
Abstract
Metaheuristic applications for information retrieval research are limited in spite of the importance of this problem domain. Ranking the retrieved documents based on their importance is a vital issue for the scientific and industrial communities. This paper proposes a novel variable neighborhood search (VNS) algorithm with adaptation based on an objective function for the learning to rank (LTR) problem. VNS is a global optimum metaheuristic algorithm that has been engaged to evolve the optimal solutions for heuristic problems based on exploring better neighbor solutions from the current one. The changes from the current to the next optimal solution are made during the perturbation stage to identify the global optimal solutions. The exploration procedure has been made through various mutation step sizes, whereas the exploitation process has been done by checking the quality of the evolved solutions using the fitness function. This research proposes a novel version of VNS based on four random probability distributions with gradient ascent. In addition to using the traditional random generator with gradient ascent for modifying the mutated genes of the neighborhood candidate solution in the following evolving iteration. This novel method in LTR is called gradient variable neighborhood (GVN). In the experiments, we utilized Microsoft Bing search (MSLR-WEB30K), Yahoo, and TREC Million Queries Competitions in 2008 and 2007 (LETOR 4) datasets. From the findings of the results, we can deduce that the GVN method outperformed recent studies on LTR methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Variable neighborhood search (VNS) is a metaheuristic algorithm suggested in [1, 2]. This method is one of the local search (LS) algorithms. However, it is a global optimization algorithm method that can overcome being stuck in local optimum solutions. This can be accomplished by more search divergence of various neighbor solutions with nondeterministic and variable mutation steps in the evolving procedure.
To find an optimum solution, metaheuristic algorithms have been used for improving the suggested solution. The improvement is based on checking the quality of the solution with the objective function in each iteration. This is done until no further improvements can be achieved. The VNS algorithm utilizes a strategy based on dynamically shifting neighborhood boundaries. There are numerous levels of freedom in designing variations and specific extensions of this algorithm. An enhanced solution s’ in the neighborhood N(s) of the current candidate solution s can be gained at each learning iteration by irregular mutation step sizes. This causes the evolved solutions to jump and avoid the stuck in local optimal to globally optimal solutions.
The reason for that is doing more exploration for search solution space which can be achieved by these nondeterministic mutation step sizes. This VNS is a modified version of LS methods that are stuck in the local optimal solution. In addition, several metaheuristics algorithms have been suggested in recent years that extend this approach in many ways to avoid them from being stuck in local maxima or minima solutions. Examples of these methodologies which were investigated in previous research studies for other research domains are: evolutionary strategies [3], evolutionary programming [4], genetic algorithms [5], and evolutionary algorithms [6]. However, VNS showed the best performance among these approaches in other problem domains [7, 8].
Intensive experimental studies have been conducted in previous research using metaheuristic methods for obtaining optimal evolved solutions. However, limited research studies of these categories have been developed for learning to rank (LTR) research in information retrieval (IR) [9,10,11]. This study introduces a novel method for the VNS algorithm which can accomplish enhancement in the accuracy of ranking documents in IR. This paper used two evaluation fitness metrics to measure the accuracy of the IR system which are the mean average precision (MAP) metric and the normalized discounted cumulative gain for the top-10 WebPages retrieved (NDCG@10) metric. The suggested approach for adapting the candidate solution, by determining a better neighborhood solution to the current one, has not been used before in the computational intelligence problem domains. Furthermore, the VNS algorithm has not been applied previously in the ranking problem.
The contributions of this paper are:
-
1.
This paper proposes a novel technique called the gradient variable neighborhood search (GVN) strategy in IR optimization research. This is achieved by utilizing 5 probability distributions which act as random number generators for mutating the neighborhood evolved solutions. It also combines gradient ascent with VNS in choosing these mutation step sizes.
-
2.
The suggested approach is used for the first time for the LTR problem.
-
3.
Making a comparative research study of the suggested approach and the most recent studies in the area of LTR. This is carried out by implementing the suggested approach using large and the latest known LTR datasets.
-
4.
For reproducible research, the Java code for the suggested algorithm is provided.
This paper is organized as follows. Section 2 illustrates the background and various information retrieval (IR) problem domains. Section 3 presents related work in the literature of LTR for IR research existing in previous studies. Section 4 gives explanations of the suggested VNS approaches. whereas Sect. 5 demonstrates the results derived using Yahoo, MSLR-WEB30K, and LETOR 4 (TREC Million Query 2008 and TREC Million Query 2007) datasets. Section 6 concludes the paper’s results and suggests future research avenues.
2 Background
This section illustrates different research problems of IR systems in which researchers used computational intelligence (CI) methods. These methods have been used to optimize them for better IR performance. First, it introduces a high-level overview of various IR system problem domains. Then, it concentrates on the ranking problem domain in which learning to rank applications was used in this study.
2.1 Information retrieval research problem domains
Figure 1 illustrates the main research problem domains existing in IR and search engines. Artificial intelligence (AI) techniques were applied in previous research. In this subsection, brief definitions for these problems concentrating on the LTR problem. More details for other various IR problem domains in which computational intelligence methods were used to optimize them are existing in [12].
From Fig. 1, the main problem domains in which AI methods were used are highlighted by dotted shapes. These domains are document or WebPage representation, user query representation, user profile feedback, and ranking the retrieved documents or WebPages list for users. Typically, every document or WebPage and user query is subjected to lexical analysis for extracting heuristic information content for the document or the query. These procedures are approximate methods that may result in inaccurate representations for them. Thus, AI techniques were used based on relevance labels provided by user interaction with the IR system in user query logs to optimize them. However, some documents may not have relevance labels for using AI methods to optimize document or query representation on the IR document collections [13]. This issue inspires the need of using machine learning methods for producing learning models that can be used on unseen data. This was the starting motivation point for learning to rank research for optimizing IR systems through a learned ranking model rather than optimizing query and document representation.
The learning to rank (LTR) problem is colored yellow in Fig. 1 to indicate it to researchers in which IR component exists. The following subsection has more explanation for LTR in IR systems that may inspire computer researchers to recognize this hot topic for its business value on the web.

Main problem domains existing in IR systems and search engines modified from figure in [13]
2.2 Learning to rank framework
The main challenge in information retrieval (IR) is ranking the retrieved documents or WebPages that respond to the user’s query. They are ranked in terms of their relevance or business importance matching. Unsupervised scoring approaches such as term frequency-inverse document frequency (TF-IDF), OKAPI-BM25, and language models, among others, were used in early information retrieval studies. These methods were applied to evaluate the similarity of the retrieved documents with the queries. The limitation of using only one scoring function in IR systems was the reason for poor IR performance and reliability problems. When applying only one scoring technique in IR systems, two problems were uncovered. These issues are the approximation of using probabilistic, and language models without considering the relevance feedback, and business importance of the WebPages or documents. These motivated the usage of several scoring methods for ranking documents in accordance with the users’ queries. Moreover, the business value of the documents on the web and the server hosting them, as well as other factors, should be considered when ranking the pages in terms of their usefulness.
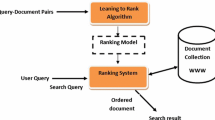
Tao Qin et al. [14] outlined a new trend for developing LETOR datasets derived from search engines and well-known TREC conference collections. These benchmarks contain features that represent more than one weighting scheme as the WebPage information content. They also included certain additional elements, such as PageRank, which is used by Google, and the importance of the host server, which is used by search engines. Furthermore, in these new benchmarks, the pages in the datasets were mapped into rated query-document pairs. As a result, the study has moved to apply computational intelligence applications to learn optimal ranking functions. Machine learning and evolutionary computational algorithms have made extensive use of learning to rank datasets in the previous studies as in [10]. Figure 2 shows a framework for the LTR problem domain.

Learning to rank architecture
3 Related work
There are three main categories of LTR approaches [15,16,17]. The first one is called the pointwise approach. The second category is the pairwise approach. The third category is the listwise approach. This classification methodology is based on how the evaluation procedure is performed. It can be done by using either the objective function or using the loss value function. For the pointwise method, every query document is considered an item of the learning process. Gradient boosted regression trees (GBRT or MART) [18, 19], boosting [20], gradient boosted regression trees (GBRT or MART) [18, 19], linear regression (LR) [21], and random forest (RF) [22] are all considered representative examples of the pointwise approach.
On the other hand, the pairwise approach uses a set of two query-document sets for the same query as the learning item and uses a loss or objective metric function for evaluations. Examples of the pairwise approach are RankBoost, RankNET (rank neural net) [23], and support vector machine (SVMRank) [17]. On the contrary, the learning item in the listwise approaches is represented as a list of query-document sets for every query of the whole list of the search. Examples of the algorithms of the listwise approach are Coordinate Ascent [24], ListNET (Listwise Neural Net) [16], AdaRank [25], and RankGPES [26, 27].
The following methods have been suggested after these previous studies for the process of modeling user clicks [28,29,30]. Recently, a new research trend in LTR is called Online LTR. This new research trend studies the use of implicit relevance labels to mimic the selections of the user. Then, measure how well the online LTR method performs. This is because the actual user click selections may undergo several bias problems which were stated in [28, 29].
Recently, a lot of research has contributed to proving that learning from explicit user relevance labels performs better than learning from the implicit relevance feedback in online LTR. This was done using user simulation Click models [10, 31]. From another point of view, user click bias corrections have been studied in order to gain better performance on ranking search engine results with an improved link between dataset features and their relevance feedback labels [32, 33]. For various aspects of bias corrections, [33] presented two well-known LTR approaches from the literature. These approaches are Deep Neural Network and \(\lambda {Mart}\) which outperformed previous research.
In this paper, we propose a novel algorithm for merging VNS with the gradient ascent procedure in the continuous optimization research field in AI. This is accomplished using five probability distributions acting as number generators for mutating step sizes of neighboring searches for generating optimal solutions. Moreover, applying the VNS algorithm for the first time in the LTR problem by the suggested approach. Further, comparing the algorithm also suggested with recent studies in the LTR research domain [9, 10, 31,32,33]. This was accomplished by using two of the largest and most recent available LTR datasets from search engines and two well-established and recognized datasets from TREC document collections.
4 The suggested method
This research suggests a novel algorithm by combining the variable neighborhood search (VNS) with gradient ascent (GVN) procedure. The GVN algorithm runs in the following steps summarized below. First: a list of various neighbor offspring solutions (OffNeighbor) is evolved, and each neighbor solution of them is then evaluated one by one.
Let \(Neighbour={OffNeighbour_1, OffNeighbour_2,...,OffNeighbour_n}\) be a \(jth\) generation of offspring neighbor ranking models specifying as the neighbor evolved solutions to the current candidate ranking model chromosome. The procedure in which they will be evaluated for their ranking accuracy compared to the best current solution for the current evolving iteration is called objective metric evaluation. In this fitness evaluation process, two prominent objective measures were applied which are mean average precision (MAP) and normalized discounted cumulative gain at the top 10 documents retrieved (NDCG@10). The GVN algorithm iteratively checks the quality of the neighborhood ranking solutions specified in each learning iteration, while the evolving iteration threshold operator is given by \(1\le j \le MaxGenerations\).
Beginning from a given candidate solution S and while MaxGenerations is the maximum number of evolving or learning iterations not reached. The GVN algorithm recommences search in the current neighbor chromosomes. This repeatedly happens in accordance with replacing the current candidate solution with the neighbor solution evolved if its performance is lower than the evolved solution. This happens in each evolving iteration until the stopping criterion is reached. The java archive packages for this novel GVN algorithm are provided in the following link GVN for enabling the research to be reproducible.


Gradient variable neighborhood flowchart for learning to rank problem
Algorithm 1 demonstrated a high-level overview of the GVN’s algorithm. This GVN approach generates the neighbor chromosome by mutating the candidate ranking model by one of five probability distributions to act as random number generators. These probability distributions are Gaussian, Cauchy, Levy, Uniform, and traditional random number methods. This has been applied as variable mutation step sizes. For each neighbor solution, the mutation step size uses a collection of random numbers from only one probability distribution for each neighbor solution. These distributions have been applied in some research studies for solving other optimization problems [3, 5, 9, 34]. Figure 3 illustrates the detailed flowchart of the GVN algorithm for more clarification.
The key terms in this flowchart in Fig. 3 are as follows:
-
1.
i is the number of neighborhood solutions in each evolving iteration. Each neighbor solution is produced by mutation stepsize for its genes from one probability distribution by equation 1. In this paper, we used 5 probability distributions. Thus,i = 5 in each evolving iteration.
-
2.
\(PD_{i}\) represents the probability distribution i as a random generator number. This paper uses Gaussian, Cauchy, Levy, Uniform, and traditional random number generators as a random generators for determining mutation step size.
-
3.
\(PM_{i}\) is a random number that represents the probability of mutations in neighbor solution i.
-
4.
\(C_{j}\) is the best current evolved ranking model for evolving iteration j, while \(N_{ij}\) is its neighbor solution produced by \(PD_{i}\) in the same evolving iteration j.
-
5.
\(fitC_{j}\) and fitN ij are the fitness evaluation values for the current solution \(C_{j}\) and its neighbor \(N_{ij}\).
5 Experimental results
The purpose of this section is to illustrate the experimental findings and compare the performance of the suggested GVN approach with previously presented Metaheuristic and ML techniques. The datasets used in the experiments include training, validation, and test data segments, used for building the models, evaluating, and measuring their performance. To determine the most efficient ranking model, we did the following: first, the proposed GVN LTR method is implemented for training or improving a solution. Then, the effectiveness of the evolved solution is evaluated using new data to measure its predictive power.
5.1 Datasets and performance evaluation measures
The experimental research presented here uses the LTR benchmarks: MSLR-WEB30K extracted from Bing search engine, Yahoo and LETOR 4 (MQ2007 and MQ2008) dataset from TREC document collection [14, 35,36,37]. The main features of these datasets are shown in Table 1. These are considered the largest available learning to rank datasets for research such as Microsoft Bing search datasets (MSLR-WEB30K) and Yahoo. There are many attributes included such as low-level features like cumulative term frequency (CTF) and cumulative inverse document frequency (CIDF) of the document terms existing in each combination of query and the corresponding document(s). For every part of the document, the basic features were calculated for the document title, anchor, body, and for the rest of the page text.
Features common between the query and corresponding document are called high-level features. These features compute the similarity between the query and the documents. There are also some features related to language models such as absolute discounted smoothing (LMIR.ABS), Jelinek-Mercer smoothing (LMIR.JM), Bayesian smoothing using Dirichlet priors (LMIR.DIR), and click user interaction-related features which have been demonstrated in previous IR studies [14, 35,36,37] as features.
Each query has a number of documents that can be either relevant or irrelevant, which constituted so-called query-document sets or pairs. For each query-document set or pair, the relevance label measures the user preference levels for the query to that document. The values of relevance labels usually range between zero and two. The value of zero refers to irrelevant, whereas one refers to partially relevant and two refers to completely irrelevant between the query and the corresponding document. The MSLR-WEB30K Benchmark, collected from the Bing search engine, and Yahoo search dataset have relevance labels ranging from zero (irrelevant) to four (perfectly relevant), while LETOR 4 Benchmark have only three levels of relevance ranging from irrelevance to totally relevance.
This research utilizes two objective performance evaluation measures to evaluate the results in this paper. These measures are mean average precision (MAP) and normalized cumulative gain at the top-10 documents retrieved (NDCG@10). Both fitness measures have been used extensively in previous research studies such as in [11, 32, 33, 36]. The MAP metric only determines whether the query document retrieved is relevant. But, it does not evaluate the levels of graded relevance for each retrieved document. Instead of only focusing on just the top-k query-document pairs, MAP evaluates the average precision levels over the complete set of search list obtained results. The graded relevance degree for each pair of the retrieved top-k query documents is considered by the NDCG@K metric.
In the next subsection, we provide a comprehensive analysis of the results in this research. The analysis is composed of two parts for both research communities’ point of views. First, from the metaheuristic researchers’ point of view and from ML researchers’ point of view. Thus, the paper includes an evaluation of the presented GVN capabilities as a metaheuristic method in evolving optimal ranking models. In addition to evaluating GVN when applied to the training and validating dataset besides evaluating their performance for obtaining the optimal predictive results on the unseen test data.
In this research, we compare the results obtained from the novel proposed GVN with the recent state-of-the-art previous research from the literature which outperformed other available methods [10, 31]. The first method in the comparison is (1+1)-evolutionary strategy LTR (ESRank), which outperformed fourteen computational intelligence methods as demonstrated in [31].
Whereas extending it by combining it with simulated annealing (SASRank) or gradient mutation step size added (EGSRank) have been suggested in recent studies for better efficiency [9, 10]. Moreover, recent research suggested correcting the bias of the user relevance feedback for better performance on the best known \(\lambda {Mart}\) and deep neural network (DNN) technique among approaches which are provided in [32, 33]. These techniques with their variants were provided in the comparative study with the GVN algorithm presented in this paper.
5.2 Main findings and discussion
The purpose of this subsection is to analyze the results obtained from the experiments and to compare the GVN approach performance with other metaheuristic algorithms to prove its effectiveness. The results of the evolving procedure are obtained from applying the suggested GVN method to the training and validation data. Whereas the predictive results are applied to the previously unseen Benchmark test data. Many comparative studies among various metaheuristic techniques have been done in other optimization problem domains. In these studies, researchers checked the quality of the evolved optimal or near-optimal solutions only on the training data. In this work experiments, rather than testing only on training, we evaluated the proposed methods using training, validation, and test data.
Thus, this paper includes the evolving results implemented on the training and validating data. Moreover, the results of the predictive evaluation on test data are also presented. The results of the training, validation, and testing are presented in Tables 2, 3, 4, 5, 6 and 7. Then, the paper compares the suggested method GVN performance with the most recent and best-performing approaches from previous studies [32, 33]. Table 8 shows the comparative results for comparing this work with state-of-the-art methods.
The highlighted bold results in tables from 2, 3, 4, 5, 6 and 7 show the best-evaluated values obtained on the benchmarks. The last column of these tables contains the number of Winner Numbers for the best performances gained by each method. Generally, the GVN approach performed better than the other techniques. The winner number of best performances using GVN is 16 (8 MAP and 8 NDCG@10) out of 24 evaluation fitness values. While the second approach that obtains the best performance is SASRank with its mutation variations by 6 (3 MAP and 3 NDCG@10) values. The reason for the effective results obtained by GVN is that there is more exploration by various probability distributions used as random generators. They were included in each neighbor evolved solution for the mutation process in GVN. Thus, GVN can jump from a locally optimal solution to the globally optimal one.
In Table 8, a comparative results between recent research studies in ranking problem domain with the proposed GVN method [32, 33]. The techniques utilized in this comparison are online and offline approaches. Dueling bandit gradient descent (DBGD), multileave gradient descent (MGD), and pairwise differentiable gradient descent (PDGD) are online LTR techniques used in this comparison. The offline approaches used in this comparison are two well-known techniques with their correction of bias methods. These approaches are \(\lambda {Mart}\), \(\lambda {Mart}\) with affine correction (AC), \(\lambda {Mart}\) with mixture-based correction (MBC), deep neural networks (DNNs), DNN with AC, and DNN with MBC. The details of these methods are introduced in [32, 33]. In this table, the results gained from our technique are compared with the best NDCG@10 results gained by the researchers in previous research. From these results, we can find that the GVN outperformed the other techniques in three benchmarks (Yahoo, MSLR-WEB30K, and MQ2007), while DBGD (linear model) outperformed other approaches applied to MQ2008 dataset.
6 Conclusions and future work
To conclude, this paper presented a new variable neighborhood-based method, which is merging variable neighborhood with gradient ascent called (GVN). In the GVN approach, a specific probability distribution was used for making all mutations in the candidate solution that are different from the mutation step size for other neighborhood solutions.
In the GVN approach, more exploration of searching for maximal solutions was accomplished using various probability distributions for mutation step size in neighborhood solutions. A global maximum solution can be found using this methodology without getting stuck in local maximum solutions by requiring less exploration of the solution space.
From the results, We can also conclude that GVN outperformed other LTR approaches of recent and most known LTR methods. Results here were illustrated from the point of view of metaheuristic research and ML research. According to these results, GVN provides 16 best fitness values (8 MAP and 8 NDCG@10) values out of 24 evaluation metric values. On the other hand, SASRank has the second best fitness values by 6 mutation variations (3 MAP and 3 NDCG@10) values, whereas ESRank approach is the third fitness performance by 2 (2 MAP) values.
In this paper, we also compared the suggested approach with recent machine learning studies. From this comparison, we can conclude that GVN outperformed the other approaches applied to the three datasets (Yahoo, MSLR-WEB30K, and MQ2007), whereas DBGD (linear model) outperformed other methods with MQ2008 dataset. The future direction of research is to browse the capabilities of other novel metaheuristic methods for achieving better performance. In addition to exploring the field of building explainable and interactive artificial intelligence techniques for IR systems.
Data availibility statement
The source code is available in section 4, while the datasets are existing on the Public Microsoft LETOR website.
References
Papalitsas C, Karakostas P, Andronikos T (2019) A performance study of the impact of different perturbation methods on the efficiency of GVNS for solving TSP. Appl Syst Innov 2(4):2571–5577. https://doi.org/10.3390/asi2040031
Mladenović N, Hansen P (1997) Variable neighborhood search. Comput Oper Res 24(11):1097–1100. https://doi.org/10.1016/S0305-0548(97)00031-2
Kramer O (2016) Machine learning for evolution strategies, vol 20. Springer, New York
Fogel DB (1999) An overview of evolutionary programming. In: Evolutionary algorithms, Springer, pp 89–109
M Zbigniew (1996) Genetic algorithms+data structures = evolution programs, 3rd edn. Springer, Berlin, Heidelberg, p 3540606769
Nannen V, Smit SK, Eiben AE (2008) Costs and benefits of tuning parameters of evolutionary algorithms. In: International conference on parallel problem solving from nature, Springer, p 528–538
Montoya-Torres JR, Moreno-Camacho CA, Vélez-Gallego MC (2022) Variable neighbourhood search for job scheduling with position-dependent deteriorating processing times. J Oper Res Soc 1–15
Pinheiro RL, Landa-Silva D, Atkin J (2016) A variable neighbourhood search for the workforce scheduling and routing problem. In: Pillay N, Engelbrecht AP, Abraham A, du Plessis MC, Snášel V, Muda AK, (eds) Advances in nature and biologically inspired computing p 247–259, Cham, Springer. ISBN 978-3-319-27400-3
Ibrahim OA (2022) Exploration and exploitation methods using (1+1)-evolutionary algorithms for better ranking models. https://doi.org/10.21203/rs.3.rs-1968676/v1
Ibrahim OA, Younis EMG (2022) Hybrid online–offline learning to rank using simulated annealing strategy based on dependent click model. Knowl Inf Syst 1–15
Ibrahim OA, Landa-Silva D (2018) An evolutionary strategy with machine learning for learning to rank in information retrieval. Soft Comput. https://doi.org/10.1007/s00500-017-2988-6
Ibrahim OA (2022) A survey on computational intelligence applications in information retrieval. URL https://doi.org/10.21203/rs.3.rs-2334978/v1
Ibrahim OA, Landa-Silva D (2016) Term frequency with average term occurrences for textual information retrieval. Soft Comput 20(8):3045–3061. https://doi.org/10.1007/s00500-015-1935-7
Qin T, Liu TY, Xu J, Li H (2010) Letor: a benchmark collection for research on learning to rank for information retrieval. Inf Retr 13(4):346–374. https://doi.org/10.1007/s10791-009-9123-y
Liu Tie-Yan (2009) Learning to rank for information retrieval. Found Trends Inf Retr 3(3):225–331
Cao Z, Qin T, Liu TY, Tsai MF, Li H (2007) Learning to rank: from pairwise approach to listwise approach. In: Proceedings of the 24th international conference on machine learning, ICML ’07, p 129–136, New York, NY, USA. ACM. ISBN 978-1-59593-793-3. https://doi.org/10.1145/1273496.1273513
Li H (2014) Learning to rank for information retrieval and natural language processing, Second Edition. Morgan and Claypool Publishers. ISBN 9781627055857
Friedman JH (2001) Greedy function approximation: a gradient boosting machine. Ann Stat 29(5):1189–1232
Mohan A, Chen Z, Weinberger KQ (2011) Web-search ranking with initialized gradient boosted regression trees. In: Journal of machine learning research, workshop and conference proceedings, vol 14. pp 77–89
Freund Y, Iyer R, Schapire RE, Singer Y (2003) An efficient boosting algorithm for combining preferences. J Mach Learn Res 4:933–969
Yan X, Su XG (2009) Linear regression analysis: theory and computing. World Scientific Publishing Co., Inc, River Edge, NJ, USA
Leo B (2001) Random forests. Mach Learn 45(1):5–32. https://doi.org/10.1023/A:1010933404324
Burges C, Shaked T, Renshaw E, Lazier A, Deeds M, Hamilton N, Hullender G (2005) Learning to rank using gradient descent. In: Proceedings of the 22nd international conference on machine learning, ICML ’05, pp 89–96, New York, NY, USA. ACM. ISBN 1-59593-180-5. 10.1145/1102351.1102363
Metzler D, Bruce Croft W (2007) Linear feature-based models for information retrieval. Inf Retr 10(3):257–274. https://doi.org/10.1007/s10791-006-9019-z
Xu J, Li H (2007) Adarank: aboosting algorithm for information retrieval. In: Proceedings of the 30th annual international ACM SIGIR conference on research and development in information retrieval, SIGIR ’07, ACM, New York, NY, USA. pp 391–398, ISBN 978-1-59593-597-7. https://doi.org/10.1145/1277741.1277809
Islam MA (2013) Rankgpes: learning to rank for information retrieval using a hybrid genetic programming with evolutionary strategies
TechTarget Contributor. What is evolutionary computation?: Definition from techtarget, Jul 2019. URL https://www.techtarget.com/whatis/definition/evolutionary-computation
Hofmann Katja, Whiteson Shimon, de Rijke Maarten (2013) Balancing exploration and exploitation in listwise and pairwise online learning to rank for information retrieval. Inf Retr 16(1):63–90
Schuth A, Hofmann K, Whiteson S, de Rijke M (2013) Lerot: an online learning to rank framework. In: Proceedings of the 2013 workshop on Living labs for information retrieval evaluation CIKM 2013, San Francisco, California, USA, November 1, pp 23–26, 2013. https://doi.org/10.1145/2513150.2513162
Qingyao Ai, Tao Yang, Huazheng Wang, Jiaxin Mao (2021) Unbiased learning to rank: online or offline? ACM Trans Inf Syst. https://doi.org/10.1145/3439861
Ibrahim OA (2017) Evolutionary algorithms and machine learning techniques for information retrieval. PhD thesis, University of Nottingham
Oosterhuis HR (2020) Learning from user interactions with rankings: a unification of the field. PhD thesis, University of Amsterdam
Vardasbi A, de Rijke M, Markov I (2021) Mixture-based correction for position and trust bias in counterfactual learning to rank. In: Proceedings of the 30th ACM international conference on information & knowledge management, CIKM ’21, pp 1869-1878, New York, NY, USA. Association for Computing Machinery. ISBN 9781450384469. https://doi.org/10.1145/3459637.3482275
Zheng Y, Wu J, Wang B (2021) Clgbo: an algorithm for constructing highly robust coding sets for dna storage. Front. Genet, 12. ISSN 1664-8021. https://doi.org/10.3389/fgene.2021.644945., URL https://www.frontiersin.org/articles/10.3389/fgene.2021.644945
Qin T, Liu T-Y (2013) Introducing LETOR 4.0 datasets. CoRR. arxiv:abs/1306.2597. http://arxiv.org/abs/1306.2597
Chapelle O, Chang Y (2010) Yahoo! learning to rank challenge overview. In: Proceedings of the Yahoo! learning to rank challenge, held at ICML 2010, Haifa, Israel, June 25, pp 1–24, 2011. http://www.jmlr.org/proceedings/papers/v14/chapelle11a.html
Liu T-Y (2011) Chapter the LETOR datasets. In: Learning to rank for information retrieval, Springer, Berlin, Heidelberg. pp 133–143. ISBN 978-3-642-14267-3. https://doi.org/10.1007/978-3-642-14267-3_10
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
All authors wrote and reviewed the paper.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there does not exist any kind of conflict of interest.
Ethical approval
There does not exist any kind of human or animal participation in this research.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ibrahim, O.A.S., Younis, E.M.G. Combining variable neighborhood with gradient ascent for learning to rank problem. Neural Comput & Applic 35, 12599–12610 (2023). https://doi.org/10.1007/s00521-023-08412-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-023-08412-4