
Abstract
Rapid detection of damages occurring as a result of natural disasters is vital for emergency response. In recent years, remote sensing techniques have been commonly used for the automatic categorization and localization of such events using satellite images. Trained based on natural disaster images, a convolutional neural network (CNN) has been applied as a highly successful method, with its ability to reveal outstanding features. Studies aiming to detect target points obtained as a result of extracting visual features from natural images within these networks have achieved their goals. In this study, ensemble learning methods have been suggested as a means to develop the detection of landslide areas from landslide satellite images. Landslide image dataset has been trained for their categorization in CNN models and then they have been used again to localize landslide regions. While model predictions develop overall performance and status, different ensemble strategies have been used and integrated to reduce the sensitivity to prediction variance and training data. Class-selective relevance mapping (CRM) has been used to visualize individual CNN models and ensemble learned behaviors. As a result of the comparisons made based on mean average precision metrics and the criteria of intersection over union, model ensembles have proved to show higher localization performance than any other individual model.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In emergency disasters, swiftly identifying and visualizing landslide-prone areas are vital steps in facilitating prompt relief efforts, enabling the timely distribution of aid. Accurate and accelerated landslide detection mitigates disaster-induced damage while enhancing the effectiveness of disaster management strategies [1]. However, manual landslide detection can be perilous, labor-intensive, and costly, necessitating the adoption of computer-assisted remote sensing techniques.
Aiming to detect landslide locations quickly and accurately, the use of remote sensing systems with machine learning has been evaluated in a wide variety of studies [2,3,4,5,6,7,8]. Among these studies, Cheng et al. [5] made an automatic landslide detection with a new classification method, while Danneels et al. [6] did the same with the maximum likelihood classification method (MLC). Mezaal et al. [7] suggest the use of repetitive nerve networks and multi-layered perceptive nerve networks for landslide detection. In another study, Wang et al. [8] performed object-based landslide detection with conventional machine learning methods (Logistic Regression, Support Vector Machines, Random Forest, Discrete AdaBoost, LogitBoost, Gentle AdaBoost, Convolutional Neural Network). Deep learning (DL) algorithms based on data using convolutional neural network (CNN) have successfully been applied for landslide detection [9,10,11] and thus have increased the interest in automatic landslide detection [12]. Different DL and visualization techniques have been developed to localize landslide regions [13,14,15,16]. The CNN is one of the most widely used DL methods for landslide detection [12]. Shi et al. [17] have come up with a method combining CNN and change perception for faster detection of landslides with remote sense images. It has been pointed out that improvements in the speed of landslide detection have been observed thanks to this approach. Transfer learning methods based on DL are frequently used to detect natural disasters with satellite images as a remote sensing technique. For this approach, CNN must be trained for the target objects in the images and the learned knowledge is transferred and reused for the proceeding tasks [18,19,20]. Catani [21] used four pre-trained CNN algorithms (GoogLeNet, GoogLeNet-Places365, ResNet.101, and Inception.V3) to detect landslides from photographs. To detect landslide locations within large-scale satellite images, an object detection algorithm called Faster-RCNN was trained by Li et al. [22]. Researchers have suggested and visualized the bounding boxes for each landslide location. In studies using Mask R-CNN [23, 24], experiments were conducted using remote sensing methods and landslide-inducing information, and satisfactory results were obtained. In another study [25] dealing with the reliability in the detection of landslide areas by the trained CNN models (Resnet-50, VGG-19, Inception, and Xception), researchers have compared such visualization techniques as Grad-CAM, Grad-CAM + + , and Score-CAM. It has been shown that VGG-19 has over 90% potential and Grad-CAM and Score-CAM techniques have proved effective in the localization of landslide areas. In addition to studies examining CNN performance [26] to develop a model that can automatically detect landslides from image streams on social media, pixel-based landslide detection studies are also increasing. In these studies, DL models called DemDet [27] and SFCNet [28] are proposed, as well as pixel, sub-pixel, and object-based image analysis techniques are compared for landslide detection [29]. Images of natural disasters, especially landslides, exhibit different visual characteristics such as color, texture, shape, image, and their combinations. Therefore, the application of DL in landslide detection primarily focuses on image analysis [30]. It is inevitable to apply performance-developing and innovative methods apart from available ones in the phase of the training of these images.
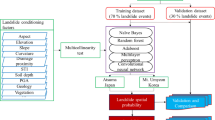
This study has set out to classify landslide and non-landslide images as well as to localize landslide areas by the DL method. A variety of pre-trained models including CNN, VGG 16, VGG-19 [31], Inception-V3 [32], Xception [33], MobileNet [34], DenseNet-121 and NASNet-mobile [35] have been trained on a set of large-scale [16] landslide data for analyses. CNN predictions have been combined with various ensemble strategies such as majority vote, average, weighted average, and stacking to reduce the prediction variance of training data and learning algorithms and improve the overall performance. Moreover, visualization techniques have been applied to interpret important characteristics contributing to the classification of landslide images. Learned behaviors of the individual models and their ensembles have been visualized by the CRM method. This method is the first study to suggest a combination of knowledge transfer based on landslide images and ensemble learning as well as to evaluate the localization of regions of interest (ROI) in landslide areas.
2 Material and methods
2.1 Data collection and preprocessing
In this study, an open source named Bijie landslide dataset has been used to automatically detect landslides by the DL method [16]. The scope of the research covers an area of 26 853 km2 in the city of Bijie in Guizhou State of China. Types of landslides in the city of Bijie consist of rockfalls and a few debris slides. The dataset imaged by the TripleSat satellite between May and August 2018 has been obtained from 770 landslide images (red dots, Fig. 1) and 2003 non-landslide images. The images of landslide and non-landslide image samples have been provided in the png extension. The spatial resolution of the air image is 0.8 m. An image sample from the Bijie landslide dataset, which is available at http://study.rsgis.whu.edu.cn/pages/download/, has been presented in Fig. 2.

Display of landslide areas [16]

Sample selected from the Bijie landslide dataset and bounding box
It was allocated as 70% of the real-world dataset for the primary model training phase. This subset served the purpose of establishing the initial model parameters and weights. For model validation, 20% of the dataset was designated. During model training, this validation dataset was utilized to monitor the model's performance, prevent overfitting, and facilitate necessary adjustments. The remaining 10% of the dataset was randomly selected and exclusively reserved for testing the final model. This data was not involved in the model development process and was used to assess the model's generalization to unseen data, contributing to predictability analysis.
2.2 Landslide bounding box
There are a lot of objects providing a negative contribution to landslide detection outside landslide areas in training images. This situation causes the CNN model to learn irrelevant features. Pixel-based labeling of target areas on the images is necessary to remove negative contributions [36]. So, it becomes possible to realize semantic segmentation with the use of different algorithms [37]. Masking landslide areas is a highly time-consuming task requiring a large workforce. In this phase, images have been arranged in a way to have only one landslide image in each photo to realize automatic localization. Efforts have been made to detect the segmented forms of landslide areas with the use of visualization techniques. This method has the major aim of detecting areas of emergency with a faster and easier workforce.
Images displaying landslide areas have first been resized with a pixel of 256 × 256. Bounding boxes including landslide pixels have been used to identify landslide areas. Coordinates of bounding boxes have been saved and stored for the calculation of IoUs. The pixel values of each image have been divided into 255 and normalized in the space of [0.1]. A sample of the bounding box from the Bijie dataset has been shown in Fig. 2.
2.3 Models and computational sources
The performances of custom CNN, VGG-16, VGG-19, Inception-V3, Xception, DenseNet-121, MobileNet, and NASNet-mobile CNN models have been evaluated in this study. A Custom CNN model has been established on a linear sequence consisting of depth-wise separable convolution, nonlinear activation, pooling, and dense layers. It applies the depth-wise separable convolution process to each channel and then follows a 1 × 1 kernelled point-wise convolution. It has been found that these processes used fewer model parameters and less overfitting, compared with conventional convolutions [33, 38]. The architecture of the custom CNN model is shown in Fig. 3:

The architecture of the custom CNN model
A convolutional block includes a separable convolution layer, batch normalization, and ReLU non-linear layers. Padding has been added to separable convolution layers to ensure the synchronization of feature map dimensions of mid-layers with the original input dimensions. 5 × 5 kernels have been used for all separable convolution layers. A max-pooling layer follows each convolutional block. The number of kernels has increased twofold for the proceeding convolution blocks to make the computation in separable layers roughly the same. Global average pooling (GAP) layer, dropout (ratio = 0.5) and Softmax-activated final dense layer for output prediction probabilities have been added to the model.
Bayesian learning method has been applied to optimize the custom CNN model and its hyperparameters for the current task [39]. 30 objective function evaluations have been released for the optimization of hyperparameters based on empirical observations. The latest model with the optimized parameters has been trained, verified, and tested in the stochastic gradient descent optimization method.
The pre-trained CNN models have been made concrete by ImageNet weights and cut into fully connected layers. Zero padding, 3 × 3 kernel, 1024 feature-mapped convolutional layer, GAP, dropout (dropout ratio = 0.5), and a dense layer with SoftMax have been added. The specialized architecture of pre-trained CNNs is shown in Fig. 4:

The architecture of pre-trained CNNs
L2-weight decay within the range of [1e−10 1e−3], momentum within the range of [0.85 0.99], and learning rate within the range of [1e−9 1e−2] have been taken into consideration as the transfer learning hyperparameters of the pre-trained CNNs [40].
Models have been re-trained by SGD optimization to minimize categorical cross-entropic loss in landslide categorization. The grandiosity of weight updates has been kept smaller to improve generalization. Higher class weights have been provided to the insufficiently represented classes to prevent model bias and overfitting [41]. Callbacks have been used to control the situation of the models in the training period. Checkpoints for each epoch have been stored as files with the.h5 extension and the early stopping process has been applied to prevent overfitting. The best model weights have been stored in memory to perform hold-out testing. Performance criteria such as accuracy, an area under the curve (AUC), sensitivity, specificity, F measure, and Matthews correlation coefficient (MCC) have been used for the models in transfer learning and ensemble learning. CUDA/CUDNN libraries and Keras API with TensorFlow backend have been used for GPU acceleration. Models have been trained and evaluated on Windows 11 software with 32 GB RAM and NVIDIA Quadro RTX 4000 GPU.
2.4 Transfer learning
The use of pre-trained models as initial parameters for a different task is called transfer learning. This method is frequently used in some DL problems. With the applied transfer learning method, designers have had the opportunity to both save time and obtain high accuracy rates. It is very difficult to obtain data and design complex models for different image processing problems. With the proposed transfer learning, it is possible to achieve higher performance with fewer data numbers.
Transfer learning, on the other hand, uses pre-trained models used in the solution of different problems as a starting parameter for the solution of the desired problems and provides solutions with faster and higher performance. Solving existing problems with deep learning methods requires a lot of data. For this reason, the number of data should be large to eliminate the overfitting problem. With the transfer learning method, transfer learning is used instead of training the network with random initial values [15, 17]. With this method, training of Convolutional Neural Network structures with less data is provided effectively.
In the study, first, the CNN model and then the transfer learning model were used for classification on the same data set. While an 80% (± 2) success rate was achieved with CNN, a 95% (± 1) success rate was obtained with the transfer learning model. The results are important in terms of showing that the transfer learning approach is useful. Figure 5 depicts a transfer learning architecture.

Transfer learning procedure
Because the lowest layers are configured as non-trainable, the weights of the pre-trained models are not lost in the proposed study. The fully connected layer is replaced by a global average pooling layer in the final convolutional layer, which takes the average of each feature map and outputs a feature map for each associated class. The flattened feature map is passed through a dense layer, a dropout layer, and another dense layer before being transmitted through the Softmax layer [42]. For a multi-class classification problem, categorical cross entropy is used. All of the pre-trained models are trained for 30 epochs with a batch size of 32 using the Adam optimizer and have a learning rate of 10–4.
2.5 CNN architectures for pre-trained models
This study involved the classification of landslide images using different CNN architectures. The networks utilized for analysis are VGG-16, VGG-19 [31], Inception-V3 [32], Xception [43], DenseNet-121 [44], MobileNet [45] and NASNet-Mobile [46], each offering a different approach to the object classification tasks at hand as detailed subsequent subsections.
Each model’s middle layers capture specific features and representations aligned with their tasks and designs. These layers shape the information processing capabilities of each model and influence how they perform in a particular task or application.
2.5.1 VGG-16 model
VGG-16 [31] is a state-of-the-art DL model pre-trained with over 1 million images from the ImageNet database. It classifies objects into 1000 categories using 16 concatenated layers of convolution and maximum pool layers. The model is optimized for 224 × 224 image input size and accurately predicts with Softmax activation. Its 138 million parameters make it a powerful tool for capturing complex features, although it requires extensive computational resources. VGG-16 is widely used in computer vision applications and AI. The image input size of the network is 224 × 224. VGG-16 architecture is illustrated in Fig. 6.

VGG-16 architecture
2.5.2 VGG-19 model
VGG-19 [31] is a CNN model with 19 layers that uses a small convolution kernel. This network can also be loaded with a pre-trained version trained on over one million images from the ImageNet database, enabling it to classify images into 1000 object categories. The network has learned to represent features from a diverse set of images, including animals, office supplies, and other objects. The image input size for this network is 224 × 224. The VGG-19 architecture is illustrated in Fig. 7.

VGG-19 architecture
VGG-16 and VGG-19 are traditional deep Convolutional Neural Network (CNN) models with a deep architecture. The features extracted by these middle layers tend to recognize low-level visual features such as edges, corners, simple patterns, and more complex object parts. The commonly used activation function is ReLU, which enhances positive features and aids in learning. These models perform well in object recognition and classification tasks.
2.5.3 Inception-V3 model
The Inception architecture, developed by [32], presents a distinctive characteristic that sets it apart from other deep networks such as VGGNet [31] and AlexNet [47]. Namely, Inception avoids the use of large convolutions, which are computationally expensive, despite their efficacy in modeling the interactions between distant activation points. As illustrated in Fig. 8, Inception-V3 architecture boasts a unique structure that enables the network to achieve state-of-the-art performance in various computer vision tasks.

Inception-V3 architecture
Inception-V3 has a unique architecture that efficiently models interactions between distant activation points without using large convolutions. Reviews indicate that Inception-V3 performs well in various computer vision tasks. The middle layers tend to capture complex features and semantic concepts with less computational cost.
2.5.4 Xception model
The Xception [43] model, which is an extension of the Inception architecture, was introduced by Google. It has 71 layers and is a convolutional neural network architecture that uses depth-wise separable convolutions. The modified deeply separable convolution in the Xception architecture has been found to improve performance compared to InceptionV3 for both ImageNet ILSVRC and JFT datasets. The architecture of Xception is depicted in Fig. 9.

The network architecture of the Xception model
Xception is an extension of the Inception architecture that utilizes depth-wise separable convolutions. The middle layers incorporate a modified separable convolution to improve performance compared to InceptionV3. They tend to capture the second large set of features more efficiently.
2.5.5 DenseNet-121 model
DenseNet-121 [44], short for Densely Connected Convolutional Networks-121, is a CNN architecture designed for image classification tasks. It is part of the DenseNet family of models, which are known for their dense connections between layers, making them highly efficient and accurate for various computer vision tasks. The architecture of DenseNet-121 is shown in Fig. 10.

The network architecture of the DenseNet-121 model
DenseNet-121 is known for its dense connections within a CNN architecture. Dense connections mean that each element in a layer is connected to all elements in the preceding layer. The middle layers facilitate better feature reuse and faster information flow. This model is recognized for its efficiency and accuracy.
2.5.6 MobileNet model
MobileNet [45] is a family of neural network architectures designed for efficient on-device vision applications, particularly on mobile and embedded devices. These models are known for their compact size and low computational requirements while maintaining reasonable accuracy in tasks like image classification and object detection. Figure 11 illustrates the network architecture of the MobileNet model.

The network architecture of the MobileNet model
MobileNet is a family of network architectures designed for on-device applications, particularly on mobile and embedded devices. These models maintain reasonable accuracy in tasks like image classification and object detection while having low computational requirements. The middle layers tend to represent important features efficiently in these lightweight models.
2.5.7 NASNet-mobile model
NASNet-Mobile [46], short for Neural Architecture Search Network-Mobile (Fig. 12), is a CNN architecture designed for efficient on-device vision applications, particularly on mobile and embedded devices. NASNet-Mobile is part of the Neural Architecture Search (NAS) family of models, which automates the process of architecture design by using reinforcement learning. It's known for its high performance and efficiency.

The network architecture of the NASNet-mobile model
NASNet-Mobile is part of the Neural Architecture Search (NAS) family of models designed for on-device applications. It is known for its high performance and efficiency. The middle layers are where this model conducts an automated learning process to design features, allowing for adaptability to different tasks.
2.6 Ensemble learning algorithm
Ensemble learning algorithms are among the most successful approaches in prediction-based analytical studies. These algorithms consist of a model set coming together for the resolution of a concrete problem. In a general sense, ensemble learning methods are the types of learning methods offering higher accuracy and performance with the combination of more than one DL model prediction rather than one single deep learning method. It is possible to acquire predictions with higher performance from a DL method by performing the training in more than one DL method. The model is based on the production of a joint prediction with the combination of predictions acquired by the classifiers rather than the combination of classifiers themselves. In this method, the results of classifiers with different accuracy rates are combined with different methods (voting, average, etc.). Thus, it becomes possible to get better results from one single classifier. Majority vote, simple averaging, weight averaging, and stacking have been applied to establish an ensemble model in this study.
Individual funding models and the acquired predictions are presented as votes in the majority vote. The prediction with the maximum vote is accepted as the ultimate prediction (Fig. 13). In simple averaging, averages of founding model predictions are used to reach the ultimate prediction.

Majority voting workflow
Weight averaging is an extension of simple averages determined by different weights according to compound model predictions and classification performances. Weights are multiplied by each prediction and later their averages are determined by the equation (w1 × pred1 + w2 × pred2 + w3 × pred3)/3. All the maximum weight can be attributed to the individual model showing the best performance. The sum of w(i) has to be 1.0.
Model stacking is a way to improve model predictions by combining the output of more than one model and getting them worked by another machine learning model named meta-learner [48]. Meta-learner tries to minimize the vulnerability of a model and optimize its robust aspects. Generally, the result is a robust model making a high level of generalization based on invisible data. The stacking workflow is shown in Fig. 14:

Ensemble stacking workflow
In the figure above, it is seen that different samples are not taken for the data training in the classifier training process. In this process, each classifier works independently, and this allows the classifiers to work in different hypotheses and algorithms. Like different ensemble techniques, stacking aims to improve the accuracy of a model by using the predictions of models that are not well-grounded and by using these predictions as input for the establishment of a better model.
3 Model visualisation
3.1 Class-selective relevance map
Visualization technique based on CRM algorithm (Eq. 1) has been used for individual models and ensembles to localize landslide regions [49, 50].CRM visualization algorithm computes the significance of activation in deepest-convolution layer featured maps of a CNN model to emphasize the most distinctive ROI in the input image. A prediction score \({S}_{c}\) is computed for each c gradient in the output layer. Another prediction score \({S}_{c}(l,m)\) is computed for a spatial component \((l,m)\) after extracting it from the deepest convolution layer. The increasing average between \({S}_{c}\) and \({S}_{c}(l,m)\) computed from all the gradients in the output layer of CNN models is identified as the linear sum of squares error.
\(R\left(l,m\right)\) represents the CRM score calculated for a specific location \(\left(l,m\right)\). The CRM score measures the significance of activation at this location in the deepest convolutional layer's feature maps. c is an index for the gradients in the output layer of the CNN model. In other words, c iterates through a loop from 1 to N, where N represents the total number of gradients in the output layer. This score reflects the characteristics of activation at this particular location in the deepest convolutional layer. N represents the total number of gradients in the output layer of the CNN model.
It can be argued that a spatial component with a high CRM score holds significant importance in the classification process. The removal of this gradient can lead to a substantial increase in squared errors within the output layers. To aid comprehension in the context of a binary classification problem, Fig. 15 presents a simplified conceptual workflow illustrating the measurement of the CRM score for a CNN model.

Class-selective relevance mapping (CRM) [49]
3.2 Ensemble CRM
A combination of multiple CRMs extracted from different CNN models as well as their averaging produces an ensemble CRM. Figure 16 shows a workflow to be followed for the acquisition of an ensemble CRM from the individual CRMs obtained from three different CNN models. The dimension of each CRM differs from the spatial dimensions of feature maps in the deepest convolution layer in the CNN model. For this reason, the dimensions of individual CRMs are normalized increasing their dimensions to those of input images. A mapping score value of less than 10% of the greatest mapping score in individual CRMs is not taken into account to minimize the probable effect of a very low mapping score during the ensemble formation process. CRMs acquired in this method are combined by the simple averaging and so ensemble CRMs are established. An ensemble CRM formed in this method sets out to improve overall localization performance with the compensation of errors in regions of interest in individual CNN models.

Workflow to construct an ensemble CRM
The effectiveness of the ensemble formation strategy presented here is shown with three ensemble CRMs acquired by the combination of the first three, five, and seven CNN models respectively with the best performance. To this end, the visual localization performances of these three CRMs have been compared with both each other and individual CRMs quantitatively in terms of Intersection of Union (IoU) [51] and Mean Average Precision (mAP) [52] evaluation metrics.
4 Results
4.1 Performance metrics evaluation
The most accurate values of hyperparameters used for custom and pre-trained CNN models are given in Table 1. Performance values acquired by approximate models for landslide class with the use of landslide and non-landslide image test sets are given in Table 2. Comparing the pre-trained NASNet-mobile model with the other models, it has been observed that it could show the best performance in Accuracy, Recall, F Measure, and Matthews correlation coefficient metric values.
Ensemble formation of predictions of the best seven CNN models for the classification of landslide categories has been realized with the use of majority voting, simple averaging, weighted averaging, and stacking methods. Table 3 shows the performance metrics of different ensemble model groups acquired by the different ensemble model formation strategies. Based on the results presented in Table 3, it can be seen that weighed averaging shows a better performance than other ensemble formation strategies. In the weighted averaging strategy, more weight is attributed to models with a more accurate performance to acquire higher prediction rates. Thus, in light of the results from the analyses, it can be said that the NASNet-mobile model shows higher performance compared with the other models. As VGG-16 is the model with the lowest performance, the weight for this model is computed as zero. Consequently, ensemble formation has been realized with the attribution of weights [0.05, 0.10, 0.19, 0.10, 0.19, 0.15, 0.25] respectively for Custom Model, VGG-19, Inception-V3, Xception, DenseNet-121, MobileNet, and NASNet-mobile models.
4.2 Visual localization evaluation
Feature extraction layers contributing to the acquisition of high performance in predicting landslide and non-landslide image classes are listed in Table 4. Visualization analyses have been performed by the features extracted from these layers.
The localization performance of CRMs established from each of the seven CNN models with the best performance in the detection of landslide areas with the use of a landslide class test set has been evaluated. Table 5 shows IoU and mAP scores acquired by the averaging of individual IoU and mAPs computed from the 154 landslide images in the landslide test set having the information ground-truth binding box. Here, mAP is computed within the range [0.1 0.6], averaging upon the ten IoU threshold value. The equation providing the score of mAP, a metrical system designed for the evaluation of performance criteria such as precision, sensitivity, and F1 measure in one single point, is given in Eq. (2):
\(P\left(R\right)\) function represents precision as a function of \(R\) (true positives). Precision is calculated by dividing the true positives by the total positive predictions. \(R\) represents the ratio of true positives and takes values in the range [0,1]. This value indicates how the object detection performance changes at a specific threshold value.
Moreover, Table 5 also shows the threshold values in which the best IoU and mAP values are acquired for each model:
Then, IoU and mAP scores for three ensemble CRMs named Ensemble-3, Ensemble-5, and Ensemble-7 have been computed. These ensemble CRMs have been formed by averaging CRMs acquired by the first three, five, and seven best-performing CNN models selected according to IoU and mAP scores, as shown in Table 5. Models in different ensemble CRMs are as follows: (a) Ensemble-3 (VGG-19, Xception, DenseNet-121) (b) Ensemble-5 (VGG-19, Xception, DenseNet-121, Inception-V3, NASNet-mobile) and (c) Ensemble-7 (Custom CNN, VGG-19, Xception, DenseNet-121, Inception-V3, NASNet-mobile, MobileNet). In Table 6, ensemble CRMs have provided much higher IoU and mAP scores than the individual CRMs. In Table 6, bold values show superior performance. Among the ensemble CRMs, Ensemble-5 has shown outstanding performance for IoU and moderate performance for mAP. This has shown that the combination of more than five CNN models does not improve localization performance more and that it has proved sufficient for this study. Figure 17 shows precision-recall curves of ensemble CRMs whose mAP scores have been computed. Figure 18 shows a CRM sample of the Ensemble-5 approach in localizing ROI taken for any landslide image from the landslide test set.

Precision-recall curves concerning different IoU thresholds for a Ensemble-3, b Ensemble-5, and c Ensemble-7 models

Examples of ensemble CRM combining of top-5 CNN models
It is seen in Fig. 18 that ROIs in CRMs for two landslide classes acquired by the most successful five CNN models have emphasized different areas. The IoUs shown here are detected using bounding boxes restricting real landslide images. While IoUs for each model are observed to have low scores, the IoUs acquired by the CRM ensemble are understood to show more outstanding performance. Stated more clearly, it has been seen that bounding boxes used for the detection of a predictable landslide area and the bounding boxes representing real landslide comply with each other and that they have more improved IoU scores than individual CRMs. Consequently, it has been understood that the ensemble approach can be used not only for classification performances but for the improvement of overall object perception performance as well.
5 Discussion
As large-scale datasets with a group of data distribution and pre-trained models have already learned classification skills, it is not surprising at all to observe better performances with the addition of further landslide images to this dataset. For this reason, the Custom CNN model has shown a lower performance than the other models, excluding the VGG-16 model. The functionality and better performance levels of ensemble models, compared with individual models, have been proved in this study aiming to focus on the classification and localization of landslide images with the use of pre-trained models. The addition of non-landslide images to the training dataset in the phase of landslide localization contributes to the improvement in performance. Compared with other models, the VGG-19, Xception, DenseNet-121, Inception-V3, NASNet-mobile models have shown outstanding performance.
The weighted average community building strategy performed relatively better than other community format strategies in terms of all performance criteria. The weighted-averaging strategy achieved much better performance than other community generation strategies by giving higher weight to the NASNet-mobile, DenseNet-121 and Inception-V3 models. In summary, the use of a weighted sum with high weights for these three prediction models is a justified approach due to their consistent and strong individual performances, their different architectures, and the desire to maintain an unbiased and robust ensemble for landslide detection and localization.
The class-selective accuracy map results depicted in Fig. 12 demonstrate noticeable discrepancies compared to the real landslide images. This observation further underscores the need for improving the predictive power of the proposed CRM algorithm. When comparing the IoU values obtained for different CNN models (VGG-19, Xception, DenseNet-121, Inception-V3, NASNet-mobile, MobileNet) to determine the landslide areas by using CRM, it is evident that the IoU values achieved through the ensemble strategies are higher than those obtained individually. This finding corroborates the accuracy and efficacy of the applied methodology. The accuracy of landslide prediction analysis with CRM was evaluated by assessing the overlap between rectangles representing the actual entire landslide area and the predicted landslide area. This evaluation was performed using numerical values known as Intersection over Union (IoU) scores. Upon examining the IoU scores, it was observed that the individual IoU values obtained from the five best-performing models were lower than the IoU values obtained by averaging the weights of these models. This indicates that the Ensemble CRM strategy outperforms the models evaluated individually in terms of prediction accuracy.
To sum up, modality-specific transfer learning contributes to the improvement of the performance and generalization of the target-oriented process. The ensemble performance has been improved with the use of models getting modality-specific knowledge from a large-scale landslide dataset. At the same time, improvement in ensemble visualization performance has been observed, with the use of models benefiting from this knowledge transmission. So, a compound prediction with a better performance than any individual model has been made.
6 Conclusion
Acquired by the combination of individual models, ensemble learning can be used to improve classification performance, decrease prediction variance and sensitivity to training data as well as increase overall performance. Despite these appealing characteristics, ensemble methods do not seem effective for practical purposes in terms of computation, increasing the duration of training needed as well as memory requirements. However, depending on the rapid progress in computer technology, the ability to perform high-performance computing solutions and access to GPU technologies at a low cost can make the use of ensemble models suitable for practical purposes. Significant information can be acquired about the functioning of individual models during the formation of ensemble models. This makes it possible to form an ensemble model showing the best performance following the dataset. Concerning ensemble model visualization, deficiencies in ROIs have been resolved with the use of individual models, and better ROI perception and localization performance have been realized. In addition, CRM has made it possible to better interpret and understand the learned behaviors of the model. It is believed that the results have contributed to the emergence of robust models for landslide image classification and ROI localization.
Data availability
Data is available at http://study.rsgis.whu.edu.cn/pages/download/.
References
Ma Z, Mei G, Piccialli F (2021) Machine learning for landslides prevention: a survey. Neural Comput Appl 33:10881–10907. https://doi.org/10.1007/s00521-020-05529-8
Chen Z, Zhang Y, Ouyang C et al (2018) Automated landslides detection for mountain cities using multi-temporal remote sensing imagery. Sensors 18:821. https://doi.org/10.3390/S18030821
Dou J, Chang KT, Chen S et al (2015) Automatic Case-based reasoning approach for landslide detection: integration of object-oriented image analysis and a genetic algorithm. Remote Sens 7:4318–4342. https://doi.org/10.3390/RS70404318
Tehrani FS, Calvello M, Liu Z et al (2022) Machine learning and landslide studies: recent advances and applications. Nat Hazards 114(2):1197–1245. https://doi.org/10.1007/S11069-022-05423-7
Cheng G, Guo L, Zhao T et al (2012) Automatic landslide detection from remote-sensing imagery using a scene classification method based on BoVW and pLSA. Int J Remote Sens 34:45–59. https://doi.org/10.1080/01431161.2012.705443
Danneels G, Pirard E, Havenith HB (2007) Automatic landslide detection from remote sensing images using supervised classification methods. In: International geoscience and remote sensing symposium (IGARSS), pp 3014–3017
Mezaal MR, Pradhan B, Sameen MI et al (2017) Optimized neural architecture for automatic landslide detection from high-resolution airborne laser scanning data. Appl Sci 7:730. https://doi.org/10.3390/APP7070730
Wang H, Zhang L, Yin K et al (2021) Landslide identification using machine learning. Geosci Front 12:351–364. https://doi.org/10.1016/j.gsf.2020.02.012
Ding A, Zhang Q, Zhou X, Dai B (2017) Automatic recognition of landslide based on CNN and texture change detection. In: Proceedings—2016 31st Youth Academic annual conference of Chinese Association of automation, YAC 2016 444–448. https://doi.org/10.1109/YAC.2016.7804935
Ghorbanzadeh O, Blaschke T, Gholamnia K et al (2019) Evaluation of different machine learning methods and deep-learning convolutional neural networks for landslide detection. Remote Sens 11:196. https://doi.org/10.3390/RS11020196
Yu H, Ma Y, Wang L et al (2017) A landslide intelligent detection method based on CNN and RSG_R. In: 2017 IEEE international conference on mechatronics and automation (ICMA). Institute of Electrical and Electronics Engineers Inc., pp 40–44
Tang X, Tu Z, Wang Y et al (2022) Automatic detection of coseismic landslides using a new transformer method. Remote Sens (Basel) 14:2884. https://doi.org/10.3390/rs14122884
Liu Y, Zhang W, Chen X et al (2021) Landslide detection of high-resolution satellite images using asymmetric dual-channel network. In: 2021 IEEE international geoscience and remote sensing symposium IGARSS. Institute of Electrical and Electronics Engineers (IEEE), pp 4091–4094
Tanatipuknon A, Aimmanee P, Watanabe Y et al (2021) Study on combining two faster R-CNN models for landslide detection with a classification decision tree to improve the detection performance. J Disaster Res 16:588–595. https://doi.org/10.20965/JDR.2021.P0588
Liu D, Li J, Fan F (2021) Classification of landslides on the southeastern Tibet Plateau based on transfer learning and limited labelled datasets. Remote Sens Lett 12:286–295. https://doi.org/10.1080/2150704X.2021.1890263
Ji S, Yu D, Shen C et al (2020) Landslide detection from an open satellite imagery and digital elevation model dataset using attention boosted convolutional neural networks. Landslides 17:1337–1352. https://doi.org/10.1007/S10346-020-01353-2/TABLES/9
Shi W, Zhang M, Ke H et al (2021) Landslide recognition by deep convolutional neural network and change detection. IEEE Trans Geosci Remote Sens 59:4654–4672. https://doi.org/10.1109/TGRS.2020.3015826
Lopes UK, Valiati JF (2017) Pre-trained convolutional neural networks as feature extractors for tuberculosis detection. Comput Biol Med 89:135–143. https://doi.org/10.1016/J.COMPBIOMED.2017.08.001
Rajaraman S, Candemir S, Kim I et al (2018) Visualization and interpretation of convolutional neural network predictions in detecting pneumonia in pediatric chest radiographs. Appl Sci 8:1715. https://doi.org/10.3390/APP8101715
Rajaraman S, Candemir S, Xue Z et al (2018) A novel stacked generalization of models for improved TB detection in chest radiographs. In: Annual international conference of the IEEE engineering in medicine and biology society 2018:718–721. https://doi.org/10.1109/EMBC.2018.8512337
Catani F (2021) Landslide detection by deep learning of non-nadiral and crowdsourced optical images. Landslides 18:1025–1044. https://doi.org/10.1007/s10346-020-01513-4
Li H, He Y, Xu Q et al (2022) Detection and segmentation of loess landslides via satellite images: a two-phase framework. Landslides 19:673–686. https://doi.org/10.1007/s10346-021-01789-0
Fu R, He J, Liu G et al (2022) Fast seismic landslide detection based on improved mask R-CNN. Remote Sens (Basel) 14:3928. https://doi.org/10.3390/rs14163928
Yang R, Zhang F, Xia J, Wu C (2022) Landslide extraction using mask R-CNN with background-enhancement method. Remote Sens (Basel) 14:2206. https://doi.org/10.3390/rs14092206
Hacıefendioğlu K, Demir G, Başağa HB (2021) Landslide detection using visualization techniques for deep convolutional neural network models. Nat Hazards 109:329–350. https://doi.org/10.1007/S11069-021-04838-Y/FIGURES/12
Ofli F, Imran M, Qazi U et al (2023) Landslide detection in real-time social media image streams. Neural Comput Appl 35:17809–17819. https://doi.org/10.1007/s00521-023-08648-0
Li D, Tang X, Tu Z et al (2023) Automatic detection of forested landslides: a case study in Jiuzhaigou County, China. Remote Sens (Basel) 15:3850. https://doi.org/10.3390/rs15153850
Janarthanan SS, Subbian D, Subbarayan S et al (2023) SFCNet: deep learning-based lightweight separable factorized convolution network for landslide detection. J Indian Soc Remote Sens 51:1157–1170. https://doi.org/10.1007/s12524-023-01685-1
Saba SB, Ali M, Turab SA et al (2023) Comparison of pixel, sub-pixel and object-based image analysis techniques for co-seismic landslides detection in seismically active area in Lesser Himalaya, Pakistan. Nat Hazards 115:2383–2398. https://doi.org/10.1007/s11069-022-05642-y
Ma Z, Mei G (2021) Deep learning for geological hazards analysis: data, models, applications, and opportunities. Earth Sci Rev 223:103858. https://doi.org/10.1016/j.earscirev.2021.103858
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. In: 3rd International conference on learning representations, ICLR 2015—conference track proceedings, pp 1–14
Szegedy C, Vanhoucke V, Ioffe S et al (2016) Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE computer society conference on computer vision and pattern recognition. IEEE Computer Society, pp 2818–2826
Chollet F (2017) Xception: deep learning with depthwise separable convolutions. In: Proceedings—30th IEEE conference on computer vision and pattern recognition, CVPR 2017. Institute of Electrical and Electronics Engineers Inc., pp 1800–1807
Sandler M, Howard A, Zhu M et al (2018) MobileNetV2: Inverted residuals and linear bottlenecks. In: Proceedings of the IEEE computer society conference on computer vision and pattern recognition, pp 4510–4520
Pham H, Guan MY, Zoph B et al (2018) Efficient neural architecture search via parameters sharing. In: Proceedings of the 35th international conference on machine learning. PMLR, pp 4095–4104
Ronneberger O, Fischer P, Brox T (2015) U-Net: convolutional networks for biomedical image segmentation. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 9351:234–241
Srivastava N, Hinton G, Krizhevsky A et al (2014) Dropout: a simple way to prevent neural networks from overfitting. J Mach Learn Res 15:1929–1958
Rajaraman S, Kim I, Antani SK (2020) Detection and visualization of abnormality in chest radiographs using modality-specific convolutional neural network ensembles. PeerJ 2020:e8693. https://doi.org/10.7717/PEERJ.8693/FIG-11
Močkus J (1974) Optimization techniques IFIP technical conference Novosibirsk. In: Marchuk GI (ed) IFIP technical conference on optimization techniques. Springer, Heidelberg, pp 400–404
Bergstra J, Bengio Y (2012) Random search for hyper-parameter optimization Yoshua Bengio. J Mach Learn Res 13:281–305
Johnson JM, Khoshgoftaar TM (2019) Survey on deep learning with class imbalance. J Big Data 6:1–54. https://doi.org/10.1186/S40537-019-0192-5/TABLES/18
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE computer society conference on computer vision and pattern recognition 2016-Decem: 770–778. https://doi.org/10.1109/CVPR.2016.90
Chollet F (2017) Xception: deep learning with depthwise separable convolutions. In: Proceedings—30th IEEE conference on computer vision and pattern recognition, CVPR 2017 2017-Janua: 1800–1807. https://doi.org/10.1109/CVPR.2017.195
Huang G, Liu Z, van der Maaten L, Weinberger KQ (2017) Densely Connected Convolutional Networks. arXiv:1608.06993 [cs.CV], pp 1–9
Howard AG, Zhu M, Chen B, et al (2017) MobileNets: efficient convolutional neural networks for mobile vision applications. arxiv:1704.04861, pp 1–9
Zoph B, Vasudevan V, Shlens J Le QV (2017) Learning transferable architectures for scalable image recognition. arXiv:1707.07012
Krizhevsky BA, Sutskever I, Hinton GE (2017) ImageNet classification with deep convolutional neural networks. Commun ACM 60:84–90
Dietterich TG (2000) Ensemble methods in machine learning. In: International workshop on multiple classifier systems, MCS 2000. Springer, Berlin, Heidelberg, pp 1–15
Kim I, Rajaraman S, Antani S (2019) Visual interpretation of convolutional neural network predictions in classifying medical image modalities. Diagnostics (Basel). https://doi.org/10.3390/DIAGNOSTICS9020038
Mozer MC, Smolensky P (1989) Using relevance to reduce network size automatically. Conn Sci 1:3–16. https://doi.org/10.1080/09540098908915626
Everingham M, Eslami SMA, Van Gool L et al (2015) The Pascal Visual object classes challenge: a retrospective. Int J Comput Vis 111:98–136. https://doi.org/10.1007/S11263-014-0733-5/FIGURES/27
Lin T-Y, Maire M, Belongie S et al (2014) Microsoft COCO: common objects in context. In: European conference on computer vision, pp 740–755
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK). No funding to declare.
Author information
Authors and Affiliations
Contributions
All of the authors have been actively involved in the research and write-up of this paper and, accordingly, acknowledge full responsibility for its content. Kemal Hacıefendioğlu: Contributed throughout the article and in the realization of deep learning analysis. Nehir Varol: Contributed to the data processing phase. Vedat Togan: Contributed to the writing and analysis of the article. Ümit Bahadır: Contributed to the editing of the article and the editing of the data. Murat Emre Kartal: Contributed to the writing of the article and the analysis.
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare that they have no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hacıefendioğlu, K., Varol, N., Toğan, V. et al. Automatic landslide detection and visualization by using deep ensemble learning method. Neural Comput & Applic 36, 10761–10776 (2024). https://doi.org/10.1007/s00521-024-09638-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-024-09638-6