
Abstract
ExSeisDat is designed using standard message passing interface (MPI) library for seismic data processing on high-performance super-computing clusters. These clusters are generally designed for efficient execution of complex tasks including large size IO. The IO performance degradation issues arise when multiple processes try accessing data from parallel networked storage. These complications are caused by restrictive protocols running by a parallel file system (PFS) controlling the disks and due to less advancement in storage hardware itself as well. This requires and leads to the tuning of specific configuration parameters to optimize the IO performance, commonly not considered by users focused on writing parallel application. Despite its consideration, the changes in configuration parameters are required from case to case. It adds up to further degradation in IO performance for a large SEG-Y format seismic data file scaling to petabytes. The SEG-Y IO and file sorting operations are the two of the main features of ExSeisDat. This research paper proposes technique to optimize these SEG-Y operations based on artificial neural networks (ANNs). The optimization involves auto-tuning of the related configuration parameters, using IO bandwidth prediction by the trained ANN models through machine learning (ML) process. Furthermore, we discuss the impact on prediction accuracy and statistical analysis of auto-tuning bandwidth results, by the variation in hidden layers nodes configuration of the ANNs. The results have shown the overall improvement in bandwidth performance up to 108.8% and 237.4% in the combined SEG-Y IO and file sorting operations test cases, respectively. Therefore, this paper has demonstrated the significant gain in SEG-Y seismic data bandwidth performance by auto-tuning the parameters settings on runtime by using an ML approach.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The oil and gas industry extensively relies on the seismic data as a critical factor for processing it to understand and visualize the structure beneath the surface of earth and the seabed [1]. The seismic data are normally stored and encapsulated in SEG-Y format files which are a global standard [2]. Figure 1 shows a complex structure layout of SEG-Y format to store the seismic data in file. It contains trace headers of 240 bytes each and actual traces data on alternate positions in the file. Usually the SEG-Y or seismic data scales to petabytes when written in file on disks. Therefore, it compellingly increase the need of high-performance computing (HPC) or super-computing systems to perform large scale I/O processing, across the oil and gas production industry as well as the research industry.

Structure of SEG-Y file format
The modern HPC clusters are normally well equipped to perform exascale operations and significantly time efficient. They usually contain high number of computing nodes and parallel storage disks connected via fast network hardware infrastructure [3, 4]. Figure 2 shows a very basic structure of HPC system. At software side a programming paradigm is also required to exploit the clusters potential by writing and executing parallel applications, which, in this case, is the standard message passing interface (MPI) library to serve the purpose [5]. The library also contains the application programming interface (API) for carrying out parallel IO processing tasks by communicating with multiple storage disks. These disks are normally controlled and managed by a parallel file system (PFS) protocols. In this research, the Lustre file system (LFS) is the PFS running on the targeted machine disks [6].

The basic view of HPC cluster system
To process the SEG-Y files data the Extreme-Scale Seismic Data (ExSeisDat) library is already developed based on the existing MPI-IO APIs [7, 8]. The ExSeisDat contains its own parallel IO library, namely PIOL, and Workflow library to perform seismic data related functionalities. In spite of this parallel processing library, it faces degradation in program execution performance. The reason is underlying running multiple MPI processes get restricted by LFS protocols, to access a disk at a same instance in parallel. This normally occurs as data-aligning is not applied and considered by users, although it does not guarantee maximum possible bandwidth performance [9,10,11,12,13]. It is also tricky to apply data-aligning to SEG-Y format file as traces data is placed on alternative positions rather than being placed consecutively, and consequently not considered in ExSeisDat functionality. This means the projection of parallel IO bandwidth performance of ExSeisDat to process seismic data critically relies on certain configuration parameters related to MPI, LFS and pattern to access data from SEG-Y file. For example, number of running MPI processes, Lustre stripe count of parallel disks, random or contiguous access pattern, etc. Therefore, it leaves the user with the choice to find and tune the suitable parameters settings that can improve the bandwidth performance from the currently existing value settings.
As our aim is to keep the user of ExSeisDat free from the overhead of manually tuning the settings of related parameters therefore, we propose auto-tuning approach based on maximum IO bandwidth prediction value. This research extends the previous paper contribution regarding the bandwidth prediction of SEG-Y IO and file sorting operations [9]. The first key contribution of this paper is the auto-tuning design strategy for SEG-Y IO and file sorting operations on the basis of related parameters bandwidth prediction to optimize performance. The recent studies have shown the notable advantages of predictive IO bandwidth or performance modeling through machine learning (ML), for auto-tuning parameters in different HPC problem scenarios [14,15,16,17,18]. Consequently, we particularly chose artificial neural networks (ANNs) ML technique for predictive modeling [19, 20], on the collected SEG-Y IO and Sorting benchmarks execution profiling data. The research studies from [21,22,23] are the source of our motivation to implement and execute ANNs ML process. This has been carried out using Python PyTorch package which has significant precision in predicting outputs. Once the ANNs are trained, they are validated and applied into auto-tuning design over the default configuration test settings.
We have tested the range of ANNs with varying number of nodes in the hidden layers to observe its impact on prediction accuracies of ANN models, which is our second key contribution. The runtime cost analysis of ANNs prediction is also presented, as it is a core component in new parameters values selection.
Additionally, the statistical analysis of resulted bandwidth values from default and auto-tuned test settings executions, is a third key contribution. This has also been conducted on the same range of ANNs with varying hidden layers nodes, as stated earlier. The purpose of this analysis is to see the most suitable ANN for auto-tuning of SEG-Y IO and file sorting operations.
Our research mainly emphasizes on the designing of auto-tuning strategy over SEG-Y IO and file sorting configurations by bandwidth prediction of ANNs. Furthermore, it focuses on the statistical analysis on varying overall bandwidth performance improvements, over the range of ANNs.
As evident from results and analysis, the auto-tuning design based on ANNs contribute to a notable increase in SEG-Y IO and file sorting bandwidth performance. This paper is structured as follows: related work in Sect. 2, design and implementation in Sect. 3, experimental result analysis in Sect. 4, discussion in 5 and conclusion in Sect. 6.
2 Related work
The ML-based predictive modeling has been an important element in the previous and recent studies, for handling IO performance degradation. The performance prediction is evaluated in the area of HPC clusters before further steps such as auto-tuning the specific configuration parameters. Those researches have been a great source of motivation for us to adapt prediction-based auto-tuning strategy. This is for optimizing the SEG-Y IO and file sorting performance across LFS employed disks in the super-computing cluster.
The work presented in [9] predicts the IO bandwidth performance on SEG-Y IO and file sorting parameters using ANNs and shows the prediction accuracy. However, those ANNs had only one type of setting in the hidden layers. The setting was 256 nodes in first hidden layer (h1) and 128 nodes in second hidden layer (h2). The SEG-Y IO READ and WRITE prediction accuracies were 96.5% and 88.1%, respectively. Whereas, the SEG-Y file sorting READ and WRITE predictions yielded to 77% and 80% in accuracy, respectively.
The study demonstrated by [14] presents the parameters such as the number of IO threads, CPU frequency and the IO scheduler impacts the HPC-IO performance throughput. Using these parameters, the IO pattern behavior is determined via predictive extrapolation and interpolation modeling approaches. It was achieved by a data analytic framework which supported the exascale modeling experiments. The performance evaluation was based on computing prediction accuracies on the unseen configurations of testing system. Subsequently, the map between Bayesian Treed Gaussian Process variability and the varying regression techniques, was used to optimize the system configurations. This leveraged the parameters selection by statistical methods insights and the HPC variability management.
The research in [15] handles the parallel IO requests by adaptively scheduling them based on the tuning of time window of executing workload within the HPC system. The aim is achieved by constructing the adaptive scheduler through reinforcement learning. As per performance evaluation, the 88% precision is achieved for runtime parameters selection once the access pattern is observed and classified. This classification is determined by deep neural networks in the initial few minutes by the system. Afterward, the system optimize and improves its IO performance for rest of the lifetime, as endorsed by the literature. The key aspect of this study is being more dynamic as compare to other technique, as it involves no training step.
In [17], the random forest regression has been used as the ML technique for predictive bandwidth modeling against the collective MPI-WRITE operation. The accuracy of the predictions has been notably high, ranges in approximately 82-99%. This was also dependent on maximum depth setting. As per the literature, the training and testing datasets have been significantly small sized as compared to our datasets. By adding further variation in the data, the prediction accuracy could be low by increasing data volume.
The work done in [16] deals with the HDF5 format data files by means of optimizing the parallel IO performance. The testing was carried on various HPC systems running the LFS and general parallel file system (GPFS) as the parallel file systems (PFSs). In this study, the auto-tuning had a vital role, based on the IO predictions. The predictive IO modeling was done using the data from LFS-IOR and some different benchmarks by nonlinear regression ML algorithm. This caused notable gain in parallel IO performance by auto-tuning the newly selected parameters. In comparison, the work in [18] demonstrates the IO predictive modeling using LFS-IOR benchmarks as well. However, for the training purpose, the ML approach has been used is Gaussian process regression.
The approach demonstrated by [21] predicts file access time on storage disks managed by LFS. The series of benchmarks were run to profile file access times, so they could be used in training ML models. The ANNs were used as the ML technique. The ANNs generated and produced around 30% less the average prediction error in comparison to the linear ML modeling techniques. The evaluation of distributed file access times was carried out in regard to similar parameters that used to access the file. The study also revealed that normally, the file access times are determined by the degree of magnitude in regard to particular IO paths.
Furthermore, the other researches explored regarding MPI application performance optimization via ML predictive modeling and then auto-tuning parameters. However, they do not consider the part of IO processing within a parallel program [24, 25].
Contrasting with existing recent research, our work in this paper stresses upon optimizing HPC IO performance for SEG-Y READ/WRITE and file sorting through auto-tuning parameters, which is based on the predictive IO bandwidth modeling over the range of ANNs. This provides different bandwidth performance statistics over variation in hidden layers nodes.
3 Design and implementation
3.1 Research methodology
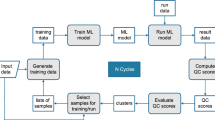
This work has been carried out with the common sequence of steps for both SEG-Y IO and file sorting operations separately. The steps comprises the: (1) identification of the key tunable and non-tunable configuration parameters, (2) re-execution of SEG-Y IO and file sorting benchmarks to generate profiling data, (3) training/testing of 6 ANNs for each SEG-Y READ/WRITE and file sorting READ/WRITE operation (total 24 ANNs), (4) applying design strategy for auto-tuning on basis of generated ANNs and 5) prediction accuracy values and statistical analysis of bandwidth performance results against all ANNs. Figure 3 explains the main components of the flow of this research.

Research flow
3.2 Key parameters identified
The SEG-Y IO and file sorting benchmarks are executed after identification of key configuration parameters, to read/write and sorting traces data in file, respectively. The benchmarks profiling datasets comprises of both training and testing sets for ANN models learning and prediction, respectively. The configuration parameters have also been used as the input features to ANN models.
Tables 1 and 2 show the complete separate list of the related key parameters for both SEG-Y IO and file sorting operations and their corresponding values settings. A complete and separate list for each operation type is generated prior to benchmarking, which contains all possible configuration settings according to the tables. A single configuration setting in SEG-Y IO list can be presented as follows:-
Similarly, a single configuration setting in a list for SEG-Y file sorting can be as follows:-
These type of configuration settings in the lists are used to execute both SEG-Y READ and WRITE benchmarks, as well as the sorting benchmarks. The 3\(^{rd}\) column in both Tables 1 and 2 tells if a particular parameter is tunable or not, which is further explained in later.
3.3 Generating SEG-Y IO and file sorting benchmarks results data
The procedure to execute SEG-Y IO and file sorting benchmarks, and collect the bandwidth profiling data, is specified in Listing 1, defined as Generate_SEG-Y_Benchmarks(). This method takes the input as all the parameter settings values specified in Tables 1 and 2. It first generate two separate lists of all possible combinations SEG-Y IO configurations and SEG-Y file sorting configurations, respectively, on Lines 2 to 3. Here each combination in either list is a set of single configuration settings values as stated in earlier section 3.2. So, Lines 4 to 6 are two nested loops applied to iterate both lists and their configuration sets.
In a loop iteration for each configuration setting, the pre-benchmark settings are applied prior to the execution of main benchmark execution, which are: LFS stripe settings, file generation and Darshan settings. From Lines 13 to 17, the LFS stripe settings are applied on an empty file, accordingly, which is then generated to be read/write or sorted with the specific access pattern or sorting order, respectively. Subsequently, on Line 19, the Darshan setting is applied which just sets the path for Darshan file to be generated after the main benchmark execution. This is to keep the IO bandwidth profiling data. It should be noted that the Darshan is a HPC IO characterization tool for parallel IO bandwidth profiling [26]. The LFS and Darshan pre-benchmark settings are also being used during auto-tuning process for test cases, discussed in later section.
For SEG-Y IO operations, the SEG-Y file is generated in uniform order with the LFS stripe settings. The file is striped across number of Lustre Object Storage Targets (OSTs) as a stripe count value, before benchmark execution. This distribution of this SEG-Y file over the parallel OST disks is according to certain stripe size unit value in a round-robin fashion [6].
The SEG-Y IO benchmarks read or write traces data that makes the amount of number of traces and samples per trace within a file. The MPI processes read or write their respective parts of trace data in either contiguous or random access pattern on Line 22. However, the file should first be generated with a uniform order on Line 19. The uniform order is the ascending order of trace data according to trace header source-x coordinate [2, 7]. According to possible value settings mentioned in Table 1, the total maximum parameters configurations makes total of 20480 benchmarks executions where 10240 are for each READ/WRITE executions.
The SEG-Y file sorting benchmarks are a bit complex in nature than the basic IO executions. An unsorted input file is given to MPI processes to sort it in ascending order with respect to source-x trace header coordinate in an output file. Here, in both cases of contiguous READ and contiguous WRITE an output file is ultimately going to be written on disks either non-contiguously or contiguously. When file is read contiguously then it is written on disk non-contiguously in sorted order, which is the case of contiguous READ. In case of contiguous WRITE the file is read non-contiguously and written to disk contiguously in sorted order.
Initially, it requires an input SEG-Y file to be created with in regard to corresponding unsorted orders values mentioned in Table 2. The uniform order means trace data is sorted in ascending order with respect to source-x coordinate from the trace header value as mentioned earlier [2]. In differentiation, the reverse order is the descending order of trace data and random order is any arbitrary order of trace data.
During the creation of an input SEG-Y file with any of the unsorted orders as stated, the file is distributed across the OSTs according to Lustre striping parameters as the pre-benchmark LFS settings, from Lines 13 to 17. This is similar to the case of SEG-Y IO benchmarks with respect to stripe count and stripe size file distribution settings. Now during the execution of a benchmark on Line 22, in case of contiguous READ the MPI processes will read contiguously their chunk of unsorted traces in their local memory. Then the traces are reordered using a mapping from unsorted input local trace index to the sorted output global trace index with respect to source-x coordinate. Subsequently, this sorted index map is used to write non-contiguously the reordered or sorted trace data into the output SEG-Y file. For the case of contiguous WRITE, the trace indices are already sorted using the unsorted local to sorted global index mapping. Therefore, each MPI process read trace from file non-contiguously using that sorted index mapping of trace indices. Once the traces are reordered or sorted by each process then they are written contiguously into the SEG-Y output file. In both scenarios the output file is also Lustre striped across OSTs using the same stripe count and stripe size values used to generate and distribute the input SEG-Y file. This happens when a configuration settings benchmark is being executed and an output file is produced.
To summarize, the trace data in an input and output SEG-Y files is generated with respect to specified unsorted order, number of traces, samples per trace and Lustre stripe values settings. By considering all the possible value settings mentioned in Table 2, the total maximum parameters configurations or benchmarks to run are 30720 where 15360 are for each contiguous READ/WRITE executions.
The initial LFS settings are applied to target files to test the IO or sorting bandwidth performance against a specific configuration settings benchmark. This is in regard to its distribution of file on parallel disks (OSTs). The parallel IO bandwidth performance during each benchmark execution is measured by the Darshan software tool. The benchmarked file is deleted after execution completion to release the cache, being a post-benchmark setting on Line 29.
The parallel IO bandwidth profiling results are appended to the end of YAML file after being parsed from generated Darshan file on Lines 25 and 26. This is against each benchmark parameters configuration settings execution. These results are kept in form of dictionary style object for each execution benchmark. Figure 4 shows the IO bandwidth profiling from all executed benchmarks results of SEG-Y IO and sorting operations.


SEG-Y benchmarks results
3.4 Predictive IO bandwidth modeling with ANNs
As mentioned earlier, to achieve our goals we have used a ML process for predictive IO modeling to estimate bandwidth value, which is the ANN technique. This is to support auto-tuning process in next step. The training and testing sets for the ML procedure are 80% and 20% of the benchmarks results, respectively. This is for each SEG-Y operation type, as mentioned in Table 3. The recent related work mentioned in [17] has closely comparable problem with the SEG-Y operations, addressed in this paper. The portion of some feature parameters is same, and train test rate is almost 80% and 20%. Therefore, we have used the similar ratio to split benchmarks results into training and testing datasets.
The ANNs generated in this research according to their structure description in Tables 4 and 5, and their corresponding hyper-parameters values in Table 6. As this is being done for both SEG-Y IO and file sorting READ/WRITE operations therefore, total trained and tested ANN models are 24. The ANNs input layer nodes map to input configuration parameters, as described in Table 5, which are essential to model training and testing.
The training of all ANN models for both SEG-Y IO and sorting operations has been carried out using the method ANN_Model_Training() specified in Listing 2. It takes arguments as: h1 specifies number of nodes in 1\(^{st}\) hidden layer, h2 specifies number of nodes in 2\(^{nd}\) hidden layer, dp specifies dropout ratio for hidden layers during training and wd specifies weight decay layers nodes, as mentioned in Line 2. On Line 5 it set the values representing number of nodes in all the layers of the ANN. This is to initialize the ANN model on Lines 9 to 14, with dropout ratios and activation function ReLU(). The ReLU() is rectified linear unit activation function which gives the anticipated value as output from layer to layer, on the nodes [27].
Afterward, on Line 16 the criteria to compute loss between actual and predicted value, has been defined, which is the Mean Squared Error (MSE) [28]. Subsequently on Line 18, the optimizer is defined by Adam() which is a gradient descent method to reach the global minimum point. When gradient is close zero or global minimum, a model is able to make precisely accurate predictions. The Adam() requires the learning rate and weight decay values as responsible for the speed of converging gradient to global minimum. Therefore, 0.002 learning rate for all SEG-Y operations modeling and their specific weight decay values mentioned in Table 6, are applied to train the model in an adequate time.
The Lines 20 and 21 set the X and y matrices containing training set configuration settings and their corresponding actual profiled IO bandwidth values, respectively. These settings and values are scaled between 0 and 1 using MaxAbsScaler [29]. Then, Lines 23 to 34 run the main training or learning loop iterations till the MAX_limit which is set with the accordance of hyper-parameters. This determines how fast a model can converge to global minimum gradient in what maximum iterations. In each iteration, on Line 25 model predicts and save the bandwidth values against all configuration settings in X via Feed Forward Propagation pass in y_predictions. Then, on Line 27, loss is being computed between actual and predicted bandwidth values using the already defined criterion function as MSE. Afterward, on Line 29, optimizer Adam zero the gradient and loss value is propagated backward on Line 31. Subsequently, Lines 33 and 34 run optimizer step function and model train function, respectively, to update the weights among nodes from layer to layer.
When iterations are completed, the ANN model is trained therefore, it is then saved in “ANN_Model.pt”, as mentioned on last Line 37 of this method. Since all the 24 models have different settings and purpose, therefore, their file names are different from each other in actual to avoid any clash. The prediction evaluation results for all the ANN models have been presented and discussed later in the section of Experimental Result Analysis section.

3.5 Full design strategy for auto-tuning parameters
The generated and saved ANNs are the basis to auto-tuning parameters during a running SEG-Y application prior to IO or the sorting operations. Therefore, it is important to note that only a proportion of configuration parameters are tunable. This depends on the SEG-Y operation type and its given non-tunable parameters values. However, the SEG-Y file sorting has only two same tunable parameters for both contiguous READ/WRITE operations. This is because both operations are ultimately writing a sorted file on the disks.
The 3\(^{rd}\) column in Tables 1 and 2, Yes means that parameter is tunable and No means non-tunable, depending on READ/WRITE operation. The common non-tunable parameters are number of MPI nodes, MPI processes per node, number of traces and samples per trace. The MPI nodes and processes cannot be changed once the SEG-Y MPI application is started, and the formation of trace data cannot be tuned as well being a user requirement. For SEG-Y IO READ case, we have only option to switch between the file access patter which is contiguous read or random read. As far as SEG-Y WRITE operation is concerned we can tune stripe count, stripe size and file access pattern settings. In case of SEG-Y READ operation, the file is already striped across networked parallel Lustre OSTs (disks) with specific stripe count and stripe size. Therefore, changing these values at runtime cannot change the file striping arrangement on the disks. Whereas, writing a file with stripe values to read is an additional overhead in this scenario. For the case of SEG-Y WRITE operation, the changed or tuned stripe values can impact the bandwidth during execution.
The SEG-Y file sorting by contiguous READ/WRITE operations has only two tunable parameters which are stripe count and stripe size values. In SEG-Y Sorting, the unsorted order is also a non-tunable parameter in addition to previous common non-tunable parameters. By changing its value also does not impact in bandwidth as this was just used to generate a SEG-Y file with a particular unsorted order before actual benchmark execution. We have options to tune stripe values in contiguous READ/WRITE operations because both write a sorted file eventually. Therefore, both operations bandwidth is expected to be impacted at runtime.
By consideration of the tunabilities of parameters, the following steps for flow of execution are: (1) retrieve the existing configurations, (2) compute the bandwidth predictions on the provided configurations and other tunable/non-tunable possible value settings, (3) select the configurations having maximum performance of IO bandwidth predicted and (4) change the tunable parameters settings with selected configurations. This procedure is exhibited in detail by Listing 3 and 4.
3.5.1 New configuration settings by SEG-Y operations models
The method New_Configs() in Listing 3 returns the set of newly suggested values of tunable configuration parameters against the existing settings in current_configs argument on Line 2. The new configurations predicting maximum bandwidth from the different combination of values are returned in max_configs at the end of this method. It also takes third argument for ANN model “.pt” file in model_path specific to second argument against SEG-Y operation type in op_type. According to SEG-Y IO and Sorting operations stated earlier, the possible string values specified for op_type are: “SEGYRead”, “SEGYWRITE”, “SortRead” and “SortWrite”, from programming point of view. The PyTorch (torch) package is imported on Line 1 for loading the specific generated ANN model on Line 5. The Lines 8 to 10 get the existing settings in X, predict the current bandwidth value as maximum in max_bandwidth_value. This is predicted by calling seg_y_model(X), and max_configs holds the current settings as maximum bandwidth settings, initially. Afterward, list of tunable and possible value settings are initialized from Lines 13 to 15. These lists are initialized as file_access_types, stripe_counts and stripe_sizes as per values mentioned in Tables 7 and 8.
The procedure to configure new parameter values checks all the possible configurations of tunable settings with the given non-tunable parameters values. The one combination of values giving the highest possible predicted bandwidth is the chosen parameters setting. This is elaborated from Lines 18 and 33. The procedure covers all the 4 types SEG-Y operations as stated earlier. The lists of file_access_types, stripe_counts and stripe_sizes are not applicable on all SEG-Y operations types except “SEGYWrite”. The “SEGYRead” operation only requires file_access_types to check and set the highest possible bandwidth setting. Both SEG-Y file sorting operations “SortRead” and “SortWrite” only require Lustre settings stripe_counts and stripe_sizes to check and set maximum bandwidth settings. In order to achieve this, we run the nested loops for checking all possible settings. However, the condition statements are set in place from Lines 21 to 23 to only set the values in iteration according to a specific type of SEG-Y operation about to execute. Subsequently onward, from Lines 31 to 33 have conditions to break loop for particular settings which are not applicable to currently executing SEG-Y operation.
In loop, once the values are set in X according to SEG-Y operation type and then new_bandwidth_value is computed by calling segy_y_model(X) on Line 27. Then, Lines 28 to 30 check if the new_bandwidth_value is greater than current max_bandwidth_value then update the max_bandwidth_value with the new_bandwidth_value and max_configs with currently checked settings in X. By the end of loop the max_configs contains the new configuration settings of tunable and unchanged values of non-tunable parameters, predicting maximum IO bandwidth value. These new maximum bandwidth settings are returned on Line 34, to the application running that particular SEG-Y operation whose method is represented in Listing 4. If for some reason the new configurations are exactly as they were initially, it means the current configuration settings predict highest possible IO bandwidth value from other combinations of settings.

3.5.2 Auto-tuning SEG-Y operations with new configuration settings
This section gives the overview of auto-tuning within the application before executing a SEG-Y operation. The Listing 4 presents the method AutoTuneAndRunSegYOp() which auto-tune settings on the basis of newly chosen settings returned from method in Listing 3 New_Configs(). It takes arguments as current parameters settings in current_configs, SEG-Y operation type in op, target file path in t_file and ANN model “.pt” file path in model_path.
Initially, the ExSeisDat Parallel IO Library (PIOL) has been included, followed by acquiring its namespace on Lines 1 and 2, respectively. Then in the scope of this method, first, the ExSeisDat environment is initialized on Line 6. Secondly, the current MPI process number is retrieved in variable rank on Line 9. Then, on Lines 12 and 13, it checks if current rank is 0, it means the current process is a head MPI process. Subsequently, it calls the New_Configs() method defined in Listing 3. This is to get the new configuration settings predicting maximum bandwidth. These settings are returned in max_configs memory of struct type max_configs_type. Meanwhile, all other MPI processes ranks are waiting until rank-0 is finished getting new settings, on Line 16 via MPI_Barrier() method. Afterward on Line 17, rank-0 process send the new settings to all other ranks. All those ranks receive the new settings in their corresponding objects of max_configs. This is executed by calling MPI_Bcast() method. The methods MPI_Barrier() and MPI_Bcast() are mentioned and explained in [8].
Once all the ranks or processes are updated with new configuration settings then, it checks for the currently required SEG-Y operation type apply tuning accordingly. On Lines 19 and 20, it checks if the current operation is one of the SEG-Y IO operations “SEGYWrite” or “SEGYRead”. Then all processes update their file_access_pattern in order to READ or WRITE SEG-Y file according to the access pattern set. Subsequently, on Lines 22 to 24, it checks if current rank is 0 and operation type is either “SEGYWrite” or one of the file sorting operations: “SortWrite” or “SortRead”. Then it removes the previous target file path specified in t_file and apply new Lustre settings specified in max_configs.stripe_count and max_configs.stripe_size on an empty target file. Meanwhile again, all other processes wait on Line 27 until rank-0 process is finished applying new Lustre stripe settings. Afterward, all processes runs the remaining section of application to complete the task of particular SEG-Y operation type with new tuned configuration settings. This is how the goal of auto-tuning parameters prior to IO execution on runtime, has been achieved.
On the completion of one execution of a SEG-Y operation through the application method in Listing 4, the new IO bandwidth value is captured via Darshan profiling as stated earlier and elaborated by method in Listing 5, explained in the next section.

3.5.3 Statistical data process upon executing auto-tuned SEG-Y operations
A statistical analysis for performance evaluation requires experimental code setup. This involves computations of specific metrics which show the real picture of our approach’s performance. In this scenario we execute default configuration settings and the auto-tuned settings to make comparison between their IO bandwidths. This is eventually conducted by computing the statistical metrics and the overall bandwidth percentage improvement. Tables 7 and 8 present the default configuration settings test cases to execute and auto-tune for SEG-Y IO and file sorting, respectively. The collected IO bandwidths against these default settings and their corresponding auto-tuned settings leveraged the statistical analysis.
In this section, we present an experimental Python code setup to run auto-tuning benchmarks on the test cases stated above for all SEG-Y operations. This procedure is elaborated in Listing 5 method Statistics_Collection_Process(). The Lines 1 to 3 import the required Python packages as torch (PyTorch), numpy and statistics. The arguments of this method are: X—a list of all possible test configuration settings specific SEG-Y operation from Tables 7 or 8, N—the total number of test cases in a test set, op—a type of a specific SEG-Y operation as stated earlier, H1—number of nodes in hidden layer 1 of an ANN, H2—number of nodes in hidden layer 2 of an ANN and model_path—ANN model file path against H1 and H2 nodes configuration.
The method begins with main loop on Line 5 which runs till N default test settings. It should be noted for SEG-Y IO operations the value of N is 1458 for each READ and WRITE execution, whereas it will be 2187 for SEG-Y file sorting operations for each contiguous READ and WRITE execution. The value of N is computed by multiplying numbers of value settings against each parameter specified in Tables 7 or 8, excluding the IO operation parameter.
On Lines 6 and 7, the two lists: Def_bandwidth and Tuned_bandwidth are initialized to contain bandwidth values against a single default configuration and its auto-tuned setting execution, respectively. Then, Line 8 has variable repetitions, which specifies the number of times the default and auto-tuned settings would be executing. Subsequently, their bandwidth values would be saved in their corresponding lists stated earlier. Since the repetitions of a configuration settings can run any number of times, therefore, the nested inner loop is applied on Line 9. So, a default and auto-tuned settings would run repeatedly according to repetitions specified on Line 8, which is 2 in our case. This has been done to ensure the bandwidth corresponding to the settings are approximately same when they are repeated and averaged later on. The reason is sometimes bandwidth can be low at an instance due interference on OSTs by other user programs.
In the inner loop after Line 9, first the IO or sorting operation is executed with default setting from Lines 11 to 16. The Line 11 runs required settings for LFS and Darshan, which set their target file names and paths for an operation in variables t_file and d_file, respectively. The naming of files is according to a specific SEG-Y operation—op, number of nodes in hidden layers—H1 and H2, and the Lustre stripe setting values of an \(i^{th}\) configuration—X. Then, Line 13 generates file according to current configuration LFS stripe settings. Subsequently, the IO or sorting operation with default configuration settings is executed on Line 14. The bandwidth value of the current configuration setting, is profiled in the Darshan file path set in d_file which is then parsed and appended in Def_bandwidth on Line 15. The target Darshan file and the operation file with LFS settings, are deleted to free the cache.
Once an operation with default setting is executed, then it will be re-executed by auto-tuning that default setting from Lines 19 to 24. The steps to execute IO or sorting operations by auto-tuning the configurations, are similar to executing with default settings. However, the first difference is on Line 22, which calls AutoTuneAndRunSegYOp method described in Listing 4, to auto-tune configurations and execute the SEG-Y operation. The second difference is on Line 23 where the bandwidth of auto-tuned SEG-Y IO or Sorting operation is appended in Tuned_bandwidth list.
After the completion of the inner iterations of a configuration setting, their default and the tuned bandwidths are averaged and appended in the main lists Old_bandwidths and New_bandwidths on Lines 26 and 27, respectively. These lists would hold the default and tuned bandwidth values against N configuration settings test cases. On Line 28, it checks for current configuration that if its tuned or new bandwidth is greater than its default or old bandwidth then improvement count C_IM is incremented.
The completion of outer main loop is followed by computing the mean default and tuned bandwidths by averaging the values of Old_bandwidths and New_bandwidths lists, respectively, on Lines 30 and 31. Then the overall percentage improvement in bandwidth is computed on Line 32. The percentage of test cases with improved bandwidths is computed in per_IMP_cases on Line 34. Afterward, from Lines 35 to 44, the remaining statistics are computed, which include maximum, minimum, median, standard deviation and variance values against both default and Tuned bandwidths, separately.
The whole procedure explained above using Listing 3, 4 and 5 completes the auto-tuning design for optimizing SEG-Y operations in HPC cluster, based on the ANNs predictions. The statistical analysis of auto-tuning results is presented in the next section of Experimental Results Analysis.

4 Experimental results analysis
The SEG-Y IO and file sorting test cases for auto-tuning have been executed from 4 to 16 nodes of KAY cluster of ICHEC, for performance optimization analysis. Each node consists of 2x 20-core 2.4 GHz Intel Xeon Gold 6148 (Skylake) processors [30]. The Lustre OSTs (disks) are utilized from 2 to 16 in range. The ML processes for ANN models have been carried out using one of the GPU node of KAY having NVIDIA Tesla V100 16 GB PCIe (Volta architecture) card, via Tensors memory construct in PyTorch [22, 31]. The results are mainly comprises of two parts: ANNs Performance Analysis and Auto-tuning Results Analysis
4.1 ANNs performance analysis
Being the prediction accuracy as one of the metric used to compare the performance of ML models in previous couple of studies [17, 21, 23]. Therefore, it is used in this research and how it is affected by variation in hidden layers configuration of nodes. In this section, we show the impact of changing hidden layers nodes on bandwidth prediction accuracy of ANN models for all SEG-Y operations.
For testing the models, the IO bandwidth data from 20% of benchmarks results as the testing set, are re-scaled to original values. Each model is loaded back in memory at an instance to predict and re-scale the bandwidth values. Then, the prediction accuracy has been measured for all models, using the following equations:
where y and r are actual and predicted n number of total bandwidth values, respectively, and i is the \(i^{th}\) row of X, y and r. Therefore, \(y_i\) is the \(i^{th}\) actual bandwidth value and \(r_i\) is the \(i^{th}\) predicted bandwidth value. This is computed by running model() on \(X_i\) the \(i^{th}\) configuration parameters values set.
4.1.1 SEG-Y IO ANNs prediction evaluation
Figure 5 shows the trend of prediction accuracy changes with increasing the number of nodes in the ANNs hidden layers, denoted as (h1, h2). For SEG-Y READ operation predictions, the accuracy is as low as closer to 39.5% with minimum nodes configuration (8, 4). The accuracy takes a significant notable increase up to 86.5% when the nodes are just doubled to (16, 8). Afterward, it is insignificantly increased and then almost constant around \(\approx \) 95% till the nodes reached to (256, 128) nodes configuration. In short, it is safe to conclude hidden nodes equal to or above (32, 16) nodes should be ideal as far as just the predictions are concerned. In later, model selection can be more specific after analyzing auto-tuning results.
For SEG-Y WRITE operation predictions, the accuracy starts from 65.5% as a minimum value for (8, 4) nodes ANN. It makes \(\approx \)3% increase accuracy to reach around 68.2% when nodes configuration is doubled as in case of (16, 8) nodes. Switching to (32, 16) nodes, it gives notable increase to 83.9% of accuracy. Afterward, it is gradually increased from \(\approx \) 87% to 89% as we change nodes configuration from (64, 32) to (256, 128). By analyzing the line gradient, it can be expected that accuracy becomes constant after switching to greater nodes configuration than (256, 128). Currently, in this scenario the most suitable ANN for SEG-Y WRITE predictions is one with (256, 128) nodes, as it is yielded to maximum accuracy value. However, after analyzing the auto-tuning results it can be more clear to choose the most suitable ANN for auto-tuning and optimizing SEG-Y WRITE operations.
The SEG-Y READ bandwidth prediction accuracy ranges from 39.5 to 96% approximately whereas, for WRITE operation, it ranges from 65.5 to 89.1%, as mentioned in Table 9. Figures 6 and 7 depict the bandwidth predictions against actual values of all the 12 ANN models for SEG-Y IO READ/WRITE operations. Each graph in the figures, represents a specific benchmark and operation type, and hidden layers nodes configuration used in an ANN model. It can be noticed that predictions of ANNs with fewer hidden layer nodes are less likely to follow the actual changing bandwidth pattern as compared to those ANNs with higher hidden layer nodes. The reason is decreased prediction accuracy with fewer hidden layer nodes.

SEG-Y IO ANNs prediction accuracy

SEG-Y IO READ predictions

SEG-Y IO WRITE predictions
4.1.2 SEG-Y file sorting ANNs prediction evaluation
Figure 8 shows the trend of SEG-Y file sorting bandwidth prediction accuracy which changes with increasing the number of hidden layers nodes. For SEG-Y file sorting with contiguous READ operation predictions, where the WRITE operation is non-contiguous, it starts with \(\approx \)75% with the least nodes configuration (8, 4). Then, it takes slight increase of 3% to reach almost 78% accuracy when nodes double to (16, 8). Afterward, a slight notable increase to \(\approx \)87% and 90% when switch to (32, 16) and (64, 32) nodes, respectively. Onward, it keeps almost constant accuracy around 90% till (256, 128) nodes configuration. It is conveniently visible that any ANN model with equal to or above (64, 32) nodes should be ideal as far as just the predictions are concerned. However, model selection can be more specific after analyzing auto-tuning results.
For SEG-Y sorting by contiguous WRITE operation predictions for file sorting, where READ unsorted file is non-contiguous, the accuracy starts from around 50% as a minimum value for (8, 4) nodes ANN. It makes a significant notable increase in accuracy till (64, 32) nodes from almost 70 to 90%. Afterward, it remain around 90% accuracy value till the last (256, 128) configuration of hidden layers nodes. Again, it can be clearly seen that ANN model with equal to or above (64, 32) nodes are ideal from only concern of predictions. The specific model selection would be possible after the analysis of auto-tuning SEG-Y file sorting operations.
The SEG-Y sorting by contiguous READ operation prediction accuracy ranges from 75.3 to 90.6% whereas, for contiguous WRITE operation, it ranges from 50 to 92.2%, as mentioned in Table 10. Figures 9 and 10 depict the bandwidth predictions against actual values of all the 12 ANN models for SEG-Y file sorting operations. Each graph in figures, represents a specific benchmark and operation type, and hidden layers nodes configuration used in an ANN model. It can be noticed again that predictions of ANNs with fewer hidden layer nodes are less likely following the actual changing bandwidth pattern as compared to the ANNs with higher hidden layer nodes. The reason is again decreased prediction accuracy with fewer hidden layer nodes.

SEG-Y file sorting ANNs prediction accuracy

SEG-Y sorting contiguous READ predictions

SEG-Y sorting contiguous WRITE predictions
4.1.3 Runtime cost analysis for new configurations selection
As the method in Listing 3 runs brute force to check all possible combinations to select new configuration settings for auto-tuning therefore, its runtime cost is also analyzed. The Line 29 in Listing 3 runs the ANN feed forward propagation pass to predict the value using model(X), over several iterations depending on an operation type. In case of our ANNs, there are three sub-passes involved in a single forward propagation pass: (1) input layer to hidden layer 1, (2) hidden layer 1 to hidden layer 2 and finally (3) hidden layer 2 to output layer. By considering the ANN with maximum hidden layers nodes (256 and 128), Table 12 presents the working of these three sub-passes. The details in the table also contain the number of computations having multiplications (Mul.) and additions (Add.) involved during a whole single pass. The first sub-pass runs the \(\approx \) 3584 computations of multiplications and additions overall. Similarly, the second sub-pass runs \(\approx \)65536 computations. This is the most expensive sub-pass by memory and CPU consumption wise. The reason is the hidden layers and their weights matrices have the most number of nodes and memory allocation in a single pass, respectively. Finally, the third sub-pass runs 128 multiplications and 128 additions which makes 256 computations in total. By adding all the computations of the sub-passes it makes total of \(\approx \) 69376 computations in a single ANN’s feed forward propagation pass to predict a bandwidth value.
Keeping the computations in view, the new parameters values selection for SEG-Y READ operation, runs a forward propagation pass 2 times. This makes \(\approx \) 138, 752 of the total executing instructions. Whereas, the new parameters selection for SEG-Y WRITE operation, runs 40 (2\(\times \)4\(\times \)5) times the execution of feed forward propagation pass. This makes \(\approx \) 2,775, 040 computations in total. In case of SEG-Y file sorting with contiguous READ/WRITE, the new parameters values selection for both operations, runs a forward propagation pass 20 (4\(\times \)5) times. This makes a total of \(\approx \) 1,387, 520 computations.
To analyze how quick the million of computations can CPU run depends on the usage of memory. Table 11 describes the layout of matrices and their memory usage in a forward propagation pass. The matrices for an ANN model are created with default float32 data type, which means each location of a matrix contains 32-bit or 4-bytes of floating point number. The total matrices used are 7 in a single pass which can be seen from Table 11. By adding all the bytes of the 7 matrices, it makes \(\approx \) 140320 bytes or \(\approx \) 137 KiB of total memory required by an ANN model. If a model would be generated with 64-bit or 8 bytes of double precision decimal memory, then the required memory would be doubled to \(\approx \) 274 KiB. In either case, this size of memory can be easily fit into the cache RAM. Since the matrices are conveniently cacheable, the execution of millions of instructions takes negligible execution time by \(\approx 10e^{-4}\) seconds. This runtime tested several times on a KAY’s [30] compute node includes the loading time of the required libraries. However, the first time program loading can take around 30 seconds. Later on, it runs by less than a second as just mentioned.
In order to keep simplicity and our convenience, the code logic for parameters selection in Listing 3 is written in python script to execute using PyTorch module. This interfaces with the caller MPI program in C++ to apply the new configuration settings and run the SEG-Y operation, stated in Listing 4. Alternatively, the parameters selection could be embedded in a single MPI program with using C++ version of PyTorch library. This can be complex than a python script however, it could be faster due to removal of the first time program loading step.
4.2 Auto-tuning results analysis
In this section, we present series of auto-tuning results of improvements in terms of bandwidth values with the statistical analysis against all the ANNs used. As stated earlier, to choose a specific ANN for a SEG-Y operation optimization, we need to analyze the auto-tuning results using all ANNs separately. Table 13 presents the formal definitions of all the statistical metrics used in the experiment, and later being referred in the tables.
The results tables presented in this section are for SEG-Y READ, WRITE and their combined IO. Similarly, the tables are also presented for SEG-Y file sorting by contiguous READ, contiguous WRITE and their combined sorting bandwidth results. The statistics of combined IO and sorting results are computed by merging the lists of bandwidth values results of their corresponding READ and WRITE operations. This has been carried out against all ANNs used by programming the code logic. However, the combined prediction accuracy READ/WRITE results has been computed by the following equation:
where \(A_r\) and \(A_w\) are prediction accuracy percentage values of READ and WRITE ANN models, respectively.
It should be noted that the metrics presenting bandwidth values are in the unit of MiB/s and the multiple of \(10^{x}\) represented as “ex” in the tables. For example, if the value is 2.54 written in a cell and its corresponding row has a metric represented in the left most column with (e5 MiB/s), this means the value is \(2.54 \times 10^{5}\) MiB/s or 2.54e5 MiB/s, which are equivalent to each other.
4.2.1 SEG-Y READ Auto-tuning results
In this section, we present the auto-tuning results of improvements in SEG-Y READ operation test cases, as mentioned in Table 14. According to the results, our auto-tuning design has resulted in majority of improvements in the test cases. The number of improved test cases ranges from 65.2% to 87.2%. In case of most of the ANNs (out of 6), the improved test cases are above 81%. The overall bandwidth improvement ranges in 35.3 % to 97.3%. The worst case of ANN is with (16,8) hidden layers nodes configuration where the lowest improved test cases and overall bandwidth improvement can be noticed. This is regardless to its significant prediction accuracy. By excluding this case, majority of ANNs show bandwidth improvement above 95% whereas, rest of them has 84.6% and 87.8%. It can also be seen that the overall statistics values of tuned mean, maximum, minimum and median bandwidth values are also significantly greater than their default values. However, the standard deviation and variance values are somehow comparable with most of the ANNs. The auto-tuning of SEG-Y READ operation has significantly optimized the bandwidth performance, is evident from these results. This is further supported by Figure 11, which shows the graph plots of auto-tuned bandwidth values against the default values, for each hidden layers (h1,h2) nodes configuration of the ANN models.
It is visible from Table 14 that the improvements do not consistently increase with increasing the number of hidden layers nodes or prediction accuracy. However, the most suitable ANN for the SEG-Y READ operation scenario is apparently the one with (64,32) hidden layers nodes. This ANN has shown maximum test cases improved by 87.2% and optimized bandwidth performance with 97.3%. Therefore, specifically this hidden layers nodes configuration can be chosen to auto-tune and execute SEG-Y READ operations by the system.

SEG-Y IO READ improvements
4.2.2 SEG-Y WRITE auto-tuning results
In this section, we present the auto-tuning results of improvements in SEG-Y WRITE operation test cases, as mentioned in Table 15. According to the results, our auto-tuning design has resulted in majority of improvements in the test cases. The number of improved test cases ranges from 86.1 to 96.7%. In case of most of the ANNs (out of 6), the improved test cases are above 90%. The overall bandwidth improvement ranges in 475.5 to 602.6%, which indicates very significant optimization for SEG-Y WRITE operation. The worst case of ANN is with (128, 64) hidden layers nodes configuration where the lowest improved test cases and overall bandwidth improvement can be noticed. This is regardless to its significant second highest prediction accuracy in all ANNs configuration. By excluding this case, majority of ANNs show bandwidth improvement above 580% whereas, rest of them has 556.0 and 558.2%. It can also be seen that the overall statistics of tuned mean, maximum, median, standard deviation and variance in bandwidth values are also significantly greater than their default values. However, the minimum bandwidth values are somehow comparable with most of the ANNs. The auto-tuning of SEG-Y WRITE operation has shown very significant increase in bandwidth performance by optimization, is evident from these results. This is further supported by Figure 12, which shows the graph plots of auto-tuned bandwidth values against the default values, for each hidden layers (h1, h2) nodes configuration used in ANN models.
It is visible from Table 15 that the improvements do not consistently increase with increasing the number of hidden layers nodes or prediction accuracy. However, the most suitable ANN for SEG-Y WRITE operation scenario is apparently the one with (256, 128) hidden layers nodes. This ANN has maximum nodes in this scenario. It has shown maximum test cases improved by 96.7% and optimized bandwidth performance with 602.6%. Therefore, specifically this hidden layers nodes configuration can be chosen to auto-tune and execute SEG-Y WRITE operations by the system. The second ideal case can be an ANN with (8, 4) hidden layers nodes. It shows closely comparable bandwidth improvement by 602.4%, despite having lowest prediction accuracy and hidden nodes.

SEG-Y IO WRITE improvements
4.2.3 Combined SEG-Y IO auto-tuning results
In this section, we present the combined auto-tuning results of improvements in SEG-Y IO operation test cases. In the HPC cluster systems, the applications are used to run both READ and WRITE operations in sequence or parallel. Therefore, it is worth noting the combined READ/WRITE improvements, as mentioned in Table 16. According to these results, first of all, the combined prediction accuracy has been increased by increasing the hidden layers nodes in the ANN model. This ranges from 52.5 to 92.5%. The improved test cases do not consistently increase but yield percentage from 79.7 to 91.7%, where (256, 128) nodes show maximum improvements. In most of ANNs, the improved test cases are above 85%. However, the overall bandwidth improvement ranges from 50.9 to 108.8%, which is significant, and (64, 32) nodes have shown maximum percentage of improvement. The worst case of ANN is with (16,8) hidden layers nodes configuration where the lowest improved test cases and overall bandwidth improvement can be noticed. This is regardless to its significant combined prediction accuracy. By excluding this case, all other ANNs have shown bandwidth improvement above 99.0%. It can also be seen that the overall statistics of tuned mean, maximum, median, standard deviation and variance in bandwidth values are also significantly greater than their default values. However, the minimum bandwidth values are somehow comparable in most of the ANNs. The combined auto-tuning results indicate that the SEG-Y IO operations have been significantly optimized in bandwidth performance, which is clearly evident.
To choose the most suitable ANN for the series of SEG-Y IO READ/WRITE operations in the HPC cluster, the one with (64, 32) hidden layers nodes is apparently the best. This is because it has shown the maximum overall SEG-Y IO bandwidth improvement with 108.8%. Therefore, specifically this hidden layers nodes configuration can be chosen to auto-tune and execute the series of SEG-Y IO operations in an application by the system. The second ideal case can be an ANN with (32, 16) hidden layers nodes, as it shows closely comparable bandwidth improvement of 108.7%, where the percentage of improved cases is a bit greater.
4.2.4 SEG-Y sorting via contiguous READ auto-tuning results
In this section, we present the auto-tuning results of improvements in SEG-Y file sorting via contiguous READ operation test cases, as mentioned in Table 17. According to the results, our auto-tuning design has resulted in majority of improvements in the test cases. The number of improved test cases ranges from 74.0 to 91.7%. In case of most of the ANNs (out of 6), the improved test cases are above 76%. The overall bandwidth improvement ranges in 130.9 to 283.9%, which indicates very significant optimization in this SEG-Y sorting operation. The worst case of ANN is with (8, 4) hidden layers nodes configuration where the lowest improved test cases and overall bandwidth improvement can be noticed. By excluding this case, majority of ANNs show bandwidth improvement above 158% whereas, rest of them has 141.6 and 156.6%. It can also be seen that the overall statistics of tuned mean, maximum, median, standard deviation and variance in bandwidth values are also significantly greater than their default values. However, the minimum bandwidth values are somehow lesser in all the ANNs cases. The auto-tuning of SEG-Y sorting with contiguous READ operation has shown very significant increase in bandwidth performance by optimization, is evident from these results. This is further supported by Figure 13, which shows the graph plots of auto-tuned bandwidth values against the default values, for each hidden layers (h1, h2) nodes configuration used in ANN models.
It is visible from Table 17 that the improvements do not consistently increase with increasing the number of hidden layers nodes or prediction accuracy. However, the most suitable ANN for SEG-Y WRITE operation scenario is apparently the one with maximum hidden layers nodes (256, 128). This ANN has shown maximum test cases improved by 91.7% and optimized bandwidth performance with 283.9%. Therefore, specifically this hidden layers nodes configuration can be chosen to auto-tune and execute SEG-Y sorting via contiguous READ operations by the system.

SEG-Y file sorting Improvements via contiguous READ
4.2.5 SEG-Y file sorting via contiguous WRITE auto-tuning results
In this section, we present the auto-tuning results of improvements in SEG-Y file sorting with contiguous WRITE operation test cases, as mentioned in Table 18. According to the results, our auto-tuning design has resulted in majority of improvements in the test cases. The number of improved test cases ranges from 67.2% to 92.2%. In case of most of the ANNs (out of 6), the improved test cases are above 81%. The overall bandwidth improvement ranges in 76.3% to 221.8%, which indicates very significant optimization for SEG-Y sorting with contiguous WRITE operation. Surprisingly, a model with lowest hidden layers nodes of (8,4) has shown maximum improved test cases about 92.2 %, as compare to other models. The worst case of ANN is with (64,32) hidden layers nodes configuration where the lowest improved test cases and overall bandwidth improvement can be noticed. This is regardless to its significant prediction accuracy. By excluding this case, majority of ANNs show bandwidth improvement above 213%. It can also be seen that the overall statistics of tuned mean, maximum, median, standard deviation and variance in bandwidth values are also significantly greater than their default values. However, the minimum bandwidth values are somehow comparable. The auto-tuning of SEG-Y file sorting via contiguous WRITE operation has shown very significant increase in bandwidth performance by optimization, is evident from these results. This is further supported by Figure 14, which shows the graph plots of auto-tuned bandwidth values against the default values, for each hidden layers (h1,h2) nodes configuration used in ANN models.
It is visible from Table 18 that the improvements do not consistently increase with increasing the number of hidden layers nodes or prediction accuracy. However, the most suitable ANN for SEG-Y sorting with contiguous WRITE operation scenario is apparently the one with maximum (256,128) hidden layers nodes. This ANN has shown second highest test cases improved by 91.4% but maximum optimized bandwidth performance of 221.8%. Therefore, specifically this hidden layers nodes configuration can be chosen to auto-tune and execute SEG-Y file sorting via contiguous WRITE operations by the system.

SEG-Y file sorting improvements via contiguous WRITE
4.2.6 Combined SEG-Y file sorting auto-tuning results
In this section, we present the combined auto-tuning results of improvements in SEG-Y file sorting operations test cases. The user of ExSeisDat library can run series of SEG-Y file sorting with both contiguous READ and contiguous WRITE in sequence or parallel, on HPC cluster system. Therefore, it is again worth noting the combined file sorting improvements, as mentioned in Table 19. According to these results, first of all, the combined prediction accuracy has been increased by increasing the hidden layers nodes in the ANN model. This ranges from 62.7 to 91.4%. The improved test cases do not consistently increase but yield percentage from 71.9 to 91.6% where (256,128) nodes show maximum improvements. In most of ANNs, the improved test cases are above 81%. However, the overall bandwidth improvement ranges from 98.4 to 237.4%, which is very significant, and (256, 128) nodes have shown maximum bandwidth improvement. The worst case of ANN is with (64, 32) hidden layers nodes configuration where the lowest improved test cases and overall bandwidth improvement can be noticed. This is regardless to its significant combined prediction accuracy. By excluding this case, all other ANNs have shown bandwidth improvement above 196.0%. It can also be seen that the overall statistics of tuned mean, maximum, median, standard deviation and variance in bandwidth values are also significantly greater than their default values. However, the minimum bandwidth values are somehow lesser in all the ANNs cases. The combined auto-tuning results indicate that the SEG-Y file sorting operations have been significantly optimized in bandwidth performance, which is clearly evident.
To choose the most suitable ANN for the series of SEG-Y file sorting operations in the HPC cluster, the one with maximum (256, 128) hidden layers nodes is apparently the best. This is because it has shown the maximum overall SEG-Y IO bandwidth improvement of 237.4% and test cases improved by 91.6%. Therefore, specifically this hidden layers nodes configuration can be chosen to auto-tune and execute the series of SEG-Y IO operations in an application by the system.
5 Discussion
Summarizing the work done in this research, the results presented in the section earlier are the prediction accuracy evaluation to the auto-tuning analysis. This has been carried out for all individual SEG-Y IO and file sorting types of operations in ExSeisDat on HPC cluster, subsequently, leading to combined statistics. The numerics show the impact of variation in ANNs on both prediction accuracy and auto-tuning results. This leverages to choose a specific ANNs hidden layers nodes configuration for having the maximum possible bandwidth performance of SEG-Y data processing. The auto-tuning involves certain parameters responsible for predicting the bandwidth performance. Nevertheless, the tunable parameters can be only tempered at the runtime, depending on the type of SEG-Y data operation executing, i.e., the file access pattern, file striping configurations, etc. Consequently, the certain tunable parameters are identified for a type of SEG-Y operation and value settings separately.
As per past research, the performance prediction and auto-tuning over various parameters have been the key elements in research to improve IO [14,15,16,17]. Since, some parameters can be tuned prior to IO execution, the predictive modeling for SEG-Y data processing has been one of the crucial requirement in our scenario, toward auto-tuning design. Consequently, the best ML approach toward predictive modeling have been ANNs for its significant forecasting capability as per couple of researches [19, 21, 23, 32].
Previously in [9], the main parameters in regard to MPI-IO, LFS and SEG-Y file format were identified to generate benchmarks bandwidth profiling data. These data were later used for the predictive modeling of ANNs with (256,128) hidden layers nodes. However, this research has conducted re-execution of benchmarks profiling on the identified tunable and non-tunable configurations in Tables 1 and 2. Subsequently, the ANNs mentioned in Table 4 have been trained with various less hidden layers node configurations. This is to predict bandwidth for all the SEG-Y IO and file sorting operations, using all these ANNs.
The ANNs have different prediction accuracy values for SEG-Y bandwidth data, depending on the ANNs hidden layers nodes (h1,h2) configuration. Then the constructed design of auto-tuning strategy, using the ANNs predictions, is applied on the default test case settings of the SEG-Y operations, as mentioned in Tables 7 and 8. This has been done to get the statistical data of bandwidth performance over default settings and the corresponding auto-tuned settings, using all the ANNs. Subsequently, to observe the impact of (h1,h2) configuration on the improvements in bandwidth performance. The steps to collect the statistical data is comprised of three main functionalities, namely: New_Configs(), AutoTuneAndRunSegYOp() and Statistics_Collection_Process(). They are indicated in Fig. 3 as part of the flow of this research, and also elaborated by Listings 3, 4 and 5.
In the experiment results, first the impact of (h1, h2) nodes configuration on prediction accuracy is discussed for both SEG-Y IO and file sorting operations ANNs, as shown in Figs. 5 and 8. It can be examine that prediction accuracy notably increases from (8, 4) to (32, 16) nodes configuration. Afterward, it is either very gradually increasing or almost constant till (256, 128) nodes configuration. This is generally the pattern for both SEG-Y operations ANNs predictive modeling. Afterward, it is followed by the runtime cost analysis of the bandwidth prediction by ANN, which is computed by the feed forward propagation pass. It is observed that the parameters selection using New_Configs() method, mostly takes negligible time in the unit of \(10^{-4}\) seconds.
Onward, the improvements in the overall bandwidth performance are analyzed, which occurred during auto-tuning process of all SEG-Y operations. The SEG-Y READ, WRITE and combined IO auto-tuning yield to maximum 97.3%, 602.6% and 108.8% of the overall bandwidth performance improvement, respectively. Similarly, SEG-Y file sorting via contiguous READ, contiguous WRITE, and their combined sorting results, yield to maximum 283.9%, 221.8% and 237.8% of improvements in the overall bandwidth performance. In addition to this, we have also discussed that which ANN can be appropriate from case to case in regard to SEG-Y operation type. In general, it has been demonstrated in this research, the advantage of adaptability over particular configuration settings at the runtime on the basis of ML predictions.
6 Conclusion
This research examined the improvements of auto-tuning over SEG-Y IO and file sorting operations for ExSeisDat, based on the IO bandwidth predictions by ANNs. The paper has demonstrated the adaptable and efficient IO optimization technique as the key requirement, that extends the work presented in [9]. The approach presented aligns with recent research works emphasizing on the challenges in area of overcoming poor IO performance in HPC. The recent works are mostly carried out via ML prediction over certain parameters, subsequently auto-tuning them in different scenarios [14,15,16,17,18, 21, 32,33,34,35]. Consequently, the indicated three key contributions in this research are: 1) the SEG-Y IO and file sorting operations auto-tuning design logic based on the ANNs bandwidth performance prediction, 2) the impact on prediction accuracy by changing hidden layers nodes configuration, and 3) statistical analysis of default and auto-tuned configuration test settings, over specified ANNs. By witnessing the results, the maximum overall bandwidth improved by 97.3%, 602.6% and 108.8% for SEG-Y READ, WRITE and combined, respectively. For SEG-Y file sorting by contiguous READ, WRITE and combined sorting results, the overall bandwidth performance improved by 283.9%, 221.8% and 237.8%, respectively. As part of this research, we have demonstrated the overall advantage of adaptive technique for SEG-Y operations optimization based on the ANNs prediction. As evident from the results, our contributions have meaningful benefits in terms of SEG-Y (Seismic) data IO and sorting optimization, thus paving the way for the efficient IO throughput for an ExSeisDat library-based application at runtime within an HPC cluster.
However, this work can be further extended by applying reinforcement learning over the ANNs and auto-tuning design, which is not the part of this research. This can enable the optimization of the SEG-Y operations at runtime without requiring the prior large time-consuming steps of the benchmarks profiling and ML model training process. Furthermore, the different performance measures can be analyzed with varying hidden layers nodes configuration of the ANNs.
References
Yilmaz Ö (2001) Seismic data analysis: processing, inversion, and interpretation of seismic data. Soc Expl Geophys,
Hagelund R, Levin SA (2017) Seg-y_r2. 0: Seg-y revision 2.0 data exchange format,
Pfister GF (2001) An introduction to the infiniband architecture. High performance mass storage and parallel I/O, 42:617–632,
Birrittella MS, Debbage M, Huggahalli R, Kunz J, Lovett T, Rimmer T, Underwood Keith D, Zak RC (2015) Intel® omni-path architecture: Enabling scalable, high performance fabrics. In 2015 IEEE 23rd Annual Symposium on High-Performance Interconnects, pages 1–9. IEEE,
Gropp W, Lusk E, Doss N, Skjellum Anthony (1996) A high-performance, portable implementation of the mpi message passing interface standard. Parallel Comput 22(6):789–828
Koutoupis Petros (2011) The lustre distributed filesystem. Linux J 2011(210):3
Fisher MA, Conbhuí PÓ, Brion C, Acquaviva J-T, Delaney Seán, O’brien Gareth S, Dagg S, Coomer J, Short R (2018) Exseisdat: a set of parallel i/o and workflow libraries for petroleum seismology. Oil & Gas Science and Technology–Revue d’IFP Energies nouvelles, 73:74,
(2015) MPI: A message-passing interface standard version 3.1, . Accessed: 2019-11-07
Tipu Abdul Jabbar S, Conbhuí PÓ, Howley E (2021) Applying neural networks to predict hpc-i/o bandwidth over seismic data on lustre file system for exseisdat. Cluster Computing, pages 1–22,
Li Y, Li H (2012) Optimization of parallel i/o for cannon’s algorithm based on lustre. In: 2012 11th International Symposium on Distributed Computing and Applications to Business, Engineering & Science, pages 31–35. IEEE,
Liao Wei-keng (2010) Design and evaluation of mpi file domain partitioning methods under extent-based file locking protocol. IEEE Trans Parallel Distrib Syst 22(2):260–272
Dickens PM, Logan J (2009) Y-lib: a user level library to increase the performance of mpi-io in a lustre file system environment. In: Proceedings of the 18th ACM international symposium on High performance distributed computing, pages 31–38. ACM,
Yu W, Vetter J, Canon RS, Jiang S (2007) Exploiting lustre file joining for effective collective io. In: Seventh IEEE International Symposium on Cluster Computing and the Grid (CCGrid’07), pages 267–274. IEEE,
Li X, Lux T, Chang T, Li B, Hong Y, Watson L, Butt A, Yao D, Cameron K (2021) Prediction of high-performance computing input/output variability and its application to optimization for system configurations. Qual Eng 33(2):318–334
Bez JL, Boito Francieli Z, Nou R, Miranda A, Cortes T, Navaux Philippe OA (2020) Adaptive request scheduling for the i/o forwarding layer using reinforcement learning. Future Gen Comput Syst 112:1156–1169
Behzad Babak, Byna Surendra, Snir Marc (2019) Optimizing i/o performance of hpc applications with autotuning. ACM Trans Parallel Comput (TOPC) 5(4):1–27
Bağbaba A (2020) Improving collective i/o performance with machine learning supported auto-tuning. In: 2020 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), pages 814–821. IEEE,
Madireddy S, Balaprakash P, Carns P, Latham R, Ross R, Snyder S, Wild Stefan M (2018) Machine learning based parallel i/o predictive modeling: a case study on lustre file systems. In: International Conference on High Performance Computing, pages 184–204. Springer,
Hopfield JJ (1988) Artificial neural networks. IEEE Circuits Devices Mag 4(5):3–10
Hagan MT, Demuth HB, Beale Mark (1997) Neural Network Design. PWS Publishing Co., USA
Schmidt JF, Kunkel Julian M (2016) Predicting i/o performance in hpc using artificial neural networks. Supercomput Front Innovat 3(3):19–33
Paszke A, Gross S, Massa F, Lerer A, Bradbury J, Chanan G, Killeen T, Lin Z, Gimelshein N, Antiga L, et al. (2019) Pytorch: an imperative style, high-performance deep learning library. In: Advances in neural information processing systems, pages 8026–8037,
Elshawi R, Wahab A, Barnawi A, Sakr S (2021) Dlbench: a comprehensive experimental evaluation of deep learning frameworks. Cluster Comput, pages 1–22,
Zheng W, Fang J, Juan C, Wu F, Pan X, Wang H, Sun X, Yuan Y, Xie M, Huang C, Tang T, Wang Z (2019) Auto-tuning mpi collective operations on large-scale parallel systems. In: 2019 IEEE 21st International Conference on High Performance Computing and Communications; IEEE 17th International Conference on Smart City; IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), pages 670–677,
Hernández ÁB, Perez MS, Gupta S, Muntés-Mulero Victor (2018) Using machine learning to optimize parallelism in big data applications. Futur Gener Comput Syst 86:1076–1092
Carns P, Harms K, Allcock W, Bacon C, Lang S, Latham R, Ross Robert (2011) Understanding and improving computational science storage access through continuous characterization. ACM Trans Storage (TOS) 7(3):1–26
Abien FA (2018) Deep learning using rectified linear units (relu). 03
James G, Witten D, Hastie T, Tibshirani R (2013) An introduction to statistical learning, volume 112. Springer,
Ivan MP, Faisal H, Nuno MG, Petre L, Eftim Z (2020) Homogeneous data normalization and deep learning: a case study in human activity classification. Future Internet, 12(11):194,
Ketkar N (2017) Introduction to pytorch. In: Deep learning with python, pages 195–208. Springer,
Michael R, Wyatt II, Stephen H, Todd G, Adam Moody, Dong H Ahn, and Michela Taufer (2018). Prionn: Predicting runtime and io using neural networks. In: Proceedings of the 47th International Conference on Parallel Processing, page 46. ACM,
Betke E, Kunkel J (2019) Footprinting parallel i/o–machine learning to classify application’s i/o behavior. In: International Conference on High Performance Computing, pages 214–226. Springer,
Zhao T, Hu J (2010) Performance evaluation of parallel file system based on lustre and grey theory. In: 2010 Ninth International Conference on Grid and Cloud Computing, pages 118–123. IEEE,
Zhao T, March V, Dong S, See S (2010) Evaluation of a performance model of lustre file system. In: 2010 Fifth Annual ChinaGrid Conference, pages 191–196. IEEE,
Funding
This research is being conducted under the funding of ExSeisDat project designed in partnership with Tullow Oil plc and DataDirect Networks (DDN). ExSeisDat and this research is supported, in part, by Science Foundation Ireland grant 13/RC/2094, co-funded under the European Regional Development Fund through the Southern & Eastern Regional Operational Programme to Lero-the Irish Software Research Centre (www.lero.ie), and Higher Education Authority (HEA), Ireland.
Author information
Authors and Affiliations
Contributions
Abdul Jabbar Saeed Tipu, Padraig Ó Conbhuí and Enda Howley contributed to the design and implementation of the research, to the analysis of the results and to the writing of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
There is no conflict of interest among the authors of this paper.
Availablity of data
The benchmarks datasets generated and used in this research are available on request.
Informed consent
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tipu, A.J.S., Conbhuí, P.Ó. & Howley, E. Seismic data IO and sorting optimization in HPC through ANNs prediction based auto-tuning for ExSeisDat. Neural Comput & Applic 35, 5855–5888 (2023). https://doi.org/10.1007/s00521-022-07991-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-022-07991-y