
Abstract
The execution of object-directed motor actions is known to be influenced by the intention to interact with others. In this study, we tested whether the effects of social intention on the kinematics of object-directed actions depended on whether the task was performed in the presence of a human or a virtual confederate. In two experiments, participants had to grasp a glass and place it to a new position, with either a personal intention (to fill the glass themselves using a bottle) or a social one (to have the glass filled by the human confederate or the virtual agent using the bottle). Experiment 1 showed that the kinematics of the object-directed actions was modulated by the social intention but only when interacting with a human confederate. Experiment 2 showed that the effects of social intention on object-directed actions performance can be improved using feedback-based learning. Specifically, participants proved able to progressively adapt their motor performances as if they were expressing social intention to a virtual confederate as well. These findings emphasize the importance of the modulatory role of social intention on non-verbal motor behaviour, and enrich the understanding of the interaction with virtual agents.
Highlights
We studied the effect of social intention on object-directed actions while interacting with a human or a virtual agent.
Results showed an effect of social intention on object-directed actions when interacting with a human confederate.
No effect of social intention on object-directed actions was found instead when interacting with a virtual agent.
Following a training, participants adapted their motor performances and expressed the social intention to the virtual agent.
These findings underline the importance of considering social intention when implementing interactions with virtual agents.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
On account of recent technological and internet advances, computer-mediated interactions are increasingly replacing face-to-face human interactions. Computer-mediated interactions usually involve virtual agents endowed with verbal and non-verbal behaviour. Virtual agents are computer-generated human or non-human characters which can be controlled by humans or by computer algorithms (Fox et al. 2015). Since they enable users to create ecological situations and control various parameters of the interaction better than natural experimental settings (Bombari et al. 2015; Parsons 2015; Parsons et al. 2009), virtual agents have been used to simulate human social interactions (Cassell et al. 1994; Nieuwenhuis et al. 2012; Pelachaud 2009a, b) of different levels of complexity (e.g., (Anderson et al. 2013; Cartaud et al. 2018; Iachini et al. 2016) in a variety of disciplines including psychology (Cartaud et al. 2018; Iachini et al. 2016), neuroscience (Parsons 2015; Parsons et al. 2017), medicine (Parsons et al. 2009), and education (Johnson et al. 2000; Johnson and Lester 2016; Van Der Meijden and Veenman 2005). For instance, systems implementing a virtual audience have been used to prepare speakers to public speech (Poeschl and Doering 2012) and to treat public speaking anxiety (Pertaub et al. 2002). Virtual agents have also proved to be effective in assisting healthcare staff during diagnosis (Auriacombe et al. 2018; Lucas et al. 2017; Philip et al. 2020). They also found promising applications in the fields of post-stroke neurorehabilitation (Perez-Marcos et al. 2017, 2018) and social skills training in populations diagnosed with schizophrenia (Park et al. 2011) or autism (Ke and Im 2013).
When implementing a social interaction in a virtual environment, a key challenge is to create a system which allows users to interact with the virtual agents as much intuitively and spontaneously as possible, and to give them the feeling of “social presence” (i.e., the feeling to be in the presence of a human-like agent whose emotions and thoughts can be accessed; Biocca et al. 2003; Nowak and Biocca 2003). Indeed, although human-like agents are usually positively evaluated in terms of their physical appearance, interacting with them often leads to an uncanny feeling. This feeling increases the more a virtual agent looks human and sometimes results in a rejection of the agent (i.e., Uncanny valley effect; Mori et al. 2012). One explanation for this effect might be that while the human physical appearance is present, the dynamics of non-verbal communication supporting social interactions is lacking. Accordingly, many studies aimed at finding the optimal level of anthropomorphism (de Visser et al. 2016; Lee and Nass 2002; Mori et al. 2012) and implementing emotional facial expressions, gaze exchanges, verbal replies and communicative gestures (e.g., waving “goodbye” gesture) in order to increase users’ trust and acceptance of the virtual agent (see (Cassell et al. 1994; Pelachaud 2009a).
However, a wealth of studies has highlighted that not only gaze, facial expressions and communicative gestures are important for social interactions (the body language; Burgoon and Bacue 2020), but also the dynamics of actions implying objects. Although the primary purpose of object-directed actions is to manipulate objects, numerous researches conducted over the past two decades have highlighted that they also play a role in social interactions (Becchio et al. 2008b, 2012; Egmose and Køppe 2017; Krishnan-barman et al. 2017; Quesque and Coello 2015). Indeed, it has been found that the way object-directed actions are executed varies not only as a function of the object’s physical characteristics (shape, weight, orientation and position in space; see for instance Cuijpers et al. 2004; Eastough and Edwards 2007; Fikes et al. 2015; Gentilucci 2002; Gentilucci et al. 1991; Paulignan et al. 1991) and the final goal of the action (e.g., grasping a pen to put it into a small or large container, grasping a glass to use or displace it; Ansuini et al. 2006, 2008; Fitts 1954; Rosenbaum et al. 1992), but also according to the individual’s intention to include another person in their actions (i.e., moving a glass to get water from someone else) or not (i.e., moving a glass for a personal purpose; Jacob and Jeannerod 2005). More specifically, it was observed that object-directed actions performed with a social intention are characterised by a longer duration, slower speed and a higher trajectory height when compared to actions performed with a personal intention (Becchio et al. 2008b; Georgiou et al. 2007; Gigliotti et al. 2020; Quesque et al. 2013, 2016). Such spatial and temporal amplifications have been supposed to render the action more communicative and to attract the attention of the person with whom the individual intends to interact (Ferri et al. 2011; Quesque and Coello 2014). In agreement with this, these kinematic variations were found to be implicitly perceived by an observer and used as cues to anticipate others’ action goals (Ansuini et al. 2014; Cavallo et al. 2016; Lewkowicz et al. 2013) and produce appropriate behaviour in response to them (Becchio et al. 2008a; Meulenbroek et al. 2007; Quesque et al. 2016).
In the field of human-virtual agents interactions, the issue of kinematic variations associated with the expression of a social intention has rarely been addressed. A few studies were conducted on the matter, but they involved humanoid robots (e.g., Duarte et al. 2018; Sciutti et al. 2015) and their main objective was to study how people understand others’ intentions (in this case those of the humanoid robot) while interacting with them. Accordingly, it is not clear yet how people initiate an interaction with a virtual agent, and whether they convey their own intentions through action as they would do in front of a human confederate. In other words, it is not established yet if the fine kinematic variations associated with the expression of social intention observed during human-human interactions (see Becchio et al. 2008b; Gigliotti et al. 2020; Quesque et al. 2013, 2016) spontaneously transfer to human-virtual agent interactions.
In order to address this issue, we conducted a first experiment (Experiment 1) in which participants were asked to grasp a dummy glass and place it in front of either a human confederate or a human-like virtual agent. Participants performed this grasp-to-place task with either a personal intention (to fill the glass themselves using a bottle) or a social intention (to have the glass filled by the human confederate or the virtual agent using the bottle). Results showed that the social intention modulated the kinematics of the grasp-to-place action when the latter was performed in the presence of a human confederate, but not when performed in the presence of a virtual agent. In view of this result, we conducted a second experiment (Experiment 2) to test whether following a feedback-based learning (acting as a reinforcement learning, Sutton and Barto 2018), participants would adapt their motor performance, and learn to express the social intention in object-directed actions in the presence of the virtual agent as well.
2 Experiment 1. Interacting with a human confederate vs. a virtual agent
The objective of Experiment 1 was to evaluate whether the effect of social intention on the kinematic features of a grasp-to-place action performed in the presence of a human confederate transfers to the interaction with a virtual agent. In line with the existing literature, we expected slower (longer movement time, lower peak velocity and longer deceleration time) and higher (greater trajectory height) movements when the grasp-to-place actions were performed with a social intention compared to a personal intention. Furthermore, we predicted that this difference in movement kinematics would be present when participants interacted with the human confederate but reduced when they interacted with the virtual agent, as a consequence of the diminished non-verbal social cues typical of virtual interactions (Maloney et al. 2020; Ruben et al. 2021).
2.1 Method
2.1.1 Participants
Sixteen healthy participants (10 women) aged between 18 and 35 years (M = 21.94, SD = 2.05) voluntarily took part in the study. They were recruited from the University of Lille. They were right-handed, as assessed by the Edinburgh Handedness Inventory (Oldfield 1971; mean laterality quotient = 0.83, SD = 0.14), they declared having no perceptual or motor deficit and having a normal or corrected-to-normal visual acuity. They had no prior information about the hypotheses tested in the study and gave their informed consent before taking part in the experiment.
The sample size of 16 was determined a priori by means of G*Power software (version 3.1.9.4). Considering an alpha level of 0.05 and a statistical power of 80%, we calculated that 15 participants would be sufficient to obtain a Cohen’s F effect size of 0.325 (i.e., large to medium effect), that we chose in order to account for the large effect size obtained by Quesque and colleagues (Quesque et al. 2013, 2016) and the novelty of the paradigm (virtual agent) expected to generate weaker effects. This result was estimated when considering running a repeated measures ANOVA- within factors module, which is the nearest option offered by G*Power to the Linear Mixed Model procedure used in the present paradigm. Finally, after considering the potential risk of losing some participants’ data due to the advanced technologies used to record participants’ performances, we decided that 16 participants would be appropriate for the purpose of the present study.
The protocol was approved by the ethical committee of the University of Lille (Ref. Number: 2019-337-S70) and was conducted in conformity with the ethical principles of the Declaration of Helsinki (World Medical Association 2013).
2.1.2 Materials and stimuli
The task consisted in manipulating a dummy bottle and a dummy glass made of wood. The bottle and the glass were placed on a 70 × 150 cm table serving as workspace, at specific locations within participants’ reach (see Fig. 1.A). These locations were indicated by landmarks on a black opaque sheet, which was used to cover the table in order to avoid that light reflections interfered with the infra-red motion capture system used to record the participants’ arm movements. For the same reason, all object surfaces were painted with a black non-reflective paint.
The task had to be performed in collaboration with either a human confederate (Human-Human interaction) or a virtual one (Human-Virtual agent interaction). During the Human-Human interaction, participants seated at the table serving as workspace, facing the human confederate. The human confederate was an accomplice of the experimenter, playing the role of a naive participant. During the Human-Virtual agent interaction, the virtual agent was displayed on a screen (SONY KD-65 × 9005 A, 168.2 * 87.5 cm) placed at the place of the human confederate’s chair. The virtual agent was situated in a virtual scenario representing the interior of a bar, giving the participant the impression to be seated at the counter. The virtual agent had the appearance of a barman who stood up while working (i.e., wiping a cup with a cloth). A virtual bottle was displayed on the top of the counter, so that it could be manipulated by the virtual agent during the task (see Fig. 1.C). A video illustration of the task and the different conditions can be found at the following link: http://fr-scv.fr/?page_id=996.

Illustration of the experimental setup. (A) Illustration of the table serving as workspace, on which were indicated: The participants’ hand starting position, the glass initial position and the bottle positions in social and personal intention trials. (B) Illustration of a Human-Human interaction trial. (C) Illustration of a Human-Virtual agent interaction trial
In order to humanise it, the virtual agent was given the name “Alphonse” and was addressed as a real person during the description of the task. Furthermore, the virtual agent was provided with human-like features and behaviours, such as looking at the participants when acting, performing fluid arm movements, and having human-like appearance. The scenario was built on Unity software (version 5.x) installed on a computer Dell Alienware 15 R4. The quality of the interface was evaluated by 20 participants in a pilot study. The results (see Table 1) showed that the interface succeeded in generating a feeling of social presence (i.e., the sense of being with another; Biocca et al. 2003; Nowak and Biocca 2003), with 66% of the participants reporting a fair to complete feeling of social presence (all items considered), and a feeling of telepresence (i.e., the sense of being in a mediated virtual space; (Nowak and Biocca 2003), with 80% of the participants reporting a fair to complete feeling of telepresence (all items considered).
2.1.3 Procedure
During the experimental task, participants were required to grasp the dummy glass from the initial position and place it to the final position (see Fig. 1.A) with either a personal or a social intention. A pre-recorded voice pronouncing two different auditory signals (“You” or “Him”) informed the participants about the type of intention to be pursued. After hearing the signal “You”, participants had to grasp and move the glass with a personal intention, to use the bottle placed on the side to fill the glass themselves. After hearing the signal “Him”, participants had to grasp and move the glass with a social intention, in order to be served by the human or the virtual agent.
A trial started with participants placing their right hand to the starting position (see Fig. 1.A), with their thumb and index finger pinched together. When the “You”/ “Him” signal was played, participants had 4 s to grasp and displace the glass and come back to the hand’s initial position. Then, participants had 4 s to grasp the bottle and serve themselves to drink or wait for the human/virtual agent to do it following the type of intention pursued. At the end of this delay, a beep was played and signalled the participants to grasp the glass and place it back to its initial location, in order to get ready for the next trial. The next trial would start after a delay varying randomly between 2 and 3 s after the beep. Participants were required to come back to the hand’s initial position at the end of each action (grasp and place the glass, grasp and use the bottle).
In both the social and personal trials, both the real and virtual confederate had to look up at the participants for a few seconds and then look down, in order to create a quick social contact and give the participant the impression they paid attention to the motor action performed. In the case of the social trials, the gaze exchange was followed by the pouring action performed by the confederate. This methodological detail was taken care of precisely to avoid a potential confounding effect of gaze modulation.
Participants performed 4 blocks of 50 trials, each block corresponding to an experimental condition: Personal intention/Human confederate, Social intention/Human confederate, Personal intention/Virtual agent, Social intention/Virtual agent. The order of blocks was counterbalanced across participants. A short pause of 2 min occurred between blocks. The whole experimental session lasted approximately 60 min.
2.1.4 Data recording and processing
Participants’ motor performances were recorded using five Oqus infrared Qualisys cameras (200 HZ sampling rate, spatial resolution less than 0.2 mm). The cameras were placed on the sides of the table to capture the entire scene and the space of interaction between the participant and the human/virtual agent (see Fig. 1.B and 1.C). The cameras were connected to the computer Dell 7010, equipped with the softwares MATLAB (version 2014a) and Qualisys Track Manager (version 2.14). Camera calibration (wand method) was realised prior to the beginning of each experimental session and retained if the system reached a standard deviation between 0.5 and 0.99 mm. The five Oqus infrared cameras tracked the 3D coordinates in space (x, y, z) of 4 passive markers fixed on a glove that participants wore during the task. The four markers were localised at the level of the index tip, the index base, the thumb tip and the scaphoid bone of the wrist. During the Human-Human interaction, no markers were placed on the hand of the human confederate.
Participants’ motor performances were recorded and analysed in real-time by means of the software interface QMT Connect for MATLAB, allowing to connect Qualisys Track Manager system (performing motion recording) to MATLAB program (performing motion analysis). Motor performances were then processed on MATLAB software, using an in-house script adapted from the RTMocap toolbox (Lewkowicz and Delevoye-Turrell 2015). In line with previous literature (Gigliotti et al. 2020; Quesque et al. 2013, 2016; Quesque and Coello 2014), we analysed the trajectory of the marker placed on the wrist, as it expresses arm movements without the influence of the grasping hand movement. When moving the glass, the action performed by the participant comprised two movement phases: a grasping phase (i.e., the period from the starting position to the grasp of the glass) and a placing phase (i.e., the period from the grasp of the glass to the end of its transportation to the new position). The onset of a movement phase was considered as the first moment in time for which the marker reached 20 mm.s-1. The end of the movement phase corresponded to the moment in time for which the marker reached 20 mm.s-1 after the peak velocity. In case this threshold was not reached between the grasping and placing movement phases, the local minima following peak velocity was considered as the movement phase end. For both the grasping and the placing phase, we extracted the following temporal and kinematic parameters: Peak wrist Elevation (mm), Peak wrist Velocity (mm.ms-1), Movement Time (ms) and Percentage of Deceleration Time (%). Table 2 provides a detailed description of the way each parameter was computed.
2.1.5 Statistical analysis
Statistical analyses were performed using R version 3.5.1 (R Core Team 2018) and R Studio version 1.1.456. Movements were excluded from statistical analysis if they were not correctly executed (i.e., impossibility to detect at least 2 local minima and/or 2 local maxima during the trajectory analysis). Prior to statistical analysis, we excluded outliers identified by means of median absolute deviation method (MAD method; Leys et al. 2013). In order to keep data loss below 5%, the threshold for outliers’ rejection was defined as the difference from the median plus or minus 3.5 times the MAD.
In both the grasping and placing phase, each kinematic parameter was analysed separately by applying a Linear Mixed-Effects Model (Baayen et al. 2008; Brauer and Curtin 2018; Judd et al. 2012). As concerns the fixed-effect parameters, the model used implied the main effects and the interaction effect between the factors Intention (Social, Personal) and Confederate (Human, Virtual). As concerns the random-effects parameters, we considered that there might exist inter- and intra-individual differences in the way participants express the social/personal intention and in their sensitivity to the real/virtual confederate. Therefore, in order to control for such individual differences, we added to the model a by-subject random intercept and by-subject random slopes for the effect of the Intention and the Confederate. Such random-effects structure was chosen on the basis of the research hypotheses (Brauer and Curtin 2018), as well as on a compromise between the most complete random-effect structure (Barr et al. 2013) and the data structure, in order to avoid model over-parametrization (Bates et al. 2015a; Matuschek et al. 2017). The final model appeared as follows:
Kinematic Parameter of interest∼Intention + Confederate + Intention: Confederate + (1 + Intention + Confederate | Participant)
Linear Mixed-Effects Models were applied using the lmer function of the “lme4 1.1–23” (Bates et al. 2015) and “lmerTest 3.1-3” packages (Kuznetsova et al. 2017). The model parameters were estimated using REstricted Maximum Likelihood approach (REML) and were statistically tested through F test with Satterthwaite approximation for degrees of freedom (Luke 2017) by using the function anova of the “lmerTest 3.1-3” package. Sum-to-zero contrasts were specified before model fitting. Finally, when the interaction was significant, we analysed the simple effects of the variable Intention within each level of the variable Confederate. For this purpose, we used the function emmeans from the “emmeans 1.7.1-1” package (Lenth et al. 2019).
2.2 Results
In Experiment 1, among the initial 3200 movements, 82 were removed from the dataset, resulting in a loss of 2.56% of the data. Table 3 shows mean, median and standard deviation values for each parameter, separately for the grasping and the placing phase.
2.2.1 Grasping phase
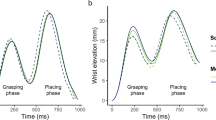
Concerning Peak wrist elevation (mm), statistical analysis revealed a non-significant effect of both the Intention (F(1,14.95) = 3.06, p = .101) and the Confederate (F(1,15.00) = 0.64, p = .434). It showed instead a significant Confederate * Intention interaction effect (F(1,3070.05) = 82.00, p < .001), the difference in peak wrist elevation between social and personal actions being greater when interacting with a human compared to a virtual agent. More specifically, simple effects analysis showed that peak wrist elevation was statistically higher for social than personal actions in the presence of the human confederate (Social - Personal estimate = 5.63 mm, SE = 1.47; t.ratio(16.7) = 3.84, p < .001), but not in the presence of the virtual one (Social - Personal estimate = -0.64 mm, SE = 1.47; t.ratio(16.8) = -0.44, p = .666, see Fig. 2.A).
Concerning Peak wrist velocity (mm.s-1), statistical analysis showed a non-significant effect of both the Intention (F(1,14.89) = 0.42, p = .526) and the Confederate (F(1,15.01) = 3.40, p = .085). It showed instead a significant Confederate * Intention interaction effect (F(1,3070.30) = 11.04, p < .001), with a higher difference in peak wrist velocity between social and personal actions when interacting with a human confederate compared to a virtual agent. More specifically, simple effects analysis showed that peak wrist velocity was statistically higher for social than personal actions in the presence of the human confederate (Social - Personal estimate = 12.5 mm.s-1, SE = 6.90; t.ratio(19.7) = 1.82, p = .042), but not in the presence of the virtual one (Social - Personal estimate = -4.20 mm.s-1, SE = 6.91; t.ratio(19.9) = -0.61, p = .725, see Fig. 2.B).
Concerning Percentage of deceleration time (%), statistical analysis revealed non-significant effects of the Intention (F(1,14.73) = 0.64, p = .436), the Confederate (F(1,14.90) = 0.26, p = .620), as well as the Confederate * Intention interaction (F(1,3070.82) = 0.62, p = .433).
Concerning Movement time (ms), statistical analysis showed a non-significant effect of the Intention (F(1,14.88) = 0.06, p = .813), but a significant effect of the Confederate (F(1,15.01) = 5.52, p = .033), with longer movement time recorded in the presence of the human confederate (estimate = 777.74 ms, SE = 25.50) than the ones recorded in the presence of the virtual one (estimate = 730.74 ms, SE = 19.40). This effect was not modulated by the Intention, as suggested by the non-significant Confederate * Intention interaction effect (F(1,3069.80) = 0.53, p = .467).
2.2.2 Placing phase
Concerning Peak wrist elevation (mm), statistical analysis showed a non-significant effect of both the Intention (F(1,14.91) = 3.25, p = .092) and the Confederate (F(1,14.98) = 0.04, p = .850). It showed instead a significant Confederate * Intention interaction effect (F(1,3069.67) = 148.81, p <. 001), the difference in peak wrist elevation between social and personal actions being higher when interacting with the human than with the virtual agent. Again, simple effects analysis showed that peak wrist elevation was statistically higher for social actions compared to personal actions in the presence of the human confederate (Social - Personal estimate = 9.85 mm, SE = 2.73; t.ratio(15.6) = 3.61, p = .001), but not in the presence of the virtual one (Social - Personal estimate = -0.125 mm, SE = 2.73; t.ratio(15.6) = -0.05, p = .518, see Fig. 2.A).
Concerning Peak wrist velocity (mm.s-1), statistical analysis showed non-significant effects of the Intention (F(1,14.93) = 1.65, p = .219), the Confederate (F(1,15.01) = 1.36, p = .262) and the Confederate * Intention interaction (F(1,3069.45) = 1.21, p = .272).
Concerning Percentage of deceleration time (%), statistical analysis showed a non-significant effect of both the Intention (F(1,14.81) = 1.66, p = .218) and the Confederate (F(1,14.80) = 0.21, p = .653). It showed instead a significant Confederate * Intention interaction effect (F(1,3069.78) = 21.79, p < .001), with a greater difference in deceleration time between social and personal actions when interacting with the human confederate compared to when interacting with the virtual one. More specifically, simple effects analysis showed that the percentage of deceleration time was statistically higher for social actions compared to personal actions in the presence of the human confederate (Social - Personal estimate = 1.66%, SE = 0.70; t.ratio(16.7) = 2.39, p = .015), but not in the presence of the virtual one (Social - Personal estimate = 0.08%, SE = 0.70; t.ratio(16.8) = 0.11, p = .458, see Fig. 2.C).
Concerning Movement time (ms), statistical analysis showed a non-significant effect of both the Intention (F(1,14.94) = 1.30, p = .273) and the Confederate (F(1,15.00) = 1.98, p = .180). It showed instead a significant Confederate * Intention interaction effect (F(1,3069.36) = 44.50, p < .001), with the difference in movement time between social and personal actions being greater when interacting with the human confederate compared to the virtual one. Moreover, simple effects analysis showed that movement time was statistically longer for social than personal actions in the presence of the human confederate (Social - Personal estimate = 52.05 ms, SE = 26.30; t.ratio(15.4) = 1.98, p = .033), but not in the presence of the virtual one (Social - Personal estimate = 7.25 ms, SE = 26.30; t.ratio(15.4) = 0.28, p = .393, see Fig. 2.D).

Experiment 1. Effect of the Intention (Social, Personal) on the kinematic parameters of the grasp-to-place actions as a function of the Confederate (Virtual agent, Human). Dots represent individual trials (one dot corresponds to one trial for one participant), thicker dots the mean values and error bars (horizontal lines) indicate standard error. Peak wrist elevation (A), Peak wrist velocity (B), Percentage of deceleration time (C) and Movement time (D) in the grasping and placing phases. *p < .050, **p < .010, ***p < .001
2.3 Interim discussion
In line with the formulated hypothesis, the results of Experiment 1 showed that when interacting with a human confederate, the kinematic features of object-directed actions were influenced by the social intention. This effect was present in both the grasping and the placing phase of the grasp-to-place action performed. In the grasping phase, actions driven by a social intention were characterised by a higher trajectory and higher velocity compared to actions driven by a personal intention. During the placing phase, social actions were characterised by higher trajectory, longer movement duration and longer deceleration period compared to personal actions. None of these effects were observed when interacting with a virtual agent, as social actions were performed similarly to personal actions.
The effects of social intention on object-directed actions in the presence of the human confederate replicated previous findings reported in the literature (Gigliotti et al. 2020; Quesque et al. 2013, 2016; Quesque and Coello 2014). The longer and higher movements observed when performing an action with the social intention have been interpreted as an amplification of the spatio-temporal parameters of the motor action. Such amplification has been supposed to make the gesture more communicative (Hostetter 2011) and attract others’ gaze (Quesque and Coello 2014), allowing the confederate to respond with the most appropriate behaviour and therefore, to facilitate the interaction (Ansuini et al. 2014; Cavallo et al. 2016; Lewkowicz et al. 2013; Meulenbroek et al. 2007; Quesque et al. 2016). Moreover, the present study extended the previous findings obtained using laboratory designed experiments, to a more ecological interactive task.
The lack of effect of social intention on motor performance in the presence of the virtual agent constitutes a novelty with respect to the existing literature. When looking at the body of research on individuals’ behaviours towards conversational agents, previous studies suggested that artificial systems endowed with basic verbal and non-verbal social cues proved to be able to influence human behaviour in a similar manner to a human interlocutor (Krämer 2008). Indeed, when interacting with virtual agents, individuals were found to adapt their gaze behaviour and facial expressions to the virtual agent’s gaze and body direction (Marschner et al. 2015), and to produce verbal utterances and discussion topics resembling the ones produced in the presence of a real human interlocutor (Bergmann et al. 2012; Lugrin et al. 2018). Nevertheless, differently from previous studies, the present one did not imply a conversational context, but rather an interaction situation involving the manipulation of objects. Within this context, the present study enriches the existing literature and shows for the first time that the social modulation of actions involving objects does not naturally transfer to the interaction with a virtual agent.
In light of this consideration, several explanations can be suggested to account for the lack of effect of social intention on the kinematics of object-directed actions in the presence of the virtual agent. One aspect is the novelty of the situation. Screen-mediated social interactions are now part of people’s daily life, and one might suppose that individuals have adapted their conversational style to the virtual context. Moreover, people are used to engaging in discussions with virtual agents (e.g., automatic chats on websites, applications, or pre-registered vocal responses when calling on the phone). On the contrary, virtual contexts do not allow yet to interact with objects, which is therefore a new situation. We might then speculate that individuals are not used yet to generalise their motor behaviour, and the social aspects characterising it, to interactions with virtual agents.
Another potential explanation could be the fact that interacting with objects involves specific factors relative to action performance. In particular, interacting with confederates implies a shared physical workspace, which might be lacking or misperceived in the case of mixed reality context, as the one used in the present study. Within such context, the mechanisms subtending the representation and exploitation of near body space (i.e., Brozzoli et al. 2012; Cléry et al. 2015; di Pellegrino and Làdavas 2015) cannot be used, and therefore, action cannot be properly calibrated with respect to the objects and the confederate’s space (Coello et al. 2018; Gigliotti et al. 2021, 2023). Finally, interacting with others requires also to synchronise each-other’s behaviour, which is a crucial factor when it comes to acting in a coordinated way on a same object. In the context of the interaction with a virtual agent, these spatial and coordination aspects are reduced, and therefore, individuals cannot calibrate and adjust their actions as they would do in real human-human interactions.
As a whole, we can conclude that despite the existence of a social presence feeling, the novelty of the interaction situation might have, for the reasons previously discussed, prevented the transfer of social cues to motor performances when interacting with a virtual agent. Within this context, it would appear logical to ask whether the effect of social intention could be improved by providing individuals with feedback about their motor performance, so that they could learn and adapt to the new interactive situation. This was the rationale of Experiment 2.
3 Experiment 2. Inducing the effects of social intention in human-virtual agent interactions through a feedback-based learning
Results from Experiment 1 showed that social intention modulated object-directed action kinematics when interacting with a human confederate, but not when interacting with a virtual agent. In light of this outcome, the objective of Experiment 2 was to investigate whether such lack of effect could be compensated through a trial-and-error training. For this purpose, in Experiment 2 we asked participants to produce the grasp-to-place actions with either a personal or a social intention as in Experiment 1, but this time only in the presence of a virtual agent. The main change in the paradigm was that the virtual agent reacted only when participants’ actions presented the kinematic features associated with the social intention. To achieve this, we used the computational method developed by Daoudi et al. (2018) (see Sect. 3.1.5 for a description of the algorithm), which allowed us to analyse online participants’ grasp-to-place actions and, on the basis of their kinematic profile, to categorise them as being driven by either a social or a personal intention. The reaction of the virtual agent would therefore serve as feedback allowing participants to progressively adapt their motor performances and succeed the task. Throughout the feedback-based learning, social actions were expected to progressively differentiate from personal actions, by becoming characterised by a higher hand trajectory and a longer movement duration in order to fulfil the requirements of the task.
3.1 Method
3.1.1 Participants
30 new right-handed participants were recruited for Experiment 2, following the same inclusion criteria used in Experiment 1. This sample size was determined a priori by means of G*Power software (version 3.1.9.4). Considering an alpha level of 0.05 and a statistical power of 80%, we calculated that 20 participants would be sufficient to obtain a Cohen’s F effect size of 0.175 (i.e., a small to medium effect, as expected η2p was unknown). This result was estimated when considering running a repeated measures ANOVA-within factors module, which is the nearest option offered by G*Power to the Linear Mixed Model procedure used in the present study. Finally, after considering the potential risk of some participants not succeeding the feedback-based learning, we decided that 30 participants would be appropriate for the purpose of the present study. One participant was excluded from the initial dataset as more than 60% of his motor actions were not correctly executed and not analysable. Hence, the final sample included 29 participants (22 women), right-handed (mean laterality quotient = 0.84, SD = 0.14) and aged between 18 and 35 years (M = 21.41, SD = 3.12).
3.1.2 Materials and stimuli
The task, the experimental setup and the stimuli were the same as used in Experiment 1, except for the reaction of the virtual agent, that was not set a priori but depended on the kinematic features of the participants’ motor actions. For this purpose, a classification algorithm (Daoudi et al. 2018; Devanne et al. 2015; see Sect. 3.1.5 for a description of the algorithm) was used to analyse participants’ trajectories online and classify them as driven by a social or a personal intention on the basis of their specific kinematic profile. Once the intention was classified by the algorithm, the virtual agent could either fill the glass of the participants (if the movement was classified as driven by a social intention) or not (if the movement was classified as driven by a personal intention). In the latter situation, he continued to wipe the cup with a cloth, but looked at the participants to indicate that he had noticed the motor action.
Finally, the virtual agent reaction served also as feedback for the participants, informing them on whether their motor performance was successful or not.
3.1.3 Procedure
Participants performed the task in the presence of the virtual agent only. They performed 8 blocks of 20 trials each (10 “You” and 10 “Him”, presented in a randomised order), for a total of 160 trials. A short pause of 1 min was provided at the end of each block of trials. The experimental session lasted approximately 60 min.
3.1.4 Data recording and processing
Movements recording and processing were similar as in Experiment 1. In addition to the analysis of temporal and kinematic parameters, in Experiment 2 we also analysed the classifier performance, namely the percentage of intentions underlying participants’ actions correctly classified by the algorithm and triggering, or not, the virtual agent action. The results of the classifier were coded using a binary system [0,1], with 1 being attributed to an action correctly classified (i.e., an action whose kinematic profile was in accordance with the expected kinematic profile for the social or the personal intention) and 0 to an action incorrectly classified (i.e., action whose kinematic profile was not in accordance with the expected profile related to the intention).
3.1.5 Description of the classification algorithm
The present section describes briefly the algorithm used to analyse participants’ actions and classify them as driven by either a personal or a social intention (for more details, see Daoudi et al. 2018; Devanne et al. 2015). The 3D trajectories of each action were first represented as curves in ℝ3 by means of the Square-Root Velocity Function (SRVF; Srivastava et al. 2010). Then, by normalising the length of curves to 1, the trajectories were represented by points and in a Riemannian manifold, having a spherical structure. In this space, the social and personal actions were represented by their SRVF curves as q1 and q2 respectively. The distance between q1 and q2 on the sphere was used to quantify the similarity between the two curves in ℝ3. Indeed, this distance quantifies the amount of deformation in terms of length and height between the two curves. This distance (called elastic distance) is invariant to rotation and scaling, and takes into account the stretching and bending of the curves.
However, machine learning algorithms such as Principal Component Analysis (PCA) and Maximum Likelihood clustering algorithms cannot be applied to manifolds in their native form due to the lack of vector space structure and Euclidean structure (norm, dot product) of manifolds. Therefore, to deal with such non-linear space, we approximated the evaluated data on the manifold by their projection onto a tangent space at a particular point in the space on the tangent space of the manifold. Such a tangent space is a linear vector space which is more convenient for computing statistics (e.g., mean, covariance) and allowed us to perform PCA to learn the distribution of tangent vectors in the tangent space. Following PCA, we obtained the principal subspace Beta, where tangent vectors were projected, and computed the covariance matrix on this principal subspace. The covariance matrix was then used to learn the multivariate normal distribution of trajectories belonging to the same class (social, personal). Finally, we used the maximum likelihood clustering to build the classifier and identify the actions driven by the social and personal intentions.
The algorithm was trained on data from Experiment 1, in order to learn the kinematic profile associated with social and personal actions and create the statistical model at the basis of the classifier.
3.1.6 Statistical analysis
Outliers analysis was carried out prior to statistical analysis. The threshold for outlier’s rejection was set at 3.75 times the MAD (Median Absolute Deviation) from the median in order to keep data loss below 5%.
As in Experiment 1, statistical analyses were carried out using the Mixed-Effects Models approach. In Experiment 2, the model included the Intention (Social, Personal) and the Block (1 to 8) as repeated measures fixed-effects parameters. The random-effects structure included a by-subject random intercept and a by-subject random slope for the effect of the Intention. The by-subject random slope for the effect of the Block was not included as its presence led to a lack of model convergence and singularity issues (Bates et al. 2015a; Matuschek et al. 2017). The final model (see formula below) accounted for both the main effects and the interaction effect of the factors Intention and Block, and was used for the analysis of the kinematic parameters and the classifier performance.
Kinematic Parameter of interest∼Intention + Block + Intention: Block + (1 + Intention | Participant)
As regards the analysis of the kinematic parameters, if the dataset followed a normal distribution, we fitted a Linear Mixed-Effects Model using the lmer function. This was the case for peak wrist elevation (grasping phase only), peak wrist velocity (grasping and placing phases), percentage of deceleration time (grasping and placing phases) and movement time (grasping phase only) datasets. This was not the case for peak wrist velocity (placing phase) and movement time (placing phase) datasets, that were rather characterised by a positively skewed distribution. For their analysis, we fitted a Generalised Linear Mixed-Effects Model using the function glmer of the “lme4 1.1–23” package (Bates et al. 2015). We used the Gamma family for characterising the distribution of the dependent variable and the log link function to define the relationship between the fixed factors and the dependent variable.
The statistical analyses of kinematic parameters were conducted as a function of three main objectives. First, we analysed the interaction effect between the Intention and Block in order to assess whether the feedback-based learning procedure was successful and led participants to execute social actions differently from personal actions in the presence of the virtual agent. Then, we analysed the simple effects of the variable Intention in the block 1 and block 8, in order to assess whether the feedback-based learning induced an effect of social intention on motor performances at the end compared to the beginning of the task. Finally, in order to establish from which block on the feedback-based learning effects occurred, we performed post-hoc analysis and compared the difference in kinematics profile between social and personal actions in each block to the difference observed in the baseline block 1.
As concerns the classifier performance, since the variable of interest was binary [0 = Fail, 1 = Success], we applied a Generalised Linear Mixed-Effects Model specifying a Binomial family distribution and a logit link function.
For the Generalised Mixed-Effects models, the model parameters were estimated using Laplace Approximation and statistically tested using Wald’s χ2 from the Anova function of the “car 3.0–8” package (John et al. 2020). Prior to model fitting, sum-to-zero contrasts were specified for the factor Intention (Social, Personal) and treatment contrasts for the factor Block (with Block 1 serving as baseline). Simple effects and post-hoc analysis were carried out using the function emmeans from the “emmeans 1.7.1-1” package (Lenth et al. 2019). Holm-Bonferroni correction method was used to adjust p-values following post-hoc multiple comparisons.
3.2 Results
Among the 29 participants who took part in the experiment, 20 showed a change in their motor performance at the end of the task compared to the beginning following the feedback-based learning. Such change was revealed by a difference in the percentage of correct classification by the algorithm between block 8 and block 1 (at least above 0%). Statistical analyses were carried out on the results from these 20 participants. Among the initial 3007 movements, 124 were removed from the dataset, resulting in a loss of 4.12% of the data.
3.2.1 Classifier performance
When analysing the classifier performance, statistical analysis showed a significant main effect of the Block (χ2(7) = 44.31, p < .001), with the percentage of actions correctly classified by the classifier being higher at the end (72.12% in block 8, estimate = 80.20, SE = 4.29) when compared to the beginning of the task (54.91% in block 1, estimate = 57.30, SE = 6.62; see Table 4 for all comparisons). The analysis also showed a significant main effect of the Intention (χ2(1) = 28.31, p < .001), with a higher correct classification percentage for personal actions (83.40%, estimate = 91.40, SE = 3.23) when compared to social actions (41.01%, estimate = 32.70, SE = 11.22). However, the significant Intention * Block interaction effect (χ2(7) = 74.25, p < .001) indicated that this tendency evolved across blocks. More specifically, while the percentage of correct classification of personal actions remained high all along the task, the percentage of correct classification for social actions increased progressively from block 5 on, with respect to baseline block 1, until the end of the task (see Table 4; Fig. 3).

Experiment 2. Correct classification percentage of the Intention (Social, Personal) as a function of the Block (1 to 8). Filled purple triangles and the purple continuous line represent the correct classification percentage relative to the personal intention. Filled green circles and the green continuous line represent the correct classification percentage relative to the social intention. Filled black dots and the dashed black line represent the global correct classification percentage (personal and social intention considered together)
3.2.2 Kinematic analysis of motor performance
Mean, median and standard deviation values for each parameter, computed separately for each phase, can be found in Table 5. In the following section we report the result for the interaction effect and the post-hoc analyses. The results for the main effects are reported in Table 6, as not crucial with respect to the core hypotheses of the present study.
3.2.3 Grasping phase
Concerning Peak wrist elevation (mm), statistical analysis showed a non-significant Intention * Block interaction effect (χ2(7) = 3.30, p = .856), the difference in peak wrist elevation between social and personal actions not changing across the blocks of trials. Accordingly, simple effects analysis confirmed that peak wrist elevation for social actions did not statistically differ from personal actions in the baseline block 1 (Social - Personal estimate = -0.01, SE = 0.01, z.ratio = -1.00, p = .842), and this did not change in block 8 (Social – Personal estimate = 0.01, SE = 0.01, z.ratio = 0.45, p = .327).
Concerning Peak wrist velocity (mm.s-1), statistical analysis showed a non-significant Intention * Block interaction effect (F(7,2848) = 0.48, p = .848), with the difference in peak wrist velocity between social and personal actions not changing across the blocks of trials. Accordingly, simple effects analysis showed that peak wrist velocity for social actions did not statistically differ from personal actions in the baseline block 1 (Social - Personal estimate = -2.63, SE = 8.19, t.ratio(362) = -0.32, p = .626), and this did not change in block 8 (Social – Personal estimate = 6.68, SE = 8.78, t.ratio(449) = 0.76, p = .224).
Concerning Percentage of deceleration time (%), statistical analysis showed a non-significant Intention * Block interaction effect (F(7,2833.08) = 0.59, p = .761), with the difference in percentage of deceleration time between social and personal actions not changing across the blocks of trials. Accordingly, simple effects analysis showed that peak wrist velocity for social actions did not statistically differ from personal actions in the baseline block 1 (Social - Personal estimate = -0.52, SE = 0.88, t.ratio(213) = -0.59, p = .723), and this did not change in block 8 (Social – Personal estimate = 1.05, SE = 0.94, t.ratio(267) = 1.12, p = .132).
Concerning Movement time (ms), statistical analysis showed a non-significant Intention * Block interaction effect (F(7,2831.34) = 0.69, p = .681), with the difference in peak wrist elevation between social and personal actions not changing across the blocks of trials. Coherently, simple effects analysis showed that peak wrist elevation for social actions did not statistically differ from personal actions neither in the baseline block 1 (Social - Personal estimate = 1.19, SE = 11.2, t.ratio(167) = 0.11, p = .458), nor in block 8 (Social – Personal estimate = 12.65, SE = 12.0, t.ratio(208) = 1.06, p = .146).
3.2.4 Placing phase
Concerning Peak wrist elevation (mm), statistical analysis showed a significant Intention * Block interaction effect (χ2(7) = 163.66, p < .001), with the difference in peak wrist elevation between social and personal actions increasing progressively throughout the blocks of trials. Coherently, simple effects analysis showed that peak wrist elevation was not statistically different in social compared to personal actions in the baseline block 1 (Social - Personal estimate = 0.04, SE = 0.05, z.ratio = 0.81, p = .210), whereas it was in block 8 (Social - Personal estimate = 0.22, SE = 0.05, z.ratio = 4.23, p < .001). Post-hoc analysis showed that the difference in peak wrist elevation between social and personal actions started to be significantly different from the baseline block 1 from block 2 on (see Fig. 4.A).
Concerning Peak wrist velocity (mm.s-1), statistical analysis showed a significant Intention * Block interaction effect (F(7,2830.21) = 2.16, p = .035), with the difference in peak wrist velocity between social and personal actions changing throughout blocks of trials. Nevertheless, simple effects analysis showed that peak wrist velocity was not statistically different in social compared to personal actions in the baseline block 1 (Social - Personal estimate = -8.43, SE = 8.20, t.ratio(59.1) = -1.03, p = .846), and that this did not change in block 8 (Social - Personal estimate = 5.03, SE = 8.54, t.ratio(69.3) = 0.59, p = .279). When performing post-hoc analysis, results showed that the difference in peak wrist velocity between social and personal actions was significantly different from the baseline block 1 only for the blocks 2, 3 and 5, but not beyond (see Fig. 4.B).
Concerning Percentage of deceleration time (%), statistical analysis showed a significant Intention * Block interaction effect (F(7,2829.70) = 3.25, p = .002), with the difference in percentage of deceleration time between social and personal actions increasing progressively throughout the blocks of trials. Coherently, simple effects confirmed that peak wrist velocity was not statistically different in social compared to personal actions in the baseline block 1 (Social - Personal estimate = -0.12, SE = 1.02, t.ratio(34.1) = -0.11, p = .545), whereas it was in block 8 (Social - Personal estimate = 2.75, SE = 1.05, t.ratio(37.6) = 2.63, p = .006). Post-hoc analysis showed that the difference in percentage of deceleration time between social and personal actions was significantly different from the baseline block 1 in block 6 and 8, but not in block 7 (see Fig. 4.C).

Experiment 2. Effect of Intention (Social, Personal) on the kinematic parameters of the grasp-to-place actions across Blocks (1 to 8). Significant effects were found only in the placing phase. Dots represent individual trials (one dot corresponds to one trial for one participant), thicker dots mean values and error bars (horizontal lines) indicate standard error. (A) Peak wrist elevation in the placing phase. (B) Peak wrist velocity in the placing phase. (C) Movement time in the placing phase. (D) Percentage of deceleration time in the placing phase. *p < .050, **p < .010, ***p < .001
Concerning Movement time (ms), statistical analysis showed a significant Intention * Block interaction effect (χ2(7) = 23.34, p = .002), with the difference between social and personal actions increasing progressively throughout the blocks of trials. Simple effects analysis showed that peak wrist elevation was already statistically different in social compared to personal actions in the baseline block 1 (Social - Personal estimate = 0.05, SE = 0.03, z.ratio = 1.66, p = .049), and that it was also in block 8 (Social - Personal estimate = 0.11, SE = 0.03, z.ratio = 3.31, p < .001). Post-hoc analysis showed that the difference in peak wrist elevation between social and personal actions became significantly different from the baseline block 1 in block 8 only (see Fig. 4.D).
3.3 Interim discussion
The results of the analysis of kinematic profile and the classifier performance indicated that at the end of the feedback-based learning procedure, participants adapted their motor performances in the expected way. In the initial block, no kinematic difference was observed between personal and social actions, suggesting that participants performed similar movements regardless of the intention to be pursued, and close to the usual kinematic profile of personal actions. Accordingly, 93.10% of actions were classified by the algorithm as driven by a personal intention (when the participants attempted to perform a personal action), while 11.80% were classified as driven by a social intention (when the participants attempted to perform a social action). Throughout the learning procedure, motor performances evolved progressively: in the final block, social actions were characterised by a higher trajectory, a longer movement time and a longer deceleration period than personal actions. Accordingly, the correct classification percentage of social actions increased significantly from block 5 on (31.10%), that is after 100 trials, and kept improving until block 8 (63.40%). As a consequence, the global correct classification percentage (including both personal and social actions) increased by approximately 40%, evolving from 57.30% (close to chance level) in the initial block to 80.20% in the final block. These results confirmed our hypothesis and showed that participants were able to adapt their motor performance in order to elicit the appropriate response from the virtual agent, thus ending up by interacting with it as they would do in the presence of a human confederate. In a way, the participants became more social towards the virtual agent at the end compared to the beginning of the experimental session. It is however worth noting that the observed improvements were not really due to a social learning per se, but rather to a reinforcement-mediated learning (e.g., Sutton and Barto 2018) of a social behaviour.
When looking at the kinematic profile supporting the motor adaptation, results showed that the adjustment of motor performances was gradual and not temporally aligned for all kinematic parameters. With respect to the baseline block 1, the trajectory height was the fastest to change, with social and personal actions starting to differ since block 2 already. Modifications of peak velocity were observed in blocks 2, 3 and 5, but not beyond, while differences in percentage of deceleration time were observed in block 6 and 8, but not in block 7. Regarding movement time, social actions were found to last significantly longer than personal ones in block 1. This difference was not observed in the following blocks, but was observed again in block 8. Since there was no effect of social intention on trajectory height in block 1, it is difficult to believe that such longer movement time was induced by the social intention per se. We rather explain this effect by the novelty of the social interaction situation and the expectations towards the virtual agent behaviour. Considered as a whole, the observed modulations of kinematic parameters might reflect the progressive adaptation of participants’ motor performances to the new interaction context, until reaching the right combination at the end of the experimental session, when all the kinematic parameters corresponded to the expected motor profile of an action performed with a social intention.
Finally, it is important to note that the adjustment of motor performances was stronger (and statistically significant) in the placing phase than in the grasping phase. Several reasons might explain the absence of an effect of motor adaptation on the grasping phase of the action. First, the grasping component is less determinant to convey social intention, because it is the phase of the action during which one grasps the targeted object. As a consequence, the kinematic profile of this action component is highly influenced by the physical features of the object/target (e.g., Cuijpers et al. 2004; Santello and Soechting 1998). Moreover, in a previous study we showed that the properties of the target of the action can also modulate the expression of social intention (Gigliotti et al. 2020). Secondly, it is also possible that the grasping phase, that is the first component of the motor action, is affected by variations in the second component of the motor action (placing phase). This is known as the co-articulation phenomenon, largely described in the past (e.g., Chary et al., 2004), whose role is to refine and optimise the entire motor sequence, and render the first component of the action dependent on the second component (through a process of motor anticipation, e.g., Orliaguet et al. 1997). Consequently, the effect of social intention on the first component of a motor sequence is not systematically observed (e.g., Lewkowicz et al., 2015; Quesque et al. 2013; Quesque and Coello 2014), which is in line with the arguments just exposed. Finally, we can add the fact that during motor learning, co-articulation phenomena usually appear later in the adaptation process. Indeed, motor adaptation studies (e.g., motor adaptation to optical prism) revealed the existence of concurrent fast and slow adaptation processes (Fleury et al. 2019). Fast processes modulate the motor components to rapidly reduce the introduced error, while slow ones lead to the optimization and refinement of the fluidity of the whole action. Therefore, the absence of adaptation in the first component might be explained by the late development of the co-articulation process, for which the adaptation procedure used in the present study was perhaps not long enough.
4 Conclusion
In the present study, our purpose was to explore whether individuals transfer the non-verbal behaviours typical of social interactions to the interaction with a virtual agent. The first main contribution of the present study was to examine the expression of social intention when manipulating objects, which is a crucial aspect of human interactions, but yet not deeply explored in situations involving virtual agents. The second main contribution was the observation of a lack of effect of social intention on object-directed actions when interacting with a virtual agent, suggesting that this non-verbal social cue does not spontaneously transfer to such specific interaction context. Finally, a last contribution was to show that this behaviour could be improved through a feedback-based learning, with participants proving able to adapt their motor performances to a virtual agent when performing object-directed action with a social intention, on the basis of the reaction of the virtual agent.
The present results open new avenues in both fundamental and applied research. In fundamental research, the present findings encourage the use of virtual agents to gain a better insight into the effect of social intention on human motor behaviour and social interactions. Furthermore, they suggest that the inclusion and implementation of object-directed actions could be highly beneficial to the study of virtual environments, the social presence feeling and virtual social interactions. In applied research, the present findings enrich the knowledge requested to design virtual agents, interfaces and programs for diverse purposes (educational, medical, rehabilitation…). This is notably relevant for interfaces conceived for the learning and training of social cognition skills, as well as for the implementation of inter-platform communications and teleoperation.
References
Anderson K, André E, Baur T, Bernardini S, Chollet M, Chryssafidou E, Damian I, Ennis C, Egges A, Gebhard P, Jones H, Ochs M, Pelachaud C, Porayska-Pomsta K, Rizzo P, Sabouret N (2013) The TARDIS framework: Intelligent virtual agents for social coaching in job interviews. Int Conf Adv Comput Entertainment Technol 476–491. https://doi.org/10.1007/978-3-319-03161-3_35
Ansuini C, Santello M, Massaccesi S, Castiello U (2006) Effects of end-goal on hand shaping. J Neurophysiol 95(4):2456–2465. https://doi.org/10.1152/jn.01107.2005
Ansuini C, Giosa L, Turella L, Altoè G, Castiello U (2008) An object for an action, the same object for other actions: effects on hand shaping. Exp Brain Res 185(1):111–119. https://doi.org/10.1007/s00221-007-1136-4
Ansuini C, Cavallo A, Bertone C, Becchio C (2014) The visible face of intention: why kinematics matters. Front Psychlogy 5:815. https://doi.org/10.3389/fpsyg.2014.00815
Auriacombe M, Moriceau S, Serre F, Denis C, Micoulaud-Franchi JA, de Sevin E, Bonhomme E, Bioulac S, Fatseas M, Philip P (2018) Development and validation of a virtual agent to screen tobacco and alcohol use disorders. Drug Alcohol Depend 193(October):1–6. https://doi.org/10.1016/j.drugalcdep.2018.08.025
Baayen RH, Davidson DJ, Bates DM (2008) Mixed-effects modeling with crossed random effects for subjects and items. J Mem Lang 59(4):390–412. https://doi.org/10.1016/j.jml.2007.12.005
Barr DJ, Levy R, Scheepers C, Tily HJ (2013) Random effects structure for confirmatory hypothesis testing: keep it maximal. J Mem Lang 68(3):255–278. https://doi.org/10.1016/j.jml.2012.11.001.Random
Bates D, Kliegl R, Vasishth S, Baayen RH (2015a) Parsimonious mixed models. ArXiv Preprint ArXiv :150604967
Bates D, Mächler M, Bolker BM, Walker SC (2015b) Fitting linear mixed-effects models using lme4. J Stat Softw 67(1). https://doi.org/10.18637/jss.v067.i01
Becchio C, Sartori L, Bulgheroni M, Castiello U (2008a) Both your intention and mine are reflected in the kinematics of my reach-to-grasp movement. Cognition 106(2):894–912. https://doi.org/10.1016/j.cognition.2007.05.004
Becchio C, Sartori L, Bulgheroni M, Castiello U (2008b) The case of Dr. Jekyll and Mr. Hyde: a kinematic study on social intention. Cognition 17(3):557–564. https://doi.org/10.1016/j.concog.2007.03.003
Becchio C, Manera V, Sartori L, Cavallo A, Castiello U (2012) Grasping intentions: from thought experiments to empirical evidence. Front Hum Neurosci 6:117. https://doi.org/10.3389/fnhum.2012.00117
Bergmann K, Eyssel F, Kopp S (2012) A second chance to make a first impression? How appearance and nonverbal behavior affect perceived warmth and competence of virtual agents over time. Lecture Notes Comput Sci (Including Subser Lecture Notes Artif Intell Lecture Notes Bioinformatics) 7502 LNAI:126–138. https://doi.org/10.1007/978-3-642-33197-8-13
Biocca F, Harms C, Burgoon JK (2003) Toward a more robust theory and measure of Social Presence: review and suggested Criteria. Presence: Teleoperators Virtual Environ 12(5):456–480. https://doi.org/10.1162/105474603322761270
Bombari D, Schmid Mast M, Canadas E, Bachmann M (2015) Studying social interactions through immersive virtual environment technology: virtues, pitfalls, and future challenges. Front Psychol 6(June):1–11. https://doi.org/10.3389/fpsyg.2015.00869
Brauer M, Curtin JJ (2018) Linear mixed-effects models and the analysis of nonindependent data: a unified framework to analyze categorical and continuous independent variables that vary within-subjects and/or within-items. Psychol Methods 23(3):389–411. https://doi.org/10.1037/met0000159
Brozzoli C, Makin TR, Cardinali L, Holmes NP, Farnè A (2012) Peripersonal space: a multisensory interface for body-objects interactions. In: Murray MM, Wallace MT (eds) The neural bases of multisensory processes. CRC Press/Taylor & Francis, pp 447–464
Burgoon JK, Bacue A (2020) Nonverbal Communication skills. In: Greene JO, Burleson BR (eds) Handbook of Communication and Social Interaction skills. Issue January. Lawrence Erlbaum Associates, Mahwah, NJ, pp 197–238. https://doi.org/10.4324/9781410607133-12
Cartaud A, Ruggiero G, Ott L, Iachini T, Coello Y (2018) Physiological response to facial xxpressions in peripersonal space determines interpersonal distance in a social interaction context. Front Psychlogy 9:657. https://doi.org/10.3389/fpsyg.2018.00657
Cassell J, Pelachaud C, Badler N, Steedman M, Achorn B, Becket T, Douville B, Prevost S, Stone M (1994) Animated conversation: rule-based generation of facial expression, gesture & spoken intonation for multiple conversational agents. Proc 21st Annual Conf Comput Graphics Interact Techniques 413–420. https://doi.org/10.1145/192161.192272
Cavallo A, Koul A, Ansuini C, Capozzi F, Becchio C (2016) Decoding intentions from movement kinematics. Sci Rep 6:37036. https://doi.org/10.1038/srep37036
Cléry J, Guipponi O, Wardak C, Ben Hamed S (2015) Neuronal bases of peripersonal and extrapersonal spaces, their plasticity and their dynamics: knowns and unknowns. Neuropsychologia 70:313–326. https://doi.org/10.1016/j.neuropsychologia.2014.10.022
Coello Y, Quesque F, Gigliotti M, Ott L, Bruyelle J-L (2018) Idiosyncratic representation of peripersonal space depends on the success of one’s own motor actions, but also the successful actions of others ! PLoS ONE 13(5):e0196874. https://doi.org/10.1371/journal.pone.0196874
Cuijpers RH, Smeets JBJ, Brenner E (2004) On the relation between object shape and grasping kinematics. J Neurophysiol 91(6):2598–2606
Daoudi M, Coello Y, A Descrosiers P, Ott L (2018) A new computational approach to identify human social intention in action. Proc – 13th IEEE Int Conf Automatic Face Gesture Recognit FG 2018 512–516. https://doi.org/10.1109/FG.2018.00082
de Visser EJ, Monfort SS, McKendrick R, Smith MAB, McKnight PE, Krueger F, Parasuraman R (2016) Almost human: Anthropomorphism increases trust resilience in cognitive agents. J Experimental Psychology: Appl 22(3):331–349. https://doi.org/10.1037/xap0000092
Devanne M, Wannous H, Pala P, Berretti S, Daoudi M, Bimbo A, Del (2015) Combined shape analysis of human poses and motion units for action segmentation and recognition. 2015 11th IEEE Int Conf Workshops Automatic Face Gesture Recognit FG 2015 2015-Janua. https://doi.org/10.1109/FG.2015.7284880
di Pellegrino G, Làdavas E (2015) Peripersonal space in the brain. Neuropsychologia 66:126–133. https://doi.org/10.1016/j.neuropsychologia.2014.11.011
Duarte NF, Rakovic M, Tasevski J, Coco MI, Billard A, Santos-Victor J (2018) Action Anticipation: reading the intentions of humans and Robots. IEEE Rob Autom Lett 3(4):4132–4139. https://doi.org/10.1109/LRA.2018.2861569
Eastough D, Edwards MG (2007) Movement kinematics in prehension are affected by grasping objects of different mass. Exp Brain Res 176(1):193–198. https://doi.org/10.1007/s00221-006-0749-3
Egmose I, Køppe S (2017) Shaping of reach-to-grasp kinematics by intentions: a meta-analysis. J Mot Behav 50(2):155–165. https://doi.org/10.1080/00222895.2017.1327407
Ferri F, Campione GC, Volta D, Gianelli R, C., Gentilucci M (2011) Social requests and social affordances: how they affect the kinematics of motor sequences during interactions between conspecifics. PLoS ONE 6(1):e15855. https://doi.org/10.1371/journal.pone.0015855
Fikes TG, Klatzky RL, Lederman SJ (2015) Effects of object texture on precontact movement time in human prehension. J Mem Lang 26(4):325–332. https://doi.org/10.1080/00222895.1994.9941688
Fitts PM (1954) The information capacity of the human motor system in controlling the amplitude of movement. J Exp Psychol 47(6):381–391. https://doi.org/10.1037/h0055392
Fleury L, Prablanc C, Priot A (2019) Do prism and other adaptation paradigms really measure the same processes? Cortex 119:480–496. https://doi.org/10.1016/j.cortex.2019.07.012
Fox J, Ahn SJG, Janssen JH, Yeykelis L, Segovia KY, Bailenson JN (2015) Avatars versus agents: a meta-analysis quantifying the effect of agency on social influence. Hum Comput Interact 30(5):401–432. https://doi.org/10.1080/07370024.2014.921494
Gentilucci M (2002) Object motor representation and reaching–grasping control. Neuropsychologia 40(8):1139–1153. https://doi.org/10.1016/s0028-3932(01)00233-0
Gentilucci M, Castiello U, Corradini ML, Scarpa M, Umiltà C, Rizzolatti G (1991) Influence of different types of grasping on the transport component of prehension movements. Neuropsychologia 29(5):361–378. https://doi.org/10.1016/0028-3932(91)90025-4
Georgiou I, Becchio C, Glover S, Castiello U (2007) Different action patterns for cooperative and competitive behaviour. Cognition 102(3):415–433. https://doi.org/10.1016/j.cognition.2006.01.008
Gigliotti MF, Sampaio A, Bartolo A, Coello Y (2020) The combined effects of motor and social goals on the kinematics of object-directed motor action. Sci Rep 10(1):1–10. https://doi.org/10.1038/s41598-020-63314-y
Gigliotti MF, Coelho S, Coutinho P, J., Coello Y (2021) Peripersonal space in social context is modulated by action reward, but differently in males and females. Psychol Res 85(1):181–194. https://doi.org/10.1007/s00426-019-01242-x
Gigliotti MF, Bartolo A, Coello Y (2023) Paying attention to the outcome of others’ actions has dissociated effects on observer’s peripersonal space representation and exploitation. Sci Rep 13(1):10178. https://doi.org/10.1038/s41598-023-37189-8
Hostetter AB (2011) When do gestures communicate? A Meta-analysis. Psychol Bull 137(2):297–315. https://doi.org/10.1037/a0022128
Iachini T, Coello Y, Frassinetti F, Senese VP, Galante F, Ruggiero G (2016) Peripersonal and interpersonal space in virtual and real environments: effects of gender and age. J Environ Psychol 45:154–164. https://doi.org/10.1016/j.jenvp.2016.01.004
Jacob P, Jeannerod M (2005) The motor theory of social cognition: a critique. Trends Cogn Sci 9(1):21–25. https://doi.org/10.1016/j.tics.2004.11.003
John A, Weisberg S, Price B, Adler D, Bates D, Baud-bovy G, Bolker B, Ellison S, Graves S, Krivitsky P, Laboissiere R, Maechler M, Monette G, Murdoch D, Ogle D, Ripley B, Venables W, Walker S, Winsemius D (2020) Package ‘car.’
Johnson WL, Lester JC (2016) Face-to-face Interaction with Pedagogical agents, twenty years later. Int J Artif Intell Educ 26(1):25–36. https://doi.org/10.1007/s40593-015-0065-9
Johnson W, Rickel J, Lester J (2000) Animated pedagogical agents: face-to-face interaction in interactive learning environments. Int J Artif Intell Educ 11(1):47–78
Judd CM, Westfall J, Kenny DA (2012) Treating stimuli as a random factor in social psychology: a new and comprehensive solution to a pervasive but largely ignored problem. J Personal Soc Psychol 103(1):54–69. https://doi.org/10.1037/a0028347
Ke F, Im T (2013) Virtual-reality-based social interaction training for children with high-functioning autism. J Educational Res 106(6):441–461. https://doi.org/10.1080/00220671.2013.832999
Krämer NC (2008) Social effects of virtual assistants. A review of empirical results with regard to communication. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 5208 LNAI, 507–508. https://doi.org/10.1007/978-3-540-85483-8_63
Krishnan-barman S, Forbes PAG, Hamilton AFDC (2017) How can the study of action kinematics inform our understanding of human social interaction? Neuropsychologia 105:101–110. https://doi.org/10.1016/j.neuropsychologia.2017.01.018
Kuznetsova A, Brockhoff PB, Christensen RHB (2017) lmerTest Package: tests in Linear mixed effects models. J Stat Softw 82(13):1–26. https://doi.org/10.18637/jss.v082.i13
Lee EJ, Nass C (2002) Experimental tests of Normative Group Influence and Representation Effects in Computer-Mediated Communication when interacting via computers differs from interacting with computers. Hum Commun Res 28(3):349–381. https://doi.org/10.1093/hcr/28.3.349
Lenth MR, Singmann H, Love J, Buerkner P, Herve M (2019) Package ‘ emmeans.’https://doi.org/https://CRAN.R-project.org/package=emmeans
Lewkowicz D, Delevoye-Turrell Y (2015) Real-time motion capture Toolbox (RTMocap): an open-source code for recording 3-D motion kinematics to study action-effect anticipations during motor and social interactions. Behav Res Methods 48(1):366–380. https://doi.org/10.3758/s13428-015-0580-5
Lewkowicz D, Delevoye-Turrell Y, Bailly D, Andry P, Gaussier P (2013) Reading motor intention through mental imagery. Adpatative Behav 21(5):1–13. https://doi.org/10.1177/1059712313501347
Leys C, Ley C, Klein O, Bernard P, Licata L (2013) Detecting outliers: do not use standard deviation around the mean, use absolute deviation around the median. J Exp Soc Psychol 49(4):764–766
Lucas GM, Rizzo A, Gratch J, Scherer S, Stratou G, Boberg J, Morency LP (2017) Reporting mental health symptoms: breaking down barriers to care with virtual human interviewers. Front Rob AI 4(OCT):1–9. https://doi.org/10.3389/frobt.2017.00051
Lugrin B, Bergmann K, Eckstein B, Heindl C (2018) Adapted foreigner-directed communication towards virtual agents. Proc 18th Int Conf Intell Virtual Agents IVA 2018 November 2018:59–64. https://doi.org/10.1145/3267851.3267859
Luke SG (2017) Evaluating significance in linear mixed-effects models in R. Behavioural Research, 49(September 2016), 1494–1502. https://doi.org/10.3758/s13428-016-0809-y
Maloney D, Freeman G, Wohn DY (2020) Talking without a Voice: Understanding Non-Verbal Communication in Social Virtual Reality. Proceedings of the ACM on Human-Computer Interaction, 4(CSCW2). https://doi.org/10.1145/3415246
Marschner L, Pannasch S, Schulz J, Graupner ST (2015) Social communication with virtual agents: the effects of body and gaze direction on attention and emotional responding in human observers. Int J Psychophysiol 97(2):85–92. https://doi.org/10.1016/j.ijpsycho.2015.05.007
Matuschek H, Kliegl R, Vasishth S, Baayen H, Bates D (2017) Balancing type I error and power in linear mixed models. J Mem Lang 94:305–315. https://doi.org/10.1016/j.jml.2017.01.001
Meulenbroek RGJ, Bosga J, Hulstijn M, Miedl S (2007) Joint-action coordination in transferring objects. Exp Brain Res 180(2):333–343. https://doi.org/10.1007/s00221-007-0861-z
Mori M, MacDorman KF, Kageki N (2012) The uncanny valley. IEEE Robot Autom Mag 19(2):98–100. https://doi.org/10.1109/MRA.2012.2192811
Nieuwenhuis R, te Grotenhuis M, Pelzer B (2012) Influence.ME: tools for detecting influential data in mixed effects models. R J 4(2):38–47. https://doi.org/10.32614/rj-2012-011
Nowak KL, Biocca F (2003) The Effect of the Agency and Anthropomorphism on users’ sense of Telepresence, Copresence, and Social Presence in virtual environments. Presence: Teleoperators Virtual Environ 12(5):481–494. https://doi.org/10.1162/105474603322761289
Oldfield RC (1971) The assessment and analysis of handedness: the Edinburgh inventory. Neuropsychologia 9(1):97–113. https://doi.org/10.1016/0028-3932(71)90067-4
Orliaguet J, Kandel S, Boe L (1997) Visual perception of motor anticipation in cursive handwriting: influence of spatial and movement information on the prediction of forthcoming letters. Perception 26(7):905–912. https://doi.org/10.1068/p260905
Park KM, Ku J, Choi SH, Jang HJ, Park JY, Kim SI, Kim JJ (2011) A virtual reality application in role-plays of social skills training for schizophrenia: a randomized, controlled trial. Psychiatry Res 189(2):166–172. https://doi.org/10.1016/j.psychres.2011.04.003
Parsons TD (2015) Virtual reality for enhanced ecological validity and experimental control in the clinical, affective and social neurosciences. Front Hum Neurosci 9:660. https://doi.org/10.3389/fnhum.2015.00660
Parsons TD, Kenny P, Cosand L, Iyer A, Courtney C, Rizzo AA (2009) A virtual human agent for assessing bias in novice therapists. Stud Health Technol Inform 142:253–258. https://doi.org/10.3233/978-1-58603-964-6-253
Parsons TD, Gaggioli A, Riva G (2017) Virtual reality for research in social neuroscience. Brain Sci 7(4):42. https://doi.org/10.3390/brainsci7040042
Paulignan Y, Mackenzie C, Marteniuk R, Jeannerod M (1991) Selective perturbation of visual input during prehension movements. Exp Brain Res 83(3):502–512. https://doi.org/10.1007/BF00229827
Pelachaud C (2009a) Modelling multimodal expression of emotion in a virtual agent. Philosophical Trans Royal Soc B: Biol Sci 364(1535):3539–3548. https://doi.org/10.1098/rstb.2009.0186
Pelachaud C (2009b) Studies on gesture expressivity for a virtual agent. Speech Commun 51(7):630–639. https://doi.org/10.1016/j.specom.2008.04.009
Perez-Marcos D, Chevalley O, Schmidlin T, Garipelli G, Serino A, Vuadens P, Tadi T, Blanke O, Millán JDR (2017) Increasing upper limb training intensity in chronic stroke using embodied virtual reality: a pilot study. J Neuroeng Rehabil 14(1):1–14. https://doi.org/10.1186/s12984-017-0328-9
Perez-Marcos D, Bieler-Aeschlimann M, Serino A (2018) Virtual reality as a vehicle to empower motor-cognitive neurorehabilitation. Front Psychol 9(OCT):1–8. https://doi.org/10.3389/fpsyg.2018.02120
Pertaub DP, Slater M, Barker C (2002) An experiment on public speaking anxiety in response to three different types of virtual audience. Presence: Teleoperators Virtual Environ 11(1):68–78. https://doi.org/10.1162/105474602317343668
Philip P, Dupuy L, Auriacombe M, Serre F, de Sevin E, Sauteraud A, Micoulaud-Franchi JA (2020) Trust and acceptance of a virtual psychiatric interview between embodied conversational agents and outpatients. Npj Digit Med 3(1):1–7. https://doi.org/10.1038/s41746-019-0213-y
Poeschl S, Doering N (2012) Designing virtual audiences for fear of public speaking training - an observation study on realistic nonverbal behavior. Annual Rev CyberTherapy Telemedicine 10(October 2014):218–222. https://doi.org/10.3233/978-1-61499-121-2-218
Quesque F, Coello Y (2014) For your eyes only: effect of confederate’ s eye level on reach-to-grasp action. Front Psychlogy 5:1407. https://doi.org/10.3389/fpsyg.2014.01407
Quesque F, Coello Y (2015) Perceiving what you intend to do from what you do: evidence for embodiment in social interactions. Socioaffective Neurosci Psychol 5(1):28602. https://doi.org/10.3402/snp.v5.28602
Quesque F, Lewkowicz D, Delevoye-Turrell YN, Coello Y (2013) Effects of social intention on movement kinematics in cooperative actions. Front Neurobiotics 7:14. https://doi.org/10.3389/fnbot.2013.00014
Quesque F, Delevoye-Turrell Y, Coello Y (2016) Facilitation effect of observed motor deviants in a cooperative motor task: evidence for direct perception of social intention in action. Q J Experimental Psychol 69(8):1451–1463. https://doi.org/10.1080/17470218.2015.1083596
Rosenbaum DA, Vaughan J, Barnes HJ, Jorgensen MJ (1992) Time course of movement planning: selection of handgrips for object manipulation. J Exp Psychol 18(5):1058–1073
Ruben MA, Stosic MD, Correale J, Blanch-Hartigan D (2021) Is technology enhancing or hindering Interpersonal Communication? A Framework and preliminary results to examine the relationship between Technology Use and Nonverbal Decoding Skill. Front Psychol 11. https://doi.org/10.3389/fpsyg.2020.611670
Santello M, Soechting JF (1998) Gradual molding of the hand to object contours. J Neurophysiol 79(3):1307–1320
Sciutti A, Ansuini C, Becchio C, Sandini G (2015) Investigating the ability to read others’ intentions using humanoid robots. Front Psychol 6(September):1–6. https://doi.org/10.3389/fpsyg.2015.01362
Srivastava A, Klassen E, Joshi SH, Jermyn IH (2010) Shape Analysis of Elastic Curves in Euclidean spaces. IEEE Trans Pattern Anal Mach Intell 33(7):1415–1428. https://doi.org/10.1109/TPAMI.2010.184
Sutton RS, Barto AG (2018) Reinforcement learning: an introduction. MIT Press
Van Der Meijden H, Veenman S (2005) Face-to-face versus computer-mediated communication in a primary school setting. Comput Hum Behav 21(5):831–859. https://doi.org/10.1016/j.chb.2003.10.005
World Medical Association (2013) World Medical Association Declaration of Helsinki. Ethical principles for medical research involving human subjects. JAMA 310(20):2191–2194. https://doi.org/10.1001/jama.2013.281053
Acknowledgements
This research was funded by the Research Federation (FR CNRS 2052) Visual Sciences and Cultures and the ANR-21-ESRE-0030- Equipex + Continuum national grant from the Program of Investments of Future. MFG was financed by the Region Hauts-de-France and the University of Lille.
Author information
Authors and Affiliations
Contributions
MFG: Data curation, Formal analysis, Investigation, Methodology, Project administration, Visualization, Writing- original draft, review & editing.PAD: Data curation, Methodology, Resources, Software.MD: Resources, Software.LO: Data curation, Methodology, Software.YC: Conceptualization, Formal analysis, Funding acquisition, Methodology, Resources, Supervision, Validation, Writing- review & editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gigliotti, M.F., Desrosiers, PA., Ott, L. et al. Different effects of social intention on movement kinematics when interacting with a human or virtual agent. Virtual Reality 28, 91 (2024). https://doi.org/10.1007/s10055-024-00992-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10055-024-00992-3