
Abstract
The emergence of digital media has changed the way people live and learn. In the context of the new era, digital media is gradually integrating into people’s life and learning. Digital media contains massive images, and fine-grained image recognition for digital media has become an important topic. The challenge of fine-grained image recognition is that the difference between different categories is small, and the difference between the same categories is sometimes large. This work designs a fine-grained image recognition based on feature enhancement (FIRFE). This extracts as much information as possible from fine-grained images under weak supervision to improve the recognition accuracy. When the existing methods extract image features, the feature extraction other than the most significant local feature is not enough. This deals with local features alone and ignores the relationship between features. First, this paper designs a feature enhancement and suppression module to process image features. Secondly, this paper designs pyramid residual convolution. This uses different scale convolution kernels to capture different levels of features in the scene. Thirdly, this paper uses the softpool method to rationally allocate the information weight in the pooling process. Fourth, this paper uses feature focus module to mine more features. This focuses on obtaining similar information in multiple local features as discriminant features to further improve the recognition. Fifthly, this paper carried out systematic experiments on the designed method. The proposed method achieves 94.3%/95.7% accuracy, 92.9%/94.1% recall, and 91.4%/92.2% F1 score on different datasets. This verified the superiority of this method for fine-grained image recognition of digital media.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
From the micro-perspective, digital media refers to information carrier, which records, transmits and processes information in binary form. At the same time, information carriers include sensory media, logical media and physical media [1]. Text, graphics, photos, sounds, video images, and animation all fall under the sense media. The presenting formats that are utilized to stand in for these sensory media are referred to as logical media [2]. Physical media is used to store, transmit and display logical media. Digital media technology has been developed rapidly and has penetrated into all aspects of people’s life. This has brought obvious and profound changes to people’s life, entertainment and work [3]. At present, the development trend of digital media technology has obvious characteristics. In terms of user environment, it has changed from single-user environment to multi-user environment and personalized user environment. In terms of operation environment, the local environment has been changed to distributed environment and remote environment [4]. In terms of media communication, from one-way communication to two-way communication. In addition, digital media technology will also develop toward distributed and networked multimedia systems [5].
With the development of the Internet and the arrival of the era of big data, a variety of massive data are generated every day. Image data containing a lot of information has gradually become an important carrier of digital media information [6]. Processing image data has extremely important practical significance and extensive application scenarios. Fine-grained image recognition can be regarded as a sub-field of image recognition, which aims to judge images with small differences between classes [7]. There is a high degree of morphological similarity between the objects depicted in the photograph, suggesting that they all share the same category. In the actual world, fine-grained picture recognition can be used in a greater variety of contexts. The species identified by fine-grained images are very similar in appearance even if they are different subclasses [8]. However, species of the same subclass are easily affected by multiple factors, such as different postures, different light intensities, little difference between foreground and background, and occlusion of objects, and their appearance is often very different. Therefore, fine-grained image recognition usually achieves the purpose of identifying different types by locating discriminating components to extract key features. The precision of fine-grained image recognition is closely related to the ability of image feature expression and the correct selection of significant component areas with discrimination. Traditional image features largely depend on human experience, and most of them are descriptions of image underlying features [9]. High-level picture semantic properties aren’t represented, and the system is hard to fine-tune for individual datasets. Using traditional image artificial design features for classification cannot achieve high recognition accuracy [10].
People have gradually abandoned the method of using traditional artificial design features to classify and recognize images. The convolution neural network can learn image features through multi-level and different size convolution layers [11]. When the image is input into the convolution neural network, forward propagation is carried out. With the deepening of convolution neural network, the extracted features are also becoming more and more advanced [12]. Hence, the network is able to learn not just the concrete low-level properties of the image, but also the more abstract high-level semantic features that are crucial for image recognition. Hence, it can be considered a hands-free, automatic feature extractor. In the forward propagation process, this can extract shallow-to-deep image features [13]. At last, the collected features are combined in the full connection layer before being categorized by the softmax layer. When compared to standard artificial design features, which can only employ the same feature learning approach across different datasets, deep learning’s ability to adapt to new datasets and extract relevant features is a clear advantage [14]. Convolutional neural networks learn convolutional features via reverse transmission, which can be directly affected by the error between the true label and the recognition result [15]. Because of this, the network’s learnt feature patterns can shift from one dataset to the next. When it comes to representing features, deep learning excels. This research explores its potential in the realm of high-resolution digital picture recognition [16].
This work designs a fine-grained image recognition based on feature enhancement.
-
First, this paper designs a feature enhancement and suppression method to process image features.
-
Secondly, this paper designs pyramid residual convolution. This uses different scale convolution kernels to capture different levels of features in the scene.
-
Thirdly, this paper uses the softpool method to rationally allocate the information weight in the pooling process.
-
Fourth, this paper uses feature focus module to mine more features. This focuses on obtaining similar information in multiple local features as discriminant features to improve the recognition.
The content of this article is arranged as follows: Sect. 2 introduces relevant literature research; Sect. 3 explains the proposed method; Sect. 4 carries out experimental analysis; Sect. 5 is the conclusion.
2 Related work
It was possible to classify deep learning-based fine-grained image identification into two main schools of thought: strong supervised learning and weak supervised learning. The primary dividing line between them was whether or not the model was trained using simply label information. A lot of the early labor was done under close watch and instruction. The fine-grained, supervised-learning-based image identification technique required not only image label information, but also costly manual annotations in the form of boxes or points during the training phase. This method of detecting target objects and parts was inspired by the design principles of models widely used in the field of target detection, such as R-CNN [17], Fast RCNN [18], Fast R-CNN [19], and so on. Part-based R-CNN proposed in reference [20] used the selective search method to generate the object region candidate frame on the dataset image with object annotation frame and part annotation point. This used the label box of the image to train and detect the important parts of the foreground and the target object in these areas. The final classification result was obtained by extracting features from the trained and modified regions and clustering with these features. However, this method also had great defects. A large number of useless candidate boxes would be generated in the process of detecting the object area. To reduce the situation of poor recognition performance caused by the difference in the attitude of the target object, the literature [21] proposed Part Normalized CNN, which was an improved version of Part-based R-CNN. This would extract features for classification after accurate image pose normalization of the clipped local image. Literature [22] proposed Part-Stack CNN, in which human participation was less. This could not only obtain high recognition accuracy, but also was widely used in practical scenes. In addition, the representative work was the SPDA-CNN based on the detection and extraction of the same semantic component proposed in document [23]. The network paid attention to the learning of middle-level features and the correlation between various parts of learning. This used a common convolution kernel to greatly reduce the complexity of multiple training and testing.
To reduce the labor cost and avoid human error, more and more researchers began to pay attention to the weak supervised learning method. Their characteristic was that only category labels were used in the training phase of network models, and the obtained model recognition accuracy could also meet the industrial requirements. Weak supervised learning method had become a popular method to solve the problem of fine-grained image recognition. Literature [24] proposed a two-level attention model, which was a typical algorithm for fine-grained image recognition based on weak supervised learning. The algorithm used the target body and key components to extract global and local features. Like the Part-based R-CNN mentioned earlier, it used the selective search method to generate candidate regions. Finally, these images were sent to convolution neural network for feature extraction and classification. Literature [25] proposed a diversified visual attention network, which improved the expression of feature diversity by locating multiple component regions to obtain more powerful discriminative features. The visual attention network based on full convolution proposed in reference [26] was an efficient reinforcement learning full convolution attention location network. This could automatically lock multiple discriminative significant regions. Literature [27] proposed a bilinear CNN model, which used two feature extractors at the same time. These two feature extractors were the same CNN or different CNN. After pictures pass through CNN, their two outputs were multiplied by the outer product and pooled to obtain image descriptors. To solve the problem of large storage memory in bilinear CNN, a compact bilinear CNN model was proposed in [28]. This ensured that the recognition accuracy did not decline, and at the same time uses the idea of kernel approximation to reduce the dimension to achieve the acquisition of high-dimensional features. Reference [29] used Taylor series kernel to capture the higher-order interaction of features, and the kernel approximation error and recognition accuracy had been well improved. Literature [30] proposed a cyclic convolution model for multiple detection of multi-scale key regions. This obtained two different scale features by locating the key areas in the image.
3 Proposed method
This work designs a fine-grained image recognition based on feature enhancement. First, this paper designs a feature enhancement and suppression module to process image features. Secondly, this paper designs pyramid residual convolution. This uses different scale convolution kernels to capture different levels of features in the scene. Thirdly, this paper uses the softpool method to rationally allocate the information weight in the pooling process. Fourth, this paper uses feature focus module to mine more features. This focuses on obtaining similar information in multiple local features as discriminant features to further improve the recognition effect.
3.1 Convolution neural network
Layered feature extraction networks like CNN are what make up this technology. As an input image is processed by successive network layers, its corresponding extracted features undergo a similar transition, moving from concrete low-level characteristics to more generalized high-level features. This forward process of feature extraction layer by layer is called forward propagation. Through the last layer of neural network, the target task is transformed into a function expression. Compare the output layer of forward propagation with the true value, and the difference obtained is back-propagated. Update the parameter value of each layer according to the deviation of the guide ladder, and the process will not end until the difference reaches a certain expected value.
The backbone of a convolutional neural network is a layer called the convolution layer, which consists of numerous convolution cores. Its primary use is to aid in the feature extraction process for network-based image classification systems. A variety of convolution kernels are included. The input image and these convolution kernels are used to produce a feature map. Hence, when the image has been processed by the convolution layer, as many feature maps will be generated as there are convolution cores. With the same input image, various convolution kernels can derive distinctive characteristics. The convolution operation is used to describe the process wherein several, identical, two-dimensional convolution cores of the convolution layer are simultaneously applied to the input image. Here, we are multiplying the value of a pixel in the image’s coverage area by the value of an element in the convolution kernel. The result of the multiplication is added to obtain the value of the corresponding pixel of the output feature map.
where \(C\) is convolutional kernel, \(X\) is input.
Compared with the traditional neural network, the advantage of convolution neural network lies in the adoption of parameter sharing mechanism. This method can effectively reduce the explosive growth of network weight, that is, the parameters in the convolution kernel are all the neural network parameters in the same channel. Compared with the traditional neural network, this method reduces the number of network parameters. In this way, the feature information of the picture can be effectively extracted. To ensure that the feature information extracted from each channel is different, multiple convolution cores need to be set in the convolution neural network.
The convolution operation reduces training parameters and connections by using the weight sharing mechanism and sparse connections between different layers. However, in the process of multiple convolution feature extraction, there will still be a large amount of computation. Thus, the network training is not easy to converge and the over-fitting probability increases. Therefore, it is generally necessary to connect a pooling layer behind the convolution layer to compress the previously extracted feature map to reduce the complexity of model calculation. At present, common pooling mainly includes average pooling, maximum pooling and global pooling. The pooling layer has two characteristics: first, translation, rotation and scale invariance. This is more concerned with describing the characteristics of objects rather than the coordinates in which they appear. Secondly, it can use different pooling layers to retain the desired features and discard the insignificant features. The dimension of the feature is lower, so the amount of computation is greatly reduced. This also reduces the problem of over-fitting and improves the applicability of the model.
When the convolution layer convolves the input image to extract features, this series of operations is often a linear superposition process, which is not conducive to the expression of complex functions. The activation function of nonlinear mapping is usually added after the convolution layer to enhance the ability of the convolution layer to express image features. There are many common activation functions at present.
where \(x\) is input.
The final step in a convolutional neural network, the FC layer does the classification. The feature map undergoes linear growth as it travels from the convolution layer and pooling layer of the convolution neural network to the full connection layer. There may be multiple connecting layers, or there may be only one. Mapping the raw data to the hidden feature space yields the convolution layer and pooling layer. To classify the sample label space, the full connection layer applies an activation function to the mapped feature information.
3.2 FIRFE architecture
The flow of fine-grained image recognition for digital media proposed in this work is shown in Fig. 1. PyConvResNet is a convolution operation combining pyramid convolution and ResNet network structure. Its structure is the same as that of ResNet’s feature extractor. It has five steps. The space size of the feature map after each step is reduced to half the size of the previous step. PyConvResNet has more image feature information and higher dimension after multiple feature extraction. Therefore, this paper places the feature enhancement and suppression module in the third, fourth and fifth stages and the last three stages. The component features processed by the feature enhancement and suppression module (FESM) are input into the feature focus module (FFM), which makes the feature extraction focus more on the discriminative region with more information. After the image passes through the feature focusing module, the softpool method is used for pooling. The final classification result is obtained by combining the results of multiple soft pools and connecting the final classifier.

FIRFE architecture
During the whole training process, the classification loss of the enhancement for each specific component is:
where \(y\) is ground truth.
3.3 FESM module
For the features extracted from the input data by different neural networks, a large number of methods have tried to use such methods as feature enhancement. Feature enhancement is added to the network for feature fusion and increases the information richness before final classification. Feature enhancement and suppression module is one of the better methods. The method is to first enhance the salient features in the fine-grained image, and at the same time suppress them in another branch. This encourages the network to learn more sub-salient features and enhance the richness of features.
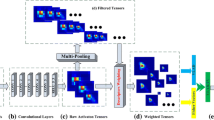
The main idea of feature enhancement and suppression is to mine enough image parts for recognition. This method is mainly to first select the most significant part of the feature map in the current step through the obtained feature map to obtain the image representation of a specific module. Then the most significant part selected will be suppressed instead. The purpose of suppression is to force the model to mine more potentially significant image parts in the next stage. The insertion position of the feature enhancement and suppression module is mainly the middle level of the convolution neural network, from which the feature representation of multiple specific parts can be obtained. These feature representations are also concentrated on different object components, as shown in Fig. 2.

FESM module
The image first passes through the upper part of the convolution neural network. Different basic models pass through different layers of the neural network, so the feature map can be obtained. Inspired by the PCB method, the feature map can be divided into several parts evenly along the width. Then, a convolution block is used to determine the importance of each image component. Then, the average value of this parameter is taken as the importance factor parameter of the characteristic graph. Then use the softmax function to standardize the importance factor parameters. Then, the features are enhanced by enhancing the most prominent module in the image. Then begin to suppress the most prominent part of the image. Suppressed image features can be obtained by compressing the most significant block part of the image.
where \(X\) is input, \(\alpha \) is control parameter.
Given a feature graph, the feature value of a specific component is output by the feature enhancement inhibition module. The second feature can be considered as a potential image feature. In the feature enhancement and suppression module, the size of the super-parameter that controls the degree of suppression is adjusted. This can make the potential information in the image relatively prominent when the parameter is passed into the subsequent module.
3.4 PyConvResNet module
The pyramid convolution structure contains a pyramid-like core. The convolution core type on each layer is different, which is manifested in different depth and size. Convolution kernels with different sizes and depths can better capture different levels of detail in the scene. Pyramid convolution contains pyramids with different types of convolution cores. The purpose is to process scales at different core scales to increase the amount of information. In pyramid convolution, the size of convolution core is different at each layer. The size of the nucleus from the bottom to the top increases gradually, and the size of the nucleus also increases gradually. The structure of pyramid convolution is shown in Fig. 3.

Pyramid convolution
This work combines pyramid convolution with the residual bottleneck block in the residual convolution neural network to form pyramid residual convolution as demonstrated in Fig. 4. In the pyramid residual convolution structure, the convolution block is used to reduce the size of the input feature image to 64. Then, four convolution kernel sizes of different sizes in pyramid residual convolution are used for convolution. The size of the four convolution kernels is different. In pyramid residual convolution, each convolution core outputs 16 characteristic graphs, so this structure outputs a total of 64 characteristic graphs. Add common batch normalization and ReLU activation functions after the convolution block. At the same time, like ResNet, a short connection is added to enhance the graphics mapping.

PyConvResNet module
Pyramid residual convolution can process input on multiple convolution kernel scales, which increases its ability to extract the overall data information. At the same time, the pyramid residual convolution and the standard residual convolution have almost the same calculation cost and parameter quantity, which makes its calculation very efficient. While capturing context information at different levels from local to global, pyramid residual convolution can be well integrated into the network structure with feature lifting methods. Because ResNet has a good fusion performance with pyramid convolution, ResNet has shown its excellent performance in various computer vision tasks. First, Pyramid convolution and ResNet network structure are combined to obtain PyConvResNet structure.
3.5 Softpool module
Softpool method is a core-based pooling method. The main method is to calculate the sum of activation values through softmax weighting. Softpool retains the descriptive activation feature to the maximum extent while ensuring that the amount and efficiency of computation are basically unchanged. The softpool method uses natural constants. Because the activation value is non-negative, it can make the large activation value have greater weight on the output. At the same time, the exponential method is differentiable, and there is a proportional gradient containing the lower limit during the back propagation. Softpool uses the smoothed maximum approximation of the active value within the region. The weight corresponding to each activation value is:
where \({a}_{i}\) is activation value.
Therefore, the weight calculated by the higher activation value is higher than the lower weight. When pooling in high-dimensional feature space, it is more effective to assign a higher activation value to a larger weight than the average weight of pooling. However, the maximum pooling method ignores too much information, and the same performance is relatively poor. The output of softpool method can be obtained by weighted sum of all activation values in the kernel region:
where \({w}_{i}\) is weight.
The softpool method does not contain trainable parameters, is independent of training data, and takes into account the advantages of the commonly used average pooling method and maximum pooling method. The average pooling method suppresses the contribution of the larger value to the final result and smoothes the gap between the larger value and the smaller value. However, maximum pooling only retains the maximum activation value, which makes the non-maximum activation value element information completely lost and ignores the overall characteristics. The softpool method balances these two points. First, all activation values in the region can affect the final output value. The part with higher activation value occupies a greater weight in the overall output than the part with lower activation value. The design of softpool makes up for the defects of average pooling and maximum pooling. This combines the advantages of the two methods and has a better effect.
3.6 FFM module
To strengthen the most important regional features in the image feature representation more pertinently, the feature enhancement and suppression module has been used in the previous article through the calculation in the module. This step extracts rich image features. To reduce the error that may be caused by part of the image with low resolution and strengthen the most important regional features, this paper designs a feature focusing module in the feature lifting network. In essence, the feature focusing module is a feature representation for image components. Based on the similar information obtained from other image components, the similarity of feature images of different image components is calculated to gather and enhance them. Through the feature focusing module to establish the model between the image components, the common features of the image components can be expressed more accurately. At the same time, it can also make the overall feature capture of the image focus more on the recognizable part, so as to distinguish the image more clearly. The biggest difference between feature focus and feature diversification is that the former calculates the similarity relationship between features and focuses on important features, while the latter uses complementary relationship.
The function principle of the feature focusing module is to gather the similar information extracted from the feature representation of other components in the image for fusion. This can enhance the features of the current assembly and generalize them into each image assembly. First, the features of the two image components are mutually enhanced by the feature focusing module, as shown in Fig. 5.

FFM module
Each pixel has established a correlation relationship. The higher the similarity of the two pixels, the greater the importance and contribution of any pixel to the similar information generated by the two pixels. In the image features of two image components, each pixel can learn its similar information from the relationship between the two pixels to the maximum extent. This can make up for the problem that the semantic information in the image component is not concentrated in the discriminative region.
4 Result and analysis
4.1 Dataset and environment
This work uses crawler technology to collect image data related to digital media from the Internet. This work builds two datasets, DMA and DMB, based on the collected data. The data of these two datasets are different, and the specific data information is shown in Table 1.
The GPU used in this experiment is GTX 1080Ti, the CPU processor is Intel (R) Core (TM) i7-8700 K CPU, and the memory is 8 GB. The Python deep learning framework is used under the Ubuntu system, and ResNet50 is used as the basic network of the whole network. The network learning rate of the network model PyConvResNet is set to 0.002, while the learning rate of other parts is 0.02. The learning rate is optimized and adjusted by cosine annealing algorithm in real time. The whole model is optimized by random gradient descent method. The momentum is 0.9. A total of 200 epochs are trained. The weight decrement is 0.00001, and the batch size is 20.
This work uses accuracy, recall and F1 scores to evaluate the image classification performance of FIRFE, and the specific calculations are as follows:
where \(\mathrm{TP}\) is true positive sample, \(\mathrm{TN}\) is true negative sample, \(\mathrm{FP}\) is false positive sample, \(\mathrm{FN}\) is false negative sample, \(P\) is positive sample, \(N\) is negative sample.
4.2 Training analysis of FIRFE
FIRFE is a fine-grained image recognition model based on deep learning, and data training is necessary. This work first analyzes the training process of FIRFE, and the main analysis indicators are training loss and training performance indicators. Specific experimental data are shown in Figs. 6 and 7.

Training loss of FIRFE

Training performance of FIRFE
From the data curves in the two figures, it can be seen that with the training, the loss gradually decreases to convergence, and the recognition performance gradually increases to convergence. The final convergence of the two curves preliminarily verified the feasibility of FIRFE for fine-grained image recognition of digital media.
4.3 Comparison with different methods
To further verify the superiority of FIRFE in fine-grained image recognition of digital media, this paper compares it with other fine-grained image recognition methods. To ensure the comparability of the experiment, this paper tries to keep the experimental settings consistent. The specific experimental data are shown in Table 2.
FIRFE has achieved the highest performance index on both DMA and DMB. Specifically, compared with the second-best method, FIRFE can achieve 2.4%, 3.7% and 2.5% improvement in DMA. On DMB, the corresponding three performance indicators were improved to 3.0%, 3.2% and 2.3%. These improvements verify the feasibility of FIRFE for fine-grained image recognition of digital media.
4.4 Analysis of FESM module
FIRFE uses FESM to process features with high performance. To verify the function of FESM in improving the performance of the model, a comparative experiment is conducted. This paper analyzes the image recognition performance without and with FESM. The specific experimental data are shown in Fig. 8.

Analysis of FESM module
After using FESM, the recognition performance has been improved accordingly. On DMA, the corresponding indicators improvement are 2.2%, 1.7% and 1.5%. In DMB, the corresponding indicators improvement are 1.8%, 1.5% and 2.0%. These improvements validate the advantages of FESM. This shows that FESM can make the network capture more non-most significant image features.
4.5 Analysis of PyConvResNet module
FIRFE uses PyConvResNet to extract more discriminative image feature. To verify the function of PyConvResNet in improving the performance of the model, a comparative experiment is conducted in this work. This paper mainly analyzes the image recognition performance without and with PyConvResNet. The specific experimental data are shown in Table 3.
After using PyConvResNet, the recognition performance has been improved accordingly. On DMA, the corresponding indicators improvement are 1.4%, 1.2% and 1.2%. In DMB, the corresponding indicators improvement are 1.6%, 1.2% and 1.5%. These improvements validate the advantages of PyConvResNet. This shows that PyConvResNet improves the network’s ability to capture different levels of detail by using multiple convolution cores of different scales.
4.6 Analysis of softpool module
FIRFE uses softpool to process the feature maps from the last step. To verify the function of softpool in improving the performance of the model, a comparative experiment is conducted. This paper analyzes the image recognition performance without and with softpool. The specific experimental data are shown in Fig. 9.

Analysis of softpool module
After using softpool, the recognition performance has been improved accordingly. On DMA, the corresponding indicators improvement are 1.4%, 1.1% and 1.3%. In DMB, the corresponding indicators improvement are 1.3%, 1.2% and 1.3%. These improvements validate the advantages of softpool. This shows that softpool combines the advantages of maximum pooling method and average pooling method. The possible contribution of all values in the matrix to the subsequent tasks is considered and the information loss is minimized.
4.7 Analysis of FFM module
FIRFE uses FFM to focus the obtained feature. To verify the function of FFM in improving the performance of the model, a comparative experiment is conducted. This paper analyzes the image recognition performance without and with FFM. The specific experimental data are shown in Table 4.
After using FFM, the recognition performance has been improved accordingly. On DMA, the corresponding indicators improvement are 2.1%, 1.8% and 1.7%. In DMB, the corresponding indicators improvement are 1.8%, 1.5% and 2.0%. These improvements validate the advantages of FFM. This shows that FFM can learn the similarity between features and focus on the most important discriminative features. This makes the final feature extraction and classification more accurate.
4.8 Analysis of BN module
FIRFE uses BN layer to normalize the feature. To verify the function of BN in improving the performance of the model, a comparative experiment is conducted. This paper analyzes the image recognition performance without and with BN. The specific experimental data are shown in Fig. 10.

Analysis of BN module
After using BN, the recognition performance has been improved accordingly. On DMA, the corresponding indicators improvement are 1.1%, 1.0% and 0.9%. In DMB, the corresponding indicators improvement are 1.2%, 0.9% and 1.1%. These improvements validate the advantages of BN. This shows that feature normalization can improve the efficiency of feature mining.
5 Conclusion
Digital media technology is broad enough to encompass a wide range of disciplines, such as computer graphics-based virtual reality technology, human–computer interface technology, sensor technology, and artificial intelligence. Digital media technology has been rapidly developed and penetrated into all aspects of people’s life. Fine-grained image recognition for digital media is to identify sub-classes in general categories. This is a delicate task in computer vision and has important research significance and application value. This work designs a fine-grained image recognition based on feature enhancement. First, this paper designs a feature enhancement and suppression module to process image features. Secondly, this paper designs pyramid residual convolution. This uses different scale convolution kernels to capture different levels of features in the scene. Thirdly, this paper uses the softpool method to rationally allocate the information weight in the pooling process. Fourth, this paper uses feature focus module to mine more features. This focuses on obtaining similar information in multiple local features as discriminant features to improve the recognition. Fifthly, this paper carried out systematic experiments on the designed method, and the experimental data verified the superiority of this method for fine-grained image recognition of digital media. Although the method proposed in this article has achieved considerable performance, there is still room for improvement compared to the latest methods. In addition, the proposed model parameters are numerous, which is not conducive to actual project deployment. In future research, we will focus on developing fine-grained image recognition models with higher accuracy and smaller volume.
Data availability
The datasets used during the current study are available from the corresponding author upon reasonable request.
Change history
08 December 2023
A Correction to this paper has been published: https://doi.org/10.1007/s00521-023-09221-5
References
Degner M, Moser S, Lewalter D (2022) Digital media in institutional informal learning places: a systematic literature review. Comput Educ Open 3:100068
Boulianne S, Theocharis Y (2020) Young people, digital media, and engagement: a meta-analysis of research. Soc Sci Comput Rev 38(2):111–127
Parry DA, Davidson BI, Sewall CJR et al (2021) A systematic review and meta-analysis of discrepancies between logged and self-reported digital media use. Nat Hum Behav 5(11):1535–1547
Twenge JM, Martin GN (2020) Gender differences in associations between digital media use and psychological well-being: evidence from three large datasets. J Adolesc 79:91–102
Guess AM, Lerner M, Lyons B et al (2020) A digital media literacy intervention increases discernment between mainstream and false news in the United States and India. Proc Natl Acad Sci 117(27):15536–15545
Liu X, Wang L, Han X (2022) Transformer with peak suppression and knowledge guidance for fine-grained image recognition. Neurocomputing 492:137–149
Yan T, Li H, Sun B et al (2022) Discriminative feature mining and enhancement network for low-resolution fine-grained image recognition. IEEE Trans Circuits Syst Video Technol 32(8):5319–5330
Pei J, Zhong K, Li J et al (2022) PAC: partial area clustering for re-adjusting the layout of traffic stations in city’s public transport. IEEE Trans Intell Transp Syst 1
Fayou S, Ngo H, Sek Y (2022) Combining multi-feature regions for fine-grained image recognition. Int J Image Graph Signal Process 14:15–25
Bera A, Wharton Z, Liu Y et al (2022) SR-GNN: spatial relation-aware graph neural network for fine-grained image categorization. IEEE Trans Image Process 31:6017–6031
Tang H, Yuan C, Li Z et al (2022) Learning attention-guided pyramidal features for few-shot fine-grained recognition. Pattern Recogn 130:108792
Lu L, Wang P, Cao Y (2022) A novel part-level feature extraction method for fine-grained vehicle recognition. Pattern Recogn 131:108869
Guo C, Lin Y, Chen S et al (2022) From the whole to detail: Progressively sampling discriminative parts for fine-grained recognition. Knowl-Based Syst 235:107651
Liu D, Wang Y, Mase K et al (2022) Recursive multi-scale channel-spatial attention for fine-grained image classification. IEICE Trans Inf Syst 105(3):713–726
Wang L, He K, Feng X et al (2022) Multilayer feature fusion with parallel convolutional block for fine-grained image classification. Appl Intell 52(3):2872–2883
Guang J, Liang J (2022) Cmsea: compound model scaling with efficient attention for fine-grained image classification. IEEE Access 10:18222–18232
Girshick R, Donahue J, Darrell T et al (2014) Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 580–587
Girshick R (2015) Fast r-cnn. In: Proceedings of the IEEE international conference on computer vision, pp 1440–1448
Ren S, He K, Girshick R et al (2015) Faster r-cnn: towards real-time object detection with region proposal networks. Adv Neural Inform Process Syst 28
Zhang N, Donahue J, Girshick R et al (2014) Part-based R-CNNs for fine-grained category detection. In: Computer vision–ECCV 2014: 13th European conference, Zurich, Switzerland, September 6–12, 2014, proceedings, part I 13. Springer International Publishing, pp 834–849
Branson S, Van Horn G, Belongie S et al (2014) Bird species categorization using pose normalized deep convolutional nets. arXiv preprint arXiv:1406.2952
Huang S, Xu Z, Tao D et al (2016) Part-stacked CNN for fine-grained visual categorization. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1173–1182
Zhang H, Xu T, Elhoseiny M et al (2016) Spda-cnn: unifying semantic part detection and abstraction for fine-grained recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1143–1152
Xiao T, Xu Y, Yang K et al (2015) The application of two-level attention models in deep convolutional neural network for fine-grained image classification. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 842–850
Zhao B, Wu X, Feng J et al (2017) Diversified visual attention networks for fine-grained object classification. IEEE Trans Multimed 19(6):1245–1256
Liu X, Xia T, Wang J et al (2016) Fully convolutional attention networks for fine-grained recognition. arXiv preprint arXiv:1603.06765
Lin TY, RoyChowdhury A, Maji S (2015) Bilinear CNN models for fine-grained visual recognition. In: Proceedings of the IEEE international conference on computer vision, pp 1449–1457
Gao Y, Beijbom O, Zhang N et al (2016) Compact bilinear pooling. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 317–326
Cui Y, Zhou F, Wang J et al (2017) Kernel pooling for convolutional neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2921–2930
Fu J, Zheng H, Mei T (2017) Look closer to see better: recurrent attention convolutional neural network for fine-grained image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4438–4446
Ding Y, Zhou Y, Zhu Y et al (2019) Selective sparse sampling for fine-grained image recognition. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 6599–6608
Sun G, Cholakkal H, Khan S et al (2020) Fine-grained recognition: Accounting for subtle differences between similar classes. Proc AAAI Conf Artif Intell 34(07):12047–12054
Zhou M, Bai Y, Zhang W et al (2020) Look-into-object: Self-supervised structure modeling for object recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 11774–11783
Luo W, Zhang H, Li J et al (2020) Learning semantically enhanced feature for fine-grained image classification. IEEE Signal Process Lett 27:1545–1549
Huang S, Wang X, Tao D (2021) Snapmix: semantically proportional mixing for augmenting fine-grained data. Proc AAAI Conf Artif Intell 35(2):1628–1636
Acknowledgements
This research was supported by 2022 youth special project of the 14th five-year plan of education science of Jiangxi Province, Research on the positive cross-cultural psychological adaptation of foreign students in Jiangxi Universities from the perspective of the Belt and Road (22QN005).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest exists.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this article was revised due to change in corresponding author from Tieyu Zhou to Yan Zhang.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhou, T., Gao, L., Hua, R. et al. Fine-grained image recognition method for digital media based on feature enhancement strategy. Neural Comput & Applic 36, 2323–2335 (2024). https://doi.org/10.1007/s00521-023-08968-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-023-08968-1