
Abstract
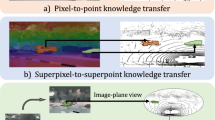
Existing cross-modal frameworks have achieved impressive performance in point cloud object representations learning, where a 2D image encoder is employed to transfer knowledge to a 3D point cloud encoder. However, the local structures between point clouds and corresponding images are unaligned, which results in a challenge for the 3D point cloud encoder to learn fine-grained image-point cloud interactions. In this paper, we introduce a novel multi-scale training strategy (PointCMC) to enhance fine-grained cross-modal knowledge transfer in the cross-modal framework. Specifically, we design a Local-to-Local (L2L) module that implicitly learns the correspondence of local features by aligning and fusing extracted local feature sets. Moreover, we introduce the Cross-Modal Local-Global Contrastive (CLGC) loss, which enables the encoder to capture discriminative features by reasoning local structures to their corresponding cross-modal global shape. The extensive experimental results demonstrate that our approach outperforms the previous unsupervised learning methods in various downstream tasks such as 3D object classification and semantic segmentation.







Similar content being viewed by others


Data availability
No data was used for the research described in the article.
References
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: Deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 652–660 (2017)
Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Advances in neural information processing systems 30 (2017)
Liu, Y., Fan, B., Xiang, S., Pan, C.: Relation-shape convolutional neural network for point cloud analysis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8895–8904 (2019)
Wang, Y., Sun, Y., Liu, Z., Sarma, S.E., Bronstein, M.M., Solomon, J.M.: Dynamic graph cnn for learning on point clouds. Acm Trans. Gr. (tog) 38(5), 1–12 (2019)
Li, Y., Bu, R., Sun, M., Wu, W., Di, X., Chen, B.: Pointcnn: Convolution on x-transformed points. Advances in neural information processing systems 31 (2018)
Wu, W., Qi, Z., Fuxin, L.: Pointconv: Deep convolutional networks on 3d point clouds. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9621–9630 (2019)
Xu, Y., Fan, T., Xu, M., Zeng, L., Qiao, Y.: Spidercnn: Deep learning on point sets with parameterized convolutional filters. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 87–102 (2018)
Achlioptas, P., Diamanti, O., Mitliagkas, I., Guibas, L.: Learning representations and generative models for 3d point clouds. In: International Conference on Machine Learning, pp. 40–49 (2018). PMLR
Li, J., Chen, B.M., Lee, G.H.: So-net: Self-organizing network for point cloud analysis. Proceedings of the IEEE conference on computer vision and pattern recognition (2018)
Xie, S., Gu, J., Guo, D., Qi, C.R., Guibas, L., Litany, O.: Pointcontrast: Unsupervised pre-training for 3d point cloud understanding. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16, pp. 574–591 (2020). Springer
Wang, P.-S., Yang, Y.-Q., Zou, Q.-F., Wu, Z., Liu, Y., Tong, X.: Unsupervised 3d learning for shape analysis via multiresolution instance discrimination. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 2773–2781 (2021)
Zhang, L., Zhu, Z.: Unsupervised feature learning for point cloud understanding by contrasting and clustering using graph convolutional neural networks. international conference on 3d vision (2019)
Afham, M., Dissanayake, I., Dissanayake, D., Dharmasiri, A., Thilakarathna, K., Rodrigo, R.: Crosspoint: Self-supervised cross-modal contrastive learning for 3d point cloud understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9902–9912 (2022)
Jing, L., Zhang, L., Tian, Y.: Self-supervised feature learning by cross-modality and cross-view correspondences. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2021)
Liu, Y.-C., Huang, Y.-K., Chiang, H.-Y., Su, H.-T., Liu, Z.-Y., Chen, C.-T., Tseng, C.-Y., Hsu, W.H.: Learning from 2d: Contrastive pixel-to-point knowledge transfer for 3d pretraining. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2021)
Liu, Y., Yi, L., Zhang, S., Fan, Q., Funkhouser, T., Dong, H.: P4contrast: Contrastive learning with pairs of point-pixel pairs for rgb-d scene understanding. arXiv: Computer Vision and Pattern Recognition (2020)
Wang, B., Chen, C., Cui, Z., Qin, J., Lu, C.X., Yu, Z., Zhao, P., Dong, Z., Zhu, F., Trigoni, N., et al.: P2-net: Joint description and detection of local features for pixel and point matching. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 16004–16013 (2021)
Rao, Y., Lu, J., Zhou, J.: Global-local bidirectional reasoning for unsupervised representation learning of 3d point clouds. Proceedings of the IEEE conference on computer vision and pattern recognition (2020)
Jing, L., Zhang, L., Tian, Y.: Self-supervised feature learning by cross-modality and cross-view correspondences. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1581–1591 (2021)
Qi, C.R., Su, H., Nießner, M., Dai, A., Yan, M., Guibas, L.J.: Volumetric and multi-view cnns for object classification on 3d data. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5648–5656 (2016)
Le, T., Duan, Y.: Pointgrid: A deep network for 3d shape understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 9204–9214 (2018)
Thomas, H., Qi, C.R., Deschaud, J.-E., Marcotegui, B., Goulette, F., Guibas, L.J.: Kpconv: Flexible and deformable convolution for point clouds. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 6411–6420 (2019)
Doersch, C., Gupta, A., Efros, A.A.: Unsupervised visual representation learning by context prediction. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1422–1430 (2015)
Zhang, R., Isola, P., Efros, A.A.: Split-brain autoencoders: Unsupervised learning by cross-channel prediction. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1058–1067 (2017)
Bachman, P., Hjelm, R.D., Buchwalter, W.: Learning representations by maximizing mutual information across views. Advances in neural information processing systems 32 (2019)
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.E.: A simple framework for contrastive learning of visual representations. international conference on machine learning (2020)
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9729–9738 (2020)
Sanghi, A.: Info3d: Representation learning on 3d objects using mutual information maximization and contrastive learning. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXIX 16, pp. 626–642 (2020). Springer
Grill, J.-B., Strub, F., Altché, F., Tallec, C., Richemond, P., Buchatskaya, E., Doersch, C., Avila Pires, B., Guo, Z., Gheshlaghi Azar, M., et al.: Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems 33, 21271–21284 (2020)
Kramer, M.A.: Nonlinear principal component analysis using autoassociative neural networks. AIChE journal, 233–243 (1991)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial networks. Communications of the ACM, 139–144 (2020)
Yang, Y., Feng, C., Shen, Y., Tian, D.: Foldingnet: Point cloud auto-encoder via deep grid deformation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 206–215 (2018)
Fan, H., Su, H., Guibas, L.J.: A point set generation network for 3d object reconstruction from a single image. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 605–613 (2017)
Zhao, Y., Birdal, T., Deng, H., Tombari, F.: 3d point capsule networks. Proceedings of the IEEE conference on computer vision and pattern recognition (2018)
Han, Z., Wang, X., Liu, Y.-S., Zwicker, M.: Multi-angle point cloud-vae: Unsupervised feature learning for 3d point clouds from multiple angles by joint self-reconstruction and half-to-half prediction. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 10441–10450 (2019). IEEE
Li, R., Li, X., Fu, C.-W., Cohen-Or, D., Heng, P.-A.: Pu-gan: A point cloud upsampling adversarial network. international conference on computer vision (2019)
Yu, L., Li, X., Fu, C.-W., Cohen-Or, D., Heng, P.-A.: Pu-net: Point cloud upsampling network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2790–2799 (2018)
Li, R., Li, X., Heng, P.-A., Fu, C.-W.: Point cloud upsampling via disentangled refinement. Proceedings of the IEEE conference on computer vision and pattern recognition (2021)
Wang, H., Liu, Q., Yue, X., Lasenby, J., Kusner, M.J.: Unsupervised point cloud pre-training via occlusion completion. international conference on computer vision (2021)
Huang, Z., Yu, Y., Xu, J., Ni, F., Le, X.: Pf-net: Point fractal network for 3d point cloud completion. Proceedings of the IEEE conference on computer vision and pattern recognition (2020)
Sharma, A., Grau, O., Fritz, M.: Vconv-dae: Deep volumetric shape learning without object labels. Proceedings of the IEEE conference on computer vision and pattern recognition (2016)
Xie, J., Zheng, Z., Gao, R., Wang, W., Zhu, S.-C., Wu, Y.N.: Learning descriptor networks for 3d shape synthesis and analysis. Proceedings of the IEEE conference on computer vision and pattern recognition (2018)
Valsesia, D., Fracastoro, G., Magli, E.: Learning localized generative models for 3d point clouds via graph convolution. international conference on learning representations (2018)
Li, C.-L., Zaheer, M., Zhang, Y., Poczos, B., Salakhutdinov, R.: Point cloud gan. arXiv preprint arXiv:1810.05795 (2018)
Du, B., Gao, X., Hu, W., Li, X.: Self-contrastive learning with hard negative sampling for self-supervised point cloud learning. In: Proceedings of the 29th ACM International Conference on Multimedia, pp. 3133–3142 (2021)
Huang, S., Xie, Y., Zhu, S.-C., Zhu, Y.: Spatio-temporal self-supervised representation learning for 3d point clouds. international conference on computer vision (2021)
Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Learning to prompt for vision-language models. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. international conference on machine learning (2021)
Wu, Z., Zhang, Y., Zeng, M., Qin, F., Wang, Y.: Joint analysis of shapes and images via deep domain adaptation. Computers & Graphics 70, 140–147 (2018)
Yan, X., Zhan, H., Zheng, C., Gao, J., Zhang, R., Cui, S., Li, Z.: Let images give you more: Point cloud cross-modal training for shape analysis. arXiv preprint arXiv:2210.04208 (2022)
Xiao, A., Huang, J., Guan, D., Lu, S.: Unsupervised representation learning for point clouds: A survey. arXiv preprint arXiv:2202.13589 (2022)
Xu, C., Yang, S., Zhai, B., Wu, B., Yue, X., Zhan, W., Vajda, P., Keutzer, K., Tomizuka, M.: Image2point: 3d point-cloud understanding with pretrained 2d convnets. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2021)
Zhang, Z., Girdhar, R., Joulin, A., Misra, I.: Self-supervised pretraining of 3d features on any point-cloud. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 10252–10263 (2021)
Chang, A.X., Funkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., et al.: Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012 (2015)
Xu, Q., Wang, W., Ceylan, D., Mech, R., Neumann, U.: Disn: Deep implicit surface network for high-quality single-view 3d reconstruction. neural information processing systems (2019)
Wu, J., Zhang, C., Xue, T., Freeman, W.T., Tenenbaum, J.B.: Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. neural information processing systems (2016)
Gadelha, M., Wang, R., Maji, S.: Multiresolution tree networks for 3d point cloud processing. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 103–118 (2018)
Han, Z., Shang, M., Liu, Y.-S., Zwicker, M.: View inter-prediction gan: Unsupervised representation learning for 3d shapes by learning global shape memories to support local view predictions. national conference on artificial intelligence (2019)
Hassani, K., Haley, M.: Unsupervised multi-task feature learning on point clouds. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 8160–8171 (2019)
Sauder, J., Sievers, B.: Self-supervised deep learning on point clouds by reconstructing space. neural information processing systems (2019)
Poursaeed, O., Jiang, T., Qiao, H., Xu, N., Kim, V.G.: Self-supervised learning of point clouds via orientation estimation. international conference on 3d vision (2020)
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E.Z., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., Chintala, S.: Pytorch: An imperative style, high-performance deep learning library. neural information processing systems (2019)
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 10012–10022 (2021)
Loshchilov, I., Hutter, F.: Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983 (2016)
Sharma, C., Kaul, M.: Self-supervised few-shot learning on point clouds. neural information processing systems (2020)
Yi, L., Kim, V.G., Ceylan, D., Shen, I.-C., Yan, M., Su, H., Lu, C., Huang, Q., Sheffer, A., Guibas, L.J.: A scalable active framework for region annotation in 3d shape collections. international conference on computer graphics and interactive techniques (2016)
Armeni, I., Sax, A., Zamir, A.R., Savarese, S.: Joint 2D-3D-Semantic Data for Indoor Scene Understanding. ArXiv e-prints (2017) arXiv:1702.01105 [cs.CV]
van der Maaten, L., Hinton, G.E.: Visualizing data using t-sne. Journal of Machine Learning Research (2008)
Liu, F., Lin, G., Foo, C.-S.: Point discriminative learning for unsupervised representation learning on 3d point clouds. Proceedings of the IEEE/CVF International Conference on Computer Vision (2021)
Acknowledgements
This work is supported by the Open Project Program of the State Key Laboratory of CADCG (Grant No. A2306), Zhejiang University.
Author information
Authors and Affiliations
Contributions
Honggu Zhou: Conceptualization, Data curation, Implementation of the computer code and supporting algorithms, Conducting a research and investigation process, Writing-Original draft preparation.Xiaogang Peng: Resources, Validation, Visualization, Editing. Yikai Luo: Resources, Validation, Visualization.Zizhao Wu: Resources, Validation, Supervision, Reviewing & Editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhou, H., Peng, X., Luo, Y. et al. PointCMC: cross-modal multi-scale correspondences learning for point cloud understanding. Multimedia Systems 30, 138 (2024). https://doi.org/10.1007/s00530-024-01335-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00530-024-01335-7