
Abstract
Non-invasive brain-computer interfaces can be implemented through different paradigms, the most used one being motor imagery and evoked potentials, although recently there has been an interest in paradigms based on perception and visual imagery. Following this approach, this work demonstrates the classification of visual imagery, visual perception and also the possibility of knowledge transfer between these two domains from EEG signals using convolutional neural networks. Also, we propose an adequate framework for such classification, which uses convolutional neural networks and the black hole heuristic algorithm for the search for optimal neural network structures.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Brain-computer interface systems allow direct communication between the brain and the outside world without using the muscles. This type of technology allows people with mobility problems to interact with the world that surrounds them, either by allowing them to browse the internet [1], move a wheelchair [2] or interact with a home automation system [3]. Interaction can occur using different paradigms, for example such as imagining the movement of the hands, known as motor imagery; or evoked potentials, such as P300 or SSVEP, which are the most studied and used paradigms within BCI [4]. Although we can create any type of BCI system using these paradigms or even combining existing ones, humans have many other cognitive activities that can be used to create more natural BCI systems, such as visual perception or visual imagery. Through these activities, more natural interfaces could be created for tasks such as drawing or generating art.
Some studies have explored the possibility of classifying visual perception (VP) and visual imagery (VI) signals [5,6,7]. Bobrov et al. [5] demonstrated that visual imagery could be classified using electroencephalographic signals (EEG), managing to classify two imagined objects (human faces and houses) together with the state of relaxation. Ehsan et al. [6] managed to classify five imagined geometric figures using the Emotiv Epoc+ [8] device consisting of 14 electrodes. These works focused only on the classification of visual imagery without making any reference to visual perception. Also, the techniques used there are not trivial; their main component is a complex stage of feature extraction that is difficult to reproduce. On the other hand, Kosmyna et al. [9] studied the classification of visual imagery and also visual perception, concluding that it was possible to distinguish between VP and VI, VP versus VP, Rest versus VP, Rest versus VI, but not VI versus VI. This raised the question of whether the classification of visual imagery is possible and what are its limits. To address this questions, some studies have attempted to shed light on the use of visual imagery classification with EEG. One of the most recent studies on this question is the one by Fu et al. [10], who analyzed the possibility of classifying visual imagery with 18 subjects that had to visualize both static and dynamic images. Using machine learning tools, visual imagery could be classified with a maximum accuracy of 87% using empirical mode decomposition (EMD) and autoregressive (AR). This provided more evidence that the visual system can be used to create new, meaningful BCI systems. However, for practical applications, we need to study in more depth the possibilities of classifying static images only, to find out how to use vision more efficiently in the field of BCI systems.
More recently, some efforts can be found that study the classification of VP and VI for six classes of geometric figures [9], reaching the conclusion that classification is possible in both VI and VP. The main contribution of this study was to use convolutional neural networks in time control, making it easier to reproduce the results. In the work of Alazrai et al. [11], a very complete study is carried out on the possibility of classifying visual imagery. The main contribution of this work is that, using different sets of visual data, such as fruits, animals, numbers, letters and arrow shapes, allows to obtain results above 88% in all categories, providing more scientific evidence that visual imagination can be classified using non-invasive EEG signals. However, in this work, the possibility of using visual perception or transferring knowledge between the two domains (visual imagery and visual perception) is not studied.
It should be mentioned that neural networks have been widely used for the creation of BCI systems, in general obtaining good results [12], being convolutional networks one of the most used techniques [13]. However, one of the main problems when dealing with neural networks is to find the optimal structure of the network, which is not easy. Some works carry out error tests and others use heuristic methods, but, to the best of our knowledge, no other work has used the Black Hole heuristic algorithm to classify EEG signals from vision using CNN networks.
Also, none of the aforementioned works has studied the transfer of knowledge between different subjects and different domains between VP and VI. It is known that the training stage of the process of any BCI system is uncomfortable in that it tires the end user. In our own experience, we have noticed that, when recording EEG signals based on visual imagery, users fatigue much more than with recording based signals in visual perception. Knowledge transfer has been used successfully in BCIs as a way to solve this stage, so here we will also focus on the study of knowledge transfer between VP and VI [14], to reduce the required training.
BCI systems are made up of different stages, which are acquisition, preprocessing, feature extraction and classification [15]. For each stage, there are different possible techniques that can be used. Many research laboratories in BCI systems study which combinations are best for given specific tasks, but in recent years deep learning techniques have dominated research, specifically Convolutional Neural Networks (CNN), which have been successfully used for the classification of EEG signals [16]. However, no previous study has evaluated the use of the Black Hole heuristic algorithm and its effect on the classification of EEG signals to automatically find optimal CNN structures for the VP and VI paradigms. This work also aims at extending the current knowledge on the classification of perception and visual imagination using non-invasive EEG signals, and to offer an optimal and easy-to-use framework to extend the potential of BCI systems.
2 Materials and methods
2.1 Data set
This paper used the public database provided by Xie et al. [17]. It consists of a data set of visual imagery and visual perception, formed by the registry of 38 people (age: mean ± SD = 24.1 ± 4.99 years, 30 female, 8 male). The data can be downloaded at the following link: https://osf.io/ykp9w/. The number of objects that have been used is 12 (Fig. 1): Apple, Car, Carrot, Chicken, Hand, Eye, Sheep, Butterfly, Rose, Ear, Chair, and Violin. Each participant viewed and imagined the object images, presented randomly for 500ms, with a viewing angle of 2.9\(^\circ \) and the images appeared on the center of the screen. All participants completed two sessions, and within each session, they completed 600 trials, split into two blocks separated by a self-paced break.

Images used during EEG signal recording in the used database
2.2 Device
The device used to record the EEG data has been the Brainvision actiCHamp amplifier EASYCAP with 64-channels. The 64 electrodes were arranged in accordance with the standard 10–10 system. The sampling frequency was 1000 Hz. EEG signals were filtered within the range 0.3–100 Hz, and all electrodes were referenced online to the Fz electrode. In this work, we used three distinct configurations, the first configuration (configuration 1) used the same electrodes as in the Emotiv Epoc (AF3, AF4, F7, F3, F4, F8, FC5, FC6, T7, T8, P7, P8, O1 and O2), the second configuration (configuration 2) was the occipital electrodes (O1, O2, Oz, PO3, PO4, PO8 and PO7), and the last configuration (configuration 3) used all electrodes. This way we studied what a good configuration for classifying VP and VI is.
2.3 Preprocessing
The data offered are in raw format and already pre-processed. Eye blinks and movements were detected and removed with an Independent Component Analysis (ICA) on frontal electrodes Fp1, Fp2, AF7 and AF8, implemented in the SSP: Eye blinks algorithm in Brainstorm [17, 18]. The continuous EEG raw data were extracted in epochs between 600 ms pre-stimulus and 1100 ms post-stimulus. The data from each trial were separated into two segments, the pre-stimulus segment of size 600 ms and the post-stimulus segment, also of size 600 ms. The post-stimulus segment occupies the interval 700 ms to 1300 ms. The pre-stimulus segments have been labeled with the label 0 that corresponds to no visualization or imagery, and the post-stimulus segments have been classified as label 1, that is, observation or imagery of an image. The preprocessing consists of two parts, one is filtering of the EEG signals and the other is normalization of the signals. For the filtering, a five-order Butterworth-type bandpass filter was used between the frequency bands 1 and 41 Hz. To normalize the signals, the following equation has been used:
where \(S(t)^{i}\) is the signal EEG of channel i, and \(S(t)_{n}^{i}\) is the i-th channel, but normalized in the interval \([0-1]\).
2.4 Convolutional neural network
Convolutional neural networks (CNN) are a type of neural networks that incorporate convolutional layers (Eq. 2), which give this type of network its name. Through layers of convolution, CNN networks create a hierarchy of spatial features. At first, they were used for image classification and processing [19], where they have had great success [20]. However, in recent years, CNN networks have been applied to other types of problems, and specifically in the classification of EEG signals [12, 16, 21]. In general, they can be described as
where x is the input two-dimensional data, y is the output of \(M\times N\), where \(0\leqslant m \leqslant M\) and \(0\leqslant n \leqslant N\). w is the convolutional kernel with size \(J\times I\), f is the activation function, and b is the bias. There are different possible activation functions, and depending on the range of the input data, one or the other should be used.
CNN networks consist of various types of layers, such as input, dimensionality reduction (that are usually applied after convolutional layers), and finally, output layers. See Fig. 2. One of the problems that we face when using CNN networks is knowing what structure the CNN network should have, that is, how many convolutional layers it should have, the size of the filters, the number of neurons per layer, what functions of activation we must use, etc. Usually researchers use their previous knowledge of the problem to gradually create the CNN networks and test which networks give the best results, but this way of proceeding requires a lot of time and does not guarantee an optimal result. This is why we have chosen to use an heuristic algorithm to find which CNN network structure is the most optimal to classify EEG signals, both pre- and post-event in visual perception. The heuristic chosen in this work has been the Black Hole Algorithm, as it is a simple algorithm to implement, it has few input parameters, and has been used in a wide variety of problems with good results [22,23,24,25].

Convolutional Neural Network schema
CNN networks have proven to be useful for use in highly changing EEG signals, since they are capable of autonomously extracting features through the hidden layers that make up the network.
2.5 Black Hole algorithm
The Black Hole Algorithm is a metaheuristic algorithm that is based on Newton’s laws of gravitation [26]. This algorithm is intended to find an optimal solution to a search problem in an n-dimensional space. The main idea is to generate candidate solutions (called stars) that approach the optimal solution by means of the laws of motion. This way, as the algorithm is iterated, the different solutions approach the solution that gives the best result (called black hole). This algorithm has been used in different problems [27] and it has even been used to select features in EEG problems [28].
The Black Hole Algorithm rests on three concepts: the stars, which are possible solutions to the problem and are uniformly distributed throughout the search space; the Black Hole, which is the star with the best fitness value, i.e., it is a candidate for a possible solution; and the movement of the stars, which is the equation that describes how the solutions are updated as the algorithm is iterated. The main idea is that the space near a black hole is a space where the best solutions can be found; therefore, once we have a black hole, it creates a gravitational field that attracts the different stars towards its closest space. As the stars move, solutions are analyzed in the search space, but it may happen that a star falls into the black hole. Then, this star disappears and a new star is created in a random place within the search space. This prevents the algorithm from falling into local minimal and the full search space can be explored.
The Black Hole Algorithm beings by randomly generating an initial population of n stars, each representing a possible solution to the problem within the search space, \(P(s) = \{s_{1}^t,s_{2}^t, ..., s_{n}^t\}\). Once the stars have been generated, the fitness value of each star is calculated using Eqs. 3 and 4 , and the star with the best fitness value is the one assigned as the black hole. Once the fitness has been calculated and the black hole assigned, we update the positions of the stars using the equation of motion 5. Any star that falls within the event horizon of the black hole disappears and a new star is generated at random. We iterate the algorithm until we find an optimal solution or a certain number of iterations have been completed.
Equation 5 describes the movement of the stars attracted by the black hole, which allows us to explore different solutions in the search space. In this equation, we can observe the \(\alpha \) factor, which is a random value between 0 and 1, and i indicates the index of the star. To calculate the fitness value in our problem, we must convert the star into a CNN network, and we train and evaluate this network with the training data, returning the accuracy value that will be the final fitness value. To know if a star will be absorbed by the black hole, we must calculate the radius of the event horizon of the black hole:
where \(s_{i}\) is the i-th star position and BH is the black hole. If the position of the star is less than R, the start crosses the event horizon and disappears. The pseudo-code of the Black Hole Algorithm can be found in Algorithm 1.

2.6 Metrics
In order to evaluate the different options, it has been chosen to use the accuracy and Cohen’s Kappa value, widely used in the literature [29, 30]. Together, they give us an explanation of how the classification model behaves: Through the accuracy, we can observe the percentage of success of the classifier, but this value by itself does not indicate if it generalizes correctly. For this, it is necessary to rely on other parameters such as the Cohen’s Kappa value, that will indicate how far away the classifier is of a random classification. Accuracy (measured as a percentage) is defined as:
where TP is true positive, TN is true negative, P number of positives and N number of negatives.
Cohen’s Kappa [31] is an indicator that informs whether the classification is random or not, taking values within the range – 1 to 1. It is expressed as:
where \(p_{0}\) is the observed accuracy and \(p_{e}\) is the theoretical accuracy. The Cohen’s Kappa is very useful for evaluating the efficiency of a classifier, as it gives an idea of how it is behaving. If the Kappa value is 1, it means that the classifier performs a perfect positive classification, if the value is 0, it means that the classification is random, and a – 1 means a perfect negative classification. Next, we can see a possible interpretation of Cohen’s Kappa values [31]:
-
< 0.20 Poor.
-
0.21–0.40 Weak.
-
0.41–0.60 Moderate.
-
0.61–0.80 Good.
-
0.81–1.00 Very good.
For the evaluation of the same person, the pipeline shown in Fig. 3 has been used. In the pipeline, EEG signals are divided into three disjoint groups, two of these groups are used for the creation and training of the model and the last one is used for validation. If it were not done in this way, the system would be training and validating with the same signals, and this would give an overestimation of the obtained results [32].

Evaluation schema
2.7 Transfer learning
With respect to the transfer learning process, the following steps were followed. First, the possibility of classifying visual imagery and visual perception has been studied. Then, we study whether it is possible to create a model with a given subject, and whether this model would work for another subject. This is of great importance because it would allow creating BCI systems without prior training for the subject who is going to use the BCI system. Next, the possibility of carrying out transfer learning between domains was also studied, creating the model using EEG signals that come from VP and classifying with these models with VI signals on the same subject, with the aim of facilitating training. Finally, we have mixed VP and VI signals to determine whether the classification improves. We tested different percentages of VI signals (out of the original 12 VI objects) to find out the optimal percentage needed to create the model with VP data.
In order to achieve these goals, we must find an optimal CNN model to classify EEG signals coming from vision. First of all, we must create the model from a well-labelled data set, that is, from a data set we called input. However, we do not know the CNN structure beforehand, although it is true that we can try different structures and see which is the one that gives us the best results, which is not very efficient as it would take a long time to test configurations to be sure that we have a good network. So, we use the BH algorithm that will look for an optimal CNN structure from the training data in an automatic manner. Once we have an optimal model, this model is tested with unlabeled data, that is, the test data, and this is where we extract the final results for all our further tests and verifications.
3 Results
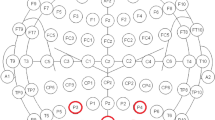
First, we study the electrode configurations for the classification of Rest versus VP, and between the 12 VP objects. As mentioned in Sect. 2.2, we used 3 different electrode configurations (Fig. 4). Configuration 1 uses the electrodes of the Emotiv Epoc+ device, which has proven useful for classifying EEG signals. Configuration 2 focuses on the occipital area, while configuration 3 focuses on the motor and temporal area.

In green the electrodes used in each configuration
First, we studied how the electrode configuration affected the result when classifying VP versus Rest, and between the 12 VP classes. For this, the pipeline shown in Fig. 3 has been followed. In this diagram, we can see that the data were divided into two groups, one for testing and the other for training. The training group is the data that will be used to obtain an optimal CNN model with the help of the Black Hole Algorithm, and finally, the model will be tested with the test group. In this way, we make sure that the model is tested with EEG signals that it has not seen before.
Using the method described, a classification was made and the results obtained can be seen in Fig. 5. The results show that it is possible to classify both VP versus Rest, and the 12 VP objects. Although all the configurations show a high success rate, configuration 2 is the one that seems to obtain the best results, with a 93% accuracy for VP versus Rest, and 28% for the 12 VP classes. In this case, the results obtained for the 12 VP classes show that the classification by CNN plus BH is possible, since chance is just 8.33%.

Accuracy obtained for different VP target groups and electrode configurations. The results obtained are the average for all the subjects
The confusion matrix for the rest versus VP classification can be seen below, in Fig. 6. Label 0 represents rest and Label 1 the visual perception of one object among the twelve that have been experienced. This confusion matrix is computed as the average of all subjects.

Average confusion matrix of all subjects for the classification of rest versus VP with configuration 2 as electrode configuration

Average confusion matrix of all subjects when classifying the 12 VP classes using configuration 2
In the confusion matrix (Fig. 7), it can be seen that practically all the images can be well classified, with the exception of the image with label 3, which corresponds to the chicken, which is often confused with the sheep image. This makes some sense as they are two animals and we may say that the two images produce a similar EEG pattern because of this.
Once it was detected that configuration 2 is the one that offers the best results, we studied which frequency range can be the best one. For this, the full frequency range was divided into several non-overlapping ranges, and it was found that the frequency bands, \(\alpha \) and \(\beta \), are the most important for classifying visual perception, as shown in Table 1
Once it was confirmed that it is possible to detect visual perception using electrodes in the occipital area, and in particular using the frequency range between \(\alpha \) and \(\beta \), it was then studied whether the designed method could be used to classify visual imagery. The results obtained were those shown in Fig. 8.

Accuracy obtained for the VI target group, with different electrode configurations. The results obtained are the average for all the subjects

Average confusion matrix of all subjects for the classification of rest versus VI with electrode configuration 2
The confusion matrix (Fig. 9) indicates that the classification of visual imagery versus relax is possible and that the results are very similar to the results obtained for rest versus VI.

Average confusion matrix of all subjects when classifying the 12 VI classes using configuration 2
In Fig. 10, we can see the average confusion matrix when classifying the 12 VI classes. As can be seen, the matrix is mainly diagonal, which is a quite positive result.
The results (Table 2) for VI versus Rest are very similar to those obtained with VP versus Rest, but for the classification of the 12 imagined objects, we can see that the use of configuration 3 obtains better results, reaching a 29% accuracy.
As happens with visual perception, the \(\alpha \) and \(\beta \) ranges are the most important frequencies, as they are the ones that obtain the best results when classifying the 12 different classes.
Once we have confirmed that the classification of visual imagery and visual perception can be done beyond chance, we decided to analyze whether it was possible to use visual perception to classify EEG signals that come from visual imagery. That is, by means of VP EEG signals to create models capable of classifying also VI EEG signals. In this way we would carry out a transfer of knowledge between domains [33], and a user could train a model simply by visualizing objects and then these models could be used to classify visual imagination. Thus, the objective is to create simpler training paradigms that do not involve a high concentration load on the side of people who want to use a BCI system, and visual perception involves less concentration load than visual imagery.
Table 3 shows the results obtained by classifying visual perception versus rest and creating a model, and then using these results to classify VI versus Rest. Although, on average, we obtained 87.84% of accuracy, that is, slightly lower than that obtained by training with signals from the same specific domain, the results clearly show that the use of transfer learning between these similar domains is feasible.
Finally, Table 4 shows the results obtained for the classification of 12 different classes. As can be seen, the results obtained are lower than when using the same domain to train and test, but they are still much higher than chance. Therefore, we can conclude that it is possible to use visual perception to train a BCI system that will then be used to classify EEG signals from visual imagery.

Topoplots averaged over all subjects. The two topoplots on the left belong to visual perception and the two on the right to visual imagery
Figure 11 shows topoplots (topographic maps of an EEG field as a 2-D circular view) of the images that offer the best results when classifying. It can be seen that the visual perception of sheep and butterfly activates the same region but in a slightly different way, as for sheep there is a stronger activation.
4 Conclusions and discussion
This paper analyzes the possibility of using imagination and visual perception for BCI systems. Working with EEG signals in general is difficult due to its high variability, and thus obtaining good results in the classification of these signals is complex and requires different processing stages. However, it has been shown that, by using convolutional neural networks together with an heuristic algorithm such as the Black Hole Algorithm, it is possible to classify imagination and perception for 12 different classes, with accuracy close to 30%. The electrode configuration that has offered the best performance has been the configuration that uses eight electrodes at the occipital area, chosen as the optimal between 3 predefined configurations. It has also been found that the \(\alpha \) and \(\beta \) range of frequencies are the most important for classifying visual perception and imagery. The possibility of using the visual perception paradigm to train a model and then use the resulting model to classify visual imagination has also been studied. The results show that knowledge transfer is possible. As a consequence, we can create BCI systems that do not impose a tiring session on the subject when training, as perceiving images is less cumbersome than imagining them.
Although the designed system is efficient and the implementation complexity is low, certain computing capabilities are required, i.e., the more computing power we have, the more complex CNN networks we can obtain, thus improving the success in the classification. In the future, it would be interesting to study the use of visual imagination in an online BCI system.
References
Yehia AG, Eldawlatly S, Taher M (2017) WeBB: A brain-computer interface web browser based on steady-state visual evoked potentials. In: 2017 12th International Conference on Computer Engineering and Systems (ICCES). IEEE. https://doi.org/10.1109/icces.2017.8275277
Abiyev RH, Akkaya N, Aytac E, Günsel I, Çağman A (2016) Brain-computer interface for control of wheelchair using fuzzy neural networks. BioMed Res Int 2016:1–9. https://doi.org/10.1155/2016/9359868
Rajmohan M, Vali SCH, Raj A, Gogoi A (2020) Home automation using brain computer interface (BCI). In: 2020 international conference on power, energy, control and transmission systems (ICPECTS). IEEE. https://doi.org/10.1109/icpects49113.2020.9336967
Abiri R, Borhani S, Sellers EW, Jiang Y, Zhao X (2019) A comprehensive review of EEG-based brain-computer interface paradigms. J Neural Eng 16(1):011001. https://doi.org/10.1088/1741-2552/aaf12e
Bobrov P, Frolov A, Cantor C, Fedulova I, Bakhnyan M, Zhavoronkov A (2011) Brain-computer interface based on generation of visual images. PLoS ONE 6(6):20674. https://doi.org/10.1371/journal.pone.0020674
Esfahani ET, Sundararajan V (2012) Classification of primitive shapes using brain-computer interfaces. Comput-Aided Des 44(10):1011–1019. https://doi.org/10.1016/j.cad.2011.04.008
Llorella FR, Patow G, Azorín JM (2020) Convolutional neural networks and genetic algorithm for visual imagery classification. Phys Eng Sci Med 43(3):973–983. https://doi.org/10.1007/s13246-020-00894-z
Williams NS, McArthur GM, de Wit B, Ibrahim G, Badcock NA (2020) A validation of emotiv EPOC flex saline for EEG and ERP research. Peer J 8:9713. https://doi.org/10.7717/peerj.9713
Kosmyna N, Lindgren JT, Lécuyer A (2018) Attending to visual stimuli versus performing visual imagery as a control strategy for EEG-based brain-computer interfaces. Sci Rep. https://doi.org/10.1038/s41598-018-31472-9
Fu Y, Li Z, Gong A, Qian Q, Su L, Zhao L (2022) Identification of visual imagery by electroencephalography based on empirical mode decomposition and an autoregressive model. Comput Int Neurosci 2022:1–10. https://doi.org/10.1155/2022/1038901
Alazrai R, Al-Saqqaf A, Al-Hawari F, Alwanni H, Daoud MI (2020) A time-frequency distribution-based approach for decoding visually imagined objects using EEG signals. IEEE Access 8:138955–138972. https://doi.org/10.1109/access.2020.3012918
Lawhern VJ, Solon AJ, Waytowich NR, Gordon SM, Hung CP, Lance BJ (2018) EEGNet: a compact convolutional neural network for EEG-based brain-computer interfaces. J Neural Eng 15(5):056013. https://doi.org/10.1088/1741-2552/aace8c
Craik A, He Y, Contreras-Vidal JL (2019) Deep learning for electroencephalogram (EEG) classification tasks: a review. J Neural Eng 16(3):031001. https://doi.org/10.1088/1741-2552/ab0ab5
Wan Z, Yang R, Huang M, Zeng N, Liu X (2021) A review on transfer learning in EEG signal analysis. J Neural Eng 421:1–14. https://doi.org/10.1016/j.neucom.2020.09.017
Vaid S, Singh P, Kaur C (2015) EEG signal analysis for BCI interface: A review. IEEE. https://doi.org/10.1109/acct.2015.72
Llorella FR, Patow G, Azorín JM (2020) Convolutional neural networks and genetic algorithm for visual imagery classification. Phys Eng Sci Med 43(3):973–983. https://doi.org/10.1007/s13246-020-00894-z
Xie S, Kaiser D, Cichy RM (2020) Visual imagery and perception share neural representations in the alpha frequency band. Curr Biol 30(13):2621–26275. https://doi.org/10.1016/j.cub.2020.04.074
Uusitalo MA, Ilmoniemi RJ (1997) Signal-space projection method for separating MEG or EEG into components. Med Biol Eng Comput 56(1):78–92. https://doi.org/10.1007/BF02534144
Rikiya Y, Mizuho N, Gian DRK, Kaori T (2018) Convolutional neural networks: an overview and application in radiology. Insights Imaging 9(4):611–629
Sangaiah AK (2019) Deep learning and parallel computing environment for bioengineering systems. Elsevier
Schirrmeister RT, Springenberg JT, Fiederer LDJ, Glasstetter M, Eggensperger K, Tangermann M, Hutter F, Burgard W, Ball T (2017) Deep learning with convolutional neural networks for EEG decoding and visualization. Hum Brain Mapp 38(11):5391–5420. https://doi.org/10.1002/hbm.23730
Azizipanah-Abarghooee R, Niknam T, Bavafa F, Zare M (2014) Short-term scheduling of thermal power systems using hybrid gradient based modified teaching-learning optimizer with black hole algorithm. Electri Power Syst Res 108:16–34. https://doi.org/10.1016/j.epsr.2013.10.012
Pashaei E, Ozen M, Aydin N (2015) An application of black hole algorithm and decision tree for medical problem. In: 2015 IEEE 15th international conference on bioinformatics and bioengineering (BIBE). IEEE. https://doi.org/10.1109/bibe.2015.7367738
Xie W, Wang JS, Xing C, Guo SS, Guo MW, Zhu LF (2020) Extreme learning machine soft-sensor model with different activation functions on grinding process optimized by improved black hole algorithm. IEEE Access 8:25084–25110. https://doi.org/10.1109/access.2020.2970429
Deeb H, Sarangi A, Mishra D, Sarangi SK (2020) Improved black hole optimization algorithm for data clustering. J King Saud Univ Comput Info Sci. https://doi.org/10.1016/j.jksuci.2020.12.013
Lung WK, Avus H, Chun-Min H, Miin-Jye W (2016) Clustering based on black hole phenomenon. Int J Adv Comput Eng Netw 4
Hatamlou A (2013) Black hole: a new heuristic optimization approach for data clustering. Info Sci 222:175–184. https://doi.org/10.1016/j.ins.2012.08.023
Munoz R, Olivares R, Taramasco C, Villarroel R, Soto R, Barcelos T, Merino E, Alonso-Sánchez M (2018) Black hole algorithm to improve eeg-based emotion recognition. Comput Intell Neurosci. https://doi.org/10.1155/2018/3050214
Ortega J, Asensio-Cubero J, Gan JQ, Ortiz A (2016) Classification of motor imagery tasks for BCI with multiresolution analysis and multiobjective feature selection. BioMed Eng Online. https://doi.org/10.1186/s12938-016-0178-x
Diez PF, Mut VA, Laciar E, Torres A, Perona EMA (2013) Features extraction method for brain-machine communication based on the empirical mode decomposition. Biomed Eng Appl Basis Commun 25(06):1350058. https://doi.org/10.4015/s1016237213500580
Jacob C (1960) A coefficient of agreement for nominal scales. Educ Psychol Meas. https://doi.org/10.1177/001316446002000104
Ma Q, Wang M, Hu L, Zhang L, Hua Z (2021) A novel recurrent neural network to classify EEG signals for customers’ decision-making behavior prediction in brand extension scenario. Front Hum Neurosci. https://doi.org/10.3389/fnhum.2021.610890
Wan Z, Yang R, Huang M, Zeng N, Liu X (2021) A review on transfer learning in EEG signal analysis. Neurocomputing 421:1–14. https://doi.org/10.1016/j.neucom.2020.09.017
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
There is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Llorella, F.R., Azorín, J.M. & Patow, G. Black hole algorithm with convolutional neural networks for the creation of brain-computer interface based in visual perception and visual imagery. Neural Comput & Applic 35, 5631–5641 (2023). https://doi.org/10.1007/s00521-022-07542-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-022-07542-5