
Abstract
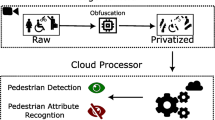
Video streaming from cameras to backend cloud or edge servers for neural-based analytics has gained significant popularity. However, the transmission of data from cameras to a backend raises substantial privacy concerns, particularly regarding sensitive information like facial data. To offer privacy protection, visual processing techniques, such as Generative Adversarial Networks (GANs), have been employed on cameras to blur and safeguard such data intelligently. However, these techniques frequently face memory challenges, particularly when dealing with high-resolution videos. In this paper, we propose PIMO, a memory-efficient visual privacy protection scheme designed to effectively blur video content leveraging adaptive slicing of frames and resolution degradation. Our extensive experimental evaluations validate that PIMO’s adaptive mechanism proficiently navigates fluctuating memory constraints. Furthermore, utilizing a content-based blur scheme, our approach can maintain an impressive mean precision of 95.2%, as compared to the original, non-blurred images.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Artificial intelligence (AI) has become pervasive in the realm of video analytics, particularly in applications such as traffic monitoring, where it provides advanced capabilities for data processing and interpretation. Meeting the increasing demand for efficient and real-time analysis, video streaming has emerged as a widely embraced solution. In this approach, cameras are deployed to collect data, which is subsequently encoded into streams and transmitted to a server or edge device for comprehensive AI-driven analysis, such as vehicle recognition.
With the increasing use of video streaming and analytics, the potential for privacy breaches is a growing concern. In particular, sensitive information such as license plates and faces, can be captured by cameras and recorded in the original video. However, when the video is transmitted to remote servers or edges for analytics, it becomes vulnerable to unauthorized access and misuse. This poses a significant risk to individuals’ privacy, as their personal information may be compromised without their consent.
In order to mitigate this risk, various privacy protection techniques are employed. Examples include image encryption [1], image false coloring [2], and image blurring. In addition to the mathematically oriented task of image encryption, various tasks in the field of image processing can be categorized. These challenges encompass a range of areas, including computer vision and graphics (such as style migration), as well as numerical problems in scientific domains (e.g., privacy protection in medical images [3]). However, existing privacy protection approaches for video data are either time-consuming or memory-intensive, which reduces their practicality.
Processing, such as for example, PECAM [4] is an approach based on Generative adversarial networks (GANs), which has good performance in real-time privacy protection for low-resolution videos. However, the increasing quality of images/video collected by advanced cameras, their limited memory cannot afford the processing of GANs in PECAM.
Objectives. Based on the aforementioned analysis, we posit that an exemplary edge system for preserving visual privacy in images should effectively fulfill the following pivotal design objectives: (1) real-time processing, (2) efficient memory utilization without overhead, and (3) ensuring privacy protection without significantly compromising the accuracy of backend analysis tasks.
Challenges. We conducted an survey of the existing research on visual privacy protection, they do not fully meet the aforementioned objectives due to three challenges as follows. To begin with, the removal of crucial privacy information often results in a concomitant reduction in the semantic content of the image. Consequently, this leads to a decrease in the recognition accuracy of essential details. Furthermore, while methods like image encryption can effectively safeguard privacy information, they frequently necessitate changes in image data storage mechanisms, which can lead to the backend analysis program being unable to achieve the original image analysis function. Last, performing complex operations on resource-limited edge devices presents yet another challenge in the pursuit of an ideal visual privacy-preserving system.
Contributions. Firstly, we propose a novel edge system that enhances computational resource utilization by dynamically adjusting image resolution and cropping while effectively preserving image privacy. This approach significantly enhances the system's versatility, enabling its extension to more intricate application environments. Secondly, the system effectively devides the foreground and background of images, facilitating varying degrees of privacy protection. This segregation enhances the accuracy of image recognition algorithms across diverse devices and application scenarios, ensuring the generalizability of results. Lastly, we assess the privacy protection efficacy of the algorithm under different parameter settings within various environmental configurations. Through extensive experimentation, we establish stable and reliable outcomes.
2 Related work
Cameras can capture a wealth of visual information from the environment, and this information has been gradually exploited with the development of computer vision over the past decades, allowing computers to evolve from the stage of acquiring information to the stage of processing it [5]. On this basis, intelligent surveillance systems have developed rapidly, and this class of systems is able to analyze and process the information after capturing the video information, and can be applied in various fields including crowd statistics [6], behavioral analysis [7], and other professional aspects. At the same time, the prolonged storage and utilization of video information also pose a threat to privacy, and privacy protection issues in computer vision are gradually gaining attention. In this section, we present an overview of past research on visual privacy preservation.
2.1 Conventional Visual privacy protection methods, differential privacy, and perturbation
Conventional visual privacy protection methods. Many past studies have been devoted to addressing the visual privacy protection problem. Some of these studies have focused on encryption techniques or image processing methods to safeguard privacy, including pixelation [8], blurring [9], and modification of data structures [10]. For example, Zhang et al. [11] proposed a High-fidelity Thumbnail-preserving Encryption scheme (HF-TPE) that can encrypt people’s portrait data stored in the cloud while balancing image privacy and availability on the cloud. The primary method employed by HF-TPE involves an image encryption algorithm. This algorithm guarantees the privacy of the original image while extracting high-quality and usable thumbnails from the encrypted image. This ensures that the user’s browsing experience remains unaffected. However, as this method is fundamentally based on image encryption, the user’s ability to distinguish the thumbnail image relies on their prior knowledge of the image. Consequently, decryption is still necessary for back-end analysis purposes.
Differential privacy and the perturbation mechanism. Differential privacy technology was originally introduced by Cynthia Dwork et al. [12], primarily aimed at protecting the privacy of personal data stored in databases. Over time, this technology has been extended to address image privacy concerns [13] and has progressively incorporated perturbation techniques, such as [14], to enhance the efficacy of privacy protection. Ji et al. [15] introduced an algorithm that utilizes differential privacy techniques to achieve privacy protection for the frequency domain representation of images. The algorithm begins by converting the input image into frequency domain features through frequency domain transformation. Subsequently, noise is generated and added to the frequency domain features, thereby achieving privacy preservation through differential privacy perturbation. While this method demonstrates superior performance on certain datasets, it is less effective when dealing with images that involve complex poses. In other words, the algorithm’s robustness in handling images with intricate poses is limited.
2.2 AI-driven visual privacy protection, privacy de-identification, replacement, and blurring
Automatically identify and blur privacy objects. The utilization of AI techniques for privacy protection in image processing is a common practice [10,11,12,13,14,21], with specific categorizations including methods such as automatic blurring of privacy objects, replacement of sensitive entities, and global blurring. An illustrative instance is iPrivacy [16], which employs AI techniques and visual trees to learn the significance of objects concerning privacy, which enables the identification of object classes that are privacy-sensitive and the automatic application of blurring methods for privacy preservation. This method tackles the challenge of ordinary users struggling to accurately configure privacy granularity while sharing photos on social networking sites. By leveraging AI techniques, it determines whether an object holds substantial privacy relevance to the user. Consequently, it achieves an adaptive privacy configuration solution to address this issue. However, despite the iPrivacy’s capability of multi-task learning and improved performance through visual correlation between classes, the blurring of privacy-sensitive objects can have a detrimental impact on the task of joint learning of the deep CNNs and tree classifier for shared images. Consequently, this results in a notable decrease in the accuracy of target detection.
Privacy information replacement. IdentityDP [17], which focuses on safeguarding facial privacy by generating a novel face and substituting it for the original face. In the algorithm, facial representations disentanglement is achieved through a deep neural network, which separates the high-level identity representation from the multi-level attribute representations in the feature space. Adjustable differential privacy perturbations are then applied to the identity representation, and subsequently, image reconstruction is performed to achieve face de-recognition. The algorithm allows for the adjustment of the degree of de-recognition by modifying the privacy budget value of the differential privacy perturbation. However, this adjustment can lead to an unforeseen issue: certain blocked face data in the image may undergo facial feature recovery due to changes in the privacy budget value, which results in the detection of otherwise undetectable faces.
Lin et al. [20] also proposed an end-to-end visual facial privacy protection method called FPGAN, which is able to generate new facial features to protect the privacy of major facial features, and they used the method for face de-identification of social robots to protect people’s facial privacy. FPGAN can generate images that are visually appealing and privacy-preserving. However, it does have certain limitations. One limitation is that it cannot handle scenarios where multiple faces are present in the input photo. Additionally, the face needs to be located in the main body of the photo, which can make the method less effective for images captured by devices such as surveillance cameras. These limitations restrict the applicability of FPGAN in certain contexts, particularly those involving complex scenes or images with multiple individuals.
Apart from the aforementioned privacy preservation techniques, there are also style migration methods, akin to CycleGAN, that find applications in privacy preservation. One such method is the Style Transfer Variational Autoencoder (ST-VAE) [21]. It is worth noting that while many style migration methods concentrate on a single style exclusively, ST-VAE possesses the capability to adapt to multiple style migrations simultaneously. ST-VAE learns the feature covariance of the target image in the feature space and subsequently mapping this covariance to the latent space. Multiple style transfers are then realized through the latent space-based linear interpolation. Our study presents a methodology for preserving image privacy within limited computational resources while effectively retaining non-private object information. In contrast to prior research, our approach achieves an equilibrium between high recognition accuracy and low resource consumption, without necessitating modifications to the underlying image recognition method. This contribution establishes a robust groundwork for future investigations and advancements in image privacy preservation systems, applicable to a broader spectrum of scenarios.
2.3 Privacy protection for videos
Previous research efforts have not solely focused on visual aspects or static images but have also encompassed the conservation of video aspects [16,17,24]. In contrast to the sharing attribute of images on social platforms, the protection of video aspects primarily targets the video surveillance domain, specifically closed circuit television (CCTV) cameras. For instance, Asghar et al. [22] proposed an algorithm that separates the foreground and background of video frames. It detects the features of interest (FOI) and determines which parts of the foreground and background pertain to the areas requiring protection based on the specific application scenarios of video surveillance. The FOI is then utilized as a privacy-protecting feature for selective encryption or data removal, effectively achieving the goal of video protection. This algorithm focuses on data protection through encryption and removal methods. However, it does not incorporate other obfuscation techniques like pixelation, blurring, masking, etc., which could potentially enhance the difficulty of back-end recovery in certain scenarios.
In order to allow video streams to have some recovery space even after processing, PECAM [4], in the context of safeguarding video stream privacy, accomplishes privacy-preserving secure reversible video conversion through the utilization of GANs. By incorporating an advanced steganography algorithm, PECAM attains bi-directional video conversion employing a cycle-consistent GAN network. However, its applicability is currently limited to lower resolution video streams due to the substantial rise in computational expenses and bandwidth requirements for edge devices when dealing with high-resolution video streams prevalent in today’s landscape.
There are also algorithms focusing on videoconferencing, which has been gradually emerging in recent years. One such algorithm is the proposed image generation system for videoconferencing [23]. Instead of transmitting actual images during a conference, this system transmits a pseudo-real-time image that is synthesized from a user-supplied, pre-photographed, and non-private image scene. The system utilizes the user’s low-resolution thermal imaging sensor, which means users only need to provide a thermal image as input, and then the system can continuously generate synthesized images that can be used in video conferences. While the system exhibits high-quality image generation, it faces a significant limitation in terms of its requirement for users to possess a thermal sensor. This constraint restricts its widespread adoption in numerous scenarios and limits its applicability.
3 Preliminary work
In this section, we introduce the fundamentals of GANs, consistency loss, and reversible networks.
3.1 Generative adversarial networks
In recent years, machine learning has made breakthroughs in many fields. Supervised learning can often achieve higher accuracy than humans after training. However, since supervised learning requires a very large number of training samples, unsupervised learning has gradually become one of the goals of researchers. As a special unsupervised learning method, GANs [25] have achieved great success in tasks such as image style transfer [26] and super-resolution [27].
The basic structure of the current GANs is divided into two parts, firstly, the generating function \(G:X\rightarrow Y\) converts images from \(X\sim \gamma\) into images from \(Y\sim \mu\), and the discriminating function \(D:Y\rightarrow [0,1]\) is responsible for determining whether the input images come from the Y domain. The goal of the generating function G is to make the distribution of its generated images similar to that of the training samples from \(\mu\), and the ultimate goal of the discriminant function D is to distinguish the images from the generating function G from the real training samples. In the training part, GAN defines the following loss function:
The optimization of the loss function is a minimal-maximum optimization problem, where the generator generates images more similar to the Y-domain to deceive the discriminator, while the discriminator wants to be able to guess more accurately whether the generator has generated the image. The minimal-maximum of the GAN is expressed as:
The function will tend to assign high values to real samples from the distribution \(\mu\) when making judgments. Thus, for a given generating function G, \(max_D\) is able to optimize the discriminant function D to distinguish D(y) with higher scores; for a given discriminant function D, \(min_G\) optimizes the generating function G to try to trick the discriminant function to assign high values. After a number of training rounds, the generating function can generate fake images with the same distribution as the training set during the test.
3.2 Cycle consistency
In the field of visual tracking, the incorporation of forward-backward consistency has been a widely adopted technique for several decades. Similarly, such techniques have been employed in language translation to enhance machine performance. For instance, translating translated statements back into the original language aids in improving the quality and consistency of the translation. In the context of CycleGAN [28], a comparable loss function is introduced to encourage consistency between two sets of image generators, facilitating effective image-to-image translation.
In theory, adversarial training using GANs alone can enable the learning of two sets of image generators, which can generate outputs in the target domains Y and X, respectively. However, when dealing with large image domains, the network may exhibit the phenomenon of producing different mappings for the same input images. This means that the network may map a set of input images to random images in the target domain, without preserving the desired semantic information. To address this issue and reduce the mapping space for image transformation, we employ algorithms such as CycleGAN. As shown in Fig. 1, CycleGAN incorporates a cycle consistency loss, which helps ensure that the transformed images retain their original semantic content. In the image domain X, we have a generator G, a discriminator D, and a cycle consistency loss \({\mathcal {L}}_{cyc}\), for any image x from domain X, we have \(x \rightarrow G(x) \rightarrow G'(G(x)) \approx x\). Similarly, in the image domain Y, we have \(y \rightarrow G'(y) \rightarrow G(G'(y)) \approx y\). Their cycle consistency loss is denoted as:

CycleGan to generate blurred frames
By incorporating cycle consistency loss, the model can effectively retain more semantic information within the images and mitigate the issue of random mapping during the image transformation process. Furthermore, it indirectly facilitates a process akin to pairwise image training, even in the absence of paired images. This approach significantly enhances the quality of the generated images and establishes a more reliable image conversion process.
4 Key designs
In this section, we provide a comprehensive overview of our technical details. The initial subsection provides a description of the dataset acquisition process and outlines how PIMO is stylized. The subsequent two subsections focus on optimizing and balancing the level of privacy preservation and the utilization of computational resources, respectively.
Metrics. We used two metrics to measure the level of privacy preservation and the level of semantic information retention, Levenshtein distance and mAP, respectively. The Levenshtein distance serves as a standard measure to quantify the dissimilarity between two strings. It is calculated as the minimum number of single-character editing operations, such as insertion, deletion, or replacement, required to transform one string into another. Considering the variability in the lengths of strings in each image, we normalize the Levenshtein distances by dividing them by the sum of the original string lengths. We utilize this ratio to gauge the disparity between strings before and after the image processing stage, providing an indicator of the level of privacy protection achieved.
In mAP, Precision is a fundamental statistical metric used in statistical machine learning. To evaluate the detection of video semantic information, we compare it against the ground truth. We employ an Intersection over Union (IoU) threshold to determine true positives (TP), where predictions with the highest confidence exceeding the threshold are considered TP. Predictions with lower confidence or IoU below the threshold are classified as false positives (FP). To obtain comprehensive performance measures, we utilize multiple IoU thresholds ranging from 0.5 to 0.95 with a step size of 0.05, mAP is then calculated by averaging the results across these thresholds. This approach provides a robust assessment of the accuracy and effectiveness of picture semantic information detection.
4.1 Privacy enhancement
Our privacy-preserving algorithm, PIMO, utilizes an image-to-image style transformation approach to achieve privacy enhancement. PIMO has the capability to segment the input raw image into smaller chunks and subsequently transform each chunk into a privacy-enhanced image. The core of PIMO is CycleGAN, which is a GAN network structure that leverages cyclic consistency loss. CycleGAN is capable of learning the mapping relationship between two domains. In PIMO, we utilize this framework to learn the style of the blurred image. Consequently, we can achieve privacy preservation by transforming the original image into a blurred image. When a user inputs an original image into PIMO, the algorithm segments the image into smaller chunks. Each chunk is then converted into a corresponding fuzzy image chunk. This process ensures that sensitive information within the original image is effectively protected and eliminated.
PIMO, like many other supervised learning techniques, requires training sets to train the network. To accomplish this, we employed a modified version of an image segmentation algorithm [29], which we refer to as DataGen. The original version of the image segmentation algorithm achieves efficient segmentation of image regions by evaluating the confidence of boundaries separating two regions. Its primary criterion for region segmentation relies on identifying color distinctiveness among similar color blocks within the image. Consequently, we can assume that the color blocks within each segmented region, as determined by this algorithm, remain within a certain threshold. In the context of DataGen, we leverage the mean value of the color blocks within a region to replace and recolor the colors present in that region. This process results in a stylized image that exhibits similarities to the oil painting style, the recoloring process effectively obscures privacy information, and obtains an image that is more visually appealing to the human eye.
Figure 2b shows the effect of DataGen’s privacy preservation measures. By implementing our modifications, DataGen has the capability to convert each input image from domain X (i.e., the original image) into domain Y (i.e., the privacy-enhanced image). After converting the original images using DataGen, we obtain a composite dataset consisting of both the original clear images and their corresponding privacy-enhanced images. Once the training of the image styles in both domains is complete, PIMO can independently generate the corresponding stylized image data based on the learned mappings between the two domains.

Images blurred with different K
In addition, DataGen introduces a parameter K to configure the degree of stylization, the value of K determines the size of the threshold range applied to the color blocks within the segmented regions during the image segmentation process. Specifically, a larger value of K results in a wider threshold range, making it more likely for adjacent regions to be merged into a single color block. Consequently, the larger the value of K, the higher the degree of stylization. Figure 2 demonstrates the relationship between the parameter K and the extent of information obscuring, illustrating the effect of K on privacy protection. Moreover, CycleGAN can also be stylized for different K during training to achieve different privacy protection effects. We chose a set of 2160P vehicle images as our base images, and for training and testing of CycleGAN, we selected ten different sets of K values (50, 100, 200, 400, 600, 800, 1000, 1200, 1400, and 1600) along with four sets of resolutions (480P, 720P, 1080P, 1440P). The results of their privacy protection effects are illustrated in Fig. 3a. Furthermore, the recognition accuracy of the target detection algorithm is also influenced by the K-value, primarily due to variations in the visual appearance resulting from the image stylization process. This effect is demonstrated in Fig. 3b.

Impact of resolutions and K on privacy and recognition accuracy
Although DataGen has better results in privacy protection and its user-friendly configuration for privacy granularity, its conversion speed is not optimal for back-end processing. Taking the input in Fig. 2a as an example, with a resolution of \(1920\times 1080\), DataGen’s processing time exceeds 40 s, which is deemed unacceptable in practical applications. Furthermore, DataGen’s approach of region division and subsequent recoloring can result in partial loss of semantic information, as depicted in Fig. 4. For instance, when the hair and facial skin exhibit similar colors, DataGen may incorrectly divide them into the same region and fill them with the same color, which will lead to a decrease in target recognition accuracy or confidence, or even recognition errors. In contrast, our PIMO solely utilizes the images generated by DataGen as a training set for style learning, without incorporating DataGen in the subsequent execution. It does not involve image segmentation and recoloring for blurring purposes. As a result, PIMO outperforms DataGen by effectively preserving semantic information within the image, mitigating such issues and ensuring superior semantic preservation.

Target detection results comparison of the training data generated by DataGen (b) and the generated images by trained CycleGAN (c). b Exhibits some errors in region delimitation. In contrast, c accurately maintains the correct semantic information
4.2 Resource cost reduction
If the original image data is processed in its raw form, the computational resources required would be unacceptable. As depicted in Fig. 5, elevating image resolution results in a rapid escalation of memory consumption, concomitant with an enhancement in image recognition accuracy. Notably, the pace of these two augmentations varies: the former displays an accelerating trend, while the latter exhibits deceleration. This contrast is particularly pronounced when the image resolution surpasses 1080P within the standard 16:9 aspect ratio. At this juncture, memory consumption experiences a steep ascent, whereas the gains in image recognition accuracy become nearly inconsequential. (Nevertheless, it remains prudent, given sufficient computational resources, to opt for higher resolutions for the purpose of optimizing image recognition accuracy.) For resolutions below 1080P, diminishing resolution yields a proportionately marked reduction in image recognition accuracy. To ensure the preservation of image recognition accuracy within acceptable bounds, the minimal image scaling size should not fall below 1080P. However, processing 1080P images on certain edge devices still exacts a substantial toll on computational resources.

Memory consumption and mAP variation with resolution
So how can we ensure that the final output image resolution reaches 1080P while meeting the processing constraints? In order to solve this problem, we opt for the approach of image segmentation, as illustrated in Fig. 7. When the front end captures an image with high resolution, we begin by reducing its resolution. After this, we divide the original image into \({\textbf {M }} \times {\textbf {N }}\) blocks, and each block undergoes the image stylization process individually. Subsequently, these images are reassembled to generate an output image with the same resolution as the original image. By dividing the image into smaller blocks, each block possesses a reduced resolution, thereby accommodating the computational resource limitations of all edge devices.
The selection of M and N is restricted by the configuration of the edge device, as it directly impacts the required memory. To address this, our algorithm is designed to directly access the available memory size of the edge device. In addition, the selection of values for M and N can influence the target recognition accuracy and processing latency. Using these information, PIMO can effectively predict the values of M and N with accuracy. Through our testing process, we manually set different values of M and N to assess their impact on memory consumption, latency, and target detection accuracy. As shown in Fig. 6, when the value of \(M \times N\) increases, there is a slight decrease in the accuracy of target identification, accompanied by a marginal increase in processing latency. Considering computational limitations on edge devices and the decrease in the memory consumption shown in Fig. 6a, it is crucial to choose the smallest values of M and N that are feasible within the available computational resources.

Processing latency and the accuracy of target identification at different values of \(M*N\)

The process of image processing. Here, we set both M and N to 4, these blocks are then fed into CycleGAN for processing. Then the blocks are reassembled together to generate the final output results
We employed trained support vector machines (SVMs) to facilitate the automated prediction process of M and N, which enables the determination of their respective values based on factors such as image resolution and available memory resources on the device. The training data for SVMs were obtained from real-world experiments conducted within our experimental environment. While keeping the aspect ratio of the image unchanged, the size of memory resources occupied after division is shown in Table 1.Where h represent the count of vertical pixels in the subdivided image, which is calculated as \(h = \frac{H}{N}.\)
Drawing upon the information presented in the provided table, we can easily deduce that memory usage exhibits a direct correlation with the initial image’s resolution(r) and an inverse relationship with the product of the parameters (M, N).
Table 1 exclusively presents the 16:9 standard aspect ratio images, while a diverse range of aspect ratio images were introduced during the actual training phase to enhance the accuracy of prediction outcomes. Based on our experimentation, we observed that the image, once scaled down to 1080P or lower and divided into 16 blocks (\(M=4\), \(N=4\)), reaches the minimum memory requirement for the model to execute. This determination is made based on the model parameters. Further reduction in resolution beyond this point does not result in a continuous decrease in memory consumption. Consequently, we have defined the range of values for M and N as [1, 4]. By multiplying M and N, we can identify a total of seven distinct values: 1, 2, 4, 6, 9, 12, and 16. Each value corresponds to a specific prediction result. Notably, our final prediction accuracy has reached 86%.
4.3 Privacy-accuracy tradeoff
Based on the preceding analysis, it becomes apparent that the selection of the K value is intricately connected to the level of privacy protection achieved. Diverse K value settings within the training set result in varying degrees of privacy information obfuscation. However, it is crucial to note that an escalation in the K value also amplifies the smearing of intricate details, thereby compromising the retention of semantic information, as illustrated in Fig. 3b. This loss of semantic information has implications for the processing capabilities of the back-end program. Hence, the determination of an appropriate K value assumes significance as it ensures a equilibrium between privacy protection and the preservation of semantic information.
Furthermore, the distinction between the front and rear views of the smart camera is more pronounced. We have observed that objects in closer proximity to the camera tend to occupy a larger portion of the captured image. Consequently, the processing effect of the front and rear views, even after applying the same K-value processing, is not identical. In some cases, the processing results for the foreground do not yield satisfactory outcomes. As shown in Fig. 8, where the license plate of the vehicle in the distance is completely unrecognizable to the naked eye, while the license plate of the closer vehicle remains partially discernible.

Difference in processing effect between the front and back view after using the same K value to process the image
Hence, we have opted to apply distinct K-value processing for each segmented image, utilizing the image segmentation process outlined in Sect. 4.2. In the case of smart cameras utilized for surveillance purposes, for instance, positional movement or changes in viewing angles are infrequent once the cameras are deployed. Consequently, we only need to establish the K-value initially based on the captured images during the early stages of deployment. This approach enables us to achieve separate processing for the near view and the far view, thereby attaining an optimal privacy protection outcome.
The primary differentiation between the foreground and background is primarily determined by the width of the vehicle license plate. The width of the vehicle is closely related to the width of the license plate and is often easier to detect compared to the width of the license plate itself. Therefore, instead of relying on the width of the license plate, the width of the vehicle can be directly used as a criterion for judgment. It is evident that as a vehicle gets closer to the camera, its width in the frame increases, resulting in a larger pixel width. We have applied various K values to the vehicles based on different pixel widths, and the resulting Levenshtein distance are illustrated in Fig. 9, where the foreground vehicle width at an image resolution of 1080P amounts to 240 pixels, it follows that all vehicles within the 1080P image possess a width that is either smaller or equal to 240 pixels. This implies that each of these vehicles corresponds to a specific K value that ensures a Levenshtein distance exceeding 0.5. In other words, PIMO can select suitable K values for segmented subgraphs based on the varying pixel widths of vehicles in the foreground and background when processing 1080P images. This enables a balance to be achieved between achieving optimal privacy protection and preserving semantic information.

Privacy degree (depends on Levenshtein distances) of vehicles with different pixel widths processed with different K values
5 Evaluation
Initially, we conducted an assessment to evaluate the degree of privacy preservation achieved by PIMO. Subsequently, we investigated the usability of the resulting images in target detection algorithms and compared them with other baseline algorithms. Our findings demonstrated that our algorithms achieve a superior balance between privacy preservation and the semantic information preserving. Furthermore, we conducted evaluations to measure the memory and time consumption of the algorithms. The conclusive findings demonstrate that our algorithms exhibit minimal computational resource requirements in both memory and time, while simultaneously achieving high privacy preservation effectiveness and recognition accuracy across various types of object detection algorithms.
Knobs. Our proposed approach incorporates four adjustable parameters: M, N, K, and Resolution. Among these parameters, K governs the level of privacy protection and simultaneously influences the retention of semantic information. On the other hand, M and N are utilized to regulate the number of image blocks generated during the input image division process, meanwhile the Resolution parameter adjusts the scaling of the original image, usually at 1080P and below, these three variables wield discernible influence over memory consumption.
5.1 Privacy protection
License plate numbers are a prominent example of personal privacy information that frequently appears in surveillance systems. Consequently, we utilized license plate number information from vehicle surveillance videos as an evaluation criterion for privacy protection. This allowed us to assess whether the converted images still contained identifiable privacy information. To ensure consistency, we standardized the video resolution to 1080P, as it is both widely used and yields the most favorable results in this study. In addition to PIMO, we selected ST-VAE and three sets of PECAM and DataGen algorithms, each corresponding to K-values of 100, 200, and 400, respectively. The results are visually presented in Fig. 10, the vertical axis in the figure represents the Levenshtein distance. The results unequivocally demonstrate that PIMO is proficient in significantly mitigating memory consumption, while consistently achieves a privacy degree exceeding 0.6 for the entire dataset, which is approximately equivalent to that of PECAM with a K value of 600. A comprehensive elucidation of PIMO’s memory utilization will be provided in Sect. 5.4.

PIMO compared with baselines in terms of privacy protection and accuracy with mAP
5.2 Semantic information preserving
In this section, we choose to use the results of target detection as a quantitative metric for assessing the retention of semantic information. The detected targets encompass cars, pedestrians, and two-wheeled vehicles, as these categories themselves do not encompass private information. Moreover, they contain vital information for subsequent processes, such as backend analysis.
For the dataset, we selected the same dataset as in Sect. 5.1, The resolution and comparison algorithm also remained consistent, employing 1080P as in the preceding subsection and applied ST-VAE and three sets of PECAM and DataGen algorithms with varying K-values. The resulting outcomes are presented in Fig. 10, where the horizontal axis indicates the mAP values of the object detection results. It is important to note that any image processing algorithm inherently leads to some loss of semantic information, which can result in a decrease in the accuracy of object detection outcomes. This effect is particularly pronounced in the case of DataGen. As the K value increases, there is a notable decrease in the mAP associated with DataGen, indicating a significant decline in detection accuracy. Since PIMO is able to adjust the degree of blurring based on the distance between the object and the camera, PIMO exhibits superior semantic information retention compared to PECAM and DataGen, without compromising the effectiveness of privacy preservation. This advantage holds true across all values of K for PECAM and DataGen algorithms. While ST-VAE may offer slightly better performance than PIMO, as we will discuss in the subsequent subsection, it comes at the cost of significantly higher resource consumption. This makes it more challenging to deploy on edge devices where resource constraints are a significant consideration.
5.3 Time consumption
In the context of image processing time, we have additionally incorporated ST-VAE for comparative analysis. The image processing time is closely linked to the number of pixels that need to be processed. Therefore, as the resolution of the image increases, it is expected that the processing time will also increase. As shown in Fig. 11a, we conduct a comparative analysis of the time required for four image processing algorithms: PIMO, PECAM, DataGen, and VAE. For PIMO, we manually set up two sets of M and N for testing, with values of (2, 2) and (3, 3), which corresponding to the resolutions of 540P and 360P as indicated in Table 1, respectively. We present the processing times for each algorithm across various resolutions, including 224P, 480P, 720P, and 1080P.
Notably, the processing time of PIMO closely aligns with that of PECAM, thus meeting the real-time processing demands of video streams.Conversely, DataGen and ST-VAE exhibit elevated processing times across all resolutions. And compared with ST-VAE, DataGen exhibits a much larger increase in processing time as the image resolution increases.

Resource consumption of PIMO and other algorithms
5.4 Resource usage
In Fig. 11b, we present the memory consumption of PIMO and draw a comparison with PECAM, DataGen, and VAE. We similarly set the M and N values to (2, 2) and (3, 3) for PIMO. Under both of these parameter configurations, PIMO consistently exhibits the lowest memory resource consumption. This enables PIMO to efficiently carry out video frame privacy processing with notably reduced memory resource requirements when juxtaposed with the other three methods.
However, it should be noted that for images captured by distinct devices, memory consumption may exhibit variations even at identical resolutions. The memory utilization of images with identical storage parameters following scaling should align with the conclusions drawn in Sect. 4.2 of our analysis. Consequently, we initiate image scaling prior to the initial processing stage, ensuring that the resultant resolution aligns with the resolutions outlined in Table 1. Subsequently, we attempt image blurring (acknowledging the potential for process failure due to limited memory capacity on edge devices) and record the corresponding memory consumption values. To establish a proportional relationship between image resolution and memory consumption, we employ linear regression to fit the acquired memory consumption data. Subsequently, we leverage this relationship in conjunction with the prevailing memory constraints of the device to compute values for parameters M and N. This enables us to tailor image resolutions to meet the operational prerequisites of various edge devices.
6 Discussion
Limitations. While PIMO has made significant advancements compared to DataGen, there are still two limitations that require improvement in the future. Firstly, the processing speed for images, although improved, is still not sufficient to meet the demands of processing every frame in a video. Secondly, when objects are in close proximity to the camera, the current level of privacy processing may not be effectively achieved, and the parameters cannot be automatically adjusted to this situation. We will consider solving these two problems in the future.
Application scenarios. In the paper, it is mentioned that to fulfill the requirements of both privacy protection and target detection accuracy, PIMO needs to address the distinction between the front and rear views of vehicles. This differentiation is based on the invariant view and position characteristics of the current surveillance system. It is necessary to assign an ambiguity, represented by a set of K-values, to each camera in the surveillance system, catering to the front and rear views. Consequently, it is essential to explore a solution for this challenge when deploying PIMO. In essence, pre-training a technique that specifically recognizes the edges of vehicles to determine their width, which can subsequently be used to estimate the distance of the vehicle can be a great solution to this problem. With the rapid advancements in deep learning and AI techniques, it is conceivable that there may be simpler methods available for distance estimation. Such algorithms could highly beneficial in deploying PIMO across a wider range of devices and scenarios.
7 Conclusion
In this paper, we present PIMO, a novel scheme crafted to enhance privacy protection in video content. PIMO strategically blurs sensitive information in video frames through the implementation of CycleGAN to maintain user privacy. Given resource-constrained devices, PIMO employs adaptive slicing for frames along with controlled degradation of resolution, ensuring that privacy protection is achieved without excessive memory consumption. Moreover, PIMO achieves this without markedly diminishing the precision of subsequent video analytics. With its versatile design, PIMO is highly applicable and serves as an ideal video protection for a wide range of computing resource-constrained devices.
Data availability
The data are available from the corresponding author on reasonable request.
References
Wang, X., Yang, J.: A privacy image encryption algorithm based on piecewise coupled map lattice with multi dynamic coupling coefficient. Inf. Sci. 569, 217–240 (2021)
Çiftçi, S., Akyüz, A.O., Ebrahimi, T.: A reliable and reversible image privacy protection based on false colors. IEEE Trans. Multimed. 20(1), 68–81 (2017)
Dou, Q., So, T.Y., Jiang, M., Liu, Q., Vardhanabhuti, V., Kaissis, G., Li, Z., Si, W., Lee, H.H., Yu, K., et al.: Federated deep learning for detecting COVID-19 lung abnormalities in CT: a privacy-preserving multinational validation study. NPJ Digit. Med. 4(1), 60 (2021)
Wu, H., Tian, X., Li, M., Liu, Y., Ananthanarayanan, G., Xu, F., Zhong, S.: Pecam: privacy-enhanced video streaming and analytics via securely-reversible transformation. In: Proceedings of the 27th Annual International Conference on Mobile Computing and Networking, pp. 229–241 (2021)
Padilla-López, J.R., Chaaraoui, A.A., Flórez-Revuelta, F.: Visual privacy protection methods: a survey. Expert Syst. Appl. 42(9), 4177–4195 (2015)
Wang, Q., Gao, J., Lin, W., Yuan, Y.: Pixel-wise crowd understanding via synthetic data. Int. J. Comput. Vis. 129(1), 225–245 (2021)
Fang, W., Ding, L., Luo, H., Love, P.E.: Falls from heights: a computer vision-based approach for safety harness detection. Autom. Constr. 91, 53–61 (2018)
Fan L, Kerschbaum F, Paraboschi S (2018) Data and applications security and privacy XXXII. In: 32nd annual IFIP WG 11.3 conference DBSec 2018 Bergamo Italy July 16–18 2018, Proceedings image pixelization with differential privacy Springer International Publishing, Cham, pp 148–162
Ribaric, S., Ariyaeeinia, A., Pavesic, N.: De-identification for privacy protection in multimedia content: a survey signal processing. Image Commun 47, 131–151 (2016). https://doi.org/10.1016/j.image.2016.05.020
Jang, W., Lee, S.Y.: Partial image encryption using format-preserving encryption in image processing systems for Internet of things environment. Int J Distrib Sens Netw 16(3), 155014772091477 (2020). https://doi.org/10.1177/1550147720914779
Zhang, Y., Zhao, R., Xiao, X., Lan, R., Liu, Z., Zhang, X.: HF-TPE: high-fidelity thumbnail-preserving encryption. IEEE Trans. Circuits Syst. Video Technol. 32(3), 947–961 (2021)
Dwork, C., Bugliesi, M., Preneel, B., Sassone, V., Wegener, I.: Automata languages and programming differential privacy, pp. 1–12. Springer, Berlin Heidelberg (2006)
Fan, L.: Differential privacy for image publication. In: Theory and Practice of Differential Privacy (TPDP) Workshop, vol 1, p 6 (2019)
Xue, H., Bo, L., Xin, Y., Ming, D., Tianqing, Z.: Face image de-identification by feature space adversarial perturbation. Concurr Comput Pract Exp 35(5):e7554 (2023). https://doi.org/10.1002/cpe.7554
Ji, J., Wang, H., Huang, Y., Wu, J., Xu, X., Ding, S., Zhang, S.C., Cao, L., Ji, R.: Privacy-preserving face recognition with learnable privacy budgets in frequency domain. Springer, Cham (2022)
Yu, J., Zhang, B., Kuang, Z., Lin, D., Fan, J.: iPrivacy: image privacy protection by identifying sensitive objects via deep multi-task learning. IEEE Trans. Inf. Forensics Secur. 12, 1005–1016 (2017). https://doi.org/10.1109/tifs.2016.2636090
Wen, Y., Liu, B., Ding, M., Xie, R., Song, L.: Identitydp: differential private identification protection for face images. Neurocomputing 501, 197–211 (2022). https://doi.org/10.1016/j.neucom.2022.06.039
Hasan, R., Crandall, D., Fritz, M., Kapadia, A.: Automatically detecting bystanders in photos to reduce privacy risks. In: 2020 IEEE Symposium on Security and Privacy (SP), pp. 318–335 (2020). https://doi.org/10.1109/SP40000.2020.00097
Sirichotedumrong, W., Kiya, H.: A gan-based image transformation scheme for privacy-preserving deep neural networks. In: 2020 28th European Signal Processing Conference (EUSIPCO), pp. 745–749 (2021). https://doi.org/10.23919/Eusipco47968.2020.9287532
Lin, J., Li, Y., Yang, G.: Fpgan: face de-identification method with generative adversarial networks for social robots. Neural Netw. 133, 132–147 (2021)
Liu, Z.-S., Kalogeiton, V., Cani, M.-P.: Multiple style transfer via variational autoencoder. In: 2021 IEEE International Conference on Image Processing (ICIP) (2021). https://doi.org/10.1109/icip42928.2021.9506379
Asghar, M.N., Ansari, M.S., Kanwal, N., Lee, B., Herbst, M., Qiao, Y.: Deep learning based effective identification of eu-gdpr compliant privacy safeguards in surveillance videos. In: 2021 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech) (2021). https://doi.org/10.1109/dasc-picom-cbdcom-cyberscitech52372.2021.00136
Chiu, S., Huang, Y., Lin, C., Tseng, Y., Chen, J., Tu, M., Tung, B., Nieh, Y.: Privacy-preserving video conferencing via thermal-generative images. In: 2023 IEEE International Conference on Robotics and Automation (ICRA), pp. 9478–9485 (2023). https://doi.org/10.1109/ICRA48891.2023.10161205
Goswami, U., Wang, K., Nguyen, G., Lagesse, B.: Privacy-preserving mobile video sharing using fully homomorphic encryption. In: 2020 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), pp. 1–3 (2020). https://doi.org/10.1109/PerComWorkshops48775.2020.9156217
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial networks. Commun. ACM 63(11), 139–144 (2020)
Lin, C.-T., Huang, S.-W., Wu, Y.-Y., Lai, S.-H.: Gan-based day-to-night image style transfer for nighttime vehicle detection. IEEE Trans. Intell. Transp. Syst. 22(2), 951–963 (2020)
Zhang, M., Ling, Q.: Supervised pixel-wise gan for face super-resolution. IEEE Trans. Multimed. 23, 1938–1950 (2020)
Zhu, J.-Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: 2017 IEEE International Conference on Computer Vision (ICCV) (2017). https://doi.org/10.1109/iccv.2017.244
Felzenszwalb, P.F., Huttenlocher, D.P.: Efficient graph-based image segmentation. Int. J. Comput. Vis. (2004). https://doi.org/10.1023/b:visi.0000022288.19776.77
Acknowledgements
Supported by the National Key Research and Development Program of China under Grant 2023YFB3107605 and Key Laboratory of Trusted Distributed Computing and Services, Ministry of Education (Beijing University of Posts and Telecommunications).
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
Jie Yuan and Zicong Wang wrote the main manuscript text under the guidance of Tingting Yuan. Jing Zhang and Rui Qian prepared figures. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interests.
Additional information
Communicated by Q. Shen.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yuan, J., Wang, Z., Yuan, T. et al. Pimo: memory-efficient privacy protection in video streaming and analytics. Multimedia Systems 30, 137 (2024). https://doi.org/10.1007/s00530-024-01337-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00530-024-01337-5