
Abstract
Bees Algorithm (BA) is a popular meta-heuristic method that has been used in many different optimization areas for years. In this study, a new version of combinatorial BA is proposed and explained in detail to solve Traveling Salesman Problems (TSPs). The nearest neighbor method was used in the population generation section of BA, and the Multi-Insert function was added to the local search section instead of the Swap function. To see the efficiency of the proposed method, 24 different TSPs were used in experimentation and the obtained results were compared with both classical combinatorial BA and other successful meta-heuristic methods. After detailed analyses and experimental studies on different problems, it has been observed that the proposed method performs well for TSPs and competes well with other methods.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
1 Introduction
Among optimization problems, routing problems are one of the most studied areas. The reasons that make this subject important are as follows: It can be applied to different fields such as entertainment, tourism, logistics, and production, and the solution to the problem is difficult even for medium-sized data sets. Amid the wide variety of problems, the traveling salesman problem (TSP) and the vehicle routing problem (VRP) are considered the most studied problems [1].
In TSP, the seller starts from a random city on a route and returns to the first city by visiting all other cities only once. The aim is to complete this traveling with minimum cost. TSP is an NP-hard problem and the number of possible solutions is directly dependent on the number of cities ((n-1)!) [2]. Therefore, it may not be possible or takes a lot of time to obtain the optimal solution for large problems. In the solution of TSPs, heuristic and meta-heuristic algorithms are preferred because they are fast, although they do not guarantee the optimal solution [3]. One of the basic heuristic methods to solve TSP is the nearest neighbor method (NNM) [4]. NNM starts from the closest two cities on the map, then goes to the third closest to them, and this process proceeds like this. Although it has a straightforward structure as a processing load, it may not always be sufficient to continue from the nearest cities for the optimal solution, especially for large-size problems [5]. Some studies have used it because of its simple structure [6,7,8]. In some studies, NNM has been integrated into population generation sections in meta-heuristic algorithms [3, 9]. A randomly generated route is unlikely close to the optimum route, and many evolutions are needed to improve these routes. Thanks to NNM, the optimization study can start with a better population and the time to reach the minimum values is reduced. Meta-heuristic algorithms are developed inspired by situations which are biological processes, group behavior, and population survival of living creatures, etc., in communities [10]. There are studies on the use of meta-heuristic algorithms in the literature. Some of these, Combinatorial Artificial Bee Colony Algorithm (CABC) [11], Heterogenous Adaptive Ant Colony Optimization (ACO) [12], ACO Extended method [13], Multi-Objective Genetic Algorithm (GA) [14], Discrete Spider Monkey Optimization (DSMO) [15], and Discrete Symbiotic Organisms Search (SOS) [16]. Due to the difficulty of the problems, hybrid algorithms formed by combining more than one meta-heuristic algorithm are also used, for instance, Genetic ACO [17], Genetic Simulated Annealing (SA) with Particle Swarm Optimization (PSO) [18], SOS with SA method [19], GA with ACO and SA [20], ACO with Partheno GA [21].
Another popular meta-heuristic method is Bees Algorithm (BA) which was developed by Pham et al. [22]. The algorithm mimics the nectar-seeking behavior of honey bees. Due to its advantages such as simplicity, flexibility, and durability, it is used in many areas from mechanical design to energy optimization. For combinatorial problems, it has been used in different areas such as single-machine scheduling problems [23,24,25], printed circuit board (PCB) assembly optimization [5, 26,27,28,29], vehicle routing problems [30], timetabling problems [31], manufacturing optimization [32, 33], disassembly process [34,35,36,37] and supply chain optimization [38, 39]. When the studies in the literature are examined, BA is used successfully in some discrete problems. However, for TSP, there are only a few studies [40,41,42,43]. In these studies, the classical combinatorial BA structure was used for TSPs between 50 and 200 cities. However, as seen from the studies in the literature, improving meta-heuristic algorithms, using hybrid structures, or supporting them with NNM and similar methods gives better results for large TSPs. The motivation for the preparation of this study is the detailed examination of combinatorial BA (CBA) and its improvement, especially for TSPs with a large number of cities. In this context, firstly, combinatorial optimization studies with BA were examined, and in the second part, BA and CBA structures were explained by referring to these studies. In the third part, population generation, local search operators, and neighborhood dimensions are examined in detail and the proposed new algorithm is explained. In the fourth part, the analyses and experimental results for the proposed new algorithm are included.
2 Combinatorial Bees algorithm (CBA)
BA solves the optimization problem iteratively, as with other population-based meta-heuristic algorithms. It has local and global search sections. In the local search section, more neighborhood searches are made on elite sites, while fewer searches are made on other sites. The algorithm starts with the determination of some parameters, such as the number of scout bees (n), number of the local search site (m), number of the elite site (e), number of recruited forager bees in the elite site (nep), number of recruited forager bees in the other local site (nsp), the size of the neighborhood (ngh), and number of iterations (I) [44].
Search sections and neighborhood definitions in combinatorial problems are different from continuous problems. In local search, routes are changed with some operators for trying to find new routes with less cost. Some operators used are reversion [32, 35, 43], insert [5, 30, 32, 34, 35, 40, 41, 43], swap [30, 32,33,34,35, 39, 43], 2-opt [5, 40, 41], 3-opt [40], double member swap [30, 39, 40], double member insert [30], block insert [5]. In some studies, genetic algorithm operators such as crossover and mutation have been used [23, 25, 35]. As can be seen, swap and insert operators and their different versions are generally used. In one of the most comprehensive studies on BA, İsmail et al. [43] used three different operators in the local search section: swap, insert, and reversion. In the swap operator, the order of two randomly selected cities is changed. In the insert operator, a randomly selected city is added to a different randomly selected sequence. In the reversion operator, the order between two randomly selected cities is reversed. These operators are used randomly in each loop, with more on elite sites and less on other local search sites.
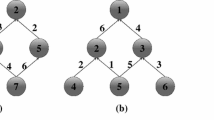
Another important parameter for the use of operators in the algorithm is neighborhood. In most of the studies, neighborhood search was not restricted and included the whole area randomly. Among these, in [5], the swap operation was made between close neighbors. Especially in large TSPs, performing swap and insert operations to cover the whole area may cause distant cities to be connected and the routes to be extended. When determining BA parameters for continuous problems, a small part of the population is usually determined for local search and a larger area is reserved for global search [22, 44]. In some studies, on combinatorial problems, the local search sites were determined as half of the population [23, 24, 43]. In [27], the population number (n) was used as 100 in only the first iteration and the same value as the number of selected sites (n = m = 20) in the following iterations. Due to randomly generated algorithms being less likely to have better costs, in these studies, the global search sites are reduced or even not used after the first iteration. The general flowchart and local search section (in red box) of the CBA are given in Fig. 1 [43]. Local search section is defined for three different operators.

The general flowchart and local search section of the CBA
3 Combinatorial Bees algorithm with nearest neighbor method (CBA-NNM)
Population generation, local search operators and neighborhood structures were emphasized in the improvement studies of CBA. There are also pseudo-codes of operators and algorithms in this section.
3.1 Generation of population
In this study, firstly, the section on population generation is discussed. In the classical BA method, the first population is randomly generated as in many other meta-heuristic algorithms. This method is very effective for finding global optimums in continuous problems. However, it is not very effective in combinatorial problems, and therefore, some studies have used NNM to start the optimization with a good generation [3, 9]. In this study, NNM was used for initial population generation. The pseudo-code of NNM is given in Fig. 2.

Pseudo-code of NNM
In Fig. 3, randomly generated routes and routes created with NNM are given.

Random route and NNM Route for kroA100
Population generation with NNM will cause additional CPU time. Tests have been carried out in MATLAB to calculate this additional time. For TSP with 51–442 cities, the additional times required for single-member generation and 20 members population generation are shown in Table 1. The time required for population generation is 0.39 s for the 200-city TSP and 2.6 s for the 442-city TSP. This process is done only once in the algorithm. (The specification of the hardware is given in the 4th chapter.)
3.2 Local search
As can be seen from the previous section, the most preferred operators in local search are insert, swap, reversion, and their different versions. The first operator in this study is insert. In insert operation, a randomly selected city is inserted to a different order, which is also randomly selected [43]. The pseudo-code of insert is given in Fig. 4 and the effect of insert on the route is shown in Fig. 5.

Pseudo-code of insert

The effect of insert
When selecting cities in these operators, random selections are generally made over the entire route. In the first versions of randomly generated routes, there may be connections between cities in many different areas. Therefore, the random selection of cities is an effective method. However, in the routes created with NNM, distant cities have few connections with each other. Therefore, in order to improve the routes, selections have been made among close neighbors in the local search section. Selecting only the closest neighbors limits variations and may only result in finding local optimums. For this reason, the neighborhood has been determined to be the nearest to 10 cities.
The second operator is multi-inserts. Unlike the single-insert operator described in the previous paragraph, it takes 2–5 cities from a randomly selected order. These cities are placed in a second randomly determined order within the neighborhood sizes. In this way, a few city’s locations can change in one move. Since the number of cities that are collectively located is generally around 5, the number of cities selected has been determined as 2–5. This number is determined randomly because collective distributions are also random. This operator is implemented in two different ways. In the first alternative, the cities selected are inserted into the other area in the same order. In the second alternative, the order of the cities is reversed and inserted. Thus, different variations are tried with two different alternative methods. The decision of this selection is also random. The pseudo-code of multi-insert is given in Fig. 6, and the effect of multi-insert on the route is shown in Fig. 7.

Pseudo-code of multi-insert

The effect of multi-insert
The last operator is reversion. In reversion operator, the order between two randomly determined cities is reversed [43]. It is particularly effective in improving the intersecting sections of routes (the connection which is passing over each other). The pseudo-code of reversion is given in Fig. 8, and the effect of reversion on the route is shown in Fig. 9.

Pseudo-code of reversion

The effect of reversion
3.3 Algorithm
New random bees are produced in the global search section of the classic BA. New bees have an important role in finding global optimums. However, as mentioned in the previous section, it is very unlikely that random routes have good costs in TSPs. Instead of generating a random route, different routes can be prepared using the NNM as in the first population. However, this will increase the processing load a lot. Therefore, the global search section is not used in this study. Similarly, Pham et al. [24] first created a 100-member random population and then used the best 20 of them for local search and did not use the global section. The pseudo-code of CBA-NNM is given in Fig. 10.

Pseudo-code of CBA-NNM
While determining the algorithm parameters, the previous studies given in detail in the second part of this study were taken as a reference. It is seen that the population numbers vary between 20 and 100. It seems that a high number of populations cause a more additional processing load due to NNM. For this reason, the population number (n) was determined as 20. Since there is no global search section, this number is also equal to the number of selected sites (m). For elite sites (e), 25% of “m” has been determined. All parameters used in the algorithm are given in Table 2.
4 Experimental analysis and results
The algorithm was developed in MATLAB R2018a. Experimental studies were carried out on a Lenovo Thinkpad computer with Intel Core i5-8265U CPU 1.60 GHz, 8 GB RAM, and Windows 10 Pro. The data of all the problems used in this study were taken from MP-TESTDATA [45].
4.1 Analysis of algorithm
In order to analyze the algorithm, some tests were made for cities of 100–442. It was done with 10 different repetitions for each experiment and boxplots were created. First, the population production section was analyzed. In this context, the algorithm with the same features but with a difference in the first population generation parts was compared. In the second algorithm, the first populations were randomly generated. Results are given in Figs. 11 and 12. Optimum values could be reached with NNM in each repetition for kroA100. Although it was approaching the optimum value on average with the random population for kroA100, each repetition did not give the same successful results. With the increase in the number of cities, the effect of NNM can be seen more clearly. As can be seen from the results, thanks to NNM better values are obtained and in addition to this repeatability is also provided.

Results by population generation for kroA100 and kroA200

Results by population generation for lin318 and pcb442
In the second study, the effect of local search operators was examined. The proposed algorithm includes Reversion (R), Insert (I), and Multi-Insert (MI) operators. Two more local search structures have been created for comparison. First, the Reversion-Insert-Swap structure was used like in similar studies. In the second, the Swap operator was added in addition to the proposed structure. Results are given in Figs. 13 and 14. For the KroA100 problem, other alternatives were also achieving optimum results in most of the tests. For other problems, it is seen that the second algorithm, where Swap is added instead of Multi-Insert, cannot produce successful solutions. As explained in the previous section, the effect of the Swap operation is on the first solutions of the randomly generated routes. Better results were obtained in the 3rd algorithm, in which the Swap operator was added to the existing structure, compared to the 2nd algorithm. But it is not better than the proposed algorithm. It can be thought that an extra operator will have a positive effect on the solution, but this situation also reduces the effectiveness of other operators.

Results by search operator for kroA100 and kroA200

Results by search operator for lin318 and pcb442
The third analysis study was done on the neighborhood. In the proposed algorithm, selections are made over close neighborhoods. For comparison, a structure has been established where there is no neighborhood limitation and selections can be made over the whole route (random). Results are given in Figs. 15 and 16. As expected here, better results were obtained with the changes made through close neighborhoods. In the routes prepared with NNM, there are few connections between cities that are far from each other. Therefore, searching between nearby cities is more likely to be successful.

Results by neighborhood type for kroA100 and kroA200

Results by neighborhood type for lin318 and pcb442
Finally, CPU times of 1, 10, 100, and 1000 iterations were calculated for seven different TSPs. In this context, MATLAB “tic-toc” function was used. To evaluate the repeatability, each test was repeated 10 times and the average values of these tests were calculated. The results are given in Table 3. It is seen that the increases in CPU times are not at the same rate as the number of cities. Changing from KroA100 to KroA200 for 1000 iterations takes only 11 s. One of the reasons for this low increase is that population production with NNM is done only once, as explained in the previous section. The second reason is that at the beginning of the algorithm, a matrix is created by calculating the distances of all cities from each other. Since the selections are made from this matrix in the next steps, the calculation load is very low.
4.2 Experimental results and comparison with other studies
In order to test the algorithm, 24 different TSPs were selected from TSPLIB. Experimental results are shown in Table 4. (The best values found for some problems are shown in the Appendix.) The first column of Table 4 gives the TSPLIB dataset names and the tour length for the best known solution (BKS). The next five columns show the results of this study. Davg expression gives the deviation of the mean value from the best known value. Dbst shows the deviation rate of the best value found in the result of 10 runs in the study from the best known value. S. dev. shows the standard deviation. Davg and Dbst equations are defined in (1) and (2) [43].
As can be seen from Table 4, with the CBA-NNM, for problems up to 150 cities, the best known values or values very close to the best known value can be obtained. For these problems, deviations in the mean of 10 tests are less than 1%. For 150–493 city problems, the results were obtained with deviations between 0.29 and 1.73% from the best known values. For these problems, the deviations in the mean of the 10 tests were between 0.56 and 2.29%. In addition to these tests, Pr1002 which has 1002 cities was also examined. The deviation values for this problem were found to be 5.7–7.1%. The results obtained with CBA-NNM were much more successful than the results obtained with Classic Combinatorial BA (CCBA) [43]. (Algorithm parameters of CCBA [43] are given in Tables 6, 7 and 8.) Comparisons of Davg values for CBA-NNM and CCBA are shown in Fig. 17.

Comparisons of Davg values for CBA-NNM and CCBA
The main comparison study was done with these algorithms: Combinatorial Artificial Bee Colony (CABC) Algorithm [11] which is the different version of honey bees method, one of the new meta-heuristic algorithms Discrete Symbiotic Organism Search (DSOS) Algorithm [16], Heterogeneous Adaptive Ant Colony Optimization (HAACO), a more advanced version of ACO [12]. (Algorithm parameters of all these studies are given in Tables 6, 7 and 8.) Davg and Dbst data are shown in Table 5.
As can be seen from Table 5, the results obtained with CBA-NNM were similar to the results of other successful meta-heuristic applications. For some problems, better results have been obtained than other algorithms. Even though it could not find the best results for others, it was able to produce solutions very close to other algorithms.
Comparisons are visualized with some bar graphs. In Fig. 18, comparisons of CBA-NNM and HAACO are given. For average values, HAACO achieved better results for problems with 50 and 70 cities, while CBA-NNM achieved better results for problems with more cities. In Fig. 19, comparisons of CBA-NNM and CABC are given. For average values, CBA-NNM achieved better results for KroA100, Ch150, KroB150, and Lin318, while CABC achieved better results for other problems. For problems with CABC leading, the differences are around 0.1–0.2%. The largest difference was in Pcb442 with 0.58%.

Comparisons of Davg values for CBA-NNM and HAACO

Comparisons of Davg values for CBA-NNM and CABC
In Fig. 20, comparisons of CBA-NNM and DSOS are given. For average values, CBA-NNM achieved better results for all problems except Berlin52. The same values were obtained for Lin318. As can be seen from the graphs, CBA-NNM can produce effective solutions to different problems regardless of the number of cities.

Comparisons of Davg values for CBA-NNM and DSOS
5 Conclusion
This study presents a new version of Bees Algorithm for traveling salesman problems. In the local search section of this new version, the multi-insert function has been added in addition to frequently used insert and reversion functions. Another innovation is that the nearest neighbor method was used in the first population generation section. The performance of CBA-NNM has been tested on various TSPs taken from the TSPLIB library, and it has been observed that the performance of BA has increased with these innovations. To evaluate the efficiency of the proposed method, its performance was compared with some other successful meta-heuristic techniques used to solve similar TSP examples in the literature. Comparison results show that the proposed CBA-NNM algorithm competes very well and can achieve optimum solutions with minimum deviation even in problems with a high number of cities.
While determining the parameters of the algorithm within the scope of this study, previous studies were taken as an example, and especially, attention was paid to low CPU time. One of the future studies may be on parameter optimization. Different combinations of parameters and different local search functions can be tried to further improve the results. Another future work might be to test the algorithm on asymmetric traveling salesman problems and multi-traveling salesman problems. See Tables 6, 7 and 8 and Fig. 21.

Best solution of KroA100, KroB150, Pr226, Pr299, Lin318, and Pcb442
Data availability
The author declare that [the/all other] data supporting the findings of this study are available within the article.
References
Osaba E, Yang X, Ser JD (2020) Traveling salesman problem: a perspective review of recent research and new results with bio-inspired metaheuristics. Nature-Inspired Comput Swarm Intell Algorithms, Theory Appl 25:135–164. https://doi.org/10.1016/B978-0-12-819714-1.00020-8
Ahmed ZH (2010) Genetic algorithm for the traveling salesman problem using sequential constructive crossover operator. Int J Biometrics ve Bioinf (IJBB) 3(6):96–105. https://doi.org/10.14569/IJACSA.2020.0110275
Martinovic G, and Bajer D (2012) “Impact of NNA implementation on GA performance for the TSP”, In 5th international conference on bioinspired optimization methods and their applications (bioma 2012), 173–184
AlSalibi BA, Jelodar MB, Venkat I (2013) A comparative study between the nearest neighbor and genetic algorithms: a revisit to the traveling salesman problem. Int J Computer Sci Electron Eng (IJCSEE) 1(1):110–123
Castellani M, Otri S, Pham DT (2019) Printed circuit board assembly time minimisation using a novel Bees Algorithm. Comput Ind Eng 133:186–194. https://doi.org/10.1016/j.cie.2019.05.015
Alemayehu TS, Kim JH (2017) Efficient nearest neighbor heuristic TSP algorithms for reducing data acquisition latency of UAV relay WSN. Wireless Pers Commun 95(3):3271–3285
Wang Y (2014) A nearest neighbor method with a frequency graph for traveling salesman problem. Sixth Int Conf Intell Human-Mach Syst Cybern IEEE 1:335–338
Zuo-Yong X, Xing-Yu G, Zhen-Yu C, Liu-Bo O, Duan-Lai C (2010) Solving TSP based on multi-segment multi-orientation nearest Neighbor algorithm. IEEE Int Conf Intell Comput Intell Syst 3:452–457
Ray SS, Bandyopadhyay S, Pal SK (2007) Genetic operators for combinatorial optimization in TSP and microarray gene ordering. Appl Intell 26(3):183–195
Hamzadayi A, Baykasoglu A, Akpinar S (2020) Solving combinatorial optimization problems with single seekers society algorithm. Knowl-Based Syst 201:106036. https://doi.org/10.1016/j.knosys.2020.106036
Karaboga D, Gorkemli B (2019) Solving traveling salesman problem by using combinatorial artificial bee colony algorithms. Int J Artif Intell Tools 28:195. https://doi.org/10.1142/S0218213019500040
Tuani AF, Keedwell E, Collett M (2020) Heterogenous adaptive ant colony optimization with 3-opt local search for the travelling salesman problem. Appl Soft Comput J 97:106720. https://doi.org/10.1016/j.asoc.2020.106720
Escario JB, Jimenez JF, Giron-Sierra JM (2015) Ant colony extended: experiments on the travelling salesman problem. Expert Syst Appl 42:390–410. https://doi.org/10.1016/j.eswa.2014.07.054
Maitya S, Royb A, Maiti M (2016) An imprecise multi-objective genetic algorithm for uncertain constrained multi-objective solid travelling salesman problem. Expert Syst Appl 46:196–223. https://doi.org/10.1016/j.eswa.2015.10.019
Akhand MAH, Ayon SI, Shahriyar SA, Siddique N, Adeli H (2020) Discrete spider monkey optimization for travelling salesman problem. Appl Soft Comput J 86:105887. https://doi.org/10.1016/j.asoc.2019.105887
Ezugwu AE, Adewumi AO (2017) Discrete symbiotic organisms search algorithm for travelling salesman problem. Expert Syst Appl 87:70–78. https://doi.org/10.1016/j.eswa.2017.06.007
Chen SM, Chien CY (2011) Parallelized genetic ant colony systems for solving the traveling salesman problem. Expert Syst Appl 38:3873–3883. https://doi.org/10.1016/j.eswa.2010.09.048
Chen SM, Chien CY (2011) Solving the traveling salesman problem based on the genetic simulated annealing ant colony system with particle swarm optimization techniques. Expert Syst Appl 38:14439–14450. https://doi.org/10.1016/j.eswa.2011.04.163
Ezugwu AS, Adewumi AO, Frîncu ME (2017) Simulated annealing based symbiotic organisms search optimization algorithm for traveling salesman problem. Expert Syst Appl 77:189–210. https://doi.org/10.1016/j.eswa.2017.01.053
Moraes RS, Freitas EP (2019) Experimental analysis of heuristic solutions for the moving target traveling salesman problem applied to a moving targets monitoring system. Expert Syst Appl 136:392–409. https://doi.org/10.1016/j.eswa.2019.04.023
Jiang C, Wan Z, Peng Z (2020) A new efficient hybrid algorithm for large scale multiple traveling salesman problems. Expert Syst Appl 139(2020):112867. https://doi.org/10.1016/j.eswa.2019.112867
Pham DT, Ghanbarzadeh A, Koc E, Otri S, Rahim S, Zaidi M (2006) The Bees algorithm – a novel tool for complex optimisation problems. Intell Prod Mach Syst 25:454–459
Packianather MS, Yuce B, Mastrocinque E, Fruggiero F, Pham DT, Lambiase A (2014) Novel genetic Bees Algorithm applied to single machine scheduling problem. World Automation Congress (WAC). https://doi.org/10.1109/WAC.2014.6936194
Pham DT, Koc E, Lee JY , and Phrueksanant J (2007), “Using the Bees Algorithm to schedule jobs for a machine”, Proceedings 8th international Conference on Laser Metrology, CMM and Machine Tool Performance (LAMDAMAP). Cardiff, UK, Euspen, 430–439
Yuce B, Fruggiero F, Packianather MS, Pham DT, Mastrocinque E, Lambiase A, Fera M (2017) Hybrid genetic bees algorithm applied to single machine scheduling with earliness and tardiness penalties. Comput Ind Eng 113:842–858. https://doi.org/10.1016/j.cie.2017.07.018
Ang MC, Pham DT, and Ng KW (2009) “Application of the Bees Algorithm with TRIZ-inspired operators for PCB assembly planning”, Proceedings of 5 th Virtual International Conference on Intelligent Production Machines and Systems (IPROMS2006), 454–459
Pham DT, Otri S, and Darwish AH (2007) Application of the Bees Algorithm to PCB assembly optimization”, Proceeding 3rd Virtual International Conferences on Innovative Production Machines and Systems (I*PROMS 2007), 511–516
Ang MC, Pham DT, Anthony JS, and Ng KW (2010) “PCB assembly optimisation using the Bees Algorithm enhanced with TRIZ operators”, IECON 36th Annual Conference on IEEE Industrial Electronics Society, 2708–2713
Ang MC, Ng KW, Pham DT, Soroka A (2013) Simulations of PCB assembly optimisation based on the bees algorithm with TRIZ-Inspired operators. IVIC 2013: Adv Visual Inf 25:335–346
Alzaqebah M, Jawarneh S, Sarim HM, Abdullah S (2018) Bees Algorithm for vehicle routing problems with time windows. Int J Mach Learn Comput 8(3):236–240. https://doi.org/10.18178/ijmlc.2018.8.3.693
Abdullah S, Alzaqebah M (2013) A hybrid self-adaptive bees algorithm for examination timetabling problems. Appl Soft Comput 13:3608–3620. https://doi.org/10.1016/j.asoc.2013.04.010
Xu W, Tian S, Liu Q, Xie Y, Zhou Z, Pham DT (2016) An improved discrete bees algorithm for correlation-aware service aggregation optimization in cloud manufacturing. Int J Adv Manuf Technol 84:17–28. https://doi.org/10.1007/s00170-015-7738-2
Xu W, Zhong X, Zhao Y, Zhou Z, Zhang L, Pham DT (2016) “Manufacturing Service Reconfiguration Optimization Using Hybrid Bees Algorithm in Cloud Manufacturing”, In: Zhang L., Ren L., Kordon F. (eds) Challenges and Opportunity with Big Data. Monterey Workshop 2016. Lecture Notes in Computer Science, vol 10228. Springer, Cham. doi.org/https://doi.org/10.1007/978-3-319-61994-1_9
Liu J, Zhou Z, Pham DT, Xu W, Ji C, Liu Q (2018) Robotic disassembly sequence planning using enhanced discrete bees algorithm in remanufacturing. Int J Prod Res 56(9):3134–3151. https://doi.org/10.1080/00207543.2017.1412527
Liu J, Zhou Z, Pham DT, Xu W, Yan J, Liu A, Ji C, Liu Q (2018) An improved multi-objective discrete bees algorithm for robotic disassembly line balancing problem in remanufacturing. Int J Adv Manuf Technol 65:1–26. https://doi.org/10.1007/s00170-018-2183-7
Liu J, Zhou Z, Pham DT, Xu W, Yan J, Liu A, Ji C, Liu Q (2020) Collaborative optimization of robotic disassembly sequence planning and robotic disassembly line balancing problem using improved discrete Bees algorithm in remanufacturing. Robot Computer Integr Manuf 61:101829. https://doi.org/10.1016/j.rcim.2019.101829
Xu W, Tang Q, Liu J, Liu Z, Zhou Z, Pham DT (2020) Disassembly sequence planning using discrete Bees algorithm for human-robot collaboration in remanufacturing. Robot Computer-Integr Manuf 62:101860. https://doi.org/10.1016/j.rcim.2019.101860
Yuce B, Mastrocinque E, Lambiase A, Packianather MS, Pham DT (2014) A multi-objective supply chain optimisation using enhanced Bees Algorithm with adaptive neighbourhood search and site abandonment strategy. Swarm Evol Comput 18:71–82
Lambiase A, Iannone R, Miranda S, Lambiase A, Pham DT (2016) Bees algorithm for effective supply chains configuration. Int J Eng Business Manage 8:1–9. https://doi.org/10.1177/1847979016675301
Koc E (2010) “Bees algorithm: theory, improvements and applications”, Ph.D Thesis, Cardiff University, UK, 2010
Otri S (2011) “Improving the bees algorithm for complex optimisation problems”, Ph.D Thesis, Cardiff University, UK
Zeybek S and Koc E (2015) “The vantage point bees algorithm”, 7th International Joint Conference on Computational Intelligence (IJCCI), 1, 340–45. doi: https://doi.org/10.5220/0005635903400345, 2015.
Ismail AH, Hartono N, Zeybek S, and Pham DT (2020) “Using the Bees Algorithm to solve combinatorial optimisation problems for TSPLIB”, IOP Conf. Series: Materials Science and Engineering 847, 012027. doi: https://doi.org/10.1088/1757-899X/847/1/012027,
Baronti L, Castellani M, Pham DT (2020) An analysis of the search mechanisms of the bees algorithm. Swarm Evol Comput 59:100746. https://doi.org/10.1016/j.swevo.2020.100746
MP-TESTDATA, The TSPLIB Symmetric Traveling Salesman Problem Instances. Retrieved from http://elib.zib.de/pub/mp-testdata/tsp/tsplib/tsp/index.html. Accessed March 5, 2021.
Acknowledgements
The author would like to thank Roketsan Inc. for their financial support for this work.
Funding
This work was funded by Roketsan Inc.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
I declare that this manuscript is original, has not been published before, and is not currently being considered for publication elsewhere. I know of no conflicts of interest associated with this publication, and there has been no significant financial support for this work that could have influenced its outcome.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sahin, M. Solving TSP by using combinatorial Bees algorithm with nearest neighbor method. Neural Comput & Applic 35, 1863–1879 (2023). https://doi.org/10.1007/s00521-022-07816-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-022-07816-y