
Abstract
This study integrates purely statistical methods of Mann–Kendall (MK) and Spearman rho (SMR) with statistical-graphical methods of Onyutha trend (OT) test and innovative trend analysis (ITA) to examine annual and seasonal rainfall variations at 12 stations across the Shire River Basin (SRB) during 1976–2005. The results reveal a general decreasing trend for annual rainfall throughout the basin. At seasonal scale, the following trends were observed: an increase for the December-January–February (DJF) season, especially in the southern portion of the basin; a decrease for the March–April-May (MAM) and June-July–August (JJA) seasons; and inconclusive results for the September–October-November (SON) season. Despite nearly all time series indicating consistent trend direction as established by the four tests, the ITA identified the most significant rainfall patterns on both annual and seasonal basis. The performance abilities for the MK, SMR, and OT tests demonstrated the closest agreement at the verified significant level. In addition to the monotonic trend results obtained statistically, sub-trends are visually distinguished using the graphical features of the OT and ITA approaches. For the former, changes are seen as step jumps in the mean of the data, and for the latter, trends regarding high and low rainfall clusters are evaluated, hence offering more details regarding rainfall variability, such as the SRB’s sensitivity to both floods and droughts. Thus, the completely different aspects offered by the visually oriented methods complement the purely monotonic trend detection methods.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Rainfall is the most important climatic variable for establishing the availability of water resources, which, in turn, contributes to the long-term socioeconomic growth of a country (Bates et al. 2008). However, as a consequence of global climate change, rainfall is subject to variability, and is closely linked to instances of floods and droughts (Wu et al. 2013; Nicholson 2016; Wang et al. 2020). Studies conducted so far suggest that spatiotemporal inconsistencies characterize this change in rainfall patterns, particularly in southern Africa. For instance, despite the fact that the majority of studies generally indicate a drop in annual rainfall across this region, some areas, including the north and east, have experienced an increase during the past century (Shongwe et al. 2009; Jury 2013; Marumbwa et al. 2019). Regarding seasonal variations, records confirm that many areas of southern Africa, notably the western regions, had a general decline in austral summer (i.e., December-January–February) rainfall in the second half of the twentieth century (New et al. 2006). Nonetheless, increased December-January–February seasonal rainfall trends have also been observed in some sections of this region (Ngongondo et al. 2011; Daron 2014).
Owing to the profound consequences that rainfall discrepancies have on the living conditions of mankind, in recent years, climate change studies have been of great concern to the scientific community, policy makers, and the general public. In this context, accurate estimation of long-term trends offers important information for regional water resources planning and management, so as to minimize the ruinous effects of such disparities in rainfall amounts (Sun et al. 2018; Yang et al. 2019; Mallick et al. 2021; Wu et al. 2022). The commonly used trend analysis approaches for hydro-climatic time series are classified as either parametric or non-parametric (Huth and Pokorná 2004). Non-parametric tests are generally less effective than their parametric analogs, but considered more popular since they do not require data that conforms to stationarity and normal distribution. Additionally, the latter approaches are more tolerant to outliers, which are prevalent in hydro-climatological time series (Mirabbasi et al. 2020).
The Mann–Kendall (MK) and Spearman’s rho (SMR) tests are well-known non-parametric tests that have been utilized for trend detection in studies all around the world, including Yue et al. (2002a), Shadmani et al. (2012), Some'e et al. (2012), Duhan and Pandey (2013), Westra et al. (2013), Sayemuzzaman and Jha (2014), and Zuzani et al. (2019). In most studies, the SMR has frequently been used together with the MK test for comparative reasons, and their findings consistently demonstrate the same power in identifying trend (Shadmani et al. 2012; Ahmad et al. 2015). Although these classical methods are popular, the presence of serial correlation increases the probability of the tests to detect a significant trend in a time series when none actually exists (von Storch 1995). This is especially true for the MK test. Moreover, these techniques are purely statistical and do not provide the graphical exploratory aspects of the analysis, consequently leading to meaningless results in some cases (Kundzewicz and Robson 2000; Cohn and Lins 2005). In the same vein, Cengiz et al. (2020) showed that when visuals in the form of graphs are combined with statistical analysis techniques, a more thorough and comprehensive depiction of regional hydrological changes can be obtained. Thus, it becomes vital to grasp the hidden sub-trends in long-term series of hydro-climatic data, and this can only be done if the trends are visualized. Furthermore, the combined use of various methods for assessing hydro-climatologic trends provides reliable uncertainty estimations (Onyutha 2016c, 2021), hence eliminating the influence of choice of method used.
In pursuit of addressing the need for visual quantitative trend detection, two graphical methods such as the Onyutha trend (OT) test (Onyutha 2016a, 2021) and the innovative trend analyses (ITA) (Şen 2012) have been developed and used over the years (Onyutha 2016c; Gedefaw et al. 2018; Caloiero 2020; Cengiz et al. 2020; Wang et al. 2020). Of the two methods, the ITA has been applied the most on observed time series and this is well reported in hydro-climatological literature (Gedefaw et al. 2018; Wu et al. 2022). Developed much more recently, the OT test has also proven to be capable of providing more meaningful results than when the purely statistical methods are applied. In fact, when applied together or against the popular MK and SMR trend tests, the ITA and OT methods tend to yield comparable results, particularly if the data has no irregularities, e.g., ties or autocorrelation. According to the studies reported by Dabanlı et al. (2016) and Kisi (2015), employing the ITA to uncover hidden trends has certain advantages over just performing the MK or SMR tests. Cengiz et al. (2020) and Onyutha (2016a) demonstrated that not only are the results of the MK, ITA, and OT methods fairly comparable but also the graphical explorations by the ITA and OT disclose interesting results about the dataset and may be applied for further research. The ITA test, for instance, demonstrates the ability to detect trends in various types of precipitation, including low, medium, and high levels (Şen 2014), whereas the OT test not only detects trends but also recognizes climatic variability (Onyutha 2021).
The Shire River Basin (SRB) is one of the most important river basins in Malawi and southern Africa, accounting for 12% of Zambezi River flow (Hamududu and Killingtveit 2016). Accordingly, regional rainfall variability and human-induced activities have a great impact on the surface runoff (Adhikari and Nejadhashemi 2016; Zuzani et al. 2019) as well as the occurrence of droughts (Mtilatila et al. 2020) and floods (Coulibaly et al. 2015) in the area. Previous research on rainfall trends in the SRB has mainly examined general temporal variations (Mtilatila et al. 2020) and the frequency of extreme events (Zuzani et al. 2019), both of which have been conducted on an annual basis and using a single trend analysis technique. Yet, given the significance of the SRB to Malawi’s developmental sector, a more detailed study that integrates various trend analyses, both statistical and graphical, is encouraged for a better understanding and validation of the results. Therefore, in this study, four rank-based tests, namely the MK, SMR, OT, and ITA, are applied to historical rainfall time series (1976–2005) in order to determine seasonal and annual trend changes in the SRB, Malawi.
2 Study area and data used
2.1 Study area description
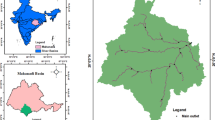
The Shire River is Malawi’s largest river and the sole outlet from Lake Malawi. Flowing over a distance of 700 km until its confluence with the Zambezi, the Shire River has a dense network of sub-catchments with surface area coverage of ~ 19,248 km2 (see Fig. 1). The SRB is thus a sub-basin of the Zambezi River Basin (ZRB), which, combined with other sub-basins, forms Africa’s fourth largest river basin and the largest in Southern Africa (Jury and Gwazantini 2002). The eastern portion of the basin is dominated by mountains, including the Mulanje Massif, while a low-lying flood plain known as the Lower Shire valley occupies the south of the region. Having a subtropical climate, the SRB has a distinct rainy season that is experienced between November and April and this is when roughly 80% of the rainfall occurs. Rainfall is season dependent and mostly influenced by the north–south migration of the intertropical convergence zone (ITCZ), which collaborates with the Congo air boundary. The proximity to the Lake Malawi and altitude are the major drivers of local rainfall patterns and variability (Kumbuyo et al. 2015).

Digital elevation model of the SRB along with the distribution of rivers and meteorological stations
Based on the acquired time series, the mean annual rainfall recorded in the SRB between 1976 and 2005 ranged from 750 mm at N’gabu to 1618 mm at Mimosa, with an overall average of 1039 mm (Table 1). The standard deviation varied between 222.6 and 338.3 mm for Chileka and Mimosa, respectively. It is seen that the CV ranges from 0.21 to 0.30, indicating that the areas with usually heavy rainfall have the least variability as compared to areas that receive low rainfall. The measure of asymmetry in the frequency distribution as shown by skewness varied between − 0.82 and 0.74, exhibiting a predominant positive skewness with an average of 0.22. In other words, the annual rainfall during the period in question is asymmetric, falling to the right of the mean across most stations.
2.2 Data set description
Daily rainfall data collected by the Department of Climate Change and Meteorological Services (MDCCMS) at 12 weather stations across the SRB from January 1976 to December 2005 were used for this study (Fig. 1 and Table 1). Meteorological data quality control is a fundamental step in weather and climate analyses; however, the data were already checked for errors and gaps by the department. Therefore, no gap filling method was necessary. Additionally, it is important to note that this study involved the use of non-parametric rank-based tests; thus, it was also deemed irrelevant to detect outliers, as these approaches are robust against such. The seasons used in this study are defined as follows: December-January–February (DJF), March–April-May (MAM), June-July–August (JJA), and September–October-November (SON).
To evaluate the homogeneity of the rainfall time series data at each station, the standard normal homogeneity test (SNHT) (Alexandersson 1986; Alexandersson and Moberg 1997) and Buishand’s range (BR) test (Buishand 1982) were applied at a 5% significance level. According to these authors, the time series is considered homogeneous if the SNHT statistic (To) is less than 9.17 while the BR statistics are less than 1.22 (\(Q\sqrt{n})\) and 1.55 (\(R\sqrt{n})\). The findings in Table 2 reveal that all the time series were homogeneous. Furthermore, all time series were checked for serial correlation using Lag-1 autocorrelation at 1%, 5%, and 10% to rule out its influence on some of the trend tests used in this study (Yue et al. 2002b). Since the time series were confirmed to be serially independent, all the trend tests were applied on original data.
3 Methodology
In this study, the non-parametric approach is chosen to detect trend in annual and seasonal rainfall for the SRB. This is accomplished in two steps. The first is to identify trend direction by using two purely statistical methods, namely the Mann–Kendall (MK) and Spearman’s rho (SMR) tests. The Thiel-Sen approach is also utilized in the first step to estimate the magnitude of the slope of the identified trends by the MK and SMR methods. However, since this study is also about the analyses of trends and sub-trends using statistical-graphical methods, Onyutha’s trend (OT) test and the innovative trend analysis (ITA) are employed in the second step.
3.1 Statistical tests
3.1.1 The Mann–Kendall (MK) test
Due to its prominence in the literature, the Mann–Kendall (Mann 1945; Kendall 1975) monotonic trend test is used to identify changes in rainfall data for this study. To execute this task, the test statistic S (as shown in Eq. 1) is calculated using the sign function \(sgn\) (\({x}_{j}-{x}_{i})=sgn (\theta )\), which is derived by comparing the provided time series data \(x({x}_{1},{x}_{2},\dots .{x}_{n})\) in turn.
where \({x}_{j}\) and \({x}_{i}\) are the sequential data values and if \(\theta\) is greater than, equal to, or less than zero, then \(sgn(\theta )\) is equivalent to 1, 0, and − 1, respectively. It is important to note that the variance of \(S\) is calculated as follows:
where \(m\) and \({t}_{i}\) are the number of tied groups (a tied group is a set of sample data having the same value) and the number of data points in the \({i}^{th}\) group, respectively. Ultimately, the standardized Mann–Kendall test statistic, denoted by \({Z}_{MK}\), is calculated as:
Since the values of \({Z}_{MK}\) are considered approximately normally distributed, the null hypothesis \(({H}_{0})\) of no trend is accepted if the Z test statistic is not statistically significant, i.e., \({-Z}_{\alpha /2}<Z<{Z}_{\alpha /2}\), where \({Z}_{\alpha /2}\) is a standard normal deviate. In this equation, the positive and negative values of Z indicate an upward and downward trend, respectively.
3.1.2 The Spearman rho (SMR) test
Similar to the MK method, the Spearman rho (Lehmann 1975; Sneyers 1990) is another non-parametric test that is rank based and commonly used to analyze monotonic trends within a time series (Shadmani et al. 2012; Ahmad et al. 2015). Since this method relies on the existence of correlation between two classifications of the same set of observations; this approach is considered quick and simple. To apply this test for identifying the rainfall trend in this study, the SR correlation coefficient \((D)\) and its test statistic \(({Z}_{SMR})\) were determined as follows (Yue et al. 2002a):
where \({R}_{i}\) is the rank of the \({i}^{th}\) observation \({X}_{i}\) in the time series, and \(n\) is the total length of the time series data. Positive and negative values of \({Z}_{SMR}\) indicate an increasing and decreasing trend across the time series, respectively. In instances when |\({Z}_{SR}\)|\({>t}_{(n-2, 1-\alpha /2)}\), the null hypothesis is rejected, meaning a significant trend in the time series exists. \({t}_{(n-2, 1-\alpha /2)}\) is defined as the critical value of t from the student’s t-distribution table, at a 5% significant level.
3.1.3 The Theil-Sen approach
The Theil-Sen approach (Theil 1950; Sen 1968) is used to estimate the magnitude of the trends identified by MK and SMR. Trend magnitude (also known as trend slope) is defined as the amount by which a variable is anticipated to change linearly over unit time of the observation. This linear change in slope (m) is computed using the following equation:
where \({X}_{j}\) and \({X}_{i}\) are the sequential data values of the time series in the years \(j\) and \(i\), and \(m\) is the estimated magnitude of the trend slope in the data series.
3.2 Graphical-statistical test
3.2.1 Onyutha trend test
Trend analysis based on Onyutha’s method comprises both graphical diagnosis and statistical tests (Onyutha 2016b), hence the rationale for its use in this study. Moreover, as already stated in Sect. 1, previous studies indicate that its performance is quite comparable to both the ITA and the MK tests (Onyutha 2016a; Cengiz et al. 2020). Onyutha’s technique of change detection addresses the non-parametric rescaling of a given time series. To execute this method, the independent and dependent variables are denoted by \(X\) and \(Y\), respectively. Given that the sample size of \(X\) or \(Y\) is n, these two variables can possibly be rescaled into series \({d}_{x}\) and \({d}_{y}\), respectively, using the equation:
where \({t}_{y,i}\) and \({t}_{x,i}\) are the number of times the \({i}^{th}\) observation exceeds other data points in \(X\) and \(Y\), respectively. In a similar vein, \({w}_{x,i}\) and \({w}_{y,i}\) are the number of times the \({i}^{th}\) data point appears within \(X\) and \(Y\), respectively.
Series \({d}_{y}\) and \({d}_{x}\) can be normalized to obtain series \({e}_{y}\) and \({e}_{x,}\), respectively, using:
where
In a situation when the data points \(y\) or \(x\) are tied n times, each value of \({d}_{y}\) or \({d}_{x}\) will become zero.
The trend statistic \(T\) using Onyutha’s method can then be calculated as follows:
When \(T\) > 0, the series displays a positive trend, while when \(T\) < 0, it exhibits a negative trend.
The mean of \(T\) is zero, and the distribution of \(T\) is approximately normal for large \(n\), with the variance of \(V(T)\) which is characterized by:
The \(V(T)\) equation applies for independent data, but it is affected by the kind of persistence in the data for dependent data. In addition, data with persistence consists of long-term series. Sub-trends can also develop over long periods, such as more than 10 years. In such circumstances, \(V\left(T\right)\) can be further adjusted for autocorrelation influence using the approach in Onyutha (2016b).
Ultimately, the computation of the standardized test statistic \(Z\) is done using the following equation:
where \({V}^{F}(T)\) is the version of \(V(T)\) adjusted for the influence of autocorrelation (refer to Onyutha 2016a, b, c, d for procedure). Suppose Zα/2 is the standard normal variate at a selected α, the null hypothesis H0 (no trend) at the significance level α% is rejected if |\(Z\)|> Zα/2 at α; alternatively, H0 is rejected.
For graphical diagnosis of sub-trends using the OT test, it is considered necessary to obtain \({a}_{j}\) and \({q}_{k}\) series (Onyutha 2021). Series \({a}_{j}\) is determined through the accumulation of \({e}_{y}\) sequentially as follows:
The \({a}_{j}\) series generated above is used to indicate sub-periods across which the cumulative effect of temporal change in the time series is consistently positive or negative. Therefore, in order to detect sub-trends graphically, \({a}_{j}\) is plotted against the observation period j and this referred to as a sub-trend plot.
Series \({q}_{k}\) is used for additional graphical diagnostics, such as determining/confirming the significance of a trend. In order to generate \({q}_{k}\), a stepwise summation is applied to \({a}_{j}\). This can be done for the entire data period or for the identified sub-trends. Thus \({q}_{k}\) is plotted against the time of observations \(k\).
Hence, the H0 (no sub-trend) is tested by adding 100 (1 α) % confidence interval limits (CILs) to the plot of \({q}_{k}\) versus \(k\) using:
If any scatter points exceed the 100–α %\({CIL}_{s}\), the H0 (no trend) is rejected; otherwise, the H0 is not rejected.
3.2.2 The innovative trend analysis (ITA)
Sen’s innovative trend analysis (ITA) is also utilized in this article because of its capacity to find trend both visually and statistically (Şen 2012, 2017). This method for investigating changes in time series is based on the concept that if two time series are identical to each other, their plot against each other reveals a dispersion of points along a 1:1 (45°) line on the Cartesian coordinate system. The scatter points are generated by arranging the data in the first and second half of the time series in either descending or ascending order, and then plotting them on the X and Y axes, respectively. The 1:1 straight line forms two triangles at its top and bottom, and the scatter points above and below it reflect an increasing and decreasing monotonic trend respectively. When analyzing a non-monotonic trend in a time series, the trends in high (> 10th percentile), medium (10th–90th percentile), and low (< 10th percentile) values are examined independently (Brunetti et al. 2004).
For the statistical analysis portion of the ITA approach, the linear slope \((s)\) was calculated as follows (Şen 2017):
where \({\overline{y} }_{1}\) and \({\overline{y} }_{2}\) are averages of two sub-series \({y}_{1}\) and \({y}_{2}\). To test the significance of the trend slope \(s\), the null hypothesis H0 (no trend) is accepted if the estimated slope value,\(s\), is less than a critical value, \({S}_{cri}\). Otherwise, the alternative hypothesis, Ha, is accepted when \(s\) is greater than the critical value, \({S}_{cri}\), indicating the sequence has a significant trend.
Since \({\overline{y} }_{1}\) and \({\overline{y} }_{2}\) are stochastic variables and of the same length, the expectations of these two sub-sequences are used to calculate the first-order matrix of slope \(s\) as follows:
In the absence of a trend, the centroid point lies on the 1:1 line, and \(E\left({\overline{y} }_{2}\right)=E({\overline{y} }_{1})\), resulting in \(E\left(s\right)=0\). Apart from that, the variation in the slope is given by the difference between the expectations of both sides:
As \(E\left({\overline{y} }_{1}^{2}\right)=E\left({\overline{y} }_{2}^{2}\right)\), the equation above can be converted in the following way:
The following equation is used to calculate the correlation coefficient between the two averages in the random process:
As \({\sigma }_{{\overline{y} }_{2}}={\sigma }_{{\overline{y} }_{1}}=\sigma /\sqrt{n}\), substituting this equation and Eq. (20) into Eq. (21), the variance of the slope can be obtained as follows:
Ultimately, the confidence limit (CL) of the standard normal distribution probability density function (PDF) with a zero mean and standard deviation is \({S}_{cri}\); thus, the trend slope’s confidence limit (CL) at a \(\alpha\) significant level is as follows:
where \({\sigma }_{s}\) is the standard deviation of the slope and is given as:
If the trend slope, s, of a time series falls outside the confidence limits, it is statistically significant. Since all of the slope variable’s odd-order moments are equal to zero, the slope PDF follows a Gaussian PDF with a zero mean and the standard deviation.
4 Results
4.1 Annual trends
The monotonic trend results of the statistical MK and SMR tests that were applied on annual rainfall time series (at a 1% and 5% significance level) between 1976 and 2005 at 12 stations in the SRB are summarized in Table 3. The associated trend magnitudes are displayed in Table 4. From the examined time series, it is noticeable that the results of both tests were comparable and that the statistics are dominated by negative trends (75%), most of which are insignificant. However, of the three stations that exhibited positive trends, only Makhanga station (with a trend magnitude of 8.09 mm/year) showed significance at the confidence level of 95%, and this applies to both tests.
The monotonic trend statistics for annual rainfall at the selected stations in the SRB using Onyutha’s trend technique are shown in Table 5. The findings from the analysis demonstrate that the OT statistic of annual rainfall is characterized by negative trends (9 of 12 stations) and are all insignificant at a 95% confidence level. Nonetheless, when the significance level for the remaining three stations identified as having positive trends was evaluated, only Makhanga demonstrated significance at the 95% confidence level. The trend results identified by this statistic, in terms of both trend direction and significance, are consistent with those detected by the MK and SMR tests. The decreasing trend of annual rainfall is also clearly seen in Fig. 2, which depicts the cumulative effect of temporal fluctuations in rainfall using sub-trend plots. From the plots, it is undeniably visible that annual rainfall at the Makhanga station trended upward, while the Mimosa and Neno stations definitely showed a downward trend. Similarly, it should be emphasized that the existence of both positive and negative sub-trends of varied lengths is apparent at the remaining stations. Even so, when the overall trend in a given series is considered, it is clear that some stations are dominated by either positive or negative trends. In addition, Chichiri and Chileka stations exhibited a distinct negative sub-trend that spanned the years 1976–1993. Figure 3 graphically shows the significance of trends in annual rainfall at the study stations. Annual rainfall trends (both positive and negative) and their significance can be depicted using this figure, where the H0 (no trend) was rejected in terms of rainfall only for Makhanga.

Sub-trend plots for annual rainfall at the twelve stations selected across the SRB

OT method graphical diagnoses of the trend significance for annual rainfall at twelves stations across the SRB
The trends in annual rainfall detected by the ITA technique are summarized in Table 6. The slope (s) of annual rainfall is dominated by negative values (accounting for 83%), and there are 10 stations that exhibit a significant trend at 95% significance level. The associated graphical results showing the decline in annual rainfall can also clearly be seen in Fig. 4, where for most stations, the blue points fall below the 1:1 line, thus supporting the findings in Table 6. Furthermore, the red, yellow, and green dots, which denote the centroid points of the low, medium, and high rainfall clusters, showed that all stations except Makhanga and Neno had a decreasing tendency for low rainfall. For medium rainfall, all of the stations indicate a negative trend, except for Bvumbwe, Makhanga, Mangochi, and Thyolo stations. High rainfall at all stations also showed a downward trend with the exception of Bvumbwe, Chichiri, N’gabu and Thyolo stations. What cannot be overlooked is that the trend aspects of each station in the three rainfall categories appear to be relatively unique. For instance, low and medium rainfall at Mwanza station were < 5 mm/year, whereas high rainfall was > 12 mm/year. At Neno station, a strong increase was observed in the low category while medium and high rainfall had a relatively stronger decrease.

Trend graphs for annual rainfall at twelve stations in the study area using the ITA approach (red, yellow, and green points illustrate mean centroid points of low, medium, and high rainfall, respectively)
4.2 Seasonal trends
The rainfall trend statistics identified by the MK and SMR tests for the four seasons over the study period (1976–2005) are summarized in Table 3. Table 4 shows the accompanying trend magnitudes. Much like annual rainfall, results for both statistical tests were in agreement with one another. DJF seasonal rainfall is dominated by positive trends; however, all but the Makhanga station (with an associated magnitude of 6.05 mm/year) are insignificant. Rainfall in the MAM season at nearly all the stations showed a downward trend, but none of these trends is significant. The JJA season showed significant negative trends at the Chichiri and Mimosa stations but had a significant positive trend at the Thyolo station. In terms of the SON season, the findings showed that no significant trends were found at any station.
The rainfall trend statistics for the 4 seasons by the OT approach have also been provided in Table 5. Similar to annual rainfall, both positive and negative trends were detected. However, positive trends predominated throughout the DJF and SON seasons, with rises at 75% and 67% of the selected stations, respectively. Makhanga is the only station that achieved significant results. On the other hand, the MAM and JJA seasons were primarily characterized by a downward trend in rainfall, with declines occurring at 67% of the stations for the JJA season and across the entire study region for MAM. Nonetheless, significant trends were spotted at Chichiri and Thyolo for JJA. The results of further investigation into the DJF seasonal rainfall trends based on sub-trend plots are presented in Fig. 5. Due to limited space, CSD plots for the MAM, JJA, and SON season are not shown, but nevertheless, readers can refer to Table 5 for the overall station level trends. According to this figure, rainfall at the Makhanga station is primarily driven by a monotonic increase during the whole data period. The remaining stations exhibit sub-periods with both increasing and decreasing trends at various points throughout the data period. However, it is apparent that the majority of the sub-trends are positive at stations like Bvumbwe, Chichiri, Makoka, Mimosa, Mwanza, N’gabu, and Thyolo, while Chileka and Neno stations are dominated by negative sub-trends. On the other hand, it appears that the Mangochi and Nsanje stations have an overall trend that is graphically inconclusive. The visual diagnosis in Fig. 6 makes it evident that throughout DJF season, positive tendencies predominate, with Makhanga indicating significance.

Sub-trend plots for DJF seasonal rainfall at the twelve stations selected across the SRB

OT method graphical diagnoses of the trend significance for DJF rainfall at twelves stations across the SRB
The statistical findings of applying the ITA to detect seasonal rainfall changes are listed in Table 7. For 67% of the stations, the DJF season slope (s) is found to be positive, and there are eight stations that exhibited trends at 95% level of significance. The remaining three seasons are dominated by negative trends; the MAM season exhibited significant trends all across the basin at the 95% level, while the JJA and SON seasons recorded a 99% significance level of trend at nine stations, respectively. The visual-graphical results for the DJF season (Fig. 7) reveal a clear dominating increasing tendency for rainfall during this season, where the blue scatter points for majority of the stations fall above the 1:1 line of the Cartesian coordinate system. This figure also depicts the DJF season trend plots in respect to the three clusters; declining trends are observed for low rainfall at most stations, medium rainfall shows a modest increasing trend, and high rainfall detects a strong upward trend at most stations.

Trend graphs for DJF seasonal rainfall at twelve stations in the study area using the ITA approach (red, yellow, and green points illustrate mean centroid points of low, medium, and high rainfall, respectively)
5 Discussions
Rainfall in the SRB fluctuates considerably both seasonally and annually, and climate change is causing this variability to become increasingly irregular and uneven. The basin receives between 750 and 1618 mm of rain each year, with more than 60% of the rainfall concentrated in the DJF season. Hence, an in-depth understanding of both long-term trends as well as the hidden sub-trends within the overall rainfall changes across the SRB is essential for better management of water resources and the mitigation of natural hazards. However, previous studies on rainfall trends in the basin have mostly focused on total rainfall (Mtilatila et al. 2020) and the frequency of extreme rainfall events (Zuzani et al. 2019), neither of which indicate seasonal rainfall features. Aside from the use of purely statistical analysis to detect these variations in rainfall, no visual quantitative study that represents trends in sub-series has been conducted. In accordance to the observed knowledge gap, this study integrated statistical and graphical approaches to analyze overall trends and sub-trends of rainfall for the SRB at seasonal and annual timescales.
The results of this study revealed decreasing trends for annual rainfall over nearly the entire study area. Similar statistical findings are reported by Mtilatila et al. (2020) for the SRB. These results are also evidenced by Ngongondo et al. (2011), Ngongondo et al. (2015), and Tadeyo et al. (2020), wherein they observed a decline in annual rainfall for most parts of Malawi. Our research showed increasing DJF season trends, particularly for sites in the south of the basin. These results also support the findings by Ngongondo et al. (2011) for the whole Malawi. The frequent occurrence of tropical cyclones from the western Indian Ocean, which generally occur in December, January, or February, might be one of the explanations for the increase during DJF season. These cyclones are associated with wet spells, i.e., large amounts of rain in a short period of time (Otto et al. 2022); examples include cyclones Delfina and Ernest that occurred during the study period (Sithole and Murewi 2009). On the other hand, declining trends for the JJA and MAM seasonal rainfall were observed. As to what concerns the SON season, the trend results were rather inconclusive. These rainfall trends in Malawi and indeed southern Africa can be linked to the abnormal shifts of the sea surface temperature (SST) in the Indian Ocean and the El Niño (La Niña) phenomenon (Ratnam et al. 2014; Haghtalab et al. 2019).
To further validate the findings, the four statistical trend analysis techniques were compared, and the summaries of the annual and seasonal results are displayed in Fig. 8. It is evident that all approaches have demonstrated the presence of comparable trends over all time scales, with the exception of the SON season. However, for the 60 annual and seasonal time series studied, significant trends are detected in 5, 4, 4, and 52 time series by the MK, SMR, OT, and ITA tests, respectively. Moreover, the ITA approach detects all significant trends identified by the MK, SMR, and OT tests. These findings align with the results reported by Bouizrou et al. (2022), who evaluated the two traditional techniques along with the OT test and found that these methods exhibited similar power in detecting monotonic trends. This is a noteworthy observation as it suggests that the OT test can provide a certain level of accuracy in trend analysis. Indeed, as highlighted by Wang et al. (2020) and Alifujiang et al. (2020), the ITA approach has the advantage of uncovering more meaningful variation trends in rainfall series than the MK. Building upon this, our findings indicate that ITA may indeed have similar benefits over SMR and OT test. Furthermore, these statistical findings partially confirm the comparability of most non-parametric methods, particularly when the data set employed is free of irregularities such as ties and autocorrelation (Huth and Pokorná 2004). The variations in trend direction as well as the capacity for ITA to identify more significant trends than the other methods reveal the complexity of the trend phenomena. Besides, the disparities in the results from the various methods generally emphasize the potential uncertainty in the findings. Consequently, if such techniques are to be taken into account to assist in the development of watershed management strategies in the SRB and anywhere in the world, careful statistical inference is required.

Comparison of the results of the MK, SMR, OT, and ITA methods in the SRB; a–e, f–j, k–o, and p–t represent annual DJF, MAM, JJA, and SON rainfall trend results based on MK, SMR, CSD, and ITA, respectively
The integrated use of statistical and graphical trend detection methods performed in this study was particularly crucial since, as Kundzewicz and Robson (2000) pointed out, relying solely on statistical approaches for trend analysis could produce results that are in some cases meaningless. Incorporating visual quantitative techniques of analyzing trend can reveal influential information, suggesting further research to enhance knowledge of the data (Onyutha 2016a; Caloiero 2020). It should be said that the sub-trend plots by OT method benefit for disclosing step jumps in the mean of the data at some stations in the SRB. As a result, while significant long-term trends were only detected in 4 time series, separate investigations on the sub-trends (Onyutha 2021) could reveal significant patterns necessary to consider for environmental management techniques. Additionally, other studies have used OT method further to assess significance of temporal variability based on sub-trends (Onyutha 2021; Bouizrou et al. 2022; Koycegiz and Buyukyildiz 2023; Mubialiwo et al. 2023), establishing its importance in environmental management. In contrast, the ITA technique graphically presents all data ranges on a Cartesian coordinate system, allowing for detailed information regarding trends in terms of evaluation of low, medium, and high rainfall clusters. This trend categorization feature illustrates the SRB’s propensity for droughts and floods in various sections of the study area, most notably the DJF season floods. A study by Zuzani et al. (2019) also suggested the potential worsening of droughts in the basin, but our work reveals additional insight into the frequency of floods because it was conducted at both annual and seasonal timeframes. In order to achieve an effective and ideal management of water resources, the completely different aspects offered by the visually oriented methods complement the purely monotonic trend detection methods.
6 Conclusion
In the present study, purely statistical approaches of MK and SMR were integrated with the statistical-graphical methods of OT and ITA to examine seasonal and annual rainfall variations across the SRB during 1976–2005. The main conclusions of this investigation are summarized as follows:
-
1)
Declining annual rainfall trends were detected at most stations in the SRB, thus indicating that the study area is likely to become drier. On seasonal basis, increasing trends were observed for the DJF season, and these are concentrated in the lower parts of the basin. Rainfall in the MAM and JJA season exhibited decreasing trends, while for the SON season, the trends were rather unclear.
-
2)
The statistical results for the four methods demonstrated partial conformity, particularly in terms of trend inclination. However, the ITA approach produced the maximum number of significant trends for both annual and seasonal rainfall series, followed by the MK, SMR, and OT tests, which gave the closest agreement of results in terms of both trend direction and significance. This suggests that the three methods are well aligned and that the ITA method exhibits a more defined significant pattern. These disparities in the results of the four statistical approaches in question highlight the complexities of applying various techniques independently for trend analysis. Hence, this necessitates a more cautious statistical inference if these methods are to be applied in water resources planning and management programs for the study area and beyond.
-
3)
The statistical-graphical approaches offer several benefits over the traditional analysis techniques. These methods detect both monotonic and non-monotonic trends, revealing not only the general tendencies of rainfall as a variable, but also hidden sub-trends in the overall time series. With their visual-graphical properties, the OT and ITA tests can disclose additional information on rainfall variability including short-durational fluctuations in the series and an area’s sensitivity to severe occurrences. For instance, our analysis highlighted the SRB’s susceptibility to flooding, especially during the DJF season. Nevertheless, for a much thorough depiction of hydro-climatologic changes, the integrated use of graphical approaches to complement the purely arithmetic methods is encouraged.
Hence, it is hoped that this study could provide relevant information to help understand rainfall trends in the SRB. The findings are valuable to water resources managers involved in predicting and mitigating hazards associated with floods and droughts in the study area. Furthermore, this study also makes contribution to the graphical OT and ITA methods and this is by quantitatively evaluating trends in sub-series.
Change history
27 June 2024
A Correction to this paper has been published: https://doi.org/10.1007/s00704-024-05083-6
References
Adhikari U, Nejadhashemi AP (2016) Impacts of climate change on water resources in Malawi. J Hydrol Eng 21:05016026. https://doi.org/10.1061/(ASCE)HE.1943-5584.0001436
Ahmad I, Tang D, Wang T, Wang M, Wagan B (2015) Precipitation trends over time using Mann-Kendall and spearman’s rho tests in swat river basin, Pakistan. AdvMeteorol 2015. https://doi.org/10.1155/2015/431860
Alexandersson H (1986) A homogeneity test applied to precipitation data. J Climatol 6:661–675. https://doi.org/10.1002/joc.3370060607
Alexandersson H, Moberg A (1997) Homogenization of Swedish temperature data. Part I: homogeneity test for linear trends. Int J Climatol: J R Meteorol Soc 17:25–34. https://doi.org/10.1002/(SICI)1097-0088(199701)17:1/3C25::AID-JOC103/3E3.0.CO;2-J
Alifujiang Y, Abuduwaili J, Maihemuti B, Emin B, Groll M (2020) Innovative trend analysis of precipitation in the Lake Issyk-Kul Basin. Kyrgyzstan Atmosphere 11:332. https://doi.org/10.3390/atmos11040332
Bates BC, Kundzewicz ZW, Wu S, Palutikof JP (2008) Climate change and water. In: Technical paper of the Intergovernmental Panel on Climate Change. IPCC, Geneva
Bouizrou I, Aqnouy M, Bouadila A (2022) Spatio-temporal analysis of trends and variability in precipitation across Morocco: comparative analysis of recent and old non-parametric methods. J Afr Earth Sc 196:104691
Brunetti M, Maugeri M, Monti F, Nanni T (2004) Changes in daily precipitation frequency and distribution in Italy over the last 120 years. J Geophys Res: Atmos 109. https://doi.org/10.1029/2003JD004296
Buishand TA (1982) Some methods for testing the homogeneity of rainfall records. J Hydrol 58:11–27. https://doi.org/10.1016/0022-1694(82)90066-X
Caloiero T (2020) Evaluation of rainfall trends in the South Island of New Zealand through the innovative trend analysis (ITA). Theoret Appl Climatol 139:493–504. https://doi.org/10.1007/s00704-019-02988-5
Cengiz TM, Tabari H, Onyutha C, Kisi O (2020) Combined use of graphical and statistical approaches for analyzing historical precipitation changes in the Black Sea region of Turkey. Water 12:705. https://doi.org/10.3390/w12030705
Cohn TA, Lins HF (2005) Nature's style: naturally trendy. Geophys Res Lett 32. https://doi.org/10.1029/2005GL024476
Coulibaly JY, Mbow C, Sileshi GW, Beedy T, Kundhlande G, Musau J (2015) Mapping vulnerability to climate change in Malawi: spatial and social differentiation in the Shire River Basin. Am J Clim Chang 4(3):282–294. https://doi.org/10.4236/ajcc.2015.43023
Dabanlı İ, Şen Z, Yeleğen MÖ, Şişman E, Selek B, Güçlü YS (2016) Trend assessment by the innovative-Şen method. Water Resour Manage 30:5193–5203. https://doi.org/10.1007/s11269-016-1478-4
Daron J (2014) Regional climate messages for Southern Africa: scientific report from the CARIAA adaptation at scale in semi-arid regions (ASSAR) project. Cape Town, available at: www.assar.uct.ac.za/sites/default/files/image_tool/images/138/RDS_reports/climate_messages/SouthernAfricaClimateMessages-Version1-RegionalLevel.pdf (accessed 13 September, 2022)
Duhan D, Pandey A (2013) Statistical analysis of long term spatial and temporal trends of precipitation during 1901–2002 at Madhya Pradesh, India. Atmos Res 122:136–149. https://doi.org/10.1016/j.atmosres.2012.10.010
Gedefaw M, Yan D, Wang H, Qin T, Girma A, Abiyu A, Batsuren D (2018) Innovative trend analysis of annual and seasonal rainfall variability in Amhara regional state, Ethiopia. Atmosphere 9:326. https://doi.org/10.3390/atmos9090326
Haghtalab N, Moore N, Ngongondo CS (2019) Spatio-temporal analysis of rainfall variability and seasonality in Malawi. Reg Environ Change 19:2041–2054. https://doi.org/10.1007/s10113-019-01535-2
Hamududu BH, Killingtveit Å (2016) Hydropower production in future climate scenarios; the case for the Zambezi River. Energies 9:502. https://doi.org/10.3390/en9070502
Huth R, Pokorná L (2004) Parametric versus non-parametric estimates of climatic trends. Theoret Appl Climatol 77:107–112. https://doi.org/10.1007/s00704-003-0026-3
Jury MR, Gwazantini M (2002) Climate variability in Malawi, part 2: sensitivity and prediction of lake levels. Int J Climatol: J R Meteorol Soc 22:1303–1312. https://doi.org/10.1002/joc.772
Jury MR (2013) Climate trends in southern Africa. S Afr J Sci 109:1–11. https://doi.org/10.1590/sajs.2013/980
Kendall M (1975) Rank correlation methods. Charles Griffin, London
Kisi O (2015) An innovative method for trend analysis of monthly pan evaporations. J Hydrol 527:1123–1129. https://doi.org/10.1016/j.jhydrol.2015.06.009
Koycegiz C, Buyukyildiz M (2023) Investigation of spatiotemporal variability of some precipitation indices in Seyhan Basin, Turkey: monotonic and sub-trend analysis. Nat Hazards 116(2):2211–2244. https://doi.org/10.1007/s11069-022-05761-6
Kumbuyo CP, Shimizu K, Yasuda H, Kitamura Y (2015) Linkage between Malawi rainfall and global sea surface temperature. J Rainwater Catchment Syst 20:7–13. https://doi.org/10.7132/jrcsa.20_2_7
Kundzewicz Z, Robson A (2000) Detecting trend and other changes in hydrological data, World Climate Program – Water, WMO/UNESCO, WCDMP-45, WMO/TD 1013, WMO, Geneva, 158 pp., 2000. https://doi.org/10.5194/hess-20-3947-2016
Lehmann EL (1975) Nonparametrics: statistical methods based on ranks, Holden-day, San Francisco, California, USA.https://doi.org/10.1007/978-1-4614-1412-4_96
Mallick J, Talukdar S, Alsubih M, Salam R, Ahmed M, Kahla NB, Shamimuzzaman M (2021) Analysing the trend of rainfall in Asir region of Saudi Arabia using the family of Mann-Kendall tests, innovative trend analysis, and detrended fluctuation analysis. Theoret Appl Climatol 143:823–841. https://doi.org/10.1007/s00704-020-03448-1
Mann HB (1945) Nonparametric tests against trend. Econometrica: J Econometric Soc 245–259. https://doi.org/10.2307/1907187
Marumbwa FM, Cho MA, Chirwa PW (2019) Analysis of spatio-temporal rainfall trends across southern African biomes between 1981 and 2016. Phys Chem the Earth, Parts A/B/C 114:102808. https://doi.org/10.1016/j.pce.2019.10.004
Mirabbasi R, Ahmadi F, Jhajharia D (2020) Comparison of parametric and non-parametric methods for trend identification in groundwater levels in Sirjan plain aquifer, Iran. Hydrol Res 51:1455–1477. https://doi.org/10.2166/nh.2020.041
Mtilatila L, Bronstert A, Bürger G, Vormoor K (2020) Meteorological and hydrological drought assessment in Lake Malawi and Shire River basins (1970–2013). Hydrol Sci J 65:2750–2764. https://doi.org/10.1080/02626667.2020.1837384
Mubialiwo A, Abebe A, Onyutha C (2023) Changes in extreme precipitation over Mpologoma catchment in Uganda, East Africa. Heliyon 9(3). https://doi.org/10.1016/j.heliyon.2023.e14016
New M, Hewitson B, Stephenson DB, Tsiga A, Kruger A, Manhique A, Gomez B, Coelho CA, Masisi DN, Kululanga E (2006) Evidence of trends in daily climate extremes over southern and west Africa. J Geophys Res: Atmos 111. https://doi.org/10.1029/2005JD006289
Ngongondo C, Xu CY, Gottschalk L, Alemaw B (2011) Evaluation of spatial and temporal characteristics of rainfall in Malawi: a case of data scarce region. Theoret Appl Climatol 106:79–93. https://doi.org/10.1007/s00704-011-0413-0
Ngongondo C, Xu CY, Tallaksen LM, Alemaw B (2015) Observed and simulated changes in the water balance components over Malawi, during 1971–2000. Quatern Int 369:7–16. https://doi.org/10.1016/j.quaint.2014.06.028
Nicholson SE (2016) An analysis of recent rainfall conditions in eastern Africa. Int J Climatol 36:526–532. https://doi.org/10.1002/joc.4358
Onyutha C (2016a) Identification of sub-trends from hydro-meteorological series. Stoch Env Res Risk Assess 30:189–205. https://doi.org/10.1007/s00477-015-1070-0
Onyutha C (2016b) Statistical analyses of potential evapotranspiration changes over the period 1930–2012 in the Nile River riparian countries. Agric for Meteorol 226:80–95. https://doi.org/10.1016/j.agrformet.2016.05.015
Onyutha C (2016c) Statistical uncertainty in hydrometeorological trend analyses. Adv Meteorol 2016. https://doi.org/10.1155/2016/8701617
Onyutha C (2016d) Variability of seasonal and annual rainfall in the River Nile riparian countries and possible linkages to ocean–atmosphere interactions. Hydrol Res 47:171–184. https://doi.org/10.2166/nh.2015.164
Onyutha C (2021) Graphical-statistical method to explore variability of hydrological time series. Hydrol Res 52(1):266–283. https://doi.org/10.2166/nh.2020.111
Otto FE, Zachariah M, Wolski P, Pinto I, Nhamtumbo B, Bonnet R, Vautard R, Philip S, Kew S, Luu L (2022) Climate change increased rainfall associated with tropical cyclones hitting highly vulnerable communities in Madagascar, Mozambique & Malawi. https://www.worldweatherattribution.org/wp-content/uploads/WWA-MMM-TS-scientific-report.pdf
Ratnam J, Behera S, Masumoto Y, Yamagata T (2014) Remote effects of El Niño and Modoki events on the austral summer precipitation of southern Africa. J Clim 27:3802–3815. https://doi.org/10.1175/JCLI-D-13-00431.1
Sayemuzzaman M, Jha MK (2014) Seasonal and annual precipitation time series trend analysis in North Carolina, United States. Atmos Res 137:183–194. https://doi.org/10.1016/j.atmosres.2013.10.012
Sen PK (1968) Estimates of the regression coefficient based on Kendall’s tau. J Am Stat Assoc 63(324):1379–1389. https://doi.org/10.1080/01621459.1968.10480934
Şen Z (2012) Innovative trend analysis methodology. J Hydrol Eng 17:1042–1046. https://doi.org/10.1061/(ASCE)HE.1943-5584.0000556
Şen Z (2014) Trend identification simulation and application. J Hydrol Eng 19(3):635–642. https://doi.org/10.1061/(ASCE)HE.1943-5584.0000811
Şen Z (2017) Innovative trend significance test and applications. Theoret Appl Climatol 127:939–947. https://doi.org/10.1007/s00704-015-1681-x
Shadmani M, Marofi S, Roknian M (2012) Trend analysis in reference evapotranspiration using Mann-Kendall and Spearman’s Rho tests in arid regions of Iran. Water Resour Manage 26:211–224. https://doi.org/10.1007/s11269-011-9913-z
Shongwe ME, Van Oldenborgh G, Van Den Hurk B, De Boer B, Coelho C, Van Aalst M (2009) Projected changes in mean and extreme precipitation in Africa under global warming. Part I: Southern Africa. J Clim 22:3819–3837. https://doi.org/10.1175/2009JCLI2317.1
Sithole A, Murewi CT (2009) Climate variability and change over southern Africa: impacts and challenges. Afr J Ecol 47:17–20. https://doi.org/10.1111/j.1365-2028.2008.01045.x
Sneyers R (1990) On the statistical analysis of series of observations. World Meteorological Organization, Geneva, Switzerland
Some’e BS, Ezani A, Tabari H (2012) Spatiotemporal trends and change point of precipitation in Iran. Atmos Res 113:1–12. https://doi.org/10.1016/j.atmosres.2012.04.016
Sun F, Roderick ML, Farquhar GD (2018) Rainfall statistics, stationarity, and climate change. Proc Natl Acad Sci 115:2305-2310.https://doi.org/10.1073/pnas.1705349115
Tadeyo E, Chen D, Ayugi B, Yao C (2020) Characterization of spatio-temporal trends and periodicity of precipitation over Malawi during 1979–2015. Atmosphere 11:891. https://doi.org/10.3390/atmos11090891
Theil H (1950) A rank-invariant method of linear and polynomial regression analysis. Indag Math 12(85):173
Von Storch H (1995) Misuses of statistical analysis in climate research.Autumn School on analysis of climate variability-applications of statistical techniques, Springer, 11–26. https://doi.org/10.1007/978-3-662-03744-7_2
Wang Y, Xu Y, Tabari H, Wang J, Wang Q, Song S, Hu Z (2020) Innovative trend analysis of annual and seasonal rainfall in the Yangtze River Delta, eastern China. Atmos Res 231:104673. https://doi.org/10.1016/j.atmosres.2019.104673
Westra S, Alexander LV, Zwiers FW (2013) Global increasing trends in annual maximum daily precipitation. J Clim 26:3904–3918
Wu P, Christidis N, Stott P (2013) Anthropogenic impact on Earth’s hydrological cycle. Nat Clim Chang 3:807–810. https://doi.org/10.1038/nclimate1932
Wu S, Zhao W, Yao J, Jin J, Zhang M, Jiang G (2022) Precipitation variations in the Tai Lake Basin from 1971 to 2018 based on innovative trend analysis. Ecol Ind 139:108868. https://doi.org/10.1016/j.ecolind.2022.108868
Yang H, Xiao H, Guo C, Sun Y (2019) Spatial-temporal analysis of precipitation variability in Qinghai Province, China. Atmos Res 228:242–260. https://doi.org/10.1016/j.atmosres.2019.06.005
Yue S, Pilon P, Cavadias G (2002a) Power of the Mann-Kendall and Spearman’s rho tests for detecting monotonic trends in hydrological series. J Hydrol 259:254–271. https://doi.org/10.1016/S0022-1694(01)00594-7
Yue S, Pilon P, Phinney B, Cavadias G (2002b) The influence of autocorrelation on the ability to detect trend in hydrological series. Hydrol Process 16:1807–1829. https://doi.org/10.1002/hyp.1095
Zuzani P, Ngongondo C, Mwale F, Willems P (2019) Examining trends of hydro-meteorological extremes in the Shire River Basin in Malawi. Phys Chem Earth, Parts A/B/C 112:91–102. https://doi.org/10.1016/j.pce.2019.02.007
Acknowledgements
The authors acknowledge the Ministry of Commerce (MOFCOM) of the People’s Republic of China for providing financial support in form of scholarship to the first author. Sincere gratitude goes to the Malawi Department of Climate Change and Meteorological Services (MDCCM) for providing the meteorological data that was used in this study. The authors recognize the NORHED II Climate Change and Ecosystems Management in Malawi and Tanzania (#63826) and the World Bank supported Centre for Resilient Agro-Food Systems (CRAFS) under the ACE 2 Project for the fourth author’s contribution to the study. Most of all, the authors acknowledge the use of CSDNAIM-v.3 and CSD-VAT v.2 tools downloaded from https://sites.google.com/site/conyutha/tools-to-download (accessed: 22 January 2021 and 24 October 2023, respectively).
Funding
This study was supported by the Key Research and Development Program, Tianjin City, China (21YFSNSN00160), and Key Program of “Science and Technology Helping Economy 2020,” Tianjin City, China (SQ2020YFF0412145).
Author information
Authors and Affiliations
Contributions
Conceptualization: S.K., L.Z., and C.N. Data curation: S.K. and C.N. Investigation: S.K., C.N., and E.C. Methodology: S.K., L.C., and C.N. Formal analysis: S.K. and C.N. Supervision: L.Z., L.C., and C.N. Writing—original draft: S.K., and C.N. Writing—review and editing: L.Z, L.C., M.A.A, and B.T.O. Resources: L.Z. Validation: L.C., C.N., and P.K. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this article was revised due to a retrospective Open Access order.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kavwenje, S., Zhao, L., Chen, L. et al. Integrated statistical and graphical non-parametric trend analysis of annual and seasonal rainfall in the Shire River Basin, Malawi. Theor Appl Climatol 155, 2053–2069 (2024). https://doi.org/10.1007/s00704-023-04743-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-023-04743-3