
Abstract
We address the problem of finding a local solution to a nonconvex–nonconcave minmax optimization using Newton type methods, including primal-dual interior-point ones. The first step in our approach is to analyze the local convergence properties of Newton’s method in nonconvex minimization. It is well established that Newton’s method iterations are attracted to any point with a zero gradient, irrespective of it being a local minimum. From a dynamical system standpoint, this occurs because every point for which the gradient is zero is a locally asymptotically stable equilibrium point. We show that by adding a multiple of the identity such that the Hessian matrix is always positive definite, we can ensure that every non-local-minimum equilibrium point becomes unstable (meaning that the iterations are no longer attracted to such points), while local minima remain locally asymptotically stable. Building on this foundation, we develop Newton-type algorithms for minmax optimization, conceptualized as a sequence of local quadratic approximations for the minmax problem. Using a local quadratic approximation serves as a surrogate for guiding the modified Newton’s method toward a solution. For these local quadratic approximations to be well-defined, it is necessary to modify the Hessian matrix by adding a diagonal matrix. We demonstrate that, for an appropriate choice of this diagonal matrix, we can guarantee the instability of every non-local-minmax equilibrium point while maintaining stability for local minmax points. Using numerical examples, we illustrate the importance of guaranteeing the instability property. While our results are about local convergence, the numerical examples also indicate that our algorithm enjoys good global convergence properties.
Similar content being viewed by others

1 Introduction
In minmax optimization, one minimizes a cost function which is itself obtained from the maximization of an objective function. Minmax optimization is a powerful modeling framework, generally used to guarantee robustness to an adversarial parameter such as accounting for disturbances in model predictive control [1, 2], security-related problems [3, 4], or training neural networks to be robust to adversarial attacks [5]. It can also be used as a framework to model more general problem such as sampling from unknown distributions using generative adversarial networks [6], reformulating stochastic programming as minmax optimization [7,8,9], or producing robustness of a stochastic program with respect to the probability distribution [10]. Minmax optimization is also known as minimax or robust optimization. Minmax optimization is related to bilevel optimization [11,12,13], as minmax optimization can sometimes be used to find solutions to bi-level optimization when the inner and outer maximization have antisymmetric criteria.
Finding a global minmax point for nonconvex–nonconcave problems is generally difficult, and one has to settle for finding a local minmax point. Surprisingly, only recently a first definition of unconstrained local minmax was proposed in [14], and the definition of constrained local minmax in [15].
In optimization, Newton’s method consists of applying Newton’s root finding algorithm to obtain a point for which the gradient is equal to zero. In convex minimization, the only such points are (global) minima [16, Theorem 2.5]. Likewise, in convex–concave minmax optimization (meaning that the function is convex in the minimizing variable and concave in the maximizing variable), Von Neumanns’ Theorem [17] states that the min and the max commute, which implies that the only points for which the gradient is zero are solutions to the optimization. This means that both in convex minimization and convex–concave minmax optimization, using Newton’s root finding method to obtain a point for which the gradient is zero is a good strategy to solve the optimization problem.
In contrast, for nonconvex minimization or nonconvex–nonconcave minmax optimization, the gradient can be zero at a point even if such point is not a solution to the optimization. So using Newton’s root finding method to obtain a point for which the gradient is equal to zero is not a good strategy to find a (local) solution to the optimization. The foundation of our work involves examining Newton’s method iterations through the lens of dynamical systems. By analyzing the linearization of the dynamics, we deduce that every equilibrium point (i.e., a point with a zero gradient) is locally asymptotically stable, which is why the iterations of the Newton’s method are attracted to them. The key contribution of this article is to study how to modify the Newton’s method such that it is only attracted to (local) solutions of the optimization, and repelled by any equilibrium points that are not (local) solutions.
Our paper’s initial contribution is an examination of the local convergence properties of a modified Newton’s method for minimization in which a multiple of the identity matrix is added to the Hessian such that the resulting matrix is positive definite [16, Chapter 3.4 “Newton’s method with Hessian modification”]. This modified Newton has two crucial properties. First, it can be shown to be equivalent to a sequence of local quadratic approximations to the minimization problem. Second, we demonstrate that incorporating this additive matrix renders every non-local-minimum equilibrium point unstable while maintaining stability for local minima. This simple modification ensures that the modified Newton’s method has the property we refer to in the previous paragraph that the iterations are only attracted to equilibrium points that are local minima, and repelled by other equilibrium points. Utilizing analogous techniques, we establish similar results for primal-dual interior-point methods in constrained minimization. These findings (outlined in Sect. 2) directly inspire the development of new Newton-type algorithms for minmax optimization.
Drawing inspiration from the Newton’s method for minimization, we develop Newton-type algorithms for minmax optimization, conceptualized as a series of local quadratic approximations of the minmax problem. For convex–concave functions, this quadratic approximation is just the second-order Taylor expansion, which leads to the (unmodified) Newton’s method, accompanied by its well-established local convergence properties. However, for nonconvex–nonconcave functions, it is necessary to add scaled identity matrices to ensure that the local approximations possess finite minmax solutions (without mandating convex-concavity). Additive terms meeting this criterion are said to satisfy the local quadratic approximation condition (LQAC). Employing a sequence of local quadratic approximations acts as a surrogate for guiding the modified Newton’s method toward a solution at each step. Nevertheless, we demonstrate that, unlike minimization, local quadratic approximation-based modifications are not enough to ensure that the algorithm can only converge toward local minmax points. Our minmax findings reveal that additional conditions are required on the modification to unsure the algorithm’s convergence to an equilibrium point is guaranteed only if that point is a local minmax. To streamline the presentation, we first introduce this result in Sect. 3.1 for unconstrained minmax and then expand it to primal-dual interior-point methods for constrained minmax in Sect. 3.2.
The conditions described above to establish the equivalence between local minmax and local asymptotic stability of the equilibria to a Newton-type iteration are directly used to construct a numerical algorithm to find local minmax. By construction, when this algorithm converges to an equilibrium point, it is guaranteed to obtain a local minmax. One could be tempted to think that the issue of getting instability for the equilibria that are not local minima (in Theorems 1 and 2) or that are not local minmax (in Theorems 3 and 4) is just a mathematical curiosity, which in practice makes little difference. However, our numerical examples in Sects. 4.1 and 4.2 show otherwise. Most especially the pursuit-evasion MPC problem in Sect. 4.2, where finding a local minmax (rather than an equilibrium that is not local minmax) leads to a completely different control. Specifically, if the instability property is not guaranteed, the evader is not able escape from the pursuer. It is important to emphasize that our results fall shy of guaranteeing global asymptotic convergence to a local minmax, as the algorithm could simply never converge. However, our numerical examples also show that our algorithm seems to enjoy good global convergence properties in practice. Using the results of this paper, we have created a solver for minmax optimization and included it in the solvers of TensCalcFootnote 1 [18]; this solver was used to generate the numerical results we present.
Notation The set of real numbers is denoted by \(\mathbb {R}\). Given a vector \(v\in \mathbb {R}^n\), its transpose is denoted by \(v'\). The operation \({{\,\textrm{diag}\,}}(v)\) creates a matrix with diagonal elements v and off-diagonal elements 0. The matrix I is the identity, \({\textbf {1}}\) is the matrix of ones and \({\textbf {0}}\) the matrix of zeros; their sizes will be provided as subscripts whenever it is not clear from context. If a matrix A only has real eigenvalues, we denote by \(\lambda _{min}(A)\) and \(\lambda _{max}(A)\) its smallest and largest eigenvalues. The inertia of A is denoted by \({{\,\mathrm{{\textbf {in}}}\,}}(A)\) and is a 3-tuple with the number of positive, negative and zero eigenvalues of A.
Consider a differentiable function \(f:\mathbb {R}^n\times \mathbb {R}^m \mapsto \mathbb {R}^p\). The Jacobian (or gradient if \(p=1\)) at a point \(({\bar{x}},{\bar{y}})\) according to the x variable is a matrix of size \(n\times p\) and is denoted by \({\varvec{\nabla }}_xf({\bar{x}},{\bar{y}})\), and analogously for the variable y. When \(p=1\) and \(f(\cdot )\) is twice differentiable, we use the notation \({\varvec{\nabla }}_{yx}f({\bar{x}},{\bar{y}}):={\varvec{\nabla }}_y\big ({\varvec{\nabla }}_xf\big )({\bar{x}},{\bar{y}})\) which has sizes \(m\times n\). We use analogous definition for \({\varvec{\nabla }}_{xy}f({\bar{x}},{\bar{y}})\), \({\varvec{\nabla }}_{xx}f({\bar{x}},{\bar{y}})\) and \({\varvec{\nabla }}_{yy}f({\bar{x}},{\bar{y}})\).
1.1 Literature Review
Traditionally, robust optimization focused on the convex–concave case, with three main methods. The first type of method is based on Von Neumann’s minmax theorem [17] that states that the min and the max commute when the problem is convex–concave and the optimization sets are convex and compact. Solving the minmax then simplifies to finding a point that satisfies the first-order condition. While there are many different methods to achieve this, many of them can be summarized by the problem of finding the zeros of a monotone operator [19]. The second type of methods consists on reformulating the minmax as a minimization problem which has the same solution as the original problem. This is generally done using either robust reformulation through duality theory or tractable variational inequalities [12, 20,21,22]. The third, cutting-set methods, solves a sequence of minimization where the constraint of each minimization is based on subdividing the inner maximization [23].
Motivated by some of the shortcomings of these methods and the necessities of machine learning, research on minmax optimization started to study first-order methods based on variations of gradient descent-ascent. The results tend to focus on providing convergence complexity given different convexity/ concavity assumptions on the target function. We can divide these first-order methods in three families. The first family solves the minmax by (approximately) solving the maximization each time the value of the minimizer is updated. When this is done using first-order methods, it is generally referred to as multi-step gradient descent ascent, unrolled gradient descent ascent or GDmax, and the minimizer is updated by a single gradient descent whereas the maximizer is updated by several gradient ascent steps. A second family uses single step, where the minimizer and maximizer are updated at each iteration. For both of these two first families, the gradient iterations can include variations such as using different step sizes for the minimization and maximization, or using momentum. A third family, which is completely different from what is described for other ones, is to include the gradient from different time steps in the computation, such as the past one (as in optimistic gradient descent-ascent), the midpoint between the current and future points (as in extra gradient descent-ascent) and at future point (as in proximal point). The literature on first-order methods is very extensive, and we refer to [14, 24,25,26,27,28,29,30,31] and the references within for the exposition on some of these methods and their convergence properties.
In recent years, researchers have also started to work on algorithms that use second-order derivatives to determine the directions. These algorithm, in their major part, have not attracted as much attention as first-order methods. In the learning with opponent learning awareness (LOLA), the minimizer anticipates the play of the maximizer using the Jacobian of the maximizer’s gradient [32, 33]. In competitive gradient descent, both minimizer and maximizer use the cross derivative of the Hessian to compute their direction [34]. Following the ridge, the gradient ascent step is corrected by a term that avoids a drift away from local maxima [35]. In the total gradient descent-ascent, similarly to LOLA, the descent direction is computed by taking to total derivative of a function which anticipates the maximizer’s response to the minimizer [36]. Finally, the complete Newton borrows ideas from follow the ridge and total gradient to obtain a Newton method which prioritizes steps toward local minmax [37]. These three last algorithms are shown to only converge toward local minmax under some conditions, but in none of them it is addressed the issue of how to adjust the Hessian far away from a local minmax point.
Recently, some second-order methods have been proposed for the nonconvex–strongly concave case, where the minimizer update is a descent direction of the objective function at its maximum. They either use cubic regularization [38, 39] or randomly perturb the Hessian [40]. Because of some of the assumptions these work make, most important the strong-concavity of the objective function with respect to the maximizer, they are able to establish complexity analysis and guarantee. It is also worth mention that these algorithms are all multi-step based, meaning they (approximately) solve the maximization between each update of the minimizer, whereas our algorithm updates both the minimizer and the maximizer simultaneously.
2 Minimization
Let \(f:\mathcal {X}\rightarrow \mathbb {R}\) be a twice continuously differentiable cost function defined in a set \(\mathcal {X}\subset \mathbb {R}^{n_x}\) where \(n_x\) is a positive integer,Footnote 2 and consider the minimization problem
We recall that a point \(x^*\) is called a local minimum of \(f(\cdot )\) if there exist \(\delta >0\) such that \(f(x^*)\le f(x)\) for all \(x\in \{x\in \mathcal {X}:\left\| x-x^*\right\| <\delta \}\). We will study the property of Newton type algorithms to solve (1) in two distinct cases, when \(\mathcal {X}=\mathbb {R}^{n_x}\) and when \(\mathcal {X}\) is defined by equality and inequality constraints.
2.1 Unconstrained minimization
Let \(\mathcal {X}=\mathbb {R}^{n_x}\), which is referred to as unconstrained minimization in the literature, in which case (1) simplifies to
If \(f(\cdot )\) is twice continuously differentiable in a neighborhood of a point x and \({\varvec{\nabla }}_xf(x)={\textbf {0}}\) and \({\varvec{\nabla }}_{xx}f(x)\succ 0\), then x is a local minimum of \(f(\cdot )\) [16, Chapter 2].
An extremely popular method to solve a minimization problem is to use Newton’s root finding method to obtain a point x such that \({\varvec{\nabla }}_xf(x)={\textbf {0}}\). In its most basic form, the algorithm’s iterations are given by
where we use the notation \(x^+\) to designate the value of x at the next iteration. Newton’s method biggest advantage is that it converges very fast near any point that satisfies the first-order condition \({\varvec{\nabla }}_xf(x)={\textbf {0}}\): at least linearly but possibly superlinearly when the function is Lipschitz [16, Theorem 3.6]. However, this is also precisely Newton’s method biggest limitation for nonconvex minimization, because it does not distinguish a local minimum from any other point satisfying the first-order condition. Let us further illustrate this limitation with an example.
Example 1
Consider the optimization,
for which \(\forall x\in \mathbb {R}\),
The corresponding Newton iteration (3) is of the form
for which both the local minimum \(x^{\min }:= 1\) and the local maximum \(x^{\max }:= -1\) are locally asymptotically stable equilibria with superlinear convergence. Specifically,
Moreover, the iteration never actually “converges” to the global “infimum” \(x\rightarrow -\infty \).
In order to address this limitation, a widely used modification of Newton’s method for unconstrained nonconvex optimization [16, Chapter 3.4], is obtained by modifying the basic Newton method such that \(d_x\) is obtained from solving the following local quadratic approximation to (1)
with \(\epsilon _x(x)\ge 0\) chosen such that \(({\varvec{\nabla }}_{xx}f(x)+\epsilon _x(x)I)\) is positive definite. For twice differentiable strongly convex functions we can choose \(\epsilon _x(x)=0\) and this corresponds to the classical Newton’s method. However, when \(f(\cdot )\) is not strongly convex, the minimization in (5) is only well-defined if \({\varvec{\nabla }}_{xx}f(x)+\epsilon _x(x)I\) is positive definite, which requires selecting a strictly positive value for \(\epsilon _x(x)\), leading to a modified Newton’s method. Regardless of whether \(f(\cdot )\) is convex, the positive definiteness of \({\varvec{\nabla }}_{xx}f(x)+\epsilon _x(x)I\) guarantees that \(d_x ' {\varvec{\nabla }}_x f(x)=-{\varvec{\nabla }}_x f(x)({\varvec{\nabla }}_{xx}f(x)+\epsilon _x(x)I)^{-1}{\varvec{\nabla }}_x f(x)<0\) and therefore \(d_x\) is a descent direction at x [16]. The corresponding Newton iteration to obtain a local minimum is then given by
Let us analyze how this modification impacts the convergence in our previous example.
Example 1
(Continuation) For the optimization in (4), the modified Newton step in (6) becomes \(x^+=x-\frac{3x^2-3}{6x+\epsilon _x(x)}\) with \(\epsilon _x(\cdot )\) such that
In this case,
Selecting the function \(\epsilon _x(\cdot )\) with \(\epsilon _x(\cdot ) = 0\) around \(x^{\min }\) results in superlinear convergence to \(x^{\min }\), but if \(\epsilon _x(\cdot ) > 0\), the convergence is only linear. For example, picking \(\epsilon _x(x)=-6x + \eta \) with \(\eta >0\), (7) holds for all x, but the modified Newton step in (6) becomes \(x^+=x-\frac{3x^2-3}{\eta }\), which is just a gradient descent.
The following result generalizes the conclusion from the previous example by establishing that the positive definiteness of \({\varvec{\nabla }}_{xx}f(x)+\epsilon _x(x)I\) not only guarantees that \(d_x\) is a descent direction, but also that every locally asymptotically stable (LAS) equilibrium point of the Newton iteration (6) is a local minimum.
Theorem 1
(Stability and instability of modified Newton method for unconstrained minimization) Let x be an equilibrium point in the sense that \({\varvec{\nabla }}_{x}f(x)={\textbf {0}}\). Assume that \({\varvec{\nabla }}_{xx}f(x)\) is invertible and that \({\varvec{\nabla }}_{xx}f(\cdot )\) is differentiable in a neighborhood around x. Then, for any function \(\epsilon _x(\cdot )\) that is constant in a neighborhood around x and satisfies \({\varvec{\nabla }}_{xx}f(x)+\epsilon _x(x)I\succ {\textbf {0}}\) one has that if:
-
i)
x is a local minimum of (2), then it is a LAS equilibrium of (6).
-
ii)
x is not a local minimum of (2), then it is an unstable equilibrium of (6).
The theorem’s first implication is that if the modified Newton iteration starts sufficiently close to a strict local minimum, it will converge at least linearly fast to it. One could think that it would always be preferable to have \(\epsilon _x(x)=0\) if \({\varvec{\nabla }}_{xx}f(x)\succ 0\), in which case not only stability can be trivially obtained but also that the Newton method has superlinear convergence if \(f(\cdot )\) is Lipschitz [16, Theorem 3.6]. However, in practice, there are situations for which one might want to take \(\epsilon _x(x)>0\). A typical case happens if the smallest eigenvalue of \({\varvec{\nabla }}_{xx}f(x)\) is positive but very small, which might bring numerical issues when computing the Newton step \({\varvec{\nabla }}_{xx}f(x)^{-1}{\varvec{\nabla }}_xf(x)\). This issue can be fixed by taking \(\epsilon _x(x)>0\), and Theorem 1 guarantees that doing so will not impair (at least locally) the algorithm’s capacity to converge toward a local minimum.
The theorem’s second implication is, in a way, even more relevant than the first one. As we mentioned earlier, the regular Newton’s method (meaning, with \(\epsilon _x(x)=0\)) is infamously known to be attracted to any point that satisfies \({\varvec{\nabla }}_{x}f(x)={\textbf {0}}\), regardless of whether it is a local minimum, a saddle point, or a local maximum. What Theorem 1 is essentially saying is that the modified Newton is only attracted to local minima, and that any other equilibrium point repels the iteration. In essence, this means that the modified Newton’s method cannot converge toward a point that is not a local minimum, thus fixing one of the biggest drawbacks of the regular Newton’s method.
While it goes beyond the point of this article, notice that for large values of \(\epsilon _x(x)\),
which shows that the modified Newton’s step (6) essentially becomes a gradient descent step with a small step size \(\epsilon _x(x)^{-1}\). This also shows that, by keeping \(\epsilon _x(x)^{-1}\) sufficiently large, the iteration (6) could be made descent with respect to the cost. However, this would be achieved at the cost of losing superlinear convergence.
Proof of Theorem 1
From our assumption that \({\varvec{\nabla }}_{xx}f(x)\) is invertible, x is a local minimum if and only if \({\varvec{\nabla }}_{xx}f(x)\succ 0\). This comes from the second-order necessary condition for minimization [16, Chapter 2].
Let us now prove the stability and instability properties. The first step in our analysis is to calculate the Jacobian of \(({\varvec{\nabla }}_{xx} f(x)+\epsilon _x(x)I)^{-1}{\varvec{\nabla }}_x f(x)\) that appears in (6) at an equilibrium point x. Using the differentiability of \({\varvec{\nabla }}_{xx}f(\cdot )\) and that \(\epsilon _x(\cdot )\) is constant in a neighborhood of x, we obtain that
where \({\varvec{\nabla }}_{x} f(x)^{(i)}\) is the ith element of \({\varvec{\nabla }}_{x} f(x)\) and \([({\varvec{\nabla }}_{xx} f(x)+\epsilon _x(x)I)^{-1}]_i\) is the ith column of \(({\varvec{\nabla }}_{xx} f(x)+\epsilon _x(x)I)^{-1}\). Since \(({\varvec{\nabla }}_{xx} f(x)+\epsilon _x(x)I)\) is positive definite, \({\varvec{\nabla }}_x[({\varvec{\nabla }}_{xx} f(x)+\epsilon _x(x)I)^{-1}]_i\) is well defined and since x is an equilibrium point, \({\varvec{\nabla }}_{x} f(x)^{(i)}=0\) for \(i\in \{1\dots N\}\) and therefore the Jacobian of right-hand side of (6) is given by
The main argument of the proof is based on the following result. Let v be an eigenvector associated to an eigenvalue \(\rho \) of (8). Then,
Therefore, \( \rho \) is an eigenvalue of (8) if and only if \( \rho {\varvec{\nabla }}_{xx}f(x) + (\rho - 1) \epsilon _x(x)I\) is singular.
We remind the reader that given a dynamical system, if the system’s dynamic equation is continuously differentiable, a point is a LAS equilibrium point if all the eigenvalues of the linearized system are inside the unit circle. Conversely, if at least one of the eigenvalues of the linearized system is outside the unit circle, then the system is unstable [41, Chapter 8].
From (9), \(\rho =0\) is an eigenvalue if and only if \(\epsilon _x(x)=0\), which, by construction, can only happen if x is a local minimum, in which case x is a LAS equilibrium point of (6), as expected.
For \(\rho \ne 0\), let us rewrite this expression as \({\varvec{\nabla }}_{xx}f(x) + \mu \epsilon _x(x)I\) with \( \mu := 1 - 1/\rho \). We conclude that x is a LAS equilibrium point of (6) if \({\varvec{\nabla }}_{xx}f(x) + \mu \epsilon _x(x)\) is nonsingular \(\forall \mu \in [0, 2]\). Conversely, x is an unstable equilibrium point of (6) if \({\varvec{\nabla }}_{xx}f(x) + \mu \epsilon _x(x)\) is singular for some \(\mu \in [0, 2]\).
If x is a local minimum, then \(\lambda _{min}({\varvec{\nabla }}_{xx}f(x))>0\). As \(\epsilon _x(x)>0\), we conclude that \(\lambda _{min}({\varvec{\nabla }}_{xx}f(x) + \mu \epsilon _x(x)I)>0\) for every \(\mu \ge 0\) and therefore x is a LAS equilibrium point of (6). Conversely, if x is not a local minimum then \(\lambda _{min}({\varvec{\nabla }}_{xx}f(x))<0\). By construction of \(\epsilon _x(x)\), we have that \(\lambda _{min}({\varvec{\nabla }}_{xx}f(x) + \mu \epsilon _x(x)I)>0\), which, by continuity of the eigenvalue, implies \(\exists \mu \in (0,1)\) such that \(\lambda _{min}({\varvec{\nabla }}_{xx}f(x) + \mu \epsilon _x(x)I)=0\). Therefore, x is an unstable equilibrium point of (6). \(\square \)
2.2 Constrained minimization
Our results from the previous section can also be extended to consider the case with more general constraint with the minimization set \(\mathcal {X}\) involving equality and inequality constraints of the form
where the functions \(G_x:\mathbb {R}^{n_x}\rightarrow \mathbb {R}^{l_x}\) and \(F_x:\mathbb {R}^{n_x}\rightarrow \mathbb {R}^{m_x}\) are all twice continuously differentiable.Footnote 3 It will be convenient for the development of the primal-dual interior-point method to use slack variables and rewrite (1) as
where \(s_x\in \mathbb {R}^{m_x}\).
Similar to what we have in the unconstrained minimization, we want a second-order conditions to determine whether a point is a local minimum. Consider the function
where we use the shorthand notation \(z:=(x,s_x,\nu _x,\lambda _x)\). L(z) is essentially the Lagrangian of (10). In order to present the second-order conditions, we need to define two concepts, the linear independence constraint qualification and strict complementarity [16, Definitions 12.4 and 12.5].
Definition 1
(LICQ and strict complementarity) Let the set of active inequality constraints for the minimization be defined by
where \(F_x^{(i)}(x)\) denote the ith element of \(F_x(x)\). Then,
-
The linear independence constraint qualification (LICQ) is said to hold at z if the vectors in the set
$$\begin{aligned} \{{\varvec{\nabla }}_x G_x^{(i)}(x), i=1,\dots ,l_x\}\bigcup \{{\varvec{\nabla }}_x F_x^{(i)}(x), i \in \mathcal {A}_x(x) \} \end{aligned}$$are linearly independent.
-
Strict complementarity is said to hold at x if \(\lambda _x^{(i)}>0 \ \forall i\in \mathcal {A}_x(x)\)
We have almost all the ingredients to present the second-order condition for constrained minimization. For unconstrained minimization, a sufficient condition for a point x to be a local minimum is that \({\varvec{\nabla }}_{x}f(x)=0\) and \({\varvec{\nabla }}_{xx}f(x)\succ 0\). If it were not for the inequality constraints in (10), we would be able to state the second-order conditions using gradients and Hessians of L(z). The inequality constraints make the statement a bit more complicated. The role of the gradient will be played by
with \(\odot \) denoting the element wise Hadamard product of two vectors and \(b\ge 0\) the barrier parameter (its role will be explained shortly). The role of \({\varvec{\nabla }}_{xx}f(x)\) in the unconstrained minimization will be played by the matrix
We also remind the reader that the inertia \({{\,\mathrm{{\textbf {in}}}\,}}(A)\) of a symmetric matrix A is a 3-tuple with the number of positive, negative and zero eigenvalues of A.
Proposition 1
(Second-order sufficient conditions for constrained minimization) Let z be an equilibrium point in the sense that \(g(z,0)={\textbf {0}}\) with \(\lambda _x,s_x\ge {\textbf {0}}\). If the LICQ and strict complementarity hold at z and
then x is a local minimum of (10).
While this result is relatively well known, we present its proof in Appendix A. The proof also makes it easier to understand the proof of the second-order sufficient conditions for constrained minmax optimization.
2.2.1 Primal-dual interior-point method
Let \(d_z:=(d_x,d_s,d_\nu ,d_\lambda )\) be the update direction for z, which will play an equivalent role to \(d_x\) in the unconstrained case. A basic primal-dual interior-point method finds a candidate solution to (10) using the iterations
where the barrier parameterFootnote 4b is slowly decreased to 0, so that z converges to a root of \(g(z,0)={\textbf {0}}\) while \(\alpha \in (0,1]\) is chosen at each step such that the feasibility condition \(\lambda _x,s_x>{\textbf {0}}\) hold [16, Chapter 19]. This basic primal-dual interior-point has similar limitation as a (non-modified) Newton method for unconstrained minimization: it might converge toward an equilibrium point that is not a local minimum and \({\varvec{\nabla }}_{z}g(z,b)\) might not be invertible. Similar to what we have done in the unconstrained case, we can modify this basic primal-dual interior-point method such that the update direction \(d_z\) is obtained from a quadratic program that locally approximates (10). The rest of this section will be spent mostly constructing such quadratic program.
Let us start with \(\mathcal {X}\) described only by equality constraints (i.e., no \(F_x(x)\) and no \(s_x\)), in which case \(L(z)=f(x)+\nu _x' G_x(x)\). Consider the optimization
which locally approximates (10) around \((x,\nu _x)\).Footnote 5 If \({\varvec{\nabla }}_xG_x(x)\) is full column rank, we can choose \(\epsilon _x(z)\) large enough such that the solution of (15) is well defined and unique. To show that, let us look at (15) as an optimization in its own right. Let \({\bar{d}}_\nu \) be the Lagrange multiplier and define the function \({\bar{g}}({\bar{d}}_x,{\bar{d}}_\nu )\) which is the function g(z, b) defined in (11) but now for problem (15):
So if one takes any \(\epsilon _x(z)\ge 0\) large enough such that
then we guarantee that any point \({\bar{d}}_x,{\bar{d}}_\nu \) that satisfies \({\bar{g}}({\bar{d}}_x,{\bar{d}}_\nu )={\textbf {0}}\) will be a strict local minimum of (15) (see Proposition 1). Moreover, this choice of \(\epsilon _x(z)\) also guarantees that (15) is a strongly convex quadratic optimization, which, with the fact that \({\varvec{\nabla }}_xG_x(x)\) is full column rank, means that the solution \(({\bar{d}}_x,{\bar{d}}_\nu )\) is unique. Therefore, we will take the update directions \((d_x,d_\nu )\) to be the solution \(({\bar{d}}_x,{\bar{d}}_\nu )\). Moreover, with some algebra, one can show that the solution to (15) is given by
Let us now address the case in which there are inequality constraints. The challenge is to take into account the constraint \(s_x\ge 0\). To address this, let us start by relaxing the inequality constraint from (10) and including it in the cost as the barrier function \(-b{\textbf {1}}'\log (s_x)\) (the \(\log (\cdot )\) is element wise).
This is a relaxation because \(-b{\textbf {1}}'\log (s_x)\) only accepts \(s\ge 0\) and goes to \(+\infty \) if \(s_x\rightarrow 0\). The optimization (18) only has equality constraints, so similar to what we did in (15), let us construct a local second-order approximation of (18) around z:
where \(\oslash \) designates the element wise division of two vectors. Equation (19) is not exactly a second-order approximation because instead of using as quadratic term for \({\bar{d}}_s\) the matrix \(b{{\,\textrm{diag}\,}}(s_x)^{-2}\) (which is the actual matrix given by second-order approximation of \(-b{\textbf {1}}'\log (s_x+d_s)\) around \(s_x\)), we used the matrix \({{\,\textrm{diag}\,}}(\lambda _x\oslash s_x)\). This is a relatively well-known substitutions for interior-point methods, and is what makes it be a primal-dual interior-point method instead of a barrier interior-point method. The technical justification is that if we were at a point such that \(g(z,b)={\textbf {0}}\), the two would be equivalent as \(\lambda _x \odot s_x - b {\textbf {1}}={\textbf {0}}\). In practice, it has been observed that this modified linearization tends to perform better because it provides directions \(d_s\) that also take into account the current value of \(\lambda _x\) in the quadratic form, which helps to get a direction \(d_z\) that does not violate the constraints \(\lambda _x,s_x>0\) [16, Chapter 19.3].
Because (19) is a quadratic program with linear equality constraints, just as it was the case for (15), we can use the exact same reasoning to choose \(\epsilon _x(z)\). Let us define the matrices
and \(E(z):={{\,\textrm{diag}\,}}(\epsilon _x(z){\textbf {1}}_{n_x},{\textbf {0}}_{m_x+l_x+m_x})\). If \(\epsilon _x(z)\) is chosen large enough such that \({{\,\mathrm{{\textbf {in}}}\,}}(J_{zz}+E(z))=(n_x+m_x,l_x+m_x,0)\), then the solution \(({\bar{d}}_x,{\bar{d}}_s)\) of (19) and associated Lagrange multipliers \(({\bar{d}}_\nu ,{\bar{d}}_\lambda )\) are unique. With some algebra, one could show that the solution of (19) is
where \(S:={{\,\textrm{diag}\,}}({\textbf {1}}_{n_x},s_x,{\textbf {1}}_{l_x+m_x})\). Putting it all together, the modified primal-dual interior-point is governed by the equation
where \(\alpha \in (0,1]\) is chosen such that \(\lambda _x,s_x>{\textbf {0}}\). Conveniently, because we used \({{\,\textrm{diag}\,}}(\lambda _x\oslash s_x)\) for the second-order linearization of the barrier, when \(\epsilon _x(x)=0\), we recover the basic primal–dual interior-point method from (14). We refer to [16, Chapter 19] for a complete description of an algorithm using (21), including a strategy to decrease the barrier parameter b. Alternatively, we describe such strategy in Sect. 4 for the minmax optimization case.
We can now state a result connecting the stability/instability of any equilibrium point of the modified primal-dual interior-point method to such point being or not a local minimum. The theorem says essentially the same thing as Theorem 1: On the one hand, even if \({{\,\mathrm{{\textbf {in}}}\,}}(J_{zz}f(z))=(n_x+m_x,l_x+m_x,0)\), taking \(\epsilon _x(z)>0\) will not impair the algorithm’s capacity to converge toward a local minimum; this can be useful, for instance, if \({{\,\mathrm{{\textbf {in}}}\,}}(J_{zz}f(z))\) has an eigenvalue close to 0. On the other hand, using the modified primal-dual interior-point method essentially guarantees that the algorithm can only converge toward an equilibrium point if such point is a local minimum, thus fixing the issue of primal-dual interior-point methods being attracted to any equilibrium point, regardless of whether such point is a local minimum.
Theorem 2
(Stability and instability of modified primal-dual interior-point method for constrained minimization) Let \(\alpha =1\) and (z, b) with \(b>0\), be an equilibrium point in the sense that \(g(z,b)={\textbf {0}}\). Assume the LICQ and strict complementarity hold at z, that \(J_{zz}f(z)\) is invertible, and that \(J_{zz}f(\cdot )\) is differentiable on a neighborhood around z. Then for any function \(\epsilon _x(\cdot )\) that is constant in a neighborhood around z and satisfies \({{\,\mathrm{{\textbf {in}}}\,}}(J_{zz}+E(z))=(n_x+m_x,l_x+m_x,0)\) one has that if:
-
i)
z is a local minimum of (10), then it is a LAS equilibrium of (21).
-
ii)
z is not a local minimum of (10), then it is an unstable equilibrium of (21).
Proof
(Proof sketch) First, using the same arguments as in the proof of Theorem 1, we conclude that the Jacobian of the dynamic system (21) around a point z for which \(g(z,b)={\textbf {0}}\) is
Second, it is straightforward to check that \(H_{zz}f(z)=S^{1/2}J_{zz}f(z)S^{1/2}\) which, using Sylvester’s law of inertia [42, Theorem 1.5], means that \({{\,\mathrm{{\textbf {in}}}\,}}(H_{zz}f(z))={{\,\mathrm{{\textbf {in}}}\,}}(J_{zz}f(z))\). This means that one can check the second-order conditions in (13) by using \(J_{zz}f(z)\).
Let us define the matrix
where \(Z_{x}(z)\in \mathbb {R}^{n_x+m_x,n_x-l_x}\) is a matrix with full column rank such that
Using the same arguments as in the proof of Proposition 1, we conclude that
which implies that \({{\,\mathrm{{\textbf {in}}}\,}}(J_{zz}f(z)+E(z))=(n_x+m_x,l_x+m_x)\) is equivalent to \(R(1)\succ 0\) and that the second-order sufficient condition is equivalent to \(R(0)\succ 0\). This means that the rest of the theorem’s proof is analogous to the one of Theorem 1, but instead of looking at the sign of the smallest eigenvalue of \({\varvec{\nabla }}_{xx}f(x)+\mu \epsilon _x(z)I\), one looks at the sign of the smallest eigenvalue of the matrix \(R(\mu )\).
If z is a local minimum, then \(\lambda _{min}(R(0))>0\). As \(\epsilon _x(z)\ge 0\), we conclude that \(\lambda _{min}(R(\mu ))>0\) for every \(\mu \ge 0\) and therefore z is a LAS equilibrium point of (14).
Conversely, if z is not a local minimum, \(\lambda _{min}(R(0))<0\). By construction, \(\epsilon _x(z)\) is such that \(\lambda _{min}(R(1))>0\), therefore, by continuity of the eigenvalue, there is a \(\mu \in (0,1)\) such that \(\lambda _{min}(R(\mu ))=0\) and therefore z is an unstable equilibrium point of (14). \(\square \)
3 Minmax optimization
Consider the minmax optimization problem
where \(f:\mathbb {R}^{n_x}\times \mathbb {R}^{n_y}\rightarrow \mathbb {R}\) is a twice continuously differentiable objective function, \(\mathcal {X}\subset \mathbb {R}^{n_x}\) is the feasible set for x and \(\mathcal {Y}:\mathcal {X}\rightrightarrows \mathbb {R}^{n_y}\) is a set-valued map that defines an x dependent feasible set for y; we do not make any convexity or concavity assumption on \(f(\cdot )\), \(\mathcal {X}\) and \(\mathcal {Y}(\cdot )\). We chose \(\mathcal {Y}(\cdot )\) to be dependent on x because this describes the most general application. Moreover, having the constraints of the inner maximization to depend on the value of outer maximization is often necessary in problems such as robust model predictive control or in bi-level optimization. Furthermore, notice that we do not make any assumption on whether the min and the max commute (and this would not be well defined as \(\mathcal {Y}(\cdot )\) depends on x). A solution \((x^*,y^*)\) to (24) is called a global minmax and satisfies
We will look at two representations of \(\mathcal {X}\text { and }\mathcal {Y}(\cdot )\): first when \(\mathcal {X}=\mathbb {R}^{n_x}\) and \(\mathcal {Y}=\mathbb {R}^{n_y}\), which is known in the literature as the unconstrained case; second a more general representation in which \(\mathcal {X}\) and \(\mathcal {Y}(\cdot )\) are defined using equality and inequality constraints.
A point \((x^*,y^*)\) is said to be a local minmax of (24) if there exist a constant \(\delta _0>0\) and a positive function \(h(\cdot )\) satisfying \(h(\delta )\rightarrow 0\) as \(\delta \rightarrow 0\), such that for every \(\delta \in (0,\delta _0]\) and for every \((x,y)\in \) \(\{x\in \mathcal {X}:\left\| x-x^*\right\| \le \delta \}\) \(\times \{y\in \mathcal {Y}(x^*):\left\| y-y^*\right\| \le h(\delta )\}\) we have
[14, 15]. Inspired by the properties of the modified Newton and primal-dual interior-point methods for minimization in Sect. 2, we want to develop a Newton-type iterative algorithm of the form
where \(d_x\) and \(d_y\) satisfy the following properties:
-
P1:
At each time step, \((d_x,d_y)\) is obtained from the solution of a quadratic program that locally approximates (24) and therefore \((x^+,y^+)\) can be seen as an improvement over (x, y). This acts as a surrogate for guiding the modified Newton’s method toward a solution at each step.
-
P2:
The iterations of (25) can converge toward an equilibrium point only if such point is a local minmax. Similar to what was the case in minimization (see Example 1), a pure Newton method will be attracted to any equilibrium point. This makes sure that the iterations will not be attracted to equilibrium points that are not local minmax.
-
P3:
The iterations of (25) can converge to any local minmax. This property means that any modification to Newton’s method needs to keep local minmax as attractor.
3.1 Unconstrained minmax
We start by considering the case where \(\mathcal {X}=\mathbb {R}^{n_x}\) and \(\mathcal {Y}(\cdot )=\mathbb {R}^{n_y}\) such that (24) simplifies to
For this case, [14] establishes second-order sufficient conditions to determine if a point (x, y) is a local minmax which can be stated in terms of the inertia of the matrix
We recall that the inertia \({{\,\mathrm{{\textbf {in}}}\,}}(A)\) of a symmetric matrix A is a 3-tuple with the number of positive, negative and zero eigenvalues of A.
Proposition 2
(Second-order sufficient condition for unconstrained minmax) Let (x, y) be an equilibrium point in the sense that \({\varvec{\nabla }}_x f(x,y)=0\) and \({\varvec{\nabla }}_y f(x,y)=0\). If
then (x, y) is a local minmax.
The second-order conditions in [14] are:
which turn out to be equivalent to the inertia conditions in Proposition 2 in view of Haynsworth inertia additivity formula [42, Theorem 1.6]. Notice that the second-order sufficient conditions are not symmetric. A point might be a local minmax even if \({\varvec{\nabla }}_{xx} f(x,y) \nsucc 0\) as long as \(- {\varvec{\nabla }}_{xy} f(x,y){\varvec{\nabla }}_{yy} f(x,y)^{-1}{\varvec{\nabla }}_{yx} f(x,y)\) (which is positive) is large enough. So the second-order conditions are what allow one to distinguish between an equilibrium point being a local minmax and a minmin, maxmax or maxmin. One can interpret the second-order sufficient conditions as saying that \(y\mapsto f(x,y)\) is strongly concave in a neighborhood around (x, y) and \(x\mapsto \max _{{\tilde{y}}:\left\| y-{\tilde{y}}\right\| <\delta } f(x,{\tilde{y}})\) is strongly convex in a neighborhood around (x, y) for some \(\delta >0\). Notice that these are only local properties around local minmax, as \(f(\cdot )\) may be nonconvex–nonconcave away from local minmax points.
In order to obtain property P1, we propose to obtain the Newton direction \((d_x,d_y)\) for (25) by solving the following local quadratic approximation to (26)
with \(\epsilon _x(\cdot )\) and \(\epsilon _y(\cdot )\) chosen so that the minmax problem in (28) has a unique solution, which means that the inner (quadratic) maximization must be strictly concave and that the outer (quadratic) minimization of the maximized function must be strictly convex, which turns out to be precisely the second-order sufficient conditions in Proposition 2, applied to the approximation in (28), which can be explicitly written as follows:
where \(E(x,y) = {{\,\textrm{diag}\,}}(\epsilon _x(x,y) {\textbf {1}}_{n_x}, -\epsilon _y(x,y) {\textbf {1}}_{n_y})\). We call these condition the Local Quadratic Approximation Condition (LQAC). It is straightforward to show that the Newton iterations (25) with \((d_x,d_y)\) obtained from the solution to (28) is given by
To obtain properties P2 and P3, we need all locally asymptotically stable equilibrium points of (28) to be local minmax of (26) and that all other equilibrium points of (28) to be unstable. For the unconstrained minimization in Sect. 2.1, to obtain the equivalent of properties P2 and P3 it was sufficient to simply select \(\epsilon _x(\cdot )\) such that the local quadratic approximation (5) has a well-defined minimum (Theorem 1). However, for minmax optimization the (LQAC) does not suffice to guarantee that P2 and P3 hold. Our first counter example bellow show how the (LQAC) are not enough to ensure that P2 holds; our second counter example show how they are not enough to guarantee that P3 holds.
Example 2
Consider \(f(x,y)= 1.5x^2 -4xy +y^2\) for which the unique equilibrium point \(x=y=0\) is not a local minmax point. Take \(\epsilon _y(0,0)=4\) and \(\epsilon _x(0,0)=0\) which satisfy (LQAC). The Jacobian of the dynamics is
which has eigenvalues approximately equal to (0, 0.54). Therefore (0, 0) is a LAS equilibrium point of (29) even though it is not a local minmax point.
Example 3
Consider \( f(x, y):= -0.25 x^2 + xy - 0.5 y^2 \), for which the unique equilibrium point \(x=y=0\) is a local minmax point. Take \(\epsilon _y(0,0)=3\) and \(\epsilon _x(0,0)=0.2\) which satisfy (LQAC). The Jacobian of the dynamics is
for which the eigenvalues are \(1.5\pm 1.5i\). Therefore, (0, 0) is an unstable equilibrium point of (29) even though it is a local minmax point.
The main contribution of this section is a set of sufficient conditions that, in addition to (LQAC), guarantee P2 and P3 hold.
Theorem 3
(Stability and instability of modified Newton’s method for unconstrained minmax) Let (x, y) be an equilibrium point in the sense that \({\varvec{\nabla }}_{x}f(x,y)={\textbf {0}}\) and \({\varvec{\nabla }}_{y}f(x,y)={\textbf {0}}\). Assume that \({\varvec{\nabla }}_{zz}f(x,y)\) and \({\varvec{\nabla }}_{yy}f(x,y)\) are invertible and that \({\varvec{\nabla }}_{zz}f(\cdot )\) is differentiable on a neighborhood around (x, y). Then there exist functions \(\epsilon _x(\cdot )\) and \(\epsilon _y(\cdot )\) that are constant in a neighborhood around (x, y), satisfy the (LQAC) at (x, y) and guarantee that if:
-
i)
(x, y) is a local minmax of (26), then it is a LAS equilibrium of (29).
-
ii)
(x, y) is not a local minmax of (26), then it is an unstable equilibrium of (29).
The theorem’s implications are similar to those of Theorem 1. On the one hand, if (x, y) is a local minmax, then it is possible to construct functions \(\epsilon _x(\cdot )\) and \(\epsilon _y(\cdot )\) that guarantee that the modified Newton method can converge toward a local minmax. A natural choice for such function near a local minmax is to take \(\epsilon _y(\cdot )=\epsilon _x(\cdot )=0\), which not only provides the stability result, but can also achieve superlinear convergence if \(f(\cdot )\) is Lipschitz. On the other hand, if (x, y) is an equilibrium point but not a local minmax, it is possible to construct functions \(\epsilon _x(\cdot )\) and \(\epsilon _y(\cdot )\) such that the algorithm’s iterations cannot converge toward it. This means that the modified Newton’s method for minmax can only converge toward an equilibrium point if such point is a local minmax.
While the statement of Theorem 3 is about existence, the proof is actually constructive. The functions \(\epsilon _x(\cdot )\) and \(\epsilon _y(\cdot )\) are not unique, and have to satisfy the following conditions:
-
i)
For the stability result, if \(\epsilon _y(x,y)=0\), then the stability property is guaranteed by any \(\epsilon _x(x,y)\ge 0\). If \(\epsilon _y(x,y)>0\), then \(\epsilon _x(x,y)\) needs to be taken large enough to satisfy the condition in equation (32) of the proof.
-
ii)
For the instability result:
-
unless \({{\,\mathrm{{\textbf {in}}}\,}}({\varvec{\nabla }}_{yy}f(x,y))\ne (0,n_y,0)\) and \({{\,\mathrm{{\textbf {in}}}\,}}({\varvec{\nabla }}_{zz}f(x,y))=(n_x,n_y,0)\), then it is sufficient for \(\epsilon _x(x,y)\) and \(\epsilon _y(x,y)\) to satisfy the (LQAC) to guarantee instability.
-
if \({{\,\mathrm{{\textbf {in}}}\,}}({\varvec{\nabla }}_{yy}f(x,y))\ne (0,n_y,0)\) and \({{\,\mathrm{{\textbf {in}}}\,}}({\varvec{\nabla }}_{zz}f(x,y))=(n_x,n_y,0)\) then for a given \(\epsilon _y(x,y)\), \(\epsilon _x(x,y)\) needs to be large enough such that for some \(\mu \in (0,1)\), \({{\,\mathrm{{\textbf {in}}}\,}}({\varvec{\nabla }}_{zz}f(x,y)+\mu E(x,y))\ne (n_x,n_y,0)\).
-
We use these results in Sect. 4 to present an efficient way to numerically construct these functions.
Proof of Theorem 3
The fact that the (LQAC) can always be satisfied is straightforward: as \({\varvec{\nabla }}_{zz}f(x,y)\) is differentiable, its eigenvalues are bounded and can be made to have the desired inertia by taking sufficiently large (but finite) values of \(\epsilon _x(x,y)\) and \(\epsilon _y(x,y)\). Moreover, from our assumption that \({\varvec{\nabla }}_{zz}f(x,y)\) and \({\varvec{\nabla }}_{yy}f(x,y)\) are invertible, (x, y) is a local minmax point if and only if (x, y) satisfy the second order sufficient in (27); this is implied by the second-order necessary conditions for local minmax in [14].
Using the same reasoning as in Theorem 1, as the (LQAC) hold then \(({\varvec{\nabla }}_{zz}f(x,y)+E(x,y))\) is nonsingular and the Jacobian of the dynamical system (29) at (x, y) is
Therefore, we can also use the same reasoning as in the proof of Theorem 1 to conclude that (x, y) is a LAS equilibrium point of (29) if \({\varvec{\nabla }}_{zz}f(x,y) + \mu E(x,y)\) is nonsingular \(\forall \mu \in [0, 2]\). Conversely, (x, y) is an unstable equilibrium point of (29) if \({\varvec{\nabla }}_{zz}f(x,y) + \mu E(x,y)\) is singular for some \(\mu \in (0, 2)\).
For the rest of the proof, it will be useful to have defined the function
and to drop the inputs (x, y) from the expressions in order to shorten them.
Let us start by proving the statement for the case when (x, y) is a local minmax, in which case the (LQAC) hold with \(\epsilon _y=\epsilon _x=0\). We will prove that if
then (x, y) is a LAS equilibrium point of (29). To prove it, we will show (32) ensures that \({\varvec{\nabla }}_{zz}f + \mu E\) is nonsingular \(\forall \ \mu \ge 0\). First, as \( {\varvec{\nabla }}_{yy}f \prec 0 \), \( \mu \ge 0 \), and \( \epsilon _y \ge 0 \), we have \( {\varvec{\nabla }}_{yy}f - \mu \epsilon _y I \prec 0 \) and is thus nonsingular. Second, let us show that the condition (32) implies that for any vector v
Taking the derivative of \(v'R(\mu )v\) with respect to \(\mu \) we obtain
in which we use the fact that \({\varvec{\nabla }}_{yy}f^{-2}\succeq ({\varvec{\nabla }}_{yy}f - \mu \epsilon _y I)^{-2}\) for all \(\mu \ge 0\) as \( {\varvec{\nabla }}_{yy}f \prec 0 \), and \( \epsilon _y \ge 0 \). Therefore, if (32) holds, the derivative of \(v'R(\mu )v\) with respect to \(\mu \) is non-negative, thus the cost does not decrease with \(\mu \), which implies that the minimum is obtained for \(\mu =0\), which proves (33). Therefore, if \( \epsilon _x\) and \(\epsilon _y\) are chosen to satisfy (32), then \(\forall \mu \in [0,2]\) it holds that \(R(\mu )\succeq R(0)\succ 0I\), where the second inequality comes from the second-order sufficient conditions for unconstrained minmax (27). As neither \( {\varvec{\nabla }}_{yy}f - \mu \epsilon _y I \prec 0 \) nor \(R(\mu )\) are singular for \(\mu \in [0,2]\), Haynsworth inertia additivity formula [42, Theorem 1.6] implies that \({\varvec{\nabla }}_{zz}f + \mu E\) is nonsingular \(\forall \mu \in [0,2]\), and therefore (x, y) is a LAS equilibrium point of (29).
Now the second part, let us prove the statement for the case in which (x, y) is not a local minmax. We will show that for every \(\epsilon _y\) such that \(\in ({\varvec{\nabla }}_{yy}f-\epsilon _yI)=(0,n_y,0)\) for any large enough \(\epsilon _x\), the (LQAC) are satisfied and
is singular for some \(\mu \in (0,1)\), which in turn guarantees that (x, y) is an unstable equilibrium point of (29) (see discussion in the beginning of the proof).
If \({{\,\mathrm{{\textbf {in}}}\,}}({\varvec{\nabla }}_{zz}f)\ne (n_x,n_y,0)\), then any large enough value of \(\epsilon _x\) such that (LQAC) holds is enough to guarantee that \({\varvec{\nabla }}_{zz}f+\mu E\) is singular for some \(\mu \in (0,1)\). The proof is straightforward: If \({{\,\mathrm{{\textbf {in}}}\,}}({\varvec{\nabla }}_{zz}f)\ne (n_x,n_y,0)\) and \({{\,\mathrm{{\textbf {in}}}\,}}({\varvec{\nabla }}_{zz}f+E)=(n_x,n_y,0)\) (from the (LQAC)), then, by continuity of the eigenvalue \(\exists \mu \in (0,1)\) such that \({\varvec{\nabla }}_{zz}f+\mu E\) is singular.
If \({{\,\mathrm{{\textbf {in}}}\,}}({\varvec{\nabla }}_{zz}f)=(n_x,n_y,0)\) but \({{\,\mathrm{{\textbf {in}}}\,}}({\varvec{\nabla }}_{yy}f)\ne (0,n_y,0)\), then the (LQAC) is not enough to guarantee that (x, y) is an unstable equilibrium point. However, it is possible to guarantee instability. The proof is the following.
Let \(\mu ^*\) be the largest \(\mu \in (0,1)\) such that \({\varvec{\nabla }}_{yy}f-\mu \epsilon _yI\) is singular. We know that this point exists because, on the one hand, by assumption \({\varvec{\nabla }}_{yy}f\) is invertible (and therefore \(\mu ^*>0\)), and on the other hand, we know that \({\varvec{\nabla }}_{yy}f \nprec 0\) and that \({\varvec{\nabla }}_{yy}f -\epsilon _yI \prec 0\) by construction (and therefore \(\mu ^*<1\)).
Now take any \({\bar{\mu }}\in (0,\mu ^*)\) such that \({\varvec{\nabla }}_{yy}f -{\bar{\mu }}\epsilon _yI\) is invertible (there are uncountable many). Suppose there exists \({\bar{\epsilon }}\) such that for any \(\epsilon _x\ge {\bar{\epsilon }}\), the (LQAC) hold and \({{\,\mathrm{{\textbf {in}}}\,}}({\varvec{\nabla }}_{zz}f+{\bar{\mu }} E)\ne (n_x,n_y,0)\). If such \({\bar{\epsilon }}\) exists, then, by the continuity of the eigenvalues, if \({{\,\mathrm{{\textbf {in}}}\,}}({\varvec{\nabla }}_{zz}f+{\bar{\mu }} E)\ne (n_x,n_y,0)\) this means that \({\varvec{\nabla }}_{zz}f+\mu E\) is singular for some \(\mu \in (0,{\bar{\mu }}]\).
So, to conclude the proof, we just need to show the existence of such \({\bar{\epsilon }}\). Take any \(\epsilon _x\) such that \({{\,\mathrm{{\textbf {in}}}\,}}({\varvec{\nabla }}_{zz}f+{\bar{\mu }} E)=(n_x,n_y,0)\) (otherwise the proof is tautological). From Haynsworth inertia additivity formula, we have that
with \({{\,\mathrm{{\textbf {in}}}\,}}(R({\bar{\mu }}))=(n_x-k,k,0)\) and \({{\,\mathrm{{\textbf {in}}}\,}}({\varvec{\nabla }}_{yy}f -{\bar{\mu }}\epsilon _yI)=(k,n_y-k,0)\) for some \(k\in \{1,\dots ,\min (n_x,n_y)\}\). On the one hand, it is straightforward to establish that \(\exists {\bar{\epsilon }}_1\) such that if \(\epsilon _x\ge {\bar{\epsilon }}_1\), then \({{\,\mathrm{{\textbf {in}}}\,}}(R({\bar{\mu }}))\ne (n_x-k,k,0)\), which means that \({{\,\mathrm{{\textbf {in}}}\,}}({\varvec{\nabla }}_{zz}f+{\bar{\mu }} E)\ne (n_x,n_y,0)\). On the other hand, \(\exists {\bar{\epsilon }}_2\) such that if \(\epsilon _x\ge {\bar{\epsilon }}_2\), then \({{\,\mathrm{{\textbf {in}}}\,}}({\varvec{\nabla }}_{zz}f+\mu E)=(n_x,n_y,0)\). Therefore, we can define \({\bar{\epsilon }}=\max ({\bar{\epsilon }}_1,{\bar{\epsilon }}_2)\), which concludes the proof \(\square \)
3.2 Constrained minmax
We now consider the case with more general constraint sets involving equality and inequality constraints of the form
where the functions \(G_x: \mathbb {R}^{n_x} \rightarrow \mathbb {R}^{l_x}\), \(F_x: \mathbb {R}^{n_x} \rightarrow \mathbb {R}^{m_x}\), \(G_y: \mathbb {R}^{n_x} \times \mathbb {R}^{n_y} \rightarrow \mathbb {R}^{l_y}\) and \(F_y: \mathbb {R}^{n_x} \times \mathbb {R}^{n_y} \rightarrow \mathbb {R}^{m_y}\) are all twice continuously differentiable. Similar to what we did in Sect. 2.2, it will be convenient for the development of the primal-dual interior-point method to use slack variables and rewrite the constrained minmax (24) as
where \(s_x\in \mathbb {R}^{m_x}\) and \(s_y\in \mathbb {R}^{m_y}\).
Similar to what we have done in the unconstrained case, we want to present second-order conditions to determine if a point is a constrained local minmax. In order to do so, we need to extend some fundamental concepts of constrained minimization to constrained minmax optimization. The function
will play an equivalent role as the Lagrangian with \((\nu _x,\nu _y,\lambda _x,\lambda _y)\) as the equivalent of Lagrange multipliers; we use the shorthand notation \(z=(x,s_x,y,s_y,\nu _y,\lambda _y,\nu _x,\lambda _x)\). Furthermore, we use the following definition of linear independence constraint qualifications (LICQ) and of strict complementarity for minmax optimization:
Definition 2
(LICQ and strict complementarity for minmax) Let the sets of active inequality constraints for the minimization and maximization be defined, respectively, by
where \(F_x^{(i)}(x)\) and \(F_y^{(i)}(x,y)\) denote the ith element of \(F_x(x)\) and \(F_y(x,y)\). Then:
-
The linear independence constraint qualification (LICQ) is said to hold at z if the vectors in the sets
$$\begin{aligned} \{{\varvec{\nabla }}_x G_x^{(i)}(x), i= & {} 1,\dots ,l_x\}\bigcup \{{\varvec{\nabla }}_x F_x^{(i)}(x), i \in \mathcal {A}_x(x) \} \text { and }\\ \{{\varvec{\nabla }}_y G_y^{(i)}(x,y), i= & {} 1,\dots ,l_y\}\bigcup \{{\varvec{\nabla }}_y F_y^{(i)}(x,y), i \in \mathcal {A}_y(x,y) \} \end{aligned}$$are linearly independent.
-
Strict complementarity is said to hold at z if \(\lambda _y^{(i)}>0 \ \forall i\in \mathcal {A}_y(x,y)\) and \(\lambda _x^{(i)}>0 \ \forall i\in \mathcal {A}_x(x)\)
We have almost all the ingredients to present the second-order conditions for constrained minimization. For the unconstrained minmax optimization, the second-order condition in Proposition 2 required that gradients (\({\varvec{\nabla }}_{x}f(x,y)\) and \({\varvec{\nabla }}_{y}f(x,y)\)) were equal to zero and that Hessians (\({\varvec{\nabla }}_{zz}f(x,y)\) and \({\varvec{\nabla }}_{yy}f(x,y)\)) had a particular inertia. Analogously to what was the case for the constrained minimization in Sect. 2.2, if it were not for the inequality constraints in (35), we would be able to state the second-order conditions using gradients and Hessians of L(z). The inequality constraints make the statement a bit more complicated. The role of the gradient will be played by
where \(\odot \) denotes the element wise Hadamard product of two vectors and \(b\ge 0\) the barrier parameter, which is the extension to minmax of the function \(g(\cdot )\) defined in (11) for the minimization. The role of \({\varvec{\nabla }}_{yy}f(x,y)\) will be played by
while the role of \({\varvec{\nabla }}_{zz}f(x,y)\) will be played by
with blocks defined by
Proposition 3
(Second-order sufficient conditions for constrained minmax) Let z be an equilibrium point in the sense that \(g(z,0)={\textbf {0}}\) with \(\lambda _y,\lambda _x,s_y,s_x\ge {\textbf {0}}\). If the LICQ and strict complementarity hold at z and
then (x, y) is a local minmax of (24).
Similar to what was the case for the second-order sufficient conditions for unconstrained minmax in Proposition 2, the conditions in (38) are not symmetric, highlighting that there is a distinction between the minimizer and maximizer. Moreover, similar to the second-order sufficient conditions for unconstrained minmax in Proposition 2, one can interpret the second-order sufficient conditions for constrained minmax as saying that the optimization \(\max _{y\in \mathcal {Y}(x)} f(x,y)\) is strongly concave in a neighborhood around (x, y) and that the optimization \(\min _{x\in \mathcal {X}} \phi (x)\) with \(\phi (x):= \max _{{\tilde{y}}\in \mathcal {Y}(x):\left\| y-{\tilde{y}}\right\| <\delta } f(x,{\tilde{y}})\) is strongly convex in a neighborhood around (x, y) for some \(\delta >0\).
The conditions for Proposition 3 are slightly stricter than the ones in [15] as we require strict complementarity and LICQ both for the max and the min. However, our conditions allow us to verify whether a point is a local minmax using the inertia, instead of having to compute solution cones. We prove that given these stricter assumptions our conditions are equivalent to those in [15] in Appendix A.
3.2.1 Primal-dual interior-point method
Let \(d_z=(d_x,d_{s_x},d_y,d_{s_y},d_{\nu _y},d_{\lambda _y},d_{\nu _x},d_{\lambda _x})\) be a shorthand notation to designate the update direction of the variables \(z=(x,s_x,y,s_y,\nu _y,\lambda _y,\nu _x,\lambda _x)\). Similar to the basic primal-dual interior-point method introduced in Sect. 2.2, a basic primal-dual interior-point method for minmax finds a candidate solution to (36) using the iterations
where the barrier parameter b is slowly decreased to 0, so that z converges to a root of \(g(z,0)={\textbf {0}}\) while \(\alpha \in (0,1]\) is chosen at each step such that the feasibility conditions \(\lambda _y,\lambda _x,s_y,s_x>0\) hold. We want to modify this basic primal-dual interior-point so it satisfies the properties P1, P2 and P3.
In order to obtain property P1, we propose to obtain \(d_z\) from the solution of a quadratic program that locally approximates (36). Using equivalent arguments as in the development of the quadratic program (19) for the constrained minimization in Sect. 2.2, we obtain that the objective function should be
where \(\epsilon _x(z)\ge 0\) and \(\epsilon _y(z)\ge 0\) are scalar and \(\oslash \) designates the element wise division of two vectors. The feasible sets \(d\mathcal {X}\) for \((d_x,d_{s_x})\) and the set-valued map that defines a feasible set \(d\mathcal {Y}(d_x)\) for \((d_y,d_{s_y})\) are obtained from the first-order linearization of the functions in \(\mathcal {X}\) and \(\mathcal {Y}(d_y)\) and are given by
If \({\varvec{\nabla }}_xG_x(x)\) and \({\varvec{\nabla }}_yG_y(x,y)\) have linearly independent columns, we propose to obtain \((d_x,d_{s_x},d_y,d_{s_y})\) as the optimizers and \((d_{\nu _y},d_{\lambda _y},d_{\nu _x},d_{\lambda _x})\) the associated Lagrange multipliers of the minmax optimization
where \(\epsilon _x(z)\) and \(\epsilon _y(z)\) are chosen such that the solution to (40) is unique. We can apply to (40) the second-order condition from Proposition 3 and obtain that \(\epsilon _x(z)\) and \(\epsilon _y(z)\) need to be chosen to satisfy
where \(E_y(z):= {{\,\textrm{diag}\,}}(\epsilon _y(z) {\textbf {1}}_{n_y}, {\textbf {0}}_{l_y+2m_y})\) and \(E(z):={{\,\textrm{diag}\,}}(\epsilon _x(z){\textbf {1}}_{n_x},{\textbf {0}}_{m_x},-\epsilon _y(z) {\textbf {1}}_{n_y}, {\textbf {0}}_{l_y+2m_y+l_x+m_x})\); \(J_{zz}f(z)\) is the equivalent of the matrix defined in (37b) for the problem (40) and can be shown to be equal to
with \(S={{\,\textrm{diag}\,}}({\textbf {1}}_{n_x},s_x,{\textbf {1}}_{n_y},s_y,{\textbf {1}}_{l_y+m_y+l_x+m_x})\); \(J_{yy}f(z)\) is the equivalent partition of \(J_{zz}f(z)\) as \(H_{yy}(z)\) is of \(H_{zz}(z)\). We will call these conditions the Constrained Local Quadratic Approximation Conditions (ConsLQAC). In this case, it is straightforward to show that modifying the basic primal-dual interior-point iterations in (39) by taking \(d_z\) from the solution of (40) leads to the iterations
Analogously to what was the case in unconstrained minmax optimization, choosing \(\epsilon _x(z)\) and \(\epsilon _y(z)\) such that the (ConsLQAC) hold is not sufficient to guarantee that P2 and P3 hold for the modified primal-dual interior-point method (a counter example can be found in Sect. 4.2). Our next theorem is the extensions of Theorem 3 to the modified primal-dual interior-point and has the equivalent consequences: For property P3 to hold, as long as \(\epsilon _x(z)\) is large enough, taking \(\epsilon _y(z)>0\) will not impair the algorithm’s capacity to converge toward a local minmax; this can be useful, for instance, if \({{\,\mathrm{{\textbf {in}}}\,}}(J_{zz})\) has an eigenvalue close to 0. For property P2 to hold, in order to guarantee that the modified primal-dual interior-point method cannot converge toward an equilibrium point that is not local minmax, the (ConsLQAC) are sufficient only whenever \({{\,\mathrm{{\textbf {in}}}\,}}(J_{zz}f(z))\ne (n_x+m_x+l_y+m_y,l_x+m_x+n_y+m_y,0)\). Otherwise, \(\epsilon _x(z)\) needs to be taken large enough such that \({{\,\mathrm{{\textbf {in}}}\,}}(J_{zz}f(z)+\mu E(z))\ne (n_x+m_x+l_y+m_y,l_x+m_x+n_y+m_y,0)\) for some \(\mu \in (0,1)\).
Theorem 4
(Stability and instability of modified primal-dual interior-point method for constrained minmax) Let \(\alpha =1\) and (z, b) with \(b>0\), be an equilibrium point in the sense that \(g(z,b)={\textbf {0}}\). Assume the LICQ hold at z, that \(J_{zz}f(z)\) and \(J_{yy}f(z)\) are invertible, and that \(J_{zz}f(\cdot )\) is differentiable in a neighborhood around z. Then there exists functions \(\epsilon _x(\cdot )\) and \(\epsilon _y(\cdot )\) that are constant in a neighborhood around z, satisfy the (ConsLQAC) at z and guarantee that if:
-
i)
z is a local minmax of (36), then it is a LAS equilibrium of (42).
-
ii)
z is not a local minmax of (36), then it is an unstable equilibrium of (42).
Proof
Let us define the partitions, \(J_{xx}f(z)\), \(J_{yx}f(z)\), and \(J_{x\lambda }f(z)\) of \(J_{zz}f(z)\) analogously to the partitions \( H_{xx}f(z)\), \( H_{yx}f(z)\), and \( H_{x\lambda }f(z)\) of \( H_{zz}f(z)\).
Using the same arguments as in the proof of Theorem 1, we conclude that the Jacobian of the dynamic system (42) around a point z such that \(g(z,b)={\textbf {0}}\) is
Moreover, from (41) we have that \({{\,\mathrm{{\textbf {in}}}\,}}(H_{zz}f(z))={{\,\mathrm{{\textbf {in}}}\,}}(S^{1/2}J_{zz}f(z)S^{1/2})\). Using Sylvester’s law of inertia [42, Theorem 1.5], this simplifies to \({{\,\mathrm{{\textbf {in}}}\,}}(H_{zz}f(z))={{\,\mathrm{{\textbf {in}}}\,}}(J_{zz}f(z))\). If a point z is such that \(g(z,b)={\textbf {0}}\), then one can check (38) using \(J_{zz}f(z)\) and \(J_{yy}f(z)\).
Let us define the matrices
where \(Z_{y}(z)\in \mathbb {R}^{n_y+m_y,n_y-l_y}\) and \(Z_{x}(z)\in \mathbb {R}^{n_x+m_x,n_x-l_x}\) are any full column rank matrices such that
Using the same reasoning as in the proof of Proposition 3, one can conclude that
which implies that the (ConsLQAC) can be stated as
This means that the exact same arguments used in the proof of the unconstrained minmax in Theorem 3 can be used for the constrained case. More specifically, each argument with
has an analogous statement with \(R_y(\mu )\) and \(R_x(\mu )\), respectively. For the sake of completeness, we highlight the main points of the analogy.
First, when z is such that (38) holds, the sufficient condition for z to be a LAS equilibrium point of (42) is that
The only extra argument needed is to show that condition (46) is always feasible for some \(\epsilon _x(z)\) large enough. This is not evident as the matrix
has size \((n_x+m_x)\times (n_x+m_x)\) while \(E_x(z)\) only has \(n_x\) nonzero elements in the diagonal. However, because of the structural zeros in \(J_{xy}f(z)\) and \(E_y(z)\), one can verify with some algebraic manipulation that \(\text { rank }(M):=r\le \min (n_x,n_y)\). Let \(\Lambda \) be the matrix with eigenvalues of M in decreasing order and V its associated eigenvectors such that \(M=V\Lambda V'\). We can partition V into \(V_1\) of size (r, r) associated to the nonzero eigenvalues of M and \(V_2=I_{n_x+m_x-r}\). This partition means that \(E_x(z)=V'E_x(z)V\), which means on can conclude that
which implies that one can always take \(\epsilon _x\) large enough such that for each negative diagonal entries of \(\Lambda \), the equivalent diagonal element of \((E_x(z)+\Lambda )\) is positive.
Now the second part, let us prove the statement when z is such that the second-order conditions in (38) do not hold. We need to prove that
is singular for some \(\mu \in (0,1)\). On the one hand, using the same analysis as in the proof of Theorem 3, we conclude that the (ConsLQAC) are sufficient to guarantee that z is an unstable equilibrium point of (42) if \({{\,\mathrm{{\textbf {in}}}\,}}(J_{zz}f(z))\ne (n_x+m_x+l_y+m_y,l_x+m_x+n_y+m_y,0)\). On the other hand, if \({{\,\mathrm{{\textbf {in}}}\,}}(J_{zz}f(z))=(n_x+m_x+l_y+m_y,l_x+m_x+n_y+m_y,0)\), than we can guarantee that by taking \(\epsilon _x\) sufficiently large, there is a \(\mu \in (0,1)\) such that \({{\,\mathrm{{\textbf {in}}}\,}}(J_{zz}f(z)+\mu E)\ne (n_x+m_x+l_y+m_y,l_x+m_x+n_y+m_y,0)\), which means that z is an unstable equilibrium point of (42). This concludes the proof. \(\square \)
4 Algorithmic development and numerical examples
The following algorithm combines the result of the previous section to propose a method for selecting \(\epsilon _x(z)\) and \(\epsilon _y(z)\) that satisfies the (ConsLQAC) and guarantees the stability properties of Theorem 4. We only state the algorithm for the constrained case, its specialization to the unconstrained case is straightforward. In order to keep the algorithm more simple and to highlight the instability property, we chose to use the functions \(\epsilon _y(\cdot )=\epsilon _x(\cdot )=0\) whenever the algorithm is near a local minmax.

Primal-dual interior-point method for minmax
Proposition 4
(Construction of the modified primal-dual interior-point method) Algorithm 1 generates functions \(\epsilon _x(\cdot )\) and \(\epsilon _y(\cdot )\) that satisfy the conditions of Theorem 4 in the neighborhood of any equilibrium point \(z^*\) that satisfy the assumptions of Theorem 4.
Proof
For each z, Algorithm 1 produces values of \(\epsilon _x\) and \(\epsilon _y\) that only depend on z, therefore it implicitly constructs functions \(\epsilon _x(\cdot )\) and \(\epsilon _y(\cdot )\). Moreover, \(\epsilon _x(\cdot )\) and \(\epsilon _y(\cdot )\) are such that either the stability condition (46) or the instability condition (47) are satisfied for each z, therefore they are satisfied in the neighborhood of any equilibrium point \(z^*\). Finally, \(\epsilon _x(\cdot )\) and \(\epsilon _y(\cdot )\) are constant in a neighborhood around each equilibrium point as the values of \(\epsilon _x\) and \(\epsilon _y\) are not adjusted when \(\left\| g(z,b)\right\| _{\infty }\le \delta _\epsilon \). \(\square \)
In Algorithm 1, for each z, \((\epsilon _x,\epsilon _y)\) is chosen to satisfy the conditions of Theorem 4, and therefore generate the desired stability and instability. This means that the algorithm essentially guarantees that the modified primal-dual interior-point method can only converge to an equilibrium point if such point is a local minmax. A key point of the algorithm is that it only uses the inertia of matrices, which can be efficiently computed using either the LBLt or LDLt decomposition, as we further detail in the following remark.
Remark 1
(Computing the inertia) It is not necessary to actually compute the eigenvalues of \(J_{zz}f(z)\) in order to determine the inertia. A first option is to use the lower-triangular-block-lower-triangular-transpose (LBLt) decomposition [16, Appendix A], which decomposes \(J_{zz}f(z)\) into the product \(LBL'\) where L is a lower triangular matrix and B a block diagonal one, the inertia of B is the same as the inertia of \(J_{zz}f(z)\).
Let \(\Gamma ={{\,\textrm{diag}\,}}(\gamma {\textbf {1}}_{n_x+m_x},-\gamma {\textbf {1}}_{n_y+m_y},\gamma {\textbf {1}}_{l_y+m_y},-\gamma {\textbf {1}}_{l_x+m_x})\), with \(\gamma \) a small positive number. A second approach is to use the lower-triangular-diagonal-lower-triangular-transpose (LDLt) decomposition, to decompose \(J_{zz}f(z)+\Gamma \) into the product \(LDL'\) where L is a lower triangular matrix and D is a diagonal matrix; the inertia of D, which is given by the number of positive, negative and zero elements of the diagonal of D, gives the inertia of \(J_{zz}f(z)+\Gamma \). The matrix \(\Gamma \) introduces a distortion in the inertia but it helps to stabilize the computation of the LDLt decomposition, which tends to be faster than the LBLt decomposition. This is the approach we use in our implementation; it has been studied in primal-dual interior-point algorithms for minimization and the distortion introduced by \(\Gamma \) tends to be compensated by a better numerical algorithm [43, 44].\(\square \)
4.1 Benchmark example for unconstrained minmax
Consider the following functions
The first three have been used as examples in [31, 35, 45], respectively, whereas the fourth one is a well-known case for a simple but challenging function to find the local minmax. These problems all satisfy the assumption of Theorem 3 and have local minmax points. We have chosen these functions because, as we will show, they illustrate some interesting behaviors.
Our goal is to compare the performance of Algorithm 1 to the performance of two well established algorithms. On the one hand, we look at the performance of a “pure” Newton algorithm, i.e., using \(\epsilon _x(\cdot )=\epsilon _y(\cdot )=0\). On the other hand, we look into the convergence of a gradient descent ascent (GDA), i.e.,
where \(\alpha _x\) and \(\alpha _y\) are constant and different for each problem; we did our best to select the best values \(\alpha _x\) and \(\alpha _y\) for each problem.
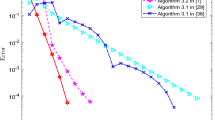
Each algorithm is initialized 1000 times, using the same initialization for the three of them each time. We compare their convergence properties according to three criteria: the number of times the algorithm converged to an equilibrium point (eq.), the number of times it converged to a local minmax point (minmax) and the average number of iterations to converge to a local minmax point (iter). The algorithm is terminated when the infinity norm of the gradient is smaller than \(\delta _s=10^{-5}\) and we declare that they did not converge if it has not terminated in less than 500 iterations for the pure Newton and Algorithm 1, and 50 000 for GDA. The result of the comparison is displayed in Table 1. The key take away from these examples is that Algorithm 1 never converges toward an equilibrium point that is not a local minmax, in contrast with the pure Newton method which is attracted to any equilibrium point. Here is a detailed observation from this comparison.
-
The pure Newton algorithm has good overall convergence for all the problems, but it also tends to often converge toward an equilibrium point that is not a local minmax problems. On the other hand, when the pure Newton converges to a local minmax, it does so in less iterations than the other two methods. This is expected when comparing to the GDA, as it is a first-order method. Pure Newton algorithm converges in (slightly) less iterations than Algorithm 1 because taking \(\epsilon _x\) and \(\epsilon _y\) different than 0 hinders the superlinear convergence property of Newton’s method.
-
The GDA algorithm seems to enjoy the property of always converging toward a local minmax, and except for \(f_3(\cdot )\) and \(f_4(\cdot )\), it has good rate of convergence. However, GDA takes an exceptionally long number of iterations to converge. This is somehow expected from the fact that it is a first-order method, and it is partially compensated by each iteration being more simple to compute. However, one must keep in mind that none of this takes into account the time that needs to be spent adjusting the step sizes until a good convergence rate can be obtained.
-
At last, Algorithm 1 is across the board the algorithm with better convergence toward local minmax, and it does so in the smallest number of iterations. As it was expected from the theory, Algorithm 1 never converges toward an equilibrium point that is not a local minmax. From a numerical perspective, the biggest takeaway is that while our results are only about local convergence, the algorithm still enjoys good global convergence properties; only in \(f_3(\cdot )\) it does not converge essentially \(100\%\) of the time.
-
Function \(f_4(\cdot )\) is particularly interesting example. First, notice that the pure Newton converges in one iteration. This is expected as the iterations are given by
$$\begin{aligned} \begin{bmatrix} x^+\\ y^+ \end{bmatrix}= \begin{bmatrix} x\\ y \end{bmatrix}- \begin{bmatrix} 0 &{} 1 \\ 1 &{} 0 \end{bmatrix}^{-1}\begin{bmatrix} y\\ x \end{bmatrix}= \begin{bmatrix} x\\ y \end{bmatrix}- \begin{bmatrix} 0 &{} 1 \\ 1 &{} 0 \end{bmatrix}^{-1}\begin{bmatrix} 0 &{} 1 \\ 1 &{} 0 \end{bmatrix} \begin{bmatrix} x\\ y \end{bmatrix}= \begin{bmatrix} 0\\ 0 \end{bmatrix}. \end{aligned}$$This is in stark contrast with GDA which, as it is well known, diverges away from the local minmax. As for Algorithm 1, it converges even though it does not satisfy the assumptions of Theorem 3, further emphasizing that these are sufficient but not necessary conditions. Notice that Algorithm 1 is not the same as the pure Newton as the Hessian will be modified with an \(\epsilon _y(x,y)>0\) to guarantee that the portion of the Hessian associated to the maximization is negative definite.
4.2 The homicidal chauffeur example for constrained minmax
In the homicidal chauffeur problem, a pursuer driving a car is trying to hit a pedestrian, who (understandably) is trying to evade it. The pursuer is modeled as a discrete time Dubins’ vehicle with equations
where \(x_p^{(i)}\) designates the ith element of the vector \(x_p\), v is a constant forward speed and u is the steering, over which the driver has control. The pedestrian is modeled by the accumulator
where d is the velocity vector. Given a time horizon T, and initial positions \(x_e(t)\) and \(x_p(t)\), we want to solve
where \(x_p^{(1,2)}\) designates the first and second elements of the vector \(x_p\); \(\gamma _u\) and \(\gamma _d\) are positive weights; and U, \(\mathcal {U}\), D and \(\mathcal {D}\) are defined for \(i=0,\dots ,T-1\)
Instead of explicitly computing the solution of the trajectory of the pursuer and evaders, we are implicitly computing them by setting the dynamics as equality constraints; we will show shortly that this has an important impact on the scalability of the algorithm.
Each player is controlled using model predictive control (MPC), meaning that at each time step t we solve (48) obtaining controls u(t) and d(t), which are then used to control the system for the next time step. The problem satisfies the assumptions of Theorem 4, as it is differentiable and has local minmax points for which the LICQ and strict complementarity hold.
The importance of guaranteeing instability
It is natural to ask whether it is important to enforce the instability guarantee, specially in the case where the (ConsLQAC) is not enough, meaning one needs to use line 7 of Algorithm 1. In Fig. 1, we show what can happen if they are not enforced. We take the homicidal chauffeur problem with a horizon of \(T=20\) and we run the MPC control for \(t=1,\dots ,50\). In one case we enforce the instability guarantee, meaning that we use line 7 of Algorithm 1, on the second case we only enforce the (ConsLQAC), and on the third case we only enforce the instability guarantees after \(t=25\). In all cases, we start the system with the exact same initial conditions.
In the first case, the evader (which is the maximizer), is able to find a control that allows it to get further from the pursuer. The average cost for all the time steps (\(t=1,\dots ,50\)) ends up being around 0.2. In the second case, the solver keeps being attracted toward a point that is not a local minmax (and more precisely, not a local maximum), which means that the evader is not capable of escaping the pursuer; as a consequence, the average cost for all the time steps ends up being around 0.05, which is lower, as expected. Finally, in the third case, at \(t=25\) the solver starts to be able to converge toward a local minmax, and the evader is able to escape from the pursuer.
This example illustrates how crucial it is to enforce instability. By doing it, we guarantee that the algorithm can only converge toward an equilibrium point that is a local minmax, and this can completely change the numerical solution.
Exploiting sparsity

Trajectory for Homicidal Chauffeur problem with and without guaranteeing instability at equilibrium points that are not a local minmax

Scaling of homicidal chauffeur with horizon length and sparsity pattern of the Hessian when using the sequential approach
Instead of setting the dynamics as equality constraints in (48), one could simply find the solution of the trajectory equation at each time step. This means to explicitly calculate \(x_p(t+i+1)=\phi _p\Big (\phi _p\big (\dots ,u(t+i-1)\big ),u(t+i)\Big )\). In the MPC literature, this is known as the sequential approach, versus the simultaneous approach we used in (48) [46, Chapter 8.1.3]. We want to study the scalability of the algorithm by enlarging the horizon T, both when using the sequential and the simultaneous approaches.
The sequential approach solves an optimization problem in a smaller state space, because it only needs to solve the optimization for \(u(t),\dots ,u(t+T)\) and \(d(t),\dots ,d(t+T)\) and it does not have to handle equality constraints. However, as we can see from the sparsity pattern in Fig. 2b, the Hessian is rather dense, with large parts of it containing nonzero entries. As it can be seen in Fig. 2a, the algorithm scales rather poorly as the horizon length (and hence, the number of variables) increases; it no longer converges reliably after \(T=80\).
The simultaneous approach on the other hand solves the optimization problem in a much larger space state, because not only it needs to also solve for \(u(t),\dots ,u(t+T)\) and \(d(t),\dots ,d(t+T)\), but also for \(x_p(t),\dots ,x_p(t+T)\) and \(x_e(t),\dots ,x_e(t+T)\) and it also needs to handle equality constraints. Fortunately, as we can see from the sparsity pattern in Fig. 3b, most of the entries in the Hessian are actually structurally zero (meaning they are always zero). TensCalc’s implementation of the LDLt factorization exploits sparsity patterns and scales roughly in O(T), which makes it substantially more efficient than standard LDLt decomposition, which scales in \(O(T^3)\) [16, Appendix A]. At each step of Algorithm 1, most of the time is spent computing the LDLt decomposition, either for adjusting \(\epsilon _x\) and \(\epsilon _y\) or to invert \(H_{zz}f(z)\). As a consequence, we can see in Fig. 3a that both the number of iterations necessary to solve the optimization and the time per iteration scale roughly linear, the first being multiplied by about 1.7 while the second by 3.5 while the horizon length T is multiplied by roughly 30.

Scaling of homicidal chauffeur with horizon length and sparsity pattern of the Hessian
Remark 2
(Minmax problems with shared dynamics) In the homicidal chauffeur, the control of the pursuer does not impact the dynamics of the evader, and vice versa. This is why in (48) the dynamics can be set as equality constraints independently for the min and for the max.
Now consider the problem
where u is the control and d is the disturbance and one wants to minimize a cost function \(V(x(1),\dots ,x(T),u(0),\dots ,u(T-1))\) given the worst disturbance \(d(1),\dots ,d(T)\). Because both the control and the disturbances influence the dynamics, we need to include the dynamics as equality constraints for the maximization, leading to the optimization problem
where \(\mathcal {U},\mathcal {D}\) are the feasible sets for the control and disturbances. It is important to notice that x just acts as a latent/dummy variable that allows us to avoid solving the trajectory equation. Setting it as a maximization variable does not changes the result as x is always exactly determined by the value of u and d. It does, however, improve the numerical efficiency of the algorithm as now the Hessian matrices are sparse and their LDL decomposition can be efficiently computed.\(\square \)
5 Conclusion
The main contribution of this article is the construction of Newton and primal-dual interior-point algorithm for nonconvex–nonconcave minmax optimization that can only converge toward an equilibrium point if such point is a local minmax. We established these results by modifying the Hessian matrices such that the update steps can be seen as the solution of quadratic programs that locally approximate the minmax problem. While our results are only local, using numerical simulations we see that the algorithm is able to make progress toward a solution even if it does not start close to it. We also illustrated using numerical examples how important it is to have a formulation of the minmax problem such that the Hessian matrix is sparse.
The main future direction would be to develop non-local convergence results. We believe that the best approach to obtain such results would be to develop a type of Armijo rule which could be used to obtain similar results to those from minimization. Developing filters and merit function could also play an important role in coming up with ways to improve the algorithm’s convergence.
Notes
The subscript \(_x\) is used to indicate that \(n_x\) refers to the size of the variable x. We introduce this notation now in anticipation of Sect. 3 where we have both minimization and maximization variables.
Similar to \(n_x\), the subscript \(_x\) is used to indicate that the functions \(G_x(\cdot )\) and \(F_x(\cdot )\) are associated to the minimization variable x. We introduce this notation now in anticipation of Sect. 3 where we have both minimization and maximization variables.
Notice that we use the second-order linearization of the Lagrangian L(z) as the cost function in (15), not the one of f(x). The justification is that, if \(x^*\) is a local minimum of (10) with associated Lagrange multiplier \(\nu ^*\), then \(x^*\) is also a local minimum of
$$\begin{aligned} \min _{x:G_x(x)={\textbf {0}}} f(x) + \nu _x^*\,'G_x(x). \end{aligned}$$Evidently, \(\nu _x^*\) is not know in advance, so instead one uses the value of \(\nu _x\) at the current iteration, which leads to the local approximation (15).
References
Bemporad A, Morari M (1999) Robust model predictive control: a survey. In: Garulli A, Tesi A (eds) Robustness in identification and control. Lecture Notes in Control and Information Sciences. Springer, London, pp 207–226. https://doi.org/10.1007/BFb0109870
Copp DA, Hespanha JP (2017) Simultaneous nonlinear model predictive control and state estimation. Automatica 77:143–154. https://doi.org/10.1016/j.automatica.2016.11.041
Pita J, Jain M, Marecki J, Ordóñez F, Portway C, Tambe M, Western C, Paruchuri P, Kraus S (2008) Deployed armor protection: the application of a game theoretic model for security at the los Angeles international airport. In: Proceedings of the 7th international joint conference on autonomous agents and multiagent systems: industrial Track, pp 125–132
Yang G, Poovendran R, Hespanha JP (2021) Adaptive learning in two-player Stackelberg games with application to network security. arXiv preprint arXiv:2101.03253
Madry A, Makelov A, Schmidt L, Tsipras D, Vladu A (2019) Towards deep learning models resistant to adversarial attacks. arXiv:1706.06083 [cs, stat]. Accessed 27 Jan 2020
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative Adversarial Nets. Advances in neural information processing systems 27:2672–2680
Chinchilla R, Hespanha JP (2019) Optimization-based estimation of expected values with application to stochastic programming. In: 2019 IEEE 58th conference on decision and control (CDC). IEEE, Nice, France, pp 6356–6361. https://doi.org/10.1109/CDC40024.2019.9029750. https://ieeexplore.ieee.org/document/9029750/ Accessed 10 Mar 2022
Chinchilla R, Hespanha JP (2022) Stochastic programming using expected value bounds. IEEE Trans Autom Control
Bandi C, Bertsimas D (2012) Tractable stochastic analysis in high dimensions via robust optimization. Math Program 134(1):23–70. https://doi.org/10.1007/s10107-012-0567-2
Rahimian H, Mehrotra S (2019) Distributionally robust optimization: a review, 90
Dempe S (2002) Foundations of bilevel programming. Springer, Berlin
Colson B, Marcotte P, Savard G (2007) An overview of bilevel optimization. Ann Oper Res 153(1):235–256. https://doi.org/10.1007/s10479-007-0176-2
Beck Y, Ljubić I, Schmidt M (2023) A brief introduction to robust bilevel optimization. arXiv:2211.16072 [math]. https://doi.org/10.48550/arXiv.2211.16072. Accessed 17 Apr 2023
Jin C, Netrapalli P, Jordan MI (2019) What is local optimality in nonconvex-nonconcave minimax optimization? arXiv:1902.00618 [cs, math, stat]. Accessed 5 Jul 2019
Dai YH, Zhang L (2020) Optimality conditions for constrained minimax optimization. CSIAM Trans Appl Math 1(2):296–315. https://doi.org/10.4208/csiam-am.2020-0014. arXiv:2004.09730. Accessed 21 Nov 2020
Nocedal J, Wright SJ (2006) Numerical optimization. Springer series in operations research, 2nd edn. Springer, New York
Jv Neumann (1928) Zur theorie der gesellschaftsspiele. Math. Ann. 100(1):295–320
Hespanha JP. Tenscalc: a toolbox to generate fast code to solve nonlinear constrained minimizations and compute Nash equilibria. https://doi.org/10.1007/s12532-022-00216-2. Accessed 14 Feb 2022
Ryu EK, Boyd S (2016) A primer on monotone operator methods. Appl Comput Math
Ben-Tal A, Nemirovski A (2002) Robust optimization—methodology and applications. Math Program 92(3):453–480. https://doi.org/10.1007/s101070100286
Ben-Tal A, Ghaoui LE, Nemirovski A (2009) Robust Optimization
Bertsimas D, Brown DB, Caramanis C (2011) Theory and applications of robust optimization. SIAM Rev 53(3):464–501. https://doi.org/10.1137/080734510
Mutapcic A, Boyd S (2009) Cutting-set methods for robust convex optimization with pessimizing oracles. Optim Methods Softw 24(3):381–406. https://doi.org/10.1080/10556780802712889
Nouiehed M, Sanjabi M, Huang T, Lee JD, Razaviyayn M. Solving a class of non-convex min-max games using iterative first order methods, 9
Metz L, Poole B, Pfau D, Sohl-Dickstein J. Unrolled generative adversarial networks arXiv:1611.02163. Accessed 15 Mar 2022
Mokhtari A, Ozdaglar A, Pattathil S (2020) A unified analysis of extra-gradient and optimistic gradient methods for saddle point problems: proximal point approach, 1497–1507
Lin T, Jin C, Jordan MI. Near-optimal algorithms for minimax optimization arXiv:2002.02417. Accessed 15 Oct 2020
Liu M, Rafique H, Lin Q, Yang T. First-order convergence theory for weakly-convex-weakly-concave min-max problems arXiv:1810.10207. version: 3. Accessed 25 Nov 2020
Nemirovski A (2004) Prox-method with rate of convergence O(1/t) for variational inequalities with lipschitz continuous monotone operators and smooth convex-concave saddle point problems. SIAM J Optim 15(1):229–251. https://doi.org/10.1137/S1052623403425629
Fiez T, Ratliff L. Gradient descent-ascent provably converges to strict local minmax equilibria with a finite timescale separation arXiv:2009.14820. Accessed 2 Apr 2021
Mertikopoulos P, Lecouat B, Zenati H, Foo CS, Chandrasekhar V, Piliouras G (2019) Optimistic mirror descent in saddle-point problems: going the extra (gradient) mile, 24
Foerster JN, Chen RY, Al-Shedivat M, Whiteson S, Abbeel P, Mordatch I. Learning with opponent-learning awareness arXiv:1709.04326. Accessed 24 Jan 2021
Letcher A, Foerster J, Balduzzi D, Rocktäschel T, Whiteson S. Stable opponent shaping in differentiable games arXiv:1811.08469. Accessed 24 Jan 2021
Schafer F, Anandkumar A (2020) Competitive Gradient Descent. arXiv:1905.12103 [cs, math]. Accessed 24 Jan 2021
Wang Y, Zhang G, Ba J (2019) On Solving Minimax Optimization Locally: A Follow-the-Ridge Approach. arXiv:1910.07512 [cs, math, stat]. Accessed 21 Sep 2020
Fiez T, Chasnov B, Ratliff LJ. Convergence of learning dynamics in Stackelberg games arXiv:1906.01217. Accessed 7 Jan 2020
Zhang G, Wu K, Poupart P, Yu Y. Newton-type methods for minimax optimization arXiv:2006.14592. Accessed 1 Oct 2020
Luo L, Chen C. Finding second-order stationary point for nonconvex-strongly-concave minimax problem arXiv:2110.04814. Accessed 10 Jan 2022
Chen Z, Li Q, Zhou Y. Escaping saddle points in nonconvex minimax optimization via cubic-regularized gradient descent-ascent arXiv:2110.07098. Accessed 10 Jan 2022
Huang M, Ji K, Ma S, Lai L. Efficiently escaping saddle points in bilevel optimization arXiv:2202.03684. Accessed 15 Mar 2022
Hespanha JP (2018) Linear systems theory, 2nd edn. University Press, Princeton
Zhang F (ed) (2005) The Schur complement and its applications. Numerical methods and algorithms, vol 4. Springer, New York
Vanderbei RJ (1995) Symmetric quasidefinite matrices. SIAM J Optim 5(1):100–113. https://doi.org/10.1137/0805005
Higham NJ, Cheng SH (1998) Modifying the inertia of matrices arising in optimization. Linear Algebra Appl 275–276:261–279. https://doi.org/10.1016/S0024-3795(97)10015-5
Adolphs L, Daneshmand H, Lucchi A, Hofmann T (2019) Local saddle point optimization: a curvature exploitation approach. arXiv:1805.05751 [cs, math, stat]. Accessed 25 Nov 2020
Rawlings JB, Mayne DQ, Diehl MM (2017) Model predictive control: theory, computation, and design, 2nd edn. Nob Hill Publishing, Madison
Acknowledgements
The authors would like to thank the reviewers and editors for their comments which greatly improved the quality of the article and helped to clarify the main challenges we were addressing. The first author, Raphael Chinchilla, would also like to acknowledge Prof. Stephen Boyd for his suggestions and interest in the paper.
Funding
This material is based upon work supported by the U.S. Office of Naval Research under the MURI grant No. N00014-16-1-2710.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A Second-order sufficient conditions for constrained minimization and minmax optimization
Appendix A Second-order sufficient conditions for constrained minimization and minmax optimization
1.1 A.1 Proof of Proposition 1 (constrained minimization)
The first step is to show that \(g(z,0)={\textbf {0}}\) is equivalent to the Karush–Kuhn–Tucker (KKT) conditions [16, Chapter 12]. Consider the “full" Lagrangian \({\tilde{L}}(x,s_x,\nu _x,\lambda _x,\tau _x)=f(x)+\nu _x'G_x(x)+\lambda _x'(F_x(x)+s_x)-\tau _x's_x\) for the optimization (10). The KKT condition would then be that
and \(s_x,\tau _x \ge {\textbf {0}}\). The second equation can be used to substitute \(\tau _x\) by \(\lambda _x\), which gives the equality \(g(z,0)={\textbf {0}}\).
Now the second-order sufficient conditions. Let us start by rewriting the minimization (1) but instead of using as slack variables \(s_x\) with the constraint \(s_x\ge 0\), using the slack variable \(w_x\odot w_x\) (where \(\odot \) is the element wise product):
Consider now the solution cone
Let \((x,w_x,\nu _x,\lambda _x)\) be a point such that the KKT conditions for (A2) hold. As, by assumption, the LICQ and strict complementarity conditions hold, if
then \((x,w_x,\nu _x,\lambda _x)\) is a local minimum of (A2). The proof can be found in [16, Theorem 12.5].
We now need to prove that (A3) is equivalent to the condition (13) from the proposition. Because the LICQ and strict complementarity hold, the set \(\mathcal {C}_x(z)\) is given by the null space (a.k.a. the kernel) of the matrix
This result can be found in [16, Chapter 12.5], in the subsection “Second-order conditions and projected Hessian". Let \(Z_x\in \mathbb {R}^{n_x+m_x,n_x+m_x-m_x-l_x}\) be a matrix with full column rank such that \( \tilde{H}_{x\lambda }f(z)'\,Z_x={\textbf {0}}\). Then, the condition (A3) can be rewritten as
which is equivalent to say that
Now consider the matrix
As the LICQ conditions hold, according to [16, Theorem 16.3]
Therefore, (A3) holds if and only if \({{\,\mathrm{{\textbf {in}}}\,}}(\tilde{H}_{zz}f)=(n_x+m_x,l_x+m_x,0)\).
We have almost finished the proof, we now just need to prove that \({{\,\mathrm{{\textbf {in}}}\,}}({\tilde{H}}_{zz}f(z))={{\,\mathrm{{\textbf {in}}}\,}}(H_{zz}f(z))\). Using the equality condition \(F_x(x)+w_x\odot w_x=0\), we obtain the relation \(w_x=(-F_x(x))^{1/2}=s_x^{1/2}\). If we substitute back this result in \({\tilde{H}}_{zz}f(z)\), we almost have that \({\tilde{H}}_{zz}f(z)\) is equal to \(H_{zz}f(z)\) except for the 2 in front of \({{\,\textrm{diag}\,}}(\lambda _x)\) and \({{\,\textrm{diag}\,}}(s^{1/2})\). Take the matrix \(\Xi \) defined by
where
with \(\lambda _x^{(i)} \text { and }s_x^{(i)}\) denoting the \(i^\text {th}\) elements of \(\lambda _x \text { and }s_x\). Then, \(\Xi \tilde{H}_{zz}f(z)\Xi = H_{zz}f(z)\) which, according to Sylvester’s law of inertia [42, Theorem 1.5], implies that \(\text {inertia}({\tilde{H}}_{zz}f(z))=\text {inertia}(H_{zz}f(z))\), which finishes the proof. \(\square \)
1.2 A.2 Proof of Proposition 3 (constrained minmax optimization)
First, using the exact same reasoning as in the proof of Proposition 1, one can show that \(g(z,0)=0\) is equivalent to the first-order necessary condition in [15].
Similarly to what we did in the proof of Proposition 1, let us start by rewriting the constrained minmax optimization (36) using the slack variables \(w\odot w\):
Consider the solution cones
and
Let z be a point such that \(g(z,0)={\textbf {0}}\). As, by assumption, the LICQ and strict complementarity hold, if
and
then \((x,w_x,\nu _x,\lambda _x)\) is a local minimum of (A2). The proof can be found in [15, Theorem 3.2].
The proof between the equivalence of the condition (A6a) and \({{\,\mathrm{{\textbf {in}}}\,}}( H_{yy}f(z))=(l_y+m_y,n_y+m_y,0)\) is almost identical to the proof of Proposition (1).
The condition on the inertia of \({{\,\mathrm{{\textbf {in}}}\,}}( H_{zz}f(z))\) requires some more development. In an analogous way to the proof of Proposition (1), let \(Z_x\) be a matrix with full column rank such that \(H_{x\lambda }f(z)'\,Z_x={\textbf {0}}\). Then, the sufficient conditions (A6b) for the reformulated outer minimization is
We want now to define a new partition of \(H_{zz}f(z)\) which we will use to finish the proof. Consider the matrices
such that
Let the matrix
One can show that \({\bar{Z}}_x\) is full column rank and such that \({\bar{H}}_{x\lambda }f(z)'\,{\bar{Z}}_x={\textbf {0}}\). Therefore, if we apply [16, Theorem 16.3] to \( H_{zz}f(z)\) (with the new partitioning) gives
In turn, \({{\,\mathrm{{\textbf {in}}}\,}}\left( {\bar{Z}}_x'{\bar{H}}_{zz} f(z){\bar{Z}}_x \right) \) can be simplified using Haynsworth inertia additivity formula [42, Theorem 1.6]:
Therefore, if (A6a) holds, (A6b) is equivalent to
which finishes the proof.\(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chinchilla, R., Yang, G. & Hespanha, J.P. Newton and interior-point methods for (constrained) nonconvex–nonconcave minmax optimization with stability and instability guarantees. Math. Control Signals Syst. (2023). https://doi.org/10.1007/s00498-023-00371-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00498-023-00371-4