
Abstract
The assessment of vascular complexity in the lower limbs provides relevant information about peripheral artery occlusive diseases (PAOD), thus fostering improvements both in therapeutic decisions and prognostic estimation. The current clinical practice consists of visually inspecting and evaluating cine-angiograms of the interested region, which is largely operator-dependent. We present here an automatic method for segmenting the vessel tree and compute a quantitative measure, in terms of fractal dimension (FD), of the vascular complexity. The proposed workflow consists of three main steps: (i) conversion of the cine-angiographies to single static images with a broader field of view, (ii) automatic segmentation of the vascular trees, and (iii) calculation and assessment of FD as complexity index. In particular, this work defines (1) a method to reduce the inter-observer variability in judging vascular complexity in cine-angiography images from patients affected by peripheral artery occlusive disease (PAOD), and (2) the use of Fractal Dimension as a metric of shape complexity of vascular tree. The inter-class correlation coefficient (ICC) is computed as inter-observer agreement metric and to account for possible systematic error, that depends on the experience of the raters. The automatic segmentation of vascular tree achieved an Area Under the Curve mean value of \(0.77~\pm ~0.07\), with a min-max range of \(0.57-0.87\). Absolute operator agreement was higher over the segmented image (\(ICC=0.96\)) compared to the video (\(ICC=0.76\)) and the a broader field of view image (\(ICC=0.92\)). Fractal Dimension computed on both manual segmented images (ground truths) and automatically showed a good correlation with the clinical score (0.85 and 0.75, respectively). Experimental analyses suggest that extracting the vascular tree from cine-angiography can substantially improve the reliability of visual assessment of vascular complexity in PAOD. Results also reveal the effectiveness of FD in evaluating complex vascular tree structures.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Peripheral Arterial Occlusive Disease (PAOD) is a severe clinical condition affecting more than a quarter of a billion subjects worldwide. Its global prevalence increased by 25% in the last decades, as its incidence is sharply rising, especially in lower-income countries, although no nation is spared [1,2,3]. Despite it is associated to a threefold increased risk of acute cardiovascular events, such as acute myocardial infarction (AMI) or stroke, and it significantly affects life expectancy, functional capacity and quality of life, PAOD is currently underdiagnosed [4] and its impact on patients’ prognosis is often underestimated [5]. This is partly due to objective difficulties in the diagnostic assessment; in fact, the heterogeneity of its clinical manifestation makes the evaluation of disease severity very challenging.
As a physiological response to ongoing ischemia, a variable degree of collateral vascularization develops. Assessing the morphology and the complexity of the new vascular tree is crucial for understanding the clinical impact on the patient. However, no standard quantitative imaging tools for the evaluation of collateral circulation in patients with PAOD are available: the current clinical practice consists of visually inspecting cine-angiograms of the interested region and in assigning a score to the complexity of the collaterals’ growth. This kind of approach is prone to errors because (i) the operator has to memorize the anatomy in each image frame and virtually reconstruct in his/her mind the whole vascular tree; (ii) cine-angiography is a 2D projective image and the contrast of vessels is jeopardized by the presence of catheters, electrode cables, screws and other anatomical structures, especially bone; (iii) the acquisition method (i.e., moving the C-arm or the patient couch) reduces the quality of images that are characterized of various lighting effects and motion blur; (iv) the final score depends on the operator’s experience.
In such a scenario, our hypothesis is that the segmentation of the whole vascular tree could substantially improve the visual assessment of vascular complexity in PAOD. In addition, the segmented anatomy could facilitate the automatic computation of a complexity metric, such as the fractal dimension (FD) which has been used as bio-marker for detecting ocular diseases associated to vascularization. In this context, Taris et al. [6] proposed a retinal blood vascular structure approach to detect neovascularization on images. This strategy is implemented using fractal analysis that allowed the authors to evaluate the performance of Proliferative Diabetic Retinopathy classification.
Fan et al. [7] analyzed the relationship between fractal dimension of the retinal vasculature and retinal nonperfusion area in diabetic retinopathy on ultrawide-field fluorescein angiography. They showed that fractal dimension is a useful surrogate bio-marker when precise quantification of nonperfusion is not feasible.
The reliability of FD index strongly depends on the quality of vessel segmentation [8,9,10]. The automatic segmentation of the peripheral vascular tree on cine-angiography is a non-trivial task because of the presence of several image artifacts in the 2D projections and this has limited the use of FD as a potential bio-marker for detecting PAOD associated disease. In the last decade, deep learning techniques have been employed to perform vessel segmentation in angiography and to tackle the above-mentioned issues.
Our group recently proposed a deep learning-based method to automatically segment the vascular tree [11]. Starting by our previous work, in this paper, we wanted to test the hypothesis that the segmentation of the entire vascular tree from cine-angiography videos provides (1) a better representation for visually assessing the vascular complexity (2) the appropriate input to compute the vascular complexity in terms of FD.
2 Materials and methods
The proposed method was tested on a 20 patient cohort imaged with cine-angiography at the Interventional Cardiology Units of Magna Graecia University Hospital (Catanzaro, Italy) and at Federico II University (Naples, Italy); each patient had previously given explicit informed consent to the use of their anonymized data for research purpose. More in detail, the herein proposed methodological approach relies on three steps:
-
Cineangiography stitching in order to convert the cine-angiography video into a single static image featuring the whole field of view (FOV);
-
Vessel segmentation by deep learning, based on the approach used in [11], to provide an automatic extraction of the vascular tree.
-
Fractal dimension computation to provide a quantitative measure of the vascular tree’s complexity.
In the following, we will refer to the cine-angiography video as \(CA_{video}\), to the stitched image as \(CA_{stitched}\), to the manual segmented stitched image (ground truth) as \(Seg_{GT}\) and to the automatically segmented stitched image as \(Seg_{auto}\).

Exemplary images from cine-angiography to stitched image. a - Original 2D image frames acquired over time; b - Example of fiducial points detected on each frame by feature detection algorithms; c - Final stitched image obtained by fiducial registration between consecutive frames
2.1 Cineangiography stitching
In order to obtain the \(CA_{stitched}\), we implemented and applied an image-stitching procedure to each frame of the \(CA_{video}\). The method was based on detecting corresponding fiducial points (features) on consecutive frames and performing a point-based rigid image registration (see Fig. 1). Speeded Up Robust Features (SURF) [12], Maximally Stable Extremal Regions (MSER) [13] and Harris corners [14] were used to identify points to be matched. These approaches have proved to be robust in feature detection, as shown in [15], and they were able to provide a sufficient number of points of interest that could be matched in successive steps (see Fig. 1b).
To maximize the number of features and improve the registration, images were pre-processed by means of (i) negative image computation, (ii) adaptive histogram equalization, (iii) non-uniform illumination estimation, (iv) edge-detection using Canny filter [16].
Feature matching was performed by Random Sample Consensus (RANSAC) algorithm which was widely used in the state-of-the-art [17,18,19]. Starting from the first frame, consecutive images were stitched together by identifying the rigid transformation that minimized the sum of absolute distance between corresponding features. This process was recursively iterated, between the partially stitched image and the other samples, until the last frame. As a result, a large FOV representation was obtained.
2.2 Vessel segmentation by deep learning
Vessel segmentation was performed by using U-net model described in [11] giving the obtained \(CA_{stitched}\) and the corresponding \(Seg_{GT}\) as input pairs (see Fig. 2). \(Seg_{GT}\) were manually drawn by an expert clinician on \(CA_{stitched}\) and revised by a second operator. Briefly, the U-net [20] consisted of a fully convolutional network with symmetrical structure, composed of (i) a contracting path that consists of the repeated application of two \(3\times 3\) convolutions and a \(2\times 2\) maxpooling operation with stride 2 for downsampling, and (ii) an expansive path that consists of an upsampling of the feature map followed by a two \(3\times 3\) convolutions. All layers used Rectified Linear Unit (ReLU), except for the last layer, where softmax was used to select the best scoring category in order to obtain, for each pixel, the probability to be part of a vessel. Dropout of 0.5 and batch normalization were used to address the over-fitting problem and improve learning. The network was trained with the categorical cross-entropy loss function. The entire dataset was subdivided into 30600 tiles at a resolution of \(128 \times 128\) pixels. The 80% of the tiles are selected as training/validation set and the remaining part is chosen as testing set; in particular, the 20% of the training set was used as validation set in order to monitor the training process and prevent overfitting.
The network was implemented in TensorFlow [21] using the Keras wrapper and trained for 800 epochs, using the Adadelta [22] optimizer with default parameters, learning rate \(10^{-5}\) and batch size 32. The output of the network is a likelihood map (L) in which each pixel is classified to a specific class (vessel or not vessel).

Workflow of the architecture, which takes in input grayscale image and corresponding ground truth and returns segmentation label. In contracting path (left blocks), the number of feature channel is 3 and the feature maps double at each pooling: they start with 32 feature maps for the first block, 64 for the second, etc. Similarly, every step in the expansive path (right blocks) consists of an upsampling of the feature map and, in the final block, 2 represents the desired number of classes. The net’s architecture is inspired by [20]
2.3 Fractal dimension
FD can provide information relevant to the complex geometrical structure of the vascular tree and it can be defined as a measure of irregularly shaped objects and fragmental property [23, 24]. In the literature, several fractal implementation have been developed. For our experiments, we used HausDim algorithm that provides an implementation of the Hausdorff Dimension [25].

In particular, HausDim returns the box-counting FD of an object represented by a binary image, where nonzero pixels belong to the object and zero pixels constitute the background.
The FD(F) value of the set F is computed as follow:
where N(e) is the number of boxes of side length e that have non-empty intersection with the set F.
The pseudo-code for the HausDim algorithm is reported in Code-block 1, which selects the number of boxes of the prefixed size “e” (s.t., the size must contain at least one object pixel) and performs least squares method through a linear equation of X and Y. The returned Haussdorf FD is the slope of the line.
3 Data analysis and method assessment
Three experienced intervention cardiologists were asked to visually judge the complexity of the vascular tree by looking at the (i) \(CA_{video}\), (ii) \(CA_{stitched}\) and (iii) \(Seg_{GT}\). The score ranged from 1 to 10 in unit steps, meaning from less to most complex vascularization. The whole methodology assessment is the described in the following subsections.
3.1 Inter-class correlation coefficient (ICC)
Inter-class correlation coefficient (ICC) was computed to account for the inter-observer judgement variability in scoring \(CA_{video}\), \(CA_{stitched}\) and \(Seg_{auto}\). ICC index can be defined in different ways depending of the 1) model (1-way random effects, 2-way random effects, or 2-way fixed effects), 2) the type (single rater/measurementor the mean of k raters/measurements), and 3) the definition of relationship considered to be important (consistency or absolute agreement) [26]. For our scopes, we adopted the two-way random model, as described in [27]. We defined a matrix nxk, with n number of scored images for each modality and k, number of observers. Let \(MS_{R}\) be the mean square for rows, \(MS_{C}\) be the mean square for columns and \(MS_{E}\) be the residual mean, the absolute agreement among raters was computed as follows:
and the degree of consistency among raters is computed as follows:
In particular, ICC(C, k) was chosen to separate possible systematic error. ICC was calculated at 95% confidence level, being the range 0 to 1 no-agreement and perfect agreement. Statistical analysis was performed by using IBM SPSS statistics software v26 (IBM Corp. in Armonk, NY).
3.2 Automatic image segmentation
The quality of automatic image segmentation was validated using fourfold cross-validation (folds are split into disjoint sets of patients) according to Receiver Operating Characteristic (ROC) metric. ROC was used to estimate the quality of the \(Seg_{auto}\). No statistical difference was found among images acquired with different machines.
According to Table 1, image pixels were labeled as True Positive (TP), True Negative (TN), False Positive (FP) and False Negative (FN); sensitivity (\(S_{e}\)) and specificity (\(S_{p}\)) were computed as in Eqs. 4 and 5, respectively.
The likelihood map L was converted in binary image to separate pixel values into two groups, black as background and white as vessels. Image binarization was performed selecting the most appropriate threshold which plays a very important role in improving the overall performance of the approach. We identify the best threshold as that one maximising the correlation between FD computed on \(Seg_{GT}\) and FD computed on \(Seg_{auto}\).
3.3 Evaluation of FD as a complexity index
FD was computed both on \(Seg_{GT}\) and \(Seg_{auto}\). The value of FD was correlated to the median clinical score (CS) to assess its viability as both quantitative measure of the morphological characteristics of the vessel and biomarker to improve risk prediction.
4 Results and discussion
In this section, we list the obtained results; hence, the quality of the approach is discussed through the proper result analyses as described in Sect. 3.

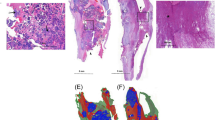
Results obtained on two patients in terms of automatic segmentation. Specifically, the left Fig. a shows the patient that achieved the worst AUC value in the whole cohort. On the other hand, Fig. b shows the patient obtaining the best AUC value. From top to bottom, we show the stitched image (i.e., grayscale input image), the ground truth (\(Seg_{GT}\)) and the automatically segmented image (\(Seg_{auto}\))
-
Inter-class correlation coefficient (ICC). Tables 2 and 3 report the ICC(A,k) and ICC(C,k), respectively, for the three image modalities (i.e., \(CA_{video}\), \(CA_{stitched}\), \(Seg_{GT}\)). In particular, results show that the ICC(A,k) is maximum for \(Seg_{GT}\) (i.e., 0.96) and lower for video (i.e., 0.76). Lower and upper bound represent the 95% confidence interval that indicates the spread of the variability, which is very large for \(CA_{video}\). Results show that inter-rater agreement improved by judging the segmented full FOV image vs. \(CA_{video}\) both considering ICC(A,k) and ICC(C,k) and (p<0.01). No statistical differences between \(CA_{stitched}\) and \(Seg_{GT}\) were revealed by ICC(C,k). In general, these results suggest that a full FOV image and the extraction of the vascular tree help the raters to agree in their judgement.
-
Automatic image segmentation. In order to optimally binarize the image generated by the U-net model, an empirically determined cutoff value was used. As a result, 0.15 was proved to be the best threshold for binarization since it led to a median ± std residual between FD computed on \(Seg_{GT}\) and FD computed on \(Seg_{auto}\) equal to \(0.05\pm 0.04\). A mean ± std AUC of \(0.77~\pm ~0.07\) was obtained (min-max range \(0.57-0.87\)). Figure 3a and b shows the best and worst cases in terms of AUC. Results show that the network is able to distinguish between catheters and vessels, confirming the overall positive performance. However, visual inspection shows some typical difficulties; in particular, false detection of noise and other artifacts near to the bones or in areas with excessive brightness, as shown in Fig. 3.
In order to assess the validity of the herein presented approach, we compared our method to the state-of-the-art methods in retina segmentation, since, to the best of our knowledge, our approach is one of the first attempts to segment vessels in the ilio-femoral district on 2-D projective images. Boudegga et al. [28] proposed a new architecture untitled “RV-Net” for retinal vessel tree segmentation, achieving an average accuracy of 0.978 and 0.98, respectively, for DRIVE and STARE database fundus images. Atli et al. [29] presented Sine-Net, a novel approach for retinal vessel segmentation. The approach first applies up-sampling and then down-sampling for catching thin and thick vessel features, respectively. It achieved an average accuracy higher than 0.95 on STARE, CHASE_DB1 and DRIVE database.
Qiangguo et al. [30] proposed a U-Net-based approach, named DUNet, in which some of convolutional layers are replaced by the deformable convolution blocks. In the task of retinal vessel segmentation, they achieved an AUC value of 0.98.
Although the previously mentioned approaches achieved a higher AUC value than our (\(0.57-0.87\)), the ilio-femoral images are composed of difficulties, e.g., reflections, motion artifacts or external objects, such as catheter, surgical instruments and tools, electrode cables that our algorithm must deal. Such difficulties can explain the decreasing performance w.r.t. the retinal segmentation which can be considered a simpler problem, confirming the effectiveness of our proposal.
-
Evaluation of FD as a complexity index. The Pearson correlation coefficients between FD \(Seg_{GT}\) and the CS and FD \(Seg_{auto}\) were 0.85 and 0.75, respectively (\(p<10^{-6}\)), showing a good correlation between the quantitative proposed metric and the clinical assessment.

Example of \(Seg_{auto}\) images used to compute the clinical score
Figure 4a and b shows patients that achieved, respectively, the lowest and highest clinical scores. We computed FD values on \(Seg_{auto}\) of such patients (Fig. 4a and b), obtaining 1.26 on the lowest score (i.e., less vascular complexity) and 1.53 on highest. These results confirm the clinical evaluation.
However, our experimental analysis also suggests that FD can be influenced by image resolution and size as well as number of background pixels. In order to obtain an FD value able to only represent the district of interest, the image has to be cropped to the exact leg FOV. In this way, we remove the extra background pixels which may decrease the FD value.
5 Conclusions
In this work, we proposed a method for improving the visual assessment of vascular complexity in cine-angiography images from patients affected by PAOD. In particular, in order to extract the vascular tree, we rely on (i) computer vision to convert cine-angiographies to single static images with a larger FOV, and (ii) deep learning approach to perform the automatic segmentation of the vascular trees. Our approach relied on the extraction of huge number of tiles and a fourfold cross-validation to overcome the limited number of patients. Both strategies allow the network to reach good performance and generalization ability, thus resulting in a robust model for vascular tree segmentation. Indeed, experimental results show that the segmentation of the whole vascular tree from cine-angiography can significantly improve the visual assessment of vascular complexity in PAOD, reducing the inter-observer variability. Furthermore, we proposed an automatic and quantitative index, referred to as FD, to score the severity of the disease, and proved that it is well correlated to the human-based clinical assessment.
We are aware the used dataset was limited and that additional data could make the conclusions stronger, both for image segmentation and pathology scoring. However, we aim to extensively test the here proposed strategy on a larger cohort in a future study.
Data availability
The datasets used during the current study are available from the corresponding author upon reasonable request.
References
Tsao CW, Aday AW, Almarzooq ZI, Alonso A, Beaton AZ, Bittencourt MS, Boehme AK, Buxton AE, Carson AP, Commodore-Mensah Y et al (2022) Heart disease and stroke statistics-2022 update: a report from the american heart association. Circulation 145(8):153–639
Annex BH, Cooke JP (2021) New directions in therapeutic angiogenesis and arteriogenesis in peripheral arterial disease. Circ Res 128(12):1944–1957
Eid MA, Mehta KS, Goodney PP (2021) Epidemiology of peripheral artery disease. Seminars in Vascular Surgery 34:38–46
Rehring TF, Sandhoff BG, Stolcpart RS, Merenich JA, Hollis HW Jr (2005) Atherosclerotic risk factor control in patients with peripheral arterial disease. J Vasc Surg 41(5):816–822
Fowkes FGR, Rudan D, Rudan I, Aboyans V, Denenberg JO, McDermott MM, Norman PE, Sampson UK, Williams LJ, Mensah GA et al (2013) Comparison of global estimates of prevalence and risk factors for peripheral artery disease in 2000 and 2010: a systematic review and analysis. The Lancet 382(9901):1329–1340
Taris GN, Handayani A, Mengko TL, Hermanto BR (2021) Proliferative diabetic retinopathy classification from retinal fundus images using fractal analysis. In: 2021 IEEE Region 10 symposium (TENSYMP), pp. 1–6
Fan W, Nittala MG, Fleming A, Robertson G, Uji A, Wykoff CC, Brown DM, van Hemert J, Ip M, Wang K et al (2020) Relationship between retinal fractal dimension and nonperfusion in diabetic retinopathy on ultrawide-field fluorescein angiography. Am J Ophthalmol 209:99–106
MacGillivray T, Patton N (2006) A reliability study of fractal analysis of the skeletonised vascular network using the” box-counting” technique. In: 2006 International conference of the IEEE engineering in medicine and biology society, pp. 4445–4448. IEEE
Nogueira AR, Gomes M, Valença M, Oréfice F et al (2007) Fractal analysis of retinal vascular tree: segmentation and estimation methods. Arq Bras Oftalmol 70(3):413–422
Huang F, Zhang J, Bekkers EJ, Dashtbozorg B, ter Haar Romeny BM (2015) Stability analysis of fractal dimension in retinal vasculature. In: Ophthalmic Medical Image Analysis International Workshop. Vol. 2. University of Iowa
Bruno P, Zaffino P, Scaramuzzino S, De Rosa S, Indolfi C, Calimeri F, Spadea MF (2018) Using cnns for designing and implementing an automatic vascular segmentation method of biomedical images. In: International conference of the Italian association for artificial intelligence, Springer, pp. 60–70.
Bay H, Tuytelaars T, Van Gool L (2006) Surf: Speeded up robust features. In: European Conference on Computer Vision, Springer, pp. 404–417
Matas J, Chum O, Urban M, Pajdla T (2004) Robust wide-baseline stereo from maximally stable extremal regions. Image Vision Comput 22(10):761–767
Harris CG, Stephens M, et al. (1988) A combined corner and edge detector. In: Alvey vision conference, Citeseer, vol. 15: pp. 10–5244
Bonny MZ, Uddin MS (2016) Feature-based image stitching algorithms. In: 2016 International workshop on computational intelligence (IWCI), IEEE, pp. 198–203
Canny J (1986) A computational approach to edge detection. IEEE Trans Pattern Anal Mach Intell 6:679–698
Li H, Qin J, Xiang X, Pan L, Ma W, Xiong NN (2018) An efficient image matching algorithm based on adaptive threshold and ransac. IEEE Access 6:66963–66971
Elashry A, Sluis B, Toth C (2021) Improving ransac feature matching based on geometric relation. Int Arch of Photogramm, Remote Sensing and Spatial Inf Sci 43:321–327
Yang J, Huang Z, Quan S, Zhang Q, Zhang Y, Cao Z (2021) Toward efficient and robust metrics for RANSAC hypotheses and 3D rigid registration. IEEE Trans Circ Syst Video Technol 32(2):893–906
Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: International conference on medical image computing and computer-assisted intervention, Springer, pp. 234–241
Abadi M, Barham P, Chen J, Chen Z, Davis A, Dean J, Devin M, Ghemawat S, Irving G, Isard M, et al. (2016) Tensorflow: A system for large-scale machine learning. In: 12th USENIX Symposium on operating systems design and implementation (OSDI 16), pp. 265–283
Zeiler MD (2012) Adadelta: an adaptive learning rate method. arXiv preprint arXiv:1212.5701
Yu S, Lakshminarayanan V (2021) Fractal dimension and retinal pathology: a meta-analysis. Appl Sci 11(5):2376
Dinesen S, Jensen PS, Bloksgaard M, Blindbæk SL, De Mey J, Rasmussen LM, Lindholt JS, Grauslund J (2021) Retinal vascular fractal dimensions and their association with macrovascular cardiac disease. Ophthalmic Res 64(4):561–566
Costa A (2013) Hausdorff (box-counting) fractal dimension. URL https://www. mathworks. com/matlabcentral/fileexchange/30329-hausdorff–box-counting–fractal-dimension
McGraw KO, Wong SP (1996) Forming inferences about some intraclass correlation coefficients. Psychol Methods 1(1):30
Koo TK, Li MY (2016) A guideline of selecting and reporting intraclass correlation coefficients for reliability research. J Chiropr Med 15(2):155–163
Boudegga H, Elloumi Y, Akil M, Bedoui MH, Kachouri R, Abdallah AB (2021) Fast and efficient retinal blood vessel segmentation method based on deep learning network. Comput Med Imaging Graph 90:101902
Atli I, Gedik OS (2021) Sine-net: a fully convolutional deep learning architecture for retinal blood vessel segmentation. Eng Sci Technol, Int J 24(2):271–283
Jin Q, Meng Z, Pham TD, Chen Q, Wei L, Su R (2019) Dunet: a deformable network for retinal vessel segmentation. Knowl-Based Syst 178:149–162
Acknowledgements
This work has been partially funded by PON “Ricerca e Innovazione” 2014-2020, CUP: H25F21001230004.
Funding
Open access funding provided by Università della Calabria within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bruno, P., Spadea, M.F., Scaramuzzino, S. et al. Assessing vascular complexity of PAOD patients by deep learning-based segmentation and fractal dimension. Neural Comput & Applic 34, 22015–22022 (2022). https://doi.org/10.1007/s00521-022-07642-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-022-07642-2