
Abstract
This paper presents an algorithm for solving N-equations of N-unknowns. This algorithm allows to determine the solution in a situation where coefficients A i in equations are burdened with measurement errors. For some values of A i (where i = 1,…, N), there is no inverse function of input equations. In this case, it is impossible to determine the solution of equations of classical methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Mathematical models that describe electric dependencies in the receiver tested are built from discrete components. For a full description of such a model, it is required to identify the parameters x i of these elements (see Eq. 1). Most frequently, this identification is carried out indirectly through the measurements of electrical quantities A i on the object tested [5, 8]. The parameters sought are determined from the mathematical relations (1) that describe the object.
where f i certain functions depending on the model, A i the values measured, y i parameters that describe the model.
The classic method to solve Eq. (1) consists in determining inverse functions (2). Measurement inaccuracies that are contained in A i are transferred to parameters y i to be determined.
In some cases, the determination of Eq. (2) may not be possible [14, 16]. This means that for adopted coefficients A i , there are no inverse functions g i . Eq. (2) are determined for the values of environment A i and which contain measurement errors. In this case, approximate solutions are sought which satisfy Relation (3).
The solution will be close to coefficients A i .
2 An example of a model for identification
The analysis covered a single phase on an induction motor. The purpose of the analysis is to determine current–voltage dependences on the terminals of one motor phase. These relationships can be determined from the model that consists of serially connected elements: R s , L s i e s (Fig. 1).

Electric model of the motor and the power source, where \( u = U_{m} \sin \omega t,\quad e_{S} (t) = \left\{ {\begin{array}{*{20}c} {E_{m} \sin (\omega t + \phi_{es} )} \hfill & {t < t_{0} } \hfill \\ {E_{m} e^{ - \alpha t} \sin (\omega t + \phi_{es} )} \hfill & {t \ge t_{0} } \hfill \\ \end{array} } \right., \) R internal resistance of sources
Coefficients R S , L S , E m , φ es , α that are being sought represent many of the phenomena that occur in the motor and the system that is driven. For example, the inertia of the rotor and the system driven will affect e s , and the angular velocity will exert an influence on mutual inductances, which are described with L S . When searching for the parameters of the model, the fact is also important that these factors cannot be determined with the engine being stopped. This means that the R S does not reflect the winding resistance and L S does not reflect their inductance. The parameters of the model are defined for a constant load on the machine shaft and for constant rotations. When changing the load, the parameters of the model change, as well.
In this situation, the parameters that are being determined cannot in any way be unified. They should be determined for a specific drive train (the motor and the machine driven). These parameters can vary considerably for the same engine with different mechanical properties of the system driven.
The identification of the model consists in searching for E m , φ es , R S , and L S . These parameters can be determined on the receiver [6, 7, 9–11] by making measurements in the steady state (in the case of an induction motor: during operation with a constant load and a constant speed) in the system as shown below (Fig. 2):

Measuring circuit for parametric identification
According to the model adopted, we know that:
In the field of complex numbers, the following can be written:
For one mesh, the voltage equation is as follows:
where \( X_{S} = \omega L_{S} . \)
Next, by transforming (7), we determine current I a :
Voltmeter V measures the difference in the supply voltage and in the voltage drop across internal resistance R. Thus, in the field of complex numbers, there will be the following:
From Eqs. (8) and (9), one can obtain the following:
Knowing that the forces and the current are equal, respectively:
We obtain the following equations:
Equation (11) is consistent with (1). The coefficients of the model of the receiver that are obtained from the above equations are not determinable for all the input parameters (U V , I a , P W , Q W ). There are those areas that result from measurement inaccuracies where the system of Eq. (11) has no solutions.
It was found that these coefficients cannot be determined using the Newton’s interpolation algorithm [15, 16]. There are no functions that are inverse to Eq. (11), either.
Process time constant 1/α that is being sought, and which is mainly related to the inertia of the rotor and the system driven, can be determined experimentally by observing the course of voltage versus time at the motor terminals immediately after commutation.
In [13], the authors proved that amplitude E S can be equal to amplitude U. In this paper, it was also observed that frequency E S is similar to the frequency of the mains voltage. It was also noted that phase shift φ es is equal to 0.
In this model, it is assumed that the frequencies of both sources are identical. This assumption does not substantially affect the results of further simulations.
3 Construction of an artificial neural network
Coefficients E m , R S , and L S can be determined from Eq. (11) using a neural network. The network input parameters x 1 = U v [V], x 2 = I a [A], x 3 = P w [W], x 4 = Q w [VAr] contain measurement errors. Due to the nature of the adopted activation function [1–3], the output neuron of the output layer must be within range \( y \in \left( {0,\,1} \right) \). The initial values were as follows: y 1 = R s [kΩ], y 2 = L s [H], y 3 = E s [kV].
Training of the network must be for those learning vectors \( \sigma = \left[ {x_{1} , \ldots ,x_{{N_{0} }} ,\left| {,d_{1}^{\left( L \right)} , \ldots ,d_{{N_{L} }}^{\left( L \right)} } \right.} \right] \) that do not contain any measurement errors. Learning vectors are constructed from Eqs. (1) or (11) for random values y 1, y 2, y 3 that lie within the set of permissible changes, and which is limited with values a and b [4, 12].
The test vector is built according to Fig. 3 for values y i that are not contained within the training set.

Construction of learning vectors
The neural network was built in a VBA environment in EXCEL.
The script associated with the button in Fig. 4 determines the random values: \( d_{1} = R_{s} \in \left\langle {0.005 \div 0.2} \right\rangle {\text{k}}\Upomega ,\quad d_{2} = L_{s} \in \left\langle {0.005 \div 0.5} \right\rangle {\text{H}},\quad d_{3} = E_{s} \in \left\langle {0.15 \div U} \right\rangle {\text{kV}} \).

The workbook that builds learning vectors

Further values U v , I a , P w and Q w are determined from Eq. (11).
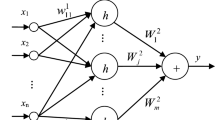
After tests of several neural networks, a decision was made to build a neural network with topology (Fig. 5), with one hidden layer. The weights of neurons are determined by back propagation.

Structure of the neural network
Individual neurons in the network are structured according to Fig. 6.

Diagram of neuron \( N_{i}^{(k)} \)
In the network being built, the following indications were accepted:
- t :
-
iteration step, t = 1, 2, …
- \( y_{i}^{(k)} (t) \) :
-
ith output of the neuron \( N_{i}^{(k)} \)
- \( y_{i}^{\left( L \right)} \left( t \right) \) :
-
ith output of the network
- k :
-
network layer, k = 1, …, L
- L :
-
network output layer, the number of network layers
- i :
-
neuron number in layer, i = 1,…, N k
- \( x_{j}^{(k)} (t) \) :
-
input signal in the kth layer
- \( x_{j} (t) = x_{j}^{(1)} (t) \) :
-
input of the network
- j :
-
number of the input signal in the kth layer, j = 1,…, N k−1
- N 0 :
-
number of inputs to the network
- N k :
-
number of neurons in the kth layer
- N L :
-
number of neurons in the last layer
- \( s_{i}^{(k)} (t) \) :
-
neuron membrane potential \( N_{i}^{(k)} \) in the kth layer
- \( w_{i,j}^{(k)} (t) \) :
-
weight of the jth input of the ith neuron \( N_{i}^{(k)} \) in the kth layer
- \( d_{i}^{(L)} (t) \) :
-
ith reference signal output from the learning vector
- \( \varepsilon_{i}^{(L)} (t) \) :
-
error of the ith network output, \( \varepsilon_{i}^{(L)} (t) = d_{i}^{(L)} (t) - y_{i}^{(L)} (t) \)
- η:
-
network learning rate
- Q(t):
-
error at the output of the network for one reference vector
- Q *(t):
-
error at the output of the network for the entire epoch
The output of neuron \( N_{i}^{(k)} \) (Fig. 6) at time t is described with the following relation:
while membrane potential \( s_{i}^{(k)} \) is equal to:
The input neuron for k = 1 layer is equal to network inputs \( x_{j} (t) = x_{j}^{(1)} (t) \). Each layer has one input \( x_{0}^{(k)} (t) = 1 \). Other inputs are the outputs of the previous layer.
The error at the output of the network for one learning vector σ is:
The weights of the individual neuron inputs are determined from the steepest descent rule:
where \( {\mathbf{g}}(w(t)) = \left[ {\begin{array}{*{20}c} {\frac{\partial Q\left( t \right)}{{\partial w_{1} \left( t \right)}},} & {\frac{\partial Q\left( t \right)}{{\partial w_{2} \left( t \right)}},} & {\frac{\partial Q\left( t \right)}{{\partial w_{3} \left( t \right)}},} & { \ldots ,} & {\frac{\partial Q\left( t \right)}{{\partial w_{n} \left( t \right)}}} \\ \end{array} } \right]^{T} \) is the vector gradient.
From Eq. (16), for any weight in any layer, the following is obtained:
Parameter \( \delta_{i}^{(k)} (t) \) is determined differently than for the output layer and the hidden layer:
where \( \varepsilon_{i}^{(L)} (t) = d_{i}^{(L)} (t) - y_{i}^{(L)} (t). \)
Network training is carried out by an incremental updating of weights, that is, each time after the entry of a successive learning vector, responses are determined and the weights are modified. The simulation is continued until the total output error for entire epoch Q *(t) is smaller than the accepted set Q min.
where M is the number of learning vectors in the epoch.
The neuron activation function was adopted as a continuous unipolar function of the signum type:
where β is the steepness factor.
With low values of coefficient β, the function is usually mild. By increasing β, the plot becomes steeper until the threshold course is obtained.
The derivative of the activation function is as follows:
The calculation sheet in Fig. 7 allows an observation of the characteristic values of the network tested. Starting of the network training produces a script written in VBA that executes in a loop of a neural network algorithm according to (12) ÷ (21) and the block diagram in Fig. 8.

Sheet for the visualization of the network operation

Block diagram of the network learning algorithm
The start of the algorithm is possible for the weights that are selected at random from range \( \left\langle { - 1,\,1} \right\rangle \) or the reading stored from the previous simulations (Fig. 9).

The reading window of the recorded data
4 Learning of the network
The set of learning vectors that form one epoch consists of 200 elements. Owing to the ability to read and write data, it is possible to pause the simulation and to change its parameters during operation [4, 12].
Reading of the stored data allows a continuation of the previously stopped simulation. The window in Fig. 9 retrieves the values from the appropriate data sheet (Fig. 10).

Sheet with the saved results of the simulation
The output values of the neurons (Fig. 8a) are determined by analyzing the neurons in layers starting from the input layer; the output layer comes last.

For all the layers, the steepness factor β (20) of activation function fx was assumed as equal to 0.1.
The determination of value \( \delta_{i}^{(k)} (t) \) (Fig. 8b) shall be in accordance with Formula (18). This determination takes place starting from the output layer; the input layer comes last.

Correction of the values of weights (Fig. 8c) is carried out according to Relation (17).

Network learning factor η from Formula (17) was adopted on the first stage of the simulation as being constant and equal to 0.1. After an analysis of ca. 70,000 epochs, the value of target function Q *(t), which was calculated in accordance with Formula (19), began to oscillate on the level of 1.42. A decrease in Q *(t) occurred only after a reduction in network learning rate η. The correct procedure for the network training should provide for an ability to change this ratio during the analysis (Fig. 11).

The method to reduce the coefficient of network learning
Oscillations around the optimal solution are manifested with a momentary increase in the value of Q *(t).
Once the required value of Q *(t) from Eq. (19) has been reached, the network test is performed (Fig. 12).

The window for testing and results analysis
5 Network test
The network test consists in determining the values of U V , I a , P W , and Q W from Relation (11). These values are then substituted into the neural network input, whose solution is R S , L S , and E S . The window in Fig. 12 also allows a determination of the network’s solution for a selected set of weights.
Table 1 illustrates the network test for randomly selected values of R S , L S , and E S .
The relative error for all the output neurons for the randomly adopted input vectors is:
The total network error for the accepted values of R S , L S , and E S are:
The percentage error made by the network is determined from the largest error (the top bar in the chart in Fig. 13), and it is equal to 26.8 %.

Mistake made by the network
6 Conclusions
The large error value is shown for the input values that occur least frequently in the training set. An improved performance is possible by enlarging the training set or by reducing the range of acceptable changes of the values being sought.
Owing to the method presented of the selection of the electrical model parameters from the values that are measured on the receiver, it is not required to build any complex physical and electrical dependences. The engineering method of voltage, current, and power measurement allows one to determine the parameters of the model for constant electrical and mechanical conditions in the engine. The method presented is particularly useful in situations where measurement errors make it impossible to solve Eq. (2).
Building of a network with the use of the VBA environment is relatively simple. It requires the knowledge of the language basics. An important advantage of this approach is the ability to build its own networks of any topology. The design loop iteration depends largely on how one defines those variables that describe the network.
In the present solution, the individual variables occupy adjacent bytes of the memory. A sample definition of the variable holding the weights of neurons is:
where Lweights is the number of weights of all neurons.This solution facilitates the construction of a loop program, but special attention is to be paid to assigning the weight number with the neuron number.
An alternative is to build one’s own variable (using the opportunity to build one’s own type of variables) that represents the neuron, and then group all the parameters that describe the type of the neuron in this variable. This approach will make the program more transparent, but there are problems in the construction of iterative loops. This will make the source code longer and will require more CPU load.
References
Duer S (2009) Artificial neural network-based technique for operation process control of a technical object. Def Sci J 59(3):305–313. http://publications.drdo.gov.in/ojs/index.php/dsj
Duer S (2010) Diagnostic system with an artificial neural network in diagnostics of an analogue technical object. Neural Comput Appl 19(1):55–60
Duer S (2010) Diagnostic system for the diagnosis of a reparable technical object, with the use of an artificial neural network of RBF type. Neural Comput Appl 19(5):691–700
Duer S, Duer R (2010) Diagnostic system with an artificial neural network which determines a diagnostic information for the servicing of a reparable technical object. Neural Comput Appl 19(5):755–766
Duer S (2010) Investigation of the operation process of a repairable technical object in an expert servicing system with an artificial neural network. Neural Comput Appl 19(5):767–774
Duer S (2011) Qualitative evaluation of the regeneration process of a technical object in a maintenance system with an artificial neural network. Neural Comput Appl 20(5):741–752
Duer S (2010) Expert knowledge base to support the maintenance of a radar system. Def Sci J 60(5):531–540. http://publications.drdo.gov.in/ojs/index.php/dsj
Duer S (2011) Modelling of the operation process of repairable technical objects with the use information from an artificial neural network. Expert Syst Appl 38:5867–5878. http://dx.doi.org/10.1016/j.eswa.2010.11.036
Duer S (2011) Assessment of the quality of decisions worked out by an artificial neural network which diagnoses a technical object. Neural Comput Appl. doi:10.1007/s00521-011-0725-0. http://www.springerlink.com/openurl.asp?genre=article&id
Duer S (2011) Examination of the reliability of a technical object after its regeneration in a maintenance system with an artificial neural network. Neural Comput Appl. doi:10.1007/s00521-011-0723-2. http://www.springerlink.com/openurl.asp?genre=article&id
Duer S (2011) Applications of an artificial intelligence for servicing of a technical object. Neural Comput Appl. doi:10.1007/s00521-011-0788-y
Duer S (2012) Artificial neural network in the control process of object’s states basis for organization of a servicing system of a technical objects. Neural Comput Appl 21(1):153–160
Gacek Z (1999) Technika wysokich napiec. Izolacja wysokonapieciowa w elektroenergetyce. Przepiecia i ochrona przed przepieciami. Skrypt uczelniany nr 2137 wyd.III. Wydawnictwo Politechniki Slaskiej, Gliwice (in polish)
Zajkowski K (2004) Algorytm do rozwiazywania ukladow rownan z danymi obarczonymi bledami pomiarowymi. In: Conference on computer applications in electrical engineering, T.II, IEP Politechniki Poznanskiej, pp 499–502(in polish)
Zajkowski K (2009) Analysis of overvoltages on inductive system with varistor and capacitor. Poznan University of Technology, Academic Journals Issue 59 2009, Electrical Engineering, Publication by Poznan University of Technology, pp 87–97
Zajkowski K (2011) (monograph) Analiza stanu nieustalonego w obwodach rezystancyjno-indukcyjnych w aspekcie minimalizacji przepiec komutacyjnych. Wydawnictwo Uczelniane Politechniki Koszalinskiej, Koszalin (in polish)
Open Access
This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Zajkowski, K. The method of solution of equations with coefficients that contain measurement errors, using artificial neural network. Neural Comput & Applic 24, 431–439 (2014). https://doi.org/10.1007/s00521-012-1239-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-012-1239-0