0\), it is immediate to see that f is 2-conditioned on \(]-1,1[\), where the relation \(\vert t \vert ^2 \le \vert t \vert ^p\) holds. We therefore assume from now that \(u \ne 0\), which also means that \({\bar{x}} \ne 0\). We now compute (we note \(q = p/(p-1)\))
meaning that we are looking for an inequality like
Using the L’Hôpital rule twice allows us to study the following limit:
Note that our assumption that \({\bar{x}} \ne 0\) ensures that we can take the derivative of the second numerator around \({\bar{x}}\). Since this limit is well-defined, and nonnegative, it means that f is 2-conditioned on a small enough neighbourhood of \({\bar{x}}\). To conclude the proof, it remains to verify that f is 2-conditioned on any bounded set. This follows immediately from Proposition 3.5 and the fact that \( \mathrm{argmin\,}f = \{{\bar{x}} \}\). \(\square \)
Lemma A.8
If \(f \in \varGamma _0(X)\) is p-uniformly convex on a bounded closed convex set \(\varOmega \subset X\) with \(p\ge 2\), then f is p-tilt-conditioned on \(\varOmega \).
Proof
Let \(u \in X\) and let \({\tilde{f}} := f + \langle u, \cdot \rangle \) which is also p-uniformly convex on \(\varOmega \). We assume without loss of generality that \(\mathrm{{argmin}}~{\tilde{f}} \ne \emptyset \). If \(\varOmega \cap \mathrm{{argmin}}~{\tilde{f}} = \emptyset \), then \({\tilde{f}}\) is p-conditioned on \(\varOmega \), according to Proposition 3.5. If instead \(\varOmega \cap \mathrm{{argmin}}~{\tilde{f}} \ne \emptyset \), then we conclude the same with Lemma A.5. This proves the claim. \(\square \)
Lemma A.9
(Kullback-Leibler divergences are \(\mathbf{2}\)-tilt conditioned). Let \({\bar{x}} \in ]0,+\infty [^N\), and \(f \in \varGamma _0({\mathbb {R}}^N)\) be the Kullback-Leibler divergence to \({\bar{x}}\):
Then f is 2-tilt-conditioned on every bounded set of \({\mathbb {R}}^N\).
Proof
Let \(d \in {\mathbb {R}}^N\), and define the tilted function \({\tilde{f}} = f + \langle d , \cdot \rangle \). Using Fermat’s rule, we see that \(\mathrm{{argmin}}~{\tilde{f}} = \partial \!f^*(-d)\). It is a simple exercice to verify that \(\mathop {\mathrm { dom}}\partial \!f^* = ]-\infty , 1[^N\), so \(\mathrm{{argmin}}~{\tilde{f}} \ne \emptyset \) if and only if \(d \in ]-1,+\infty [^N\). Let d be such vector, and write, for any \(x_i>0\):
Let \(X_i := \frac{{\bar{x}}_i}{1+d_i}\), which is well defined under our assumption that \(d_i > -1\). Then
where \(a_i = X_i (1+d_i) \log (1+d_i)\). We then observe that \(\mathrm{{argmin}}~{\tilde{f}}_i = \{X_i\}\), from which we deduce that \(\mathrm{{argmin}}~{\tilde{f}} = \{X\}\) with \(X = (X_i)_{i=1}^N\).
Now, let \(\delta >0\) be fixed, and let \(x \in {\mathbb {B}}(X,\delta )\). Let \({\underline{d}} := \min _i d_i > -1\), \(c := N \Vert X \Vert _\infty \), and
which is nonnegative since \(t > \ln (1+t) \text { on} ]0,+\infty [.\) For each \(i \in \{1,\dots ,N\}\), we have \(\vert x_i - X_i \vert \le \delta \), so we can use [24, Lemma A.2] on \({\tilde{f}}_i\) to write
This proves that \({\tilde{f}}\) is 2-conditioned on \({\mathbb {B}}(X,\delta )\), which conludes the proof. \(\square \)
1.3 A.3 The Forward-Backward algorithm and proofs of Section 4
Definition A.10
Given a positive real sequence \((r_n)_{{n\in {\mathbb {N}}}}\) converging to zero, we say that \(r_n\) converges:
-
sublinearly (of order \(\alpha \in ]0,+\infty [\)) if \(\exists C \in ]0,+\infty [\) such that \(\forall {n\in {\mathbb {N}}}\), \(r_n \le C n^{-\alpha }\),
-
Q-linearly if \(\exists \varepsilon \in ]0,1[\) such that \(\forall {n\in {\mathbb {N}}}\), \(r_{n+1} \le \varepsilon r_n\),
-
R-linearly if \(\exists (s_n)_{n\in {\mathbb {N}}}\) Q-linearly converging such that \(\forall {n\in {\mathbb {N}}}\), \(r_n \le s_n\),
-
Q-superlinearly (of order \(\beta \in ]1,+\infty [\)) if \(\exists C \in ]0,+\infty [\) such that \(\forall {n\in {\mathbb {N}}}\), \(r_{n+1} \le C r_n^\beta \),
-
R-superlinearly if \(\exists (s_n)_{n\in {\mathbb {N}}}\) Q-superlinearly convergent such that \(\forall {n\in {\mathbb {N}}}\), \(r_n \le s_n\).
It is easy to verify that \(r_n\) is R-superlinearly convergent of order \(\beta > 1\) if and only if
Note that R-linear and R-superlinear convergence ensures only the overall decrease of the sequence, while Q-linear and Q-superlinear convergence requires the sequence to decrease at a certain speed for each index. It is immediate from the definition that Q-convergence implies R-convergence.
Lemma A.11
(Estimate for sublinear real sequences). Let \((r_n)_{n\in {\mathbb {N}}}\) be a real sequence being strictly positive and satisfying, for some \(\kappa > 0\), \(\alpha > 1\) and all \({n\in {\mathbb {N}}}\): \(r_n - r_{n+1} \ge \kappa r_{n+1}^\alpha .\) Define \({\tilde{\kappa }}:= \min \{\kappa ,\kappa ^\frac{\alpha -1}{\alpha } \}\), and \(\delta := \max \limits _{s \ge 1} \min \left\{ \frac{ \alpha -1}{s} , \kappa ^{-\frac{\alpha - 1}{\alpha }} r_0^{1-\alpha } \left( 1 - s^{-\frac{\alpha - 1}{ \alpha }} \right) \right\} \in ]0, + \infty [.\) Then, for all \({n\in {\mathbb {N}}}\), \(r_n \le ({\tilde{\kappa }} \delta n)^{-1/(\alpha -1)}.\)
Proof
It can be found in [72, Lemma 7.1], see also the proofs of [3, Theorem 2] or [46, Theorem 3.4]. \(\square \)
Lemma A.12
If Assumption 2.1 holds, then for all \((x,u)\in X^2\) and all \(\lambda >0\):
-
i)
\(\Vert T_\lambda x - u \Vert ^2 - \Vert x - u \Vert ^2 \le \left( {\lambda L} - 1 \right) \Vert T_\lambda x - x \Vert ^2 + 2\lambda ( f(u) - f(T_\lambda x)).\)
-
ii)
\(\Vert \partial \!f(T_\lambda x) \Vert _\_ \le \lambda ^{-1} \Vert T_\lambda x - x \Vert \le \Vert \partial \!f(x) \Vert _\_.\)
Proof of Lemma A.12
To prove item i), start by writing
The optimality condition in (2) gives \({x - T_\lambda x}\in \lambda \partial g(T_\lambda x) + \lambda \nabla h(x)\) so that, by using the convexity of g:
Since we can write \(\langle \nabla h(x),u -T_\lambda x \rangle = \langle \nabla h(x),u -x \rangle + \langle \nabla h(x),x - T_\lambda x\rangle \), we deduce from the convexity of h and the Descent Lemma ([11, Theorem 18.15]) that
Item i) is then proved after combining the two previous inequalities. For item ii), the optimality condition in (2), together with a sum rule (see e.g. [88, Theorem 3.30]), allows to deduce that
For the first inequality, use (50) with \((u,v)=(x-\lambda \nabla h(x),T_\lambda x)\), together with the contraction property of the gradient map \(x \mapsto x - \lambda \nabla h(x)\) when \(0<\lambda \le 2/L\) (see [11, Corollary 18.17 & Proposition 4.39 & Remark 4.34.i]) to obtain:
For the second inequality, consider \(x^* := \mathrm{proj}(-\nabla h(x),\partial g(x))\), and use (50) with \((u,v)=(x + \lambda x^*,x)\), together with the nonexpansiveness of the proximal map (see [11, Proposition 12.28]):
\(\square \)
Lemma A.13
(Descent Lemma for Hölder smooth functions). Let \(f : X \longrightarrow {\mathbb {R}}\) and \(C \subset X\) be convex. Assume that f is Gâteaux differentiable on C, and that there exists \((\alpha ,L) \in ]0,+\infty [^2\), such that for all \((x,y) \in C^2\), \(\Vert \nabla f(x) - \nabla f(y) \Vert \le L \Vert x - y \Vert ^\alpha \) holds. Then:
Proof
The argument used in [102, Remark 3.5.1, p.212] for \(C=X\) extends directly to convex sets. \(\square \)
Now we can prove the convergence rate results of Sect. 4.1:
Proof of Theorem 4.1
We first show that \((x_n)_{{n\in {\mathbb {N}}}}\) has finite length. Since \(\inf f > - \infty \), \(r_n:=f(x_n) - \inf f \in [0, + \infty [\), and it follows from Lemma A.12 that
If there exists \({n\in {\mathbb {N}}}\) such that \(r_n=0\) then the algorithm would stop after a finite number of iterations (see (51)), therefore it is not restrictive to assume that \(r_n>0\) for all \({n\in {\mathbb {N}}}\). We set \(\varphi (t):=p t^{1/p}\) and \(c:=c_{f,\varOmega }\), so that the Łojasiewicz inequality at \(x_n \in \varOmega \cap \mathop {\mathrm { dom}}^* f\) can be rewritten as
Combining (51), (52), and (53), and using the concavity of \(\varphi \), we obtain for all \(n \ge 1\):
By taking the square root on both sides, and using Young’s inequality, we obtain
Sum this inequality, and reorder the terms to finally obtain
We deduce that \((x_n)_{n\in {\mathbb {N}}}\) has finite length and converges strongly to some \(x_\infty \). Moreover, from (52) and the strong closedness of \(\partial \!f : X \rightrightarrows X\), we conclude that \(0 \in \partial \!f(x_\infty )\), meaning that \(x_\infty \in \mathrm{{argmin}}~f\).
Now we prove the convergence rates. Let \(c=c_{f,\varOmega }\) for short. We first derive rates for the sequence of values \(r_n:=f(x_n) - \inf f\), from which we will derive the rates for the iterates. Equations (51) and (52) yield
The Łojasiwecz inequality at \(x_{n+1} \in \varOmega \cap \text{ dom}^* f\) implies \(c^2 r_{n+1}^{2/p}(r_n - r_{n+1}) \ge ab^{-2} r_{n+1}^2,\) so we deduce that
The rates for the values are derived from the analysis of the sequences satisfying the inequality in (55). Depending on the value of p, we obtain different rates.
\(\bullet \) If \(p=1\), then we deduce from (55) that for all \({n\in {\mathbb {N}}}, r_{n+1}\ne 0\) implies \(r_{n+1} \le r_n - \kappa .\) Since the sequence \((r_n)_{n\in {\mathbb {N}}}\) is decreasing and positive, \(r_{n+1}\ne 0\) implies \( n\le r_0\kappa ^{-1}\).
For the other values of p, we will assume that \(r_n >0\). In particular, we get from (55)
\(\bullet \) If \(p\in ]1,2[\), then \(\alpha \in ]0,1[\). The positivity of \(r_{n+1}\) and (56) imply that for all \({n\in {\mathbb {N}}}\), \(r_{n+1} \le \kappa ^{-1/\alpha } r_n^{1/\alpha }\), meaning that \(r_n\) converges Q-superlinearly.
\(\bullet \) If \(p=2\), then \(\alpha =1\) and we deduce from (56) that for all \({n\in {\mathbb {N}}}\), \(r_{n+1} \le {(1+\kappa )^{-1}} r_n\), meaning that \(r_n\) converges Q-linearly.
\(\bullet \) If \(p \in ]2,+\infty [\), then \(\alpha \in ]1,2[\), and the analysis still relies on studying the asymptotic behaviour of a real sequence satisfying (56). Lemma A.11 shows that we have \(r_{n+1} \le (C_p')^{p/(p-2)} n^{-p/(p-2)}\), by taking
To end the proof, we will prove that the rates for \(\Vert x_n - x_\infty \Vert \) are governed by the ones of \(r_n\). Let \(1\le n \le N < +\infty \), and sum the inequality in (54) between n and N to obtain (remind that \(b=\lambda ^{-1}\)):
Next, we pass to the limit for \(N \rightarrow \infty \), we use (51), and the fact that \(r_n\) is decreasing to obtain
Note that \({r_{n-1}^{1/2}} \le r_0^{\frac{1}{2}-\frac{1}{p}} r_{n-1}^{1/p}\) if \(p\in [2,+\infty [\), and \(r_{n-1}^{1/p} \le r_0^{\frac{1}{p}-\frac{1}{2}} {r_{n-1}^{1/2}}\) if \(p\in [1,2]\). So, by defining
we finally conclude from (58) that \(\Vert x_\infty - x_n \Vert \le C_p r_{n-1}^{1/\max \{2,p\}}\) when \(n \ge 1\). \(\square \)
Proof of Proposition 4.7
Use the fact that \(p<0\), the definition of \(\varOmega \) in the claim and (44) to write that for all \(x \in \varOmega \cap \text{ dom}^* f\), \(\ (f(x) - \inf f)^{1 - \frac{1}{p}} \le (f(x) - \inf f) r^{- \frac{1}{p}} \le \delta r^{- \frac{1}{p}}\Vert \partial \!f(x) \Vert _\_ \ .\) \(\square \)
Proof of Proposition 4.8
It is the same as for Proposition 3.4, as the positivity of \(p,p'\) is not needed. \(\square \)
Proof of Theorem 4.9
The proof is as for the case \(p \in ]2,+\infty [\) of Theorem 4.1: the p-Łojasiewicz property implies (55), and the statement follows from Lemma A.11 with \(\alpha =2(p-1)/p \in ]2,+\infty [ \). \(\square \)
Proof of Theorem 4.11
The proofs of Theorems 4.1 and 4.9 rely on the combination of the Łojasiewicz inequality with the estimations (51) and (52), which can be replaced by (19) and (20). \(\square \)
1.4 A.4 Linear inverse problems and proofs of Section 5.1
Here we will make use of is the Moore-Penrose pseudo-inverse of A. It is a linear operator (not necessarily bounded), whose domain is \(D(A^\dagger ):= R(A) + R(A)^\perp \), and satisfying
It is easy to see that, whenever \(y \in D(A^\dagger )\), the set of minimizers of the least squares (29) is \(A^\dagger y + \ker A\).
Lemma A.14
Let A be a bounded linear operator from X to Y. Then \(\mathrm{{spec}}^*(A^*A) = \mathrm{{spec}}^*(AA^*)\).
Proof
Let \(\lambda \ne 0\) and denote by \(I_X\) and \(I_Y\) the identity operators of X and Y, respectively. It is enough to show that \(\lambda I_Y - AA^*\) has a bounded linear inverse if and only if \(\lambda I_X - A^*A\) has. Assume that \(\lambda I_Y - AA^*\) has a bounded linear inverse, and consider \(B = \frac{1}{\lambda }\left( I_X + A^*(\lambda I_Y-AA^*)^{-1} A \right) \). Clearly B is a bounded linear operator, and simple computations show that \((\lambda I_X - A^*A)B = I_X\). We see then that \(\lambda I_X - A^*A\) has a bounded inverse. Repeating this argument by exchanging the roles of A and \(A^*\) concludes the proof. \(\square \)
Lemma A.15
Let A be a bounded linear operator from X to Y. Then we have \(A (A^*A)^\alpha = (AA^*)^\alpha A\) for every \(\alpha >0\).
Proof
We remember from Sect. 5.1.1 that the power of a selfadjoint operator is defined in [56, Theorem VI.32.1]. A simple induction argument shows that, for every \(k \in {\mathbb {N}}\), \(A(A^*A)^k = (AA^*)^k A\). Taking linear combinations of this equality allows to see that, for every polynomial \(P \in {\mathbb {R}}[X]\), \(AP(A^*A) = P(AA^*)A\). Now, let \(\phi : t \in [0,+\infty [ \mapsto t^\alpha \). Since \(\phi \) is continuous on \([0,+\infty [\), it is in particular continuous on \([0, \Vert A \Vert ^2]\), which is an interval containing the spectrum of both \(A^*A\) and \(AA^*\). Thus, \(\phi \) restricted to this interval can be written as the uniform limit of a certain sequence of polynomials \((P_n)_{n\in {\mathbb {N}}}\). This implies that
The conditions of [56, Theorem VI.32.1] are therefore met, and we obtain that \((A^*A)^\alpha \) is the limit of \(P_n(A^*A)\) (the same reasoning applies to \(AA^*\)). Since \(AP_n(A^*A) = P_n(AA^*)A\) as observed above, passing to the limit gives the desired result. \(\square \)
Lemma A.16
For all \(b \in Y\), \(r \in ]0,+\infty [\), the following two properties are equivalent:
-
(1)
\((\exists x \in \ker A^\perp ) \quad b=Ax, \quad \Vert x \Vert = r \)
-
(2)
\((\exists y \in \mathrm{cl\,}R(A)) \quad b=\sqrt{AA^*} y, \quad \Vert y \Vert =r,\) where \(\sqrt{AA^*}\) is a shorthand for \((AA^*)^{1/2}\).
Proof
It is shown in [42, Proposition 2.18] that \(R(A) = R( \sqrt{AA^*})\), so it is enough to verify this implication:
Let (x, y) be such a pair. Since \(Ax=\sqrt{AA^*}y\) and \(y \in \mathrm{cl\,}R(A)=\ker \sqrt{AA^*}^\perp \), we deduce that \(y=(\sqrt{AA^*})^\dagger Ax\). Therefore, since \((AA^*)^\dagger Ax = (A^*)^\dagger x\) (see [42, p.35]) and \(A^*(A^*)^\dagger x= \mathrm{proj}(x;\ker A^\perp ) {=x}\), we get
\(\square \)
Proof of Proposition 5.5
Recall that \(y^\dagger =Ax^\dagger \) and let \(\nu =\mu +1/2\). From Definition 5.4 we derive:

This equivalence proves the desired expression for \(X_{\mu ,\delta }\). Since it holds for any \(\delta >0\), it implies that \(X_\mu =\{x^\dag \}+\ker A+R((A^*A)^\mu )\). \(\square \)
Lemma A.17
(Interpolation inequality[42, p. 47, eq. 2.49]). For all \(x \in X\) and \(0\le \alpha < \beta \), we have
Lemma A.18
(Powers of self-adjoint operators). Let S be a bounded selfadjoint positive linear operator on a Hilbert space. Then, for all \(\alpha >0\), \(\ker S = \ker S^\alpha \), and \( \mathrm{cl\,}R(S^\alpha ) = \mathrm{cl\,}R(S)\).
Proof
Given any \(0<\alpha <\beta \), we can write \(S^\beta = S^{\beta - \alpha } S^\alpha \), from which we deduce that \(\ker S^\alpha \subset \ker S^\beta \). This means that \((\ker S^\alpha )_{\alpha >0}\) is a nondecreasing family. To prove that this family is constant, it remains to verify that \(\ker S^2 \subset \ker S\): If \(x \in \ker S^2\), then \(\Vert Sx \Vert ^2 = \langle Sx,Sx \rangle = \langle S^2 x,x \rangle = 0\), therefore \(x \in \text{ Ker }~S\). Since \(S^{2\alpha }=(S^\alpha )^2\), what we proved shows that for all \(\alpha >0\), \(\mathrm{{Ker}}~S^{2\alpha } \subset \mathrm{{Ker}}~S^\alpha \). But we have seen that this family of null spaces is nondecreasing with respect to \(\alpha \), so we can deduce that \(\mathrm{{Ker}}~S^\alpha = \mathrm{{Ker}}~S^\beta \) for all \(\beta \in [\alpha , 2\alpha ]\). This being true for any \(\alpha >0\), we deduce that this family of null spaces is constant. The conclusion follows from the fact that \(\ker S^\perp = \mathrm{cl\,}R(S)\). \(\square \)
Proof of Proposition 5.7
Given any \(x \in X\), observe that \(x \in X_0\) is, by definition, equivalent to \(Ax \in Y_{1/2}\). Since \(R(A)= R(({AA^*})^{1/2})\), the latter is equivalent to \(Ax \in y^\dagger + R(A)\). We can then easily deduce that \(X_0 = X \Leftrightarrow X_0 \ne \emptyset \). Indeed, \(X_0\) is nonempty if and only if \(y^\dagger \in R(A)\). But if \(y^\dagger \in R(A)\) then every \(x \in X\) verifies \(Ax \in y^\dagger + R(A)\), since the latter is equivalent to \(Ax \in R(A)\). Proposition 5.1 yields \( X_0 = X \Leftrightarrow X_0 \ne \emptyset \Leftrightarrow y^\dagger \in R(A) \Leftrightarrow \mathrm{argmin\,}f \ne \emptyset .\) For items i) and ii), the claim follows directly from the nonincreasingness of \(\{X_\mu \}_{-1/2< \mu < + \infty }\). For item iii), let \(\mu ,\delta >0\). Start by assuming that R(A) is closed. Observe that for \(\nu = \mu + 1/2 >0\), \( \mathrm{spec}((AA^*)^\nu ) = \mathrm{spec}(AA^*)^\nu \) [56, §32 Theorem 3]. As a consequence of Proposition 5.2, we deduce that \(R (AA^*)^\nu \) is closed, and therefore \(R((AA^*)^\nu )=R(A)\) (see Lemma A.18). Moreover, R(A) being closed implies that \(y^\dagger \in R(A)\). So \(Y_\nu = y^\dagger + R((AA^*)^\nu ) = R(A)\), from which we deduce that \(X_\mu = X\). Assume now that \(X_\mu = X\), and let us show that \(\mathrm{{int}}~X_{\mu ,\delta } \ne \emptyset \). Note that \(X_\mu =X\) implies that \(\mathrm{{argmin}}~f \ne \emptyset \) according to item i). Proposition 5.5 implies that \(\{x^\dagger \} + {{\,\mathrm{Ker}\,}}A + P \subset X_{\mu ,\delta }\) where \(P:=\{(A^*A)^\mu (w) \ | \ w \in \mathrm{{Ker}}~A^\bot , \Vert w \Vert < \delta \}\). To prove the claim, it is enough to show that \(\ker A + P\) is open. We start by noting that P is the image by \((A^*A)^\mu \) of \(\ker A^\bot \cap \delta {\mathbb {B}}_X\), which is a relatively open set in \(\mathrm{{Ker}}~A^\bot \). Since \(R((A^*A)^\mu ) \subset \mathrm{{Ker}}~A^\bot \) (see Lemma A.18) and \(X_{\mu }=X\), we deduce from Proposition 5.5 that \(R((A^*A)^\mu ) = \mathrm{{Ker}}~A^\bot \). Since \(\mathrm{{Ker}}~(A^*A)^\mu = \mathrm{{Ker}}~A\) (Lemma A.18 again), we see that the restriction of \((A^*A)^\mu \) to \(\mathrm{{Ker}}~A^\bot \) induces a surjective linear operator \(\mathrm{{Ker}}~A^\bot \longrightarrow \mathrm{{Ker}}~A^\bot \), where \(\mathrm{{Ker}}~A^\bot \) is a Hilbert space endowed with the induced metric of X. Therefore, the Banach-Schauder (open mapping) theorem tells us that P is relatively open in \(\mathrm{{Ker}}~A^\bot \): there exists a set U open in X such that \(P=\ker A^\bot \cap U\). Concluding that \(\mathrm{{Ker}}~A + P\) is open is a simple exercise that we detail now. Given any \(x \in \mathrm{{Ker}}~A +P\), we can decompose it as \(x = k + p\), where \(k \in \mathrm{{Ker}}~A\), \(p \in P\). Since \(P \subset U\), there exists \(\varepsilon >0\) such that \({\mathbb {B}}(p,\varepsilon )\subset U\). Let us verify that \({\mathbb {B}}(x,\varepsilon ) \subset \mathrm{{Ker}}~A +P\). Every \(x' \in {\mathbb {B}}(x,\varepsilon )\) can be decomposed as \(x'=k' +p'\), where \(k' \in \mathrm{{Ker}}~A\), \(p'\in \mathrm{{Ker}}~ A^\bot \). Then we see that \(p-p' = x-x' +k-k'\), where \(p-p' \in \mathrm{{Ker}}~A^\bot \) and \(k-k' \in \mathrm{{Ker}}~A\), which means that \(p-p' = \mathrm{proj}(x-x'; \mathrm{{Ker}}~A^\bot )\). We conclude that \(\Vert p-p'\Vert \le \Vert x-x'\Vert < \varepsilon \), which means that \(p' \in U\), and proves that \(x' \in \mathrm{{Ker}}~A + P\). We turn now to the last implication of this Proposition, by supposing that \(\mathrm{{int}}~X_{\mu ,\delta } \ne \emptyset \). It implies in particular that \(X_\mu \) has nonempty interior, and that \(\mathrm{{argmin}}~f\ne \emptyset \) (see item i)). With Proposition 5.5, we see that \(\mathrm{{Ker}}~A + R((A^*A)^\mu )\) has nonempty interior. Because it is a linear subspace, this means that \(\mathrm{{Ker}}~A + R((A^*A)^\mu ) = X\). Reasoning as above, we obtain that \(R((A^*A)^\mu ) = \ker A^\bot \), which is closed. Combining Proposition 5.2 with the fact that \( \mathrm{spec}^*(A^*A)= \mathrm{spec}^*(AA^*)\) (see Lemma A.14), we conclude that R(A) is closed. \(\square \)
1.5 A.5 Regularized inverse problems and proofs of Section 5.2
Proposition A.19
A matrix \(S\in {\mathcal {S}}_+({\mathbb {R}}^N)\) is coercive on a closed cone \(K \subset {\mathbb {R}}^N\) if and only if \(K \cap \ker S = \{0\}\).
Proof
The direct implication is immediate from Definition 5.15. For the reverse implication, let K be a closed cone such that \(K \cap \ker S = \{0\}\). Since S is linear, we know that \(d \mapsto \langle Sd,d \rangle \) is convex and continuous. So, using the compactness of \(K \cap {\mathbb {S}}\) we deduce that:
Because \({\bar{d}} \in K\) and \({\bar{d}} \ne 0\), we deduce from our assumption that \({\bar{d}} \notin \text{ Ker }~S\). Therefore, \( \gamma :=\langle S {\bar{d}}, {\bar{d}} \rangle > 0\), from which we deduce that S is \(\gamma \)-coercive on K. \(\square \)
Definition A.20
(Cone enlargement). Let \(K \subset {\mathbb {R}}^N\) be a cone, and \( \theta \in [0, \frac{\pi }{2}]\). We define the \(\theta \)-enlargement of K as
Lemma A.21
If K is a closed cone, then \(K_\theta \) is a closed cone containing K for all \(\theta \in [0, \frac{\pi }{2}]\).
Proof
By definition, \(K_\theta \) is a cone containing K and
is compact, due to the compactness of \(K\cap {\mathbb {S}}\). Since \(0\not \in \varDelta _\theta \), by compactness of \(\varDelta _\theta \), we deduce that \(K_\theta ={\mathbb {R}}\varDelta _\theta \) is a closed cone (see e.g. [48, Proposition A.1.1]). \(\square \)
Proposition A.22
Let \(S\in {\mathcal {S}}_+({\mathbb {R}}^N)\) which is \(\gamma \)-coercive on a closed cone K. Then, for every \(\gamma ' \in ]0,\gamma ]\), S is \(\gamma '\)-coercive on \(K_\theta \), with \(\theta :=\arcsin \left( \frac{\gamma - \gamma '}{\Vert S \Vert } \right) \in [0, \frac{\pi }{2}[\).
Proof
Let \(\theta \) and \(\gamma \) be as in the statement. Since S is \(\gamma \)-coercive on K, we see that \(\gamma \le \Vert S \Vert \), which guarantees that \(\theta \in [0, \frac{\pi }{2}[\). Now, the fact that \(K_\theta \) is closed (Lemma A.21) implies that \(K_\theta \cap {\mathbb {S}}\) is compact in X, so we can use the same arguments as in (60) to deduce that there exists \({\bar{d}} \in K_\theta \cap {\mathbb {S}}\) such that \(\langle S{\bar{d}}, {\bar{d}} \rangle = \inf \limits _{d \in K_\theta \cap {\mathbb {S}}} \langle Sd,d \rangle \). Since \({\bar{d}} \in K_\theta \), there exists by definition of \(K_\theta \) some \({\bar{v}} \in K \cap {\mathbb {S}}\) such that \(\arccos (\vert \langle {\bar{d}}, {\bar{v}} \rangle \vert ) \le \theta \). We can use [62, Theorem 1] to write
Since \({\bar{v}} \in K \cap {\mathbb {S}} \subset K_\theta \cap {\mathbb {S}}\), we have \(\langle S {\bar{v}}, {\bar{v}} \rangle \ge \langle S {\bar{d}}, {\bar{d}} \rangle \). Moreover, \(\arccos (\vert \langle {\bar{v}}, {\bar{d}} \rangle \vert ) \le \theta \), so (61), implies
We deduce from the definition of \({\bar{d}}\) that S is \(\gamma '\)-coercive on \(K_\theta \). \(\square \)
Proposition A.23
Let \(C \subset {\mathbb {R}}^N\) be locally closed at \({\bar{x}} \in C\).
-
i)
For \(\rho >0\), C is \(\rho \)-reached at \({\bar{x}}\) if and only if :
$$\begin{aligned} (\forall x \in C)(\forall \eta \in N_C({\bar{x}})) \quad \langle \eta , x - {\bar{x}} \rangle \le \frac{\rho }{2} \Vert \eta \Vert \Vert x - {\bar{x}} \Vert ^2. \end{aligned}$$(62) -
ii)
Every \(C^2\) manifold is prox-regular.
Proof
Item i) : Definition 5.20 can be rewritten as
where the condition \(x \notin {\mathbb {B}}({\bar{x}} + \frac{1}{\rho } \eta , \frac{1}{\rho })\) is equivalent to, after developing the square:
The conclusion follows after cancelling and reorganizing the terms. Item ii) : By definition, every \(C^2\)-manifold C is strongly amenable in the sense of [94, Def. 10.23.b)]. Then [94, Proposition 13.32] tells us that C is prox-regular in the sense of [94, Exercice 13.31] : for every \({\bar{x}} \in C\), there exists \(\delta , \rho >0\) such that for every \(x \in C \cap \overline{{\mathbb {B}}}({\bar{x}},\delta )\), and for every \(\eta \in N_C({\bar{x}}) \cap \overline{{\mathbb {B}}}(0, \delta )\), we have
Taking any nonzero \({\hat{\eta }} \in N_{C \cap {{\mathbb {B}}}({\bar{x}}, \delta )}(x) = N_C(x)\), we can define \(\eta := {\hat{\eta }} \frac{\delta }{\Vert {\hat{\eta }} \Vert } \in N_C(x) \cap {\mathbb {B}}(0,\delta )\) and see that
This being true independently of the choice of \({\hat{\eta }}\), we deduce from item i) that \(C\cap {\mathbb {B}}({\bar{x}},\delta )\) is \(\frac{\rho }{\delta }\)-reached at x. We can then conclude that C is prox-regular in the sense of Definition 5.20. \(\square \)
Here is a needed result estimating locally the coercivity of a matrix on a reached set via its coercivity on the tangent cone.
Proposition A.24
Let \(C \subset {\mathbb {R}}^N\) be \(\rho \)- reached at \({\bar{x}} \in C\). Let \(S \in {\mathcal {S}}_+({\mathbb {R}}^N)\) be \(\gamma \)-coercive on \(T_C({\bar{x}})\). Then, for all \(\gamma ' \in ]0, \gamma [\), there exists a cone \(K \subset {\mathbb {R}}^N\) such that S is \(\gamma '\)-coercive on K, and \(C \cap {\mathbb {B}}({\bar{x}},\delta ) \subset {\bar{x}} + K\), with \(\delta = \frac{2(\gamma - \gamma ')}{\rho \Vert S \Vert }\).
Proof
Let \(\gamma ' \in ]0, \gamma [\) be fixed, and define \(\theta :=\arcsin ((\gamma - \gamma ')\Vert S \Vert ^{-1}) \in ]0, \frac{\pi }{2}[\). Let \(K_\theta \) be the \(\theta \)-enlargement of \(T_{C}({\bar{x}})\), then Proposition A.22 guarantees that S is \(\gamma '\)-coercive on \(K_\theta \). It remains to prove that there exists \(\delta \in ]0,+\infty [\) such that \(C \cap {\mathbb {B}}({\bar{x}} , \delta ) \subset {\bar{x}} + K_\theta \). Let \(x \in C\). Because C is \(\rho \)-reached at \({\bar{x}}\), we know that \(T_C({\bar{x}})\) is a convex cone (use [44, Theorem 4.8.(12)] and the fact that C is locally closed at \({\bar{x}}\)), so we can define \(y:= \mathrm{proj}(x - {\bar{x}}, T_C({\bar{x}})) \), and \(\eta := \mathrm{proj}(x - {\bar{x}}, N_C({\bar{x}}))\). Using Moreau’s Theorem [11, Theorem 6.30], we deduce that \(\eta =x - {\bar{x}} -y\) with \(\langle \eta , y \rangle = 0\). We define \(\delta := \Vert x- {\bar{x}}\Vert \), and look for a condition on it so that \(x \in {\bar{x}} + K_\theta \). For this to happen, it is enough to verify that
Now, use Proposition A.23.i) together with the Cauchy-Schwarz inequality, and the polynomial inequality \(X^2 - cX \ge -c^2/4\), to write
This inequality, together with the facts that \(x - {\bar{x}} = y + \eta \) and \(\langle y,\eta \rangle =0\) (so \(\langle x - {\bar{x}},y \rangle = \Vert y \Vert ^2\)), imply that
This allows us to conclude that (63) holds as long as:
\(\square \)
Proof of Proposition 5.18
Let \(0<\gamma ' < \gamma \), and set \(S:= \mathrm{argmin\,}f\). Since h is of class \(C^2\) around \({\bar{x}} \in S\), there exists some \(\delta >0\) such that for all \(u \in \delta {\mathbb {B}}\), \(\Vert \nabla ^2 h({\bar{x}} + u) - \nabla ^2 h({\bar{x}}) \Vert \le \gamma - \gamma '.\) Notice that when \(\nabla ^2 h\) is Lipschitz continuous, we can take \(\delta =(\gamma - \gamma ')/L\). Let us show that f is 2-conditioned on \(\varOmega := {\bar{x}} + (K \cap \delta {\mathbb {B}})\) with the constant \(\gamma _{f,\varOmega }=\gamma '\). Take \(x \in \varOmega \cap \mathop {\mathrm { dom}}g\) and use the optimality condition at \({\bar{x}} \in S\) and the convexity of g to obtain
By Taylor’s theorem applied to h, we deduce from the inequality above that there exists \(y \in [x,{\bar{x}}]\) such that:
On the one hand, since \(x\in \varOmega \), we have that \(x - {\bar{x}} \in K\). Thus, from the coercivity of \(\nabla ^2 h({\bar{x}})\) we have
On the other hand, we use the Cauchy-Schwarz inequality together with the definition of \(\delta \) and the fact that \(\Vert y - {\bar{x}} \Vert \le \Vert x - {\bar{x}} \Vert < \delta \) to obtain
By combining the three previous inequalities, we deduce that
This implies that \(\varOmega \cap \mathrm{argmin\,}f=\{\bar{x}\}\), and the statement follows from \(\Vert x - {\bar{x}} \Vert \ge \mathrm{dist\,}(x;S)\). \(\square \)
Rights and permissions
About this article

Cite this article
Garrigos, G., Rosasco, L. & Villa, S. Convergence of the forward-backward algorithm: beyond the worst-case with the help of geometry. Math. Program. 198, 937–996 (2023). https://doi.org/10.1007/s10107-022-01809-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10107-022-01809-4
Keywords
- Forward Backward algorithm
- Convergence rates
- Conditioned functions
- Łojasiewicz property
- Inverse problems
- Source condition