
Abstract
Information theory provides a fundamental framework for the quantification of information flows through channels, formally Markov kernels. However, quantities such as mutual information and conditional mutual information do not necessarily reflect the causal nature of such flows. We argue that this is often the result of conditioning based on σ-algebras that are not associated with the given channels. We propose a version of the (conditional) mutual information based on families of σ-algebras that are coupled with the underlying channel. This leads to filtrations which allow us to prove a corresponding causal chain rule as a basic requirement within the presented approach.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction: Information Theory and Causality
Classical information theory [20] is based on the definition of Shannon entropy, a measure of uncertainty about the outcome of a variable Z:
where \(p(z) = \mathbb {P}(Z = z)\) denotes the distribution of Z. (Throughout this introduction, we consider only variables X, Y, and Z with finite state sets X, Y, and Z, respectively.) Shannon entropy serves as a building block of further important quantities. The flow of information from a sender X to a receiver Z, for instance, can be quantified as the reduction of uncertainty about the outcome of Z based on the outcome of X. More precisely, we compare two uncertainties here, the uncertainty about the outcome of Z, that is H(Z), with the uncertainty about the outcome of Z after knowing the outcome of X, that is
where \(p(z | x) = \mathbb {P}(Z = z | X = x)\) denotes the conditional distribution of Z given X. (Note that for x with p(x) = 0, conditioning is not well-defined. This ambiguity, however, has no effect on (1), due to the multiplication with p(x).) Naturally, the latter uncertainty, H(Z|X), is smaller than or equal to the first one, H(Z), leading to another fundamental quantity of information theory, the mutual information:
This difference can also be expressed in geometric terms as the KL-divergence
The KL-divergence plays an important role in information geometry as a canonical divergence [1,2,3,4]. Such a divergence is characterised in terms of natural geometric properties. It is remarkable that this purely geometric approach yields the fundamental information-theoretic quantities which were previously derived from a set of axioms that are formulated in non-geometric terms.
Typically, the conditional distribution p(z|x) is interpreted mechanistically as a channel which receives x as an input and generates z as an output. In this interpretation, the stochasticity of a channel is considered to be the effect of external or hidden disturbances of a deterministic map. This is formalised in terms of a so-called structural equation
with a deterministic map f and a noise variable U that is independent of X [17]. Integrating out the noise variable U, we obtain a Markov kernel, the formal model of a channel. What do we gain by this construction? Formally, we do not gain much, as a Markov kernel is basically a conditional probability distribution, defined for all x. However, with the representation (4) and the associated Markov kernel, the conditional probability distribution p(z|x) can be interpreted as the result of a (probabilitic) causal effect of X on Z. This interpretation provides the basis for Pearl’s influential proposal of a general theory of causality [17]. The mutual information (2) then becomes a measure of the causal information flow from X to Z [6], which is consistent with Shannon’s original idea of the amount of information transmitted through a channel [20]. This consistency, however, is apparently violated when dealing with variations or extensions of the sender-receiver setting. In Section 2, we are now going to highlight instances of such inconsistency that will play an important role in this article.
Later in this article, a channel will be formally given in terms of a Markov kernel, with a more explicit notation. In what follows, however, we keep the notation of a conditional probability distribution and state explicitly when we interpret it mechanistically as a channel.
2 Confounding Ghost Channels
The mutual information is symmetric, that is I(X;Z) = I(Z;X). Interpreting it as a measure of causal information flow, this symmetry suggests that we have the same amount of causal information flow in both directions, even though the channel goes from X to Z so that there cannot be any flow of information in the opposite direction. What is wrong here? This apparent problem, let us call it “the symmetry puzzle”, can be resolved quite easily. We can revert the direction and compute the conditional distribution \(p(x | z) = \frac {p(x)}{p(z)} p(z | x)\), based on elementary rules of probability theory and without reference to any mechanisms. Furthermore, this conditional distribution can be mechanistically interpreted and represented in terms of a structural equation (4). (This is always possible for a given conditional distribution.) Such a representation introduces a hypothetical channel for generating the reverted conditional distribution p(x|z), a kind of “ghost” channel that is actually not there. The mutual information then quantifies the causal information flow of this hypothetical channel. The symmetry of the mutual information simply means that the actual causal information flow in forward direction will be equal to the causal information flow of any hypothetical channel in backward direction that is capable of generating the conditional distribution p(x|z). The symmetry puzzle, however, is not the only apparent inconsistency between the (conditional) mutual information and causality. We are now going to highlight another problem, which is closely related to the symmetry puzzle but requires a deeper analysis for its solution.
We now assume that the channel receives x and y as inputs and generates z as an output. With the corresponding conditional distribution \(p(z | x, y) = \mathbb {P}(Z = z | X = x, Y = y)\) we have the conditional mutual information of Y and Z given X:
According to (5), the conditional mutual information compares the uncertainty about z given x, before and after observing the outcome y, reflected by the conditional probabilities p(z|x) and p(z|x,y), respectively. The representation (6) makes this comparison more explicit as a deviation of p(z|x,y) from p(z|x). Together with (3), we obtain the chain rule
For the computation of both terms, I(X;Z) and I(Y ;Z|X), we have to evaluate the “reduced” conditional distribution p(z|x). It is obtained from the original one in the following way:
This conditional distribution represents a second kind of hypothetical channel, a “ghost channel”, which screens off the actual flow of information. It can be sensitive to information about x that is not necessarily employed by the original channel p(z|x,y). More precisely, given two states x, \(x^{\prime }\) that satisfy \(p(z | x,y) = p(z| x^{\prime },y)\) for all z and all y, we cannot expect \(p(z| x) = p(z | x^{\prime })\) for all z. This is a consequence of the coupling through p(y|x), on the right-hand side (RHS, for short) of (10). In the most extreme case, y is simply a deterministic map of x, so that the knowledge of y does not provide any additional information about z, that is p(z|x,y) = p(z|x). In the following example we study this case more explicitly and thereby highlight the inconsistency of the terms I(X;Z) and I(Y ;Z|X) in (9) with the underlying causal structure. We will argue that the conditional distribution (10) has to be modified in order to allow for a causal interpretation.
Example 1
Consider three variables X,Y,Z with values − 1 and + 1, and assume that Z is obtained as a copy of Y, that is
We interpret this conditional distribution, which is well-defined for all arguments x and y, as a mechanism. This means that all information required for the output Z is contained in Y. Intuitively, we would expect from a measure of information flow to assign zero for the flow from X to Z and a positive value to the flow of information from Y to Z given X. This is however not what we get with the usual definitions of mutual information and conditional mutual information. The reason for that is the stochastic dependence of the inputs X and Y. To be more precise, let us assume that the input distribution is given as
where the parameter β controls the coupling of the inputs. This implies \(p(x) = \mathbb {P}(X = x) = 1/2\) and \(p(y) = \mathbb {P}(Y = y) = 1/2\) for all x,y ∈{± 1}. We can decompose the full mutual information, as a measure of information flow from X and Y together to Z, in the following way:
(The subscript β indicates the dependence of the respective information-theoretic quantities on this parameter.) This is consistent with the intuition that Z is receiving all information from Y and no information from X. However, we observe an inconsistency if we decompose the full mutual information in a different way:
For the two terms on the RHS of (13) we obtain
These functions are shown in Fig. 1. In the limit \(\beta \to - \infty \) the two inputs become completely anti-correlated with support (− 1,+ 1) and (+ 1,− 1). Correspondingly, for \(\beta \to + \infty \) we have complete correlation, and the support is (− 1,− 1) and (+ 1,+ 1). With (13), we obtain the following decomposition:
The decomposition (14) gives the impression that Z is receiving all information from X and no information from Y. However, we know, by the definition of the mechanism (11), that this is not the case. The actual situation is better reflected by the decomposition (12).

The mutual information Iβ(X;Z) and the conditional mutual information Iβ(Y ;Z|X) as functions of β. Even though the channel does not employ any information from X, the mutual information Iβ(X;Z) converges to the maximal value for \(\beta \to \infty \)
The problem highlighted in Example 1 can be resolved by an appropriate modification of the conditional probability (10). We are now going to outline this modification, which will provide the main idea of this article. In a first step, let us assume that \(\bar {y}\) is fixed as an input to the channel. Which information about x does the channel then use for generating z? In order to qualitatively describe that information, we lump any two states x and \(x^{\prime }\) together whenever the channel cannot distinguish them, that is
for all z. This defines a partition \(\alpha _{X,\bar {y}}\) of the state set of X that depends on \(\bar {y}\). In a second step, we consider the join of all these partitions, that is their coarsest refinement. More precisely, we define
The partition αX represents a qualitative description of the information in X that is used by the channel p(z|x,y). Denote by Ax the set in αX that contains x. When the channel receives x, in addition to y, then it does not “see” the full x but only the class Ax, and it is easy to verify p(z|x,y) = p(z|Ax,y). Therefore, we replace the conditioning p(z|x) in the above formula (10) by
This shows that the new conditional distribution \(\hat {p}(z | x)\) is obtained by averaging the previous one, p(z|x), according to the information that is actually used by the channel p(z|x,y). Now, replacing in (8) the conditional distribution p(z|x) by \(\hat {p}(z | x)\) leads to a corresponding modification of the mutual information and the conditional mutual information:
It is easy to see that
However, the sum does not change and we have the chain rule
With this new definition, we come back to Example 1. The channel defined by (11) does not use any information from X. Therefore, \(\alpha _{X,\bar {y}} = \{\mathsf {X}\}\) for all \(\bar {y} \in \mathsf {Y}\), which implies αX = {X}. With formula (16) we obtain \(\hat {p}(z | x) = p(z | \mathsf {X}) = p(z)\), and therefore
If we compare this with (14) we see that the information is shifted from the first to the second term which corresponds to the variable that has the actual causal effect on Z. On the other hand, in both cases the sum of the two contributions equals \(\log 2\), the full mutual information I(X,Y ;Z).
Causality plays an important role in time series analysis. In this context, Granger causality [12, 13] has been the subject of extensive debates which tend to highlight its non-causal nature. Schreiber proposed an information-theoretic quantification of Granger causality, referred to as transfer entropy, which is based on conditional mutual information [9, 19]. Even though transfer entropy is an extremely useful and widely applied quantity, it is generally accepted that it has shortcomings as a measure of causal information flow. In particular, it can vanish in cases where the causal effect is the strongest possible. We argue that this is again a result of a ghost channel that is involved in the computation of the classical conditional mutual information and screens off the actual causal information flow. This is demonstrated in the following example which is taken from [6]. Essentially, this example is a reformulation of Example 1, thereby adjusted to the context of time series and stochastic processes.
Example 2 (Transfer entropy)
Consider a stochastic process (Xm,Ym), \(m = 1,2,\dots \), with state space {± 1}2 and define \(X^{m} := (X_{1},\dots ,X_{m})\) and \(Y^{m} := (Y_{1},\dots , Y_{m})\). The transfer entropy at time m is defined as
Thus, the transfer entropy quantifies how much information the variables \(Y_{1}, \dots , Y_{m - 1}\) contribute to the evaluation of Xm, in addition to the information in \(X_{1},\dots ,X_{m - 1}\). We assume that the process is a Markov chain, given by a transition matrix of the form
where
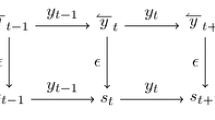
The causal structure of the dynamics is represented by the following diagram:

As a stationary distribution we have
where
The transfer entropy can be upper bounded as follows (the subscript β indicates the dependence on the coupling parameter β):
For β = 0, we have an i.i.d. process with uniform distribution over the states (+ 1,+ 1), (− 1,+ 1), (+ 1,− 1), and (− 1,− 1). For \(\beta \to \infty \), we obtain the deterministic transition
In this limit, the variables (Xm,Ym) are completely correlated with \(p(+1,+1) = p(-1,-1) = \frac {1}{2}\). In both cases, β = 0 and \(\beta \to \infty \), the conditional mutual information Iβ(Ym− 1;Xm|Xm− 1), and therefore the transfer entropy Tβ(Ym− 1 → Xm), vanishes. For β = 0, this does not represent a problem because any measure of causal information flow should vanish in the i.i.d. case. However, for \(\beta \to \infty \), the variable Xm is causally determined by Ym− 1. Therefore, a measure of casual information flow should be maximal in this case. This is not reflected by the transfer entropy. Let us compare this with the information flow measure proposed in this article. Given that Xm only depends on Ym− 1, the partition (15) is trivial, that is α = {X}. Therefore,
This quantity is converging to the maximal value \(\log 2\) for \(\beta \to \infty \). For comparison, both functions are plotted in Fig. 2.

Dashed line: the conditional mutual information Iβ(Ym− 1;Xm|Xm− 1) as an upper bound of the transfer entropy Tβ(Ym− 1 → Xm); solid line: the causal information flow Iβ(Ym− 1 → Xm|Xm− 1) which coincides with the mutual information Iβ(Ym− 1;Xm) in this example
In what follows, we will extend the idea outlined in this section to a more general context of measurable spaces, probability measures, and Markov kernels. In further steps, we will also consider more input nodes.
3 General Information-Theoretic Quantities
In the previous sections, we reviewed fundamental information-theoretic quantities as they are introduced in standard textbooks such as [10]. In this section, we offer an alternative review from a measure-theoretic perspective (see, for instance, [15]). This more abstract setting will allow us to identify natural operations and definitions which are not always visible when dealing with finite state spaces.
Shannon Entropy
For a probability space \(({\varOmega }, {\mathscr{F}}, \mathbb {P})\) and a finite measurable partition \(\gamma = \{C_{1}, \dots , C_{m}\}\), that is \(C_{i} \in {\mathscr{F}}\), Ci ∩ Cj = ∅ for all i≠j, and \(\bigcup _{i = 1}^{m} C_{i} = {\varOmega }\), the Shannon entropy of γ is given by
As a local version of the Shannon entropy, we define

where  is the indicator function of C. Denoting by Cω the set in γ that contains ω ∈Ω, we have \(h (\gamma )(\omega ) = - \log \mathbb {P}(C_{\omega })\). If we integrate the function h(γ), we recover the entropy (17) of the partition γ:
is the indicator function of C. Denoting by Cω the set in γ that contains ω ∈Ω, we have \(h (\gamma )(\omega ) = - \log \mathbb {P}(C_{\omega })\). If we integrate the function h(γ), we recover the entropy (17) of the partition γ:

Conditional Entropy
Consider two finite measurable partitions α and γ of Ω, where we assume \(\mathbb {P}(A) > 0\) for all A ∈ α. The conditional entropy of γ given α is then defined by
As a local version h(γ|α) of H(γ|α), we define

If we evaluate this function for ω ∈Ω we obtain \(h(\gamma | \alpha )(\omega ) = - \log \mathbb {P}(C_{\omega } | A_{\omega })\), where Aω and Cω are the atoms in α and γ, respectively, that contain ω. Integrating h(γ|α), we recover (18):
The function h(γ|α) can be generalised by replacing the partition α by an arbitrary σ-subalgebra \({\mathscr{A}}\) of \({\mathscr{F}}\):

where  . Note that this function is only \(\mathbb {P}\)-almost everywhere defined (abbreviated as \(\mathbb {P}\)-a.e.). In the case where the σ-algebra \({\mathscr{A}}\) is given by a finite partition α with \(\mathbb {P}(A) > 0\) for all A ∈ α, we have
. Note that this function is only \(\mathbb {P}\)-almost everywhere defined (abbreviated as \(\mathbb {P}\)-a.e.). In the case where the σ-algebra \({\mathscr{A}}\) is given by a finite partition α with \(\mathbb {P}(A) > 0\) for all A ∈ α, we have

This shows that the definition (20) is indeed an extension of (19). Correspondingly, integrating (20) yields a generalistaion of (18):

Mutual Information
If we subtract from the entropy of a partition γ the conditional entropy of γ given a partition α, we obtain the mutual information:
Let us relate this function to the corresponding local functions h(γ) and h(γ|α). Taking the difference, we obtain

If we evaluate this for ω ∈Ω we obtain \(i(\alpha ; \gamma )(\omega ) = \log \frac {\mathbb {P}(C_{\omega } | A_{\omega })}{\mathbb {P}(C_{\omega })}\), and thus we have
For the general case where the partition α is replaced by a σ-subalgebra \({\mathscr{A}}\) of \({\mathscr{F}}\), we obtain

This leads to a corresponding generalisation of (21):

Conditional Mutual Information
Finally, we define the conditional mutual information. With two σ-subalgebras \({\mathscr{A}}\) and \({\mathscr{B}}\) of \({\mathscr{F}}\), we define

(Here, \({\mathscr{A}} \vee {\mathscr{B}}\) denotes the smallest σ-algebra that contains \({\mathscr{A}}\) and \({\mathscr{B}}\).) Integration of this function leads to

In a final step, we could further extend \(i({\mathscr{B}} ; \gamma | {\mathscr{A}})\) and \(I({\mathscr{B}} ; \gamma | {\mathscr{A}})\) to the case where γ is replaced by a σ-algebra \({\mathscr{C}}\), by taking the supremum over all finite partitions γ in \({\mathscr{C}}\). However, in this article we restrict attention to a fixed finite partition γ.
4 The Chain Rule as a Guiding Scheme
4.1 Two Inputs
In the introduction, Section 1, we have used the two-input case for discrete random variables in order to highlight the main issue with the classical definitions of the mutual information and the conditional mutual information and to outline the core idea of this article. After having introduced the required information-theoretic quantities for more general variables in Section 3, we now revisit the instructive two-input case and demonstrate how measure-theoretic concepts come into play here very naturally.
Consider measurable spaces \((\mathsf {X},{\mathscr{X}})\), \((\mathsf {Y},{\mathscr{Y}})\), \((\mathsf {Z},{\mathscr{Z}})\), and their product
In order to ensure the existence of various (regular versions of) conditional distributions, we need to assume that these measurable spaces carry a further structure. Typically, it is sufficient to require that \((\mathsf {X},{\mathscr{X}})\), \((\mathsf {Y},{\mathscr{Y}})\), and \((\mathsf {Z},{\mathscr{Z}})\) are Polish spaces (see [11], Theorem 13.1.1), which will be implicitly assumed hereinafter for all measurable spaces.
Now, consider a probability measure μ on \((\mathsf {X} \times \mathsf {Y}, {\mathscr{X}} \otimes {\mathscr{Y}})\) and a Markov kernel
which models a channel that takes two inputs, x ∈X and y ∈Y, and generates a possibly random output z ∈Z. This allows us to define a probability measure on the joint space \(({\varOmega }, {\mathscr{F}})\), given by
With the natural projections
we have
where the set of probability one to which “μ-almost everywhere” refers in (25) is independent of C. Furthermore, we have the marginals
and, finally, the ν-push-forward measure of μ,
Note that the definition of the conditional distribution \(\mathbb {P}(Z \in C | X = x, Y = y)\) on the RHS of (25) is quite general and does not exclude cases where \(\mathbb {P}(X = x, Y= y) = 0\). It requires a formalism that goes beyond the context of variables with finitely many state sets X, Y, and Z. It is important to outline this formalism in some detail here, which will provide the basis for an appropriate definition of marginal channels. The definition of the conditional distribution
involves two steps:
- Step 1.:
-
We interpret the indicator function
 as an element of the Hilbert space \(L^{2}({\varOmega }, {\mathscr{F}}, \mathbb {P})\) and project it onto the (closed) linear subspace of (X,Y )-measurable functions \({\varOmega } \to \mathbb {R}\). Its projection is referred to as conditional expectation and denoted by
as an element of the Hilbert space \(L^{2}({\varOmega }, {\mathscr{F}}, \mathbb {P})\) and project it onto the (closed) linear subspace of (X,Y )-measurable functions \({\varOmega } \to \mathbb {R}\). Its projection is referred to as conditional expectation and denoted by
 (27)
(27)Note that the elements of the Hilbert space \(L^{2}({\varOmega }, {\mathscr{F}}, \mathbb {P})\) are equivalence classes of functions where two functions are identified if they coincide on a measurable set of probability one. Therefore, the conditional expectation (27) is only almost surely well defined, where the set of probability one to which “almost surely” refers is dependent on C.
- Step 2.:
-
Formally,
 is a real-valued function defined on Ω. On the other hand, it is (X,Y )-measurable so that we should be able to interpret it as a function of x and y. Indeed, it follows from the factorisation lemma that there is a unique measurable function \(\varphi _{C}: (\mathsf {X} \times \mathsf {Y}, {\mathscr{X}} \otimes {\mathscr{Y}}) \to \mathbb {R}\) satisfying
is a real-valued function defined on Ω. On the other hand, it is (X,Y )-measurable so that we should be able to interpret it as a function of x and y. Indeed, it follows from the factorisation lemma that there is a unique measurable function \(\varphi _{C}: (\mathsf {X} \times \mathsf {Y}, {\mathscr{X}} \otimes {\mathscr{Y}}) \to \mathbb {R}\) satisfying  . The conditional distribution (26) is then simply defined to be the function φC, which has x and y as arguments. In the special situation where we start with a Markov kernel ν, we recover it, μ-almost everywhere, in terms of equation (25). It turns out that this equation already describes a quite general situation. Under mild conditions, assuming, for instance, that all measurable spaces are Polish spaces, the conditional distribution (26) can be considered to be a Markov kernel, as a function of x, y, and C.
. The conditional distribution (26) is then simply defined to be the function φC, which has x and y as arguments. In the special situation where we start with a Markov kernel ν, we recover it, μ-almost everywhere, in terms of equation (25). It turns out that this equation already describes a quite general situation. Under mild conditions, assuming, for instance, that all measurable spaces are Polish spaces, the conditional distribution (26) can be considered to be a Markov kernel, as a function of x, y, and C.
 as an element of the Hilbert space
as an element of the Hilbert space 
 is a real-valued function defined on Ω. On the other hand, it is (X,Y )-measurable so that we should be able to interpret it as a function of x and y. Indeed, it follows from the factorisation lemma that there is a unique measurable function
is a real-valued function defined on Ω. On the other hand, it is (X,Y )-measurable so that we should be able to interpret it as a function of x and y. Indeed, it follows from the factorisation lemma that there is a unique measurable function  . The conditional distribution (
. The conditional distribution (For the definition of mutual information and conditional mutual information, as generalisations of (3) and (6), respectively, we have to find an appropriate notion of a marginal kernel. We begin with the conditional distribution \(\mathbb {P}(Z \in C | X = x)\), as generalisation of p(z|x). For its evaluation we repeat the arguments of the above two steps and consider the conditional expectation

This is an X-measurable random variable \({\varOmega } \to \mathbb {R}\). By the factorisation lemma we have a unique measurable function \(\nu _{X}(\cdot ;C) : (\mathsf {X}, {\mathscr{X}}) \to \mathbb {R}\) satisfying  , and we set
, and we set
Under mild conditions we can assume that νX(x;C) defines a Markov kernel when considered as a function \(\nu _{X}: \mathsf {X} \times {\mathscr{Z}} \to [0,1]\) in x and C.
We can now easily extend the classical definitions of mutual information and conditional mutual information to the context of this section. For a finite measurable partition ξ of Z, the sets Z− 1(C), C ∈ ξ, form a corresponding finite measurable partition Z− 1(ξ) of Ω, and we can use (22) to define the mutual informations
and
Furthermore, with (23) we define the conditional mutual information
We repeat the computation (8) and decompose the mutual information Iξ(X,Y ;Z) as follows:
We argue that, in order to have a causal decomposition of the full mutual information Iξ(X,Y ;Z) into two terms similar to Iξ(X;Z) and Iξ(Y ;Z|X), we have to modify the marginal channel
in (31). In this modification, the conditioning with respect to X has to be adjusted to the actual information used by the kernel ν(x,y;C). To this end, we consider the smallest σ-subalgebra \({\mathscr{A}}_{X, \bar {y}}\) of \({\mathscr{X}}\) for which all functions \(\nu _{X,\bar {y}} (\cdot ; C) := \nu (\cdot , \bar {y} ; C)\), \(C \in {\mathscr{Z}}\), are measurable. It corresponds to the partition \(\alpha _{X,\bar {y}}\) that appears in (15). Now we generalise the definition (15) of the partition αX by combining all the σ-algebras \({\mathscr{A}}_{X , \bar {y}}\):
Note that, typically, \({\mathscr{A}}_{X , \bar {y}}\), \(\bar {y} \in \mathsf {Y}\), as well as \({\mathscr{A}}_{X}\) cannot be naturally identified with corresponding σ-subalgebras of the σ-algebra generated by the channel ν, that is the smallest σ-subalgebra of \({\mathscr{X}} \otimes {\mathscr{Y}}\) for which (x,y)↦ν(x,y;C) is measurable for all \(C \in {\mathscr{Z}}\). This is illustrated by the following example.
Example 3
We consider
where \({\mathscr{B}}(\mathbb {R})\) denotes the Borel σ-algebra of \(\mathbb {R}\). We assume that the channel ν is simply given by the addition (x,y)↦x + y:

As \({\mathscr{B}}(\mathbb {R})\) is generated by the intervals \([r - \varepsilon , r + \varepsilon ] \subseteq \mathbb {R}\), the smallest σ-algebra \({\mathscr{A}} \subseteq {\mathscr{X}} \otimes {\mathscr{Y}}\) for which all functions ν(⋅,⋅;C) are measurable is generated by the following sets
Now let us consider \({\mathscr{A}}_{X,\bar {y}}\), the σ-algebra generated by the kernel
It is easy to see that \({\mathscr{A}}_{X, \bar {y}}\) is the smallest σ-subalgebra of \({\mathscr{X}}\) containing the \(\bar {y}\)-sections
that is, \({\mathscr{A}}_{X, \bar {y}} = {\mathscr{B}}(\mathbb {R})\). This example shows that the cylinder sets \(A \times \mathbb {R}\), \(A \in {\mathscr{A}}_{X , \bar {y}}\), are not necessarily contained in \({\mathscr{A}}\) (see illustration in Fig. 3).

Illustration of the ν-measurable sets in \(\mathbb {R}^{2}\) and their sections in \(\mathbb {R}\)
With the σ-subalgebra \({\mathscr{A}}_{X}\) of \({\mathscr{X}}\), we can now modify the random variable \(X: ({\varOmega }, {\mathscr{F}}, \mathbb {P}) \to (\mathsf {X}, {\mathscr{X}})\) by simply reducing the image σ-algebra to \({\mathscr{A}}_{X}\):
We will see that this step is crucial here, even though it might appear like a minor technical step at first sight. It allows us to modify (28) by replacing the full σ-algebra of X, \({\mathscr{X}}\), by the σ-algebra of \(\widehat {X}\):

This is, by definition, an \(\widehat {X}\)-measurable random variable \({\varOmega } \to \mathbb {R}\). By the factorisation lemma, we can find a unique measurable function \(\hat {\nu }_{X}(\cdot ; C) : (\mathsf {X}, {\mathscr{A}}_{X}) \to {\Bbb R}\) satisfying  . This yields a new marginal channel,
. This yields a new marginal channel,
as a modification of νX(x;C) which appears twice in (31). Note that the kernel \(\hat {\nu }_{X}(x;C)\) is defined almost surely. However, the definition of a conditional mutual information will be independent of the version of that kernel.
Now we come to the definition of a causal version of the mutual information (29) and the conditional mutual information (30). We simply replace in these definitions νX(x;C) by \(\hat {\nu }_{X}(x ; C)\):
The following proposition relates the causal quantities (34) and (35) to the corresponding non-causal ones, (29) and (30).
Proposition 4
We have the chain rule
Furthermore,
Proof
With Cz denoting the set in ξ that contains z, we have
Integrating this with respect to ν(x,y;dz) we get
Further integrating the first term of (38) with respect to μ gives us Iξ(Y → Z|X) (see (35)). For the corresponding integration of the second term, we obtain
The crucial step (40) follows from the general property of the conditional expectation of a function f with respect to a σ-subalgebra \({\mathscr{A}}\):
Here, f is given by \(\mathbb {P}(Z \in C | X, Y)\), \({\mathscr{A}}\) is the σ-algebra generated by \(\widehat {X}\), and g is given by \(\log \frac {\mathbb {P}(Z \in C | \widehat {X})}{\mathbb {P}(Z \in C)}\) which is \(\widehat {X}\)-measurable. The steps (39) and (41) follow directly from the definitions of the Markov kernels, and we finally obtain Iξ(X → Z) (see (34)). This concludes the proof of the chain rule (36).
We now prove the inequalities (37) where we can restrict attention to the first one. We consider the convex function \(\phi (r) := r \log \frac {r}{\nu _{\ast }(\mu )(C)}\), for r > 0, and ϕ(0) := 0, and apply Jensen’s inequality for conditional expectations:
This implies
The second inequality in (37) follows from the first one and the chain rule (36). □
Let us interpret this result. The first inequality in (37) highlights the fact that the stochastic dependence between X and Z, here quantified by the usual mutual information Iξ(X;Z), cannot be fully attributed to the causal effect of X on Z. Some part of Iξ(X;Z) is purely associational, and Iξ(X → Z) constitutes the causal part of it. The second inequality in (37) highlights a different fact. Conditioning on the variable X may “screen off” some part of the causal effect of Y on Z. More precisely, the uncertainty reduction about the outcome of Z through X can be so strong that a further reduction through Y becomes “invisible”. Therefore, the classical conditional mutual information, Iξ(Y ;Z|X), tends to reflect only part of the causal influence of Y on Z given X, Iξ(Y → Z|X). Even though the classical information-theoretic quantities are replaced by their causal versions, the full mutual information can still be decomposed according to the chain rule (36). However, in comparison to the decomposition (32), some amount of it is shifted from one term to the other so that both terms can be interpreted causally.
It turns out that the definitions (34) and (35) require a careful extension if we want to have a general chain rule for more than two input variables. We are now going to highlight this for three input variables.
4.2 Three Inputs
We now consider three input variables. This will reveal that the previous case with two input variables is quite special. An extension to more than two variables requires an adjustment of our definition of causal information flow.
We consider a third input variable (denoted below by W ) with values in a measurable space \((\mathsf {W}, {\mathscr{W}})\), a probability measure
and an input-output channel, given by a Markov kernel
This gives rise to a probability space, consisting of the measurable space
and the probability measure \(\mathbb {P}\) defined by
Finally, we have the natural projections W : Ω →W, X : Ω →X, Y : Ω →Y, and Z : Ω →Z.
The definition of the marginal kernel \(\hat {\nu }_{X}(x ; C)\), as introduced in Section 4.1, is directly applicable to the situation of three input variables. It allows us to define marginal channels by an appropriate grouping of two input variables into one input variable, which formally reduces the three-input case to a two-input case. In particular, we can define the channels \(\hat {\nu }_{W,X}(w, x ; C)\) and \(\hat {\nu }_{W}(w ; C)\), by grouping W,X and X,Y, respectively, into one variable. Denoting the set in ξ that contains z by Cz, we then have
By integration we obtain
An integration of the last term (45) with respect to μ yields, by the same reasoning as in the steps (39), (40), and (41),
A corresponding integration of the first term (43) with respect to μ yields a non-negative quantity that can be interpreted as Iξ(Y → Z|W,X) (see definition (35)). Even though we will have to slightly adjust this first term, the problem we are facing here is most clearly highlighted by the second term, (44). In order to naturally generalise the chain rule (36) we have to interpret the integral of the second term as Iξ(X → Z|W). However, it turns out that, in general,
where (46) is the integral of the term (44) with respect to μ. We cannot even ensure that this integral is non-negative. The reason is that the σ-algebra used for the definition of \(\hat {\nu }_{W}(w; C)\) is not necessarily a σ-subalgebra of the one used for the definition of the kernel \(\hat {\nu }_{W,X}(w, x ; C)\) (the situation is similar to the one of Example 3). Therefore, the reasoning of the steps (39), (40), and (41), cannot be applied here.
The problem highlighted in this section will now be resolved. This will be done by a modification of the involved σ-algebras, which should define a filtration in order to imply a general causal version of the chain rule. In the next section, this modification will be presented for the general case of n input variables.
5 The General Definition of Causal Information Flow
5.1 Filtrations and Information
Let \((\mathsf {X}_{i}, {\mathscr{X}}_{i})\), \(i \in N := [n] = \{1,\dots ,n\}\), be a family of measurable spaces, the state spaces of the input variables. For each subset M of N, we have the corresponding product space \((\mathsf {X}_{M}, {\mathscr{X}}_{M})\) consisting of XM := ×i∈MXi and \({\mathscr{X}}_{M} := \otimes _{i \in M} {\mathscr{X}}_{i}\). Note that for M = ∅, the set X∅ consists of one element, the empty sequence 𝜖, and \({\mathscr{X}}_{\emptyset } = \{\emptyset , \{\epsilon \} \}\) is the trivial σ-algebra with two elements. In addition to the input variables, we consider an output variable with state space \((\mathsf {Z}, {\mathscr{Z}})\). The input-output channel is given by a Markov kernel
Together with a probability measure μ on \((\mathsf {X}_{N}, {\mathscr{X}}_{N})\) this defines the probability space \(({\varOmega }, {\mathscr{F}}, \mathbb {P})\) where
and
Finally, we have the canonical projections
We are now going to define the M-marginal of the channel based on a general σ-subalgebra \({\mathscr{B}}_{M}\) of \({\mathscr{X}}_{M}\). Below, in Section 5.2, this will allow us to incorporate causal aspects of ν by an appropriate adaptation of \({\mathscr{B}}_{M}\) to ν. In order to highlight the flexibility that we have here, let us begin with the usual definition where \({\mathscr{B}}_{M}\) equals the largest σ-subalgebra of \({\mathscr{X}}_{M}\), that is \({\mathscr{X}}_{M}\) itself. Given a measurable set \(C \subseteq \mathsf {Z}\), we have the conditional expectation

This is by definition an XM-measurable function \({\varOmega } \to \mathbb {R}\). By the factorisation lemma we can represent it as a composition  with a measurable function \(\nu _{M}(\cdot ; C) : (\mathsf {X}_{M}, {\mathscr{X}}_{M}) \to \mathbb {R}\). This allows us to define the conditional distribution
with a measurable function \(\nu _{M}(\cdot ; C) : (\mathsf {X}_{M}, {\mathscr{X}}_{M}) \to \mathbb {R}\). This allows us to define the conditional distribution
which can be interpreted as a channel
We now modify the outlined marginalisation of ν by reducing the maximal σ-algebra \({\mathscr{X}}_{M}\) to the σ-subalgebra \({\mathscr{B}}_{M}\). More precisely, we replace XM in (47) by
and consider the conditional expectation

This is now an \(\widehat {X}_{M}\)-measurable function \({\varOmega } \to \mathbb {R}\), and, by the factorisation lemma, we can represent it as a composition  with a measurable function \(\hat {\nu }(\cdot ; C) : (\mathsf {X}_{M}, {\mathscr{B}}_{M}) \to \mathbb {R}\). Finally, we have the modification
with a measurable function \(\hat {\nu }(\cdot ; C) : (\mathsf {X}_{M}, {\mathscr{B}}_{M}) \to \mathbb {R}\). Finally, we have the modification
of the conditional distribution (48), which corresponds to a modified channel
By construction, \(\hat {\nu }_{M}\) is \({\mathscr{B}}_{M}\)-measurable, that is, it uses only information that is contained in \({\mathscr{B}}_{M}\). For the maximal σ-algebra we recover νM. We can also consider the other extreme where \({\mathscr{B}}_{M}\) equals the smallest σ-algebra, {∅,XM}. In that case, we obtain \(\hat {\nu }(x_{M} ; C) = \nu _{\ast }(\mu )(C)\). An adjustment of \({\mathscr{B}}_{M}\) to the information actually used by ν will allow us to interpret \(\hat {\nu }\) causally. In contrast, if we do not have such an adjustment, \(\hat {\nu }_{M}\) will represent a hypothetical channel, a “ghost channel”, based on the σ-algebra of an external observer rather than the σ-algebra of the actual mechanisms of the channel. As we will see in Section 5.2, there are various natural ways to adjust \({\mathscr{B}}_{M}\) to ν. However, for the largest subset M of inputs, N, ν will always be measurable with respect to \({\mathscr{B}}_{N}\). This ensures that we recover ν when we condition with respect to \({\mathscr{B}}_{N}\), that is, \(\hat {\nu }_{N} = \nu \).
We now consider a family \({\mathscr{B}} = ({\mathscr{B}}_{M})_{M \subseteq N}\) of σ-algebras. It gives rise to a corresponding family
of σ-algebras on Ω. We call the family \({\mathscr{B}}\) projective, if the maps
are \({\mathscr{B}}_{M}\)-\({\mathscr{B}}_{L}\)-measurable. For projective families, we have the following monotonicity:
Given a projective family \({\mathscr{B}}\), we now define a corresponding family of information-theoretic quantities which generalise (conditional) mutual information. We begin with a local version, applied to a measurable partition ξ of Z. For z ∈Z, we denote the set in ξ that contains z by Cz. For \(L \subseteq M \subseteq N\), we consider xM = (xL,xM∖L) ∈XM and define
This is a local version of the conditional mutual information. Integration over z yields
With a second integration, with respect to μ, we obtain

where μM denotes the M-marginal of μ. This suggests the following version of the conditional mutual information which we refer to as information flow.
Definition 5
Let \({\mathscr{B}} = ({\mathscr{B}}_{M})_{M \subseteq N}\) be a projective family of σ-algebras, let ξ be a finite measurable partition of Z, and let \(L \subseteq M \subseteq N\). Then we define the information flow from XM∖L to Z given XL as
For L = ∅ we simplify the notation by \(I^{{\mathscr{B}}}_{\xi }(X_{M} \to Z)\) and refer to the information flow from XM to Z.
Given disjoint subsets \(M_{1}, M_{2}, {\dots } , M_{k}\) of N, we use a filtration of σ-algebras for proving a general chain rule for information flows, thereby extending the chain rule in Proposition 4 and resolving the problem highlighted in Section 4.2 for three inputs.
Theorem 6
(General chain rule) Let \({\mathscr{B}} = ({\mathscr{B}}_{M})_{M \subseteq N}\) be a projective family of σ-algebras, let ξ be a finite measurable partition of Z, and let \(M_{1}, M_{2}, {\dots } , M_{k}\) be disjoint subsets of N. Then
Proof
Let \(M^{j} := \cup _{i = 1}^{j} M_{i}\), \(j = 0,1,\dots ,k\). The monotonicity (49) implies that the sequence
is increasing and therefore represents a filtration of σ-algebras. This implies
□
We now state basic properties of the information flow. Some of these properties are listed in [14] as natural postulates (P0–P4) for a measure of causal strength.
Proposition 7
(Natural properties) Let \({\mathscr{B}} = ({\mathscr{B}}_{M})_{M \subseteq N}\) be a projective family of σ-algebras such that ν is measurable with respect to \({\mathscr{B}}_{N}\), and let ξ be a finite measurable partition of Z. Then the following properties hold:
-
(a)
The information flow from all input variables to the output variable coincides with the mutual information: \(I^{{\mathscr{B}}}_{\xi }(X_{N} \to Z) = I_{\xi } (X_{N} ; Z)\).
-
(b)
For a subset M of N, the set of all input variables, the information flow \(I^{{\mathscr{B}}}_{\xi }(X_{M} \to Z )\) is smaller than or equal to the mutual information Iξ(XM;Z).
-
(c)
For a subset M of N, the information flow \(I^{{\mathscr{B}}}_{\xi }(X_{M} \to Z | X_{N \setminus M})\) is greater than or equal to the conditional mutual information Iξ(XM;Z|XN∖M).
-
(d)
If the information flow \(I^{{\mathscr{B}}}_{\xi }(X_{M} \to Z | X_{N \setminus M})\) vanishes then Z is independent of XM given XN∖M.
-
(e)
For \(L \subseteq M \subseteq N\), we have \(I^{{\mathscr{B}}}_{\xi }(X_{L} \to Z ) \leq I^{{\mathscr{B}}}_{\xi }(X_{M} \to Z)\). In particular, if \(I^{{\mathscr{B}}}_{\xi }(X_{M} \to Z ) = 0\) then \(I^{{\mathscr{B}}}_{\xi }(X_{L} \to Z ) = 0\).
Proof
Statement (a) follows from \(\hat {\nu }_{N}(x_{N} ; C) = \nu (x_{N} ; C)\) and \(\hat {\nu }_{\emptyset }(x ; C) = \nu _{\ast }(\mu )(C)\). The statements (b) and (c) can be proven in the same way as the corresponding inequalities (37) of Proposition 4, thereby using the chain rule
for \(M \subseteq N\) (this follows from the general chain rule (50), with M1 = M and M2 = N ∖ M). In order to prove (d), note that with (c) we have
This implies that XM is independent of Z given XN∖M. Finally, (e) follows from the chain rule
by the general chain rule (50), with M1 = L and M2 = M ∖ L. □
Now let us come back to the two- and three-input cases which we studied in Sections 4.1 and 4.2, respectively. These cases guided our search for the setting that allows us to prove the general chain rule. In the two-input case, we have considered the σ-algebra \({\mathscr{A}}_{X}\), defined by (33). Similarly, we can consider the correspondingly defined σ-algebras \({\mathscr{A}}_{Y}\) and \({\mathscr{A}}_{X,Y}\). The latter is simply the σ-algebra generated by the channel ν. Example 3 then demonstrates that the projections (x,y)↦x and (x,y)↦y do not have to be \({\mathscr{A}}_{X,Y}\)-\({\mathscr{A}}_{X}\)- and \({\mathscr{A}}_{X,Y}\)-\({\mathscr{A}}_{Y}\)-measurable, respectively. This simply means that the family, extended by \({\mathscr{A}}_{\emptyset } = \{\emptyset , \{\epsilon \}\}\), is not necessarily projective. Why does the chain rule still hold this case? The reason is that we can simply extend \({\mathscr{A}}_{X,Y}\) to the full σ-algebra \({\mathscr{X}} \otimes {\mathscr{Y}}\), thereby making the family projective. This extension is trivial in the sense that it has no “visible” effect, simply because conditioning ν with respect to \({\mathscr{X}} \otimes {\mathscr{Y}}\) is the same as conditioning it with respect to \({\mathscr{A}}_{X,Y}\). As a result, we obtain the chain rule in Proposition 4 from Theorem 6. Going from the two-input case to the three-input case, we can define the corresponding family of σ-algebras, which is again not necessarily projective. However, in this case it is not possible to make it projective without visible effect. This demonstrates that the two-input case is quite special. If we want to consider the chain rule as a fundamental property of causal information flows, we have to accept the construction of a projective family of σ-algebras that are associated with ν as a natural step. The individual causal information flows will then crucially depend on this family. In the following section, we are going to propose two natural ways of such a construction.
5.2 Adaptation of the Filtration to the Channel
We are now going to couple the family \(({\mathscr{B}}_{M})_{M \subseteq N}\) to the channel ν so that we can interpret the corresponding marginals \((\hat {\nu }_{M})_{M \subseteq N}\) causally. In order to simplify the presentation, we first consider an arbitrary σ-subalgebra \({\mathscr{A}}\) of \({\mathscr{X}}_{N}\). (Below, \({\mathscr{A}}\) will be chosen to be the σ-algebra generated by ν.) We begin with information in M in the context of a configuration \(\bar {x}\) outside of M, that is \(\bar {x} \in \mathsf {X}_{N \setminus M}\). Given such an \(\bar {x}\), we define the \((M,\bar {x})\)-trace of \({\mathscr{A}}\) as follows: For each \(A \in {\mathscr{A}}\), we consider the \((M,\bar {x})\)-section of A,
These sections then form the \((M,\bar {x})\)-trace of \({\mathscr{A}}\), that is
Considering all possible contexts \(\bar {x} \in \mathsf {X}_{N \setminus M}\), we finally define the M-trace of \({\mathscr{A}}\) as
The \((M,\bar {x})\)-trace as well as the M-trace of \({\mathscr{A}}\) are σ-subalgebras of \({\mathscr{X}}_{M}\). Note that in the extreme cases M = ∅ and M = N, we recover \({\mathscr{A}}_{\emptyset } = \{\emptyset , \{ \epsilon \} = \mathsf {X}_{\emptyset }\}\) (where 𝜖 denotes the empty sequence), and \({\mathscr{A}}_{N} = {\mathscr{A}}\), respectively.
The family of all M-traces of \({\mathscr{A}}\) describes how \({\mathscr{A}}\) is “distributed” over the subsets M of N. However, there is a problem here: The canonical projections \({\pi ^{M}_{L}}\) are not necessarily \({\mathscr{A}}_{M}\)-\({\mathscr{A}}_{L}\)-measurable. This projectivity property is required for the definition of a measure of causal information flow that satisfies the general chain rule of Theorem 6. We highlighted this problem for the three-input case in Section 4.2. There are two ways to recover the projectivity, first by extending and second by reducing \({\mathscr{A}}_{M}\) appropriately. Let us begin with the extension:
We have the following characterisation of the family \(\overline {{\mathscr{A}}}_{M}\), \(M \subseteq N\), as the smallest projective extension of the family \({\mathscr{A}}_{M}\), \(M \subseteq N\).
Proposition 8
(Extension of \({\mathscr{A}}_{M}\), \(M \subseteq N\)) The family \(\overline {{\mathscr{A}}}_{M}\), \(M \subseteq N\), satisfies the following two conditions:
-
1.
For all \(M \subseteq N\), \({\mathscr{A}}_{M}\) is contained in \(\overline {{\mathscr{A}}}_{M}\).
-
2.
For all \(L \subseteq M \subseteq N\), the canonical projection \({\pi ^{M}_{L}}\) is \(\overline {{\mathscr{A}}}_{M}\)-\(\overline {{\mathscr{A}}}_{L}\)-measurable.
Furthermore, for every family \({\mathscr{A}}_{M}^{\prime }\), \(M \subseteq N\), that satisfies these two conditions (where \(\overline {{\mathscr{A}}}_{M}\) is replaced by \({\mathscr{A}}^{\prime }_{M}\)), we have
Proof
The first statement is clear (simply choose on the RHS of (51) L = M). For the second statement, we have to show
Given that
it is sufficient to verify
The LHS of (53) reduces to \(({\pi ^{M}_{K}})^{-1} ({\mathscr{A}}_{K})\) which is by definition contained in \(\overline {{\mathscr{A}}}_{M}\).
Finally, we prove the minimality. It is easy to see that any family \({\mathscr{A}}^{\prime }_{M}\), \(M \subseteq N\), that satisfies the two conditions has to contain \(({\pi ^{M}_{L}})^{-1} ({\mathscr{A}}_{L})\), \(L \subseteq M\). By definition, \(\overline {{\mathscr{A}}}_{M}\) is the smallest σ-algebra that contains these σ-subalgebras (see (51)). This implies (52). □
After having defined the smallest extension of the family \({\mathscr{A}}_{M}\), \(M \subseteq N\), as one way to recover projectivity, we now come to the alternative way, which is by reduction of that family. More precisely, we define
We have the following characterisation of this family as the largest projective reduction of \({\mathscr{A}}_{M}\), \(M \subseteq N\).
Proposition 9
(Reduction of \({\mathscr{A}}_{M}\), \(M \subseteq N\)) The family \(\underline {{\mathscr{A}}}_{M}\), \(M \subseteq N\), satisfies the following two conditions:
-
1.
For all \(M \subseteq N\), \(\underline {{\mathscr{A}}}_{M}\) is contained in \({\mathscr{A}}_{M}\).
-
2.
For all \(L \subseteq M \subseteq N\), the canonical projection \({\pi ^{M}_{L}}\) is \(\underline {{\mathscr{A}}}_{M}\)-\(\underline {{\mathscr{A}}}_{L}\)-measurable.
Furthermore, for every family \({\mathscr{A}}_{M}^{\prime }\), \(M \subseteq N\), that satisfies these two conditions (where \(\underline {{\mathscr{A}}}_{M}\) is replaced by \({\mathscr{A}}^{\prime }_{M}\)), we have
Proof
In order to prove the first statement, let \(A \in \underline {{\mathscr{A}}}_{M}\). This means that
For all \(\bar {x} \in \mathsf {X}_{N \setminus M}\), we have
This means that \(A \in \text {tr}_{M}({\mathscr{A}}) = {\mathscr{A}}_{M}\), which concludes the proof of the first statement. Now we come to the measurability of the canonical projection \({\pi ^{M}_{L}}\). For this, we choose \(A \in \underline {{\mathscr{A}}}_{L}\) and have to show \(({\pi ^{M}_{L}})^{-1}(A) \in \underline {{\mathscr{A}}}_{M}\):
Finally, we have to prove the maximality. Let \({\mathscr{A}}_{M}^{\prime }\), \(M \subseteq N\), be a family that satisfies the two conditions. Then
This means that \({\mathscr{A}}^{\prime }_{M} \subseteq \underline {{\mathscr{A}}}_{M}\). □
By the definitions, we have
where equalities hold for M = N and M = ∅. More precisely,
This concludes the constructions for a given σ-algebra \({\mathscr{A}}\), without explicit reference to the channel \(\nu : \mathsf {X} \times {\mathscr{Z}} \to [0,1]\). We now couple the studied σ-algebras with the channel ν and therefore choose \({\mathscr{A}}\) to be the σ-algebra generated by the channel ν, that is σ(ν). We highlight this coupling by writing \({\mathscr{A}}^{\nu }\), as a particular choice of \({\mathscr{A}}\), and consider the family \(({\mathscr{A}}_{M}^{\nu })_{M \subseteq N}\) of its traces, together with the corresponding smallest projective extension \((\overline {{\mathscr{A}}}_{M}^{\nu })_{M \subseteq N}\) and the largest projective reduction \((\underline {{\mathscr{A}}}_{M}^{\nu })_{M \subseteq N}\). In the context of a channel, the traces of \({\mathscr{A}}^{\nu }\) have a natural interpretation. In order to see this, we first consider a configuration \(\bar {x} \in \mathsf {X}_{N \setminus M}\) and define the “constrained” Markov kernel
We denote the σ-algebra generated by \(\nu _{M, \bar {x}}\) by \(\sigma _{M, \bar {x}}(\nu )\). Taking all “constraints” \(\bar {x}\) into account, we then define
Proposition 10
Let \({\mathscr{A}}^{\nu } \subseteq {\mathscr{X}}_{N}\) be the σ-algebra generated by the Markov kernel \(\nu : \mathsf {X}_{N} \times {\mathscr{Z}} \to [0,1]\). Then for all \(M \subseteq N\) and all \(\bar {x} \in \mathsf {X}_{N \setminus M}\),
Proof
The σ-algebra \({\mathscr{A}}^{\nu }\) is the smallest σ-algebra that contains all measurable sets of the form
with some \(C \in {\mathscr{Z}}\) and a Borel set B in \({\mathscr{B}}([0,1])\). Now consider the \((M, \bar {x})\)-section of such a set A:
This shows that the sections \(\sec _{M, \bar {x}}(A)\) of measurable sets A of the form (55) generate \(\sigma _{M, \bar {x}}(\nu )\), which proves the first equality. The second equality is a direct implication of the first one. □
The results of the previous section, Theorem 6 and Proposition 7, apply to the information flows, defined for the projective families \((\overline {{\mathscr{A}}}_{M}^{\nu })_{M \subseteq N}\) and \((\underline {{\mathscr{A}}}_{M}^{\nu })_{M \subseteq N}\). These families take into account the information that is actually used by the channel ν. Therefore, we can interpret the corresponding marginal channels \(\hat {\nu }_{M}\) causally, where we have to distinguish two kinds of causality. For the projective family \((\overline {{\mathscr{A}}}_{M}^{\nu })_{M \subseteq N}\), the channel \(\hat {\nu }_{M}\) incorporates the information in any input configuration xK, \(K \subseteq M\), that is used by ν in conjunction with a context configuration \(\bar {x}_{N \setminus K} = \bar {x}_{N \setminus M} \bar {x}_{M \setminus K}\) outside of K. For the projective family \((\underline {{\mathscr{A}}}_{M}^{\nu })_{M \subseteq N}\), on the other hand, the channel \(\hat {\nu }_{M}\) incorporates the information used by ν that is solely contained in xM, independent of any context. When comparing a marginal channel \(\hat {\nu }_{M}\) with another marginal channel \(\hat {\nu }_{L}\), where \(L \subseteq M\), the corresponding information flows \(\overline {I}_{\xi } (X_{M\setminus L} \to Z | X_{L})\) and \(\underline {I}_{\xi } (X_{M\setminus L} \to Z | X_{L})\), respectively, quantify the causal effects in \(\hat {\nu }_{M}\) that exceed those in \(\hat {\nu }_{L}\). These measures will capture different causal aspects, where the difference can be large. This is illustrated by the following extension of Example 3.
Example 11
Let
where \({\mathscr{B}}(\mathbb {R})\) denotes the Borel σ-algebra of \(\mathbb {R}\). We define the channel simply by the sum of the input states, interpreted as a Markov kernel,

As \({\mathscr{B}}(\mathbb {R})\) is generated by the intervals \([r - \varepsilon , r + \varepsilon ] \subseteq \mathbb {R}\), the smallest σ-algebra \({\mathscr{A}}^{\nu }\) for which all functions ν(⋅;C) are measurable is generated by the following sets
For a set \(M \subseteq N\) and a context configuration \(\bar {x} = (\bar {x}_{i})_{i \in N \setminus M}\in \mathbb {R}^{N \setminus M}\), the \((M, \bar {x})\)-section of Ar,ε is given by
Therefore, the M-trace of \({\mathscr{A}}^{\nu }\), \({\mathscr{A}}^{\nu }_{M}\), is generated by the halfspaces
For |M| = 1, we recover the half lines, so that \({\mathscr{A}}^{\nu }_{\{i\}} = {\mathscr{B}}(\mathbb {R})\). The projective extension then leads to the largest σ-algebra, the Borel algebra of \(\mathbb {R}^{M}\):
Therefore, the marginal channel \(\hat {\nu }_{M}(x ; C)\) equals the usual marginal νM(x;C) for the projective extension. For the projective reduction, on the other hand, we obtain the trivial σ-algebra except for M = N:
In this case we have \(\hat {\nu }_{M}(x; C) = \nu _{\ast }(\mu ) (C)\) for M≠N and \(\hat {\nu }_{N}(x; C) = \nu (x; C)\), where μ is the joint distribution of the input variables.
We now consider the information flows associated with \(L \subsetneq M \subseteq N\), for the projective extension as well as for the projective reduction. In both cases these flows coincide with usual (conditional) mutual informations, in an instructive way. More precisely, for the extension we have
For the reduction, we obtain
Interestingly, (56) does not depend on L. The vanishing of the information flow for M≠N is due to the fact that the output of the channel, the sum x1 + ⋯ + xn, cannot be computed from a proper subset of the inputs. The flow of information only takes place if all inputs are given.
The following example, which is closely related to Example 1, highlights continuity issues of the introduced measures of information flow. They result from the fact that small changes in the mechanisms can lead to large differences of the involved σ-algebras.
Example 12
Consider two input variables, X and Y, and one output variable Z, with corresponding state spaces
Furthermore, consider two channels, ν and \(\nu ^{\prime }\), where ν simply copies the second input, y, and \(\nu ^{\prime }\) the first one, x. More precisely,

With 0 ≤ ε ≤ 1, we define the convex combination
For ε = 0, only the channel ν is acting. Obviously, we have \(\underline {I}_{\xi }(X \to Z) = \overline {I}_{\xi }(X \to Z) = 0\), as expected in this case, because ν simply copies y and is not sensitive to x at all. One might intuitively expect that the causal information flow from X to Z stays close to 0 if ε is small but greater than 0. However, this intuition is not reflected by the actual quantities, as defined in this article. It is easy to see that for ε≠ 0, \(\underline {I}_{\xi }(X \to Z) = \overline {I}_{\xi }(X \to Z) = I_{\xi }(X ; Z)\). Thus, these quantities are not at all sensitive to the parameter ε and behave discontinuously in the limit ε → 0.
6 Conclusions
Conditioning is an important operation within the study of causality. The theory of causal networks, pioneered by Pearl [17], introduces interventional conditioning as an operation, the so-called do-operation, that is fundamentally different from the classical conditioning based on the general rule \(\mathbb {P}(B | A) = \mathbb {P}(A \cap B)/\mathbb {P}(A)\). It models more appropriately experimental setups and avoids confusion with purely associational dependencies. Information theory has been classically used for the quantification of such dependencies, in terms of mutual information and conditional mutual information [20]. Within the original setting of information theory, the mutual information between the input and the output of a channel can be interpreted causally. In the more general context of causal networks, however, confounding effects make a distinction between associations and causal effects more difficult. In such cases, information-theoretic quantities can be misleading as measures of causal effects. In order to overcome this problem, information theory has been coupled with the interventional calculus of causal networks, and corresponding measures of causal information flow have been proposed [5, 6]. Given that such measures are based on the notion of an experimental intervention, which represents a perturbation of the system, it remains unclear to what extent they quantify causal information flows in the unperturbed system. As another consequence of the interventional conditioning, one cannot expect that causal information flow, as defined in [6], decomposes according to a chain rule. The current article is based on an idea of the author from 2003 which precedes the above-mentioned works on combining the theory of causal networks with information theory. It proposes a way to quantify causal information flows without perturbing the system through intervention. Instead, it is based on classical conditioning in terms of the conditional distribution \(\mathbb {P}(B | {\mathscr{A}})\), where the σ-algebra \({\mathscr{A}}\) is adjusted to the intrinsic mechanisms of the system. The derived information flow measure satisfies the chain rule and the natural properties of a general measure of causal strength postulated in [14]. The chain rule, together with the generalised Pythagoras relation from information geometry, provide powerful tools within the study of the problem of partial information decomposition [7, 8, 16].
Even though the introduced information flows satisfy natural properties, the aim of the present article is relatively moderate. For instance, the analysis is focussed on a simple network consisting of a number of inputs and one output, which is a strong restriction compared to the setting of [6]. The extension of the present work to more general casual networks remains to be worked out. Furthermore, this article does not address the important problem of causal inference [18]. In addition to these general directions of research, there are various ways to modify and extend the constructions of the present work and thereby potentially highlight further causal aspects of a given channel. The following perspectives are particularly important:
-
1.
In the present article, the information flow has been defined for a fixed finite measurable partition ξ of the state space \((\mathsf {Z}, {\mathscr{Z}})\) of the output variable Z. A natural further step would be to consider the limit of information flows with respect to an increasing sequence ξn, \(n = 1,2,\dots \), so that
$$ \bigvee_{n = 1}^{\infty} \sigma(\xi_{n}) = \mathscr{Z}. $$This limit will be an information flow measure that is independent of a particular partition.
-
2.
Throughout this article, the partition ξ has not been coupled with the σ-algebra of the channel ν. This is the smallest σ-algebra for which all functions ν(x;C), \(C \in {\mathscr{Z}}\), are measurable. Given that the channel is analysed with respect to the partition ξ, one can restrict attention to the smallest σ-algebra for which the functions ν(x;C), C ∈ ξ, are measurable. This will be a potentially small σ-subalgebra of the one generated by the channel. We would then have a natural coupling of the partition ξ with the information used by the channel.
-
3.
We started with the family \({\mathscr{A}}_{M}^{\nu }\) of M-traces of \({\mathscr{A}}^{\nu }\), the σ-algebra generated by ν, as the natural family associated with the channel. However, these traces do not form a projective family of σ-algebras. Such a projectivity is required for the chain rule for corresponding information flows. One can recover projectivity by extension and by reduction, leading to \(\overline {{\mathscr{A}}}^{\nu }_{M}\) and \(\underline {{\mathscr{A}}}^{\nu }_{M}\), respectively. Example 11 shows that the extension can lead to the largest σ-algebra and the reduction to the trivial one. Given this fact, one might ask whether the extension is too large and the reduction is too small to capture the causal aspects of ν. Even though we argued above that these two projective families associated with ν capture two different kinds of causal aspects, this question remains to be further pursued. One possible direction would be the analysis of the context-dependent traces of \({\mathscr{A}}^{\nu }\), that is the family of \(\text {tr}_{M, \bar {x}}({\mathscr{A}}^{\nu })\), \(\bar {x} \in \mathsf {X}_{N \setminus M}\). Instead of conditioning with respect to the join
$$ \text{tr}_{M}(\mathscr{A}^{\nu}) = \bigvee_{\bar{x} \in \mathsf{X}_{N \setminus M}} \text{tr}_{M, \bar{x}}(\mathscr{A}^{\nu}), $$one could adjust the conditioning to the individual σ-algebras \(\text {tr}_{M, \bar {x}}({\mathscr{A}}^{\nu })\). This would represent an important refinement of the presented theory.
References
Amari, S.-i.: Information Geometry and its Applications. Applied Mathematical Sciences, vol. 194. Springer, Tokyo (2016)
Amari, S.-i., Nagaoka, H.: Methods of Information Geometry. Translations of Mathematical Monographs, vol. 191. Oxford University Press, Oxford (2000)
Ay, N., Amari, S.-i.: A novel approach to canonical divergences within information geometry. Entropy 17, 8111–8129 (2015)
Ay, N., Jost, J., Lê, H.V., Schwachhöfer, L.: Information Geometry. A Series of Modern Surveys in Mathematics, vol. 64. Springer International Publishing, New York (2017)
Ay, N., Krakauer, D.C.: Geometric robustness theory and biological networks. Theory Biosci. 125, 93–121 (2007)
Ay, N., Polani, D.: Information flows in causal networks. Adv. Complex Syst. 11, 17–41 (2008)
Ay, N., Polani, D., Virgo, N.: Information decomposition based on cooperative game theory. Kybernetika 56, 979–1014 (2020)
Bertschinger, N., Rauh, J., Olbrich, E., Jost, J., Ay, N.: Quantifying unique information. Entropy 16, 2161–2183 (2014)
Bossomaier, T., Barnett, L., Harré, M., Lizier, J.T.: An Introduction to Transfer Entropy. Springer International Publishing (2016)
Cover, T.M., Thomas, J.A.: Elements of Information Theory, 2nd edn. Wiley-Interscience, Hoboken (2006)
Dudley, R. M.: Real Analysis and Probability, 2nd edn. Cambridge Studies in Advanced Mathematics, vol. 74. Cambridge University Press, Cambridge (2002)
Granger, C.W.J.: Investigating causal relations by econometric models and cross-spectral methods. Econometrica 37, 424–438 (1969)
Granger, C.W.J.: Testing for causality: A personal viewpoint. J. Econ. Dyn. Control 2, 329–352 (1980)
Janzing, D., Balduzzi, D., Grosse-Wentrup, M., Schölkopf, B.: Quantifying causal influences. Ann. Stat. 41, 2324–2358 (2013)
Kakihara, Y.: Abstract Methods in Information Theory. Multivariate Analysis, vol. 4. World Scientific, New Jersey (1999)
Lizier, J., Bertschinger, N., Jost, J., Wibral, M.: Information decomposition of target effects from multi-source interactions: Perspectives on previous, current and future work. Entropy 20, 307 (2018)
Pearl, J.: Causality: Models, Reasoning, and Inference. Cambridge University Press, Cambridge (2000)
Peters, J., Janzing, D., Schölkopf, B.: Elements of Causal Inference: Foundations and Learning Algorithms. Adaptive Computation and Machine Learning Series. The MIT Press, Cambridge (2017)
Schreiber, T.: Measuring information transfer. Phys. Rev. Lett. 85, 461–464 (2000)
Shannon, C.E.: A mathematical theory of communication. Bell Syst. Tech. J. 27, 623–656 (1948)
Acknowledgements
The author is grateful for valuable comments of two anonymous reviewers. He acknowledges the support of the Deutsche Forschungsgemeinschaft Priority Programme “The Active Self” (SPP 2134).
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Dedicated to Jürgen Jost on the occasion of his 65th birthday.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ay, N. Confounding Ghost Channels and Causality: A New Approach to Causal Information Flows. Vietnam J. Math. 49, 547–576 (2021). https://doi.org/10.1007/s10013-021-00511-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10013-021-00511-w