
Abstract
Accurate forecasting of electricity generation from renewable energy sources is crucial for the operation, planning and management of smart grids. For reliable planning and operation of photovoltaic (PV) systems in grid-connected or islanded utilities, an hourly day-ahead forecast of PV output is critical. The forecast of PV power can be done indirectly by estimating solar irradiance. For forecasting day-ahead hourly global horizontal irradiance (GHI), two forecasting models with different multivariate inputs are proposed in this paper, and the results are compared. These models use a hybrid algorithm of discrete wavelet decomposition and bidirectional long short-term memory (BILSTM). The inputs of the first model contain GHI and weather type data. The other model allows for observation of the effect of meteorological values including GHI, temperature, humidity, wind speed, and weather type data. The forecasting performance of deep learning algorithms which contain recurrent neural network (RNN), long short-term memory (LSTM), and BILSTM algorithms for day ahead hourly solar irradiance forecasting problems are also compared. To evaluate the performance of proposed models, two datasets are used for Model 1 and one dataset is used for Model 2. An experiment is also done to demonstrate that the proposed Model 1 is applicable in datasets collected in the vicinity of the city of Trabzon. On the other hand, BILSTM algorithm outperforms RNN and LSTM algorithms. It is seen that the test successes of both proposed models are better than the results given in the literature.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Reliable operation of power systems relies on the planning of energy generation and consumption. A power system of conventional energy sources is planned and operated with the experiences gained over the years. However, due to rapidly increasing installation of renewable energy sources in consumption sites, the power distribution systems have been getting more complex with the high penetration of renewable power generation. This structure of power distribution system having generation units side by side with the consumption is called distributed generation, which have different operational challenges than the conventional ones due to the variable and intermittent nature of these resources. Therefore, the forecasting of electric consumption and required power generation become very important for reliable planning and operation of a power system with renewable sources. The power forecasting of RES is critical for energy generation, transmission, distribution, and the electric markets.
The power forecasting is one of the core steps for scheduling of the generation, transmission, and distribution of electrical energy as well as maintenance of power systems, management of the demand response, and financial planning [1,2,3,4,5,6]. Although the power forecasting is important to manage the power system planning and operations, inaccurate forecasting might cause insufficient or overpower generation, which yield voltage and frequency fluctuations, power quality problems, and the inability to manage the system economically and efficiently [2, 3]. Besides, inaccurate forecasting might also cause power system instabilities.
The forecasted power is also used for the trading of electric power. Incorrect energy forecasting might result in economic losses and even bankruptcy of energy companies. For this reason, companies try to keep their estimation error at low values to avoid these penalties. In addition, incorrect estimation of the power to be generated by renewable resources affects the trading profit of the companies. [7].
Lan et al. [8] propose discrete Fourier transform (DFT)-principal component analysis (PCA)-Elman hybrid method for forecasting solar radiation in one and twenty-four hours horizons. The authors also demonstrate that the proposed model has less forecasting error than autoregressive integrated moving average (ARIMA), PCA- back propagation neural network (BPNN) and DFT-PCA-back propagation (BP) models. Bouzgou and Gueymard [9] present minimum redundancy maximum relevance (MRMR)—extreme learning machine (ELM) hybrid model. MRMR is used for extracting the features and ELM is applied for prediction. MRMR-ELM hybrid method with the 177.8 W/m2 in root mean square error (RMSE) metric outperforms the methods, which are multilayer perceptron (MLP), gaussian process and least squares support vector machine (LSSVM). Ensemble empirical mode decomposition (EEMD)—self organizing maps (SOM)—BP hybrid model is introduced by Lan et al. [10]. The forecasting error of the introduced model is 72.5 W/m2 in mean absolute error (MAE) metric and the model outperforms the BP and radial basis function models. Qing and Niu [11] have designed an LSTM model. In this study, with 76.24 W/m2 forecasting error in the RMSE metric, the proposed method has less forecasting error than linear regression and BPNN models. Che et al. [12] have designed the weather research and forecasting (WRF)-Kalman filter model for forecasting day-ahead hourly solar radiation. The designed model's forecasting error in the mean absolute error (MAE) metric is 79.4 W/m2 and in the RMSE metric is 158.1 W/m2. Husein and Chung [13] have developed a three-layer LSTM model and compared this model with feed forward neural networks (FFNN) and persistence models. In this study, the forecasting error in the MAE metric is 42.52 W/m2 and in the RMSE metric is 71.17 W/m2. Hong et al. [14] introduce a convolutional LSTM (ConvLSTM) model. They show the superiority of their model to the ARIMA, LSTM and a hybrid convolutional neural networks (CNN) and LSTM models. Wang et al. [15] present a hybrid CNN and LSTM methods and compared it with existing CNN and LSTM methods showing that CLSTM method has less forecasting error on all seasonal test samples. Gao et al. [6] have compared different forecasting methods including LSTM, BP, LSSVM and wavelet neural network for forecasting day-ahead PV power. They show that the LSTM method has higher forecasting accuracy. Zang et al. [16] propose residual neural network and dense convolutional network models for forecasting day-ahead solar power forecasting. Their models have less forecasting errors than support vector regression, random forest regression, MLP, and CNN models. Variational mode decomposition and empirical wavelet transform decomposition methods are also used to extract the features and increase forecasting ability. A physical hybrid artificial neural network (ANN) method is designed by Ogliari et al. [17] to show that the inputs of the forecasting method affect the forecasting error. Gigoni et al. [18] use a hybrid forecasting model of gray box, k-nearest neighbors, ANN, SVM, quantile random forest. This hybrid model outperforms only one forecasting method. Raza et al. [19] propose a WT—neural network ensemble—particle swarm optimization (PSO) hybrid method and have compared it with WT and back propagation neural network (WT-BPNN), wavelet transform-feed forward neural networks-particle swarm optimization (WT-FFNN-PSO) for day-ahead PV power forecasting. For day-ahead PV power forecasting, Aslam et al. [20] propose a deep learning model based on a two-stage attention mechanism over LSTM. They examined the impact of the predictive performance of different input features and compared the performance of different forecast models such as LSTM-Attention and CNN-LSTM. Their proposed model gave a more accurate forecast than the others. Zafar et al. [21] have classified each day as either sunny or cloudy using k-means clustering and proposed a hybrid LSTM-RNN approach for day-ahead solar irradiation forecasting. In addition, the model they proposed has more accurate prediction results than LSTM, SVM, FFNN and the persistence approach. A decomposition-based hybrid model for forecasting hourly day-ahead PV power has been presented by Gupta et al. [22]. They used a noise-assisted multivariate empirical mode decomposition method to extract intrinsic mode functions (IMFs) from the dataset and designed a separate LSTM network for each IMF. In addition, they have reported that the forecasting performance of the decomposition-based LSTM model is superior to that of the standalone LSTM model. Singla et al. [23] have presented an ensemble model using the extended scope of wavelet transform and BILSTM deep learning network to forecast 24 h ahead GHI. They used different finite IMF to extract input time series using wavelet transform and designed BILSTM network for each IMF. They have also reported that the proposed ensemble model has less forecasting error than LSTM, GRU and BILSTM models. Asiri et al. [24] have presented an artificial neural network (ANN)-based model to achieve regional-scale day-ahead PV power forecasts. Except the solar irradiance, weather variables from numerical weather predictions are used as inputs of forecasting model. Their results show at least a 29-percent RMSE reduction over the benchmarking models. Hoyos-Gómez et al. [25] have designed and compared four prediction models, which contain ARIMA, single layer feedforward neural network (SLFNN), multilayer feedforward neural network (MLFNN), and LSTM for one day-ahead global solar irradiance. They concluded that the LSTM model exhibits better forecasting performance than the others. Haider et al. [26] have compared the performance for forecasting solar irradiance in different horizons of various models that contain statistical methods such as seasonal autoregressive integrated moving average exogenous and prophet, and machine learning methods such as LSTM, CNN and ANN. Their results show that the ANN and CNN models outperform the LSTM model in 24 h ahead forecasting horizon. For forecasting solar power in different horizons, Rai et al. [27] develop auto-encoder (AE) and gated recurrent unit (GRU)-based hybrid deep learning approach. They have also compared their model with CNN-LSTM, CNN-GRU, CNN, and LSTM algorithms. In 24 h horizon, the AE-GRU model outperforms in MSE and MAE metrics. A dual-stage attention mechanism and LSTM-based encoder-decoder are proposed by Huang et al. to forecast the displacement of concrete arch dams in [28]. The proposed approach performs better than CNN-LSTM, LSTM with attention mechanism, and some other conventional techniques.
According to literature review, it is seen that the hybrid method with deep learning algorithms is in the fore and outperforms the single method and classical machine learning algorithms.
The main contributions of this study are as follows:
-
A simple and applicable forecasting model based on DWT-BILSTM algorithm has been proposed.
-
The effects of meteorological parameters in prediction accuracy have been investigated.
-
The performance of different deep learning algorithms containing RNN, LSTM, and BILSTM has been compared.
-
A second test has been performed to demonstrate the applicability of one the proposed models.
The methodologies of proposed models are explained theoretically in Sect. 2, and experimental results and discussions are given in Sect. 3. Then, the conclusions are given in Sect. 4.
2 Methodology
In this section, the main techniques used in the proposed models are introduced briefly.
2.1 Determination of weather type
Weather type information is quite essential for the day-ahead solar radiation/power forecasting. In practice, this knowledge is obtained with high accuracy. In order to determine the weather type, firstly, the clearness index (K) should be calculated. Two methods are used in the literature to determine the clearness index for forecasting applications. The first one is the ratio of the solar radiation diffuse on the horizontal axis to the global solar radiation [16]. The second one, which has been used in this study because the solar radiation dataset has only global solar irradiation, is the ratio of global solar radiation to extraterrestrial solar radiation as in (1) [19].
To calculate extraterrestrial global horizontal solar irradiation (GHIext), the following equations have been used, where Isc is the solar constant and considered as 1367 W/m2. N is the day number of days from January 1; ∅ is 41° latitude for Trabzon; and δ is the declination angle.
The weather type is determined by the clearness index K as follows: sunny day (K > 0.45), cloudy (0.25 < K < 0.45), and rainy day (K < 0.25).
2.2 Discrete wavelet transform (DWT)
The wavelet transform is a method used for time frequency analysis of time varying data. It can be used to analyze sub-functions in different frequencies in the data without losing time information. In the wavelet transform, the wavelets created by scaling and shifting the mother wavelet are multiplied by the original signal in all time intervals. As a result of the transformation, wavelet coefficients representing scale and position functions are obtained. If the scaling and translation are in continuous steps, it is called continuous wavelet transform, and if it is discretely, then, it is called a discrete wavelet transform. Discrete wavelet transform is preferred because it processes less data and is faster. The wavelet function and the discrete wavelet transform are described as follows, where t is time, a is a time dilation, and b is a time translation [29].
In addition to the formulas mentioned above, in practice, Mallat algorithm [30] can also be used for the implementation of DWT. The Mallat algorithm uses the filtering method. Low and high-pass filters determined by a mother wavelet are used in the this algorithm. It calculates the approximation (A) and detail coefficient (D) of a signal using a low-pass filter and a high-pass filter. The original signal equals to the sum of the detail and approximation components as in (8). Where M is the decomposition level. At the first level, the original signal is decomposed into approximation and detail components. In the second level, the approximation component in the first level is taken as input and the new approximation and detailed components are calculated. Finally, as a result of above mentioned methods, an approximation component and a couple of detailed components are obtained.
The mother wavelet and the decomposition level must be set to implement DWT. The mother wavelet has finite energy and is a zero mean function and consists of Haar, Daubechies, Coiflet, Symlet, Biorthogonal, Meyer and so on. In solar irradiation/power forecasting studies, the dmey (discrete Meyer) wavelet comes to the fore [31, 32] and so, dmey wavelet has been used in this paper. For the level of decomposition, the correlation between the detail and approximation components of the solar radiation on the day ahead and the solar irradiation data of the forecast day has been examined.
2.3 LSTM
LSTM is a type of recurrent neural network with long-term memory. LSTM network, with the ability to remember information for a long time, is developed to eliminate the short-term remembering disadvantage of recurrent neural networks [33]. LSTM cell consists of input, forget and output gates. The forget gate decides which information from previous steps is important and stores this information. The input gate decides which information to add from the current step and determines the candidate of the cell state. The output gate determines what the next hidden state should be. The internal structure of the LSTM cell is shown in Fig. 1.

LSTM architecture
The forget gate decides whether a piece of information should be kept. The information from the previous state (ht−1) and the current input (xt) are multiplied by the Whf and Wxf weights, respectively, and then are subjected to the sigmoid function. If the obtained values are close to 0, it means forgetting, and if it is close to 1, it means carrying the information to the future state. The next gate which has a sigmoid layer and a tanh layer decides and stores information from the new input (xt) in the cell state as well as updates the cell state (ct). The previous hidden state (ht−1) and the current input (xt) are multiplied by the weights Whu and Wxu, respectively, and passed through the sigmoid function, and this value between 0 and 1 decides which value to update. A value of 1 means important and 0 means not important. Moreover, to calculate the candidate value of the cell state (\(\tilde{c}_{t}\)), the current input (xt) and the previous hidden state (ht−1) are passed through the tanh function by multiplying Whc and Wxc, respectively, and summing the resulting product with bc. This result (− 1 to 1) decides the level of importance of new information. The obtained information (\(\tilde{c}_{t}\)) is multiplied by the sigmoid function output (ut), and it is decided which information to protect. To determine the cell state (ct), the cell state is multiplied by the candidate value \(\tilde{c}_{t}\)) and ut, and this value is summed by multiplying the forget gate output with the cell state information of the previous time step. The output gate decides what should be the next hidden state and also the value to be calculated as the cell output (ht). After multiplying the previous hidden state (ht−1) and the current input (xt) multiplied by the weights and summing it with the base value, the obtained result is subjected to the sigmoid function. Then, calculated cell state (ct) in the previous gate is subjected to the tanh function. The tanh output is multiplied by the sigmoid function output (ot) to obtain the new hidden state (ht) that will be moved to the next time step.
2.4 BILSTM
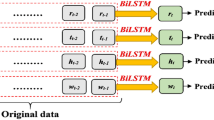
BILSTM is a combined form of an LSTM model that processes information in both forward and backward directions with two separate hidden layers as in Fig. 2. To calculate the BILSTM output, firstly, the outputs of a forward and a backward LSTM unit are calculated separately.

Unfolded architecture of BILSTM
Here the σ function is used to combine two output sequences. An aggregation function can be an addition function, an average function, or a multiplication function [34].
2.5 The framework of proposed models
In this section, the framework of the proposed Model 1 and the parameters of the Model 2 are presented. The whole process for Model 1 with BILSTM can be seen in Fig. 3. In this model, the original global solar irradiation data series are decomposed into detail and approximation sub-series by DWT. The decomposition level is six, and six details and one approximation sub-series are obtained. Weather types are calculated for all days according to a clearness index as in Sect. 2.1. DWT components and weather types of information have been combined into a matrix. The DWT solar irradiation data from the previous 24 h with the weather type information are set as input of BILSTM. The next day 24 h solar irradiation data are used as output, as in Fig. 3. GHI is affected by weather parameters such as temperature, humidity and wind speed. To examine the effect of weather, features Model 2 is created. In addition to the inputs of the Model 1, temperature, humidity and wind speed are added in Model 2. The input and output details for Model 1 and Model 2 are given in Table 1.

The framework of the proposed Model 1 with BILSTM
3 Experimental results and discussions
3.1 Data description
To evaluate the performance of the proposed Model 1, two different datasets are used: Trabzon and Basel. The performance of Model 2 has been presented for only Trabzon dataset. The data for Trabzon have global solar irradiation, temperature, humidity and wind speed data sets which recorded at the Sustainable Energy Utilization Laboratory (SEUL) of Karadeniz Technical University in Trabzon, Turkey. The hourly data with accumulated mean values recorded every 10 min have been used. The data range is from November 19, 2016 to December 20, 2021. In the case of Basel, Switzerland (47.5584, 7.5733) only the global solar irradiation data from 2007 to 2018 has been used. Historical hourly solar radiation data for Basel come from the CAMS Radiation Service [35]. The main statistical characteristics of two global solar irradiation datasets are shown in Table 2. Trabzon dataset has been splitted into different datasets such as the training dataset (70%) and the test dataset (30%). Moreover, training datasets has been splitted into sub-training (80%) and validation datasets (20%). Training, validation and test sets for Basel have been splitted as in [13].
In the proposed models, the batch size is set to 32, and the activation function is set to ‘Relu.’ The mean squared error (MSE) is used as the loss function and optimized by using ADAM algorithm. The training is terminated if there is no improvement in validation set forecasting performance during 30 consecutive epoch values. The maximum number of epochs is set at 500 in this study. The best number of cells for each of the deep learning algorithms has been chosen among 30, 50 and 100. Based on these cell numbers, each deep learning algorithm has been trained and the MSE loss values of the validation set have been calculated. The one with the least MSE loss value has been selected as the best cell number. As a result, the number of cells for each deep learning algorithm in Model 1 has been determined as 100. In Model 2, the best cell numbers have been calculated as 100, 50, 30 and 50 for the algorithms RNN1, RNN2, LSTM and BILSTM, respectively. Python, Keras with a tensorflow v1.12 backend, has been used to implement all deep learning models. To train the models, the hardware configuration of the machine used is Intel(R) Core(TM) i7-6700 CPU @ 3.40GHZ 3.41GHZ.
3.2 Performance evaluation criteria
One of the performance measures frequently used in the literature is RMSE. As this criterion is proportional to the size of the squared error, large errors have a disproportionately large impact on the RMSE criterion. Therefore, it is sensitive to outliers.
MAE is a measure of errors between paired observations for the same unit, often used in time series analysis.
3.3 Forecasting results
To evaluate the forecasting performance of the proposed DWT-BILSTM algorithm, three different deep learning algorithms have been performed for the proposed two models. Single-layer recurrent neural networks (RNN1), two-layer recurrent neural networks (RNN2), and LSTM methods as forecasting algorithms have been used and compared with the proposed model. The test results which contain all hours of a day are given in Table 3.
According to Table 3, for proposed Model 1, the lowest MAE and RMSE are obtained by BILSTM with 27.67 and 53.20, respectively. RNN2 follows BILSTM with 35.44 and 67.96. The lowest accuracy is found in RNN1 with 37.60 and 70.56. For Model 2, the lowest MAE and RMSE are calculated by BILSTM with 28.46 and 50.63. LSTM follows BILSTM with 31.85 and 59.00. The performance of the BILSTM algorithm outperforms the others in both proposed models in terms of MAE and RMSE. According to best performance of the proposed two models, it is seen that the forecasting results are very close to each other.
The training durations of RNN1, RNN2, LSTM and BILSTM algorithms in Model 1 are recorded as 30.9, 42.8, 79 and 176 s, respectively. For Model 2, these durations are 44, 51.8, 106 and 120 s, respectively. As the comparison shows, Model 2 requires more training times for RNN1, RNN2 and LSTM, but less time for BILSTM than Model 1. It is clear that the training times have got been affected from different cell numbers of deep learning algorithms and different input dimensions of Model 1 and Model 2. In addition, the use of an early stop function instead of a constant maximum epoch number also affects the training time.
Most studies calculate forecasting error in all 24 h [8,9,10, 12] or for fixed hours [11, 13] throughout the year. However, daylight hours vary along the year. Therefore, only the errors in daylight hours have been calculated with BILSTM using the best values from Table 3 to yield better results as given in Table 4.
According to the forecasting daylight hour results given in Table 4, Model 2 has slightly less forecasting error than Model 1. Although Model 2 has a slightly better performance by using additional data sets such as forecasting day and one day ahead temperature, humidity and wind speed, these additional data sets cause increments in the training times while reducing the applicability of this model. Even though Model 2 with its larger input data set dimension has a slightly better performance compared to Model 1, one must consider the applicability and longer training time issues. The results show that meteorological parameters such as wind speed, humidity and temperature have improve the prediction success with a small amount. In fact, the most important parameters for GHI prediction are the day-ahead GHI and the weather type information of the day-ahead and the forecasting day.
The proposed Model 1 with BILSTM has also been applied to Basel dataset with a time horizon which is 16 h as in [13]. Table 5 shows the forecasting results of the proposed Model 1 with BILSTM and results from [13].
The forecasting results for the Basel dataset show that the proposed Model 1 with BILSTM has less forecasting error than those in [13] in terms of MAE and RMSE as seen in Table 5. According to Table 5, the proposed Model 1 has 47% and 45% less prediction errors in MAE and RMSE metrics, respectively.
In [13], the authors use hourly and monthly information of the forecasting day and weather parameters, which contain temperature, and humidity data to forecast GHI. The obtained results depend on the fact that the information used for the forecast day can be obtained with high accuracy one day ahead. However, an applicable and outperforming model for forecasting day-ahead GHI has been proposed in this study.
To prove the superiority of the proposed model, the obtained results are compared with some other studies given in Table 6, which depicts that the proposed model has excellent forecasting accuracy over the other studies.
3.4 Experimental results for Model 1 using Trabzon dataset
In this part, to demonstrate that the proposed Model 1 is applicable, an experiment is performed. The weather type is used in papers by calculation. In practice, the weather type information for forecasting day is obtained from meteorological stations. The comparison of the calculated weather type and the weather type information given by the meteorology in this work results in that the proposed model is applicable.
The second test has 9 samples form the 1st of January 2022 to 9th of January 2022. The weather type information is taken from [35]. Figure 4 shows weather type from January 1 to 7. Figure 5a shows the forecasting and the actual GHI values for all 9 samples’ daylight hours. Figure 5b shows the absolute error values for each hour of 9 samples’ daylight hours. The forecasting results for 9 samples (90 h) are 27.79 W/m2 in MAE criteria. As for Model 2, for it to be applicable, the forecast day's temperature, humidity and wind speed data must be given one hundred percent correctly by meteorology.

Weather type from1 January to 7 January [36]

a Actual and forecasting GHI for 9 samples (90 h) b absolute error values for all hours
4 Conclusions
Two different forecasting models based on DWT-BILSTM have been proposed in this work. These models have different multivariate inputs to forecast day-ahead hourly GHI. The first model inputs are GHI and weather type data. The second model inputs are GHI, temperature, humidity, wind speed, and weather type data. With two different models, the effect of meteorological parameters has been investigated. In addition, the performances of RNN, LSTM, and BILSTM algorithms have been compared to forecast the day ahead hourly solar irradiance problems. The forecasting results from the proposed two models are very close. However, in terms of less training time and less data usage, Model 1 has an advantage over the others. Moreover, Model 1 is more applicable than Model 2, because Model 2 contains the meteorological parameters of forecasting day. For the proposed Model 2, the forecasting day's temperature, humidity, and wind speed data must be given hundred percent correctly one day ahead by meteorology. An experiment-like test is also performed with Trabzon dataset to verify that Model 1 is applicable. In addition, BILSTM algorithm outperforms both RNN and LSTM algorithms. A comparison with the results given in literature proves that both proposed models have high accuracy.
The performance of the presented forecasting frameworks can be evaluated at different time horizons such as 3, 2 and 1 h ahead cases in future works. In addition, the proposed frameworks can be applied to other types of time series data, such as wind and wave power. More analysis can be performed with various feature extraction methods to see the effect of the features on the overall model performance. Finally, this study contributes to power system applications such as unit commitment, economic dispatch, optimal scheduling and other day-ahead market operations.
Data availability
The datasets used in this study were derived from the following resources: Irradiation, temperature and wind speed datasets: Available on request from authors for Trabzon dataset. Irradation data for Basel dataset: http://www.soda-pro.com/web-services/radiation/cams-radiation-service and Climatic data for Trabzon dataset: https://www.accuweather.com/tr/tr/trabzon/321281/daily-weather-forecast/321281.
References
Antonanzas J, Osorio N, Escobar R, Urraca R, Martinez-de-Pison FJ, Antonanzas-Torres F (2016) Review of photovoltaic power forecasting. Sol Energy 136:78–111. https://doi.org/10.1016/j.solener.2016.06.069
Ahmed R, Sreeram V, Mishra Y, Arif MD (2020) A review and evaluation of the state-of-the-art in PV solar power forecasting: techniques and optimization. Renew Sustain Energy Rev 124:109792. https://doi.org/10.1016/j.rser.2020.109792
Wan C, Zhao J, Song Y, Xu Z, Lin J, Hu Z (2015) Photovoltaic and solar power forecasting for smart grid energy management. CSEE J Power Energy Syst 1(4):38–46. https://doi.org/10.17775/CSEEJPES.2015.00046
Guermoui M, Melgani F, Gairaa K, Mekhalfi ML (2020) A comprehensive review of hybrid models for solar radiation forecasting. J Clean Prod. https://doi.org/10.1016/j.jclepro.2020.120357
Chang WY (2014) A literature review of wind forecasting methods. J Power Energy Eng 2(04):161. https://doi.org/10.4236/jpee.2014.24023
Gao M, Li J, Hong F, Long D (2019) Day-ahead power forecasting in a large-scale photovoltaic plant based on weather classification using LSTM. Energy 187:115838. https://doi.org/10.1016/j.energy.2019.07.168
Bitar EY, Rajagopal R, Khargonekar PP, Poolla K, Varaiya P (2012) Bringing wind energy to market. IEEE Trans Power Syst 27(3):1225–1235. https://doi.org/10.1109/TPWRS.2012.2183395
Lan H, Zhang C, Hong YY, He Y, Wen S (2019) Day-ahead spatiotemporal solar irradiation forecasting using frequency-based hybrid principal component analysis and neural network. Appl Energy 247:389–402. https://doi.org/10.1016/j.apenergy.2019.04.056
Bouzgou H, Gueymard CA (2017) Minimum redundancy–maximum relevance with extreme learning machines for global solar radiation forecasting: toward an optimized dimensionality reduction for solar time series. Sol Energy 158:595–609. https://doi.org/10.1016/j.solener.2017.10.035
Lan H, Yin H, Hong YY, Wen S, David CY, Cheng P (2018) Day-ahead spatio-temporal forecasting of solar irradiation along a navigation route. Appl Energy 211:15–27. https://doi.org/10.1016/j.apenergy.2017.11.014
Qing X, Niu Y (2018) Hourly day-ahead solar irradiance prediction using weather forecasts by LSTM. Energy 148:461–468. https://doi.org/10.1016/j.energy.2018.01.177
Che Y, Chen L, Zheng J, Yuan L, Xiao F (2019) A novel hybrid model of WRF and clearness index-based Kalman filter for day-ahead solar radiation forecasting. Appl Sci 9(19):3967. https://doi.org/10.3390/app9193967
Husein M, Chung IY (2019) Day-ahead solar irradiance forecasting for microgrids using a long short-term memory recurrent neural network: a deep learning approach. Energies 12(10):1856. https://doi.org/10.3390/en12101856
Hong YY, Martinez JJF, Fajardo AC (2020) Day-ahead solar irradiation forecasting utilizing gramian angular field and convolutional long short-term memory. IEEE Access 8:18741–18753. https://doi.org/10.1109/ACCESS.2020.2967900
Wang K, Qi X, Liu H (2019) A comparison of day-ahead photovoltaic power forecasting models based on deep learning neural network. Appl Energy 251:113315. https://doi.org/10.1016/j.apenergy.2019.113315
Zang H, Cheng L, Ding T, Cheung KW, Wei Z, Sun G (2020) Day-ahead photovoltaic power forecasting approach based on deep convolutional neural networks and meta learning. Int J Electr Power Energy Syst 118:105790. https://doi.org/10.1016/j.ijepes.2019.105790
Ogliari E, Dolara A, Manzolini G, Leva S (2017) Physical and hybrid methods comparison for the day ahead PV output power forecast. Renew Energy 113:11–21. https://doi.org/10.1016/j.renene.2017.05.063
Gigoni L, Betti A, Crisostomi E, Franco A, Tucci M, Bizzarri F, Mucci D (2017) Day-ahead hourly forecasting of power generation from photovoltaic plants. IEEE Trans Sustain Energy 9:831–842. https://doi.org/10.1109/TSTE.2017.2762435
Raza MQ, Mithulananthan N, Li J, Lee KY, Gooi HB (2019) An ensemble framework for day-ahead forecast of pv output power in smart grids. IEEE Trans Ind Inf 15:4624–4634. https://doi.org/10.1109/TII.2018.2882598
Aslam M, Lee SJ, Khang SH, Hong S (2021) Two-stage attention over LSTM with Bayesian optimization for day-ahead solar power forecasting. IEEE Access 9:107387–107398. https://doi.org/10.1109/ACCESS.2021.3100105
Zafar R, Vu BH, Husein M, Chung IY (2021) Day-ahead solar irradiance forecasting using hybrid recurrent neural network with weather classification for power system scheduling. Appl Sci 11(15):6738. https://doi.org/10.3390/app11156738
Gupta P, Singh R (2023) Forecasting hourly day-ahead solar photovoltaic power generation by assembling a new adaptive multivariate data analysis with a long short-term memory network. Sustain Energy Grids Netw 35:101133. https://doi.org/10.1016/j.segan.2023.101133
Singla P, Duhan M, Saroha S (2022) An ensemble method to forecast 24-h ahead solar irradiance using wavelet decomposition and BILSTM deep learning network. Earth Sci Inf 15(1):291–306. https://doi.org/10.1007/s12145-021-00723-1
Asiri EC, Chung CY, Liang X (2023) Day-ahead prediction of distributed regional-scale photovoltaic power. IEEE Access 11:27303–27316. https://doi.org/10.1109/ACCESS.2023.3258449
Hoyos-Gómez LS, Ruiz-Muñoz JF, Ruiz-Mendoza BJ (2022) Short-term forecasting of global solar irradiance in tropical environments with incomplete data. Appl Energy 307:118192. https://doi.org/10.1016/j.apenergy.2021.118192
Haider SA, Sajid M, Sajid H, Uddin E, Ayaz Y (2022) Deep learning and statistical methods for short-and long-term solar irradiance forecasting for Islamabad. Renew Energy 198:51–60. https://doi.org/10.1016/j.renene.2022.07.136
Rai A, Shrivastava A, Jana KC (2022) A robust auto encoder-gated recurrent unit (AE-GRU) based deep learning approach for short term solar power forecasting. Optik 252:168515. https://doi.org/10.1016/j.ijleo.2021.168515
Huang B, Kang F, Li J, Wang F (2023) Displacement prediction model for high arch dams using long short-term memory based encoder–decoder with dual-stage attention considering measured dam temperature. Eng Struct 280:115686. https://doi.org/10.1016/j.engstruct.2023.115686
Shensa MJ (1992) The discrete wavelet transform: wedding the a trous and Mallat algorithms. IEEE Trans Signal Process 40:2464–2482. https://doi.org/10.1109/78.157290
Mallat SG (1989) A theory for multiresolution signal decomposition: the wavelet representation. IEEE Trans Pattern Anal Mach Intell 11:674–693. https://doi.org/10.1109/34.192463
Zhu H, Li X, Sun Q, Nie L, Yao J, Zhao G (2016) A power prediction method for photovoltaic power plant based on wavelet decomposition and artificial neural networks. Energies 9:11. https://doi.org/10.3390/en9010011
Monjoly S, André M, Calif R, Soubdhan T (2017) Hourly forecasting of global solar radiation based on multiscale decomposition methods: a hybrid approach. Energy 119:288–298. https://doi.org/10.1016/j.energy.2016.11.061
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9:1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
Cui Z, Ke R, Pu Z, Wang Y (2018) Deep bidirectional and unidirectional LSTM recurrent neural network for network-wide traffic speed prediction. arXiv:1801.02143
http://www.soda-pro.com/web-services/radiation/cams-radiation-service. Accessed 12 January 2022
https://www.accuweather.com/tr/tr/trabzon/321281/daily-weather-forecast/321281. Accessed 8 January 2022
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Çevik Bektaş, S., Altaş, I.H. DWT-BILSTM-based models for day-ahead hourly global horizontal solar irradiance forecasting. Neural Comput & Applic 36, 13243–13253 (2024). https://doi.org/10.1007/s00521-024-09701-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-024-09701-2