
Abstract
Time series forecasting is ubiquitous in various scientific and industrial domains. Powered by recurrent and convolutional and self-attention mechanism, deep learning exhibits high efficacy in time series forecasting. However, the existing forecasting methods are suffering some limitations. For example, recurrent neural networks are limited by the gradient vanishing problem, convolutional neural networks cost more parameters, and self-attention has a defect in capturing local dependencies. What’s more, they all rely on time invariant or stationary since they leverage parameter sharing by repeating a set of fixed architectures with fixed parameters over time or space. To address the above issues, in this paper we propose a novel time-variant framework named Self-Attention-based Time-Variant Neural Networks (SATVNN), generally capable of capturing dynamic changes of time series on different scales more accurately with its time-variant structure and consisting of self-attention blocks that seek to better capture the dynamic changes of recent data, with the help of Gaussian distribution, Laplace distribution and a novel Cauchy distribution, respectively. SATVNN obviously outperforms the classical time series prediction methods and the state-of-the-art deep learning models on lots of widely used real-world datasets.













Similar content being viewed by others


Notes
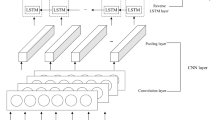
The first layer is an input layer.
References
Yule GU (1927) On a method of investigating periodicities in disturbed series, with special reference to Wolfer’s sunspot numbers. Philos Trans R Soc A 226:267–298
Box GEP, Pierce DA (1970) Distribution of residual in autoregressive-integrated moving average time series. J Am Stat Assoc 65:1509–1526
Chen S, Wang XX, Harris CJ (2007) NARX-based nonlinear system identification using orthogonal least squares basis hunting. IEEE Trans Control Syst Technol 16(1):78–84
Bouchachia A, Bouchachia S (2008) Ensemble learning for time series prediction. NDES
Frigola R, Rasmussen CE (2013) Integrated pre-processing for Bayesian nonlinear system identification with gaussian processes. In: IEEE CDC
Rumelhart DE, Hinton GE, Williams RJ (1986) Learning representations by back-propagating errors. Nature 323(6088):533–536
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780
Gers FA, Schmidhuber J, Cummins F (2000) Learning to forget: continual prediction with LSTM. Neural Comput 12(10):2451–2471
Gers FA, Eck D, Schmidhuber J (2001) Applying LSTM to time series predictable through time-window approaches. In: ICANN, pp 669–676
Khandelwal U, He H, Qi P, Jurafsky D (2018) Sharp nearby, fuzzy far away: how neural language models use context. ACL, pp 284–294
Mariet Z, Kuznetsov V (2019) Foundations of sequence-to-sequence modeling for time series. CoRR arXiv:1805.03714
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A, Kaiser L, Polosukhin I (2017) Attention is all you need. In: NIPS
Guo M, Zhang Y, Liu T (2019) Gaussian transformer: a lightweight approach for natural language inference. AAAI 33:6489–6496
Im J, Cho S (2017) Distance-based self-attention network for natural language inference. In: CoRR arXiv:1805.03714
Dabrowski JJ, Zhang Y, Rahman A ForecastNet: A time-variant deep feed-forward neural network architecture for multi-step-ahead time-series forecasting. In: ICONIP
Qin Y, Song D, Chen H, Cheng W, Jiang G, Cottrell G (2017) A dual-stage attention-based recurrent neural network for time series prediction. In: IJCAI
Lai G, Chang WC, Yang Y, Liu H (2018) Modeling long- and short-term temporal patterns with deep neural networks. ACM
Taieb SB, Atiya AF (2015) A bias and variance analysis for multistep-ahead time series forecasting. IEEE Trans Neural Netw Learn Syst 27:62–76
Taieb SB, Bontempi G, Atiya AF, Sorjamaa A (2012) A review and comparison of strategies for multi-step ahead time series forecasting based on the NN5 forecasting competition. Expert Syst Appl 39(8):7067–7083
Salinas D, Flunkert V, Gasthaus J, Januschowski T (2020) DeepAR: probabilistic forecasting with autoregressive recurrent networks. Int J Forecast 36(3):1181–1191
Rangapuram SS, Seeger MW, Gasthaus J, Stella L, Wang Y, Januschowski T (2018) Deep state space models for time series forecasting. In: NIPS, pp 7785–7794
Wang Y, Smola A, Maddix D, Gasthaus J, Foster D, Januschowski T (2019) Deep factors for forecasting. In: ICML, pp 6607–6617
Bengio Y, Simard P, Frasconi P (1994) Learning long-term dependencies with gradient descent is difficult. IEEE Trans Neural Netw 2:157–166
Sutskever I, Vinyals O, Le QV (2014) Sequence to sequence learning with neural networks. NIPS, pp 3104–3112
Yu R, Zheng S, Anandkumar A, Yue Y (2017) Long-term forecasting using higher order tensor RNNs. CoRR arXiv:1711.00073
Wen R, Torkkola K, Narayanaswamy B, Madeka D (2017) A multi-horizon quantile recurrent forecaster. NIPS
Guen VL, Thome N (2019) Shape and time distortion loss for training deep time series forecasting models. In: NIPS, pp 4189–4201
Laptev N, Yosinski J, Li LE, Smyl S (2017) Time-series extreme event forecasting with neural networks at uber. ICML 34:1–5
Xiong H, He Z, Wu H, Wang H (2018) Modeling coherence for discourse neural machine translation. In: AAA I, pp 7338–7345
Yang B, Wang L, Wong DF, Chao LS, Tu Z (2019) Convolutional self-attention network. CoRR arXiv:1810.13320
Shaw P, Uszkoreit J, Vaswani A (2018) Self-attention with relative position representations. In: NAACL
Zhang J, Luan H, Sun M, Zhai F, Xu J, Zhang M, Liu Y (2018) Improving the transformer translation model with document-level context. In: EMNLP
Im J, Cho S (2017) Distance-based self-attention network for natural language inference. CoRR arXiv:1712.02047
Yang B, Tu Z, Wong DF, Meng F, Chao LS, Zhang T (2018) Modeling localness for self-attention networks. CoRR arXiv:1810.10182
Devlin J, Chang MW, Lee K, Toutanova K (2019) BERT: pre-training of deep bidirectional transformers for language understanding. In: NAACL, pp 4171–4186
Kang WC, Mcauley J (2018) Self-attentive sequential recommendation. In: ICDM
Sun F, Liu J, Wu J, Pei C, Lin X, Ou W, Jiang P (2019) BERT4Rec: sequential recommendation with bidirectional encoder representations from transformer. CoRR arXiv:1904.06690
Zhang S, Tay Y, Yao L, Sun A (2018) Next item recommendation with self-attention. CoRR arXiv:1808.06414
Chen Q, Zhao H, Li W, Huang P, Ou W (2019) Behavior sequence transformer for E-commerce recommendation in Alibaba. In: KDD
Liu PJ, Saleh M, Pot E, Goodrich B, Sepassi R, Kaiser L, Shazeer N (2018) Generating wikipedia by summarizing long sequences. In: ICLR
Hoang A, Bosselut A, Celikyilmaz A, Choi Y (2019) Efficient adaptation of pretrained transformers for abstractive summarization. CoRR arXiv:1906.00138
Subramanian S, Li R, Pilault J, Pal C (2019) On extractive and abstractive neural document summarization with transformer language models. CoRR arxiv:1909.03186
Zhang X, Meng K, Liu G (2019) Hie-transformer: a hierarchical hybrid transformer for abstractive article summarization. In: ICONIP, pp 248–258
Wu N, Green B, Ben X, O’Banion S (2020) Deep transformer models for time series forecasting: the influenza prevalence case. CoRR arXiv:2001.08317
Huang S, Wang D, Wu X, Tang A (2019) DSANet: dual self-attention network for multivariate time series forecasting. ACM, pp 2129–2132
Song H, Rajan D, Thiagarajan JJ, Spanias A (2018) Attend and diagnose: clinical time series analysis using attention models. In: AAAI
Yang B, Tu Z, Wong DF, Meng F, Chao LS, Zhang T (2018c) Modeling localness for self-attention networks. In: EMNLP, pp 4449–4458
Oppenheim AV, Schafer RW, Buck JR (1999) Pearson Education Signal Processing Series, Discrete-Time Signal Processing (2nd ed.)
Hyndman R Time series data library. https://robjhyndman.com/tsdl/
Guin A (2006) Travel time prediction using a seasonal autoregressive integrated moving average time series model. In: ITSC, pp 493–498
Fildes R (1992) Bayesian forecasting and dynamic models. Int J Forecast 8:635–637
Bahdanau D, Cho K, Bengio Y (2014) Neural machine translation by jointly learning to align and translate. In: ICLR
Bai S, Kolter JZ, Koltun V (2018) An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. CoRR arxiv:1803.01271
Hyndman RJ, Koehler AB (2006) Another look at measures of forecast accuracy. Int J Forecast 22(4):679–688
Hyndman R, Athanasopoulos G (2018) Forecasting: principles and practice. OTexts
Makridakis S, Spiliotis E, Assimakopoulos V (2018) The M4 competition: results, findings, conclusion and way forward. Int J Forecast 34(4):802–808
Sun M (2009) Iterative learning neurocomputing. In: WNIS, pp 158–161
Acknowledgements
This work was supported by the Fundamental Research Funds for the Central Universities (Grant No. 2020-JBZD004).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Proof of convergence of SATVNN
The weight of the time-invariant network is often constant, and the mapping between the input and output of the network is fixed after training. However, the mapping relationship between the input and output of the time-variant system will change with time. In this paper, we propose a SATVNN with time-variant weights, which is used to establish a neural network each time, and the neural network at that time is used to approach the mapping relationship between the input and output of the system at that time. We regard time-variant weight learning as an unknown time-variant parameter estimation problem for nonlinear time-variant systems. In [57], an iterative learning least squares algorithm is proposed to train the weights of the time-variant network. Theoretical analysis shows that the iterative learning least squares algorithm can ensure that the modeling error converges to zero along the iteration axis in the whole time interval. We will elaborate on the reasons in the following paragraphs.
Time-variant neural network The time-variant neural network whose input, output and weight change with time can be expressed as follows:
or
where \(x(t)=\left[ x_{1}(t), x_{2}(t), \ldots , x_{n}(t)\right] ^{\mathrm{T}} \in {\mathbb{R}}^{n}\) is input vector. \({\mathcal {E}}(x(t)) = [{\mathcal {E}}_{1}(x(t)), {\mathcal {E}}_{2}(x(t)), \ldots , {\mathcal {E}}_{l}(x(t))]^{\mathrm{T}}\) is a set of activation function vectors. y(t) is output. \({W}(t)=\left[ w_{1}(t), \ldots , w_{l}(t)\right] ^{\mathrm{T}}\) is an adjustable time-variant weight vector. l is the number of neuron nodes.
Time-variant system Let the nonlinear discrete time-variant system be:
where f is a nonlinear time-variant function, \(x_{m}(t)\) is input vector. \(t \in \{0,1, \ldots , N\}\) is a finite time interval. \(m \in \{0,1, \ldots \}\) is the number of iterations and \(y_{m}(t)\) is output. In the following discussion, we all assume that \(x_{m}(t)\) is bounded.
Iterative learning least square method Let the nonlinear time-variant system (33) be run repeatedly for m time from the 0th time, and the input and output data pairs \(\{\left( x_{i}(t), y_{i}(t)\right) , t=0,1, \ldots , N, i=0,1,\ldots ,m\}\) are generated by the system. We will use the time-variant neural network (32) to approximate the above input–output mapping.
First, we define \({{E}}_{m}(t)=[{\mathcal {E}}_{0}^{\mathrm{T}}(t), {\mathcal {E}}_{1}^{\mathrm{T}}(t), \ldots , {\mathcal {E}}_{m}^{\mathrm{T}}(t)]^{\mathrm{T}}\) and \({Y}_{m}(t)=[y_{0}(t), y_{1}(t), \ldots , y_{m}(t)]^{\mathrm{T}}\),where \({\mathcal {E}}_{i}(t)={\mathcal {E}} (x_{i}(t), t)\), according to Eq. (32),
We hope to find out the least square solution for W(t), \({\hat{W}}_{m}(t)\), so that the following loss function is minimized.
Write Eq. (35) further as:
Note that only the second term on the right side of the above formula is related to \({\hat{W}}_{m}(t)\), set this item zero. We assume that \({{E}}_{m}^{\mathrm{T}}(t) {{E}}_{m}(t)\) is invertible and achieve the minimum value:
According to Eq. (37), calculating \({\hat{W}}_{m}(t)\) requires calculating the inverse of \({E}_{m}(t)\). The dimension of \({E}_{m}(t)\) will increase, and the inverse computation will become time-consuming as iteration increases. To solve this problem, an iterative learning least square algorithm is derived.
Let us define \(Q_{m}^{-1}(t)={E}_{m}^{\mathrm{T}}(t) {E}_{m}(t)\), according to the definition of \({E}_{m}(t)\), we can get:
\(Q_{m+1}^{-1}(t)=\sum _{i=0}^{m+1} {\mathcal {E}}_{i}(t) {\mathcal {E}}_{i}^{\mathrm{T}}(t)=\sum _{i=0}^{m} {\mathcal {E}}_{i}(t) {\mathcal {E}}_{i}^{\mathrm{T}}(t)+{\mathcal {E}}_{m+1}(t) {\mathcal {E}}_{m+1}^{\mathrm{T}}(t)\) and namely:
Use Matrix inversion lemma, \((A^{-1}+H R^{-1} H^{\mathrm{T}})^{-1}=A-A H({H}^{\mathrm{T}} A {H}+{R})^{-1} {H}^{T} {A}\), let \({A}={Q}_{m}(t)\), \({H}={\mathcal {E}}_{m+1}(t)\), \({R}=1\). we can get:
According to the definition of \(Q_{m}^{-1}(t)\), we can compute \({\hat{W}}_{m}\) such that:
Define error \(e_{m+1}(t)=y_{m+1}(t)-{\mathcal {E}}_{m+1}(t) {\hat{W}}_{m}(t)\)
According to Eq. (39), we get:
According to Eqs. (39) and (41), update laws for \(Q_{m}(t)\) and \({{\hat{W}}}_{m}(t)\) indicate iterative learning least square algorithm of time-variant neural for network training.
Convergence analysis We analyze the convergence of iterative learning algorithm.
Theorem 1
For system (33), the learning algorithm Eqs. (39)–(41) has the following properties:
-
(i)
For \(t=0,1, \ldots , N\) and \(m=0,1, \ldots ,\)
$$\begin{aligned} \left\| {\tilde{W}}_{m+1}(t)\right\| ^{2}&\leqslant \rho _{m}(t)\left\| {\tilde{W}}_{m}(t)\right\| ^{2} \end{aligned}$$(42)$$\begin{aligned} \left\| {\tilde{W}}_{m}(t)\right\| ^{2}&\leqslant \rho _{0}(t)\left\| {\tilde{W}}_{0}(t)\right\| ^{2} \end{aligned}$$(43)where \(\rho _{m}(t)={\lambda _{\max }(Q_{m}^{-1}(t))}/{\lambda _{\min }(Q_{m}^{-1}(t))}\), minimum eigenvalues and maximum eigenvalues of \(Q_{m}^{-1}(t)\) are represented by \(\lambda _{\min }(Q_{m}^{-1}(t))\) and \(\lambda _{\max }(Q_{m}^{-1}(t))\), respectively.
-
(ii)
For \(t=0,1, \ldots , N\),
$$\begin{aligned} \lim _{m \rightarrow \infty } e_{m+1}(t)=0 \end{aligned}$$(44)
Proof
By definition, \(e_{m+1}(t)={\mathcal {E}}_{m+1}^{\mathrm{T}}(t) \tilde{{W}}_{m}(t)\), according to Eqs. (39)–(41), we can get:
Combine Eqs. (45) and (46), we can get:
Define \(V_{m}(t)={\tilde{W}}_{m}^{\mathrm{T}}(t) Q_{m}^{-1}(t) {\tilde{W}}_{m}(t)\), use Eq. (45), we can get:
Therefore, \(V_{m}(t)\) are non-increasing and nonnegative for m, namely
According to Eq. (38), we can get:
Combine Eq. (49), we can get:
Therefore:
Apparently there is \(V_{m}(t) \leqslant V_{0}(t)\), combine Eq. (49), we can get:
This ensures that \(\left\| {\tilde{W}}_{m}(t)\right\| ^{2}\) is uniformly bounded. The property (i) is proved. \(\hfill\square\)
Proof
According to Eq. (48), we can get:
Sum the above formula from 0 to m, we get:
Because \(V_{0}(t)\) is bounded, therefore:
Use \(\lambda _{\max }\left( Q_{m+1}(t)\right) \leqslant \lambda _{\max }\left( Q_{m}(t)\right)\), we can get:
According to Eq. (56), we can get:
The input \(x_{m}(t)\) is bounded; then, \({\mathcal {E}}_{m+1}(t)\) is bounded. In Eq. (58), the denominator term is bounded and nonzero; then, we can get:
\(\hfill\square\)
This ensures the uniform convergence of the estimation error and proves the property (ii). Therefore, the learning algorithm we give ensures the boundedness of time-variant weights. The estimation error on a finite time interval can asymptotically converge to zero.
Rights and permissions
About this article

Cite this article
Gao, C., Zhang, N., Li, Y. et al. Self-attention-based time-variant neural networks for multi-step time series forecasting. Neural Comput & Applic 34, 8737–8754 (2022). https://doi.org/10.1007/s00521-021-06871-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-021-06871-1