
Abstract
The temporal and spatial operation of commodity business activities is neither random nor accidental. It is characterized by inner laws and features. Based on spatio-temporal analysis in GIS, the objective of this study was to use spatial autocorrelation method and kernel density estimation to study the temporal and spatial distribution pattern of customer sources in tea trade extracted from enterprise supply chains in Fujian Province, China. Using data of Fujian tea business as an example, customer sources showed a typical clustered pattern overall that could be classified into several hot areas. The distribution of customer sources is dynamic along with time. These hot areas spread from coastal cities to inland cities, ranging from urban to suburban. Meanwhile, it showed a relatively irregular distribution in suburban areas with aggregation distribution near urban areas. This study applied GIS spatio-temporal analysis technology to the analysis of an enterprise supply chain, synthesizing both spatial and temporal information and successfully integrating business with geography.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The occurrence of commodity business activities is not random or accidental in time or space. Instead, it demonstrates some regularity and features (Qin et al. 2012). Based on research of correlation between commodity business and geographical conditions, we can well relate some seemingly unrelated events together after value extracting and data mining. We can obtain temporal and spatial distribution law and evolution of supply chain that are of great practical significance (Pearce et al. 2016). Previous studies have mainly focused on the management system of a supply chain while research and exploration on spatial agglomeration feature of supply chain have been seldom carried out. Neither temporal information of data have been given enough attention nor contents contained in temporal information could be delved in depth. In recent years, specialists and scholars have shown attention and interest in both temporal and spatial distribution (Aljawarneh et al. 2017; Bourbonnais et al. 2017; Cheewinsiriwat 2013). Besides, in the field of geography, spatial point pattern analysis method has been applied to many areas, including geology, landscape ecology, spatial analysis of economics, epidemiology, crime, meteorology, tourism science, and archeology (Minghao et al. 2011; Dauner et al. 2016; Lopes-Rocha et al. 2017).
How to delve into temporal and spatial relationship of a supply chain in depth becomes an issue to be solved. There are few domestic research studies on supply chain using authentic and high-precise sales data. Analysis on supply chain data distribution tendency from temporal and spatial perspective is even fewer. Therefore, the objective of this study was to perform point pattern research on supply chain from a temporal and spatial perspective using 3D visualization technology. By applying GIS technology of spatial autocorrelation and kernel density estimation, the aim of this study was to demonstrate the temporal and spatial distribution tendency of customer sources in tea trade in space–time cube and provide concrete application examples (Fang et al. 2017). Representative data will be subjected to point pattern value extracting and data mining to link some seemingly unrelated events together. By further analyzing the hidden tendency, results of this study will play a positive and active role in the production, sales, and circulation of tea. They will effectively promote the upgrading of Fujian tea industry and enhance the popularity of national tea industry and other relevant industries, thus producing significant economic and social benefits.
2 Research approaches
A supply chain is also called a logistics network. It includes suppliers, warehouses, distribution centers, retail outlets, and flowing commodities between various agencies. Activities of production, storage, and sales in logistics network will produce a large amount of data concerning customer and goods source (Pearce et al. 2016; Zhou et al. 2015). They will all manifest traits of data points under conditions of geographical phenomenon. Such data can be abstracted into different spatial points with data model. Through the change of time and space, temporal and spatial distribution relationship of a supply chain will show a certain regularity and tendency. If business activities are studied in the supply chain, as time changes, they not only show a certain dynamic, but also show different events at various points or the same event at different points. In this research, approaches of spatial autocorrelation and kernel density will be applied to analyze data distribution tendency. Furthermore, the correlation function of GIS platform will be invoked to generate customer source distribution tendency image layer. Sales aggregation regions with different degrees of aggregation will then be outputted to show “sale hot spots”, thus realizing data visualization (de los Ríos Escalante 2017). They can reveal the temporal and spatial distribution tendency of customer source of supply chain from different perspectives. The spatial autocorrelation method can quantitatively reveal the general tendency of spatial points while the Kernel Density method is helpful for detecting hot spot regions of customer distribution.
2.1 Characteristic indicators of customer sources
Customer sources can be characterized by their physical properties, including quantitative characteristics and complex characteristics. In this research, complex characteristics are classified into primary customer sources, secondary customer sources, and tertiary customer sources (Table 1).
Cities are divided into four types by the complex characteristic of R_PD (Table 2). Cities with R_PD value more than 0.6 are classified as primary customer sources, that is, with excellent customer sources; Cities with R_PD value between 0.4 and 0.6 are considered as secondary customer sources; Cities with R_PD value between 0.2 and 0.4 are classified as tertiary customer sources; Cities with R_PD value less than 0.2 are classified as quaternary customer sources.
2.2 Exploratory spatial data analysis (ESDA)
ESDA is an extension of exploratory data analysis that focuses on the description and interpretation of spatial relationships of regionalized variables, particularly spatial autocorrelation and spatial heterogeneity. ESDA has been used to describe and visualize spatial distributions, identify atypical locations or spatial outliers, discover patterns of spatial association, and suggest all types of spatial heterogeneity (Anselin 1995; Anselin et al. 2007). In this paper, we adopted Global Moran Index to explore the spatial–temporal evolution of the distribution pattern of customer sources in tea trade.
2.2.1 Global Moran’s I index
Spatial Autocorrelation (abbreviated as SA) method can be used to study the potential interdependency of observed data of variables in the same distribution region (Zhu et al. 2010; Kerner 2014). Based on point pattern research on a supply chain, the aim of this study was to determine whether customer sources in some regions might be affected by adjacent regions. First, global index of customer source spatial autocorrelation will be calculated. This index will be used to detect the relationship between spatial distributions of whole customer source. Global Moran’s I Index will be used to reflect the degree of autocorrelation of the region using the following formula (1):
where N is equal to the total number of cities to be analyzed; Xi and Xj represent actual values of characteristic indicators of customer sources in cities i and j, and wij is the spatial weight between city i and city j. The product between the adjacent matrix W and \( (X_{i} - \bar{X})(X_{j} - \bar{X}) \) defines that \( (X_{i} - \bar{X})(X_{j} - \bar{X}) \) is only effective for adjacent units. Therefore, the value of I depends on the degree of deviation of the variable value from the mean value of units i and j. Different weight matrix W can define different neighborhood units, thus producing different correlations. The value range of global Moran’ I index falls within [− 1, 1], with higher value indicating stronger autocorrelation. The index of Moran’s I is used to study whether spatial distribution of customer source is aggregated or dispersed. The statistical significance of I value is generally tested by applying significant test formula Z-Score (Chen et al. 2016):
where E(I) and var(I) represent the expectation and variance of I value, respectively. On the basis of normal distribution, this study will test the hypothesis by selecting 5% as the level of significance with critical value of 1.96 for the absolute value of Z(I). It Z(I) is greater than 1.96, it means that the variable has significant spatial autocorrelation. However, if the value of Z score is negative or less than − 1.96, it means that the distribution is dispersed. Other results reveal a random distribution. Moran’s I index will be applied to study the effect of global spatial autocorrelation while the kernel density estimation method will be used to study the effect of local space.
2.2.2 Local Moran’s I
Local statistics for each observation gives an indication of the extent of significant spatial clustering of similar values around that observation. Local indoctrinators of spatial association (LISA) is a method starts from micro-level. It analyzes the value of each object within research regions. Using LISA, we can know each object’s distribution in the domain space. Based on the value of each object and its domain objects, we can judge whether the space is aggregated or dispersive. Local Moran’s I index is defined as below (Pozo et al. 2014):
where N refers to the amount of cities to be analyzed; Xi and Xj represents the actual values of characteristic indicators of customer sources in cities i and j, respectively, and wij is the spatial weight between city i and city j. If Ii has a positive value, then spatial agglomeration around the regional unit is similar (high–high or low–low). If it has a negative value, it means non-similar spatial agglomeration. If its value is close to zero, it means that the region and its neighborhood have no spatial correlation, i.e., the region’s spatial distribution is random. Larger Ii values indicate more intense clustering of high values (hot spots) of customer sources’ distributions while smaller Ii values indicate more intense clustering of low values (cold spots) of customer sources’ distributions.
2.3 Space kernel density estimation method
A LISA clustering map is formed through a combination of LISA significant level and Moran’s I, a scatter map can discriminate “hot spots” and “cold spots” of local spatial agglomeration and reveal spatial singular value. Local Moran’s I only presents the spatial agglomeration of observed value with attribute similarity or dissimilarity. It does not represent the height of the attribute value. Therefore, this study attempts to reveal “hot spots” or “cold spots” of local spatial agglomeration by applying kernel density estimation method.
We should pay attention to both place and time of transaction concerning customer source point distribution of a supply chain because event’s distribution tendency is co-determined by time and place. We also should analyze the development tendency of customer source distribution and spatial aggregation extent of customer source as time changes. Therefore, we need to haven an overall consideration of information concerning time and place and apply integrated space–time method. The kernel density estimation method is shown below (Sohel et al. 2015; Sha et al. 2016):
where K1 represents the kernel function of bidimensional space, K2 represents the kernel function of dimensional time, τ1 refers to bidimensional bandwidth, τ2 refers to tridimensional bandwidth, n refers to the total quantity of event point (xi, yi, ti), and i = 1, …, n. In the method of kernel density estimation, the choice of kernel function K and its bandwidth is a problem because it will cause a big effect on the result if it is too big or too small. In specific applications, the test should be carried out according to different values to detect the kernel density hood face that can better match the actual situation. Gaussian kernel is selected as the kernel function in this study.
2.4 Gravity centre model
The gravity centre model (Liu et al. 2017) is a spatial statistics method that evaluates geographic distribution and identifies the geographic centre (or the centre of concentration) of regionalized variable. The direction, velocity, and distance of gravity centre movement can describe the degree of clustering and migration of a regionalized variable in time and space:
where xi and yi are coordinates for feature i, wi is the weight at feature I, and n is equal to the total number of features.
3 Data sources
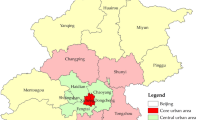
Core data of this study are tea sales data in 2014 mainly coming from three tea companies in Fujian province, China: Fujian Xiamen Onecn Tea. Co., Ltd, Fujian Minyuan Agricultural Science and Technology Development Co., Ltd, and Fuding Sanyu Tea Co., Ltd. Fujian Xiamen Onecn Tea Co., Ltd mainly produces Tieguanyin and other varieties of green tea. Minyuan Agricultural Science and Technology Development Co., Ltd and Fuding Sanyu Tea Co., Ltd mainly produce black tea and white tea, respectively. Regarding our tea sales data, some of them are obtained from the companies’ present system. Some are obtained from accumulated data of long-term information processing. They come from these three companies and their franchisers and distributors at different levels. With regard to every transaction, its time and place are recorded with a text description of each sale volume, price, and quality. Due to time-consuming feature of data processing, we only selected data of 3 years (2014–2016) as our research data for customer sources with over 5000 records. After preprocessing these data sources, each record has its corresponding time and place information. After picking a coordinate from Baidu LBS development platform, we can transform these data into spatial information according to their locations in the coordinate. We can then use a national provincial administrative regional digital map of 1:1,000,000 as the digital background map and associate it with customer source for conducting relevant analysis. Customer source distribution is shown in Fig. 1.

Customer source of tea sale distribution in China during 2014–2016
Figure 2 displays total numbers of tea trading in Chinese provinces between 2014 and 2016. There were 1285 total records summed by cities in the year of 2014, 1439 total records in 2015, and 2627 total records in 2016. The top three provinces with the largest numbers in tea trades were Beijing, Fujian, and Guangdong provinces. Fujian and Guangdong are places where tea is produced. They have their own processing enterprises. Local people have developed the habit of drinking tea. Beijing is known to be a cultural exchange center. It is a city with large sales of tea.

Detailed trade number distribution of customer source during 2014–2016
4 Analysis of experimental results
Customer source can be characterized by their physical properties, including original descriptive indicators and complex integrated indicators. Original descriptive indicators such as customer source, including trade numbers, city population, city area, and city GDP have rarely been used directly in previous studies. Customer source is a complex integrated indicator that we must define and process, including population density, GDP per capita (P_GDP), average purchasing power (R_PD), and average GDP possession ratio (R_PGDP). Collected data were analyzed by Microsoft Excel 2013. Results are shown in Figs. 3 and 4.

Patterns of R_PD indicator distribution between 2014 and 2016 in China

Patterns of R_PGDP indicator distribution between 2014 and 2016 in China
Figures 3 and 4 show that all curve features are similar in some degree. In comparison with other cities in China, the R_PD indicator concentration detected in Fujian in this study was relatively higher than that in Guangdong, Hunan, Sichuan, or Inner Mongolia. The indicator had an upward trend in cities. This was because the country economic development was relatively fast during 2014–2016. However, R_PGDP indicator had a different trend from R_PD. Its value in 2016 was higher than that in 2015 but lower than that in 2014. The overall slowdown in world economy was the main reason for the decline of China’s economy in 2015 during which time tea exports were decreased. This phenomenon is also associated with our country’s policy.
One important quantity in spatial autocorrelation is spatial weight matrix. It can be used to determine and describe spatial relation. It will directly affect the value of Moran’s I statistic. It can even affect researchers’ analysis and understanding of the problem of spatial autocorrelation. The Global Moran’s I Index of characteristic indicators of customer sources during the 3 years (2014–2016) was calculated by spatial statistics tools of spatial autocorrelation (Moran’s I) in ArcGIS10.2. Moreover, the adjacency method was adopted to calculate the spatial weight matrix. Table 3 shows Moran’s I values of characteristic indicators of customer sources. It indicates clustered characteristics of the spatial distribution of customer sources. Z score values of PD in these 3 years were significantly different at 95% confidence level. Z score values of P_GDP in 2014 and those during 2015 and 2016 showed significant difference at confidence levels of 95% and 90%, respectively. Regions with higher (or lower) characteristic indicators were close to each other. Large differences were found between Moran’s I values of the following three characteristic indicators: P_GDP, PD, R_DP, and R_PGDP.
Local Moran’s I statistic was used to measure local spatial autocorrelation of characteristic indicators of customer sources and identify the evolution trend of distribution pattern of customer sources in a supply chain. Here, hot spots and sub-hot spots are regions with high value of tea trades of customer sources due to their larger characteristic values of customer sources while cold spots and sub-cold spots regions are under high trades.
Figure 5 shows hot and cold spots of different regions in a supply chain in 3 years (2014–2016). Compared with other regions, population distribution is mainly in eastern and central parts of China. Shanghai, Beijing, Tianjin, and Jiangsu showed high population density (PD) in 2014. However, the density in Jiangsu changed from 2015. A main reason was that the eastern region of Jiangsu has good jobs. In Jiangsu, population changes with the adjustment of its industry. Thus, the main hot spots were located in Beijing, Tianjin, and Shanghai. The hot spot of GDP per capita (P_GDP) was in Beijing in 2014. It was gradually concentrated in Beijing, Tianjin, Shanghai, and Jiangsu provinces from 2015. Sub-hot spots of P_GDP were in eastern coastal areas and Inner Mongolia. The purchasing power relative to the population density (R_DP) changed frequently between 2014 and 2016. Its hot spots were in eastern and central parts of China, including Fujian, Zhejiang, Hunan, Chongqing, Liaoning, and Inner Mongolia. The main reason is that people in these provinces like to drink tea and their population density is not high. Thus, the indicator of R_DP is relatively high. Hot spot distribution of R_PGDP regions is similar to that of R_DP. However, Inner Mongolia is not in the hot spot because its GDP is relative below.

Trades evolution of the distribution pattern of customs source in tea trade in China during 2014–2016
Cities are divided into four types by complex characteristic of R_PD values. For example, Fujian is a hot city during the 3 years. It belongs to the type of primary customer sources. Guangdong is a sub-hot city. It belongs to the type of secondary customer sources during the 3 years. Zhejiang is a sub-cold city. It belongs to the type of tertiary customer sources. Tibet is a cold city. It belongs to the type of quaternary customer sources.
The above analysis revealed global and local spatial differences in distribution pattern of customer sources in tea trade at different periods. The gravity centre model was used to calculate the gravity centre coordinates of characteristic indicators of customer sources at different periods to further explore the spatial evolution process of supply chain in tea trade. Figure 7 shows gravity centres of R_PGDP indicator of customer sources in difference years. Two different gravity centers formed in 2014 and 2016 were located in different places of the same province. However, these two places are geographically very close. Figure 6 shows that the center place is important in the supply chain. We can conclude that a tea trading center does no change widely. However, it shows a trend to spread to the North in recent years.

Percent of hot and cold cities in China in 2014–2016
To determine patterns of similarity and dissimilarity in the clustering of customer source distribution, we further examined with kernel density method. The determination or selection of research radius has a great effect on calculation results. When radius h increases, the spatial point density’s change becomes smoother, although it will cover the density’s structure. When radius h decreases, the special point density’s change will become abruptly uneven. Kernel Density in ARCGIS 10 was applied based on relevant research findings. Through trial and error, 7000 m search radius was applied to conduct the kernel density estimation of customer source point spatial distribution. In this way, it is likely to get a better-effect kernel density distribution figure of tea customer source as is shown in Fig. 8. The overall customer source distribution centers are in Fujian and Guangdong provinces. Local distribution centers include Shanghai, Beijing, Shandong, Hunan, Chongqing, and so on, indicating high customer source distribution density in coastal regions and some big cities to some degree related to road transportation.
To determine whether customer source distribution might vary with time and place, we also selected relevant data of these 3 years (2014, 2015, and 2016) to generate their kernel density figures, respectively, and examine their distribution features and changing process. Results are shown in Figs. 8, 9, and 10.
Figure 7 shows the density of tea sales during 2014 and 2016. With steady growth of China’s economy, amount of tea sales is increasing gradually. We can see details from these graphs. For example, tea sales in Fujian, Guangdong, and Chongqing regions are increasing greatly. By comparing these kernel density distribution figures (Figs. 8, 9, 10), we can see that “hot spots” of tea sales are evolving and migrating. They are gradually migrating from coastal regions toward inland regions, particularly into sub-centers of cities. Furthermore, the temporal and spatial distribution feature of customer source data showed a changing tendency, forming different trend regions. For example, Henan and Liaoning belonged to growth regions of customer source. Fujian and Guangdong belonged to steady regions of customer source while Beijing and Shanghai’s customer source was showing a decreasing trend. The spatial structure model is gradually evolving into a multi-core agglomeration model. The core is demonstrating a trend to be continuously expanding to peripheries as shown in the faint yellow part of Fig. 10. The ongoing expansion may form a secondary center agglomeration model. It may again evolve into different multi-core agglomeration models.

Migration of gravity centres and feature of the R_PGDP indicators in 2014 and 2016

The kernel density chart of customer source in tea trade in 2014

The kernel density chart of customer source in tea trade in 2015

The kernel density chart of the customer source in tea trade in 2016
Two analytical methods including autocorrelation and kernel density estimation were introduced and applied in this study to reveal the temporal and spatial distribution of a supply chain in tea trade. In addition, point pattern analysis was performed from different perspectives. Results of this study showed that all Moran’s I indices of Fujian tea customer source distribution points are greater than 0.3, with z score of 2.86. AS for the spatial distribution, typical aggregation mode has generally taken shape, forming different levels of customer source hot spots such as Fujian and Guangdong. These hot spots have a strong trend to expand toward peripheries. From the perspective of local aggregation and dispersion features, we found that the aggregation of customer source point distribution was stronger when the customer source points were closer to the downtown. As for research methods, each of these two methods had its own advantage. Using autocorrelation method can easily reveal spatial points’ general features from their quantity while using kernel density method can more effectively detect hot spots of customer source distribution from spatial perspective.
The distribution of tea sale hot spots is closely connected with the region’s geographical conditions. It is also the result of people’s long-term adaptation to the local natural environment. Meanwhile, national and historical cultural background also plays a role. Besides, a tea production place has relatively more customers. Thanks to their climatic environment, Fujian and Guangdong are suitable for tea cultivation. Since consumers in Beijing and Shanghai have higher income, they have higher demand for the grade of tea. Although the number of customers in these places is manifesting a decreasing trend, it will not have a big effect on the sale coverage of tea.
5 Conclusion
Through GIS spatial analysis with temporal and spatial analysis technology, this study determined temporal and spatial distribution feature of a supply chain in tea trade using spatial autocorrelation and kernel density estimation methods. By making an example of Fujian tea production enterprises, the application of GIS technology in research on enterprises’ supply chain was realized by combining commercial data and geographic information. Due to the time–space characteristic of supply chain, we were able to give overall consideration to information both in time and space. By applying static GIS technology in a dynamic way, we can express distribution regularity more accurately from different temporal and spatial scales, reflect geo-science characteristic, link some seemingly unrelated events, and analyze the characteristic and regularity hidden in the sales data, providing new perspective for research on the temporal and spatial distribution mode of supply chain. However, limited data and narrow data sources used in this study might have affected research results. Thus, further studies with more time–space range of data is needed to verify our research results.
References
Aljawarneh SA, Vangipuram R, Puligadda VK et al (2017) An approach to discover temporal association patterns and trends in internet of things. Fut Gener Comput Syst 74:430–443
Anselin L (1995) Local indicators of spatial association-LISA. Geogr Anal 27(2):93e115
Anselin L, Sridharan S, Gholston S (2007) Using exploratory spatial data analysis to leverage social indicator databases: the discovery of interesting patterns. Soc Indic Res 82(2):287e309
Bourbonnais ML, Nelson TA, Stenhouse GB et al (2017) Characterizing spatial-temporal patterns of landscape disturbance and recovery in western Alberta, Canada using a functional data analysis approach and remotely sensed data. Ecol Inf 39:140–150
Cheewinsiriwat P (2013) The use of GIS in exploring settlement patterns of the ethnic groups in Nan, Thailand. Asian Ethn 14(4):490–504
Chen H, Sun R, Zhang C et al (2016) Occurrence, spatial and temporal distributions of perfluoroalkyl substances in wastewater, seawater and sediment from Bohai Sea, China. Environ Pollut 219:389–398
Dauner ALL, Lourenço RA, Martins CC (2016) Effect of seasonal population fluctuation in the temporal and spatial distribution of polycyclic aromatic hydrocarbons in a subtropical estuary. Environ Technol Innov 5:41–51
de los Ríos Escalante P (2017) Non randomness in spatial distribution in two inland water species malacostracans. J King Saud Univ 29(2):260–262
Fang J, Liu W, Yang S et al (2017) Spatial-temporal changes of coastal and marine disasters risks and impacts in Mainland China. Ocean Coast Manag 139:125–140
Kerner BS (2014) Three-phase theory of city traffic: moving synchronized flow patterns in under-saturated city traffic at signals. Phys A 397:76–110
Liu Y, Liu J, Zhou Y (2017) Spatio-temporal patterns of rural poverty in China and targeted poverty alleviation strategies. J Rural Stud 52:66–75
Lopes-Rocha M, Langone L, Miserocchi S et al (2017) Spatial patterns and temporal trends of trace metal mass budgets in the western Adriatic sediments (Mediterranean Sea). Sci total Environ 599–600:1022–1033
Minghao Liu, Zhizhong Dai, Daochi Qiu et al (2011) Influencing factors analysis and rational distribution on rural settlements in mountains region. Econ Geogr 31(3):476–482
Pearce JL, Waller LA, Sarnat SE et al (2016) Characterizing the spatial distribution of multiple pollutants and populations at risk in Atlanta, Georgia. Spat Spatiotemporal Epidemiol 18:13–23
Pozo MI, Herrera CM, Alonso C (2014) Spatial and temporal distribution patterns of nectar-inhabiting yeasts: how different floral microenvironments arise in winter-blooming Helleborus foetidus. Fungal Ecol 11:173–180
Qin TT, Qi W, Li YQ et al (2012) Suitability evaluation of rural residential land based on niche theory in mountainous area. Acta Ecol Sin 32(16):5175–5183
Sha J, Wang Y, Pan Y et al (2016) Temporal and spatial distribution patterns of the marine–brackish-water bivalve Waagenoperna in China and its implications for climate and palaeogeography through the Triassic-Jurassic transition. Palaeogeogr Palaeoclimatol Palaeoecol 464:43–50
Sohel MSI, Alamgir M, Akhter S et al (2015) Carbon storage in a bamboo (Bambusa vulgaris) plantation in the degraded tropical forests: implications for policy development. Land Use Policy 49:142–151
Zhou Q, Wang W, Pang Y et al (2015) Temporal and spatial distribution characteristics of water resources in Guangdong Province based on a cloud model. Water Sci Eng 8(4):263–272
Zhu XX, Wang HM, Yuan XJ et al (2010) Evaluation and optimization of spatial distribution of rural settlements based on GIS. Trans Chin Soc Agric Eng 26(6):326–333
Acknowledgements
This work was supported by a grant (2018J0106) of the Natural Science Foundation (NRF) of Fujian Province, China, a Science and Technology Project (JAT170652) funded by the Education Department of Fujian Province, China, and a Project (2017T05) of Innovation Team of Ningde Normal University. The authors would like to thank valuable comments and suggestions provided by editors and reviewers.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Zhang, S., Chang, T. Spatial–temporal evolution of the distribution pattern of customer sources in tea trade of Fujian enterprise supply chain. Microsyst Technol 27, 1305–1315 (2021). https://doi.org/10.1007/s00542-018-4228-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00542-018-4228-0