
Abstract
In this paper, we study the lower iteration complexity bounds for finding the saddle point of a strongly convex and strongly concave saddle point problem: \(\min _x\max _yF(x,y)\). We restrict the classes of algorithms in our investigation to be either pure first-order methods or methods using proximal mappings. For problems with gradient Lipschitz constants (\(L_x, L_y\) and \(L_{xy}\)) and strong convexity/concavity constants (\(\mu _x\) and \(\mu _y\)), the class of pure first-order algorithms with the linear span assumption is shown to have a lower iteration complexity bound of \(\Omega \,\left( \sqrt{\frac{L_x}{\mu _x}+\frac{L_{xy}^2}{\mu _x\mu _y}+\frac{L_y}{\mu _y}}\cdot \ln \left( \frac{1}{\epsilon }\right) \right) \), where the term \(\frac{L_{xy}^2}{\mu _x\mu _y}\) explains how the coupling influences the iteration complexity. Under several special parameter regimes, this lower bound has been achieved by corresponding optimal algorithms. However, whether or not the bound under the general parameter regime is optimal remains open. Additionally, for the special case of bilinear coupling problems, given the availability of certain proximal operators, a lower bound of \(\Omega \left( \sqrt{\frac{L_{xy}^2}{\mu _x\mu _y}}\cdot \ln (\frac{1}{\epsilon })\right) \) is established under the linear span assumption, and optimal algorithms have already been developed in the literature. By exploiting the orthogonal invariance technique, we extend both lower bounds to the general pure first-order algorithm class and the proximal algorithm class without the linear span assumption. As an application, we apply proper scaling to the worst-case instances, and we derive the lower bounds for the general convex concave problems with \(\mu _x = \mu _y = 0\). Several existing results in this case can be deduced from our results as special cases.
Similar content being viewed by others

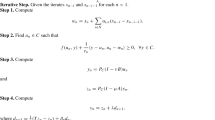

Notes
In Nesterov’s original paper [30], the author did not give a name to his algorithm. For convenience of referencing, in this paper we shall call it accelerated dual extrapolation.
References
Abadeh, S.S., Esfahani, P.M., Kuhn, D.: Distributionally robust logistic regression. In: Advances in Neural Information Processing Systems, pp. 1576–1584, (2015)
Agarwal, N., Hazan, E.: Lower bounds for higher-order convex optimization. arXiv preprint arXiv:1710.10329, (2017)
Arjevani, Y., Shamir, O., Shiff, R.: Oracle complexity of second-order methods for smooth convex optimization. Math. Progr. 178(1–2), 327–360 (2019)
Arjovsky, M., Chintala, S., Bottou, L.: Wasserstein Gan. arXiv preprint arXiv:1701.07875, (2017)
Azizian, W., Scieur, D., Mitliagkas, I., Lacoste-Julien, S., Gidel, G.: Accelerating smooth games by manipulating spectral shapes. arXiv preprint arXiv:2001.00602, (2020)
Bertsekas, D.P.: Nonlinear Progr. Athena Scientific, Nashua (1997)
Carmon, Y., Duchi, J.C., Hinder, O., Sidford, A.: Lower bounds for finding stationary points I. Math. Progr. 184, 71–120 (2017)
Carmon, Y., Duchi, J.C., Hinder, O., Sidford, A.: Lower bounds for finding stationary points II: first-order methods. Math. Progr. 158, 1–2 (2019)
Chambolle, A., Pock, T.: A first-order primal-dual algorithm for convex problems with applications to imaging. J. Math. Imaging Vis. 40(1), 120–145 (2011)
Chambolle, A., Pock, T.: On the ergodic convergence rates of a first-order primal-dual algorithm. Mah. Progr. 159(1–2), 253–287 (2016)
Gao, X., Zhang, S.: First-order algorithms for convex optimization with nonseparable objective and coupled constraints. J. Oper. Res. Soc. China 5(2), 131–159 (2017)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversaria nets. In: Advances in Neural Information Processing Systems, pages 2672–2680, (2014)
Ibrahim, A., Azizian, W., Gidel, G., Mitliagkas, I.: Linear lower bounds and conditioning of differentiable games. arXiv preprint arXiv:1906.07300, (2019)
Jin, C., Netrapalli, P., Jordan, M.I.: Minmax optimization: Stable limit points of gradient descent ascent are locally optimal. arXiv preprint arXiv:1902.00618, (2019)
Jin, C., Netrapalli, P., Jordan, M.I.: What is local optimality in nonconvex-nonconcave minimax optimization? arXiv preprint arXiv:1902.00618, (2019)
Juditsky, A., Nemirovski, A., Tauvel, C.: Solving variational inequalities with stochastic mirror-prox algorithm. Stoch. Syst. 1(1), 17–58 (2011)
Korpelevich, G.M.: The extragradient method for finding saddle points and other problems. Matecon 12, 747–756 (1976)
Lin, Q., Liu, M., Rafique, H., Yang, T.: Solving weakly-convex-weakly-concave saddle-point problems as weakly-monotone variational inequality. arXiv preprint arXiv:1810.10207, (2018)
Lin, T., Jin, C., Jordan, M.: Near-optimal algorithms for minimax optimization. In: Annual Conference on Learning Theory, (2020)
Lin, T., Jin, C., Jordan, M.I.: On gradient descent ascent for nonconvex-concave minimax problems. arXiv preprint arXiv:1906.00331, (2019)
Lu, S., Tsaknakis, I., Hong, M., Chen, Y.: Hybrid block successive approximation for one-sided non-convex min-max problems: algorithms and applications. arXiv preprint arXiv:1902.08294, (2019)
Marcotte, P., Dussault, J.-P.: A note on a globally convergent newton method for solving monotone variational inequalities. Oper. Res. Lett. 6(1), 35–42 (1987)
Mokhtari, A., Ozdaglar, A., Pattathil, S.: A unified analysis of extra-gradient and optimistic gradient methods for saddle point problems: Proximal point approach. arXiv preprint arXiv:1901.08511, (2019)
Nemirovski, A.: Prox-method with rate of convergence \(o(1/t)\) for variational inequalities with lipschitz continuous monotone operators and smooth convex-concave saddle point problems. SIAM J. Optim. 15(1), 229–251 (2004)
Nemirovsky, A.: Information-based complexity of linear operator equations. J. Complex. 8(2), 153–175 (1992)
Nemirovsky, A., Yudin, D.B.: Problem complexity and method efficiency in optimization. (1983)
Nesterov. Yu.: Implementable tensor methods in unconstrained convex optimization. CORE Discussion Paper, 2018/05
Nesterov, Yu.: Dual extrapolation and its applications to solving variational inequalities and related problems. Math. Progr. 109(2–3), 319–344 (2007)
Nesterov, Yu.: Lectures on convex optimization, vol. 137. Springer, Cham (2018)
Yu. Nesterov and L. Scrimali. Solving strongly monotone variational and quasi-variational inequalities. Available at SSRN 970903, 2006
Nisan, N., Roughgarden, T., Tardos, E., Vazirani, V.: Algorithmic game theory. Cambridge University Press, Cambridge (2007)
Ouyang, Y., Chen, Y., Lan, G., Pasiliao Jr., E.: An accelerated linearized alternating direction method of multipliers. SIAM J. Imaging Sci. 8(1), 644–681 (2015)
Ouyang, Y., Xu, Y.: Lower complexity bounds of first-order methods for convex-concave bilinear saddle-point problems. arXiv preprint arXiv:1808.02901, (2018)
Rockafellar, R.T.: Convex analysis. Princeton University Press, Princeton (1970)
Sanjabi, M., Razaviyayn, M., Lee, J.D.: Solving non-convex non-concave min-max games under Polyak-Lojasiewicz condition. arXiv preprint arXiv:1812.02878, (2018)
Taji, K., Fukushima, M., Ibaraki, T.: A globally convergent newton method for solving strongly monotone variational inequalities. Math. Progr. 58(1–3), 369–383 (1993)
von Neumann, J., Morgenstern, O., Kuhn, H.W.: Theory of games and economic behavior (commemorative edition). Princeton University Press, Princeton (2007)
Wang, Y., Li, J.: Improved algorithms for convex-concave minimax optimization. arXiv preprint arXiv:2006.06359, (2020)
Xiao, L., Yu, A., Lin, Q., Chen, W.: DSCOVR: randomized primal-dual block coordinate algorithms for asynchronous distributed optimization. J. Mach. Learn. Res. 20(43), 1–58 (2019)
Xu, Y.: Accelerated first-order primal-dual proximal methods for linearly constrained composite convex programming. SIAM J. Optim. 27(3), 1459–1484 (2017)
Acknowledgements
We thank the two anonymous reviewers for their insightful suggestions on orthogonal invariance argument for breaking the linear span assumption and the suggestion on applying scaling to obtain lower bounds for general convex-concave problems.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Proof of lemma 3.4
By the subspace characterization (20), we have
where the last inequality is due to the fact that \(q\le 1, k\le \frac{n}{2}\) and \(y^0 = 0\). Note that by Lemma 3.3, if we require \(n\ge 2\log _q\left( \frac{\alpha }{4\sqrt{2}}\right) \), then we can guarantee that
where the last inequality is due to \(\frac{q^{\frac{n}{2}}}{\alpha }\le \frac{1}{4\sqrt{2}}\) and \(q/(1-q)\le \Vert y^0-\hat{y}^*\Vert \). Therefore, we have
where the fourth line is due to that \(d(t^2 - 2\Vert \hat{y}^*-y^*\Vert t)/dt = 2(t-\Vert \hat{y}^*-y^*\Vert )\ge 0\) when \(t\ge \delta _k\). Hence the quadratic function is monotonically increasing in the considered interval. In addition, we also have
where the third inequality is due to that \(\Vert y^0-\hat{y}^*\Vert \ge \hat{y}^*_1 = q/(1-q)\). For the last inequality, if \(\alpha \ge 1\), then \(q^n/\alpha <1\); if \(\alpha \le 1\), then \(q^n/\alpha \le \alpha /32\le 1\) since \(n\ge 2\log _q\left( \frac{\alpha }{4\sqrt{2}}\right) \). Combining the above two inequalities, the desired bound (21) follows.
Proof of proposition 3.6
Here we only prove the last inequality of (23). Due to the fact that \((\ln (1+z))^{-1}\ge 1/z\) for \(\forall z>0\), we know
which completes the proof.
Proof of theorem 3.7
Before proceeding the proof, let us first quote a lemma from [33].
Lemma C.1
[Lemma 3.1, [33]] Let \(\mathcal {X}\subsetneqq \bar{\mathcal {X}}\subseteqq \mathbb {R}^{p}\) be two linear subspaces. Then for any \(\bar{x}\in \mathbb {R}^p\), there exists an orthogonal matrix \(\Gamma \in \mathbb {R}^{p\times p}\) s.t. \(\Gamma x = x, \forall x\in \mathcal {X}\) and \(\Gamma \bar{x}\in \bar{\mathcal {X}}\).
Note that for an orthogonal matrix \(\Gamma \), if \(\Gamma x = x\), then we also have \(\Gamma ^\top x = x\). Now let us start our proof of Theorem 3.7.
Proof
To prove this theorem, we only need to show
We separate the proof into two parts.
Part I. There exist orthogonal matrices \(\hat{U}\), \(\hat{V}\) s.t. when \(\mathcal {A}\) is applied to the rotated instance \(F_{\hat{U},\hat{V}}\), \(\{(x^0,y^0),...,(x^k,y^k)\}\subseteq \hat{U}^\top \mathcal {H}_x^{4k-1}\times \hat{V}^\top \mathcal {H}_y^{4k-1}.\)
Let \(\theta = (L_{xy},\mu _x,\mu _y)\) be the set of algorithmic parameters. To prove the result, let us construct the worst-case function \(F_{U,V}\) in a recursive way.
Case \(k = 1\): Let us define \(U_0 = V_0 = I\). When \(\mathcal {A}\) is applied to the function \(F_{U_0,V_0}\in \mathcal {B}(L_{xy}, \mu _x, \mu _y)\), the iterate sequence is \((x_{0}^0, y_{0}^0) = (0, 0)\) and
By Lemma C.1, there exists orthogonal matrices \(\Gamma _x^0\) and \(\Gamma _y^0\) such that \(\Gamma _x^0x^1_0\in \mathcal {H}_x^3 = \mathrm {Span}\{Ab\}\), \(\Gamma _y^0y^1_0\in \mathcal {H}_y^3=\mathrm {Span}\{b, A^2b\}\), and \(\Gamma _y^0b = (\Gamma _y^0)^\top b = b.\) That is
where \(U_1 = U_0\Gamma _x^0\) and \(V_1 = V_0\Gamma _y^0\).
Now we prove that when we apply the algorithm \(\mathcal {A}\) to \(F_{U_1,V_1}\), the generated iterates \(\{(x^0_1, y^0_1), (x^1_1, y^1_1)\}\) satisfy that \((x^0_1, y^0_1) = (0, 0)\) and \((x^1_1, y^1_1) = (x^1_0, y^1_0)\). That is, the first two iterates generated by \(\mathcal {A}\) is completely the same for \(F_{U_0,V_0}\) and \(F_{U_1,V_1}\). The reason is because \(u^1_1 = \mathcal {A}_u^1(\theta ; x^0_1, U_1^\top AV_1y^0_1) = \mathcal {A}_u^1(\theta ; 0, 0) = \mathcal {A}_u^1(\theta ; x^0_0, U_0^\top AV_0y^0_0) = u^1_0\), therefore
Through similar argument, we know \((y^1_1,\tilde{y}^1_1) = (y^1_0,\tilde{y}^1_0)\). Therefore, (42) indicates that
Case \(k=2\). For the ease of the readers to follow, we perform one extra step of discussion for \(k=2\), before presenting the construction on general k.
For the problem instance \(F_{U_1,V_1}\), the iterates generated by \(\mathcal {A}\) are \((x_{1}^0, y_{1}^0) = (0, 0)\) and
Note that \(x_1^1 \in U_1^\top \mathcal {H}_x^3 \subsetneqq U_1^\top \mathcal {H}_x^5\subsetneqq U_1^\top \mathcal {H}_x^7\) and \(\{y_1^1,b\}\subsetneqq V_1^\top \mathcal {H}_y^3\subsetneqq V_1^\top \mathcal {H}_y^5\subsetneqq V_1^\top \mathcal {H}_y^7\). Therefore, there exist orthogonal matrices \(\Gamma _x^1\) and \(\Gamma _y^1\) such that
Now, let us define
Now we prove that if \(\mathcal {A}\) is applied to \(F_{U_2,V_2}\), the generated iterates \(\{(x_{2}^0, y_{2}^0), (x_{2}^1, y_{2}^1), (x_{2}^2, y_{2}^2)\}\) satisfy \((x_{2}^0, y_{2}^0) = (0, 0)\), \((x_{2}^1, y_{2}^1) = (x_{1}^1, y_{1}^1)\), and \((x_{2}^2, y_{2}^2) = (x_{1}^2, y_{1}^2)\). The argument for \((x_{2}^1, y_{2}^1) = (x_{1}^1, y_{1}^1)\) is almost the same as that of the case \(k=1\). We only provide the proof for \((x_{2}^2, y_{2}^2) = (x_{1}^2, y_{1}^2)\).
Next, we need to show \(u_2^2 = u_1^2\), which can be proved by arguing that all the inputs to \(\mathcal {A}_u^2\) are the same for both \(u_2^2\) and \(u_1^2\). First, it is straightforward that \(x_1^0 = 0 = x^0_2, U_1^\top AV_1 y_1^0 = 0 = U_2^\top AV_2 y_2^0\). By previous argument \(x_2^1 = x_1^1\). Finally, consider the last input \(U_2^\top AV_2 y_2^1\), because \(y_2^1 = y_1^1\in V_1^\top \mathcal {H}_y^3\subsetneqq V_1^\top \mathcal {H}_y^5\), we have \(\Gamma _y^1 y_2^1 = y_2^1 = y_1^1\in V_1^\top \mathcal {H}_y^3.\) Then \(V_2y_2^1 = V_1\Gamma _y^1y_2^1\in V_1V_1^\top \mathcal {H}_y^3 = \mathcal {H}_y^3.\) Therefore \(U_1^\top AV_2y_2^1\in U_1^\top A\mathcal {H}_y^3 = U_1^\top \mathcal {H}_x^5\) and
Consequently,
and
Through a similar argument, we have \((y_2^2,\tilde{y}_2^2) = (y_1^2,\tilde{y}_1^2)\). By (43) and (44), we have
Case k. Suppose we already have orthogonal matrices \(U_{k-1}, V_{k-1}\), such that when \(\mathcal {A}\) is applied to \(F_{U_{k-1},V_{k-1}}\), we have
Again, by Lemma C.1, there exist orthogonal matrices \(\Gamma _x^{k-1}\) and \(\Gamma _y^{k-1}\), such that
Now we define that
Therefore, similar to our previous discussion, we only need to argue that when \(\mathcal {A}\) is applied to \(F_{U_k,V_k}\), the generated iterates \(\{(x_k^0,y_k^0), (x_k^1,y_k^1),\cdots ,(x_k^k,y_k^k)\}\) satisfy \((x_k^i,y_k^i) = (x_{k-1}^i,y_{k-1}^i)\) for \(i = 0,1,...,k\). We prove this argument by induction. First, it is straightforward that \((x_k^0,y_k^0) = (0,0) = (x_{k-1}^0,y_{k-1}^0)\). Suppose \((x_k^i,y_k^i) = (x_{k-1}^i,y_{k-1}^i)\) holds for \(i = 0,1,...,j-1\le k-1\), now we prove \((x_k^j,y_k^j) = (x_{k-1}^j,y_{k-1}^j)\), which is almost identical to the case \(k=2\).
For any \(i\in \{0,1,...,j-1\}\), let us show \(U_{k-1}^\top AV_{k-1} y_{k-1}^i = U_k^\top AV_k y_k^i\). Because \(y_k^i = y_{k-1}^i\in V_{k-1}^\top \mathcal {H}_y^{4k-5}\subsetneqq V_{k-1}^\top \mathcal {H}_y^{4k-3}\), we have \(\Gamma _y^{k-1} y_k^i = y_k^i = y_{k-1}^i\in V_{k-1}^\top \mathcal {H}_y^{4k-5}.\) Then \(V_ky_k^i = V_{k-1}\Gamma _y^{k-1}y_k^i\in V_{k-1}V_{k-1}^\top \mathcal {H}_y^{4k-5} = \mathcal {H}_y^{4k-5}.\) Therefore \(U_{k-1}^\top AV_{k}y_k^i\in U_{k-1}^\top A\mathcal {H}_y^{4k-5} = U_{k-1}^\top \mathcal {H}_x^{4k-3}\) and
for \(0\le i\le j-1\). Consequently,
and
Through a similar argument, we have \((y_k^i,\tilde{y}_k^i) = (y_{k-1}^i,\tilde{y}_{k-1}^i)\). By induction, we know \((y_k^i,\tilde{y}_k^i) = (y_{k-1}^i,\tilde{y}_{k-1}^i)\) for \(i = 0,1,...,k\). Consequently, we have
By setting \(\hat{U} = U_k\) and \(\hat{V} = V_k\), we prove the result for Part I.
Part II. There exist orthogonal matrices U, V such that when \(\mathcal {A}\) is applied to the rotated instance \(F_{U,V}\), \(\{(x^0,y^0),...,(x^k,y^k)\}\subseteq U^\top \mathcal {H}_x^{4k-1}\times V^\top \mathcal {H}_y^{4k-1},\) and \((\tilde{x}^k,\tilde{y}^k)\in U^\top \mathcal {H}_x^{4k+1}\times V^\top \mathcal {H}_y^{4k+1}\).
Given the result of Part I, and let \(\{(x_k^0, y_k^0),...,(x_k^k, y_k^k)\}\) and \((\tilde{x}_k^k, \tilde{y}_k^k)\) be generated by \(\mathcal {A}\) when applied to \(F_{\hat{U},\hat{V}} = F_{U_k,V_k}\). Therefore, by Lemma C.1, there exist orthogonal matrices P, Q such that
Define \(U = U_kP\), and \(V = V_kQ\). Let \(\{(x^0,y^0),...,(x^k,y^k)\}\) and the output \((\tilde{x}^k,\tilde{y}^k)\) be generated by \(\mathcal {A}\) when applied to \(F_{{U,V}}\). Then following the same line of argument of Case k, Part I, we have
Therefore, combining (49), we complete the proof of Part II. \(\square \)
Proof of lemma 4.2
For the ease of analysis, let us perform a change of variable \(r:=(1-q)^{-1}\). Then the quartic equation (26) can be transformed to
Although the quartic equation does have a root formula, it is impractical to use the formula for the purpose of lower iteration complexity bound. Instead, we will provide an estimation of a large enough lower bound of r, which corresponds to lower bound on q.
First, we let \(\bar{r} = \frac{1}{2}+\sqrt{\frac{\alpha }{\beta } + \frac{1}{4}}\). Then \(f(\bar{r}) = 1>0.\)
Second, we let \(\underline{r} = \frac{1}{2}+\sqrt{\frac{\alpha }{2\beta } + \frac{1}{4}}\). Then,
Together with the fact that \(f(\bar{r}) = 1>0\), by continuity we know there is a root r between \(\left( \underline{r}, \bar{r}\right) \), where
and
This further implies
which proves this lemma.
Proof of lemma 4.3
First, by setting \(\nabla \Phi (x^*) = 0\), we get
Note that matrix A is invertible, with

Therefore, by the interchangability of \(A(B_yA^2+\mu _yI) = (B_yA^2+\mu _yI)A\), we can take the inverse and get \((B_yA^2+\mu _yI)^{-1}A^{-1} = A^{-1}(B_yA^2+\mu _yI)^{-1}\). Left multiply by A and right multiply by A for both sides we get the interchangablity of
Applying this on equation (51) and multiplying both sides by \(\frac{1}{B_xB_y}(B_yA^2 + \mu _yI)\), we can equivalently write the optimality condition as
where
The values of matrices \(A^2\) and \(A^4\) can be found in (13). For the ease of discussion, we may also write equation (52) in an expanded form as:
Because \(q\in (0,1)\) is a root to the quartic equation \(1 -(4+\alpha )q + (6+2\alpha + \beta )q^2 - (4+\alpha )q^3 + q^4 = 0\), and our approximate solution \(\hat{x}^*\) is constructed as \(\hat{x}^*_i = q^i\). By direct calculation one can check that the first \(n-2\) equations are satisfied and the last 2 equations are violated with controllably residuals. Indeed, for the \((n-1)\)-th equation the violation is of the order \(q^{n+1}\), and for the n-th equation the violation is of the order \(|-q^{n} + (4+\alpha )q^{n+1} - q^{n+2}|\). Similar to the arguments for (18), we have
That is, \(\Vert \hat{x}^*-x^*\Vert \le \frac{7+\alpha }{\beta }\cdot q^n\), which completes the proof.
Proof of lemma 4.4
By the subspace characterization (32), we have
When we set \(k\le \frac{n}{2}\) and \(n\ge 2\log _q\left( \frac{\beta }{4\sqrt{2}(7+\alpha )}\right) +2\), by (31) we also have
Therefore, similar to (41), we also have
which proves the lemma.
Proof of \(\ln (2ac^2) = \Omega (1)\)
Proof
Note that \(a = \min \{c^{-2},d^{-2}\}\), if \(c^{-2}\le d^{-2}\), then \(ac^2 = 1\). Consequently,
However, when \(c^{-2}\ge d^{-2}\), the situation is more complicated. In this case,
where \(\hat{x}^*\) and \(\hat{y}^*\) is the solution to the unscaled worst-case instance \(\hat{F}_\epsilon \in \mathcal {F}(L_x,L_y,L_{xy},\mu _x,\mu _y)\). For the ease of discussion, let us take the dimension n is sufficiently large so that we can view the approximate solution constructed in Lemma 4.3 as the exact solution. Therefore, we have
where q is defined by Theorem 4.5 and the second equality is due to the first-order stationary condition. Note that equation (51) also provides that
Combining the above two relations, we have
Substituting the specific forms of A and \(A^{-1}\), we have
Therefore, we have
For ease of discussion, the following simplifications are made. First, we omit the \(q^{2n}\) term since \(q<1\) and n is sufficiently large. Second, note that Lemma 4.2 indicates that \(1-q = \Theta (\epsilon )\), the term \(\frac{2B_x}{L_{xy}} (1-q) = {\mathcal {O}}(\epsilon )\) and the term \(\frac{128\epsilon }{L_{xy}R_x^2(1-q)} = \Omega (1)\). Thus we also omit the \(\frac{2B_x}{L_{xy}} (1-q)\) term which is significantly smaller. Therefore, we can write
As a result,
In Lemma 4.2, we also have a lower bound of \(1-q\) as
where (i) is because we have omitted the terms of smaller magnitude. Therefore,
Thus we complete the proof. \(\square \)
Rights and permissions
About this article

Cite this article
Zhang, J., Hong, M. & Zhang, S. On lower iteration complexity bounds for the convex concave saddle point problems. Math. Program. 194, 901–935 (2022). https://doi.org/10.1007/s10107-021-01660-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10107-021-01660-z