
Abstract
Portfolio management is a multi-period multi-objective optimisation problem subject to various constraints. However, portfolio management is treated as a single-period problem partly due to the computationally burdensome hyper-parameter search procedure needed to construct a multi-period Pareto frontier. This study presents the Pareto driven surrogate (ParDen-Sur) modelling framework to efficiently perform the required hyper-parameter search. ParDen-Sur extends previous surrogate frameworks by including a reservoir sampling-based look-ahead mechanism for offspring generation in evolutionary algorithms (EAs) alongside the traditional acceptance sampling scheme. We evaluate this framework against, and in conjunction with, several seminal multi-objective (MO) EAs on two datasets for both the single- and multi-period use cases. When considering hypervolume ParDen-Sur improves marginally (0.8%) over the state-of-the-art (SOTA)-NSGA-II. However, for generational distance plus and inverted generational distance plus, these improvements over the SOTA are 19.4% and 66.5%, respectively. When considering the average number of evaluations and generations to reach a 99% success rate, ParDen-Sur is shown to be 1.84× and 2.02× more effective than the SOTA. This improvement is statistically significant for the Pareto frontiers, across multiple EAs, for both datasets and use cases.
Similar content being viewed by others
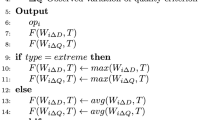

Avoid common mistakes on your manuscript.
1 Introduction
Markowitz [1] formulated the portfolio selection problem as a multi-objective optimisation problem (MOP), in which an investor aims to satisfy the conflicting objectives of maximising return while minimising risk. Since this seminal work, the portfolio optimisation problem has been expanded to include additional constraints and objectives to incorporate real-world considerations [2]. In addition, real-world portfolio management involves making a sequence of portfolio decisions over time and is thus more appropriately represented as a multi-period optimisation problem [3].
Adopting a multi-period perspective for the portfolio optimisation problem allows the optimisation framework to include intertemporal aspects of portfolio management. This includes trading costs [4], multi-period and time-varying forecasts, intertemporal hedging, and addressing other intertemporal constraints [5]. However, these advantages come with challenges. Firstly, Multiperiod Portfolio Optimisation (MPO) requires multi-period forecasts adding difficulty to the already challenging task of single-period forecasting. Secondly, MPO is computationally burdensome, especially when incorporating real-world considerations. Consequently, portfolio management in practice typically consists of repeatedly performing myopic single-period optimisations. This work addresses the second key problem—the computational intractability of a realistic multi-period portfolio management problem.
1.1 Background
Starting with Merton [6, 7], and others [8,9,10], MPO has been studied as a Markov decision problem (MDP) where optimal policies are found using dynamic programming (DP). Here, the portfolio optimisation problem is typically restricted to idealised settings that enable the construction and solution of the Bellman optimality equation. However, formulations relying on DP are typically unable to capture real-world market dynamics adequately and require several simplifications for the problem to be tractable. In particular, it is typical for the state-space to be limited to a few variables to avoid the curse of dimensionality and for the state transition function to be treated as known. In addition, the objective function is often chosen from a class of utility functions with convenient analytic properties. These utility functions typically render the problem as a single-objective optimisation problem where the risk-return trade-off is not explicit.Footnote 1 Furthermore, problems are restricted to one or two constraints of theoretical interest. Thus, studies investigating MPO through DP are largely theoretical, focusing on a qualitative understanding of normative investor behaviour.
Instead of DP, approximate policies can be determined by considering simpler (although sub-optimal) MO stochastic programming (SP) formulations that do not depend on Bellman optimality. SP is a highly flexible modelling framework for multi-period optimisation, capable of incorporating a diverse array of real-world considerations, including alternative risk measures, risks and uncertainty hedging, hard and soft constraints, and intermediate goals (including stochastic and irregular outflows) [2]. Moreover, SPs model uncertainty using scenarios, defined as sequences of states, and are not restricted to MDP formulations. However, an SP becomes computationally intractable as its specification grows more complex, necessitating approximate programs to find a policy. Common approximations include discretisation of the observed variables, aggregation of stages, reduction of the problem horizon, and replacing random quantities with their expectations [13]. When the expectations are unknown, they are replaced with forecasts sequentially updated at each timestep, more broadly referred to as a rolling horizon procedure or model predictive control (MPC), which is widely adopted in practice.
For example, Boyd et al. [2] present a convex optimisation framework for MPO suitable for MPC. They achieve this by extending the single-period mean-variance problem to multiple periods using additional risk and return objectives and constraints for each period. Competing objectives are linearly combined into a single function using trade-off parameters that reflect the relative importance of each objective (i.e. they “trade-off” different objectives). By varying the trade-off parameters and solving the optimisation problem, one can uncover the Pareto frontier or, in the finance jargon, the efficient frontierFootnote 2 [14, 15].
MO evolutionary algorithms (EAs) have been extensively applied in portfolio optimisation [16] and treat portfolio optimisation as a deterministic problem, where the objective function is known. However, in reality, portfolio optimisation more closely resembles a learning problem, where finding the Pareto frontier is akin to selecting hyper-parameters [2]. In particular, the risk and return terms of the objective function are estimated from the data. Objective values of optimised portfolios are considered in-sample (and hence highly inflated) estimates of their true performance [17], and there is also no guarantee that in-sample Pareto optimal solutions are optimal out-of-sample. Similar to hyper-parameter search in machine learning, the Pareto frontier is determined by estimating the performance of each trade-off parameter’s corresponding portfolios on separate out-of-sample data using a process known as backtesting. This process involves repeatedly solving an optimisation problem at each time step in the backtest period for each choice of trade-off parameters. MO EAs can be applied to improve the computational efficiency of the hyper-parameter selection process [18, 19].
1.2 Problem statement
In summary, despite being extensively investigated, crucial gaps remain in the portfolio optimisation literature. On the one hand, the multi-period nature of real-world portfolio management is largely unexplored in applications of MO EA. On the other hand, the MPO literature has largely ignored the MO aspects of portfolio optimisation. Both strands of literature give little consideration to the implications of formulating the portfolio optimisation problem stemming from the uncertainty of the data-generating process encountered in practice. In particular, the Pareto frontier must be determined on separate test data, which involves a computationally intensive hyper-parameter selection procedure.Footnote 3 To address these gaps, this study extends that of van Zyl et al. [19] by investigating MPO to answer the following research questions:
-
1.
How can the computational burden of constructing the Pareto frontier in a realistic MPO problem be alleviated?
-
2.
How can we improve the efficiency and performance of existing algorithms for hyper-parameter selection in the context of MO, MPO?
-
3.
What is the impact of surrogate-assisted optimisation in MO, MPO, and can it be further enhanced?
Recognising that real-world portfolio management is a type of learning problem, Boyd et al. [2] and Nystrup et al. [18] adopt a hybrid approach, where the construction of the Pareto frontier is split into a convex portfolio optimisation problem and a hyper-parameter selection problem. Solving the portfolio optimisation problem determines the solution set, whilst solving the hyper-parameter selection problem determines the non-dominated solutions from the solution set. Since most real-world considerations can be incorporated in a convex specification of the portfolio optimisation problem [2], the computational intractability of evaluating all possible hyper-parameter combinations arises from the cost associated with performing multiple evaluations on test data (backtesting). A poor strategy for selecting candidate hyper-parameters can yield many dominated solutions, resulting in unnecessary computation. The key issue, therefore, is determining the efficient frontier with as few evaluations as possible.
1.3 Contributions
Nystrup et al. [18] shows that using the MO-CMA-ES EA for determining the efficient frontier improves upon the grid search procedure used by Boyd et al. [2]. Most recently, van Zyl et al. [19] compared several seminal MO EAs and proposed a surrogate-assisted procedure to enhance their performance, but their investigation is limited to the single-period case. The objectives of this work are to extend the aforementioned studies to the multi-period setting and to present a novel method that improves not only the efficiency of the algorithms but also the overall quality and performance of the solutions. To this end, the contributions of this study are:
-
An empirical performance comparison of several seminal MOP EA for both Single-period Portfolio Optimisation (SPO) and MPO,
-
The demonstration of the superior efficacy of surrogate-assisted optimisation to alleviate the computational burden of constructing the Pareto frontier for the MPO case,
-
And the presentation of a new algorithm, Pareto driven surrogate (ParDen-Sur), that improves upon the state-of-the-art surrogate-assisted portfolio optimisation
The presented method, ParDen-Sur, recognises several deficiencies in the originally developed ParDen algorithm [19] and contains several extensions to overcome these. Firstly, whilst ParDen only allows for generative models as surrogates, ParDen-Sur can also allow for the integration of discriminative models, allowing for a much broader range of models to be used as surrogates. Secondly, ParDen-Sur is especially cognisant of the limitations of adding additional free parameters to a surrogate-assisted algorithmic framework. To limit the number of free parameters and ensure the diversity of the population, ParDen-Sur introduces a reservoir sampling-based look-ahead mechanism that uses the surrogate model to iterate the EA forward several generations. Introducing a look-ahead procedure allows one to consider forgoing the acceptance sampling.Footnote 4 Lastly, ParDen-Sur uses a rank-based metric in the surrogate framework resulting in improved empirical performance. We argue that this is attributed to rankings being an easier learning target than accuracy but acknowledge that performance increases may arise from selective bias, which we investigate in future work.
2 Preliminaries
2.1 A convex optimisation framework for portfolio optimisation
The original mean-variance optimisation problem is a SPO specified by a bi-objective criterion, where risk is measured by the variance of the portfolio’s return [1]. These objectives are combined linearly into a single optimisation problem. Using the SP approach, Boyd et al. [2] extends Markowitz’s formulation by presenting a convex optimisation framework for MPO, which includes the single-period problem as a special case. Notably, trading and holding costs are treated as soft constraints selected to achieve some desired trading behaviour and are typically used as regularisation methods. The portfolio optimisation problem can be equivalently formulated by including the soft constraints as additional criteria in the objective function, with associated trade-off parameters:
where \(H \in {\mathbb {N}}\) represents the investment horizon, \({\textbf{w}}_{\tau }\) is a vector of portfolio weights at each period \(\tau = t, \dots , t+H\), \(\mathbf {\mu }_{\tau }\) and \(\Sigma _{\tau }\) are the return and risk forecasts, \({\mathcal {W}}_{\tau }\) and \({\mathcal {Z}}_{\tau }\) are convex sets representing the holding and trading constraints, respectively, and \(\gamma _{\text {risk}}\), \(\gamma _{\text {trade}}\), and \(\gamma _{\text {hold}}\) are the trade-off parameters for risk, trading costs, and holding costs, respectively. Note that setting \(H=1\) specifies the single-period problem.
The extended formulation of the mean-variance problem in Eq. 1 is analytically intractable. Computational methods determine the efficient frontier by repeatedly solving the optimisation problem for different trade-off parameters (\(\gamma _{\text {risk}}\), \(\gamma _{\text {trade}}\) and \(\gamma _{\text {hold}}\)). Given that SPO is a quadratic programming problem, it is reasonable to assume that a solver such as ECOS used in the study’s empirical evaluation will be polynomial of order \({\mathcal {O}}(n^3)\) where n is the number of assets [20]. Extending the single-period formulation to H periods increases the number of decision variables to Hn, resulting in the computational complexity further increasing to order \({\mathcal {O}}\left( (Hn)^3\right)\) [2]. The search for a Pareto frontier considers three trade-off parameters, so the aforementioned optimisation problem of order \({\mathcal {O}}\left( (Hn)^3\right)\) must search over a volume in three dimensions d resulting in an overall complexity \({\mathcal {O}}\left( d^3(Hn)^3\right)\). However, unlike Markowitz’s original formulation, not all selected trade-off parameters are non-dominated and associated with the Pareto optimal solutions. These dominated solutions result in excess computation.
2.2 Backtesting
When the data-generating process is unknown, the performance of a portfolio is evaluated on data not used during the portfolio optimisation process. The backtesting process consists of sequentially performing the optimisation in Eq. 1 to construct a portfolio \({\textbf{w}}_{t}\) at each time t, which earns a return \({\tilde{r}}_{\gamma , t+1}\) at time \(t+1\), for each hyper-parameter combination \(\gamma =\left( \gamma _{\text {risk}}, \gamma _{\text {trade}}, \gamma _{\text {hold}} \right)\) over a historical period \(t = 1, \dots , T-1\). The backtest performance of each hyper-parameter is summarised by its out-of-sample mean and standard deviation of returns \(({\tilde{\mu }}_{\gamma }, {\tilde{\sigma }}_{\gamma })\). A hyper-parameter combination \(\gamma\) is dominated by another \(\gamma '\) if \({\tilde{\mu }}_{\gamma } < {\tilde{\mu }}_{\gamma '}\) and \({\tilde{\sigma }}_{\gamma } > {\tilde{\sigma }}_{\gamma '}\). The backtesting procedure aims to find the set of non-dominated hyper-parameters in terms of out-of-sample performance.
2.3 Evolutionary algorithms
Numerous evolutionary MOP algorithms exist in the literature [21, 22]. Amongst these, certain algorithms are successful in applications across several different domains [23,24,25,26,27,28]. The use of evolutionary algorithms (EAs) for finding solutions to portfolio optimisation problems has been covered extensively in the portfolio optimisation literature [29,30,31] with the focus almost exclusively given to the single-period problem. The presented study aims to apply various representative EAs and demonstrate the utility of a surrogate-assisted evolutionary optimisation approach to solving portfolio optimisation problems described in this paper. To this end, this study implements the evolutionary MOP methods described below.
2.3.1 MO-CMA-ES
The Covariance Matrix Adaptation Evolution Strategy (CMA-ES) is an elitist evolutionary strategy for numerical optimisation. Multi-objective CMAES (MO-CMA-ES) maintains a population of individuals that adapt their search strategy as in the elitist CMA-ES. The elites are subjected to MO selection pressure. The selection pressure originates from non-dominated sorting using the crowding-distance first and hypervolume as the second criterion [25].
2.3.2 NSGA-II
The NSGA-II algorithm follows the form of a Genetic Algorithm (GA) with modified crossover and survival. The surviving individuals are chosen Pareto front-wise first. A situation arises where a front needs to be split since not all individuals can survive. When splitting the front, solutions are selected based on a Manhattan crowding distance in the objective space. However, the method seeks to hold onto the extreme points from each generation, and as a result, they are assigned a crowding distance of infinity. Furthermore, the method uses a binary tournament mating selection to increase selection pressure. Each individual is first compared by rank and then crowding distance [32].
2.3.3 R-NSGA-II
The R-NSGA-II algorithm follows NSGA-II with a modified survival selection mechanism. Unlike NSGA-II, solutions are selected based on rank in splitting the front. This rank is calculated based on the Euclidean distance to supplied reference points. The solution closest to a reference point is assigned a rank of one. The algorithm then selects the points with the highest rank to each reference point as offspring. After each reference point has selected the solution with the best rank for survival, all solutions within the epsilon distance of surviving solutions are “cleared”, meaning they cannot be selected for survival until all fronts have been processed. The cleared points are considered if more solutions still need to be selected-the free parameter epsilon with a smaller value results in a tighter set of solutions [32].
2.3.4 NSGA-III
The NSGA-III algorithm is based on reference directions instead of reference points. For the survival mechanism, the algorithm has a modified approach to dealing with the front splitting after non-dominated sorting. The algorithm fills up the under-represented reference direction first. If the reference direction does not have any solution assigned, the solution with the smallest perpendicular distance in the normalised objective space is assigned as the survivor. If additional solutions for a reference direction are required, these are assigned randomly. Consequently, when this algorithm converges, each reference direction attempts to find a suitable non-dominated solution [32].
2.3.5 R-NSGA-III
The R-NSGA-III algorithm follows the general NSGA-III procedure with a modified survival selection operator. First, non-dominated sorting is done as in NSGA-III. Solutions are associated with aspiration points based on perpendicular distance, and solutions from the underrepresented reference direction are chosen. For this reason, when this algorithm converges, each reference line seeks to find a good representative, non-dominated solution [32].
2.3.6 U-NSGA-III
The U-NSGA-III algorithm uses tournament pressure to improve the original NSGA-III approach that randomly selects parents for mating [32]. The advantages of tournament selection include promoting better convergence by favouring individuals with higher fitness and maintaining diversity within the population, which is essential for avoiding premature convergence. Additionally, the selection pressure can be controlled by adjusting the size of the tournament, allowing for a balance between exploration and exploitation. This feature makes the U-NSGA-III algorithm more versatile and adaptable for different problem sizes and complexities, improving the overall performance and reliability of the multi-objective optimisation process [33, 34].
2.4 Surrogate-assisted optimisation
Surrogate models are used in optimisation problems where the objective function is unknown and costly to evaluate. In the surrogate-assisted approach, objective values (outputs) are first evaluated for a sample of different decision variable choices (inputs). Then, a supervised learning algorithm (the surrogate) is trained on the input–output pairs to estimate the objective function. The surrogate model can then assist in numerically optimising the objective function. The surrogate model can also be sequentially improved by including input–output pairs for candidate solutions at each iteration as the optimisation algorithm proceeds [35]. This study’s unknown objective function is the out-of-sample performance over the hyper-parameter space of both SPO and MPO (Figs. 1, 2).

SPO versus MPO primary example: optimal frontiers
3 Pareto Driven Surrogate
Surrogate methods have been extensively applied in single objective optimisation [36,37,38,39,40,41,42,43], whereas the applications of surrogate-assisted methods within a MO setting is substantially less common. In particular, the literature for data-driven evolutionary MO surrogate-assisted optimisation is especially sparse [44,45,46,47]. To this end, the presented Pareto driven surrogate (ParDen-Sur) framework is sufficiently general that it can be applied together with most evolutionary MO algorithms.
ParDen-Sur relies on the use of supervised learning models to act as a surrogate drop-in replacement \({\hat{f}}(\cdot )\) to evaluate a computationally resource-intensive real-world experiment or simulation \(f(\cdot )\). The core idea of ParDen-Sur is to limit the evaluation of candidates using the simulation \(f(\cdot )\) to only those that have a high probability of advancing the Pareto front (the non-dominated solution set \({\mathcal {P}}\)). The likelihood that a candidate would advance the Pareto front is determined by: i) whether the surrogate model predicts that the candidate advances the Pareto front and ii) the extent to which the surrogate is correct. In particular, ParDen-Sur attempts to estimate the probability that the surrogate is correct, which is used as a threshold within an acceptance sampling scheme, and to set the size of a reservoir sampling look-ahead scheme when selecting candidates.
To determine the extent to which the surrogate is correct, a mechanism is required for assessing the probability \(P\left[ (x_i, y_i) \in {\mathcal {P}} | {\hat{f}}\right]\) that a pretender \((x_i, y_i)\) will be in the current non-dominated set \({\mathcal {P}}\) given the surrogate’s prediction \({\hat{y}}_i = {\hat{f}}(\cdot )\). ParDen-Sur employs k-fold cross-validation \({\text {CV}}_k(\cdot )\) together with the non-dominating rank [48] of each candidate to estimate this probability as a non-dominated score (\({\text {NDScore}}\)).
Calculating an \({\text {NDScore}}\) requires fitting surrogates \({\hat{f}}_{_{X_T, Y_T}}(\cdot )\) to the training splits \((X_T, Y_T)\) with the MO \(Y_T\) as the target. For each point in a validation split \((X_V, Y_V)\), its non-dominating rank r in the split is calculated. The surrogates estimate the objective values on the validation split, \({\hat{Y}}_V={\hat{f}}_{_{X_T, Y_T}}(X_V)\), and their non-dominating ranks are calculated, producing predicted ranks \({\hat{r}}\). The performance of the predicted non-dominated ranks is evaluated using any error metric \({\mathcal {E}}({\hat{r}}, r)\), that is constrained to sum to one. Finally, the non-dominated score can be calculated by aggregating the errors calculated for the different splits: ParDen-Sur allows the use of any metric \({\mathcal {E}}({\hat{r}}, r)\) constrained to sum to one, to compare r with \({\hat{r}}\):
with
where \(\lceil \cdot \rceil ^\uparrow\) assigns the non-dominating rank to each vector, since ParDen-Sur uses the k-fold cross-validation function \({\text {CV}}_k(\cdot )\) to estimate this value, the mean error across the k splits is a suitable aggregation.

ParDen-Sur Algorithm

Flowchart for the ParDen-Sur Algorithm
4 Methodology
In this study, the experimentation is split into two stages, referred to as the motivating and primary examples, respectively, for both the SPO and MPO cases. The motivating example is a scaled-down version of the problem presented in the primary example. In the motivating example, several well-known MOP EAs are initially applied to the aforementioned problem (see Sect. 2) to determine which performs best and to provide a relevant baseline, after which, the study then applies ParDen-Sur with the two best performing EAs in the primary example.
All experiments are repeated ten times, and average results are compared to the baseline EAs. The outperformance of the Parden-Sur algorithm is assessed for statistical significance using one-sided Mann-Whitney U tests and adjusted for multiple testing using the Simes-Hochberg procedure. Hyper-parameters for the EAs are manually adapted from van Zyl et al. [19].
4.1 Method metrics
This study considers three metrics as performance indicators for the solution set generated by each algorithm. These include the two modified distance calculations, generational distance plus (GD+) and inverted generational distance plus (IGD+) [49], as well as the Hypervolume (HV) [50]. For GD+ and IGD+, an optimal target set needs to be specified, which is specified in the results below as the Pareto frontier from a random grid search with 6510 hyper-parameters. For HV, only a reference point needs to be provided, which is (40, 0) in the risk-return space.
This study considers three metrics as performance indicators for the solution set generated by each algorithm. These include the two modified distance calculations, generational distance plus (GD+) and inverted generational distance plus (IGD+) [49], as well as the Hypervolume (HV) [50].
Consider the objective vector set \(A = \lbrace a_1, a_2, \dots , a_{|A|}\rbrace\) representing the points found by the algorithm, and the reference points set \(Z = \lbrace z_1, z_2, \dots , z_{|Z|}\rbrace\), which corresponds to the Pareto frontier.
For GD+ and IGD+, an optimal target set needs to be specified, which is specified in the results below as the Pareto frontier from a random grid search with 6510 hyper-parameters. For HV, only a reference point must be provided, chosen to be (40, 0) in the risk-return space.
-
Generational distance plus (GD+): This metric measures the average distance between the non-dominated solutions generated by the algorithm and the closest points in the optimal target set (Pareto frontier). A smaller GD+ value indicates better algorithm convergence towards the Pareto frontier. The formula for GD+ is:
$$\begin{aligned} \begin{aligned} \text {GD}^+(A)&= \; \frac{1}{|A|} \; \bigg ( \sum _{i=1}^{|A|} {d_i^{+}}^2 \bigg )^{1/2}\\ \end{aligned} \end{aligned}$$(4)where \(d_i^{+} = \max {(a_i - z_i, 0)}\) represents the modified distance from \(a_i\) to its nearest reference point in Z with the corresponding value \(z_i\).
-
Inverted generational distance plus (IGD+): This metric calculates the average distance between the points on the Pareto frontier and the closest non-dominated solutions generated by the algorithm. A smaller IGD+ value implies better convergence and diversity of the solutions, as they cover the optimal target set more effectively. The formula for IGD+ is:
$$\begin{aligned} \begin{aligned} \text {IGD}^{+}(A)&= \; \frac{1}{|Z|} \; \bigg ( \sum _{i=1}^{|Z|} {d_i^{+}}^2 \bigg )^{1/2}\\ \end{aligned} \end{aligned}$$(5)where \(d_i^{+} = \max {(a_i - z_i, 0)}\) represents the modified distance from \(z_i\) to the closest solution in A with the corresponding value \(a_i\).
-
Hypervolume (HV): This metric quantifies the volume of the objective space dominated by the current set of solutions generated by the algorithm. Higher Hypervolume values indicate better convergence and diversity of the solutions, as they cover a larger portion of the Pareto-optimal region. As the algorithm progresses through generations, an increase in Hypervolume signifies that the algorithm is approaching the Pareto frontier more closely, achieving better trade-offs between the multiple objectives.
Evaluating the solution quality of evolutionary approaches can be challenging, as no single metric can provide a complete picture of the performance across all scenarios. Therefore, it is essential to consider multiple metrics to assess the algorithms’ effectiveness comprehensively. In this study, we employ solution quality metrics as defined by [51]:
-
Success rate (SR): Success is defined as meeting a required quality criterion, such as a solution within 99% or 95% of the known optimal value. For this analysis, the Hypervolume of the random 6510 grid search is considered the optimal solution. The success rate is the percentage of algorithm executions that meet the success criterion.
-
Average evaluations to success rate (AESR): This metric measures the average number of evaluations required by the EA to reach a solution at a selected success rate. For example, the AESR at a 99% SR would be the average number of evaluations needed to achieve that SR. The runs of the EA that do not meet the SR criterion are disregarded.
-
Average generations to success rate (AGSR): Similar to AGSR, AGSR calculates the average number of generations required by the EA to reach a solution at a given success rate. For instance, the AGSR at a 99% SR would be the average number of generations needed to reach that level. Runs of the EA that do not meet the SR criterion are not considered.
We can better understand their performance and robustness in different circumstances by evaluating the algorithms using multiple solution quality metrics. This approach helps identify the strengths and weaknesses of each algorithm and supports informed decision-making when selecting an optimisation method.
4.2 Hyper-parameters
The experiments use Latin Hyper-cube Sampling for random selection for all the EAs, real Uniform Crossover (UX) for crossover, and real Polynomial Mutation (PM) for mutation. For all comparisons, the results use a population size of 60 and an offspring size of 30. The EAs techniques all had a total evaluation budget of 510. The study uses Riesz s-Energy to generate reference directions or reference points. Table 1 shows the selected hyper-parameter values unique to the individual EAs. In the study, the hyper-parameters are selected once, and these values are re-used for both the SPO and MPO problems [32].
For ParDen-Sur, the free parameter is the termination criteria for the look-ahead reservoir sampling. Multi-objective space tolerance termination was selected with a value of 0.0001 [32] set according to the scale of the solutions, which are values in the range 0 to 60 with up to three decimal places being significant.
4.3 Research instruments and data
The motivating and primary examples for the SPO and MPO cases are prepared using two different datasets. The dataset used in the primary examples is prepared exactly as in Boyd et al. [2]. In contrast, a scaled-down version of this dataset is used in the motivating example. The scaled-down version is explored to determine the most appropriate application of ParDen-Sur within the primary example. The need arises from the time-consuming nature of the experiments - on the order of days.
In the primary example, consideration is limited to \(\pm\, 410\) assets from the S&P 500 Index with a full set of \(\pm\, 1800\) daily price data points over the five years from January 2012 to December 2016. Daily volatilities for determining transaction costs are calculated using the absolute difference between log open and close prices, while the bid-ask spread is fixed at \(0.05\%\). Holding costs are fixed at \(0.01\%\). These quantities are used to calculate the backtest performance of a policy.
Furthermore, risk, return, and trading cost forecasts are required at each backtest period to construct the portfolio. Investigating different forecasting techniques is out of the scope of this study. Instead, return forecasts are imitated by adding zero-mean Gaussian noise to realised returns, whilst volatility and volume forecasts are specified using ten-day moving averages. For the MPO case, we consider a two-period optimisation (i.e. \(H=2\) in Eq. 1). The two-period case increases the computational time by a factor of three over the single period-case.
The datasets for the motivating example are prepared similarly, except that consideration is limited to \(\pm 30\) assets from the Dow Jones Industrial Index over the eighteen months (\(\pm 547\) data points) from July 2015 to December 2016. For further details, consult the supplementary materials.
All experiments use Ubuntu 20.04.1 LTS and are run on Intel(R) Xeon(R) CPU E5-2683 and E5-2695 v4 @ 2.10GHz. The study uses pymoo v0.5, pysamoo v0.1, and cvxportfolio [2]. The source code and data for reproducing the results are available on GitHub, here.
5 Results
The following section discusses the results for the SPO and then for the MPO.
5.1 Single-period portfolio optimisation
5.1.1 Motivating example
One of the objectives of the motivating example is to ascertain which two of the various seminal MO EA optimisation techniques are most appropriate for applying the ParDen-Sur algorithm within the Single-period Portfolio Optimisation (SPO) problem. Considering Table 2 we note that the results for NSGA-II and R-NSGA-II are mixed, with neither method outperforming the other across all indicators. It is worth noting that none of the implemented methods outperforms the 6510 random points.
Having identified the top-performing MO EA optimisation, the second objective of the motivating example is to determine which of the two selected methods is best suited for the application of ParDen-Sur. The results in Table 2 highlight the superiority of ParDen-Sur applied to NSGA-II over R-NSGA-II. Further, the statistical tests indicate that ParDen-Sur results are indeed significant and support an argument for ParDen-Sur’s superiority over the baseline EA as well as the superiority of using look-ahead with reservoir sampling over the original ParDen-Sur algorithm. Further, the results show that no matter which underpinning EA is used, the ParDen-Sur results are always statistically significantly superior.
We consider the quality indicators next, where the objective is to ascertain the degree to which ParDen-Sur is assisting the underpinning EA. Table 3 reinforces the selection of NSGA-II over R-NSGA-II given the superior SR and similar total evaluations as measured by AESR and AGSR. Further, the results show that no matter which underpinning EA is used, the superiority of ParDen-Sur results is always statistically significant.
5.1.2 Primary example
The main objective of the SPO primary example is to replicate the existing research and provide context for the current ParDen-Sur results. To this end, Table 4 replicates the previous studies by [18] and [19]. The results reinforce the superior performance of ParDen-Sur over both NSGA-II and MO-CMA-ES as underpinning EAs. Further, the results highlight the superiority of look-ahead with reservoir sampling as found in ParDen-Sur over using just acceptance sampling. One interesting result requiring further investigation is the superior performance of R-NSGA-II when considering GD+.
Looking toward the quality indicators, the results in Table 5 reinforce the superior performance of ParDen-Sur with look-ahead over ParDen-Sur without for both NSGA-II and MO-CMA-ES. Having established the superiority of ParDen-Sur with a look-ahead in the SPO problem space, the study now turns to the more challenging MPO problem.
5.2 Multi-period portfolio optimisation
5.2.1 Motivating example
The main objective of the motivating example was to establish which MO EA algorithms to use in conjunction with ParDen-Sur. Table 6, like in the SPO motivating example, indicates that NSGA-II and R-NSGA-II are superior choices for underpinning EAs. These techniques significantly outperform MO-CMA-ES previously proposed by Nystrup et al. [18].
When considering the second objective of the motivating example as to which of the top two underpinnings EAs are best suited to further exploration with ParDen-Sur, Table 6 shows a slight benefit in favour of NSGA-II. However, when we consider the quality indicators in Table 7, the results show that any gains by R-NSGA-II are also linked to substandard Success Rates at the 99% threshold. Interestingly, the quality indicators indicate that ParDen-Sur has lower AESR@99 and AGSR@99 than the underpinning EAs. However, the jump in SR@99 to 100% warrants further exploration and points to the superiority of ParDen-Sur not just for reducing the convergence rate but also for improving the probability of convergence. This argument is further supported when considering the superiority of ParDen-Sur at the 95% threshold.
Having established the superiority of ParDen-Sur coupled with NSGA-II on the multi-period portfolio optimisation (MPO) motivating example, the study now focuses on the MPO primary results.
5.2.2 Primary example
The main aim of this study is to evaluate the use of ParDen-Sur in the context of MPO in the primary example. Table 9 shows the out-performance of all variants of ParDen-Sur. HV improvement is marginal (0.8%) over the state-of-the-art (SOTA) - NSGA-II. However, for GD+ and IGD+, these improvements over the SOTA (R-NSGA-II and NSGA-II) are 19.4% and 66.5%, respectively. Most interesting is the superior performance obtained using look-ahead. The p-values of the Mann–Whitney U tests (with multiple testing adjustments) in Table 8 add further weight by demonstrating the out-performance is statistically significant at the \(5\%\) level for all tests (with nearly all tests being significant at the \(1\%\) level).
When considering the quality indicators in Table 10 the results show marked improvements in both AESR@99 and AGSR@99, with ParDen-Sur having a \(1.84\times\) and \(2.02\times\) speedup over the underpinning EA in both these metrics. We also note that ParDen-Sur without acceptance sampling outperforms when considering the AESR@99. This interesting result suggests the benefit of one less free parameter and a possible algorithm simplification. It is worth contrasting this with the results in Tables 3 and 7, which have both supporting and conflicting support of this observation.
6 Discussion
The presented results demonstrate that the challenges of optimal hyper-parameter search related to multi-period optimisation are tractable within the context of surrogate-assisted MO optimisation. Further, the results support the use of the ParDen-Sur algorithm with NSGA-II to significantly improve the rate at which one can arrive at a solution and the quality of the solutions found. These solutions could be acquired using commodity hardware without significantly impacting computational resources other than the need for additional CPUs.
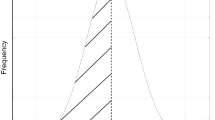
Previously, surrogate-assisted portfolio optimisation has been shown to speed up single-period hyper-parameter searches [19]. This study confirms and extends those results to the multi-period optimisation use case. The outcome suggests that all versions of ParDen-Sur, the proposed method, lead to a speed-up in acquiring optimal frontiers in the portfolio optimisation task, as seen in Fig. 3.
Previous work [19] showed that the ParDen framework could speed up both MO-CMA-ES and NSGA-II, and the results in this study show that this extends to R-NSGA-II. Furthermore, the results are demonstrated on more than one dataset and for multiple periods. However, without testing this statement across the full battery of EAs, it is impossible to ascertain if the extensions to ParDen as contained in ParDen-Sur are a general-purpose surrogate-assisted optimisation framework.
In the previous study, ParDen used only acceptance sampling to improve speed-up [19]. The results demonstrate that including look-ahead with acceptance, sampling is a superior approach, as confirmed in Fig. 4. Further, when AESR is not a concern, forgoing acceptance sampling in favour of looking ahead provides the best speed-up.
It is worth noting that the combination of acceptance sampling and look-ahead has a net positive impact on AESR. The case for minimal AESR would occur when one is, for instance, being charged for resources. Here using the smallest amount of simulation evaluations is desirable over the smallest number of generations as measured by AGSR.

Hypervolume comparison of ParDen-Sur variants and NSGA-II (higher is better). All ParDen-Sur variants with Look-ahead achieve, on average, an optimal solution in fewer generations, as indicated by their positions in the upper left-hand corners. Trial lines are shown in grey

Hypervolume comparison of the best ParDen-Sur variants and NSGA-II (higher is better). The max-fill variant with Look-ahead achieves an optimal solution in the fewest generations, as indicated by its dominant position in the upper left-hand corner
7 Conclusion
This study presents the ParDen-Sur surrogate-assisted optimisation algorithm, an extension to the original ParDen algorithm by van Zyl et al. [19], to address the computational difficulty of finding the efficient frontier for multi-period portfolio optimisation. The extension is a reservoir sampling-enabled look-ahead mechanism for generating new offspring. Both the look-ahead and the acceptance sampling rely on the NDScore. Here the NDScore is extended to include Kendall-\(\tau\). The extension and the original acceptance sampling mechanism are tested on the problems of SPO and MPO. The three variants of ParDen-Sur are evaluated across several EAs. Both performance and quality metrics are taken into account.
The experiments involve an empirical performance comparison of several seminal MOP EA for both SPO and MPO. The effects demonstrate the superior efficacy of surrogate-assisted optimisation in alleviating the computational burden of constructing a Pareto frontier and support the presentation of a new algorithm, ParDen-Sur, which improves upon the state-of-the-art surrogate-assisted portfolio optimisation by introducing a reservoir sampling-based look-ahead mechanism. The results demonstrate a statistically significant improvement in both performance and quality of solutions when ParDen-Sur is applied to the aforementioned problems with the underpinning EAs considered. However, reservoir sampling-enabled look-ahead has the most impact on the results.
The HV improvement with ParDen-Sur is marginal over the state-of-the-art (SOTA). However, for GD+ and IGD+, these improvements are statistically significant. In practice, these improvements are both realisable on commodity hardware and would result in substantive improvements in arriving at optimal solutions to the multi-period portfolio optimisation problem.
The study has demonstrated the benefit of ParDen-Sur for the portfolio optimisation hyper-parameter search problem. Although the study evaluates the use of surrogates in general, the study does not say anything about which of the current multitude of approaches to the surrogate-assisted optimisation is best overall. Extensive coverage of further approaches to surrogate-assisted optimisation would go a long way towards answering these questions. Secondly, the study is constrained to a particular market with particular characteristics. Future work will look to explore additional markets as well as additional problem domains in which ParDen-Sur might be of value.
Data availability
The datasets generated during and/or analysed during the current study are available on GitHub, here.
Code availability
The source code used during the current study is available on GitHub, here.
Notes
We use the terms Pareto frontier and efficient frontier interchangeably throughout this work.
Another important implication of uncertainty in the data-generating process is that statistical comparison between solution methods needs to account for an additional source of randomness arising from the sampling variation of the backtest data. This is in contrast to the typical use of statistical methods to compare algorithm performance, which only accounts for the variation due to the stochastic elements of the algorithm. However, proposing a statistical test that includes this additional source of variation is outside the scope of this study.
Forgoing acceptance sampling without look-ahead is equivalent to the original EA algorithm.
References
Markowitz H (1952) Portfolio selection. J Financ 7(1):77–91
Boyd S, Busseti E, Diamond S, Kahn RN, Koh K, Nystrup P, Speth J et al (2017) Multi-period trading via convex optimization. Found Trends Optim 3(1):1–76
Lee W (2000) Theory Methodol Tactical Asset Alloc, vol 65. John Wiley & Sons, Hoboken
Hendricks D, Wilcox D (2014) A reinforcement learning extension to the almgren-chriss framework for optimal trade execution. In: 2014 IEEE conference on computational intelligence for financial engineering & economics (CIFEr). IEEE, pp 457–464
Kolm PN, Tütüncü R, Fabozzi FJ (2014) 60 years of portfolio optimization: Practical challenges and current trends. Eur J Oper Res 234(2):356–371
Merton RC (1969) Lifetime portfolio selection under uncertainty: The continuous-time case. Rev Econ Stat 51(3):247–257
Merton RC (1971) Optimum consumption and portfolio rules in a continuous-time model. J Econ Theory 3(4):373–413
Mossin J (1968) Optimal multiperiod portfolio policies. J Bus 41(2):215–229
Samuelson PA (1975) Lifetime portfolio selection by dynamic stochastic programming. Stoch Optim Models Financ 12:517–524
Constantinides GM (1979) Multiperiod consumption and investment behavior with convex transactions costs. Manag Sci 25(11):1127–1137
Zhou XY, Li D (2000) Continuous-time mean-variance portfolio selection: A stochastic lq framework. Appl Math Optim 42(1):19–33
Li D, Ng W-L (2000) Optimal dynamic portfolio selection: Multiperiod mean-variance formulation. Math Financ 10(3):387–406
Powell WB (2019) A unified framework for stochastic optimization. Eur J Oper Res 275(3):795–821
Paskaramoorthy AB, Gebbie TJ, van Zyl TL (2020) A framework for online investment decisions. Invest Anal J 49(3):215–231
Paskaramoorthy A, Gebbie T, Van Zyl TL (2021) The efficient frontiers of mean-variance portfolio rules under distribution misspecification. In: 2021 IEEE 24th international conference on information fusion (FUSION). IEEE, pp 1–8
Ponsich A, Jaimes AL, Coello CAC (2012) A survey on multiobjective evolutionary algorithms for the solution of the portfolio optimization problem and other finance and economics applications. IEEE Trans Evol Comput 17(3):321–344
Kan R, Smith DR (2008) The distribution of the sample minimum-variance frontier. Manag Sci 54(7):1364–1380
Nystrup P, Lindström E, Madsen H (2020) Hyperparameter optimization for portfolio selection. J Financ Data Sci 2(3):40–54
van Zyl TL, Woolway M, Paskaramoorthy A (2021) Parden: Surrogate assisted hyper-parameter optimisation for portfolio selection. In: 2021 8th International Conference on Soft Computing & Machine Intelligence (ISCMI). IEEE, pp 101–107
Domahidi A, Chu E, Boyd S (2013) Ecos: An socp solver for embedded systems. In: 2013 European cntrol cnference (ECC). IEEE, pp 3071–3076
Liu Q, Li X, Liu H, Guo Z (2020) Multi-objective metaheuristics for discrete optimization problems: A review of the state-of-the-art. Appl Soft Comput 12:16082
Bowditch Z, Woolway M, van Zyl T (2019) Comparative metaheuristic performance for the scheduling of multipurpose batch plants. In: 2019 6th International Conference on Soft Computing & Machine Intelligence (ISCMI). IEEE, pp 121–125
Deb K, Pratap A, Agarwal S, Meyarivan T (2002) A fast and elitist multiobjective genetic algorithm: Nsga-ii. IEEE Trans Evol Comput 6(2):182–197
Zhang Q, Li H (2007) Moea/d: A multiobjective evolutionary algorithm based on decomposition. IEEE Trans Evol Comput 11(6):712–731
Igel C, Hansen N, Roth S (2007) Covariance matrix adaptation for multi-objective optimization. Evol Comput 15(1):1–28
Helbig M, Engelbrecht AP (2014) Population-based metaheuristics for continuous boundary-constrained dynamic multi-objective optimisation problems. Swarm Evol Comput 14:31–47
AlSattar H, Zaidan A, Zaidan B, Bakar MA, Mohammed R, Albahri O, Alsalem M, Albahri A (2020) Mogsabat: A metaheuristic hybrid algorithm for solving multi-objective optimisation problems. Neural Comput Appl 32(8):3101–3115
Halim Z et al (2020) Optimizing the dna fragment assembly using metaheuristic-based overlap layout consensus approach. Appl Soft Comput 92:106256
Doering J, Kizys R, Juan AA, Fitó À, Polat O (2019) Metaheuristics for rich portfolio optimisation and risk management: Current state and future trends. Oper Res Perspect 6:100121
Loukeris N, Donelly D, Khuman A, Peng Y (2009) A numerical evaluation of meta-heuristic techniques in portfolio optimisation. Oper Res 9(1):81–103
Fernandez E, Gomez C, Rivera G, Cruz-Reyes L (2015) Hybrid metaheuristic approach for handling many objectives and decisions on partial support in project portfolio optimisation. Inf Sci 315:102–122
Blank J, Deb K (2020) pymoo: Multi-objective optimization in python. IEEE Access 8:89497–89509
Seada H, Deb K (2014) U-nsga-iii: A unified evolutionary algorithm for single, multiple, and many-objective optimization. COIN Report 2014022
Seada H, Deb K (2015) U-nsga-iii: a unified evolutionary optimization procedure for single, multiple, and many objectives: proof-of-principle results. In: Evolutionary multi-criterion optimization: 8th international conference, EMO 2015, Guimarães. Proceedings, Part II. Springer, pp 34–49
Sobester A, Forrester A, Keane A (2008) Engineering design via surrogate modelling: a practical guide. John Wiley & Sons, Hoboken
Ben Salem M, Roustant O, Gamboa F, Tomaso L (2017) Universal prediction distribution for surrogate models. SIAM/ASA J Uncertain Quant 5(1):1086–1109
Zhou Z, Ong YS, Nair PB, Keane AJ, Lum KY (2006) Combining global and local surrogate models to accelerate evolutionary optimization. IEEE Trans Syst Man Cybern Part C Appl Rev 37(1):66–76
Wan X, Pekny JF, Reklaitis GV (2005) Simulation-based optimization with surrogate models-application to supply chain management. Comput Chem Eng 29(6):1317–1328
Stander L, Woolway M, van Zyl T (2020) Extended surrogate assisted continuous process optimisation. In: 2020 7th international conference on soft computing & machine intelligence (ISCMI). IEEE, pp 275–279
Perumal R, van Zyl TL (2020) Surrogate assisted methods for the parameterisation of agent-based models. In: 2020 7th international conference on soft computing & machine intelligence (ISCMI). IEEE, pp 78–82
Stander L, Woolway M, Van Zyl TL (2022) Surrogate-assisted evolutionary multi-objective optimisation applied to a pressure swing adsorption system. Neural Comput Appl 13:1–17
Perumal R, van Zyl TL (2022) Surrogate-assisted strategies: the parameterisation of an infectious disease agent-based model. Neural Comput Appl 12:1–11
Timilehin O, van Zyl TL (2021) Surrogate parameters optimization for data and model fusion of covid-19 time-series data. In: 2021 IEEE 24th international conference on information fusion (FUSION). IEEE, pp 1–7
Wang H, Jin Y (2018) A random forest-assisted evolutionary algorithm for data-driven constrained multiobjective combinatorial optimization of trauma systems. IEEE Trans Cybern 50(2):536–549
Yang C, Ding J, Jin Y, Chai T (2019) Offline data-driven multiobjective optimization: Knowledge transfer between surrogates and generation of final solutions. IEEE Trans Evol Comput 24(3):409–423
Chugh T, Chakraborti N, Sindhya K, Jin Y (2017) A data-driven surrogate-assisted evolutionary algorithm applied to a many-objective blast furnace optimization problem. Mater Manuf Process 32(10):1172–1178
Stander L, Woolway M, van Zyl T (2020) Data-driven evolutionary optimisation for the design parameters of a chemical process: A case study. In: 2020 IEEE 23rd international conference on information fusion (FUSION). IEEE, pp 1–8
Selvi ST, Baskar S, Rajasekar S (2018) Application of evolutionary algorithm for multiobjective transformer design optimization. In: Classical and recent aspects of power system optimization. Elsevier, Amsterdam, pp 463–504
Ishibuchi H, Masuda H, Tanigaki Y, Nojima Y (2015) Modified distance calculation in generational distance and inverted generational distance. In: International conference on evolutionary multi-criterion optimization. Springer, pp 110–125
Fonseca CM, Paquete L, López-Ibánez M (2006) An improved dimension-sweep algorithm for the hypervolume indicator. In: 2006 IEEE international conference on evolutionary computation. IEEE, pp 1157–1163
Eiben A, Smith J (2015) Introduction to evolutionary computing. Springer, Heidelberg, New York, Dordrecht, London
Acknowledgements
This study was partly supported by the National Research Foundation of South Africa (Grant Number: 129541). This study was also supported in part by the Nedbank Research Chair.
Funding
Open access funding provided by University of Johannesburg.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors have no competing interests to declare.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
van Zyl, T.L., Woolway, M. & Paskaramoorthy, A. Surrogate-assisted hyper-parameter search for portfolio optimisation: multi-period considerations. Neural Comput & Applic (2023). https://doi.org/10.1007/s00521-023-09176-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00521-023-09176-7