
Abstract
Traditional stochastic programs assume that the probability distribution of uncertainty is known. However, in practice, the probability distribution oftentimes is not known or cannot be accurately approximated. One way to address such distributional ambiguity is to work with distributionally robust convex stochastic programs (DRSPs), which minimize the worst-case expected cost with respect to a set of probability distributions. In this paper we analyze the case where there is a finite number of possible scenarios and study the question of how to identify the critical scenarios resulting from solving a DRSP. We illustrate that not all, but only some scenarios might have “effect” on the optimal value, and we formally define this notion for our general class of problems. In particular, we examine problems where the distributional ambiguity is modeled by the so-called total variation distance. We propose easy-to-check conditions to identify effective and ineffective scenarios for that class of problems. Computational results show that identifying effective scenarios provides useful insight on the underlying uncertainties of the problem.



Similar content being viewed by others
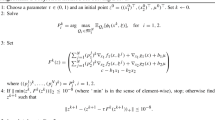

Notes
Observe that by the triangle inequality, \(\text {V}(\mathbf {p},\mathbf {q};\mathcal {F}) \ge \frac{1}{2}|\sum _{\omega \in {\mathcal {F}}^{\mathsf {c}}} (p_{\omega } - q_{\omega })|\). Because the second constraint in (10) dictates \(\sum _{\omega \in {\mathcal {F}}^{\mathsf {c}}}p_{\omega }=1\), we have \(\text {V}(\mathbf {p},\mathbf {q};\mathcal {F}) \ge \frac{1}{2}\mathbb {Q}(\mathcal {F})\). When \(0<\gamma <\mathbb {Q}(\mathcal {F})\), we have \(\gamma -\frac{1}{2}\mathbb {Q}(\mathcal {F})< \frac{1}{2}\mathbb {Q}(\mathcal {F})\), resulting in an infeasibility in (10).
References
Acerbi, C.: Spectral measures of risk: a coherent representation of subjective risk aversion. J. Bank. Financ. 26(7), 1505–1518 (2002)
Analui, B., Pflug, G.C.: On distributionally robust multiperiod stochastic optimization. Comput. Manag. Sci. 11(3), 197–220 (2014)
Artzner, P., Delbaen, F., Eber, J.M., Heath, D.: Coherent measures of risk. Math. Financ. 9(3), 203–228 (1999)
Bayraksan, G., Love, D.K.: Data-driven stochastic programming using phi-divergences. In: Tutorials in Operations Research, INFORMS, pp. 1–19 (2015)
Ben-Tal, A., den Hertog, D., De Waegenaere, A., Melenberg, B., Rennen, G.: Robust solutions of optimization problems affected by uncertain probabilities. Manag. Sci. 59(2), 341–357 (2013)
Bonnans, J.F., Shapiro, A.: Perturbation Analysis of Optimization Problems. Springer, Berlin (2013)
Boyd, S., Vandenberghe, L.: Convex Optimization. Cambridge University Press, Cambridge (2004)
Calafiore, G.: Ambiguous risk measures and optimal robust portfolios. SIAM J. Optim. 18(3), 853–877 (2007)
Calafiore, G., Campi, M.C.: Uncertain convex programs: randomized solutions and confidence levels. Math. Program. 102(1), 25–46 (2005)
Campi, M.C., Garatti, S.: The exact feasibility of randomized solutions of uncertain convex programs. SIAM J. Optim. 19(3), 1211–1230 (2008)
Carè, A., Garatti, S., Campi, M.C.: Scenario min–max optimization and the risk of empirical costs. SIAM J. Optim. 25(4), 2061–2080 (2015)
Delage, E., Ye, Y.: Distributionally robust optimization under moment uncertainty with application to data-driven problems. Oper. Res. 58(3), 595–612 (2010)
Erdoğan, E., Iyengar, G.: Ambiguous chance constrained problems and robust optimization. Math. Program. 107(1–2), 37–61 (2006)
Esfahani, P.M., Kuhn, D.: Data-driven distributionally robust optimization using the Wasserstein metric: performance guarantees and tractable reformulations. Math Program. (2017). https://doi.org/10.1007/s10107-017-1172-1
Gao, R., Kleywegt, A.J.: Distributionally robust stochastic optimization with Wasserstein distance (2016). arXiv:160402199v2 [mathOC]
Hanasusanto, G.A., Kuhn, D., Wallace, S.W., Zymler, S.: Distributionally robust multi-item newsvendor problems with multimodal demand distributions. Math. Program. 152(1), 1–32 (2014)
Hanasusanto, G.A., Roitch, V., Kuhn, D., Wiesemann, W.: A distributionally robust perspective on uncertainty quantification and chance constrained programming. Math. Program. 151(1), 35–62 (2015)
Higle, J., Sen, S.: Stochastic Decomposition: A Statistical Method for Large Scale Stochastic Linear Programming. Kluwer Academic Publishers, Dordrecht (1996)
Hiriart-Urruty, J.B., Lemaréchal, C.: Fundamentals of Convex Analysis. Springer, Berlin (2001)
Hu, Z., Hong, L.J.: Kullback–Leibler divergence constrained distributionally robust optimization. Optimization Online (2012). http://www.optimization-online.org/DB_HTML/2012/11/3677.html
Hu, Z., Hong, L.J., So, A.M.C.: Ambiguous probabilistic programs. Optimization Online (2013). http://www.optimization-online.org/DB_HTML/2013/09/4039.html
Infanger, G.: Monte Carlo (importance) sampling within a Benders decomposition algorithm for stochastic linear programs. Ann. Oper. Res. 39(1), 69–95 (1992)
Jiang, R.: Data-driven stochastic optimization: integrating reliability with cost effectiveness. Ph.D. dissertation, University of Florida, Gainesville (2013)
Jiang, R., Guan, Y.: Data-driven chance constrained stochastic program. Math. Program. 158(1), 1–37 (2015a)
Jiang, R., Guan, Y.: Risk-averse two-stage stochastic program with distributional ambiguity. Optimization Online (2015). http://www.optimization-online.org/DB_HTML/2015/05/4908.html
Klabjan, D., Simchi-Levi, D., Song, M.: Robust stochastic lot-sizing by means of histograms. Prod. Oper. Manag. 22(3), 691–710 (2013)
Love, D.K.: Data-driven methods for optimization under uncertainty with application to water allocation. Ph.D. dissertation, University of Arizona, Tucson (2013)
Love, D.K., Bayraksan, G.: Phi-divergence constrained ambiguous stochastic programs for data-driven optimization. Optimization Online (2015). http://www.optimization-online.org/DB_HTML/2016/03/5350.html
Luo, F., Mehrotra, S.: Decomposition algorithm for distributionally robust optimization using Wasserstein metric (2017). arXiv:170403920 [mathOC]
Mehrotra, S., Zhang, H.: Models and algorithms for distributionally robust least squares problems. Math. Program. 146(1–2), 123–141 (2014)
Pflug, G.C., Pichler, A.: The problem of ambiguity in stochastic optimization. In: Mikosch, T.V., Resnick, S.I., Robinson, S.M. (eds.) Multistage Stochastic Optimization, pp. 229–255. Springer (2014)
Pflug, G.C., Wozabal, D.: Ambiguity in portfolio selection. Quant. Financ. 7(4), 435–442 (2007)
Rahimian, H., Bayraksan, G., Homem-de Mello, T.: Distributionally robust newsvendor problems with variation distance. Optimization Online (2017). http://www.optimization-online.org/DB_HTML/2017/03/5936.html
Rockafellar, R.T., Uryasev, S.: Conditional value-at-risk for general loss distributions. J. Bank. Financ. 26(7), 1443–1471 (2002)
Römisch, W.: Stability of stochastic programming problems. In: Ruszczyński, A., Shapiro, A. (eds.) Stochastic Programming, Handbooks in Operations Research and Management Science, vol. 10, pp. 483–554. Elsevier, Amsterdam (2003)
Rossi, M.E., Deutsch, C.V.: Mineral Resource Estimation. Springer, Berlin (2014)
Ruszczynski, A., Shapiro, A.: Optimization of convex risk functions. Math. Oper. Res. 31(3), 433–452 (2006)
Scarf, H.: A min–max solution of an inventory problem. In: Scarf, H., Arrow, K., Karlin, S. (eds.) Studies in the Mathematical Theory of Inventory and Production, vol. 10, pp. 201–209. Stanford University Press, Stanford (1958)
Shapiro, A.: Rectangular sets of probability measures. Oper. Res. 64(2), 528–541 (2016)
Shapiro, A.: Distributionally robust stochastic programming. SIAM J. Optim. 27(4), 2258–2275 (2017)
Shapiro, A., Tekaya, W., Soares, M.P., da Costa, J.P.: Worst-case-expectation approach to optimization under uncertainty. Oper. Res. 61(6), 1435–1449 (2013)
Shapiro, A., Dentcheva, D., Ruszczyński, A.: Lectures on Stochastic Programming: Modeling and Theory. MPS-SIAM Series on Optimization, 2nd edn. Society for Industrial and Applied Mathematics, Philadelphia (2014)
Wang, Z., Glynn, P.W., Ye, Y.: Likelihood robust optimization for data-driven problems. Comput. Manag. Sci. 13(2), 241–261 (2016)
Wiesemann, W., Kuhn, D., Sim, M.: Distributionally robust convex optimization. Oper. Res. 62(6), 1358–1376 (2014)
Wozabal, D.: A framework for optimization under ambiguity. Ann. Oper. Res. 193(1), 21–47 (2012)
Xin, L., Goldberg, DA., Shapiro, A.: Time (in)consistency of multistage distributionally robust inventory models with moment constraints (2013). arXiv:13043074 [mathOC]
Zhang, W., Rahimian, H., Bayraksan, G.: Decomposition algorithms for risk-averse multistage stochastic programs with application to water allocation under uncertainty. INFORMS J. Comput. 28(3), 385–404 (2016)
Zhao, C., Guan, Y.: Data-driven risk-averse two-stage stochastic program with \(\zeta \)-structure probability metrics. Optimization Online (2015). http://www.optimization-online.org/DB_HTML/2015/07/5014.html
Acknowledgements
This work has been partially supported by the National Science Foundation through Grants CMMI-1345626 and CMMI-1563504 of the second author and CONICYT PIA Anillo ACT1407 (Chile) of the third author.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendix
Appendix
In Sect. A.1, we provide the results and proofs that were relegated to the Appendix. Then, in Sect. A.2, we propose a decomposition method to solve (DRSP-V).
1.1 A-1 Proofs
In this section, we first provide the proof of Proposition 4. Then, in Sect. A.1.2, we present Proposition A-1. In Sect. A.1.3, we state Lemma A-1, used in the proof of Proposition 5. In Sect. A.1.4, we provide Lemma A-2, used in the proof of Proposition 7. Finally, in Sect. A.1.5, we preset Lemmas A-3 and A-4, which are used in the proof of Theorem 5.
1.1.1 A-1.1 Proof of Proposition 4
Proof of Proposition 4
For a fixed \(x \in \mathbb {X}\), the worst-case expected problem can be written as follows
where \(u^{\prime }_{\omega }\), \(u^{\prime \prime }_{\omega }\), \(\lambda (x) \), and \(\mu (x)\) are the associated dual variables for the constraints. Define now
We consider two cases (i) \(\mathrm {VaR}_{\gamma } \left[ \mathbf {h}(x) \right] <\sup _{\omega \in \varOmega } h_{\omega }(x)\) and (ii) \(\mathrm {VaR}_{\gamma } \left[ \mathbf {h}(x) \right] =\sup _{\omega \in \varOmega } h_{\omega }(x)\). In case (i), we have \(\lambda (x)>0\). Then,
together with \(\sum _{\omega \in \varOmega } p_\omega =1\), is primal-dual feasible. For the complementary slackness condition to hold, (A-1d) must hold with equality at an optimal \((\mathbf {p}, \mathbf {e}, \mu (x), \lambda (x), \mathbf {u}^{\prime }, \mathbf {u}^{\prime \prime })\) when \(\lambda (x)>0\). Indeed, we have
where the last equality follows from (8). Now, by substituting (8) in (A-2) we obtain (7).
On the other hand, in case (ii), we have \(\lambda (x)=0\), \(\varOmega _{3}(x)=\emptyset \) and \(\varOmega _{2}(x)=\varOmega _{4}(x)\). Then, all \(u^{\prime }_{\omega }\)s and \(u^{\prime \prime }_{\omega }\)s are zero, and we have \(\mu (x)=\sup _{\omega \in \varOmega } h_{\omega }(x)\). In this case, if \(h_\omega (x) = \sup _{\omega \in \varOmega } h_{\omega }(x)\), we have \(e_\omega =|p_\omega -q_\omega |\) and \(p_\omega \ge 0\) is chosen so that it satisfies \(\sum _{\omega \in \varOmega } p_{\omega }=1\) and \(\frac{1}{2}\sum _{\omega \in \varOmega } e_{\omega } \le \gamma \). Otherwise, \(p_\omega = 0\). \(\square \)
1.1.2 A-1.2 Proposition A-1
Proposition A-1 shows the equivalence of the ambiguity sets induced by the right- and left-sided variation distances.
Proposition A-1
The ambiguity sets induced by the right- and left-sided variation distances are the same.
Proof of Proposition A-1
Let \(\mathcal {P}^{\text {V}^{\text {R}}}_{\gamma }\) and \(\mathcal {P}^{\text {V}^{\text {L}}}_{\gamma }\) denote the ambiguity set induced by the right- and left-sided variation distances, respectively. Recall \(\text {V}^{\text {R}}(\mathbf {p},\mathbf {q})= \frac{1}{2}\sum _{\omega \in \varOmega } (p_{\omega }-q_{\omega })_{+}\) and \(\text {V}^{\text {L}}(\mathbf {p},\mathbf {q})= \frac{1}{2}\sum _{\omega \in \varOmega } (q_{\omega }-p_{\omega })_{+}\). Now, if we show \(\text {V}^{\text {R}}(\mathbf {p},\mathbf {q})\) and \(\text {V}^{\text {L}}(\mathbf {p},\mathbf {q})\) are equal, it would show the equivalence of \(\mathcal {P}^{\text {V}^{\text {R}}}_{\gamma }\) and \(\mathcal {P}^{\text {V}^{\text {L}}}_{\gamma }\). Let \(M:=\{\omega \in \varOmega \,:\, p_{\omega } \ge q_{\omega } \}\). So, we can write \(\text {V}^{\text {R}}(\mathbf {p},\mathbf {q})=\frac{1}{2}\sum _{\omega \in M} (p_{\omega }-q_{\omega })=\frac{1}{2}\sum _{\omega \in {M}^{\mathsf {c}}} (q_{\omega }-p_{\omega })= \text {V}^{\text {L}}(\mathbf {p},\mathbf {q})\) by using the facts that \(\sum _{\omega \in \varOmega } p_{\omega }=1\) and \(\sum _{\omega \in \varOmega } q_{\omega }=1\). \(\square \)
1.1.3 A-1.3 Lemma A-1
In this section, we state Lemma A-1, which is used in the proof of Proposition 5. The proof of this lemma is presented in the Online Supplement.
Lemma A-1
Consider a fixed \(x \in \mathbb {X}\) and level \(\beta \in [0,1)\). Then, \(\mathrm {CVaR}_{\beta } \left[ \mathbf {h}(x) \right] =\max _{\mathbf {z}\in \mathfrak {A}_{\beta }} \sum _{\omega \in \varOmega } z_{\omega }h_{\omega }(x)\), where
Moreover, the set of all optimal solutions \(\mathbf {z}\) is given by
1.1.4 A-1.4 Lemma A-2
In this section, we present Lemma A-2, which is used in the proof of Proposition 7.
Lemma A-2
Consider a scenario \(\omega ^{\prime }\) with \(q_{\omega ^{\prime }}>0\). If \(h_{\omega ^{\prime }}(x^{*}) > \mathrm {VaR}_{\gamma } \left[ \mathbf {h}(x^{*}) \right] \), then scenario \(\omega ^{\prime }\) is effective for (DRSP-V).
Proof of Lemma A-2
Suppose \(\bar{x}\) solves the assessment problem of \(\mathcal {F}=\{\omega ^{\prime }\}\) with \(q_{\omega ^{\prime }}>0\). By (3), we have \(f^\text {A}_{\gamma }(\bar{x};\mathcal {F}) \le f^\text {A}_{\gamma }(x^{*};\mathcal {F}) \le f_{\gamma }(x^{*})\). Consequently, \(f_{\gamma }(x^{*})-f^\text {A}_{\gamma }(x^{*};\mathcal {F})\) gives a lower bound on \(f_{\gamma }(x^{*})- f^\text {A}_{\gamma }(\bar{x};\mathcal {F})\). If this lower bound is positive, then scenario \(\omega ^{\prime }\) is effective. To check this lower bound, let us consider the objective function of the dual problem of (A-1a) (presented in the proof of Proposition 3 in the Online Supplement) and (13), both evaluated at \(x^{*}\). Note that \((\mu ^{*}, \lambda ^{*})\) belongs to the feasible region of (13) because \(\mu ^{*}+\frac{\lambda ^{*}}{2}= \sup _{\omega \in \varOmega } h_{\omega }(x^{*}) \ge \sup _{\omega \in {\mathcal {F}}^{\mathsf {c}}} h_{\omega }(x^{*})\) and \(\lambda ^{*} \ge 0\). Thus, we have
where the last equality follows from the fact \(\mu ^{*}-\frac{\lambda ^{*}}{2}=\mathrm {VaR}_{\gamma } \left[ \mathbf {h}(x^{*}) \right] \) by (5). Now, dividing by \(q_{\omega ^{\prime }}\) shows that the lower bound is positive if \(h_{\omega ^{\prime }}(x^{*}) > \mathrm {VaR}_{\gamma } \left[ \mathbf {h}(x^{*}) \right] \). \(\square \)
1.1.5 A-1.5 Lemmas used in the Proof of Theorem 5
For the following two lemmas, we consider a fixed \(x \in X\). Also, we suppose \(\mathbf {p}\) solves the worst-case expected problem in (DRSP-V) at x, and \((\mu , \lambda )\) are the optimal dual variables at x, given by (5).
Lemma A-3
For a fixed \(x \in \mathbb {X}\), suppose \(\lambda =0\) and there is a scenario \(\omega ^{\prime } \in \varOmega _{4}(x)\) with \(p_{\omega ^{\prime }}=0\). Then, \(\varOmega _{4}(x)\) is not a singleton set, and for a scenario \(\omega ^{\prime \prime } \in \varOmega _{4}(x)\) with \(p_{\omega ^{\prime \prime }}>0\), there is always \(\epsilon >0\) such that \(\mathbf {p}^{\prime }\), with \(p^{\prime }_{\omega ^{\prime }}=p_{\omega ^{\prime }}+\epsilon \), \(p^{\prime }_{\omega ^{\prime \prime }}=p_{\omega ^{\prime \prime }}-\epsilon \), and \(p^{\prime }_{\omega }=p_{\omega }\), \(\omega \notin \{ \omega ^{\prime }, \omega ^{\prime \prime }\}\), is feasible to the worst-case expected problem at x.
Proof of Lemma A-3
Note that \(\varOmega _{4}(x)\) is not a singleton set by Corollary 3. To show the existence of another feasible solution \(\mathbf {p}^{\prime }\), we first examine the left-hand side of the distance constraint \(\frac{1}{2} \sum _{\omega \in \varOmega } |p_{\omega }-q_{\omega }|\le \gamma \) in (4). Then, we find \(\epsilon >0\) such that the change in the left-hand side of the distance constraint in (4) is smaller than or equal to zero; hence, \(\mathbf {p}^{\prime }\) is feasible to the worst-case expected problem at x. We consider two cases.
-
Case 1.
\(q_{\omega ^{\prime }}=0\). Let us consider two further cases.
-
Case 1.1.
There is a scenario \(\omega ^{\prime \prime } \in \varOmega _{4}(x)\) with \(p_{\omega ^{\prime \prime }}>q_{\omega ^{\prime \prime }}\). By choosing \(\epsilon \le p_{\omega ^{\prime \prime }}-q_{\omega ^{\prime \prime }}\) for \(\mathbf {p}^{\prime }\), the change in the left-hand side of the distance constraint is zero.
-
Case 1.2.
For all \(\omega ^{\prime \prime } \in \varOmega _{4}(x)\), we have \(p_{\omega ^{\prime \prime }} \le q_{\omega ^{\prime \prime }}\). Then, set \({\varOmega }^{\mathsf {c}}_{4}(x)\) is either empty or there is no scenario \(\omega \in {\varOmega }^{\mathsf {c}}_{4}(x)\) with \(q_{\omega }>0\). Otherwise, \(\sum _{\omega \in \varOmega } p_\omega \le \sum _{\omega \in \varOmega _{4}(x)} q_\omega <1\). Moreover, we must have \(p_{\omega ^{\prime \prime }} = q_{\omega ^{\prime \prime }}\) for all \(\omega ^{\prime \prime } \in \varOmega _{4}(x)\). Otherwise, \(\sum _{\omega \in \varOmega } p_\omega < \sum _{\omega \in \varOmega _{4}(x)} q_\omega =1\). Consequently, the left-hand side of the distance constraint for \(\mathbf {p}\) is zero. Because for \(\mathbf {p}^{\prime }\) the change in the left-hand side of the distance constraint is \(\epsilon \), we choose \(\epsilon \le \gamma \).
-
Case 1.1.
-
Case 2.
\(q_{\omega ^{\prime }}>0\). Then, there is a scenario \(\omega ^{\prime \prime } \in \varOmega _{4}(x)\) with \(p_{\omega ^{\prime \prime }}>q_{\omega ^{\prime \prime }}\). Otherwise, \(\sum _{\omega \in \varOmega } p_\omega \le \sum _{\begin{array}{c} \omega \in \varOmega _{4}(x) \\ \omega \ne \omega ^{\prime } \end{array}} q_{\omega } <1\). By choosing \(\epsilon \le \min \{q_{\omega ^{\prime }}, p_{\omega ^{\prime \prime }}-q_{\omega ^{\prime \prime }}\}\) for \(\mathbf {p}^{\prime }\), the change in the left-hand side of the distance constraint is \(-\epsilon \). \(\square \)
Lemma A-4
For a fixed \(x \in \mathbb {X}\), suppose \(\lambda =0\) and there is a scenario \(\omega ^{\prime } \in \varOmega _{4}(x)\) with \(p_{\omega ^{\prime }}>0\). Moreover, suppose there is a scenario \(\omega ^{\prime } \ne \omega ^{\prime \prime } \in \varOmega _{4}(x)\). Then, there is always \(\epsilon >0\) such that either \(\mathbf {p}^{\prime }\) or \(\mathbf {p}^{\prime \prime }\) is feasible to the worst-case expected problem at x, where \(\mathbf {p}^{\prime }\) is defined as \(p^{\prime }_{\omega ^{\prime }}=p_{\omega ^{\prime }}+\epsilon \), \(p^{\prime }_{\omega ^{\prime \prime }}=p_{\omega ^{\prime \prime }}-\epsilon \), and \(p^{\prime }_{\omega }=p_{\omega }\), \(\omega \notin \{ \omega ^{\prime }, \omega ^{\prime \prime }\}\), and \(\mathbf {p}^{\prime \prime }\) is defined as \(p^{\prime \prime }_{\omega ^{\prime }}=p_{\omega ^{\prime }}-\epsilon \), \(p^{\prime \prime }_{\omega ^{\prime \prime }}=p_{\omega ^{\prime \prime }}+\epsilon \), and \(p^{\prime \prime }_{\omega }=p_{\omega }\), \(\omega \notin \{ \omega ^{\prime }, \omega ^{\prime \prime }\}\).
Proof of Lemma A-4
Similar to Lemma A-3, we examine the left-hand side of the distance constraint and find \(\epsilon >0\) such that \(\mathbf {p}^{\prime }\) or \(\mathbf {p}^{\prime \prime }\) is feasible to the worst-case expected problem at x. We consider two cases.
-
Case 1.
\(p_{\omega ^{\prime }} \ge q_{\omega ^{\prime }}\). Let us consider two further cases.
-
Case 1.1.
There is a scenario \(\omega ^{\prime \prime } \in \varOmega _{4}(x)\) with \(p_{\omega ^{\prime \prime }} \ge q_{\omega ^{\prime \prime }}\). By choosing \(\epsilon \le p_{\omega ^{\prime \prime }}-q_{\omega ^{\prime \prime }}\) for \(\mathbf {p}^{\prime }\) or \(\epsilon \le p_{\omega ^{\prime }}-q_{\omega ^{\prime }}\) for \(\mathbf {p}^{\prime \prime }\), the change in the left-hand side of the distance constraint is zero.
-
Case 1.2.
For all \(\omega ^{\prime } \ne \omega ^{\prime \prime } \in \varOmega _{4}(x)\), we have \(p_{\omega ^{\prime \prime }} < q_{\omega ^{\prime \prime }}\). By choosing \(\epsilon \le \min \{p_{\omega ^{\prime }}-q_{\omega ^{\prime }}, q_{\omega ^{\prime \prime }}-p_{\omega ^{\prime \prime }}\}\) for \(\mathbf {p}^{\prime \prime }\), the change in the left-hand side of the distance constraint is \(-\epsilon \).
-
Case 1.1.
-
Case 2.
\(p_{\omega ^{\prime }}<q_{\omega ^{\prime }}\). Then, there is a scenario \(\omega ^{\prime \prime } \in \varOmega _{4}(x)\) with \(p_{\omega ^{\prime \prime }}>q_{\omega ^{\prime \prime }}\). Otherwise, \(\sum _{\omega \in \varOmega } p_\omega < \sum _{\omega \in \varOmega _{4}(x)} q_{\omega } \le 1\). By choosing \(\epsilon \le \min \{p_{\omega ^{\prime \prime }}-q_{\omega ^{\prime \prime }}, q_{\omega ^{\prime }}-p_{\omega ^{\prime }}\}\) for \(\mathbf {p}^{\prime }\), the change in the left-hand side of the distance constraint is \(-\epsilon \). \(\square \)
1.2 A-2 Primal decomposition
As the number of scenarios increases, solving (DRSP-V) becomes computationally expensive. Decomposition-based methods could significantly reduce the solution time and allow larger problems to be solved efficiently. In the following, we propose a cutting-plane approach, referred to as Primal Decomposition, to solve (DRSP-V) and obtain an optimal solution \(x^{*}\) and an optimal worst-case probability distribution \(\mathbf {p}^{*}\).
Let us consider, \(\mathcal {P}_{\gamma }\), the ambiguity set induced by the total variation distance. Let \(\{\mathbf {p}^k\}_{k \in K}\) denote the set of extreme points of the polytope \(\mathcal {P}_{\gamma }\). Then, (DRSP-V) can be written equivalently as
One can solve this problem using a cut generation approach. That is, the restricted master problem is solved with a smaller subset of constraints (A-5) in order to get \((\hat{x}, \hat{\theta })\). Then, the worst-case expected problem is solved at \(\hat{x}\) to obtain optimal value \(f_{\gamma }(\hat{x})\). If \(\hat{\theta } < f_{\gamma }(\hat{x})\), then the optimality cut (A-5)—corresponding to the extreme point \(\mathbf {p}^k\), \(k \in K\), that solves the worst-case expected problem at \(\hat{x}\)—is added to the restricted master problem. The Primal Decomposition approach to obtain \(x^{*}\) and \(\mathbf {p}^{*}\) is presented in Algorithm A-1.

Since the restricted master problem is a relaxation of (DRSP-V), \( \hat{\theta }\) provides a lower bound on the optimal value of (DRSP-V). Moreover, since \(\hat{x} \in \mathbb {X}\), \( f_{\gamma }(\hat{x})\) gives an upper bound on the optimal value of (DRSP-V). The algorithm continues until \(\hat{\theta }=f_{\gamma }(\hat{x})\), where \(\hat{x}\) and the extreme point that solves the worst-case expected problem at \(\hat{x}\) are an optimal \(x^{*}\) and \(\mathbf {p}^{*}\), respectively. Because the polytope \(\mathcal {P}_{\gamma }\) has finitely many extreme points, finitely many optimality cuts (A-5) are added before \(x^{*}\) and \(\mathbf {p}^{*}\) are obtained. In other words, the Primal Decomposition algorithm converges in a finite number of iterations. However, at each iteration a convex optimization problem is solved. For algorithms to solve these problems, we refer interested readers to [7] and references therein. In the particular case of SLP-2, one can apply a decomposition-based method to obtain an outer approximation to \(h_\omega (x)\). In fact, this is what we use in our numerical illustration in Sect. 5.
Algorithm A-1 decomposes primal formulation of (DRSP-V) and obtain \(x^{*}\) and \(\mathbf {p}^{*}\) concurrently and directly. Because the Primal Decomposition exploits the polyhedral structure of the ambiguity set formed using the total variation distance, it might have computational benefits over those decomposition methods that solve the dual formulation. A comprehensive computational study will provide more insight on the performance of these algorithms; however, such a study is out of the scope of this paper.
Rights and permissions
About this article

Cite this article
Rahimian, H., Bayraksan, G. & Homem-de-Mello, T. Identifying effective scenarios in distributionally robust stochastic programs with total variation distance. Math. Program. 173, 393–430 (2019). https://doi.org/10.1007/s10107-017-1224-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10107-017-1224-6