
Abstract
The paper presents the neuro-fuzzy system with weighted attributes. Its crucial part is the fuzzy rule base composed of fuzzy rules (implications). In each rule the attributes have their own weights. In our system the weights of the attributes are numbers from the interval [0, 1] and they are not global: each fuzzy rule has its own attributes’ weights, thus it exists in its own weighted subspace. The theoretical description is accompanied by results of experiments on real life data sets. They show that the neuro-fuzzy system with weighted attributes can elaborate more precise results than the system that does not apply weights to attributes. Assigning weights to attributes can also discover knowledge about importance of attributes and their relations.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Neuro-fuzzy systems proved to be efficient in many fields of data mining. They combine the ability to handle imprecise data and to modify the parameters of elaborated models to better fit the data. The more complicated a model is, the more suitable it is to use fuzzy approach (Zadeh et al. 1973). The fuzzy approach can provide better models, even for non-fuzzy data, than non-fuzzy systems.
The crucial part of the fuzzy system is the fuzzy rule base composed of fuzzy rules (implications). Creation of the fuzzy rule base is a difficult task. This procedure has enormous influence on the quality of results elaborated by the system. The rules can implement the knowledge of experts or can be created automatically from the presented data. The rules of the fuzzy model split the input domain into regions. This procedure can be reversed in order to obtain the rules from presented data. The domain is split into regions and the regions are transformed into premises of the rules. This approach is commonly used. There are three main ways of domain partition grid split (Jang 1993; Setnes and Babuška 2001), scatter split (clustering) and hierarchical split (Hoffmann and Nelles 2001; Jakubek et al. 2006; Nelles and Isermann 1996; Nelles et al. 2000; Simiński 2008, 2009, 2010). The most common method is scatter split (clustering) (Abonyi et al. 2002; Bauman et al. 1990; Chen et al. 1998; Czogała et al. 2000; Wang et al. 1994). Clustering avoids the curse of dimensionality, which is the main problem of grid partition. The main disadvantage of many clustering algorithms is their inability to discover the number of clusters. Is such cases the number of clusters is passed to the algorithm as a parameter.
In high dimensional data sets not always all dimensions (attributes) are relevant. Some of them can be treated as noise and have minor importance. The reduction of dimensionality may be done for a whole data set (global dimensionality reduction) or individually for each cluster. The global feature transformation (e.g. PCA or SVD) causes problems with interpretability of elaborated models. Dimension reduction without feature transformation can be achieved by feature selection. The global approach selects the same subset of attributes for all clusters whereas each cluster may need its own subspace. This is the idea of subspace clustering (Friedman and Meulman 2004; Gan et al. 2006; Kriegel et al. 2009; Müller et al. 2009; Parsons et al. 2004; Sim et al. 2012) where each cluster may be extracted in its own subspace. There are two kinds of subspace clustering: bottom-up and top-down (Parsons et al. 2004). The former approach splits the clustering space with a grid and analyses the density of data examples in each grid cell extracting the relevant dimensions [e.g. CLIQUE (Agrawal et al. 1998), ENCLUS (Cheng et al. 1999), MAFIA (Goil et al. 1999)]. The latter (top–down) approach starts with full dimensional clusters and tries to throw away the dimensions of minor importance [e.g. PROCLUS (Aggarwal et al. 1999), ORCLUS (Aggarwal et al. 2000), δ-Clusters (Yang et al. 2002), FSC (Gan and Wu 2008; Gan et al. 2006)]. In algorithms mentioned above the attribute is valid or invalid in a certain cluster, the weight of the attribute in each cluster is either 0 or 1. In our solution the clustering algorithm assigns values from the interval [0, 1]. The attributes have partial importance in the subspace. This approach creates fuzzy rules in individual weighted subspaces.
The contribution of the paper is the neuro-fuzzy system with weighted attributes.
In the paper we follow the general rule for symbols: the blackboard bold uppercase characters \({(\mathbb{A})}\) are used to denote the sets, uppercase italics (A)—the cardinality of sets, uppercase bolds \((\mathbf{A})\)—matrices, lowercase bolds \((\mathbf{a})\)—vectors, lowercase italics (a)—scalars and set elements. Table 1 lists the symbols used in the paper.
The paper is organised as follows: Sect. 2 introduces the new neuro-fuzzy system with parameterized consequences and weighted attributes (architecture—Sect. 2.1, creation of a fuzzy model—Sect. 2.2). Section 3 describes the data sets (Sect. 3.1) and experiments with results (Sect. 3.2). Finally Sect. 4 summarises the paper.
2 Fuzzy inference system with parameterized consequences and attributes’ weights
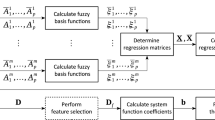
Fuzzy inference system with parameterized consequences and weights attributes is an extension of the neuro-fuzzy system with parameterized consequences ANNBFIS (Czogała et al. 2000; Łęski and Czogała 1999) which is the combination of the Mamdani and Assilan (1975), Takagi and Sugeno (1985) and Sugeno and Kang (1988) approach. The fuzzy sets in consequences are isosceles triangles (as in the Mamdami–Assilan system), but are not fixed—their location is calculated as a linear combination of attribute values as in the Takagi–Sugeno–Kang system. The important feature is the logical interpretation of fuzzy implication (cf. Eq. 11). The idea of the system with parameterized consequences is presented in Fig. 1. The figure is taken from (Czogała et al. 2000) with modifications.

The scheme of the neuro-fuzzy system with parameterized consequences. The input has two attributes and the rule base is composed of two fuzzy rules. The premises of the rules are responsible for determining the firing strength of the rules. The firing strength is the left operand of the fuzzy implication. The right hand operand is the \({\mathbb{B}}\) fuzzy triangle set, the location of which is determined by formula 7. The result of the rth fuzzy implication is a fuzzy set \({\mathbb{B}^{\prime}_l}\). The fuzzy results of the implications are then aggregated. The non-informative part (the gray rectangular in the picture) is thrown away in aggregation. The informative part (the white mountain-like part of \({\mathbb{B}^{\prime}}\) set) is then defuzzyfied with the centre of gravity method. The defuzzyfied answer of the system is number y 0
2.1 Architecture of the system
The system with parameterized consequences is the MISO system. The rule base \({\mathbb{L}}\) contains fuzzy rules l in form of fuzzy implications
where \(\mathbf{x} = [x_1, x_2, \ldots, x_N]^\mathrm{T}\) and y are linguistic variables, \({\mathfrak{a}}\) and \({\mathfrak{b}}\) are fuzzy linguistic terms (values). Data tuples are represented by vectors \(\left[\mathbf{x}, y\right]^\mathrm{T}\), where \(\mathbf{x}\) is a vector of descriptors and y is the decision attribute of the tuples. Both the descriptors and decision are real numbers.
In the following text we will describe the situation only for one rule, but we will omit the index of the rule in the following formulae as not to complicate the notation.
The linguistic variable \({\mathfrak{a}}\) (in the rule’s premise) is represented in the system as a fuzzy set \({\mathbb{A}}\) in N-dimensional space. Each fuzzy rule has its own premise and consequence. For each dimension n the set \({\mathbb{A}_n}\) is described with the Gaussian membership function:
where v n is the core location for nth attribute and s n is this attribute Gaussian bell deviation (fuzziness).
The membership of a tuple \(\mathbf{x}\) to the premise \({\mathbb{A}}\) of the rule is the T-norm of memberships to all dimensions in the rule’s premise. Because each dimension i has its own weight z i , we use the weighted T-norm (Rutkowski and Cpałka 2003) to determine the membership of the data example to the fuzzy set \({\mathbb{A}}\) in rule’s premise:
In the system the product T-norm is used so the above Eq. (3) is expressed as:
Membership of a data tuple to the fuzzy set in lth rule’s premise is the firing strength of the rule for the tuple (from now on we use the rule’s index l)
To avoid misunderstandings please keep in mind the meanings of the symbols: \({u_{\mathbb{A}_n}}\) stands for membership of the nth descriptor to the fuzzy set \({\mathbb{A}_n}\) in the premise for nth attribute of a certain rule (the index of which we omit here) as in formulae 2, 3, 4, \({u_{l \mathbb{A}}}\) stands for membership of the whole data tuple to the premise of the lth rule—it is lth rule’s firing strength (as in formula 5).
Combining 2 and 4 we get firing strength F of lth rule for data vector (tuple) \(\mathbf{x}\):
The term \({\mathfrak{b}}\) (in formula (1)) describing the lth rule’s consequence is represented by an isosceles triangle fuzzy set \({\mathbb{B}_l}\) with the base width w l , the altitude of the triangle equals 1. The localisation y l of the core of the triangle fuzzy set is determined by linear combination of input attribute values with attribute weights taken into account:
The above formula 7 can also be written as
where z l0 = 1 and x 0 = 1.
The output of the lth rule is the fuzzy value of the fuzzy implication:
where squiggle arrow \((\rightsquigarrow)\) stands for fuzzy implication. The shape of the fuzzy set \({\mathbb{B}^{\prime}}\) depends on the used fuzzy implication (Czogała et al. 2000). In our system we use Reichenbach implication (Reichenbach et al. 1935)
The answers \({u_{l\mathbb{B}^{\prime}}}\) of all L rules are then aggregated into one fuzzy answer of the system:
where \(\bigoplus\) stands for the aggregation operator. In order to get the non-fuzzy answer y 0 the fuzzy set \({\mathbb{B}^{\prime}}\) is defuzzified with MICOG method (Czogała et al. 2000). This approach removes the non-informative parts of the aggregated fuzzy sets and takes into account only the informative parts (cf. description of Fig. 1). The aggregation and defuzzyfication may be quite expensive, but it has been proved (Czogała et al. 2000) that the defuzzyfied system output can be expressed as:
The function g depends on the fuzzy implication, in the system the Reichenbach one is used, so for the lth rule function g is
The forms of g function for various implications can be found in the original work introducing the ANNBFIS system (Czogała et al. 2000). Some inaccuracies are discussed in Nowicki (2006) and Łęski (2008).
2.2 Creation of the fuzzy model
Creation of the fuzzy model (fuzzy rule base) is done in three steps: partition of the input domain (Sect. 2.2.1), extraction of rules’ premises (Sect. 2.2.2) and tuning of the rules (this step is also responsible for creation of rules consequences)—Sect. 2.2.3.
2.2.1 Partition of the input domain
For domain partition we use modification (Simiński 2012) of the FCM clustering algorithm (Dunn 1973) where the weights are the values from the interval [0, 1]. Thus each cluster is fuzzy in two ways:
-
1.
Data tuples have fuzzy membership to clusters. The sum of membership of one data tuple to all clusters is 1 (cf. Eq. 16). This is common in the fuzzy clustering paradigm.
-
2.
The cluster itself has fuzzy possession of attributes. This means that the cluster spreads in a fuzzy way upon the dimensions. The sum of dimensions weight of one cluster is 1 (cf. Eq. 16).
Our clustering method is based on minimising the criterion function J
where m and f ≠ 1 (the case of f = 1 is discussed on Eq. 20) are parameters, u ci stands for membership of ith data example \(\left(\mathbf{x}_i\right)\) to cth cluster, z cn stands for weight of nth attribute (descriptor) in cth cluster, x in is nth descritor of ith data tuple, v cn is nth attibute of centre of cth cluster.
The centre of cth cluster is defined as
Two constraints are put on dimension weights and partition matrix:
-
1.
The sum of membership values to all clusters for each data tuple is one:
$$ \forall {i \in [1,X]} : \; \sum^C_{c = 1} u_{c i} = 1. $$(16) -
2.
The sum of dimension weights z for all dimensions N in each cluster c equals one:
$$ \forall {i \in [1, C]} : \; \sum^N_{n = 1} z_{in} = 1. $$(17)
Applying of Langrange multipliers leads to the following formulae:
The data are clustered by alternating application of formulae 15, 18 and 19.
The procedure described above cannot be used if f = 1. The objective function (14) becomes
In such a case the attribute n of the lth rule for which the sum
is minimal gets the weight z ln = 1 and other attributes of this rule get zero weights (because of the constraint expressed by formula 17).
2.2.2 Extraction of rules
The clustering procedure elaborates memberships and weights gathered in matrices \(\mathbf{U} = \{u_{ij}\}\) and \(\mathbf{Z} = \{z_{ij}\}\) respectively which are then converted into premises’ parameters v, s and z. The number of rules is equal to the number of clusters: L = C.
The cores v of rules’ premises are calculated with formula 15. The fuzzification parameter s is calculated with formula (Czogała et al. 2000)
The extraction of the weights of attributes is slightly more complicated. The constraint expressed by formula 17 makes the sum of all weights in a rule equal one. If two attributes have weights greater than zero, their values have to be lower than one. If all N attributes have the same weights, their weight is z = 1/N (cf. Eq. 17) and if firing strengths of all attributes are the same and equal F n , the firing strength of the whole rule is (cf. Eq. 6)
If all attributes are minimally fired (zero firing strengths) the total firing strength of the whole rule tends to one (with increase in the number of attributes), so there is no difference if the attributes are fired or not. This is highly unsatisfactory. The Fig. 2 presents this phenomenon.

Firing strength F for the whole rule (Eq. 6) when all attributes have the equal firing strength F n in function of number of attributes (N) and attribute’s weight exponent f = 2 without augmentation. If the weights of the attributes are not augmented the firing strength of the whole rule tends to one independently whether the attributes are fired of not. The figure comprises 11 draws for values from F n = 0.0 to 1.0 with 0.1 step. The gray lines are only to join the firing strengths for the same F n values. They have no physical meaning, because the number of attributes N has only discrete values
This can be easily avoided by augmenting of the weights of the attributes in a rule. The attribute weights for one rule are divided by the maximal values of them. This maximal values is always greater than zero. In this procedure all weights in this rule are scaled and the maximum weights become one:
2.2.3 Tuning of rule parameters
In neuro-fuzzy systems the parameters of the model are tuned to better fit the data. In this system the parameters of the premises (v and s in Eq. 2, z in Eq. 4) and the values of the supports w of the sets in consequences are tuned with the gradient method. The linear coefficients p (Eq. 7) for the calculation of the localisation of the consequence sets are calculated with the pseudoinverse matrix. For tuning parameters of the model the square error is used
where y is the original value and y 0 is the value elaborated by the system (cf. Eq. 12). For q parameter in jth rule the differential has the following form:
Formula (26) is valid for v, s and z parameters. For width w of the isosceles triangle in the rule’s consequence the following formula is used:
The differentials in Eq. 26 are:
and
The differentials \(\frac{\partial g}{\partial F}\) and \(\frac{\partial g}{\partial w}\) depend on the used implication (cf. Eq. 13). For Reichenbach implication we have:
and
For q j being v jm parameter (the core of the mth attribute in jth rule) we get (cf. Eq. 6)
For q j being s jm parameter (the fuzzification of the mth attribute in jth rule) in Eq. 26 we get:
And finally for q j being z jm (the weight of the mth attribute in jth rule) parameter in Eq. 26 we get:
The linear parameters for localisation of the cores of triangle fuzzy sets in consequences are calculated as a solution to the linear equation expressed by Eq. 7. To avoid numerical problems the pseudoreverse matrix is calculated. In the calculation the weights are also taken into account.
For f = 0 (which switches off the attributes’ weights) the proposed system is identical with ANNBFIS system described in (Czogała et al. 2000).
3 Experiments
The experiments were conducted on real-life data sets depicting methane concentration, death rate, breast cancer recurrence time, concrete compressive strength and ozone concentration. All real life data sets are normalised (to mean 0 and standard deviation 1). Some parameters of data sets are gathered in Table 2.
3.1 Data set description
The ‘Methane’ data set contains the real life measurements of air parameters in a coal mine in Upper Silesia (Poland). The parameters (measured in 10 s intervals) are: AN31—the flow of air in the shaft, AN32—the flow of air in the adjacent shaft, MM32—concentration of methane (CH4), production of coal, the day of week. The 10-min sums of measurements of AN31, AN32, MM32 are added to the tuples as dynamic attributes (Sikora et al. 2005). The task is to predict the concentration of the methane in 10 min. The data is divided into a train set (499 tuples) and test set (523 tuples).
The ‘Death’ data represent the tuples containing information on various factors, the task is to estimate the death rate (Späth 1992). The first attribute (the index) is excluded from the dataset. The precise description of the attributes is available with the data set, the names of the attributes are listed in Table 7, so the description is omitted here. The data can be downloaded from a public repository. Footnote 1
The ‘Breast cancer’ data set represents the data for the breast cancer case (Asuncion and Newman 2007). Each data tuple contains 32 continuous attributes and one predictive attribute (the time to recur). Here again we will omit the description of attributes, their names are listed in Table 6. The symbol ‘se’ in the attribute’s name stands for ‘standard error’ and the adjective ‘worst’ means the ‘largest’. The data can be downloaded Footnote 2 from a public repository (Frank et al. 2010).
The ‘Concrete’ set is a real life data set describing the parameters of the concrete sample and its strength (Yeh 1998). The attributes are: cement ratio, amount of blast furnace slag, fly ash, water, superplasticizer, coarse aggregate, fine aggregate, age; the decision attribute is the concrete compressive strength. The original data set can be downloaded Footnote 3 from public repository (Frank et al. 2010).
The ‘Ozone’ set—a real life data set—describes the level of ozone in the air (Zhang and Fan 2008). The data set includes 2536 tuples with 73 attributes. The original data set can be downloaded Footnote 4 from a public repository (Frank et al. 2010). The data set has 687 tuples with missing values, these were deleted from the data set and 1847 full tuples were left. The first attribute (date) was deleted from the tuples. The tuples were numbered starting with 1. The tuples with odd numbers are used as a train set (924 tuples), the even numbered tuples constitute the test data set (923 tuples). All attributes are real numbers. The task is to predict the level of ozone (high 1 or low 0).
3.2 Results of experiments
The fuzzy models were created with train sets. The number of rules is always the same as the number of clusters and was assumed a priori as L = 5 (for the ‘Ozone’ dataset L = 3). Finding the optimal number of clusters in clustering is a difficult task. Our aim here is not to discuss this problem, but to compare the precision of our system with the one already existing. This is why we assume the a priori number of rules.
The experiments were conducted in two paradigms. In the first one—data approximation (DA)—the models are created and tested with the same train data sets. In the other—knowledge generalisation (KG)—the models are created with train data sets and tested with unseen tuples of test data sets.
Root mean square error (RMSE) measure is used to evaluate the elaborated results:
where \(y \left( \mathbf{x}_i \right)\) stands for original (expected) value for ith tuple and \(y_0 \left( \mathbf{x}_i \right)\) is the value elaborated by the system; X is the number of tuples.
Two main features were tested: (1) the precision of created models and (2) the weights assigned to dimensions (attributes).
3.3 Precision of models
Table 3 presents the RMSE results elaborated for various values of f parameter. For f = 0 the system elaborates the same results as ANNBFIS system. The results gathered in Table 3 are also presented as graphs in Fig. 3a–d.

Root mean square errors for the real life data sets. The results for data approximation (DA) are denoted with times signs, for knowledge generalisation (KG)—black squares. The symbols are accompanied by auxiliary lines for higher readability
The experiments reveal that for \(f \in [1.5, 2]\) the RMSE, elaborated by the systems for various data sets, achieves its most advantageous values both for DA and KG. For f > 2 the KG error starts to grow, whereas the DA error is kept on more or less the same level. The optimal interval of f parameter seems independent from the data sets.
The Figs. 4, 5, 6 and 7 present the comparison of results elaborated by ANNBFIS (the gray lines) and our system (the black lines) with f = 2. The squares denote the expected values. The Figs. 8 and 9 present in a more detailed way the result for tuples 50–150 and 250–400 respectively. Similarly, the Fig. 10 presents the details of the Fig. 5 for tuples 400–500.

The values elaborated for the ‘Death’ data set (KG). The original values are marked with the black squares, the values elaborated by ANNBFIS by the gray line, elaborated by NFS with weighted attributes by the black line. Number of rules L = 5, f = 2

The values elaborated for the ‘Methane’ data set (KG). The original values are marked with the black squares, the values elaborated by ANNBFIS by the gray line, elaborated by NFS with weighted attributes by the black line. Number of rules L = 5, f = 2

The values elaborated for the ‘Breast cancer’ data set (KG). The original values are marked with the black squares, the values elaborated by ANNBFIS by the gray line, elaborated by NFS with weighted attributes by the black line. Number of rules L = 5, f = 2

The values elaborated for the ‘Concrete’ data set (KG). The original values are marked with the black squares, the values elaborated by ANNBFIS by the gray line, elaborated by NFS with weighted attributes by the black line. Number of rules L = 5, f = 2

The values elaborated for the ‘Concrete’ data set (KG). The original values are marked with the black squares, the values elaborated by ANNBFIS by the gray line, elaborated by NFS with weighted attributes by the black line. Number of rules L = 5, f = 2. The figure presents in a more detailed way the part of Fig. 7

The values elaborated for the ‘Concrete’ data set (KG). The original values are marked with the black squares, the values elaborated by ANNBFIS by the gray line, elaborated by NFS with weighted attributes by the black line. Number of rules L = 5, f = 2. The figure presents in a more detailed way the part of Fig. 7

The values elaborated for the ‘Methane’ data set (KG). The original values are marked with the black squares, the values elaborated by ANNBFIS by the gray line, elaborated by NFS with weighted attributes by the black line. Number of rules L = 5, f = 2. The figure presents in a more detailed way the part of Fig. 5
The figures show that applying attribute weights in the fuzzy rule base results in a more precise prediction. The better prediction can be observed in Fig. 8, where the expected values are better elaborated by our systems (the black line) than by the original ANNBFIS system that does not use attribute weights in rules (the gray line).
3.3.1 Weights of attributes
Another feature tested in experiments are the weights assigned to attributes (dimensions). The Tables 4, 5, 6, 7 and Figs. 11, 12, 13 and 14 present the weights of attributes in models elaborated for real life data sets.

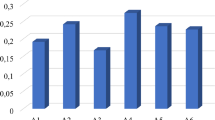
Weights of attributes elaborated for the ‘Methane’ data set (cf. Table 4)

Weights of attributes elaborated for the ‘Concrete’ data set (cf. Fig. 12)

Weights of attributes elaborated for the ‘Breast cancer’ data set (cf. Table 6)

Weights of attributes elaborated for the ‘Death’ data set (cf. Table 7)
The attributes’ weights for the ‘Methane’ data set (prediction of methane concentration in a coal mine shaft) gathered in Table 4 and presented in Fig. 11 show a very interesting fact: the actual concentration of methane (the third attribute) turned out to be of minor importance in all the rules, although the task was the 10-min prediction of the concentration of the methane in the shaft. The most important attributes are the flow of air in the mine shaft (the first attribute) and the production of coal (the fourth attribute). It can be explained by the fact that excavation of coal causes tensions and splits in the rock that may release the methane gas. In two rules the most important attribute is the first one, the flow of the air in the shaft in question. In the fifth rule an interesting phenomenon can be observed. The most important attribute is the fifth one, the 10-min sum of the first attribute (flow of the air), whereas the first attribute itself has lower weight. The similar situation occurs in the case of the second attribute (flow of the air in the adjacent shaft), where the sum of air flow measurements in the adjacent shaft (the sixth attribute) is more important than the summed air flow itself (the second attribute).
The weights of attributes elaborated for the ‘Concrete’ data set are presented in Table 5 and Fig. 12. The most important attributes (all others have low weights) are: blast furnace slag (the second attribute), ratio of fly ash (the third attribute), fine aggregate (the seventh attribute) and age of concrete (the eighth attribute). In one rule the weights are more varied: the most important attribute is age, but concentration of blast furnace slag and fly ash have also quite high weights.
The weights of attributes elaborated for the ‘Breast cancer’ data set are presented in Table 6 and Fig. 6. In rule I the most important attribute is the first one (lymph nodes), which is in concordance with medical diagnose procedures. In all the rules the importance of three attributes: radius mean (the second attribute), perimeter mean (the fourth attribute) and area mean (the fifth attribute) are correlated. In rule III there are two triples of attributes of higher importance. The triple of high importance comprises: area worst (the 25th attribute), perimeter worst (the 24th attribute) and radius worst (the 22nd attribute). This triple is accompanied be the triple of slightly lower importance: area mean (the fifth attribute), perimeter mean (the fourth attribute) and radium mean (the second attribute). In one rule the weights are more varied. The important attributes are fractal dimension worst (the 31st attribute), fractal dimension standard deviation (the 21st attribute) and fractal dimension mean (the 11th attribute), smoothness standard deviation (the 16th attribute) and compactness worst (the 27th attribute).
The weights of attributes elaborated for the ‘Death’ data set are presented in Table 7 and Fig. 14. In rules I, III and V the most important attributes are the hydrocarbon pollution index (the 12th attribute) and the nitric oxide pollution index (the 13th attribute). It is interesting that the pollution index for sulphur dioxide has low weight in all rules. In the second rule the most important attribute describes scholarisation of persons over 22 (the sixth attribute).
The experiments were also executed on the ‘Ozone’ data set. This real life data set comprises 72 attributes describing the meteorological measurements (the original data set has 73 attributes, but the first one—the date—has been deleted as mentioned in the data set’s description above). The attributes are not listed here, their short description is available at the data repository, from which the data set can be downloaded. The tuples are labelled 0 or 1. The task is to classify the unseen data examples. Our system was trained with 0 or 1 labels, but it elaborates the real value answer. The answers lower than 0.5 were labelled with zero, otherwise with one. The experiments were conducted with ANNBFIS and our subspace neuro-fuzzy systems. The ANNBFIS system assigned the major class to all the answers. The subspace approach elaborated more precise results (precision: 0.926). The weights of attributes are presented in Fig. 15. In the next experiment only the attributes with weights higher than 0.7 in at least two rules were selected. This led to the selection of attributes 27 to 53. All these attributes describe the results of temperature measurements. The results were a bit poorer (precision: 0.921) than in the case when all attributes were used.

Weights of attributes elaborated for the ‘Ozone’ data set
4 Summary
The paper describes the novel neuro-fuzzy system with weighted attributes. In this approach the attributes in a fuzzy rule have weights. The weights of attributes are numbers from the interval [0, 1]. The weights of the attributes are not assigned globally, but each fuzzy rule has its own weights of attributes. Each rule exists in its own subspace. An attribute can be important in a certain rule, but unimportant in another. This approach is inspired by subspace clustering, but in our system the attribute can have partial weight, which is uncommon in subspace clustering where attributes have full (1) or none (0) weights in a subspace.
There are two main advantages of the approach proposed in the paper:
-
1.
The experiments show that fuzzy models with weighted attributes can elaborate more precise results, both for data approximation and knowledge generalisation for real life data sets in comparison with a neuro-fuzzy system that does not assign weights to attributes.
-
2.
Assigning weights to attributes discovers knowledge on importance of attributes in a problem. Individual weights of attributes in each rule discover the relation between attributes. This may explain why the weights of the same attribute are low in one rule and high in another one.
The experiments show that assigned weights of the attributes are in concordance with experts’ knowledge on the physical or medical mechanisms described by the data sets.
References
Abonyi J, Babuška R, Szeifert F (2002) Modified Gath–Geva fuzzy clustering for identification of Takagi–Sugeno fuzzy models. IEEE Trans Syst Man Cybern B 32(5):612–621
Aggarwal CC, Wolf JL, Yu PS, Procopiuc C, Park JS (1999) Fast algorithms for projected clustering. SIGMOD Rec 28(2):61–72. doi:10.1145/304181.304188
Aggarwal CC, Yu PS (2000) Finding generalized projected clusters in high dimensional spaces. In: SIGMOD ’00: Proceedings of the 2000 ACM SIGMOD international conference on management of data. ACM, New York, pp 70–81. doi:10.1145/342009.335383
Agrawal R, Gehrke J, Gunopulos D, Raghavan P (1998) Automatic subspace clustering of high dimensional data for data mining applications. SIGMOD Rec 27(2):94–105. doi:10.1145/276305.276314
Asuncion A, Newman DJ (2007) UCI machine learning repository. University of California, School of Information and Computer Sciences, Irvine, CA
Bauman E, Dorofeyuk A (1990) Fuzzy identification of nonlinear dynamical systems. In: Proceedings of the international conference on fuzzy logic and neural nets, pp 895–898
Chen JQ, Xi YG, Zhang ZJ (1998) A clustering algorithm for fuzzy model identification. Fuzzy Sets Syst 98(3):319–329. doi:10.1016/S0165-0114(96)00384-3
Cheng CH, Fu AW, Zhang Y (1999) Entropy-based subspace clustering for mining numerical data. In: KDD ’99: Proceedings of the fifth ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, New York, pp 84–93. doi:10.1145/312129.312199
Czogała E, Leski J (2000) Fuzzy and neuro-fuzzy intelligent systems. Series in fuzziness and soft computing. Physica-Verlag, Heidelberg
Dunn JC (1973) A fuzzy relative of the ISODATA process and its use in detecting compact, well separated clusters. J Cybern 3(3):32–57
Frank A, Asuncion A (2010) UCI machine learning repository
Friedman JH, Meulman JJ (2004) Clustering objects on subsets of attributes. J R Statist Soc B 66:815–849
Gan G, Wu J (2008) A convergence theorem for the fuzzy subspace clustering (FSC) algorithm. Pattern Recogn 41(6):1939–1947. doi:10.1016/j.patcog.2007.11.011
Gan G, Wu J, Yang Z (2006) A fuzzy subspace algorithm for clustering high dimensional data. In: Advanced data mining and applications, second international conference, ADMA 2006, Xi’an, China, August 14–16, 2006, Proceedings. Lecture notes in computer science, vol 4093. Springer, Berlin, pp 271–278
Goil S, Goil S, Nagesh H, Nagesh H, Choudhary A, Choudhary A (1999) Mafia: efficient and scalable subspace clustering for very large data sets. Tech rep (1999)
Hoffmann F, Nelles O (2001) Genetic programming for model selection of tsk-fuzzy systems. Inf Sci 136:7–28
Jakubek S, Keuth N (2006) A local neuro-fuzzy network for high-dimensional models and optimalization. In: Engineering applications of artificial intelligence, pp 705–717
Jang JSR (1993) ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans Syst Man Cybern 23(3):665–684
Kriegel HP, Kroger P, Zimek A (2009) Clustering high-dimensional data: a survey on subspace clustering, pattern-based clustering, and correlation clustering. ACM Trans Knowl Discov Data (TKDD) 3(1):1–58. doi:10.1145/1497577.1497578
Łęski J (2008) Systemy neuronowo-rozmyte [Neuro-fuzzy systems]. Wydawnictwa Naukowo-Techniczne, Warszawa. ISBN 978-83-204-3229-9
Łęski J, Czogała E (1999) A new artificial neural network based fuzzy inference system with moving consequents in if-then rules and selected applications. Fuzzy Sets Syst 108(3):289–297. doi:10.1016/S0165-0114(97)00314-X
Mamdani EH, Assilian S (1975) An experiment in linguistic synthesis with a fuzzy logic controller. Int J Man-Mach Stud 7(1):1–13
Müller E, Günnemann S, Assent I, Seidl T (2009) Evaluating clustering in subspace projections of high dimensional data. Proc VLDB Endow 2(1):1270–1281
Nelles O, Fink A, Babuška R, Setnes M (2000) Comparison of two construction algorithms for Takagi–Sugeno fuzzy models. Int J Appl Math Comput Sci 10(4):835–855
Nelles O, Isermann R (1996) Basis function networks for interpolation of local linear models. In: Proceedings of the 35th IEEE conference on decision and control, vol 1, pp 470–475
Nowicki R (2006) Rough-neuro-fuzzy system with MICOG defuzzification. In: 2006 IEEE international conference on fuzzy systems. Vancouver, Canada, pp 1958–1965. doi:10.1109/FUZZY.2006.1681972
Parsons L, Haque E, Liu H (2004) Subspace clustering for high dimensional data: a review. SIGKDD Explor Newsl 6(1):90–105. doi:10.1145/1007730.1007731
Reichenbach H (1935) Wahrscheinlichkeitslogik. Erkenntnis 5:37–43. doi:10.1007/BF00172280
Rutkowski L, Cpałka K (2003) Flexible neuro-fuzzy systems. IEEE Trans Neural Netw 14(3):554–574. doi:10.1109/TNN.2003.811698
Setnes M, Babuška R (2001) Rule base reduction: some comments on the use of orthogonal transforms. IEEE Trans Syst Man Cybern C Appl Rev 31(2):199–206. doi:10.1109/5326.941843
Sikora M, Krzykawski D (2005) Application of data exploration methods in analysis of carbon dioxide emission in hard-coal mines dewater pump stations. Mech Autom Mining 413(6)
Sim K, Gopalkrishnan V, Zimek A, Cong G (2012) A survey on enhanced subspace clustering. In: Data mining and knowledge discovery, pp 1–66. doi:10.1007/s10618-012-0258-x
Simiński K (2008) Neuro-fuzzy system with hierarchical partition of input domain. Studia Inf 29(4A (80, 43–53):43–53
Simiński K (2009) Patchwork neuro-fuzzy system with hierarchical domain partition. In: Kurzyński M, Woźniak M (eds.) Computer Recognition Systems 3. Advances in intelligent and soft computing, vol 57. Springer, Berlin, pp 11–18. doi:10.1007/978-3-540-93905-4_2
Simiński K (2010) Rule weights in neuro-fuzzy system with hierarchical domain partition. Int J Appl Math Comput Sci 20(2):337–347. doi:10.2478/v10006-010-0025-3
Simiński, K (2012) Clustering in fuzzy subspaces. Theoret Appl Inf 24(4):313–326. doi:10.2478/v10179-012-0019-y
Späth H (1992) Mathematical algorithms for linear regression. Academic Press Professional, Inc., San Diego
Sugeno M, Kang GT (1988) Structure identification of fuzzy model. Fuzzy Sets Syst 28(1):15–33 9
Takagi T, Sugeno M (1985) Fuzzy identification of systems and its application to modeling and control. IEEE Trans Syst Man Cybern 15(1):116–132
Wang L, Langari R (1994) Building Sugeno-type models using fuzzy discretization and orthogonal parameter estimation techniques. NAFIPS/IFIS/NASA ’94. In: Proceedings of the first international joint conference of the north american fuzzy information processing society biannual conference. The industrial fuzzy control and intelligent systems conference, and the NASA Joint Technolo, pp 201–206. doi:10.1109/IJCF.1994.375098
Yang J, Wang W, Wang H, Yu P (2002) δ-clusters: capturing subspace correlation in a large data set. In: Proceedings 18th international conference on data engineering, 2002, pp 517–528
Yeh IC (1998) Modeling of strength of high-performance concrete using artificial neural networks. Cement Concrete Res 28(12):1797–1808. doi:10.1016/S0008-8846(98)00165-3
Zadeh LA (1973) Outline of a new approach to the analysis of complex systems and decision processes. IEEE Trans Syst Man Cybern SMC-3, pp 28–44
Zhang K, Fan W (2008) Forecasting skewed biased stochastic ozone days: analyses, solutions and beyond. Knowl Inf Syst 14(3):299–326
Acknowledgments
The author is grateful to the anonymous reviewers for their constructive comments that have helped to improve the paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by W. Pedrycz.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Simiński, K. Neuro-fuzzy system with weighted attributes. Soft Comput 18, 285–297 (2014). https://doi.org/10.1007/s00500-013-1057-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-013-1057-z