
Abstract
We propose a novel Mixed-Integer Nonlinear Programming (MINLP) model for sparse optimization based on the polyhedral k-norm. We put special emphasis on the application of sparse optimization in Feature Selection for Support Vector Machine (SVM) classification. We address the continuous relaxation of the problem, which comes out in the form of a fractional programming problem (FPP). In particular, we consider a possible way for tackling FPP by reformulating it via a DC (Difference of Convex) decomposition. We also overview the SVM models and the related Feature Selection in terms of multi-objective optimization. The results of some numerical experiments on benchmark classification datasets are reported.
Similar content being viewed by others
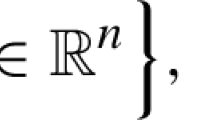


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Machine learning is concerned with developing computer techniques and algorithms that can learn (Weston et al. 2000). Machine learning algorithms can essentially be divided into Supervised learning, Unsupervised and Data clustering (Forman et al. 2003; Nolfi et al. 1994).
All learning algorithms perform model selection and parameter estimation based on one or multiple criteria; in such a framework numerical optimization plays a significant role (Gambella et al. 2021). In this paper, we focus on Classification, a supervised learning area based on the separation of sets in finite-dimensional spaces (the Feature ones) by means of appropriate separation surfaces. The most popular approach to classification is the Support Vector Machine (SVM) model, where one looks for a hyperplane separating two given sample sets (Cristianini et al. 2000).
Optimization methods that seek sparsity of solutions have recently received considerable attention (Bach et al. 2011; Bauschke and Combettes 2011; Bertsimas et al. 2016), mainly motivated by the need of tackling Feature selection problems, defined as ”the search for a subset of the original measurements features that provide an optimal tradeoff between probability error and cost of classification” Swain and Davis (1981). The Feature selection methods are discussed in Al-Ani et al. (2013); Cervante et al. (2012).
In this paper, we tackle Feature Selection (FS) in the general setting of sparse optimization, where one is faced to the problem (Gaudioso et al. 2018a):
where \( f: {\mathbb {R}}^{n} \rightarrow {\mathbb {R}} \) and \( \Vert .\Vert _{0} \) is the \( l _{0} \) pseudo-norm, which counts the number of nonzero components of any vector. Sometimes sparsity of the solution, instead of acting on the objective function, is enforced by introducing a constraint on the \( l _{0} \) pseudo-norm of the solution, thus defining a cardinality-constrained problem (Gaudioso et al. 2018b, 2020; Chen et al. 2010; Pilanci et al. 2015).
In many applications, the \( l _{0} \) pseudo-norm in (1) is replaced by the \( l _{1} \)-norm, which is definitely more tractable from the computational point of view, yet ensuring sparsity, to a certain extent (Wright 2012).
In the seminal paper (Watson 1992), a class of polyhedral norms (the \( k \)-norms), intermediate between \( \Vert .\Vert _{1} \) and \( \Vert .\Vert _{\infty } \), is introduced to obtain sparse approximation solutions to systems of linear equations. Some other norms have been used in different applications (Jafari-Petroudi and Pirouz 2016; Petroudi et al. 2022; Jafari-Petroudi and Pirouz 2015b, a; Petroudi and Pirouz 2015). The use of other norms to recover sparsity is described in Gasso et al. (2009). In more recent years the use of \( k \)-norms has received much attention and has led to several proposals for dealing with \( l _{0} \) pseudo-norm cardinality constrained problem (Gotoh et al. 2018; Hempel and Goulart 2014; Soubies et al. 2017; Wu et al. 2014).
An alternative way to deal with Feature selection is the multi-objective approach discussed in the Hamdani et al. (2007). Multi-objective optimization is a basic process in many fields of science, including mathematics, economics, management, and engineering applications (Ehrgott 2005). In most real situations, the decision-maker needs to make tradeoffs between disparate and conflicting design objectives rather than a single one. Having conflicting objectives means that it is not possible to find a feasible solution where all the objectives could reach their individual optimal, but one must find the most satisfactory compromise between the objectives. These compromise solutions, in which none of the objective functions can be improved in value without impairing at least one of the others, are often referred to as Pareto optimal or Pareto efficient (Neshatian and Zhang 2009). The set of all objective function values at the Pareto and weak Pareto solutions is said to be the Pareto front (or efficient set) of the multi-objective optimization problem (MOP) in the objective value space (Dolatnezhadsomarin et al. 2019). In general, solving a MOP is associated with the construction of the Pareto frontier. The problem of finding the whole solution set of a MOP is important in applications (Ceyhan et al. 2019). Many methods have been proposed to find the Pareto front of the multi-objective optimization problems (See Ghane-Kanafi and Khorram (2015); Pirouz and Khorram (2016); Pirouz and Ramezani Paschapari (2019); Das and Dennis (1998); Dutta and Kaya (2011); Fonseca et al. (1993); Pirouz et al. (2021)).
In this paper, we have specifically emphasized the application of sparse optimization in Feature Selection for SVM classification. We propose a novel model for sparse optimization based on the polyhedral k-norm. Also, to demonstrate the advantages of considering SVM classification models as multi-objective optimization problems, we propose some multi-objective reformulation of these models. In these cases, a set of Pareto optimal solutions is obtained instead of one in the single-objective cases.
The rest of the paper is organized as follows. Section 2 contains some basic concepts and notations about binary classification, the Support Vector Machine model and Feature Selection as a sparse optimization problem. Our approach to sparse optimization via k-norms is presented in Sect. 3, together with a discussion on possible relaxation and algorithmic treatment. In Sect. 4 some basic concepts and notations of multi-objective optimization problems (MOPs) are resumed and a reformulation of the feature selection model in the form of MOPs is given. The results of some numerical experiments on benchmark datasets are in Sect. 5. Section 6 is devoted to conclusions.
2 Basic concepts and notations
This section presents some basic concepts and notations that make more accessible the understanding of this paper. We start by giving a brief description of the classification problem (especially binary classification) in supervised learning. We then focus on a specific task: support vector machine, feature selection, and sparse optimization.
2.1 Binary classification
In this paper, we consider the classification task in the basic form of binary classification. In binary classification we have the representation of two classes of individuals in the form of two finite sets \( {\mathcal {A}} \) and \( {\mathcal {B}} \subset {\mathbb {R}}^{n} \), such that \( {\mathcal {A}} \cap {\mathcal {B}} =\emptyset \), and we want to classify an input vector \( x \in {\mathbb {R}}^{n} \) as a member of the class represented by \( {\mathcal {A}} \) or that by \( {\mathcal {B}} \). The training set for binary classification is defined as follows (Rinaldi 2009):
with the two sets \( {\mathcal {A}} \) and \( {\mathcal {B}} \) labelled by \( +1 \) and \( -1 \), respectively. The functional dependency \( f: {\mathbb {R}}^{n} \rightarrow \left\{ \pm 1\right\} \), which determines the class membership of a given vector \( x \), assumes the following form Rinaldi (2009); Rumelhart et al. (1986); Haykin and Network (2004):
Assume that the two finite point sets \( {\mathcal {A}} \) and \( {\mathcal {B}} \) in \( {\mathbb {R}}^{n} \) consist of \( m \) and \( k \) points, respectively. They are associated with the matrices \( A \in {\mathbb {R}}^{m \times n} \) and \( B \in {\mathbb {R}}^{k \times n} \), where each point of a set is represented as a row of the corresponding matrix. In the classic SVM method, we want to construct a separating hyperplane:
with normal \( w \in {\mathbb {R}}^{n} \) and distance (Rinaldi 2009):
to the origin. The separating plane P determines two open halfspaces:
-
\( P_{1} = \left\{ x: x \in {\mathbb {R}}^{n} , \quad x^{T}w>\gamma \right\} \) it is intended to contain most of the points belonging to \( {\mathcal {A}} \).
-
\( P_{2} = \left\{ x: x \in {\mathbb {R}}^{n} , \quad x^{T}w<\gamma \right\} \) it is intended to contain most of the points belonging to \( {\mathcal {B}} \).
Therefore, letting e be a vector of ones of appropriate dimension, we want to satisfy the following inequalities:
to the possible extent. The problem can be equivalently put in the form.
Conditions (5) and (6) are satisfied if and only if the convex hulls of \( {\mathcal {A}} \) and \( {\mathcal {B}} \) are disjoint (the two sets are linearly separable) (Rinaldi 2009).
Application of Feature Selection to SVM, as we will see next, amounts to suppressing as many of the components of w as possible.
2.2 Support vector machine and feature selection
In real-world classification problems based on supervised learning, the information available are the vectors \(a_i\)’s and \(b_l\)’s (the rows of A and B, respectively) defining the (labelled) training set. Nothing is known about the mapping function \( f \) (John et al. 1994). A separating plane is generated by minimizing a weighted sum of distances of misclassified points to two parallel planes that bound the sets and which determine the separating plane midway between them. In the Support Vector Machine (SVM) approach in addition to minimizing the error function, that is the weighted sum of distances of misclassified points to the bounding planes, we also maximize the distance (referred to as the separation margin) between the two bounding planes that generate the separating plane (Bradley and Mangasarian 1998).
The standard formulation of SVM is the following, where variables \(y_i\) and \(z_l\) represent the classification error associated with the points of \({\mathcal {A}}\) and \({\mathcal {B}}\), respectively:
Positive parameter C defines the trade-off between the objectives of minimizing the classification error and maximizing the separation margin.
Feature selection is primarily performed to select informative features (Rinaldi 2009), and has become one of the most important issues in the field of machine learning (Rinaldi et al. 2010).
Referring to the above model, the goal is to construct a separating plane that gives good performance on the training set while using a minimum number of problem features. This objective can be pursued by a looking for a normal w to the separating hyperplane characterized by the smallest possible number of nonzero components. This can be achieved by adding a sparsity enforcing term to the objective function (Rinaldi 2009; Rinaldi et al. 2010).
As we will see next, a companion model aimed at suppressing as many elements of w as possible, known as LASSO approach, is obtained by replacing \( l_{2} \)-norm with the \( l_{1}\) (Rinaldi 2009; Bradley and Mangasarian 1998).
2.3 Sparse optimization
As previously mentioned, in sparse SVM the objective is to control the number of nonzero components of the normal vector to the separating hyperplane while maintaining satisfactory classification accuracy (Gaudioso et al. 2020). Therefore, the following two objectives should be minimized (Rinaldi 2009):
-
The number of misclassified training data;
-
The number of nonzero elements of vector w.
We tackle Feature Selection in SVM as a special case of sparse optimization by stating the following problem (Gaudioso et al. 2020; Rinaldi et al. 2010):
where \( \Vert . \Vert _{0} \) is the \( l_{0} \)-pseudo-norm, which counts the number of nonzero components of any vector. This problem is equivalent to the following parametric program (Rinaldi 2009):
Where \( s: {\mathbb {R}} \rightarrow {\mathbb {R}}^{+} \) is the step function such that \( s\left( t\right) =1 \) for \( t>0 \) and \( s\left( t\right) =0 \) for \( t \le 0 \). This is the fundamental feature selection problem in the general setting of sparse optimization, as defined in Mangasarian (1996).
A simplification of the models (8) and (9) can be obtained by replacing the \( l_{0} \)-pseudo-norm with the \( l_{1} \)-norm, thus obtaining:
It has been demonstrated that model (10) exhibits in practice good sparsity properties of the solution.
Our approach to feature selection based on sparse optimization is presented in the next section.
3 A new approach to feature selection
This section introduces a new Feature Selection approach based on the use of k-norm in Sparse Optimization (see Gaudioso et al. (2020) and Gaudioso and Hiriart-Urruty (2022)). Then a relaxation for the model is provided. Finally, some differential properties and some algorithms for solving the proposed nonlinear model are introduced.
We consider, in a general setting, the following sparse optimization problem:
where we assume that \( f: {\mathbb {R}}^{n} \rightarrow {\mathbb {R}} \) is convex and \( f\left( x\right) \ge 0 \) for all \( x \in {\mathbb {R}}^{n} \), as it is the case when f is the error function in the SVM model. We introduce now the k-norm.
Definition 1
. (k-norm). Gaudioso et al. (2020). The k-norm is defined as the sum of k largest components (in modulus) of the vector X:
The k-norm is polyhedral, it is intermediate between \( \Vert .\Vert _{1} \) and \( \Vert .\Vert _{\infty } \) and enjoys the fundamental property linking \( \Vert .\Vert _{\left[ k\right] } \) to \(\Vert .\Vert _0\), \(1 \le k\le n\):
The property above is used to define the following Mixed Integer Nonlinear Programming (MINLP) formulation of problem (11), where we have introduced the set of binary variables \(y_k\), \(k=1,\ldots ,n\).
Note that, at the optimum of (14), the following hold:
thus, taking into account (13), \(y_k=1\) if \(\Vert x\Vert _0 \le k\). Summing up we have:
from which we obtain that maximization of \(\displaystyle \sum _{k=1}^{n} y_{k}\) implies minimization of \(\Vert x\Vert _{0}\).
We can relax the integrality constraint on \( y_{k} \) in problem (14) by setting \( y_{k} \in \left[ 0, 1\right] \) for \( k=1, \ldots , n \). We observe that at the optimum of the relaxed problem all constraints \(\Vert x\Vert _{\left[ k\right] } \ge \Vert x\Vert _{1} y_{k}\) are satisfied by equality, which implies that for variables \(y_k\) it is \(y_k = \dfrac{\Vert x\Vert _{\left[ k\right] }}{\Vert x\Vert _{1}}\) and, consequently, they can be eliminated, obtaining:
From now on, we will consider problem (17) as our main problem and call it “Our Model”. We rewrite it in following fractional programming form:
Problem above can be tackled via Dinkelbach’s method (Rodenas et al. 1999), which consist in solving the scalar nonlinear equation \( F\left( p\right) = 0 \) where:
Remark 1
Calculation of \( F\left( p\right) \) amounts to solving an optimization problem in DC (Difference of Convex) form. Observe, in fact, that function \(f(x) \Vert x\Vert _{1}\) is convex, being the product of two convex and non-negative functions. Thus function \(f_p(x)\) can be put in DC form \(f_p(x)=f^{(1)}_p(x)- f^{(2)}_p(x)\) by letting:
\( \text{ if } \,\, p \ge 0 \), and:
\( \text{ if } \,\, p< 0 \).
Remark 2
Function \(f_p(x)\) is nonsmooth. Thus the machinery provided by the literature on optimization of nonsmooth DC functions can be fruitfully adopted to tackle (19) (see Gaudioso et al. (2018a, 2018b) and the references therein). We recall some differential properties of the k-norm. In particular, given any \( x \in {\mathbb {R}}^{n} \), and denoting by \( J_{\left[ k\right] } \left( {\bar{x}}\right) = \left\{ j_{1}, \ldots , j_{k} \right\} \) the index set of k largest absolute-value components of \( {\bar{x}} \), a subgradient \( g^{\left[ k\right] } \in \partial \Vert {\bar{x}}\Vert _{\left[ k\right] } \) can be obtained as Gaudioso et al. (2020, 2017):
Note that the subdifferential \( \partial \Vert .\Vert _{\left[ k\right] } \) is a singleton (i.e. the vector k-norm is differentiable) any time the set \( J_{\left[ k\right] } \left( .\right) \) is uniquely defined.
In the next section, we will first introduce some basic concepts in the field of multi-objective optimization problems and then we will present the previous models in the form of multi-objective optimization problems.
4 Multi-objective optimization problem and reformulated feature selection problems
A Multi-objective optimization problem (MOP) is given as follows (Ehrgott 2005):
where \( X \subseteq {\mathbb {R}}^{n} \), and the objective functions \( f_{k}: {\mathbb {R}}^{n} \rightarrow {\mathbb {R}} \), \( k=1, \ldots ,p \) are continuous. The image of the feasible set X under the objective function mapping f is denoted as \( Y = f\left( X\right) \). Assuming that at least two objective functions are conflicting in (23), no single \( x \in X \) would generally minimize all \( f_{k}\)’s simultaneously. Therefore, Pareto optimality or Pareto efficiency come into play (Ehrgott 2005).
In Pirouz and Khorram (2016) the following computational algorithm based on the \( \epsilon \)-constraint method has been proposed for MOP.
In Phase I, solve the following single-objective optimization problems for \( k=1, \ldots ,p \):
and let \( x_{1}^{*}, \ldots , x_{p}^{*} \) be the optimal solutions of these problems, respectively. Then in the space of objective functions the restricted region is defined as follows, for \( k=1, \ldots ,p \):
Pareto optimal solutions will be searched only inside this restricted region. Note that, according to the definition of the Pareto optimal solution, there is no any Pareto solution outside this restricted region (Pirouz and Khorram 2016).
In Phase II, the following steps are performed in order:
Step 1: For arbitrary values \( d\in {\mathbb {N}} \), the step length \( \Delta _{k} \) determine as follows:
Step 2: In each stage, for any arbitrary \( j \in \{1,\ldots , p\} \) the following single-objective optimization problems will solve for \( l=0,1,\ldots , d \):
According to the following theorem, this method can give the approximation of the Pareto frontier. For more details, refer to Pirouz and Khorram (2016).

The Result of Separator Hyperplanes for Test Problem 1, (\( {C = 10} \))
Theorem 1
Pirouz and Khorram (2016). If \( x^{*} \) is an optimal solution of (27), then it is clear that: 1. \( x^{*} \) is a weakly efficient solution of multi-objective optimization (23), and, 2. Let \( x^{*} \) be a unique optimal solution of (27), then \( x^{*} \) is a strictly efficient solution of multi-objective optimization (23) (and therefore is an efficient solution of multi-objective optimization (23)).
4.1 Multi-objective optimization problem for feature selection
The MOP reformulations of the problems \( l_{1} \), \( l_{2} \) in Sect. 2.2, are as follows, respectively:
Our FS model, formulated according to (17) in section 3 is reformulated as the following MOP:
To solve these multi-objective optimization problems, we can use a modified algorithm based on the Epsilon constraint method which was introduced in Sect. 4. The methods presented in Jaggi (2013) and Sivri et al. (2018) can be used as well.
5 Numerical experiments
In this section, some numerical experiments are presented to compare the results of different models. We will take at first the results of single-objective problems for all of our numerical experiments. Then we will consider the results of MOP reformulations for two of our numerical experiments. To solve the test problems in this paper, we used the Global Solve solver of the global optimization package in MAPLE v.18.01. The algorithms in the Global Optimization toolbox are global search methods, which in this method systematically search the entire feasible region for a global extremum (see Pintér et al. (2006)). To compare the results, we ran all the models for C=1 and C=10. However, we did not report the results of the models with C = 1 in Test Problems 1 to 3, because the error of some models was not equal to zero for this value.
Test Problem 1. (Single objective testing). The following two sets are given:
In this example, the number of samples is 6 and the number of features is 3. We have set \( C = 10 \). All models provide the correct separator of the sets (the error of all models is equal to zero). But \( l_{1} \) and \( l_{2} \) return a vector w where components are all nonzero, whereas the vector w returned by our sparse optimization method has just one nonzero component. The results of this example are depicted in Table 1 and Fig. 1.
Test Problem 2. (Single objective testing). In this example, the number of samples is 14, and the number of features is 3. Suppose that we have the following two sets:
The results are similar to those obtained for Test problem 1 (See Fig. 2 and Table 2).

Data set and the Result of Separator Hyperplanes for Test Problem 2, (\( {C = 10} \))
Test Problem 3. (Single objective testing). In this example, the number of samples is 6, and the number of features is 4. Suppose that we have the following two sets:
We have set \( C = 10 \), and in this test problem also all models provide the correct separator of the sets. Models \( l_{1} \) and \( l_{2} \) return a vector w where components are all nonzero, but the vector w returned by our method has just one nonzero component. The results of this test problem is shown in Table 3.
Test Problem 4. (Single objective testing for Benchmark Problems). We have performed our experiments on a group of five datasets adopted as benchmarks for the feature selection method described in Gaudioso et al. (2018a). These datasets are available at (https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/). They are listed in Table 4, where m is the number of samples and n is the number of features.
A standard tenfold cross-validation has been performed in datasets. The results are in Tables 5, 6 and 7, where the Average Training Correctness (ATC) column is expressed as the average percentage of samples correctly classified.
Columns \( \Vert w\Vert _{1} \) report the average \( l_{1} \) norm of w. Finally, columns “\( \%ft(0) \)” “\( \%ft(-8) \)” report the average percentage of components of w whose modulus is greater than or equal to \( 10^{0}-10^{-8} \), respectively. Note that, assuming, conventionally, to be equal to “zero” any component \( w_{j} \) of w such that \( w_{j} < 10^{-8} \), the percentage of zero-components is \( (100-\%ft(-8)) \). Two different values of parameter C have been adopted for all datasets, \( C=1 \) and 10.
As shown in column \( \%ft(-8) \) of Tables 5, 6 and 7, our model resets the number of more components of the w vector equal to zero in all datasets. Also, our model results in a smaller error value compared to the \( l_{1} \) and \( l_{2} \) methods. In comparison, the correctness of our model classification is better for the whole datasets. For \( c = 10 \), the value of \( \Vert w\Vert _{1} \) in our model results in a smaller value in all datasets.
In the next two test problem, our goal is to demonstrate the benefits of considering the model as a multi-objective optimization problem. In this case, we can obtain a set of Pareto optimal solutions instead of one optimal solution. We consider the \( l_{1} \), \( l_{2} \) and our model as two-objective optimization problems described in Section 4.
Test Problem 5. (MOP Testing). We used the dataset of Test problem 2 for MOP models. The Algorithm introduced in section 4 has been used to solve these MOPs. Here we have set \( d=100 \). Out of 100 Pareto solutions that were obtained for each model we have considered only 2 Pareto solutions for more consideration. The results are displayed in Tables 8, 9 and 10.
For the \( l_1 \) MOP model, as shown in Table 8, for the first Pareto solution with an error value equal to zero, a smaller value for the \( \Vert w\Vert _{1} \) has been achieved compared to the results of the single-objective problem \( l_{1} \), presented in Table 2. For second Pareto solution we have obtained the smallest value for \( \Vert w\Vert _{1} \), where one of the components of w equal to zero, but the error value is nonzero.
For the \( l_2 \) MOP model, as shown in Table 9, for the first Pareto solution with an error value equal to zero, a smaller value for the \( \Vert w\Vert _{1} \) has been achieved compared to the results of the single-objective problem \( l_{2} \) presented in Table 2. For second Pareto solution we have obtained the smallest value for \( \Vert w\Vert _{1} \), but the error value is nonzero.
For our MOP model, as shown in Table 10, for the first Pareto solution with an error value equal to zero, a smaller value for \( \Vert w\Vert _{1} \) has been achieved compared to the results of our single-objective model presented in Table 2. Also, in this Pareto solution, similar to the solution obtained in the single-objective case, two components of the vector w are equal to zero. In the second Pareto solution, a smaller value for \( \Vert w\Vert _{1} \) has been achieved, and the vector w has only one nonzero component, but the error value is nonzero.
Test Problem 6. (MOP Testing). In this example we used the dataset of Test problem 3 for MOP models. We have used the algorithm introduced in section 4 to solve these MOPs, and in this algorithm, we have set \( d=100 \). Out of 100 Pareto solutions that were obtained for each model we have considered only 2 Pareto solutions that seemed interesting for more consideration that are displayed in Tables 11, 12 and 13.
For the \( l_1 \) MOP model, as shown in Table 11, for the first Pareto solution with an error value equal to zero we have obtained a smaller value for \( \Vert w\Vert _{1} \), compared to the results of the \( l_1 \) single-objective model presented in Table 3. For the second Pareto solution, we have obtained a solution where one of the components of w is equal to zero, but the error value is nonzero.
For the \( l_2 \) MOP model, as shown in Table 12, for the first Pareto solution with an error value equal to zero a smaller value for \( \Vert w\Vert _{1} \) is obtained, compared to the results of the \( l_2 \) single-objective model presented in Table 3. For the second Pareto solution we have obtained smallest value for \( \Vert w\Vert _{1} \), but the error value is nonzero.
For our MOP model, as shown in Table 13, the first Pareto solution is similar to the solution that was obtained in the single-objective model in which the vector w returned only one nonzero component. For the second Pareto solution also three components of vector w are equal to zero while \( \Vert w\Vert _{1} \) has decreased but the error value is nonzero .
6 Conclusion
In this paper, we emphasized the application of sparse optimization in Feature Selection for Support Vector Machine classification. We have proposed a new model for sparse optimization based on the polyhedral k-norm. Due to the advantages of using multi-objective optimization models instead of single-objective models, some multi-objective reformulation of Support Vector Machine classification was proposed. The results of some test problems on classification datasets are reported for both single-objective and multi-objective models.
Data availibility
The datasets analysed during the current study are available in the Manuscript and in at (https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/).
References
Al-Ani A, Alsukker A, Khushaba RN (2013) Feature subset selection using differential evolution and a wheel based search strategy. Swarm Evol Comput 9:15–26
Bach F, Jenatton R, Mairal J et al (2011) Convex optimization with sparsity-inducing norms. Optim Mach Learn 5:19–53
Bauschke H, Combettes P (2011) Convex analysis and monotone operator theory in Hilbert spaces. Springer, New York
Bertsimas D, King A, Mazumder R (2016) Best subset selection via a modern optimization lens. Ann Stat 44(2):813–852
Bradley PS, Mangasarian OL (1998) Feature selection via concave minimization and support vector machines. In: ICML, Citeseer, pp 82–90
Cervante L, Xue B, Zhang M, et al (2012) Binary particle swarm optimisation for feature selection: a filter based approach. In: 2012 IEEE Congress on Evolutionary Computation, IEEE, pp 1–8
Ceyhan G, Köksalan M, Lokman B (2019) Finding a representative nondominated set for multi-objective mixed integer programs. Eur J Oper Res 272(1):61–77
Chen Y, Miao D, Wang R (2010) A rough set approach to feature selection based on ant colony optimization. Pattern Recogn Lett 31(3):226–233
Cristianini N, Shawe-Taylor J et al (2000) An introduction to support vector machines and other kernel-based learning methods. Cambridge University Press, Cambridge
Das I, Dennis JE (1998) Normal-boundary intersection—a new method for generating the pareto surface in nonlinear multicriteria optimization problems. SIAM J Optim 8(3):631–657
Dolatnezhadsomarin A, Khorram E, Pourkarimi L (2019) Efficient algorithms for solving nonlinear fractional programming problems. Filomat 33(7):2149–2179. https://doi.org/10.2298/FIL1907149D
Dutta J, Kaya CY (2011) A new scalarization and numerical method for constructing the weak pareto front of multi-objective optimization problems. Optimization 60(8–9):1091–1104
Ehrgott M (2005) Multicriteria optimization, vol 491. Springer Science, London
Fonseca CM, Fleming PJ, et al (1993) Genetic algorithms for multiobjective optimization: Formulation discussion and generalization. In: ICGA, Citeseer, pp 416–423
Forman G et al (2003) An extensive empirical study of feature selection metrics for text classification. J Mach Learn Res 3:1289–1305
Gambella C, Ghaddar B, Naoum-Sawaya J (2021) Optimization problems for machine learning: a survey. Eur J Oper Res 290(3):807–828. https://doi.org/10.1016/j.ejor.2020.08.045
Gasso G, Rakotomamonjy A, Canu S (2009) Recovering sparse signals with a certain family of nonconvex penalties and DC programming. IEEE Trans Signal Process 57(12):4686–4698
Gaudioso M, Hiriart-Urruty JB (2022) Deforming \(||.||_1\) into \(||.||_{\infty }\) via polyhedral norms: A pedestrian approach. SIAM Rev 64(3):713–727. https://doi.org/10.1137/21M1391481
Gaudioso M, Gorgone E, Labbé M et al (2017) Lagrangian relaxation for SVM feature selection. Comput Oper Res 87:137–145. https://doi.org/10.1016/j.cor.2017.06.001
Gaudioso M, Giallombardo G, Miglionico G (2018) Minimizing piecewise-concave functions over polyhedra. Math Oper Res 43(2):580–597
Gaudioso M, Giallombardo G, Miglionico G et al (2018) Minimizing nonsmooth DC functions via successive dc piecewise-affine approximations. J Global Optim 71(1):37–55
Gaudioso M, Gorgone E, Hiriart-Urruty JB (2020) Feature selection in SVM via polyhedral k-norm. Optim Lett 14(1):19–36. https://doi.org/10.1007/s11590-019-01482-1
Ghane-Kanafi A, Khorram E (2015) A new scalarization method for finding the efficient frontier in non-convex multi-objective problems. Appl Math Model 39(23–24):7483–7498
Jy G, Takeda A, Tono K (2018) Dc formulations and algorithms for sparse optimization problems. Math Program 169(1):141–176
Hamdani TM, Won JM, Alimi AM, et al (2007) Multi-objective feature selection with NSGA II. In: International conference on adaptive and natural computing algorithms, Springer, pp 240–247
Haykin S, Network N (2004) A comprehensive foundation. Neural Netw 2(2004):41
Hempel AB, Goulart PJ (2014) A novel method for modelling cardinality and rank constraints. In: 53rd IEEE Conference on Decision and Control, IEEE, pp 4322–4327
Jafari-Petroudi S, Pirouz M (2016) On the bounds for the spectral norm of particular matrices with Fibonacci and Lucas numbers. Int J Adv Appl Math Mech 3(4):82–90
Jafari-Petroudi SH, Pirouz B (2015a) An investigation on some properties of special Hankel matrices. In: The 46 th Annual Iranian Mathematics Conference, p 470
Jafari-Petroudi SH, Pirouz B (2015) A particular matrix, its inversion and some norms. Appl Comput Math 4:47–52
Jaggi M (2013) Revisiting frank-wolfe: Projection-free sparse convex optimization. In: International Conference on Machine Learning, PMLR, pp 427–435
John GH, Kohavi R, Pfleger K (1994) Irrelevant features and the subset selection problem. In: Machine learning proceedings 1994. Elsevier, p 121–129
Mangasarian O (1996) Machine learning via polyhedral concave minimization. In: Applied Mathematics and Parallel Computing. Springer, p 175–188
Neshatian K, Zhang M (2009) Pareto front feature selection: using genetic programming to explore feature space. In: Proceedings of the 11th Annual conference on Genetic and evolutionary computation, pp 1027–1034
Nolfi S, Parisi D, Elman JL (1994) Learning and evolution in neural networks. Adapt Behav 3(1):5–28
Petroudi SHJ, Pirouz B (2015) On the bounds and norms of a particular hadamard exponential matrix. Appl Math Eng, Manag Technol 3(2):257–263
Petroudi SHJ, Pirouz M, Akbiyik M et al (2022) Some special matrices with harmonic numbers. Konuralp J Math 10(1):188–196
Pilanci M, Wainwright MJ, El Ghaoui L (2015) Sparse learning via Boolean relaxations. Math Program 151(1):63–87
Pintér JD, Linder D, Chin P (2006) Global optimization toolbox for maple: an introduction with illustrative applications. Optim Methods Softw 21(4):565–582. https://doi.org/10.1080/10556780600628212
Pirouz B, Khorram E (2016) A computational approach based on the \(\varepsilon \)-constraint method in multi-objective optimization problems. Adv Appl Stat 49:453
Pirouz B, Ramezani Paschapari J (2019) A computational algorithm based on normalization for constructing the pareto front of multiobjective optimization problems. In: In 2019, 5th International Conference on Industrial and Systems Engineering
Ferrante AP, Pirouz B, Pirouz B et al (2021) Machine learning and geo-based multi-criteria decision support systems in analysis of complex problems. ISPRS Int J Geo Inf 10(6):424. https://doi.org/10.3390/ijgi10060424
Rinaldi F (2009) Mathematical programming methods for minimizing the zero-norm over polyhedral sets. Sapienza, University of Rome http://www.mathunipdit/rinaldi/papers/thesis0pdf
Rinaldi F, Schoen F, Sciandrone M (2010) Concave programming for minimizing the zero-norm over polyhedral sets. Comput Optim Appl 46(3):467–486. https://doi.org/10.1007/s10589-008-9202-9
Rodenas RG, Lopez ML, Verastegui D (1999) Extensions of Dinkelbach’s algorithm for solving non-linear fractional programming problems. TOP 7(1):33–70. https://doi.org/10.1007/BF02564711
Rumelhart DE, Hinton GE, Williams RJ (1986) Learning representations by back-propagating errors. Nature 323(6088):533–536
Sivri M, Albayrak I, Temelcan G (2018) A novel solution approach using linearization technique for nonlinear programming problems. Int J Comput Appl 181(12):1–5
Soubies E, Blanc-Féraud L, Aubert G (2017) A unified view of exact continuous penalties for \(\backslash \)ell_2-\(\backslash \)ell_0 minimization. SIAM J Optim 27(3):2034–2060
Swain PH, Davis SM (1981) Remote sensing: the quantitative approach. IEEE Trans Pattern Anal Mach Intell 3(06):713–714
Watson GA (1992) Linear best approximation using a class of polyhedral norms. Numer Algorithms 2(3):321–335
Weston J, Mukherjee S, Chapelle O, et al (2000) Feature selection for SVMS. In: Advances in neural information processing systems 13
Wright SJ (2012) Accelerated block-coordinate relaxation for regularized optimization. SIAM J Optim 22(1):159–186
Wu B, Ding C, Sun D et al (2014) On the Moreau–Yosida regularization of the vector k-norm related functions. SIAM J Optim 24(2):766–794
Funding
Open access funding provided by Università della Calabria within the CRUI-CARE Agreement. The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose. The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any study with human participants or animals performed by the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pirouz, B., Gaudioso, M. New mixed integer fractional programming problem and some multi-objective models for sparse optimization. Soft Comput 27, 15893–15904 (2023). https://doi.org/10.1007/s00500-023-08839-w
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-023-08839-w