
Abstract
Tactics to determine the emotions of authors of texts such as Twitter messages often rely on multiple annotators who label relatively small data sets of text passages. An alternative method gathers large text databases that contain the authors’ self-reported emotions, to which artificial intelligence, machine learning, and natural language processing tools can be applied. Both approaches have strength and weaknesses. Emotions evaluated by a few human annotators are susceptible to idiosyncratic biases that reflect the characteristics of the annotators. But models based on large, self-reported emotion data sets may overlook subtle, social emotions that human annotators can recognize. In seeking to establish a means to train emotion detection models so that they can achieve good performance in different contexts, the current study proposes a novel transformer transfer learning approach that parallels human development stages: (1) detect emotions reported by the texts’ authors and (2) synchronize the model with social emotions identified in annotator-rated emotion data sets. The analysis, based on a large, novel, self-reported emotion data set (n = 3,654,544) and applied to 10 previously published data sets, shows that the transfer learning emotion model achieves relatively strong performance.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Billions of social networking service users engage in their areas of interest by sharing their opinions and information, mainly as text. Predicting the emotions they express in these texts is critical for both researchers and businesses [31]; consumer emotions expressed in online restaurant reviews [37] or tweets about COVID-19 [18] for example may provide valuable insights for commercial firms and public policy makers. Yet detecting such expressions of human emotions is challenging, particularly when the analyzed data only include text, not facial expressions or other nonverbal information [30].
One option is to task human annotators with generating labels of emotions and categorizing text passages [2, 8, 9, 14, 26, 27, 29, 34]. This stream of research reflects a classical view of emotion theory [35], which postulates that categories such as fear and joy have universal biological fingerprints, inherited by humans through evolution, that get aroused by certain situations. Therefore, annotators should be able to detect emotions expressed in texts authored by others [8, 26, 27, 32]. Yet empirical studies also reveal that the number and categories of emotions vary across individuals, depending their age [11], gender [23], social contexts, and culture [16, 24]. Accordingly, annotators may not be able to judge every emotion expressed by others in all situations, especially those that the annotators have not experienced. In addition, personal experiences are inherently subjective, reflecting the effects of experiential blindness and a person’s current state of mind [5]. For example, one and the same person can be evaluated differently by others, depending on those evaluators’ states of mind. Men who have just crossed a high suspension bridge perceive women as more attractive than men who have not crossed the bridge, because they confuse their fear with attraction [12]. Wang et al. [41] caution that annotators’ assessments of emotions can be subjective and varied too.
Thus an alternative approach analyzes larger data sets, to which emotion labels have been added by the texts’ authors [25, 32, 33], which we refer to as self-rated labels. According to the theory of constructed emotions [6], the human brain uses past experiences, categorized as concepts, to guide people’s actions and give meaning to their observations of their surroundings. Emotions are part of the meaning attributed by and expressed in texts. Data sets with self-reported emotions are relatively easy to collect and can train artificial intelligence (AI), machine learning (ML), and natural language processing (NLP) algorithms [25, 32, 33]. For example, tweets by authors who label them with emotion hashtags, such as #joy, #anger, and #sadness, can be submitted to AI, ML, and NLP models, which produce general emotion detection rules. These rules then can be applied to other tweets that contain emotional content but do not feature labels created by the text’s author or another annotator.
Such ML-based approaches suffer their own limitations; when authors report their own emotions, they might overlook some socially constructed emotions that annotators might be able to identify. Furthermore, models based on self-reported emotion data sets need sufficient amounts of text and labels for training, but what those precise amounts are remains unclear. In particular, ML models do not have previous experience (as annotators might), so they may require more data. Considering these strengths, weaknesses, and gaps, we ask,
-
RQ1. Are models based on (1) annotator-labeled or (2) self-reported emotions more accurate in detecting emotions in texts with (a) self-reported or (b) annotated emotion labels?
-
RQ2. Does the size of the data set featuring self-reported emotions affect the classification accuracy of ML-based emotion detection models?
Rather than either self-reported emotions or annotated emotion labels, we propose a novel, combined approach, the transformer transfer learning (TTL) model. In this approach, the transformer model gets trained in a series of stages that mimic human development. Over the course of their social-emotional development [22], children first identify their own emotions and then learn to synchronize their emotions with those of others, such as in response to relationship issues [38]. The proposed TTL approach replicates these two stages by first training a transformer model, such as the RoBERTa-large model [21], on a large, self-reported emotion data set, and then on a relatively small, socially agreed emotion data set with annotator-generated labels.
With this novel two-step approach, we aim to improve forecasting accuracy in terms of predicting emotions across different types of data sets, with self-reported or annotator-labeled emotions. To the best of our knowledge, this study is the first to train models sequentially on self-reported emotion data, followed by data gathered from annotator labels. Previous transformer models trained on large emotion data sets achieve higher classification accuracy than those trained on small data sets only [9], though previous research focuses on differences in size of the data sets, not the types of emotion data. We also note a previous study [43] that offers similar findings for chemical reactions, though unrelated to emotion detection.
To confirm whether the newly introduced TTL approach achieves greater emotion detection accuracy than alternative modeling approaches, including non-sequentially trained models that also involve (1) annotator-rated emotion data, (2) self-reported emotion data, and (3) both types, we investigate the following question:
-
RQ3. Does the TTL approach achieve higher classification accuracy than models that have been non-sequentially trained on annotator-rated or self-reported emotion data?
In search of answers for these questions, we gather a novel data set with 3,654,544 tweets that include emotion hashtags, inserted by their authors. We analyze this large data set, along with 10 previously published data sets that contain text with emotion labels, whether provided by the texts’ authors or annotators. The new data set can be leveraged for further research; it represents one of the largest data sets of tweets containing self-reported emotion hashtags (n = 3,654,544), posted on Twitter between October 2008 to October 2021. It is available as an open data set for academic purposes (https://github.com/EmotionDetection/Self-Reported-SR-emotion-dataset.git).
In turn, the methodological contribution of this paper is threefold. First, we offer the first (to the best of our knowledge) assessment of the generalizability of the forecasting accuracy of emotion detection models developed on the basis of either self-reported or annotator-labeled emotion data sets. To do so, we apply models trained on each self-reported emotion data set to predict the emotions that annotators have used to label the texts and vice versa. Second, regarding the relevance of large databases, we assess whether models developed on the newly collected self-reported data set achieve higher forecasting accuracy than models developed on smaller, previously published data sets that also contain self-reported emotions. Third, we propose and apply the TTL approach, which replicates the social-emotional development stages of children.
2 Related work
Growing literature recognizes the importance of specific (fine-grained) emotion detection models and data sets. Existing emotion detection algorithms rely on the concepts of (1) word-level affect lexicon, (2) phrase-level traditional ML, (3) document-level deep learning, and (4) document-level pretrained transformer models.
A word-level affect lexicon entails the identification of a corpus of words related to specific emotions. For example, "stole" relates to the emotion of anger; "amazing" is related to joy. This vocabulary-based approach assigns the primary emotion to a label in the text by searching for the frequency of words associated with various, specific emotions (e.g., [4, 25]).
Phrase-level traditional ML analyzes texts beyond simple counts of words. The algorithms learn the meaning of words or phrases from the training data set, using an n-gram function (i.e., sequence of N words; [17]). For example, the 2-g word tokens “fine young” and “young man” can be extracted from the phrase “fine young man” [20, 28, 40].
For document-level deep learning, Goodfellow et al. [15] point out that as the amount of data used for NLP increases, traditional ML algorithms suffer from insufficient lexical feature extraction. Deep learning algorithms instead use many hidden layers to find complex document-level representations of large amounts of text, without lexical feature extraction [1, 26, 32, 41].
In 2018, Google introduced a pretrained transformer model, “Bidirectional Encoder Representations from Transformers” (BERT) [10], that outperformed other models in many NLP tasks, including specific emotion classifications [3, 7, 9]. Previously published studies indicate that transformer models are optimal for emotion detection, but classification accuracy varies depending on the emotion data set being analyzed [3, 7, 9]. As, Table 1 shows, accuracy for classifying human emotions varies from 50 to 80%; it seems difficult to surpass 80%.
Yet it is not clear whether models based on self-reported emotions generalize to data sets containing annotator labels or vice versa (RQ1). Previous research tends to compare different algorithms used for emotion detection, not the type of data being used to define the emotions expressed in texts. According to this comparison, transformer models outperform alternative algorithms [3, 7, 9], so we integrate them into our proposed TTL approach. Table 1 also shows that emotion data sets exhibit a trend of increasing sizes over time (RQ2) but cannot indicate whether a larger data sets, containing authors’ self-reported emotions, enhance forecasting accuracy.
Finally, recent studies [9, 43] propose that researchers can increase model accuracy by sequentially training a transformer model, first on a large general data set and then on a small, target data set (RQ3). For example, BERT [10] was sequentially trained on a large emotion data set (GoEmotions [9]; n = 58 k) and then small data sets (sampled from various emotion data sets, [2] [8] [14] [25] [27] [32] [33]; n < 1,000). It achieves greater classification accuracy than models trained only on a small data set [9]. Prior studies include various annotator-rated and self-reported emotion data sets, but the focus is primarily on size differences, rather than types of labels, self-reported or human annotator labels. As noted in the introduction, we aim to extend this approach to replicate the social-emotional development stages of humans and thereby achieve robust performance across emotion data sets.
3 Data sets
3.1 Annotator-rated and self-reported emotion data sets
A total of 11 data sets were analyzed, each containing at least four of Ekman's [13] six commonly applied specific emotions (anger, disgust, fear, joy, sadness, and surprise). The data sets consist of emotion labels and accompanying text sentences, such as news headlines, tweets, and Reddit comments. Table 2 summarizes seven previously collected annotator-rated emotion data sets:
-
Affective Text (D_A1): Six annotators labeled 1000 news headlines from Google News and CNN (https://web.eecs.umich.edu/~mihalcea/affectivetext/),
-
Emotion Cause data set (D_A2): Four annotators labeled 2,000 automatically generated sentences (https://www.site.uottawa.ca/~diana/resources/emotion_stimulus_data/),
-
CrowdFlower Sentiment Analysis (D_A3): 40,000 tweets labeled by crowdsourcing (https://data.world/crowdflower/ sentiment-analysis-in-text),
-
Emotion Intensities 2017 in Tweets (D_A4): Annotators labeled 7,000 tweets (https://saifmohammad.com/WebPages/EmotionIntensity-SharedTask.html),
-
GoEmotions (D_A5): Three to five annotators labeled 58,000 Reddit comments (https://github.com/google-research/google-research/tree/master/goemotions),
-
Stance Sentiment Emotion Corpus (SSEC) (D_A6): Three to six annotators labeled 4,800 tweets used in the SemEval 2016 competition (http://www.romanklinger.de/ssec/), and
-
SemEval-2018 Affect in Tweets Data (D_A7): Seven annotators labeled 2,500 tweets (http://saifmohammad.com/ WebPages/SentimentEmotionLabeledData.html).
Table 3 lists the three previously published self-reported emotion data sets:
-
CARER emotion data set (D_S1): 664,000 tweets with self-reported emotions (https://github.com/dair-ai/emotion_data set),
-
International Survey on Emotion Antecedents and Reactions (ISEAR) (D_S2): 7,500 sentences in which participants reported emotions through a survey (https://github.com/sinmaniphel/py_isear_data set),
-
Twitter Emotion Corpus (TEC) (D_S3): Collection of 21,000 tweets with emotion hashtags (http://saifmohammad.com/WebPages/SentimentEmotionLabeledData.html).
-
Collecting the self-reported emotion data set
We collected the new self-reported emotion data set (D_SR) by using the Twitter Application Programming Interface (API), with approval from Twitter. The collected data set consists of publicly available information and excludes personally identifiable information.
We collected tweets in English (n = 5,367,357) posted between March 2008 and October 2021 that feature one of Ekman’s six basic emotions with a hashtag [13]: #anger, #disgust, #fear, #joy, #sadness, and #surprise [25]. For example, the text “Spring is coming!!!!” featured “#joy,” as inserted by the tweet’s author. Emotion hashtags in the tweets (independent variables) affect the dependent variables and were used exclusively as label values. Website addresses and special characters were removed to obtain only English words [25]. For example, exclamation marks were removed from “Spring is coming!!!!,” resulting in “Spring is coming.”
Duplicate tweets also were removed, retaining the first one only (11.32% of tweets in our data set). Tweets including multiple emotion hashtags were removed to capture unique emotion, such as “Everything makes me cry … everything #sadness #angry #joy” [1] (3.95% of tweets). Tweets containing words that may not represent each emotion were also removed, such as #anger together with “management” or “mentalhealth”; #disgust containing “insideout”; #fear in conjunction with “god”; #joy containing “redvelvet”; and #surprise with “birthday” (4.83% of tweets). Also, tweets that had fewer than three English words and re-tweets were excluded [25] (11.81% of tweets). This process resulted in n = 3,654,544.
A first descriptive analysis shows that the number of words in a tweet is defined by Mean = 15.59, SD = 8.85, Median = 14, Min = 3, Max = 71, Q1 = 9, and Q3 = 20. In Fig. 1, the word cloud of the most frequently occurring words shows that “love” (n = 399,484) is the most mentioned emotion word, which reflects general valence. The most mentioned specific emotion is “joy.”

Word cloud of most frequent words
3.2 Integration of eleven emotion data sets
We included only cases reflecting one of Ekman's [13] six emotions (anger, disgust, fear, joy, sadness, and surprise) from the 11 emotion data sets mentioned previously. Table 4 reports the ten previously collected emotion data sets, which contain a total of 108,317 cases that feature four to six Ekman emotions. The new self-reported data set features 3,654,544 cases. The annotator-rated emotion data sets, D_A1 to D_A7, contain a total of 63,516 cases. The previously collected self-reported data sets, D_S1 to D_S3, include 44,801 cases, and D_SR contains 3,654,544 cases. The occurrence of specific emotions across the 11 data sets ranges, defined by proportions from 1.42 to 38.81%.
4 Methodology
4.1 Transformer models
As discussed in Sect. 2, transformer models such as BERT [10] outperform alternative ML algorithms [3, 7] for detecting specific emotions in texts. As the first transformer model, BERT relies on text encoders trained on the BooksCorpus (with 800 million words) and the English-language Wikipedia (with 2500 million words) [36]. Its bidirectional training references both left and right sides of sentences simultaneously. Masked language modeling optimizes the weights in BERT model, such that it can train a language model that calculates the probability distribution of words appearing in a sentence on the basis of large, unlabeled texts with unsupervised learning (see Fig. 2). In turn, pretrained BERT models can be fine-tuned with an additional output layer (Fig. 3) to develop high-performing models for a wide range of NLP tasks, such as linguistic acceptability, natural language inferencing, similarity prediction, and sentiment analysis [10]. The fine-tuning process is introduced in more detail in Sect. 4.2.

Overview of pretraining BERT [10]

BERT fine-tuning network architecture [10]
We also note two versions of BERT: BERT-base (L = 12, H = 768, A = 12, total parameters = 110 M) and BERT-large (L = 24, H = 1024, A = 16, total parameters = 340 M), where L is the number of transformer blocks, H is the hidden size, and A is the number of attention blocks [10]. Because BERT-large contains more training parameters, its training time for a million sentences in our study is prolonged (approximately seven hours per epoch), compared with BERT-base (approximately three hours per epoch), using the latest RTX3090 GPU. Nevertheless, BERT-large achieves better performance than BERT-base.
Liu et al. [21] point out that Robustly optimized BERT approaches (RoBERTa) outperformed BERT in various NLP tasks. This version uses the same architecture as BERT but pretrains ten times more data, including both BERT data and 63 million news articles, a web text corpus, and stories. Because it offers the highest level of forecasting accuracy to date, we apply RoBERTa-large to compare emotion detection models [19].
4.2 Fine-tuning process
With RoBERTa, a fine-tuning process takes place for sequence-level classification tasks, as in the BERT architecture. We follow an existing process [19], in which emotion data sets get split into a training (80%) and a testing (20%) data set for the transformer model training. At the beginning of the sequence, a special class token [CLS] gets added for classification tasks. The representation values of dimensions are converted from token values. Because the transformer blocks reflect the relationships of all pairs of words in a sentence, the [CLS] vector indicates the contextual meaning of the entire sentence. In the output layer of the transformer model, we add a fully connected layer to categorize the class labels into specific emotions (Fig. 3). During training, we fine-tuned all parameters of the transformer model together, and the output label probabilities were calculated using the Adam function [19]. This process appears as the middle area in Fig. 4.

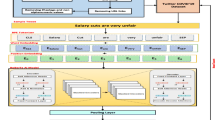
TTL architecture
Figure 4 summarizes the new two-step TTL architecture that we introduce. First, the transformer model, RoBERTa-large (upper area of Fig. 4), was trained on large self-reported emotion data sets. In our study, the self-reported emotion transformer model (middle area in Fig. 4) was trained on the large, integrated, self-reported emotion data sets, D_S1 to D_S3 and D_SR (n = 3,699,345). Second, the emotion model is synchronized to detect socially agreed emotions by retraining on relatively small, annotator-rated emotion data sets. For our study, the model undergoes further training (lower area in Fig. 4) on the combined annotator-rated emotion data sets, D_A1 to D_A7 (n = 63,516), through a fine-tuning process, by re-using the self-reported emotion model (middle area in Fig. 4).
The purpose of RoBERTa and other ML models trained with word vectors is to perform a classification in which the output indicates the likelihood of the input sentence being classified as one of the possible emotion labels, such as fear, anger, sadness, joy, surprise, and disgust. We use the weighted F1 score [20] to assess forecasting accuracy; this measure provides a suitable measure of unbalanced data distributions [39], as exist for our analyses. The formula for the F1 score of each label (class) can be expressed as follows:
where l is the label (anger, disgust, fear, joy, sadness, or surprise), precision(l) is \(\frac{\mathrm{true positive}(l)}{\mathrm{true positive}(l) +\mathrm{ false positive}(l)}\), and recall(l) is \(\frac{\mathrm{true positive}(l)}{\mathrm{true positive}(l) +\mathrm{ false negative}(l)}\). To calculate the weighted F1 score, we take the mean of all F1 scores of each label while weighting the data set size of each label.
5 Evaluation
5.1 Evaluation by models trained on separate data sets
To address RQ1 and RQ2, we trained 11 RoBERTa-large models on the 11 separate emotion data sets defined in Table 4. The 11 models take the labels M_A1 to M_A7, M_S1 to M_S3, and M_SR, depending on the specific data set on which they rely. We applied an 80/20 data set splitting strategy to derive a training and a test set from each of the 11 data sets, so for example, the M_A1 model was trained on 80% of the D_A1 data set, and the test set included 20% of D_A1.
Input variables were stored as word vector tokens (pretrained embedding for different words), segment embeddings (sentence number encoded into a vector), and position embeddings (encoded word within the sentence). Output variables consisted of four to six labels, depending on the Ekman emotions available in the data set (Tables 2 and 3).
For the RoBERTa-large models, we used Hugging Face [42], one of the most frequently applied transformer libraries for the Python programming language. The batch size and learning rate are 16 and 0.00001, respectively, in all models. Devlin et al. [10] point out that overfitting may occur after approximately four epochs, due to the transformer model’s numerous parameters, up to 340 million. Thus, training of the RoBERTa-large models was completed in three epochs.
For RQ1, we evaluated the classification accuracy of the seven models based on annotator-labeled data (M_A1 to M_A7) in the seven annotator-rated emotion test sets (D_A1 to D_A7) and in the four self-reported emotion test sets (D_S1 to DS_3 and D_SR). Thus we obtain 77 weighted F1 scores (upper part of Table 5). For example, the first two cells in the top row of Table 5 show that M_A1 produces F1 = 0.70 in the 20% test set derived from D_A1, whereas it indicates F1 = 0.52 in test set derived from D_A2.
The annotator-rated models tend to perform best on test sets derived from the data set on which they were developed, i.e., the diagonal results in Table 5 are relatively high. For example, M_A1 was developed on the training set derived from D_A1, and it achieved an F1 score of 0.70 on the test set derived from D_A1—higher than the scores for the ten other test sets (i.e., 0.38 to 0.62). Thus, data sets may be rated by annotators with idiosyncratic rules for labeling emotions.
Table 5 also shows that annotator-rated models (M_A1 to M_A7) resulted in a higher average F1 score in test sets of the seven annotator-rated emotion data sets (F1 = 0.62; upper left quarter of Table 5) than in the four self-reported emotion test sets (F1 = 0.53; upper right quarter of Table 5). For example, in the first row of Table 5, the average F1 score of M_A1 is 0.55 for annotator-rated emotion test sets (D_A1 to D_A7) and 0.46 for self-reported emotion test sets (D_S1 to D_S3 and D_SR). The unique rules that annotators apply when specifying emotions in each data set thus appear susceptible to bias in relation to classifying self-reported emotions.
Next, we evaluate the four models trained on the four self-reported emotion data sets, D_S1 to D_S3 and D_SR, in all 11 test sets. The resulting 44 weighted F1 scores appear in the lower part of Table 5. Here again, the self-reported models tend to perform best on the test set derived from the data set on which they were developed. We find relatively high diagonal results in Table 5 for the four models developed on the self-reported data sets. Furthermore, the four self-reported models achieve higher average F1 scores in self-reported emotion data sets (F1 = 0.65; lower right quadrilateral, Table 5) than in annotator-rated emotion data sets (F1 = 0.57; lower left quadrilateral, Table 5). Individual authors, across different data sets or in different writing contexts, may exhibit biases similar to those indicated by annotators when expressing their emotions. According to Table 5, this bias has a relatively strong effect when models based on self-reported emotions are applied to data sets with annotator-labeled emotions.
For RQ2, in the self-reported test sets (D_S1 to D_S3 and D_SR), the M_SR model, based on the larger data set, results in the highest average F1 score of 0.70, compared with scores from 0.60 to 0.65 for M_S1 to M_S3 (lower right quadrilateral, Table 5). In contrast, the M_SR model achieved the lowest average F1 score of 0.49, compared with scores ranging from 0.52 to 0.66 for M_S1 to M_S3, when testing the annotator-rated test sets (lower left quadrilateral, Table 5). Thus, a RoBERTa model trained on large data sets can achieve good performance in similar contexts but not as much in different contexts.
5.2 Evaluation by models trained on multiple data sets
To address RQ3, we used the same input and output variables as in Sect. 5.1. To start, we trained the TTL emotion model on the large, self-reported training set, and then on the smaller, annotator-rated training set. To test the proposed advantages of the TTL approach, we consider three alternative RoBERTa models as benchmarks: (1) the annotator-rated emotion RoBERTa model, trained on the seven annotator-rated training sets (containing 80% of D_A1 to D_A7, n = 63,516); (2) the self-reported emotion RoBERTa model, trained on the four self-reported training sets (containing 80% of D_S1 to D_SR, n = 3,699,345); and (3) the integration RoBERTa emotion model, trained simultaneously on all 11 data sets, (n = 3,762,861), instead of consecutively.
Table 6 contains the 44 weighted F1 scores for the TTL emotion model and the three alternatives. The TTL emotion model achieved the highest average F1 score of 0.84 across the 11 analyzed data sets. The annotator-rated emotion model achieved the second highest average F1 score (0.79).
Figure 5 reports the plot of the loss, which reflects the classification error in the training and testing sets that occurs while training annotator-rated training sets. The loss associated with the self-reported emotion model is greater than that linked to the TTL emotion model; that is, the TTL approach can improve the performance of the transformer model during the model training stage. The TTL emotion model achieved the highest (D_A1, D_A5, and D_A7), second highest (D_A2, D_A3, and D_A6), or third highest (D_A4) F1 scores in the separate annotator-rated test sets. Furthermore, it achieved above-average F1 scores, from fifth (D_S1, D_S2, and D_SR) to sixth (D_S3) highest among of 15 emotion models in the separate self-reported test sets.

Plots of the losses of a annotator-rated emotion model and b TTL emotion model during training by annotator-rated training sets
Figure 6 plots the average F1 scores of the 15 emotion models from Sects. 5.1 and 5.2. The TTL emotion model achieves an average F1 of 0.84, which is higher than the values for the 11 models trained on separate data sets (M_A1 to M_SR; F1 between 0.52 and 0.68) and three models trained on multiple data sets (annotator-rated, self-reported, and integration emotion models; F1 between 0.62 and 0.79).

Average F1 scores of fifteen emotion models
6 Discussion
We examined annotator-rated and self-reported emotion data sets as sources for developing emotion detection models. Each data set has its own rules; any model tends to do best when applied to the test set taken from the data set on which the focal model was trained. This result provides further empirical support for the theory of constructed emotions [6], which argues that the concept of emotion can produce different categories across different people, depending on their personal experiences. This first finding contradicts the classical view of emotion theory [35] that people possess inherent emotions, like universal biological fingerprints.
In relation to RQ1, we find that models developed on annotator-rated emotion data sets perform less well on data sets with self-reported emotions (average F1 = 0.53) than on those with annotator-rated emotions (average F1 = 0.62). Also relevant for RQ1 is our finding that people are biased in expressing their own emotions, similar to the biases shown by annotators. That is, models developed on self-reported emotion data sets perform less well on data sets with annotator-rated emotions (average F1 = 0.57) than on those with self-reported emotions (average F1 = 0.65).
For RQ2, the comparison of the findings with models trained on self-reported emotion data sets confirms that the M_SR model trained on a relatively large self-reported data set achieves better performance (average F1 = 0.70) in the self-reported emotion test sets than the three models trained on smaller, self-reported emotion data sets (M_S1 = 0.60; M_S2 = 0.65, M_S3 = 0.64). To the best of our knowledge, the D_SR emotion data set is the largest collection of tweets with emotion hashtag labels (n = 3,654,544) ever collected, spanning 13 years from October 2008 to October 2021. Nevertheless, M_SR earns a relatively low score on annotator-rated emotion data sets (average F1 = 0.49) compared with the other three models that are based on self-reported emotion labels (M_S1 = 0.60, M_S2 = 0.66, M_S3 = 0.64).
To answer RQ3, we offer the TTL emotion model, initially trained on the four combined self-reported emotion data sets (n = 3,699,345) and then on the combined annotator-rated emotion data set (n = 63,516). The model displays relatively strong performance, with the highest average F1 score of 0.84; it achieves the highest average F1 score of 0.87 on annotator-rated emotion test sets, but only 0.79 on self-reported emotion test sets. Notably, the TTL emotion model reveals substantial improvements over the annotator-rated emotion models trained on corresponding training sets (D_A1, D_A3, D_A4, D_A5, and D_A7). The average F1 score of the TTL emotion model also is higher than those of the integration emotion model that trained all data sets simultaneously, as well as the annotator-rated and self-reported emotion models (Fig. 6).
Further studies might apply the proposed TTL approach to other target domains with small annotator-rated emotion data sets. For example, it might be useful for developing universally applicable emotion detection models that reflect other target domains, such as specific countries (e.g., USA and China), age groups (e.g., children and adults), and genders, based on large, self-reported emotion data sets.
A limitation of this study is that we only collected emotions expressed in tweets, which may not generalize to other text posted on various social media platforms. The TTL emotion model achieved the highest average F1 score of 0.84, which is only 0.05 higher than the annotator-rated emotion model value of 0.79. Considering that the classification accuracy of previous emotion detection studies falls between 0.50 and 0.80, it may be difficult to increase the performance of human emotion detection dramatically. Continued research should integrate other types of social media data sets. Also, methods such as ensemble techniques can be used to investigate potential improvements to the accuracy of transformer models.
Data availability
The analyzed emotion-labeled data set is shared as an open data set for academic purposes (https://github.com/EmotionDetection/Self-Reported-SR-emotion-dataset.git).
Code availability
Not applicable.
Change history
02 March 2023
Missing Open Access funding information has been added in the Funding Note.
References
Abdul-Mageed M, Ungar L (2017) Emonet: Fine-grained emotion detection with gated recurrent neural networks. In: Proceedings of the 55th annual meeting of the association for computational linguistics (volume 1: Long papers), pp 718–728
Agirre E, Màrquez L, Wicentowski R (2007) Proceedings of the Fourth International Workshop on Semantic Evaluations (SemEval-2007) In: Proceedings of the fourth international workshop on semantic evaluations (SemEval-2007)
Al-Omari H, Abdullah MA, Shaikh S (2020) Emodet2: emotion detection in English textual dialogue using BERT and BILSTM models. In: 2020 11th international conference on information and communication systems (ICICS), IEEE, pp 226–232
Balahur A, Hermida JM, Montoyo A, Muñoz R (2011) Emotinet: a knowledge base for emotion detection in text built on the appraisal theories. In: international conference on application of natural language to information systems, Springer, Berlin, Heidelberg, pp 27–39
Barrett LF (2017) The theory of constructed emotion: an active inference account of interoception and categorization. Soc Cogn Affect Neurosci 12(1):1–23
Barrett LF (2017) Categories and their role in the science of emotion. Psychol Inq 28(1):20–26
Chatterjee A, Narahari KN, Joshi M, Agrawal P (2019) SemEval-2019 task 3: EmoContext contextual emotion detection in text. In: Proceedings of the 13th international workshop on semantic evaluation, pp 39–48
Crowdflower (2017) Crowdflower's data sets. https://data.world/crowdflower. Accessed 19 Dec 2021
Demszky D, Movshovitz-Attias D, Ko J, Cowen A, Nemade G, Ravi S (2020) GoEmotions: a data set of fine-grained emotions. arXiv preprint arXiv:2005.00547.
Devlin J, Chang MW, Lee K, Toutanova K (2018) Bert: pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Dunfield K, Kuhlmeier VA, Connell L, Kelley E (2011) Examining the diversity of prosocial behavior: helping, sharing, and comforting in infancy. Infancy 16(3):227–247
Dutton DG, Aaron AP (1974) Some evidence for heightened sexual attraction under conditions of high anxiety. J Pers Soc Psychol 30(4):510–517
Ekman P (1972) Universals and cultural differences in facial expression of emotions, Nebraska. In: symposium on motivation, University Nebraska Press, Lincoln, pp 83–207
Ghazi D, Inkpen D, Szpakowicz S (2015) Detecting emotion stimuli in emotion-bearing sentences. In: international conference on intelligent text processing and computational linguistics, Springer, Cham, pp 152–165
Goodfellow I, Bengio Y, Courville A (2016) Deep learning. MIT Press, Cambridge
Kitayama S, Mesquita B, Karasawa M (2006) Cultural affordances and emotional experience: socially engaging and disengaging emotions in Japan and the United States. J Pers Soc Psychol 91(5):890
Kumar N, Dangeti P, Bhavsar K (2019) Natural language processing with Python cookbook. Packt Publishing, Birmingham
Lee SJ, Kishore S, Lim J, Paas L, Ahn HS (2021) Overwhelmed by fear: emotion analysis of COVID-19 Vaccination Tweets. In: TENCON 2021–2021 IEEE Region 10 Conference (TENCON), pp 429–434
Lim J, Sa I, Ahn HS, Gasteiger N, Lee SJ, MacDonald B (2021) Subsentence extraction from text using coverage-based deep learning language models. Sensors 21(8):2712
Liu CH (2017) Applications of twitter emotion detection for stock market prediction. Doctoral dissertation, Massachusetts Institute of Technology
Liu Y, Ott M, Goyal N, Du J, Joshi M, Chen D, Stoyanov, V (2019) Roberta: A robustly optimised BERT pretraining approach. arXiv preprint arXiv:1907.11692
Malik F, Marwaha R (2018) Developmental stages of social emotional development in children. StatPearls Publishing, Treasure Island
Mcconatha JT, Lightner E, Deaner SL (1994) Culture, age, and gender as variables in the expression of emotions. J Soc Behav Pers 9(3):481
Mesquita B, Walker R (2003) Cultural differences in emotions: a context for interpreting emotional experiences. Behav Res Ther 41(7):777–793
Mohammad S (2012) # Emotional tweets. In: * SEM 2012: the first joint conference on lexical and computational semantics–Volume 1: proceedings of the main conference and the shared task, and Volume 2: proceedings of the sixth international workshop on semantic evaluation (SemEval 2012), pp 246–255
Mohammad S, Bravo-Marquez F, Salameh M, Kiritchenko S (2018) Semeval-2018 task 1: affect in tweets. In: proceedings of the 12th international workshop on semantic evaluation, pp 1–17
Mohammad SM, Bravo-Marquez F (2017) Emotion intensities in tweets. arXiv preprint arXiv:1708.03696
Mohammad SM, Kiritchenko S (2015) Using hashtags to capture fine emotion categories from tweets. Comput Intell 31(2):301–326
Mohammad SM, Sobhani P, Kiritchenko S (2017) Stance and sentiment in tweets. ACM Trans Internet Technol (TOIT) 17(3):1–23
Sailunaz K, Dhaliwal M, Rokne J, Alhajj R (2018) Emotion detection from text and speech: a survey. Soc Netw Anal Min 8(1):1–26
Salehan M, Kim DJ (2016) Predicting the performance of online consumer reviews: a sentiment mining approach to big data analytics. Decis Support Syst 81:30–40
Saravia E, Liu HCT, Huang YH, Wu J, Chen YS (2018) Carer: Contextualized affect representations for emotion recognition. In: Proceedings of the 2018 conference on empirical methods in natural language processing, pp 3687–3697
Scherer KR, Wallbott HG (1994) Evidence for universality and cultural variation of differential emotion response patterning. J Pers Soc Psychol 66(2):310
Schuff H, Barnes J, Mohme J, Padó S, Klinger R (2017) Annotation, modelling and analysis of fine-grained emotions on a stance and sentiment detection corpus. In: Proceedings of the 8th workshop on computational approaches to subjectivity, sentiment and social media analysis, pp 13–23
Siegel EH, Sands MK, Noortgate WVD, Condon P, Chang Y, Dy J, Barrett FL (2018) Emotion fingerprints or emotion populations? A meta-analytic investigation of autonomic features of emotion categories. Psychol Bull 144(4):343
Tenney I, Das D, Pavlick E (2019) BERT rediscovers the classical NLP pipeline. arXiv preprint arXiv:1905.05950
Tian GLUL, McIntosh C (2021) What factors affect consumers’ dining sentiments and their ratings: evidence from restaurant online review data. Food Qual Prefer 88:104060
Uhls YT, Michikyan M, Morris J, Garcia D, Small GW, Zgourou E, Greenfield PM (2014) Five days at outdoor education camp without screens improves preteen skills with nonverbal emotion cues. Comput Hum Behav 39:387–392
Vinodhini G, Chandrasekaran RM (2012) Sentiment analysis and opinion mining: a survey. Int J 2(6):282–292
Volkova S, Bachrach Y (2016) Inferring perceived demographics from user emotional tone and user-environment emotional contrast. In: Proceedings of the 54th annual meeting of the association for computational linguistics (Volume 1: Long Papers), pp 1567–1578
Wang W, Chen L, Thirunarayan K, Sheth AP (2012) Harnessing twitter" big data" for automatic emotion identification. In: 2012 international conference on privacy, security, risk and trust and 2012 international conference on social computing, IEEE, pp 587–592
Wolf T, Chaumond J, Debut L, Sanh V, Delangue C, Moi A, Rush, M A (2020) Transformers: state-of-the-art natural language processing. In: Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, pp 38–45
Zhang Y, Wang L, Wang X, Zhang C, Ge J, Tang J, Duan H (2021) Data augmentation and transfer learning strategies for reaction prediction in low chemical data regimes. Organ Chem Front 8(7):1415–1423
Acknowledgements
This article was supported by Twitter, which provided the academic research API that enabled us to collect tweets.
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions. This work was not funded.
Author information
Authors and Affiliations
Contributions
SJL drafted the manuscript and designed the study. All authors considered the results and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lee, S.J., Lim, J., Paas, L. et al. Transformer transfer learning emotion detection model: synchronizing socially agreed and self-reported emotions in big data. Neural Comput & Applic 35, 10945–10956 (2023). https://doi.org/10.1007/s00521-023-08276-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-023-08276-8