
Abstract
This article proposes a novel children–computer interaction (CCI) approach for the task of age group detection. This approach focuses on the automatic analysis of the time series generated from the interaction of the children with mobile devices. In particular, we extract a set of 25 time series related to spatial, pressure, and kinematic information of the children interaction while colouring a tree through a pen stylus tablet, a specific test from the large-scale public ChildCIdb database. A complete analysis of the proposed approach is carried out using different time series selection techniques to choose the most discriminative ones for the age group detection task: (i) a statistical analysis and (ii) an automatic algorithm called sequential forward search (SFS). In addition, different classification algorithms such as dynamic time warping barycenter averaging (DBA) and hidden Markov models (HMM) are studied. Accuracy results over 85% are achieved, outperforming previous approaches in the literature and in more challenging age group conditions. Finally, the approach presented in this study can benefit many children-related applications, for example, towards an age-appropriate environment with the technology.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Children’s exposure to mobile devices has increased dramatically in recent decades due to technological innovation [21]. They are growing up in environments overloaded with multiple digital technologies such as smartphones, tablets, and smart TVs, among others. In addition, parents often let their children use mobile devices to keep them calm in public places, after school homework or household chores, and at bedtime before going to sleep [12]. As a result, the average daily usage of mobile devices in children aged 0–8 years has increased over 11 times from 2011 to 2020 [22].

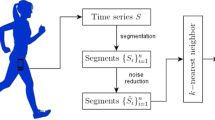
Architecture of the proposed approach to detect the children’s age group through the interaction of the children with mobile devices and the automatic analysis of the time series generated. Blue dashed arrows represent the different configurations studied in this article in terms of time series and classification. First, children perform the input stage by colouring a tree on a tablet device using a stylus as an acquisition tool (Drawing Test). Next, time series extraction and selection are performed. Finally, to predict the children’s age group, two different classifiers are tested independently: DBA and HMM
Recent studies in the literature highlight how the correct use of mobile devices can positively affect children’s development and learning (e.g. through educational games or creative applications [14]). For example, Huber et al. conducted a study in [10] in which children learned to solve the popular game “Tower of Hanoi” using a touchscreen device and subsequently apply this learning with a physical replica of the game. The results concluded that, for certain activities, children are quite capable of transferring learning from touchscreen devices to real-life problems. Language enhancement through mobile interaction games was also studied in [8]. In that work, children aged 4 years played with an interactive word-learning application on a mobile device. The experiments concluded that children who played with the application gained a receptive and expressive understanding of the target words. With respect to self-regulation development, an interesting study was presented in [11]. The authors reported that when children from 2 to 3 years old played with an educational app for an appropriate amount of time, their self-regulation scores were higher than, for example, after exposure to watching cartoons on TV.
However, intensive and unsupervised exposure to digital devices in childhood can also be associated with adverse effects on growth (e.g. learning, self-regulation, well-being, social–emotional skills, sleep, media addiction, etc.). For example, Bozzola et al. stated in [2] that excessive touchscreen use can affect children’s correct development due to the lack of real experiences that challenge their thinking and problem-solving skills. Another interesting work in this line was presented in [4]. The authors analysed the correlation between tablet use and physical discomforts, such as headaches and neck and shoulder pain. The results revealed that poor posture while using tablets significantly reduces the flexion angles of the head and neck. As a result, correct posture is essential for children’s well-being. The associations between children’s socio-emotional development and mobile media use were explored in [21]. Results showed that children with social–emotional difficulties are more likely to be given mobile devices as a calming tool. Similar conclusions were obtained in [20], stating that one of the reasons for children having self-regulation difficulties (e.g. self-control, sleep, emotional regulation, and attention) is related to high media exposure at 2 years old. The effect of children mobile interaction on the sleep quality was also studied in [3]. In that work, the authors showed how increased exposure to media devices in the bedroom during childhood can reduce sleep duration by forming long-lasting habits that lead to significant sleep deficits. Finally, Csibi et al. analysed in [5] the risk of smartphone addiction in different age groups and concluded that children and young adults are at the highest risk of addictive behaviour. Smartphone addiction can negative affect children’s mental health, well-being, and academic performance [24].
All in all, the interaction of children with mobile devices can have both positive and negative effects, depending on the scenario considered. As a result, it seems critical to provide an age-appropriate environment for children (e.g. limiting exposure time to devices depending on the age, assisting children with specific touch input, preventing access to age-inappropriate applications or websites, etc.) in order to improve their development and creative skills, among others [10, 14]. This is specially important as more and more children are exposed to mobile devices for longer time and at a younger age.
This study aims to advance in this research line by presenting a novel approach for the task of children age group detection based on the automatic analysis of time series (commonly known as local features [16]) generated from the interaction of the children with mobile devices.
The main contributions of the present work are:
-
An in-depth analysis of state-of-the-art approaches for the task of children age group detection through their interaction with mobile devices, remarking key public databases and results.
-
Proposal of a novel children–computer interaction (CCI) approach for the task of age group detection. This approach focuses on the automatic analysis of the time series generated from the interaction of the children with mobile devices. In particular, our proposed approach extracts a set of 25 time series related to spatial, pressure, and kinematic information of the children interaction while colouring a tree through a pen stylus on a tablet device. Figure 1 shows the graphical architecture of the proposed approach.
-
A complete analysis of the proposed approach is carried out using two different feature selection techniques to choose the most discriminative ones for the age group detection task: i) a statistical analysis and ii) an automatic algorithm called sequential forward search (SFS). In addition, different classification algorithms such as DTW barycenter averaging (DBA) and hidden Markov models (HMM) are studied.
-
Our proposed approach achieves accuracy results over 85%, outperforming previous approaches in the literature and in more challenging age group conditions. Finally, the approach presented in this study can benefit many children-related applications, for example, towards an age-appropriate environment with the technology.
The remainder of the article is organized as follows. Section 2 presents an overview of recent works studying different approaches for the task of children age group detection through mobile computer interaction. Section 3 describes the database used in the experimental work of this study. In Sect. 4, we present the time series and selection techniques, and the classification algorithms considered. Section 5 describes the experimental protocol and results obtained for the task of children age group detection, as well as a comparison with the state of the art. Finally, Sect. 6 presents the conclusions and future research lines.
2 Related works
In the existing literature, different studies have evaluated the age detection of children through their interaction with mobile devices. Table 1 shows a comparison of the most relevant studies ordered by date. Most studies have focused on the detection of two age groups: children from adults. Vatavu et al. released in [31] a dataset comprising smartphone touch interaction data from 30 adults and 89 children aged 3–6 years. In that work, the authors achieved 86.5% accuracy in detecting children from adults using a set of features extracted from touch spatial coordinates x and y. Vera-Rodriguez et al. also considered this database in their experimental protocol [32]. They presented a set of neuromotor skill features to detect children from adults. Results showed the discriminative ability of the proposed system with correct classification rates over 96%. An interesting article in this line was presented by Li et al. [15]. The study aimed to investigate the different screen-touch patterns between children and adult users. Experiments were carried out using 17 children (3 to 11 years) and 14 adults (22 to 60 years), achieving 97% accuracy for child–adult detection using only a single finger and 8 consecutive swipes on the touch screen.
A different approach was presented by Nguyen et al. in [18]. In that work, the authors tried to predict if a child or an adult is using a smartphone based on behavioural differences extracted from the touchscreen and built-in sensors (accelerometer and gyroscope). An accuracy over 99% was achieved after 5 s of sensor reading or 8 consecutive touch gestures. Similar conclusions were obtained by Davarci et al. in [6], where rates over 92% were achieved in detecting children from adults based only on accelerometer data.
The user interaction with mobile devices is not only studied with the finger as input but also using a stylus [25, 29]. In line with the task of children and adults detection, Kim et al. proposed in [13] a sketch recognition system able to assess children’s developmental skills from their sketches created with a stylus on a tablet. In total, 20 children (3 to 8 years) and 4 adults participated in the study. Two main significant differences between children and adults were found: (i) the stroke lengths of adults’ sketches were larger, and (ii) adults took less time to draw sketches.
Focusing on the stylus scenarios, only a few recent studies go one step further in the task of children age group detection, trying to detect the children’s age group rather than just differentiating them from adults. Tolosana et al. released in [30] a public database called ChildCIdb, including over 400 children aged 18 months to 8 years interacting with mobile devices (stylus and finger). The authors grouped the children into 3 age groups without overlap: 1 to 3 years, 3 to 6 years, and 6 to 8 years. Accurate results were obtained between different children age groups (over 90% accuracy) by analysing only one task in which children had to colour a tree using a stylus. It is important to highlight that the children age group approach was based on a set of 148 global features, not time series analysis as in this study. Ruiz-Garcia et al. obtained similar conclusions in [23], where authors also considered ChildCIdb as an experimental database. They analysed the correlation between children’s chronological age and their motor and cognitive development while interacting with all the tests included in ChildCIdb. Children were grouped into the same three age groups considered in [30]. Good results above 93% accuracy were achieved in the age group detection task by combining three different ChildCIdb tests (i.e. Drag and Drop, Spiral Test, and Drawing Test), using both stylus and finger as input.
In the present article, we propose a novel children age group detection based on the automatic analysis of time series, different compared with previous approaches in the literature (based on global features). In addition, and as we have seen along this section, most studies in the literature focus on detecting children from adults or grouping children in wide age groups. We go deeper by performing a more complex task: detecting the age group of the children based on their educational level (7 different groups in ChildCIdb [26]), i.e. one-year precision. Table 2 shows the relationship between children’s age range and their educational level groups based on the Spanish education system.
3 Database: ChildCIdb
The experimental work of this study considers the public ChildCIdb database. Tolosana et al. presented in [30] the first version of this database (ChildCIdb_v1Footnote 1). ChildCIdb is an ongoing CCI database collected in collaboration with the school GSD Las Suertes in Madrid (Spain). This database is planned to be extended yearly to enable longitudinal studies. The first version contains children interaction using both finger and stylus. In total, it comprises 438 children aged from 18 months to 8 years, grouped in 7 different educational levels according to the Spanish education system. In particular, 6 different tests are considered in ChildCIdb, grouped in 2 main blocks: (i) touch and (ii) stylus. All tests were designed considering many of the cognitive and neuromuscular aspects highlighted in the state of the art, e.g. the evolution of children’s gestures with age. In addition, tests were discussed and approved by neurologists, child psychologists, and educators of the GSD school. The database also considers other children’s interesting information such as grades at school, previous experience using mobile devices, attention deficit/hyperactivity disorder (ADHD), prematurity (under 37 weeks gestation), and birthday, among other things. In the present study we focus on the analysis of the time series generated in Test 6 (Drawing Test) of ChildCIdb, in which children have to colour a tree using a pen stylus as good as they can and a maximum time of 2 min. We select this test as children have a high degree of freedom to show their motor and cognitive development skills.
In this study, we consider an extension of the current ChildCIdb_v1 database, including two more acquisition sessions in time. The first one was captured in May 2021 and 376 children participated in the acquisition, adding new young children (18 months). In addition, children who participated in the first version of the database were also acquired again but this time they belong to the next educational level as one year passed since the first acquisition. Children who moved to a higher educational level than the last considered in ChildCIdb (over 8 years old) were excluded from the acquisition. The second acquisition was captured in October 2021 and involved 315 children (similar trend as described before). This extension of ChildCIdb comprises in total 502 different children’s metadata and, in total, 1,129 samples of children interaction with mobile devices. Table 3 describes the total number of samples collected for each age group. Finally, for completeness, a set of 70 adults aged 25–65 years with fully developed motor and cognitive skills was also captured. This set is not considered in the present work but could be used in future research.
4 Age group detection: proposed approach
This section describes our proposed approach for the task of children age group detection based on the automatic analysis of the time series generated while children colouring a tree, i.e. the Drawing Test of the ChildCIdb database. Figure 1 provides a graphical representation of the proposed approach. We describe next the details of each module. Section 4.1 shows the time series extracted from the Drawing Test. Section 4.2 provides the main details of the classification algorithms and metrics studied. Finally, Sect. 4.3 describes the time series selection techniques considered in this study.
4.1 Time series extraction
Each time a child performs the Drawing Test, a set of 6 time series is captured by the tablet device containing the following information: x and y spatial coordinates, whether the child is colouring inside the tree or not, the pressure performed on the screen using the stylus, time stamp, and type of action performed (pen-down or pen-up). Taking this as a starting point, we extract a set of 25 total time series related to velocity, acceleration, pressure, and stylus position, among others. In particular, 21 time series are based on previous studies on handwriting and signature biometric recognition [26], and the remaining 4 presented in this work are related to stylus pressure and position information. Table 4 shows the final set of time series considered in this study.
4.2 Classifiers and metrics
4.2.1 Metrics
We consider 2 metrics to measure the results achieved in the task of children age group detection:
-
Accuracy (%): this metric measures the overall accuracy of the classification system by taking into account only whether the predicted age group of a child is the same as the real one (label).
-
Age Group Distance (AGD): this metric measures the absolute distance between the real age group of a child (label) and the predicted one.
4.2.2 Classification algorithms
In total, 2 different classifiers are studied as part of our experimental framework. The optimal configuration parameters for each of them depend on the time series selection technique used (Sect. 4.3).

Statistical analysis + DBA: average DTW distance calculated for each time series considered. The green line refers to the 70th percentile of DTW distance. We highlight in dark blue the selected time series (colour figure online)
-
DTW barycenter averaging (DBA): this algorithm generates for each time series and age group the template/prototype that best represent that time series in that specific age group. As a result, we have 175 prototypes in total (one for each age group, 7, and time series type, 25). DBA computes each prototype by minimizing the dynamic time warping (DTW) distance between the extracted time series of the same type and all children of the same age group. Classification is performed by comparing the extracted time series of an input test with each of the generated prototypes, giving as output the age group associated with the smallest DTW distance. The specific implementation considered in this study was presented by Petitjean et al. in [19].
-
Hidden Markov model (HMM): this algorithm represents a dual stochastic process, governed by an underlying Markov chain with a finite number of states (N) and a random set of symbol-generating functions (M), each associated with one state. In contrast to DBA, which is an elastic distance algorithm, HMM is a statistical algorithm. In particular, an HMM model is generated for each age group. HMM models have been widely used in the field of speech recognition and signature verification using time series with accurate results [9, 27, 28]. The classification is done by obtaining the probability that the child behaves like most children in that age group. In other words, each child is assigned the age group associated with the most similar HMM model. In our experiments, the configuration parameters N and M of the HMM models depend on the time series selection technique used. The specific implementation considered in this study is publicly available in HMM-Learn toolbox.Footnote 2
4.3 Time series selection techniques
The following time series selection techniques are studied to choose the most discriminative time series from the 25 total time series considered in the present study:
-
Statistical Analysis: a different statistical analysis of the time series has been conducted according to the classification algorithm used. Focusing on DBA, for each prototype extracted for each time series, we first calculate the DTW distance with respect to the rest of prototypes of the same time series but from different age groups in order to see the discriminative power of that time series with respect to all the age groups (inter-class variability). A similar analysis is carried out for HMM models but using AGD.
-
Sequential forward search (SFS): this is a widely used feature selection algorithm that automatically selects an optimal feature subset (time series subset in this case) from the original set using a specific optimization criteria (AGD in this study). In particular, SFS offers a suboptimal solution because it does not take into account all possible combinations, but it does consider correlations between features. The specific implementation considered in this study is publicly available in Scikit-Learn.Footnote 3
5 Experiments and results
5.1 Experimental protocol
The experimental protocol considered has been designed to detect the age group of the children based on their educational level through the analysis of their interactions with mobile devices. In particular, 7 age groups are considered according to the Spanish education system as we can see in Table 2. ChildCIdb is divided into development (80% of the children) and evaluation (20% remaining children) datasets, where children in each age group are equally distributed in number and gender to allow an objective comparison of the results obtained. In addition, the development dataset is divided in 2 different subsets: training (80%) and validation (20%) datasets. During the development stage, the children considered in the evaluation dataset are excluded. Only the training subset is used to train the different age group detection systems, while the validation subset is used to test their performance. Finally, the final evaluation dataset is used to test the age group detection systems under realistic conditions, considering children unseen during the development stage. All experiments are run on a machine with an Intel i7-9700 processor and 32GB of RAM.
5.2 Experimental results
5.2.1 Time series selection
This section analyses which are the most discriminative and robust time series for each classification algorithm considered, using both SFS and statistical analysis selection techniques. For this purpose, we only consider the training and validation datasets. The following 4 cases are studied:

Statistical analysis + HMM: results achieved using different HMM parameters. We highlight in brown the configuration with the best performance (colour figure online)

Statistical analysis + HMM: average AGD achieved for each time series considered. The green line refers to the 70th percentile of average AGD. We highlight in brown the selected time series (colour figure online)
-
Statistical Analysis for DBA: we create 7 prototypes (one for each age group) for each time series using DBA. Then, for each time series, we calculate the DTW distance between the 7 age groups using the corresponding prototypes (inter-class variability). The higher the average DTW distance is, the higher the discriminative power of that time series will be to detect different age groups. We select those time series whose average DTW distance is above the 70th percentile (see Fig. 2).
-
Statistical Analysis for HMM: first, we create a single HMM model and consider different HMM parameter configurations using all the time series. The HMM parameters with the best performance (lowest average AGD) in the validation dataset are N=32 and M=16 (see Fig. 3). Then, we generate a new HMM model for each time series, and finally, we calculate the average AGD for the task of children age group detection. The lower the average AGD is, the higher the discriminative power of that time series will be. We select those time series whose average AGD is in the 70th percentile (see Fig. 4).
-
SFS Algorithm for DBA: first, SFS selects the time series with the highest discriminative power (lowest AGD). Then, SFS selects the time series that obtains the lowest AGD by performing combinations of 2. This procedure is performed successively until the result on the validation dataset gets worse. Figure 5 provides a graphical representation of the development stage. The best performance of the system is achieved with 8 time series (\(v^r\), i, \(\theta \), \(x'\), \(y''\), \(\theta '\), a, \(\alpha '\)).
-
SFS Algorithm for HMM: the same procedure described before is applied to HMM. The HMM parameters with the best performance in the validation dataset are N=64 and M=8. The best performance of the system (Fig. 5) is achieved with 9 time series (t, \(r^7\), z, \(x''\), \(z'\), x, y, \(\theta '\), \(p'\)).

SFS algorithm for DBA and HMM: average AGD achieved for DBA and HMM during the execution of SFS in the development stage (training + validation)
5.2.2 Results
This section analyses the performance achieved on the final evaluation dataset for the task of children’s age group detection, considering the optimal configurations described in the previous section. Table 5 shows the results achieved in terms of accuracy (%) and average AGD (distance measured in age groups). For completeness, we show in Fig. 6 the average AGD obtained for each age group and classification algorithm considered.
Focusing first on DBA, it seems that using prototypes for representing each age group of children is not an accurate approach. On the one hand, the time series selection technique used (i.e. Statistical Analysis or SFS) does not greatly affect the results obtained. In terms of accuracy (%), the best result achieved is 33.19%. On the other hand, focusing on the average AGD, although the DBA system is not able to detect correctly the age group, the distance between the label and the predicted class is not so bad (average AGD of 0.99 age groups for the SFS approach, i.e. average distance lower than one group). This aspect can be better observed in Fig. 6. It seems that the higher average AGD values happen with the intermediate groups (4 to 6). We believe this can be produced due to at these educational levels children face a developmental stage full of multiple educational changes and learning phases. In particular, children in group 3 have just moved from nursery school to preschool and those in group 6 are about to move from preschool to primary education. This generates challenges in classification.
Analysing the HMM system, we can see in Table 5 that different results are achieved depending on the time series selection technique. The SFS approach outperforms the statistical analysis in terms of accuracy (85.39% vs. 75.22%) and average AGD (0.17 vs. 0.31). Again, as shown in Fig. 6, the intermediate groups are also the most challenging ones for the HMM models. Nevertheless, HMM models obtain a very low average AGD, with less than 0.2 age groups. Hence, HMM seems to be an accurate statistical approach to model the children patterns in the time domain by exploiting the correlation of the chosen time series.

Average AGD achieved for each of the age groups, classification algorithms, and time series selection techniques in the final evaluation dataset of ChildCIdb
5.2.3 Comparison with the state of the art
Finally, we compare the results obtained with the state of the art. It is important to remark that, as indicated in Table 1 of the article, a direct comparison with previous studies in the literature is not feasible as different tasks, databases, and experimental protocols are usually considered. Nevertheless, and although the tasks considered in previous studies are simpler (e.g. detecting children from adults), we include them for a better understanding of the results achieved with our proposed approach. For example, in [32] the authors obtained an accuracy of 93% on the task of detecting children from adults using an automatic detection system based on finger touch interaction. Similar results were achieved by Vatavu et al. in [31], over 80%, using a feature set extracted from the interaction of adults and children on mobile devices.
It is also interesting to compare the results achieved in the present work with our previous approach [30] focusing on the same Drawing Test, although a simpler task was considered. Concretely, we considered 3 age groups (i.e. 1–3 years, 3–6 years, and 6–8 years) instead of the 7 age groups considered in the present article (i.e. one for each educational level as indicated in Table 2). In [30], we presented an approach based on 148 global features. We achieved results above 90% accuracy on the children age group detection task. This approach based on global features presented a less discriminative way of detecting the age group associated with a child than the approach proposed in the present article based on the analysis of the complete realization process of the Drawing Test through the time signals. The present approach (local features or time series) captures more detailed patterns of children’s interaction, allowing us to consider a more challenging scenario in which to detect each educational level of children (7 possible groups). For completeness, we include in Table 6 a comparison between the results obtained using the proposed approach (local features) and the previous one presented in [30] (global features) focusing on the same task, i.e. detection of the 7 possible age groups of children. To obtain the results using the global features approach, we consider the best configuration obtained in [30]. Therefore, comparing the results obtained in the present work (accuracy results over 85% and average AGD of 0.17 age groups) with the results achieved by using the global features approach (30.09% accuracy and average AGD of 1.62 age groups), we can conclude that the automatic analysis of the time series (local features) generated while colouring the tree provides much more discriminative information of the children age group compared with approach based on the global features considered in [30].
Finally, the results achieved in this study prove the high potential of combining CCI and automatic analysis of time series for the task of children age group detection. This can benefit many children-related applications, for example, towards an age-appropriate environment with the technology.
6 Conclusion and future work
This study proposes a novel children–computer interaction (CCI) approach for the task of children age group detection in order to benefit many children-related applications, for example, towards an age-appropriate environment with the technology. In particular, we have focused on the automatic analysis of the time series generated from the interaction of children with mobile devices. We have focused on a specific test of ChildCIdb, Drawing Test, where children have to colour a tree over a pen stylus tablet. After that, we extract 25 total time series related to spatial, pressure, and kinematic information.
Our proposed approach has been studied using two different time series selection techniques to choose the most discriminative ones: (i) a statistical analysis and (ii) an automatic feature selection algorithm called sequential forward search (SFS). In addition, two classification algorithms have been considered for the task of children age group detection: (i) DTW barycenter averaging (DBA) and (ii) hidden Markov models (HMM).
Analysing the results obtained, our proposed HMM + SFS approach has achieved better accuracy results for the task of children age group detection (7 possible groups) compared to previous studies in the literature, which focused on global features by considering simpler tasks such as detecting children from adults or group children in only 3 age groups. In particular, the proposed approach achieves an average AGD lower than 0.2 age groups and accuracy over 85%. These results prove the high potential of combining an innovative approach based on CCI and automatic analysis of time series (local features) for the task of children age group detection.
Future works will be oriented to: (i) a longitudinal analysis of the children, studying the motor and cognitive evolution of them through the interaction with the tests of ChildCIdb, (ii) consider the ChildCIdb database in other areas of e-Health and e-Learning, for example in terms of privacy [7, 17], and (iii) analyse the relationship of children’s metadata (grades, ADHD, prematurity, etc.) to their interaction with mobile devices.
References
Acien, A., Morales, A., Fierrez, J., et al.: Active detection of age groups based on touch interaction. IET Biom. 8(1), 101–108 (2019). https://doi.org/10.1049/iet-bmt.2018.5003
Bozzola, E., Spina, G., Ruggiero, M., et al.: Media devices in pre-school children: the recommendations of the Italian pediatric society. Ital. J. Pediatr. 44(1), 69 (2018). https://doi.org/10.1186/s13052-018-0508-7
Cespedes, E., Gillman, M., Kleinman, K., et al.: Television viewing, bedroom television, and sleep duration from infancy to mid-childhood. Pediatrics 133, e1163 (2014). https://doi.org/10.1542/peds.2013-3998
Chiang, H.A., Liu, C.H.: Exploration of the associations of touch-screen tablet computer usage and musculoskeletal discomfort. Work 53(4), 917–925 (2016). https://doi.org/10.3233/WOR-162274
Csibi, S., Griffiths, M.D., Demetrovics, Z., et al.: Analysis of problematic smartphone use across different age groups within the components model of addiction. Int. J. Ment. Health Addict. 19(3), 616–631 (2021). https://doi.org/10.1007/s11469-019-00095-0
Davarci, E., Soysal, B., Erguler, I., et al.: Age group detection using smartphone motion sensors. In: Proceeding European Signal Processing Conference (EUSIPCO), pp. 2201–2205 (2017). https://doi.org/10.23919/EUSIPCO.2017.8081600
Delgado-Santos, P., Stragapede, G., Tolosana, R., et al.: A survey of privacy vulnerabilities of mobile device sensors. ACM Comput. Surv. 54(11), 1–30 (2022). https://doi.org/10.1145/3510579
Dore, R.A., Shirilla, M., Hopkins, E., et al.: Education in the app store: using a mobile game to support us preschoolers vocabulary learning. J. Child. Med. 13(4), 452–471 (2019). https://doi.org/10.1080/17482798.2019.1650788
Fahad, M.S., Deepak, A., Pradhan, G., et al.: DNN-HMM-based speaker-adaptive emotion recognition using MFCC and epoch-based features. Circuits Syst. Signal Process. 40(1), 466–489 (2021). https://doi.org/10.1007/s00034-020-01486-8
Huber, B., Tarasuik, J., Antoniou, M.N., et al.: Young children’s transfer of learning from a touchscreen device. Comput. Hum. Behav. 56, 56–64 (2016). https://doi.org/10.1016/j.chb.2015.11.010
Huber, B., Yeates, M., Meyer, D., et al.: The effects of screen media content on young children’s executive functioning. J. Exp. Child Psychol. 170, 72–85 (2018). https://doi.org/10.1016/j.jecp.2018.01.006
Kabali, H.K., Irigoyen, M.M., Nunez-Davis, R., et al.: Exposure and use of mobile media devices by young children. Pediatrics 136(6), 1044–1050 (2015). https://doi.org/10.1542/peds.2015-2151
Kim, H.H., Taele, P., Valentine, S., et al.: KimCHI: a sketch-based developmental skill classifier to enhance pen-driven educational interfaces for children. In: Proceeding International Symposium on Sketch-Based Interfaces and Modeling, pp. 33–42 (2013). https://doi.org/10.1145/2487381.2487389
Lawrence, A., Choe, D.E.: Mobile media and young children’s cognitive skills: a review. Acad. Pediatr. 21(6), 996–1000 (2021). https://doi.org/10.1016/j.acap.2021.01.007
Li, X., Malebary, S., Qu, X., et al.: ICare: automatic and user-friendly child identification on smartphones. In: Proceeding 19th International Workshop on Mobile Computing Systems & Applications, pp. 43–48 (2018). https://doi.org/10.1145/3177102.3177119
Martinez-Diaz, M., Fierrez, J., Krish, R.P., et al.: Mobile signature verification: feature robustness and performance comparison. IET Biom. 3(4), 267–277 (2014). https://doi.org/10.1049/iet-bmt.2013.0081
Melzi, P., Rathgeb, C., Tolosana, R., et al.: An overview of privacy-enhancing technologies in biometric recognition (2022). https://doi.org/10.48550/ARXIV.2206.10465
Nguyen, T., Roy, A., Memon, N.: Kid on the phone! Toward automatic detection of children on mobile devices. Comput. Secur. 84, 334–348 (2019). https://doi.org/10.1016/j.cose.2019.04.001
Petitjean, F., Ketterlin, A., Gançarski, P.: A global averaging method for dynamic time warping, with applications to clustering. Pattern Recogn. 44(3), 678–693 (2011). https://doi.org/10.1016/j.patcog.2010.09.013
Radesky, J., Silverstein, M., Zuckerman, B., et al.: Infant self-regulation and early childhood media exposure. Pediatrics 133, e1172 (2014). https://doi.org/10.1542/peds.2013-2367
Radesky, J., Weeks, H., Ball, R., et al.: Young children’s use of smartphones and tablets. Pediatrics 146, e20193518 (2020). https://doi.org/10.1542/peds.2019-3518
Rideout, V., Robb, M.B.: The Common Sense Census: Media Use by Kids Age Zero to Eight. Common Sense Media, San Francisco (2020)
Ruiz-Garcia, J.C., Tolosana, R., Vera-Rodriguez, R., et al.: ChildCI framework: analysis of motor and cognitive development in children-computer interaction for age detection (2022). https://doi.org/10.48550/ARXIV.2204.04236
Samaha, M., Hawi, N.S.: Relationships among smartphone addiction, stress, academic performance, and satisfaction with life. Comput. Hum. Behav. 57, 321–325 (2016). https://doi.org/10.1016/j.chb.2015.12.045
Tolosana, R., et al.: SVC-onGoing: signature verification competition. Pattern Recogni. (2022). https://doi.org/10.1016/j.patcog.2022.108609
Tolosana, R., Vera-Rodriguez, R., Ortega-Garcia, J., et al.: Preprocessing and feature selection for improved sensor interoperability in online biometric signature verification. IEEE Access 3, 478–489 (2015). https://doi.org/10.1109/ACCESS.2015.2431493
Tolosana, R., Vera-Rodriguez, R., Ortega-Garcia, J., et al.: Update strategies for HMM-based dynamic signature biometric systems. In: Proceeding IEEE International Workshop on Information Forensics and Security (WIFS) (2015b). https://doi.org/10.1109/WIFS.2015.7368583
Tolosana, R., Vera-Rodriguez, R., Fierrez, J., et al.: Reducing the template ageing effect in on-line signature biometrics. IET Biom. 8(6), 422–430 (2019). https://doi.org/10.1049/iet-bmt.2018.5259
Tolosana, R., Delgado-Santos, P., Perez-Uribe, A., et al.: DeepWriteSYN: on-Line handwriting synthesis via deep short-term representations. In: Proceeding 35th AAAI Conference on Artificial Intelligence (2021). https://doi.org/10.1609/aaai.v35i1.16139
Tolosana, R., Ruiz-Garcia, J.C., Vera-Rodriguez, R., et al.: Child-computer interaction with mobile devices: recent works, new dataset, and age detection. IEEE Trans. Emerg. Top. Comput. 10(4), 1–1 (2022). https://doi.org/10.1109/TETC.2022.3150836
Vatavu, R.D., Anthony, L., Brown, Q.: Child or adult? Inferring smartphone users’ age group from touch measurements alone. In: Proceeding conference on human-computer interaction (2015). https://doi.org/10.1007/978-3-319-22723-8_1
Vera-Rodriguez, R., Tolosana, R., Hernandez-Ortega, J., et al.: Modeling the complexity of signature and touch-screen biometrics using the lognormality principle. In: The Lognormality Principle and its Applications in e-Security, e-Learning and e-Health, pp. 65–86. World Scientific, Singapore (2020)
Acknowledgements
This is an ongoing project carried out with the collaboration of the school GSD Las Suertes in Madrid, Spain.
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature. INTER-ACTION (PID2021- 126521OB-I00 MICINN/ FEDER). J.C. Ruiz-Garcia is supported by the Madrid Government (Comunidad de Madrid-Spain) under the Multiannual Agreement with Autonomous University of Madrid in the line Encouragement of the Research of Young Researchers, in the context of the V PRICIT (Regional Programme of Research and Technological Innovation).
Author information
Authors and Affiliations
Contributions
JCR-G and CH were involved in conceptualization, investigation, writing—original draft, writing—reviewing and editing, and visualization. RT was responsible for conceptualization, investigation, writing—original draft, writing—reviewing and editing, visualization, and funding acquisition. RV-R, AM, JF, and JO-G contributed to conceptualization, investigation, writing—reviewing and editing, visualization, and funding acquisition. JH-R took part in conceptualization, investigation, writing—reviewing and editing, visualization.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare they have no competing financial or non-financial interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ruiz-Garcia, J.C., Hojas, C., Tolosana, R. et al. Children age group detection based on human–computer interaction and time series analysis. IJDAR (2024). https://doi.org/10.1007/s10032-024-00462-1
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10032-024-00462-1