
Abstract
In the framework of data envelopment analysis (DEA), Tone (Eur J Oper Res 130(3):498–509, 2001) introduced the slacks-based measure (SBM) of efficiency, which is a nonradial model that incorporates all the slacks of the evaluated decision-making units (DMUs) into their efficiency scores, unlike classical radial efficiency models. Next, Tone (Eur J Oper Res 143(1):32–41, 2002) developed the SBM super-efficiency model in order to differentiate and rank efficient DMUs, whose SBM efficiency scores are always 1. However, as pointed out by Chen (Eur J Oper Res 226(2):258–267, 2013), some interpretation problems arise when the so-called super-efficiency projections are weakly efficient, leading to an overestimation of the SBM super-efficiency score. Moreover, this overestimation is closely related to discontinuity issues when implementing SBM super-efficiency in conjunction with SBM efficiency. Chen (Eur J Oper Res 226(2):258–267, 2013) and Chen et al. (Ann Oper Res 278(1):101–121, 2019) treated these problems, but they did not arrive to a fully satisfactory solution. In this paper, we review these papers and propose a new complementary score, called composite SBM, that actually fixes the discontinuity problems by counteracting the overestimation of the SBM super-efficiency score. Moreover, we extend the composite SBM model to different orientations and variable returns to scale, and propose additive versions. Finally, we give examples and state some open problems.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Data envelopment analysis (DEA) is a well known nonparametric mathematical programming technique, developed by Charnes et al. (1978) based on a previous work of Farrell (1957), which allows us to assess the relative efficiency of a homogeneous set of decision-making units (DMUs) which consume several inputs in order to produce a number of outputs. In the last two decades, there have been remarkable advances in both DEA methodologies and practical applications in a wide range of fields. Although there are several bibliographic reviews available (see, for instance, Seiford (1997), Tavares (2002), Emrouznejad et al. (2008), Cook and Seiford (2009)), the recent bibliographic compilation by Emrouznejad and Yang (2018), providing a full listing of more than 10000 DEA-related articles ranging from 1978 to late 2016, is noteworthy.
Roughly speaking, from the observed inputs and outputs and assuming no functional relationship between them, a DEA model estimates a best-practice frontier, also known as efficient frontier, with respect to which all DMUs are evaluated. In the original CCR (Charnes et al. 1978) and BCC (Banker et al. 1984) DEA radial models, the inputs are proportionally reduced while maintaining the outputs unchanged or the outputs are proportionally expanded keeping constant the inputs, depending on the orientation of the model. Shortly after, the additive model was introduced by Charnes et al. (1982) (see also Charnes et al. (1985)). This model could handle both input excesses and output shortfalls simultaneously, but it could not deliver an efficiency score as the ones obtained by the CCR and BCC radial models. To address this shortcoming, Pastor et al. (1999) and Tone (2001) proposed the enhanced Russell graph measure (ERGM) and the slacks-based measure (SBM) of efficiency respectively, which are equivalent. These models incorporate all the slacks of the evaluated DMUs into their efficiency scores, unlike classical radial efficiency models.
Usually, an efficiency DEA model classifies DMUs into two groups: efficient and inefficient. Efficient DMUs always have an efficiency score equal to 1 but, are all efficient DMUs equally efficient? To discriminate between efficient DMUs and rank them, Andersen and Petersen (1993) proposed the so-called radial super-efficiency model, whose fundamental idea is to eliminate the DMU under evaluation from the reference set. Tone (2002) developed the SBM super-efficiency model which consists on projecting the DMU under evaluation onto the subset of the production possibility set dominated by the DMU, and then estimating the distance between the original DMU and its projection. However, SBM super-efficiency has overestimation problems when the aforementioned projections are weakly efficient, as pointed out by Chen (2013). Moreover, this overestimation is closely related to discontinuity issues when implementing SBM super-efficiency together with SBM efficiency (see for example Chen (2013), Fang et al. (2013), Guo et al. (2017), Chen et al. (2019)), contrary to what happens with radial models. In words of Chen (2013), this discontinuity or gap between the SBM efficiency and super-efficiency scores may lead to interpretation problems because of the sensitivity to small measurement errors or noise in the data. That is, an efficient DMU may become extremely SBM inefficient upon a small increase in inputs or a small decrease in outputs (and vice versa).
Since continuity is a very important and desirable property for DEA models (Robert Russell 1990; Scheel and Scholtes 2003), the joint SBM and the continuous SBM models were introduced by Chen (2013) and Chen et al. (2019) respectively, in order to solve the aforementioned discontinuity problems. However, although the joint SBM model was thought to be continuous at first, we show that, in fact, it is not always continuous. On the other hand, we also show that the continuous SBM model introduced by Chen et al. (2019) is not always weakly monotonic and can lead to conflicting scores in some cases. Moreover, we propose a new model, called composite SBM, that solves the discontinuity problems by counteracting the overestimation of the SBM super-efficiency score and is weakly monotonic. Nevertheless, this model presents some issues, like nonlinearity or problems related to strong monotonicity.
This paper is organized as follows. In Sect. 2 we briefly introduce some general concepts and notation. In Sect. 3 we review the original SBM efficiency and super-efficiency models. In Sect. 4 we review the models presented by Chen (2013) and Chen et al. (2019) in order to face the aforementioned discontinuity issue. In Sect. 5 we present the composite SBM model, studying its main properties and giving some programs for computing its score. In Sect. 6 we extend the study to different orientations, variable returns to scale, zero or negative data, and weights. Moreover, we propose an additive version of the composite SBM model. In Sect. 7 we give some examples showing that the interpretation and discontinuity issues are fixed by the composite SBM model. Finally, in Sect. 8 we present some concluding remarks and state some open problems. For the sake of readability, the proofs of all the results presented in this work have been placed in Appendix A at the end of the paper.
2 Preliminaries
Notation and basic concepts are taken from Cooper et al. (2007). Vectors will be denoted by lowercase bold-face letters (either roman or greek), and they will be considered as one-column matrices when necessary. The elements of a vector will be denoted by the same letter as the vector, but unbolded and with subscripts. The 0-vector will be denoted by \({\varvec{0}}\) and the context will determine its dimension. All definitions and results are within the framework of constant returns to scale. Variable returns to scale are discussed in Sect. 6.
2.1 Definitions
An activity with m inputs and s outputs is a pair of nonnegative vectors \(\left( {\mathbf {x}},{\mathbf {y}}\right) ,\) where \({\mathbf {x}}\in {\mathbb {R}}_+^m\) and \({\mathbf {y}}\in {\mathbb {R}}_+^s\) are the inputs and outputs vector respectively. In this work, we are going to suppose that all activities are strictly positive and, therefore, the set of activities is identified with \({\mathbb {R}}_{>0}^{m+s}\). Nevertheless, we discuss the possibility of zero or negative data in Sect. 6.
Given a DMU that consumes m inputs and produces s outputs, it has an associated activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) given by the inputs vector \({\mathbf {x}}=\left( x_1,\ldots x_m\right) \) and the outputs vector \({\mathbf {y}}=\left( y_1,\ldots y_s\right) \), where \(x_i\) is the amount of the ith input consumed by the DMU and \(y_r\) is the amount of the rth output produced by the DMU, \(i=1,\ldots ,m\), \(r=1,\ldots ,s\). Therefore, we can identify a DMU with its activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) in the same way that a point is identified with its coordinates. It is very important to remark that, in this work, any element of \({\mathbb {R}}_{>0}^{m+s}\) is called “activity”, regardless of whether it is associated with an existing DMU or not.
Let \({\mathscr {D}}=\left\{ \text {DMU}_1, \ldots ,\text {DMU}_n \right\} \) be a set of n DMUs, all of them having m inputs and s outputs. The corresponding inputs vectors \({\mathbf {x}}_j\), \(j=1,\ldots ,n\), can be arranged as the columns of the so-called \(m\times n\) input data matrix X. Analogously, the outputs vectors \({\mathbf {y}}_j\) conform the columns of the \(s\times n\) output data matrix Y. The production possibility set defined by \({\mathscr {D}}\) is a set of activities given by
although it is also denoted by T (of Technology) in the literature. Given two activities \(\left( {\mathbf {x}},{\mathbf {y}}\right) ,\left( {\mathbf {x}}',{\mathbf {y}}'\right) \), we say that \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is dominated by \(\left( {\mathbf {x}}',{\mathbf {y}}'\right) \) if \({\mathbf {x}}'\le {\mathbf {x}}\) and \({\mathbf {y}}'\ge {\mathbf {y}}\); in this case, we say that \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is strictly dominated by \(\left( {\mathbf {x}}',{\mathbf {y}}'\right) \) if \(\left( {\mathbf {x}}',{\mathbf {y}}'\right) \ne \left( {\mathbf {x}},{\mathbf {y}}\right) \). The relation “to be dominated by” defines a partial order over the set of activities and establishes when an activity outperforms another in the sense that consumes less inputs while producing more outputs. Moreover, the production possibility set (1) is formed by the activities that are dominated by positive combinations of DMUs of the form \(\left( X{\varvec{\lambda }},Y{\varvec{\lambda }}\right) \) with \({\varvec{\lambda }}\in {\mathbb {R}}^n_+\), and hence, it is interpreted as the set of “feasible activities” defined by \({\mathscr {D}}\) (Cooper et al. 2007).
Given a real-valued function f defined on a set of activities \({\mathscr {A}}\), we say that f is weakly monotonic at \(\left( {\mathbf {x}},{\mathbf {y}}\right) \in {\mathscr {A}}\) if for any activity \(\left( {\mathbf {x}}',{\mathbf {y}}'\right) \in {\mathscr {A}}\) such that \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is dominated by \(\left( {\mathbf {x}}',{\mathbf {y}}'\right) \), we have that \(f\left( {\mathbf {x}},{\mathbf {y}}\right) \le f\left( {\mathbf {x}}',{\mathbf {y}}'\right) \). Moreover, we say that f is strongly monotonic at \(\left( {\mathbf {x}},{\mathbf {y}}\right) \in {\mathscr {A}}\) if \(f\left( {\mathbf {x}},{\mathbf {y}}\right) < f\left( {\mathbf {x}}',{\mathbf {y}}'\right) \) when \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is strictly dominated by \(\left( {\mathbf {x}}',{\mathbf {y}}'\right) \). We say that f is weakly monotonic on \({\mathscr {A}}\) if it is weakly monotonic at each activity in \({\mathscr {A}}\), i.e. it is order-preserving. We say that f is strongly monotonic on \({\mathscr {A}}\) if it is strongly monotonic at each activity in \({\mathscr {A}}\).
We say that an activity or a DMU is efficient (with respect to a given set \({\mathscr {D}}\) of DMUs) if it is not strictly dominated by any positive combination of DMUs in \({\mathscr {D}}\); otherwise, we say that it is inefficient. This concept of “efficiency” is equivalent to the classic “Pareto-efficiency” concept and it does not depend on any efficiency model. If P is the production possibility set defined by \({\mathscr {D}}\), then any activity out of P results efficient. The set of efficient activities in P is known as the (strongly) efficient frontier (or Pareto-Koopmans frontier) of P, and we denote it by \(\partial ^{\text {S}}(P)\). It is clear that \(\partial ^{\text {S}}(P)\) is in the frontier of P, known as the weakly efficient frontier of P and denoted by \(\partial ^{\text {W}}(P)\). The inefficient activities in \(\partial ^{\text {W}}(P)\) are known as weakly efficient, although in fact they are not efficient.
2.2 Score functions and efficiency scores
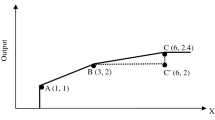
Classically, given a set of DMUs, a model is applied to one of these DMUs in order to obtain, among other things, its score (efficiency, super-efficiency, etc.). But in this work, we are going to compute scores through what we call “score functions”: given a model and a set \({\mathscr {D}}\) of DMUs (which we call reference DMUs), a score function (with respect to \({\mathscr {D}}\)) is a real-valued function defined on activities (i.e. from \({\mathbb {R}}_{>0}^{m+s}\) to \({\mathbb {R}}\)), such that the image of \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is the score that the model would assign to a new hypothetical DMU with activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \), considering \({\mathscr {D}}\cup \left\{ \left( {\mathbf {x}},{\mathbf {y}}\right) \right\} \) as the set of DMUs (see Fig. 1). There are a wide variety of models and hence, of score functions, but all of them must be at least weakly monotonic and satisfy some continuity properties, because similar activities must obtain similar scores in order to avoid sensitivity problems. Precisely, the main advantage of this methodology is that results about continuity, differentiability and monotonicity can be directly applied to score functions.

a) Classically, a model is applied to a DMU (called \(\hbox {DMU}_o\)) in a given set of DMUs in order to obtain its score. b) Given a model and a set of reference DMUs, we construct a score function defined on activities. The image of an activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is the score that the model would assign to a new hypothetical DMU with activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \)
Efficiency measures (also called inefficiency measures) are the core of the DEA methodology. Restricted to inefficient activities, continuity is a property that any efficiency measure should satisfy, because discontinuities can produce serious interpretation problems (Robert Russell 1990; Scheel and Scholtes 2003). Moreover, monotonicity is also an important property that should be required. In this aspect, strong monotonicity is the most desirable property, but we have to note that even weak monotonicity is an elusive property for efficiency measures. For example, Ando et al. (2012) proved that there does not exist any weakly monotonic efficiency measure that uses a p-norm least-distance approach to the closest projections over the efficient frontier. Later, Fukuyama et al. (2014) showed that ratio-form least-distance efficiency measures do not satisfy weak monotonicity either. Ando et al. (2017) gave a further discussion about monotonicity of minimum distance efficiency measures. Nevertheless, any efficiency measure should be at least weakly monotonic for the sake of interpretability.
Given \({\mathscr {D}}\) a set of reference DMUs, an efficiency score (with respect to \({\mathscr {D}}\)) is a score function such that, applied to inefficient activities, represents an efficiency measure. Apart from being continuous in P (the production possibility set defined by \({\mathscr {D}}\)) and weakly monotonic, Fukuyama et al. (2014) pointed out some other desirable properties that any efficiency score f should satisfy:
-
1.
\(f\left( {\mathbf {x}},{\mathbf {y}}\right) =1\) if and only if \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is efficient.
-
2.
\(0\le f\left( {\mathbf {x}},{\mathbf {y}}\right) \le 1\) for any \(\left( {\mathbf {x}},{\mathbf {y}}\right) \in P\).
Note that if \(\left( {\mathbf {x}},{\mathbf {y}}\right) \notin P\), then it is efficient and hence, \(f\left( {\mathbf {x}},{\mathbf {y}}\right) =1\). So, we cannot demand global continuity, because weakly efficient activities in \(\partial ^{\text {W}}(P)\) are inefficient and, according to property 1, their efficiency scores cannot be equal to 1. Precisely, the discontinuity of efficiency scores in \(\partial ^{\text {W}}(P)\) leads to discontinuity problems when implementing SBM efficiency in conjunction with SBM super-efficiency, exposed by Chen (2013). Note that the classical radial efficiency score is globally continuous but it does not hold property 1, since inefficient activities in \(\partial ^{\text {W}}(P)\) have radial efficiency score equal to 1 (Charnes and Cooper 1962).
3 Original SBM models
In this Section we are going to review the SBM efficiency and super-efficiency models given by Tone (2001, 2002) and define their corresponding score functions. In the rest of the paper, we are going to suppose that \({\mathscr {D}}\) is a set of n reference DMUs, X, Y are the input and output data matrices of \({\mathscr {D}}\) respectively, and P is the production possibility set defined by \({\mathscr {D}}\).
We define the SBM efficiency score (with respect to \({\mathscr {D}}\)) of an activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) as
if \(\left( {\mathbf {x}},{\mathbf {y}}\right) \in P\), and \(\rho ^*\left( {\mathbf {x}},{\mathbf {y}}\right) =1\) if \(\left( {\mathbf {x}},{\mathbf {y}}\right) \notin P\). The vectors \({\mathbf {s}}^-,{\mathbf {s}}^+\) are called inefficiency slack vectors (Guo et al. 2017). Considering \({\mathbf {s}}^{-*},{\mathbf {s}}^{+*}\) optimal inefficiency slack vectors, we refer to the activities of the form \(\left( {\mathbf {x}} -{\mathbf {s}}^{-*}, {\mathbf {y}} +{\mathbf {s}}^{+*}\right) \) as efficient (or optimal) targets. Program (2) is based on the original SBM efficiency model given by Tone (2001), in the sense that \(\rho ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \) is the score that the Tone’s original SBM efficiency model would assign to a new DMU with activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \). We conclude that \(\rho ^*\) is an efficiency score because it satisfies properties 1 and 2, it is weakly monotonic and \(\rho ^*|_P\) is clearly continuous. With respect to monotonicity, we have the next result:
Proposition 1
The SBM efficiency score \(\rho ^*|_P\) is strongly monotonic.
We define the SBM super-efficiency (S-SBM) score (with respect to \({\mathscr {D}}\)) of an activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) as
where \({\mathbf {t}}^-,{\mathbf {t}}^+\) are called super-efficiency slack vectors (Guo et al. 2017). Taking into account the SBM super-efficiency model given by Tone (2002), we have that \(\delta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \) is the score that a new DMU with activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) would have. Note that in Tone’s S-SBM program, the DMU under evaluation must be excluded from the original set of DMUs. However, in program (3), there is no need to make any exclusion. This is one of the advantages of working with score functions.
The set of activities in P that are dominated by \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is given by
Hence, the constraints of (3) are equivalent to \(\left( {\mathbf {x}}+{\mathbf {t}}^-,{\mathbf {y}}-{\mathbf {t}}^+\right) \in {\bar{P}}\) and then, according to Tone (2002), \(\delta \) can be interpreted as a weighted \(l_1\) distance from \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) to activities in \({\bar{P}}\). Note that although technically \(\delta \) is not a distance in the mathematical sense, we are going to use the term “distance” in the same way that it is used in Tone (2002). In this case, if \({\mathbf {t}}^{-*},{\mathbf {t}}^{+*}\) are optimal super-efficiency slack vectors for (3), then \(\left( {\mathbf {x}}+{\mathbf {t}}^{-*},{\mathbf {y}}-{\mathbf {t}}^{+*}\right) \) are the activities in \({\bar{P}}\) closest to \(\left( {\mathbf {x}},{\mathbf {y}}\right) \), which are called super-efficiency projections of \(\left( {\mathbf {x}},{\mathbf {y}}\right) \). Note that, since the distance between a point and a closed set is defined by the distance between the point and the closest point in the set, \(\delta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \) can also be interpreted as a distance from \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) to \({\bar{P}}\). It is important to remark that, according to Chen (2013), an overestimation of the S-SBM score \(\delta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \) is produced when \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) has weakly efficient (and hence inefficient) super-efficiency projections. This overestimation occurs because the inefficiency of such projections is not taken into account by \(\delta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \). This fact is closely related to discontinuity issues when implementing SBM efficiency in conjunction with SBM super-efficiency, as we will see in Sect. 4.
It is clear that the S-SBM score \(\delta ^*\) is continuous. With respect to monotonicity, Tone (2002) proved that \(\delta ^*\left( \alpha {\mathbf {x}}, \beta {\mathbf {y}}\right) \ge \delta ^*\left( {\mathbf {x}}, {\mathbf {y}}\right) \) for any activity \(\left( {\mathbf {x}}, {\mathbf {y}}\right) \), \(\alpha \le 1\) and \(\beta \ge 1\). Next, we present a more general result.
Proposition 2
The S-SBM score \(\delta ^*\) is weakly monotonic.
Remark 1
(Strong monotonicity) The S-SBM score \(\delta ^*\) is constantly equal to 1 for activities in P and hence, it is obvious that it is not strongly monotonic for inefficient activities. However, it is important to note that \(\delta ^*\) is not strongly monotonic for efficient activities either, because it does not take into account the inefficiency of super-efficiency projections. For example, let us consider \({\mathscr {D}}=\left\{ \text {D1},\text {D2},\text {D3}\right\} \) a set of reference DMUs with two inputs and one normalized output, where \(\text {D1}=\left( \left( 10,40\right) ,1\right) \), \(\text {D2}=\left( \left( 15,25\right) ,1\right) \) and \(\text {D3}=\left( \left( 30,20\right) ,1\right) \). As we will see in Example 2, activities of the form \(\left( \left( 30+c,x_2\right) ,1\right) \) with \(0<x_2<20\) have the same S-SBM score \(\delta ^*\) (with respect to \({\mathscr {D}}\)) when \(c\ge 0\) varies.
4 Global continuous SBM models
From the SBM efficiency and super-efficiency models defined by Tone (2001) and Tone (2002) respectively, it is possible to construct a global SBM score function defined on the whole \({\mathbb {R}}_{>0}^{m+s}\) such that it coincides with \(\rho ^*\) for activities in the corresponding production possibility set P and, on the other hand, it coincides with \(\delta ^*\) for the rest of activities (see Fang et al. (2013); Guo et al. (2017)). Nevertheless, as it was firstly showed by Chen (2013), this score is not continuous in the weakly efficient frontier \(\partial ^{\text {W}}(P)\), making it hard to interpret and justify the scores in applications. As it is also pointed out by Chen (2013), this discontinuity issue is closely related to the overestimation of the S-SBM score produced when the super-efficiency projections are weakly efficient. So, the idea to fix the discontinuity problem is to define a new model that penalizes the inefficiency of such projections in some way.
In this section we are going to review the joint SBM (J-SBM) and the continuous SBM (CSBM) models introduced by Chen (2013) and Chen et al. (2019) respectively. Both models try to solve the discontinuity problem but, unfortunately, they do not give a fully satisfactory solution for different reasons that we are going to show. Specifically, the J-SBM score is not continuous in some cases and the CSBM score, even being continuous, is not weakly monotonic in some cases. It must be taken into account that we have changed some notation to simplify and adapt it to our study.
4.1 The joint SBM model
Given \({\mathscr {D}}\), the space of activities \({\mathbb {R}}_{>0}^{m+s}\) is splitted into three regions:
-
Region (I) or technical inefficiency zone: \(P-\partial ^{\text {S}}(P)\), i.e. inefficient activities.
-
Region (II): efficient activities with all super-efficiency projections being efficient.
-
Region (III): efficient activities with at least one inefficient super-efficiency projection.
With respect to the notation of Chen (2013), super-efficiency projections are called “S-SBM reference points” and, analogously for inefficient activities, efficient targets are called “SBM reference points”.
Given an activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \), the J-SBM model assigns a score \(\phi ^* \left( {\mathbf {x}},{\mathbf {y}}\right) \) that coincides with \(\rho ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \) if \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is in Region (I), is equal to \(\delta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \) if \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is in Region (II) and, for activities in Region (III), the author introduces a relaxed SBM super-efficiency model that penalizes the inefficiency of super-efficiency projections:
The reference points given by model (5) are those of the form \(\left( {\mathbf {x}}-\tilde{{\mathbf {s}}}^{-*},{\mathbf {y}}+\tilde{{\mathbf {s}}}^{+*}\right) \) where \(\tilde{{\mathbf {s}}}^{-*}\), \(\tilde{{\mathbf {s}}}^{+*}\) are optimal. Note that \(\tilde{{\mathbf {s}}}^-\), \(\tilde{{\mathbf {s}}}^+\) are free slack vectors.
Chen (2013) uses binary variables in order to express the J-SBM score in a single model, constructing a “switch” between the three different models from each region (see Equation (9) in Chen (2013)). However, in the way the model is expressed, the “switch” does not work correctly between Region (II) and Region (III). Anyway, this mistake could be fixed by re-defining the J-SBM score piecewisely instead of using binary variables, although its computation would need several stages. Namely, in a first stage, we need to know to which region the activity belongs and then, in a second stage, we apply (2), (3) or (5) for activities in Region (I), (II) or (III), respectively.
Moreover, Corollary 1 in Chen (2013), which states that the reference points given by the J-SBM model are efficient, is not fulfilled. This issue is treated by Lin et al. (2018), giving a counterexample and a revised model.
Finally, and most importantly, according to Theorem 5 in Chen (2013), the J-SBM score is supposed to connect all three regions in a continuous way. Unfortunately, this is not true in some cases as we show in Example 2 (see Fig. 3 (b)), and this mistake can not be fixed. The reason for this to happen is that, sometimes, the relaxed model (5) gives a reference point quite far away from the evaluated activity. The discontinuity of the J-SBM score was recognised in a corrigendum paper by Chen (2014), ensuring that “it can be easily corrected by constraining the reference point to be fixated on a specific strongly Pareto-efficient point”. However, the details of this proposition were not given and, as far as we know, there is not any further paper that clarifies it.
4.2 The continuous SBM model
Given an efficient activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) with \({\mathbf {t}}^{-*},{\mathbf {t}}^{+*}\) optimal super-efficiency slack vectors for (3), the SBM efficiency score (with respect to \({\mathscr {D}}\)) of its super-efficiency projection given by \(\left( {\mathbf {x}}+{\mathbf {t}}^{-*}, {\mathbf {y}}-{\mathbf {t}}^{+*}\right) \) is
The following propositions allow us to simplify program (6). Moreover, Proposition 4 implies that the programs given in (Chen et al. 2019, Equation (2)) and (Chen et al. 2019, Equation (4)) are equivalent.
Proposition 3
Let \({\mathbf {s}}^{-*},{\mathbf {s}}^{+*}\) be optimal for (6), if \(t_i^{-*}>0\) for some \(i\in \left\{ 1,\ldots ,m\right\} \), then \(s_i^{-*}=0\), and if \(t_r^{+*}>0\) for some \(r\in \left\{ 1,\ldots ,s\right\} \), then \(s_r^{+*}=0\).
Proposition 4
The objective function of (6) can be replaced by
According to Chen et al. (2019), we define the continuous SBM (CSBM) score (with respect to \({\mathscr {D}}\)) of an activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) as
where \({\mathbf {t}}^{-*},{\mathbf {t}}^{+*}\) are optimal super-efficiency slack vectors for (3) and \({\mathbf {s}}^{-*},{\mathbf {s}}^{+*}\) are optimal inefficiency slack vectors for (6). Note that (8) may not be well-defined if optimal slacks \({\mathbf {t}}^{-*}\), \({\mathbf {t}}^{+*}\), \({\mathbf {s}}^{-*}\) or \({\mathbf {s}}^{+*}\) are not unique for the activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \). In this case, the CSBM score may depend on which optimal slacks we choose.
The CSBM model can calculate both SBM efficiency (for activities in Region (I)) and SBM super-efficiency (for activities in Region (II)) scores, and it is indeed continuous. Nevertheless, as we show in Example 1, it may not be weakly monotonic for activities in Region (III) and hence, in these cases, it is not a valid score.
Example 1
We are going to consider a set of DMUs used in Doyle and Green (1993), Tone (2002) that consists of six efficient DMUs with four inputs and two outputs (see Table 1). In order to evaluate the first DMU, we are going to consider \({\mathscr {D}}=\left\{ \text {D2},\ldots ,\text {D6}\right\} \) as the set of reference DMUs. Then, the S-SBM score (with respect to \({\mathscr {D}}\)) of D1 is 1.0116 and its super-efficiency projection is \(\left( \left( 80,627.89,54,8\right) ,\left( 90, 5\right) \right) \) whose SBM efficiency score is 0.7299. The nonzero optimal slacks for programs (3) and (6) are \(t_2^{-*}=27.89\), \(s_4^{-*}=4.4\) and \(s_2^{+*}=1.82\), giving a CSBM score of 0.7397.
Now, let us consider \(\text {D1}'\) equal to D1 except for the first input, that is increased in one unity, changing from 80 to 81. The S-SBM score (with respect to \({\mathscr {D}}\)) of \(\text {D1}'\) is 1.0103 with super-efficiency projection \(\left( \left( 81,624.82,54,8\right) ,\left( 90, 5\right) \right) \) whose SBM efficiency score is 0.7428. The corresponding nonzero optimal slacks are \(t_2^{-*}=24.82\), \(s_4^{-*}=4.35\) and \(s_2^{+*}=1.63\), giving a CSBM score of 0.7517.
Since \(\text {D1}'\) is strictly dominated by D1 and \(\text {CSBM}\left( \text {D1}'\right) >\text {CSBM}\left( \text {D1}\right) \), we conclude that the CSBM score is not weakly monotonic in this case. Using the same technique as in the proofs of propositions 1 and 2, it can be proved that this type of example can only appear when an input or output that does not have any associated optimal slack is altered. In our case, when the first input is worsened, the decrease in the S-SBM score is not able to compensate for the increase in the SBM efficiency score of the super-efficiency projection.
According to Fukuyama et al. (2014), there does not exist any weakly monotonic efficiency measure that uses a ratio-form least-distance approach to the closest projections over the efficient frontier. It seems that something similar can happen with the CSBM score, since (8) is a ratio-form expression.
5 The composite SBM model
Example 1 shows that optimal slacks (and hence the SBM efficiency score) of super-efficiency projections do not serve to quantify the overestimation of the S-SBM score in some cases. Hence, for this purpose, we need scores that do not just take into account the super-efficiency projection. Following this idea, in Sect. 5.1 we are going to define a continuous score function \(\gamma \) that is equal to \(\rho ^*\) in Region (I) and coincides with \(\delta ^*\) in Region (II). Moreover, unlike the CSBM, \(\gamma \) will always be weakly monotonic. Nevertheless, the computation of \(\gamma \) involves nonlinear programming and hence, in Sect. 5.2, we are going to study some computational aspects.
5.1 Definitions and properties
We define the composite SBM (CompSBM) score (with respect to \({\mathscr {D}}\)) of an activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) as
where \({\bar{P}}\) is the set of activities in P that are dominated by \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) (see (4)) and \(\max \rho ^*|_{{\bar{P}}}\) is the best (i.e. highest) SBM efficiency score of activities in \({\bar{P}}\), that can be interpreted as the SBM efficiency score of \({\bar{P}}\) as a set. Note that it is well-defined since \({\bar{P}}\) is closed.
The idea behind the CompSBM score \(\gamma \) given by (9) is not to focus only on super-efficiency projections, but on the entire set \({\bar{P}}\): instead of interpreting \(\delta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \) as a distance from \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) to its super-efficiency projection and penalize the inefficiency of such projection, let us interpret \(\delta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \) as a distance from \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) to \({\bar{P}}\) and penalize the inefficiency of \({\bar{P}}\), i.e. the fact that any activity in \({\bar{P}}\) is inefficient. These two points of view are not equivalent, as we will see in Remark 5.
Remark 2
(Unit-invariance) In the J-SBM, CSBM and CompSBM models, we are implicitly assuming that slacks from different inputs and/or outputs can somehow compensate for each other, as pointed out and discussed by Chen (2013). In the case of the CompSBM model, according to expression (9), the optimal super-efficiency slacks of \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) (which are contained inside \(\delta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \)) are compensated by the optimal inefficiency slacks of the most efficient activity in \({\bar{P}}\) (which are contained inside \(\max \rho ^*|_{{\bar{P}}}\)). For this reason, unit-invariance is a very important property that these models should satisfy. On one hand, J-SBM and CSBM models are proved to be unit-invariant (see Chen (2013), Chen et al. (2019), respectively); on the other hand, the CompSBM model is unit-invariant because the SBM efficiency and super-efficiency models are unit-invariant (see Tone (2001, 2002)).
Next proposition clarifies the behavior of the CompSBM model, showing that it integrates the SBM efficiency \(\rho ^*\) and the S-SBM \(\delta ^*\) in its score.
Proposition 5
Let \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) be an activity and let \({\bar{P}}\) be the set given by (4). Then
-
1.
\(\gamma \left( {\mathbf {x}},{\mathbf {y}}\right) =\rho ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \) if \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is inefficient.
-
2.
\(\gamma \left( {\mathbf {x}},{\mathbf {y}}\right) =\delta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \) if \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is efficient and \(\max \rho ^*|_{{\bar{P}}}=1\), i.e. there are efficient activities in \({\bar{P}}\).
-
3.
\(\max \rho ^*|_{{\bar{P}}}<\gamma \left( {\mathbf {x}},{\mathbf {y}}\right) <\delta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \) if \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is efficient and \(\max \rho ^*|_{{\bar{P}}}<1\), i.e. any activity in \({\bar{P}}\) is inefficient.
Analogously to what happens with the J-SBM and CSBM scores, Proposition 5 ensures that \(\gamma =\rho ^*\) in Region (I), \(\gamma =\delta ^*\) in Region (II), and \(\rho ^*\left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*\right) <\gamma \left( {\mathbf {x}},{\mathbf {y}}\right) \le \delta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \) for \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) in Region (III), where \(\left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*\right) \) is any super-efficiency projection of \(\left( {\mathbf {x}},{\mathbf {y}}\right) \). In the next results, we prove global continuity and weak monotonicity of the CompSBM score.
Proposition 6
The CompSBM score \(\gamma \) is continuous.
Proposition 7
The CompSBM score \(\gamma \) is weakly monotonic.
Remark 3
(Super-inefficiency) The CompSBM model is based on the SBM efficiency and super-efficiency models, providing a continuous score in the weakly efficient frontier. However, since there is continuity, inevitably there will be efficient activities (in Region (III)) with CompSBM scores less than 1 around the weakly efficient frontier, as it also happens with J-SBM and CSBM scores. Although this may seem a little counter-intuitive at first, Chen (2013) gives a clarifying example in his “Discussion and summary” section. Following the same criteria as Chen (2013), an efficient activity with score less than 1 is said to be super-inefficient. In fact, super-inefficiency is interpreted by Chen (2013) as a “hidden” inefficiency, and Chen et al. (2019) affirms that super-inefficiency is a new division for efficiency, different from existing studies such as SBM efficiency and SBM super-efficiency. It is important to note that super-inefficiency has to be interpreted under the assumption that slacks from different inputs and/or outputs can somehow compensate for each other (see Remark 2). In the case of the CompSBM score, an efficient activity is super-inefficient if the model estimates that the magnitude of its optimal super-efficiency slacks is less than the magnitude of the optimal inefficiency slacks of the most efficient activity in \({\bar{P}}\).
Following Chen (2013), the super-inefficiency zone is formed by all the super-inefficient activities; on the other hand, the super-efficiency zone is formed by all the efficient activities that are not in the super-inefficiency zone, i.e. with scores greater than or equal to 1. Each score (J-SBM, CSBM or CompSBM) can define a different super-inefficiency zone, but they are always in Region (III), around the weakly efficient frontier (see Fig. 2).
According to Remark 3, any global continuous SBM model cannot determine whether an activity is efficient or not, because super-inefficient activities have scores less than 1 but they are efficient. For this reason, any score that produces super-inefficient activities has to be taken as a complement to SBM efficiency and super-efficiency models. On the other hand, it could be interesting to define an alternative SBM super-efficiency score that penalizes the lack of efficient activities in \({\bar{P}}\) but it does not produce super-inefficient activities. Hence, in Remark 4 we construct a super-efficiency score \(\gamma _{\text {se}}\) based on \(\gamma \) such that efficient activities obtain scores greater than or equal to 1 (see (11)). However, as it happens with the S-SBM score \(\delta ^*\), discontinuities inevitably appear when implementing \(\gamma _{\text {se}}\) in conjunction with SBM efficiency, leading to serious interpretation problems related to sensitivity.
Remark 4
(Composite SBM super-efficiency score)Lee (2021) defined a composite super-efficiency index \(\ddot{\sigma }^*\) such that efficient activities have scores greater than or equal to 1 and the inefficiency of super-efficiency projections is penalized. Given an activity \( \left( {\mathbf {x}},{\mathbf {y}}\right) \), the corresponding score function (with respect to \({\mathscr {D}}\)) would have this form:
where \(\left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*\right) \) is a super-efficiency projection of \( \left( {\mathbf {x}},{\mathbf {y}}\right) \). However, \(\ddot{\sigma }^*\) may not be well-defined if super-efficiency projections are not unique and, more importantly, it is not weakly monotonic in some cases, as we show in this example: considering the set of DMUs of Table 1, we have that the S-SBM score of D2 (with respect to \(\left\{ D1,D3,\ldots ,D6\right\} \)) is 1.4146 and the SBM efficiency of its super-efficiency projection is 0.3185, giving a \(\ddot{\sigma }^*\) score of 1.132; but increasing the fourth input of D2 from 1 to 1.5, we obtain that the S-SBM score is 1.3528 and the SBM efficiency of the super-efficiency projection is 0.4392, that gives a \(\ddot{\sigma }^*\) score of 1.1549.
In order to fix this, based on (9) and (10), we define the composite SBM super-efficiency (CompS-SBM) score (with respect to \({\mathscr {D}}\)) of an activity \( \left( {\mathbf {x}},{\mathbf {y}}\right) \) by
which is always well-defined, unit-invariant, continuous and weakly monotonic. Moreover, it fulfils \(\gamma _{\text {se}}=1\) in Region (I), \(\gamma _{\text {se}}=\delta ^*\) in Region (II), and \(1\le \gamma _{\text {se}}\le \delta ^*\) in Region (III), penalizing the lack of efficient activities in \({\bar{P}}\). It is important to remark that, although \(\gamma _{\text {se}}\) fixes the overestimation of the S-SBM score, it obviously produces discontinuities in the weakly efficient frontier when implementing in conjunction with SBM efficiency, i.e. considering \(\rho ^*\) for inefficient activities (Region (I)) and \(\gamma _{\text {se}}\) for efficient ones (Region (II) and (III)).
Remark 5
(Strong monotonicity) We will show in Example 4 (specifically with D5) that there exist uncommon cases in which super-efficiency projections are inefficient but there are efficient activities in \({\bar{P}}\). In these cases, \(\max \rho ^*|_{{\bar{P}}}=1\) and hence, the CompSBM score \(\gamma \) does not penalize the inefficiency of super-efficiency projections, unlike J-SBM and CSBM scores. As a consequence, \(\gamma \) is not strongly monotonic for efficient activities, as it happens with the S-SBM score \(\delta ^*\) (see Remark 1), although for other reasons and with a much lower frequency of cases.
Remark 6
(Alternative composite scores) We can use any weakly monotonic efficiency score f instead of \(\rho ^*\) in the definition of the CompSBM score \(\gamma \) (9). In this case, we need continuity of \(f|_P\) and the fulfilment of properties 1 and 2 of Fukuyama et al. (2014) (see Sect. 2.2). Hence, it is easy to prove that \(\gamma \) results continuous and weakly monotonic, even if the efficiency score f is not weakly monotonic. This makes it possible to use efficiency scores like the SBM-Max efficiency (Tone 2010, 2016), that is not weakly monotonic in some cases (Fukuyama et al. 2014; Ando et al. 2017). It could be interesting since there is a close connection between SBM-Max efficiency and SBM super-efficiency models (Tone 2017).
5.2 Computational aspects
Given an activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \), the set \({\bar{P}}\) is formed by all the activities in P that are dominated by \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) (see (4)). Hence,
where, according to (2), the objective function of (12) is
Note that \({\varvec{\lambda }}\) in (12) and (13) are different internal variables of these programs. In fact, the constraints of (13) assure that the constraints of (12) involving \({\varvec{\lambda }}\) are satisfied and hence, it suffices to demand nonnegativity of \({\mathbf {t}}^-,{\mathbf {t}}^+\) and \({\mathbf {t}}^+<{\mathbf {y}}\) in (12). But, in this case, we have to note that (13) may result infeasible for some nonnegative small values of \({\mathbf {t}}^-,{\mathbf {t}}^+\). The next result allows us to simplify (12).
Proposition 8
Let \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) be an activity and let \({\bar{P}}\) be the set given by (4). Then
The inner minimization program of (14) can be linearized using the Charnes-Cooper transformation (Charnes and Cooper 1962; Charnes et al. 1978). Note that in the outer maximization program we only demand nonnegativity of \({\mathbf {t}}^-,{\mathbf {t}}^+\) and hence, the inner minimization program may result infeasible for some small values of \({\mathbf {t}}^-,{\mathbf {t}}^+\). If we do not want this to happen, we must demand all the constraints of (12) in the outer program. Note that program (14) can be viewed as a nonlinear maximization program, but it is also a continuous maximin problem with coupled constraints. Some methods for solving this kind of problems are provided by Shimizu and Aiyoshi (1980), Rustem et al. (2008), Tsoukalas et al. (2009), among others.
Remark 7
(Lower bound) In some cases, computation of \(\max \rho ^*|_{{\bar{P}}}\) by means of (14) may result too expensive (see Example 4). In these cases, we can compute a lower bound given by \(\rho ^*\left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*\right) \) where \(\left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*\right) \) is a super-efficiency projection of \(\left( {\mathbf {x}},{\mathbf {y}}\right) \). Then,
is a lower bound of the CompSBM score \(\gamma \left( {\mathbf {x}},{\mathbf {y}}\right) \). Usually, \(\rho ^*\left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*\right) \) is very close (or even equal) to \(\max \rho ^*|_{{\bar{P}}}\), and its computation only involves linear programs (applying the Charnes-Cooper transformation): (3) for the super-efficiency projection and (6) for its efficiency. On the other hand, Tsoukalas et al. (2009) propose an algorithm for solving continuous maximin problems that requires a lower bound and hence, \(\rho ^*\left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*\right) \) could serve for computing \(\max \rho ^*|_{{\bar{P}}}\) using this algorithm.
6 Extensions
In this section we are going to extend the CompSBM model to different orientations and returns to scale. Moreover, we discuss nonpositive data, and weighted inputs and/or outputs. Finally, we present a version adapted to the additive model.
Orientations. The CompSBM score is defined in a nonoriented form. Nevertheless, considering the input and output oriented versions of the S-SBM model (Tone 2002), we can adapt our CompSBM score to these orientations. In this way, the input oriented CompSBM score (with respect to \({\mathscr {D}}\)) of an activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is given by \( \gamma _{\mathrm {I}}\left( {\mathbf {x}},{\mathbf {y}}\right) =\delta _{\mathrm {I}}^*\left( {\mathbf {x}},{\mathbf {y}}\right) \cdot \max \rho ^*_{\mathrm {I}}|_{{\bar{P}}} \), where \(\delta ^*_{\mathrm {I}}\) and \(\rho ^*_{\mathrm {I}}\) are the input oriented versions of \(\delta ^*\) and \(\rho ^*\) respectively. In order to compute \(\max \rho ^*_{\mathrm {I}}|_{{\bar{P}}}\), it is easy to prove that
which is a linear continuous minimax problem with coupled constraints. Analogously, the output oriented CompSBM score (with respect to \({\mathscr {D}}\)) of \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is given by \( \gamma _{\mathrm {O}}\left( {\mathbf {x}},{\mathbf {y}}\right) =\delta _{\mathrm {O}}^*\left( {\mathbf {x}},{\mathbf {y}}\right) \cdot \max \rho ^*_{\mathrm {O}}|_{{\bar{P}}} \), where \(\delta ^*_{\mathrm {O}}\) and \(\rho ^*_{\mathrm {O}}\) are the output oriented versions of \(\delta ^*\) and \(\rho ^*\) respectively. In order to compute \(\max \rho ^*_{\mathrm {O}}|_{{\bar{P}}}\), it is easy to prove that
which is also a linear continuous minimax problem with coupled constraints.
Returns to scale. In this work, all definitions and results are within the framework of constant returns to scale. Nevertheless, we can modify the programs to consider different returns to scale. For example, for variable returns to scale in the CompSBM model we have to add the constraint \(\sum _{j=1}^n\lambda _j=1\) to programs (3) and (14). It is worth noting that, taking variable returns to scale, nonoriented S-SBM models are always feasible (Tone 2002), but oriented models may result infeasible. In these cases, it will be impossible to compute oriented CompSBM scores.
Zero or negative data. The CompSBM model can accept zero or negative data as long as the SBM efficiency and super-efficiency models accept it. In fact, how to deal with zeros in data is discussed in Tone (2001, 2002) and, more recently, how to handle with nonpositive data in general is discussed in Tone et al. (2020), Lee (2021).
Weights. We can consider different weights for each input and/or output. For example, we can compute the S-SBM score in (3) by means of the weighted objective function
where \({\mathbf {w}}^-,{\mathbf {w}}^+\) are the corresponding weights vectors. Analogously, the SBM efficiency model would also have to take into account these weights.
Additive model. Finally, we can adapt the CompSBM score to the additive model. Following Charnes et al. (1982), the additive efficiency score (with respect to \({\mathscr {D}}\)) of an activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) in unit-invariant form is defined as
Note that \(\alpha ^*\) is not an efficiency score satisfying properties 1 and 2 (see Sect. 2.2). In fact, an activity \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is efficient if and only if \(\alpha ^*\left( {\mathbf {x}},{\mathbf {y}}\right) =0\). On the other hand, following Du et al. (2010), we define the additive super-efficiency score (with respect to \({\mathscr {D}}\)) of \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) as
If \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is inefficient, then \(\beta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) =0\). So, from (16) and (17) we can define the additive composite score (with respect to \({\mathscr {D}}\)) of \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) as \( \gamma _{\text {add}} \left( {\mathbf {x}},{\mathbf {y}}\right) =\beta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) -\min \alpha ^*|_{{\bar{P}}} \). Hence, \(\gamma _{\text {add}}\) is negative for inefficient activities, and nonnegative for activities with efficient activities in \({\bar{P}}\).
7 Examples
In this section we are going to illustrate the J-SBM, CSBM and CompSBM models with some examples. We have used R 3.6.0 (R Core Team 2020) for computations. Specifically, we have used the deaR package (Coll-Serrano et al. 2020) for computing linear scores, and the NLopt package (Johnson 2019) for solving the nonlinear program (14) in Example 4.
Example 2
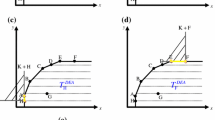
Let us consider \({\mathscr {D}}=\left\{ \text {D1},\text {D2},\text {D3}\right\} \) a set of reference DMUs with two inputs and one normalized output, where \(\text {D1}=\left( \left( 10,40\right) ,1\right) \), \(\text {D2}=\left( \left( 15,25\right) ,1\right) \) and \(\text {D3}=\left( \left( 30,20\right) ,1\right) \). In Figs. 2 and 3, we have computed binary logarithms of different scores of activities of the form \(\left( \left( x_1,x_2\right) ,1\right) \). The super-inefficiency zones are represented, showing how discontinuity issues on weakly efficient activities are fixed by the CSBM and CompSBM scores, but not by the J-SBM score. Note that in cases where there is only one output (as in this example) the super-efficiency projections \(\left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*\right) \) are among the most efficient activities in the corresponding set \({\bar{P}}\), and hence \(\max \rho ^*|_{{\bar{P}}}=\rho ^*\left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*\right) \). Then, computing the CompSBM score \(\gamma \) is equivalent to computing \(\gamma _{\text {low}}\) (see (15)), whose program is linear.

Diagrams representing binary logarithms of different scores (with respect to the reference DMUs of Example 2) of activities with a normalized output equal to 1: (a) SBM efficiency in conjunction with S-SBM, (b) J-SBM, (c) CSBM, (d) CompSBM. The solid lines separate activities with score \(<1\) from activities with score \(\ge 1\), and dashed lines represent the weakly efficient frontier. In plots (b), (c) and (d), the zones between solid and dashed lines are the super-inefficiency zones, fixing the discontinuity issues in (c) and (d)

Details of super-inefficiency zones in Figure 2
Activities of the form \(\left( \left( 30+c,x_2\right) ,1\right) \) with \(0<x_2<20\) have the same S-SBM score \(\delta ^*\) when \(c\ge 0\) varies. But only when \(c=0\) the super-efficiency projection is efficient and, in this case, it is equivalent to the fact that only when \(c=0\) there are efficient activities in the corresponding \({\bar{P}}\). According to this, the J-SBM, CSBM and CompSBM models penalize activities of the form \(\left( \left( 30+c,x_2\right) ,1\right) \) with \(0<x_2<20\) and \(c>0\).
Example 3
In this example we want to illustrate how to introduce the CompSBM model into the Malmquist index computation. Note that this methodology is also applicable to the J-SBM and CSBM models. We consider the set of DMUs \({\mathscr {D}}=\left\{ \text {D1},\text {D2},\text {D3}\right\} \) of Example 2 and another DMU D4 with activity changing from \(\text {A1}=\left( \left( 30,10\right) ,1\right) \) to \(\text {A2}=\left( \left( 40,10\right) ,1\right) \), while the activities of the DMUs in \({\mathscr {D}}\) remain unchanged. In this way, using the SBM efficiency and super-efficiency models, we can compute the SBM Malmquist index (Tone 2004) of D4, that is the product of two factors: the catch-up and the frontier-shift. On one hand, the catch-up (or recovery) is interpreted as the DMU’s relative efficiency change, so catch-up values greater than 1 indicate progress, values less than 1 indicate regress, and a catch-up equal to 1 means no change. On the other hand, the frontier-shift (or innovation) is related to the technological change in the efficient frontiers and hence, analogously to the catch-up, values greater, less and equal to 1 indicate progress, regress, and no change, respectively, of the efficient frontier with respect to the evaluated DMU.
Nevertheless, we can also compute a Malmquist index using the CompSBM score (or the J-SBM or CSBM scores) instead of the S-SBM score. Table 2 shows the scores of A1 and A2, while Table 3 shows the results of the Malmquist index with no orientation and using the exclusive scheme (see Tone (2004) for details). The original SBM Malmquist index does not detect the catch-up, and its frontier-shift does not take into account the inefficiency of the super-efficiency projection of A2. On the other hand, these problems do not appear when the CompSBM score is used instead, obtaining a catch-up smaller than one and a frontier-shift indicating less technological regress of the efficient frontier with respect to D4.
Now, let us consider that the activity of D4 changes from \(\text {A3}=\left( \left( 50,20\right) ,1\right) \) (that is weakly efficient) to \(\text {A4}=\left( \left( 50,19\right) ,1\right) \), while the activities of the DMUs in \({\mathscr {D}}\) remain unchanged. Analogously, we can compute the SBM Malmquist index of D4 in its original form or using the CompSBM score instead. Table 2 shows the scores of A3 and A4, while Table 3 also shows the results of the Malmquist index with no orientation and using the exclusive scheme. The catch-up of the original SBM Malmquist index is overestimated due to the discontinuity of the SBM efficiency score on weakly efficient activities described in Example 2. This problem is again solved when the CompSBM score is used instead, resulting in a catch-up very close to 1.
Example 4
We are going to consider the same set of DMUs of Example 1, used in Doyle and Green (1993), Tone (2002), consisting of six efficient DMUs (power plant locations) with four inputs and two outputs (see Table 1). Table 4 shows nonoriented scores (although Tone (2002) only considers the input oriented scenario) and Table 5 shows the corresponding efficient targets of super-efficiency projections, with optimal slacks in parentheses. Note that the difference between the original DMU and the efficient target of a super-efficiency projection is given either by optimal super-efficiency slacks or by optimal inefficiency slacks (of the super-efficiency projection), separately in each input and output. This fact is shown in Table 5, where super-efficiency slacks are displayed in bold italic, inefficiency slacks in bold, and each input or output has either bold italic or bold slacks, but not both (see Proposition 3). It should be also noted that the S-SBM score only takes into account “bold italic slacks”, ignoring “bold slacks”.
Note that, for D5, \(\rho ^*\left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*\right) < 1\) and it does not coincide with \(\max \rho ^*|_{{\bar{P}}}\), whose value is 1. Hence, D5 has super-efficiency projections that are inefficient, but there are also efficient activities in the corresponding \({\bar{P}}\). In this case, the CompSBM model does not penalize the inefficiency of such super-efficiency projections (because there are efficient activities in \({\bar{P}}\)), contrary to the J-SBM and CSBM models. An important conclusion is that the CompSBM score is not strongly monotonic in some cases, because D5 can be improved (specifically, the second input can be lowered up to 525) keeping the original S-SBM score and, since there are efficient activities in \({\bar{P}}\), the CompSBM score of D5 will not change.
We have used the NLopt package (Johnson 2019) for solving the nonlinear program (14) in the computation of \(\max \rho ^*|_{{\bar{P}}}\). Specifically, we have used the following global nonlinear algorithms included in this package: DIRECT (Dividing RECtangles) (Jones et al. 1993), its “locally biased” version DIRECT-L (Gablonsky and Kelley 2001), and COBYLA (Constrained Optimization BY Linear Approximations) (Powell 1998). Computation time varies depending on the algorithm: 150 seconds for DIRECT, 20 seconds for DIRECT-L, and 2 seconds for COBYLA, using a 2 GHz processor. Nevertheless, computation time grows exponentially with the number of efficient DMUs, inputs and/or outputs, making it practically impossible to solve problems with, for example, more than 30 efficient DMUs with 5 inputs and 5 outputs.
8 Concluding remarks
The problem of ranking efficient DMUs continues to be an active issue that keeps generating new studies and methods within DEA (Jablonsky 2012; Zýková 2022). Since its inception in the papers of Pastor et al. (1999) and Tone (2001), the SBM super-efficiency model has proved to be an important tool for ranking efficient DMUs which has been widely used by DEA practitioners in the last years. However, some interpretation problems appear when super-efficiency projections are weakly efficient, since the SBM super-efficiency model does not take into account the inefficiency slacks of such projections and therefore, some efficient DMUs can not be properly ranked. Moreover, this fact is closely related to discontinuities produced in the weakly efficient frontier when implementing SBM super-efficiency in conjunction with SBM efficiency. Authors like Chen (2013) and Chen et al. (2019) tried to solve these problems, but they did not arrive to a fully satisfactory solution. Nevertheless, their papers lay the foundations for future studies on the subject.
In order to shed some light on this matter, we have introduced the CompSBM model, leading to the first example of a weakly monotonic score that integrates the SBM efficiency and S-SBM scores in a continuous way. Indeed, we have shown that it coincides with the S-SBM score when the DMUs are efficient with no inefficient super-efficiency projections, and coincides with the SBM efficiency score when the DMUs are inefficient. Moreover, the CompSBM model gives a continuous ranking of DMUs, avoiding the abrupt changes in the scores shown by other models and hence, solving the discontinuity problems in the weakly efficient frontier. It can also be adapted to other models such as the additive model or the SBM Malmquist index, or even we can use alternative efficiency scores different from \(\rho ^*\) in the construction of a composite score, giving us a deeper insight into the evolution of the performance of DMUs.
The idea behind the CompSBM model is not to consider only the super-efficiency slacks, but also to penalize the lack of efficient activities in the set \({\bar{P}}\) onto which super-efficiency projections are projected. Since we demand continuity, super-inefficient activities (i.e. efficient activities with scores less than 1) inevitably appear around the weakly efficient frontier. Although it can be counter-intuitive at first, super-inefficiency is interpreted as a “hidden” inefficiency (Chen 2013), assuming that slacks from different inputs/outputs can somehow compensate for each other. According to Chen et al. (2019), super-inefficiency is a new division for efficiency, different from existing studies such as SBM efficiency and SBM super-efficiency. Nevertheless, since super-inefficiency is a relatively new concept, it is not yet considered by some researchers who prefer to deal with discontinuities rather than with super-inefficiencies, although discontinuities have serious interpretation problems related to sensitivity. Hence, we have also defined a new weakly monotonous SBM super-efficiency score (based on the CompSBM score and the work of Lee (2021)) that penalizes the lack of efficient activities in \({\bar{P}}\) without producing super-inefficient activities (see Remark 4). However, discontinuities obviously appear in the weakly efficient frontier when implementing this new super-efficiency in conjunction with SBM efficiency.
To sum up, the CompSBM score:
-
is continuous,
-
is weakly monotonous, and
-
it allows ranking the efficient DMUs.
However, this score presents two difficulties, namely:
-
its calculation requires solving nonlinear optimization problems, and
-
it presents super-inefficiencies, which is the price we have to pay for having a global continuous score.
We believe that the methodology employed in the construction of the CompSBM score can help in the development of other models with better properties, as for example to be strongly monotonic (see Remark 5) or be easier to compute. Moreover, there are some pending tasks that may be interesting, such as the use of the SBM-Max efficiency model in the construction of the composite score (see Remark 6), or the study of the potential infeasibility of oriented composite models under variable returns to scale. In our opinion, these and other questions could lead to future results which, beyond any doubt, will help to increase the understanding of the DEA methodology.
Availability of data and material
Not applicable.
References
Andersen P, Petersen N (1993) A procedure for ranking efficient units in data envelopment analysis. Manage Sci 39(10):1261–1264. https://doi.org/10.1287/mnsc.39.10.1261
Ando K, Kai A, Maeda Y, Sekitani K (2012) Least distance based inefficiency measures on the pareto-efficient frontier in dea. J Oper Res Soc Jpn 55(1):73–91. https://doi.org/10.15807/jorsj.55.73
Ando K, Minamide M, Sekitani K, Shi J (2017) Monotonicity of minimum distance inefficiency measures for data envelopment analysis. Eur J Oper Res 260(1):232–243. https://doi.org/10.1016/j.ejor.2016.12.028
Banker R, Charnes A, Cooper W (1984) Some models for estimating technical and scale inefficiencies in data envelopment analysis. Manage Sci 30(9):1078–1092. https://doi.org/10.1287/mnsc.30.9.1078
Charnes A, Cooper W (1962) Programming with linear fractional functionals. Nav Res Logist Q 9(3–4):181–186. https://doi.org/10.1002/nav.3800090303
Charnes A, Cooper W, Golany B, Seiford L, Stutz J (1985) Foundations of data envelopment analysis for Pareto-Koopmans efficient empirical production functions. J Econom 30(1–2):91–107. https://doi.org/10.1016/0304-4076(85)90133-2
Charnes A, Cooper W, Rhodes E (1978) Measuring the efficiency of decision making units. Eur J Oper Res 2(6):429–444. https://doi.org/10.1016/0377-2217(78)90138-8
Charnes A, Cooper W, Seiford L, Stutz J (1982) A multiplicative model for efficiency analysis. Socioecon Plann Sci 16(5):223–224. https://doi.org/10.1016/0038-0121(82)90029-5
Chen C-M (2013) Super efficiencies or super inefficiencies? insights from a joint computation model for slacks-based measures in dea. Eur J Oper Res 226(2):258–267. https://doi.org/10.1016/j.ejor.2012.10.031
Chen C-M (2014) Corrigendum to “super efficiencies or super inefficiencies? insights from a joint computation model for slacks-based measures in dea”. [eur. j. oper. res. 226 (2013) 258–267]. Eur J Oper Res 234(3):921. https://doi.org/10.1016/j.ejor.2013.12.001
Chen Y, Li Y, Liang L, Wu H (2019) An extension on super slacks-based measure dea approach. Ann Oper Res 278(1):101–121. https://doi.org/10.1007/s10479-017-2495-2
Coll-Serrano V, Bolós V, Benítez R (2020) deaR: Conventional and Fuzzy Data Envelopment Analysis. R package version 1.2.0
Cook WD, Seiford LM (2009) Data envelopment analysis (dea) - thirty years on. Eur J Oper Res 192(1):1–17. https://doi.org/10.1016/j.ejor.2008.01.032
Cooper W, Seiford L, Tone K (2007) Data Envelopment Analysis - A Comprehensive Text with Models, Applications, References and DEA-Solver Software, 2nd edn. Springer, New York. https://doi.org/10.1007/978-0-387-45283-8
Doyle J, Green R (1993) Data envelopment analysis and multiple criteria decision making. Omega 21(6):713–715. https://doi.org/10.1016/0305-0483(93)90013-B
Du J, Liang L, Zhu J (2010) A slacks-based measure of super-efficiency in data envelopment analysis: A comment. Eur J Oper Res 204(3):694–697. https://doi.org/10.1016/J.EJOR.2009.12.007
Emrouznejad A, Parker B, Tavares G (2008) Evaluation of research in efficiency and productivity: A survey and analysis of the first 30 years of scholarly literature in DEA. Socioecon Plann Sci 42(3):151–157. https://doi.org/10.1016/J.SEPS.2007.07.002
Emrouznejad A, Yang G (2018) A survey and analysis of the first 40 years of scholarly literature in dea: 1978–2016. Socioecon Plann Sci 61:4–8. https://doi.org/10.1016/j.seps.2017.01.008
Fang H, Lee H, Hwang S, Chung C (2013) A slacks-based measure of super-efficiency in data envelopment analysis: An alternative approach. Omega 41(4):731–734. https://doi.org/10.1016/J.OMEGA.2012.10.004
Farrell M (1957) The measurement of productive efficiency. J R Stat Soc. Ser A (General) 120(3):253–290. https://doi.org/10.2307/2343100
Fukuyama H, Masaki H, Sekitani K, Shi J (2014) Distance optimization approach to ratio-form efficiency measures in data envelopment analysis. J Prod Anal 42(2):175–186. https://doi.org/10.1007/s11123-013-0366-7
Gablonsky J, Kelley C (2001) A locally-biased form of the direct algorithm. J Global Optim 21(1):27–37. https://doi.org/10.1023/A:1017930332101
Guo I, Lee H, Lee D (2017) An integrated model for slack-based measure of super-efficiency in additive DEA. Omega 67:160–167. https://doi.org/10.1016/J.OMEGA.2016.05.002
Jablonsky J (2012) Multicriteria approaches for ranking of efficient units in DEA models. Cent Eur J Oper Res 20(3):435–449. https://doi.org/10.1007/s10100-011-0223-6
Johnson S (2019) The NLopt nonlinear-optimization package
Jones DR, Perttunen CD, Stuckman BE (1993) Lipschitzian optimization without the lipschitz constant. J Optim Theory Appl 79(1):157–181. https://doi.org/10.1007/BF00941892
Lee H-S (2021) Slacks-based measures of efficiency and super-efficiency in presence of nonpositive data. Omega 103:102395. https://doi.org/10.1016/j.omega.2021.102395
Lin D-L, Chyr W-L, Gan G-Y, Lee H-S (2018) Super-efficient or super-inefficient? insights from a joint computation model for slacks-based measure in dea: a note. J Mar Sci Technol 26(2):166–169. https://doi.org/10.6119/jmst.2018.04_(2).0003
Pastor J, Ruiz J, Sirvent I (1999) An enhanced dea russell graph efficiency measure. Eur J Oper Res 115(3):596–607. https://doi.org/10.1016/S0377-2217(98)00098-8
Powell MJD (1998) Direct search algorithms for optimization calculations. Acta Numer 7:287–336. https://doi.org/10.1017/S0962492900002841
R Core Team (2020) R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria
Robert Russell R (1990) Continuity of measures of technical efficiency. J Econ Theory 51(2):255–267. https://doi.org/10.1016/0022-0531(90)90018-F
Rustem B, Žaković S, Parpas P (2008) Convergence of an interior point algorithm for continuous minimax. J Optim Theory Appl 136(1):87–103. https://doi.org/10.1007/s10957-007-9290-1
Scheel H, Scholtes S (2003) Continuity of dea efficiency measures. Oper Res 51(1):149–159. https://doi.org/10.1287/opre.51.1.149.12803
Seiford L (1997) A bibliography for Data Envelopment Analysis (1978–1996). Ann Oper Res 73:393–438. https://doi.org/10.1023/A:1018949800069
Shimizu K, Aiyoshi E (1980) Necessary conditions for min-max problems and algorithms by a relaxation procedure. IEEE Trans Autom Control 25(1):62–66. https://doi.org/10.1109/TAC.1980.1102226
Tavares G (2002) A bibliography of Data Envelopment Analysis (1978–2001). RRR (Rutgers Research Report) 01–02:186
Tone K (2001) A slacks-based measure of efficiency in data envelopment analysis. Eur J Oper Res 130(3):498–509. https://doi.org/10.1016/S0377-2217(99)00407-5
Tone K (2002) A slacks-based measure of super-efficiency in data envelopment analysis. Eur J Oper Res 143(1):32–41. https://doi.org/10.1016/S0377-2217(01)00324-1
Tone K (2004) Malmquist Productivity Index. In: Cooper WW, Seiford LM, Zhu J (eds) Handbook on Data Envelopment Analysis, pages 203–227. Kluwer Academic Publishers, Boston. https://doi.org/10.1007/1-4020-7798-X_8
Tone K (2010) Variations on the theme of slacks-based measure of efficiency in dea. Eur J Oper Res 200(3):901–907. https://doi.org/10.1016/j.ejor.2009.01.027
Tone K (2016) Data envelopment analysis as a kaizen tool: Sbm variations revisited. Bull Math Sci Appl 16:49–61. https://doi.org/10.18052/www.scipress.com/BMSA.16.49
Tone K (2017) On the consistency of slacks-based measure-max model and super-slacks-based measure model. Univers J Manag 5(3):160–165. https://doi.org/10.13189/ujm.2017.050307
Tone K, Chang T-S, Wu C-H (2020) Handling negative data in slacks-based measure data envelopment analysis models. Eur J Oper Res 282(3):926–935. https://doi.org/10.1016/j.ejor.2019.09.055
Tsoukalas A, Rustem B, Pistikopoulos E (2009) A global optimization algorithm for generalized semi-infinite, continuous minimax with coupled constraints and bi-level problems. J Global Optim 44(2):235–250. https://doi.org/10.1007/s10898-008-9321-y
Zýková P (2022) The overall efficiency of the dynamic DEA models. Cent Eur J Oper Res 30(2):495–506. https://doi.org/10.1007/s10100-021-00777-y
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature. Not applicable.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest/Competing interests
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Proof of Proposition 1
We are going to prove that \(\dfrac{\partial \rho ^*}{\partial x_k} <0\) for \(k\in \left\{ 1,\ldots ,m\right\} \) and \(\dfrac{\partial \rho ^*}{\partial y_k} >0\) for \(k\in \left\{ 1,\ldots ,s\right\} \) using the Karush-Kuhn-Tucker (KKT) conditions. Let \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) be an activity in P and \({\mathbf {s}}^{-*},{\mathbf {s}}^{+*}\) be optimal inefficiency slack vectors for program (2). Given \(k\in \left\{ 1,\ldots ,m\right\} \), we replace in (2) the parameter \(x_k\) by a new variable x and add the constraint \(x=x_k\) whose KKT multiplier is \(\dfrac{\partial \rho ^*}{\partial x_k}\left( {\mathbf {x}},{\mathbf {y}}\right) \). Hence, the stationarity condition associated to the new variable x is given by
where \(\mu ^-_k\) is the KKT multiplier of the k-th constraint in (2). The stationarity condition associated to \(s^-_k\) of (2) is given by
where \(\nu [s^-_k]\) is the KKT multiplier of the nonnegativity condition of \(s^-_k\). Hence, applying (19) in (18) we obtain
since \(s^{-*}_k<x_k\). Analogously, given \(k\in \left\{ 1,\ldots ,s\right\} \), it can be proved that
\(\square \)
Proof of Proposition 2
Let \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) be an activity and \({\mathbf {t}}^{-*},{\mathbf {t}}^{+*}\) be optimal super-efficiency slack vectors for program (3). Given \(k\in \left\{ 1,\ldots ,m\right\} \), we replace in (3) the parameter \(x_k\) by a new variable x and add the constraint \(x=x_k\) whose KKT multiplier is \(\dfrac{\partial \delta ^*}{\partial x_k}\left( {\mathbf {x}},{\mathbf {y}}\right) \). Hence, the stationarity condition associated to the new variable x is given by
where \(\mu ^-_k\) is the KKT multiplier of the k-th constraint in (3).
Let us suppose that \(t_k^{-*}>0\). The KKT stationarity condition associated to \(t^-_k\) of (3) is given by
where \(\nu [t^-_k]\) is the KKT multiplier of the nonnegativity condition of \(t^-_k\), that vanishes in virtue of the corresponding complementary slackness condition. Hence, applying (21) in (20) we obtain
since \(t_r^{+*}<y_r\) for \(r=1,\ldots ,s\).
On the other hand, let us suppose that \(t_k^{-*}=0\). From the KKT dual feasibility conditions of (3), we have \(\mu ^-_k\ge 0\) and hence, from (20) we obtain
Analogously to (22) and (23), it can be proved that given \(k\in \left\{ 1,\ldots ,s\right\} \), if \(t_k^{+*}>0\) then \(\dfrac{\partial \delta ^*}{\partial y_k} \left( {\mathbf {x}},{\mathbf {y}}\right) >0\), and if \(t_k^{+*}=0\) then \(\dfrac{\partial \delta ^*}{\partial y_k} \left( {\mathbf {x}},{\mathbf {y}}\right) \ge 0\). \(\square \)
Proof of Proposition 3
We define \({\varvec{\tau }}^-,{\varvec{\tau }}^+\) such that \(\tau _i^-=\max \left\{ 0,t_i^{-*}-s_i^{-*}\right\} \), \(\tau _r^+=\max \left\{ 0,t_r^{+*}-s_r^{+*}\right\} \), for \(i=1,\ldots ,m\) and \(r=1,\ldots ,s\). From the constraints of (6), we have
where \({\varvec{\lambda }}^*\) is optimal for (6), along with \({\mathbf {s}}^{-*},{\mathbf {s}}^{+*}\). From (24) and taking into account that \({\varvec{\tau }}^-,{\varvec{\tau }}^+\) are nonnegative, we have that \(\left( {\varvec{\lambda }}^*, {\varvec{\tau }}^-, {\varvec{\tau }}^+\right) \) satisfies the constraints of (3), and hence
On the other hand, if we suppose that there exists \(i\in \left\{ 1,\ldots ,m\right\} \) such that \(t_i^{-*},s_i^{-*}>0\), then \(\tau _i^-<t_i^{-*}\) and hence \(\delta \left( {\mathbf {x}},{\mathbf {y}},{\varvec{\tau }}^-,{\varvec{\tau }}^+\right) < \delta \left( {\mathbf {x}},{\mathbf {y}},{\mathbf {t}}^{-*},{\mathbf {t}}^{+*}\right) \), that contradicts (25). Analogously, if we suppose that there exists \(r\in \left\{ 1,\ldots ,s\right\} \) such that \(t_r^{+*},s_r^{+*}>0\), then we arrive to the same contradiction. \(\square \)
Proof of Proposition 4
Let (6)\('\) be the program (6) with objective function (7), and let \(\rho _0^*\left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*\right) \) be the optimal result of (6)\('\), where \(\left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*\right) =\left( {\mathbf {x}}+{\mathbf {t}}^{-*}, {\mathbf {y}}-{\mathbf {t}}^{+*}\right) \) is a super-efficiency projection of \(\left( {\mathbf {x}},{\mathbf {y}}\right) \). On one hand, if \({\mathbf {s}}^{-*},{\mathbf {s}}^{+*}\) are optimal for (6) then, by Proposition 3, we have
On the other hand, if \({\mathbf {s}}^{-*},{\mathbf {s}}^{+*}\) are optimal for (6)\('\) then, it can be proved analogously to Proposition 3 that if \(t_i^{-*}>0\) for some \(i\in \left\{ 1,\ldots ,m\right\} \), then \(s_i^{-*}=0\), and if \(t_r^{+*}>0\) for some \(r\in \left\{ 1,\ldots ,s\right\} \), then \(s_r^{+*}=0\). Hence
By (26) and (27) we have that \(\rho ^*\left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*\right) =\rho _0^*\left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*\right) \). So, if \({\mathbf {s}}^{-*},{\mathbf {s}}^{+*}\) are optimal for (6) we have that \( \rho \left( {\mathbf {x}}, {\mathbf {y}}, {\mathbf {s}}^{-*},{\mathbf {s}}^{+*}\right) =\rho \left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*, {\mathbf {s}}^{-*},{\mathbf {s}}^{+*}\right) =\rho ^*\left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*\right) = \rho _0^*\left( \bar{{\mathbf {x}}}^*,\bar{{\mathbf {y}}}^*\right) \), and then \({\mathbf {s}}^{-*},{\mathbf {s}}^{+*}\) are also optimal for (6)\('\). Analogously, if \({\mathbf {s}}^{-*},{\mathbf {s}}^{+*}\) are optimal for (6)\('\), then they are also optimal for (6). \(\square \)
Proof of Proposition 5
Property 2. can be deduced directly from (9).
-
1.
If \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is inefficient, then \(\delta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) =1\). On the other hand, \(\left( {\mathbf {x}},{\mathbf {y}}\right) \in {\bar{P}}\) and hence \(\max \rho ^*|_{{\bar{P}}}=\rho ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \) since \(\rho ^*\) is strongly monotonic (although only weak monotonicity is needed) and any activity in \({\bar{P}}\) is dominated by \(\left( {\mathbf {x}},{\mathbf {y}}\right) \). So, \(\gamma \left( {\mathbf {x}},{\mathbf {y}}\right) =\rho ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \) by (9).
-
3.
Since \(\max \rho ^*|_{{\bar{P}}}<1\), by (9), \(\gamma \left( {\mathbf {x}},{\mathbf {y}}\right) <\delta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \). On the other hand, since \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) is efficient and there are not efficient activities in \({\bar{P}}\), we have that \(\left( {\mathbf {x}},{\mathbf {y}}\right) \notin {\bar{P}}\) and hence, there are optimal super-efficiency slack vectors for (3) that are not simultaneously zero. So, \(\delta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) >1\) and then \(\gamma \left( {\mathbf {x}},{\mathbf {y}}\right) >\max \rho ^*|_{{\bar{P}}}\) by (9).
\(\square \)
Proof of Proposition 6
We have that \(\max \rho ^*|_{{\bar{P}}}\) depends on \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) through \({\bar{P}}\) (i.e. the set of activities in P that are dominated by \(\left( {\mathbf {x}},{\mathbf {y}}\right) \)). From (4), it is clear that \({\bar{P}}\) varies in a continuous way with respect to \(\left( {\mathbf {x}},{\mathbf {y}}\right) \). Moreover, since \(\rho ^*|_P\) is continuous and \({\bar{P}}\subseteq P\), we have that \(\max \rho ^*|_{{\bar{P}}}\) is continuous. Finally, since \(\delta ^*\) is continuous, we conclude that \(\gamma =\delta ^* \cdot \max \rho ^*|_{{\bar{P}}}\) is also continuous. \(\square \)
Proof of Proposition 7
Let \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) be an activity strictly dominated by \(\left( {\mathbf {x}}',{\mathbf {y}}'\right) \). Considering \({\bar{P}}\) and \({\bar{P}}'\) the sets of activities in P that are dominated by \(\left( {\mathbf {x}},{\mathbf {y}}\right) \) and \(\left( {\mathbf {x}}',{\mathbf {y}}'\right) \) respectively, it holds that \({\bar{P}} \subseteq {\bar{P}}'\) and hence, \(\max \rho ^*|_{{\bar{P}}}\le \max \rho ^*|_{{\bar{P}}'}\). On the other hand, \(\delta ^*\left( {\mathbf {x}},{\mathbf {y}}\right) \le \delta ^*\left( {\mathbf {x}}',{\mathbf {y}}'\right) \) since \(\delta ^*\) is weakly monotonic. So, \(\gamma \left( {\mathbf {x}},{\mathbf {y}}\right) \le \gamma \left( {\mathbf {x}}',{\mathbf {y}}'\right) \) by (9). \(\square \)
Proof of Proposition 8
We are going to prove that, in order to compute (12), the objective function of (13) can be replaced by \(\rho \left( {\mathbf {x}},{\mathbf {y}},{\mathbf {s}}^-,{\mathbf {s}}^+\right) \). Let (13)\('\) be the program (13) with objective function \(\rho \left( {\mathbf {x}},{\mathbf {y}},{\mathbf {s}}^-,{\mathbf {s}}^+\right) \), let \(\rho _0^*\left( {\mathbf {x}}+{\mathbf {t}}^{-}, {\mathbf {y}}-{\mathbf {t}}^{+}\right) \) be the optimal result of (13)\('\), and let \({\bar{P}}'\) be the subset of \({\bar{P}}\) whose activities are not strictly dominated by any other activity in \({\bar{P}}\). It is clear that if an activity \(\left( \bar{{\mathbf {x}}}, \bar{{\mathbf {y}}}\right) \in {\bar{P}}\) maximizes \(\rho ^*|_{{\bar{P}}}\) or \(\rho _0^*|_{{\bar{P}}}\), then \(\left( \bar{{\mathbf {x}}}, \bar{{\mathbf {y}}}\right) \in {\bar{P}}'\), because \(\rho ^*|_{{\bar{P}}}\) and \(\rho _0^*|_{{\bar{P}}}\) are strongly monotonic (see Proposition 1). Hence
Let \(\left( \bar{{\mathbf {x}}}, \bar{{\mathbf {y}}}\right) =\left( {\mathbf {x}}+{\mathbf {t}}^-,{\mathbf {y}}-{\mathbf {t}}^+\right) \in {\bar{P}}'\) and let \(\left( {\varvec{\lambda }}^*,{\mathbf {s}}^{-*},{\mathbf {s}}^{+*}\right) \) be an optimal solution for (13) or (13)\('\). We define \({\varvec{\tau }}^-,{\varvec{\tau }}^+\) such that \(\tau _i^-=\max \left\{ 0,t_i^{-}-s_i^{-*}\right\} \), \(\tau _r^+=\max \left\{ 0,t_r^{+}-s_r^{+*}\right\} \) for \(i=1,\ldots ,m\) and \(r=1,\ldots ,s\). From the constraints of (13) or (13)\('\) we have
and so \(\left( {\mathbf {x}}+{\varvec{\tau }}^-,{\mathbf {y}}-{\varvec{\tau }}^+\right) \in P\). Moreover, \(\left( {\mathbf {x}}+{\varvec{\tau }}^-,{\mathbf {y}}-{\varvec{\tau }}^+\right) \in {\bar{P}}\) because \(\tau _i^-,\tau _r^+\ge 0\). Let us suppose that there exists \(i\in \left\{ 1,\ldots ,m\right\} \) such that \(s_i^{-*},t_i^->0\). Then \(\tau _i^-<t_i^-\) and hence, taking into account that \({\varvec{\tau }}^-\le {\mathbf {t}}^-\) and \({\varvec{\tau }}^+\le {\mathbf {t}}^+\), we have that \(\left( {\mathbf {x}}+{\mathbf {t}}^-,{\mathbf {y}}-{\mathbf {t}}^+\right) \) is strictly dominated by \(\left( {\mathbf {x}}+{\varvec{\tau }}^-,{\mathbf {y}}-{\varvec{\tau }}^+\right) \), that is a contradiction because \(\left( {\mathbf {x}}+{\mathbf {t}}^-,{\mathbf {y}}-{\mathbf {t}}^+\right) \) is not strictly dominated by any other activity in \({\bar{P}}\). Analogously for outputs. So, if \(t_i^->0\) then \(s_i^{-*}=0\), and if \(t_r^+>0\) then \(s_r^{+*}=0\), concluding that
On one hand, if \({\mathbf {s}}^{-*},{\mathbf {s}}^{+*}\) are optimal for (13) then, by (29) we have
On the other hand, if \({\mathbf {s}}^{-*},{\mathbf {s}}^{+*}\) are optimal for (13)\('\) then, by (29) we have
Hence, by (30) and (31) we have that \(\rho ^*\left( \bar{{\mathbf {x}}}, \bar{{\mathbf {y}}}\right) =\rho _0^*\left( \bar{{\mathbf {x}}}, \bar{{\mathbf {y}}}\right) \) for all \(\left( \bar{{\mathbf {x}}}, \bar{{\mathbf {y}}}\right) \in {\bar{P}}'\), and then \(\rho ^*|_{{\bar{P}}'} = \rho _0^*|_{{\bar{P}}'}\). Taking into account (28) we conclude that \(\max \rho ^*|_{{\bar{P}}}=\max \rho ^*|_{{\bar{P}}'}=\max \rho _0^*|_{{\bar{P}}'}=\max \rho _0^*|_{{\bar{P}}}\). \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bolós, V.J., Benítez, R. & Coll-Serrano, V. Continuous models combining slacks-based measures of efficiency and super-efficiency. Cent Eur J Oper Res 31, 363–391 (2023). https://doi.org/10.1007/s10100-022-00813-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10100-022-00813-5