
Abstract
For optimum performance, deep learning methods, such as those applied for retinal and choroidal layer segmentation in optical coherence tomography (OCT) images, require sufficiently large and diverse labelled datasets for training. However, the acquisition and labelling of such data can be difficult or infeasible due to privacy reasons (particularly in the medical domain), accessing patient images such as those with specific pathologies, and the cost and time investment to annotate large volumes of data by clinical experts. Data augmentation is one solution to address this issue, either using simple variations and transformations of the images (e.g. flips, brightness) or using synthetic data from sophisticated generative methods such as generative adversarial networks (GANs). Semi-supervised learning (SSL) is another technique which aims to utilise unlabelled data to enhance the performance of deep learning methods and is beneficial where significant amounts of data may be available but are not labelled. In this study, we aim to enhance patch-based OCT retinal and choroidal layer segmentation with both GAN-based data augmentation and SSL. In particular, we employ a conditional StyleGAN2 to generate synthetic patches for data augmentation and a similar unconditional GAN for pre-training the patch classifier to perform SSL. In doing so, we propose a new patch classifier architecture based on the discriminator architecture to improve performance, in addition to the SSL benefit. Compared to previous methods, the proposed data augmentation approach provides an improved data augmentation performance for patch classification with its effectiveness widespread, particularly in the case of low data, across three different OCT datasets encompassing a range of scanning parameters, noise levels, pathology and participant variability. The method provides some subsequent improvements in boundary delineation which is of high importance from a clinical perspective. Additionally, the proposed SSL approach boosts classification performance and boundary delineation performance in some cases which provides further usefulness in the case of low data. The proposed methods can be utilised to enhance OCT segmentation methods, which may be of considerable benefit for both clinicians and researchers.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Optical coherence tomography (OCT) is a fast and non-invasive imaging modality that provides high-resolution, high-volume, detailed images of the retinal and choroidal layers. In both clinical practice and research, quantifying and tracking the thickness of these layers is important for disease detection, ocular health assessment and as a proxy for treatment efficacy. Although manual image analysis is one option to extract these metrics, this often takes considerable time and is prone to grader subjectivity. A more desirable option is to utilise an automated software algorithm for which there are a multitude of approaches that can be divided into two main categories: (1) those based on traditional image processing methods, and (2) those based on machine learning (ML) and deep learning (DL) methods.
Techniques based on traditional image processing methods have included Markov boundary models [1], sparse higher order potentials [2], diffusion filtering [3], diffusion maps [4], graph theory [5,6,7], Chan-Vase models [8], and kernel regression [9], among others. Recently, deep learning has gained widespread adoption in retinal OCT [10]. Several techniques for OCT retinal layer segmentation have opted for ML and DL approaches with the vast majority of methods employing convolutional neural networks due to their effectiveness on image-based tasks in several other areas. These include several techniques based on patch-based approaches [11,12,13,14] as well as those utilising semantic segmentation [12, 15,16,17,18,19,20,21,22,23,24,25,26,27]. The advantages of deep learning approaches over traditional ones are: (1) the rules for feature extraction are automatically learnt instead of manually determined, and (2) it is significantly easier to recalibrate deep learning algorithms with additional data.
A challenge associated with deep learning methods is the need to have a sufficiently large and diverse image dataset for training. In many cases, these datasets can be difficult or infeasible to obtain due to privacy and confidentiality reasons as well as the cost and time to annotate vast amounts of data. To address this issue, data augmentation is a common technique that has been adopted to artificially enhance the size and variability of a given training dataset in machine learning. Such augmentations can consist of simple variations or transformations to the images such as rotations, flips, warps, brightness and contrast adjustments, gamma corrections as well as adding noise [28]. Another approach to data augmentation involves using synthetic data created by a generative adversarial network (GAN) to enhance the training set. GANs are deep learning techniques which can learn complex data distributions such as those of images. These methods have proven to be powerful generative models which can synthesise realistic, high-resolution images which are indistinguishable from the true image data. The basic premise of a GAN involves two neural networks, a generator and a discriminator, trained alongside/against one another. The goal of the generator is to produce synthetic images that are realistic such that the discriminator cannot distinguish them from the real images.
Several previous studies have adopted GAN-based data augmentation techniques for other medical imaging modalities including for colorectal histopathology [29], abdominal computed tomography (CT) [30], X-ray angiography [31], brain magnetic resonance imaging (MRI) [32, 33], mammography images [34], lung nodule CT [35], gastric cancer endoscopy [36], skin lesion dermoscopic images [37], liver lesion CT [38], COVID-19 X-ray [39], breast ultrasound [40], brain positron emission tomography (PET) [41], lung cytology [42], and retinal fundus photography [43]. The majority of previous studies can be categorised into five main types including: (1) Unpaired (unsupervised) image-to-image translation, (2) Paired (supervised) image-to-image translation, (3) Class-based: conditional GANs, (4) Class-based: separate unconditional GANs, and (5) Unconditional GANs. From the literature, it is evident that GAN-based data augmentation is effective at enhancing training datasets and improving the performance in different applications across various imaging modalities.
GANs have been applied for OCT image analysis for various applications [44] but, despite the plethora of work in medical image analysis with GAN data augmentation, there are only a few prior studies which investigate data augmentation for ophthalmic OCT image analysis applications including classification and segmentation. Kugelman et al. [45, 46] used conditional GANs to construct OCT patches (conditioned on class labels) for data augmentation which improved patch classification performance for OCT chorio-retinal segmentation, particularly for small and sparse datasets (i.e. low number of participants). Also for segmentation, Mahapatra et al. [47] adopted a geometry-aware GAN to generate both an image and mask for data augmentation to enhance OCT segmentation of pathological regions. Kugelman et al. [48] adopted a StyleGAN [49] with a dual output to synthesise OCT images and their corresponding masks for semantic segmentation of the retina and the choroid. For classification, Chen et al. [50] used conditional GANs to generate OCT images of different types of retinal diseases, while Yoo et al. [51] used separately trained CycleGANs to generate pathological OCT images (from healthy ones).
Semi-supervised learning (SSL) is another technique for enhancing deep learning methods and can be useful where a significant amount of data is available but is not labelled. One approach for semi-supervised learning in classification problems involves first training a GAN to simply generate images (using both labelled and unlabelled data while ignoring labels). Here, the discriminator learns to distinguish between real and fake (synthetic) images by learning about the features within the images. These learnt feature extraction capabilities can then be exploited by using the discriminator’s weights for pre-training the classifier network. In turn, the classifier network (initialised with the discriminator’s weights) is subsequently trained in a supervised manner on the labelled data only. Thus, the discriminator can learn useful features and information from the unlabelled data which would otherwise not be used. Other approaches to GAN-based semi-supervised learning train both the discriminator and classifier simultaneously either using a single model with multiple outputs (i.e. adding an extra class for fake images) [52], separate models with shared weights (similar to the first approach), or using stacked models with shared weights [53, 54] (i.e. output of unsupervised model feeds into the supervised model).
Only one study has investigated SSL for OCT semantic segmentation [55] and none have considered OCT patch-based classification methods. Likewise, there are few GAN-based data augmentation methods for OCT segmentation and the demonstrated performance benefits are limited overall. Therefore, we aim to delve further into data augmentation and semi-supervised learning for OCT segmentation using GANs, with the goal of enhancing performance. In this study, a conditional StyleGAN2 is employed to synthesise OCT image patches for patch-based segmentation of the retina and choroid in posterior segment OCT images of both healthy eyes and those exhibiting pathology. StyleGAN2 is a state-of-the-art deep learning generative method and has demonstrated remarkable results in generating high-resolution, realistic, and diverse images for a range of applications in several areas [56]. We employ data augmentation by combining the synthetic GAN-generated patches with real ones to improve performance of the patch-classification task and subsequently the overall segmentation task. As an alternative to this method, we also investigate SSL to enhance performance by training a similar unconditional StyleGAN2 model on unlabelled data to pre-train the patch classifier.
2 Methods
2.1 Data
Three separate OCT datasets from previous studies were used to validate the proposed method, in order to test its performance under different pathological conditions, scanning parameters, participant variability, and noise levels which can vary significantly between datasets. For each, patches are generated for the training and validation sets by sampling 32 × 32 (pixels) patches from the full-size OCT images. Here, we adopt the patch sampling and class strategy proposed by Kugelman et al. [45, 46]. For Datasets 1 and 3, there are 10 classes in total including 1 for each of the layer boundaries comprising patches centred upon the boundaries (3 classes total, called boundary patches), 1 for each of the regions close to (within 8 pixels above and below) but not centred upon the layer boundaries (3 classes total, called adjacent background patches), and 1 for each of the background regions comprising of patches that are not centred or close to the layer boundaries of interest (4 classes total, called background patches). Dataset 2 uses seven total classes instead comprising two boundary classes, two adjacent background classes, and three background classes. The benefit of using additional patch classes is twofold: 1) it provides a more precise segmentation problem and 2) it allows for a more well-defined setup for conditioning the generator.
2.1.1 Dataset 1: Normal
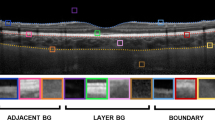
This dataset [57] consists of a range of spectral domain OCT (SD-OCT) images of the posterior segment of the eye from healthy participants. Scans were acquired from a total of 99 participants across a period of approximately 18 months, comprising four visits. At each visit, a participant had two sets of six equally spaced radial cross-sectional scans acquired of their retina and choroid centred at the fovea. For this study, we use just a single set from a single visit for each participant. Each B-scan image measures 1536 pixels wide and 496 pixels high corresponding to an approximate physical size of 8.8 mm × 1.9 mm with a vertical scale of 3.9 µm per pixel and a horizontal scale of 5.7 µm per pixel. Scans were acquired using the Heidelberg Spectralis SD-OCT instrument. For all scans, 30 frames were averaged using the inbuilt automated real-time function to reduce noise while enhanced depth imaging was used to improve the visibility of the choroidal tissue. All scans were annotated by an expert human observer for three layer boundaries within the retinal and choroidal tissue including: the inner boundary of the inner limiting membrane (ILM), the outer boundary of the retinal pigment epithelium (RPE), and the choroid–sclera interface (CSI). Figure 1 provides an example OCT image with the corresponding boundaries. For the purposes of training a deep learning model, the selected data were divided into a training (40 participants, 240 scans total), validation (10 participants, 60 scans total), and testing set (49 participants, 294 scans total) with no overlap of any participant’s data between sets. Patches are created from each image by sampling one patch for each class for each column within the image. For the background classes, a patch is randomly sampled within the desired range for each column. In total there are 2,882,400 total patches for the training set and 720,600 patches for the validation set. An example OCT scan and corresponding patch sampling are illustrated in Fig. 1.

Example OCT scan (left) from Dataset 1 showing samples from the different patch classes (right) indicated by the coloured windows [Orange: adjacent background patches, Green: background patches, Pink: boundary patches] and the positions of the three layer boundaries of interest indicated by the dotted lines [Blue: ILM boundary, Red: RPE boundary, Yellow: CSI boundary]
2.1.2 Dataset 2: Stargardt disease
This dataset, described in detail in a prior study [16], consists of SD-OCT scans of patients with varying stages of Stargardt disease. Scans were taken from 17 participants, with 4 volumes (captured at different visits at different times) of approximately 50–60 B-scans from each. The dimensions of the scans are 1536 pixels wide by 496 pixels high, with a vertical scale of 3.9 µm per pixel and a horizontal scale of 5.7 µm per pixel, corresponding to an approximate physical area of size 8.8 × 1.9 mm (width × height). Scans were acquired using the Heidelberg Spectralis SD-OCT instrument with ART mode enabled to enhance the definition of each B-scan by averaging nine OCT images. Each scan was labelled by an expert human observer, with annotations provided for two layer boundaries including: the inner boundary of the inner limiting membrane (ILM) and the outer boundary of the retinal pigment epithelium (RPE). Each participant is categorised into one of two categories based on retinal volume (low or high). This is calculated based on the total macular retinal volume based on the boundary annotations such that there is an even number of participants in each category. For this study, the data are divided into training (9 participants), validation (2 participants), and testing (6 participants) sets ensuring that there is an even split of low and high volume participants in each set. For computational reasons, patches are created from each image by sampling one patch for each class in every 4th column with one patch for the background classes randomly sampled from each of these columns. In total there are 2,718,807 patches for training and 600,187 patches for validation with 294 full size scans used for training. An example B-scan and set of corresponding sampled patches are provided in Fig. 2.

Example OCT scan (left) from Dataset 2 showing samples from the different patch classes (right) indicated by the coloured windows [Orange: adjacent background patches, Green: background patches, Pink: boundary patches] and the positions of the three layer boundaries of interest indicated by the dotted lines [Blue: ILM boundary, Red: RPE boundary]
2.1.3 Dataset 3: Age-related macular degeneration
This dataset consists of OCT scans of patients exhibiting age-related macular degeneration (AMD) [58]. All scans were acquired using the Bioptigen SD-OCT with data sourced from four different sites with scanning resolutions varying slightly between the site [59]. No image averaging is employed. A total of 269 participants are utilised, each with a single volume of 100 scans. However, only a subset of the scans is used. A scan is used only if it contains at least 512 pixels (approximately half the width) of available boundary annotations, otherwise it is discarded. Each scan is then cropped to a central 512 pixels horizontally with each scan also measuring 512 pixels in height (no cropping). Each scan was labelled by an expert human annotator with boundary annotations for three layer boundaries including the inner boundary of the ILM, the outer boundary of the retinal pigment epithelium drusen complex (RPEDC) and the outer boundary of Bruch’s membrane (BM). An example B-scan and set of corresponding sampled patches are provided in Fig. 3. A total of 163 participants are used for training, 54 participants for validation, and 52 participants for testing with all participants assigned randomly with no overlap or duplication. For computational reasons, patches are created from each image by sampling one patch for each class in every 7th column with one patch for the background classes randomly sampled from each of these columns. In total there are 3,284,860 patches for training and 1,095,940 patches for validation with 356 full size scans used for testing. An example scan and set of corresponding sampled patches are provided in Fig. 3.

Example OCT scan (left) from Dataset 3 showing samples from the different patch classes (right) indicated by the coloured windows [Orange: adjacent background patches, Green: background patches, Pink: boundary patches] and the positions of the three layer boundaries of interest indicated by the dotted lines [Blue: ILM boundary, Red: RPEDC boundary, Yellow: BM boundary]
2.2 Patch classification and segmentation method
For segmenting the OCT scans, a commonly used OCT patch-based retinal layer segmentation method [11, 13, 14] is employed consisting of a CNN classifier followed by a graph search algorithm to delineate the boundaries from the CNN-derived probability maps. The CNN architecture proposed by Fang et al. [11] (called ‘Cifar’) is compared to another architecture proposed in this study (called ‘Residual’) that is designed to closely match the discriminator architecture of the GAN model (see the next section). The purpose of comparing this proposed architecture is twofold: (1) To examine potential architectural-related improvements in performance, and (2) To analyse whether a simple semi-supervised technique can be employed to improve performance by pre-training the classifier with a discriminator that learns features from the unlabelled data during the training of the GAN. Additionally, another variant of the proposed network architecture (“Residual dropout”) is considered, which applies dropout for improved regularisation. Figure 4 illustrates these architectures. All architectures are trained until convergence (with respect to the validation loss) with a batch size of 1024, binary cross-entropy loss, and the Adam optimizer [60], with default parameters. From training, the model at epoch with the highest validation accuracy is selected.

CNN patch-classifier architectures used within this study. #F: filters, #S: stride, #P: padding, NP: no pooling, #R: dropout rate. Arrows show direction of information flow through the network. Note: “DISCRIM BLOCK” is defined in Fig. 5
2.3 Generative adversarial network model
With the goal of generating synthetic data for data augmentation purposes, we train a state-of-the-art GAN using the training set of patches described in the Data section. Here, the StyleGAN2 [56] was selected for its demonstrated ability to generate high-resolution, realistic and diverse images. Another benefit of the StyleGAN2 is the noise image input which allows this GAN method to be more adaptable and generate images with significant levels of noise such as the speckle noise inherent to the OCT imaging modality. We modify the StyleGAN2 to operate in a conditional manner by adopting an auxiliary input consisting of the patch class label. A few approaches to perform this conditioning are compared including:
-
concatenating one-hot labels.
-
multiplying label embeddings (same as previous approach in [45, 46]).
-
concatenating label embeddings.
-
concatenating hidden label embeddings (inject at intermediate discriminator layer, before mini-batch discrimination).
The StyleGAN2 is setup with 256 filters in each layer of both the generator and discriminator to ensure sufficient learning capacity while the latent code size is set at 128 along with the mapping network filters. The generator and discriminator are trained using the Adam optimizer [60], (lr = 5e−4, beta1 = 0, beta2 = 0.999) while the mapping network uses the same parameters with the exception of a magnitude lower learning rate (lr = 5e−5). No learning rate equalisation is used. In order to enhance the diversity of the generated data, we compare the mini-batch standard deviation layer (default for StyleGAN2) with a learned mini-batch discrimination layer [53] which demonstrated significant improvements in image generation in [45, 46]. Here, the ‘regular’ size layer is employed (25 kernels each of size 15). An illustration of the StyleGAN2 architecture is provided in Fig. 5. Training is performed in batches of 64 patches for 500,000 steps with a gradient penalty (loss weight of 10) applied to the discriminator loss every second step and path length regularisation penalty applied every 16th step (to reduce computational load). The coupled gradient penalty is employed (using interpolated real-fake images). The hinge loss function is utilised and compared with logistic [61], Wasserstein [62, 63], and least squares [64] losses. These loss functions were chosen for comparison as they have all seen extensive adoption in literature. Note that the validation set is not used for training the GAN at all. Also note that the full training dataset (e.g. 40 participants for Dataset 1) can be used for training or a subset of the full dataset (e.g. 1 participant).

Overview of the mapping network, generator, and discriminator/critic architectures used in the StyleGAN2 in this study. #F: number of filters, #A: Leaky ReLU negative slope coefficient, #S: stride, NP: no pooling. Note that all convolutional layers are padded such that the input spatial size is equal to the output spatial size. Arrows show direction of information flow through the network
2.4 Patch synthesis and data augmentation
Once the GAN has been trained as described in the previous subsection, synthetic patches may be generated and combined with the real training data for data augmentation purposes. To do so, we take every 1000th generator from the last 100 k steps of training (100 generators total) and generate an equal number of patches from each generator and from each class (e.g. 28,820 patches per generator with 2,882 patches per class for the full dataset for Dataset 1) and combine these together to create a synthetic training dataset which is of approximately equal size to the real training set. This dataset may be used in place of the real training dataset (synthetic-only) or used to augment the real set (synthetic-real combined). This is inspired by the approach used in [45, 46] which demonstrated substantial improvements when sampling images from multiple trained generators.
2.5 Semi-supervised learning
GANs that are trained using no class-label conditioning are effectively an unsupervised learning technique. Hence, we can exploit this property to also perform semi-supervised learning to improve patch classification and segmentation performance. One option for this is to train the StyleGAN2 on all data (both labelled and unlabelled) without class labels to effectively pre-train the classifier by using the trained discriminator weights to initialise the classification network. For instance, data from 1 participant may be taken as labelled and data from the 39 other participants (in the case of Dataset 1) unlabelled. The StyleGAN2 architecture remains unchanged in this unlabelled case with the exception of the auxiliary input which we forego, dropout if it is required, and the number of filters in the discriminator layers which can be easily adjusted accordingly to match the desired classifier architecture. We investigate this idea in this setting using the ‘Residual’ and ‘Residual dropout’ architecture variants where the weights can be directly tied to and based off the trained GAN discriminator. In particular, we pre-train all the layers of these classifier networks with the exception of the final dense layer which is randomly initialised.
2.6 Evaluation metrics
There are a number of evaluation metrics used in this study. For patch classification, we employ the accuracy metric on the validation set indicating the total percentage of image patches that have been correctly identified and also observe the classification network validation loss as an additional indicator of model performance. For layer boundary segmentation, the mean absolute error is used to reflect the average error the algorithm yields from its output segmentation boundary locations relative to the ground truth boundary locations. The error represents the axial distance (along the A-scan) between the predicted and the reference (ground truth) boundary positions. The median mean absolute error (rather than the mean) across the testing set is used to avoid outliers causing bias. For evaluating the image quality of a trained GAN, the Frechet Inception Distance (FID) [65] is employed with smaller values corresponding to generators that produce more realistic and diverse synthetic images with respect to the real data.
3 Results and discussion
Using the proposed methods, we first perform a series of experiments to better understand and optimise the performance of the StyleGAN2 for synthesising OCT patches. These experiments are crucial for two reasons: (1) given the considerable complexity and variability in training GANs and (2) there is very limited prior work using GANs applied to our task of OCT retinal and choroidal layer segmentation. After the performance of the method has been optimised, a number of experiments are performed to explore and demonstrate the effectiveness of the technique for data augmentation and for semi-supervised learning. All experiments and analysis in Sects. 3.1–3.11 are performed using Dataset 1, while Sect. 3.12 examines the performance and effectiveness of the method on two separate and different OCT datasets. For clarity, we omit the standard deviations from the results in this section given their high level of similarity.
3.1 Mini-batch discrimination versus mini-batch standard deviation
The default mini-batch standard deviation layer is compared to the mini-batch discrimination layer using the Frechet Inception Distance (FID), calculated for every 1000th generator over the course of training. It is clear from Fig. 6 that using a mini-batch discrimination layer not only improves the stability (i.e. lower FID variability) of the training process but it also improves the convergence with lower FID scores evident. Three GAN training runs are performed to reduce bias in the comparison.

Mean FID scores over training for mini-batch discrimination (MD) [blue] and mini-batch standard deviation (MSTD) [orange] using input multiplication conditioning (MUL) (left) and input concatenation conditioning (CON) (right) (average of 3 runs shown)
3.2 Multiplicative versus concatenative conditioning
The input multiplication conditioning technique used in [45, 46] is compared to an input concatenation technique. From Fig. 7, it is clear that replacing the multiplication with a concatenation for the auxiliary input results in improved convergence with lower FID scores during training. This shows that the new conditioning technique results in high quality and more diverse images that are closer to the true real data distribution. Three GAN training runs are performed to reduce bias in the comparison.

Mean FID scores over training for input multiplication conditioning (MUL) [orange] and input concatenative conditioning [blue] using mini-batch discrimination (MD) (left) and mini-batch standard deviation (MSTD) (right) (average of 3 runs shown)
3.3 GAN loss function
Four loss functions are compared to assess data augmentation capability including: hinge loss, Wasserstein loss, least squares loss and logistic loss. This comparison was performed using a single participant’s data as this is likely to result in the largest data augmentation effect. From Table 1, it appears that the least squares GAN and WGAN present reduced performance compared to both the hinge and logistic loss functions in terms of accuracy. However, in all cases, data augmentation results in clear improvements to patch classification performance. Therefore, the default choice of hinge loss appears to be a logical one which we use throughout this study.
3.4 GAN network capacity
Three different network capacity setups are compared to test for a potential bottleneck in performance including: 128 filters (all layers), 256 filters (all layers), 256 filters (incremental) (i.e. 32, 64, 128, 256 filters in each of the layers). This comparison was performed using the full training dataset as this is where network capacity bottlenecks are most likely to be observed. From Table 2, there is no clear performance bottleneck that was observed. We use the 256 filters (all layers) setup for the proposed method.
3.5 Dataset size
With a sparser dataset used to train the GAN, performance at the baseline (real data only) will be lower, and therefore, there is a greater potential to improve performance using data augmentation. To analyse this effect, the number of participants from which the training data are derived can be varied and the data augmentation performance compared. Table 3 illustrates these results with data augmentation performance improvement appearing to be more significant on sparser datasets (lower number of participants) when compared with the full training dataset (40 participants). These results further emphasise the capability of the method for data augmentation with each tested case resulting in patch classification performance improvements.
3.6 One-hot encoding versus embedding conditioning
For conditioning the StyleGAN2, while it was discovered that concatenation conditioning provided much better results than multiplicative conditioning, there is also the question of whether concatenating a one-hot encoded representation of the label (one-hot) or a label embedding (embed) is the preferred option. The case for using a hidden label embedding (in an intermediate layer of the discriminator) is also considered. Table 4 provides results for different cases and combinations of the choice of concatenation conditioning for both the generator (G) and discriminator (D). These results suggest that concatenating a label embedding to the generator input (embed G) is sub-optimal with reduced accuracies and increased losses in these cases. In the other more optimal cases (one-hot G), there is little observable difference between the different conditioning techniques for the discriminator with respect to the performance. We employ the first case in our proposed method, using one-hot encoded label inputs concatenated for both the generator and discriminator.
3.7 Classifier architecture and semi-supervised learning
The three network architectures summarised in Fig. 4 were compared using real data and GAN-based data augmentation. Here, we also analyse the effect of semi-supervised learning on patch-classification performance with the Residual and Residual dropout network variants. Table 5 demonstrates that the Residual-based architectures perform significantly better than the default Cifar model in terms of accuracy and loss, for a single participant’s data. It also appears there is some potential benefit using semi-supervised learning in the case of the Residual architecture with notable improvements to the real, synthetic, and combined accuracies and losses. Similarly, there are significant improvements to the synthetic and combined accuracies when performing semi-supervised learning using the Residual architecture with dropout. Table 6 shows a much smaller difference in overall performance when considering the full training dataset (40 participants). However, using dropout with the Residual CNN does appear to outperform the Cifar architecture slightly in terms of accuracy. Without dropout, however, it appears as though the Residual network performs more poorly potentially as a result of insufficient regularisation.
3.8 Comparison to previous method
A pair of previous studies [45, 46] are the only other relevant applications of GAN-based data augmentation to OCT patch-based segmentation. Therefore, we consider these as the state-of-the-art for our application of interest. These studies employ a more rudimentary conditional deep convolutional (DCGAN) as opposed to the conditional StyleGAN2 proposed in this study. Hence, we compare the two approaches here using the optimal DCGAN proposed previously [45, 46] taking the average of runs from three GANs and three training classifier training runs for each (9 total). Table 7 demonstrates improved (compared to the previous approach) synthetic and combined performance (accuracy and loss) on both the 1 participant and 40 participant cases further highlighting the value of the proposed approach. The greater stability of the training process, improved diversity in the synthetic samples, and noise image inputs are all potential explanations for this improvement in performance compared to the previous method. Given the promising performance improvements demonstrated using StyleGAN2, a valuable direction for future work would be to consider comparisons to other GAN methods for this particular application, as this is outside the scope of this study.
3.9 Segmentation boundary errors
The second stage of the segmentation method (after patch classification) involves delineating the layer boundaries (ILM, RPE and CSI) of the test images. The error between the predicted boundary locations and the ground truth can be measured in mean absolute error (in pixels). Here, we analyse GAN-based data augmentation and semi-supervised learning with pre-training and their effects on the boundary error performance. Table 8 reports the median mean boundary errors for the three layer boundaries of interest for the different network architectures in the real, synthetic and combined cases using a single participant’s data. The effect of network architecture here is clear for all three boundaries with the Residual CNN outperforming the Cifar CNN. The inclusion of dropout encourages the performance to improve even further. However, any clear or consistent effect of GAN-based data augmentation is difficult to observe. Similarly, Table 9 demonstrates a clear improvement when using the Residual architecture with dropout and in this case the effect of GAN-based data augmentation again appears to be negligible. The lack of any clear boundary error improvement from data augmentation is in direct contrast to the patch classification accuracy improvements which are substantial. One possible explanation for this difference is that the areas of improvement are not focused around the boundary locations in the probability map (e.g. background classification). Another possibility is that, the areas around the boundaries are affected but those changes do not influence the overall graph search solution.
For semi-supervised learning, it is difficult to observe clear performance improvements on the CSI boundary likely due to the greater variability and difficulty in delineating this boundary. For the ILM and RPE, however, there are small but clear performance improvements when using semi-supervised learning (i.e. pre-training the classifier using discriminator weights). Indeed, median boundary error is lower when using semi-supervised learning in 10 out of 12 cases for the ILM and RPE across the real, synthetic, and combined data for both “Residual SSL” and “Residual DO SSL” while in the other two cases, it is largely comparable.
3.10 Data visualisation
Figure 8 provides an example of real OCT patches compared with synthetic ones generated using the proposed conditional StyleGAN2 method for data augmentation demonstrating the high level of realism and diversity present. In the semi-supervised learning case, Fig. 9 provides an example of synthetic labelled OCT patches for a single participant (conditional) and synthetic unlabelled OCT patches for the full dataset (unconditional) again demonstrating a high level of realism and diversity. In this second case, separate GANs are used to learn to generate each set of these images (labelled and unlabelled). For the unlabelled data (Fig. 9, right), unlike the labelled case, each row does not correspond to a particular patch class, as the labels are not known. The labelled images are used for data augmentation purposes, while the GAN training process for synthesising realistic unlabelled images means the discriminator learns additional feature extraction capabilities for this data. The discriminator’s weights are then used for initialising the weights (pre-training) of the classification network to improve performance.

Example real OCT image patches (left) and synthetic OCT image patches (right) generated by the proposed GAN method for data augmentation on the full dataset. Each row corresponds to a different class. From top to bottom: adjacent ILM, adjacent RPE, adjacent CSI, background vitreous, background retina, background choroid, background sclera, boundary ILM, boundary RPE, boundary CSI

Example synthetic labelled OCT image patches (from 1 participant) (left) and synthetic unlabelled OCT patches (full dataset) (right) for the same participant and semi-supervised learning cases. Each row corresponds to a different class. From top to bottom: adjacent ILM, adjacent RPE, adjacent CSI, background vitreous, background retina, background choroid, background sclera, boundary ILM, boundary RPE, boundary CSI
3.11 Analysis
To gain further insight into the classification accuracy performance gains we firstly investigate the per-class accuracies. Figure 10 illustrates a confusion matrix reporting the average differences in classification accuracy for each class between the Residual CNN DO variant trained on only the real data and the Residual CNN variant trained on the combined real and synthetic dataset. The average differences are taken across three runs due to variability of individual model runs. Considering the diagonal elements (correctly classified samples), the results suggest that there are significant improvements in classification performance for the vitreous background (+ 6.8%) and choroid background (+ 4.9%) classes. There are also notable improvements for RPE boundary (+ 2.8%), sclera background (+ 1.8%), and adjacent ILM (+ 1.5%) classes. Despite this, there is a significant decrease in performance on the CSI adjacent (− 4.2%) and CSI boundary (− 3.2%) classes indicating that the model has some difficulty modelling and synthesising these more difficult and less well-defined classes. These results provide some insight into the negligible improvement in boundary delineation performance with the largest improvements occurring in two background classes which are less likely to influence the path taken by the segmentation algorithm.

Confusion matrix consisting of per-class accuracy (%) differences averaged across three runs between a Residual CNN DO trained on combined data and real data. Positive values (blue boxes) indicate an increase using combined data, while negative values (red boxes) indicate a decrease using combined data. The elements on the diagonal indicate differences in correctly classified samples for each class
Next, we analyse the distributions of the real and synthetic samples using the hidden feature vector representations from a trained patch classifier (Residual CNN DO). For this, we firstly take the output of the final hidden layer and flatten it (4096 features). Next, we utilise the uniform manifold approximation and projection (UMAP) [66] algorithm to perform dimensionality reduction to two dimensions for visualisation purposes on a combined dataset (both real and synthetic images together). We utilise the ‘umap-learn’ [66] Python library and employ UMAP with default parameters. The results are illustrated in Fig. 11 with three subplots: (1) classes coloured, (2) real data overlaid on synthetic data and (3) synthetic data overlaid on real data. From the first subplot it is clear that some classes are much more easily separated than others with little overlap to other classes. On the other hand, some classes are much more difficult to separate, in particular the CSI and adjacent CSI, which supports the greater subjectivity and difficulty in delineating the CSI boundary. The second subplot (real samples overlaid on synthetic ones) allows for visualisation of synthetic samples (areas of blue) that do not exist within the real data (not overlaid by orange points). Here, it is quite evident that the GAN is creative and synthesises new vitreous samples, evidenced by the distinct blue regions surrounding the orange on the left side of the subplot (referencing red points in subplot 1 for location of vitreous samples). To a lesser degree, a similar observation can be made for the sclera samples (referencing pink points in subplot 1). This supports and directly aligns with the observed classification accuracy improvements for these classes suggesting that not only does the GAN generate new samples that are significantly different, but that these are also sufficiently useful for data augmentation purposes. There is also evidence of synthetic samples throughout other classes which are not simply direct copies of real ones (see areas of non-overlapping orange and blue points). The third subplot (synthetic samples overlaid on real ones) allows for the visualisation of real samples which are not synthesised, well learnt, or well represented by the GAN. It appears as though the GAN misses some of the edge cases of the CSI samples (at bottom of the CSI cluster) which may explain some of the reason for some performance degradation on the related classes. Despite the newly learnt samples and the increase in performance, it appears as though the GAN misses some edge cases of the vitreous samples as well.

Visualisations of dimensionality reduction. Top: classes coloured, middle: real data points (orange) overlaid on synthetic ones (blue), bottom: synthetic data points (orange) overlaid on real ones (blue)
3.12 Other OCT datasets
We also examine the performance of the proposed method using other OCT datasets (Stargardt disease and AMD) as described in the Data section. This is of interest given the variability of pathology, scanning parameters, noise levels, and participant variability between different OCT datasets. For both these datasets, similar to the previous experiments using the normal dataset, we analyse the patch classification performance (Tables 10 and 11) and boundary segmentation performance (Tables 12 and 13) for both the Cifar and RCNNDO classification networks for two cases: (1) a single training participant (partial training dataset) and (2) all training participants (full training dataset). We also consider the SSL case using the Residual DO network with a single participant.
For the Stargardt disease dataset (Dataset 2), we take the average performance of each of the 9 individual training participants as the single training participant, whereas for the AMD dataset we utilise a single randomly selected participant similar to the approach used in the previous experiments. For the Stargardt disease dataset, the results suggest that the use of the Residual DO classifier architecture improves performance for both the classification accuracy and segmentation performance which aligns with previous results obtained on the normal dataset. Additionally, there is a clear improvement in classification accuracy and reduction in model loss in all cases using GAN-based data augmentation (combined performance) which further supports the robustness of the method. Indeed, for both classification architectures, partial and full datasets, as well as using SSL, this result holds. There are also some small improvements observed for the segmentation performance of the RPE boundary for the single participant case. However, there does not appear to be a corresponding improvement in the ILM boundary performance as it already performs very well on the real data alone. There are also no observable improvements in the boundary errors for the full dataset case. The performance of SSL in this case does not appear to have a significant effect on either classification accuracy or segmentation performance in any situation with potentially only marginal improvements observed.
For the AMD dataset (Dataset 3) the results suggest that the use of the Residual DO classifier architecture improves performance for both the classification accuracy and segmentation performance which aligns with previous results on the normal dataset and the Stargardt disease dataset. Additionally, there is a clear improvement in classification accuracy and reduction in model loss in the single participant cases using GAN-based data augmentation (combined performance) which further supports the application of the proposed method. However, classification accuracies for the full dataset case do not appear to improve, likely as a result of the greater difficulty in learning to generate these types of images that contain high levels of noise and pathology. Despite this, there still appears to be some small reductions in the model loss in this case. For this dataset, the effect of using SSL on classification performance is mixed, with a significant improvement to the real only performance but no observable improvement in the combined case. However, there is a clear benefit demonstrated by using either the SSL approach or a data augmentation approach in a low-data setting. Indeed, this appears to also translate to the segmentation performance with either comparable or greater performance on all three boundaries in the single participant cases. There is once again an improvement using SSL with the real data but not in the combined case while the performance on the full dataset is comparable between the real and combined cases.
From these results, it is evident that the benefits of the proposed method extend beyond that of just one dataset which supports the effectiveness of the method. Within this, there are some differences, as mentioned here, with some of the benefits either less or more pronounced between the different datasets. These may be due to any of the several aforementioned differences between OCT datasets such as noise levels, pathology, participant variation or scanning parameters. These are important and interesting to note and are worthy of a future investigation.
4 Conclusion
This study has proposed StyleGAN2-based methods for data augmentation (conditional GAN) and semi-supervised learning (unconditional GAN) to enhance patch-based OCT segmentation of the retina and the choroid. A number of experiments were performed to better understand and optimise the performance of the model. For this application, the choice of loss function and network capacity for the GAN had little effect on the patch classification performance. On the other hand, using a mini-batch discrimination layer (as opposed to mini-batch standard deviation) resulted in a substantial improvement in the quality of the trained generators. Likewise, the choice of conditioning technique for the generator and discriminator was important with concatenation outperforming multiplication, while one-hot encoding appeared to be the preferred approach to conditioning the generator compared to using a label embedding. The performance of the proposed method is validated using three different OCT datasets to further highlight its effectiveness and application with each consisting of different scanning parameters, noise levels, pathologies and variability between participants.
While considering the application of the proposed method, data augmentation (using synthetic data combined with the real data) had a noticeable improvement in the patch classification performance in all cases albeit with diminishing returns when using larger datasets. Additionally, the proposed method outperformed the previously proposed GAN-based data augmentation approach for OCT patch classification in terms of accuracy and loss. There also appeared to be some benefit to the OCT segmentation boundary error performance in some cases across the three different OCT datasets. New patch classifier architectures were proposed based on the GAN discriminator architecture resulting in substantial performance improvements in patch classification in all cases. The advantage of these architectures is further demonstrated by performing semi-supervised learning using the pre-trained discriminator as the basis for the classifier from which noticeable performance improvements were observed for both patch classification and boundary error in some cases. The proposed methods can be utilised to enhance OCT segmentation methods which are of considerable benefit for clinicians and researchers, with a particular focus on cases where large labelled training sets are not available which is common in practice.
Data availability
The dataset used within this study is currently not publicly available.
Code availability
The algorithms developed in this work are available from the corresponding author on reasonable request.
References
Koozekanani D, Boyer K, Roberts C (2001) Retinal thickness measurements from optical coherence tomography using a Markov boundary model. IEEE Trans Med Imaging 20(9):900–916
Oliveira J, Pereira S, Gonçalves L, Ferreira M, Silva CA (2017) Multi-surface segmentation of OCT images with AMD using sparse high order potentials. Biomed Opt Express 8(1):281–297
Fernández DC, Salinas HM, Puliafito CA (2005) Automated detection of retinal layer structures on optical coherence tomography images. Opt Express 13(25):10200–10216
Kafieh R, Rabbani H, Abramoff MD, Sonka M (2013) Intra-retinal layer segmentation of 3D optical coherence tomography using coarse grained diffusion map. Med Image Anal 17(8):907–928
Chiu SJ, Li XT, Nicholas P, Toth CA, Izatt JA, Farsiu S (2010) Automatic segmentation of seven retinal layers in SDOCT images congruent with expert manual segmentation. Opt Express 18(18):19413–19428
Li K, Wu X, Chen DZ, Sonka M (2005) Optimal surface segmentation in volumetric images-a graph-theoretic approach. IEEE Trans Pattern Anal Mach Intell 28(1):119–134
Tian J, Varga B, Somfai GM, Lee W-H, Smiddy WE, Cabrera De Buc D (2015) Real-time automatic segmentation of optical coherence tomography volume data of the macular region. PLoS ONE 10(8):e0133908
Niu S, de Sisternes L, Chen Q, Leng T, Rubin DL (2016) Automated geographic atrophy segmentation for SD-OCT images using region-based CV model via local similarity factor. Biomed Opt Express 7(2):581–600
Chiu SJ, Allingham MJ, Mettu PS, Cousins SW, Izatt JA, Farsiu S (2015) Kernel regression based segmentation of optical coherence tomography images with diabetic macular edema. Biomed Opt Express 6(4):1172–1194
Viedma IA, Alonso-Caneiro D, Read SA, Collins MJ (2022) Deep learning in retinal optical coherence tomography (OCT): a comprehensive survey. Neurocomputing 8:22
Fang L, Cunefare D, Wang C, Guymer RH, Li S, Farsiu S (2017) Automatic segmentation of nine retinal layer boundaries in OCT images of non-exudative AMD patients using deep learning and graph search. Biomed Opt Express 8(5):2732–2744
Kugelman J et al (2019) Automatic choroidal segmentation in OCT images using supervised deep learning methods. Sci Rep 9(1):13298
Hamwood J, Alonso-Caneiro D, Read SA, Vincent SJ, Collins MJ (2018) Effect of patch size and network architecture on a convolutional neural network approach for automatic segmentation of OCT retinal layers. Biomed Opt Express 9(7):3049–3066
Kugelman J, Alonso-Caneiro D, Read SA, Vincent SJ, Collins MJ (2018) Automatic segmentation of OCT retinal boundaries using recurrent neural networks and graph search. Biomed Opt Express 9(11):5759–5777
Masood S et al (2019) Automatic choroid layer segmentation from optical coherence tomography images using deep learning. Sci Rep 9(1):1–18
Kugelman J et al (2020) Retinal boundary segmentation in stargardt disease optical coherence tomography images using automated deep learning. Transl Vis Sci Technol 9(11):12–12
Devalla SK et al (2018) DRUNET: a dilated-residual U-Net deep learning network to segment optic nerve head tissues in optical coherence tomography images. Biomed Opt Express 9(7):3244–3265
Venhuizen FG et al (2017) Robust total retina thickness segmentation in optical coherence tomography images using convolutional neural networks. Biomed Opt Express 8(7):3292–3316
Roy AG et al (2017) ReLayNet: retinal layer and fluid segmentation of macular optical coherence tomography using fully convolutional networks. Biomed Opt Express 8(8):3627–3642
Borkovkina S, Camino A, Janpongsri W, Sarunic MV, Jian Y (2020) Real-time retinal layer segmentation of OCT volumes with GPU accelerated inferencing using a compressed, low-latency neural network. Biomed Opt Express 11(7):3968–3984
Pekala M, Joshi N, Liu TA, Bressler NM, DeBuc DC, Burlina P (2019) Deep learning based retinal OCT segmentation. Comput Biol Med 114:103445
Sousa JA et al (2021) Automatic segmentation of retinal layers in OCT images with intermediate age-related macular degeneration using U-Net and DexiNed. PLoS ONE 16(5):e0251591
Apostolopoulos S, Zanet SD, Ciller C, Wolf S, Sznitman R (2017) Pathological OCT retinal layer segmentation using branch residual u-shape networks. In: International conference on medical image computing and computer-assisted intervention, 2017. Springer, pp 294–301
Alsaih K, Yusoff MZ, Tang TB, Faye I, Mériaudeau F (2020) Deep learning architectures analysis for age-related macular degeneration segmentation on optical coherence tomography scans. Comput Methods Programs Biomed 195:105566
Xuehua W, Xiangcong X, Yaguang Z, Dingan H (2021) A new method with SEU-Net model for automatic segmentation of retinal layers in optical coherence tomography images. In: 2021 IEEE 2nd international conference on big data, artificial intelligence and internet of things engineering (ICBAIE), 2021. IEEE, pp 260–263
Mishra Z, Ganegoda A, Selicha J, Wang Z, Sadda SR, Hu Z (2020) Automated retinal layer segmentation using graph-based algorithm incorporating deep-learning-derived information. Sci Rep 10(1):1–8
Chen M, Ma W, Shi L, Li M, Wang C, Zheng G (2021) Multiscale dual attention mechanism for fluid segmentation of optical coherence tomography images. Appl Opt 60(23):6761–6768
Kugelman J, Alonso-Caneiro D, Read SA, Vincent SJ, Chen FK, Collins MJ (2020) Effect of altered oct image quality on deep learning boundary segmentation. IEEE Access 8:43537–43553
Wei J et al (2019) Generative image translation for data augmentation in colorectal histopathology images. Proc Mach Learn Res 116:10
Russ T et al (2019) Synthesis of CT images from digital body phantoms using CycleGAN. Int J Comput Assist Radiol Surg 14(10):1741–1750
Tmenova O, Martin R, Duong L (2019) CycleGAN for style transfer in X-ray angiography. Int J Comput Assist Radiol Surg 14(10):1785–1794
Deepak S, Ameer P (2020) MSG-GAN based synthesis of brain MRI with meningioma for data augmentation. In: 2020 IEEE international conference on electronics, computing and communication technologies (CONECCT), 2020. IEEE, pp 1–6
Yao Q, Lu H (2019) Brain functional connectivity augmentation method for mental disease classification with generative adversarial network. In: Chinese conference on pattern recognition and computer vision (PRCV), 2019. Springer, pp 444–455
Shen T, Hao K, Gou C, Wang F-Y (2021) Mass image synthesis in mammogram with contextual information based on GANs. Comput Methods Programs Biomed 202:106019
Wang Q, Zhang X, Chen W, Wang K, Zhang X (2020) Class-aware multi-window adversarial lung nodule synthesis conditioned on semantic features. In: International conference on medical image computing and computer-assisted intervention, 2020. Springer, pp 589–598
Kanayama T et al (2019) Gastric cancer detection from endoscopic images using synthesis by GAN. In: International conference on medical image computing and computer-assisted intervention, 2019. Springer, pp 530–538
Chi Y, Bi L, Kim J, Feng D, Kumar A (2018) Controlled synthesis of dermoscopic images via a new color labeled generative style transfer network to enhance melanoma segmentation. In: 2018 40th Annual international conference of the IEEE engineering in medicine and biology society (EMBC), 2018. IEEE, pp 2591–2594
Frid-Adar M, Diamant I, Klang E, Amitai M, Goldberger J, Greenspan H (2018) GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification. Neurocomputing 321:321–331
Waheed A, Goyal M, Gupta D, Khanna A, Al-Turjman F, Pinheiro PR (2020) Covidgan: data augmentation using auxiliary classifier gan for improved covid-19 detection. IEEE Access 8:91916–91923
Pang T, Wong JHD, Ng WL, Chan CS (2021) Semi-supervised GAN-based radiomics model for data augmentation in breast ultrasound mass classification. Comput Methods Programs Biomed 203:106018
Islam J, Zhang Y (2020) GAN-based synthetic brain PET image generation. Brain Inf 7(1):1–12
Teramoto A et al (2020) Deep learning approach to classification of lung cytological images: two-step training using actual and synthesized images by progressive growing of generative adversarial networks. PLoS ONE 15(3):e0229951
Lim G, Thombre P, Lee ML, Hsu W (2020) Generative data augmentation for diabetic retinopathy classification. In: 2020 IEEE 32nd international conference on tools with artificial intelligence (ICTAI), 2020, pp 1096–1103
Kugelman J, Alonso-Caneiro D, Read SA, Collins MJ (2022) A review of generative adversarial network applications in optical coherence tomography image analysis. J Optomet 15:1–11
Kugelman J, Alonso-Caneiro D, Read SA, Vincent SJ, Chen FK, Collins MJ (2019) Constructing synthetic chorio-retinal patches using generative adversarial networks. In: 2019 Digital image computing: techniques and applications (DICTA), 2019, pp 1–8
Kugelman J, Alonso-Caneiro D, Read SA, Vincent SJ, Chen FK, Collins MJ (2021) Data augmentation for patch-based OCT chorio-retinal segmentation using generative adversarial networks. Neural Comput Appl 33:7393–7408
Mahapatra D, Bozorgtabar B, Shao L (2020) Pathological retinal region segmentation from OCT images using geometric relation based augmentation. In: 2020 IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2020, pp 9608–9617
Kugelman J, Alonso-Caneiro D, Read SA, Vincent SJ, Chen FK, Collins MJ (2020) Dual image and mask synthesis with GANs for semantic segmentation in optical coherence tomography. In: 2020 Digital image computing: techniques and applications (DICTA), 2020, pp 1–8
Huang X, Belongie S (2017) Arbitrary style transfer in real-time with adaptive instance normalization. In: Proceedings of the IEEE international conference on computer vision, 2017, pp 1501–1510
Chen H, Cao P (2019) Deep learning based data augmentation and classification for limited medical data learning. In: 2019 IEEE international conference on power, intelligent computing and systems (ICPICS), 2019, pp 300–303
Yoo TK, Choi JY, Kim HK (2021) Feasibility study to improve deep learning in OCT diagnosis of rare retinal diseases with few-shot classification. Med Biol Eng Comput 59(2):401–415
Odena A (2016) Semi-supervised learning with generative adversarial networks. arXiv:1606.01583 [stat.ML]
Salimans T, Goodfellow I, Zaremba W, Cheung V, Radford A, Chen X (2016) Improved techniques for training gans. arXiv:1606.03498 [cs.LG]
Sricharan K, Bala R, Shreve M, Ding H, Saketh K, Sun J (2017) Semi-supervised conditional gans. arXiv:1708.05789 [stat.ML]
Liu X et al (2019) Semi-supervised automatic segmentation of layer and fluid region in retinal optical coherence tomography images using adversarial learning. IEEE Access 7:3046–3061
Karras T, Laine S, Aittala M, Hellsten J, Lehtinen J, Aila T (2020) Analyzing and improving the image quality of stylegan. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp 8110–8119
Read SA, Collins MJ, Vincent SJ, Alonso-Caneiro D (2013) Choroidal thickness in childhood. Invest Ophthalmol Vis Sci 54(5):3586–3593
Farsiu S et al (2014) Quantitative classification of eyes with and without intermediate age-related macular degeneration using optical coherence tomography. Ophthalmology 121(1):162–172
Chiu SJ, Izatt JA, O’Connell RV, Winter KP, Toth CA, Farsiu S (2012) Validated automatic segmentation of AMD pathology including drusen and geographic atrophy in SD-OCT images. Invest Ophthalmol Vis Sci 53(1):53–61
Kingma DP, Ba J (2014) Adam: a method for stochastic optimization. arXiv:1412.6980 [cs.LG]
Goodfellow IJ et al (2014) Generative adversarial nets. In: Proceedings of the 27th international conference on neural information processing systems, vol 2, Montreal, Canada, 2014. MIT Press, pp 2672–2680
Gulrajani I, Ahmed F, Arjovsky M, Dumoulin V, Courville A (2017) Improved training of wasserstein GANs. In: Proceedings of the 31st international conference on neural information processing systems, Long Beach, California, USA, 2017. Curran Associates Inc., pp 5769–5779
Arjovsky M, Chintala S, Bottou L (2017) Wasserstein generative adversarial networks. In: Proceedings of the 34th international conference on machine learning, proceedings of machine learning research, 2017, vol 70. PMLR, pp 214–223
Mao X, Li Q, Xie H, Lau RYK, Wang Z, Smolley SP (2017) Least squares generative adversarial networks. IEEE Int Conf Comput Vis 2017:2813–2821
Heusel M, Ramsauer H, Unterthiner T, Nessler B, Hochreiter S (2017) Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv Neural Inf Process Syst 30:52
McInnes L, Healy J, Melville J (2018) Umap: uniform manifold approximation and projection for dimension reduction. arXiv:1802.03426 [stat.ML]
Acknowledgements
Computational resources and services used in this work were provided in part by the HPC and Research Support Group, Queensland University of Technology, Brisbane, Australia. We gratefully acknowledge support from the NVIDIA Corporation for the donation of GPUs used in this work.
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions. DAC is partly supported by the Australian National Health and Medical Research Ideas Grant (APP1186915).
Author information
Authors and Affiliations
Contributions
Design of the research was done by J.K and D.A-C. Software development was done by J.K. Analysis and interpretation of data were done by J.K. and D.A-C. Drafting the manuscript was done by J.K. and D.A-C. Reviewed and approved final manuscript was done by J.K., D.A-C., S.A.R., S.J.V., and M.J.C.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kugelman, J., Alonso-Caneiro, D., Read, S.A. et al. Enhancing OCT patch-based segmentation with improved GAN data augmentation and semi-supervised learning. Neural Comput & Applic (2024). https://doi.org/10.1007/s00521-024-10044-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00521-024-10044-1