
Abstract
In the coming decades, most of Asia’s population will reside in megacities, vast urban regions accommodating 10–30 million people. However, Asian megacities will be at the same time situated in the countries whose national population is projected to decline rapidly in the coming decades. Hence, for scholars and policymakers of Asian countries, understanding how the socio-demography of mature, post-growth, megacities will evolve within space and time is crucial to envision long-term and effective spatial governance. Prior studies have shown that varied migration patterns among socio-demographic groups lead to synchronized re-urbanization, post-suburbanization, and urban shrinkage in mature city regions. However, existing studies have limitations: they often exclude large Asian megacities, lack micro-scale analyses, and use predefined spatial typologies/divisions that obscure detailed patterns. To address these research gaps, this study investigated sub-municipal spatiotemporal patterns in Tokyo, the largest Asian megacity, using micro-scale job-household data and unsupervised machine learning clustering. The study revealed that Tokyo, like Euro-American cities, has experienced regional synchronization of (re)urbanization and (post)suburbanization within a complex landscape of shrinkage. However, the synchronized sub/urban growth is not uniform across localities within Tokyo. Complex migration flows seem to create disparities in demographic growth and decline, emphasizing the need for collaborative governance among localities within a megacity. The study contributes to a wider audience who are interested not only in the evolution of cities but also in an emerging application of machine learning to quantitative urban analyses.
Zusammenfassung
In den kommenden Jahrzehnten wird der größte Teil der asiatischen Bevölkerung in Megastädten leben, d. h. in riesigen städtischen Regionen, in denen 10–30 mio Menschen leben. Die asiatischen Megastädte werden jedoch gleichzeitig in Ländern liegen, deren Bevölkerung in den kommenden Jahrzehnten rapide abnehmen wird. Für Wissenschaftler und politische Entscheidungsträger in den asiatischen Ländern ist es daher von entscheidender Bedeutung zu verstehen, wie sich die Soziodemografie reifer Megastädte nach dem Wachstum räumlich und zeitlich entwickeln wird, um eine langfristige und wirksame räumliche Governance zu planen. Frühere Studien haben gezeigt, dass unterschiedliche Migrationsmuster zwischen soziodemografischen Gruppen zu synchronisierter Reurbanisierung, Post-Suburbanisierung und Stadtschrumpfung in reifen Stadtregionen führen. Die vorhandenen Studien weisen jedoch Einschränkungen auf: Sie schließen häufig große asiatische Megastädte aus, es fehlen Analysen auf Mikroebene, und es werden vordefinierte räumliche Typologien/Unterteilungen verwendet, die detaillierte Muster verschleiern. Um diese Forschungslücken zu schließen, untersuchte diese Studie subkommunale räumlich-zeitliche Muster in Tokio, der größten asiatischen Megastadt, unter Verwendung von mikroskaligen Arbeitsplatz-Haushalts-Daten und unüberwachtem maschinellem Lernen (Clustering). Die Studie ergab, dass Tokio, ähnlich wie euro-amerikanische Städte, eine regionale Synchronisierung von (Re‑)Urbanisierung und (Post‑)Suburbanisierung innerhalb einer komplexen Schrumpfungslandschaft erlebt hat. Allerdings ist das synchrone suburbane Wachstum innerhalb Tokios nicht gleichmäßig über alle Orte verteilt. Komplexe Migrationsströme scheinen Ungleichheiten im demografischen Wachstum und Rückgang zu schaffen, was die Notwendigkeit einer kooperativen Governance zwischen den Gemeinden innerhalb einer Megastadt unterstreicht. Die Studie richtet sich an ein breiteres Publikum, das nicht nur an der Entwicklung von Städten interessiert ist, sondern auch an einer aufkommenden Anwendung des maschinellen Lernens für quantitative Stadtanalysen.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The global urban population has been rapidly increasing, with a projected 70% living in large cities by 2050 (UN 2018a). This global urbanization is driven by rural-to-urban migration and population growth within cities (thanks to low mortality and high fertility rates in today’s developing cities) (UN-Habitat 2010, p. 22; Kourtit and Nijkamp 2013, p. 172; Jedwab et al. 2017; UN 2018a, p. 12). As a result of this global urbanization, megacities, defined as large urban regions with over 10 million inhabitants (UN 2018a), are emerging worldwide. Notably, South, East, and Southeast Asian countries (i.e., Bangladesh, China, India, Indonesia, Japan, Malaysia, Pakistan, Philippines, the Republic of Korea, Thailand, and Vietnam) are at the forefront of this megacity development, with 29 out of 48 projected world megacities located in these nations by 2035 (UN 2018a, see Appendix-Fig. 13).
Conversely, ongoing urbanization may lead to declining and aging populations globally (Bricker and Ibbitson 2019; Vollset et al. 2020). This trend is driven by today’s mature cities offering females improved access to education, employment, reproductive health services, and life planning freedom, resulting in reduced urban fertility rates (Bricker and Ibbitson 2019; also c.f., Lesthaeghe 2020). If access to education and healthcare is highly improved across human society, studies (Lutz and Goujon et al. 2018; Vollset et al. 2020)Footnote 1 project that the global population could peak in the middle of this century and will start declining worldwide.
Under such a global depopulation (and concomitant aging population), 17 up to 27 (out of 29) Asian megacities will be situated in countries whose national population will decrease by 10–50% by 2100 (Lutz and Goujon et al. 2018; Vollset et al. 2020). These numbers account for 74–79% of all megacities in the (future) population-shrinking countries (Appendix-Fig. 13). In other words, ‘megacities in decline’ will be the most salient socio-demographic phenomenon for Asian megacities during the 21st century. These projections based on the relatively optimistic development of human society are certainly not free from disagreement across demographers (Adam 2021). Nevertheless, Japan, China, and the Republic of Korea, which are expected to host 13 megacities by 2035, are already experiencing rapid population declines (National Bureau of Statistics of China 2023; Statistics Bureau of Japan 2023; Statistics Korea 2023). According to the IHME and IIAASA normal projections, these countries will lose nearly half of their national population by 2100.
These projections suggest that Asian megacities of the 21st century will be characterized by a complex spatiotemporal socio-demographic process of growth and decline. Hence, for scholars and policymakers of these (emerging) Asian megacities, understanding how the socio-demographic composition of their megacities will spatially and temporally evolve, or the spatiotemporal socio-demography of megacities, will be ever more necessary to discuss and plan a long-term and effective spatial governance (Ohashi and Phelps 2020; Tateishi et al. 2021; also c.f., Sorensen 2019).
Urban scholars have long been interested in the spatiotemporal socio-demography of cities, seeking to understand it within a systematic framework (Klaassen et al. 1981; van den Berg et al. 1982). This is because this knowledge is significant for various purposes: analyzing the historical evolution of cities (Szmytkie 2021), comprehending the intricate interplay between housing policies/markets and sociodemographic shifts (Brombach et al. 2017), forecasting the future prosperity/decline of cities (Haase et al. 2021), and guiding urban policymakers in achieving balanced and sustainable spatial planning (Kroll and Kabisch 2012; Jain and Jehling 2020).
As such, numerous studies on spatiotemporal socio-demography already exist (Kabisch and Haase 2011; Kroll and Kabisch 2012; Salvati and Carlucci 2016; Brombach et al. 2017; Hierse et al. 2017; Hartt 2018; Wolff and Wiechmann 2018; Cividino et al. 2020; Haase et al. 2021). They reveal a complex, synchronized process in metropolitan socio-demography: re-urbanization (inner city population growth), post-suburbanization (densification, complexification, and diversification of the suburbanization process (Charmes and Keil 2015, p. 581)), and urban shrinkage (sustained depopulation). Scholars think that such a synchronized urban process is driven by a complex mixture of the immigration of the young-talented into inner-city neighborhoods (Ogden and Schnoebelen 2005; Moos 2016; Brombach et al. 2017; Siedentop et al. 2018; Rérat 2019) and the outmigration of diverse socio-demographic groups from the re-urbanizing, or gentrifying, inner city to relatively affordable suburbs (Haase et al. 2010; Hierse et al. 2017). Such diversification of migration flows to suburbs could, in turn, further drive post-suburbanization (Phelps and Wood 2011; Charmes and Keil 2015; Dembski et al. 2019; Ohashi and Phelps 2020).
However, considering the knowledge production in the evolution of Asian megacities, these studies and produced findings are not free from limitations. First, existing studies overlook Asian megacities, primarily drawing from observations in mature Euro-American cities. We are not sure whether such Euro-American insights into urban socio-demographic evolution can be immediately applied to Asian megacities with larger population size and spatial extent, a more complex urban system, embedded in a context where the national population is (or will be) declining rather quickly (it is projected that no Euro-American megacities will, at least by 2100, face such a nation-wide shrinkage, see Appendix-Fig. 13). Second, due to data availability, these studies use coarse spatial units and basic socio-demographic indicators, limiting insight into micro-scale socio-demographic dynamics, especially migration patterns across re-urbanizing, post-urbanizing, and shrinking areas within megacity-regions. Finally, these studies often aggregate socio-demographic variables into predefined spatial typologies/divisions (e.g., urban core, inner city, suburb, and urban concentric rings, etc.) for ease of analysis and interpretation. Such a spatial aggregation of statistics can obscure detailed spatiotemporal patterns, reduce result robustness due to the modifiable areal unit problem, and even hinder the exploration of hidden socio-demographic patterns beyond preconceived spatial typologies/divisions.
In sum, for the discussion and planning of long-term and effective spatial governance of mature (or ‘post-growth’) Asian megacities (Ohashi and Phelps 2020; Tateishi et al. 2021; also c.f., Sorensen 2019), the existing knowledge on the evolution of cities needs to be updated by exploring similarities and differences between the spatiotemporal sociodemography of Euro-American cities and that of Asian megacities using detailed job-household data at a finer spatial resolution without any pre-assumed spatial aggregation.
To fill the research gaps, the presented explorative, data-driven study has three objectives: (1) to empirically explore the spatiotemporal sociodemography of an Asian megacity; (2) to use micro-scale job-household data for the analysis; and (3) to analyze the spatiotemporal demography of megacities without a pre-defined spatial aggregation for statistical analysis.
To achieve these objectives, this study uses the Tokyo Capital Region (hereafter Tokyo) as a learning case of the future post-growth Asian megacities. Tokyo is considered to be the learning case for Asian megacities not only because its spatial and population size, as well as the complexity of its urban system, are closer to those of other future Asian megacities, but also because—and importantly—it is projected to be the first shrinking megacity in the world (MLIT 2018; UN 2018b; Suzuki and Asami 2019). Thus, other Asian megacities—those that also will witness their decline in the coming decades—can learn from Tokyo about what will happen when a large and complex megacity region becomes mature and is about to decline. In addition, Tokyo is an analytically advantageous choice because Japanese census data provides job-household statistics whose spatial resolution is much finer than the city district level between 2000 and 2015. Thus, we can explore the micro-dynamics of the spatiotemporal sociodemography of Tokyo. In order to find spatiotemporal patterns from the given high-resolution job-household statistics data, an unsupervised machine learning clustering method was employed. Based on the objectives, data, and method, this study strives to answer the following guiding questions: (1) How did the spatiotemporal sociodemography of the megacity Tokyo change between 2000 and 2015? (2) What are the similarities and differences between the spatiotemporal sociodemography of the megacity Tokyo and that observed in the Euro-American medium-large cities?
The results show that, in agreement with the findings of existing studies in Euro-American cities, Tokyo has experienced the synchronization of (re)urbanization and (post)suburbanization at its regional scale. However, the study also revealed that Tokyo’s re-urbanization has occurred not only in its inner city but also in its suburban cores/corridors. Alongside the aging and empty-nesting conventional suburbs, the re-urbanization of suburban cores/corridors appears to drive post-suburbanization. The study argues that this synchronized sub/urban growth seems to be supported by core-to-exurb cascade-like migration flows.
However, the results also show that, at a micro-scale, the synchronized sub/urban growth in Tokyo was not spatially homogeneous. The small-area-level clustering results revealed nuanced disparities across localities in terms of population growth and decline. The study argues that such variations in prospering and declining localities appear to be created by intra-core and intra-suburb migrations determined by a mix of local contingencies. The emergence of these local disparities suggests that in post-growth Asian megacities, the formation of functional inter-local collaborative governance to balance prospering and declining localities will be a crucial policy challenge.
Finally, the study analyzed that constant migration flows from ‘population reservoir’ hinterlands seem to underpin the synchronized sub/urban growth. Hence, it is unclear whether the synchronized sub/urban growth could be sustained once the hinterlands of Tokyo (and Japan) become unable to supply new migrants.
The novelty of this study lies in its position as one of the initial academic attempts to intricately illustrate how the socio-demography of mature Asian megacities will evolve over space and time. It employs a machine learning clustering method that is not yet widely acknowledged or applied in the field of urban studies. With this novelty, the study contributes to a broader scholarly and policy-making audience interested not only in the evolution of cities but also in envisioning long-term and effective land management, infrastructure planning, (sub)urban development, rural revitalization, and metropolitan governance. It also addresses emerging opportunities for quantitatively understanding the spatiotemporal complexity of cities through the application of machine learning and large-sized, multi-dimensional datasets.
The outline of the article is as follows: First, Sect. 2 reviews previous studies to elaborate on the empirical evidence, theories, and insights related to the spatiotemporal sociodemography of the city, highlighting their research gaps. Then, Sect. 3 reviews the application of machine learning in urban studies and explains the workings of the selected Gaussian Finite Mixture Model clustering method. Section 4 provides context for Tokyo and details the nature and treatment of Japanese census data (2000–2015) and how it will be analyzed using GMM. Section 5 presents the analytical results and interprets the identified clusters and their temporal transitions. Section 6 discusses these findings in relation to the existing body of literature. Finally, in Sect. 7, the study concludes the entire discussion while also recommending potential directions for future research.
2 Literature review
2.1 Spatiotemporal socio-demographic change in mature cities
How the socio-demographic composition of the city region can spatially and temporally evolve, or spatiotemporal socio-demography of the city, has long mattered in urban studies. This is because such knowledge is crucial for urban scholars to analyze the history of cities (Szmytkie 2021), understand the dynamics between housing policies/markets and sociodemographic changes (Brombach et al. 2017), answer why some cities thrive and others do not (Haase et al. 2021), and inform urban policymakers balanced and sustainable spatial planning (Kroll and Kabisch 2012; Jain and Jehling 2020).
The urban life-cycle theory, first theorized by Klaassen et al. (1981) and empirically applied by van den Berg et al. (1982), is widely used to systematically capture the spatiotemporal dynamics of urban demographic transition (Hierse et al. 2017, p. 190; also c.f., Wolff 2018). This theory investigates changes in total population growth and density within pre-defined geographical divisions (core, fringe, and the entire city region) (van den Berg et al. 1982; Kroll and Kabisch 2012; Salvati and Carlucci 2016; Wolff 2018). The urban life-cycle theory postulates that these population changes follow cyclical (or sequential) trajectories divided into four different stages (van den Berg et al. 1982; Kabisch and Haase 2011; Kroll and Kabisch 2012; Haase et al. 2021): urbanization, suburbanization, urban shrinkage (first, the core starts losing its population, then the fringe follows), and re-urbanization (the population of the core regrows).
However, a growing body of studies empirically shows that the spatiotemporal sociodemographic change of mature urban regions involves more diverse and complex dynamics than simplistic cyclical urbanization. Since our research interest is limited to mature cities, we shall ignore the urbanization phase (as mature cities have already passed this phase). Instead, we will focus on reviewing findings related to re-urbanization, (post-)suburbanization, and urban shrinkage.
Many studies (Haase et al. 2010; Salvati and Carlucci 2016; Brombach et al. 2017; Hierse et al. 2017; Siedentop et al. 2018; Dembski et al. 2019; Kabisch et al. 2019; Rérat 2019) have empirically illustrated that Euro-American cities have experienced re-urbanization, defined as the “revival of the residential function of the inner city after a longer phase of population decline by becoming (re)populated by a diversity of population groups of different ages and socio-economic backgrounds” (Kabisch et al. 2019, p. 2). Acknowledging the diversity in the socio-demographic groups driving re-urbanization, studies also indicate that there are major sociodemographic groups that drive Euro-American re-urbanization. Young and small households, including singles, cohabitating couples, and married couples, with higher educational attainment and higher income, are often considered a major sociodemographic group driving Euro-American re-urbanization (Ogden and Schnoebelen 2005; Kabisch and Haase 2011; Brombach et al. 2017; Siedentop et al. 2018; Rérat 2019). Moos (2016) calls this spatiotemporal trend of sociodemographic change in the city ‘youthification.’ Additionally, in some European countries, scholars have observed that child-raising families have also played a major role in the re-urbanization process (Buzar et al. 2007: Italy; Siedentop et al. 2018: Germany).
The re-urbanization of mature cities can be attributed to demand-side explanations: people want to live in the inner city. For example, as the economy undergoes post-industrialization—a shift from manufacturing industries to service and creative industries (see, Florida 2005, 2012)—young, talented individuals from rural and local areas seem to prefer the inner cities of large cities that offer better educational and career opportunities for creative industries (Martinez-Fernandez et al. 2012a; Elzerman and Bontje 2015; Nelle 2016; Brombach et al. 2017; Makkai et al. 2017; Rérat 2019) and urban amenities and services that are attractive to post-industrial workers (Kotkin 2000; Glaeser et al. 2001; Florida 2002, 2012; Lee 2010; Rérat 2019).
Additionally, across Europe, the United States, and Japan, it is observed that post-industrialization has also feminized the labor market through an intertwined process involving the rise of the service sector, the advent of information technology, and the political will to enhance national productivity (Frank 2008; Nagamatsu 2010; Crouch 2016, p. 119; Raymo and Fukuda 2016; Ling 2017; Swinth 2018). In this trend, professional jobs (such as consultants, lawyers, programmers, and researchers) have also become feminized, fostering the concentration of highly educated, dual-income households in the inner-city neighborhoods of large cities (Rouwendal and Van Der 2004; Compton and Pollak 2007; Gautier et al. 2010; Koizumi et al. 2011; Tano et al. 2018; Oishi 2019). This is because ‘power couples’ appear to prefer central locations in large cities that are equally accessible for the opportunities where power singles can be coupled (Compton and Pollak 2007), the means to solve collocation problems (Costa and Kahn 2000), and the means to maximize work and household production (Markusen 1980, p. 35).
In relation to these explanations, an increasing social acceptance of fertility postponement and premarital cohabitation (van de Kaa 1987; Inglehart 1997; Lesthaeghe 2011, 2020) seems to encourage young professional singles and flat-sharers to stay in inner-city areas for a longer time, as opposed to traditional child-raising families who move to suburbs for a spacious house (Buzar et al. 2005; Ogden and Schnoebelen 2005, p. 265; Kabisch and Haase 2011, p. 237).
However, it is important to note that these demand-side explanations alone are not sufficient to account for re-urbanization. Scholars point to the importance of a supply-side explanation—the inner city supplies new residences for people who have the above-mentioned residential demands. For example, an increasing supply of renovated old houses/apartments as well as newly constructed housing stocks within the inner city is crucial to adequately accommodate re-urbanizing households (Brombach et al. 2017; Kabisch et al. 2019; Rérat 2019). Siedentop et al. (2018) also argue that an increasing supply of ‘family-friendly’ housing stocks (e.g., spacious apartments specifically targeting families) can explain an increasing flow (and stay) of child-raising families in the inner city—the familification of the inner city—as opposed to traditional child-raising families actively moving to the suburbs.
Finally, the demand-side explanation should not be separated from an institutional-side explanation—changes in urban institutions offer (re)development opportunities in the inner city. It is often challenging for mature cities to increase the supply of inner-city housing stocks without housing policies and urban planning that aim at inner-city redevelopments—such as urban densification strategies, transit-oriented planning, and strategic upgrades of urban amenities and infrastructures (Brombach et al. 2017; Haase et al. 2021).
While the inner city of Euro-American cities has been undergoing re-urbanization, suburbanization has also been progressing at the same time (Kabisch and Haase 2011; Salvati and Carlucci 2016; Hierse et al. 2017; Rérat 2019). This observation contradicts the sequential urban development that the urban life-cycle theory assumes. This is because suburbanization can be seen as a ‘population decentralization’ process that occurs once the inner city population and/or development saturates (Dembski et al. 2019; also c.f., Smith 1996). Importantly, suburbia is not only expanding but also changing. In many mature Euro-American cities, post-suburbanization—‘densification, complexification, and diversification of the suburbanization process’ (Charmes and Keil 2015, p. 581)—has also emerged as a new urban reality (Phelps and Wood 2011; Hudalah and Firman 2012; McArthur 2017; Sweeney and Hanlon 2017).
Studies suggest that this spatiotemporal synchronicity of re-urbanization and (post-)suburbanization can be driven by migration flows of particular socio-demographic groups induced by re-urbanization. For example, Hierse et al. (2017) argue that the increasing socio-demographic diversity in suburbia can be explained by potential exit flows of vulnerable socio-demographic groups who are pushed out from the re-urbanizing inner city—where housing markets are becoming less and less affordable—to the outer suburbs (p. 197). Other studies similarly point out that the suburbanization of poverty, or the dismantling of ‘middle-class’ suburbs, is connected to the gentrification of inner-city neighborhoods that push out lower-income, lower-status households (Hanlon 2008; Kavanagh et al. 2016; Dembski et al. 2019). In addition, urban fringes—previously ‘unlabeled’ areas in-between the inner city and suburbs—also appear to comprise a post-suburbanization process as neighborhoods where both relative affordability and better accessibility to the city center are likely to attract middle-class family households (c.f., Kabisch et al. 2019).
Such a complex relocation decision by particular socio-demographic groups (e.g., relatively lower- and middle-income families), seeking more affordable and spacious housing, appears to generate cascade-like migration flows from the intensifying inner-city housing market and drive post-urbanization at different suburban scales (Hierse et al. 2017, p. 197).
Finally, both re-urbanization and post-suburbanization cannot be detached from the complex landscape of urban shrinkage: the sustained depopulation of human settlements. Scholars argue that rather than being a temporary stage in the urban life cycle, urban shrinkage is becoming an enduring spatial symptom of globalization and post-industrialization that increasingly disconnects population growth from economic cycles (Martinez-Fernandez et al. 2012a; Weaver et al. 2017; Hartt 2018; Döringer et al. 2019; Silverman 2020).
As we have seen, the post-industrialization of the economy is one of the major drivers of re-urbanization because it can induce immigration flows of young-talented people who want better educational and career opportunities in post-industrial large cities. In relational terms, this means that selective outmigration of these young-talented people from local towns and rural areas dependent on declining light/heavy industries and agriculture is one of the major drivers of the shrinkage of these local/rural areas (Martinez-Fernandez et al. 2012b; Elzerman and Bontje 2015; Nelle 2016; Makkai et al. 2017). Besides, the feminization of (professional) jobs and changing social norms regarding females’ lives seem to play a crucial role in urban shrinkage because such changes can foster the selective outmigration of females to large cities for better educational and job opportunities (Elzerman and Bontje 2015; Leibert 2016; Rauhut and Littke 2016; Wiest 2016), which consequently lowers fertility rates and accelerates aging and declining populations in shrinking areas (Martinez-Fernandez et al. 2012b; Elzerman and Bontje 2015; Silverman 2020).
Finally, it is important to note that urban shrinkage is not unique to rural villages, towns, and medium-sized cities whose economies highly depend on agriculture or declining light/heavy industries. Sarzynski and Vicino (2019) found that 22% of suburbs in the United States experienced shrinkage between 1980 and 2010. Interestingly, they revealed that 65% of these shrinking suburbs were situated within population-growing metropolitan areas, demonstrating ‘pockets’ of suburban decline within city-regional growth (p. 10). Moreover, they observed that the socio-demographic trajectories of these shrinking suburbs are diverse, suggesting that the underlying dynamics “affecting the populations of shrinking suburbs are complex, both at specific points in time and within specific places” (Sarzynski and Vicino 2019, p. 12).
Such socio-demographic diversity across shrinking suburbs, along with an emerging mixture of growing, stable, and shrinking suburbs, likely adds more complexity to post-suburbanization, as it deconstructs the homogenous suburban landscape and socio-demography (Ohashi and Phelps 2020). Yet, as there is still a quite limited number of empirical studies on shrinking suburbs (Sarzynski and Vicino 2019), further academic and policy research on how suburbs will shrink is needed.
2.2 Research gaps
As shown, recent findings, both at empirical and theoretical levels, suggest that re-urbanization, post-suburbanization, and urban shrinkage form a synchronized, spatial-relational process, rather than being separate, independent phenomena (Lang 2012; Weck and Beißwenger 2014; Kühn 2015; Wiest 2016; Dembski et al. 2019). Overall, the current literature empirically demonstrates that the urbanization of mature cities appears to be a more complex phenomenon than the conventional urban life-cycle theory once postulated. Although these studies have already provided insights into the complexity of the spatiotemporal sociodemography of the mature city, considering the knowledge production in the evolution of Asian megacities, we need to address at least three major limitations of the existing studies and their findings.
First, the findings of the reviewed studies were based solely on the metropolitan-level spatiotemporal socio-demography of mature Euro-American cities. To my knowledge, no study has yet comprehensively analyzed the spatiotemporal socio-demography of Asian megacities at their megacity-regional scale. Indeed, some Euro-American mature cities consist of large metropolitan regions (note here that as of 2018 there are only three megacities in the USA and Europe, i.e., Paris, New York, and Los Angeles, UN (2018b)). Yet, megacities in general, and Asian megacities with 20–30 million inhabitants in particular, surpass average Euro-American city regions in terms of population size, spatial extent, and even complexity in the urban system. Such a gigantic urban system tends to have complex socio-functional networking of inner-city districts, cities, towns, suburbs, villages, and hinterlands (Gottmann 1961; Hall and Pain 2006; Hall 2009; Castells 2010; Scott 2019).
In addition, it is important to note that no Euro-American megacities will, at least by 2100, face rapid national population decline whereas a quick decline in the national population will be the most salient, albeit not unique, socio-demographic context of Asian megacities in the coming decades. As Appendix-Fig. 13 shows, out of 29 emerging Asian megacities, 17 up to 27 of them will be situated in countries whose national population will decrease by 10–50% by 2100 (Lutz and Goujon et al. 2018; Vollset et al. 2020). These numbers account for 74–79% of all megacities in the (future) population-shrinking countries. Considering these points, it is still empirically unclear whether the observed synchronization of re-urbanization, post-suburbanization, and urban shrinkage is immediately applied to spatiotemporal processes in Asian megacities whose base national population will constantly decline in the coming decades.
Second, due to data availability, these existing studies often rely on a coarse spatial unit of analysis (e.g., district) and basic socio-demographic indicators (e.g., population, household size). The lack of analyses on a micro-scale, detailed socio-demographic dynamics seems to limit our understanding of the in/out-migration of diverse socio-demographic groups (Ogden and Hall 2004; Ogden and Schnoebelen 2005; Rérat 2019) across re-urbanizing, post-urbanizing, and shrinking areas within a megacity-region.
Finally, for ease of analysis and interpretation—often following the convention of the urban life-cycle theory—these studies usually aggregate socio-demographic variables into pre-defined spatial typologies/divisions (urban core, inner city, suburb, and urban concentric rings, etc.) (Klaassen et al. 1981; van den Berg et al. 1982; Hierse et al. 2017, p. 190; also c.f., Wolff 2018). Methodologically, such spatial aggregation of statistics obscures detailed spatiotemporal patterns and even reduces the robustness of the findings due to the modifiable areal unit problem—changes in the unit of spatial aggregation can yield different statistical results (Fotheringham and Wong 1991; Il et al. 2019). Spatial aggregations also prevent us from exploring hidden spatiotemporal patterns of urban socio-demography that could be beyond “human’s a priori knowledge” (Wang and Biljecki 2022, p. 1) by aggregating information into pre-assumed spatial typologies/divisions.
These research gaps suggest that for the discussion and planning of long-term and effective spatial governance in mature (or ‘post-growth’) Asian megacities (Ohashi and Phelps 2020; Tateishi et al. 2021; also c.f., Sorensen 2019),, the existing knowledge on the evolution of cities needs to be updated by exploring similarities and differences between the spatiotemporal sociodemography of Euro-American cities and that of Asian megacities using detailed job-household data at a finer spatial resolution without any pre-assumed spatial aggregation. Yet, such an explorative analysis seems to be challenging for conventional statistical approaches as it needs to handle a large amount of job-household data structured at a micro-spatial scale but covering a large geographical extent (i.e., a megacity region) and finding hidden patterns from such a complex large dataset without using any spatial aggregation. The next section will review emerging machine learning (ML), unsupervised ML clustering in particular, because it appears to be a promising method for performing such a large-data-driven explorative task in urban studies.
3 Machine learning and urban studies
3.1 Supervised ML
As computational capacity increases, in many academic disciplines, Machine Learning (ML) methods have increasingly become a major analytical approach for quantitatively discovering patterns in massive data (Fradkov 2020; Kopczewska 2022). In the field of urban studies, most applications of ML so far rely on supervised-ML methods that predict unknown labels in input data using a training dataset in which the relationship between features (referred to as independent variables in the ML discipline) and correct labels (typically considered dependent variables in inferential statistics) is provided (Ali et al. 2019; Grekousis 2019; Waggoner 2020). Supervised-ML methods are mainly divided into regression (which attempts to predict continuous dependent variables such as house prices from various explanatory variables) and classification (which aims to predict the probability of discrete classes such as yes/no, true/false, cat/dog) (Kopczewska 2022).
Although supervised-ML methods are a powerful analytical tool with a solid background of application in various disciplines, their application to urban studies is not always easy for two reasons.
First, it is often difficult to obtain a suitable training dataset for an urban phenomenon of interest. Whether for regression-based ML or classification-based ML, a large volume of training data in which the relationship between features and correct labels is known is necessary to teach the ML algorithm how to predict what researchers are interested in (Ali et al. 2019). In other words, this approach heavily relies on the availability of a well-structured dataset that theoretically links a dependent variable (labels) and independent variables (features). Yet, in real-world urban analysis, available data are often unlabeled, and if available, they can be hard to access (Wang and Biljecki 2022).
Second, controlling spatial autocorrelation in regression-based supervised ML is still in its technical infancy. It is well known in the field of spatial statistics that the presence of similarities/dependencies based on geographic proximity—spatial autocorrelation (Griffith 1992; Getis 2008)—within data often diminishes the inferential quality of regression analyses as it violates the basic assumption of regression (Getis 2008) (see Footnote (Footnote 2) for more technical details on spatial autocorrelation and its control). A recently emerging body of studies has revealed that the predictive accuracy of regression-based supervised ML methods can also be improved by controlling spatial autocorrelation (Georganos and Kalogirou 2022; Kopczewska 2022; Liu et al. 2022). This means that appropriately controlling spatial autocorrelation is necessary to reliably apply supervised ML methods to urban studies because (training) data for urban analyses are usually spatially structured. However, the technical solution for controlling spatial autocorrelation in regression-based supervised ML is still under research and development, and thus it is not widely and readily available to urban scholars.
3.2 Unsupervised ML
Given the difficulties associated with the application of supervised ML to urban studies, unsupervised ML could be a suitable and technically accessible option for urban scholars interested in exploring hidden patterns of urban phenomena from a large, unlabeled dataset. In contrast to the regression and classification of supervised ML (Ali et al. 2019; Waggoner 2020), unsupervised ML performs clustering of the given data. In the field of ML in general, clustering specifically refers to the grouping of data without correct labels (Waggoner 2020). Clustering by unsupervised ML aims to divide a given unlabeled dataset based solely on the similarity of the input features using unsupervised ML algorithms such as K‑means, agglomerative algorithm, self-organizing maps (SOMs), Density-Based Spatial Clustering of Applications with Noise (DBSCAN), and Gaussian mixture models (EM methods) (Ali et al. 2019; Waggoner 2020; Wang and Biljecki 2022). Since unsupervised ML methods do not rely on regression inference, they are free from concerns related to spatial autocorrelation.
In summary, while supervised ML methods are suitable for predictive and causal analyses, a more data-driven explorative approach using unsupervised ML clustering provides urban scholars with opportunities to uncover unknown, hidden patterns of the city from massive datasets. Thus, it can offer “new perspectives for urban studies beyond human’s a priori knowledge” (Wang and Biljecki 2022, p. 1).
Considering the inherent complexity of the city and urbanization (Ortman et al. 2020; Cai and Chen 2022) and the increasing availability of (unlabeled) spatial data (Li et al. 2016), unsupervised ML clustering is becoming a promising tool for discovering hidden urban phenomena from massive (spatial) data (Wang and Biljecki 2022) that can aid data-driven planning (Koutra and Ioakimidis 2023) and inductive theory building (Choudhury et al. 2016) regarding complex urban processes.
However, it is important to note that the unsupervised-ML methods also have their drawbacks.
First, researchers usually need to decide how many clusters an unsupervised-ML algorithm should divide the given data (Scrucca et al. 2016). Thus, selecting the number of clusters seems to be arbitrary. Yet, there are statistical scores to inform the number of clusters in which clustering algorithms perform best. Using these statistics together with analytical needs, we can reduce arbitrariness and provide support for the chosen number of clusters. We shall return to this point in Section 3.4 when we discuss more specifically the Gaussian Finite Mixture Model (GMM), one of the unsupervised-ML algorithms, for this study.
Second, by their nature, unsupervised-ML methods divide the given data into clusters without any predictive/causal hypotheses. In other words, the data will be clustered simply by similarities/differences across the features, and the resulting clustering numbers (e.g., 1, 2, 3, 4, 5 if the researchers choose ‘5’ for the number of clusters) are mere labels to discern clusters and have no inherent meaning. Hence, it is the researchers who should interpret the meaning of the yielded clusters (Waggoner 2020). This interpretation process can be exploratory, arbitrary, and time-consuming.
While acknowledging these drawbacks, this study will employ unsupervised-ML methods as we are interested in uncovering hidden spatial patterns from large-size, unlabeled job-household data. In other words, the methodological goal of this study is, using an unsupervised-ML method, to visually represent and interpret the clustering results of given sociodemographic variables rather than testing hypotheses based on any spatial models/patterns.
The rest of this section will further review how different unsupervised-ML clustering methods approach spatial data and how each method has been applied to urban studies in particular. In ML clustering, the approach to spatial data can be roughly divided into three typical approaches, namely, (1) clustering based on spatial features, (2) clustering based on non-spatial features, and (3) dual clustering based on both spatial and non-spatial features (c.f., Kopczewska 2022).
3.3 Un-supervised ML clustering in spatial application
-
1.
Clustering based on spatial features
In conventional “spatial” clustering methods, the similarity across observations is assessed based solely on geometric/spatial features (e.g., XY coordinates of point location data, various morphological characteristics of polygon data) (Lin et al. 2005; Jiao et al. 2011; Xiao et al. 2022). In such clustering approaches, data partitioning is based purely on the similarity of spatial location and/or geometric shape of the observations of interest.
In the field of urban studies, this approach may be particularly effective when geometric/spatial information—such as the density of points, size, perimeter, and shape complexity of polygons—is considered sufficient for clustering the data (and/or when non-geometric/non-spatial information of the data is hard to access). For example, by applying Gaussian mixture models clustering to building footprint data from some African cities, Jochem et al. (2021) demonstrate how to cluster different urban types based only on morphological features (e.g., size, density, shape complexity) of the footprints. Xue et al. (2020) also show that unsupervised-ML clustering can effectively distinguish urban objects from a Light Detection And Ranging point dataset without any non-spatial information. In other words, as pointed out by Jochem et al. (2021), this approach can also be used to derive new non-spatial information from spatial data.
-
2.
Clustering based on non-spatial features
In contrast to such conventional clustering methods based solely on geometric/spatial features, as pointed out by Lin et al., “in many real applications, the non-geometric attributes are what users are concerned about” (2005, p. 628). This analytical demand can be satisfied by mapping (i.e., spatially visualizing) a clustering result generated solely from a set of non-geometric/non-spatial features (Kopczewska 2022, p. 716). Contrary to the clustering based on spatial features approach, we can consider that this approach yields new spatial information from non-spatial information.
As a recent extensive literature review on the application of unsupervised ML to urban studies (Wang and Biljecki 2022) reveals, urbanization and regional studies are among the major fields where this approach is often applied (c.f., Wang and Biljecki (2022), section 5.2, p. 9). More specifically, clustering and spatial visualization of non-spatial multivariate sociodemographic data (e.g., census data) is the most relevant application for this paper. For example, Dias and Silver (2021) demonstrate that by combining network-based data representation and a sorted maximal matching algorithm (Dias et al. 2017), it is possible to spatiotemporally visualize sociodemographic patterns across geographically unharmonized census datasets in both the US and Canada. Delmelle (2017) also successfully clusters different trajectories of sociodemographic composition, including the process of gentrification, in 50 US metropolitan areas by applying Self-Organizing Maps (SOMs) and K‑means to the selected 18 sociodemographic census variables.
An emerging body of similar applications of unsupervised ML clustering of non-spatial data aims to yield spatiotemporal insights, such as identifying gentrified areas (Liu et al. 2019; Yuan et al. 2021), typology clustering of suburbs (Mikelbank 2004), and identifying different urbanization trajectories, including urbanization and urban shrinkage (Serra et al. 2014).
-
3.
Clustering based on both spatial and non-spatial features
Some researchers have been developing an advanced ML clustering approach that is based on both spatial/geometric and non-spatial features simultaneously. This approach is sometimes called dual-clustering (Lin et al. 2005; Jiao et al. 2011; Xiao et al. 2022). Dual-clustering seems to be particularly effective when one needs to cluster granular spatial data (e.g., satellite images, point location data, building footprints) while minimizing spatial overlaps/disconnectivity and non-spatial dispersion of the resulting clusters (Jiao et al. 2011; Xiao et al. 2022).
Dual-clustering appears promising for clustering fine-scale spatial data, such as very-high-resolution (VHR) satellite images, location points, and building footprints, where both geometric shape and spatial connectivity, along with non-spatial attributes, could be important for meaningful clustering. As shown by Jiao et al. (2011), in urban studies, dual-clustering holds promise for clustering urban land use patterns considering both geometric features and other non-spatial features like land prices.
However, this study does not elaborate on it further because the input data for this study is census data aggregated at a territorialized unit level, which is much coarser spatially compared to these high-resolution spatial data.
As we have reviewed, clustering based on non-spatial features (2) has been widely applied in spatiotemporal explorative analyses of census and/or micro socio-demographic data in urbanization and regional studies (Mikelbank 2004; Serra et al. 2014; Delmelle 2017; Liu et al. 2019; Dias and Silver 2021; Yuan et al. 2021). Thus, this study shall also follow this strand of research and employ the Gaussian Finite Mixture Model clustering method to perform clustering based on non-spatial features. The next section will elaborate on the Gaussian Finite Mixture Model clustering method.
3.4 Gaussian finite mixture model clustering
The Gaussian Finite Mixture Model (GMM) assumes that all given data points can be described as a mixture of a finite number of Gaussian distributions (i.e., normal distributions) with unknown parameters (Jochem and Tatem 2021, p. 10). GMM is selected because it provides a more flexible model fitting than other unsupervised-ML methods, such as K‑means. This flexibility is achieved by allowing the volume, shape, and orientation (mathematically, within-group covariance matrices) of each cluster to vary (Scrucca et al. 2016, p. 292; Jochem and Tatem 2021, p. 10). There is an increasing number of applications of the GMM method in the field of urban geography to cluster settlement patterns (Jochem and Tatem 2021; Jochem et al. 2021), urban land cover (Tao et al. 2016), and urban road networks (Batista et al. 2021), for example.
Conceptually speaking, GMM allows the drawing of circles/ellipsoids (i.e., different shapes) with different sizes (e.g., small/large) and various angles (i.e., different directions) to group data points on, say, a scatter plot. Each clustering circle/ellipsoid is computed by a (multivariate) Gaussian probability function. The clustering result of the given data is composed of a mixture of all computed (a finite number of) Gaussians. Thus, it is called the Gaussian Finite ‘Mixture’ model.
To put it more intuitively, imagine that you are now asked to encircle the points on a scatter plot based on their locational similarities (you have to encircle densely gathered points). Here, you are allowed to change the shape of each circle to an ellipsoid, the size of each circle/ellipsoid, and the orientation of ellipsoids, if you think these modifications can group the points effectively. Yet, you are allowed to draw only a limited (i.e., finite) number of circles/ellipsoids that were specified before the task (say, 5 circles/ellipsoids). In this example, the ‘mixture’ of the 5 circles/ellipsoids you have drawn represents the clustering result of the given points.
The mathematical expression of GMM is as follows. A probability density function p (X) through a mixture of n Gaussians (i.e., the number of clusters) with m variables (X = [x1, x2, x3, … xm]) is defined as
Here, \({\sum }_{k=1}^{n}\pi _{k}=1\), \(\pi _{k}(0\leq \pi _{k}\leq 1)\) is the mixing weight (i.e., the linear combination coefficient), μk is the mean vector, Σk is the m × m covariance matrix of the kth cluster respectively. These Gaussian parameters (i.e., \(\pi {,}\mu {,}\Upsigma\)) are usually unknown, so need to be estimated. GMM estimates the parameters by maximizing its log-likelihood function, which is defined as:
Yet, the direct maximization of the log-likelihood function is complicated (Scrucca et al. 2016, p. 291), so an expectation-maximization (EM) algorithm is employed (McLachlan and Peel 2000). For brevity, this study will not elaborate on how the EM algorithm works.
Here, the central question of GMM is how to determine the number of “n” (i.e., the number of clusters/Gaussian components) (Scrucca et al. 2016). To address this question, we can compute the BIC (Bayesian Information Criterion) and ICL (Integrated Complete-data Likelihood) scores for each “n” (e.g., 1, 2, 3, 4, 5, 6, …) (Scrucca et al. 2016). Typically, both BIC and ICL scores tend to decrease rapidly as the number of clusters increases. We can decide that the number of clusters with the lowest scores (or the point where the curves of BIC and ICL become asymptotic) suggests the best-performing clustering (Scrucca et al. 2016; Boon Kai et al. 2019).
Furthermore, by comparing the BIC and ICL scores of different model specifications, we can determine which one exhibits the best clustering performance (similarly to deciding the number of “n,” where the lowest scores indicate the highest performance). It is important to note that GMM allows clusters to change their volume, shape, and orientation. However, this does not necessarily mean that we must change all of them. Rather, fixing some of them (e.g., keeping volume equal across clusters) may improve clustering performance, i.e., BIC and ICL. Hence, we can create different clustering specifications by varying combinations of volume, shape, and orientation, such as volume: Equal, shape: Variable, orientation: Equal (GMM-EVE model) and volume: Variable, shape: Equal, orientation: Variable (GMM-VEV model).
In summary, by analyzing the BIC and ICL scores for different cluster numbers and model specifications, we can determine which GMM specification with how many clustering groups will perform the best (Scrucca et al. 2016). We will discuss how to implement GMM clustering with the selection of the number of clusters and model specifications in the next section.
4 Case, data, and methods
4.1 Case overview
This study selected the Tokyo Capital Region (hereafter referred to as Tokyo)—the largest megacity in the world today (UN 2018a). According to the Census 2015, about 43.8 million people resided within the Capital Region. Tokyo can serve as the best possible learning case as of 2023 for other emerging Asian megacities. This is partly because Tokyo’s spatial extent, population size, and the complexity of its urban system (with complex socio-functional networking of inner-city districts, cities, towns, suburbs, villages, and hinterlands) seem to provide a comparable setting for other Asian megacities after 2035. More importantly, this is also because Tokyo is projected to be the first shrinking megacity in the world (MLIT 2018; UN 2018b; Suzuki and Asami 2019). Thus, other Asian megacities—those that also will witness their decline in the coming decades—can learn from Tokyo about what will happen when a large and complex megacity region becomes mature and is about to decline.
Tokyo consists of Tokyo Metropolis, the urban core of Tokyo, and seven surrounding prefectures (Fig. 1). Over 100 years, the major urban structure of Tokyo has been developed around station precincts (the dark gray areas in Fig. 1), which forms one of the largest and most functional transit-oriented megacities (Yajima and Ieda 2015) whose development stage is “much further than other cities in the world” (Chorus and Bertolini 2016, p. 87). Figure 1 also depicts Tokyo Station and other major stations within suburban/regional urban centers.

Spatial structure of the Tokyo Capital Region. (Source: own elaboration based on several open sources and Nakano (2019))
The western and northern parts of the megacity region are mostly mountainous, with rural villages and towns scattered throughout (the light gray areas in Fig. 1). However, they are functionally connected to the regional urban centers within the region via rail and road networks. For analytical reference, a rough spatial division of the urban core (Red) and the suburbia (Green), as defined by Nakano (2019), is also displayed on the map. Note that the suburbia in Fig. 1 is not entirely suburbanized but rather is a mixture of suburban centers, low-density suburban residential areas, and under-urbanized areas with more exurb-rural characteristics. This study defines the rest of Tokyo as the exurb-rural region (Blue).
Table 1 shows the population change in the Tokyo Capital Region within different 10-kilometer buffer rings between 2000 and 2015. The Tokyo Capital Region as a whole gained roughly 2.5 million people between 2000 and 2015. The population of the urban core was decreasing until the 1990s (Ajisaka 2015). However, after 2000, the urban core of Tokyo has been re-urbanizing and gained roughly 1.3 million new residents during the 15 years. Tokyo’s suburbia has also gained 1.6 million people, yet some suburbs started losing their population in the 2000s (MLIT 2018). The observed population growth of the urban core and the suburbia is considered to be mainly driven by migration flows of young people from outside the Tokyo Capital Region (MLIT 2020). In contrast, as the table shows, the exurb-rural region has been experiencing a generalized population decline. Overall, the table confirms that Tokyo’s shrinkage has already started from its exurban-rural peripheries, yet it has not yet clearly appeared in the suburbia and urban core in terms of aggregated statistics.
4.2 Census data and its treatment
The census data of Japan (2000 and 2015) at the scale of Small Administrative Areas (Cho-cho-moku, hereafter ‘small areas’) were used for the analysis of Tokyo’s spatiotemporal demography. All CSV-format census tables were attained from ‘e-Stat: Statistics of JapanFootnote 3.’ There are about 34,000 small areas within Tokyo. A challenge of making use of Japanese census data is that the unique IDs assigned to each small area are sometimes modified across different census years, so they lost the inter-year comparability. To overcome this challenge, the author developed an algorithm that matches small areas across different census years if their geometric center points are the same (which means the geographical shape of these small areas is also the same). This algorithm matched roughly 30,000 small areas regardless of the differences in their unique IDs.
The remaining 4000 small areas are subject to land adjustment projects that modified the shape of the small areas. For these areas, the largest shape before/after the land adjustment project is identified and the census statistics of the land-adjusted small areas were aggregated into this ‘surrogate’ area. More specifically, if the project divided an area shape into smaller areas, the original (which theoretically accommodates all divided areas) was used as a surrogate area. If the project gathered small areas into a larger area, then the post-project area is used as a surrogate area. For this data processing, the author developed Arc-GIS-based Python scripts to identify surrogate areas. Algorithmically identified 700 surrogate areas and corresponding aggregated small areas were also manually double-checked one by one to ensure the matching quality. This operation resulted in 30,557Footnote 4 small and surrogate areas that ensure the inter-year compatibility of census statistics. Note that hereafter we call surrogate areas too as small areas.
The average size of these small and surrogate areas is 1.15 km2 (median = 0.22 km2, max = 353 km2, min = 0.00009 km2), which is about 1/120th of the average size of municipal-level boundaries (i.e., 139 km2) within Tokyo.
4.3 Demographic variables and their treatment
In order to analyze job-household socio-demography, 3 job characteristic variables (i.e., the number of workers in Creative-service jobs, Production & Transport jobs, and Primary jobs) and 8 household characteristic variables (i.e., the number of households in Single Junior household, Couple Junior household, Family with 0–17-year-old child/children, Family with 18+-year-old child/children, Single Senior household, Couple Senior household, Multi-generation Family with 0–17-year-old children, and Total multi-generation Family) were selected from the cleaned and validated census data. Note that this study uses ‘junior’ with a special definition: those who are between 0 and 64 years old. Table 2 summarizes these 11 variables. These variables are separated into the year 2000 dataset and the year 2015 dataset.
To control the size effect (i.e., the area size of each small area or high population density), all variables were converted into the share of each variable to the total population/households of each small area. For example, if there are 50 Single Senior households in a small area whose total household number is 300, the share of Single Senior is 50/300 = 0.167. These share numbers were further rescaled by Z‑score normalization (x scaled = (x original − mean) / Standard deviation) into new values with a mean of 0 and a standard deviation of 1 at each variable. It is empirically known across ML communities that rescaling all input variables to the same scale can improve the performance and training stability of ML analysesFootnote 5. Hereafter, the rescaled values shall be called Standardized Share (of each variable).
4.4 Selecting the GMM model specification and the number of clusters
To implement a GMM clustering, this study uses the mclust R packageFootnote 6. The package was chosen as it is a popular GMM clustering package that is used in a wide range of scientific disciplines such as chemometrics, industrial engineering, clinical psychology, food science, political science, and anthropology (Scrucca et al. 2016). The package is capable of automatically implementing and comparing 14 different GMM model specifications (8 models with fully-flexible Shape-Volume-Orientation combinations and 6 models with orientation-constrained combinationsFootnote 7) that enable us to implement an efficient and comprehensive GMM analytical workflow.
First, the treated job-household census data (30,557 rows represented by each small area × 11 columns represented by the job-household variables = 336,127 data cells) were GMM-clustered by varying the number of clusters from 1 to 10 for both the 2000 and 2015 datasets. This preliminary clustering was performed by the 14 different models that are specified by different combinations (i.e., variable/equal) of the volume, shape, and orientation of the clusters (see Sect. 3.4 and p. 292 in Scrucca et al. (2016) for details). Here, the BIC and ICL scores for each model specification were also computed at each cluster number.
Specification-wise, the BIC and ICL scores suggested that the GMM-VEV, namely volume: Variable, shape: Equal, and orientation: Variable, model specification is the most well-performed to cluster the 11 predictive variables. Hence, this study went with the GMM-VEV model for further steps.
Then, to select the minimum number of clusters for the GMM-VEV model, the percent change in BIC and ICL scores in the GMM-VEV model was assessed (Fig. 2). The graph shows how much VEV model performance is improved per one-unit cluster increase. For both the 2000 and 2015 datasets, the improvement of model performance (in % change) became asymptotic for both BIC and ICL scores at around five clusters or more. So, we can safely select 5 as the minimum number of clusters (Boon Kai et al. 2019).

The minimum number of clusters was selected from the percent change in the BIC and ICL scores per one-unit cluster increase in the GMM-VEV model. The improvement of model performance (in % change) became asymptotic for both BIC and ICL at around five clusters or more. So, we can safely select 5 as the minimum number of clusters. NOTE: The original values are negative as the mclust R package calculates the BIC and ICL scores opposite to the usual. (Source: own calculation)
4.5 Preparation for the analysis and interpretation of the GMM clusters
By fitting the GMM-VEV model with 5 clusters to the 11 predictive variables (in 2000 and 2015), all small areas were clustered into one of the five classes that are discerned by numeric labels 1, 2, 3, 4, and 5. Here, 197 small areas become invalid clustering results due to the lack of data and are excluded. Hence, 30,360 valid small areas were used for the further steps.
An important note here is that, as we have seen in Sect. 3.2, these numeric labels are just for discerning clusters and do not have any qualitative meaning. Hence, Cluster 5 in the 2000 data and Cluster 5 in the 2015 data, although they have the same ‘5’ label, do not necessarily mean that they are qualitatively the same.
To analyze how different clusters changed between 2000 and 2015 at the small-area scale, small areas sharing the same Cluster-Transition Path were grouped into a Cluster-Transition Category. For example, if a small area is detected as Cluster 1 in 2000 and Cluster 4 in 2015, the Cluster-Transition Path of this small area is 1 ⇨ 4. All small areas having this path (1 ⇨ 4) are grouped into the same Cluster-Transition Category. The same was performed for other cluster-transition paths.
After identifying Cluster-Transition Categories, to analyze the relationship between the demographic cluster transitions and population change, the small areas were divided into those that experienced population growth (the Population-growth small areas) and those that experienced population decline (the Population-decline small areas) between 2000 and 2015. Fig. 3 displays the total number of small areas, their % share, and share rank by each Cluster-Transition Category that are grouped by the population change groups (i.e., population-growth vs. population-decline).

Total number of small areas, % share, and share rank (by each Cluster-Transition Category by the population change groups). (Source: own elaboration)
Theoretically, there are 25 different Cluster-Transition Categories (5 clusters in 2000 × 5 clusters in 2015 = 25 paths). As we have discussed in Sect. 3.2, unsuverpised-ML clusters need to be interpreted by the researchers one by one. Therefore, interpreting all 25 Cluster-Transition Categories will generate a cumbersome pile of descriptions. Instead, this study selected the top 6 categories in terms of their % share from the Population-growth small areas and the Population-decline small areas respectively (yellowed in Fig. 3). So, there are 12 categories (6 from the growth group +6 from the decline group).
However, 3 categories (i.e., 2 > 2, 3 > 3, and 5 > 5) out of the 12 categories exist in both the Population-growth group and the Population-decline group (indicated as ‘<- BOTH ->’ in Fig. 3). So, we have 9 unique categories for further processes. Namely, 2 > 2, 3 > 3, and 5 > 5 for both growth (G) and decline (D) (labeled by ‘GD-’ in the results section), 2 > 3, 2 > 5, 4 > 3 only for growth (labeled by ‘G-’ in the results section), 1 > 1, 3 > 2, 4 > 4 > only for decline (labeled by ‘D-’ in the results section). See Fig. 3 for more details on labeling and coloring for each category.
These 9 categories cover 76.5% of the entire small areas (23,226/30,360, see Appendix-Fig. 14 for the map of selected areas). Population-wise, the covered areas accommodate 92% of the total regional population (i.e., 40.2 million/43.8 million as of 2015). Hence, we can consider that these 9 categories sufficiently represent a large picture of the spatiotemporal demography of Tokyo during the period of analysis.
Finally, to visually assist the analysis and interpretation of the 9 transition categories, the qualitative change in the household socio-demographic characteristics (hereafter HSD characteristics) per selected Cluster-Transition Category, the Mean Standardized Share of the 11 variables was plotted for the 9 categories. Also, to see the spatial patterns of the selected Cluster-Transition Categories, 6 maps were created that are divided into the Population-growth group and the Population-decline group.
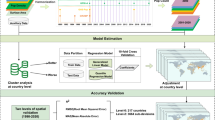
To overview the data preparation, GMM clustering, and post-clustering processes, see the workflow in Fig. 4 below.

Workflow of the GMM-clustering of this study. (Source: own elaboration)
5 Results
5.1 Expanding urban, suburban, and regional cores/corridors
Figure 5 displays the population-growth small areas within the urban core and those around the regional transit infrastructure. We can observe that GD‑1 (Red) occupies most of the urban core. The GD‑1 areas also form corridor-like clusters around major suburban stations (i.e., suburban centers) and suburban transit lines. In the exurb-rural region, the GD‑1 areas are also clustered, albeit rather small, around the major stations of the regional urban centers (i.e., Takasaki, Maebashi, Utsunomiya, Tsukuba, Mito).

(Also study Fig. 11) Population-growth urban and suburban cores and regional cores/corridors. Urban cores and suburban cores/corridors (GD‑1) are spaces for single creative-service workers. During the 15 years (2000–2015), while these basic characteristics remain the same, these areas have become younger and more family-oriented spaces as well. On the other hand, the peripheral areas (G‑2) of these areas have lost their family-space characteristics and altered into spaces for single working for creative-service industries. This suggests that the original characteristics of the urban cores and suburban cores/corridors have spatially expanded towards their peripheries. (Source: own elaboration)
As Fig. 11 shows, the household socio-demographic (HSD) characteristics of the GD‑1 areas have not changed radically during 2000 (the grey line) and 2015 (the blue line). A distinctively high share of the Creative-service workers and the Single Junior households most characterizes this category. However, there are increases in the shares of Junior families (i.e., Couple Junior and Family with 0–17-yo children) and decreases in those of the Senior households (i.e., Single Senior and Couple Senior). This indicates that the growing urban, suburban, and regional cores/corridors have experienced youthification (Moos 2016) and the transition to a more family-oriented space—familification—between 2000 and 2015.
These cores/corridors are surrounded by the G‑2 (Light blue) areas that show a radical change in their HSD characteristics. These peripheries of the cores and corridors used to be a family-oriented urban space (i.e., a high share of Couple Junior, Family with 0–17-yo children, and Family with +18 children). However, whilst these junior families considerably lost their share, the mean share of Single-Junior households skyrocketed in 2015. This indicates that the core-corridor peripheries have experienced a rapid singlification (Yamada 2014; Allison 2018) by the junior households. It is also important to note that the share of the Single Senior households increased, albeit moderately. This suggests that the singlification of the core-corridor peripheries is more accentuated than that of the cores and corridors.
In addition, a sharp decrease of the Production-&-Transport workers vis-a-vis the gain of the Creative-service workers indicates a radical shift of job composition towards the creative-service job—the tertiarization of employment—across the core-corridor peripheries. These changes indicate that the urban, suburban, and regional cores/corridors have spatially expanded towards their core-corridor peripheries from a socio-demographic perspective.
5.2 Aging and empty-nesting suburbs
In Fig. 6, we can observe that these expanding urban, suburban, and regional cores/corridors (gray-colored) are surrounded by the GD‑2 (Orange) areas that are the most major category across growing suburbs. In 2000, the GD‑2 suburbs were a family-oriented urban space. Yet, in 2015, these areas lost the mean share of the junior single and junior family households. Notably, the loss of the mean share becomes larger as the family stage becomes younger (i.e., Couple Junior > Family with 0–17-yo children > Family with +18-yo children). It is also important to note that the share of Single Senior and Single Couple households increased sharply.

(Also study Fig. 11) Population-growth suburbs (GD‑2). These areas used to be typical suburbs where child-raising families gathered. After 15 years, these suburbs have become aged and empty-nested (i.e., their child/children left the home for education/work). The population growth of these areas seems to be supported by migration flows of the seniors from shrinking suburbs. (Source: own elaboration)
Overall, this transition pattern suggests that the family groups that made the family-oriented space in 2000 aged while there was no intake of new junior single and couples to keep the family-space socio-demographic characteristics.
The sharp increase in the single and couple senior households also suggests that these aging suburbs have been empty-nesting (Dvořáková and Horňáková 2021). The progress of the empty-nesting implies that these suburbs have also experienced ‘relative’ aging populations as the exit of the young. Hence, the GD‑2 suburbs have experienced both absolute (i.e., increases of the senior) and relative (i.e., losses of the young) aging populations.
5.3 Diversifying suburbanization
In Fig. 7, we can observe that GD‑3 (Light green), G‑1 (Pink), and G‑3 (Blue) extend across a large area of Tokyo. These categories tend to be patchily interwoven into the suburban fabric of Tokyo Metropolis (the gray-colored area in the suburbia) whilst they tend to surround the regional cores and regional suburbs (see Maebashi, Takasaki, Utsunomiya, Tsukuba, Mito, Kofu, Isesaki, Ota). Let us call these particular areas patchy-peripheral suburbs for brevity. At the 2015 snapshot level, these patchy-peripheral suburbs show the same socio-demographic pattern (see their blue line). This means that they became similar areas in terms of their HSD characteristics. Yet, from a temporal perspective, they have passed different HSD paths thus they were in the middle of rather diversified suburbanization trajectories.

(Also study Fig. 11) Population-growth patchy-peripheral suburbs. G‑3 areas used to be a typical exurb-rural space showing high shares of primary workers and traditional multi-generation families. However, after the 15 years, these areas have turned into emerging suburbs for junior households working in creative-service industries. GD‑3 areas have lost the seniors while having slightly gained the juniors and child-raising families. The Production-&-Transport and Primary workers have slightly increased vis-à-vis unchanged creative-service workers, suggesting relative de-tertiarization of employment in these areas. G‑1 areas show an evolution from child-raising families to multi-gen families, suggesting a Japanese traditional family formation still works: children got married and had their children while living together with their parents (i.e., multi-gen families). Job-wise, Production-&-Transport as well as Primary workers have become more prevalent in these areas. (Source: own elaboration)
G‑3 shows radical HSD changes. In 2000, the G‑3 patchy-peripheral suburbs were a typical exurb-rural space whose share of primary workers and traditional multi-generation families was distinctively high. However, in 2015, the mean share of the Creative-service workers increased drastically whilst the share of the Primary workers fell plumb down. As for the household composition, the share of Single Junior, Couple Junior, and Family with 0–17-yo children skyrocketed. On the other hand, the mean share of the multi-generation families plunged and that of the senior households also clearly decreased. Thus, these areas have experienced a mixed process of singlification, youthification, familification, and employment tertiarization. These changes suggest that the G‑3 patchy-peripheral suburbs have become emerging suburbs for junior households working for creative-service industries.
In GD‑3, we can see that there are clear decreases in the mean share of senior households. On the other hand, Single Junior and Family with 0–17-yo children slightly gained mean shares whilst the share of Junior Couple remained at the almost same level as in 2000. We can also observe a slight increase in multi-generation families. These changes suggest that the GD‑3 patchy-peripheral suburbs have also experienced, albeit slightly, a mixed process of singlification, youthification, and familification. As for the job composition, the Production-&-Transport workers gained a share that is followed by a nuanced increase in the Primary workers. As the share of the Creative-service workers is almost unchanged, we can say that the GD‑3 suburbs have experienced relative de-tertiarization of employment composition.
Finally, we can observe that the G‑1 patchy-peripheral suburbs have lost their junior family-oriented status. The mean share of Families with +18-yo children dropped sharply which is followed by a moderate decrease of the junior couple and families with 0–17-yo children. Instead, G‑1 is the only population-growth category whose mean share of the multi-generation families (i.e., Multi-gen with 0–17-yo children and Total multi-generation family) has considerably increased since 2000. One potential explanation for this transition is that the Families with 18-yo-over children (more realistically, 20-yo or over) households have transformed into multi-gen families as their children got married and had their children while living together with their parents (who now became grandparents). As for the job composition, G‑1 lost the Creative-service workers while gaining the share of the Production-&-Transport as well as Primary workers. These changes suggest that the G‑1 patchy-peripheral suburbs have experienced a shift to larger family households with both absolute and relative de-tertiarization of employment.
5.4 Shrinking urban, suburban, and regional cores/corridors
Figure 8 shows the Population-decline small areas within the urban, suburban, and regional cores/corridors (i.e., GD‑1, Red. Note: The gray areas indicate the population-growing, spatially-expanding urban, suburban, and regional cores/corridors). As we have seen in 5.1., the majority of the urban core has experienced population growth with youthification and familification. Yet, the figure implies that a few parts of the urban core lost their population although they have also experienced youthification and familification.

(Also study Fig. 11) Population-decline urban-suburban cores and regional cores/corridors. Some GD‑1 areas (spaces for single creative-service workers with youthification and familifiction) have declined in their population even though they are spatially situated in the re-urbanizing sub/urban cores and regional corridors (see the greyed areas labeled by ‘GD‑1 & G‑2 (Growth)’ in the map). This indicates that the re-urbanization of Tokyo’s cores/corridors is not a spatially homogenous process. Rather, at the micro-spatial scale, it consists of a heterogeneous landscape of population-growing localities and population-declining localities. (Source: own elaboration)
This result indicates that despite the overall tendency of (re-)urbanization of the urban core (see Table 1), at the micro-spatial scale, re-urbanization consists of a complex landscape of population-growing localities and population-declining localities. This observation applies to suburban and regional cores/corridors. In addition, we can observe that the proximity of these areas (including the population-declining core) to the regional transit infrastructure is not considerably different from that of the population-growing areas. This result suggests that the proximity to the regional infrastructure and the macro tendency of re-urbanization does not necessarily ensure population growth at a local level.
5.5 Aging and empty-nesting suburbs, the spatially-expanding singlifying, youthifying, familifying, and de-tertiarizing suburbs and exurbs
Figure 9 shows the Population-decline suburban/exurban small areas (GD‑2, Orange, D‑2, Purple, and GD‑3, Light green) around Tokyo Metropolis and the regional cores. Note that the gray areas indicate the population-growth aging and empty-nesting suburbs (GD-2) and diversifying patchy-peripheral suburbs (GD‑3, G‑1, G‑3).

(Also study Fig. 11) Population-decline suburbs and exurbs. Both D‑2 and GD‑2 shrinking areas have become aging and empty-nesting suburbs although their job-houshould transition path is different. Same as the population-growth GD‑3 areas, the population-decline GD‑3 areas have experienced slight singlification, youthification, familification, and employment de-tertiarization. This suggests that suburban/exurban spaces for the juniors and families working in non-creative-service industries have spatially expanded even to shrinking remote areas. (Source: own elaboration)
Similar to the population-growth patchy-peripheral suburbs (see 5.3), the GD‑2 population-declining suburbs are patchily interwoven into the suburban fabric of Tokyo. Yet, they are more distinctive in the suburbia of Tokyo’s urban core. Although, at the regional scale, the suburbanization of Tokyo has pushed the population of Tokyo’s suburbia by roughly 1.6 million, its micro-scale landscape shows a complex mixture of the population-decline and -growth suburbs that have experienced absolute and relative aging populations.
In addition, similar to the observation in 5.4, the proximity to the regional transit infrastructure seems to not largely differentiate the spatial distribution of these growing and declining aging suburbs. These observations suggest that, rather than accessibility and demographic composition at a regional scale, nuanced local contingencies (e.g., the dynamism of local property markets, the condition of socio-technological infrastructures, the image of the locality, and local regulations and institutions) can affect the population dynamics within the urban, suburban, and regional cores/corridors and the suburbia of Tokyo.
D‑2 is a transition category unique to the population-decline small areas that are sparsely distributed across the Tokyo Capital Region. Its 2015 HSD characteristics are the same as GD‑2 (i.e., the growing/declining aging suburbs). This means that the D‑2 areas became a typical suburban HSD composition. Yet, their HSD transition patterns are different. In 2000, same as GD‑3 (Light green), the D‑2 suburbs were a loose mixture of the family-oriented space for relatively younger households (i.e., a relatively high share of Couple Junior and Families with 0–17-yo children) and the senior space (i.e., Single Senior and Couple Senior). In 2015, we can observe that Couple Junior and Families with 0–17-yo children have lost their share while the share of Family with +18-yo children and Couple Senior has clearly increased. We can also point to the clear decrease in the share of multi-generation households. As for the job composition, there is no large difference between 2000 and 2015. Yet, we can observe that the Creative-service workers gained a slight share relative to the other two job categories.
These changes suggest, albeit subtle, that these population-declining D‑2 suburbs have transformed into a family-oriented space for the creative-service households at a later point of their life stage (e.g., families with adult children, households of the empty-nested senior couples). In this sense, the D‑2 suburbs are also considered to be a type of aging and empty-nesting suburbs like the GD‑2 suburbs.
Finally, we can observe that the population-declining GD‑3 suburbs/exurbs are scattered over the Tokyo Capital Region. A notable observation here is that these shrinking GD‑3 suburbs, compared to the GD‑2 and D‑2 counterparts, more frequently appear in the remote exurban areas that are less accessible to the suburban and regional cores or even regional transit infrastructure. This tendency of ‘spatial diffusion’ is more distinctive for the population-decline GD‑3 areas than its population-growth counterparts (compare with Fig. 7).
As we have seen in 5.3., these patchy suburbs/exurbs have experienced the nuanced mix of singlification, youthification, familification, and employment de-tertiarization. Hence, we can say that the suburban spaces for the junior singles, couples, and young families who work for the Production & Transport jobs (e.g., factory production, farming, transportation, construction, machine operation) have geographically expanded towards the population-declining remote areas during 2000 and 2015.
5.6 Shrinking exurb-rural region
Figure 10 shows that, except for the urban and suburban areas, most of Tokyo’s landscape consists of D‑1 (Green) and D‑3 (Dark green) small areas. Both categories are unique to the Population-decline small areas. On the actual landscape, these areas roughly correspond to farmlands and mountains. These areas tend to be not populated (D‑1: total 2,000,000 people, average 414/small area; D‑3: total 140,000 people, average 165/small area in 2015). Thus, the changes in the mean share of each HSD character can be more volatile than those in other populated (i.e., urban and suburban) areas. Hence, the remainder of this section will explore the overall HSD patterns of the D‑1 and D‑3 areas rather than their detailed changes.

(Also study Fig. 11) Population-decline exurb-rural region. The job-household pattern of D‑1 areas has not changed radically through the 15 years: high shares of primary and production-transport workers with a large share of multi-generation families. This shows that these shrinking exurbs are farmlands operated by conventional multi-gen farmers supported by other production and transport industries. The job-household pattern of D‑3 has also not changed drastically. Similar to the D‑1 farmlands, the D‑3 areas are also characterized by high shares of agriculture, forestry, production, and transport workers. Yet, these areas show particularly high shares of single and couple seniors, suggesting that aging populations are accentuated. (Source: own elaboration)
In the D‑1 small areas, we can observe that their overall HSD pattern has not changed radically through the 15 years (Fig. 11). The mean share of the primary workers and the production-transport workers is the highest across all other transition categories whilst the share of the creative-service workers shows the lowest. Additionally, multi-generation families also show the highest share whilst the shares of Senior Single and Senior Couple keep relatively lower level. These observations suggest that these D‑1 areas are farmlands operated by conventional multi-generation farmers supported by other production and transport industries (which fits the actual land use of these areas).

The overall HSD pattern of D‑3 has also not changed drastically. Similar to the D‑1 farmlands, the D‑3 areas are also characterized by high shares of agriculture, forestry, production, and transport workers. Yet, its household composition looks different from that of D‑1. Notably, the share of Single Senior is the highest across all other categories and that of Couple Senior also shows a relatively high share. On the other hand, the shares of families with children (both 0–17 yo and +18 yo) and multi-generation families are smaller than those in the D‑1 farmlands. These observations suggest that aging populations (especially of the single households) are accentuated in the D‑3 farmlands in contrast to the D‑1 farmlands.
6 Discussions
Figure 12 summarizes the spatiotemporal socio-demography of the Tokyo Capital Region. The urban, suburban, and regional cores/corridors of Tokyo have re-urbanized between 2000 and 2015. Socio-demographically speaking, Tokyo’s re-urbanization is driven by junior singles, junior couples, and relatively younger junior families (i.e., families with 0–17-yo children) who likely work for creative and service industries. This overall socio-demographic trend of re-urbanization matches the observations of European re-urbanization (Ogden and Schnoebelen 2005; Moos 2016; Brombach et al. 2017; Siedentop et al. 2018; Rérat 2019). Yet, we can point to a difference—Tokyo’s re-urbanization is not limited to its most-central urban spaces. Rather, suburban cores/corridors also experienced re-urbanization. Such multiple and simultaneous re-urbanizations appear to be unique to Tokyo consisting of various suburban cores and transit corridors that are functionally connected through a mature transit network.

The simplified map of the Spatiotemporal Demography of Tokyo (2000–2015). As the map shows, similar to Euro-American cities, Tokyo has experienced the synchronization of (re)urbanization and (post)suburbanization within a complex landscape of shrinkage. However, Tokyo’s (re)urbanization and (post)suburbanization are not homogenous across different localities. Rather, complex migration flows within Tokyo’s megacity region seem to create disparities across the localities in terms of demographic growth and decline. (Source: own elaboration)
A plausible explanation of the re-urbanization of Tokyo is, similar to the (re)urbanization in the European context (Kabisch et al. 2010; Kroll and Kabisch 2012; Rérat 2019) where young singles (including students) and junior professionals selectively migrated to neighborhoods where urban amenities, educational access, and job opportunities are agglomerated.
The increasing share of junior married couples and families with young children—the familification of the inner city—is similar to the re-urbanization observed in the European context where family households also play a driving role in the inner re-development (Buzar et al. 2007; Siedentop et al. 2018). This observation suggests that Tokyo’s re-urbanization is different from the childless urban renaissance, or new-build gentrification, in the US cities—the re-urbanization of the inner city without growth of family households (Siedentop et al. 2018). In other words, the re-urbanization of Tokyo is considered to be a spatiotemporal process in which the inner-city urban spaces are fundamentally reconfigured into a place for families.
Such familification of the urban, suburban, and regional cores/corridors of Tokyo is likely explained by an increasing number of dual-earner households. In Japan, the number of dual-earner households exceeded that of male-breadwinner in around 2000, and this gap doubled in 2018 (Gender Equality Bureau Cabinet Office 2019, pp. 115–116)Footnote 8. As Markusen argues, these highly-urbanized, highly-functional, and highly-accessible areas can provide the means to maximize work and household production for these dual-earner couples and families (1980, p. 35). Considering the high share of creative-service workers and the high housing rent/price of the inner city, the familification of Tokyo’s (sub)urban cores, in particular, is likely driven by the upper-middle segment of such dual-earner households who work for creative or professional-service industries.
A market report by RecruitFootnote 9 (2020) supports this analysis: 56% of the new apartment owners in TokyoFootnote 10 in 2019 were dual-earner couples/families and their average household annual income is about 10 million Japanese Yen, which is more than doubles the national average annual income (4.4 million Yen).
In addition, from a supply-side point of view, a continuous supply of high-rise condominiums in the inner city (Tokyo Kantei 2022) seems to reciprocally drive the increasing demand for high-income dual-earner couples/families wanting the high functionality of the inner city.
The selective migration of the households working for the creative-service industries, especially economically affluent dual-earner households, to the (sub)urban cores could induce gentrification, and intensify the housing markets. In fact, several authors report that the inner cities of the Tokyo Metropolis have been radically gentrified (Hashimoto 2012; Ajisaka 2015; Fujitsuka 2017; Kohama 2017). The intensification of the housing markets in the (sub)urban cores is also evident. According to Real Estate Economic Institute (2022)Footnote 11, the average price of apartments in TokyoFootnote 12 in 2021 reached 62 million Japanese Yen, which broke the highest record marked in 1990 just before the Japanese bubble economy collapsed.
Although we emphasize the potential impact of upper-middle households on the dynamics of re-urbanization, this does not mean either the entire cores/corridors have been gentrified or Tokyo’s (re)urbanization is macro-scale gentrification. Rather, together with the ‘spotty’ geography of the population-declined inner-city neighborhoods, we would better view that singlification, familixfication, and gentrification constitute the heterogeneous landscape of (re)urbanization of the cores and corridors (c.f., Haase et al. 2010; Carlucci et al. 2018).
In addition, we have found that the family-oriented spaces around the urban, suburban, and regional cores/corridors have drastically transformed into urban spaces for creative-service singles between 2000 and 2015 (i.e., G‑2). This observation aligns with what Ohashi and Phelps (2020) that the peripheral areas of the urban core have been revitalized under the back-to-the-city movement (p. 14) between 1995 and 2015. This spatial expansion of the ‘re-urbanizing’ cores/corridors towards the old suburbs suggests the progress of de-suburbanization of the core/corridor peripheries, which is likely driven by the increasing demands for accessible, functional, and relatively affordable areas for economically active singles who work for creative-service industries in the inner city.
While observing the growth of Tokyo’s cores and corridors, we also have observed that the mixed process of new suburbanization and post-suburbanization has progressed during the 15 years. Some accessible farmlands around the cores/corridors have transformed into newly emerging suburbs for junior singles, couples, and families working in the creative-service industries (i.e., G‑3). Similarly, other accessible areas around the cores/corridors have slightly shifted towards the spaces for non-creative-service couples and families (i.e., GD-3). Interestingly, these GD‑3 areas have geographically extended towards the less-accessible, population-declining suburban/exurban areas. One plausible explanation of this spatial expansion of the exurbs for non-creative-service couples and families is that the housing market of these population-losing suburbs/exurbs is becoming affordable (as the decline in housing market participants) for these households whilst these areas are accessible to their workplaces like farms, factories, and distribution centers. As we shall discuss later, increasing preferences for local/rural living may also explain this spatial expansion of the exurbs.
Apart from the emerging suburbs, the major suburban landscape around Tokyo’s cores and corridors has been aging and empty-nesting (i.e. GD‑2 and D‑2). Such an absolutely and relatively aging suburban landscape consists of a complex fabric of population-growing and population-declining areas. As the HSD composition of these growing and shrinking suburbs is consistent with each other, it is reasonably concluded that the population dynamics of the (aging) suburbia are likely driven by the intra-suburban migration (i.e., suburban residents have immigrated to other suburban areas). This analysis is consistent with the analysis by Nakano (2019) that about 70% of the relocations of suburban settlers between 1995 and 2015 were made within Tokyo’s suburbia (pp. 26–27). Some European authors are interested in re-urbanization by the senior who seeks the functional socio-technical infrastructures of the inner city (Haase et al. 2010, p. 454; Wolff 2018, p. 26). Yet, our analysis suggests that intra-suburban migrations of the seniors will be one of the important regional socio-demographic dynamism of aging and declining Tokyo.
In contrast to the aging and empty-nesting old suburbs, we have observed that some old suburbs (i.e., G‑1) have gained the share of multi-generation households together with the share of conventional jobs (such as factory workers, truck drivers, and farmers). Considering the fact that the total share of multi-generation households is continuously decreasing in Japan, this observation is particularly illuminated.
One potential explanation of this trend is that the multi-generation family is strategically revalued by young people and families raising children as well as national and municipal governments. In 2006, the government of Japan stated that by utilizing existing housing stock, the government assists multi-generation living in order to support families raising children (MLIT 2006, p. 5). Also, after the financial crisis in 2008, there has been an increasing trend of ‘U-turn’ (going back to hometown) movement across the 20–39-year-old urban dwellers who want to prioritize ‘community-tie,’ ‘a better environment for children,’ and ‘to change the job to those related closely to the local community (Furusato-kaiki-shine Center 2016; Hamaguchi 2016).
The progressing deconstruction of conventional multi-generation families and relevant ethics and values (Lesthaeghe 2011, 2020) is often emphasized as the primary theoretical explanation of socio-demographic changes in the city region, especially those relevant to re-urbanization (Buzar et al. 2005; Ogden and Schnoebelen 2005, p. 265; Kabisch and Haase 2011, p. 237). However, our observation suggests that, at least in the case of Tokyo, analyzing the spatiotemporal socio-demography of the aging and declining megacities likely requires more diverse theoretical perspectives that can account for households’ lifestyle strategies, family values, and political and public discourses constructing the image of particular localities.
These complex landscapes of (re)urbanization and (post)suburbanization (as well as exurbanization) are embedded within the largely shrinking hinterland of Tokyo. The overall socio-demographic composition of these hinterlands (i.e., the dominance by primary workers, conventional large families, and senior people) is opposite to that of growing cores and corridors. This observation implies that Tokyo’s strong re-urbanization trend can be underpinned by the selective out-migration of young and talented people, within a structural shift to creative economies, from Tokyo’s (and Japan’s) hinterlands to post-industrialized cores/corridors of Tokyo to seek better educational or career opportunities.
Supporting this argument, the Science Council of Japan (2017) points out that the strong (re)urbanization of Tokyo has been driven by the outmigration of the 15–24-year-old young people (not only in the hinterlands of Tokyo but also in entire Japan) who seek better job opportunities that are largely agglomerated in Tokyo. In addition, MLIT (2020) reports that 20–29-year-old young people account for +50% of the migration flows to Tokyo. MLIT (2020) points out that after 2009 the migration flows of females constantly exceeded those of males, which could be explained by an increasing number of female college enrollment rates (pp. 31–32). Such relational demographic dynamics are in line with what an international body of literature on urban shrinkage observes and theorizes (Kroll and Kabisch 2012; Martinez-Fernandez et al. 2012a; Elzerman and Bontje 2015; Nelle 2016; Makkai et al. 2017).
Overall, the geographically expanding (re)urbanization and socio-demographically diversifying suburbanization observed in the world-largest megacity Tokyo agree with the European observations that these two urban processes are synchronized within a complex city-regional fabric (Kabisch and Haase 2011; Salvati and Carlucci 2016; Hierse et al. 2017; Rérat 2019).
Our analyses suggest that these synchronized (sub)urban processes are not relationally separated from each other. Rather, we can assume here cascade-like migration flows from the (re)urbanizing cores/corridors to the de-suburbanizing core/corridor periphery and from there to the emerging suburbs/exurbs (the black arrows in Fig. 12). This is similar to what Hierse et al. (2017) observed in Berlin. They argue that this cascade-like migration flow could be driven by the relocation decision of particular socio-demographic groups (e.g., relatively lower- and middle-income families) to seek more affordable and spacious housing to leave the intensifying inner-city housing market (Hierse et al. 2017, p. 197).
In other words, this synchronicity is likely coupled through the dynamism of urban housing markets that is driven by political-economic tension between those who drive re-urbanization and those who move outwards. The expanding and gentrifying cores and corridors, the employment segregation of the suburbanizing areas (i.e., the creative-service and non-creative-service suburbs), and emerging suburbs/exurbs for non-creative-service households in the population-declining areas hint at the applicability of this hypothesis to Tokyo. Yet, due to the explorative nature of this study, we leave detailed political-economic analyses of the dynamics between megacity-regional housing markets and spatiotemporal socio-demography to future studies.
In addition to such cascade-like migrations driven potentially by the political economy on housing markets, our observations also point to intra-region population dynamics that engender the geographic variation of declining and growing localities within the aging suburbs as well as (re)urbanizing cores and corridors (the black dotted arrows in Fig. 12). This intra-regional fluidity of the demographic flows can be seen as a unique feature of megacities where many medium towns and large cities are socio-functionally interconnected.
Our observations suggest that such variation does not emerge from macro (regional) characteristics (such as proximity to the regional transit infrastructures and regional socio-demographic composition). Rather, it can be determined by a mix of micro (local) contingencies. Thus, future studies need to explore not only quantitative aspects of local contingencies (e.g. the condition of local property markets and socio-technological infrastructures), but also qualitative aspects of local contingencies such as municipal regulations and institutions, “lifestyles and values which promote urbanity, (new) images and representation of cities, or political and media discourse” (Rérat 2019, p. 372).
At a regional scale, one promising approach to such an analytical need is to quantify qualitative information—by applying emerging Natural Language Processing technologies (e.g., word2vec, see Mikolov et al. 2013)—from different sets of online materials such as blogs, online review services, Facebook, and Twitter (Rahimi et al. 2018; Vargas-Calderón and Camargo 2019; Qi and Shabrina 2023) and adding it, as non-spatial features, to unsupervised-ML clustering analyses.
Finally, we have pointed to a wider flow of population from Tokyo’s population-declining hinterlands as well as other shrinking areas in Japan to the growing cores and corridors of Tokyo (the black dashed arrows in Fig. 12). Although the presented analysis cannot directly capture this flow, the largely shrinking Tokyo’s hinterlands whose HSD characteristics are a ‘mirror’ of those in Tokyo’s cores and corridors suggest the relational demographic dynamics between the regions. As the population of the hinterlands is projected to continuously decline and age (PRIMAFF 2019), we will need to follow-up studies to explore how the weakening or loss of ‘population reservoir’ will affect the observed megacity-regional spatiotemporal demography, that is, (re)urbanization, (post)suburbanization, exurbanization, intra-region migrations, and potential cascade-like migration flows.
7 Conclusions
Asian megacities of the 21st century will witness their growth and decline. For the formation of effective spatial governance of mature Asian megacities, it is needed to update the existing knowledge on the evolution of cities. The presented study has contributed directly to this knowledge update by empirically exploring the spatiotemporal sociodemography of the Tokyo Capital Region at a high spatial resolution using unsupervised-ML clustering method that is not yet well acknowledged and applied in the field of urban studies. This study demonstrated in detail how the GMM clustering method can enable us to effectively explore a large volume of micro-scale job-household data without imposing any pre-defined spatial aggregations for statistical analysis. Thus, this study has also methodologically contributed to a wider audience who are interested in the emerging application of unsupervised-ML methods to explore the spatiotemporal complexity of cities.
To guide the study, we posed two research questions: (1) How did the spatiotemporal sociodemography of the megacity Tokyo change between 2000 and 2015? (2) What are the similarities and differences between the spatiotemporal sociodemography of the megacity Tokyo and that observed in the Euro-American medium-large cities?
For the first question, the GMM clustering analysis revealed that the Tokyo megacity region has experienced the synchronization of (re)urbanization and (post)suburbanization during the 15-year period. More specifically, the population of the urban cores of Tokyo grew, which appears to be driven by junior singles, junior couples, and relatively younger junior families who likely work for creative and service industries. Especially, the increasing share of junior married couples and families with young children in Tokyo’s inner city suggests that the inner-city spaces have gradually transformed into a place for families.
In contrast to the re-urbanizing cores, some accessible farmlands around the cores/corridors transformed into new suburbs for diverse socio-demographic groups such as junior singles, couples, and families working in the creative-service industries as well as non-creative-service couples and families. The growth of the non-creative-service group in particular geographically extended towards even less-accessible, population-declining suburban/exurban areas. Apart from these new suburbs, the major old suburbs of Tokyo have been aging and empty-nesting, yet some of them gained the share of multi-generation households together with the share of conventional jobs.
For the second question, these observations agreed with what the existing studies observed in Euro-American medium-large cities. Yet, Tokyo’s re-urbanization happened not only in its urban cores but also in its suburban cores/corridors. Such multiple and simultaneous re-urbanizations appear to be unique to Tokyo whose urban structure consists of various suburban cores and corridors that are functionally connected by a mature transit network. The spatial pressure of the multiple re-urbanizations seems to de-suburbanize their adjacent suburban spaces, namely, altering family-oriented suburbs to inner-city-like spaces for creative-service singles. Together with the socio-demographic diversity in the new/old suburbs, such transformation of Tokyo’s suburban cores, corridors, and even adjacent suburban spaces into inner-city-like spaces illustrates the progress of post-suburbanization is not unique to Euro-American cities.
By relating the empirical findings to the existing theories of re-urbanization and (post-)suburbanization, the study tried to explain the synchronized sub/urban growth of Tokyo. Namely, we argued that this synchronized regional process is underpinned by core-to-exurb cascade-like migration flows, which are driven by the dynamism of political-economic tension within urban housing markets between those who drive re-urbanization (i.e., high-income households, especially dual-earner family households) and those who move outwards (e.g., the singles, the workers on the non-creative-service job). Yet, this explanation remains theoretical level due to the explorative nature of this study. Hence, the study recommends future studies to perform in-depth political-economic analyses of the dynamics between megacity-regional housing markets and spatiotemporal socio-demography.
When it comes to the small-area scale, the GMM clustering of the job-household data has illustrated that this synchronized sub/urban growth in Tokyo was not spatially homogenous. Rather, intra-core and intra-suburb migrations seem to create nuanced disparities across the localities in terms of population growth and decline. Why some localities prosper while others decline, or why core/suburban residents move to other cores/suburbs, seems to be determined by a mix of micro (local) contingencies. However, this explorative study is unable to give clear answers to these questions. Thus, to explain why such disparities in population growth/decline happen, this study recommends future studies to explore both quantitative (e.g., the condition of local property markets and socio-technological infrastructures) and qualitative (e.g., regulations, institutions, lifestyle preference, family values, discourses and image of particular localities) aspects of local contingencies. In addition, this observation suggests that urban scholars and policymakers not only of Tokyo, but also of Asian megacities where national (and likely megacity-regional) population decline is projected will need to consider how to form a functional inter-local collaborative governance, or metropolitics (Ohashi and Phelps 2020), to balance prospering and declining localities.
Finally, this synchronized sub/urban growth seems to be underpinned by constant migration flows, especially of young people, from ‘population reservoir’ hinterlands where shrinkage is prevalent. Hence, we do not have any idea whether synchronized (re)urbanization and (post)suburbanization could be sustained once the hinterlands of Tokyo (and Japan) became unable to supply the young population. In this sense, even Tokyo, the frontrunner of Asian megacities, still needs some time to face its real old age. Yet, we can imagine that such timing will be the true beginning of the post-growth, or the decline and fall, of megacities.
Notes
As the first law of geography, Tobler argues that “everything is related to everything else, but near things are more related than distant things” (Tobler 1970, p. 236). In other words, non-spatial information within spatially represented data may have similarities/dependencies based on geographic proximity. Such spatial similarities/dependencies are referred to as neighborhood effects in the fields of urban sociology and housing studies and are considered to have causal effects on socio-political characteristics, public transportation choices, and real estate prices of the neighborhood, just to name a few (Wilson 1987; Tse 2002; Sampson 2019; Kuai and Wang 2020).
In spatial statistics, these spatial similarities/dependencies have been conceptualized more broadly as ‘spatial autocorrelation’ (Griffith 1992; Getis 2008) and researchers have long been paying attention to it from both theoretical and methodological perspectives. In particular, within the framework of the stochastic inference analysis approach, typically as a form of multivariate (linear) regression analysis, the presence of spatial autocorrelation in the data violates the ‘independence of observations, thus of residuals’ assumption (Getis 2008) in which the analysis assumes. Hence, several techniques such as Geographically Weighted Regression (GWR) (Fotheringham et al. 2002), Spatial Lag Model (SL), and Spatial Error Model (SE) (Anselin 2003; Anselin and Rey 2014) have been developed to deal with the issue to ensure the inferential quality of the analysis.
Regression analysis focuses on the estimation of the causal effect of multiple explanatory variables on a target variable (e.g., estimating hotel prices from hotel size/quality and location (Kim et al. 2020)). Incorporating spatial dependence into the regression model as some kind of explanatory variable and controlling for spatial autocorrelation is essential to estimate a reliable causal effect (i.e., coefficient) of each explanatory variable. In other words, in ‘spatial’ econometrics (Paelinck and Klaassen 1979; Anselin 1988), the coefficients of explanatory variables are estimated in a spatially varying manner based on pre-defined spatial bandwidth (i.e., GWR), or a spatial pattern is assumed in advance in the form of a spatial weight matrix (i.e., SL, SE), thereby controlling for spatial autocorrelation (Anselin 2003; Anselin and Rey 2014; Fotheringham et al. 2002).
Excluding not-habitable areas such as rivers, lakes, industrial areas, etc.
See p. 292 in Scrucca et al. (2016) for the details of different GMM model specifications.
In 2018, the number of dual-earner households reached 12 million whilst that of male-breadwinner households dropped to 6 million.
One of the biggest private real estate information providers in Japan. https://suumo.jp/.
In this report, Tokyo Metropolis, Kanagawa, Chiba, and Saitama.
A private firm specifically publishes several reports on Japanese housing markets: https://www.fudousankeizai.co.jp/companyInfo.
In this report, Tokyo Metropolis, Kanagawa, Chiba, and Saitama.
References
Adam D (2021) How far will global population rise? Nature 597:462–465
Ajisaka M (2015) Upper-middle class condominium residents and their local lives in the era of Urban core revival: the cases of chuo ward in tokyo and Kita ward in osaka. Ann Jpn Assoc Urban Sociol 33:21–38
Ali M, Alqahtani A, Jones MW, Xie X (2019) Clustering and classification for time series data in visual analytics: a survey. IEEE Access 7:181314–181338. https://doi.org/10.1109/ACCESS.2019.2958551
Allison A (2018) Not-waiting to die badly: facing the precarity of dying alone in Japan. In: Janeja MK, Bandak A (eds) Ethnographies of waiting: doubt, hope and uncertainty. Routledge, New York, pp 181–202
Anselin L (1988) Spatial econometrics: methods and models. Martinus Nijhoff, Dordrecht
Anselin L (2003) Spatial econometrics. In: Baltagi BH (ed) A companion to theoretical econometrics. Blackwell, Oxford, pp 310–330
Anselin L, Rey SJ (2014) Modern spatial econometrics in practice: a guide to GeoDa, GeoDaspace and PySAL. GeoDa Press, Chicago
Batista SFA, Lopez C, Menéndez M (2021) On the partitioning of urban networks for MFD-based applications using Gaussian Mixture Models. In: 2021 7th Int Conf Model Technol Intell Transp Syst MT-ITS 2021, pp 29–34 https://doi.org/10.1109/MT-ITS49943.2021.9529296
van den Berg L, Klaassen LH, Drewett R et al (1982) Urban Europe: a study of growth and decline. Pergamon Press, Oxford
Boon Kai KS, Chong E, Balachandran V (2019) Anomaly detection on DNS traffic using big data and machine learning. CEUR Workshop Proc 2622:95–104
Bricker D, Ibbitson J (2019) Empty planet: the shock of global population decline. Penguin Rondom House, New York
Brombach K, Jessen J, Siedentop S, Zakrzewski P (2017) Demographic patterns of reurbanisation and housing in metropolitan regions in the US and Germany. Comp Popul Stud 42:281–318. https://doi.org/10.12765/CPoS-2017-16en
Buzar S, Ogden PE, Hall R (2005) Households matter: the quiet demography of urban transformation. Prog Hum Geogr 29:413–436. https://doi.org/10.1191/0309132505ph558oa
Buzar S, Hall R, Ogden PE (2007) Beyond gentrification: the demographic reurbanisation of Bologna. Environ Plan A 39:64–85. https://doi.org/10.1068/a39109
Cai J, Chen Y (2022) A novel unsupervised deep learning method for the generalization of urban form. Geo-spatial Inf Sci 25:568–587. https://doi.org/10.1080/10095020.2022.2068384
Carlucci M, Chelli FM, Salvati L (2018) Toward a new cycle: Short-term population dynamics, gentrification, and re-urbanization of Milan (Italy). Sustainability. https://doi.org/10.3390/su10093014
Castells M (2010) Globalisation, networking, urbanisation: reflections on the spatial dynamics of the information age. Urban Stud 47:2737–2745. https://doi.org/10.1177/0042098010377365
Charmes E, Keil R (2015) The politics of post-suburban densification in Canada and France. Int J Urban Reg Res 39:581–602. https://doi.org/10.1111/1468-2427.12194
Chorus P, Bertolini L (2016) Developing transit-oriented corridors: Insights from Tokyo. Int J Sustain Transp 10:86–95. https://doi.org/10.1080/15568318.2013.855850
Choudhury P, Allen R, Endres MG (2016) Developing theory using machine learning methods Prithwiraj. SSRN Electron J: 1–23
Cividino S, Halbac-Cotoara-Zamfir R, Salvati L (2020) Revisiting the “City Life Cycle”: Global urbanization and implications for regional development. Sustainability 12:1–18. https://doi.org/10.3390/su12031151
Compton J, Pollak RA (2007) Why are power couples increasingly concentrated in large metropolitan aras? J Labor Econ 25:475–512
Costa DL, Kahn ME (2000) Power couples: changes in the locational choice of the college educated, 1940–1990. Q J Econ 115:1287–1315
Crouch C (2016) Society and social change in 21st century Europe. Palgrave, London
Delmelle EC (2017) Differentiating pathways of neighborhood change in 50 U.S. metropolitan areas. Environ Plan A 49:2402–2424. https://doi.org/10.1177/0308518X17722564
Dembski S, Sykes O, Couch C et al (2019) Reurbanisation and suburbia in Northwest Europe: a comparative perspective on spatial trends and policy approaches. Prog Plann. https://doi.org/10.1016/j.progress.2019.100462
Dias F, Silver D (2021) Neighborhood dynamics with unharmonized longitudinal data. Geogr Anal 53:170–191. https://doi.org/10.1111/gean.12224
Dias MD, Mansour Moussa R, Dias F et al (2017) A hierarchical network simplification via non-negative matrix factorization. In: Proc—30th conf graph patterns images, SIBGRAPI 2017, pp 119–126 https://doi.org/10.1109/SIBGRAPI.2017.22
Döringer S, Uchiyama Y, Penker M, Kohsaka R (2019) A meta-analysis of shrinking cities in Europe and Japan. Towards an integrative research agenda. Eur Plan Stud 0:1–20. https://doi.org/10.1080/09654313.2019.1604635
Dvořáková N, Horňáková M (2021) Retiring in the suburbs? Residential strategies in two Prague suburbs. Geogr Tidsskr Danish J Geogr 121:114–127. https://doi.org/10.1080/00167223.2021.1994866
Elzerman K, Bontje M (2015) Urban Shrinkage in Parkstad Limburg. Eur Plan Stud 23:87–103. https://doi.org/10.1080/09654313.2013.820095
Florida R (2002) The rise of creative class: and how it’s transforming work, leisure, community, and everyday life. Basic Books, New York
Florida R (2005) Cities and the creative class. Routledge, New York
Florida R (2012) The rise of the creative class: revisited, 2nd edn. Basic Books, New York
Fotheringham AS, Wong DWS (1991) The modifiable areal unit problem in multivariate statistical analysis. Environ Plan A 23:1025–1044. https://doi.org/10.1068/a231025
Fotheringham AS, Brunsdon C, Charlton M (2002) Geographically weighted regression: the analysis of spatially varying relationships. John Wiley and Sons, West Sussex
Fradkov AL (2020) Early history of machine learning. In: Prepr 21st IFAC World Congr July 12–17. Berlin, pp 1411–1146 https://doi.org/10.1016/j.ifacol.2020.12.1888
Frank S (2008) Gender trouble in paradise: suburbia reconsidered. In: DeSena JN (ed) Gender in an urban world. JAI Press, Bingley, pp 127–148
Fujitsuka Y (2017) Globalization and gentrification in inner Tokyo. Ann Japan Assoc Econ Geogr 4:320–334
Furusato-kaiki-shine Center (2016) The 2016 ranking of rural/local areas to live
Gautier PA, Svarer M, Teulings CN (2010) Marriage and the city: search frictions and sorting of singles. J Urban Econ 67:206–218. https://doi.org/10.1016/j.jue.2009.08.007
Gender Equality Bureau Cabinet Office (2019) White paper on gender equality. Tokyo
Georganos S, Kalogirou S (2022) A forest of forests: a spatially weighted and computationally efficient formulation of geographical random forests. Int J Geo Inform. https://doi.org/10.3390/ijgi11090471
Getis A (2008) A history of the concept of spatial autocorrelation: a geographer’s perspective. Geogr Anal 40:297–309. https://doi.org/10.1111/j.1538-4632.2008.00727.x
Glaeser EL, Kolko J, Saiz A (2001) Consumer city. J Econ Geogr 1:27–50
Gottmann J (1961) Megalopolis: The urbanized Northeastern seaboard of the United States. The Twentieth Century Fund, New York
Grekousis G (2019) Artificial neural networks and deep learning in urban geography: a systematic review and meta-analysis. Comput Environ Urban Syst 74:244–256. https://doi.org/10.1016/j.compenvurbsys.2018.10.008
Griffith DA (1992) What is spatial autocorrelation? Reflections on the past 25 years of spatial statistics. Espac Geogr 21:265–280. https://doi.org/10.3406/spgeo.1992.3091
Haase A, Kabisch S, Steinführer A et al (2010) Emergent spaces of reurbanisation. Popul Space Place 463:443–463
Haase A, Bontje M, Couch C et al (2021) Factors driving the regrowth of European cities and the role of local and contextual impacts: A contrasting analysis of regrowing and shrinking cities. Cities 108:1–16
Hall P (2009) Looking backward, looking forward: The city region of the Mid-21st Century. Reg Stud 43:803–817. https://doi.org/10.1080/00343400903039673
Hall P, Pain K (2006) The Polycentric metropolis: learning from mega-city regions in Europe. Routledge, London
Hamaguchi S (2016) U/I retunr of the young is increasing—how to success? In: ITmedia Bus. https://www.itmedia.co.jp/business/articles/1611/28/news046.html. Accessed 5 Feb 2022
Hanlon B (2008) The decline of older, inner suburbs in metropolitan America. Hous Policy Debate 19:423–456. https://doi.org/10.1080/10511482.2008.9521642
Hartt M (2018) The diversity of north American shrinking cities. Urban Stud 55:2946–2959. https://doi.org/10.1177/0042098017730013
Hashimoto K (2012) Kaikyu Toshi: Kakusa ga Machi wo Shinsyoku Suru (Class Cities: Social stratification eats away the city). Chikuma Shobou, Tokyo
Hierse L, Nuissl H, Beran F, Czarnetzki F (2017) Concurring urbanizations? Understanding the simultaneity of sub-and re-urbanization trends with the help of migration figures in Berlin. Reg Stud Reg Sci 4:189–201. https://doi.org/10.1080/21681376.2017.1351886
Hudalah D, Firman T (2012) Beyond property: Industrial estates and post-suburban transformation in Jakarta Metropolitan Region. Cities 29:40–48. https://doi.org/10.1016/j.cities.2011.07.003
Il LS, Lee M, Chun Y, Griffith DA (2019) Uncertainty in the effects of the modifiable areal unit problem under different levels of spatial autocorrelation: a simulation study. Int J Geogr Inf Sci 33:1135–1154. https://doi.org/10.1080/13658816.2018.1542699
Inglehart R (1997) Modernisation and postmodernisation. Cultural, economic and political change in 43 societies. Princeton University Press, Princeton
Jain M, Jehling M (2020) Urban cycle models revisited: insights for regional planning in India. Cities 107:102923. https://doi.org/10.1016/j.cities.2020.102923
Jedwab R, Christiaensen L, Gindelsky M (2017) Demography, urbanization and development: Rural push, urban pull and … urban push? J Urban Econ 98:6–16. https://doi.org/10.1016/j.jue.2015.09.002
Jiao LM, Liu YL, Zou B (2011) Self-organizing dual clustering considering spatial analysis and hybrid distance measures. Sci China Earth Sci 54:1268–1278. https://doi.org/10.1007/s11430-011-4222-1
Jochem WC, Tatem AJ (2021) Tools for mapping multi-scale settlement patterns of building footprints: an introduction to the R package foot. PLoS ONE 16:1–19. https://doi.org/10.1371/journal.pone.0247535
Jochem WC, Leasure DR, Pannell O et al (2021) Classifying settlement types from multi-scale spatial patterns of building footprints. Environ Plan B Urban Anal City Sci 48:1161–1179. https://doi.org/10.1177/2399808320921208
van de Kaa DJ (1987) Europe’s second demographic transifion. Popul Bull 42:1–55
Kabisch N, Haase D (2011) Diversifying European agglomerations: evidence of urban population trends for the 21st century. Popul Space Place 17:236–253. https://doi.org/10.1002/psp.600
Kabisch N, Haase D, Haase A (2010) Evolving reurbanisation? spatio-temporal dynamics as exemplified by the east german city of leipzig. Urban Stud 47:967–990. https://doi.org/10.1177/0042098009353072
Kabisch N, Haase D, Haase A (2019) Reurbanisation: a long-term process or a short-term stage? Popul Space Place 25:1–13. https://doi.org/10.1002/psp.2266
Kavanagh L, Lee D, Pryce G (2016) Is poverty decentralizing? Quantifying uncertainty in the decentralization of urban poverty. Ann Am Assoc Geogr 106:1286–1298. https://doi.org/10.1080/24694452.2016.1213156
Kim J, Jang S, Kang S, Kim SH (2020) Why are hotel room prices different? Exploring spatially varying relationships between room price and hotel attributes. J Bus Res 107:118–129. https://doi.org/10.1016/j.jbusres.2018.09.006
Klaassen LH, Molle W, Paelinck JHP (1981) Dynamics of urban development. St. Martin’s Press, New York
Kohama F (2017) Gentrification and the spatial polarization in Tokyo:the restructuring of the Kyojima area in Sumida ward. In: Bull Grad Sch Humanit Sociol Rissho Univ, pp 15–42
Koizumi R, Nishiyama H, Kubo T et al (2011) New dimensions of housing acquisition in the Tokyo Bay area: skyscraper condominium residents in Toyosu. Geogr Rev Japan Ser A 84:592–609. https://doi.org/10.16194/j.cnki.31-1059/g4.2011.07.016
Kopczewska K (2022) Spatial machine learning: new opportunities for regional science. Springer, Berlin Heidelberg
Kotkin J (2000) The new geography: how the digital revolution is reshaping the American landscape. Random House, New York
Kourtit K, Nijkamp P (2013) In praise of megacities in a global world. Reg Sci Policy Pract 5:167–182. https://doi.org/10.1111/rsp3.12002
Koutra S, Ioakimidis CS (2023) Unveiling the potential of machine learning applications in urban planning challenges. Land. https://doi.org/10.3390/land12010083
Kroll F, Kabisch N (2012) The relation of diverging urban growth processes and demographic change along an urban-rural gradient. Popul Space Place 18:260–276. https://doi.org/10.1002/psp.653
Kuai X, Wang F (2020) Global and localized neighborhood effects on public transit ridership in Baton Rouge, Louisiana. Appl Geogr 124:1–12. https://doi.org/10.1016/j.apgeog.2020.102338
Kühn M (2015) Peripheralization: theoretical concepts explaining socio-spatial inequalities. Eur Plan Stud 23:367–378. https://doi.org/10.1080/09654313.2013.862518
Lang T (2012) Shrinkage, metropolization and peripheralization in East Germany. Eur Plan Stud 20:1747–1754. https://doi.org/10.1080/09654313.2012.713336
Lee S (2010) Ability sorting and consumer city. J Urban Econ 68:20–33. https://doi.org/10.1016/j.jue.2010.03.002
Leibert T (2016) She leaves, he stays? Sex-selective migration in rural East Germany. J Rural Stud 43:267–279. https://doi.org/10.1016/j.jrurstud.2015.06.004
Lesthaeghe R (2011) The “second demographic transition”: a conceptual map for the understanding of late modern demographic developments in fertility and family formation. Hist Soc Res 36:178–218
Lesthaeghe R (2020) The second demographic transition, 1986–2020: sub-replacement fertility and rising cohabitation—a global update. Genus. https://doi.org/10.1186/s41118-020-00077-4
Li S, Dragicevic S, Castro FA et al (2016) Geospatial big data handling theory and methods: a review and research challenges. ISPRS J Photogramm Remote Sens 115:119–133. https://doi.org/10.1016/j.isprsjprs.2015.10.012
Lin CR, Liu KH, Chen MS (2005) Dual clustering: Integrating data clustering over optimization and constraint domains. IEEE Trans Knowl Data Eng 17:628–637. https://doi.org/10.1109/TKDE.2005.75
Ling W (2017) The Duality of Female Participation to the Labor Market of Contemporary Japan: focusing on the interaction between business culture, family norm, and socio-economic policies. Bull Hannan Univ Hannan Ronshu Soc Sci 52:37–62
Liu C, Deng Y, Song W et al (2019) A comparison of the approaches for gentrification identification. Cities 95:102482. https://doi.org/10.1016/j.cities.2019.102482
Liu X, Kounadi O, Zurita-Milla R (2022) Incorporating spatial autocorrelation in machine learning models using spatial lag and eigenvector spatial filtering features. ISPRS Int J Geo Inform. https://doi.org/10.3390/ijgi11040242
Lutz W, Goujon A et al (2018) Demographic and human capital scenarios for the 21st century: 2018 assessment for 201 countries. European Union, Luxembourg (International Inssitute of Applied System Analysis)
Makkai B, Máté É, Pirisi G, Trócsányi A (2017) Where have all the youngsters gone? the background and consequences of young adults’ Outmigration from Hungarian small towns. Eur Countrys 9:789–807. https://doi.org/10.1515/euco-2017-0044
Markusen AR (1980) City spatial structure, women’s household work, and national urban policy. Signs J Women Cult Soc 5:S23–S44. https://doi.org/10.1086/495709
Martinez-Fernandez C, Audirac I, Fol S, Cunningham-Sabot E (2012a) Shrinking cities: urban challenges of globalization. Int J Urban Reg Res 36:213–225. https://doi.org/10.1111/j.1468-2427.2011.01092.x
Martinez-Fernandez C, Kubo N, Noya A, Weyman T (2012b) Demographic change and local development: shrinkage, regeneration, and social dynamics. OECD
McArthur J (2017) Auckland: rescaled governance and post-suburban politics. Cities 64:79–87. https://doi.org/10.1016/j.cities.2017.01.010
McLachlan GJ, Peel D (2000) Finite mixture models. Wiley, New York
Mikelbank BA (2004) A typology of U.S. suburban places. Hous Policy Debate 15:935–964. https://doi.org/10.1080/10511482.2004.9521527
Mikolov T, Chen K, Corrado G, Dean J (2013) Efficient estimation of word representations in vector space. 1st Int Conf Learn Represent ICLR 2013—Work Track Proc, pp 1–12
MLIT (2006) Basic plans for housing for people (National version)
MLIT (2018) H 30 Annual report on the Tokyo Capital Regiond evelopment (Japanese)
MLIT (2020) White Paper on Land, Infrastructure, Transport and Tourism in Japan, 2020. MLIT, Tokyo
Moos M (2016) From gentrification to youthification? The increasing importance of young age in delineating high-density living. Urban Stud 53:2903–2920. https://doi.org/10.1177/0042098015603292
Nagamatsu N (2010) The changes in the way of work induced by post-industrialization: focusing on the quality of work. Mon J Jpn Inst Labour 666:27–39
Nakano T (2019) Suburban centers in Tokyo metropolis. The University of Tokyo
National Bureau of Statistics of China (2023) National economy withstood pressure and reached a new level in 2022. In: Natl. Bur. Stat. China. http://www.stats.gov.cn/english/PressRelease/202301/t20230117_1892094.html. Accessed 6 Sept 2023
Nelle A (2016) Tackling human capital loss in shrinking cities: urban development and secondary school improvement in Eastern Germany. Eur Plan Stud 24:865–883. https://doi.org/10.1080/09654313.2015.1109611
Ogden PE, Hall R (2004) The second demographic transition, new household forms and the urban population of France during the 1990s. Trans Inst Br Geogr 29:88–105. https://doi.org/10.1111/j.0020-2754.2004.00116.x
Ogden PE, Schnoebelen F (2005) The rise of the small household: demographic change and household structure in Paris. Popul Space Place 11:251–268. https://doi.org/10.1002/psp.370
Ohashi H, Phelps NA (2020) Diversity in decline: the changing suburban fortunes of Tokyo Metropolis. Cities 103:102693. https://doi.org/10.1016/j.cities.2020.102693
Oishi AS (2019) Why did Japanese dual-earner couples increase since the late 1980s? Jpn Labor Issues 3:15–29
Ortman SG, Lobo J, Smith ME (2020) Cities: complexity, theory and history. PLoS ONE. https://doi.org/10.1371/journal.pone.0243621
Paelinck JHP, Klaassen LH (1979) Spatial econometrics. Saxon House, Farnborough
Phelps NA, Wood AM (2011) The new post-suburban politics? Urban Stud 48:2591–2610. https://doi.org/10.1177/0042098011411944
PRIMAFF (2019) Future projections of rural population and agricultural settlements
Qi Y, Shabrina Z (2023) Sentiment analysis using Twitter data: a comparative application of lexicon- and machine-learning-based approach. Soc Netw Anal Min 13:1–14. https://doi.org/10.1007/s13278-023-01030-x
Rahimi S, Mottahedi S, Liu X (2018) The geography of taste: using yelp to study urban culture. Int J Geo Inform. https://doi.org/10.3390/ijgi7090376
Rauhut D, Littke H (2016) “A one way ticket to the city, please!” on young women leaving the Swedish peripheral region Västernorrland. J Rural Stud 43:301–310. https://doi.org/10.1016/j.jrurstud.2015.05.003
Raymo J, Fukuda S (2016) The rise of female participation to Japanese labor market: the role of behavioral changes in getting married. Mon J Jpn Inst Labour 674:
Real Estate Economic Institute (2022) The 2021 summary of the new apartment markets in Tokyo. https://www.fudousankeizai.co.jp/share/mansion/493/s2021.pdf. Accessed 4 Feb 2021
Recruit (2020) The 2019 report on the new apartment buyers in Tokyo
Rérat P (2019) The return of cities: the trajectory of Swiss cities from demographic loss to reurbanization. Eur Plan Stud 27:355–376. https://doi.org/10.1080/09654313.2018.1546832
Rouwendal J, Van Der SJW (2004) Dual earners, urban labour markets and housing demand. In: Capello R, Nijkamp P (eds) Urban dynamics and growth: udvances in urban economics Amsterdam, pp 249–283
Salvati L, Carlucci M (2016) In-between stability and subtle changes : urban growth, population structure, and the city life cycle in rome. Popul Space Place 227:216–227
Sampson RJ (2019) Neighbourhood effects and beyond: explaining the paradoxes of inequality in the changing American metropolis. Urban Stud 56:3–32. https://doi.org/10.1177/0042098018795363
Sarzynski A, Vicino TJ (2019) Shrinking suburbs: analyzing the decline of American suburban spaces. Sustainability. https://doi.org/10.3390/su11195230
Scott AJ (2019) City-regions reconsidered. Environ Plan A 51:554–580. https://doi.org/10.1177/0308518X19831591
Scrucca L, Fop M, Murphy TB, Raftery AE (2016) Mclust 5: Clustering, classification and density estimation using Gaussian finite mixture models. R J 8:289–317. https://doi.org/10.32614/rj-2016-021
Serra P, Vera A, Tulla AF (2014) Spatial and Socio-environmental dynamics of Catalan regional planning from a multivariate statistical analysis using 1980s and 2000s data. Eur Plan Stud 22:1280–1300. https://doi.org/10.1080/09654313.2013.782388
Siedentop S, Zakrzewski P, Stroms P (2018) A childless urban renaissance? Age-selective patterns of population change in north american and german metropolitan areas. Reg Stud Reg Sci 5:1–20. https://doi.org/10.1080/21681376.2017.1412270
Silverman RM (2020) Rethinking shrinking cities: peripheral dual cities have arrived. J Urban Aff 42:294–311. https://doi.org/10.1080/07352166.2018.1448226
Smith N (1996) The new urban frontier: gentrification and the revanchist city. Routledge, New York
Sorensen A (2019) Tokaido Megalopolis: lessons from a shrinking mega-conurbation. Int Plan Stud 24:23–39. https://doi.org/10.1080/13563475.2018.1514294
Statistics Bureau of Japan (2023) Population Estimates (March 2023 Final Figures, August 2023 Estimates) (Announced on August 21, 2023). In: Stat. Bur. Japan. https://www.stat.go.jp/data/jinsui/new.html. Accessed 6 Sept 2023
Statistics Korea (2023) 2022 Population and Housing Census (Register-based Census). In: Stat. Korea. https://kostat.go.kr/board.es?mid=a20108010000&bid=11747&act=view&list_no=426676&tag=&nPage=1&ref_bid=11742,11743,11744,11745,11746,11747,11748,11749,11773,11774,11750&keyField=&keyWord=
Suzuki M, Asami Y (2019) Shrinking Metropolitan Area: costly homeownership and slow spatial shrinkage. Urban Stud 56:1113–1128. https://doi.org/10.1177/0042098017743709
Sweeney G, Hanlon B (2017) From old suburb to post-suburb: the politics of retrofit in the inner suburb of Upper Arlington, Ohio. J Urban Aff 39:241–259. https://doi.org/10.1111/juaf.12313
Swinth K (2018) Post-family wage, postindustrial society: reframing the gender and family order through working mothers in Reagan’s America. J Am Hist 105:311–335. https://doi.org/10.1093/jahist/jay146
Szmytkie R (2021) The cyclical nature of the territorial development of large cities : a case study of Wrocław (Poland). J Urban Hist 47:771–793. https://doi.org/10.1177/0096144219877866
Tano S, Nakosteen R, Westerlund O, Zimmer M (2018) Youth-age characteristics as precursors of power couple formation and location choice. Labour Econ 52:98–111. https://doi.org/10.1016/j.labeco.2018.04.005
Tao J, Shu N, Wang Y et al (2016) A study of a Gaussian mixture model for urban land-cover mapping based on VHR remote sensing imagery. Int J Remote Sens 37:1–13. https://doi.org/10.1080/2150704X.2015.1101502
Tateishi E, Takahashi K, Nakano T (2021) Governance reaction to the emerging megacity shrinkage in Tokyo: the case of the Tsukuba express transit-suburban region. Cities. https://doi.org/10.1016/j.cities.2020.103033
The Science Council of Japan (2017) For sustainable and systematic regional development in Japan in an era of declining population
Tobler WR (1970) A computer movie simulating Urban growth in the detroit region. Econ Geogr 46:234–240. https://doi.org/10.1126/science.ns-13.332.462
Tokyo Kantei (2022) Tokyo Kantei press release: the number of stocks of high-rise condominiums by prefecture 2022 January 31. Tokyo
Tse RYC (2002) Estimating Neighbourhood effects in house prices: towards a new hedonic model approach. Urban Stud 39:1165–1180. https://doi.org/10.1080/0042098022013554
UN (2018a) World urbanization prospects the 2018 revision. United Nations (UN) Department of Economic and Social Affairs Population Division, New York
UN (2018b) The World’s Cities in 2018. New York
UN-Habitat (2010) State of the world’s cites 2010/2011: bridging the urban divide. UN-Habitat, New York
Vargas-Calderón V, Camargo JE (2019) Characterization of citizens using word2vec and latent topic analysis in a large set of tweets. Cities 92:187–196. https://doi.org/10.1016/j.cities.2019.03.019
Vollset SE, Goren E, Yuan CW et al (2020) Fertility, mortality, migration, and population scenarios for 195 countries and territories from 2017 to 2100: a forecasting analysis for the Global Burden of Disease Study. Lancet. https://doi.org/10.1016/S0140-6736(20)30677-2
Waggoner PD (2020) Unsupervised machine learning for clustering in political and social research. Cambridge University Press, New York
Wang J, Biljecki F (2022) Unsupervised machine learning in urban studies: a systematic review of applications. Cities 129:103925. https://doi.org/10.1016/j.cities.2022.103925
Weaver R, Bagchi-Sen S, Knight J, Frazier AE (2017) Shrinking cities: understanding urban decline in the United States. Routledge, New York
Weck S, Beißwenger S (2014) Coping with peripheralization: governance response in two German small cities. Eur Plan Stud 22:2156–2171. https://doi.org/10.1080/09654313.2013.819839
Wiest K (2016) Migration and everyday discourses: peripheralisation in rural Saxony-Anhalt from a gender perspective. J Rural Stud 43:280–290. https://doi.org/10.1016/j.jrurstud.2015.03.003
Wilson WJ (1987) The truly disadvantaged: the inner city, the underclass, and public policy. University of Chicago Press, Chicago
Wolff M (2018) Understanding the role of centralization processes for cities—Evidence from a spatial perspective of urban Europe 1990–2010. Cities 75:20–29. https://doi.org/10.1016/j.cities.2017.01.009
Wolff M, Wiechmann T (2018) Urban growth and decline: Europe’s shrinking cities in a comparative perspective 1990–2010. Eur Urban Reg Stud 25:122–139. https://doi.org/10.1177/0969776417694680
Xiao T, Wan Y, Jin R et al (2022) Integrating Gaussian mixture dual-clustering and DBSCAN for exploring heterogeneous characteristics of urban spatial agglomeration areas. Remote Sens. https://doi.org/10.3390/rs14225689
Xue F, Lu W, Chen Z, Webster CJ (2020) From LiDAR point cloud towards digital twin city: clustering city objects based on Gestalt principles. ISPRS J Photogramm Remote Sens 167:418–431. https://doi.org/10.1016/j.isprsjprs.2020.07.020
Yajima T, Ieda H (2015) Global City Tokyo: The city built by transit network (Japanese), 2nd edn. The Institute of Behavioral Sciences, Tokyo
Yamada M (2014) Kazoku nanmin (Family Refugees). Asahi Shinbun Shuppan, Tokyo
Yuan J, Beard K, Johnson TR (2021) A quantitative assessment of spatial patterns of socio-demographic change in coastal Maine: one process or many? Appl Geogr 134:102502. https://doi.org/10.1016/j.apgeog.2021.102502
Funding
Open access funding provided by Malmö University.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
I, E. Tateishi as the sole author of this manuscript, hereby declare that I have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this manuscript.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix

There will be 29 Asian megacities (yellow) out of 48 megacities in the world by 2035. Out of these 29 Asian megacities, 17–27 of them will be situated in Asian countries whose national population is projected to lose by at least 10% up to more than 50%. Across megacities in the (future) population-shrinking countries, 74–79% of them are Asian megacities. Hence, a quick decline in the national population will be the most salient, albeit not unique, socio-demographic context of Asian megacities in the coming decades. (Source: own elaboration based on (UN 2018b; Lutz and Goujon et al. 2018; Vollset et al. 2020))

Map displaying the small and surrogate areas showing the TOP 6 cluster-transition categories (yellow, N = 23,226). The areas outside of the TOP 6 and invalid clustering results (grey) and not-habitable areas (red) were excluded. The selected areas cover about 76.5% of all valid-clustering areas (record base). (Source: own elaboration)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tateishi, E. The spatiotemporal socio-demography of the Tokyo capital region: a data-driven explorative approach. Rev Reg Res 43, 467–519 (2023). https://doi.org/10.1007/s10037-023-00198-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10037-023-00198-1