
Abstract
This paper is focused on the unbalanced fixed effects panel data model. This is a linear regression model able to represent unobserved heterogeneity in the data, by allowing each two distinct observational units to have possibly different numbers of associated observations. We specifically address the case in which the model includes the additional possibility of controlling the conditional variance of the output given the input and the selection probabilities of the different units per unit time. This is achieved by varying the cost associated with the supervision of each training example. Assuming an upper bound on the expected total supervision cost and fixing the expected number of observed units for each instant, we analyze and optimize the trade-off between sample size, precision of supervision (the reciprocal of the conditional variance of the output) and selection probabilities. This is obtained by formulating and solving a suitable optimization problem. The formulation of such a problem is based on a large-sample upper bound on the generalization error associated with the estimates of the parameters of the unbalanced fixed effects panel data model, conditioned on the training input dataset. We prove that, under appropriate assumptions, in some cases “many but bad” examples provide a smaller large-sample upper bound on the conditional generalization error than “few but good” ones, whereas in other cases the opposite occurs. We conclude discussing possible applications of the presented results, and extensions of the proposed optimization framework to other panel data models.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In many situations involving economics, engineering, physics, and other fields, it is required to approximate a function on the basis of a finite set of input–output noisy examples. This belongs to the typical class of problems addressed by supervised machine learning (Vapnik 1998). In some cases, the output noise variance can be reduced to some extent, by increasing the cost of each supervision. For example, devices with higher precision could be used to acquire measurements, or experts could be involved in the data analysis procedure. However, in the presence of a budget constraint, increasing the cost of each supervision could reduce the total number of available labeled examples. In such cases, the investigation of an optimal trade-off between the sample size and the precision of supervision plays a key role. In Gnecco and Nutarelli (2019a), this analysis was carried out by employing the classical linear regression model, suitably modified in order to include the additional possibility of controlling the conditional variance of the output given the input. Specifically, this was pursued by varying the time (hence, the cost) dedicated to the supervision of each training example, and fixing an upper bound on the total available supervision time. Based on a large-sample approximation of the output of the ordinary least squares regression algorithm, it was shown therein that the optimal choice of the supervision time per example is highly dependent on the noise model. The analysis was refined in Gnecco and Nutarelli (2019b)Footnote 1, where an additional algorithm (weighted least squares) was considered, and shown to produce similar results at optimality as the ordinary least squares algorithm, for a model in which different training examples are possibly associated with different supervision times.
In this work, we analyze the optimal trade-off between sample size, precision of supervision, and selection probabilities for a more general linear model of the input–output relationship, which is the unbalanced fixed effects panel data model. The (either balanced or unbalanced) fixed effects model is commonly applied in the econometric analysis of microeconomic and macroeconomic data (Andreß et al. 2013; Arellano 2004; Cameron and Trivedi 2005; Wooldridge 2002), where each unit may represent, e.g., a firm, or a country. It is also applied, among other fields, in biostatistics (Härdle et al. 2007), educational research (Sherron et al. 2000), engineering (Reeve 1988; Yu et al. 2018; Zeifman 2015), neuroscience (Friston et al. 1999), political science (Bell and Jones 2014), and sociology (Frees 2004). In a fixed effects panel data model, observations related to different observational units (individuals) are associated with possibly different constants, which are able to represent unobserved heterogeneity in the data. Moreover, the same unit is observed along another dimension, which is typically time. In the unbalanced case, at each instant, different units may be not observed with some positive probability (possibly unit-dependent), resulting in a possibly unbalanced panel. In this framework, the balanced case corresponds to the situation in which the number of observations is the same for all the units.
The present work extends significantly the analysis of our previous conference article (Gnecco and Nutarelli 2020) to the unbalanced fixed effects panel data model, which is more general than the balanced case considered therein, and leads to an optimization problem that is more complex to investigate. Indeed, in Gnecco and Nutarelli (2020), all the units are always selected at each instant, therefore the selection probabilities do not appear as optimization variables in the corresponding model. Moreover, theoretical arguments are reported in much more details in the current work.
The results that will be presented in this paper concerning the unbalanced fixed effects panel data model are consistent with those of Gnecco and Nutarelli (2020) for the balanced case, and those of Gnecco and Nutarelli (2019a, (2019b) concerning simpler linear regression models. Specifically, we show that, also for the unbalanced fixed effects panel data model, the following holds. When the precision of the supervision increases less than proportionally with respect to the supervision cost per example, the minimum (large-sample upper bound on the) generalization error (conditioned on the training input dataset) is obtained in correspondence of the smallest supervision cost per example. As a consequence of the problem formulation, this corresponds to the choice of the largest number of examples. Instead, when the precision of the supervision increases more than proportionally with respect to the supervision cost per example, the optimal supervision cost per example is the largest one. Again, as a consequence of the problem formulation, this corresponds to the choice of the smallest number of examples. The structure of the optimal selection probabilities is also investigated, under the constraint of a constant expected number of observed units for each instant. In summary, the results of the theoretical analyses performed, for different regression models of increasing complexity, in Gnecco and Nutarelli (2019a, (2019b, (2020), and in this paper highlight that, in some circumstances, collecting a smaller number of more reliable data is preferable than increasing the size of the sample set. This looks particularly relevant when one is given a certain flexibility in designing the data collection process.
Up to our knowledge, the analysis and the optimization of the trade-off between sample size, precision of supervision, and selection probabilities in regression has been carried out rarely in the machine-learning literature. Nevertheless, the approach applied in this paper resembles the one used in the optimization of sample survey design, where some of the design parameters are optimized to minimize the sampling variance (Groves et al. 2004). Such an approach is also similar to the one exploited in Nguyen et al. (2009) for the optimization of the design of measurement devices. In that framework, however, linear regression is marginally involved, since only arithmetic averages of measurement results are considered therein. The search for optimal sample designs can be also performed by the Optimal Computing Budget Allocation (OCBA) method (Chen and Lee 2010). Differently from that approach, however, our analysis provides the optimal design a priori, i.e., before actually collecting the data. Our work can also be related to recent literature dealing with the joint application of machine learning, optimization, and econometrics (Varian 2014; Athey and Imbens 2016; Bargagli Stoffi and Gnecco 2018, 2019; Crane-Droesch 2017). For instance, the generalization error—which is typically investigated by machine learning, and optimized by solving suitable optimization problems—is not addressed in the classical analysis of the either balanced or unbalanced fixed effects panel data model (Wooldridge 2002, Chapters 10 and 17). Finally, an advantage of the approach considered in this work with respect to other possible ones grounded on Statistical Learning Theory (SLT) (Vapnik 1998) is that, being based on a large-sample approximation, it provides bounds on the conditional generalization error that do not need any a-posteriori evaluation of empirical risks.
The paper is structured as follows. Section 2 provides a background on the unbalanced fixed effects panel data model. Section 3 presents the analysis of its conditional generalization error, and of the large-sample upper bound on the latter with respect to time. Section 4 formulates and solves the optimization problem modeling the trade-off between sample size, precision of supervision, and selection probabilities for the unbalanced fixed effects panel data model, using the large-sample upper bound above. Finally, Sect. 5 discusses some possible applications and extensions of the theoretical results obtained in the work.
2 Background
We recall some basic facts about the following (static) unbalanced fixed effects panel data model (see, e.g., (Wooldridge 2002, Chapters 10 and 17)). Let \(n=1,\ldots ,N\) denote observational units and, for each n, let \(t=1,\ldots ,T_n\) be time instants. Moreover, let the inputs \(\varvec{x}_{n,t}\) (\(n=1,\ldots ,N,t=1,\ldots ,T_n\)) to the model be random column vectors in \({\mathbb {R}}^p\) and, for each \(n=1,\ldots ,N\) and \(t=1,\ldots ,T_n\), let the output \(y_{n,t} \in {\mathbb {R}}\) be a scalar. The parameters of the model are some individual constants \(\eta _n\) (\(n=1,\ldots ,N)\), one for each unit, and a column vector \(\varvec{\beta }\in {\mathbb {R}}^p\). The (noise-free) input–output relationship is expressed as follows:
Equation (1) represents an unbalanced panel data model, which can be applied in the following two situations:
-
distinct units n are associated with possibly different numbers \(T_n\) of data collected at each time instant \(t=1,\ldots ,T_n\) over a whole observation period \(T \ge \max _{n=1}^N T_n\);
-
the observations related to the same unit are associated with a subsequence \(\{t_1,t_2,\ldots ,t_{T_n}\}\) of the sequence \(\{1,2,\ldots ,T\}\).
In the next sections, we focus on the second situation. To avoid burdening the notation by introducing an additional index, we still indicate, also in this case, by \(\{1,2,\ldots ,T_n\}\) the subsequence \(\{t_1,t_2,\ldots ,t_{T_n}\}\). A possible way to get different numbers of observations \(T_n\) for distinct units consists in associating to each unit n a scalar \(q_n \in (0, 1]\), which denotes the (positive) probability that n is observed at any time t. Selections for different units are supposed to be mutually independent. For simplicity, for each unit, selections at different times are also assumed to be mutually independent. For a total observation time T, denoting by \({\mathbb {E}}\) the expectation operator, the expected number of observations for each unit n is \({\mathbb {E}}\left\{ T_n\right\} =q_n T\). The balanced case, which was considered in the analysis of Gnecco and Nutarelli (2020), corresponds to the situation \(q_n=1\) for each n.
Let \(\{\varepsilon _{n,t}\}_{n=1,\ldots ,N,\,t=1,\ldots ,T_n}\) be a collection of mutually independent and identically distributed random variables, having mean 0 and the same variance \(\sigma ^2\). Moreover, let all the \(\varepsilon _{n,t}\) be independent also from all the \(\varvec{x}_{n,t}\). It is assumed that noisy measurements \({\tilde{y}}_{n,t}\) of the outputs \(y_{n,t}\) are available; specifically, the following additive noise model is considered:
The input–output pairs \(\left( \varvec{x}_{n,t}, {\tilde{y}}_{n,t}\right) \) for \(n=1,\ldots ,N\), \(t=1,\ldots ,T_n\), are used to train the model, i.e., to estimate its parameters. In the following, for \(n=1,\ldots ,N\), let \(\varvec{X}_n \in {\mathbb {R}}^{T_n,p}\) denote the matrix whose rows are the transposes of the \(\varvec{x}_{n,t}\); \(\tilde{\varvec{y}}_n\) be the column vector that collects the noisy measurements \({\tilde{y}}_{n,t}\); \(\varvec{I}_{T_n} \in {\mathbb {R}}^{T_n \times T_n}\) denote the identity matrix; \(\varvec{1}_{T_n} \in {\mathbb {R}}^{T_n}\) be the column vector whose elements are all equal to 1; and
be a symmetric and idempotent matrix, i.e., such that \(\varvec{Q}_n'=\varvec{Q}_n=\varvec{Q}_n^2\). Hence, for each unit n,
and
represent, respectively, the matrix of time de-meaned training inputs, and the vector of time de-meaned corrupted training outputs. The aim of time de-meaning is to generate another dataset that does not include the fixed effects, making it possible to estimate first the vector \({\varvec{\beta }}\), then—going back to the original dataset—the fixed effects \(\eta _n\).
Assuming in the following the invertibility of the matrix \(\sum _{n=1}^N \varvec{X}_n' \varvec{Q}_n \varvec{X}_n\) (see the next Remark 3.2 for a mild condition ensuring this), the fixed effects estimate of \(\varvec{\beta }\) for the unbalanced case is
The unbalanced Fixed Effects (FE) estimates of the \(\eta _n\), for \(n=1,\ldots ,N\), are
Let \(\varvec{0}_p \in {\mathbb {R}}^p\) be the column vector whose elements are all equal to 0. By taking expectations and recalling the respective definitions and the fact that the measurement errors have 0 mean, it follows that the estimates (6) and (7) are conditionally unbiased with respect to the training input dataset \(\{\varvec{X}_{n}\}_{n=1}^{N}\), i.e.,
and, for any \(i=1,\ldots ,N\),
Finally, the covariance matrix of \(\varvec{{\hat{\beta }}}_\mathrm{FE}\), conditioned on the training input dataset, is
3 Large-sample upper bound on the conditional generalization error
This section analyzes the generalization error associated with the FE estimates (6) and (7), conditioned on the training input dataset, by providing its large-sample approximation, and a related large-sample upper bound on it. Then, in the next section, the resulting expression is optimized, after choosing a suitable model for the variance \(\sigma ^2\) of the measurement noise, and imposing appropriate constraints.
Let \(\varvec{x}_i^\mathrm{test} \in {\mathbb {R}}^p\) be a random test vector, which is assumed to have finite mean and finite covariance matrix, and to be independent from the training data. We express the generalization error for the i-th unit (\(i=1,\ldots ,N\)), conditioned on the training input dataset, as followsFootnote 2:
The conditional generalization error (11) represents the expected mean squared error of the prediction of the output associated with a test input, conditioned on the training input dataset.
For \(n=1,\ldots ,N\), let \(\varvec{\varepsilon }_n \in {\mathbb {R}}^{T_n}\) be the column vector whose elements are the \(\varepsilon _{n,t}\); \(\varvec{\eta }_n \in {\mathbb {R}}^{T_n}\) be the column vector whose elements are all equal to \(\eta _n\); and \(\varvec{0}_{T_n \times T_n} \in {\mathbb {R}}^{T_n \times T_n}\) be a matrix whose elements are all equal to 0. Noting that
and
we can express the conditional generalization error (11) as follows, highlighting its dependence on \(\sigma ^2\) and \(T_i\) (see “Appendix 1” for the details):
Next, we obtain a large-sample approximation of the conditional generalization error (18) with respect to T, for a fixed number N of unitsFootnote 3.
For \(n=1,\ldots ,N\), let the symmetric and positive semi-definite matrices \(\varvec{A}_n \in {\mathbb {R}}^{p \times p}\) be defined as
In the following, the positive definiteness (hence, the invertibility) of each matrix \(A_n\) is assumed. This is a quite mild condition because it is associated with the fact that, with positive probability, the random vectors \(\varvec{x}_{n,1}-{\mathbb {E}} \left\{ \varvec{x}_{n,1}\right\} \) do not belong to any given subspace of \({\mathbb {R}}^p\) with dimension smaller than p (so, they are effectively p-dimensional random vectors).
Under mild conditions (e.g., if the \(\varvec{x}_{n,t}\) are mutually independent, identically distributed, and have finite moments up to the order 4), the following convergences in probabilityFootnote 4 hold:
and
where
which is the weighted summation, with positive weights \(q_n\), of the symmetric and positive definite matrices \(\varvec{A}_n\), hence it is also a symmetric and positive definite matrix.
Remark 3.1
Equations (20) and (21) follow from the extension of Chebyschev’s weak law of large numbers (Ruud 2000, Section 13.4.2) to the case of the summation of a random number of mutually independent random variables (Révész 1968, Theorem 10.1), combined with other technical results. First, for each \(n=1,\ldots ,N\), convergence in probability of \(\frac{1}{T_n} \varvec{X}_n' \varvec{Q}_n' \varvec{Q}_n \varvec{X}_n\) to \(\varvec{A}_n\) is proved element-wise, by applying (Révész 1968, Theorem 10.1). Then, one exploits the fact that, as a consequence of the Continuous Mapping Theorem (Florescu 2015, Theorem 7.33), the probability limit of the product of two random variables (in this case, \(\frac{T_n}{T}\) and each element of \(\frac{1}{T_n} \varvec{X}_n' \varvec{Q}_n' \varvec{Q}_n \varvec{X}_n\)) equals the product of their probability limits, when the latter two exist (which is the case for \(\frac{T_n}{T}\) and each element of \(\frac{1}{T_n} \varvec{X}_n' \varvec{Q}_n' \varvec{Q}_n \varvec{X}_n\)). Finally, one applies the fact that, for a random matrix, element-wise convergence in probability implies convergence in probability of the whole random matrix (Lee 2010).
Remark 3.2
The existence of the probability limit (21) and the positive definiteness of the matrix \(\varvec{A}_N\) guarantee that the invertibility of the matrix
(see Sect. 2) holds with probability close to 1 for large T. Due to the generalization of Slutsky’s theorem reported in (Greene 2003, Theorem D.14)Footnote 5, under the stated assumptions also the sequence of random matrices
converges in probability to \(\varvec{A}_N^{-1}\). This is needed to obtain the next large-sample approximation (25) of the conditional generalization error.
Remark 3.3
We point out that the conditional generalization error (11) is investigated in this work, instead of its unconditional version because, in general, probability limits and expectations cannot be inverted in order. This could prevent the application of (Greene 2003, Theorem D.14) (or of similar results about probability limits) when performing a similar analysis for the unconditional generalization error.
Let \(\Vert \cdot \Vert _2\) denote the \(l_2\)-norm, and \(\varvec{A}_N^{-\frac{1}{2}}\) be the principal square root (i.e., the symmetric and positive definite square root) of the symmetric and positive definite matrix \(\varvec{A}_N^{-1}\). When (20) and (21) hold, from (18) and the assumed independence of \(\varvec{x}_i^\mathrm{test}\) from all the other random vectors we get the following large-sample approximation (with respect to T) for the conditional generalization error (11):
In the following, we denote, for a generic symmetric matrix \(\varvec{A} \in {\mathbb {R}}^{s \times s}\), by \(\lambda _\mathrm{min}(\varvec{A})\) and \(\lambda _{\mathrm{max}}(\varvec{A})\), respectively, its minimum and maximum eigenvalue. Starting from the large-sample approximation (25), the following steps can be proved (see “Appendix 2” for the details):
We refer to the inequality
as the large-sample upper bound on the conditional generalization error. Interestingly, its right-hand side is expressed in the separable form \(\frac{\sigma ^2}{T} K_i (\{q_n\}_{n=1}^N)\), where
depends only on the \(q_n\). As shown in the next section, this simplifies the analysis of the trade-off between sample size, precision of supervision, and selection probabilities performed therein, since one does not need to compute the exact expression of the function \(K_i (\{q_n\}_{n=1}^N)\) to find the optimal trade-off with respect to a suitable subset of optimization variables.
4 Optimal trade-off between sample size, precision of supervision, and selection probabilities
In this section, we are interested in optimizing the large-sample upper bound (27) of the conditional generalization error when the variance \(\sigma ^2\) is modeled as a decreasing function of the supervision cost per example c, and a given upper bound \(C>0\) is imposed on the expected total supervision cost \(\sum _{n=1}^N q_n T c\) associated with the whole training set. For large T, this upper bound practically coincides with the total supervision cost \(\sum _{n=1}^N T_n c\). This follows by an application of Chebyschev’s weak law of large numbers.
Remark 4.1
In our previous conference work (Gnecco and Nutarelli 2020), the large-sample approximation (25) was optimized, instead of (27). This was motivated by the fact that all the selection probabilities \(q_n\) were fixed to 1, implying that both \(q_i\) and \(A_N\), hence also the term
were constant therein.
In the following analysis of the optimal trade-off, N is kept fixed; furthermore, one imposes the constraints
for some given \(q_{n,\mathrm{min}} \in (0,1)\) and \(q_{n,\mathrm{max}} \in [q_{n,\mathrm{min}}, 1]\), and
for some given \({\bar{q}} \in \left[ \frac{\sum _{n=1}^N q_{n,\mathrm{min}}}{N},\frac{\sum _{n=1}^N q_{n,\mathrm{max}}}{N}\right] \subseteq (0,1]\). In Eq. (31), \(\sum _{n=1}^N q_n\) represents the expected number of observed units for each instant, which is fixed. Moreover, T is chosen as \(\left\lfloor \frac{C}{{\bar{q}} N c} \right\rfloor \). Finally, the supervision cost per example c is allowed to take values on the interval \([c_{\mathrm{min}}, c_{\mathrm{max}}]\), where \(0< c_{\mathrm{min}} < c_{\mathrm{max}}\), so that the resulting T belongs to \(\left\{ \left\lfloor \frac{C}{{\bar{q}} N c_{\mathrm{max}}} \right\rfloor , \ldots , \left\lfloor \frac{C}{{\bar{q}} N c_{\mathrm{min}}} \right\rfloor \right\} \). In the following, C is supposed to be sufficiently large, so that the large-sample upper bound (27) can be assumed to hold for every \(c \in [c_{\mathrm{min}}, c_{\mathrm{max}}]\) and every \(q_n \in [q_{n, \mathrm{min}}, q_{n, \mathrm{max}}]\) (for \(n=1,\ldots ,N\)).
Consistently with (Gnecco and Nutarelli 2019a, b, 2020), we adopt the following model for the variance \(\sigma ^2\), as a function of the supervision cost per example c:
where \(k,\alpha > 0\). For \(0< \alpha < 1\), if one doubles the supervision cost per example c, then the precision \(1/\sigma ^2(c)\) (i.e., the reciprocal of the conditional variance of the output) becomes less than two times its initial value (or equivalently, the variance \(\sigma ^2(c)\) becomes more than one half its initial value). This case is referred to as “decreasing returns of scale” in the precision of each supervision. Conversely, for \(\alpha > 1\), if one doubles the supervision cost per example c, then the precision \(1/\sigma ^2(c)\) becomes more than two times its initial value (or equivalently, the variance \(\sigma ^2(c)\) becomes less than one half its initial value). This case is referred to as “increasing returns of scale” in the precision of each supervision. Finally, the case \(\alpha =1\) is intermediate and refers to “constant returns of scale”. In all the cases above, the precision of each supervision increases by increasing the supervision cost per example c.

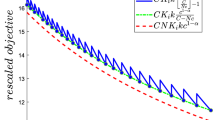
Plots of the rescaled objective functions \(C K_i (\{q_n\}_{n=1}^N) k\frac{c^{-\alpha }}{\left\lfloor \frac{C}{{\bar{q}} N c} \right\rfloor }\) and \({\bar{q}} N K_i (\{q_n\}_{n=1}^N) k c^{1-\alpha }\) for \(\alpha = 0.5 \) (a), \(\alpha = 1.5 \) (b), and \(\alpha = 1\) (c). The values chosen for the other parameters are detailed in the text
Summarizing, under the assumptions above, the optimal trade-off between sample size, precision of supervision, and selection probabilities for the unbalanced fixed effects panel data model is modeled by the following optimization problem:
By a similar argument as in the proof of (Gnecco and Nutarelli 2019b, Proposition 3.2), which refers to an analogous function approximation problem, when C is sufficiently large, the objective function \(C K_i (\{q_n\}_{n=1}^N) k\frac{c^{-\alpha }}{\left\lfloor \frac{C}{{\bar{q}} N c} \right\rfloor }\) of the optimization problem (33), rescaled by the multiplicative factor C, can be approximated, with a negligible error in the maximum norm on \([c_{\mathrm{min}}, c_{\mathrm{max}}] \times \Pi _{n=1}^N [q_{n,\mathrm{min}}, q_{n,\mathrm{max}}]\), by \({\bar{q}} N K_i (\{q_n\}_{n=1}^N) k c^{1-\alpha }\). Figure 1 shows the behavior of the rescaled objective functions
and
for the three cases \(0<\alpha = 0.5 < 1\), \(\alpha = 1.5 > 1\), and \(\alpha = 1\). The values of the other parameters are \(k=0.5\), \({\bar{q}}=0.5\), \(K_i (\{q_n\}_{n=1}^N)=2\) (which can be assumed to hold for a fixed choice of the set of the \(q_n\)), \(N=10\), \(C=125\), \(c_{\mathrm{min}}=0.4\), and \(c_{\mathrm{max}}=0.8\). One can show by standard calculus that, for \(C \rightarrow +\infty \) and the \(q_n\) fixed to constant values, the number of discontinuity points of the rescaled objective function \(C K_i (\{q_n\}_{n=1}^N) k\frac{c^{-\alpha }}{\left\lfloor \frac{C}{{\bar{q}} N c} \right\rfloor }\) tends to infinity, whereas the amplitude of its oscillations above the lower envelope \({\bar{q}} N K_i (\{q_n\}_{n=1}^N) k c^{1-\alpha }\) tends to 0 uniformly with respect to \(c \in [c_{\mathrm{min}}, c_{\mathrm{max}}]\).
Concluding, under the approximation above, one can replace the optimization problem (33) with
Such optimization problem appears in a separable form, in which one can optimize separately the variable c and the variables \(q_n\), for \(n=1,\ldots ,N\). In particular, the optimal solutions \(c^\circ \) have the following expressions:
-
(a)
if \(0< \alpha < 1\) (“decreasing returns of scale”): \(c^\circ = c_{\mathrm{min}}\);
-
(b)
if \(\alpha > 1\) (“increasing returns of scale”): \(c^\circ = c_{\mathrm{max}}\);
-
(c)
if \(\alpha = 1\) (“constant returns of scale”): \(c^\circ =\) any cost c in the interval \([c_{\mathrm{min}}, c_{\mathrm{max}}]\).
In summary, the results of this part of the analysis show that, in the case of “decreasing returns of scale”, “many but bad” examples are associated with a smaller large-sample upper bound on the conditional generalization error than “few but good” ones. The opposite occurs for “increasing returns of scale”, whereas the case of “constant returns of scale” is intermediate. These results are qualitatively in line with the ones obtained in Gnecco and Nutarelli (2020) for the balanced case and in Gnecco and Nutarelli (2019a, (2019b) for simpler linear regression problems, to which the ordinary/weighted least squares algorithms were applied. This depends on the fact that, in all these cases, the large-sample approximation of the conditional generalization error (or its large-sample upper bound) has the functional form \(\frac{\sigma ^2}{T} K_i\), where \(K_i\) is either a constant, or depends on optimization variables related to neither \(\sigma \) nor T.
One can observe that, in order to discriminate among the three cases of the analysis reported above, it is not needed to know the exact values of the constants k and N, neither the expression of \(K_i\) as a function of the \(q_n\). Moreover, to discriminate between the first two cases, it is not necessary to know the exact value of the positive constant \(\alpha \). Indeed, it suffices to know if \(\alpha \) belongs, respectively, to the interval (0, 1) or the interval \((1,+\infty )\). Finally, for this part of the analysis, knowledge of the probability distributions of the input examples associated with the different units is limited to the determination of the expressions of the constants \(\lambda _{\mathrm{min}}({\varvec{A}}_n)\) involved in the optimization of the variables \(q_n\).
Assuming that the constant terms \(\lambda _{\mathrm{min}}({\varvec{A}}_n)\) and \({\mathbb {E}} \left\{ \left\| \left( {\mathbb {E}} \left\{ \varvec{x}_{i,1}\right\} -\varvec{x}_i^\mathrm{test}\right) \right\| _2^2\right\} \) are known, optimal \(q_n^{\circ }\) can be derived as follows. First, note that, for each fixed admissible choice of \(q_i\), the optimization of the other \(q_n\) can be restated as follows:
More precisely, an admissible choice for \(q_i\) is one for which \(q_i \in \left[ {\hat{q}}_{i,\mathrm{min}}, {\hat{q}}_{i,\mathrm{max}} \right] \), where
and
The optimization problem (37) is a linear programming one, which can be reduced to a continuous knapsack problem (Martello and Toth 1990, Section 2.2.1), after a rescaling of all its optimization variables and of their respective bounds. It is well known that, due to its particular structure, such a problem can be solved by the following greedy algorithm, which is divided into three steps (for simplicity of exposition, we assume that all the \(\lambda _{\min }({\varvec{A}}_n)\) are different from each other):
-
1.
first, the variables \(q_n\) are re-ordered according to decreasing values of the associated \(\lambda _{\min }({\varvec{A}}_n)\). So, let \(\check{q}_{n}:=q_{\pi (n)}\) and \(\check{\varvec{A}}_n:={\varvec{A}}_{\pi (n)}\), where the function \(\pi : \{1,\ldots ,N\} \rightarrow \{1,\ldots ,N\}\) is a permutation satisfying \(\lambda _{\min }(\check{\varvec{A}}_m) < \lambda _{\min }(\check{\varvec{A}}_n)\) for every \(m \ge n\). Let also \(\check{i}=\pi (i)\);
-
2.
starting from \(\check{q}_{n}=\check{q}_{n,\mathrm{min}}\) for every \(n \ne \check{i}\), the first variable \(\check{q}_{1}\) (if \(\check{i} \ne 1\)) is increased until either the constraint \(\sum _{n=1,\ldots ,N, n \ne \check{i}} \check{q}_n = {\bar{q}} N-\check{q}_{\check{i}}\), or the constraint \(\check{q}_{1}=\check{q}_{1,\mathrm{max}}\), is met; if \(\check{i}=1\), then the procedure is applied to the second variable \(\check{q}_{2}\);
-
3.
step 2 is repeated for the successive variables (excluding \(\check{q}_{\check{i}}\)), terminating the first time the constraint \(\sum _{n=1,\ldots ,N, n \ne \check{i}} \check{q}_n = {\bar{q}} N-\check{q}_{\check{i}}\) is met (this surely occurs, since \(q_i\) is admissible).
The resulting optimal \(q_n^{\circ }\) (for \(n=1,\ldots ,N\) with \(n \ne i\)) are parametrized by the remaining variable \(q_i\). Then, the optimal value of the objective function of the optimization problem (37) is a real-valued function of \(q_i\) which, in the following, is denoted by \(f_i(q_i)\). It follows from the procedure above that \(f_i(q_i)\) is a continuous and piece-wise affine function of \(q_i\), with piece-wise constant slopes \(\lambda _{\min }(\check{\varvec{A}}_{\check{i}})-\lambda _{\min }(\check{\varvec{A}}_{n(q_i)})\), where the choice of the index n is a function of \(q_i\), and is such that \(\lambda _{\min }(\check{\varvec{A}}_{n(q_i)})\) is a nonincreasing function of \(q_i\). Hence, \(f_i(q_i)\) is concave, and is nondecreasing for \(q_i \le {\bar{q}} N - \sum _{n=1}^{\check{i}-1} \check{q}_{n, \mathrm{max}}\), where \(\check{q}_{n, \mathrm{max}}:=q_{\pi (n), \mathrm{max}}\), and nonincreasing otherwise.
Exploiting the results above, the optimal value of \(q_i\) for the original optimization problem (36) is obtained by solving the following optimization problem:
This is a convex optimization problem, since the function \(\frac{1}{q_i}\) is convex, whereas the function
is of the form \(h(f_i)\), where \(f_i\) is concave and h is convex and nonincreasing, so \(h(f_i)\) is convex (Boyd and Vandenberghe 2004, Section 3.2). After solving the optimization problem (40), the optimal values of the other \(q_n\) for the original optimization problem (36) are obtained as a consequence of the three steps detailed above.
It follows from the reasoning above that the structure of the optimal solutions \(q_n^\circ \) is as follows. First, there exists a threshold \({\bar{\lambda }}^\circ > 0\) such that
-
(i)
for any \(n \ne i\) with \(\lambda _{\min }({\varvec{A}}_n) > {{\bar{\lambda }}^\circ }\), \(q_n^\circ \) is equal to its maximum admissible value \(q_{n,\mathrm{max}}\);
-
(ii)
for any \(n \ne i\) with \(\lambda _{\min }({\varvec{A}}_n) < {{\bar{\lambda }}^\circ }\), \(q_n^\circ \) is equal to its minimum admissible value \(q_{n,\mathrm{min}}\);
-
(iii)
for at most one unit \(n \ne i\) (for which \(\lambda _{\min }({\varvec{A}}_n) = {{\bar{\lambda }}^\circ }\), provided that there exists one value of n for which this condition holds), \(q_n^\circ \) belongs to the interior of the interval \([q_{n,\mathrm{min}}, q_{n,\mathrm{max}}]\).
Moreover,
-
(iv)
if \(\left( {\bar{q}} N - \sum _{n=1}^{\check{i}-1} \check{q}_{n, \mathrm{max}}\right) \ge {\hat{q}}_{i,\mathrm{max}}\), then
$$\begin{aligned} q_i^\circ ={\hat{q}}_{i,\mathrm{max}}, \end{aligned}$$(42)and
$$\begin{aligned} {\bar{\lambda }}^\circ \in (0,\lambda _{\min }({\varvec{A}}_i))\,; \end{aligned}$$(43) -
(v)
if \(\left( {\bar{q}} N - \sum _{n=1}^{\check{i}-1} \check{q}_{n, \mathrm{max}}\right) < {\hat{q}}_{i,\mathrm{max}}\), then
$$\begin{aligned} q_i^\circ \in \left[ \left( {\bar{q}} N - \sum _{n=1}^{\check{i}-1} \check{q}_{n, \mathrm{max}}\right) , {\hat{q}}_{i,\mathrm{max}}\right] , \end{aligned}$$(44)and
$$\begin{aligned} {\bar{\lambda }}^\circ > \lambda _{\min }({\varvec{A}}_i). \end{aligned}$$(45)
Finally, it is worth observing that the structure highlighted above for the optimal solutions \(q_n^\circ \) and \(c^\circ \) (the latter reported under Eq. (36)), which is valid for any fixed value of \({\bar{q}}\), can be useful to solve the modification of the optimization problem (36) obtained in case the constraint (31) is replaced by
for some given \({\bar{q}}_{\mathrm{min}}, {\bar{q}}_{\mathrm{max}} \in (0,1]\), with \({\bar{q}}_{\mathrm{min}}<{\bar{q}}_{\mathrm{max}}\).
5 Conclusions
In this paper, the optimal trade-off between sample size, precision of supervision, and selection probabilities, has been studied with specific reference to a quite general linear model of input–output relationship representing unobserved heterogeneity in the data, namely the unbalanced fixed effects panel data model. First, we have analyzed its conditional generalization error, then we have minimized a large-sample upper bound on it with respect to some of its parameters. We have proved that, under suitable assumptions, “many but bad” examples provide a smaller upper bound on the conditional generalization error than “few but good” ones, whereas in other cases the opposite occurs. The choice between “many but bad” and “few but good” examples plays an important role when better supervision implies higher costs.
The theoretical results obtained in this work could be applied to the acquisition design of unbalanced panel data related to several fields, such as biostatistics, econometrics, educational research, engineering, neuroscience, political science, and sociology. Moreover, the analysis of the large-sample case could be extended to deal with large N, or with both large N and T. These cases would be of interest for their potential applications in microeconometrics (Cameron and Trivedi 2005). Another possible extension concerns the introduction, in the noise model, of a subset of not controllable parameters (beyond the controllable one, i.e., the noise variance), which could be estimated from a subset of training data. As a final extension, one could investigate and optimize the trade-off between sample size and precision of supervision (and possibly, also selection probabilities) for the random effects panel data model (Greene 2003, Chapter 13). This is also commonly applied in the analysis of economic data, and differs from the fixed effects panel data model in that its parameters are considered as random variables. In the present context, however, a possible advantage of the fixed effects panel data model is that it also allows one to obtain estimates of the individual constants \(\eta _n\) (see Eq. (7)), which appear in the expression (11) of the conditional generalization error. Moreover, the application of the random effects model to the unbalanced case requires stronger assumptions than the ones needed for the application of the fixed effects model (Wooldridge 2002, Chapter 17).
Notes
See the next Remark 3.3 for a justification of the choice of the conditioned generalization error for the analysis, instead of its unconditional version.
Such an approximation is useful, e.g., in the application of the model to macroeconomics data, for which it is common to investigate the case of a large horizon T. The case of finite T and large N is of more interest for microeconometrics (Cameron and Trivedi 2005), and will be investigated in future research.
We recall that a sequence of random real matrices \(\varvec{M}_{T}\) of the same dimension, \(T=1,2,\ldots ,\) converges in probability to the real matrix \(\varvec{M}\) if, for every \(\varepsilon >0\), \(\mathrm{Prob} \left( \left\| \varvec{M}_{T} - \varvec{M}\right\| > \varepsilon \right) \) (where \(\Vert \cdot \Vert \) is an arbitrary matrix norm) tends to 0 as T tends to \(+\infty \). In this case, one writes \(\mathrm{plim}_{T \rightarrow +\infty } \varvec{M}_T=\varvec{M}\).
It states that, given a sequence of random real square matrices \(\varvec{M}_{T}\) of the same dimension, \(T=1,2,\ldots ,\) if \(\mathrm{plim}_{T \rightarrow +\infty } \varvec{M}_{T}={\varvec{B}}\) and \({\varvec{B}}\) is invertible, then also \(\mathrm{plim}_{T \rightarrow +\infty } \varvec{M}_{T}^{-1}={\varvec{B}}^{-1}\).
References
Andreß H-J, Golsch K, Schmidt AW (2013) Applied panel data analysis for economic and social surveys. Springer, Berlin
Arellano M (2004) Panel data econometrics. Oxford University Press, Oxford
Athey S, Imbens G (2016) Recursive partitioning for heterogeneous causal effects. Proc Nat Acad Sci 113:7353–7360
Bhatia R (1997) Matrix analysis. Springer, Berlin
Bargagli Stoffi FJ, Gnecco G (2019) Causal tree with instrumental variable: an extension of the causal tree framework to irregular assignment mechanisms. Int J Data Sci Anal. https://doi.org/10.1007/s41060-019-00187-z
Bargagli Stoffi FJ, Gnecco G (2018) Estimating heterogeneous causal effects in the presence of irregular assignment mechanisms. In Proceedings of the 5th IEEE international conference on data science and advanced analytics (IEEE DSAA 2018), Turin, Italy, pp 1–10
Bell A, Jones K (2014) Explaining fixed effects: random effects modeling of time-series cross-sectional and panel data. Polit Sci Res Methods 3:133–153
Boyd S, Vandenberghe L (2004) Convex optimization. Cambridge University Press, Cambridge
Cameron AC, Trivedi PK (2005) Microeconometrics: methods and applications. Cambridge University Press, Cambridge
Chen C-H, Lee LH (2010) Stochastic simulation optimization: an optimal computing budget allocation. World Scientific, Singapore
Crane-Droesch A (2017) Semiparametric panel data using neural networks. In: Proceedings of the 2017 annual meeting of the agricultural and applied economics association, Chicago, USA
Florescu I (2015) Probability and stochastic processes. Wiley, Hoboken
Frees EW (2004) Longitudinal and panel data: analysis and applications in the social sciences. Cambridge University Press, Cambridge
Friston KJ, Holmes AP, Worsley KJ (1999) How many subjects constitute a study? Neuroimage 10:1–5
Gnecco G, Nutarelli F (2019) On the trade-off between number of examples and precision of supervision in regression problems. In: Proceedings of the 4th international conference of the international neural network society on big data and deep learning (INNS BDDL 2019), Sestri Levante, Italy, pp 1–6
Gnecco G, Nutarelli F (2019) On the trade-off between number of examples and precision of supervision in machine learning problems. Optim Lett. https://doi.org/10.1007/s11590-019-01486-x
Gnecco G, Nutarelli F (2019) On the optimal trade-off between sample size and precision of supervision. In: Program of the international conference on optimization and decision science (ODS 2019), Genoa, Italy, p 27
Gnecco G, Nutarelli F (2020) Optimal trade-off between sample size and precision of supervision for the fixed effects panel data model. In: Proceedings of the 5th international conference on machine learning, optimization & data science (LOD 2019), Certosa di Pontignano (Siena), Italy, vol 11943 of Lecture notes in computer science, pp 531–542
Greene WH (2003) Econometric analysis. Pearson Education, London
Groves RM, Fowler FJ Jr, Couper MP, Lepkowski JM, Singer E, Tourangeau R (2004) Survey methodology. Wiley, Hoboken
Härdle W, Mori Y, Vieu P (2007) Statistical methods for biostatistics and related fields. Springer, Berlin
Lee M-J (2010) Micro-econometrics: methods of moments and limited dependent variables. Springer, Berlin
Martello S, Toth P (1990) Continuous knapsack problems: algorithms and computer implementations. Wiley, Hoboken
Nguyen HT, Kosheleva O, Kreinovich V, Ferson S (2009) Trade-off between sample size and accuracy: case of measurements under interval uncertainty. Int J Approx Reason 50:1164–1176
Reeve CP (1988) A new statistical model for the calibration of force sensors, NBS Technical Note 1246. National Bureau of Standards, pp 1–41
Révész P (1968) The laws of large numbers. Academic Press, Cambridge
Ruud PA (2000) An introduction to classical econometric theory. Oxford University Press, Oxford
Sherron T, Allen J, Shumacker, RE (2000) A fixed effects panel data model: mathematics achievement in the U.S. In: Proceedings of the annual meeting of the American educational research association, New Orleans, USA
Vapnik VN (1998) Statistical learning theory. Wiley, Hoboken
Varian HR (2014) Big data: new tricks for econometrics. J Econ Perspect 28:3–38
Wooldridge JM (2002) Econometric analysis of cross section and panel data. MIT Press, Cambridge
Yu Q, Qin Y, Liu P, Ren G (2018) A panel data model-based multi-factor predictive model of highway electromechanical equipment faults. IEEE Trans Intell Transp Syst 9:3039–3045
Zeifman M (2015) Measurement and verification of energy saving in smart building technologies. In: Proceedings of the IEEE symposium on signal processing applications in smart buildings (GlobalSIP 2015), Orlando, USA, pp 343–347
Acknowledgements
G. Gnecco and F. Nutarelli are members of GNAMPA (Gruppo Nazionale per l’Analisi Matematica, la Probabilità e le loro Applicazioni)—INdAM (Istituto Nazionale di Alta Matematica). The work was partially supported by the 2020 Italian project “Trade-off between Number of Examples and Precision in Variations of the Fixed-Effects Panel Data Model”, funded by INdAM-GNAMPA.
Funding
Open access funding provided by Scuola IMT Alti Studi Lucca within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval/informed consent
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Communicated by A. Di Nola.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1: Proof of Equation (18)
First, we expand the conditional generalization error (11) as follows:
Exploiting the conditional unbiasedness of \({\hat{\eta }}_{i,\mathrm{FE}}\), and the expressions (1) of \(y_{n,t}\), (2) of \({\tilde{y}}_{n,t}\), and (7) of \({\hat{\eta }}_{i,\mathrm{FE}}\) (with the index n replaced by the index i), one gets
It follows from Eq. (48) that Eq. (47) can be re-written as
Using the expression (6) of \(\varvec{{\hat{\beta }}}_\mathrm{FE}\), and Eq. (16), one can simplify the term \(\varvec{{\hat{\beta }}}_\mathrm{FE}-\varvec{\beta }\) above as follows:
Then, Eq. (49) becomes
Expanding the square in the first term in the expression above, and splitting its last term in two parts, one obtains the following expression for Eq. (51):
In order to simplify the various terms contained in Eq. (52), one observes that, due to Eqs. (12), (13), and (15), one gets
and
Then, by an application of the two equations just derived above, one obtains the following equivalent expression for Eq. (52):
where, in some cases, the conditional expectations of deterministic matrices (and of random matrices, like \(\varvec{X}_i\), that become known once the set of conditioning matrices \(\{\varvec{X}_{n}\}_{n=1}^{N}\) has been fixed) have been replaced by the matrices themselves. Finally, exploiting Eq. (17), one can get rid of the third and sixth terms in Eq. (55), which then becomes
which is Eq. (18).
Appendix 2: Proof of Equation (26)
The first inequality
in Eq. (26) is obtained by exploiting the definition of induced \(l_2\)-matrix norm, i.e.,
and the fact that, being \(\varvec{A}_N^{-\frac{1}{2}}\) symmetric, one has
Then, the equality
follows from the relationship \(\lambda _\mathrm{min}(\varvec{A}_N)=\frac{1}{\lambda _{\mathrm{max}}(\varvec{A}_N^{-1})}\).
Finally, the last inequality in Eq. (26) is obtained by exploiting Weyl’s inequalities (Bhatia 1997, Theorem III.2.1) for the eigenvalues of the sum of symmetric matrices, as detailed in the following remark.
Remark 5.1
Given any pair of symmetric matrices \(\varvec{A},\varvec{B} \in {\mathbb {R}}^{s \times s}\), let their eigenvalues and those of \(\varvec{C}:=\varvec{A}+\varvec{B}\) be ordered nondecreasingly (with possible repetitions in case of multiplicity larger than 1) as
Then, Weyl’s inequalities, in their simplest form, state that, for every \(k=1,\ldots ,s\), one has
Hence, \(\lambda _{\mathrm{min}}(\varvec{C}) \ge \lambda _{\mathrm{min}}(\varvec{A})+\lambda _{\mathrm{min}}(\varvec{B})\). Similarly, for any \(\mu _1,\mu _2 \ge 0\), when \(\varvec{A}\) and \(\varvec{B}\) are also positive semi-definite (as in the case of the matrices \(\varvec{A}\) defined in Eq. (19)), one gets
Finally, Eq. (63) extends directly to the case of a weighted summation (with non-negative weights) of symmetric and positive semi-definite matrices, proving the last inequality in Eq. (26).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gnecco, G., Nutarelli, F. & Selvi, D. Optimal trade-off between sample size, precision of supervision, and selection probabilities for the unbalanced fixed effects panel data model. Soft Comput 24, 15937–15949 (2020). https://doi.org/10.1007/s00500-020-05317-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-020-05317-5