
Abstract
This paper proposes an enhancement to the Harris’ Hawks Optimisation (HHO) algorithm. Firstly, an enhanced HHO (EHHO) model is developed to solve single-objective optimisation problems (SOPs). EHHO is then further extended to a multi-objective EHHO (MO-EHHO) model to solve multi-objective optimisation problems (MOPs). In EHHO, a nonlinear exploration factor is formulated to replace the original linear exploration method, which improves the exploration capability and facilitate the transition from exploration to exploitation. In addition, the Differential Evolution (DE) scheme is incorporated into EHHO to generate diverse individuals. To replace the DE mutation factor, a chaos strategy that increases randomness to cover wider search areas is adopted. The non-dominated sorting method with the crowding distance is leveraged in MO-EHHO, while a mutation mechanism is employed to increase the diversity of individuals in the external archive for addressing MOPs. Benchmark SOPs and MOPs are used to evaluate EHHO and MO-EHHO models, respectively. The sign test is employed to ascertain the performance of EHHO and MO-EHHO from the statistical perspective. Based on the average ranking method, EHHO and MO-EHHO indicate their efficacy in tackling SOPs and MOPs, as compared with those from the original HHO algorithm, its variants, and many other established evolutionary algorithms.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Multi-objective optimisation problems (MOPs) need to consider more than one conflicting objective simultaneously, and they are ubiquitous in many real-world engineering applications. Unlike single-objective optimisation problems (SOPs), MOPs are more challenging and difficult to solve because the objectives in MOPs are often conflicting and/or incommensurable with each other, and improvement of one objective deteriorates other objectives. Hence, finding a set of equally-optimal solutions, i.e. the Pareto optimal set (PS), is necessary, since there is no single solution that can fulfill all objectives simultaneously (Akbari et al. 2012; Li et al. 2011).
Evolutionary algorithms (EAs) have become popular in recent years, mainly due to their population-based search capabilities that can approximate the PS. The applicability of EAs, however, is not always as good as that of other metaheuristics (Khan et al. 2016, 2019). Metaheuristic algorithms are flexible and easy to implement for solving SOPs and MOPs because they do not rely on gradient information of the objective landscape. While metaheuristic algorithms have been widely used to tackle various SOPs and MOPs, one key limitation is that the user-defined parameters of each metaheuristic algorithm require accurate tuning to realise its full potential. Another downside is the slow or premature convergence towards the global optimum solution (Talbi 2009; Heidari et al. 2019).
Two main types of metaheuristic algorithms are single solution-based and population-based models. Simulated Annealing (SA) (Van Laarhoven and Aarts 1987) and Variable Neighbourhood Search (VNS) (Mladenović and Hansen 1997) are examples of single solution-based metaheuristics, while Genetic Algorithm (GA) (Holland 1992b) and Differential Evolution (DE) (Price 1996; Storn and Price 1997) are examples of population-based metaheuristics (p-metaheuristic) (Talbi 2009). Single solution-based metaheuristics methods only solve one solution at a time during the optimisation process, while p-metaheuristics methods process a set of solution in each iteration. As expected, p-metaheuristics methods are more efficient than single solution-based metaheuristic and can often find an optimal solution, or suboptimal solutions that are located in the neighbourhood of the optimal solution space. By maintaining a population of solutions, these algorithms can avoid local optima and explore new regions of the search space.
Heidari et al. (2019) presents the four main types of p-metaheuristics methods, namely EAs, physics-based, human-based, and swarm intelligence (SI) models. The first types of p-metaheuristics methods are EAs. GA and DE are the most popular EAs, and many enhancements have been introduced (Holland 1992b; Price 1996). The algorithms use a variety of operators, such as mutation, crossover, and selection in the GA, to generate new solutions and improve the quality of the population. The search process involves the evaluation of multiple solutions simultaneously, and the selection of a pool of good solutions for the next generation. Genetic Programming (GP) and Biogeography-Based Optimiser (BBO) are other examples of EAs (Kinnear et al. 1994; Simon 2008). The physics-based metaheuristics methods include Big-Bang Big-Crunch (BBBC) (Erol and Eksin 2006), Central Force Optimisation (CFO) (Formato 2007) and Gravitational Search Algorithm (GSA) (Rashedi et al. 2009).
As the name suggests, these metaheuristics methods are based on the physics principles of a system. Human-based metaheuristics methods imitate human behaviours such as Teaching Learning-Based Optimisation (TLBO) (Rao et al. 2011), Tabu Search (TS) (Glover and Laguna 1998) and Harmony Search (HS) (Geem et al. 2001). SI algorithms have been the current trend for solving MOPs. SI algorithms are generally based on the social behaviours of organisms and social interactions of the population, e.g. the Particle Swarm Optimisation (PSO) algorithm that simulates the bird clustering behaviours (Kennedy and Eberhart 1995).
Recently, many new nature-inspired SI models have been proposed, such as Grey Wolf Optimisation (GWO) algorithm (Mirjalili et al. 2014), Whale Optimisation Algorithm (WOA) (Mirjalili and Lewis 2016), Grasshopper Optimisation Algorithm (GOA) (Mirjalili et al. 2018), Moth-flame optimisation (MFO) (Mirjalili 2015), Artificial Bee Colony (ABC) (Karaboga and Basturk 2008), and Harris’ Hawk Optimisation (HHO) (Heidari et al. 2019). The general procedure of these SI models can be summarised as follows:
-
Generate a set of individuals (population), where each individual represents a solution
-
Each individual in the population is updated using a metaheuristic algorithm
-
The newly generated population replaces the current population on an iterative manner
The above procedure continues for every iteration until a termination condition is satisfied, e.g. the maximum number of iterations. In accordance with the ’no free lunch’ theorem (NFL), there is no universal optimisation methods for solving all possible problems (Wolpert and Macready 1997). Many new optimisation methods and their enhanced variants have been introduced, since no single algorithm is effective for solving all classes of optimisation problems.
SI models have been used to solve various optimisation problems in different fields. Nonetheless, there is room for further research to improve their performance and extend their applications. Several enhancements of metaheuristic algorithms have been proposed to improve the efficiency of an algorithm. In general, four categories of enhancements are: (i) hybrid metaheuristic algorithms, (ii) modified metaheuristic algorithms, (iii) integration with chaos theory, and (iv) multi-objective metaheuristic algorithms. Note that hybrid metaheuristic algorithms integrate two or more algorithms for performance enhancement, while modified metaheuristic algorithms change the search process to improve the performance of an algorithm.
One major problem of all metaheuristic algorithms is pre-mature convergence and local optima, particularly in large-scale optimisation problems. Hybrid metaheuristic algorithms are used to solve optimisation problems with more efficient characteristics and with higher flexibility (Bettemir and Sonmez 2015; Li and Gao 2016). The GA and SA models are useful stochastic search algorithms for solving combinatorial optimisation problems. GA has been developed based on the principle of the survival-of-the-fittest and natural selection principles while SA is inspired by the physical process of annealing (Kirkpatrick et al. 1983; Van Laarhoven and Aarts 1987; Holland 1992a). SA often is coupled with GA to avoid local optima by irregularly allowing the acceptance of non-improving solutions. Hybrid Genetic Algorithm and Simulated Annealing (HGASA) is good at tackling optimisation problems, such as project scheduling with multiple constraints and railway crew scheduling (Chen and Shahandashti 2009; Hanafi and Kozan 2014; Bettemir and Sonmez 2015). Leveraging the capability of DE in searching for good and diverse solutions, many researchers have proposed integration of DE and other p-metaheuristics algorithms. Wang and Li (2019) enhanced the solution diversity by combining DE and GWO. An adaptive DE model was combined with GOA for multi-level satellite image segmentation (Jia et al. 2019). The resulting hybrid algorithm was evaluated with a series of experiments using satellite images, demonstrating search efficiency and population diversity.
Modification methods in metaheuristic algorithms refer to the process of changing the search process to improve the performance of an algorithm. One such method is the use of local search techniques to improve the solution quality. Local search techniques involve searching the local neighbourhood of a solution to find a better solution. Another modification method is the use of diversity mechanisms to prevent an algorithm from converging prematurely. Diversity mechanisms involve maintaining a diverse population of solutions to explore different regions of the search space. As an example, Gao et al. (2008) employed a logarithm decreasing inertia weight and chaos mutation with PSO to improve the convergence speed and diversity of solutions. In Gao and Zhao (2019), a variable weight was assigned to the leader of grey wolves, and a controlling parameter was introduced to decline exponentially and alter the transition pattern between exploration and exploitation. Moreover, Xie et al. (2020) enhanced GWO by integrating a nonlinear exploration factor to increase exploration in the early stage and improve exploitation in the second half of the search process.
This paper proposes enhancements to the HHO algorithm. Specifically, the nonlinear exploration factor, DE scheme, chaos strategy, and mutation mechanism from EAs are leveraged, leading to the proposed enhanced HHO (EHHO) model and its extension to multi-objective EHHO for solving SOPs and MOPs, respectively. A nonlinear exploration factor is introduced to replace the linear exploration factor in the original HHO algorithm. This nonlinear exploration factor aims to improve the exploration capability in the early search stage and facilitate the transition from exploration to exploitation. The DE scheme is then used to generate new, diverse individuals through mutation, crossover and selection. A chaos strategy is adopted to replace the DE mutation factor, in order to increase the randomness and find more valuable search areas. In MO-EHHO, a mutation mechanism is introduced to increase diversity of individuals in the external archive. The fast non-dominated sorting and crowding distance techniques from NSGA-II are also employed to select the optimal solution in each iteration and to maintain diversity of the non-dominated solutions.
Benchmark SOPs and MOPs are used to evaluate the effectiveness of EHHO and MO-EHHO (Yao et al. 1999; Digalakis and Margaritis 2001). The benchmark suite of SOPs includes the following tasks: unimodal (UM) functions F1–F7, multimodal (MM) functions F8–F23, and composition (CM) functions F24–F29. On the other hand, MO-EHHO is applied to tackling high-dimensional bi-objective problems without equality or inequality constraints and scalable tri-objective problems without equality or inequality constraints for performance evaluation. These include ZDT benchmark functions (ZDT1-4,6) (Deb et al. 2002; Deb and Agrawal 1999) and DTLZ benchmark functions (DTLZ1-DTLZ7) (Deb et al. 2005). The statistical sign test with a 95% confidence level is used for performance comparison. Four performance indicators are used, namely convergence, diversity, generational distance (GD), and inverted generational distance (IGD). The average ranking method (Yu et al. 2018) is leveraged to rank the performance of MO-EHHO against its competitors on each performance indicator.
This study introduces enhanced HHO-based models for solving SOPs snd MOPs. The organisation of this paper is as follows. In Sect. 2, a review on HHO, chaos theory, and DE is provided. In Sect. 3, the HHO algorithm and the proposed enhancements, namely EHHO and MO-EHHO, are explained in detail. The effectiveness of EHHO and MO-EHHO for solving SOPs and MOPs is evaluated, compared, analysed and discussed in Sect. 4. Concluding remarks and suggestions for future work are presented in Sect. 5.
2 Literature review
This section provides the concepts of multi-objective optimisation and current methods in meta-heuristics for solving MOPs.
2.1 Harris’ Hawks optimisation algorithm
Proposed by Heidari et al. (2019), the HHO algorithm is a swarm-based, nature-inspired metaheuristic model. It imitates the collaboration behaviours of Harris’ hawks working together to search and chase for a prey in different directions. A variety of hunting strategies are performed by Harris’ hawks based on the prey’s escaping energy. The mathematical model pertaining to the behaviours of Harris’ hawks are formulated for solving optimisation problems. The HHO algorithm has received extensive interest from researchers due to its effectiveness and fast convergence speed; however, the HHO algorithm suffers from the following problems:
-
1.
greatly affected by the tuning parameters;
-
2.
weak transition between exploration and exploitation;
-
3.
easily fall into local optima;
-
4.
poor convergence for high-dimensional problems and multimodal problems; and
-
5.
limited diversity of the solutions.
Enhancements of HHO have been proposed, e.g. hybridisation of HHO, modification of HHO and chaotic HHO (Alabool et al. 2021). Hybridisation is a popular method to improve the performance of an algorithm. HHO has been integrated with other optimisation methods to find the solution faster, avoid falling into local optima, provide better solution quality, and improve algorithm stability (Chen et al. 2020a; Gupta et al. 2020; Ewees and Abd Elaziz 2020). Chen et al. (2020a) integrated the DE algorithm and a multi-population strategy into HHO to overcome its convergence issue and prevent HHO from being trapped in local optima. In addition, opposition-based learning was applied to HHO by Gupta et al. (2020) to reduce the number of opposite solutions and increase the convergence speed. HHO has also been used to improve the performance of other algorithms, e.g. accelerating the search process of multi-verse optimisation (MVO) and maintaining the MVO population (Ewees and Abd Elaziz 2020).
Other HHO modifications include improving the convergence speed, increasing the population diversity, and enhancing the transition from exploration to exploitation (Alabool et al. 2021). HHO was integrated with a chaotic map to improve the balance between exploration and exploitation (Zheng-Ming et al. 2019; Qu et al. 2020). Specifically, Zheng-Ming et al. (2019) used a tent map in the exploration phase to identify the optimal solution rapidly, while Qu et al. (2020) employed a logistic map in the escaping energy factor to balance global exploration and local exploitation. The use of HHO for solving MOPs was investigated in Islam et al. (2020) and Jangir et al. (2021). Table 1 summarises the main enhancement methods of HHO.
2.2 Differential evolution (DE)
Introduced by Price (1996) and Storn and Price (1997), DE is well-known for its simplicity, fewer control parameters and superior performance in optimisation. Storn and Price (1997) employed DE to solve global optimisation problems. However, one major problem of all metaheuristics algorithms is the potential of early convergence and local optima. Leveraging on DE’s capability in finding better and diverse solutions, many researchers have proposed integration of DE and other p-metaheuristics algorithms. As an example, Wang and Li (2019) enhanced the solution diversity by integrating DE and the GWO algorithm. An adaptive DE was combined with GOA by Jia et al. (2019) for multi-level satellite image segmentation. The hybrid algorithm was evaluated with a series of experiments using satellite images. It was able to increase search efficiency and population diversity through iterations. In addition, hybrid models of DE and HHO can elevate the performance of the original HHO algorithm. Birogul (2019) introduced HHODE, which blends HHO and DE, which uses mutation operators from DE to harness its exploration strengths. The hybridisation manages to strike a balance between exploratory and exploitative tendencies. It was tested on an altered IEEE 30-bus test system for optimal power flow problem and proved to be more effective than other optimisation algorithms. Besides, DE is used by Chen et al. (2020a) in HHO to boost its local search capability and exploit the DE operations, such as mutation, crossover and selection, to discover better and more diverse solutions. A new HHO variant was introduced by Islam et al. (2020) to solve the power flow optimisation problem. Multiple researchers conducted studies to demonstrate hybridisation of DE with HHO for improving the HHO performance. Table 1 summarises the main publications in this topic (Birogul 2019; Bao et al. 2019; Wunnava et al. 2020; Abd Elaziz et al. 2021; Abualigah et al. 2021; Liu et al. 2022). In short, DE is useful for maintaining a more diverse and quality individual without losing the convergence speed in HHO.
2.3 Chaos theory
Chaos theory helps enhance the population diversity and cover wider search areas that an algorithm may miss. As mentioned before, HHO has a poor changeover from exploration to exploitation; hence, its susceptibility to local optima. Besides, HHO exhibits a poor performance in tackling high-dimensional and multimodal problems. In this respect, chaos theory is often applied to an optimisation algorithm to enhance their global search capability (Ewees and Abd Elaziz 2020; Chen et al. 2020b; Liu et al. 2020; Dhawale et al. 2021; Hussien and Amin 2022). A variety of chaotic maps are available: Chebyshev, circle, intermittency, iterative, Leibovich, logistic, piecewise, sawtooth, sine, singer, sinusoidal and tent map. Researchers popularly use logistic and tent maps to improve the HHO performance (Zheng-Ming et al. 2019; Menesy et al. 2019; Chen et al. 2020a). Chen et al. (2020a) introduced chaotic sequence into the escaping energy of the rabbit in HHO to enhance the global searchability and cover broader search areas. A chaotic map was incorporated into the adaptive mutation strategy and integrated into the external archive by Liu et al. (2020) to attain a set of diverse non-dominated solutions. Moreover, Xie et al. (2020) employed a chaotic strategy to assign weights for the leader wolf in GWO to increase the diversity of the leader wolves. Barshandeh and Haghzadeh (2021) integrated a chaos strategy to initialise the population and improve the solution diversity, allowing a larger search space to be covered. Table 1 Chaos shows the key publications on the use of chaos theory for improvement of the HHO algorithm.
2.4 Multi-objective optimisation
MOPs are similar to SOPs in terms of problem definition, but with multiple objective functions that cannot be efficiently solved by a single-objective algorithm. A set of equilibrium solutions exists for solving an MOP, i.e. a set of non-inferior solutions or Pareto optimal solutions (Fonseca and Fleming 1998). An MOP can be formulated as follows:
where n is the number of design variables, o is the number of objective functions, r is the number of inequality constraints, s is the number of equality constraints, \(g_{j}\) and \(h_{j}\) are the j-th inequality and equality constraints, respectively, and \(Lb_{i}\) and \(Ub_{i}\) are the lower and upper bounds of the i-th design variables.
In a single-objective function, solution \(\mathbf {x_1}\) is better than \(\mathbf {x_2}\) if \(f(\mathbf {x_1}) < f(\mathbf {x_2})\); however, this definition cannot be used in a MOP that has two or more objective functions. Using the Pareto dominance concept in solving MOP, solution \(\mathbf {x_1}\) is better than (dominates) \(\mathbf {x_2}\) if all objective functions \(f(\mathbf {x_1}) < f(\mathbf {x_2})\) (Fonseca and Fleming 1998). Two solutions are denoted as non-dominated if, for at least one objective function, but not all of them, \(f(\mathbf {x_1}) \nless f(\mathbf {x_2})\).
Recently, p-metaheuristics algorithms have been utilised to solve MOPs due to their population-based search capabilities in yielding multiple solutions in a single run. The Pareto dominance concept is used to determine the PS. Most p-metaheuristics algorithms employ non-dominated ranking and Pareto strategy to ensure the diversity of PS. Several useful p-metaheuristics algorithms that store the best PS when there are multiple optimum solutions are: NSGA-II (Deb et al. 2002), SPEA2 (Zitzler et al. 2001), and MOPSO with an archive (Coello et al. 2004). Mirjalili et al. (2016) discussed several multi-objective p-metaheuristics algorithms, such as multi-objective grey wolf optimiser (MOGWO) (Mirjalili et al. 2016), multi-objective ant lion optimiser (MOALO) (Mirjalili et al. 2017b), multi-objective multi-verse optimisation (MOMVO) (Mirjalili et al. 2017a) and multi-objective grasshopper optimisation algorithm (MOGOA) (Mirjalili et al. 2018), to solve MOPs. Jangir and Jangir (2018) embedded the non-dominated sorting into GWO to solve several multi-objective engineering design problems and apply it to a constraint multi-objective emission dispatch problems with economic constrained and integration of wind power. Liu et al. (2020) modified a MOGWO with multiple search strategies to solve MOPs. Hence, this paper extended the EHHO to a multi-objective EHHO that incorporated the non-dominated sorting from NSGA-II to sort and rank the non-dominated solution by calculating the crowding distance between solution sets to ensure a diverse PS. An external archive with a mutation strategy is utilised to diversify the obtained PS.
3 The proposed enhanced Harris’ Hawk optimiser
3.1 Harris’ Hawk optimisation

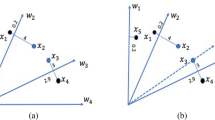
Different stages of HHO (Heidari et al. 2019)
HHO was originally proposed by Heidari et al. (2019) to solve SOPs. It mimics the hunting strategy of harris’ hawks, focusing on their "surprise pounce" and "seven kills" to catch a prey (e.g. a rabbit). The hawks collaborate with each other in chasing or attacking the prey, and change their attack mode dynamically based on the escaping pattern of the prey. The hawk’s behaviour is modelled in three main stages: exploration, the transition from exploration to exploitation, and exploitation. Figure 1 presents the different stages of HHO, while the pseudocode of the HHO algorithm is presented in Algorithm 1.
The HHO algorithm begins by initialising a fixed number of randomised individuals (population), in which every individual represents a candidate solution. The individuals are random within the lower and upper boundaries of the problems. The fitness value of each individual is calculated every iteration until the stopping criteria are satisfied.
The key mathematical formulation of each HHO stage is as follows:
- \({\textbf {Exploration stage:}}\):
-
$$\begin{aligned}{} & {} X(t+1)= {\left\{ \begin{array}{ll} X_\textrm{rand}(t)-r_1 |X_\textrm{rand}(t)\\ -2r_2X(t) |&{} q \ge 0.5\\ (X_\textrm{rabbit}(t)-X_m(t))\\ -r_3(LB+r_4(UB-LB))) &{} q < 0.5 \end{array}\right. }\nonumber \\ \end{aligned}$$(2)$$\begin{aligned}{} & {} X_m(t+1)=\frac{1}{N} \sum _{i=1}^{N} X_i(t) \end{aligned}$$(3)
- \({\textbf {Transition stage:}}\):
-
$$\begin{aligned}{} & {} e = 2 (1-\frac{t}{T}) \end{aligned}$$(4)$$\begin{aligned}{} & {} E_0 = 2rand()-1 \end{aligned}$$(5)$$\begin{aligned}{} & {} E = E_0 \times e \end{aligned}$$(6)
Exploitation stage: Soft besiege (\(r \ge 0.5 \text {and} |E |\ge 0.5\))
Hard besiege (\(r \le 0.5\) and \(|E |< 0.5\))
Soft besiege with progressive rapid dives(\(r < 0.5\) and \(|E |\ge 0.5\))
Hard besiege with progressive rapid dives (\(r < 0.5\) and \(|E |\le 0.5\))
where \(X(t+1)\) is the position vector of an individual in the next iteration t, \(X_\textrm{rabbit}(t)\) is the best position of a prey, X(t) is the current position of the individual, \(X_\textrm{rand}(t)\) is the random position of the individual, \(X_m(t)\) is the average position of the population, \(r_1\),\(r_2\), \(r_3\), \(r_4\), \(r_5\), q, v and \(\beta \) are random factors within [0,1], while LB and UB are the lower and upper bounds of the search space, respectively. In addition, E denotes the escaping energy of the prey, \(E_0\in (-1,1)\) is the initial state of the prey’s energy, \(e\in (2,0)\) is the exploration factor, and T is the maximum number iterations (e.g. 100 iterations). Besides, J is the jumping strength of the prey and \(\Delta X(t)\) denotes the difference between the position of an individual with the best position of the prey, while LF, D and S represent the dimensions of the search space (Heidari et al. 2019; Chen et al. 2020a). The detailed processes of the original HHO algorithm are shown in Algorithm 1 (Heidari et al. 2019).

Harris’ Hawk Optimiser
3.2 Nonlinear exploration factor
A nonlinear exploration factor is introduced to replace the linear version from the original HHO algorithm. In the HHO algorithm, the exploration factor, e controls the transition pattern from exploration to exploitation as defined in Eq. (4), which decreases linearly from 2 to 0, resulting in an acute shrinkage of the search space and insufficient search attention. Multiple studies in the literature have explored adaptive control of diverse search operations to improve the conversion between exploration and exploitation. Trigonometric (Mirjalili 2016; Gao and Zhao 2019), exponential (Mittal et al. 2016; Long et al. 2018a), and logarithmic-based functions (Gao et al. 2008; Long et al. 2018b) functions are useful for controlling the exploration factor nonlinearly. In this research, we use a nonlinear exploration factor proposed by Xie et al. (2020), which is a combination of the trigonometric functions, i.e. cos and sin, and a hyperbolic function, i.e tanh. This nonlinear exploration factor aims to amplify the diversification capabilities in the early exploration phase and smoothen the changeover from exploration to exploitation. The proposed nonlinear exploration factor and newly proposed escaping energy are defined as follows:
where \(e'\) is the newly proposed exploration factor to govern the switch between exploration to exploitation, t and Max\(_\textrm{iter}\) are the current iteration and maximum iteration of each iteration, respectively. Coefficient k controls the descending slope of the exploration factor, \(e'\), while \(k = 5\) is adopted, as used in Xie et al. (2020). The new exploration factor and escaping energy descending pattern are presented in Fig. 2a, b, respectively. As shown in Fig. 2a, the proposed nonlinear exploration factor decreases with a descending slope. The first half of the search path has a more effective exploration rate, while the second half has a lower exploration rate. The search space is significantly expanded in the first half, which helps EHHO to focus on exploration and finish the search with exploitation.

Proposed enhancements of the exploration and exploitation of EHHO
3.3 Differential evolution (DE)
Developed by Price (1996), Storn and Price (1997), DE is a robust yet straightforward EA for optimising real-valued, multi-modal functions. DE is utilised in EHHO to enhance its searchability and solution quality. Three primary processes exist in DE, namely mutation, crossover and selection (Price 1996; Storn and Price 1997). They are described in the following subsection.
3.3.1 Mutation
Following the DE process, three random solutions are selected from the population for mutation. A constant mutation factor is applied to the difference between two individuals. The third individual is combined with the mutated difference vector to produce a new individual, as follows:
where \(X_{r1}\), \(X_{r2}\), \(X_{r3}\) are three random solutions selected from the population, \(V_i\) is the new individual, F is the mutation factor \(\in [0.5,1]\), which is generated by a sinusoidal mapping defined in Eq. (22). The sinusoidal mapping is a chaotic sequence, as shown in Fig. 3. In accordance with chaos theory, a chaotic sequence has three important features, i.e. its initilisation condition, ergodicity, and randomness. The chaotic mutation factor can avoid local optima and premature convergence by exploiting randomness of the chaotic sequence.

A sinusoidal chaotic map is used in the DE mutation factor
3.3.2 Crossover
The crossover operation is modelled as follows:
where \({\text {rand}}_j\) is randomised between [0, 1] and Cr is the crossover ratio. The solution from the mutation process will replace the current solution if Cr is higher than \({\text {rand}}_j\) in Eq. 23. The \(Cr_l\) and \(Cr_u\) are the lower and upper boundaries of Cr.
3.3.3 Selection
The selection operation is modelled as follows:
where \(X_ {i,g} \) is the original individual, \(U_{i,g}\) is the individual from crossover, and \(X_{i,g+1}\) is the new individual for the next iteration. Following crossover, DE determines the solution using equation 25. In this regard, f is the fitness function before and after mutation and crossover. The new solution with lower fitness value will replace the current solution with higher fitness lower in a minimisation problem.
3.4 EHHO for multi-objective optimisation
3.4.1 Mutation strategy
A mutation strategy is employed in the external archive to increase the chance of generating better non-dominated solutions when the mutation probability is smaller than the mutation factor. An adaptive mutation factor is applied and modelled as follows:
where \(m_l\) and \(m_u\) are the lower and upper boundaries of the mutation factor (m). Generally, \(m_l=0.1\) and \(m_u=0.9\). A set of new solutions is obtained after the mutation operation is completed (Fig. 4).

Flowchart of the proposed multi-objective enhanced Harris’ Hawks Optimiser (MO-EHHO)
3.4.2 External archive
Zhang and Sanderson (2009) proposed an adaptive DE algorithm with an optimal external archive to solve MOPs. The external archive is a solution set, Arc, that acts as a storage unit to keep historical PS obtained from each iteration. When a new and better solution is found, the existing solution is replaced by the new non-dominated solution. Moreover, other non-dominated solutions are removed based on the crowding distance when the maximum capacity q is reached. Note that q is denoted as the maximum number of solutions can be stored in the external archive, which has the same size of that of the population.
3.4.3 Fast non-dominated sorting
The fast non-dominated sorting method is integrated into the multi-objective p-metaheuristics algorithm for finding non-dominated solutions. Developed by Deb et al. (2002), it is used to sort the Pareto optimal solutions according to their degree of dominance in NSGA-II. The non-dominated solution is assigned as rank 1, the solution that is dominated by only one solution is assigned as rank 2, and so on. The solutions are chosen based on their ranks, in order to preserve quality of the solution base.
3.4.4 Crowding distance
The crowding distance is computed as follows (Deb et al. 2002):
where q is the size of solution set, \(i\in q\). n is the number of objectives; \({\text {obj}}_j (S_ i+1)\) is the value of the jth objective of solution \(S_i\), and \({\text {obj}}_j^\text {max}\) and \({\text {obj}}_j^\text {min}\) are the maximum and minimum values of the jth objective of the solution set. Specifically, the crowding distance is the distance between two adjacent solutions on the same front; the larger the crowding distance, the closer the two adjacent solutions.

Multi-objective Enhanced Harris’ Hawk Optimiser
4 Experimental results and analysis
4.1 Evaluation with single-objective optimisation problems
4.1.1 Experimental setup and compared algorithms
A set of diverse benchmark problems (Yao et al. 1999; Digalakis and Margaritis 2001) is used to evaluate the proposed EHHO algorithm. The benchmark suite includes the following problems: unimodal (UM) functions F1–F7, multimodal (MM) functions F8–F23, and composition (CM) functions F24–F29. The UM functions evaluate the exploitative capabilities of optimisers with respect to their global best. The MM functions are designed to assess the diversification or exploration capabilities of optimisers. The characteristic and mathematical formulation of the UM and MM functions are presented in Tables 22, 23 and 24 in the Appendix. The CM functions are selected from the IEEE CEC 2005 competition (García et al. 2009), which include rotated, shifted and multi-modal hybrid composition functions. Details of the CM functions are presented in Table 25 in the Appendix. These functions are beneficial to investigate the interchange from exploration to exploitation and the capabilities of an optimiser in escaping from the local optima of an optimiser.
EHHO is implemented in Python and executed on a computer with Windows 10 64-bit professional and 16 GB RAM. The population size and maximum iterations of EHHO are set to 30 and 500, respectively, as proposed in the original HHO (Heidari et al. 2019) and HHODE (Birogul 2019). The EHHO results are documented and compared with other algorithms across the average performance over 30 independent runs. The results of other algorithms are extracted from the original HHO publication (Heidari et al. 2019) and HHODE publication (Birogul 2019). The average (AVG) and standard deviation (STD) of EHHO are compared with those of the following algorithms: GA (Simon 2008), BBO (Simon 2008), DE (Simon 2008), PSO (Simon 2008), FPA (Yang et al. 2014), GWO (Mirjalili et al. 2016), BAT (Yang and Gandomi 2012), FA (Gandomi et al. 2011), CS (Gandomi et al. 2013), MFO (Mirjalili 2015), TLBO (Rao et al. 2012) and DE (Simon 2008). These include commonly utilised optimisers, such as GA, DE, PSO and BBO, and also newly emerged optimisers such as FPA, GWO, BAT, FA, CS, MFO and TLBO. Additionally, EHHO is compared with a modified version of HHO, i.e. HHODE, from Birogul (2019).
A statistical hypothesis test, i.e. the non- parametric sign test at the 95% confidence level, is used for performance assessment from the statistical perspective. The sign test results at the 95% confidence interval and the associated p-values are presented in Tables 6, 7, 8 and 9. Symbol "+/=/-" indicates a better/equal/worse performance between two compared algorithms. The \(\checkmark \) indicates the target algorithm has significant difference in performance with the compared algorithm, \(\times \) is vice versa, and \(\approx \) depicts no significant difference in performance between the two algorithms.
To compare an algorithm with others in a more general form, lexicographic ordering and average ranking are used. Lexicographic ordering has been adopted to obtain the final ranking for all algorithms in the CEC 2009 competition (Yu et al. 2018). The average ranking method is used to reveal accuracy and stability of an algorithm against other competitors. All algorithms are ranked based on their average results pertaining to the total number of benchmark functions, N. To measure accuracy of the target algorithm, the mean rank \(\mu _r\) is used, i.e.
where \(R = \{ R_1,R_2,\ldots ,R_n \}\) is a rank set of the target algorithm. The lower the mean rank \(\mu _r\), the better the performance of the target algorithm.
4.2 Quantitative results of EHHO and discussion
By observing the quantitative results from different classes of benchmark functions, the AVG and STD measures from 30 independent runs indicate the performance and stability of EHHO. The EHHO results versus those from other competitors in dealing with UM and MM functions (F1–F13) on 30, 100, 500 and 1000 dimensions are tabulated in Tables 2, 3, 4 and 5. Table 8 shows the EHHO results versus those from competitors in dealing with MM and CM functions. The best AVG and STD scores of EHHO are in bold. The statistical results of UM, MM, and CM benchmark functions are tabulated in Tables 6, 7, 8 and 9. The average ranking results are tabulated in Tables 7, 8, 9 and 10.
From Table 2, EHHO generates superior results on F2, F4–F7, and F9–F13. From the statistical evaluation veiwpoint, EHHO outperforms its competitors in all 30-dimensional UM functions at the 95% confidence level, as indicated by \(p < 0.05\) in Table 6. Moreover, EHHO achieves better results than other models on F1, F2, F4–F6, and F9–F13 on 100-dimensional UM functions, as shown in Table 3. As indicated in Table 6, EHHO performs significantly better than its competitors at the 95% confidence level. It can be noticed that EHHO yields the best results on 9 out of 13 500-dimensional benchmark problems, as presented in Table 4. In addition, Table 6 shows EHHO performs statistically better than its competitors, achieving comparable results than those of HHODE/rand/1, HHODE/best/1, HHODE/current-to-best/2, and HHODE/best/2. From Table 5, EHHO depicts its superior performance with 10 out of 13 best results on the benchmark problem with 1000-dimension. Comparing with other models statistically, EHHO performs significantly better than its competitors at the 95% confidence level, and no statistically difference with HHODE/current-to-best/2. From the results, integrating DE can certainly achieve more diverse solutions, leading to the attainment of the global optimum solution. In summary, EHHO proves to be highly effective in solving the F4–F6 and F9–F13 benchmark functions. Furthermore, EHHO outperforms other algorithms in almost all instances, and achieves the most optimal global solution for F9 and F11 in search spaces ranging from 30 to 1000 dimensions.
According to the results presented in Table 8, EHHO outperforms other models on several functions, including F14–F17, F19, F21–F22, and F25–F27. It also depicts similar performance to other models on F23 and F29. However, when it comes to hybrid composition functions F18, F20, F24, and F28, EHHO has a relatively lower performance on those hybrid composition functions. From Table 10, the average ranking results reinforce the findings from the statistical analysis, providing additional insights into the comparative performance of algorithms on benchmark functions F14–F29. EHHO is inferior to HHODE/current-to-best/2, HHODE/rand/1, HHODE/best/1, HHODE/best/2, and HHO, but it outperforms GA, PSO, BBO, FPA, GWO, BAT, FA, CS, MFO, TLBO, and DE. These findings provide valuable insights into the strengths and weaknesses of the EHHO algorithm on specific benchmark functions.
Based on the results, it can be seen that using a hybrid of HHO and DE method can enhance the diversity of solutions and prevent local optima. By incorporating a chaotic mutation rate in DE, the population diversity can be further improved while avoiding stagnation. Additionally, the ergodicity and randomness of the chaotic mutation assist EHHO in avoiding premature convergence. The nonlinear escaping factor further enhances EHHO in transitioning from exploration to exploitation, which enabling its attainment of the global optimum solution. Overall, EHHO outperforms the original HHO algorithm in solving SOPs. However, there are certain composition functions, such as F18, F20, F24, and F28, where HHODE performance proposed by Birogul (2019) is superior to that of EHHO.
4.2.1 Runtime analysis
Table 11 presents the runtime (seconds) of EHHO for different benchmark functions and dimensions (30D, 100D, 500D, and 1000D), providing information into its computational efficiency and scalability. It takes more time to solve most benchmark functions as the number of dimensions increases, implying that the computational complexity of EHHO increases with larger problem dimensions. From Table 11, functions F1, F4, F5, F6, F8, F9, and F10 have lower runtimes across different dimensions. On the other hand, functions F3, F7, F11, F12, and F13 experience significant increases in runtimes with higher dimensions. This suggests that these functions may face scalability issues, as the algorithm takes longer to reach optimal solutions in higher-dimensional spaces. It is therefore essential to evaluate the scalability of the EHHO algorithm and find ways to improve its performance for higher-dimensional optimisation problems.
From Table 12, functions F15, F16, F17, F18, F19, and F20 have shorter completion times, which indicates that the algorithm can find satisfactory solutions for these functions rapidly. However, functions F14, F21, F22, and F23 take longer to complete, indicating that EHHO needs more computational power to find optimal solutions for these functions.
In addition, Table 12 presents the average runtime for functions F24–F29, which comprise rotated, shifted, and hybrid composition functions from the IEEE CEC 2005 competition (García et al. 2009). Function F29 has the shortest runtime, indicating that the algorithm is able to find satisfactory solutions faster for this function. F24 and F25–F27 have similar runtimes, with each run taking 47 s and 49 s, respectively. Function F28 takes the longest time to run, suggesting that it has more difficult optimisation properties that slow down the convergence of EHHO (Table 13).
To obtain a comprehensive understanding of the computational efficiency of EHHO, it is valuable to compare its runtimes with other competing algorithms on the same benchmark functions and dimensions. Unfortunately, the authors of these algorithms did not disclose their computational times. Nevertheless, this study has employed the same maximum iterations as those published in Heidari et al. (2019) and Birogul (2019).
4.3 Evaluation with multi-objective optimisation problems
4.3.1 Experimental setup and compared algorithms
MO-EHHO is applied to high-dimensional bi-objective problems without equality or inequality constraints and scalable tri-objective problems without equality or inequality constraints for performance evaluation. A total of 12 test functions are available, as follows:
-
ZDT benchmark functions (ZDT1-4,6) (Deb et al. 2002; Deb and Agrawal 1999)
-
DTLZ benchmark functions (DTLZ1-DTLZ7) (Deb et al. 2005).
The MO-EHHO performance is compared with those reported in Liu et al. (2020), Xiang et al. (2015), and Yang et al. (2022). The evaluation constitutes a comprehensive analysis of MO-EHHO to ascertain its effectiveness. A summary of performance comparison is as follows:
-
Comparison with a variety of MOEAs reported in Yang et al. (2022), i.e. CMPMOHHO (Yang et al. 2022), NSGA-II, SPEA2, NSGA-III (Deb and Jain 2013), PESA-II (Corne et al. 2001), CMOPSO (Zhang et al. 2018), CMOEA/D (Asafuddoula et al. 2012), MOEA/D-FRRMAB (Li et al. 2013), hpaEA (Chen et al. 2019), PREA (Yuan et al. 2020), ANSGA-III (Cheng et al. 2019), ar-MOEA (Yi et al. 2018), RPD-NSGA-II (Elarbi et al. 2017), and PICEA-g (Wang et al. 2012).
-
Comparison with a variety of MOEAs reported in Liu et al. (2020), i.e. MMOGWO (Liu et al. 2020), SPEA2 (Zitzler et al. 2001), NSGA-II (Deb et al. 2002), MOPSO (Coello et al. 2004), MOGWO (Mirjalili et al. 2016), MOALO (Mirjalili et al. 2017b), MOMVO algorithm (Mirjalili et al. 2017a), MOGOA (Mirjalili et al. 2018) and Multi-objective artificial bee colony (MOABC) algorithm (Akbari et al. 2012).
-
Comparison with a variety of MOEAs reported in Xiang et al. (2015) and Liu et al. (2020), i.e. PAES, SPEA2, NSGA-II, IBEA (Zitzler and Künzli 2004), OMOPSO (Lin et al. 2015), AbYSS (Nebro et al. 2008), CellDE (Durillo et al. 2008), MOEA/D, SMPSO (Lin et al. 2015), MOCell (Nebro et al. 2009), GDE3 (Kukkonen and Lampinen 2009) and eMOABC (Xiang et al. 2015).
4.3.2 Performance metrics
Three common objective functions for evaluating the performance of a multi-objective algorithm in solving MOPs are as follows:
-
minimise the distance between the true PF and the obtained PS
-
maximise the spread of the obtained PS along with the true PF
-
maximise the extent of the obtained PS in covering the true PF
Based on these objectives, the following performance metrics are used to assess the MO-EHHO efficacy.
Convergence metric (\(\gamma \)): the distance between the PF and the obtained PS (Deb et al. 2002), i.e.
Diversity metric (\(\Delta \)): the degree of spread achieved by the obtained PS (Deb et al. 2002), i.e.
Generational distance (GD): the distance between the true PF and the obtained PS (Van Veldhuizen and Lamont 1998), i.e.
Inverted generational distance (IGD): the distance between each solution composing the true PF and the obtained PS (Zitzler and Thiele 1999), i.e.
where i the index of a solution set, \(d_i\) is the Euclidean distance between the ith solution in the non-dominated set and the ith solution in the true PF. n is the number of obtained PS, m is the number of solutions in the true PF. In addition, \(d_\textrm{min}\) and \(d_\textrm{max}\) are the minimum and maximum Euclidean distances of the extreme non-dominated solution, respectively, in the objective space, \(\bar{d}\) is the mean of all \(d_i\).
4.4 Quantitative results of MO-EHHO and discussion
4.4.1 Comparison between MO-EHHO and other enhanced models in Yang et al. (2022)
MO-EHHO and other enhanced models presented in Yang et al. (2022) are compared using the ZDT and DTLZ functions. In accordance with the experimental procedure in Yang et al. (2022), the population size and external archive are set to 100. The number of maximum function evaluations of ZDT is 30,000, i.e. the same as that in Yang et al. (2022). However, the number of maximum function evaluations of DTLZ is 300,000 in Yang et al. (2022), as compared with only 50,000 for MO-EHHO in this research. In this comparison, 18 algorithms are compared with MO-EHHO, i.e. CMPMO-HHO, NSGA-II, SPEA2, NSGA-III, PESA-II, CMOPSO, C-MOEA/D, MOEA/D- FRRMAB, hpaEA, PREA, ANSGA-III, ar-MOEA, RPD-NSGA-II, PICEA-g, MOHHO/SP (multiobjective HHO algorithm with single population), CMPMOHHO/NoP (CMPMO-HHO without LCSDP) and CMPMOHHO/SES (CMPMO-HHO with single elite selection), and CMPMO-GA which is a CMPMO/des-based many-objective GA.
The average results and standard deviation of MO-EHHO and those presented in Yang et al. (2022) are depicted in Table 14. MO-EHHO generates the best or second-best scores on 9 out of 12 test problems in terms of IGD. Table 15 presents the sign test results of all MO-EHHO in terms of IGD as compared with those in Yang et al. (2022). MO-EHHO achieves comparable IGD results as compared with those of CMPMO-HHO, NSGA-III, NSGA-II, SPEA2, ANSGA-III, and ar-MOEA, but outperforms others at the 95% confidence interval with \(p<0.05\). Table 16 summarises the ranking outcomes of all algorithms. MO-EHHO is ranked in the top 1 position as the overall best performer in solving the ZDT and DTLZ problems. Note that the number of maximum function evaluations of MO-EHHO is lower than that in Yang et al. (2022), i.e. 50,000 versus 300,000, indicating the effectiveness of MO-EHHO in tackling MOPs.
4.4.2 Comparison between MO-EHHO and other algorithms published in Liu et al. (2020)
The performance of MO-EHHO is evaluated using the ZDT and DTLZ benchmark functions. The obtained results are compared with those published in Liu et al. (2020). In accordance with the experimental procedure in Liu et al. (2020), the maximum numbers of function evaluations are set to 25,000 and 50,000 for ZDTs and DTLZ problems, respectively; the population size and external archive size are set to 100; while the maximum numbers of iterations of each run are set to \(25,000 / 100 = 250\) for ZDT problems and \(50,000 / 100 = 500\) for DTLZ problems. The experiment is conducted in a Python environment. The obtained results are tabulated in Tables 27, 28, 29 and 30 in the Appendix. Besides, Table 17 presents the sign test results of MO-EHHO as compared with those of MMOGWO, SPEA2, NSGA-II, MOPSO, MOGWO, MOALO, MOMVO, MOGOA, and MOABC.
From Table 17, MO-EHHO outperforms SPEA2, NSGA-II and MOABC in terms of both \(\gamma \) and GD. In addition, MO-EHHO achieves better results than those of MOGOA in terms of GD. It should be noted that the \(\Delta \) metric evaluates the spread among the non-dominated solutions obtained by an algorithm, indicating the diversity property of the solutions. In terms of \(\Delta \), MO-EHHO achieves comparable results with those of SPEA2, NSGA-II, MOGWO, and MOABC. It yields better results as compared with those of MMOGWO, MOPSO, MOALO, MOMVO, and MOGOA at the 95% significance level (\(\alpha = 0.05\)). MO-EHHO depicts a superior performance as compared with those of its competitors. MO-EHHO results show a statistically significant difference in performance at the 95% confidence level as compared with those of MMOGWO, SPEA2, NSGA-II, MOPSO, MOGWO, MOALO, MOMVO, MOGOA, and MOABC, indicating a better balance between diversity and convergence by MO-EHHO.
From the analysis above, MO-EHHO outperforms their competitors at the 95% confidence interval in terms of IGD. The IGD metric evaluates both the convergence and diversity properties of an algorithm. Hence, the solutions produced by MO-EHHO have a good balance between convergence and diversity. Besides that, Table 18 depicts the ranking outcome of the algorithms on each metric. MO-EHHO ranks the first in terms of \(\gamma \), GD and IGD. Moreover, MOPSO occupies the top rank in terms of \(\Delta \), which is the diversity metric. In summary, MO-EHHO has a good overall performance in terms of convergence, but is inferior in diversity as compared with NSGA-II and MOPSO.
4.4.3 Comparison between MO-EHHO and several improved MOEA models in Liu et al. (2020)
MO-EHHO is compared with a variety of MOEA models presented in Liu et al. (2020) and Xiang et al. (2015), namely MMOGWO, PAES, SPEA2, NSGA-II, IBEA, OMOPSO, AbYSS, CellDE, MOEA/D, SMPSO, MOCell, GDE3, and eMOABC. The ZDTs and DTLZs benchmark functions are used for performance evaluation and comparison. In accordance with the experimental procedure in Liu et al. (2020) and Xiang et al. (2015), the number of maximum function evaluations is set to 50,000 for all problems, and the population size and external archive are set to 100, respectively. As such, the number of maximum iteration is \(50,000/100 = 500\) for each of the 30 independently runs. Only the IGD metric is used for performance evaluation, as per the results presented in Liu et al. (2020) and Xiang et al. (2015). This experiment is performed in a Python environment.
The mean IGD results of MO-EHHO over 30 independent runs are shown in Table 19. MO-EHHO is the best algorithm, producing the best scores on 10 out of 12 test problems. Table 20 presents the sign test outcomes of MO-EHHO against those of other algorithms. MO-EHHO demonstrates a superior performance as compared with those from its competitors in a statistical context. From Table 21, MO-EHHO is the best in ranking against its competitors. In short, MO-EHHO is the best among other MOEA models.
5 Conclusions
In this study, we have proposed enhancements to the HHO algorithm, namely EHHO and MO-EHHO to solve SOPs and MOPs, respectively. Both EHHO and MO-EHHO models have been evaluated with 29 SOPs and 12 MOPs. Specifically, EHHO has been evaluated using a variety of single-objective benchmark problems, including unimodal functions F1–F7, multimodal functions F8–F23, and composition functions F24–F29. Two sets of well-known multi-objective benchmark functions, i.e. ZDT and DTLZ, have been employed to evaluate MO-EHHO. Four performance metrics, i.e. \(\gamma \), \(\Delta \), GD, and IGD, have been utilised to measure the convergence and diversity properties of MO-EHHO. In addition, the sign test is employed to deduce a statistical conclusion for the performance comparison between two compared algorithms at the significance level of \(\alpha =0.05\). The average ranking method has also been adopted to reveal accuracy and stability of an algorithm against other competitors. All algorithms have ranked based on their average results pertaining to the total number of benchmark functions.
The DE scheme has been integrated into EHHO, while the chaos theory has been utilised to formulate its mutation factor. It leverages the DE/best/1 mutation scheme, where the "best" indicates that the non-dominated solution is stored in the external archive, while "1" represents one mutated vector is used. The nonlinear exploration factor contributes towards the diversification capability in the early exploration phase, which facilitates a smooth changeover from exploration to exploitation. Additionally, the incorporation of DE into EHHO and the mutation strategy in the population are useful to prevent EHHO from falling into local optima. Despite its strengths, EHHO struggles in certain benchmark problems that involve higher dimensions and more complex search landscapes in comparison with those from the HHODE variants. For MOPs, the non-dominated sorting strategy from NSGA-II has been employed in MO-EHHO. MO-EHHO is able to exploit the Pareto optimal solutions while preserving its diversity.
The results of EHHO and MO-EHHO are compared with those from popular optimisation algorithms published in the literature. The results indicate that in most SOPs and MOPs, EHHO and MO-EHHO perform better than their competitors, as presented in Sect. 4. For further work, several research directions can be pursued. Firstly, the proposed models still have room for improvement. In particular, MO-EHHO can be combined with other multi-objective algorithms to attain more diverse solutions. Secondly, the proposed models can be applied to various optimisation tasks, including job-shop scheduling and other real-world problems.
Data availability
Enquiries about data availability should be directed to the authors.
References
Abd Elaziz M , Yang H , Lu S (2021) A multi-leader harris hawk optimization based on differential evolution for feature selection and prediction influenza viruses h1n1. Artif Intell Rev 1–58
Abualigah L, Abd Elaziz M, Shehab M, Ahmad Alomari O, Alshinwan M, Alabool H, Al-Arabiat DA (2021) Hybrid Harris hawks optimization with differential evolution for data clustering. In: Metaheuristics in machine learning: theory and applications. Springer, pp 267–299
Akbari R, Hedayatzadeh R, Ziarati K, Hassanizadeh B (2012) A multi-objective artificial bee colony algorithm. Swarm Evol Comput 2:39–52
Alabool HM, Alarabiat D, Abualigah L, Heidari AA (2021) Harris hawks optimization: a comprehensive review of recent variants and applications. Neural Comput Appl 3315:8939–8980
Asafuddoula M, Ray T, Sarker R, Alam K (2012) An adaptive constraint handling approach embedded moea/d. In: 2012 IEEE congress on evolutionary computation, pp. 1–8
Bao X, Jia H, Lang C (2019) A novel hybrid Harris Hawks optimization for color image multilevel thresholding segmentation. IEEE Access 7:76529–76546
Barshandeh S, Haghzadeh M (2021) A new hybrid chaotic atom search optimization based on tree-seed algorithm and levy flight for solving optimization problems. Eng Comput 37:43079–3122
Bettemir ÖH, Sonmez R (2015) Hybrid genetic algorithm with simulated annealing for resource-constrained project scheduling. J Manag Eng 31:504014082
Birogul S (2019) Hybrid Harris Hawk optimization based on differential evolution (hhode) algorithm for optimal power flow problem. IEEE Access 7:184468–184488
Chen P-H, Shahandashti SM (2009) Hybrid of genetic algorithm and simulated annealing for multiple project scheduling with multiple resource constraints. Autom Constr 18(4):434–443
Chen H, Tian Y, Pedrycz W, Wu G, Wang R, Wang L (2019) Hyperplane assisted evolutionary algorithm for many-objective optimization problems. IEEE Trans Cybern 50(7):3367–3380
Chen H, Heidari AA, Chen H, Wang M, Pan Z, Gandomi AH (2020a) Multi-population differential evolution-assisted Harris Hawks optimization: framework and case studies. Future Gener Comput Syst 111:175–198
Chen H, Jiao S, Wang M, Heidari AA, Zhao X (2020b) Parameters identification of photovoltaic cells and modules using diversification-enriched Harris Hawks optimization with chaotic drifts. J Clean Prod 244:118778
Cheng Q, Du B, Zhang L, Liu R (2019) Ansga-iii: a multiobjective endmember extraction algorithm for hyperspectral images. IEEE J Sel Top Appl Earth Obs Remote Sens 12(2):700–721
Coello CAC, Pulido GT, Lechuga MS (2004) Handling multiple objectives with particle swarm optimization. IEEE Trans Evol Comput 8(3):256–279
Corne DW, Jerram NR, Knowles JD, Oates MJ (2001) Pesa-ii: region-based selection in evolutionary multiobjective optimization. In: Proceedings of the 3rd annual conference on genetic and evolutionary computation, pp. 283–290
Deb K, Agrawal S (1999) A niched-penalty approach for constraint handling in genetic algorithms. In: Artificial neural nets and genetic algorithms, pp 235–243
Deb K, Jain H (2013) An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part i: solving problems with box constraints. IEEE Trans Evol Comput 184:577–601
Deb K, Pratap A, Agarwal S, Meyarivan T (2002) A fast and elitist multiobjective genetic algorithm: Nsga-ii. IEEE Trans Evol Comput 62:182–197
Deb K , Thiele L, Laumanns M, Zitzler E (2005) Scalable test problems for evolutionary multiobjective optimization. In: Evolutionary multiobjective optimization. Springer, pp 105–145
Dhawale D, Kamboj VK, Anand P (2021) An improved chaotic Harris Hawks optimizer for solving numerical and engineering optimization problems. Eng Comput, 1–46
Digalakis JG, Margaritis KG (2001) On benchmarking functions for genetic algorithms. Int J Comput Math 77(4):81–506
Durillo JJ, Nebro AJ, Luna F, Alba E (2008) Solving three-objective optimization problems using a new hybrid cellular genetic algorithm. In: International conference on parallel problem solving from nature, pp 661–670
Elarbi M, Bechikh S, Gupta A, Said LB, Ong Y-S (2017) A new decomposition-based nsga-ii for many-objective optimization. IEEE Trans Syst Man Cybern Syst 48(7):1191–1210
Erol OK, Eksin I (2006) A new optimization method: big bang-big crunch. Adv Eng Softw 37(2):106–111
Ewees AA, Abd Elaziz M (2020) Performance analysis of chaotic multi-verse Harris Hawks optimization: a case study on solving engineering problems. Eng Appl Artif Intell 88:103370
Fonseca CM, Fleming PJ (1998) Multiobjective optimization and multiple constraint handling with evolutionary algorithms. I. A unified formulation. IEEE Trans Syst Man Cybern Part A Syst Hum 28(1):26–37
Formato RA (2007) Central force optimization. Prog Electromagn Res 77(1):425–491
Gandomi AH, Yang X-S, Alavi AH (2011) Mixed variable structural optimization using firefly algorithm. Comput Struct 89(23–24):2325–2336
Gandomi AH, Yang X-S, Alavi AH (2013) Cuckoo search algorithm: a metaheuristic approach to solve structural optimization problems. Eng Comput 29(1):17–35
Gao Z.-M, Zhao J (2019) An improved grey wolf optimization algorithm with variable weights. Comput Intell Neurosci 2019
Gao Y, An X, Liu J (2008) A particle swarm optimization algorithm with logarithm decreasing inertia weight and chaos mutation. In: 2008 international conference on computational intelligence and security, vol 1, pp 61–65
García S, Molina D, Lozano M, Herrera F (2009) A study on the use of non-parametric tests for analyzing the evolutionary algorithms’ behaviour: a case study on the cec’ 2005 special session on real parameter optimization. J Heuristics 15(6):617–644
Geem ZW, Kim JH, Loganathan GV (2001) A new heuristic optimization algorithm: harmony search. Simulation 76(2):60–68
Glover F, Laguna M (1998) Tabu search. In: Handbook of combinatorial optimization. Springer, pp 2093–2229
Gupta S, Deep K, Heidari AA, Moayedi H, Wang M (2020) Opposition-based learning Harris Hawks optimization with advanced transition rules: principles and analysis. Expert Syst Appl 158:113510
Hanafi R, Kozan E (2014) A hybrid constructive heuristic and simulated annealing for railway crew scheduling. Comput Ind Eng 70:11–19
Heidari AA, Mirjalili S, Faris H, Aljarah I, Mafarja M, Chen H (2019) Harris hawks optimization: algorithm and applications. Futur Gener Comput Syst 97:849–872
Holland JH (1992a) Adaptation in natural and artificial systems: an introductory analysis with applications to biology, control, and artificial intelligence. MIT Press, Cambridge
Holland JH (1992b) Genetic algorithms. Sci Am 267(1):66–73
Hussien AG, Amin M (2022) A self-adaptive Harris Hawks optimization algorithm with opposition-based learning and chaotic local search strategy for global optimization and feature selection. Int J Mach Learn Cybern 13(2):309–336
Islam MZ, Wahab NIA, Veerasamy V, Hizam H, Mailah NF, Guerrero JM, Mohd Nasir MN (2020) A Harris Hawks optimization based single-and multi-objective optimal power flow considering environmental emission. Sustainability 12:135248
Jangir P, Jangir N (2018) A new non-dominated sorting grey wolf optimizer (ns-gwo) algorithm: development and application to solve engineering designs and economic constrained emission dispatch problem with integration of wind power. Eng Appl Artif Intell 72:449–467
Jangir P, Heidari AA, Chen H (2021) Elitist non-dominated sorting Harris Hawks optimization: framework and developments for multi-objective problems. Expert Syst Appl 186:115747
Jia H, Lang C, Oliva D, Song W, Peng X (2019) Hybrid grasshopper optimization algorithm and differential evolution for multilevel satellite image segmentation. Remote Sens 11:91134
Jiao S, Chong G, Huang C, Hu H, Wang M, Heidari AA, Zhao X (2020) Orthogonally adapted Harris Hawks optimization for parameter estimation of photovoltaic models. Energy 203:117804
Karaboga D, Basturk B (2008) On the performance of artificial bee colony (abc) algorithm. Appl Soft Comput 8(1):687–697
Kennedy J, Eberhart R (1995) Particle swarm optimization. In: Proceedings of ICNN’95-international conference on neural networks, vol 4, pp 1942–1948
Khan B, Johnstone M, Hanoun S, Lim CP, Creighton D, Nahavandi S (2016) Improved nsga-iii using neighborhood information and scalarization. In: 2016 IEEE international conference on systems, man, and cybernetics (SMC), pp 003033–003038
Khan B, Hanoun S, Johnstone M, Lim CP, Creighton D, Nahavandi S (2019) A scalarization-based dominance evolutionary algorithm for many-objective optimization. Inf Sci 474:236–252
Kinnear KE, Langdon WB, Spector L, Angeline PJ, O’Reilly U-M (1994) Advances in genetic programming, vol 3. MIT Press, Cambridge
Kirkpatrick S, Gelatt CD Jr, Vecchi MP (1983) Optimization by simulated annealing. Science 220(4598):671–680
Kukkonen S, Lampinen J (2009) Performance assessment of generalized differential evolution 3 with a given set of constrained multi-objective test problems. In: 2009 IEEE congress on evolutionary computation, pp 1943–1950
Li X, Gao L (2016) An effective hybrid genetic algorithm and Tabu search for flexible job shop scheduling problem. Int J Prod Econ 174:93–110
Li J-Q, Pan Q-K, Gao K-Z (2011) Pareto-based discrete artificial bee colony algorithm for multi-objective flexible job shop scheduling problems. Int J Adv Manuf Technol 55(9):1159–1169
Li K, Fialho A, Kwong S, Zhang Q (2013) Adaptive operator selection with bandits for a multiobjective evolutionary algorithm based on decomposition. IEEE Trans Evol Comput 18(1):114–130
Li C, Li J, Chen H, Jin M, Ren H (2021) Enhanced Harris Hawks optimization with multi-strategy for global optimization tasks. Expert Syst Appl 185:115499
Lin Q, Li J, Du Z, Chen J, Ming Z (2015) A novel multi-objective particle swarm optimization with multiple search strategies. Eur J Oper Res 247(3):732–744
Liu J, Yang Z, Li D (2020) A multiple search strategies based grey wolf optimizer for solving multi-objective optimization problems. Expert Syst Appl 145:113134
Liu J, Liu X, Wu Y, Yang Z, Xu J (2022) Dynamic multi-swarm differential learning Harris Hawks optimizer and its application to optimal dispatch problem of cascade hydropower stations. Knowl Based Syst 242:108281
Long W, Jiao J, Liang X, Tang M (2018a) An exploration-enhanced grey wolf optimizer to solve high-dimensional numerical optimization. Eng Appl Artif Intell 68:63–80
Long W, Jiao J, Liang X, Tang M (2018b) Inspired grey wolf optimizer for solving large-scale function optimization problems. Appl Math Model 60:112–126
Menesy AS, Sultan HM, Selim A, Ashmawy MG, Kamel S (2019) Developing and applying chaotic Harris Hawks optimization technique for extracting parameters of several proton exchange membrane fuel cell stacks. IEEE Access 8:1146–1159
Mirjalili S (2015) Moth-flame optimization algorithm: a novel nature-inspired heuristic paradigm. Knowl Based Syst 89:228–249
Mirjalili S (2016) Sca: a sine cosine algorithm for solving optimization problems. Knowl Based Syst 96:120–133
Mirjalili S, Lewis A (2016) The whale optimization algorithm. Adv Eng Softw 95:51–67
Mirjalili S, Mirjalili SM, Lewis A (2014) Grey wolf optimizer. Adv Eng Softw 69:46–61
Mirjalili S, Saremi S, Mirjalili SM, Coelho LDS (2016) Multi-objective grey wolf optimizer: a novel algorithm for multi-criterion optimization. Expert Syst Appl 47:106–119
Mirjalili S, Jangir P, Mirjalili SZ, Saremi S, Trivedi IN (2017a) Optimization of problems with multiple objectives using the multi-verse optimization algorithm. Knowl Based Syst 134:50–71
Mirjalili S, Jangir P, Saremi S (2017b) Multi-objective ant lion optimizer: a multi-objective optimization algorithm for solving engineering problems. Appl Intell 46(1):79–95
Mirjalili SZ, Mirjalili S, Saremi S, Faris H, Aljarah I (2018) Grasshopper optimization algorithm for multi-objective optimization problems. Appl Intell 48(4):805–820
Mittal N, Singh U, Sohi BS (2016) Modified grey wolf optimizer for global engineering optimization. Appl Comput Intell Soft Comput 2016
Mladenović N, Hansen P (1997) Variable neighborhood search. Comput Oper Res 24(11):1097–1100
Nebro AJ, Luna F, Alba E, Dorronsoro B, Durillo JJ, Beham A (2008) Abyss: adapting scatter search to multiobjective optimization. IEEE Trans Evol Comput 12(4):439–457
Nebro AJ, Durillo JJ, Luna F, Dorronsoro B, Alba E (2009) Mocell: a cellular genetic algorithm for multiobjective optimization. Int J Intell Syst 24(7):726–746
Price K.V. (1996). Differential evolution: a fast and simple numerical optimizer. In: Proceedings of North American fuzzy information processing, pp 524–527
Qu C, He W, Peng X, Peng X (2020) Harris hawks optimization with information exchange. Appl Math Model 84:52–75
Rao RV, Savsani VJ, Vakharia D (2011) Teaching-learning-based optimization: a novel method for constrained mechanical design optimization problems. Comput Aided Des 43(3):303–315
Rao RV, Savsani VJ, Vakharia D (2012) Teaching-learning-based optimization: an optimization method for continuous non-linear large scale problems. Inf Sci 183:11–15
Rashedi E, Nezamabadi-Pour H, Saryazdi S (2009) Gsa: a gravitational search algorithm. Inf Sci 179(13):2232–2248
Simon D (2008) Biogeography-based optimization. IEEE Trans Evol Comput 12(6):702–713
Storn R, Price K (1997) Differential evolution-a simple and efficient heuristic for global optimization over continuous spaces. J Global Optim 11(4):341–359
Talbi E-G (2009) Metaheuristics: from design to implementation, vol 74. Wiley, New York
Van Laarhoven PJ, Aarts EH (1987) Simulated annealing. In: Simulated annealing: theory and applications. Springer, pp 7–15
Van Veldhuizen DA, Lamont GB (1998) Multiobjective evolutionary algorithm research: a history and analysis. Tech Rep. Citeseer
Wang, J.- S., & Li, S.- X. (2019) An improved grey wolf optimizer based on differential evolution and elimination mechanism. Sci Rep 9:11–21
Wang R, Purshouse RC, Fleming PJ (2012) Preference-inspired coevolutionary algorithms for many-objective optimization. IEEE Trans Evol Comput 17(4):474–494
Wang S, Jia H, Abualigah L, Liu Q, Zheng R (2021) An improved hybrid Aquila optimizer and Harris hawks algorithm for solving industrial engineering optimization problems. Processes 2021(9):1551
Wolpert DH, Macready WG (1997) No free lunch theorems for optimization. IEEE Trans Evol Comput 1(1):67–82
Wunnava A, Naik MK, Panda R, Jena B, Abraham A (2020) A differential evolutionary adaptive Harris Hawks optimization for two dimensional practical masi entropy-based multilevel image thresholding. J King Saud Univ Comput Inf Sci 34:3011–3024
Xiang Y, Zhou Y, Liu H (2015) An elitism based multi-objective artificial bee colony algorithm. Eur J Oper Res 245(1):168–193
Xie H, Zhang L, Lim CP (2020) Evolving cnn-lstm models for time series prediction using enhanced grey wolf optimizer. IEEE Access 8:161519–161541
Yang X-S, Gandomi AH (2012) Bat algorithm: a novel approach for global engineering optimization. Eng Comput 29:464–483
Yang X-S, Karamanoglu M, He X (2014) Flower pollination algorithm: a novel approach for multiobjective optimization. Eng Optim 46(9):1222–1237
Yang N, Tang Z, Cai X, Chen L, Hu Q (2022) Cooperative multi-population Harris Hawks optimization for many-objective optimization. Complex Intell Syst 8:3299–3332
Yao X, Liu Y, Lin G (1999) Evolutionary programming made faster. IEEE Trans Evol Comput 3(2):82–102
Yi J, Bai J, He H, Peng J, Tang D (2018) ar-moea: a novel preference-based dominance relation for evolutionary multiobjective optimization. IEEE Trans Evol Comput 23(5):788–802
Yin Q, Cao B, Li X, Wang B, Zhang Q, Wei X (2020) An intelligent optimization algorithm for constructing a dna storage code: Nol-hho. Int J Mol Sci 21:62191
Yu D, Hong J, Zhang J, Niu Q (2018) Multi-objective individualized-instruction teaching-learning-based optimization algorithm. Appl Soft Comput 62:288–314
Yuan J, Liu H-L, Gu F, Zhang Q, He Z (2020) Investigating the properties of indicators and an evolutionary many-objective algorithm using promising regions. IEEE Trans Evol Comput 25(1):75–86
Zhang J, Sanderson AC (2009) Jade: adaptive differential evolution with optional external archive. IEEE Trans Evol Comput 13(5):945–958
Zhang X, Zheng X, Cheng R, Qiu J, Jin Y (2018) A competitive mechanism based multi-objective particle swarm optimizer with fast convergence. Inf Sci 427:63–76
Zhang X, Zhao K, Niu Y (2020) Improved Harris Hawks optimization based on adaptive cooperative foraging and dispersed foraging strategies. IEEE Access 8:160297–160314
Zheng-Ming G , Juan Z, Yu-Rong H, Chen H-F (2019) The improved harris hawk optimization algorithm with the tent map. In: 2019 3rd International conference on electronic information technology and computer engineering (EITCE), pp 336–339
Zitzler E, Thiele L (1999) Multiobjective evolutionary algorithms: a comparative case study and the strength pareto approach. IEEE Trans Evol Comput 3(4):257–271
Zitzler E, Künzli S (2004) Indicator-based selection in multiobjective search. In: International conference on parallel problem solving from nature, pp 832–842
Zitzler E, Laumanns M, Thiele L (2001) Spea2: improving the strength pareto evolutionary algorithm. TIK Report 103
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions. The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
All authors have equally contributed to the research design, data analysis research summary and recommendation, written manuscript, and coordinated for submission of this paper.
Corresponding author
Ethics declarations
Ethical approval
This article does not contain any studies with animals performed by any of the authors.
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A
Single-objective Benchmark Functions
Appendix B
Quantitative results for multi-objective functions quantitative results for multi-objective functions
See Tables 26, 27, 28, 29, and 30.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Choo, Y.H., Cai, Z., Le, V. et al. Enhancing the Harris’ Hawk optimiser for single- and multi-objective optimisation. Soft Comput 27, 16675–16715 (2023). https://doi.org/10.1007/s00500-023-08952-w
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-023-08952-w