
Abstract
Wearable-sensor gait signals processed using advanced machine learning algorithms are shown to be reliable for user authentication. However, no study has been reported to investigate the influence of elapsed time on wearable sensor-based gait authentication performance. This work is the first exploratory study that presents accelerometer and gyroscope signals from 144 participants with slow, normal, and fast walking speeds from 2 sessions (1-month elapse time) to evaluate IMU gait-based authentication performance. Gait signals are recorded in six positions (i.e., left and right pocket, left and right hand, handbag, and backpack). The users' identities are verified using a robust gait authentication method called Adaptive 1-Dimensional Time Invariant Learning (A1TIL). In A1TIL, 1D Local Ternary Patterns (LTP) with an adaptive threshold is proposed to extract discriminative time-invariant features from a gait cycle. In addition, a new unsupervised learning method called Kernelized Domain Adaptation (KDA) is applied to match two gait signals from different time spans for user verification. Comprehensive experiments have been conducted to assess the effectiveness of the proposed approach on a newly developed time invariant inertial sensor dataset. The promising result with an Equal Error Rate (EER) of 4.38% from slow walking speed and right pocket position across 1 month demonstrates that gait signals extracted from inertial sensors can be used as a reliable means of biometrics across time.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
How an individual walks, combined with unique postures, has become an assertion that gait is unique [1, 2]. Many studies have shown that humans' gait has the potential to be robust biometrics [3, 4]. Gait verification is a system that authenticates the claimed identity of an individual from his/her gait signature [5]. The rapid development of mobile technology has probed many researchers' interests in employing inertial sensors for human gait verification. Several shortcomings are associated with the conventional gait analysis system's optical motion capture (OMC) system. For example, these systems are sensitive to light, require a complex setup and extensive database, and are high cost (which involves space setting to provide sufficient field of view, camera equipment, professional setup, etc.). According to [6], five main covariates influence vision-based gait authentication, namely: (1) clothing and shoe type, (2) viewing angle, (3) walking surface, (4) object carriage, and (5) elapse time between gait sequences.
Inertial Measurement Units (IMU), such as accelerometers, gyroscopes, and magnetometers embedded in smartphones can be employed to overcome the limitations of OMC. Signals from these sensors are being considered for gait-based authentication. IMU has been widely used to monitor physical activities and gait behaviors. It is low-cost and unobtrusive, and the data can be continuously recorded without interrupting the individual's activity [7]. Therefore, IMU can be used to obtain potential gait signals from day-to-day activities to meet the requirement of real-time applications. Additionally, the study in [8] concludes that it is possible to perform gait assessment for health monitoring without needing to attach the phone to the subject's body strictly.
Despite the advantages of wearable sensor-based gait authentication, several covariates affect its performance. Three real-world settings were investigated in [9] using wearable sensors for human activity recognition (HAR). A triple formed a set of distinct domains, namely: (1) cross-user diversity where individuals perform the same daily lifestyle activities but in a different manifestation, (2) device-type diversity where multiple personal devices carried by individuals and different placements on the body, and (3) device-instance diversity where an individual performs similar activities but utilizing different device instances (e.g., switching from one smartphone model to another). High accuracy was achieved when the same classifier was trained for a specific individual or device, but the result reduced dramatically when the same method was applied to a different device located at different on-body positions. The work by [10] found that different clothing, shoe types, moods, physical conditions, and subject's body tilt caused sensor orientation inconsistency, although the sensor and placement configuration was fixed in the experiments.
Most existing works analyze the first four covariates in [6] for vision-based gait authentication, and only limited studies are devoted to the elapsed time factor. This also applies to studies related to wearable sensor-based gait authentication (except for the viewing angle factor). One of the reasons not many researchers consider the time-lapse problem is mainly because of the lack of suitable temporal databases. Almost all studies that investigate elapsed time are performed using machine vision approaches. Therefore, finding an inertial sensor gait dataset containing temporal information is challenging. Nonetheless, it is pertinent to know the impact of time-lapse on gait biometric traits when coupled with the influence of various covariate factors (i.e., clothing, shoe, object carriage, time elapse) and the effects of using different device instances placed on the body. This is crucial to demonstrate the practical deployment of gait-based authentication in real-life applications.
Most of the existing public datasets were collected under laboratory control or with strict protocol imposed on the sensor location and its position with respect to the human body. Besides, the walking speed was predetermined to ensure the data was appropriately taken to obtain consistent performance. However, these situations are unlikely to occur in the real world, and the reported classification accuracy drops for real-life activities compared to laboratory studies [11]. Therefore, a realistic dataset is needed to provide sufficient reliability for biometric gait-based authentication evaluation.
These days, sensitive information such as login credentials, banking details, and even private photographs are stored on smartphones. Phone security thus plays an essential role in protecting the data, which has motivated the development of various phone authentication mechanisms like gait verification. Gait verification has the advantage that it is non-intrusive, and authentication can be performed in the background without interrupting the user's daily activities. Therefore, investing in the practical deployment of inertial sensor-based gait in real-life situations is essential. The elapsed time problem is one of the major concerns. Previous works have never explored time variation in inertial sensor-based gait authentication.
In this paper, we introduce a robust method for verifying the legitimate user of a smartphone device by using the user's walking gait pattern acquired by the inertial sensors. A new self-collected gait inertial temporal dataset is presented. The dataset is developed to resemble real-life situations as closely as possible. Toward this end, no restriction is placed on the types of clothing worn, the shoe types, and the carrying conditions. In addition, we do not predetermine the particular android smartphone model used and do not fix the sensor position for a particular subject between the first and second data collection sessions. The free settings above have led to the following research questions: Can variations in the gait pattern associated with dress and shoes changes and device instances across time significantly affect gait-based authentication performance? A hypothesis can be drawn is that a natural gait pattern will not change drastically except for injuries or other problems at the lower limb. In this study, where the dataset was collected without controlling any of those factors between the first and second data collection sessions, there are increased challenges in performing gait-based authentication using the close-to-real-life dataset.
A new IMU gait-based authentication approach dubbed Adaptive 1-Dimensional Time Invariant Learning (A1TIL) is presented. The challenge is to create a high-performance learner for a target domain trained from a related source domain. Therefore, this work uses the domain adaptation method to solve the issue. Throughout this paper, the terms authentication and verification are used interchangeably. They refer to the one-to-one matching procedure between a template to be verified and the stored reference template. Note that a one-to-one authentication (verification) is often performed on a smartphone for enhanced performance and security. This is because a mobile device has lower computational power than a conventional desktop computer. The main contributions and highlights of this paper are as follows:
-
1.
This work is the first exploratory study that evaluates IMU gait-based authentication performance based on a temporal inertial sensors dataset.
-
2.
A 144 subjects inertial gait database called MMUISD was collected to be as close to the real world as possible to see how elapsed time affects gait-based authentication performance. The dataset will be made publicly available for future research in this domain.
-
3.
A time-invariant feature extraction technique known as 1D Local Ternary Pattern (LTP) with an adaptive threshold is presented to extract useful features from the gait signals.
-
4.
A domain adaptation learning technique named Kernelized Domain Adaptation (KDA) is proposed as an unsupervised learning task to match two gait signals from different time lapses for identity verification.
2 Related works
The efficiency of human gait analysis has been studied in many papers providing insightful learning on a vital part of human activity, which has been a hot topic in pervasive computing. Typically, preprocessing procedures are employed for solving the time series classification problem of human activity recognition (HAR). However, most machine learning techniques suffer when the training and testing data are from different domains/distributions or when there are changes in the system configuration, such as adding a new sensor. As a result, the machine learning algorithms must be retrained using new sensors' data. Furthermore, the machine learning algorithms are commonly developed under a presumption that a small sample of the target domain labeled samples are presented during the learning phase. However, this assumption does not hold in most real-world cases. Moreover, there is a need to transfer knowledge from the existing annotated datasets to unlabeled data, especially when they come from two different domains. Therefore, there is a need to create a high-performance learner for a target domain trained from a related source domain.
In particular, Domain Adaptation (DA), which is one of the well-known transfer learning algorithms, can be a solution to solve this issue [12, 13]. The intuition behind this idea stems from the fundamental human learning in real life, where humans use knowledge from past experiences to solve a new task. DA typically adjusts the information obtained from both the source and target domains during the learning phase. The prior works in DA show that the correlation between the two domains can be empirically assessed based on the corresponding underlying distributions from the proper similarity metrics [14]. Therefore, minimization of the distribution discrepancy is a crucial idea.
The existing domain adaptation works in [15, 16, 17] aim to map the source data into the target data by minimizing the gap between domains with an optimization procedure. This approach is known as the subspace-based adaptation method and is adopted in [15, 16]. In the subspace-based adaptation method, a low-dimensional representation of original data in the linear subspace form will be created for each domain, with the discrepancy between the subspaces will and being reduced to construct the intermediate representation. Geodesic Flow Kernel (GFK) was proposed by Gong et al. [15] and utilized the intrinsic low-dimensional structures from the datasets to obtain truly domain-invariant features from subspace directions. This kernel-based domain adaptation method aims to represent the smooth transition from a source to a target domain by incorporating an infinite number of subspaces from the source subspace that lay on the geodesic flow (geometric and statistical properties will be gradually shifted between two domains) to the target subspace. However, it can be computationally expensive to sample more subspaces to get the mapping from the source into the target subspace more precisely. Basura et al. [16] proposed Subspace Alignment (SA) that transformed the source subspace into a target with optimization of a mapping function. Hence, the dissimilarity between the two domains will be reduced by shifting the source and target subspaces closer. It can be performed by learning a linear mapping function that projects the source directly to the target in the Grassmann manifold. However, this method ignores the difference between subspace distributions and only aligns the subspace bases.
Another approach known as the transformation-based adaptation method incorporates metrics, such as Maximum Mean discrepancy (MMD), Kullback-Leibler Divergence (KL-divergence), or Bregman Divergence to measure the dissimilarity across domains. The aim is to reduce the domain discrepancy while preserving the original data's underlying structure and characteristics. Pan et al. [17] extended maximum mean discrepancy (MMD) by transfer components learning that transformed the domain into feature space in the form of parameterized kernel maps. However, MMD also had a shortcoming: it depended on a nonlinear kernel map to reckon the distribution discrepancy. The kernel function may not be optimal for kernel learning machines (e.g., Support Vector Machine).
A study in [18] implemented Stratified Transfer Learning (STL) with SVM, KNN, and Random Forest classifiers significantly increase recognition accuracy for cross-domain activity. First, the majority voting technique was used to obtain pseudo labels for the target domain. Then, to obtain the same subspaces of the source and target domain, intra-class knowledge transfer was performed via iterative optimization. Three datasets were evaluated: OPPORTUNITY, PAMAP2, and UCI Daily and Sports Dataset (DSADS). The results show that the accuracy was improved by 7.68% over the state-of-the-art methods. Compared to the work in [18], this study investigates the influence of gait variations (i.e., associated with different kinds of worn clothes and shoes and different device instances) on wearable sensor gait-based authentication performance across time. For vision-based sensors, it is reported that the other covariates significantly affect gait authentication performance regardless of elapsed time [6]. Furthermore, this paper investigates various Android phone types different from [9].
An enhanced domain adaptation method that relies on kernel-based domain adaptation is introduced as a learning algorithm from the source, a known wearable sensor, and extended to the target so the recognition model can adapt to the changes caused by various covariate factors across time. A comprehensive study comparing the proposed and state-of-the-art methods is presented in Sect. 5.
3 Description of dataset
Our previous work [19] presented an inertial gait database called MMUISD. The same data collection protocol is deployed in this study to obtain a new data set 1 month apart from the first data collection session. To our knowledge, this is the first temporal gait inertial database collected. No other public database under the same category could be identified until this paper is completed.
A total of 144 undergraduate students from Multimedia University (Malaysia) and Gunadarma University (Indonesia) were involved in the second data collection (1 month after the first data collection described in [19]). However, it is worth noting that the number of participations for the second data collection is lesser because it is challenging to engage the same person in the first data collection process to attend the second data collection session.
An online survey was conducted to decide the sensor placement before data collection. The sensor placement positions were determined based on the participant's top-voted choices. On top of that, several studies were conducted to know how smartphone users carried or placed their phones. As a result, we find that the six standard placements of smartphones are in the left and right pockets, the hand carry bag, the backpack, and the left and right hands, as illustrated in Fig. 1a.

MMUISD dataset
The participants were asked to install an Android application we developed on their smartphones (i.e., they must be equipped with accelerometer and gyroscope sensors; otherwise, the other group member's phone was used). Then, they were asked to form groups with 4 or 5 students for each group to make the data collection process systematic.
During the data collection process, we did not strictly control how the participants should place their phones. Thus, there is a high chance that the data from the first data collection session are very different from that collected during the second session. We also did not fix the smartphone's orientation (such as with strap or clips). The participants were only told to place their phones vertically, and the screen should face the front. However, if the participants held their phones using their hands, the orientation of the phones could not be fixed due to hand swaying movement.
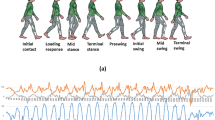
Each participant performed at three different walking speeds: slow, normal, and fast. They needed to stop for 3 s during the walking speed transition (Fig. 1b). They were asked to walk straight in a natural position without any constraints for around 5–8 min to complete all the walks with six sensor positions. Therefore, each participant provided 18 gait samples, giving a total of 2592 (144 × 18) gait samples.
We did not control the types of clothing and footwear during data collection, except that we requested the female participants to wear pants with left and right pockets. All the participants needed to fill out a consent form before data collection, following Multimedia University regulation's ethical conduct. The data collection took place along a straight corridor within the university campus. The dataset endeavors to resemble a real-world scenario and have the following characteristics in Table 1.
4 Proposed method
The proposed A1TIL framework consists of three main steps. First is preprocessing the training and testing data, followed by feature extraction, and lastly, authentication. The block diagram of the proposed framework is shown in Fig. 2. Our dataset contains diverse user preferences, including device-type diversity and device-instance diversity that might adversely affect the system's performance.

An overview of the A1TIL framework
It is reported in [20] that the accelerometer sensors embedded in different smartphones portray perceptible signals' differences. Therefore, the prediction results are evaluated with conventional machine learning techniques; the system will most probably fail due to the disparity between the domain and target data [21]. Moreover, most traditional machine learning methods incorporate cross-validation to select and compare different models for a given predictive modeling problem. However, this is not possible in our case since the distribution of the testing data is not known during model training. In other words, only information from the training data is used to create the learning model without knowledge of the testing data.
4.1 Data preprocessing
The data from 144 participants are used in this work for both training and testing. First, a human operator manually segments the raw signal into three parts, i.e., slow, normal, and fast, by identifying the abnormal spikes which distinguish the transition of different walking speeds (Fig. 1b).
After that, the resultant magnitude vector is computed from the three accelerometer axes and three gyroscope axes,
4.1.1 Gait cycle extraction
Based on the hypothesis from the previous works for sensor-based user authentication, each person's unique gait pattern is embedded in gait cycles [22, 23]. Hence, it is essential to perform gait cycle extraction in this study. Two important gait events can be obtained with peak detection, namely heel strike (HS) and toe-off (TO) to differentiate a gait cycle into swing phase or stance phase. Usually, the frequency and amplitude of HS and TO vary over time since the IMU signals are nonstationary and stochastic. In [24], wavelet transform is justified to be adequate to handle nonstationary signals.
The proposed methods are performed separately on the accelerometer and gyroscope magnitude data. First, the mean \(\Phi\) for each magnitude vector of the accelerometer and gyroscope are computed. The \({\text{remove}}\;{\text{outlier}}\) function is used to remove the outliers from the magnitude vectors by using the mean. In \({\text{Wavelet}}\;{\text{findpeak}}\), the mother wavelet of the Daubechies family (db5) is used to highlight the gait events. The decomposition of the signal will generate the wavelet coefficients associated with the data set. If the wavelet coefficients are less than the threshold, they will be replaced by zero. Next, the signals are reconstructed as a linear combination of the prototype functions weighted by the wavelet coefficients. Lastly, the reconstructed signal's local minima and local maxima will be used to detect HS and TO, respectively. To maintain the length consistency of all cycles, the gait signals are interpolated using linear interpolation. The interpolation length is taken from the maximum length of all gait cycle signals with \({\text{find}}\;{\text{max}}\;{\text{length}}\). Thus, we obtain \({\Psi }\) as the magnitude accelerometer and gyroscope gait sequences for the training and testing data, respectively. The procedure to perform the gait cycle extraction algorithm is summarized in Algorithm 1.

4.1.2 Gait cycle selection
In long-term continuous monitoring of gait signals, selecting the best gait cycle as the biometric feature for user authentication is essential. The gait signals might vary drastically due to mood swings and walking speed [25].
Most previous works performed data collection under laboratory control or strict protocol to ensure the data was taken properly and followed a consistent distribution. However, the gait signals acquired in real life will be long-term and contain large variations. The proposed gait cycle selection method helps to identify the most relevant gait cycle for the authentication method and keep the main discriminative feature intact.
Given a test gait cycle \({\Psi }_{T}\) and a train gait cycle \({\Psi }_{S}\), the relation between \({\Psi }_{S}\) and \({\Psi }_{T}\) is measured by the correlation between the signals using Pearson correlation. In this study, the accelerometer and gyroscope gait sequences are evaluated separately. Specifically, cross-correlation is performed to measure the relation of each gait cycle in gait sequences training data with every gait cycle in gait sequences of the testing data. The identified corresponding pairs from the training and testing data gait sequences are chosen based on the maximum correlation. A total of 144 participants' data is used for the experiment where each individual has a consistent single gait cycle across time-lapse. The generated single gait cycle for the accelerometer and gyroscope are normalized separately using z-score normalization. The selection procedure is shown in Algorithm 2.

4.2 Adaptive 1D LTP
Feature extraction is one of the most critical steps in signal processing. Among the known techniques, LBP, which is 2D, offers several advantages such as solid discriminative capabilities, less computational power, and fast processing. Therefore, LBP has been extensively applied in several input types, not limited to images.
Chatlani et al. [26] were the first to consider using 1D-LBP for signal processing [27]. However, due to some shortcomings of LBP, like sensitivity to noise, a variant of LBP known as LTP is introduced. LTP has become popular as it is less noise-sensitive and more discriminative in uniform regions. The pixel neighbor in two dimensions is utilized for LTP and is known as 2D LTP [28].
In this paper, we propose an approach called 1D LTP with an adaptive threshold to extract discriminative time-invariant features from the gait signals. The proposed approach is an extension of 2D LTP. Furthermore, we introduce an adaptive thresholding technique to eliminate the need for parameter tuning. It is challenging to set the threshold manually, and the use of central pixel is susceptible to noise [29]
The proposed adaptive 1D LTP method is used to captivate helpful information over the average gait cycle signals for more effective authentication. LTP assigns a ternary code to each sample by examining its neighboring points. First, the 1D average gait cycle is divided into a segment size window. Based on a few trials with a small dataset, a segment size window of 8 neighbors gives a promising result. However, the discrepancy effect should be associated with the current data in determining the threshold. For this reason, an adaptive threshold is selected by utilizing the data from each segment size window.
Let s(θ) be a segment size window with 8 neighbors of the center point \(c_{p}\)The adaptive threshold t can be obtained with the subtracted mean and standard deviation of the current observing segment size data \(t\; = \;\overline{\theta } - \sigma (s(\theta ))\), where \(\overline{\theta }\; = \;\left( {\mathop \sum \nolimits_{i}^{l} \theta } \right)/l\) and \(l\) is the length of \(\theta\).
Each data point in the segment size \(s^{\prime}({\theta )}\) is replaced with a 3-valued function except for the center point that is only used for the threshold with (2). Then, a similar process is performed on the next segment size window. Using (3), the LTP code can be computed from \(s^{\prime}({\theta )}\) by using the \(3^{n}\) value weights where in this case \(n\) runs over the 8 neighbors of the center point. The process that illustrates the proposed 1D adaptive LTP is shown in Fig. 3. After the LTP code is generated for accelerometer and gyroscope signals, both the extracted features are concatenated in a vector and fed as input to the authentication method.

1D LTP with adaptive threshold
4.3 Kernelized domain adaption
This section proposes a Kernelized Domain Adaptation (KDA) method to model the extracted LTP features and verify the user identity from the learned embedding. KDA is the enhancement of the Extreme Learning Machine (ELM) method by [30]. Specifically, only a single gait cycle is used in the proposed method to represent each gait pattern. This is to testify to our hypothesis that the gait cycle can be reliable biometrics to represent an individual over time. The KDA is built by projecting the temporal signals from two different sessions into the reproducing kernel Hilbert space (RKHS). Hence, the properties of domain-specific data distributions can be preserved, and the distance between domain distributions can be reduced significantly using DA. Then, a kernel-based network is defined on the hidden layer outputs to generate new representations for the two domains. Finally, the outputs from the network are used to predict the labels of the target test data.
Let \(P\left( {X_{S} } \right)\) and \(Q\left( {X_{T} } \right)\) denote the marginal distributions from the source and target domains, respectively, and let \(D_{S} \; = \;\left\{ {\left( {X_{{\text{S}}}^{1} ,{ }Y_{{\text{S}}}^{1} } \right), \ldots ,\left( {X_{{\text{S}}}^{{{\text{n}}1}} ,{ }Y_{{\text{S}}}^{{{\text{n}}1}} } \right)} \right\}{ }\) and \(D_{{\text{T}}} = \left\{ {X_{{\text{T}}}^{1} ,{ } \ldots ,{ }Y_{{\text{T}}}^{{{\text{n}}2}} } \right\}\) be the source domain with available labeled data and the target domain with unlabeled data, respectively. The hypothesis for DA is that the source and target domains data exhibit different distributions: \(P \ne Q\), but the conditional probability between the source and target domain is \(P\left( {Y_{S} |X_{S} } \right) \; = \; P\left( {Y_{T} |X_{T} } \right)\). On the other hand, conditional probability \(P\left( {Y|X} \right)\) might also change across domains because of noisy data or dynamic factors underlying the observed data in real-world applications.
To gauge the difference between the source and target domain, Maximum Mean Discrepancy (MMD) can be used to measure the distance between empirical means of two domains in the RKHS \({\mathcal{H}}\). Let a feature map induced by a universal kernel be defined as ϕ. Learning the transformation \(\phi : X \to {\mathcal{H}}\) such that \(P\left( {\phi \left( {X_{S} } \right)} \right)\; \approx \; P\left( {\phi \left( {X_{T} } \right)} \right)\) and \(P\left( {Y_{S} | \phi \left( {X_{S} } \right)} \right)\; \approx \; P\left( {Y_{T} | \phi \left( {X_{T} } \right)} \right)\) is the primary motivation of DA by kernel function [31]. Distance minimization via MMD cannot be directly applied since a nonlinear mapping yields a semi-definite programming (SDP) in kernel matrix \({\mathbf{K}}\). Therefore, a unified kernel learning with explicit low-rank representation is introduced to obtain the nonlinear mapping ϕ based on kernel feature extraction to overcome the limitation of MMD i.e., transductive, and obviate the use of SDP because of expensive computation [32].
Equation (4) reformulates MMD with a kernel trick to optimize the kernel matrix \({\mathbf{K}}\) on all the data so that the distances between the projected source and target domain are minimum while the data variance is maximized. Thus, \({\mathbf{K}}\) can be computed in the embedded space for the source domain \({\mathbf{K}}_{{\left( {S,S} \right)}}\), target domain \({\mathbf{K}}_{{\left( {T,T} \right)}}\) and cross-domain data \({\mathbf{K}}_{{\left( {S,T} \right)}}\), \({\mathbf{K}}_{{\left( {T,S} \right)}}\).
where \({\mathbf{K}} = \left[ {\phi \left( {x_{a} } \right)^{{\text{T}}} \phi \left( {x_{b} } \right)} \right]\) and the label kernel matrix \({\mathbf{Z}}_{ab} = 1/\left( {n_{1}^{2} } \right)\) if \(x_{a} ,x_{b } \in X_{S}\), else \({\mathbf{Z}}_{ab} = 1/(n_{2}^{2} )\) if \(x_{a} ,x_{b } \in X_{T}\), otherwise \({\mathbf{Z}}_{ab} = - ( 1/(n_{1} n_{2} ))\). KDA relies on a projection matrix \({\tilde{\mathbf{W}}}\user2{ } \in {\mathbb{R}}^{{\left( {n_{1} + n_{2} } \right) \times m }}\) of the empirical kernel map to an m-dimensional space with typically m"\(n_{1} + n_{2}\). The kernel matrix \({\mathbf{K}}\) is decomposed into an empirical kernel map \({\mathbf{K}} = \left( {{\mathbf{KK}}^{{ - \frac{1}{2}}} } \right)\left( {{\mathbf{K}}^{{ - \frac{1}{2}}} {\mathbf{K}}} \right)\). Then, it is transformed to an m-dimensional space and generates a resultant kernel matrix \({\tilde{\mathbf{K}}}\) as follows:
where \({\mathbf{W}} = {\mathbf{K}}^{{ - \frac{1}{2}}} {\tilde{\mathbf{W}}}\). Specifically, the corresponding kernel between two patterns \(x_{a}\) and \(x_{b}\) are
where \(k_{x} = \left[ {k\left( {x_{1} ,x} \right), \ldots ,k\left( {x_{{n_{1} + n_{2} }} ,x} \right)} \right]^{{\text{T}}} \in {\mathbb{R}}^{{\left( {n_{1} + n_{2} } \right)}}\). Hence, the kernel \(\tilde{k}\) simplifies an instant parametric form for out-of-sample kernel evaluations. The empirical means of the two domains \(X_{S}^{^{\prime}}\) and \(X_{T}^{^{\prime}}\) i.e., the transform input sets from the source and target, respectively, in (4) can be written as
Optimization of (8) can be constrained by preserving the variance of the data with (9):
where \({\mathbf{U}} = {\mathbf{I}}_{{n_{1} + n_{2} }} - \left( {1/n_{1} + n_{2} } \right)11^{{\text{T}}} \user2{ } \in {\mathbb{R}}^{{\left( {n_{1} + n_{2} } \right) \times \left( {n_{1} + n_{2} } \right)}}\)is the centering matrix, a projection onto the space orthogonal to the vector \(1\). A regularizer \({\text{tr}}\left( {{\mathbf{W}}^{{\text{T}}} {\mathbf{W}}} \right)\) is introduced to control the complexity of \({\mathbf{W}}\). Then, the final optimization problem becomes:
where \({\mathbf{I}}_{{\text{d}}} \in {\mathbb{R}}^{{{\text{d}} \times d}}\) is the identity matrix and \(\mu\) is a tradeoff parameter. The solving of \({\mathbf{W}}\) via (10) can be done by preserving the d eigenvectors of \({\mathbf{M}} = \left( {{\mathbf{KZK}} + \mu {\mathbf{I}} } \right)^{ - 1} {\mathbf{KUK}}\) with the largest eigenvalue [33]. The data can then be embedded in the new space as \({\mathbf{\rm X}}^{*} =\) KW.
After that, the input data \({\mathbf{\rm X}}^{*}\) are projected onto a higher dimensional kernel space for authentication. KDA solves the prediction output \({\mathbf{R}}_{T}\) analytically via linear least square solution as follows:
\({\mathbf{R}}_{T} \user2{ }\) can be viewed as a one-hidden layer network with L hidden neurons, \({{\varvec{\upomega}}}\) is the weights vector connecting the hidden nodes and input \({\mathbf{\rm X}}^{*}\), \({\mathbf{b}}\) is the hidden layer bias, and \(\rho \left( \cdot \right)\) is an activation function (i.e., sigmoid function, hard limit function, RBF function) [30]. \({\mathbf{v}}\left( {{\mathbf{\rm X}}^{*} } \right)\) can be considered as a mapping function that maps the data from n-dimensional input space to the L-dimensional hidden layer \({\mathbf{V}}\) (i.e., the hidden layer output matrix). A kernel-based network is used to handle DA by improving the transfer learning capability between the source and target domains with only the source domain labeled data included in the learning model. In addition, it provides better generalization performance at an exceedingly fast learning speed.
We define \(\lambda \in {\mathbb{R}}^{L \times m}\) as the output weights between the hidden layer and the output layer being learned, where L is the number of hidden neurons and m is the output neurons. The output weights can be solved using regularized least square problem defined as
where \({\mathbf{R}} = \left[ {r_{1} ,r_{2} , \ldots , r_{{\text{n}}} } \right]^{{\text{T}}}\) is the corresponding ground truth. By minimizing the norm of the output weights, the distance of the separating margins of the two different classes in the feature space can be maximized. The two conditions are applied when solving \(\lambda\):
Otherwise
where \(\alpha\) is a penalty coefficient on the training errors, \({\text{I}}_{n \times n}\) and \({\text{I}}_{L \times L}\) are the identity matrix. A summary of the proposed method is presented in Algorithm 3.

5 Experimental results with MMUISD
This paper has performed several trial configurations to quantify the free parameters. The setting for penalty coefficient α is configured to 0.1 based on the experiment results in Fig. 4. While for the hidden neurons, L is configured to 1000 as it was mentioned in [30] that good generalization performance could be achieved if the number of hidden nodes is large enough. The performance of the MMUISD dataset is assessed by segregating the 144 training and testing sets, respectively, into walking speed and sensor position (Table 1).

Performance comparison of the proposed 1D LTP with an adaptive threshold (AT) and 1D LTP with user preference threshold for RBF and Sigmoid activation
A workstation with a 2.5 GHz processor and 16 GB of memory was used to run the experiments. We performed preliminary analysis to compare 1D LTP with user preference thresholds = {0.01, 0.1, 1}and our proposed feature extraction method 1D LTP with adaptive threshold. The purpose of this experiment is to evaluate the performance of the proposed method compared to traditional implementation, which refers to the use of user preference threshold for the LTP method. The results are presented in terms of identification accuracy in Fig. 4.
The results demonstrate three observations. First, the sigmoid activation function performs better than the RBF activation function. Second, it is found that the setting of a threshold equal to 1 yields the worst performance for both \(\alpha\) and activation function. Meanwhile, the setting of the threshold equals 0.1 yields the second highest performance. Third, our proposed 1D LTP with adaptive threshold outperforms the 1D LTP with user preference.
Table 2 presents the Equal Error Rates (EER) of the experiment results using RBF and sigmoid activation functions for KDA with the proposed MMUISD dataset. A one-to-one matching procedure conducts the identity verification between a template to be verified and the stored reference template. Thus, the experiment contains 144 genuine attempts and 143 × 144 = 20.592 impostor attempts for each sensor position and each respective walking speed.
Table 2 shows that the results for the pocket position yield the best performance compared to the other positions for all the walking speeds. Conversely, the phone in hand position generates good performance after the pocket position, especially for slow walking speed, and the backpack position and handbag position follow this. Overall, it is clear that the sigmoid activation function performs better than the RBF activation function. Based on Table 2, the highest performance result is achieved for "Slow" walking speed with "Right Pocket" position for the Sigmoid activation function.
Figure 5 shows the proposed algorithm's ROC curves for the MMUISD dataset. The Equal Error Rates with 90% confidence intervals for slow right pocket, normal left pocket, and fast right pocket are 4.383%, 4.687%, and 5.380%, respectively. The results from Fig. 5 demonstrate that gait signals extracted from inertial sensors have the potential to be used as a reliable means of biometrics across time.

ROC curves for MMUISD dataset with EER 90% confidence intervals
5.1 Comparison with state-of-the-art methods
In this section, a comparison with state-of-the-art domain adaptation methods, namely Domain Adaptation Support Vector Machine (DASVM) [14], Geodesic Flow Kernel (GFK) [15], Subspace Alignment (SA) [16], and Transfer Component Analysis (TCA) [17] are presented. KDA is evaluated as unsupervised learning for identity verification where only labeled source data are incorporated during the learning model to predict the unlabeled target domain. The evaluation is performed using the proposed dataset in Sect. 5.1.1, and the comparative performance between the proposed dataset and public datasets is given in Sect. 5.1.2.
5.1.1 Comparison of the state-of-the-art and the proposed methods using MMUISD
This section reports the experimental results on the proposed time invariant inertial sensor dataset with 144 participants' data which contain certain variations such as walking speed and sensor placement. For KDA, the best result from the sigmoid activation function is presented in Table 3. The features are set to lie between −1 and + 1. The performances assessed with EER are listed in Table 3. Several configurations were performed to set the free parameter for the state-of-the-art DA algorithms used in this experiment, i.e., DASVM, SA, GFK, and TCA. The test aims to get the parameter values that can generate the best performance.
After a few trials, we find that some parameters significantly influence the algorithms, such as the regularization parameter on DASVM, dimensionality on GFK and TCA, and energy ratio on TCA. Therefore, the parameters reported in the original paper are kept. Based on the evaluation scenario performed, we found that the same parameters can give the best optimizations of those algorithms for our dataset.
From Table 3, it can be seen that KDA significantly outperforms the other competing methods in most cases. The performance of SA is second to KDA, followed by DASVM in the third position. SA gives better performance as compared to DASVM for sensor placement of "Normal" walking speed with "Right Hand and Right Pocket" and "Fast" walking speed with "Left Hand". It is asserted that the SA approach can minimize the discrepancy between the source and target domains. Thus, applying SA for some particular cases where DASVM cannot perform well might be helpful.
Conversely, DASVM has better processing time than SA, with a slight difference in the average performance result. The reason could be because DASVM implements an adaptive weighting strategy that prevents the system from forming improper solutions. However, it also depends on the intrinsic correlation between the two domains. Therefore, iis suggested in [14] to measure the correlation with similarity metrics between the source and target domains, which is achieved in this study by performing gait cycle selection.
On the other hand, the performance of TCA ranked third after DASVM, while the performance of GFK is the worst. One limitation of GFK is that the input data might not be represented accurately with low-dimensional subspaces i.e., to ensure the smooth transition of different subspaces along the geodesic flow thus, the subspace dimension should be small enough.
The proposed framework aims to improve data quality with the proposed adaptive LTP descriptor. Moreover, KDA helps make the features have identical data distributions between the two domains and preserves the target domain's time-invariant information. Therefore, this study achieves the transfer of the learning model with better knowledge adaptability from the source domain to match the target distribution better. It is worth noting that the time is taken to perform training and testing costs about several seconds and microseconds. Specifically, the proposed method tends to have fast knowledge transfer with good generalization.
Most of the high-performance results are given by the pocket position. A viable result can be obtained mainly because the signal is more stable by putting the phone inside the pocket. The performance for the phone in hand yields the second-best accuracy after the pocket position. This experiment shows that even though the hand swaying movement will most likely influence the collected gait signal for this position, it can still generate reasonably good performance. On the other hand, the results for the bag position, in general, yield the poorest performance as compared to the other positions. This could be because the data collected with an empty handbag can cause instability in the phone position and thus cause significant fluctuation during the participants' walk. Therefore, it might create undesirable patterns and noises in the gait signal. Another factor like swinging the bags that usually happens while walking creates irrelevant movements that could also change the gait signal. As for the backpack, we did not control the contents of the participants' bag (used as it is); usually, it will not be empty.
The classification performance over a particular walking speed yields a pretty good result. The analysis of our time-invariant gait inertial dataset shows that the results are auspicious. Using an accelerometer and gyroscope with a correct sampling rate can capture sufficient human gait features. Moreover, an appropriate preprocessing and feature extraction method can construct proper data for gait verification purposes. As reported in [34], it is demonstrated that the two main covariates that affect gait verification are environmental changes and the types of clothing the subjects wear.
In our experiments, we did not control both of these factors. Elapse time might have some influence that affects the performance, but it is not critical. However, some variables that can affect the performance also need to be considered (e.g., the participants' mood during data collection after 1 month, clothing, shoes, phone orientation, sensors, etc.). For example, the way the participant walks might change because of mood swings (i.e., feeling nervous for the first data collection, excited, need to rush for time, etc.). As for the environmental factor, the data are taken along the corridor of the university. However, the participants must avoid crowds of non-participants sometimes along the walking path as the corridor is near the student's lab.
5.1.2 Comparison of the state-of-the-art and the proposed methods with public datasets and MMUISD
In this section, the performance of the proposed method for user identity verification is compared to four state-of-the-art DA methods mentioned in Sect. 5.1.1 with the recent domain adaptation method called Stratified Transfer Learning (STL) [18]. It is worth noting that no available time invariant gait inertial sensor-based public dataset is found. The existing public datasets for inertial gait data are from the same-day data. Hence, we select different categories for training and testing data for the public datasets to evaluate the authentication performance using state-of-the-art DA methods.
Four public datasets are used in the experiments, namely: (1) Pervasive dataset [35], (2) Human Activities and Postural Transitions Dataset (HAPT) from The UCI Machine Learning Repository [36], (3) Chonnam National University dataset (CNU) [37] and (4) OU ISIR gait database inertial sensor dataset [38]. It is worth mentioning that although some of the public datasets might not control the clothing worn by the subject, the experiment was conducted with the phone fixed to the participant's body, for example, attached to the waist, arm, etc. A comparison of the existing public datasets and our MMUISD dataset is presented in Table 4. Figure 6 illustrates the EER of the proposed time invariant method A1TIL compared to the state-of-the-art methods on different datasets.

The performance of the proposed framework compared to the state-of-the-art DA methods is assessed with four benchmark public datasets and the time-invariant MMUISD dataset
Three gait cycles are extracted from the raw gait data of each subject for each public dataset. Then, we split the data in the public datasets into training and testing with a ratio of 80–20 (the details of total gait samples used for this experiment can be seen in Table 4. For MMUISD, the average accuracy from 1D LTP features for slow walking speed is chosen because the best results can be obtained from such walking speed in Table 3.
Several important observations are revealed in the study. First, the Pervasive dataset yields the highest performance compared to the other datasets. It is shown that EERs of 3.68% and 3.78% can be achieved with DASVM and KDA methods, respectively. The reason could be because the algorithm was performed over the left and right pocket, thus, resulting in proper gait data for gait-based authentication. The small number of samples (containing only 10 participants' data) also affects the results. The Pervasive dataset for the training and testing were obtained from different body parts on the same person, referred to as right and left pocket, respectively. Our preliminary analysis with only 9 participants' right pocket data makes the results comparable to the Pervasive dataset.
Second, for UCI HAPT, we evaluate two different activities: walking straight and walking upstairs. The Kernel-based DA results in the highest performance, followed by STL and DASVM. Although the data was obtained from the same person, the two different activities might provide different types of information. For example, according to [37], a gyroscope can better recognize the walking downstairs action, while an accelerometer can better recognize the straight walking activity. Thus, the use of both sensors in this dataset has a significant contribution to the performance result.
Third, the CNU dataset appears in the fourth position with KDA. In [37], the CNU dataset is used to study the phone disorientation problem that might affect the gait-based authentication performance. For these experiments, we apply the disorientation fix algorithm following the work in their paper to obtain accelerometer data with a disorientation fix. It is applied to 38 participants' data for walking sequence 0 to walking sequence 9. Since the data were only collected with an accelerometer, the disorientation fix algorithm might influence the performance result. Notably, more features were applied in their work, but only three gait cycles are used in this paper.
On the other hand, Osaka, as the most extensive dataset, yields the poorest performance compared to the other datasets, with the best performance achieved with the KDA method. Therefore, in this experiment, we reduce the number of 408 participants' data (408 out of 744 data collected with smartphone sensor—we want to limit the covariate to only smartphone data) to 142 to have a fair comparison for the data taken with young, healthy adults. Although with a reduced number of participants, the dataset still contains different conditions such as testing scenario, sensor location, and other external factors that can affect the performance results.
Two crucial findings are associated with our proposed dataset that can be highlighted from the results shown in Fig. 6. First, our dataset yields the third position after the Pervasive and UCI datasets. Our dataset is taken at different time intervals and is acquired as close to the real world as possible. Additionally, only a single gait cycle is evaluated where the unlabeled target data is used. Second, when the dataset is evaluated using state-of-the-art methods using the average performance result from the extracted single gait cycle of slow walking speed, it shows inferior results compared to our proposed time-invariant methods (i.e.,1D LTP adaptive threshold, and KDA for feature extraction and classification, respectively). This is especially evident with the STL method, which yields the poorest performance result. From both observations, we demonstrate that the proposed framework can perform better than state-of-the-art methods when evaluated with four benchmark public datasets and our time-invariant dataset.
5.2 Ablation study
In this work, ablation studies have been conducted to investigate the effects of the corresponding procedures, namely, gait cycle extraction, gait cycle selection, and feature extraction with the 1D LTP adaptive threshold of the proposed method. Results are presented in terms of identification accuracy in Fig. 7. The purpose of this study is to identify which procedure plays an important role and contributes significantly to improving the performance result.

Ablation study results of average performance result from three walking speeds with right and left pocket sensor data
Three ablation studies are addressed in this work. First, Ablation 1 (Ab 1) investigates the proposed method without performing the gait cycle selection technique. The gait cycle is extracted from the raw data, and the 1D LTP features are generated from the gait cycle. Second, Ablation 2 (Ab 2) is performed where gait cycle extraction and gait cycle selection are eliminated from the proposed method. For Ab 2, the 1D LTP features are extracted from the raw features for user identification. Finally, the third ablation study, known as Ablation 3 (Ab 3), is conducted to check the performance of the proposed method without 1D LTP adaptive threshold. First, gait cycle extraction is performed on the raw data, followed by gait cycle selection. The generated features are fed to the proposed method.
The data used in this study are taken from the average performance result of slow, normal, and fast walking speeds with left and right pocket sensor positions. In addition, sigmoid and RBF activation functions are utilized.
The setting of the free parameters, such as penalty coefficient \(\alpha\) = {0.1, 1} is employed in this experiment. The results shown in Fig. 7 demonstrate two important points. First, the analysis shows that gait cycle selection impacts the performance result significantly. Based on the result of Ablation 3, it is clear that the gait cycle selection method can improve the performance compared to Ablation 1 and 2, where the gait cycle selection method is absent. Second, from the obtained average performance result, the results lead to a similar conclusion to the previous experiments where the sigmoid activation function can give the best performance result compared to the RBF activation function. Therefore, in this study, it can be concluded that each component in A1TIL contributes to improving performance.
It can be observed that the performance is improved with the contribution of the proposed 1D LTP method. Furthermore, a significant improvement can be acquired from the combination of gait cycle selection and 1D LTP adaptive threshold, as shown in Fig. 7, where the results for the right and left pocket positions with all walking speeds have been included.
5.3 Discussions
Overall, the summary of the main findings of the study is given as follows:
-
1.
In this study, only a single gait cycle is used for identity verification, and a promising result is achieved with the proposed method. In other words, the gait signals extracted from inertial sensors can be used as a reliable means of biometrics over time. Alternatively, the problem of covariate factors can be diminished by incorporating an IMU sensor to capture the gait signal continuously and obtain a highly consistent gait signal characteristic as input to the learning model.
-
2.
A new covariate factor with the use of different smartphones for data collection (i.e., device-instance diversity [9] is introduced in this work. This shows that different types of IMU sensors can be used. Furthermore, based on the performance observation, it is found that device-instance diversity does not affect the performance over time. However, it might have a significant influence if the sensor is not in good condition (i.e., faulty hardware, calibration problem, etc.).
-
3.
The use of both accelerometer and gyroscope improves performance. It is shown that datasets like OU ISIR and CNU that only incorporate accelerometer sensors produce inferior results compared to Pervasive, MMUISD, and UCI HAPT, which incorporate both sensors. Therefore, future research in mobile gait authentication should opt for both accelerometer and gyroscope sensors in smartphones for personal authentication.
6 Conclusion and future works
In this paper, a robust time invariant gait inertial sensor-based dataset is introduced, and we show that gait signals extracted from inertial sensors can be used as a reliable means of biometrics over time. This paper aims to study and analyze the effect of time on gait-based authentication under the influence of covariate factors in three diverse forms. The lack of an available database in this domain is the major hurdle in quantifying the influence of time on inertial gait-based authentication, and this has become the primary motivation of this work. Experimental results show that the major covariate factors, i.e., environment, clothes, and shoes related to the cross-user diversity, are the main causes of performance degradation compared to time variation. This coerces the finding in [34]. Furthermore, the effects of covariates factors can be diminished by incorporating an IMU sensor to capture the gait signal continuously and obtain a highly consistent gait signal characteristic as input to the learning model.
Different types of Android phones with our temporal dataset have also been investigated. The results confirm the findings in [19] that different types of Android phones do not affect the performance result. The proposed A1TIL framework achieves promising results. From Table 2, the proposed method can obtain an Equal Error Rate (EER) of 4.38% from slow walking speed and right pocket position. Meanwhile, from Table 3, an average of 4.84% EER from the slow walking speed with an average execution time of 0.46 s can be achieved as compared to State-of-the-Art methods. This suggests that gait-based authentication is feasible for practical deployment over some time. The proposed dataset can contribute to the gait-based authentication research community to meet the demand for developing new techniques and practical applications.
Moreover, the use of both accelerometer and gyroscope sensors improves performance. It is shown that datasets like OU ISIR and CNU that only include accelerometer sensors produce inferior results compared to Pervasive, MMUISD, and UCI HAPT, which incorporate both sensors. Therefore, future research in mobile gait-based authentication should opt for both sensors for personal authentication.
This work can be further extended by proposing new authentication algorithms that can overcome data from various sources. Furthermore, the performance for cross sensor position with device-type diversity will also be explored. Finally, efforts will be spent investigating how the results will vary with an extended time invariant dataset and uncontrolled covariate factors.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Change history
10 November 2022
A Correction to this paper has been published: https://doi.org/10.1007/s00521-022-07907-w
References
Murray MP (1967) Gait as a total pattern of movement. Am J Phys Med 46:290
Axente M-S, Dobre C, Ciobanu R-I, Purnichescu-Purtan R (2020) Gait recognition as an authentication method for mobile devices. Sensors 20(15):4110. https://doi.org/10.3390/s20154110
Sarah D (2019) Chinese police test gait-recognition technology from AI start-up Watrix that identifies people based on how they walk. South China Morning Post. https://www.scmp.com/tech/start-ups/article/2187600/chinese-police-surveillance-gets-boost-ai-start-watrix-technology-can (accessed Jun. 30, 2020)
De Marsico M, Fartade EG, Mecca A (2018) Feature-based analysis of gait signals for biometric recognition. In: ICPRAM 2018-7th international conference on pattern recognition applications and methods, pp 630–637. https://doi.org/10.5220/0006719106300637
Wan C, Wang Li, Phoha VV (2019) A survey on gait recognition. ACM Comput Surv 51(5):1–35. https://doi.org/10.1145/3230633
Sarkar S, Phillips PJ, Liu Z, Vega IR, Grother P, Bowyer KW (2005) The humanID gait challenge problem: data sets, performance, and analysis. IEEE Trans Pattern Anal Mach Intell. https://doi.org/10.1109/TPAMI.2005.39
Santos G, Pisani PH, Leyva R, Li C-T, Tavares T, Rocha A (2020) Manifold learning for user profiling and identity verification using motion sensors. Pattern Recogn 106:107408. https://doi.org/10.1016/j.patcog.2020.107408
Arnold Z, LaRose D, Agu E (2015) A factorial experiment to investigate naturalistic factors affecting smartphone gait analysis. In: 2015 17th international conference on E-health networking, application & services (HealthCom), pp 451–454. IEEE. https://doi.org/10.1109/HealthCom.2015.7454543
Khan MAAH, Roy N, Misra A (2018) Scaling human activity recognition via deep learning-based domain adaptation. In: 2018 IEEE international conference on pervasive computing and communications (PerCom), pp 1–9. IEEE. https://doi.org/10.1109/PERCOM.2018.8444585
Ngo TT, Makihara Y, Nagahara H, Mukaigawa Y, Yagi Y (2014) Orientation-compensative signal registration for owner authentication using an accelerometer. IEICE Trans Inf Syst. https://doi.org/10.1587/transinf.E97.D.541
Brodie MAD et al (2016) Wearable pendant device monitoring using new wavelet-based methods shows daily life and laboratory gaits are different. Med Biolo Eng Comput. https://doi.org/10.1007/s11517-015-1357-9
Xu W, He J, Shu Y (2020) Transfer learning and deep domain adaptation. In: Advances and applications in deep learning, 45. https://doi.org/10.5772/intechopen.94072
Farahani A, Voghoei S, Rasheed K, Arabnia HR (2021) A brief review of domain adaptation. pp. 877–894. https://doi.org/10.1007/978-3-030-71704-9_65
Bruzzone L, Marconcini M (2009) Domain adaptation problems: A DASVM classification technique and a circular validation strategy. IEEE Trans Pattern Anal Mach Intell 32(5):770–787. https://doi.org/10.1109/TPAMI.2009.57
Gong B, Shi Y, Sha F, Grauman K (2012) Geodesic flow kernel for unsupervised domain adaptation. In: 2012 IEEE conference on computer vision and pattern recognition, pp 2066–2073. IEEE. https://doi.org/10.1109/CVPR.2012.6247911
Fernando B, Habrard A, Sebban M, Tuytelaars T (2013) Unsupervised visual domain adaptation using subspace alignment. https://doi.org/10.1109/ICCV.2013.368
Pan SJ, Tsang IW, Kwok JT, Yang Q (2011) Domain adaptation via transfer component analysis. IEEE Trans Neural Netw. https://doi.org/10.1109/TNN.2010.2091281
Wang J, Chen Y, Hu L, Peng X, Philip SY (2018) Stratified transfer learning for cross-domain activity recognition. In: 2018 IEEE international conference on pervasive computing and communications (PerCom), pp 1–10. IEEE. https://doi.org/10.1109/PERCOM.2018.8444572
Permatasari J, Connie T, Song OT (2020) The MMUISD gait database and performance evaluation compared to public inertial sensor gait databases. In: Computational science and technology, pp 189–198. Springer, Singapore. https://doi.org/10.1007/978-981-15-0058-9_19
Dey S, Roy N, Xu W, Choudhury RR, Nelakuditi S (2014) AccelPrint: imperfections of accelerometers make smartphones trackable. https://doi.org/10.14722/ndss.2014.23059
Stisen A et al. (2015) Smart devices are different: assessing and mitigatingmobile sensing heterogeneities for activity recognition. In: Proceedings of the 13th ACM conference on embedded networked sensor systems - SenSys '15, pp. 127–140. https://doi.org/10.1145/2809695.2809718
Gadaleta M, Rossi M (2018) IDNet: Smartphone-based gait recognition with convolutional neural networks. Pattern Recogn. https://doi.org/10.1016/j.patcog.2017.09.005
Muaaz M, Mayrhofer R (2017) Smartphone-based gait recognition: from authentication to imitation. IEEE Trans Mob Comput 16(11):3209–3221. https://doi.org/10.1109/TMC.2017.2686855
Soangra R, Lockhart TE, van de Berge N (2011) An approach for identifying gait events using wavelet denoising technique and single wireless IMU. Proc Human Factors Ergon Soc. https://doi.org/10.1177/1071181311551415
Yeoh TW, Daolio F, Aguirre HE, Tanaka K (2017) On the effectiveness of feature selection methods for gait classification under different covariate factors. Appl Soft Comput 61:42–57. https://doi.org/10.1016/j.asoc.2017.07.041
Chatlani N, Soraghan JJ (2010) Local binary patterns for 1-D signal processing. In: 2010 18th European signal processing conference, pp 95–99. IEEE. https://doi.org/10.5281/ZENODO.42230
Tirunagari S, Kouchaki S, Abasolo D, Poh N (2017) One dimensional local binary patterns of electroencephalogram signals for detecting Alzheimer's disease. In: 2017 22nd International conference on digital signal processing (DSP), pp 1–5. IEEE. https://doi.org/10.1109/ICDSP.2017.8096133
Tan X, Triggs B (2010) Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans Image Process. https://doi.org/10.1109/TIP.2010.2042645
Wang Z, Huang R, Yang W, Sun C (2014) An enhanced Local Ternary Patterns method for face recognition. In: Proceedings of the 33rd Chinese control conference, pp 4636–4640. IEEE. https://doi.org/10.1109/ChiCC.2014.6895720
Huang GB, Zhou H, Ding X, Zhang R (2012) Extreme learning machine for regression and multiclass classification. IEEE Trans Syst, Man, Cybern, Part B: Cybern. https://doi.org/10.1109/TSMCB.2011.2168604
Zhang L, Zhang D (2015) Domain adaptation transfer extreme learning machines. In: Proceedings of ELM-2014 Volume 1, pp 103–119. Springer, Cham. https://doi.org/10.1007/978-3-319-14063-6_10
Pan SJ, Kwok JT, Yang Q (2008) Transfer learning via dimensionality reduction. In: AAAI, vol 8, pp 677–682
Müller KR, Mika S, Rätsch G, Tsuda K, Schölkopf B (2001) An introduction to kernel-based learning algorithms. IEEE Trans Neural Netw. https://doi.org/10.1109/72.914517
Matovski DS, Nixon MS, Mahmoodi S, Carter JN (2012) The effect of time on gait recognition performance. IEEE Trans Inf Forensics Sec. https://doi.org/10.1109/TIFS.2011.2176118
Shoaib M, Bosch S, DurmazIncel O, Scholten H, Havinga PJM (2014) Fusion of smartphone motion sensors for physical activity recognition. Sensors (Switzerland) 14(6):10146–10176. https://doi.org/10.3390/s140610146
Reyes-Ortiz JL, Oneto L, Samà A, Parra X, Anguita D (2016) Transition-aware human activity recognition using smartphones. Neurocomputing. https://doi.org/10.1016/j.neucom.2015.07.085
Hoang T, Choi D, Nguyen T (2015) On the instability of sensor orientation in gait verification on mobile phone. In: Proceedings of the 12th international conference on security and cryptography, pp. 148–159. https://doi.org/10.5220/0005572001480159
Ngo TT, Makihara Y, Nagahara H, Mukaigawa Y, Yagi Y (2014) The largest inertial sensor-based gait database and performance evaluation of gait-based personal authentication. Pattern Recogn 47(1):228–237. https://doi.org/10.1016/j.patcog.2013.06.028
Acknowledgements
This project is supported by the Multimedia University Graduate Research Assistant Scheme (Grant no. MMUI/170122). The authors would also like to thank University of California, Irvine, School of Information and Computer Sciences, University of Twente, Chonnam National University and Osaka University for sharing their gait databases.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflicts of interest to declare. All co-authors have seen and agreed with the contents of the manuscript and there is no financial interest to report.
Ethical approval
The project has received ethics approval from the Research Ethics Committee in Multimedia University for data collection (Approval number: EA0012018).
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Permatasari, J., Connie, T., Ong, T.S. et al. Adaptive 1-dimensional time invariant learning for inertial sensor-based gait authentication. Neural Comput & Applic 35, 2737–2753 (2023). https://doi.org/10.1007/s00521-022-07741-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-022-07741-0