
Abstract
Human activity recognition (HAR) generates a massive amount of the dataset from the Internet of Things (IoT) devices, to enable multiple data providers to jointly produce predictive models for medical diagnosis. That the accuracy of the models is greatly improved when trained on a large number of datasets from these data providers on the untrusted cloud server is very significant and raises privacy concerns. With the migration of a deep neural network (DNN) in the learning experience in HAR, we present a privacy-preserving DNN model known as Multi-Scheme Differential Privacy (MSDP) depending on the fusion of Secure Multi-party Computation (SMC) and 𝜖-differential privacy, making it very practical since existing proposals are unable to make all the fully homomorphic encryption multi-key which is very impracticable. MSDP inputs a secure multi-party alternative to the ReLU function to reduce the communication and computational cost at a minimal level. With the aid of experimental verification on the four of the most widely used human activity recognition datasets, MSDP demonstrates superior performance with very good generalization performance and is proven to be secure as compared with existing ultramodern models without breach of privacy.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Human activity recognition (HAR) generates massive amounts of data from the synergy of communication [1,2,3] and the medical Internet of Things [4, 5]. Analysis of HAR datasets is useful since it enhances the health status of patients as experts have demonstrated a clear correlation between overweight, physical activity, cardiac arrest, obesity, and metabolism-related syndromes. However, preserving the privacy of these datasets is a fundamental problem for many real-world applications. To avoid the violation of user’s privacy and the exposure of healthcare providers to legal (HIPPA/HITECH law) [6] subpoenas, two major privacy-preserving techniques have been proposed to control the high risk of leakage to address privacy concerns. The two major algorithms are fully homomorphic encryption [7, 8] and differential privacy [9].
Differential privacy as a data distortion method perturbs the existing raw dataset by the addition of statistical noise or dataset swapping to avoid inferring information about any specific record whiles retaining the statistical property over the processed datasets. The injection of statistical noise is independent of the magnitude of the data. Consequently, considering a very large dataset, a considerable level of data privacy preservation can be accomplished by the addition of a small amount of noise. Data owners also require careful calibration to balance privacy and model usability. Fully homomorphic encryption [30] has demonstrated more promising solutions towards the protection of privacy of user data. It allows data owners to encrypt their datasets with their individual public keys before outsourcing computations to the cloud service provider. Mathematical computations and training of the models are performed by the cloud server on the encrypted dataset to output ciphertext results. The cloud server cannot access any of the user information at this point since it does not possess the private keys. As the size of data and computation increases, Fully Homomorphic Encryption (FHE) [22] has been integrated into deep learning to take advantage of the convenience, flexibility, storage, and higher computational capabilities to process inference queries. On the grounds that DNN has also been increasingly used in various human activity recognition tasks to exhibit excellent levels of performance, obviously, the generalization of the performance of deep neural network models is distinctly stimulated by the value and capacity of the dataset for training the model.
To improve on the training models, collaborative learning has been the preferred choice with the consolidation of multiple datasets which is extremely difficult for an individual data owner to provide.
Motivation
Consider the deployment of Industrial Internet of Things (IIoT) [28] or Internet of Medical Things (IoMT) [29] devices by different industry or medical centers. These wearable devices are used to recognize human activities to aid in the production of diagnostic models, with the potential to monitor the health-related behavior of individuals from these encrypted patient datasets.
However, this paper is motivated by three fundamental issues: (i) The black-box properties of the deep neural network have the potential of leading to privacy concerns of applications on data obtained from human activity recognition, i.e., it is very difficult to pre-expect exactly what the networks learn from the datasets, due to result of the optimization; they possibly learn features that could accurately estimate user demographics without any intentional design. This might expose the datasets to the malicious cloud server or unauthorized users, e.g., hackers, which results in the disclosure of the user’s confidential data. (ii) The malicious cloud server is untrusted and might render the data vulnerable to attacks during storage and computation. During this time, data owners are unable to control the usage of their private data by the cloud service provider. (iii) With respect to the anticipated malicious behavior of the cloud server, multiple data owners may choose a pre-treat FHE Privacy-Preserving (PP) technology to encrypt individual raw datasets prior to outsourcing the datasets to an untrusted cloud server for computational analysis and data storage. Another interesting issue evolves from whether all the different FHE schemes from the individual data owners can be transformed to multi-key in MK-FHE [24] to aid the data aggregation of the training of the collaborative deep learning model. The construction of a privacy-preserving deep learning model to learn from the aggregated datasets from multiple parties with multiple keys still remains a challenge in both industry and academia.
With the exploitation of the unique potential of differential privacy (DP) and careful examination of existing FHE primitives, we present a collaborative privacy-preservation scheme over encrypted data from multiple parties with different public keys to address these issues. This paper proposes an innovative paradigm named Multi-Scheme Privacy-preserving DNN learning with differential privacy (MSDP). This is to resolve the outlined issues. The inherent blueprint depends on demonstrating that regardless of the aggregated ciphertext encrypted with multiple encryption keys, the cloud server will be allowed to inject the corresponding different statistical noise based on different queries of the data owner. This proposed scheme differs from existing work where statistical noise is infused by the DP before outsourcing to the cloud server. The presence of the Evaluate algorithm enables the user to generate ciphertext ψ of the required result. In the honest-but-curious model, MSDP architecture expresses the necessary security [10] assurance based on differential privacy and its underlying FHE [22] cryptosystem, i.e., there is a highly negligible chance by hackers to leak the privacy of the dataset since they are globally protected by encryption. MSDP offers a more feasible approach while improving the accuracy and efficiency of the computations.
In the MSDP framework, our assumption depends on data analyst (DA) and computational evaluator (CE) may not collude since both participating entities are curious and semi-honest. During these stages in MSDP primitive, several data providers do not collude with one another. The principal contribution to this work can be summarized threefold as follows:
-
In our proposed MSDP, a collaborative privacy-preserving DNN architecture gives the computational evaluator the authority to inject different statistical noise to the offloaded datasets based on the distinct queries from the DA without delegating this task to the data providers. In MSDP, the computational evaluator (cloud server) is not required to choose any type of FHE [22] scheme for data providers before meeting the encryption requirements of the computational evaluator.
-
The Multi-Scheme privacy-preserving DNN scheme is capable of aggregating data provider’s datasets, preserving the privacy of the confidential datasets, intermediate results, and the learning model. MSDP has greatly improved the accuracy and efficiency of the training model while circumventing the errors that dramatically degrade the accuracy with the introduction of alternative nonlinear ReLU function polynomial approximation and Batch Normalization (BN) without privacy leakages.
-
MSDP is validated on a randomized dataset with 𝜖-DP rather than on the encrypted dataset to improve the productivity and accuracy of the learning model. Our simulations indicate the practicality and feasibility of our model.
The organization of the rest of the paper is as follows: Section 3 presents some preliminaries and the definition of FHE related to this paper. The proposed architecture is given in Section 4. Experimental results for the proposed architecture will be demonstrated in Section 5, Section 6 deals with the comparative evaluation of MSDP, and Section 7 performs the security analysis of our innovative model while Section 8 completes our whole work.
2 Related works
A majority of the existing privacy-preserving methods in DNN are based on Secure Multiparty Computation (SMC) to ensure a possible method for computational privacy. This allows the entity executing the privacy-preserving algorithm to be replaced with multiple entities during the training of the model in the distributed settings, while individual data owners remain oblivious to both the input dataset and the intermediate output. One of the promising alternatives currently is 𝜖-DP which has gained considerable research attention for the provision of privacy against adversaries. Since diverse records or columns of a database may contain unrelated confidential data [11], 𝜖-DP has been generalized to consider all these properties. Personalized differential privacy [12], therefore, assigns a privacy budget separately to each record in the database, not the entire database which will also improve on the commutation involving data utility and privacy. Output to queries basically may depend predominantly on a subset of entire records, while the budget will be the only record lowered therefore giving additional independence to the data requesters to efficiently formulate their queries. Exploring the synergy between 𝜖-DP and SMC on a joint distribution of multiple entities is a significant and difficult challenge [13]. Considering the joint multi-party domain, given n local datasets {D1,D2,D3,...Dn} with a function f, computation of a \(f({\bigcup }_{i=1}^{n} D_{i})\) with the aim of satisfying 𝜖-differential privacy on each of the local datasets D is a difficult problem. Based on the SHAREMIND SMC framework [14, 15] Pettai et al. [16] demonstrated the fast method of applying DP with less noise on top of SMC in order to obtain reasonable accuracy and efficiency, while Goryczka et al. [17] also explored the potential of differential privacy and secure multi-party computations to propose an enhanced fault-tolerant scheme to solve the complexities of secured [18] data aggregation in distributed settings. Dataset aggregation is achieved with the aid of their enhanced secured multi-party computations schemes. 𝜖-DP of the intermediate results is achieved either by distributed Laplace of geometric mechanism while the approximated 𝜖-DP is achieved by diluted mechanism before making the data public. The unprecedented accuracy of machine learning algorithms is also confronted with privacy concerns. Machine learning (ML) has therefore been turned into privacy-preserving with differential privacy protection. This is to enable hospitals, insurance companies, and other corporate bodies to generate large-scale volumes of data to benefit from this technology due to the successful achievement of ML methods is directly proportional to the amount of dataset accessibly during the learning processes.
3 Preliminaries
In this section, we design our MSDP algorithms by composing a number of existing tools based on the literature, namely NTRU Encryption [23], Multikey Homomorphism [24], Laplace mechanism [25] of Dwork, deep neural network, formal definition, security model and system model as the building blocks used throughout the whole paper. In this paper, we are motivated by FHE from NTRU primitive with modification of NTRUEncrypt.
This unit presents specific notations and FHE schemes applied in our framework in Table 1.
Definition 1
(NTRU Encryption). Let n,q,p,σ,α be the parameters. The parameters n and q define the rings \(\mathcal {R}\) and \(\mathcal {R}_{q}\). \(p\in \mathcal {R}_{q}^{\times }\) defines the plaintext message space as \(\mathcal {P}=\mathcal {R}/p\mathcal {R}\). This must be a polynomial with “small” coefficients with respect to q while requiring \(\mathcal {N}({p}) = \rvert \mathcal {P}\rvert = 2^{\varOmega (n)}\) at the same time to enable lot of bits to be encoded at once. Typical choices applied in the schemes are p = 3 and p = x + 2 but in this scenario since q is prime, we may also choose p = 2. By the reduction of the modulo pxi’s can be written in any element as \({\sum }_{0\leq i<n}\epsilon _{i}x^{i}p\) with 𝜖i ∈ (− 1/2,1/2). Using the fact that \(R=\mathbb {Z}[x]/(x^{n}+1)\), we therefore assume that any element of \(\mathcal {P}\) is an element of \(\mathcal {R}\) with the infinity norm ≤ (deg(p) + 1)⋅∥ p ∥. α is the R-LWE noise distribution parameter. Finally, the parameter σ is the standard deviation of the discrete Guassian distribution used during the key generation process. Given the security parameter k, NTRUEncrypt scheme can be specialized as follows:
-
KeyGen(1k): The key generation algorithm samples polynomials \(f^{\prime }\) from \(\mathcal {D}_{{z}^{n}},\sigma ;\) let f=p.f’+ 1 (f mod q ) \(\notin \mathcal {R}^{\times }_{q}\) then resample g from \(\mathcal {D}_{{z}^{n}}\); if (g mod q ) \(\notin \mathcal {R}^{\times }_{q}\), by resampling the secret key and public key will return sk = f and \(pk=h=pg/f \in \mathcal {R}^{\times }_{q}\)
-
Enc(pk,m): Given ciphertext \({\mathscr{M}}\in \mathcal {P}\), set s,e↩Υα and return ciphertext \(\mathcal {C} = hs +p\epsilon +{\mathscr{M}} \in \mathcal {R}_{q}\)
-
Dec(sk,c): Given ciphertext \(\mathcal {C}\) and secret key f, compute \(\mathcal {C}^{\prime }= f.\mathcal {C} \in \mathcal {R}_{q}\) and return \(\mathcal {C}^{\prime }\) mod p
3.1 MS-FHE in MSDP architecture
The Multi-Key Fully Homomorphic Encryption (MK-FHE) [24, 26, 27] scheme in MSDP comprises six algorithms: KeyGen, Enc, Dec, Eval, uDecrypt and uEvaluate. These primitives are basically well-defined as follows:
-
KeyGen(1k): For a security parameter k, outputs a public key pk, a private key sk, and a (public) evaluation key ek.
-
Enc(pk, m): Given a public key pk and a message m, outputs a ciphertext c.
-
Dec(sk,c): Given a private key sk and a ciphertext c, outputs a message m.
-
Eval(\(ek, \mathcal {C}, c_{1}, . . . , c_{l}\)): Given an evaluation key ek, a (description of a) circuit \(\mathcal {C}\) and l ciphertexts c1,...,cl, outputs a ciphertext c.
-
Decrypt: It is a deterministic scheme when input a ciphertext ψ and scheme-key pairs (si,ski), outputs a plaintext: \(x \leftarrow \) Decrypt(〈s1,sk1〉,...〈st,skt〉,ψ), where si indicates scheme ε(si) and ski is a secret key generated by KeyGen(si)
-
uEvaluate: It takes the circuit \(\mathcal {C}\) as input, a number of 3-tuples 〈si,pki,ψi〉, 1 ≤ i ≤ t, where si is an index indicating scheme εsi, pki is a public key generated by KeyGensi and ψi is a ciphertext under encryption key pki and scheme εsi, i.e., \(\psi _{i} \leftarrow \) Enc(si)(pki,xi) for some plaintext xi. The output of uEvaluate is a ciphertext: ψ := uEvaluate\((\mathcal {C},\langle s_{1},pk_{1},\psi _{1}\rangle , . . . , \langle s_{t},pk_{t},\psi _{t}\rangle )\).
3.2 Dynamic 𝜖-differential privacy
Let us recollect the basic description of 𝜖- differential privacy.
Definition 2
(𝜖-DP). A randomized mechanism \({f}:{D} \rightarrow \mathcal {R}\) satisfies 𝜖-differential privacy (𝜖-DP) if for any adjacent \(\mathcal {D},\mathcal {D}^{\prime } \in \mathcal {D}\) and \(\mathcal {S}\subset \mathcal {R}\)
where the probability Pr[⋅] is taken over the randomness of mechanism f and also shows the risk of privacy disclosure.
The definition above is contingent on the notion of adjacent input \(\mathcal {D}\) and \(\mathcal {D}^{\prime }\) which is domain-specific and it is typically chosen to capture the contribution to the mechanism’s input by a single individual. 𝜖 is a predefined privacy parameter for controlling the privacy budget; the smaller 𝜖 the stronger the privacy protection. The formal definition of sensitivity is given below (Definition 3).
Definition 3
(Sensitivity) Assume f is a numeric query function that maps a datasets D into a d-dimensional real space \(\mathbb {R}^{d}\), i.e., \(f:D \leftarrow \mathbb {R}^{d}\). For a pair of neighboring datasets D and \(D^{\prime }\), the sensitivity f is defined as:
where \(\|\cdot \|_{L_{1}}\) denotes the L1 norm.
Theorem 1
(Laplace mechanism) The Laplace mechanism is a prototypical 𝜖-differentially private algorithm, therefore allowing the release of an approximate to an arbitrary query with values in \(\mathbb {R}^{d}\). Let \(\sigma \in \mathbb {R}^{+}\), and f is a numeric query function that maps a domain D into d-dimensional real space \(\mathbb {R}^{d}\), i.e., \(f:D\leftarrow \mathbb {R}^{d}\). The computation \({\mathscr{M}}\)
provides 𝜖-differential privacy, where the noise Lap1(σ)(i ∈ [1,d]) is drawn from the Laplace distribution with scaling parameter σ, whose density function is:
At this point, the parameter σ = △f/𝜖 is controlled by the privacy budget 𝜖 and the function’s sensitivity △f
3.3 System model
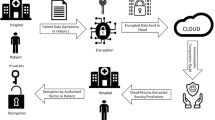
MSDP scheme is a composition of four different parties, involving groups of data providers (DP), computational evaluator (CE), data analyst (DA) (i.e., individual data owners), and crypto service provider (CSP). More specifically, respective parties in this system are explained in Fig. 1.
-
DP: In this setting the assumption is DP contains n DP, denoted by {P1,P2,Pn}, each DP Pi ∈ DP is a cloud user who keeps dataset \(D_{i}=\left \{\left ({x}_{j}^{i},y^{i},_{j}\right )\right \} \in X\times Y:j\in [1,p_{i}], i\in [1,n]\}\) with data records ri = pub(r)∥sec(r), which is the concatenation of public fields pub(r) and secret field which is denoted as sec(r). Each of the Di(i ∈ [1,n]) is of size pi with data vector \({x^{i}_{j}}\mathbb {R}\), and the corresponding binary label \({y^{i}_{j}}\in Y:=\{0,1\}\). To protect the privacy of the dataset, each of the DP Pi ∈ DP independently generating a pair of public and private keys \((pk_{i},sk_{i})\leftarrow keyGen(1^{\lambda })\). They then encrypt their sensitive fields generating a ciphertext: ci = pubri∥Enc(pki,sec(ri)).
Fig. 1 
System model
-
CE: CE is honest-but-curious and holds the data center, it provides the aggregated database by constructing the encrypted database \(Enc (\mathcal {X})\), which is a composition of the public key and ciphertext tuples \( \langle pk_{i},\mathcal {c}_{i}\rangle \) from each data provider. CE combines Laplace noise ηi to the encrypted data for individual DP. The noised-added encrypted dataset can be computed by \(Enc(pk_{i},\widehat {c}_{i})\bigotimes Enc(pk_{i},\eta _{i})\). The noised-added dataset encrypted with diverse public keys is then published by the CE.
-
CSP: The CSP simply offers online cryptographic assistances to client. For instance, CSP can manage encrypted and decrypted ciphertext transmitted by CE.
-
DA: The DA are most of the time individual clients to the cloud service provider and they are capable of gathering feature vectors of their records. In situations where DA queries the CE for secure predictive services, DP then encrypts the queries proceeded by outsourcing to the CE.
-
Malicious adversaries: In this setting, adversaries are not counted among participants in MSDP architecture. They rather exist since we want to consider the confidentiality of our architecture. This work is basically interested in any malicious adversaries capable of corrupting any subsection of t > N entities as considered. During the process of analyzing the privacy of MSDP, our assumption is based on adversaries possessing strong fundamental knowledge

The interactive scenario between the entities and components is illustrated in Fig. 1.
3.4 Problem statement
In this setting, we assume that the set of DP comprises n DP, expressed as {P1,P2,Pn}, each DP Pi ∈ DP is a cloud client keeping dataset \(D_{i}=\left \{\left ({x^{i}_{j}},y^{i},_{j}\right )\right \} \in X\times Y:j\in [1,p_{i}], i\in [1,n]\}\) with data records ri = pub(r)∥sec(r), concatenation of public fields pub(r) with corresponding private fields which is denoted as sec(r). Each of the Di(i ∈ [1,n]) comprises pi with dataset vector \({x^{i}_{j}}\in \mathbb {R}\), and resultant binary label \({y^{i}_{j}}\in Y:=\{0,1\}\). Owing to the confidential concerns, each DP Pi ∈ DP independently generating pairs of public and private keys \((pk_{i},sk_{i})\leftarrow keyGen(1^{ \lambda })\) to encrypt individual local data prior to outsourcing to CE for data storage and mathematical computations. On these premises, ciphertext under diverse schemes or public keys, CE produces a synthetic data, whereby distinctive statistical noises are added based on dissimilar applications.We therefore discharge the synthetic dataset with 𝜖-DP to perform a PP DNN model on our synthetic datasets.
As an MSDP example, we study the problems below:
-
Towards overcoming key management budget reduction, DP {P1,P2,...,Pn} should be capable of generating their own pk and sk keys without interacting with DA.
-
Furthermore, sustaining computations over encrypted space, CE constructs an aggregated encrypted database \(\{Enc(\mathcal {X})\overset {\vartriangle }{=}\{\langle pk_{i},c_{i} \rangle \}\}\) and these encryption schemes from DP should possess the characteristics of some malleability and homomorphism.
3.5 Threat model
Assumption in MSDP is that entities involved in the privacy-preserving multi-party process data providers Pi ∈ DP(i ∈ [1,n]), data analyst, computational evaluator, and cryptographic service providers are non-colluding (i.e., curious-but-honest) adversaries rigorously following our algorithm. On the other hand, their interest is in learning or gathering confidential information throughout the training of the privacy-preserving model. Based on this security assumption, our scheme presents an active malicious adversary Ad in the learning model. The main aim of Ad is to try decrypting the challenge DP’s original encrypted data and the challenge CE′s encrypted model parameters with the resulting potential:
-
Ad may eavesdrop entire interactions between DP and CE to gain access to the ciphertext to unleash an active attack to tamper, intercept, and forge the transferred messages.
-
Ad may compromise CE to presume the value of the plaintext of the entire ciphertexts offloaded from DPs, and the whole ciphertexts driven from CSP by implementing the training processes.
-
Ad may corrupt some DP in generating plaintext data of another ciphertext from other DPs
-
Ad may compromise an individual or multiple DPs, with the exemption of attacking DPs, gaining access to individual decryption potentials, to guess entire ciphertexts belonging to the DP attack.
Conversely, Ad is therefore prevented from compromising: (i) both CE and CSP concurrently, (ii) the challenge DPs. We state that such constraints are normal in the cryptographic protocol.
3.6 Design goals
As a PP collaborative deep learning model, MSDP enables CE to train and construct models over collaborative DPs while responding to data analyst predictive queries. MSDP should meet the following requirement to resolve the adversary and security model:
-
Classifier accuracy: MSDP should be capable of classifying correctly for every query from the data analyst while making accurate predictions with high probabilities.
-
Privacy-preserving: Provision of privacy guarantee by the system should be assured without disclosing confidential information about DP’s and classifiers. To achieve our security target, the learning and prediction stage should remain constructed in ciphertext settings. The data analyst is the only one who will be capable of obtaining the decrypted intermediate results by the application of the private key after the CE has responded to a predictive query. The CSP is not revealed therefore making it hidden to DP.
-
Flexibility: During MSDP, the CSP is not a static service provider. In this domain, the CSP can be different entities or institutions publishing their corresponding different schemes or different public keys based on different functions or motivations.
4 Proposed MSDP architecture
MSDP architecture focuses on the training of a classification model over aggregated datasets from multiple DP with the aim of offering confidential prediction services for DA with this classification model. In this instance, a set of n mutually non-colluding DPs {P1,P2,...Pn} outsourced their encrypted data to the CE for storage while allowing it to perform some computational operations on these concatenated datasets. In other to promote the processing over encrypted dataset through possibly diverse fully homomorphic encryption schemes or with even dissimilar public keys, the Multi-Scheme FHE algorithm will contribute to our PP technique while concatenating encrypted datasets from DP prior to offloading to CE. The application of offloaded concatenated ciphertext enables the CE to construct a classification model while storing and maintaining the model in an encrypted form. The classification model in the CE is therefore ready to respond to queries from DP.
4.1 MSDP overview
This section gives a description of the MSDP scheme as a solution to the problem formulated in Section 4. We outline a comprehensive construction of MSDP and demonstrate procedures to achieve secure offloading of data and classification in a secure environment.
-
Secure dataset offloading. DP encrypts their individual datasets with their preferred choice of Fully Homomorphic encryption primitive to enable them to securely outsource their dataset to the computational evaluator. Each DP individually produces a pair of public/secret keys coupled with the keyGen(1λ) to outsource encrypted dataset under individual public keys to CE. During this domain, the algorithm for the aggregated private data computation depends on εi which is capable of concatenating all the dissimilar public keys into ciphertext under the same public key.
-
Noise adding. At this stage, based on the differential application of queries from the data analyst, the computational evaluator CE adds differential Laplace statistical noise to the offloaded ciphertext. Laplace statistical noise then encrypted under related outsourced constructed database \(Enc(\mathcal {X})\)
-
Deep learning-based 𝜖-DP. The DA is capable of learning the DNN model with εi-DP on the noise-added encrypted dataset.
4.2 MSDP detail design
This subsection offers a comprehensive narrative of the MSDP algorithm basically dividing it into three stages: PP training classifiers, generating PP prediction query from DA, PP intermediate results. The general construction of MSDP is shown in Algorithm 3.
4.2.1 Data outsourcing
In this subsection, we discuss our proposed MSDP model. The main work is directed towards the training of classifiers over encrypted settings with data contributed from multiple DP {D1,D2,...Dn}. In this scenario, all parties are encrypting their data with a different fully homomorphic encryption scheme. For a lucid discussion, initially, a setup process for all the schemes is independently initialized and distribute the system confidential parameters. Furthermore, during this stage, depending on diverse motivations or objectives may determine CSP elements with their special functions. Therefore, as soon as the CSP is established, it then distributes private or public key pairs {ski,pki}. In this process, each of the data providers individually generates pairs of public and secret keys pki,ski \(\leftarrow \) \(KeyGen(1^{\leftthreetimes })\). Then, they encrypt their secret fields to generate cipher: ri = pub(ri)||Enc(pkisec(ri). All DP outsourced their encrypted data ψi, along with encryption key pki to CE.
4.2.2 Addition of noise
After outsourcing the datasets, the CE therefore generates noise \(\left \{\eta ^{i}=\left ({\eta ^{i}_{1}},{\eta ^{i}_{2}},...,{\eta ^{i}_{n}}\right )\right \}\) for each of the DP Pi ∈ DP. CE constructs an aggregated encrypted noised database \(Enc (\mathcal {X}^{\prime })\). At this stage, DA can download the noise-added aggregated ciphertext which is now in the form \(Enc(\mathcal {X}^{\prime })\). The data analyst can therefore perform any computation for an n-input function \(\mathcal {C}\) on the aggregated noise database as specified in Section 5.
4.2.3 Deep learning-based 𝜖-differential privacy
On one occasion, the transformed query results will be computed, and CE sends it back to the DP. As the data provider obtains the encrypted query, the ciphertext ψi decrypts to \(\mathcal {C}(\mathcal {X})\) with \(Decrypt(sk_{1},....,sk_{n};\psi )=\mathcal {C}(X)\) look.

4.3 Polynomial approximation of ReLU
Our proposed model MSDP for a PP classification on DNN has three major requirements: data privacy, the efficiency with reasonably low multiplicative intensity, and higher precision closer to the ultramodern convolutional neural network (CNN). The ReLU function and max pooling functions with high multiplicative depth in the CNN architecture are incompatible with the efficiency requirement of MSDP. At this stage, we modify the CNN model to replace the layers with higher multiplicative intensity, i.e., max pooling and ReLU with lower multiplicative intensity polynomial layers into the CNN model, with a reduction in degradation of the accuracy of the classification. Our aim is to approximate the ReLU function. We, therefore, focus on approximating the ReLU function derivatives instead approximating the rectified linear unit function. The derivative of the activation function is a non-differentiable function similar to a step function at point 0. In situations where the function is the non-infinitely or continuously differentiable function, we thereby approximate it to an appreciable accuracy. We therefore perform an experiment on the derivative of the rectified linear unit function. The sigmoid activation function is an infinitely differentiable, bounded, and continuous function. The structure is similar to the derivative of the rectified linear unit in the large intervals. Furthermore, the sigmoid function is approximated with the polynomials by finding the integral of the polynomial and using it as the activation function. To achieve our goal, we integrate the polynomial approximation of the ReLU plus BN while substituting max pooling by the sum pooling possessing a null multiplicative depth. Furthermore, each ReLU layer is added to the BN layer to enforce a restrictive stable distribution during the entry of the ReLU.The BN layers are therefore added to the training and the classification stage to circumvent high accuracy degradation involving the training stage and classification stage with respect to numerous alterations to the CNN model as described in Table 2, Fig. 2, and Algorithm 1.

Approximation of Rectified Linear Unit Function
After outsourcing the datasets, the CE therefore generates noise \(\left \{\eta ^{i}=\left ({{\eta }_{1}^{i}},{\eta }_{2}^{i},...,{\eta }_{n}^{i}\right )\right \}\) for each of the DP Pi ∈ DP. CE constructs an aggregated encrypted noised database \(Enc (\mathcal {X}^{\prime })\). At this stage, DA can download the noise-added aggregated ciphertext which is now in the form \(Enc(\mathcal {X}^{\prime })\). The data analyst can therefore perform any computation for an n-input function \(\mathcal {C}\) on the aggregated noise-database as specified in Section 5.
4.3.1 Deep learning-based 𝜖-differential privacy
On one occasion, the transformed query results will be computed, and CE sends it back to the DP. As the data provider obtains the encrypted query, the ciphertext ψi decrypts to \(\mathcal {C}(\mathcal {X})\) with \(Decrypt(sk_{1},....,sk_{n};\psi )=\mathcal {C}(X)\) look.
Our proposed MSDP proposed scheme is a composition of privacy-preserved feedforward propagation (Algorithm 2) and backpropagation (Algorithm 3) with the specifics in Algorithm 3.


5 Simulation results
In this segment, we provided experimental outcomes of the MSDP algorithm on data from multiple data owners in the cloud while evaluating the presented algorithm with respect to aggregated encryption time, the cost of deep neural network computation, and the accuracy of our classification model.
5.1 Datasets
In this work, training and testing data are chosen from four benchmark datasets encrypted and outsourced to the cloud representing the typical drawbacks of human activity recognition.
SBHARPT
SBHARPT is available publicly online. HAR signals are generated by cellphones with integrated triaxial gyroscope and accelerometer. These devices are attached to the waist possessing a constant frequency rate of 50 Hz to collect 12 different types of activity signals such as walking downstairs, standing and laying, walking upstairs, sitting, and 6 potential activity evolutions: stand-sit, lie-sit, sit-lie, sit-stand, lie-stand, and stand-lie. This database contains 815,614 proceedings of data from sensors.
Opportunity
Dataset from the Opportunity activity recognition is a composition of atomic activities generated with a sensor-based environment in excess of 27,000. The Opportunity dataset comprises recordings of 12 subjects with the application of 15 interconnected sensors along 72 sensors with 10 modalities, incorporated into the WBAN attached to the human body. In this experiment, we consider the sensors on the body, which include initial measurement units and a 3-axis accelerometer. Each of the sensor channels is therefore managed as an individual channel with a whole channel of 113. Opportunity dataset captures different postures and gestures while ignoring the null class. It is a composition of an 18-class classification challenge
PAMAP2
PAMAP2 is human physical activity data generated from 18 activities such as cycling, rope jump, Nordic walk, dancing, lie, sit, stand, run, vacuum clean, iron, ascend and descend stairs, playing soccer recorded from 9 participants (1 female and 8 males), in addition to a variety of leisure activities such as computer work, watch TV, drive a car, clean house, and fold laundry. The gyroscope, accelerometer, magnetometer, and heart rate datasets were recorded via 9 subjects wearing 3 IMU with the aid of a heart rate monitor. The 3 caliber wireless IMU with a selected frequency of 100 Hz: on the dominant arm 1 IMU is placed on the wrist and on the chest respectively, while 1 IMU is also on the dominant side of the ankle. The human recognition monitor with a sampled frequency of 9 Hz is therefore used to monitor the system over 10 h.
Smartphone
Smartphone dataset as public dataset is recorded with a waist-mounted cell phone with inertial sensors embedded in the component to collect 30 subjects of activities of daily living (ADL). Thirty volunteers between the ages of 19–48 years were employed in this experiment. Each of the volunteers was engaged in six activities, i.e., walking-upstairs, walking, walking-to-downstairs, standing, sitting, and laying while recording with a Samsung Galaxy S II on their waist. With the aid of the inserted gyroscope and accelerometer, 3-axial angular velocity and 3-axial linear acceleration were captured at a constant rate of 50 Hz. In order to manually label the dataset, the investigations were recorded with a video camera. The dataset was arbitrarily segregated into 70% as learning data and 30% as test data respectively. Noise filters are applied on the accelerometer and gyroscope for the pre-processing while sampling them in a static-width sliding window of 50% overlap and 2.56 s for 128 readings/window. The signals from the accelerometer and gyroscope possess body and gravitational motion devices which stayed disjointed with butter worth limited-pass screened hooked onto gravity and the accelerated body. The assumption is that gravitational force possesses only limited frequency components, leading to the application of filters with 0.3-Hz termination frequency. In each window, features in the form of vectors were obtained with the calculation of variables from the frequency and time settings grounded on proposed and comparative techniques.
6 Comparison evaluation
This section demonstrates how the MSDP algorithm can protect the data privacy based on MS-FHE cryptosystem and 𝜖-differential privacy for deep learning by the addition of noise statistically to the aggregated input. Note that all experiments were carried out on iMac with the specification of 3.4 GHz Intel Core i5, NVIDIA GeForce GTX 780M 4096 MB, and 16 GB 1600 MHz DDR3 RAM. The datasets for this experiment are available public HAR data from PAMAP2, Smartphone, Opportunity, and SBHART datasets. The aggregated samples of datasets are randomly partitioned into 70% of training, 20% validation with 10% testing. We trained a series of different binary classifiers with MSDP based on the four aggregated datasets from HAR. The learning parameters in our experiments are set to iterationmax = 200, while η = 0.01.
Accuracy
The accuracy loss in MSDP algorithm is analyzed; we performed our classification based on the parameters in our proposed MSDP algorithm and compared it with the non-privacy preserving neural network model.
Table 3 shows the average classification accuracy of the MSDP model and the conventional deep learning computational model which is a non-privacy preserving model. Our algorithm attains promising accuracy as compared to the conventional non-privacy-preserving DNN computational model as exhibited in Fig. 2. The effectiveness of our training model on clean and sanitized datasets is shown in Fig. 3, while the comparison of MSDP with existing models in the HAR public datasets is also demonstrated in Fig. 4.

Comparing the accuracy on clean and sanitized datasets

Performance comparison of MSDP with state-of-the-art models on public datasets
7 Security analysis
This unit basically demonstrates the security evaluation of our fundamental cryptographic encryption schemes with Dynamic 𝜖-DP then leading to analyzing the security of the MSDP algorithm.
7.1 Analyzing our encryption algorithm
In the subsequent narratives, we present security proof of the privacy parameter for both our proposed scheme and the security proof of our classifiers. We, therefore, provide a definition of semantic security, also well-known as IND-CPA security.
Definition 4
(IND-CPA): Let 𝜖 = (KeyGen,Enc,Eval, Dec,uEvaluate,uDecrypt) be a Multi-Scheme Fully homomorphic Encryption scheme and if for any stateful PPT adversary let \(\mathcal {A} = (\mathcal {A}_{1}, \mathcal {A}_{2})\). For \(1^{\lambda } \in \mathbb {R}\) let
where \(\mathcal {O}_{1}(.)\) and \(\mathcal {O}_{2}(.)\) are evaluation oracles while “state” is secret information using the public key pk. The adversary \(\mathcal {A}_{1}\) output two plaintext a0,a1 possesses equivalent dimension ∣a0∣ = ∣a1∣ and padding messages capable of being applied otherwise. We therefore state the cryptosystem 𝜖 is IND-CPA secure if \(Adv^{IND-CPA}_{{\varepsilon }.{A}}(1^{\lambda })\) and only if the probability that any \(\mathcal {A}\) given \(\mathcal {C}\), is unable to determine which one is the original message, i.e., there exists a negligible function negl of security parameter λ.
In the one-time encryption (OTE), we present the formal definition as follows:
Definition 5
where a0 and a1 are the output of the adversary \(\mathcal {1}\) possessing equivalent length. We can therefore state that a symmetric encryption SE=(Enc,Dec) is OTE secure if \(Adv^{(OTE)}_{{SE}}\) is negligible.
Data privacy
The concatenation \(Enc({\mathcal {X}})\) of all individual data from data providers is to ensure security and privacy and also promote secure multi-party computation. Based on the previous assertion, we define semantic security.
Lemma 1
(MS-FHE (SS)): Individual encryption primitives are semantically secure therefore making our MS-FHE also semantically secure.
Proof
(1) In our assumption, public-key encryption primitive 𝜖 = {KeyGen,Enc,Dec} is semantically secure. Depending on 𝜖, there is a construction of evaluate algorithm Eval by the challenger to 𝜖i = {KeyGen,Enc,Dec,Eval} maintaining homomorphic computations of multiplication and addition. In situations where the evaluation key is public, the adversary will be capable of computing Eval directly based on the public key pk to produce a ciphertext ψ with evaluation key ek. For that reason, MS-FHE is secure semantically. □
In this setting, there is no collusion between participating entities, and DPs cannot communicate with each other until the decryption stage. The semantic security of MS-FHE should also enable the CSP to be probabilistic polynomially bounded in the processes of transferring individual ciphertext to the computational evaluator for computation. The cryptographic service provider should not necessarily have to possess computational power that is bounded since its only duty is to concatenate contributing ciphertext. Computational evaluator and data providers are unable to intercept any of the learning results. The confidentiality of the learning results is hereby assured. We, therefore, obtained the following lemma:
Lemma 2
In Algorithm 2, Algorithm 3, and Algorithm 4 privacy preservation for the following parameters, i.e., z2,z3, a2,a3 and W1,W2(forward and backpropagation) is enforced leading to the avoidance of privacy leakages during the mathematical computations.

Privacy of MSDP model
Computational evaluator is honest-but-curious capable of privately training the collaborative DNN MSDP model. On the other hand, MSDP has securely protected against systems malicious adversary as described in Section 4.2. Initially, if Ad is able to corrupt DA or CE to get access to offloaded datasets. Ad is unable to obtain the corresponding plaintext due to the presence of the IND-CPA of our MSDP scheme. Furthermore, Ad has corrupted some of the DP and has been able to obtain the ski,pki of these corrupted DP. As a result of the non-interactive and independent key generated by the DP, these diverse ski and pki keys are uncorrelated. Therefore, the adversary Ad is incapable of decrypting the encrypted data.
7.2 Analyzing the 𝜖-differential privacy
This subsection demonstrates the differential privacy of the aggregated database (\(\mathcal {X^{\prime }}\)) with data records ri = pub(r)∥sec(r) in a disjointed dataset HCode \(D^{\prime }\) which is individually independent of the datasets \(\{\mathcal {D}_{1}, \mathcal {D}_{2}, . . ., \mathcal {D}_{n}\}\). The privacy level basically relies on the worst of assurances of individual analysis. A description of this circumstance is in the preceding theorem:
Theorem 2
(Parallel composition). Let \(\{\mathcal {D}_{1}, \mathcal {D}_{2},...\mathcal {D}_{n}\}\) be n instrument, where individual instrument \({\mathscr{M}}_{i}(i\in [1,n])\) provides 𝜖i-DP. Let {D1,D2,...Dn} be an arbitrary mutually independent datasets with data records ri = pub(r)∥sec(r) of the input domain D. For a latest instrument \({\mathscr{M}}\), the sequence of \({\mathscr{M}}({\mathscr{M}}_{1}(D_{1}),{\mathscr{M}}_{2}(D_{2}),...,{\mathscr{M}}_{n}(D_{n}))\) which provides (max1≤i≤n∈i)-DP.
Proof
(2) In our case, for any of the sequence r of outcomes \({\mathcal {D}^{\prime }}_{i} \in Rang({\mathscr{M}}_{i}) \), let \({\mathcal {D}^{\prime }_{i}}\) be mechanism \({{\mathscr{M}}_{i}}\) applied to the dataset \({\mathcal {D}_{i}}\), i.e.,\({\mathcal {D}^{\prime }_{i}}={{\mathscr{M}}^{r}_{i}(\mathcal {D}_{i})}\). The probability of the output \({\mathcal {D}^{\prime }_{i}}\) from the sequence of \({{\mathscr{M}}^{r}_{i}}\) is
Therefore, if \(\mathcal {x}\) is smaller than 1 then e𝜖 ≈ 1 + x. Based on Definition 2, we now have
Due to the inequality in the triangle ∥ A∣ −∣B ∥≥|r|B ∥−∥ A|− r|, and \(\parallel A|-|B\parallel \leq |A \boxplus B|\), the \(\boxplus \) denotes the symmetric difference between datasets A and B and \(|A\boxplus B|\) also denotes the shifted count from A and B datasets, with the help of 𝜖-DP, \({\prod }_{i}[{\mathscr{M}}^{r}_{i}(\mathcal {A}_{i})]=\mathcal {D}^{\prime }_{i}] \leq \) \({\prod }_{i}[{\mathscr{M}}^{r}_{i}({\mathscr{B}}_{i})]=\mathcal {D}^{\prime }_{i}] \times {\prod }_{i}e^{{\epsilon }\times \mid A_{i}\boxplus B_{i}\mid }\) ≤ \({\prod }_{i}[{\mathscr{M}}^{r}_{i}({\mathscr{B}}_{i})]=\mathcal {D}^{\prime }_{i}] \times {\prod }_{i}e^{{\epsilon }\times \mid A \boxplus B\mid }\). □
7.3 Analysis of MSDP architecture
Concretely, our proposed MSDP is grounded on Multi-Scheme (MS) FHE ε which uses additional algorithm uEvaluate such that given any model \(\mathcal {C}\) and ciphertext, it returns a ciphertext c which can be decrypted. It is semantically secure in the standard model. Furthermore, we are able to demonstrate MSDP can overcome the attack from adversaries as explained in Section 3.5. Detailed analysis is given as follows:
-
In the situation where \(\mathcal {A}_{d}\) has corrupted the computational evaluator or data analyst to obtain the outsourced dataset, Ad is incapable of obtaining the resultant plaintext due to the presence of INC-CPA security of our MSDP architecture.
-
On the other hand, when Ad is able to corrupt some of the DPs to pk or sk of these DPs, the independent keys generation coupled with non-interactivity of the data providers makes the multiple schemes or secret keys unrelated. Consequently, Ad cannot decrypt these encrypted data from the data providers.
Furthermore, MSDP is also capable of supporting 𝜖-DP. The evaluation of some of the deep learning models on the aggregated database is a non-linear function, i.e., derivative operation, exponential operations, etc. Evaluation of these models directly in the encrypted setting is not possible; however, these non-linear models may be evaluated with fitting, an approximation of a polynomial, and interpolation since the value of the ciphertext setting is huge as compared to the evaluation on an unencrypted dataset. On this premise, MSDP has greatly improved the precision and productivity of the learning model. This is because MSDP architecture is capable of transforming all the public keys with the addition of noise to the aggregated database by the CE. The data analyst can, therefore, perform 𝜖-DP on the aggregated database without privacy leakage.
8 Conclusion
We conceptually present a privacy-preserving deep neural network MSDP architecture for wearable Internet of Thing devices based on human activity recognition applications by the injection of statistical noise to the constructed aggregated database by the computational evaluator (cloud server), BN, and alternative technique for approximating nonlinear ReLU function. Compared to ultramodern and baseline frameworks, MSDP demonstrated a reduction of communication cost, reduction of computational cost, higher accuracy, and efficiency on the four most widely used public datasets. In our future paper, we will consider the privacy preservation of the massive amount of real-time human activity recognition datasets from these wearable devices while considering the adjustment of connection methods and kernel size.
References
Zhang N, Yang P, Ren J, Chen D, Li Y, Shen X (2018) Synergy of big data and 5G wireless networks: opportunities, approaches, and challenges. IEEE Wireless Communications. https://doi.org/10.1109/MWC.2018.1700193
Zhang N, Yang P, Zhang S, Chen D, Zhuang W, Liang B, Shen XS (2017) Software defined networking enabled wireless network virtualization: Challenges and solutions. IEEE Network. https://doi.org/10.1109/MNET.2017.1600248
Chen D, Zhang N, Qin Z, Mao X, Qin Z, Shen X, Li XY (2017) S2M: A lightweight acoustic fingerprints-based wireless device authentication protocol. IEEE Internet of Things Journal. https://doi.org/10.1109/JIOT.2016.2619679
Qin Z, Hu L, Zhang N, Chen D, Zhang K, Qin Z, Choo KKR (2019) Learning-aided user identification using smartphone sensors for smart homes. IEEE Internet of Things Journal. https://doi.org/10.1109/JIOT.2019.2900862
Qin Z, Wang Y, Cheng H, Zhou Y, Sheng Z, Leung VCM (2018) Demographic information prediction: a portrait of smartphone application users. IEEE Transactions on Emerging Topics in Computing. https://doi.org/10.1109/TETC.2016.2570603
Freundlich RE, Freundlich KL, Drolet BC (2018) Pagers, Smartphones, and HIPAA: finding the best solution for electronic communication of protected health information. Journal of Medical Systems. https://doi.org/10.1007/s10916-017-0870-9
Wagh S, Gupta D, Nishanth C (2018) SecureNN: efficient and private neural network training. IACR Cryptology EPrint Archive
Mohassel P, Zhang Y (2017) SecureML: a system for scalable privacy-preserving machine learning. In: Proceedings - IEEE symposium on security and privacy. https://doi.org/10.1109/SP.2017.12
Yin C, Xi J, Sun R, Wang J (2018) Location privacy protection based on differential privacy strategy for big data in industrial internet of things. IEEE Transactions on Industrial Informatics. https://doi.org/10.1109/TII.2017.2773646
Xiong H, Qian M, Yanan Z (2020) Efficient and provably secure certificateless parallel key-insulated signature without pairing for IIoT environments. IEEE Systems Journal. https://doi.org/10.1109/JSYST.2018.2890126
Chen D, Zhang N, Lu R, Fang X, Zhang K, Qin Z, Shen X (2018) An LDPC code based physical layer message authentication scheme with prefect security. IEEE Journal on Selected Areas in Communications. https://doi.org/10.1109/JSAC.2018.2825079
Cheng X, Tang P, Su S, Chen R, Wu Z, Zhu B (2020) Multi-party high-dimensional data publishing under differential privacy. IEEE Transactions on Knowledge and Data Engineering. https://doi.org/10.1109/TKDE.2019.2906610
Cui L, Qu Y, Nosouhi MR , Yu S, Niu J, Xie G (2019) Improving data utility through game theory in personalized differential privacy. Journal of Computer Science and Technology. https://doi.org/10.1007/s11390-019-1910-3
Li P, Ye H, Li J (2017) Multi-party security computation with differential privacy over outsourced data. Security, Privacy and Anonymity in Computation, Communication, and Storage China. https://doi.org/10.1007/978-3-319-72389-1-39
Bogdanov D, Laur S, Willemson J (2008) Sharemind: a framework for fast privacy-preserving computations. https://doi.org/10.1007/978-3-540-88313-5-13
Bogdanov D, Niitsoo M, Toft T, Willemson J (2012) High-performance secure multi-party computation for data mining applications. International Journal of Information Security. https://doi.org/10.1007/s10207-012-0177-2
Pettai M, Laud P (2015) Combining differential privacy and secure multiparty computation. In: ACM International conference proceeding series. https://doi.org/10.1145/2818000.2818027
Goryczka S, Xiong L (2017) A comprehensive comparison of multiparty secure additions with differential privacy. IEEE Transactions on Dependable and Secure Computing. https://doi.org/10.1109/TDSC.2015.2484326
Roggen D, Calatroni A, Rossi M, Holleczek T, Förster K, Tröster G, Lukowicz P, Bannach D, Pirkl G, Ferscha A, Doppler J, Holzmann C, Kurz M, Holl G, Chavarriaga R, Sagha H, Bayati H , Creatura M, Millán JR (2010) Collecting complex activity datasets in highly rich networked sensor environments. INSS 2010 - 7th International Conference on Networked Sensing Systems. https://doi.org/10.1109/INSS.2010.5573462
Reiss A, Stricker D (2012) Introducing a new benchmarked dataset for activity monitoring. proceedings - international symposium on wearable computers, ISWC. https://doi.org/10.1109/ISWC.2012.13
Anguita D, Ghio A, Oneto L, Parra X, Reyes-Ortiz JL (2013) A public domain dataset for human activity recognition using smartphones. In: ESANN 2013 proceedings, 21st european symposium on artificial neural networks, computational intelligence and machine learning
El-Yahyaoui A, Kettani MDECE (2019) An efficient fully homomorphic encryption scheme. Int. J. Netw. Secur. 21(1):91–99. [Online]. Available: http://ijns.femto.com.tw/contents/ijns-v21-n1/ijns-2019-v21-n1-p91-99.pdf
Hoffstein J., Pipher J, Silverman JH (1998) NTRU: a ring-based public key cryptosystem. In: Algorithmic number theory, third international symposium, ANTS-III, Portland, Oregon, USA, June 21-25, 1998, Proceedings pp 267–288. https://doi.org/10.1007/BFb0054868
López-Alt A, Tromer E, Vaikuntanathan V (2012) On-the-fly multiparty computation on the cloud via multikey fully homomorphic encryption. In: Proceedings of the 44th symposium on theory of computing conference, STOC 2012, New York, NY, USA, May 19 - 22, 2012, pp 1219–1234. https://doi.org/10.1145/2213977.2214086
Dwork C (2010) Differential privacy in new settings. In: Proc. 21st annu. ACM-SIAM symp. discret. algorithms. pp 174–183. https://doi.org/10.2307/2374806
Mukherjee P, Wichs D (2016) Two round multiparty computation via multi-key FHE. In: Advances in cryptology - EUROCRYPT 2016 - 35th annual international conference on the theory and applications of cryptographic techniques, Vienna, Austria, May 8-12. Proceedings, Part II, 2016, 9666, pp 735–763. https://doi.org/10.1007/978-3-662-49896-5-26
Mukherjee P, Wichs D (2015) Two round MPC from LWE via multi-key FHE. IACR Cryptol. ePrint Arch., 2015, 345. [Online]. Available: http://eprint.iacr.org/2015/345
Abuhasel KA, Khan MA (2020) A secure industrial internet of things (IIot) framework for resource management in smart manufacturing. IEEE Access 8:117354–117364. https://doi.org/10.1109/ACCESS.2020.3004711
Wei K, Zhang L, Yi G, Jiang X (2020) Health monitoring based on internet of medical things: architecture, enabling technologies, and applications. IEEE Access 8:27468–27478. https://doi.org/10.1109/ACCESS.2020.2971654
Gentry C (2009) Fully homomorphic encryption using ideal lattices. In: Proceedings of the forty-first annual ACM symposium on theory of computing
Funding
This work was supported in part by the National Natural Science Foundation of China (No.61672135), the Frontier Science and Technology Innovation Projects of National Key R&D Program (No.2019QY1405), the Sichuan Science and Technology Innovation Platform and Talent Plan (No.20JCQN0256), and the Fundamental Research Funds for the Central Universities (No.2672018ZYGX2018J057).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Owusu-Agyemeng, K., Qin, Z., Xiong, H. et al. MSDP: multi-scheme privacy-preserving deep learning via differential privacy. Pers Ubiquit Comput 27, 221–233 (2023). https://doi.org/10.1007/s00779-021-01545-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00779-021-01545-0