
Abstract
Meteorological drought is a climatic phenomenon that affects all global climates with social, political, and economic impacts. Consequently, it is essential to develop drought forecasting tools to minimize the impacts on communities. Here, probabilistic models based on Markov chains (first and second order) and Bayesian networks (first and second order) were explored to generate forecasts of meteorological drought events. A Ranked Probability Score (RPS) metric selected the best-performing model. Long-term precipitation data from Liberia Airport in Guanacaste, Costa Rica, from 1937 to 2020 were used to estimate the 1-month Standardized Precipitation Index (SPI-1) characterizing four meteorological drought states (no drought, moderate drought, severe drought, and extreme drought). The validation results showed that both models could reflect the climatic seasonality of the dry and rainy seasons without mistaking 4–5 months of the rain-free dry season for a drought. Bayesian networks outperformed Markov chains in terms of the RPS at both reproducing probabilities of drought states in the rainy season and when compared to the months in which a drought state was observed. Considering the forecasting capability of the latter method, we conclude that these models can help predict meteorological drought with a 1-month lead time in an operational early warning system.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Drought is a climatic feature that affects all climate zones of the planet, and its impact is reflected in social, political, and economic costs (UNDRR 2021; IPCC 2021). For instance, in 2011, the drought in the Horn of Africa affected almost 13 million people, and in 2012, the USA experienced its worst drought since the 1950s, affecting 80% of croplands (Ki-moon 2014). Other prominent global examples include the decadal droughts in Chile and Australia since 2010 (Saft et al. 2015; Garreaud et al. 2020). Furthermore, climate change projections for tropical regions indicate that droughts are likely to become more frequent and severe, mainly due to rising temperatures (Van Lanen et al. 2015; UNDRR 2021; IPCC 2021). The Central American Dry Corridor (CADC) is the most vulnerable region in Central America to climate variability and change, as identified by the FAO 2016. A minimum of 4 months without rainfall (dry season) and a population vulnerable to socio-economic change commonly characterize the CADC (Gotlieb et al. 2019; Quesada-Hernández et al. 2019). In 2015, parts of Central America and the CADC experienced one of the most severe droughts in the previous 10 years, as more than 3.5 million people needed assistance; the most significant impacts were reflected in food insecurity, as crops suffered a poor harvest, resulting in large economic losses (FAO 2016).
Despite the socio-economic impacts caused by droughts, Mishra and Desai (2006) alerted of a deficiency in drought mitigation efforts and the limitations in forecasting dry conditions. The importance of drought forecasting, mainly meteorological drought, can be inferred from a decrease in precipitation as the beginning of several cascading effects such as the decrease in soil moisture, streamflows, and groundwater levels, with the consequent impact on agricultural production and societal welfare. Van Loon (2015) defines drought as a sustained period of low water availability compared to average conditions, with spatial and temporal characteristics that vary from one region to another. Wilhite and Glantz (1985) classified drought into meteorological, agricultural, hydrological, and socio-economic drought according to the chronological order of reduced precipitation and its impacts, where meteorological drought is usually defined as the degree of dryness compared to the average amount and duration of a dry period. The degree of dryness is often characterized in terms of duration, severity, and frequency using precipitation indices (WMO; Global Water Partnership 2016; Romero et al. 2020). Among different indices, the most widely applied is the Standardized Precipitation Index – SPI (McKee et al. 1993; WMO 2012). Albeit the SPI does not consider actual rainfall volume due to the normalization process with a fitted statistical distribution, it is a comparable unit-less index (WMO; Global Water Partnership 2016). Nonetheless, the SPI possesses limitations, as, for example, it cannot determine the impact of rising temperatures on future drought patterns (Vicente-Serrano et al. 2010).
Northern Costa Rica forms part of the CADC and is no exception to other drought-affected regions; however, few studies exist to understand the behavior of droughts (Birkel 2006). A major challenge characterizing droughts in the seasonally dry tropics is the 4 to 5 months dry season with virtually no rainfall. The latter dry season is part of the climate variability of the region and has to be clearly differentiated from droughts that mostly manifest as a rainfall deficit over the rainy season (Quesada-Hernández et al. 2019; Romero et al. 2020). Linked to the latter is the challenge that poses the methodology used to determine the beginning and end of drought events (Mishra and Singh 2011). Therefore, many different modeling techniques were used for different purposes, such as regression analysis assuming a linear relationship between predictor and predictand. However, the linearity assumption precludes from adequate long-term forecasting (Avilés et al. 2016).
Time series models such as Autoregressive Integrated Moving Average (ARIMA) (Modarres 2007; Han et al. 2010) and Seasonal Autoregressive Integrated Moving Average (SARIMA) (Fernández et al. 2008) models were proposed for drought forecasting. However, identification, estimation, and diagnostics of the most appropriate time series model depends on the user and the purpose of the model (Mishra and Singh 2011). Neural networks (Mokhtarzad et al. 2017; Khan et al. 2020) are nonlinear models that can characterize complex data patterns at the expense of increased computational burden (Mishra et al. 2011; Avilés et al. 2016).
Probabilistic models can explicitly account for the uncertainty of drought-related variables with Markov chains (MC) being the most commonly used (Paulo and Pereira 2007; Avilés et al. 2016; Estácio et al. 2021). Past studies used MC to forecast short-term rainfall deficits in Paulo et al. (2005) and (Yeh and Hsu 2019). More sophisticated Bayesian networks were not as widely used for drought forecasting (Madadgar and Moradkhani 2013) and therefore need testing in tropical regions (Avilés et al. 2016) and particularly in Central America, where Maldonado et al. (2018) mentions that there is no standardized methodology to produce forecasts, which suggest that some of these forecasts are based on subjective evaluations.
Therefore, we tested and compared two probabilistic models to detect and forecast meteorological drought in the seasonally dry tropics of northern Costa Rica. The first model was based on Markov chains, and the second model used Bayesian networks based on copula functions. These models were set up and run with a continuous and high-quality monthly precipitation time series from 1937 to 2020, utilizing a single weather station.
The specific objectives were to
-
i)
test Markov chains of first and second order with a long precipitation time series.
-
ii)
evaluate the performance of Bayesian network models of two- and three-dimensional copulas.
-
iii)
compare these probabilistic models to establish the region’s most suitable drought forecast method.
2 Study area
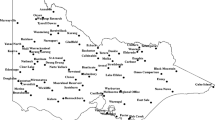
The Tempisque catchment (Fig. 1) belongs to the province of Guanacaste and is located in the North Pacific of Costa Rica. According to the National Meteorological Institute (2008), this region is the most water limited in the country. Water scarcity develops due to the low rainfall rates and resultant streamflow during the dry season from December until April. The average annual rainfall in the region is 1700 mm, with mean temperatures of 32 °C during the day and 22 °C at night. The rainy season extends from May to November with lower rainfalls around July which is known as Veranillo de San Juan (Ramírez 1983) or canícula (Fig. 1). Mean monthly rainfall from Liberia International Airport weather station over the dry season months is 17 mm with a monthly wet season average of 226 mm. The driest year was 1997 with an annual monthly average precipitation of 57 mm. The wettest year was 1955, with an average of 238 mm. From 1973 to 2003, the mean daily streamflow of the Tempisque River at Guardia gauging station was 24.6 m3/s with the lowest flow of 2.6 m3/s measured in late April (Birkel et al. 2017). This marked intra-annual seasonality is associated with the seasonal movement of the Intertropical Convergence Zone (ITCZ) and other oceanic-atmospheric regulators such as the El Niño Southern Oscillation (Durán-Quesada et al. 2010).

Overview of the study region (small inlet map), the main Tempisque River, and the weather station location in the main panel (a) showing the mean annual spatial rainfall distribution and (b) the average monthly precipitation (1981–2020) with the black lines indicating the precipitation range for each month. Data source: Liberia International Airport weather station and CHIRPSv2 (Funk et al. 2014) for the spatial rainfall map
Despite the marked seasonality and drought proneness of the region, the area used for agriculture increased from 0% in 1950 to 27.8% in 2010, changing from a subsistence model to an export-oriented industrial model (Birkel et al. 2017). The region is one of the primary producers of rice and melon and processes more than 50% of the sugar cane of the country (PIAAG 2019). These activities are carried out intensively and use extracted water from the Tempisque River as the main source to support the irrigation needs.
3 Materials and methods
3.1 Data sources
For the analysis and modeling of drought, precipitation records from the Liberia International Airport weather station with an 84-year time series (1937–2020) were used (location in Fig. 1). The data were obtained from the National Meteorological Institute with less than 5% information gaps. Missing data was linearly infilled from a double mass curve using the Climate Hazards Group Infrared Precipitation with Stations (CHIRPSv2) (Funk et al. 2014). The CHIRPS product correlated well (R2 > 0.8) with observed precipitation in the region (Arciniega et al. 2022) and could adequately simulate the duration of streamflow droughts (Venegas-Cordero et al. 2021) in the Tempisque catchment.
3.2 Drought classification
The infilled precipitation series were checked for outliers, and a Mann-Kendall statistical test was performed to verify that the series was stationary. We did not detect non-stationary behavior, and subsequently, no transformation was performed prior to the drought analysis. The R package SPEI (Beguería and Vicente-Serrano 2017) was used for all calculations. The Standardized Precipitation Index (SPI) was selected to characterize drought periods (McKee et al. 1993) and was based on fitting a Gamma statistical distribution to the rainfall empirical distribution. It was calculated on a monthly scale (SPI-1) due to our focus on meteorological drought as the precursor to other drought phenomena and then reclassified into four drought states (Table 1). SPI-1 values greater than −0.99 were considered as “no drought.” The “moderate drought” category includes values between −1 and −1.49, while the “severe drought” category consists of −1.5 to −1.99. SPI-1 values less than −2 are categorized as “extreme drought.” The SPI-1 time series was divided into a calibration period (1937–1999), in which the probabilities were calculated, and a validation period (2000–2020), in which the calculated probabilities were tested as an indicator of forecasting performance.
3.3 Probabilistic models
3.3.1 Markov chains
Probabilistic models based on Markov chains are commonly used for drought prediction (Mishra and Singh 2011; Avilés et al. 2016). According to Avilés (2017), these models are composed of “a set of transition probability matrices that indicate the probabilities of occurrence of the states of a system for a time interval of the future from the information of the current state and/or states of past intervals, depending on the order of the model.” These transition probabilities determine the behavior of the Markov chains, and this converts them into conditional probabilities (Wilks 2003).
It is from these transition matrices that the next month’s drought category can be predicted based on the current month’s observation for first-order Markov chains (MC1). In the case of second-order Markov chains (MC2), it is the same principle, but with the difference that the forecast of the next month is based on the observation of two previous months. Here, we used non-homogeneous Markov chains considering the climatic seasonality of the study area. The latter means that the probabilities are not fixed for any given month, but instead will vary from month to month. The transition probability of a month is determined by the category of the previous month. According to Steinemann (2003), this characteristic is known as the Markov Property, which is expressed as follows:
where pij represents the transition probability in which X(t+1) equals the category j given that Xt equals the category i. To calculate the transition probability (pij), the relative frequencies, which are the conditional probabilities of the transitions between each category (mij), must be estimated. This can be expressed as
where the numerator represents the number of transitions of the category i to the category j, while the denominator is the sum of the number of transitions of the category i to any other category.
Unlike MC1 models, MC2 models require three subscripts for the estimation of transition probabilities since dependencies of more than two time periods are considered for their calculation (Wilks 2003). The first subscript is the state or category at time t−1, the second is the category at time t, and the third is the state at future time t+1. According to Avilés et al. (2015), this is formulated as follows:
In this case, the transition probability phij, in which X(t+1) is equal to state j, is given by Xt being equal to drought state category i, and X(t-1) being equal to category h. The transition probabilities phij are estimated by
The numerator is the number of transitions from categories h and i to category j; and the denominator is equal to the sum of the number of transitions from categories h and i to any other category. This model considers values further back in time, so the number of possible transitions increases exponentially, resulting in larger matrices, compared to the MC1 model.
3.3.2 Bayesian networks
According to Madadgar and Moradkhani (2013), Bayesian networks describe the conditional dependence of a set of random variables based on direct acyclic graphs (DAG). Following Heckerman (1998), the first step in developing a Bayesian network is to define the variables and states to be modeled, in this case, the drought categories. The second step consists of generating the DAG that encodes the conditional independence assertions, which is called the structure of the Bayesian network:
where xtn represents the forecast probabilities, which are calculated from the division of the predictive variables, i.e., the joint distributions associated with the variables. To define these distributions, we used copula functions, which model the joint behavior of the variables (Avilés et al. 2016; Madadgar and Moradkhani 2013). Copulas form multivariate functions by linking uni-variate functions (Shiau 2006), which make it possible to separate the effects of dependence from the effects of marginal distributions. This simplifies the modeling of the dependence of the random variables (Schmidt 2006). These functions were introduced by Sklar (1959), who, in his theorem, describes how copulas interact between multivariate distribution functions and their marginal distribution. The theorem states that a multivariate distribution F(X1,…,Xn), for all X in the domain F, can be expressed as follows:
where the marginal distribution in the interval (0,1) is represented by U1 (X1), while C is the cumulative distribution (CDF) of the copula. Therefore, Eq. (5) can be reformulated as
Based on Eq. (7), the Bayesian network models can be calculated. For Bayesian networks of first order (BN1), it is necessary that n = 2; whereas if n = 3, we have the models of Bayesian networks of second order (BN2), which are expressed as follows:
Equations (8) and (9) must be rewritten so that the probabilities of each category do not exceed the CDF thresholds established in Table 1. Considering that xds represents the CDF threshold, the equations are defined as
The next step identifies the appropriate dependence structures to form the joint distributions (Avilés et al. 2016). For this, the temporal dependence is modeled by performing a copula fitting according to the marginal distributions. The CDF is used to convert the observations into pseudo-observations with values in the interval (0,1), which are the marginal distribution used in the copula fitting.
A total of four types of copulas are used: two elliptic (Normal and Student) and two Archimedean (Clayton and Frank). The best fit is selected according to two criteria:
-
a p value greater than 0.05 and
-
the lowest statistical value (S), based on the Cramér-von Mises statistic, which is a measure of the distance between empirical and parametric copulas(Anderson 1962) expressed as
where S is the Cramér-von Mises statistic value; cEmp and Cθ are the empirical and parametric copulas, respectively, both of which fit the n-size data. Once the best-fit copulas are selected monthly and applied to Eqs. (10) and (11), they are used to develop the Bayesian networks of both first and second order.
3.4 Model forecast evaluation
From the previous steps, four models are obtained and statistically validated to select the most appropriate for drought forecasting. This validation uses a weighted probability score, known as Ranked Probability Score (RPS), and expressed as
This method calculates the forecast errors in terms of the probability attributed to the events. Additionally, it penalizes the forecasts that are further away from the observations (Avilés 2017). The result of Eq. (13) is the difference between the predicted probabilities (Ym) and the observed probabilities (Om). A perfect forecast should have an RPS equal to zero, and the further away from this value, the greater the difference between the predicted and observed probabilities.
4 Results
4.1 Long-term climatic variability and meteorologic droughts
Data from the airport weather station showed (Fig. 1) a marked difference in the amount of precipitation between the dry and rainy seasons. The dry months from December to April exhibited monthly rainfall averages of less than 25 mm, while in the rainy months from May to November, rainfall exceeded 150 mm per month, except for November. There was a difference of approximately 165 mm between April and May, while from November to December, the change in average rainfall was almost 90 mm. Hence, no transition period between the seasons could be detected, as the increase in rainfall in May is almost immediate, and the decrease in precipitation in November is just as abrupt (Fig. 2); however, an analysis of daily or weekly data may reveal a transition period. The highest monthly rainfall occurs in September and October with an average close to 340 mm. Between July and August, rainfalls are lower compared to May to June and September to October. This period was also called mid-summer drought or “veranillo” (Alfaro 2014). A Mann-Kendall test was performed on the time series which resulted in a z-value = 1.134 and a p-value = 0.257, evidencing the stationarity of the time series.

Heat map depicting average monthly precipitation (1937–2020) for the airport weather station. The white shading represents low-to-zero precipitation, while the blue tiles represent higher accumulated precipitation
The monthly Standardized Precipitation Index (SPI-1) was calculated from the precipitation data (Fig. 3) and clearly identified that drought events have occurred historically. In fact, two months of extreme drought were detected in July and August 1939 with SPI-1 = −3.7. This condition of an SPI-1 being equal to or less than −3.7 did not occur again in 57 years, until September 1996, with a record low SPI-1 of −4, and a year later, in September 1997, the absolute minimum SPI-1 of −4.5 was detected. The most extreme drought in recent years occurred in July 2014, with an SPI-1 of −3.4.

Monthly standardized precipitation index (SPI-1) for the airport weather station (1937−2020). The letter A indicates the extreme drought of July–August 1939. Letter B marks the extreme droughts of September 1996 and 1997, while letter C highlights the extreme drought of July 2014
In summary (Table 2), the lowest monthly precipitation of the weather station was 0 mm, which exclusively occurred in dry months, while the maximum monthly precipitation was 818 mm. The monthly average was 137 mm, and the annual average was 1630 mm. The maximum SPI-1 was 3.0, corresponding to June 1979, with an accumulated monthly rainfall of 761 mm compared to a monthly long-term average of 137 mm.
4.2 Categorization of drought states
The SPI-1 values were reclassified according to Table 1, with the aim of identifying the months that presented a drought event, as well as recognizing the severity of the events and the frequency of occurrence.
Out of the 1002 months of the time series, 91 were in some category of drought, which represents about 9% of the data. As shown in Table 3, the moderate drought category occurred most frequently with 45 events, followed by severe drought with 27 observed events, and finally, extreme drought with 18 events. Interestingly, the majority of extreme drought events occurred in July and August, whereas moderate droughts occurred in May and October/November.
4.3 Markov chain drought modeling
Equation (2) was applied to obtain the relative MC1 frequencies of the transitions between months. Twelve transition matrices were obtained which established the transition probabilities for the current month given the previous month. The results for the rainy season are shown in Table 4. We only show the rainy months since the dry season months from December to April are a natural climatic feature of the seasonally dry tropics. Furthermore, the results for the dry season established a 100% probability of transition to the non-drought category for all dry months. Therefore, the MC1 model calculated – as expected – no drought probability for the dry season.
To interpret Table 4, the probabilities of the occurrence of a specific state for a month need to be compared with the probabilities of the same state of the previous month. For example, if May is in the no drought category, June has an 88% chance of remaining in that same category; an 8% chance of moving to state 1 (moderate drought); a 0% chance of state 2 (severe drought); and there is a 4% chance of an extreme drought event (state 3). The MC1 model did not assign transition probabilities from one drought state to another in the month of May. The reason was that historically April has never presented any drought event, as shown in Fig. 4. In contrast, May has presented drought events, which allows calculating the transitions between drought states for the following months. For instance, when May presents a state 3, June has a 67% probability of changing to state 0, and a 33% probability of changing to state 2. August, September, and October are the months with the highest probability of transition to state 3, which, according to MC1, was the most likely trimester of extreme drought occurrence.

(a) Cumulative distribution function of the SPI-1 time series for the airport station showing the thresholds for each drought category and (b) the resulting heatmap of historical drought occurrence
Equation (4) was used to calculate the drought state transition frequencies for the second-order Markov chains. These transitions consider the states of two months prior to the month to be forecast. The possible combinations increase from 16 possibilities in model MC1 to 64 in MC2 (Table 5).
The interpretation of Table 5 is similar to that of model MC1, with the difference that model MC2 takes into account two previous states. Thus, when May was in state 3 and April in state 0, June has a 67% probability of presenting a no drought event (state 0); it also has a 33% probability of being in state 2, while it has a 0% probability for states 1 and 3. Another example is that if September is in state 0 and August is in state 1, then October has a 60% probability of no drought. Even if it would have a 40% probability of being state 1, no resulting state 2 and 3 droughts are possible.
It is also important to note that with MC1 and MC2, a 50% probability of two opposite states can occur. This situation occurred in both models in September and October. This means that even considering two previous months, the Markov chain models have the disadvantage of giving the same probability for two opposite states, which represents a problem when deciding whether there will be a drought state.
4.4 Bayesian networks applied to analyze meteorological drought
The results from the validation period for the probabilities of the first-order Bayesian network per month in the rainy season are shown in Fig. 5. For all months, the no drought category exhibited the highest probability of occurrence, while the drought states 1–3 have a much lower probability, each below 20% since the distributions observed in the calibration period tend to be above the no drought threshold. However, the no drought category showed a decrease in the probability of occurrence after a drought event was observed, together with an increase in the probabilities of occurrence of a drought event. For example, in the month of May, the average probability of the no drought 0 category was 77%, but in 2008, that probability dropped to 65%, and in 2015, the probability was 60%; in those two years, meteorological drought events occurred.

Monthly probabilities of the first-order Bayesian network model for the rainy season of the validation period from 2000 to 2020
This behavior was also present in other months, most notably in July, where two drought events occurred (2012 and 2014), and the drought probabilities increased to almost 25%, while those of the no drought category dropped to 35% probability. The only month that does not present this behavior is June due to the weak correlation of pseudo-observations between May and June (Table 6), generating greater uncertainty in the transition of those months. In general, the best-fit dry season Copula was the symmetric Frank type, while in the rainy season, it was the asymmetric Clayton copula that predominated. The wider range of the Frank dependence parameter seems to better adapt to the dry season characteristics compared to the negative tail dependence of the Clayton copula.
Similar to the first-order model, the second-order Bayesian networks required the copula parameters to be fitted, which results in three-dimensional copulas. Therefore, the selection of copulas for this model included three parameters. The elliptic copulas (normal and T) were the best fit, except for June. This means that when two months are grouped together, the distributions were of an elliptic shape. The difference in the statistical value of the normal and T copulas was very small, considering more than five decimal places. Figure 6 shows the results of the second-order Bayesian network model with the no drought category acquiring the highest probability (average of 84% probability) for all months. In addition, moderate drought has an average probability of 8%, severe drought of 5%, while extreme drought has an average probability of 3%. With the 2nd-order Bayesian model, the probabilities remained stable throughout the validation period. July was the only exception since the probabilities were more inconsistent during the validation period and due to the heavy tail of the fitted Clayton copula. Therefore, this month showed that the probabilities of drought states increased when a drought event was observed, while the probability of the no drought category decreased with respect to its historical behavior.

Monthly probabilities of the second-order Bayesian network model for the rainy season of the validation period from 2000 to 2020
4.5 RPS evaluation for all drought states
We compared the models using the RPS validation method for all categories, including the no drought category, for the validation period (2000–2020). The RPS values obtained are shown in Table 7 and visualized in Fig. 7.

Model validation for all state categories from January to December using the RPS criterion
From December to April, the MC1 resulted in an RPS = 0, meaning a perfect prediction. However, this is because this model predicts a 100% probability of no drought in the dry months. The latter is to be expected, as shown in Fig. 4, since the dry season months do not experience meteorological drought. In the case of the Bayesian network models, there is a difference between the forecast and the observed for those same months due to the Bayesian models always assigning probabilities of occurrence to the four drought categories. For the rainy season months, differences between forecasts and observations were observed contrary to the dry season.
In the first two months of the rainy season (May–June), the models showed a similar behavior; however, from July to November, the Bayesian networks outperformed the Markov chain models with RPS statistics closer to zero, more closely representing the observed drought states. The RPS calculated for the validation period and observed droughts from Table 8 and Fig. 8 showed the differences between the modeled forecast and the observed droughts.

Model validation for the months presenting a drought category 1–3 using the RPS criterion (excluding the dry season from December to April)
The two Markov chain models had similar behavior, except in July, where the first-order model showed a greater difference. In October, forecasts showed a decrease in performance, but an improvement in November. The second-order Bayesian model showed a similar performance to those of the Markov chains with greater differences in May. The first-order Bayesian networks showed the best performance throughout the rainy season. The best results were obtained for August and November.
5 Discussion
5.1 Drought characterization in the tropics using SPI
The Standardized Precipitation Index (SPI) was used to characterize drought events monthly from January 1937 to June 2020. At the long-term Airport meteorological station, meteorological drought events have historically occurred between May and November throughout the rainy season. The dry season months are characterized by little or no precipitation, which is a climate feature, meaning that a significant decrease in precipitation in relation to the average rainfall for the dry season months is not possible. This variability in the behavior of meteorological drought can condition the results of the forecasts since the construction of the probabilities depends on the amount of input information given to the models. However, the 84-year precipitation record can be considered sufficiently long including enough information content in the form of climatic variability and drought events that historically occurred.
Large parts of Costa Rica including the Tempisque catchment in the Guanacaste region are characterized by a climate condition known as mid-summer drought (MSD) or “veranillo” in Spanish in July and August, which is characterized by an increase in trade winds and a decrease in precipitation (Ramírez 1983). This period occurs annually; however, its initiation and duration are variable (Amador 2008). Alfaro (2014) found that in the Tempisque basin between the period 1949–2010, the MSD had an average duration of 45 days with an average rainfall of 2.7 mm. Therefore, it is important to take the MSD into consideration for drought forecasting to be able to differentiate between a drought event and the recurrent MSD. The latter distinction could be achieved using the Bayesian networks, especially the first-order Bayesian network model which provides enough flexibility in assigning drought probabilities in the months when drought was observed, as shown in Fig. 5. However, it is important to mention that these probabilities of a drought state did not exceed those of the no drought state.
Another important climate influence on the Costa Rican Pacific is ENSO (El Niño Southern Oscillation) that associates a warming Pacific Ocean with a decrease in precipitation compared to average conditions. However, in the periods 1982–1983 and 1992–1993, when El Niño showed a strong signal (Wolter and Timlin 1998), this was not reflected in a state of drought. Between 1982 and 1983, there were only two months of drought, but these were not consecutive and rather with a separation of eight months. Between 1992 and 1993, only May 1992 showed a moderate drought, with an SPI-1 value of −1 and slightly below normal precipitation. However, other periods classified as strong ENSO, which occurred in the years 1972–1973 and 1997–1998 (Wolter and Timlin 1998), showed drought states in the observed time series. In 1972, there were four consecutive months of drought between July and October; in 1973, there was no drought since El Niño had already weakened by the end of the previous rainy season. Between 1997 and 1998, a very strong El Niño was recorded in the region, resulting in a 3-month long extreme drought event from August to October 1998, also shown by Muñoz-Jiménez et al. (2018) relating rainfall deficit to ENSO indicators. The latter authors also identified that strong ENSO events do not always result in a significant rainfall deficit and subsequent drought events in northwestern Costa Rica, mainly due to the complex teleconnection with the nearby Caribbean Sea (Enfield and Alfaro 1999).
5.2 Forecasting capability of the tested probabilistic drought models
The framework of the Markov chain models is both simple and efficient (Sharma and Panu 2012); however, the results of these models showed, in this study, transition combinations between states that have not been observed historically. The latter resulted in the MC1 and MC2 models being unable to calculate probabilities (these cases are represented in Tables 3 and 4 with a dash). However, the fact that some combinations have not been observed does not mean they cannot occur in the future. Similar to Cancelliere et al. (2006), this generates errors in the transition probabilities, which makes these models unsuitable for very complex systems (Fung et al. 2020).
The Markov chains showed reasonable performance in the dry season since they were able to predict the no drought events with perfect RPS values (Table 8). However, this was expected since (Fig. 4) the dry season is a climatic feature of the study region rather than a drought event. Similarly to Liu et al. (2009), Markov chains achieved better performance in the no drought and moderate drought states but presented problems in forecasting events of greater severity. On the other hand, the first-order model (MC1) performed slightly better than the second-order model (MC2), meaning that, although MC2 has more information to base the forecast upon, this does not necessarily lead to better forecasts (Rahmat et al. 2016).
According to Avilés et al. (2016) and Madadgar and Moradkhani (2013), models based on Bayesian networks (BN) have the potential to better forecast droughts than Markov chain models. The Bayesian networks (BN1, BN2) obtained the lowest RPS scores, in addition to monthly distributions that appropriately reflected observed droughts. Then, the probabilities of no drought decreased, and those of any drought category increased. Thus, as in Ji Yae Shin et al. (2016), Guo et al. (2019), and Raza et al. (2021), BNs generated a solid framework for forecasting drought events in the rainy season of our study region, particularly for the months August and November. The latter because although the likelihood of a non-drought state is higher, the decrease in probability during months when droughts were observed and the slight increase in drought probability suggested that the precipitation data distribution is not normal compared to past years, warranting caution in case this trend continues, as it may obscure the occurrence of a drought state.
Furthermore, the use of time-variable copula functions in BN models was an advantage to better match the observed data distributions despite more complexity. Thus, each month has a specific fit, and even when the same copula type is applied for multiple months, the fitted parameters allow the forecasts to adapt to the climatic condition of each month according to the behavior of the distributions. According to Shiau (2006), copula functions allow to construct a dependence structure between variables. The best-fit Clayton copulas were fitted in June, July, August, and October and obtained the best results in forecasting the observed drought events. This type of copula is characterized by a strong density and concentration of data in the left tail (Mendoza and Galvanovskis 2014), meaning that there is a relationship with negative events or, in this case, drought states. It can, therefore, be expected that drought events in any month increase the probability of a drought in the month to follow.
The BN1 models incorporated 2 months of information and can use the actual SPI data, unlike the MC1 models, which only contemplate the binary information (drought categories) of a single month. This allows the BN1 model to be more dynamic since the information is constantly adapted and updated monthly using parametric copula and marginal distributions. In the case of MC2, it was found that higher-order Markov chains presented problems when sizing and projecting data since the more months accumulated, the fewer transitions are considered. The latter thus generates a poor approximation of the transition probabilities (Lall and Sharma 1996). Even though we tested different types of copulas, non-parametric approaches allow us to avoid a priori assumptions about the choice of a model similar to Sharma and Lall (1999).
One of the limitations of the probabilistic models presented is that they depend on the time series characteristics of historic data and, in our case, on the probabilities calculated based on monthly SPI values. In other words, to forecast the following months’ drought category, it is necessary to know the precipitation in advance. Therefore, this class of time series models needs to be coupled to a regional climate model precipitation forecast. Steyn et al. (2016) stated that a double Gaussian function effectively modeled the annual precipitation cycle in Guanacaste, which could be an option to build a model that predicts precipitation and forecasts droughts within a BN. Additionally, the models presented are strictly only valid in the case of stationarity, which might limit their use with strongly non-stationary time series. Here, we could show that since 1937, the precipitation record did not show changing mean nor variance over time, justifying the use and potential of the models applied.
6 Conclusions
Historical drought events in Guanacaste, Costa Rica, were analyzed, and probabilistic meteorological drought forecasts were obtained using the 84-year long-term airport weather station records. From the comparison and validation of these models, we conclude that the first-order Bayesian networks showed the best performance for monthly forecasts with the ability to differentiate between the climatic characteristics of dry and rainy season months. The probability of predicting a drought never reached the level of the non-drought state with Bayesian networks, which also showed greater sensitivity with a slight increase in the probability of drought for some months compared to the other models. The Bayesian network model also automatically adjusted the probabilities during the wet season according to the monthly behavior, even when the no drought category had the highest probability. The latter is a critical advantage since it allows the forecast to be dynamically based on the drought status of increasing or decreasing drought probabilities. Future research will explore the applicability of these models with SPI at different temporal scales to detect and forecast other types of droughts that have a more direct impact on communities, such as hydrological and agricultural droughts. The latter will also enable to increase in the lead time of forecasted drought events.
Data availability
The data can be obtained upon reasonable request to the first author.
References
Alfaro E (2014) Caracterización del “veranillo” en dos cuencas de la vertiente del Pacífico de Costa Rica, América Central. Rev Biol Trop 62(Supl. 4):1–15. https://doi.org/10.15517/rbt.v62i4.20010
Amador JA (2008) The intra-Americas sea lowlevel jet overview and future research. Ann N Y Acad Sci 1146(1):153–188. https://doi.org/10.1196/annals.1446.012
Anderson TW (1962) On the distribution of the two-sample Cramer–von Mises criterion. Ann Math Stat 33:1148–1159. https://doi.org/10.1214/aoms/1177704477
Arciniega-Esparza S, Birkel C, Chavarría-Palma A, Arheimer B, Breña-Naranjo JA (2022) Remote sensing-aided rainfall–runoff modeling in the tropics of Costa Rica. Hydrol Earth Syst Sci 26:975–999. https://doi.org/10.5194/hess-26-975-2022
Avilés A, Célleri R, Paredes J, Solera A (2015) Evaluation of Markov chain based drought forecasts in an Andean Regulated River Basin using the skill scores RPS and GMSS. Water Resour Manag 29:1949–1963. https://doi.org/10.1007/s11269-015-0921-2
Avilés A, Célleri R, Solera A, Paredes J (2016) Probabilistic forecasting of drought events using Markov chain- and Bayesian network-based models: a case study of an Andean Regulated River Basin. Water 8:37. https://doi.org/10.3390/w8020037
Avilés A (2017) Pronóstico probabilístico de eventos de sequías y evaluación del riesgo en la gestión de sistemas de recursos hídricos. Caso de estudio en una cuenca andina regulada. Doctoral Thesis. In: Ingeniería del Agua y Medioambiental. Universidad Politécnica de Valencia
Beguería, S., & Vicente-Serrano, S. M. (2017). Package ‘SPEI’. https://cran.r-project.org/web/packages/SPEI/SPEI.pdf. Accessed 10 August 2022
Birkel C (2006) Sequía Hidrológica en Costa Rica ¿Se han vuelto más severas y frecuentes en los últimos años? Revista Reflexiones 85(1-2):107–116
Birkel C, Brenes A, Sánchez-Murillo R (2017) The Tempisque-Bebedero catchment system: energy-water-food consensus in the seasonally dry tropics of northwestern Costa Rica. In: Al-Saidi M, Ribbe L (eds) Nexus Outlook: assessing resource use challenges in the water, energy and food nexus. Nexus Research Focus. University of Applied Sciences, TH-Koeln, pp 73–77
Cancelliere A, Mauro GD, Bonaccorso B, Rossi G (2006) Drought forecasting using the Standardized Precipitation Index. Water Resour Manag 21(5):801–819. https://doi.org/10.1007/s11269-006-9062-y
Durán-Quesada AM, Gimeno L, Amador JA, Nieto R (2010) Moisture sources for Central America: identification of moisture sources using a Lagrangian analysis technique. J Geophys Res 115. https://doi.org/10.1029/2009JD012455
Estácio A, Silva S, Souza Filho F (2021) Statistical uncertainty in drought forecasting using Markov chains and the Standard Precipitation Index (SPI). Revista Brasileira De Climatologia 28:471–493. https://ojs.ufgd.edu.br/index.php/rbclima/article/view/14625. Accessed 30 Aug 2023
Enfield DB, Alfaro EJ (1999) The dependence of Caribbean rainfall on the interaction of the tropical Atlantic and Pacific Oceans. J Climate 12:2093–2103
FAO (2016) Corredor Seco América Central. Informe de Situación. https://www.fao.org/resilience/resources/recursos-detalle/es/c/422100/. Accessed 08 January 2022
Fernández C, Vega JA, Fonturbel T, Jiménez E (2008) Streamflow drought time series forecasting: a case study in a small watershed in North West Spain. Stoch Environ Res Risk Assess 23(8):1063–1070. https://doi.org/10.1007/s00477-008-0277-8
Funk CC, Peterson PJ, Landsfeld MF, Pedreros DH, Verdin JP, Rowland JD, Romero BE, Husak GJ, Michaelsen JC, Verdin AP (2014) A quasi-global precipitation time series for drought monitoring: U.S. Geol Surv Data Series 832:4
Fung KF, Huang YF, Koo CH, Soh YW (2020) Drought forecasting: a review of modelling approaches 2007–2017. J Water Clim Chang 11(3):771–799. https://doi.org/10.2166/wcc.2019.236
Garreaud RD, Boisier JP, Rondanelli R, Montecinos A, Sepúlveda HH, Veloso-Aguila D (2020) The Central Chile Mega Drought (2010–2018): a climate dynamics perspective. Int J Climatol 40:421–439. https://doi.org/10.1002/joc.6219
Gotlieb Y, Pérez-Briceño P, Hidalgo H, Alfaro E (2019) The Central American Dry Corridor: a consensus statement and its background. Revista Yu’am 3(5):42–51
Guo C, Khan F, Imtiaz S (2019) Copula-based Bayesian network model for process system risk assessment. Process Saf Environ Prot. https://doi.org/10.1016/j.psep.2019.01.022
Han P, Wang PX, Zhang SY, Zhu DH (2010) Drought forecasting based on the remote sensing data using ARIMA Models. Math Comput Model 51(11–12):1398–1403. https://doi.org/10.1016/j.mcm.2009.10.031
Heckerman D (1998) A tutorial on learning with Bayesian networks. In: Learning in Graphical Models. Springer, Dordrecht, The Netherlands, pp 301–354
IPCC (2021) In: Masson-Delmotte V, Zhai P, Pirani A, Connors SL, Péan C, Berger S, Caud N, Chen Y, Goldfarb L, Gomis MI, Huang M, Leitzell K, Lonnoy E, Matthews JBR, Maycock TK, Waterfield OY, Yu R, Zhou B (eds) Climate Change 2021: the physical science basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change. Cambridge University Press In Press
Shin JY, Ajmal M, Yoo J, Kim T-W (2016) A Bayesian network-based probabilistic framework for drought forecasting and outlook. Adv Meteorol 2016:10. https://doi.org/10.1155/2016/9472605
Ki-moon, B. (2014). Día Mundial de Lucha contra la Desertificación y la Sequía. https://www.cepal.org/es/articulos/2014-dia-mundial-lucha-la-desertificacion-la-sequia. Accessed 08 January 2022
Lall U, Sharma A (1996) A nearest neighbor bootstrap for resampling hydrologic time series. Water Resour Res 32(3):679–693. https://doi.org/10.1029/95WR02966
Liu X, Ren L, Yuan F, Yang B (2009) Meteorological drought forecasting using Markov chain model. 2009 International Conference on Environmental Science and Information Application Technology. https://doi.org/10.1109/ESIAT.2009.19
Madadgar S, Moradkhani H (2013) A Bayesian framework for probabilistic seasonal drought forecasting. J Hydrometeorol 14:1685–1705. https://doi.org/10.1175/JHM-D-13-010.1
Maldonado T, Alfaro EJ, y Hidalgo H.G. (2018) A review of the main drivers and variability of Central America Climate and seasonal forecast systems. Rev Biol Trop 66(S1):S153–S175. https://doi.org/10.15517/rbt.v66i1.33294
McKee TB, Doesken NJ, Kleist J (1993) The relationship of drought frequency and duration to time scales. In: Proceedings of the 8th Conference on Applied Climatology, vol 17. American Meteorological Society, Anaheim, CA, USA, pp 179–183
Mendoza A, Galvanovskis E (2014) La cópula GED bivariada. Una aplicación en entornos de crisis. El Trimestre Económico LXXXI(3):721–746
Mishra A, Desai V (2006) Drought forecasting using stochastic models. Stoch Environ Res Risk Assess 19:326–339. https://doi.org/10.1007/s00477-005-0238-4
Mishra AK, Singh VP (2011) Drought modeling – A review. J Hydrol 403(1–2):157–175. https://doi.org/10.1016/j.jhydrol.2011.03.049
Modarres R (2007) Streamflow drought time series forecasting. Stoch Environ Res Ris Assess 21:223–233. https://doi.org/10.1007/s00477-006-0058-1
Mokhtarzad M, Eskandari F, Jamshidi Vanjani N, Arabasadi A (2017) Drought forecasting by ANN, ANFIS, and SVM and comparison of the models. Environ Earth Sci 76:729. https://doi.org/10.1007/s12665-017-7064-0
Khan MMH, Muhammad NS, El-Shafie A (2020) Wavelet based hybrid ANN-ARIMA models for meteorological drought forecasting. J Hydrol:125380. https://doi.org/10.1016/j.jhydrol.2020.125380
Muñoz-Jiménez R, Giraldo-Osorio JD, Brenes-Torres A, Avendaño-Flores I, Nauditt A, Hidalgo-León HG, Birkel C (2018) Spatial and temporal patterns, trends and teleconnection of cumulative rainfall deficits across Central America. Int J Climatol. https://doi.org/10.1002/joc.5925
Paulo AA, Ferreira E, Coelho C, Pereira LS (2005) Drought class transition analysis through Markov and loglinear models, an approach to early warning. Agric Water Manag 77:59–81. https://doi.org/10.1016/j.agwat.2004.09.039
Paulo AA, Pereira LS (2007) Prediction of SPI drought class transitions using Markov chains. Water Resour Manage 21:1813–1827. https://doi.org/10.1007/s11269-006-9129-9
PIAAG. (2019). Proyecto Cuenca Media Río Tempisque y Comunidades Costeras. http://www.da.go.cr/wp-content/uploads/2019/02/Proyecto-Cuenca-Media-R%C3%ADo-Tempisque-y-Comunidades-Costeras.pdf. Accessed 08 January 2022
Quesada-Hernández LE, Calvo-Solano OD, Hidalgo HG, Pérez-Briceño PM, Alfaro EJ (2019) Dynamical delimitation of the Central American Dry Corridor (CADC) using drought indices and aridity values. Prog Phys Geogr: Earth and Environ. https://doi.org/10.1177/0309133319860224
Rahmat SN, Jayasuriya N, Bhuiyan MA (2016) Short-term drought forecasts using Markov chain model in Victoria, Australia. Theor Appl Climatol 129:445–457. https://doi.org/10.1007/s00704-016-1785-y
Ramírez P (1983) Estudio Meteorológico de los Veranillos en Costa Rica. Informe Técnico. Instituto Meteorológico Nacional, Ministerio de Agricultura y Ganadería, Nota de investigación No 5. San José, Costa Rica
Raza A, Hussain I, Ali Z et al (2021) A seasonally blended and regionally integrated drought index using Bayesian network theory. Meteorol Appl 28:e1992. https://doi.org/10.1002/met.1992
Romero D, Alfaro E, Orellana R, Hernandez Cerda M-E (2020) Standardized drought indices for pre-summer drought assessment in tropical areas. Atmosphere 11:1209. https://doi.org/10.3390/atmos11111209
Saft M, Western AW, Zhang L, Peel MC, Potter NJ (2015) The influence of multiyear drought on the annual rainfall-runoff relationship: an Australian perspective. Water Resour Res 51:2444–2463. https://doi.org/10.1002/2014WR015348
Schmidt T (2006) Coping with copulas. Copulas - from theory to applications in finance. Risk Books, Londres, pp 3–34
Sharma A, Lall U (1999) A nonparametric approach for daily rainfall simulation. Math Comput Simul 48(4–6):361–371. https://doi.org/10.1016/S0378-4754(99)00016-6
Sharma TC, Panu US (2012) Prediction of hydrological drought durations based on Markov chains: case of the Canadian prairies. Hydrol Sci J 57(4):705–722. https://doi.org/10.1080/02626667.2012.672741
Steyn D, Moisseeva N, Harari O, Welch WJ (2016) Temporal and spatial variability of annual rainfall patterns in Guanacaste, Costa Rica. University of British Columbia Library, Vancouver. https://doi.org/10.14288/1.0340318
Shiau JT (2006) Fitting drought duration and severity with two-dimensional copulas. Water Resour Manage 20:795–815. https://doi.org/10.1007/s11269-005-9008-9
Sklar A (1959) Fonctions de Répartition à n Dimensions et Leurs Marges, vol 8. Publications de l’Institut Statistique de l’Université de Paris, pp 229–231
Steinemann A (2003) Drought indicators and triggers: a stochastic approach to evaluation. JAWRA 39:1217–1233. https://doi.org/10.1111/j.1752-1688.2003.tb03704.x
UNDRR (2021) GAR Special Report on Drought 2021, Geneva
Van Lanen HAJ, Tallaksen LM, Assimacopoulos D, Stahl K, Wolters W, Andreu J, Seneviratne SI, De Stefano L, Seidl I, Rego FC, Massarutto A, Garnier E (2015) Fostering drought research and science-policy interfacing: achievements of the DROUGHT-R&SPI project. In: Andre J, Solera A, Paredes-Arquiola J, Haro-Monteagudo D, Van Lanen H (eds) Drought: Research and Science-Policy Interfacing. CRC Press/Balkema, Leiden, The Netherlands
Van Loon A (2015) Hydrological drought explained. WIREs. Water 2:359–392. https://doi.org/10.1002/wat2.1085
Vicente-Serrano SM, Beguería S, López-Moreno JI (2010) A multiscalar drought index sensitive to global warming: the standardized precipitation evapotranspiration index. J Climate 23:1696–1718. https://doi.org/10.1175/2009JCLI2909.1
Venegas-Cordero N, Birkel C, Giraldo-Osorio JD, Correa-Barahona A, Duran-Quesada AM, Arce-Mesen R, Nauditt A (2021) Can hydrological drought be efficiently predicted by conceptual rainfall-runoff models with global data products? J Nat Resour Dev 2:1–18. https://doi.org/10.18716/ojs/jnrd/2021.11.01
Wilhite DA, Glantz MH (1985) Understanding the drought phenomenon: the role of definitions. Water Int 10(3):111–120
Wilks DS (2003) Statistical methods in the atmospheric sciences, 3rd edn. Academic Press, Cambridge, MA, USA, p 2011
WMO; Global Water Partnership (2016) Handbook of drought indicators and indices. In: Svoboda M, Fuchs BA (eds) Integrated drought management programme, integrated drought management tools and guidelines series 2. World Meteorological Organization, Geneva, Switzerland
WMO (2012) Standardized Precipitation Index user guide (WMO-No.1090), Geneva
Wolter K, Timlin MS (1998) Measuring the strength of ENSO events - how does 1997/98 rank? Weather 53:315–324. https://doi.org/10.1002/j.1477-8696.1998.tb06408.x
Yeh H-F, Hsu H-L (2019) Using the Markov chain to analyze precipitation and groundwater drought characteristics and linkage with atmospheric circulation. Sustainability 11:1817. https://doi.org/10.3390/su11061817
Acknowledgements
KG would like to acknowledge a DAAD travel grant to work with AA at the University of Cuenca, Ecuador.
Code availability
The model codes can be obtained upon reasonable request to the first author.
Funding
Open Access funding enabled and organized by Projekt DEAL. This research was supported by the DAAD and BMBF-funded “TropiSeca” project and received support by the University of Costa Rica funds to OACG (ED-3199).
Author information
Authors and Affiliations
Contributions
Conceptualization, all authors; methodology, K.G., A.A., R.A., C.B.; resources and funding, A.N., C.B.; data curation, K.G., C.B.; writing—original draft preparation, K.G., A.N., C.B.; writing—review and editing, all authors.; visualization, K.G. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gutiérrez-García, K., Avilés, A., Nauditt, A. et al. Evaluating Markov chains and Bayesian networks as probabilistic meteorological drought forecasting tools in the seasonally dry tropics of Costa Rica. Theor Appl Climatol 154, 1291–1307 (2023). https://doi.org/10.1007/s00704-023-04623-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-023-04623-w