
Abstract
We analyze an inner approximation scheme for probability maximization. The approach was proposed in Fábián et al. (Acta Polytech Hung 15:105–125, 2018), as an analogue of a classic dual approach in the handling of probabilistic constraints. Even a basic implementation of the maximization scheme proved usable and endured noise in gradient computations without any special effort. Moreover, the speed of convergence was not affected by approximate computation of test points. This robustness was then explained in an idealized setting. Here we work out convergence proofs and efficiency arguments for a nondegenerate normal distribution. The main message of the present paper is that the procedure gains traction as an optimal solution is approached.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Let \( F( {{\textit{\textbf{z}}}} ) \) denote an n-dimensional nondegenerate standard normal distribution function. Due to logconcavity of the normal distribution, the probabilistic function \( \phi ( {{\textit{\textbf{z}}}} ) = -\log F( {{\textit{\textbf{z}}}} ) \) is convex. We consider a probability maximization problem in the form
where vectors are \( {{\textit{\textbf{x}}}} \in \mathrm{I}\mathrm{R}^m,\; {{\textit{\textbf{b}}}} \in \mathrm{I}\mathrm{R}^r \), and the matrices T and A are of sizes \( n \times m \) and \( r \times m \), respectively.
We are going to examine a simple and straightforward solution method, the one proposed in Fábián et al. (2018). It builds an inner approximation of the epigraph of \( \phi ( {{\textit{\textbf{z}}}} ) \), based on function evaluations in certain test points. A master problem is formulated using this approximation. Further test points are selected in the course of the procedure, with a view of gradually improving the optimum of the master problem.
In the computational study of Fábián et al. (2018), the speed of the convergence was not affected by approximate computation of test points. This robustness was then explained in an idealized setting, considering a globally well-conditioned objective function. In this paper we work out convergence proofs for the probabilistic function \( \phi ( {{\textit{\textbf{z}}}} ) \) specified above.
1.1 The broader context: inner approximation in probabilistic problems
Our scheme is analogous to the well-known dual approach in the handling of probabilistic constraints of the form
where \( p \gg 0 \) is a prescribed probability. The classic dual approach applies an inner approximation of the level set \( \mathcal{L}_p \). The approach has been initiated by Prékopa (1990), and the inner approximation was first applied to a probabilistic constraint by Prékopa et al. (1998). In Dentcheva et al. (2000), a cone generation scheme was developed for the continual improvement of the approximation. In this scheme, new test points are found by minimizing a tractable function over the level set \( \mathcal{L}_p \). Since this minimization entails a substantial computational effort, the master part of the decomposition framework should succeed with as few test points as possible. Efficient solution methods were developed by Dentcheva et al. (2004) and Dentcheva and Martinez (2013), approximating the original distribution by a discrete one and applying regularization to the master problem. More recently, van Ackooij et al. (2017) employed a special bundle-type method for the solution of the master problem, based on the on-demand accuracy approach of de Oliveira and Sagastizábal (2014). Each of these methods are quite complex, and, looking at them in a chronological order, an increasing level of complexity is noticeable. An effective solver based on this approach demands a sophisticated implementation.
In the classic scheme for probabilistic constraints, finding a new test point amounts to minimization over the level set \( \mathcal{L}_p \). In the scheme we are going to examine, a new approximation point is found by unconstrained minimization, with considerably less computational effort. The unconstrained problems can be approximately solved by a simple gradient descent method. Of course the probability maximization problem (1) is easier than the handling of a probabilistic constraint (2). A Newton-type scheme for the handling of the latter was proposed in Fábián et al. (2019). It requires the approximate solution of a short sequence of problems of the former type. (Initial problems in this sequence are solved with a large stopping tolerance, and the accuracy is gradually increased.)
Typically, gradient computations of probabilistic functions require a far greater effort than function evaluations. Computing a single non-zero component of a gradient vector will involve an effort comparable to that of computing a function value. (An alternative means of alleviating the difficulty of gradient computation in case of multivariate normal distribution has recently been proposed by Hantoute et al. 2018.)
In comparison with the outer approximation approach widely used in probabilistic programming, we mention that it requires a sophisticated implementation to deal with noise in gradient computation. Even a fairly accurate gradient may result in a cut cutting into the level set. The analogous difficulty does not occur in case of inner approximation. We can easily keep the inner approximating model from bulging out of the epigraph. A procedure that employs an inner approximation of the epigraph will endure noise in gradient computation without any special effort, provided function values are evaluated with appropriate accuracy. Inherent stability of the model enables the application of randomized methods of simple structure. Such methods have been worked out in Fábián et al. (2019).
1.2 Overview of the paper
Section 2 contains problem and model formulation, under mild assumptions. We formulate the probability maximization problem and its Lagrangian dual. Moreover, we construct respective polyhedral models of this primal-dual pair of convex problems.
Section 3 is a brief overview of the solution method proposed in Fábián et al. (2018). This is a simple procedure, formulated here as a column generation scheme with a linear programming master problem. The column generating subproblems are unconstrained convex problems, conveniently solved by the steepest descent method. In the computational study reported in Fábián et al. (2018), we applied approximate solutions of the subproblems, performing just a few line searches in each subproblem. This heuristic procedure never resulted in any substantial increase in the number of the iterations needed to solve a test problem. We actually found that a single line search performs well in practice.
This paper presents a convergence analysis of the simple procedure of Sect. 3, and an explanation of the experimental efficiency of a single line search, in case the objective function is derived from a nondegenerate normal distribution. The objects defined in the remaining sections are not employed in the algorithm itself. Their sole role is to enable convergence proofs and to support efficiency arguments. (The only exception is the box \(\mathcal{Z}^{\backprime }\) in Sect. 8.2, which has some minor role in a modified algorithm.)
Spadework for the analysis is done in Sect. 4, where we show that, with proper initialization of the test points, the solutions of the successive model problems will remain within well-defined bounds. These bounds, however, may be huge and have no practical relevance.
The bounds are applied in Sect. 5, where we present a theoretical estimate concerning the efficiency of a single line search in the column generating subproblem of Sect. 3. Though this estimate is not suitable for practical considerations.
In Sect. 6, we look at the whole column generation scheme from a dual viewpoint, and interpret it as an inexact cutting-plane scheme. The theoretical efficiency estimate of Sect. 5 is interpreted here as a rule that controls cut tolerance. The advantage of this viewpoint is that we can apply classic results concerning the uniform convergence of convex functions and the convergence of exact cutting-plane schemes. We prove that the resulting inexact cutting-plane scheme is convergent. Though this proof does not directly yield practical efficiency results.
In Sect. 7, we return to the primal viewpoint of the column generation scheme. We assume that the probabilistic function \( \phi ( {{\textit{\textbf{z}}}} ) \) is well-conditioned in the optimal solution of the original probability maximization problem. The convergence results of Sect. 6 imply that, starting with a certain iteration in the column generation scheme, we can focus on a certain neighborhood of the optimal solution. We show that, starting with that certain iteration, a practicable version of the theoretical efficiency estimate of Sect. 5 will hold.
In Sect. 8, we consider the master problem in a linear programming form, to be solved by the simplex method. In the simplex context, we look on the estimate of Sect. 7 as a guarantee of the workability of the column-selection rule of our simplex variant. Our arguments will then be based on the practical efficiency of the simplex method.
In Sect. 9, we illustrate the locally well-conditioned character of the probabilistic objective function, and a closing discussion is included in Sect. 10.
2 Problem and model formulation
We assume that the feasible domain of the probability maximization problem (1) is not empty, and is contained in the box \( \mathcal{X} = \{\, {{\textit{\textbf{x}}}} \in \mathrm{I}\mathrm{R}^m\, |\, -1 \le x_j \le 1\; ( j = 1, \ldots , m )\, \}. \) Exploiting the monotonicity of the objective function, problem (1) can be written as
Assumption 1
A significantly high probability can be achieved in the probability maximization problem. Specifically, a feasible point \( \check{{{\textit{\textbf{z}}}}} \) is known such that \( F( \check{{{\textit{\textbf{z}}}}} ) \ge 0.5 \).
The purpose of this assumption is not just to provide a starting solution. It will also help keeping the solution process in a safe area where the slope of the \( \log (.) \) function is moderate.
A further speciality of the normal distribution function is the existence of a bounded box \( \mathcal{Z} \) outside which the probability weight can be ignored. For the sake simplicity, we assume that this box has the form \( \mathcal{Z} = \{\, {{\textit{\textbf{z}}}} \in \mathrm{I}\mathrm{R}^n\, |\, -1 \le z_j \le 1\; ( j = 1, \ldots , n )\, \} \). Including the constraint \( {{\textit{\textbf{z}}}} \in \mathcal{Z} \) in (3) results in the approximating problem
As observed in Fábián et al. (2019), the difference between the respective optima of problems (3) and (4) is insignificant. (In the proof, we need an upper bound on the gradients of the objective function \( \phi ( {{\textit{\textbf{z}}}} ) = - \log F( {{\textit{\textbf{z}}}} ) \) at the optimal solutions. Such a bound can be derived from Assumption 1.)
The bound \( {{\textit{\textbf{z}}}} \in \mathcal{Z} \) in (4) allows regularization of the objective function, in the form of
with some \( \rho > 0 \). Substituting this regularized objective in (4) makes no significant variation in the objective value of \( {{\textit{\textbf{z}}}} \in \mathcal{Z} \), provided \( \rho \) is small enough. On the other hand, the regularizing term improves the condition of the objective and ensures that the conjugate function \( \phi ^{\star }( . ) \) is finite valued. In this paper, we are going to work with this regularized objective, with an appropriately small \( \rho \). The aim is just to improve numerical characteristics of \( \phi ( {{\textit{\textbf{z}}}} ) \). We do not wish to omit \( \mathcal{Z} \) in the problem formulation, because it will have a role in the algorithm.
Splitting the variables \( {{\textit{\textbf{z}}}} \), we transform (4) into the equivalent form
Problem (6) has an optimal solution because the feasible domain is nonempty and bounded.
We relax the constraints \(\, {{\textit{\textbf{z}}}} - {{\textit{\textbf{z}}}}^{\prime } = {{\textit{\textbf{0}}}} ;\; {{\textit{\textbf{z}}}}^{\prime } - T{{\textit{\textbf{x}}}} \le {{\textit{\textbf{0}}}} \,\) and \(\, A {{\textit{\textbf{x}}}} - {{\textit{\textbf{b}}}} \le {{\textit{\textbf{0}}}} \,\) by introducing respective multiplier vectors \(\, {{\textit{\textbf{u}}}} \in \mathrm{I}\mathrm{R}^n ;\; -{{\textit{\textbf{v}}}} \in \mathrm{I}\mathrm{R}^n, -{{\textit{\textbf{v}}}} \ge {{\textit{\textbf{0}}}} \,\) and \(\, -{{\textit{\textbf{y}}}} \in \mathrm{I}\mathrm{R}^r, -{{\textit{\textbf{y}}}} \ge {{\textit{\textbf{0}}}} \). The Lagrangian is
(In a strict sense, we actually applied the multiplier \( -{{\textit{\textbf{u}}}} \) to the first constraint.)
The relaxed problem falls apart into three separate minimization problems:
The first minimum is by definition the negative of the conjugate function value \( \phi ^{\star }( {{\textit{\textbf{u}}}} ) \). Due to the special form of the box \( \mathcal{Z} \), the second minimum is \( - \Vert {{\textit{\textbf{u}}}} - {{\textit{\textbf{v}}}} \Vert _1 \). The third minimum can be computed in a similar manner, and the optimum of the relaxed problem is
Introducing the function
the Lagrangian dual of (6) can be written as
According to the theory of convex duality, this problem has an optimal solution. Even strong duality relationship holds between (6) and (11), because we assumed linear constraints in the primal problem. We could even allow nonlinear convex constraints, assumed that Slater’s condition is satisfied. For a recent treatise on Lagrangian duality, see, e.g., Chapter 4 in the book Ruszczyński (2006).
An optimal solution of the primal problem (6) has the form of \( ( {{\textit{\textbf{z}}}}^{\star }, {{\textit{\textbf{z}}}}^{\prime \star }, {{\textit{\textbf{x}}}}^{\star } ) \). With some laxity, I will call a vector \( {{\textit{\textbf{z}}}}^{\star } \in \mathrm{I}\mathrm{R}^n \) an optimal solution of (6), if it can be extended into a strict-sense optimal solution \( ( {{\textit{\textbf{z}}}}^{\star }, {{\textit{\textbf{z}}}}^{\prime \star }, {{\textit{\textbf{x}}}}^{\star } ) \). This \( {{\textit{\textbf{z}}}}^{\star } \) is unique due to the strict convexity of the regularized objective function \( \phi ( {{\textit{\textbf{z}}}} ) \). The objective function is also smooth, hence its conjugate is strictly convex (see Theorem 26.1 in Rockafellar (1970)). Hence the dual problem (11) has a unique optimal solution \( {{\textit{\textbf{u}}}}^{\star } \).
Observation 2
Let \( {{\textit{\textbf{z}}}}^{\star } \) and \( {{\textit{\textbf{u}}}}^{\star } \) denote the respective optimal solutions of the primal problem (6) and the dual problem (11). We have
Proof
Let us extend \( {{\textit{\textbf{z}}}}^{\star } \) to a strict-sense optimal solution \( ( {{\textit{\textbf{z}}}}^{\star }, {{\textit{\textbf{z}}}}^{\prime \star }, {{\textit{\textbf{x}}}}^{\star } ) \) of the primal problem (6). Given \( {{\textit{\textbf{u}}}}^{\star } \), let \( {{\textit{\textbf{v}}}}^{\star }, {{\textit{\textbf{y}}}}^{\star } \) denote an optimal solution of the supremum problem in (10). Then \( \big (\, ( {{\textit{\textbf{z}}}}^{\star }, {{\textit{\textbf{z}}}}^{\prime \star }, {{\textit{\textbf{x}}}}^{\star } ),\, ( -{{\textit{\textbf{u}}}}^{\star }, -{{\textit{\textbf{v}}}}^{\star }, -{{\textit{\textbf{y}}}}^{\star } )\, \big ) \) is a saddle point of the Lagrangian (7). Hence the Karush–Kuhn–Tucker conditions for the optimality of \( ( {{\textit{\textbf{z}}}}^{\star }, {{\textit{\textbf{z}}}}^{\prime \star }, {{\textit{\textbf{x}}}}^{\star } ) \) in (6) hold with Lagrange multipliers \( ( -{{\textit{\textbf{u}}}}^{\star }, -{{\textit{\textbf{v}}}}^{\star }, -{{\textit{\textbf{y}}}}^{\star } ) \), and (12) is part of the Karush–Kuhn–Tucker conditions. Proofs of the cited statements can be found, e.g. in Ruszczyński (2006), Theorems 4.9, 4.7 and 3.34. \(\square \)
2.1 Polyhedral models
Suppose we have evaluated the function \( \phi ( {{\textit{\textbf{z}}}} ) \) at points \( {{\textit{\textbf{z}}}}_i\; ( i = 0, 1, \ldots , k ) \); we introduce the notation \( \phi _i = \phi ( {{\textit{\textbf{z}}}}_i ) \) for respective objective values. An inner approximation of \( \phi ( . ) \) is
If \( {{\textit{\textbf{z}}}} \not \in \text{ Conv }( {{\textit{\textbf{z}}}}_0, \ldots , {{\textit{\textbf{z}}}}_k ) \), then let \( \phi _k( {{\textit{\textbf{z}}}} ) := +\infty \). A polyhedral model of problem (6) is
We assume that (14) is feasible, i.e., its optimum is finite. This can be ensured by proper selection of the initial \( {{\textit{\textbf{z}}}}_0, \ldots , {{\textit{\textbf{z}}}}_k \) points. With some laxity, I will call a vector \( \overline{{{\textit{\textbf{z}}}}} \in \mathrm{I}\mathrm{R}^n \) an optimal solution of (14), if it can be extended into a strict-sense optimal solution \( ( \overline{{{\textit{\textbf{z}}}}}, \overline{{{\textit{\textbf{z}}}}^{\prime }}, \overline{{{\textit{\textbf{x}}}}} ) \).
The convex conjugate of \( \phi _k( {{\textit{\textbf{z}}}} ) \) is
As \( \phi _k^{\star }( . ) \) is a cutting-plane model of \( \phi ^{\star }( . ) \), the following problem is a polyhedral model of problem (11):
At the same time, (16) is the linear programming dual of (14).
Let \( \overline{{{\textit{\textbf{z}}}}} \) denote an optimal solution of the primal model problem (14), and let \( \overline{{{\textit{\textbf{u}}}}} \) denote an optimal solution of the dual model problem (16)—existing due to our assumption concerning the feasibility of (14). The following observation was proved in Fábián et al. (2018).
Observation 3
We have \(\; \phi _k( \overline{{{\textit{\textbf{z}}}}} ) + \phi _k^{\star } \left( \overline{{{\textit{\textbf{u}}}}} \right) = \overline{{{\textit{\textbf{u}}}}}^T \overline{{{\textit{\textbf{z}}}}} \;\) and hence \( \overline{{{\textit{\textbf{u}}}}} \) is a subgradient of \( \phi _k( {{\textit{\textbf{z}}}} ) \) at \( {{\textit{\textbf{z}}}} = \overline{{{\textit{\textbf{z}}}}} \).
3 A simple solution method
The convex problem (6) can be solved through approximation. The approximating problem (14) can be formulated as a linear programming problem. The idea is to progressively improve the approximation by adding further approximation points, a traditional and widely used approach.
In Fábián et al. (2018), we applied a straightforward and unsophisticated method for the construction of approximation points. That is an iterative method. The initialization will be presented in Sect. 3.1. An iteration consist in building and solving the model problem as described in Sect. 3.2, and finding an improving approximation point as described in Sect. 3.3.
3.1 Initialization of the model
We initialized the model function (13) with \( n + 1 \) points (n being the dimension of the distribution). The 2-dimensional case is illustrated in Fig. 1. The shaded area represents the bounded box \( \mathcal{Z} \) outside which the probability weight can be ignored.
The ‘most positive’ vertex of \( \mathcal{Z} \) was selected as \( {{\textit{\textbf{z}}}}_0 \), and \( {{\textit{\textbf{z}}}}_1, \ldots , {{\textit{\textbf{z}}}}_n \) were respective points from the edges adjoining \( {{\textit{\textbf{z}}}}_0 \). In this paper we follow this way of initialization, further adding the vector of Assumption 1, as \( {{\textit{\textbf{z}}}}_{n+1} = \check{{{\textit{\textbf{z}}}}} \). This of course always results in a feasible primal model problem (14).

Initial test points in a two-dimensional case
3.2 A linear programming formulation of the model problem
Taking into account the model function definition (13), the primal model problem (14) can obviously be formulated as follows.
The variable \( {{\textit{\textbf{z}}}} \) of (14) is represented here as the convex combination \( \sum \, \lambda _i {{\textit{\textbf{z}}}}_i \). Hence the splitting constraint \( {{\textit{\textbf{z}}}} - {{\textit{\textbf{z}}}}^{\prime } = {{\textit{\textbf{0}}}} \) of (14) takes the form \( \sum \, \lambda _i {{\textit{\textbf{z}}}}_i - {{\textit{\textbf{z}}}}^{\prime } = {{\textit{\textbf{0}}}} \).
The columns corresponding to the approximation points \( {{\textit{\textbf{z}}}}_0, \ldots , {{\textit{\textbf{z}}}}_k \) are involved only in the convexity constraint \( \sum \lambda _i = 1 \) and in the splitting constraint. The dual variable (shadow price) belonging to the convexity constraint will be denoted by \( \vartheta \), and the dual vector belonging to the splitting constraint will be denoted by \( {{\textit{\textbf{u}}}} \). (These are shown above, attached to the respective constraints with \( \perp \) signs.)
The linear programming problem (17) is easy to solve (and an optimal solution always exists, due to the initialization described above.) Let \( (\, \overline{\lambda }_0, \ldots , \overline{\lambda }_k \,) \) denote a part of an optimal solution of (17). Then an optimal solution \( \overline{{{\textit{\textbf{z}}}}} \) of (14) can be constructed in the form
3.3 Column generation
We aim to find a new approximation point \( {{\textit{\textbf{z}}}}_{k+1} \) whose addition to the model function (13) will result in an improvement in the optimal objective value of (17).
Let \( \overline{\vartheta } \) denote the optimal dual variable belonging to the convexity constraint in (17). Similarly, let \( \overline{{{\textit{\textbf{u}}}}} \) denote the optimal dual vector belonging to the splitting constraint.
Given a vector \( {{\textit{\textbf{z}}}} \in \mathrm{I}\mathrm{R}^n \), we can add the corresponding column \( ( 1, {{\textit{\textbf{z}}}}, {{\textit{\textbf{0}}}} ) \) to the linear programming problem (17), with objective component \( \phi ( {{\textit{\textbf{z}}}} ) \). This is an improving column if its reduced cost is positive; formally, if \( \overline{\varrho }( {{\textit{\textbf{z}}}} ) > 0 \) holds for
A vector yielding a good reduced cost can be found by approximately solving the column generating problem
In the context of the simplex method, the optimal solution of this problem corresponds to the Markowitz column selection rule. This is a classic column selection rule that is still considered fairly efficient and is widely used.
3.4 Our experience with the iterative method
As we have seen, an improving column for (17) can be found by maximizing the reduced cost function \( \overline{\varrho }( {{\textit{\textbf{z}}}} ) \). In the computational study reported in Fábián et al. (2018), we applied a steepest descent method to \( - \overline{\varrho }( {{\textit{\textbf{z}}}} ) \), a natural starting point being \( \overline{{{\textit{\textbf{z}}}}} \). In the first round of test runs, we solved the column generating problems to near-optimality. However, we found the computational effort excessive. (Most of the computational effort was spent in the computation of probabilistic function gradients.) Hence we decided to perform just a few line searches in each column generating problem (20). This heuristic procedure never resulted in any substantial increase in the number of the iterations needed to solve a test problem. We actually found that a single line search performs well in practice.
3.5 Convergence arguments for an idealized setting
We thought that the experimental efficiency of the above mentioned simplified scheme needs explanation. In Fábián et al. (2018) we explained it in an idealized setting, considering a globally well-conditioned objective function. Let \( f : \mathrm{I}\mathrm{R}^n \rightarrow \mathrm{I}\mathrm{R}\) such that the following assumption holds.
Assumption 4
(Bounded Hessians) The function \( f( {{\textit{\textbf{z}}}} ) \) is twice continuously differentiable, and real numbers \( \alpha , \omega \; ( 0 < \alpha \le \omega ) \) exist such that
Here \( \nabla ^2 f ( {{\textit{\textbf{z}}}} ) \) is the Hessian matrix, I is the identity matrix, and the relation \( U \preceq V \) between matrices means that \( V - U \) is positive semidefinite.
Let me note that lower-bounded Hessians imply strong convexity – this is an easy consequence of Taylor’s theorem. The following well-known theorem can be found e.g., in Chapter 8.6 of Luenberger and Ye (2008). (Ruszczyński 2006 in Chapter 5.3.5, Theorem 5.7 presents a slightly different form.)
Theorem 5
Let Assumption 4 hold. We minimize \( f( {{\textit{\textbf{z}}}} ) \) over \( \mathrm{I}\mathrm{R}^n \) using a steepest descent method, starting from a point \( {{\textit{\textbf{z}}}}^0 \). Let \( {{\textit{\textbf{z}}}}^1, \ldots , {{\textit{\textbf{z}}}}^j, \ldots \) denote the iterates obtained by applying exact line search at each step. Then we have
where \( \mathcal{F} = \min _{{{\textit{\textbf{z}}}}} f( {{\textit{\textbf{z}}}} ) \).
If our objective function \( \phi ( {{\textit{\textbf{z}}}} ) \) should have bounded Hessians, then the function \( -\overline{\varrho }( {{\textit{\textbf{z}}}} ) \) of (19) would inherit this property. (The column generating subproblem can be formulated as minimization of \( -\overline{\varrho }( {{\textit{\textbf{z}}}} ) \).)
In Fábián et al. (2018), we applied Theorem 5 to \( f( {{\textit{\textbf{z}}}} ) = -\overline{\varrho }( {{\textit{\textbf{z}}}} ) \;\) with \( {{\textit{\textbf{z}}}}^0 = \overline{{{\textit{\textbf{z}}}}} \). We showed that
is a straight consequence of the theorem. In view of the Markowitz rule mentioned above, we find a fairly good improving vector in the column generation scheme in a very few iterations, provided the condition number \( \alpha / \omega \) is not extremely bad.
The efficiency of the whole iterative procedure can then be explained by the practical efficiency of the simplex method.
4 Bounds on optimal solutions
Our first aim is to construct a compact set that contains every optimal solution \( \overline{{{\textit{\textbf{z}}}}} \) of any model problem (14). An obvious choice would be the box \( \mathcal{Z} \). But, for reasons that will become apparent shortly, we need a set well inside \( \mathcal{Z} \).
The constraints \( {{\textit{\textbf{z}}}} = {{\textit{\textbf{z}}}}^{\prime } \le T {{\textit{\textbf{x}}}} \) and \( {{\textit{\textbf{x}}}} \in \mathcal{X} \) appear in the model problem (14). Hence the set \( \{\, T {{\textit{\textbf{x}}}} \,|\, {{\textit{\textbf{x}}}} \in \mathcal{X} \,\} + \mathcal{N} \), where \( \mathcal{N} \) denotes the negative (closed) orthant in \( \mathrm{I}\mathrm{R}^n \), contains every optimal solution \( \overline{{{\textit{\textbf{z}}}}} \) of (14).
As we include \( \check{{{\textit{\textbf{z}}}}} \) of Assumption 1 among the initial test points, every optimal solution satisfies also \( \phi ( \overline{{{\textit{\textbf{z}}}}} ) \le \phi ( \check{{{\textit{\textbf{z}}}}} ) \). We have set the regularization term in the objective (5) in such a way that the variation of \( \frac{\rho }{2} \Vert {{\textit{\textbf{z}}}} \Vert ^2 \) on \( \mathcal{Z} \) is small. This results a reasonably large lower bound for the probability belonging to the optimal solution, like \( F( \overline{{{\textit{\textbf{z}}}}} ) \,\ge 0.49 \). It follows that the set
contains every optimal solution \( \overline{{{\textit{\textbf{z}}}}} \) of any model problem (14). In a similar manner, it can be shown that \( {{\textit{\textbf{z}}}}^{\star } \in \mathcal{O}_{{{\textit{\textbf{z}}}}} \) with the optimal solution \( {{\textit{\textbf{z}}}}^{\star } \) of the primal problem (6).
The set \( \mathcal{O}_{{{\textit{\textbf{z}}}}} \) is compact. Indeed, let us consider the two intersecting sets on the right-hand side of (23): the former has the negative orthant as its recession cone, while the recession cone of the latter is the positive orthant.
Now we are going to construct an upper bound for the subgradients of the model function on \( \mathcal{O}_{{{\textit{\textbf{z}}}}} \). The idea is to have a wide border around \( \mathcal{O}_{{{\textit{\textbf{z}}}}} \), on which border the model function is finite valued.
Initialization of the approximation points was described in Sect. 3.1, and illustrated in Fig. 1. (The ’most positive’ vertex of \( \mathcal{Z} \) is selected as \( {{\textit{\textbf{z}}}}_0 \), and \( {{\textit{\textbf{z}}}}_1, \ldots , {{\textit{\textbf{z}}}}_n \) are respective points from the edges adjoining \( {{\textit{\textbf{z}}}}_0 \).) Let \( \mathcal{S} = \text{ Conv }( {{\textit{\textbf{z}}}}_0, \ldots , {{\textit{\textbf{z}}}}_n ) \) denote the convex hull of these \( n+1 \) test points. As the box \( \mathcal{Z} \) can be extended arbitrarily, we may assume not only that \( \mathcal{O}_{{{\textit{\textbf{z}}}}} \subset \mathcal{S} \) holds, but even that
where \( \mathcal{S}_{\eta } \) denotes the simplex obtained by shrinking \( \mathcal{S} \) towards its barycenter, the ratio of decrease being 1 to \( \eta \). In what follows, we work with a fixed value \( \eta \) satisfying (24).
Observation 6
Assume that the model functions have been initialized in such a way that (24) holds.
Then there exists a finite upper bound \( \Gamma _{{{\textit{\textbf{u}}}}} \) such that \( \Vert {{\textit{\textbf{u}}}} \Vert \le \Gamma _{{{\textit{\textbf{u}}}}} \) holds for every subgradient \( {{\textit{\textbf{u}}}} \) of any model function \( \phi _k( {{\textit{\textbf{z}}}} ) \) on \( \mathcal{O}_{{{\textit{\textbf{z}}}}} \).
Moreover, with the true objective function, we have \( \Vert \nabla \phi ( {{\textit{\textbf{z}}}} ) \Vert \le \Gamma _{{{\textit{\textbf{u}}}}}\;\; ( {{\textit{\textbf{z}}}} \in \mathcal{O}_{{{\textit{\textbf{z}}}}} ) \) as well.
The proof is straightforward but somewhat technical, hence I include it in the “Appendix, section A.1”.
5 On the efficiency of a single line search
Let \( \overline{{{\textit{\textbf{z}}}}} \) denote an optimal solution of the model problem, constructed in the form (18). Let moreover \( \overline{{{\textit{\textbf{u}}}}} \) be the optimal dual vector belonging to the splitting constraint in the linear programming form (17) of the model problem. According to the column generating procedure of Sect. 3.3, the next test point \( {{\textit{\textbf{z}}}}_{k+1} = {{\textit{\textbf{z}}}}^{\backprime } \) is obtained by approximate maximization of \( \overline{{{\textit{\textbf{u}}}}}^T {{\textit{\textbf{z}}}} - \phi ( {{\textit{\textbf{z}}}} ) \).
The column generating subproblem is conveniently reformulated as approximate minimization of the function \( f( {{\textit{\textbf{z}}}} ) = \phi ( {{\textit{\textbf{z}}}} ) - \overline{{{\textit{\textbf{u}}}}}^T {{\textit{\textbf{z}}}} \), and a steepest descent method can be applied from the convenient starting point \( \overline{{{\textit{\textbf{z}}}}} \). In accordance with our experience described in Sect. 3.4, we are actually going to work out proofs for a single line search performed in the opposite direction of the gradient \( \overline{{{\textit{\textbf{g}}}}} = \nabla f( \overline{{{\textit{\textbf{z}}}}} ) = \nabla \phi ( \overline{{{\textit{\textbf{z}}}}} ) - \overline{{{\textit{\textbf{u}}}}} \).
We have \( \overline{{{\textit{\textbf{z}}}}} \in \mathcal{O}_{{{\textit{\textbf{z}}}}} \) and \( \Vert \overline{{{\textit{\textbf{g}}}}} \Vert \le 2 \Gamma _{{{\textit{\textbf{u}}}}} \) as shown in Sect. 4. Hence any line search is performed on a ray of the form
Due to the regularizing term in the objective (5), all eigenvalues of the Hessians are increased by \( \rho \), hence \( \nabla ^2 \phi ( {{\textit{\textbf{z}}}} ) \succeq \rho I \;\; ( {{\textit{\textbf{z}}}} \in \mathrm{I}\mathrm{R}^n ) \) holds. Though there exists no finite upper bound on the eigenvalues, it turns out that a local version of Assumption 4 is sufficient.
Given \( {{\textit{\textbf{z}}}} \in \mathrm{I}\mathrm{R}^n \), let \( \omega ( {{\textit{\textbf{z}}}} ) \) denote the largest eigenvalue of \( \nabla ^2 f ( {{\textit{\textbf{z}}}} ) \). Continuity of this function is a straight consequence of a theorem of Ostrowski that I cite as Theorem 17 in “Appendix” B. Since the set \( \mathcal{O}_{{{\textit{\textbf{z}}}}} \) is compact, it follows that
is finite. With this, let
This again is a compact set, hence
is again finite. As \( \overline{\mathcal{O}} \supseteq \mathcal{O}_{{{\textit{\textbf{z}}}}} \), it follows that \( \overline{\Omega } \ge \Omega \).
Proposition 7
With \( {{\textit{\textbf{z}}}}^{\backprime } \) found by performing a single line search, we have
where \( \mathcal{F} = \min _{{{\textit{\textbf{z}}}}} f( {{\textit{\textbf{z}}}} ) \).
The proof will be an adaptation of that of Theorem 5, as related in Chapter 8.6 of Luenberger and Ye (2008). We restrict our investigation to \( \overline{\mathcal{O}} \).
Proof of Proposition 7
Due to the above construction, we have \( \overline{{{\textit{\textbf{z}}}}} - t \overline{{{\textit{\textbf{g}}}}} \in \overline{\mathcal{O}} \) for t such that \( 0 \le t \le 1/\Omega \). Hence \( \nabla ^2 \phi ( {{\textit{\textbf{z}}}} ) \preceq \overline{\Omega } I \) holds for \( {{\textit{\textbf{z}}}} = \overline{{{\textit{\textbf{z}}}}} - t \overline{{{\textit{\textbf{g}}}}} \) with these t values. It follows that
holds (a consequence of Taylor’s theorem). We consider the respective minima in \( t \in \mathrm{I}\mathrm{R}\) separately of the two sides. The right-hand side is a quadratic expression, yielding minimum at \( t = 1/\overline{\Omega } \). (Note that \( 1/\overline{\Omega } \le 1/\Omega \).) It follows that
From \( \nabla ^2 \phi ( {{\textit{\textbf{z}}}} ) \succeq \rho I\;\; ( {{\textit{\textbf{z}}}} \in \mathrm{I}\mathrm{R}^n ) \), it follows in a similar manner that
The right-hand side expression is a quadratic function of \( {{\textit{\textbf{z}}}} \), which yields its minimum at \( {{\textit{\textbf{z}}}} = \overline{{{\textit{\textbf{z}}}}} - \frac{1}{\rho } \overline{{{\textit{\textbf{g}}}}} \). Hence
The proof is concluded by simple transformations of (28) and (30). The improving column \( {{\textit{\textbf{z}}}}^{\backprime } \) is found by solving the minimization problem in the left-hand side of (28). Subtracting \( \mathcal{F} \) from both sides of (28), and applying (30) to underestimate \( \Vert \overline{{{\textit{\textbf{g}}}}} \Vert ^2 \), we get (27). \(\square \)
6 Dual viewpoint: an approximate cutting-plane method
The method to be described in this section is not new. It is just the simple solution method of Sect. 3, described from a new viewpoint that will enable us to apply some classic tools in the convergence proof.
The column generation procedure, as described in Sects. 3.2 and 3.3, yields an inner approximation of the epigraph of the objective function \( \phi ( {{\textit{\textbf{z}}}} ) \). Looking at the same procedure from a dual viewpoint we can see a cutting-plane method. This relationship between the primal and dual approaches is well known, see, e.g., Frangioni (2002, (2018), but it is immediately apparent in the present case: (16) is clearly a cutting-plane model of (11). From the dual point of view, the procedure yields an outer approximation of the epigraph of the conjugate function \( \phi ^{\star }( {{\textit{\textbf{u}}}} ) \).
As the linear programming problem (17) is just a re-formulation of the primal model problem (14), it follows that the dual of (17) is equivalent to the dual model problem (16). Specifically, let \( \overline{{{\textit{\textbf{u}}}}} \) denote an optimal dual vector belonging to the splitting constraint in (17). Then, at the same time, \( \overline{{{\textit{\textbf{u}}}}} \) is an optimal solution of the dual model problem (16).
If we wish to apply a cutting-plane method for the minimization of a convex function \( \varphi : \mathrm{I}\mathrm{R}^n \rightarrow \mathrm{I}\mathrm{R}\), we must be able to construct an approximate support function at any given point \( \widehat{{{\textit{\textbf{u}}}}} \in \mathrm{I}\mathrm{R}^n \). This is a linear function \( \ell ( {{\textit{\textbf{u}}}} ) \) such that \( \ell ( {{\textit{\textbf{u}}}} ) \le \varphi ( {{\textit{\textbf{u}}}} )\;\; ( {{\textit{\textbf{u}}}} \in \mathrm{I}\mathrm{R}^n ) \) holds, and the difference \( \varphi ( \widehat{{{\textit{\textbf{u}}}}} ) - \ell ( \widehat{{{\textit{\textbf{u}}}}} ) \) is under control. If the difference is 0 then \( \ell ( {{\textit{\textbf{u}}}} ) \) is an exact support function to \( \varphi ( {{\textit{\textbf{u}}}} ) \) at \( \widehat{{{\textit{\textbf{u}}}}} \).
6.1 Problem specification and dual interpretation of former results
Introducing the function \( d( {{\textit{\textbf{u}}}} ) :=\; \phi ^{\star }( {{\textit{\textbf{u}}}} ) + \nu ( {{\textit{\textbf{u}}}} ) \), the dual problem (11) can be solved in the form
The kth model function is \( d_k( {{\textit{\textbf{u}}}} ) :=\; \phi _k^{\star }( {{\textit{\textbf{u}}}} ) + \nu ( {{\textit{\textbf{u}}}} ) \), with \( \phi _k^{\star }( {{\textit{\textbf{u}}}} ) \) defined in (15). The dual model problem (16) can be solved in the form
Let \( \overline{{{\textit{\textbf{u}}}}} \) denote an optimal solution of the model problem (32). Moreover let
with the bound \( \Gamma _{{{\textit{\textbf{u}}}}} \) of Observation 6. This is a compact ball that contains the optimal solution \( \overline{{{\textit{\textbf{u}}}}} \) of the model problem (32), as well as the optimal solution \( {{\textit{\textbf{u}}}}^{\star } \) of the convex problem (31).
An approximate support function to \( d( {{\textit{\textbf{u}}}} ) \) at \( \overline{{{\textit{\textbf{u}}}}} \) is constructed in the form
where the right-hand-side functions are separate support functions to \( \phi ^{\star }( {{\textit{\textbf{u}}}} ) \) and \( \nu ( {{\textit{\textbf{u}}}} ) \), respectively.
As for \( \nu ( {{\textit{\textbf{u}}}} ) \), we can construct an exact support function \( \ell ^{\prime \prime }( {{\textit{\textbf{u}}}} ) \) by solving the problem (10\(\,: {{\textit{\textbf{u}}}} = \overline{{{\textit{\textbf{u}}}}} \,\)). This can be formulated as a linear programming problem whose optimal dual variables will give a subgradient at \( \overline{{{\textit{\textbf{u}}}}} \).
The approximate support function to \( \phi ^{\star }( {{\textit{\textbf{u}}}} ) \) is constructed in the form
with an appropriate vector \( {{\textit{\textbf{z}}}}^{\backprime } \). (Note that \( \ell ^{\prime }( . ) \le \phi ^{\star }( . ) \) holds by the definition of the conjugate function.) An exact support function at \( \overline{{{\textit{\textbf{u}}}}} \) could be obtained by setting \( {{\textit{\textbf{z}}}}^{\backprime } \) to be the exact maximizer of \( \overline{{{\textit{\textbf{u}}}}}^T {{\textit{\textbf{z}}}} - \phi ( {{\textit{\textbf{z}}}} ) \). This is just the column generating problem (20). An approximate solution of the column generating problem yields an approximate support function. Approximate solution of the column generation problem was described in Sect. 3. Let \( \overline{{{\textit{\textbf{z}}}}} \) denote a primal optimal solution, constructed in the form (18). Let moreover \( {{\textit{\textbf{z}}}}^{\backprime } \) be found by a single line search starting from \( \overline{{{\textit{\textbf{z}}}}} \). We analyzed this procedure in Sect. 5. Translating Proposition 7 to the present setting, we get
Corollary 8
The support function (35) satisfies
with the constant \( \theta = \rho /\overline{\Omega } \). Here \( \rho \) is the regularization constant of (5), and \( \overline{\Omega } \) defined in (26). Of course we have \( 0< \theta < 1 \), and it is independent of the iteration count k.
Proof of Corollary 8
We start with formulating (27) in terms of \( \phi ( {{\textit{\textbf{z}}}} ) \) and \( \phi ^{\star }( {{\textit{\textbf{u}}}} ) \). By the definition \( f( {{\textit{\textbf{z}}}} ) = \phi ( {{\textit{\textbf{z}}}} ) - \overline{{{\textit{\textbf{u}}}}}^T {{\textit{\textbf{z}}}} \), we have \( \mathcal{F} = - \phi ^{\star }( \overline{{{\textit{\textbf{u}}}}} ) \). Substituting these, we get
A simple transformation results in
By Observation 3, we have \( \overline{{{\textit{\textbf{u}}}}}^T \overline{{{\textit{\textbf{z}}}}} = \phi _k^{\star }( \overline{{{\textit{\textbf{u}}}}} ) + \phi _k( \overline{{{\textit{\textbf{z}}}}} ) \). Substituting this in the bracketed expression, and taking into account \( \phi ( {{\textit{\textbf{z}}}} ) \le \phi _k( {{\textit{\textbf{z}}}} )\;\; ( {{\textit{\textbf{z}}}} \in \mathrm{I}\mathrm{R}^n ) \), we get \( \phi ^{\star }( \overline{{{\textit{\textbf{u}}}}} ) + \phi ( \overline{{{\textit{\textbf{z}}}}} ) - \overline{{{\textit{\textbf{u}}}}}^T \overline{{{\textit{\textbf{z}}}}} \; \le \; \phi ^{\star }( \overline{{{\textit{\textbf{u}}}}} ) - \phi _k^{\star }( \overline{{{\textit{\textbf{u}}}}} ), \) directly yielding (36). \(\square \)
The support function (34) obviously inherits the property of Corollary 8. That is,
holds with the same constant \( \theta = \rho /\overline{\Omega } \).
6.2 Convergence
A more detailed notation will be needed, including indexing of the iterates and support functions in the cutting-plane scheme. Let \( \overline{{{\textit{\textbf{u}}}}}_1, \ldots , \overline{{{\textit{\textbf{u}}}}}_k \) denote the known iterates. Let \( \ell _i( {{\textit{\textbf{u}}}} ) \;\; ( i = 1, \ldots , k ) \) denote approximate support functions at the respective iterates. These take the form \( \ell _i( {{\textit{\textbf{u}}}} ) = \ell ^{\prime }_i( {{\textit{\textbf{u}}}} ) + \ell ^{\prime \prime }_i( {{\textit{\textbf{u}}}} ) \), where \( \ell ^{\prime }_i( {{\textit{\textbf{u}}}} ) \) is an approximate support function to \( \phi ^{\star }( {{\textit{\textbf{u}}}} ) \), and \( \ell ^{\prime \prime }_i( {{\textit{\textbf{u}}}} ) \) is an exact support function to \( \nu ( {{\textit{\textbf{u}}}} ) \), at \( \overline{{{\textit{\textbf{u}}}}}_i \).
The model function \( d_k( {{\textit{\textbf{u}}}} ) \) is the upper cover of the support functions \( \ell _i( {{\textit{\textbf{u}}}} ) \;\; ( i = 1, \ldots , k ) \), and the next iterate \( \overline{{{\textit{\textbf{u}}}}}_{k+1} \) is a minimizer of \( d_k( {{\textit{\textbf{u}}}} ) \). At \( \overline{{{\textit{\textbf{u}}}}}_{k+1} \), again, we construct a support function to \( d( {{\textit{\textbf{u}}}} ) \). By (39),
holds with the constant \( \theta = \rho /\overline{\Omega } \).
Theorem 9
We have seen that the compact set \( \mathcal{O}_{{{\textit{\textbf{u}}}}} \) of (33) contains all the iterates \( \overline{{{\textit{\textbf{u}}}}}_{k} \). Moreover, all the approximate supporting functions satisfy (40) with the constant \( \theta \) independent of k.
The approximate cutting plane method generates a sequence of models and points satisfying
where \( D_k \) and D are the minima of \( d_k( {{\textit{\textbf{u}}}} ) \) and \( d( {{\textit{\textbf{u}}}} ) \), respectively.
A nice elementary proof of the convergence of the exact cutting plane method can be found in Ruszczyński (2006), Theorem 7.7. The following proof uses some of the ideas presented there. To handle inexactness, I’ll need a well-known though strong theorem from convex analysis. Using that, the proof becomes surprisingly simple.
Proof of Theorem 9
We have \( d_1( {{\textit{\textbf{u}}}} ) \le d_2( {{\textit{\textbf{u}}}} ) \le \cdots \le d( {{\textit{\textbf{u}}}} )\;\; ( {{\textit{\textbf{u}}}} \in \mathrm{I}\mathrm{R}^n ) \), hence
exists and is finite. \( d_{\infty }( {{\textit{\textbf{u}}}} ) \) is a convex function and the sequence of the model functions converges uniformly on the compact set \( \mathcal{O}_{{{\textit{\textbf{u}}}}} \)—see, e.g., Theorem 10.8 in Rockafellar’s book Rockafellar (1970).
We have \( D_{k} = \min _{{{\textit{\textbf{u}}}} \in \mathrm{I}\mathrm{R}^n} d_{k}( {{\textit{\textbf{u}}}} ) = d_{k}( \overline{{{\textit{\textbf{u}}}}}_{k+1} ) \). Moreover, let \( D_{\infty } = \min _{{{\textit{\textbf{u}}}} \in \mathrm{I}\mathrm{R}^n} d_{\infty }( {{\textit{\textbf{u}}}} ) \). These are finite and \( D_{k} \le D_{\infty } \le D \). With any index k, we have
Let us now take into account the uniform convergence of the sequence of the model functions. Given \( \epsilon > 0 \), there exist a finite number \( K_{\epsilon } \) such that \( | d_{k}( {{\textit{\textbf{u}}}} ) - d_{\infty }( {{\textit{\textbf{u}}}} ) | \le \epsilon \) holds for \( k \ge K_{\epsilon },\; {{\textit{\textbf{u}}}} \in \mathcal{O}_{{{\textit{\textbf{u}}}}} \). Specifically, this holds with \( {{\textit{\textbf{u}}}} = \overline{{{\textit{\textbf{u}}}}}_{k+1} \), showing that the difference between the left-hand side and the right-hand side of (42) is small for large enough k. It follows that
Now let \( ( \overline{{{\textit{\textbf{u}}}}}_{k_i +1} ) \) be a convergent subsequence of \( ( \overline{{{\textit{\textbf{u}}}}}_{k+1} ) \), and let \( \widetilde{{{\textit{\textbf{u}}}}} := \lim _{i \rightarrow \infty } \overline{{{\textit{\textbf{u}}}}}_{k_i +1} \). We have
due to the continuity of \( d( {{\textit{\textbf{u}}}} ) \).
With any index k, we have \( d_{\infty }( \overline{{{\textit{\textbf{u}}}}}_{k+1} ) \ge \ell _{k+1}( \overline{{{\textit{\textbf{u}}}}}_{k+1} ) \). Taking into account (40), we get
Here we have \( d_{\infty }( \overline{{{\textit{\textbf{u}}}}}_{k+1} ) \rightarrow D_{\infty } \) and \( D_k \rightarrow D_{\infty } \) as \( k \rightarrow \infty \), according to (43). As for the remaining expression \( d( \overline{{{\textit{\textbf{u}}}}}_{k+1} ) \), we have (44). Taking limits in (45), we get \( D_{\infty } \ge d( \widetilde{{{\textit{\textbf{u}}}}} ) \). But \( d( \widetilde{{{\textit{\textbf{u}}}}} ) \ge D \ge D_{\infty } \) by definition. It follows that \( d( \widetilde{{{\textit{\textbf{u}}}}} ) = D = D_{\infty } \) holds.
The proof can be completed in an indirect fashion. Assume that (41) does not hold, i.e., there exists some \( \epsilon > 0 \) and a subsequence \( ( \overline{{{\textit{\textbf{u}}}}}_{k_j} ) \) such that \( | d( \overline{{{\textit{\textbf{u}}}}}_{k_j} ) - D | > \epsilon \) for every j. But due to the compactness of the domain \( \mathcal{O}_{{{\textit{\textbf{u}}}}} \), there exists a convergent subsequence of \( ( \overline{{{\textit{\textbf{u}}}}}_{k_j} ) \), which is a contradiction with the argument above. \(\square \)
Using the notation of Sect. 2, the \( {{\textit{\textbf{z}}}}\)-part of the optimal solution of the true problem (6) will be denoted by \( {{\textit{\textbf{z}}}}^{\star } \), and the optimal solution of the true dual problem (11) will be denoted by \( {{\textit{\textbf{u}}}}^{\star } \).
Corollary 10
We have \( \overline{{{\textit{\textbf{u}}}}}_k \rightarrow {{\textit{\textbf{u}}}}^{\star } \) and \( \overline{{{\textit{\textbf{z}}}}}_k \rightarrow {{\textit{\textbf{z}}}}^{\star } \).
Proof
Strict convexity of \( \phi ^{\star }( {{\textit{\textbf{u}}}} ) \) results in strict convexity of \( d( {{\textit{\textbf{u}}}} ) \). The latter, combined with the second statement of Theorem 9, yields \( \overline{{{\textit{\textbf{u}}}}}_k \rightarrow {{\textit{\textbf{u}}}}^{\star } \).
Using the notation of Theorem 9, \( -D_k \) is the maximum of the dual model problem (16) which in turn equals the minimum of the primal model problem (14), the latter minimum being \( \phi _k( \overline{{{\textit{\textbf{z}}}}}_{k+1} ) \). Similarly, \( -D \) is the maximum of the true dual problem (11) which in turn equals the minimum of the true primal problem (6), the latter minimum being \( \phi ( {{\textit{\textbf{z}}}}^{\star } ) \). As we mentioned in Sect. 2, a strong duality relationship holds between the true primal and the true dual problem.
Hence the statement \( D_k \rightarrow D \) of Theorem 9 translates to primal setting in the form
As \( \phi _k( {{\textit{\textbf{z}}}} ) \) is an upper approximation of \( \phi ( {{\textit{\textbf{z}}}} ) \), we have \( \phi _k( \overline{{{\textit{\textbf{z}}}}}_{k+1} ) \ge \phi ( \overline{{{\textit{\textbf{z}}}}}_{k+1} ) \ge \phi ( {{\textit{\textbf{z}}}}^{\star } ) \) for every k. Taking into account (46), we get \( \phi ( \overline{{{\textit{\textbf{z}}}}}_{k+1} ) \rightarrow \phi ( {{\textit{\textbf{z}}}}^{\star } ) \). Strict convexity of \( \phi ( {{\textit{\textbf{z}}}} ) \) then yields \( \overline{{{\textit{\textbf{z}}}}}_k \rightarrow {{\textit{\textbf{z}}}}^{\star } \). \(\square \)
7 Line search revisited
In this section we review the efficiency of applying a single line search in the solution of the column generating problem. We assume that the probabilistic objective function is locally well-conditioned. (I am going to make a case for this assumption in Sect. 9.) We are going to consider the convergence results of Sect. 6 in the primal setting. They will enable us to focus on a locality where the objective function is well-conditioned. Our aim is to develop a practicable version of Proposition 7.
Assumption 11
(Locally well-conditioned objective) The function \( \phi ( {{\textit{\textbf{z}}}} ) \) is well-conditioned in the optimal solution \( {{\textit{\textbf{z}}}}^{\star } \) of the true problem (6).
Formally, \( \alpha ^{\star } / \omega ^{\star } \gg 0 \) holds, where \( \omega ^{\star } \) and \( \alpha ^{\star } \) denotes the smallest and the largest eigenvalue, respectively, of the Hessian matrix \( \nabla ^2 \phi ( {{\textit{\textbf{z}}}}^{\star } ) \).
Let \( \alpha ( {{\textit{\textbf{z}}}} ) \) and \( \omega ( {{\textit{\textbf{z}}}} ) \) denote the smallest and the largest eigenvalue, respectively, of the Hessian matrix \( \nabla ^2 \phi ( {{\textit{\textbf{z}}}} ) \) as a function of \( {{\textit{\textbf{z}}}} \in \mathrm{I}\mathrm{R}^n \). Continuity of both functions follows from a theorem of Ostrowski that I cite in “Appendix B”.
Let the real numbers \( \alpha ^{_-}, \omega ^{_+} \) be such that \( 0< \alpha ^{_-} < \alpha ^{\star } \) and \( \omega ^{\star } < \omega ^{_+} \). (The idea is to have \( \alpha ^{_-} \) near \( \alpha ^{\star } \), and \( \omega ^{_+} \) near \( \omega ^{\star } \).) From the continuity of the functions \( \alpha ( {{\textit{\textbf{z}}}} ) \) and \( \omega ( {{\textit{\textbf{z}}}} ) \), it follows that there exists a ball \( \mathcal{B}_r \) around \( {{\textit{\textbf{z}}}}^{\star } \) with radius \( r > 0 \), such that \( \alpha ( {{\textit{\textbf{z}}}} ) \ge \alpha ^{_-} \) and \( \omega ( {{\textit{\textbf{z}}}} ) \le \omega ^{_+} \) holds for every \( {{\textit{\textbf{z}}}} \in \mathcal{B}_r \), and hence
Let us consider the convergence results of Sect. 6 in the primal setting. I start by reviewing the notation. \( \overline{{{\textit{\textbf{z}}}}}_{k} \) denotes an optimal solution of the \( ( k - 1 )\)th primal model problem, and \( \overline{{{\textit{\textbf{u}}}}}_{k} \) denotes an optimal solution of the \( ( k - 1 )\)th dual model problem, for \( k = 1, 2, \ldots \). In the column generating subproblem, an improving column is found by approximate minimization of the function \( f_{k}( {{\textit{\textbf{z}}}} ) = \phi ( {{\textit{\textbf{z}}}} ) - \overline{{{\textit{\textbf{u}}}}}_{k}^T {{\textit{\textbf{z}}}} \). Specifically, \( {{\textit{\textbf{z}}}}_{k}^{\backprime } \) denotes the point found by performing a single line search from \( \overline{{{\textit{\textbf{z}}}}}_{k} \), in the opposite direction of \( \overline{{{\textit{\textbf{g}}}}}_{k} = \nabla f_{k}( \overline{{{\textit{\textbf{z}}}}}_{k} ) \).
Observation 12
We have \( \overline{{{\textit{\textbf{g}}}}}_{k} \rightarrow {{{\textit{\textbf{0}}}}} \).
Proof
We have
the latter equality being a consequence of Observation 2. In the right-hand side, we have \( \overline{{{\textit{\textbf{u}}}}}_k \rightarrow {{\textit{\textbf{u}}}}^{\star } \) by Corollary 10, and \( \nabla \phi ( \overline{{{\textit{\textbf{z}}}}}_k ) \rightarrow \nabla \phi ( {{\textit{\textbf{z}}}}^{\star } ) \) by Corollary 10 and \( \phi ( {{\textit{\textbf{z}}}} ) \) being continuously differentiable. \(\square \)
For technical reasons, we’ll need some further notation. Let \( {{\textit{\textbf{z}}}}_{k}^{\circ } \) be the exact minimizer of the function \( f_{k}( {{\textit{\textbf{z}}}} ) \). (This is never computed in the course of the column generation scheme.)
Observation 13
We have \( {{\textit{\textbf{z}}}}_{k}^{\circ } \rightarrow {{\textit{\textbf{z}}}}^{\star } \).
The proof is simple but rather technical, hence I include it in the “Appendix, section A.2”.
7.1 Focusing on a locality
Given the radius \( r > 0 \) of the ball \( \mathcal{B}_r \) of (47), there exists a natural number \( K_r \) such that
The above statement holds because we have \( \overline{{{\textit{\textbf{z}}}}}_k \rightarrow {{\textit{\textbf{z}}}}^{\star }, \; \overline{{{\textit{\textbf{g}}}}}_{k} \rightarrow {{\textit{\textbf{0}}}}, \; {{\textit{\textbf{z}}}}_{k}^{\circ } \rightarrow {{\textit{\textbf{z}}}}^{\star } \) by Corollary 10 and Observations 12 and 13.
In the remainder of this section, we consider a fixed \( k \ge K_r \). For the sake of simplicity, we are going to omit the lower index k. Let me sum up this simplified notation. An improving column is found by approximate minimization of the function \( f( {{\textit{\textbf{z}}}} ) = \phi ( {{\textit{\textbf{z}}}} ) - \overline{{{\textit{\textbf{u}}}}}^T {{\textit{\textbf{z}}}} \). Specifically, \( {{\textit{\textbf{z}}}}^{\backprime } \) denotes the point found by performing a single line search from \( \overline{{{\textit{\textbf{z}}}}} \), in the opposite direction of \( \overline{{{\textit{\textbf{g}}}}} = \nabla f( \overline{{{\textit{\textbf{z}}}}} ) \). The exact minimizer of \( f( {{\textit{\textbf{z}}}} ) \) is denoted by \( {{\textit{\textbf{z}}}}^{\circ } \).
Theorem 14
We have
where \( \mathcal{F} = \min _{{{\textit{\textbf{z}}}}} f( {{\textit{\textbf{z}}}} ) \).
The proof will be an adaptation of the proof of Proposition 7. It turns out that we only need \( \nabla ^2 \phi ( {{\textit{\textbf{z}}}} ) \preceq \omega ^{_+} I \) for \( {{\textit{\textbf{z}}}} = \overline{{{\textit{\textbf{z}}}}} - t \overline{{{\textit{\textbf{g}}}}} \) such that \( 0 \le t \le \frac{1}{\omega ^{_+}} \). Moreover, \( \nabla ^2 \phi ( {{\textit{\textbf{z}}}} ) \succeq \alpha ^{_-} I \) is only needed for \( {{\textit{\textbf{z}}}} \in [ \overline{{{\textit{\textbf{z}}}}},\, {{\textit{\textbf{z}}}}^{\circ } ] \).
Proof of Theorem 14
Due to the first and the second assumption in (48), we have \( \overline{{{\textit{\textbf{z}}}}} - t \overline{{{\textit{\textbf{g}}}}} \in \mathcal{B}_r \) for \( t \in [ 0,\, 1/\omega ^{_+} ] \). Let \( T = 1/\omega ^{_+} \). According to (47), \( \nabla ^2 \phi ( {{\textit{\textbf{z}}}} ) \preceq \omega ^{_+} I \) holds for \( {{\textit{\textbf{z}}}} = \overline{{{\textit{\textbf{z}}}}} - t \overline{{{\textit{\textbf{g}}}}} \) with \( t \in [ 0,\, T ] \). It follows that
holds (a consequence of Taylor’s theorem). We consider the respective minima in \( t \in \mathrm{I}\mathrm{R}\) separately of the two sides. The right-hand side is a quadratic expression, yielding minimum at \( t = 1/\omega ^{_+} \in [ 0,\, T ] \). It follows that
Coming to lower bounds, we have \( [ \overline{{{\textit{\textbf{z}}}}},\, {{\textit{\textbf{z}}}}^{\circ } ] \subset \mathcal{B}_r \) according to the first and the third assumption in (48).
By (47), we have \( \nabla ^2 \phi ( {{\textit{\textbf{z}}}} ) \succeq \alpha ^{_-} I\;\; ( {{\textit{\textbf{z}}}} \in [ \overline{{{\textit{\textbf{z}}}}},\, {{\textit{\textbf{z}}}}^{\circ } ] ) \). From this, it follows by Taylor’s theorem that
The left-hand side is \( \mathcal{F} \) by definition. A lower estimate of the right-hand side is obtained by taking its minimum in \( {{\textit{\textbf{z}}}}^{\circ } \). The minimum is easily computed as the right-hand side expression is a quadratic function of \( {{\textit{\textbf{z}}}}^{\circ } \). We get
The proof is concluded by simple transformations of (50) and (52). The improving column \( {{\textit{\textbf{z}}}}^{\backprime } \) is found by solving the minimization problem in the left-hand side of (50). Subtracting \( \mathcal{F} \) from both sides of (50), and applying (52) to underestimate \( \Vert \overline{{{\textit{\textbf{g}}}}} \Vert ^2 \), we get (49). \(\square \)
8 Arguments based on the efficiency of the simplex method
We are going to interpret the column generation scheme of Sect. 3 as the solution process, by the simplex method, of a single linear programming problem. Specifically, the procedure for finding improving columns, described in Sect. 3.3, will be interpreted as a column selection procedure in the context of the simplex method.
We assume a locally well-conditioned \( \phi ( {{\textit{\textbf{z}}}} ) \), and are going to the apply the results of Sect. 7. As the column generation scheme progresses, we are bound to arrive at a neighborhood on which the objective function is well-conditioned. For a more precise exposition, let me include a summary of the first half of Sect. 7. Let the real numbers \( \alpha ^{_-}, \omega ^{_+} \) be such that \( 0< \alpha ^{_-} < \alpha ^{\star } \) and \( \omega ^{\star } < \omega ^{_+} \). There exists a ball \( \mathcal{B}_r \) around \( {{\textit{\textbf{z}}}}^{\star } \) with radius \( r > 0 \), such that (47) holds. For the radius r, in turn, there exists a natural number \( K_r \) such that (48) holds.
From that point on (i.e., in any iteration \( k > K_r \)), our column selection procedure will conform to a practical simplex rule, as I am going to show in the remainder of this section. The practical efficiency of the simplex method will then explain the behavior of our method.
In accordance with former notation, let \( \overline{{{\textit{\textbf{z}}}}} \) denote the vector constructed in the form of (18), using optimal weights from the linear programming problem (17). Let moreover \( \overline{\vartheta } \) and \( \overline{{{\textit{\textbf{u}}}}} \) denote the optimal dual variable and the optimal dual vector belonging to the convexity constraint and the splitting constraint, respectively, in (17).
In our column generation scheme, an improving column is found by approximate minimization of the function \( f( {{\textit{\textbf{z}}}} ) = \phi ( {{\textit{\textbf{z}}}} ) - \overline{{{\textit{\textbf{u}}}}}^T {{\textit{\textbf{z}}}} \). This is of course the same problem as the approximate minimization of \( -\overline{\varrho }( {{\textit{\textbf{z}}}} ) \), the negative of the reduced cost function whose definition I copy here for convenience: \( -\overline{\varrho }( {{\textit{\textbf{z}}}} ) =\, \phi ( {{\textit{\textbf{z}}}} ) - \overline{{{\textit{\textbf{u}}}}}^T {{\textit{\textbf{z}}}} - \overline{\vartheta } \).
Let \( {{\textit{\textbf{z}}}}^{\backprime } \) denote the point found by performing a single line search from \( \overline{{{\textit{\textbf{z}}}}} \), in the opposite direction of \( \overline{{{\textit{\textbf{g}}}}} = \nabla \phi ( \overline{{{\textit{\textbf{z}}}}} ) - \overline{{{\textit{\textbf{u}}}}} \). Theorem 14 is applicable to \( f( {{\textit{\textbf{z}}}} ) = -\overline{\varrho }( {{\textit{\textbf{z}}}} ) \), and (49) transforms to
where \( \mathcal{R} = \max _{{{\textit{\textbf{z}}}}} \overline{\varrho }( {{\textit{\textbf{z}}}} ) \).
In Fábián et al. (2018), we have shown that \( \overline{\varrho }( \overline{{{\textit{\textbf{z}}}}} ) \ge 0 \) holds (as an obvious consequence of the convexity of \( \phi ( {{\textit{\textbf{z}}}} ) \).) Hence the right-hand side of (53) is majorated by \( \left( 1 - {\alpha ^{_-}}/{\omega ^{_+}} \right) \mathcal{R} \). A simple transformation then results in
In the simplex context, (54) means that the vector \( {{\textit{\textbf{z}}}}^{\backprime } \) has a substantial reduced cost in the linear programming master problem, hence we may expect a substantial improvement from including it as a new column. Equation (54) is a realistic counterpart of (22) that was obtained in an idealized setting. More importantly, (54) is an approximate version of the Markowitz column selection rule, well-known in the context of the simplex method.
8.1 Arguments based on experimental results
A long-standing rule of thumb states that, in solving a linear programming problem having M rows and N columns (with \( N \gg M \)), the number of pivot steps needed is proportional with M. As confirmation, let me cite from the computational study of Cutler and Wolfe (1963): ’It would appear that the rule of “2M iterations” from folklore is fairly good ...’ After a more detailed examination, they observe: ’... an estimate of between M and 3M iterations will almost always be correct.’
In our case, the linear programming model problem (17) was built using a finite set of test points \( {{\textit{\textbf{z}}}}_0, {{\textit{\textbf{z}}}}_1, \ldots , {{\textit{\textbf{z}}}}_k \). Let us include every vector \( {{\textit{\textbf{z}}}} \in \mathrm{I}\mathrm{R}^n \) among the initial test points; the resulting infinite problem will then be equivalent to the convex problem (6). Though the number of the columns is infinite, the construction (18) of the optimal solution \( \overline{{{\textit{\textbf{z}}}}} \) is still usable, because the number of the rows and hence the cardinality of the bases remains finite.
Our column generation scheme is equivalent to a simplex method applied to this infinite linear programming problem. As we have seen in the previous section, the column selection rule is such that the incoming column \( {{\textit{\textbf{x}}}}^{\backprime } \) satisfies (54) from iteration \( K_r \). From this point on, we can expect the simplex method to be fairly efficient.
8.2 Arguments based on theoretical results
Most of the theoretical results concerning the behavior of the simplex method are incapable of explaining its practical efficiency. Specifically, results based on worst-case analysis are generally very far from experimental results. The results of Karl Heinz Borgwardt are fundamental to bridging this gap. He studies average behavior. A further important contribution is Spielman and Teng (2004). The results of Dempster and Merkovsky (1995) are related, from a dual viewpoint. They presented a geometrically convergent version of the cutting-plane method, for a continuously differentiable, strictly convex case.
The review paper Borgwardt (2009) deals with rudimentary problem types of maximizing a linear function subject to \( A {{\textit{\textbf{x}}}} \le {{\textit{\textbf{b}}}} \) or \( A {{\textit{\textbf{x}}}} \le {{\textit{\textbf{b}}}}, {{\textit{\textbf{x}}}} \ge {{\textit{\textbf{0}}}} \) or \( A {{\textit{\textbf{x}}}} = {{\textit{\textbf{b}}}}, {{\textit{\textbf{x}}}} \ge {{\textit{\textbf{0}}}} \). The matrix has M rows and N columns. The matrix and the objective vectors are populated with random variables of special joint distributions. Borgwardt focuses on the rotation symmetry model: \( {{\textit{\textbf{b}}}} = {{\textit{\textbf{1}}}} \) and the rows of A and the objective vectors are distributed on \( \mathrm{I}\mathrm{R}^n \setminus \{{{\textit{\textbf{0}}}}\} \) independently, identically and symmetrically under rotations. Taking into account several rotation-symmetric distributions and several special simplex-type algorithms, he examines the expected number of the pivot steps required. In Borgwardt (2009), he summarizes several related bounds for problems with \( M \ge N \), and also asymptotic results for N fixed and \( M \rightarrow \infty \). These are typically of the form
with a moderate \(\nu \) and a constant C. Let us play, for a moment, with the idea that bounds of the type (55) grasp the average behavior of the simplex method in a general sense.
Let us make a minor extension to the column generation scheme described in Sect. 3. There exists a bounded box \( \mathcal{Z}^{\backprime } \) and a natural number \( K^{\backprime } \) such that \( \mathcal{Z}^{\backprime } \) contains every possible improving vector \( {{\textit{\textbf{z}}}}^{\backprime } \) that we may obtain, in iterations after \( K^{\backprime } \), by approximately solving the column generating problem. In the following arguments, we need to know \( \mathcal{Z}^{\backprime } \) explicitly, but need not know \( K^{\backprime } \). The construction of \( \mathcal{Z}^{\backprime } \) is easy but somewhat technical, hence I include it in the “Appendix, section A.3”.
We could include every \( {{\textit{\textbf{z}}}} \in \mathcal{Z}^{\backprime } \) among the initial test points of the linear programming model problem (17), like we did in the previous section. But here we wish to avoid an infinite problem. Though we can settle for a closely approximating problem that has a finite (huge) number of columns. This is easily constructed. Given a prescribed precision \( \varepsilon > 0 \), let us divide the box \( \mathcal{Z}^{\backprime } \) into small boxes whose edges are not longer then \( \varepsilon \). Let us include the center of each cell among the initial test points. The number of the initial test points, considered as a function of the prescribed accuracy, is on the order of \( \left( 1 / \varepsilon \right) ^n \).
We can now make a slight modification in the column generation process. In a certain iteration, let \( {{\textit{\textbf{z}}}}^{\backprime } \) denote the vector obtained by performing a line search. If this falls into the box \( \mathcal{Z}^{\backprime } \), then we add no new test point, because there is a cell center close enough among the initial test points. In case \( {{\textit{\textbf{z}}}}^{\backprime } \not \in \mathcal{Z}^{\backprime } \), we add \( {{\textit{\textbf{z}}}}^{\backprime } \) as a new test point, like in the original scheme. We know that there exists a natural number \( K^{\backprime } \) such that no new columns are added after iteration \( K^{\backprime } \). I.e., we have an unchanging master problem from that point.
For iterations \( k > K^{\backprime } \), this modified column generation scheme can be modelled as the solution, by the simplex method, of the unchanging master problem. Let \( {{\textit{\textbf{z}}}}^{\backprime } \) denote the vector obtained by a line search in the column generation scheme. In the simplex method, we can then select an existing column (i.e., cell center) closest to \( {{\textit{\textbf{z}}}}^{\backprime } \). For iterations \( k > \max \{ K^{\backprime }, K_r \} \), this is a practicable selection rule in the simplex context. Let us consider the number of the iterations needed to finish from here, as a function of the prescribed accuracy \( \varepsilon \).
Let us assume that a bound of the form (55) applies in the present setting. In the dual of our huge linear programming problem, the number M of the rows is on the order of \( \left( 1 / \varepsilon \right) ^n \). As for the number N of columns, we have \( N > n \) (and N is of a moderate magnitude.) Hence we may expect the iteration count to be on the order of \( 1 / \varepsilon \), that is by no means discouraging.
9 Illustration of the locally well-conditioned character of the probabilistic objective function
In Sect. 7, we assumed that the objective function is well-conditioned in the optimal solution, i.e., \( \alpha ^{\star } / \omega ^{\star } \gg 0 \) holds with the smallest and largest eigenvalue, respectively, of the Hessian matrix \( \nabla ^2 \phi ( {{\textit{\textbf{z}}}}^{\star } ) \) (Assumption 11). Let me make a case for this assumption by a simple illustration.
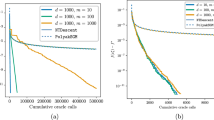
Figure 2 shows contour lines of a two-dimensional standard normal distribution function \( F( {{\textit{\textbf{z}}}} ) \), where the covariance between the marginals is 0.5.

Contour lines of a two-dimensional normal distribution function \( F( {{\textit{\textbf{z}}}} ) \), and optimal solutions \( {{\textit{\textbf{z}}}}^{\star }, {{\textit{\textbf{z}}}}^{\star \star } \). From top right, the contour lines belong to the probabilities 0.99, 0.95, and 0.90, respectively. The contour lines tend to be straight as we move away from the diagonal \( z_1 = z_2 \)
Let us consider a probability maximization problem of the form (3), with the un-regularized objective function \( \phi ( {{\textit{\textbf{z}}}} ) = -\log F( {{\textit{\textbf{z}}}} ) \). The feasible region for the \( {{\textit{\textbf{z}}}} \) vector has the negative orthant for regression cone.
Let \( {{\textit{\textbf{z}}}}^{\star } \) in Fig. 2 denote an optimal solution, with \( F( {{\textit{\textbf{z}}}}^{\star } ) = 0.9 \). Let \( {{\textit{\textbf{z}}}}^{\star \star } \) denote another point on the same contour line, i.e., we have \( F( {{\textit{\textbf{z}}}}^{\star \star } ) = 0.9 \) as well. As the section of the contour line between \( {{\textit{\textbf{z}}}}^{\star } \) and \( {{\textit{\textbf{z}}}}^{\star \star } \) is practically straight and horizontal, we have \( {{\textit{\textbf{z}}}}^{\star \star } \le {{\textit{\textbf{z}}}}^{\star } \), implying that \( {{\textit{\textbf{z}}}}^{\star \star } \) is a feasible solution. Hence \( {{\textit{\textbf{z}}}}^{\star \star } \) is also an optimal solution. This shows that an optimal solution can be located ’near’ the curved part of a contour line, i.e., ’near’ the diagonal \( z_1 = z_2 \).
In case the optimal probability falls between 0.9 and 0.99, we may locate an optimal \( {{\textit{\textbf{z}}}}^{\star \star } \) in the neighborhood of (2, 2) , where the objective function is well-conditioned. Eigenvalues of the Hessian matrix \( \nabla ^2[ -\log F(2,2) ] \) are \( \alpha (2,2) = 0.0929 \) and \( \omega (2,2) = 0.1140 \), their ratio beeing above 0.8.
Contour lines of the eigenvalue functions \( \alpha ( {{\textit{\textbf{z}}}} ) \) and \( \omega ( {{\textit{\textbf{z}}}} ) \) for \( {{\textit{\textbf{z}}}} \in [ -6, +6 ]^2 \) are shown in Fig. 3, taken from Fábián et al. (2018). \( \alpha ( {{\textit{\textbf{z}}}} ) \) and \( \omega ( {{\textit{\textbf{z}}}} ) \) are the smaller and the larger eigenvalue, respectively, of the Hessian matrix \( \nabla ^2 \phi ( {{\textit{\textbf{z}}}} ) = \nabla ^2[ -\log F( {{\textit{\textbf{z}}}} ) ] \).

Contour lines of the smaller and the larger eigenvalue, respectively, of \( \nabla ^2[ -\log F( {{\textit{\textbf{z}}}} ) ] \) as a function of \( {{\textit{\textbf{z}}}} \), for a two-dimensional normal distribution function \( F( {{\textit{\textbf{z}}}} ) \). In the left-hand figure (smaller eigenvalue), contour lines from top right are \( 1e-5, 1e-4, 1e-3, 1e-2 \). In the area not shaded gray, the smaller eigenvalue is above \( 1e-5 \). In the right-hand figure (larger eigenvalue), contour lines from top right are 1, 1.2, 1.4, 1.6. In the area not shaded gray, the larger eigenvalue is below 1.6
10 Discussion
We worked out a convergence proof and presented efficiency arguments, for a simple column generation scheme. The rigorous convergence statements of Sect. 6 do not directly yield a practicable efficiency estimate. However, they enable us to focus on a neighborhood of the optimal solution (where we may depend on the locally well-conditioned character of the objective function.) In Sect. 7, we argued that, starting with iteration \( K_r \), the process remains in a well-defined neighborhood. The threshold \( K_r \) may, in theory, be large. But in our experiments, a rough approximate solution was always found relatively quickly, and the main computational effort was devoted to refine the approximation. The diagrams included in Fábián et al. (2019) show similar behavior. In that paper, we developed a randomized version of the method, and performed an experimental study. We always found a rough approximate solution with a relatively small effort.
In (5), we regularized the probabilistic objective function by adding the term \( \frac{\rho }{2} \Vert {{\textit{\textbf{z}}}} \Vert ^2 \) with an appropriate \( \rho > 0 \). In the present paper, we worked with a fixed \( \rho \). However, from a practical point of view, it makes sense to start with a large \( \rho \), and decrease it gradually as the optimal solution is approached. The resulting procedure, when observed from a dual viewpoint, shows an interesting relationship with bundle methods. In the context of Sect. 6, the regularization (5) can be interpreted as a smoothing operation applied to the conjugate function \( \phi ^{\star }( {{\textit{\textbf{u}}}} ) \) in (31). This smoothing operation improves the conditioning of \( \phi ^{\star }( {{\textit{\textbf{u}}}} ) \). (On the inverese relationship between Hessian matrices of \( \phi ( {{\textit{\textbf{z}}}} ) \) and \( \phi ^{\star }( {{\textit{\textbf{u}}}} ) \), see, e.g., Gorni 1991.)
References
Borgwardt KH (2009) Probabilistic analysis of simplex algorithms. In: Floudas CA, Paradlos PM (eds) Encyclopedia of optimization. Springer
Cutler L, Wolfe P (1963) Experiments in linear programming. In: Graves R, Wolfe P (eds) Recent advances in mathematical programming. McGraw-Hill, first published as a technical report of the RAND Corporation
de Oliveira W, Sagastizábal C (2014) Level bundle methods for oracles with on-demand accuracy. Optim Methods Softw 29:1180–1209
Dempster MAH, Merkovsky RR (1995) A practical geometrically convergent cutting plane algorithm. SIAM J Numer Anal 32:631–644
Dentcheva D, Martinez G (2013) Regularization methods for optimization problems with probabilistic constraints. Math Program 138:223–251
Dentcheva D, Prékopa A, Ruszczyński A (2000) Concavity and efficient points of discrete distributions in probabilistic programming. Math Program 89:55–77
Dentcheva D, Lai B, Ruszczyński A (2004) Dual methods for probabilistic optimization problems. Math Methods Oper Res 60:331–346
Fábián CI, Csizmás E, Drenyovszki R, van Ackooij W, Vajnai T, Kovács L, Szántai T (2018) Probability maximization by inner approximation. Acta Polytech Hung 15:105–125, special issue dedicated to the memory of András Prékopa (editors: A. Bakó, I. Maros and T. Szántai)
Fábián CI, Csizmás E, Drenyovszki R, Vajnai T, Kovács L, Szántai T (2019) A randomized method for handling a difficult function in a convex optimization problem, motivated by probabilistic programming. Ann Oper Res. https://doi.org/10.1007/s10479-019-03143-z. To appear in S.I.: Stochastic Modeling and Optimization, in memory of András Prékopa (editors: E. Boros, M. Katehakis, A. Ruszczyński). Open access
Frangioni A (2002) Generalized bundle methods. SIAM J Optim 13:117–156
Frangioni A (2018) Standard bundle methods: untrusted models and duality. In: Bagirov A, Gaudioso M, Karmitsa N, Mäkelä MM (eds) Numerical nonsmooth optimization. Springer, Berlin, pp 61–116 (Former version: Technical report, Department of Informatics, University of Pisa, Italy)
Gorni G (1991) Conjugation and second-order properties of convex functions. J Math Anal Appl 158:293–315
Hantoute A, Henrion R, Pérez-Aros P (2018) Subdifferential characterization of probability functions under Gaussian distribution. Math Program 174:167–194
Luenberger DG, Ye Y (2008) Linear and nonlinear programming. International Series in Operations Research and Management Science. Springer, Berlin
Ostrowski A (1960) Solution of equations and systems of equations. Academic Press, New York
Prékopa A (1990) Dual method for a one-stage stochastic programming problem with random RHS obeying a discrete probability distribution. ZOR Methods Models Oper Res 34:441–461
Prékopa A, Vizvári B, Badics T (1998) Programming under probabilistic constraint with discrete random variable. In: Giannesi F, Rapcsák T, Komlósi S (eds) New trends in mathematical programming. Kluwer, Dordrecht, pp 235–255
Rockafellar RT (1970) Convex analysis. Princeton University Press, Princeton
Ruszczyński A (2006) Nonlinear optmization. Princeton University Press, Princeton
Spielman D, Teng SH (2004) Smoothed analysis of algorithms: why the simplex algorithm usually takes polynomial time. J ACM 51:385–463
Szidarovszky F (1974) Introduction to numerical methods. Közgazdasági és Jogi Könyvkiadó, Budapest (in Hungarian)
van Ackooij W, Berge V, de Oliveira W, Sagastizábal C (2017) Probabilistic optimization via approximate p-efficient points and bundle methods. Comput Oper Res 77:177–193
Acknowledgements
Open access funding provided by John von Neumann University. The author gives his thanks to the editors of the special issue ’VOCAL and Hungarian OR Conference’ and to the anonymous reviewers for many helpful suggestions and constructive remarks.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This research is supported by EFOP-3.6.1-16-2016-00006 project titled ’The development and enhancement of the research potential at John von Neumann University’. The Project is supported by the Hungarian Government and co-financed by the European Social Fund.
Appendices
A Technical proofs
1.1 A.1 Bounding the subgradients of the model functions
Before proving Observation 6, we need some preliminary observations.
It is easily seen that the shrunk simplex \( \mathcal{S}_{\eta } \) of (24) can be obtained in the form
Due to \( \eta < 1 \), the common lower bound of the weights is positive.
Let \( \mathcal{R} := \left\{ \, {\varvec{\varrho }} \in \mathrm{I}\mathrm{R}^n \left| \; \Vert {\varvec{\varrho }} \Vert = 1 \right. \right\} \) denote the unit sphere.
Lemma 15
There exists a positive constant \( \Delta \) such that
holds for any \( {{\textit{\textbf{z}}}} \in \mathcal{S}_{\eta } \) and \( {\varvec{\varrho }} \in \mathcal{R} \).
Proof
Let \( {{{\textit{\textbf{z}}}}} = \sum _{i=0}^n \lambda _i {{\textit{\textbf{z}}}}_i \) be the representation according to (56). We have
because \( \sum \lambda _i ( {{\textit{\textbf{z}}}}_i - {{\textit{\textbf{z}}}} ) = {{\textit{\textbf{0}}}} \) holds by the definition of the weights \( \lambda _i \). As the simplex \( \mathcal{S} \) is non-degenerate, we cannot have \( {\varvec{\varrho }}^T ( {{\textit{\textbf{z}}}}_i - {{\textit{\textbf{z}}}} ) = 0 \) for all i. Moreover, as the weights \( \lambda _i \) are all positive, a nonzero \( {\varvec{\varrho }}^T ( {{\textit{\textbf{z}}}}_i - {{\textit{\textbf{z}}}} ) \) results in a nonzero addend in (57). Hence there exists i such that \( {\varvec{\varrho }}^T ( {{\textit{\textbf{z}}}}_i - {{\textit{\textbf{z}}}} ) > 0 \). It means that the function
is positive-valued on the compact set \( \mathcal{R} \times \mathcal{S}_{\eta } \). Since the function is also continuous, it obtains its infimum by Weierstrass’ extreme value theorem. Let \( \Delta > 0 \) denote the minimum. \(\square \)
Proof of Observation 6
Given \( {{{\textit{\textbf{z}}}}} \in \mathcal{O}_{{{\textit{\textbf{z}}}}} \), we have \( {{\textit{\textbf{z}}}} \in \mathcal{S}_{\eta } \) according to (24). Let \( {\phi } \) denote the current model function value at \( {{{\textit{\textbf{z}}}}} \). Moreover, let \( {{\textit{\textbf{u}}}} \) be a subgradient of the current model function at \( {{{\textit{\textbf{z}}}}} \). We put it in the form \( {{\textit{\textbf{u}}}} = t {\varvec{\varrho }} \) with some \( t \ge 0 \) and \( {\varvec{\varrho }} \in \mathcal{R} \), and will find a bound on \( t = \Vert {{\textit{\textbf{u}}}} \Vert \). By the definition of the subgradient, we get
where \( \phi _i \) denotes the objective value at \( {{\textit{\textbf{z}}}}_i \). As the model function is an upper approximation of the true objective, the model function value satisfies
The latter minimum exists and is finite as the objective function is continuous and \( \mathcal{S}_{\eta } \) is compact. Hence all the right-hand sides in (58) are bounded from above by \( \max _{0 \le i \le n} \phi _i - \min _{{{\textit{\textbf{z}}}} \in \mathcal{S}_{\eta }} \phi ( {{\textit{\textbf{z}}}} ) \).
According to Lemma 15, we have \( {\varvec{\varrho }}^T \left( {{\textit{\textbf{z}}}}_i - {{{\textit{\textbf{z}}}}} \right) > \Delta \) for some i. It follows that
Recall that \( t = \Vert {{\textit{\textbf{u}}}} \Vert \). This gives an upper bound \( \Gamma _{{{\textit{\textbf{u}}}}}\, \) as claimed in the first part of Observation 6. The statement with the true objective function, \( \Vert \nabla \phi ( {{\textit{\textbf{z}}}} ) \Vert \le \Gamma _{{{\textit{\textbf{u}}}}}\;\; ( {{\textit{\textbf{z}}}} \in \mathcal{S}_{\eta } ) \), can be proved in a similar manner. \(\square \)
1.2 A.2 Convergence of improving columns
Proof of Observation 13
In accordance with former notation, \( \overline{{{\textit{\textbf{z}}}}}_{k} \) denotes an optimal solution of the current primal model problem, and \( \overline{{{\textit{\textbf{u}}}}}_{k} \) denotes an optimal solution of the current dual model problem. Moreover, \( {{\textit{\textbf{z}}}}_{k}^{\circ } \) denotes the exact maximizer of the function \( \overline{{{\textit{\textbf{u}}}}}_{k}^T {{\textit{\textbf{z}}}} - \phi ( {{\textit{\textbf{z}}}} ) \).
By the definition of \( {{\textit{\textbf{z}}}}_{k}^{\circ } \), we have
Due to the regularized objective (5), we have \( \nabla ^2 \phi ( {{\textit{\textbf{z}}}} ) \succeq \rho I\;\; ( {{\textit{\textbf{z}}}} \in \mathrm{I}\mathrm{R}^n ) \), which, in turn, implies strong convexity. Specifically,
holds with the optimal solution \( {{\textit{\textbf{z}}}}^{\star } \). – In the right-hand side, we can substitute \( {{\textit{\textbf{u}}}}^{\star } \) for \( \nabla \phi ( {{\textit{\textbf{z}}}}^{\star } ) \), according to Observation 2.
Coming back to (60), let us subtract \( \overline{{{\textit{\textbf{u}}}}}_{k}^T {{\textit{\textbf{z}}}}^{\star } \) from both sides, and let us substitute the lower bound of (61) for \( \phi ( {{\textit{\textbf{z}}}}_{k}^{\circ } ) \) in the right-hand side. We get
Simple transformations yield
Applying the Cauchy-Bunyakovsky-Schwarz inequality on both sides, and multiplying by \( \frac{2}{\rho } \), we get
An elementary transformation will then yield a square on the right-hand side:
We have \( \overline{{{\textit{\textbf{u}}}}}_k \rightarrow {{\textit{\textbf{u}}}}^{\star } \) and \( \overline{{{\textit{\textbf{z}}}}}_k \rightarrow {{\textit{\textbf{z}}}}^{\star } \) according to Corollary 10. Taking into account the continuity of \( \phi ( {{\textit{\textbf{z}}}} ) \), the right-hand side of (63) converges to zero. Hence \( \Vert {{\textit{\textbf{z}}}}_{k}^{\circ } - {{\textit{\textbf{z}}}}^{\star } \Vert \rightarrow 0 \) must hold. \(\square \)
Remark 16
In the above proof, we applied the lower bound \( \nabla ^2 \phi ( {{\textit{\textbf{z}}}} ) \succeq \rho I\;\; ( {{\textit{\textbf{z}}}} \in \mathrm{I}\mathrm{R}^n ) \). However, if we can focus on the locality \( \mathcal{B}_r \) of (47), we’ll have the stronger bound \( \nabla ^2 \phi ( {{\textit{\textbf{z}}}} ) \succeq \alpha ^{_-} I\;\; ( {{\textit{\textbf{z}}}} \in \mathcal{B}_r ) \).
This yields faster convergence, because in (63), we can substitute \( \alpha ^{_-} \) for \( \rho \).
1.3 A.3 Computing a moderate bound for improving columns
In Sect. 8.1, we need a bounded box \( \mathcal{Z}^{\backprime } \) that contains every possible improving vector \( {{\textit{\textbf{z}}}}_k^{\backprime } \) that we may obtain by approximately solving the column generating problem in iterations \( k \ge K^{\backprime } \), with some natural number \( K^{\backprime } \). (We do not need to know \( K^{\backprime } \) in Sect. 8.1, only its existence is important.) I’m going to sketch the construction of a workable box. We can apply the inequalities of section A.2.
Since \( {{\textit{\textbf{z}}}}_k^{\backprime } \) is obtained by a line search starting from \( \overline{{{\textit{\textbf{z}}}}}_k \), the analogue of (60) holds:
Applying the transformations of section A.2, we arrive at the following analogue of (63):
Like section A.2, it follows that \( \Vert {{\textit{\textbf{z}}}}_{k}^{\backprime } - {{\textit{\textbf{z}}}}^{\star } \Vert \rightarrow 0 \).
Hence, in theory, any box containing \( {{\textit{\textbf{z}}}}^{\star } \) in its interior is a feasible candidate for \( \mathcal{Z}^{\backprime } \).
For a practicable construction, let us consider \( k \ge K_r \) of (48). Then we can focus on the locality \( \mathcal{B}_r \) of (47), where \( \nabla ^2 \phi ( {{\textit{\textbf{z}}}} ) \succeq \alpha ^{_-} I\;\; ( {{\textit{\textbf{z}}}} \in \mathcal{B}_r ) \) holds. In accordance with Remark 16, we can substitute \( \alpha ^{_-} \) for \( \rho \) in (64).
B On the convergence of eigenvalues
The following theorem is due to Ostrowski. (I learned it from the textbook Szidarovszky 1974 that cited it in Chapter 7.4.)
Theorem 17
(from Appendix K in Ostrowski 1960) Given matrices \( A, B \in \mathrm{I}\mathrm{R}^{n \times n} \) having components \( a_{ij} \) and \( b_{ij}\;\; ( 1 \le i, j \le n ) \), respectively, let
For any eigenvalue \( \lambda \) of A, there exists an eigenvalue \( \mu \) of B such that
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fábián, C.I. Gaining traction: on the convergence of an inner approximation scheme for probability maximization. Cent Eur J Oper Res 29, 491–519 (2021). https://doi.org/10.1007/s10100-020-00697-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10100-020-00697-3