
Abstract
The purpose of this review is to present a comprehensive overview of the theory of ensemble Kalman–Bucy filtering for continuous-time, linear-Gaussian signal and observation models. We present a system of equations that describe the flow of individual particles and the flow of the sample covariance and the sample mean in continuous-time ensemble filtering. We consider these equations and their characteristics in a number of popular ensemble Kalman filtering variants. Given these equations, we study their asymptotic convergence to the optimal Bayesian filter. We also study in detail some non-asymptotic time-uniform fluctuation, stability, and contraction results on the sample covariance and sample mean (or sample error track). We focus on testable signal/observation model conditions, and we accommodate fully unstable (latent) signal models. We discuss the relevance and importance of these results in characterising the filter’s behaviour, e.g. it is signal tracking performance, and we contrast these results with those in classical studies of stability in Kalman–Bucy filtering. We also provide a novel (and negative) result proving that the bootstrap particle filter cannot track even the most basic unstable latent signal, in contrast with the ensemble Kalman filter (and the optimal filter). We provide intuition for how the main results extend to nonlinear signal models and comment on their consequence on some typical filter behaviours seen in practice, e.g. catastrophic divergence.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Consider a time-invariant, continuous-time, signal and observation model of the form,
where \(\mathscr {X}_t\) is the underlying signal (latent) process, \(\mathscr {Y}_t\) is the observation signal, \(a(\cdot )\) and \(h(\cdot )\) are the signal and sensor model functions, and \(\mathscr {V}_t\) and \(\mathscr {W}_t\) are continuous-time Brownian motion (noise) signals. The filtering problem [4, 9] is concerned with estimating some statistic(s) of the signal \(\mathscr {X}_t\) conditioned on the observations \(\mathscr {Y}_s\), \(0\le s\le t\). For example, one may want to characterise fully the distribution of \(\mathscr {X}_t\) given \(\mathscr {Y}_t\), or one may seek some moments of this distribution. The conditional distribution of \(\mathscr {X}_t\) given \(\mathscr {Y}_s\), \(0\le s\le t\) is called the (optimal, Bayesian) filtering distribution. When the model functions \(a(\cdot )\), \(h(\cdot )\) are linear, the exact (optimal, Bayesian) solution to this problem is completely characterised by the first two moments of the filtering distribution and these moments are given by the celebrated Kalman–Bucy filter [4, 16, 77].
Apart from the most special of nonlinear models, there is in general no finite dimensional optimal filter [9, 12]. In practice, some filter approximations are needed. For example, one may consider a type of “extended” Kalman filter [4] based on linearisation of the nonlinear model and application of the classical Kalman–Bucy filter. This method works well in suitably regular, and sufficiently close to linear problems. This method does not handle well multiple modes in the true filtering distribution. So-called Gaussian-sum filters are another Kalman-filter-type/based approximation designed to handle in some sense multiple modes in the filtering distribution [4]. More recently, there has been some focus on Monte Carlo integration methods for approximating the optimal Bayesian filter [9, 47]. Such methods, termed particle filters or sequential Monte Carlo filters/methods [56, 57, 63], have the advantage of not being subject to the assumption of linearity or Gaussianity in the model. These particle filters are consistent in the number of Monte Carlo samples, i.e. with infinite computational power these methods converge to the optimal nonlinear filter. However, typical particle filtering algorithms exhibit high computational costs with approximation errors that grow (with a fixed sample size) with the signal/observation dimensions [47, 118]. These methods are not scalable to the high-dimensional filtering or state estimation problems found in the geosciences and other areas [60, 78, 97, 121].
The ensemble Kalman–Bucy filter (generally abbreviated EnKF) [59, 60] is a type of Monte Carlo sample approximation of a class of linear (in the observations) filter in the spirit of the Kalman filter. The EnKF is a recursive algorithm for propagating and updating the sample mean and sample covariance of an approximated Bayesian filter [60]. The filter works via the evolution of a collection (i.e. an ensemble) of samples (i.e. ensemble members, or particles) that each satisfies a type of Kalman–Bucy update equation, linear in the observations. In classical Kalman–Bucy filtering [4, 16, 77], a gain function, that depends on the filter error covariance, is used to weight a predicted state estimate with the signal observations, see [16, 60]. In the EnKF, the error covariance in the gain function is replaced by a type of sample covariance. The result is a system of interacting particles in the spirit of a mean-field approximation of a certain McKean–Vlasov-type diffusion equation [53, 107]. We may refine this discussion by giving the relevant equations for a most basic form of EnKF. Let \((\mathcal {V}^i_t,\mathcal {W}^i_t,\mathcal {X}_0^i)\) with \({1\le i\le \textsf{N}+1}\) be \((\textsf{N}+1)\) independent copies of \((\mathscr {V}_t,\mathscr {W}_t,\mathscr {X}_0)\). The most basic ensemble Kalman filter, originally due to Evensen [34, 59, 60], is defined by,
with \(1\le i\le \textsf{N}+1\) and the (particle) sample mean and the sample cross-covariance defining the so-called Kalman gain matrix given by,
and we may also write the standard sample covariance,
In this work, we study this most basic ensemble Kalman filter as described above, and also more sophisticated variants, including the method of Sakov and Oke [125], that exhibit less fluctuation due to sampling noise. Readers familiar with the Kalman filter will recognise immediately some structural similarities as discussed above. However, there is no evolution equation given above for the covariance as in the Kalman filter (e.g. no Riccati-type matrix flow equation). Instead, we replace the relevant covariance matrices with their sample-based counterparts.
Importantly, if the underlying model is linear and Gaussian, then the filtering distribution is Gaussian, and the EnKF propagates exactly the sample mean and covariance of the optimal Bayesian filter and is provably consistent. If the model is nonlinear and/or non-Gaussian, then a standard implementation of the EnKF propagates a sample-based estimate of the filtering mean and covariance (but not the true posterior sample mean or covariance and with no results on consistency). In the context of estimation theory, we may contrast the notion of a state estimator (or observer) with the notion of a Bayesian filter. The goal of the former is to design an observer that tracks in some suitable (typically point-wise) sense the underlying signal and perhaps provides some usable measure of uncertainty on this estimate. The goal of the latter is to compute or approximate the true (Bayesian) filtering distribution (or some related statistics). In the nonlinear setting, even with infinite computational power, the EnKF methods do not converge to the optimal nonlinear filter; and indeed their limiting objects are not well understood in this setting. As discussed more technically later, ensemble Kalman filters are probably best viewed in practice as a type of (random) sample-based state estimator for nonlinear signal/observation models. However, in the special case of linear signal and observation models they are indeed provably consistent approximations of the optimal Bayesian filter.
In practice, the ensemble Kalman filtering methodology is applied in high-dimensional, nonlinear state-space models, e.g. see [59, 60] and the application references listed later in this introduction. Empirically, this method has shown good tracking performance in these applications, see [60] and the application references listed later. This tracking behaviour of the EnKF when applied to practical models may be explainable by viewing the EnKF as a dynamic state estimator. The fluctuation, stability, and contraction properties of the EnKF studied in this article (albeit mainly for linear-Gaussian models) may be viewed in this context also and provide some insight into the state estimate tracking behaviour seen in practice.
1.1 Purpose
The purpose of this review is to present a comprehensive overview of the theory of ensemble Kalman–Bucy filtering with an emphasis on rigorous results and behavioural characterisations for linear-Gaussian signal/observation models. We present a system of equations that describe the flow of individual particles, the flow of the sample covariance, and the flow of the sample mean in continuous-time ensemble filtering. We consider these equations and their characteristics in a number of popular EnKF varieties. Given these equations, we study in detail some fluctuation, stability, and error contraction results for the various ensemble Kalman filtering equations. We discuss the relevance and importance of these results in terms of characterising the EnKF behaviour, and we contrast these results with those considered in classical studies of stability in Kalman–Bucy filtering.
Classical studies of stability in (traditional, non-ensemble-type) Kalman–Bucy filtering are important because they rigorously establish the type of “tracking” properties desired in a filtering or estimation problem; and they establish intuitive, testable, model-based conditions (e.g. model observability) for achieving these convergence properties. Classical results in Kalman–Bucy filtering also establish the (exponential) convergence of the error covariance to a fixed steady-state value computable from the model parameters. See the review [16, 18] for detailed results in the classical context and historical remarks. The results in this work seek to characterise in an analogous manner the practical performance and behaviour of ensemble Kalman filtering, and these results then provide guidance and intuition on the tracking, approximation error, and other properties of these practical methods. Notably, the stochastic fluctuation properties of ensemble Kalman methods also need to be established; and counterparts of this latter analysis do not arise at all in classical Kalman filtering analyses.Our results are presented under testable, model-based assumptions. In particular, we rely on the standard controllability assumption from classical Kalman filtering theory; and, typically, a more restrictive (but testable) observability-type assumption (i.e. linear fully observed processes, which imply classical observability).
1.2 Overview of the main topics and literature
In this subsection, we touch on the main topics and related literature as it pertains to the EnKF. These topics include the fluctuation, stability, and contractive properties of the relevant EnKF stochastic equations. Later, toward the end of this article, we discuss some of these topics in the context of filtering and state estimation more broadly, and we touch on other related but somehow distinct results as they pertain to the EnKF more specifically.
The EnKF is a key numerical method for solving high-dimensional forecasting and data assimilation problems; see, e.g. [59, 60]. In particular, applications have been motivated by inference problems in ocean and atmosphere sciences [78, 102, 104, 112], weather forecasting [5, 6, 34, 70], environmental and ecological statistics [1, 75], as well as in oil reservoir simulations [61, 110, 129], and many others. This list is by no means exhaustive, nor the cited articles fully representative of the respective applications. We refer to (some of) the seminal methodology papers in [5,6,7, 26, 34, 58, 65, 70, 71, 120, 125, 136, 142, 144]. This long list is not exhaustive; see also the books [60, 78, 97, 121] for more background, and the detailed chronological list of references in Evensen’s text [60].
In continuous-time, we may broadly break down the class of EnKF methods into three distinct types; distinguished by the level of fluctuation added via sampling noise needed to ensure that the EnKF sample mean and covariance are consistent in the linear-Gaussian setting. The original form of the EnKF is the so-called vanilla EnKF of Evensen [34, 60], see also [94]; and this method exhibits the most fluctuations due to sampling of both signal and observation noises. The next class is the so-called deterministic EnKF of Sakov and Oke [125], see also [13, 120], which exhibits (considerably) less fluctuation. In the continuous-time linear-Gaussian setting, this class is representative of the so-called square-root EnKF methods [95, 136] (which differ somewhat in discrete-time, e.g. contrast [125] with [136], see also [95]). Finally, there has been recent interest in so-called transport-inspired EnKF methods [120, 132], which apart from initialisation noise/randomisation are completely deterministic and whose analysis in the linear model setting follows closely that of the classical Kalman–Bucy filter, cf. [16]. These classes do not distinguish the totality of EnKF methodology (especially in nonlinear or non-Gaussian models); which may further consist of so-called covariance regularisation methods [7, 59, 65, 71, 108], etc. However, in the linear-Gaussian case, these three classes broadly capture the fundamentals.
As discussed later, the fully deterministic, transport-inspired EnKF method, see [120, 132], is a rather special case in the linear-Gaussian setting and is not studied in detail in this article where linear-Gaussian models are the focus. Nevertheless, we point to [43, 44] for certain mean-field consistency results, non-asymptotic fluctuation (e.g. finite sample size) results, and the long-time behaviour of this particular method in the case of a nonlinear signal model and linear observations. We also touch on this method briefly throughout; but when we refer to the general EnKF we typically mean the so-called vanilla [34, 94] or deterministic [13, 125] methods (which will become clear as the article progresses).
Convergence to a mean-field limit, and large-sample asymptotics, of the discrete-time EnKF was studied in [90, 93, 99, 106], in the sense of taking the number of particles to infinity. The discrete-time square root form of the EnKF is accommodated in [90, 93], and nonlinear state-space models are accommodated in [99]. In the continuous-time, linear-Gaussian, setting, the convergence (in sample size) of the three broad classes of EnKF to the true Kalman–Bucy filter is more immediate and follows from the sample mean and sample covariance evolution equations in [19, 53]. In this latter sense, we recover the fact that the EnKF is a consistent approximation of the optimal, Bayesian filter (i.e. the classical Kalman–Bucy filter) in the linear-Gaussian setting as discussed earlier. The mean-field limit of various EnKF methods in the continuous-time, nonlinear model setting is studied in [43, 93, 98].
We remark in the nonlinear model setting (discrete or continuous-time), see [43, 93, 98, 99, 122], the mean-field limiting equations (and distribution) are not easily related to the optimal filter. Moreover, in practice, one is typically interested in the non-asymptotic (in terms of ensemble size) fluctuation properties as well as the long time/stability behaviour of the particle-type filtering approximations.
The fluctuation analysis of the EnKF is studied in detail in the linear-Gaussian setting in [19, 21, 22]. In [22], a complete Taylor-type stochastic expansion of the sample covariance is given at any order with bounded remainder terms and estimates. Both non-asymptotic and asymptotic bias and variance estimates for the EnKF sample covariance and sample mean are given explicitly in [22]. These latter expansions directly imply an almost sure strong form of a central limit-type result on the sample covariance and sample mean at any time. The analysis in [22] is considered over the entire path space of the matrix-valued Riccati stochastic differential equation that describes the flow of the sample covariance. However, most of the non-asymptotic time-uniform results in [22] hold only when the underlying signal is stable. In [19, 21], we consider the case in which the underlying signal may be unstable, and we provide time-uniform, non-asymptotic moment estimates and time-uniform control over the fluctuation of the sample covariance and mean about their limiting Riccati and Kalman–Bucy filtering terms.
The emphasis of time-uniformity on the moment bounds and on the fluctuation bounds on the sample mean and sample covariance (about the true optimal Bayesian filtering mean and covariance) is important. If these bounds are allowed to grow in time, e.g. typically in this analysis one can easily obtain bounds that grow exponentially in time, then these bounds quickly become useless for any practical numerical application; e.g. an exponent \(>200\) may induce an exceedingly pessimistic bound greater than the estimated number of particles of matter in the visible universe. We remark also that our emphasis on accommodating unstable (latent) signal models is important because time-uniform fluctuation results in such cases (which are of real practical importance) are significantly more difficult to obtain under testable and realistic model assumptions (like the classical observability and controllability model assumptions in the control and filtering literature [4, 16]).
In [53], stability of the EnKF in continuous-time linear-Gaussian models is considered under the assumption that the underlying signal model is also stable. This latter assumption is in contrast with classical Kalman–Bucy filter stability results, which hold in the linear-Gaussian setting under the much weaker (and more natural) condition of signal detectability [16, 18, 139]. The classical Kalman–Bucy filter is stable as a result of the closed-loop stabilising properties of the so-called Kalman gain matrix, which is closely connected to the flow of the filter error covariance described by a Riccati differential equation. The EnKF analogue, in linear-Gaussian settings, is the sample covariance, and its random fluctuation properties (noted in the preceding paragraph) are the main source of difficulty in establishing the closed-loop filter stability in those models in which the underlying signal itself is unstable.
In [137], the authors analyse the long-time behaviour of the (discrete-time) EnKF in a class of nonlinear systems, with finite ensemble size, using Foster-Lyapunov techniques. Applying the results of [137] to the basic linear-Gaussian filtering problem, the analysis and assumptions in [137] then also require stability of the underlying signal model. In a traditional sense, the conditions needed in [137] are hard to check, e.g. as compared to the classical observability or controllability-type model conditions in Kalman filtering analysis, but a range of examples are given in [137]. In [81], the long-time behaviour of the EnKF is analysed in both discrete and continuous time settings with similar conditions on the model as in [137], and which again if linearised equates to a form of stability on the signal model.
We emphasise again that the type of analysis in [53, 81, 137] cannot handle unstable, or transient, signal models; i.e. signals with sample paths with at least one coordinate that may grow unbounded. In the context studied in [53, 81, 137] dealing with stable or bounded latent signal processes (e.g. the Lorenz-class of signal models [81, 137]), the important question on the filter stability or filtering error estimates relies on obtaining meaningful quantitative fluctuation constants decreasing with the number of ensemble members to achieve a desired performance. Of course, time uniformity of these bounds follows trivially in this setting from the boundedness properties of the latent signal process.
Covariance inflation is a mechanism used in practical methods to increase the positive-definiteness of the sample covariance matrix and essentially amplify its effect on the stabilisation properties of the Kalman gain matrix. In [81], time-uniform EnKF error boundedness results follow under a true signal stability condition and given a sufficiently large variance inflation regime. See also [105, 138] for related stability analysis in the presence of adaptive covariance inflation and projection techniques. In [19], in the continuous-time linear-Gaussian setting, the mechanism by which covariance inflation acts to stabilise the ensemble filter is exemplified, see also [24]. Covariance localisation is studied rigorously in [44] in the case of the fully deterministic, transport inspired ensemble filter [120, 132].
In the continuous-time, and linear-Gaussian setting, the first work to relax the assumption of underlying signal stability for the EnKF is in [19, 21, 22]. In those articles, latent signals with sample paths that may grow unbounded (to infinity exponentially fast) are accommodated. That work is based on both a fluctuation analysis of the sample covariance and the sample mean [19, 21, 22], followed by studies on the long-time behaviour, e.g. stability properties, of both the sample covariance and mean [19, 21]. Time-uniform fluctuation properties are given under a type of (strong) signal observability condition. In this setting, time-uniformity of these results is non-trivial. This assumption is in keeping with classical Kalman–Bucy filtering and Riccati equation results and does not require any form of underlying signal stability. As the authors of [137] note in their stability analysis, they use “few properties of the forecast [predicted] covariance matrix other than positivity”. As noted in [137], this lends generality to their results, but conversely places the burden back on the signal model assumptions (including those assumptions of true signal stability). Contrast this with the work in [19, 21, 22] where emphasis is placed on the fluctuation analysis of the sample covariance, with a primary aim of removing the stability assumptions needed on the underlying signal model. The time-uniform fluctuation and stochastic perturbation contributions in [19, 21, 22] were discussed earlier. Given this fluctuation analysis, the stability of the filter sample mean and sample covariance and their (time) asymptotic properties are studied in [19, 21, 22] without stability assumptions on the underlying signal model. These results rigorously establish the type of “tracking” properties desired by a filtering or estimation solution.
Although of lesser practical use in applications, strong results in the one-dimensional setting are also derived in [21] that converge, e.g. in the limit with the ensemble size, to those properties of the classical Kalman–Bucy filter. For example, we can recover the optimal exponential contraction and filter stability rates, etc. In the multidimensional setting, the decay rates to equilibrium are not sharp, and the stationary measures are not given in closed form.
1.3 Aims and contributions
The main goal of this article is to: (1) present a novel formulation for ensemble filtering in linear-Gaussian, continuous-time, systems that lends itself naturally to analysis; (2) provide detailed fluctuation analysis of the ensemble Kalman–Bucy flow, the sample mean, and the stochastic Riccati equation describing the sample covariance; (3) study the stability of the resulting stochastic Riccati differential equation that describes the flow of the sample covariance; (4) study the stability of the continuous-time ensemble Kalman–Bucy update equation that is coupled to this stochastic Riccati equation, and which describes the flow of the sample mean (or the sample mean minus the true signal, i.e. the sample error signal). This article is primarily a review of the literature and results in these directions. The prime focal point of this review are the articles [17, 19, 21, 22, 53], which focus heavily on the linear-Gaussian model setting. In this review, an emphasis is placed on deriving time-uniform fluctuation, stability, and contraction results under testable model conditions equivalent and/or closely related to the classical observability and controllability-type model assumptions. Importantly, we do not generally assume the true underlying signal is stable in this review.
Throughout this review, we contrast and discuss the presented results with the broader literature on the rigorous mathematical behaviour of ensemble Kalman-type filtering. For example, we find easily that the sample covariance matrix in the broad class of EnKF methods considered is always under-biased when compared to the true covariance matrix. This may motivate, from a pure uncertainty quantification viewpoint, some form of covariance regularisation [7, 59, 65, 71, 108]. We provide detailed analysis illustrating the effect of inflation regularisation on stability (similarly to [81, 105, 138]). As another example, we provide strong intuition for so-called catastrophic filter divergence (studied previously in [64, 66, 82]) based on rigorous (heavy-tailed) fluctuation properties inherent to the relevant sample covariance matrices and their invariant distributions. We contrast the so-called vanilla EnKF of [34, 60] with the ‘deterministic’ EnKF of Sakov and Oke [125] in terms of their fluctuation and sample noise characteristics, and we show how this affects their respective sample behaviour and stability properties.
As with classical (non-ensemble) Kalman filtering, the importance of the results reviewed is in rigorously establishing the type of tracking and stability behaviour desired in filtering applications [4, 9, 16, 47]. For example, our results imply conditions under which the initial estimation errors are forgotten, and that the flow of the sample mean converges to the true Kalman filtering (conditional mean) state estimate (and thus the signal) in the average. In the case of the EnKF, there must be some emphasis placed on the stochastic behaviour of the ensemble (Monte Carlo) mean and covariance in order to establish filter stability. We also provide the analogue of the error covariance fixed point in classical Kalman filtering [4, 16]; whereby we state results that ensure the sample covariance matrix converges to an invariant, steady-state, distribution. We characterise the properties of this invariant distribution and relate this to the sample behaviour of the ‘vanilla’ EnKF [34, 60] and the ‘deterministic’ EnKF [125].
We focus on the linear, continuous-in-time, Gaussian setting in this review and note that in this case the sample mean and sample covariance are consistent approximations of the optimal Bayesian filtering mean and covariance. We emphasise that even in the linear-Gaussian case, the samples themselves are not in general independent. The analysis even in the linear setting is highly technical [17, 19, 21, 22, 53], and the results presented in this case are aimed as a step in the progression to more applied results and intuition in nonlinear model settings. There is some precedent for studying the relative properties, behaviour, or performance of ensemble Kalman filtering firstly with linear-Gaussian signal models [59]. For example, the seminal article [34] illustrated that a perturbation of the observations in the ensemble Kalman filter was necessary to recover a consistent covariance limit (to the true Kalman filter for linear-Gaussian systems); or to achieve the standard Monte Carlo error rate with a finite set of particles. The analysis (and even derivation) of ensemble square root filters for linear-Gaussian system models is standard [103, 126], etc. Convergence of the ensemble Kalman filter in inverse problems is studied in [127] in the linear setting. We discuss connections and extensions of the results in this article to the nonlinear model setting toward the end.
We also briefly contrast the approximation capabilities of particle filtering (sequential Monte Carlo) methods [57, 63] with the EnKF. We give a revealing, and perhaps surprising, simple result illustrating the complete failure of the bootstrap particle filter [63] to track unstable linear-Gaussian latent signals. Compared to the EnKF, the fluctuation and stability of various particle filtering methods (e.g. see [39, 47,48,49, 55, 113, 141]) is a rather mature topic. Nevertheless, time-uniform particle filtering estimates rely on mixing-type, or certain contractive, conditions on the mutation transition which do not hold in general in the case of unstable linear-Gaussian models. We contrast this new (rather negative) particle filtering result with its (positive) counterpart for the EnKF.
Note that the analysis and proofs in [17, 19, 21, 22, 53], while motivated originally by ensemble Kalman-type filtering methods, are largely presented as independent technical results on certain general classes of matrix-valued Riccati diffusion equations and associated linear stochastic differential equations with random coefficients. In this review, we emphasise the work in [17, 19, 21, 22, 53] via a series of results directly and solely stated in the context of ensemble Kalman-type filtering. Throughout we relate our results to the broader technical literature on ensemble Kalman filtering and we emphasise the practical significance of these results, e.g. via the tracking property of the filter, its stability, or via their error fluctuation or catastrophic divergence behaviour, among other topics. We also contrast the behaviour of the various classes of continuous-time EnKF methods.
1.4 Notation
We remark firstly that some care must be taken throughout to keep track of the font stylings; e.g. upright vs. calligraphic vs. script, etc. There is typically a relationship between like symbols appearing with different stylings.
Hatted terms \({\widehat{\cdot }}\) should be viewed as being indexed to the ensemble size \(\textsf{N}\ge 1\), i.e. \({\widehat{\cdot }}:=\cdot ^\textsf{N}\). Time is indexed variously by \(s,t,u,\tau \in [0,\infty [\). We write \(c,c_{n},c_{\tau },c_{n,\tau },c_{n,\tau }(Q),c_{n,\tau }(z,Q)\ldots \) for some positive constants whose values may vary from result to result, and which only depend on the indexed/referenced parameters \(n,\tau ,z,Q\), etc, as well as implicitly on the model parameters \((A,H,R,R_1)\) introduced later. Importantly, these constants do not depend on the time horizon t, nor on the number of ensemble particles \(\textsf{N}\).
Let \(\mathbb {M}_{d}\) be the set of \((d\times d)\) real matrices with \(d\ge 1\) and \(\mathbb {M}_{d_1,d_2}\) the set of \((d_1\times d_2)\) real matrices. Let \(\mathbb {S}_d\subset \mathbb {M}_{d}\) be the subset of symmetric matrices, and \(\mathbb {S}^0_d\), and \(\mathbb {S}^+_d\) the subsets of positive semi-definite and definite matrices, respectively. We write \(A \ge B\) when \(A-B\in \mathbb {S}^0_d\); and \(A > B\) when \(A-B\in \mathbb {S}^+_d\). We denote by 0 and I the null and identity matrices, for any \(d\ge 1\). Given \(R\in \partial \mathbb {S}_d^+:= \mathbb {S}_d^0-\mathbb {S}_d^+\) we denote by \(R^{1/2}\) a (non-unique) symmetric square root of R. When \(R\in \mathbb {S}_d^+\), we choose the unique symmetric square root. We write \(A^{\prime }\) the transpose of A, and \(A_{\textrm{sym}}=(A+A^{\prime })/2\) its symmetric part. We denote by \(\textrm{Absc}(A):=\max {\left\{ \textrm{Re}(\lambda )\,:\,\lambda \in \textrm{Spec}(A)\right\} } \) its spectral abscissa. We also denote by \(\textrm{Tr}(A)\) the trace. When \(A\in \mathbb {S}_d\), we let \(\lambda _1(A)\ge \ldots \ge \lambda _d(A)\) denote the ordered eigenvalues of A. We equip \(\mathbb {M}_{d}\) with the spectral norm \(\Vert A \Vert =\Vert A \Vert _2=\sqrt{\lambda _{1}(AA^{\prime })}\) or the Frobenius norm \(\Vert A \Vert =\Vert A \Vert _{\textrm{Frob}}=\sqrt{\textrm{Tr}(AA^{\prime })}\).
Let \(\mu (A)\) denote a matrix logarithmic “norm” (which can be \(<0\)), see [131]. The logarithmic norm is a tool to study the growth of solutions to ordinary differential equations and the error growth in approximation methods. For any square matrix \(A\in \mathbb {M}_{d}\), the logarithmic norm is the smallest element in the set \(\{h\in \mathbb {R}\,:\, \Vert \exp (At) \Vert \le \exp (ht),\,t\ge 0\}\) where \(\Vert \cdot \Vert \) is any matrix norm and the value \(\mu (A)\) may be considered to be indexed to the matrix norm employed. For example, the (2-)logarithmic “norm”, or spectral log-norm, is given by \(\mu (A)=\lambda _{1}(A_{\textrm{sym}})\). We have \(\mu (\cdot )\ge \textrm{Absc}(\cdot )\) in general, but importantly we note that if \(\textrm{Absc}(\cdot )<0\), then there is a matrix norm \(\Vert \cdot \Vert \) defining a logarithmic norm such that \(\mu (\cdot )<0\), see [131, Theorem 5].
2 Kalman–Bucy filtering
Consider a time-invariant linear-Gaussian filtering model of the following form,
where \(A\in \mathbb {M}_{d}\) and \(H\in \mathbb {M}_{d_y,d}\) are the signal and sensor model matrices, respectively, and \(R\in \mathbb {S}^0_{d}\) and \(R_1\in \mathbb {S}^+_{d_y}\) are the respective signal and sensor noise covariance matrices. The noise inputs \(\mathscr {V}_t\) and \(\mathscr {W}_t\) are d and \(d_y\)-dimensional Brownian motions, and \(\mathscr {X}_0\) is an d-dimensional Gaussian random variable (independent of \((\mathscr {V}_t,\mathscr {W}_t)\)) with mean \(\mathbb {E}(\mathscr {X}_0)\) and covariance \(P_0\in \mathbb {S}_d^0\).
We let \(\mathscr {Y}_0=0\) and \(\mathcal {Y}_t=\sigma \left( \mathscr {Y}_s,~s\le t\right) \) be the \(\sigma \)-algebra generated by the observations. The conditional distribution \(\eta _t:=\textrm{Law}\left( \mathscr {X}_t~|~\mathcal {Y}_t\right) \) of the signal states \(\mathscr {X}_t\) given \(\mathcal {Y}_t\) is Gaussian with a conditional mean and covariance given by
The mean and the covariance obey the Kalman–Bucy and the Riccati equations
with the Riccati drift function from \(\mathbb {S}^0_{d}\) into \(\mathbb {S}_{r}\) defined for any \(Q\in \mathbb {S}^0_{d}\) by
and with,
Importantly, the covariance of the conditional distribution \(\textrm{Law}(\mathscr {X}_t~|~\mathcal {Y}_t)\) in this case does not depend on the observations \(\mathcal {Y}_t\). The error \(Z_t:= (X_t - \mathscr {X}_t)\) satisfies
where \(\mathscr {B}_t\) is some independent d-dimensional Brownian motion. Here, we make use of a martingale representation theorem, e.g. [79, Theorem 4.2], see also [54].
Let \(\phi _t(Q):=P_t\) denote the flow of the matrix differential equation (2.3) with \(P_0=Q\in \mathbb {S}^0_d\). Let \(\psi _t(z,Q):=Z_t\) denote the flow of the stochastic error (2.6) with \(Z_0=z=(x-\mathscr {X}_0)\in \mathbb {R}^d\) and \(P_t= \phi _t(Q)\). Finally, we denote the flow of the Kalman–Bucy update (2.2) with \(X_0=x\in \mathbb {R}^d\) by \(\chi _t(x,Q):=X_t\). This notation allows us to reference the flows \(\psi _t(z,Q)\), \(\phi _t(Q)\), \(\chi _t(x,Q)\) with respect to their initialisation at \(t=0\) which is useful when we compare flows and study stability.
Throughout this section, we assume that \((A,R^{1/2})\) and (A, H) are controllable and observable pairs in the sense that
Note that if \(R\in \mathbb {S}^+_d\) is positive definite, which is quite common in filtering problems, it follows that controllability holds trivially. We consider the observability and controllability Gramians \((\mathcal {O}_{t},\mathcal {C}_{t}(\mathcal {O}))\) and \((\mathcal {C}_{t},\mathcal {O}_{t}(\mathcal {C}))\) associated with the triplet (A, R, S) and defined by
Given (2.7), for any finite \(\tau >0\), there exists some finite parameters \(\varpi ^{o,c}_{\pm },\varpi ^{c}_{\pm }(\mathcal {O}),\varpi ^{o}_{\pm }(\mathcal {C})>0\) such that
The parameter \(\tau \) is often called the interval of observability-controllability, see [30].
These rank conditions (2.7) ensure the existence and the uniqueness of a positive definite fixed-point matrix \(P_\infty \) solving the algebraic Riccati equation
Indeed, if (2.7) holds, then \(P_\infty \in \mathbb {S}_d^+\) and \(\textrm{Absc}(A-P_\infty S)<0\). We may relax the controllability assumption to just stabilisability, in which case \(P_\infty \in \mathbb {S}_d^0\) and \(\textrm{Absc}(A-P_\infty S)<0\); see [87, 91, 109] and the convergence results in [35, 89]. Under just a detectability condition, it follows that \(P_\infty \in \mathbb {S}_d^0\) and \(\textrm{Absc}(A-P_\infty S)\le 0\), i.e. \((A-P_\infty S)\), is only marginally stable, and convergence to this solution is given under mild additional conditions in [36, 115, 117]. In [139], given only detectability, the time-varying “closed loop” matrix \((A-\phi _t(Q)S)\) is shown to be stabilising, even when \((A-P_\infty S)\) is only marginally stable.
In the context of ensemble Kalman–Bucy filtering considered later, we will require the same controllability assumption as considered above, and a more restrictive observability condition (that implies the classical observability/detectability discussed above).
For any \(s\le t\) and \(Q\in \mathbb {S}_{d}^0\), we define the state-transition matrix,
When \(s=0\), we often write \(\mathcal {E}_{t}(Q)\) instead of \(\mathcal {E}_{0,t}(Q)\). The matrix \(\mathcal {E}_{t}(Q)\) is the fundamental matrix. We have \(\mathcal {E}_{s,t}(Q)=\mathcal {E}_{t}(Q)\mathcal {E}_{s}(Q)^{-1}\). The following convergence estimates follow from [16, 18]: For any \(Q,Q_1,Q_2\in \mathbb {S}^{0}_{d}\) and any \(t\ge 0\), we have the local contraction inequalities
for some finite \(\alpha ,c>0\) and with \({P}_\infty \) solving (2.11) and
for some finite constant \(c( Q_1, Q_2)>0\). In addition, there exists some parameter \(\tau > 0\) such that for any \(s\ge 0\) and any \(t\ge \tau >0\) we have the uniform estimates,
Note it is desirable to relate the decay of \(\mathcal {E}_{s,s+t}(Q)\) to the decay at the fixed point \(\Vert \mathcal {E}_{t}({P}_{\infty })\Vert = \Vert e^{t(A-P_\infty S)} \Vert \le c\,e^{-\alpha \, t}\) (since as \(t\rightarrow \infty \) it is clear that we cannot do better). See [18] for an explicit Floquet-type expression of \(\mathcal {E}_{t}(Q)\) in terms of \(\mathcal {E}_{t}(P_\infty )\).
The convergence and stability properties of the Kalman–Bucy filter and the associated Riccati equation are directly related to the contraction properties of the state-transition matrix \(\mathcal {E}_{s,t}(Q)\). To get some intuition for this we note,
and
for any \(s\le t\).
From [16], for any \(t\ge \tau >0\) and any \(Q\in \mathbb {S}_d^0\) we have the uniform estimates
We also have
The following stability result follows from [16, 18]: For any \(Q_1,Q_2\in \mathbb {S}^{0}_{d}\) and for any \(t\ge 0\),
and recall the exponential contraction estimate on \(\Vert \mathcal {E}_{t}({P}_{\infty })\Vert \) in (2.13). Similarly, using (2.15), for any \(s\ge 0\) and any \(t\ge \tau >0\), we have
Note that both (2.20) and (2.21) imply immediately that \(\phi _{t}(Q)\rightarrow _{t\rightarrow \infty }{P}_\infty \) exponentially fast for any \(Q\in \mathbb {S}^0_d\); e.g. by letting \(Q_2=P_\infty \).
Note that the uniform estimates with constants independent of the initial condition stated throughout, involve some arbitrarily small, positive time parameter \(\tau \), which can be directly related to the notion of a so-called observability/controllability interval introduced earlier; for further details on this topic, we refer to [16, 30]. Contrast, for example, the stability results (2.20) and (2.21). The symbol \(\tau \) is reserved for this arbitrary small time parameter throughout the article.
Results (e.g. bounds and convergence results) on the flow of the inverse of the solution of the Riccati equation are considered in [16] and are relevant for proving results on the flow of the Riccati equation itself; e.g. upper bounds on the flow of the inverse solution help to lower bound solutions of the Riccati flow. The flow of the inverse Riccati solution may also be of interest on its own as it relates to the flow of “information” (as the inverse of covariance).
Given the contraction properties on \(\mathcal {E}_{s,t}(Q)\), it is often said the “deterministic part” of the filter error \(\partial _tZ_t=\left( A-P_t\,S\right) Z_t\) is stable. From [16], we can be more explicit if desired, for example, for any \(t\ge \tau \) we have the uniform estimate,
for some rate \(\alpha >0\) and some finite constant \(c>0\). Moreover, the conditional probability of the following event
given the state variable \(\mathscr {X}_0\) is greater than \(1-e^{-\delta }\), for any \(\delta \ge 0\). And, for any \(t\ge 0\), \(z_1,z_2\in \mathbb {R}^{d}\), \(Q_1,Q_2\in \mathbb {S}^0_{d}\) and any \(n\ge 1\) we have the almost sure local contraction estimate
with some rate \(\alpha >0\) and the finite constants \(c(Q_1,Q_2),c_n(Q_1,Q_2)>0\).
3 Kalman–Bucy diffusion processes
For any probability measure \(\eta \) on \(\mathbb {R}^d\), we let \(\mathcal {P}_{\eta }\) denote the \(\eta \)-covariance
with the identity function \(\iota (x):=x\) and the column vector \(\eta (f):=\int f\, d\eta \) for some measurable function \(f:\mathbb {R}^d\rightarrow \mathbb {R}^d\).
We now consider three different cases of a conditional nonlinear McKean–Vlasov-type diffusion process,
where
and thus, the diffusions in (3.2) depend in some nonlinear fashion on the conditional law of the diffusion process itself. In all three cases, \((\mathcal {V}_t,\mathcal {W}_t,\mathcal {X}_0)\) are independent copies of \((\mathscr {V}_t,\mathscr {W}_t,\mathscr {X}_0)\). These diffusions are time-varying Ornstein–Uhlenbeck processes [53] and consequently \({\overline{\eta }}_t\) is Gaussian; see also [16]. These Gaussian distributions have the same conditional mean \({\overline{\eta }}_t(\iota )\) and conditional covariance \(\mathcal {P}_{{\overline{\eta }}_t}\).
Proposition 3.1
and \({X}_t:={\overline{\eta }}_t(\iota )={\eta }_t(\iota )\) and \(P_t=\mathcal {P}_{{\overline{\eta }}_t}=\mathcal {P}_{\eta _t}\) where \(X_t\) and \(P_t\) correspond to the Kalman–Bucy filter update and Riccati equations in (2.2) and (2.3).
We may refer to this specific class (3.2) of McKean–Vlasov-type diffusion as a Kalman–Bucy diffusion process [16]. The case (F1) corresponds to the limiting object that is sampled in the continuous-time version of the ‘vanilla’ EnKF [60]; while (F2) is the continuous-time limiting object that is sampled in the ‘deterministic’ EnKF of [125], see also [120]; and (F3) is a fully deterministic transport-inspired equation [120, 132]. Note that in this case (F3) the existence of the inverse of \(\mathcal {P}_{{\overline{\eta }}_t}\) is given by the positive-definiteness properties of the solution of the Riccati equation in (2.3). In the next section, we detail the Monte Carlo ensemble filters derived from these Kalman–Bucy diffusion processes.
Note we may define a generalised version of case (F3) by,
for any skew symmetric matrix \(G^\prime _t=-G_t\) that may also depend \({\overline{\eta }}_t\). This added tuning parameter may be related to an optimality metric, when deriving this transport equation from an optimal transport beginning. We may also write similar generalised versions (F1\('\)) and (F2\('\)) by adding \(G_t\,\mathcal {P}_{{\overline{\eta }}_t}^{-1}\left( \mathcal {X}_t-{\overline{\eta }}_t(\iota )\right) \) to (F1) and (F2); though practically it likely makes little sense.
4 Ensemble Kalman–Bucy filtering
Ensemble Kalman–Bucy filters (EnKF) coincide with the mean-field particle interpretation of the nonlinear diffusion processes defined in (3.2).
Let \((\mathcal {V}^i_t,\mathcal {W}^i_t,\mathcal {X}_0^i)\) with \({1\le i\le \textsf{N}+1}\) be \((\textsf{N}+1)\) independent copies of \((\mathcal {V}_t,\mathcal {W}_t,\mathcal {X}_0)\). Again, we consider three different cases of Kalman–Bucy-type interacting diffusion process,
with \(1\le i\le \textsf{N}+1\) and the rescaled (particle) sample mean and covariance
In cases \((\texttt {F1})\) and \((\texttt {F2})\), we have \(\textsf{N}\ge 1\), and in case \((\texttt {F3})\), we require \(\textsf{N}\ge d\) for the almost sure invertibility of \(\widehat{P}_{t}\) (although in case \((\texttt {F3})\) one may substitute a pseudo-inverse of \(\widehat{P}_{t}\) without changing the mathematical analysis). The scaling factor on the sample covariance ensures unbiasedness. A sampled version of case \((\texttt {F3}')\) may also be derived in the same way.
The filters of (4.1) are mean-field approximations of those in (3.2). In (4.1), we see the utility of the Kalman–Bucy filter formulation in (3.2). In particular, in (4.1) we have eliminated the classical Riccati matrix differential equation completely and replaced it with an ensemble of (interacting) particle flows and the computation of a sample covariance matrix from this ensemble. The sample mean and covariance of (4.2) can also be used for inference or decision making, etc.
4.1 Vanilla ensemble Kalman–Bucy filter
The vanilla EnKF, denoted by VEnKF, is associated with the first case \((\texttt {F1})\) of nonlinear process \(\mathcal {X}_t\) in (3.2) and is defined by the Kalman–Bucy-type interacting diffusion process \((\texttt {F1})\) in (4.1). We then have the following key result.
Proposition 4.1
[53] Let \(\textsf{N}\ge 1\). The stochastic flow of the sample mean satisfies,
where \(\mathcal {B}_t\) is an independent d-dimensional Brownian motion.
The sample covariance evolves according to a so-called matrix-valued Riccati diffusion process of the form,
where \(\mathcal {M}_t\) is a \((d\times d)\)-matrix with independent Brownian entries (also independent of \(\mathcal {B}_t\)).
We see that for the vanilla EnKF, the convergence of \(\widehat{X}_{t}\rightarrow X_{t}\) and \(\widehat{P}_{t}\rightarrow P_{t}\) as \(\textsf{N}\rightarrow \infty \) follows immediately. This result follows via the martingale representation theorem, e.g. Theorem 4.2 in [79], see also [54].
4.2 ‘Deterministic’ ensemble Kalman–Bucy filter
The ‘deterministic’ EnKF, denoted DEnKF, is associated with the second case \((\texttt {F2})\) of nonlinear process \(\mathcal {X}_t\) in (3.2) and is defined by the Kalman–Bucy-type interacting diffusion process \((\texttt {F2})\) in (4.1). This ‘deterministic’ epithet in the DEnKF follows because the update ‘part’ of the particle flow is deterministic and does not rely on the stochastic perturbations by \(\mathcal {W}_t^i\) appearing in the VEnKF. This name and idea was taken from [125]; see also [13, 120] and [95, 136]. We have the following key result.
Proposition 4.2
[19, 21] Let \(\textsf{N}\ge 1\). The stochastic flow of the sample mean satisfies,
where \(\mathcal {B}_t\) is an independent d-dimensional Brownian motion.
The sample covariance evolves according to a so-called matrix-valued Riccati diffusion process of the form,
where \(\mathcal {M}_t\) is a \((d\times d)\)-matrix with independent Brownian entries (also independent of \(\mathcal {B}_t\)).
Again, for the DEnKF, the convergence of \(\widehat{X}_{t}\rightarrow X_{t}\) and \(\widehat{P}_{t}\rightarrow P_{t}\) as \(\textsf{N}\rightarrow \infty \) follows immediately. Note the simplified diffusion weighting(s) in the case of the DEnKF, as compared to the VEnKF.
4.3 Transport-inspired ensemble transport filter
The fully deterministic ensemble transport filter DEnTF is associated with the third case \((\texttt {F3})\), defined by the Kalman–Bucy-type interacting diffusion process \((\texttt {F3})\) in (4.1). In this case, we have the special result.
Proposition 4.3
[120, 132] Let \(\textsf{N}\ge 1\). The flow of sample mean is given by,
The sample covariance evolves according to the deterministic Riccati equation,
Note that the particle mean \(\widehat{X}_{t}\) and the particle covariance \(\widehat{P}_{t}\) associated with the particle interpretation \((\texttt {F3})\) discussed in (4.1) satisfy exactly the equations of the Kalman–Bucy filter with the associated deterministic Riccati equation.
The “randomness” in this case only comes from the initial conditions. The stability analysis of this class of DEnTF model resumes to the one of the Kalman–Bucy filter and the associated Riccati equation. Thus, the results, e.g. in (2.20), (2.22), (2.23) and (2.24) hold immediately; see also [16] in the linear-Gaussian setting. In [43, 44], this filter is analysed in the case of a nonlinear signal, but fully observed (linear observation) model. The fluctuation analysis in this case can also be developed easily by combining certain stability results w.r.t. the initial state (see [16]) with conventional sample estimates based on independent copies of the initial states (see, e.g. [23] for estimates associated with classical sample covariance estimates). Consequently, we do not consider this class of model going forward, but recommend [16, 43, 44].
When \(\textsf{N}\) is small compared to d, the inverse of the sample covariance defining the DEnTF is ill-posed and this is likely a limiting factor in the applicability of this method in high-dimensional applications with stochastic state evolutions. With non-Gaussian signal noise, one may also prefer the stochastic perturbation method in the DEnKF.
4.4 Nonlinear ensemble filtering in practice
In practice, the ensemble Kalman filtering methodology is applied in high-dimensional, nonlinear state-space models, e.g. see [59, 60] and the application references listed in the introduction.
It is rather straightforward to extend the algorithmic particle methods in (4.1) to nonlinear systems as we now outline. Consider a time-invariant nonlinear diffusion model of the form,
where \(a:\mathbb {R}^d\rightarrow \mathbb {R}^d\) and \(h:\mathbb {R}^d\rightarrow \mathbb {R}^{d_y}\) are the nonlinear signal and sensor model functions of some sufficient regularity.
Let \((\mathcal {V}^i_t,\mathcal {W}^i_t,\mathcal {X}_0^i)\) with \({1\le i\le \textsf{N}+1}\) be \((\textsf{N}+1)\) independent copies of \((\mathscr {V}_t,\mathscr {W}_t,\mathscr {X}_0)\). We consider the three EnKF variants as before and define the flow of particles by,
with \(1\le i\le \textsf{N}+1\) and the (particle) sample mean \(\widehat{X}_{t}\) and sample covariance \(\widehat{P}_{t}\) defined as usual, e.g. see (4.2), and with the observation function sample mean and sample cross-covariance defined as,
The mean-field limit of these interacting nonlinear conditional particle diffusion systems (4.10) is studied in [43, 93]. The (conditional) law of these mean field McKean–Vlasov diffusions may even be given in terms of a Kushner/Fokker-Planck-type partial differential equation, e.g. see [43, 93]. However, if the mean-field limit in this nonlinear setting is denoted by, say, \(\mathcal {X}_t\), then it is certainly true that,
in the nonlinear model setting. Said differently, even with infinite computational power, the EnKF methods as applied in this nonlinear model setting do not converge to the optimal nonlinear Bayes filter. As noted earlier, and again later, the EnKF in this nonlinear model setting is probably best viewed in practice as a type of (random) sample-based (point-valued) state estimator or a stochastic observer. In general, it should not be seen as an approximation of the optimal Bayesian filter.
We discuss connections and extensions of our results to the nonlinear model setting, including different instances of the EnKF in these settings, in a later section (at the end of this article).
5 Theory in the linear-Gaussian setting
Going forward, we consider only the VEnKF (case (F1)) and DEnKF (case (F2)) since as noted the theory of the DEnTF in the linear-Gaussian setting reverts to that of the standard Kalman–Bucy filter as detailed in [16]. The parameter \(\kappa \in \{0,1\}\) will distinguish the two cases (\(\kappa =1\) in case (F1), and \(\kappa =0\) in case (F2)) throughout.
We may unify the analysis via the following representation,
with the mapping,
Let \(\widehat{Z}_t:=(\widehat{X}_t-\mathscr {X}_t)\) and observe that
for some independent d-dimensional Wiener process \({\widehat{\mathscr {B}}}_t\) and with,
Note we often refer to the flows \(\widehat{Z}_t\) or \({Z}_t\) as error flows.
We also underline that
so that the difference between the noisy error flow \(\widehat{Z}_t\) and the classical Kalman–Bucy error flow \(Z_t\) is equal to the difference between the EnKF (sample mean) state estimate and the classical Kalman–Bucy state estimate.
Let \({\widehat{\phi }}_t(Q):=\widehat{P}_t\) denote the flow of the Riccati diffusion equation in (5.2) with \(\widehat{P}_0=Q\in \mathbb {S}^0_d\). Let \({\widehat{\psi }}_t(z,Q):=\widehat{Z}_t\) denote the flow of the stochastic error (5.4) with \(\widehat{Z}_0=z=(x-\mathscr {X}_0)\in \mathbb {R}^d\) and \(\widehat{P}_t= {\widehat{\phi }}_t(Q)\). Finally, we denote the flow of the sample mean in (5.1) with \(\widehat{X}_0=x\in \mathbb {R}^d\) by \({\widehat{\chi }}_t(x,Q):=\widehat{X}_t\).
We underline further that the difference between two error flows satisfies,
and is thus equal to the difference between the two corresponding sample means (with compatible starting points). Studying the difference between two error flows \(({\widehat{\psi }}_{t}(z_1,Q_1) - {\psi }_{t}(z_2,Q_2))\) subsumes the study of something like \(({\widehat{\chi }}_t(x_1,Q_1) - {\chi }_t(x_2,Q_2))\) which is the difference between the EnKF (sample mean) state estimate and the classical Kalman–Bucy state estimate (with different initial conditions).
For any \(s\le t\) and \(Q\in \mathbb {S}_{d}^0\), we define the stochastic state-transition matrix,
As with the classical Kalman–Bucy filter, e.g. see (2.16) and (2.17), the convergence and stability properties of the ensemble Kalman–Bucy filter and the associated Riccati diffusion equation are directly related to the contraction properties of the stochastic state-transition matrix \({\widehat{\mathcal {E}}}_{s,t}(Q)\). For example, the flow of the stochastic error equation (5.4) is given by,
and the stochastic flow of the matrix Riccati diffusion (5.2) is given implicitly by
for any \(s\le t\). We denote by \({\widehat{\Pi }}_t\) the Markov semigroup of \({\widehat{\phi }}_t(Q)\) defined for any bounded measurable function F on \(\mathbb {S}_d\) and any \(Q\in \mathbb {S}_d^0\) with the property that,
When Q is random with distribution \(\Gamma (dQ)\) on \(\mathbb {S}_d^+\), by Fubini’s theorem we have,
This yields the formula
for the distribution of \({\widehat{\phi }}_t(Q)\) on \(\mathbb {S}_d^+\).
We then have the first result concerning the quadratic, matrix-valued, Riccati diffusion process (5.10).
Theorem 5.1
For any \(\textsf{N}\ge 1\), the Riccati diffusion (5.10) has a unique weak solution on \(\mathbb {S}^0_d\). For \(\textsf{N}\ge d+1\), there exists a unique strong solution on \(\mathbb {S}^+_d\). Moreover, \({\widehat{\Pi }}_t(Q,dP)\) is a strongly Feller and irreducible semigroup with a unique invariant probability measure \({\widehat{\Gamma }}_{\infty }\) on \(\mathbb {S}^+_d\). This measure admits a positive density with respect to the natural Lebesgue measure on \(\mathbb {S}_d\).
Given the existence of a solution to the Riccati diffusion (5.2), it follows a solution for \(\widehat{X}_t\) in (5.1) or a solution \(\widehat{Z}_t\) in (5.4) exists and is unique. This result is proven in [19, Theorem 2.1].
Once the problem of existence and uniqueness is tackled, one major problem in this equation is the behaviour at infinity: existence of a stationary measure and speed of convergence towards this stationary measure or even distance between two solutions starting at different points.
We will make wide use of the following two assumptions in the remainder of this article.
Assumption O
The matrix \(S:=H^{\prime }R_1^{-1}H\) is strictly positive-definite, i.e. \(S\in \mathbb {S}_d^+\). This is a strong form of observability, and it implies classical observability as defined in (2.7).
Assumption C
The pair \((A,R^{1/2})\) is controllable, as defined in (2.7).
Under both Assumptions O and C, it follows that \(P_\infty \in \mathbb {S}_d^+\) and \(\textrm{Absc}(A-P_\infty S)<0\), see the earlier discussion on this topic. We may relax the controllability Assumption C to just stabilisability. We discuss Assumption O more later as it (re-)appears throughout our presentation and is more restrictive than the classical observability/detectability assumptions in classical Kalman filtering (noting again it implies observability/detectability).
We emphasise the following:
Proof of this statement follows from the fact that \(\textrm{Absc}(A-P_\infty S)<0\) under just detectability and stabilisability model conditions, and then, an application of [131, Theorem 5]. The logarithmic norm \({\overline{\mu }}(\cdot )\) is not necessarily unique, but any particular chosen logarithmic norm \({\overline{\mu }}(\cdot )\) is indexed to the model parameters \((A,H,R,R_1)\). We use the notation \({\overline{\mu }}(\cdot )\) to distinguish the log-norms for which \({\overline{\mu }}(A-P_\infty S)<0\) whenever \(\textrm{Absc}(A-P_\infty S)<0\) holds, or more specifically throughout this work whenever Assumptions O and C hold.
In prior work [17, 19, 21, 22, 53] and even the first draft of this article, we state certain results in terms of \({\mu }(A-P_\infty S)\), and under the assumption \({\mu }(A-P_\infty S)<0\); for some, but we do not care which, logarithmic norm \(\mu (\cdot )\). We knew of course that certain observability and controllability model conditions ensured \(\textrm{Absc}(A-P_\infty S)<0\). However, it was unclear that negativity of the spectral abscissa translated in general to \({\mu }(A-P_\infty S)<0\) for some version of the logarithmic norm. Thus, in many results we start with the assumption \({\mu }(A-P_\infty S)<0\) in prior work [17, 19, 21, 22, 53] and claimed somewhat informally that this amounts to asking for a strong form of observability and controllability (given its similarity to \(\textrm{Absc}(A-P_\infty S)<0\), but without actually giving testable model conditions). Owing to [131, Theorem 5], we can begin results simply with some form of observability and controllability assumption (typically we need the stronger observability Assumption O, for different reasons) and state results in terms of the special class of logarithmic norms \({\overline{\mu }}(A-P_\infty S)<0\); which we know is negative because \(\textrm{Absc}(A-P_\infty S)<0\). This is a significant relaxation of the conditions precedent in many of the subsequent results and places these results back in the testable and relatable context of classical controllability and observability assumptions.
In Table 1, we denote the relevant flows and notation of interest going forward. This notation allows us to relate (for example) the flow of the approximation relative to the true object with respect to their initial conditions, e.g. fluctuation-type results: \({\widehat{\chi }}_t(x,Q) - {\chi }_t(x,Q)\); or (for example) the flow of two approximated objects with respect to different initial positions, e.g. stability/contraction-type results: \({\widehat{\psi }}_{t}(z_1,Q_1) - {\widehat{\psi }}_{t}(z_2,Q_2)\).
In Fig. 1, we plot the flow of some of the subsequent sections and the main results. The presentation ordering is given mostly in terms of the dependencies and natural progression of the derivations. We discuss briefly the dependencies and reasoning as we progress.

Flowchart of the general result and topics in this article. Although detailed proof in most cases is not given, the arrows and top-down direction in the flowchart depict both the presentation of the results in this article, and the dependency in terms of the proof and derivation of the results
5.1 Fluctuation and contraction results for the Riccati diffusion
5.1.1 Fluctuation properties of the Riccati diffusion
In this section, we consider the fluctuation of \({\widehat{\phi }}_t(Q)\) about \({\phi }_t(Q)\) and of \({\widehat{\psi }}_t(z,Q)\) about \({\psi }_t(z,Q)\).
The fluctuation properties and moment boundedness properties of \({\widehat{\phi }}_t(Q)\) and \({\widehat{\psi }}_t(z,Q)\) depend naturally on the size on the fluctuation as determined by \(\textsf{N}\).
Typically, we will write either of the following expressions in stating our results,
In case (F1) with \(\kappa =1\), there is often a minimum threshold on \(\textsf{N}\) needed to prove the results. In case (F1), this lower threshold on \(\textsf{N}\) may be large. In case (F2) with \(\kappa =0\), these same results typically hold, but moreover, we can often refine the relevant results and at the same time relax the conditions on \(\textsf{N}\), often needing just \(\textsf{N}\ge 1\). This is a significant analytical advantage of the DEnKF over the VEnKF. In some cases, this advantage is practically realised and provable (and not just a by-product of analysis methods). For example, we will show later that some moments of the VEnKF sample covariance in one-dimension provably do not exist in the steady-state without a sufficient number of particles, whereas in the DEnKF these moments always exist with \(\textsf{N}\ge 1\). In some cases, the results stated in this work are only known for the DEnKF. If we do not specify a particular case, or a value for \(\kappa \in \{0,1\}\), then the stated results may be assumed to hold for both the VEnKF and the DEnKF.
We start with the following under-bias estimate on the sample covariance which holds for both the VEnKF and the DEnKF.
Theorem 5.2
For any \(t\ge 0\), any \(Q\in \mathbb {S}_d^0\), and any \(\textsf{N}\ge 1\), we have the uniform under-bias estimate,
for a finite constant \(c>0\) that does not depend on the time horizon.
We may refine this under-bias result as is done in [19]. For example, if we assume further that \(S\in \mathbb {S}_d^+\), i.e. under Assumption O, then for any \(t\ge 0\) we also have the refined bias estimates,
when \(\textsf{N}\) is sufficiently large in case (F1), \(\kappa =1\); or for any \(\textsf{N}\ge 1\) in case (F2), \(\kappa =0\). The proof of this refinement, and details on the constant c(Q), is in [19, Theorem 2.3] and in [22].
We will see subsequently that Assumption O, i.e. the condition \(S\in \mathbb {S}_d^+\), ensures that for any \(n\ge 1\), the n-th moments of the trace of the sample covariance are uniformly bounded w.r.t. the time horizon (with a sufficient number of particles) even when the matrix A is unstable.
The next theorem concerns these time-uniform moment estimates on the stochastic Riccati flow in (4.4), i.e. on the flow of the sample covariance matrix.
Theorem 5.3
Suppose Assumption O holds. For any \(n\ge 1\), \(t\ge 0\), any \(Q\in \mathbb {S}_d^0\), and any \(\textsf{N}\) sufficiently large, we have the uniform estimate,
Furthermore, for any time horizon \(t\ge \tau >0\) we also have the uniform estimates
In addition, in case (F2), for any \(\textsf{N}\ge 1\), any \(n\ge 1\), \(Q\in \mathbb {S}_d^0\), \(t\ge 0\) and any \(s\ge \tau >0\) we have the refined estimates,
The proof of this result is provided in [19, Theorem 2.2] where a precise description of the (finite) parameters \(c_{n},c_{n,\tau },c,c_{\tau }>0\) is also provided. The first estimate in (5.17) also holds without Assumption O, and even if \(S=0\), when \(\textrm{Absc}(A)<0\). The proof of this Theorem is based on a reduction in (4.4) to a scalar Riccati diffusion, a novel representation of its n-th powers, and a comparison of its moments to a judiciously designed deterministic scalar Riccati equation. We discuss this proof later, but this scalar reduction necessitates the condition \(S\in \mathbb {S}_d^+\), i.e. Assumption O. The proof is conservative by nature (due to the scalar reduction and comparison).
Now, we turn to quantifying the fluctuations of the matrix Riccati diffusions around their limiting (deterministic) values as found when \(\textsf{N}\) tends to \(\infty \). That is, we quantify the fluctuation of the EnKF sample covariance about the limiting covariance of the classical Kalman–Bucy filter.
Theorem 5.4
Suppose Assumption O holds. For any \(n\ge 1\), \(t\ge 0\), any \(Q\in \mathbb {S}_d^0\), and any \(\textsf{N}\) sufficiently large we have the uniform estimates,
In case (F2), for any \(\textsf{N}\ge 1\), any \(n\ge 1\), \(t\ge 0\), and any \(Q\in \mathbb {S}_d^0\), we have
The estimates in Theorem 5.4 do not depend on \(Q\in \mathbb {S}_d^0\) when \(t\ge \tau \) for any \(\tau >0\) and with \(c_n,c\) replaced with \(c_{n,\tau },c_\tau \); e.g. similarly to (5.18) in Theorem 5.3.
The proof of the preceding Theorem is provided in [19, Theorem 2.3] and in [22]. The proof follows from a second-order expansion of the stochastic flow \({\widehat{\phi }}_t\) about the deterministic flow \(\phi _t\) and then an appropriate bounding of the first- and second-order stochastic terms. More generally, in [22] we consider a Taylor-type perturbation expansion of the form,
for any \(n\ge 1\), and a stochastic flow \({\varphi }^{(k)}_t\) whose values do not depend on the ensemble size \(\textsf{N}\), and a stochastic remainder term \(\widehat{{\varphi }}^{\,(n)}_t\). Odd order stochastic terms \({\varphi }^{(k)}_t\), with k odd, are zero mean (i.e. centred). This representation allows us in [22] to present sharp and non-asymptotic expansions of the matrix moments of the matrix Riccati diffusion with respect to \(\textsf{N}\).
In [22], we provide uniform estimates of the stochastic flow \({\varphi }^{(k)}_t\) w.r.t. the time horizon even when the matrix A is unstable. These estimates are stronger than the conventional functional central limit theorems for stochastic processes. For example, these results imply the almost sure central limit theorem on the sample covariance,
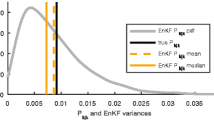
Bias and variance estimates based on the expansion (5.22) are also given in [22]. See also in particular [22, Section 1.3] for detailed exposition of this functional central limit theorem and the bias and variance estimates. In the scalar case, we explore this expansion (5.22) up to second-order in detail in a later section to illustrate this form.
The under bias result (5.15) holds with any \(\textsf{N}\ge 1\) in both the VEnKF of case (F1), and in the DEnKF of case (F2). This under-bias is a motivation for so-called sample covariance regularisation in practice; e.g. so-called sample covariance inflation or localisation methods [7, 59, 65, 71, 108]. Later, we discuss the effects of inflation in particular.
As with the deterministic Riccati equation, we may bound the moments of the inverse of the stochastic Riccati flow \({\widehat{\phi }}_t(Q)\) under stronger conditions on the number of particles \(\textsf{N}\) required; e.g. see [19]. It follows that with \(Q\in \mathbb {S}_d^+\) and with additional conditions on \(\textsf{N}\), that for \(t\ge \tau >0\) there exists a uniform positive definite lower bound on \(\mathbb {E}[{\widehat{\phi }}_t(Q)]\).
A number of basic corollaries follow the proofs in [19, 22]; for instance, we have the monotone property,
and, for any \(Q\in \mathbb {S}_d^0\), the fixed upper bound,
These estimates hold for any \(\textsf{N}\ge 1\) without any additional assumptions, as in Theorem 5.2.
Several spectral estimates can be deduced from the estimates (5.16), (5.20) and (5.21). For example, in case (F2), with \(\kappa =0\) and \(\textsf{N}\ge 1\) then combining (5.21) with the n-version of the Hoffman-Wielandt inequality we have the uniform estimate,
Finally, it is worth noting briefly that all moment boundedness and fluctuation results stated in this section hold with any \(\textsf{N}\ge 1\) and without further assumptions, if one replaces the constants \(c,c_{n}, c_{\tau },c_{n}(Q),\ldots \) with functions that now depend on (and grow with) the time horizon \(t\ge 0\). However, if these bounds depend exponentially on time (as is quite typical in analysis), an exponent of the form \((\alpha \,t)>200\) induces an exceedingly pessimistic estimate larger than the estimated number of elementary particles of matter in the visible universe. In this sense, non-time-uniform bounds of this form are clearly impractical from a numerical user-case perspective.
5.1.2 Contraction and long time properties of the Riccati diffusion
With \(Q\in \mathbb {S}_d^+\), we set \(\Lambda (Q):=\Vert Q\Vert _2+\Vert Q^{-1}\Vert _2\) and we consider the collection of \(\Lambda \)-norms on the set of probability measures \(\Gamma _1,\Gamma _2\) on \(\mathbb {S}_d^+\), indexed by \(\hbar >0\), and defined by,
In the above display, the supremum is taken over all measurable function F on \(\mathbb {S}_d\) such that
It is known that the deterministic Riccati equation that describes the flow of the covariance matrix in classical Kalman–Bucy filtering tends to a fixed point \(P_\infty \) for any initial point \(Q\in \mathbb {S}_d^0\) when the (time-invariant) model (2.1) is detectable and stabilisable; e.g. see (2.20) and [16]. The next result is the analogue of this idea in the EnKF setting and describes the stability of the flow of the sample covariance.
Theorem 5.5
Assume the fluctuation parameter \(\textsf{N}\) is sufficiently large such that \(\mathbb {E}[\Vert {\widehat{\phi }}_t(Q)\Vert ]\) and \(\mathbb {E}[\Vert {\widehat{\phi }}^{-1}_t(Q)\Vert ]\) are uniformly bounded (e.g. as in Theorem 5.3 for bounds on \(\mathbb {E}[\Vert {\widehat{\phi }}_t(Q)\Vert ]\)). Then, there exists some finite constants \(c, \alpha ,\hbar >0\) such that for any \(t\ge 0\) and probability measures \(\Gamma _1,\Gamma _2\) on \(\mathbb {S}_d^+\), we have the \(\Lambda \)-norm contraction inequality
Of course, setting \(\Gamma _2={\widehat{\Gamma }}_{\infty }\) where \({\widehat{\Gamma }}_{\infty }\) is the unique invariant probability measure described in Theorem 5.1 implies that for any initial probability measure \(Q\sim \Gamma \) on \(\mathbb {S}^+_d\) we have that \({\widehat{\phi }}_t(Q)\) tends to be distributed according to \({\widehat{\Gamma }}_{\infty }\). The proof of the above theorem is provided in [19, Theorem 2.4] and is based on matrix-valued Lyapunov and minorisation conditions (choosing the Lyapunov candidate, \(\Lambda (\cdot )\)).
For one-dimensional models, the article [21] provides explicit analytical expressions for the reversible measure of \(\widehat{P}_t\) in terms of the model parameters. As expected, heavy tailed reversible measures arise when \(\kappa =1\), and weighted Gaussian distributions when \(\kappa =0\). The article [21] also provides sharp exponential decay rates to equilibrium, in the sense that the decay rates tend to those of the limiting deterministic Riccati equation when \(\textsf{N}\) tends to \(\infty \).
In a later section, we explore the one-dimensional case in more detail and explicitly examine the invariant measures in each model \(\kappa \in \{0,1\}\). The contrast between the steady-state invariant measures in each case \(\kappa \in \{0,1\}\) provides some insight into various phenomenon seen in practice we believe, e.g. so-called catastrophic divergence, and fluctuations of the sample covariance, etc. We also state the strong \(\mathbb {L}_n\)-type contraction of \({\widehat{\phi }}_t(Q)\) in both cases (F1) and (F2).
5.2 Contraction properties of exponential semigroups
Recall that the stability properties of the deterministic (\(\textsf{N}=\infty \)) semigroups \(\mathcal {E}_{s,t}(Q)\) associated with the classical Kalman–Bucy filter are rather well understood, e.g. see (2.13), (2.15), and (2.14) and also [16, 18]. We emphasise that in the deterministic case, stability of the matrix-valued Riccati differential equation, e.g. as in (2.20), follows from the contraction properties of \(\mathcal {E}_{s,t}(Q)\) in (2.13); see [16, 18] for the derivation. Some intuition for this follows from the implicit form for the solution in (2.17). Similarly, in classical Kalman–Bucy filter, the stability properties of the error flow (2.6) are related to the contraction properties of the state-transition matrix \(\mathcal {E}_{s,t}(Q)\). Again, the intuition follows from the solution form in (2.16). The stability properties of the classical Kalman–Bucy error flow are given in, e.g. (2.22) and (2.24); see [16].
We come now to the contractive properties of \(\widehat{\mathcal {E}}_{s,t}(Q)\) defined in (5.8). The stability of \(\widehat{\mathcal {E}}_{s,t}(Q)\) will naturally play a role in the derivation of contraction results on, e.g. the sample error flow \({\widehat{\psi }}_t(z,Q)\), see (5.9). Indeed, we also require stability of \(\widehat{\mathcal {E}}_{s,t}(Q)\) to derive fluctuation results on the sample error flow \({\widehat{\psi }}_t(z,Q)\). Note we did not need stability of the exponential semigroup to derive fluctuation results on the sample covariance \({\widehat{\phi }}_t(z,Q)\) earlier.
Firstly, we remark that if \(S\in \mathbb {S}_d^+\), then up to a change of basis we can always assume that \(S=I\). Then, for any \(s,t\in [0,\infty [\) we immediately have the rather crude almost sure estimate
for any logarithmic norm. Note again that if \(\textrm{Absc}(A)<0\), then \(\mu \left( A\right) <0\) for some log-norm. In any case, in general, asking for A to be stable is a very strong and restrictive condition. We typically seek contraction results on \(\widehat{\mathcal {E}}_{s,t}(Q)\) that accommodate arbitrary \(A\in \mathbb {M}_d\) matrices; in particular, we seek to accommodate unstable signal matrices A, i.e. matrices with (some) non-negative eigenvalues. To this end, fix \(Q\in \mathbb {S}^0_d\) and consider the process \({\widehat{\mathcal {A}}}\) defined by
We write \(\mathcal {A}\) for the analogous process driven by \(\phi _t(Q)\), i.e. with \(\textsf{N}=\infty \), which we know under just detectability conditions is a time-varying stabilising matrix process [139].
We seek to characterise, in a useful manner, the fluctuation of the stochastic process \( {\widehat{\mathcal {A}}}\) about \(\mathcal {A}\), with the hope that the contractive properties of \(\widehat{\mathcal {E}}_{s,t}\) can then be in some sense related to the established contractive properties of \({\mathcal {E}}_{s,t}\).
For example, given Assumption O and \(\kappa =0\), combining (5.19) (5.21) and (2.15) with Krause’s inequality [86] for any \(nd\ge 1\), we have the uniform fluctuation estimate,
where we define the optimal matching distance between the spectrum of matrices \(A,B\in \mathbb {M}_d\) by
where the minimum is taken over the set of d! permutations of \(\{1,\ldots ,d\}\). This spectral estimate is of interest on its own, but is not immediately usable for controlling the contraction properties of the exponential semigroups.
By Theorem 5.3 and Theorem 5.4, under Assumption O, the collection of processes \((\mathcal {A},{\widehat{\mathcal {A}}})\) satisfy the following regularity properties:
-
Case \(\kappa \in \{1,0\}\): For any \(n\ge 1\), \(t\ge 0\), \(Q\in \mathbb {S}_d^0\), and any \(\textsf{N}\) sufficiently large, we have the uniform estimates
$$\begin{aligned} \sqrt{\textsf{N}}\, \mathbb {E}\left[ \left\| \mathcal {A}_t-{\widehat{\mathcal {A}}}_t \right\| ^n\right] ^{\frac{1}{n}} \,\le \, c_n\,(1+\Vert Q\Vert ^7)~\quad \textrm{and}\quad ~ \mathbb {E}\left[ \left\| {\widehat{\mathcal {A}}}_t \right\| ^n\right] ^{\frac{1}{n}} \,\le \, c_n\,(1+ \Vert Q\Vert )\nonumber \\ \end{aligned}$$(5.34) -
Case \(\kappa =0\): For any \(n\ge 1\), \(t\ge 0\), \(Q\in \mathbb {S}_d^0\), and any \(\textsf{N}\ge 1\), we have the uniform estimates
$$\begin{aligned} \sqrt{\textsf{N}}\,\mathbb {E}\left[ \left\| \mathcal {A}_t-{\widehat{\mathcal {A}}}_t \right\| ^n\right] ^{\frac{1}{n}} \,&\le \, c\,(1+ \Vert Q\Vert ^5)\,\left( 1+\frac{\sqrt{n}}{\sqrt{\textsf{N}}}\right) ^5, \end{aligned}$$(5.35)and
$$\begin{aligned} \sqrt{\textsf{N}} \,\mathbb {E}\left[ \left\| {\widehat{\mathcal {A}}}_t \right\| ^n\right] ^{\frac{1}{n}} \,&\le \, c\,(1+ \Vert Q\Vert )\,(1+\sqrt{n}) \end{aligned}$$
The stability properties of stochastic semigroups associated with a general collection of stochastic flows \((\mathcal {A},{\widehat{\mathcal {A}}})\) satisfying fluctuation and moment boundedness properties in a general form accommodating both (5.34) and (5.35) have been developed in our prior work [17]. Several local-type contraction estimates can now be derived.
Theorem 5.6
Let \(\kappa \in \{1,0\}\) and suppose Assumptions O and C hold. Then, for any increasing sequence \(0\le s \le t_k\uparrow _{k\rightarrow \infty }\infty \), and for any \(Q\in \mathbb {S}_d^0\), the probability of the following event
for any \(\nu \in ]0,1[\), as soon as \(\textsf{N}\) is sufficiently large (as a function of \(\nu \in ]0,1[\)).
This log-Lyapunov estimate (5.36) immediately implies the semigroup \(\widehat{\mathcal {E}}_{s,t_k}(Q)\) is exponentially contracting with a high probability (in both cases \(\kappa \in \{1,0\}\)); given a sufficient number of particles, and the observability and controllability Assumptions O and C.
A number of reformulations of this result that offer insight individually are worth stating:
-
Let \(\kappa \in \{1,0\}\). For any \(0\le s \le t_{k_1}\uparrow _{{k_1}\rightarrow \infty }\infty \), there exists a sequence \(\textsf{N}:=\textsf{N}_{k_2}\uparrow _{{k_2}\rightarrow \infty } \infty \) such that we have the almost sure Lyapunov estimate
$$\begin{aligned} \limsup _{{k_2}\rightarrow \infty }\limsup _{{k_1}\rightarrow \infty }\frac{1}{t_{k_1}}\,\log {\Vert \widehat{\mathcal {E}}_{s,s+t_{k_1}}(Q))\Vert }\,\le \, \frac{1}{2}\,{\overline{\mu }}(A-{P}_{\infty }S) \end{aligned}$$(5.37) -
Let \(\kappa \in \{1,0\}\). Then, for any increasing sequence of times \(0\le s \le t_k\uparrow _{k\rightarrow \infty }\infty \), the probability of the following event,
$$\begin{aligned} \left\{ \begin{array}{l} \forall 0<\nu _2\le 1~~~ \exists l\ge 1 ~~~\hbox {such~that}~~~ \forall k\ge l~~~\hbox {it~holds~that~} \\ ~ \qquad \qquad \qquad \qquad \qquad \qquad \qquad \displaystyle \frac{1}{t_k}\log {\Vert \widehat{\mathcal {E}}_{s,t_k}(Q)\Vert } \,\le \, \frac{1}{2}\,(1-\nu _2)\,{\overline{\mu }}(A-{P}_{\infty }S) \end{array}\right\} \end{aligned}$$(5.38)is greater than \(1-\nu _1\), for any \(\nu _1\in ]0,1[\), as soon as \(\textsf{N}\) is sufficiently large (as a function of \(n\ge 1\) and \(\nu _1\in ]0,1[\)).
-
Let \(\kappa \in \{1,0\}\). Consider any \(s\ge 0\), any increasing sequence of time horizons \(t_k\uparrow _{{k_1}\rightarrow \infty }\infty \), and any sequence \(\textsf{N}:=\textsf{N}_{k_2,n}\uparrow _{{k_2}\rightarrow \infty } \infty \) such that \(\sum _{{k_2}\ge 1}1/\sqrt{\textsf{N}_{k_2,n}}<\infty \) for some \(n\ge 1\). Then, we have the almost sure Lyapunov estimate,
$$\begin{aligned} \left\{ \begin{array}{l} \forall 0<\nu \le 1~~~ \exists l_1,l_2\ge 1 ~~~\hbox {such~that}~~~ \forall k_1\ge l_1,~\forall k_2\ge l_2~~~\hbox {it~holds~that~} \\ \qquad \qquad \qquad \qquad \qquad \qquad \quad \displaystyle \frac{1}{t_{k_1}}\log {\Vert \widehat{\mathcal {E}}_{s,s+t_{k_1}}(Q)\Vert } \,\le \, \frac{1}{2}\,(1-\nu )\,{\overline{\mu }}(A-{P}_{\infty }S) \end{array}\right\} \end{aligned}$$(5.39)
The first dot-point result captured by (5.37) is derived from (5.36) in Theorem 5.6 via the Borel–Cantelli lemma. The next two dot-point results provide some reformulation of the supremum limit estimates (5.36) and (5.37) in terms of random relaxation time horizons and random relaxation-type fluctuation parameters. The last reformulation in (5.39) underlines the fact that after some random time (i.e. determined by \(l_1\)), and given some randomly sufficiently large number of particles (determined by \(l_2\)) the semigroup \({\widehat{\mathcal {E}}}_{s,t}(Q)\) is exponentially contractive. We have no direct control over the parameters \(l_1\) and \(l_2\) in (5.39) which depend on the randomness in any realisation.
Stronger results hold if we restrict \(\kappa =0\), i.e. in case (F2). We have the following immediate corollary of our prior work in [17] and the earlier fluctuation analysis leading to (5.35):
Theorem 5.7
Let \(\kappa =0\) and suppose Assumptions O and C hold. Then, for any \(n\ge 1\), \(s\ge 0\), \(Q\in \mathbb {S}_d^0\), there is some time horizons \(\mathfrak {t}_n<\widehat{\mathfrak {t}}_n\rightarrow _{\textsf{N}\rightarrow \infty }\infty \) such that for any \(\mathfrak {t}_n\le t\le \widehat{\mathfrak {t}}_n\) we have
whenever \(\textsf{N}\) is sufficiently large such that \(\widehat{\mathfrak {t}}_n>\mathfrak {t}_n\); see [17] for details on these time parameters.
Importantly, in this last result we have \(\widehat{\mathfrak {t}}_n\longrightarrow _{\textsf{N}\rightarrow \infty }\infty \) and thus, we can control (via \(\textsf{N}\)) the horizon on which the semigroup \(\widehat{\mathcal {E}}_{s,t}(Q)\) is asymptotically \(\mathbb {L}_n\)-stable for any \(n\ge 1\) when \(\kappa =0\). In other words, the estimate (5.40) ensures that the stochastic semigroup \(\widehat{\mathcal {E}}_{s,t}(Q)\) is stable on arbitrary long finite time horizons, as soon as \(\kappa =0\), and when the ensemble size is sufficiently large. We have the following fact immediate from Theorem 5.7:
-
Assume \(\kappa =0\). For any \(n\ge 1\), \(s\ge 0\), we have
$$\begin{aligned} \limsup _{\textsf{N}\rightarrow \infty }\, \frac{1}{\widehat{\mathfrak {t}}_n}\,\log {\mathbb {E}\left[ \Vert {\widehat{\mathcal {E}}}_{s,s+\widehat{\mathfrak {t}}_n}(Q)\Vert ^{n}\right] } \,\le \, \frac{n}{4}\,{\overline{\mu }}(A-{P}_{\infty }S) \end{aligned}$$
Combining Theorem 5.6 and Theorem 5.7, we may draw the basic (qualitative) conclusion that, after some initial time period, and given enough particles, the (noisy) exponential semigroups \(\widehat{\mathcal {E}}_{s,t}(Q)\) are exponentially contractive (in some sense, e.g. almost-sure or \(\mathbb {L}_n\)-type) at a rate related to a logarithmic norm \({\overline{\mu }}(A-{P}_{\infty }S)\).
We remind the reader again that weak detectability and stabilisability assumptions ensure \(\textrm{Absc}(A-{P}_{\infty }S)<0\) and consequently, via the earlier discussion and [131, Theorem 5], there exists some logarithmic norm such that \({\overline{\mu }}(A-{P}_{\infty }S) <0\). Assumptions O and C imply weak detectability and stabilisability.
Finally, we also have the following new result which extends the exponential decay results for one-dimensional models presented in [21] to the determinant of the matrix-valued Riccati diffusions considered herein. This is a type of stochastic Liouville formula.
Theorem 5.8
Suppose Assumptions O and C hold. Then, for any \(n\ge 1\), \(t\ge 0\), any \(Q\in \mathbb {S}_d^+\), and \(\textsf{N}\) sufficiently large we have the exponential decay estimate
with
In addition, there exists some function \({\widehat{\nu }}_{n}\) with \(\lim _{\textsf{N}\rightarrow \infty }{\widehat{\nu }}_{n}=0\) such that
The proof of this theorem is in [19, Theorem 2.7]. In the one-dimensional case, \(d=1\), this result collapses to capture the strong exponential contraction results presented in [21]. Indeed in one dimension, Theorem 5.8 can be seen as a significant improvement over both Theorem 5.6 and Theorem 5.7 in both theoretical development and practical usability.
In the scalar case, strong stability results on the stochastic Riccati flow \({\widehat{\phi }}_t\) analogous to the deterministic setting, e.g. (2.20), also follow from Theorem 5.8; see also [21] and the results and illustrative examples in a later section in this article.
5.3 Fluctuation and stability of the ensemble Kalman–Bucy filter
In this section, we consider the fluctuation of the sample mean \(({\widehat{\chi }}_t(x,Q):=\widehat{X}_t\) with \(x\in \mathbb {R}^d\) and \(\widehat{{P}}_{0} = Q\in \mathbb {S}_d^0\); or more typically the sample mean error \({\widehat{\psi }}_t(z,Q):= \widehat{Z}_t =(\widehat{X}_t-\mathscr {X}_t)\) with \(\widehat{Z}_0 =(x-\mathscr {X}_0)=z\in \mathbb {R}^d\). We also consider the contraction properties of the error flow of \({\widehat{\psi }}_t(z,Q)\). This flow may be related to the Ornstein–Uhlenbeck process (5.4) and whose solution can be written more generally as in (5.9).
The first result is a fluctuation result of the ensemble sample mean about the Kalman–Bucy filter estimate, i.e. the true conditional mean; and also a conditional bias, or fluctuation, result on the conditional expectation of the ensemble sample mean given the observation sequence, with respect to the true conditional mean given by the Kalman–Bucy filter.
The first result is given under the strong assumption that the latent signal is stable, i.e. \(\textrm{Absc}(A)<0\), and this result holds for both the VEnKF and the DEnKF.
Theorem 5.9
Let \(\kappa \in \{1,0\}\) and suppose Assumption O holds and \(\textrm{Absc}(A)<0\). For any \(n\ge 1\), any \(x\in \mathbb {R}^d\), any \(Q\in \mathbb {S}_d^0\), and for \(\textsf{N}\ge 1\) sufficiently large, we have the fluctuation estimate,
We also have the conditional bias estimate,
Proof of the fluctuation estimate (5.44) is given in [53]. Proof of the conditional bias estimate (5.45) is given in [40, Theorem 2.4]. The latter result (5.45) is used in [40] to study the estimation of the log-normalization constant associated with a class of continuous-time filtering models.
The next theorem concerns time-uniform moment estimates on the sample mean error; and the fluctuation of the sample mean error around its limiting value (found when \(\textsf{N}\) tends to \(\infty \)). The next result relaxes the assumption that the latent signal be stable.
Theorem 5.10
Consider only case (F2) and suppose Assumptions O and C hold. Then, for any \(n\ge 1\), \(z\in \mathbb {R}^d\), \(Q\in \mathbb {S}_d^0\), there exists a time \(\widehat{\mathfrak {t}}_n\rightarrow _{\textsf{N}\rightarrow \infty }\infty \) such that for any \(0\le t\le \widehat{\mathfrak {t}}_n\) we have,
and
See [17] for details on the time parameter \(\widehat{\mathfrak {t}}_n\longrightarrow _{\textsf{N}\rightarrow \infty }\infty \).
Note again the difference \(({\widehat{\psi }}_{t}(z_1,Q_1) - {\psi }_{t}(z_2,Q_2))\) resumes to that of \(({\widehat{\chi }}_t(x_1,Q_1) - {\chi }_t(x_2,Q_2))\). Thus, e.g. (5.47) is comparable to (5.44), under different antecedent conditions.
Unlike Theorems 5.3 and 5.4, the proof of both Theorems 5.9 and 5.10 requires contraction properties to be established a priori for the stochastic transition matrix \(\widehat{\mathcal {E}}_{s,t}(Q)\) defined in (5.8). Hence, in Theorem 5.9 we rely on \(\textrm{Absc}(A)<0\) which ensures the contractive property holds for \(\widehat{\mathcal {E}}_{s,t}(Q)\), see (5.30). In Theorem 5.10, we rely on Theorem 5.7 which establishes the \(\mathbb {L}_n\)-contractivity of \(\widehat{\mathcal {E}}_{s,t}(Q)\) without asking for A to be stable, but only in the case of the DEnKF with \(\kappa =0\), at least in the multi-dimensional setting.
The proof of Theorem 5.10 is provided in [21] in the one-dimensional setting where a detailed description of the (finite) parameters \(c_{n}(z,Q)>0\) is provided. The multi-dimensional result follows using similar proof methods to those used in [21] in combination with the contraction properties of the transition matrix \(\widehat{\mathcal {E}}_{s,t}(Q)\) established in Theorem 5.7. In the one-dimensional setting studied in [21], contraction of \(\widehat{\mathcal {E}}_{s,t}(Q)\) is given under very general model conditions which also accommodate both the VEnKF and the DEnKF. Consequently, in one dimension Theorem 5.10 holds on an infinite time horizon for any \(t\ge 0\) and with any \(\kappa \in \{0,1\}\).
One may consider a perturbation expansion of the sample mean flow as
for any \(n\ge 1\), and some stochastic flow \({\vartheta }^{(k)}_t\) that does not depend on the ensemble size \(\textsf{N}\), and some stochastic remainder term \(\widehat{{\vartheta }}^{\,(n)}_t\). This implies the almost sure central limit theorem on the sample mean,
See in particular [22, Section 1.3] for detailed exposition of this functional central limit theorem.
Uniform propagation of chaos follows from the proceeding central limit theorems and the development in this subsection. In particular, we have
in some suitable metric (e.g. Wasserstein).
Now, we turn to the stability of the error flow \({\widehat{\psi }}_t(z,Q)\) and its contraction properties. The subsequent study on the stability of \({\widehat{\psi }}_t(z,Q)\) relies again on the contraction of \({\widehat{\mathcal {E}}}_{s,t}\) studied previously.
The following uniform error contraction estimate follows from (5.9) and Theorem 5.7,
and holds for the DEnKF, with \(\kappa =0\), for some \(\alpha ,c>0\), and under conditions compatible with the conditions in Theorem 5.7. This contraction result is analogous to (2.22) for the classical Kalman–Bucy filter; but under stronger conditions dictated by the available results on the contraction properties of \({\widehat{\mathcal {E}}}_{s,t}\) stated in Theorem 5.7. In particular, our methods prove this contraction (5.51) only in the case of the DEnKF, with \(\kappa =0\), with \(\textsf{N}\) sufficiently large, and on time horizons compatible with those detailed in Theorem 5.7.
If \(\textrm{Absc}(A)<0\) and Assumption O holds, then (5.51) holds on any infinite time horizon for both the VEnKF and DEnKF; because in this case \(\widehat{\mathcal {E}}_{s,t}(Q)\) is contractive from (5.30). This is analogous to the setting of Theorem 5.9, as compared to that of Theorem 5.10; in line with the earlier discussion on the conditions leading to stability of \(\widehat{\mathcal {E}}_{s,t}(Q)\).
The next results on the stability of \({\widehat{\psi }}_t(z,Q)\) similarly follow immediately from those stability results in the preceding section, but are stated at the level of the process \({\widehat{\psi }}_t(z,Q)\) itself, rather than the stochastic exponential semigroup \({\widehat{\mathcal {E}}}_{s,t}\).
Theorem 5.11
Let \(\kappa \in \{1,0\}\) and suppose Assumptions O and C hold. Then, for any increasing sequence of times \(t_k\uparrow _{k\rightarrow \infty }\infty \), any \(z_1\not =z_2\) and any \(Q\in \mathbb {S}_d^0\), the probability of the following event
for any \(\nu \in ]0,1[\) and some \(\alpha >0\), as soon as \(\textsf{N}\) is sufficiently large (as a function of \(\nu \)).
Two reformulations of this result may shed insight individually and are worth highlighting:
-
Let \(\kappa \in \{1,0\}\). For \(0 \le t_{k_1}\uparrow _{{k_1}\rightarrow \infty }\infty \), there exists a sequence \(\textsf{N}:=\textsf{N}_{k_2}\uparrow _{{k_2}\rightarrow \infty } \infty \) such that we have the almost sure Lyapunov estimate
$$\begin{aligned} \limsup _{{k_2}\rightarrow \infty }\limsup _{{k_1}\rightarrow \infty }\frac{1}{t_{k_1}}\,\log {\Vert {\widehat{\psi }}_{t_{k_1}}(z_1,Q) - {\widehat{\psi }}_{t_{k_1}}(z_2,Q) \Vert }\,<\, \alpha \,{\overline{\mu }}(A-{P}_{\infty }S)\nonumber \\ \end{aligned}$$(5.53) -
Let \(\kappa \in \{1,0\}\). Consider any increasing sequence of time horizons \(t_k\uparrow _{{k_1}\rightarrow \infty }\infty \), and any sequence \(\textsf{N}:=\textsf{N}_{k_2,n}\uparrow _{{k_2}\rightarrow \infty } \infty \) such that \(\sum _{{k_2}\ge 1}1/\sqrt{\textsf{N}_{k_2,n}}<\infty \) for some \(n\ge 1\). Then, we have the almost sure Lyapunov estimate,
$$\begin{aligned} \left\{ \begin{array}{l} \forall 0<\nu \le 1~~~ \exists l_1,l_2\ge 1 ~~~\hbox {such~that}~~~ \forall k_1\ge l_1,~\forall k_2\ge l_2~~~\hbox {it~holds~that~} \\ ~ \qquad \qquad \qquad \displaystyle \frac{1}{t_{k_1}}\log {\Vert {\widehat{\psi }}_{t_{k_1}}(z_1,Q) - {\widehat{\psi }}_{t_{k_1}}(z_2,Q)\Vert } \,\le \, \alpha \,(1-\nu )\,{\overline{\mu }}(A-{P}_{\infty }S) \end{array}\right\} \end{aligned}$$(5.54)
Again we emphasise that the reformulation in (5.54) highlights that after some random time (i.e. determined by \(l_1\)), and given a random sufficiently large number of particles (determined by \(l_2\)) the difference of error flows (or sample means; see (5.7)) is exponentially stable.
We have stronger \(\mathbb {L}_n\)-type stability results in those settings analogous to Theorems 5.9 and 5.10 and in line with the discussion after Theorem 5.10 on the conditions for of \(\widehat{\mathcal {E}}_{s,t}(Q)\).
Theorem 5.12
Let \(\kappa \in \{1,0\}\) and suppose Assumption O holds and \(\textrm{Absc}(A)<0\). Then, for any \(n\ge 1\), any \(z_1\not =z_2\), and any \(Q\in \mathbb {S}_d^0\) we have the stability estimate,
whenever \(\textsf{N}\) is sufficiently large.
In the case (F2), i.e. for the DEnKF only, when \(\kappa =0\), we can relax the strong assumption that the latent signal be stable.
Theorem 5.13
Let \(\kappa =0\) and suppose Assumptions O and C hold. Then, for any \(n\ge 1\), any \(z_1\not =z_2\), and any \(Q\in \mathbb {S}_d^0\), there exists some time horizons \(\mathfrak {t}_n<\widehat{\mathfrak {t}}_n\longrightarrow _{\textsf{N}\rightarrow \infty }\infty \) such that for any \(\mathfrak {t}_n\le t\le \widehat{\mathfrak {t}}_n\) we have the stability estimate,
whenever \(\textsf{N}\) is sufficiently large such that \(\widehat{\mathfrak {t}}_n>\mathfrak {t}_n\); see [17] for details on these time parameters.
We emphasise again that \(\widehat{\mathfrak {t}}_n\longrightarrow _{\textsf{N}\rightarrow \infty }\infty \). With regards to qualitative reasoning, we may combine Theorem 5.11 and Theorem 5.13 and draw the basic (qualitative) conclusion that, after some initial time period, and given enough particles, the difference in (noisy) error flows \(({\widehat{\psi }}_{t}(z_1,Q) - {\widehat{\psi }}_{t}(z_2,Q))\), or the difference in sample means \(({\widehat{\chi }}_t(x_1,Q) - {\widehat{\chi }}_t(x_2,Q))\), is exponentially stable (in some sense) with a rate related to \({\overline{\mu }}(A-{P}_{\infty }S)\).
In the scalar case \(d=1\), stronger stability results on the error flow \({\widehat{\psi }}_{t}(z,Q)\) follow from the contraction properties in Theorem 5.8 under weaker model and ensemble size assumptions. The strong \(\mathbb {L}_n\)-type stability results in the scalar \(d=1\) case are quantitative and hold over infinite horizons for both the VEnKF and the DEnKF, i.e. with \(\kappa \in \{0,1\}\), with unstable latent signals, with differing initial variance states, and with exponential rates that collapse to the optimal deterministic rates (explicitly computable when \(d=1\)) as \(\textsf{N}\rightarrow \infty \). See [21]; and the results, and illustrative examples in the next section.
6 Strong results in one-dimensional illustrative examples
Throughout this section, we let \(d=1\) and \(R\wedge S>0\). The latter condition \(R\wedge S>0\) is both necessary and sufficient for observability and controllability to hold in one dimension; and besides, in some cases, conditions on \(\textsf{N}\ge 1\) no other conditions are needed in this section (and we emphasise that the latent signal may be unstable). The purpose of this section is to illustrate in more detailed quantitative terms some of the more abstract or qualitative results given in the general multi-variate setting. In some cases, the derivation of a multi-variate counterpart of a result in this section remains an open problem. In the scalar setting, the analysis of the EnKF is rather complete in the linear-Gaussian case.
When \(P_0\in [0,\infty [\), the deterministic Riccati equation defined on \([0,\infty [\), in the classical Kalman–Bucy filter, satisfies the quadratic differential equation (2.3) which may be written also as,
with the equilibrium states \((\varrho _-,\varrho _+)\) defined by
With \(P_0\in [0,\infty [\), we have \(P_t\rightarrow _{t\rightarrow \infty }P_\infty =\varrho _+\). It follows that,
and thus simplifying, e.g. (2.13), we have the equality,
where \(-\sqrt{A^2+RS}\) may be viewed explicitly as the optimal semigroup contraction rate in the scalar case. The explicit form of the constants \(c_t(Q)\), c(Q) is also available in the scalar case, see [21] and also the general Floquet-type multivariate result in [18].
The Riccati drift function \(\textrm{Ricc}(\cdot )\) is also the derivative of the double-well potential function
with the roots
In this situation, the general Riccati diffusion (5.2) describing the flow of the sample covariance in both case (F1) and case (F2) resumes to the Langevin–Riccati drift-type diffusion process,
with the mapping \(\Sigma _\kappa \) defined in (5.3). Recall that case (F1) corresponds to the vanilla EnKF, denoted by VEnKF, and case (F2) corresponds to the ‘deterministic’ EnKF, denoted by DEnKF. Also observe that \(\partial F>0\) on the open interval \(]0,\zeta _+[\) and \(\partial F(0)=R>0=\sigma (0)\) so that the origin is repellent and instantaneously reflecting.
At any time \(t\ge 0\), we may comment on the boundedness of certain moments of the sample variance and the fluctuation of the sample variance and sample mean about their limiting (classical Kalman–Bucy variance and mean) values.
For example, we have the under-bias result \(\mathbb {E}[{\widehat{\phi }}_t(Q)]\le \phi _{t}\) with any \(\textsf{N}\ge 1\) in both the VEnKF of case (F1), and in the DEnKF of case (F2). This under-bias motivates so-called variance/covariance regularisation methods in practice; e.g. so-called sample covariance inflation or localisation methods. Later we discuss the effects of inflation in particular. However, more generally, in the scalar case we have the result of Theorem 5.3 with explicit expressions on the ensemble size, i.e. we have for any \(n\ge 1\), \(t\ge 0\), \(Q\in [0,\infty [\), and any \(\textsf{N}\ge 1\vee 2\,\kappa \,(n-1)\), the uniform estimates,
We also have bounds on the inverse Riccati flow (leading to lower bounds on the sample covariance) under stronger conditions on \(\textsf{N}\); see [21]. We remark here, and again later when we explicitly examine the invariant measure for \({\widehat{\phi }}_t\), that these conditions on \(\textsf{N}\) while explicit, may still conservative (in the case of the VEnKF). From Theorem 5.4 and the scalar exposition in [21] we have the uniform fluctuation estimate \(\mathbb {E}[{\widehat{\phi }}_t(Q)-\phi _{t}(Q)^{n}]^{1/n} \le c_n(Q)/\sqrt{N}\) with the explicit \(\textsf{N}\ge 1\vee 2\,\kappa \,(n-1)\). The constant \(c_n(Q)\) is also studied in [21] with \(d=1\) in explicit detail.
Note that we may expand the stochastic flow of the sample variance as in (5.22). Exploring this idea further in the scalar case for illustrative purposes, we may write the first- and second-order fluctuations as,
where in the second line we emphasise the superscript \(\cdot ^{(2)}\) is an order index (not a power) and where,
and the derivatives \(\partial ^k \phi _{t}\) of any order are explicitly given in [21]. In this case, \(\partial \phi _{t}(Q) = \mathcal {E}_t^2(Q)\) (where the superscript here is now a power). We then have,
The natural central limit theorem follows, i.e. \(\sqrt{\textsf{N}}[{\widehat{\phi }}_t-\phi _t]\,\longrightarrow _{\textsf{N}\rightarrow \infty }\,{\varphi }_t\). The (non-)asymptotic variance is estimated in [21, 22].
The expansion (6.12) allows ones to better understand the bias properties of the sample covariance \({\widehat{\phi }}_t\). Writing the third-order fluctuation as,
and expanding and taking expectations,
and limits we have the dominating (N-order-asymptotic) bias is given by
which is always negative (agreeing with the under-bias result \(\mathbb {E}[{\widehat{\phi }}_t(Q)]\le \phi _{t}\)). See [21, 22] for further exploration of these general expansions. A detailed study of these expansions may aid in the development and tuning of (adaptive) sample covariance regularisation methods.
Significantly generalising Theorem 5.10 in the scalar case [21], we have for any \(t\ge 0\), and any \(\textsf{N}>2(4n+1)(1+4\kappa )\), the uniform bound \(\mathbb {E}[{\widehat{\psi }}_t(z,Q)^{n}]^{1/n} \le c_{n}(z,Q)\). We also have the generalisation that for any \(t\ge 0\), and any \(\textsf{N}>2(6n+1)(1+4\kappa )\), the uniform fluctuation estimate,
holds.
The expansion (5.48) of the sample mean (error) may be explored similarly to the above expansion of the sample covariance. The first-order terms \(\vartheta _t\) in (5.48) related to the central limit theorem are studied in [22, Section 1.3].
The infinitesimal generator of the diffusion (6.7) on \(]0,\infty [\) is given in Sturm–Liouville form by the equation
for any \(\delta >0\) and where we recall the identity function \(\iota (x):=x\). This implies that a reversible measure of the Riccati diffusion (5.2) in the scalar \(d=1\) case is given by the formula
In case (F1) corresponding to the VEnKF, we have that L is reversible w.r.t. the probability measure \({\widehat{\Gamma }}_\infty \) on \(]0,\infty [\) defined by,
See also [21] for alternate derivations/forms of this heavy tailed invariant measure. The heavy tailed nature of the stationary measure implies that for the n-th moment to exist one requires \(\textsf{N}>0\vee 2(n-2)\). As expected, this condition on \(\textsf{N}\) is generally weaker than that required for n-th moment boundedness at any time \(t\ge 0\) in (6.8) in terms of the VEnKF. In Fig. 2, we plot the line defined by \((2n-4)/\textsf{N}\) for various \(\textsf{N}\) values. With any \(\textsf{N}\ge 1\), we have existence of the first two moments.

Existence of moments for the VEnKF. Each line corresponds to some number \(\textsf{N}\) with \(\textsf{N}\) moving from 1 to 50 fanning left to right. The ‘x-axis’ corresponds to moment orders n and a moment n exists whenever the line \((2n-4)/\textsf{N}\) is strictly less than one
Higher-order moments even in one dimension are still troublesome (for the VEnKF, \(\kappa =1\)). In fact, the diffusion \(\widehat{P}_t\) for the sample variance in case (F1) does not have any exponential moments in the stationary regime for any finite \(\textsf{N}\ge 1\). That is, for any \(t\ge 0\) and any finite \(\alpha >0\) we have
for any \(\textsf{N}\ge 1\).
We also remark that the heavy tailed nature of this stationary distribution, in the case of the VEnKF, implies that numerical stability in practice may be worrisome. In the stationary regime, it is realistic to expect samples from the tails in this case, and these may be large enough and/or frequent enough to cause numerical divergence. This property may lead to so-called catastrophic divergence as studied in, e.g. [82]. In [64, 66, 82], mechanisms for catastrophic divergence are studied in complex nonlinear systems. Here, we argue that even in linear systems, the heavy-tailed nature of the invariant measure of the sample covariance may lead to samples numerically large enough to cause numerical catastrophe in any practical computing system.
In case (F2) corresponding to the DEnKF, we have that L is reversible w.r.t. the probability measure \({\widehat{\Gamma }}_\infty \) on \(]0,\infty [\) defined by,
Note this measure has Gaussian tails, and we contrast this with the heavy tailed nature of (6.19). This is significant, since it implies that the sample variance (and mean) of this DEnKF will exhibit smaller fluctuations than the VEnKF, and that all moments (including exponential moments) exist in this case for any choice of \(\textsf{N}\ge 1\). This latter result is consistent with Theorem 5.3 at any time \(t\ge 0\) (and in the general multivariate setting). We can also expect better numerical stability (e.g. less outliers); including better time-discretisation properties [73] in case (F2). These better fluctuation properties are already apparent in the preceding results (e.g. see Theorem 5.3, 5.4 and 5.13) in the full multi-dimensional setting.
As an illustrative example, take \(A=20\) (i.e. the underlying signal model is highly unstable), \(R=S=1\) and \(\textsf{N}=6\). In Fig. 3, we compare the invariant measure for the flow of the sample variance in each case.

The invariant measure of the sample variance of the ‘vanilla’ EnKF in case (F1), versus that of the ‘deterministic’ EnKF in case (F2)
We see in Fig. 3 the heavy tails of the invariant measure (6.19) for the vanilla EnKF sample variance, and conversely the Gaussian-type tails in the case (6.21) of the ‘deterministic’ EnKF. Note also the positioning of the mode/mean in each case. In case (F1) of the VEnKF, n-th order moments exist only when \((2n-4)/\textsf{N}\) is strictly less than one (in this case for \(n<5\)); while all moments exist in case (F2) for the DEnKF.
The benefit and real interest in the scalar case is the ability to explicate the convergence rates, e.g. as in (6.4). We finally turn to the convergence/stability properties of the EnKF sample variance and sample mean. In the case of the sample variance, we know from Theorem 5.5 that convergence of \({\widehat{\phi }}_t\) to its invariant measure \({\widehat{\Gamma }}_\infty \) (e.g. as depicted in Fig. 3 and described by (6.19) or (6.21)) holds if \(\textsf{N}>4+(\kappa \,S)/(2\,R)\). Proof of this condition on \(\textsf{N}\) follows from Theorem 5.5, the original multivariate statement of the same result in [19, Theorem 2.4] and bounds on the mean of the sample variance flow and its inverse [19, 21]. In [21], we also consider contraction and stability properties of the distribution of the sample covariance with respect to a particular Wasserstein metric; as opposed to the \(\Lambda \)-norm contraction used in Theorem 5.5. An interesting result from [21] is that when \(\kappa =0\), and for stable signal models (i.e. \(A<0\)), the Riccati diffusion (6.7) (describing the flow of the sample covariance) may converge faster to its invariant measure in (6.21), than the deterministic Riccati (6.1) does to its fixed point in (6.2).
In one-dimensional (\(d=1\)) settings, we may say more on the (stochastic) stability of the EnKF sample covariance \(\phi _t\) and sample mean \(\psi _t\) based on the contraction properties of the stochastic transition matrix \({\widehat{\mathcal {E}}}_t(Q)\) defined in (5.8). It follows from Theorem 5.8 that we have the exponential decay estimate with \(\textsf{N}> 4 \vee (4n-2)\kappa \) which comes from [19, Theorem 2.7],
where \(\widehat{R}_{n}\) and \(\widehat{S}_{n}\) follow from (5.42). In addition, there exists some function (of \(\textsf{N}\)) \(\lim _{\textsf{N}\rightarrow \infty }{\widehat{\nu }}_{n}=0\) such that
which we may relate (or contrast) with the exact contraction rate of the exponential semigroup associated with the deterministic Riccati equation in (6.4) describing the true filter variance in the classical Kalman–Bucy filter. The rate parameter \({\widehat{\nu }}_{n}\) is different between the VEnKF and DEnKF. Details on the parameter \({\widehat{\nu }}_{n}\) are given in [21] but importantly for both \(\kappa \in \{0,1\}\) we recover naturally the convergence rate of the deterministic Riccati flow in (6.4).
The exponential decay of the exponential semigroup \({\widehat{\mathcal {E}}}_t(Q)\) plays a central role in the stability of the pair of processes \(({\widehat{\phi }}_t,{\widehat{\psi }}_t)\). For large time horizons, the Lyapunov exponent can be estimated by the formula
where \({\widehat{\Gamma }}_\infty \) denotes the reversible measure (6.19) or (6.21). We also have the following estimates of the Lyapunov exponent (6.24) from [21], and that relate also to the under-bias \(\mathbb {E}[{\widehat{\phi }}_t(Q)]\le \phi _{t}\). Let \(\kappa =0\) and let \(\textrm{Law}(Q)={\widehat{\Gamma }}_\infty \) be the reversible probability measure defined in (6.21). Then, for any \(t\ge 0\), we have
Similarly assuming \(\kappa =1\) with \(\textrm{Law}(Q)={\widehat{\Gamma }}_\infty \) and \({\widehat{\Gamma }}_\infty \) defined in (6.19), we have for any \(t\ge 0\),
As noted, the left hand inequalities in the preceding two equations follows immediately from the under-bias result \(\mathbb {E}[{\widehat{\phi }}_t(Q)]\le \phi _{t}\)
From the contraction properties on \(\mathbb {E}[{\widehat{\mathcal {E}}}_t(Q)^{n}]\), we may deduce, in the scalar setting, strong stability results on the stochastic Riccati flow \({\widehat{\phi }}_t\) analogous to the deterministic setting, e.g. (2.20). Similarly, strong stability results on the error flow \({\widehat{\psi }}_{t}\) follow from the contraction properties of \(\mathbb {E}[{\widehat{\mathcal {E}}}_t(Q)^{n}]\). Importantly, in the scalar \(d=1\) case of \({\widehat{\psi }}_{t}(z,Q)\) we may relax the multivariate results like Theorem 5.11 and Theorem 5.13 which require more restrictive model (e.g. the strong observability/stability \(\mu (A-{P}_{\infty }S)<0\) condition) and ensemble (particle) size assumptions.
From [21, Theorem 5.10], we have that for any \(\textsf{N}>4\vee 4\kappa (n-1)\),
for some function (of \(\textsf{N}\)) \(\lim _{\textsf{N}\rightarrow \infty }{\widehat{\nu }}_{n}=0\). Note we have found no analogue of this result in the multivariate setting.
From [21, Theorem 6.1], we have that for any \(\textsf{N}>2(4n+1)(1+4\kappa )\),
for some function (of \(\textsf{N}\)) \(\lim _{\textsf{N}\rightarrow \infty }{\widehat{\nu }}_{n}=0\). We may contrast this result with the more restrictive Theorem 5.13 in the multivariate setting. Note in the scalar setting we accommodate both the VEnKF and DEnKF, different initial variance states, and we recover, over fully infinite horizons, a continuous relationship with the optimal stability rates of (6.4).
The constants in (6.23), (6.27), and (6.28) are given explicitly in terms of the model parameters in [21]. We remark that across these three stability results, the details of \({\widehat{\nu }}_{n}\) vary [21], but importantly we recover the optimal (classical Kalman–Bucy) rates \(\lim _{\textsf{N}\rightarrow \infty }{\widehat{\nu }}_{n}=0\).
We consider an illustration of the fluctuation and stability properties of the sample variance in the different EnKF variants. Consider again the model leading to Fig. 3, and let \(\widehat{{P}}_0=0\). The deterministic Riccati flow (\(\textsf{N}=\infty \), in (6.1)) of the classical Kalman–Bucy filter and with the chosen model parameters (\(A=20\), \(R=S=1\)) is given in Fig. 4, along with 100 sample paths of the sample variances for both the VEnKF and the DEnKF (with \(\textsf{N}=6\)).

Flow of the deterministic Riccati equation, and 100 sample paths of the VEnKF sample variance of case (F1), and 100 sample paths of the DEnKF sample variance of case (F2)
Note in Fig. 4 the drastically reduced fluctuations in the ‘deterministic’ EnKF sample variance sample paths. At equilibrium, these fluctuations are related to the invariant measures of the two EnKF varieties in (6.19) and (6.21).
In Fig. 5, we plot the flow of the first two central moments and the 3rd through the 9th standardised central moments for both the VEnKF and DEnKF sample variance distribution. Recall that \(\textsf{N}=6\) in this example, and we expect moments of the VEnKF sample variance in case (F1) to exist up to \(n=4\) with \(n=5\) the boundary case, while all moments exist for the DEnKF of case (F2).

Flow of the sample variance moments for the VEnKF and the DEnKF
We note in Fig. 5 that the sample variance moments for the VEnKF in case (F1) begin to destabilize around the 5th/6th moments as expected. Importantly, the mean of the sample variance for the VEnKF is very negatively biased in this case, while the mean of the DEnKF in case (F2) is quite accurate. Note also the very large variance in the sample variance for the VEnKF.
Lastly, observe that (6.7) has non-globally Lipschitz coefficients in case (F1). The drift is quadratic, while the diffusion has a polynomial growth of order 3/2. It follows by [73] that the naive Euler-type time-discretization may blow up, regardless of the boundedness properties of the limiting (continuous-time) diffusion.
7 Regularisations and comparisons
7.1 Covariance regularisation: inflation
Let \((\mathcal {V}^i_t,\mathcal {W}^i_t,\mathcal {X}_0^i)\) with \({1\le i\le \textsf{N}+1}\) be \((\textsf{N}+1)\) independent copies of \((\mathcal {V}_t,\mathcal {W}_t,\mathcal {X}_0)\). Now, consider a modification of the individual particle update equations in the two cases of interest,
where \(\varepsilon \in [0,\infty [\), and \(T\in \mathbb {S}_r^0\) is some given reference matrix. Here, \(\widehat{P}^\varepsilon _{t}={\widehat{\phi }}^\varepsilon _t(Q)\) denotes the sample covariance-type function of \(\mathcal {X}_t^{i,\varepsilon }\) given by,
Recall the unified representation (for both the VEnKF and the DEnKF) for the flow of the sample mean, sample covariance, and the sample error flow in equations (5.1) through to (5.4).
Now, consider the modification of the state estimator (sample mean) update equation resulting from the \((\varepsilon \,T)\)-modification to the particle updates,
with the mapping,
With \(\widehat{Z}^\varepsilon _t:=(\widehat{X}^\varepsilon _t-\mathscr {X}_t)\), we then also have that,
with,
In un-regularised ensemble Kalman filtering, we approximate \(\phi _t\) by the sample covariance \({\widehat{\phi }}_t\) since the dimension of \(\widehat{X}_t\) may be in the many millions; see [59]. However, when computing the sample covariance in high-dimensions, rank deficient estimation is common due to a lack of enough samples. Covariance inflation, leading to an approximation of the form \(({\widehat{\phi }}^\varepsilon _t(Q) + \varepsilon \,T)\), in the update equation (e.g. (7.1)), is a common, simple means of addressing this rank deficiency [59]. The under-bias result in Theorem 5.2 or equation (5.16) can also motivate the use of some form of regularisation such as inflation.
Note that the perturbation in the resulting flow of \({\widehat{\phi }}^\varepsilon _t(Q)\) comes from a (rather delicate) feedback loop adding \(\varepsilon \,T\) to the covariance of the signal \(\widehat{X}^\varepsilon _t\) at each instant. The flow of \({\widehat{\phi }}^\varepsilon _t(Q)\) is given by,
In the limit \(\textsf{N}\rightarrow \infty \), we recover a perturbed, deterministic, Riccati equation that describes the flow of the limiting covariance. This perturbed Riccati equation is studied in [20, 24]. For any size \(\Vert \varepsilon T\Vert <\infty \), the perturbed Riccati flow qualitatively retains all the stability properties of the nominal Riccati flow (e.g. (2.20), but with a different steady state value), and the size of the error between the two grows in a well-quantified continuous way.
In the limiting case, we have via [20, Theorem 2.1] that \(\phi _{t}(Q)\le \phi ^\varepsilon _{t}(Q)\) in case (F1). In case (F2), we have that \( \phi ^\varepsilon _{t}(Q)\le \phi _{t}(Q)\) in the limit \(\textsf{N}\rightarrow \infty \).
For any \(s\le t\) and \(Q\in \mathbb {S}_{d}^0\), we define the stochastic state-transition matrix,
Note that this semigroup \({\widehat{\mathcal {E}}}^{\,\varepsilon }_{s,t}(Q)\) is associated with the evolution of the (inflation) regularised sample mean in (7.3) or the error flow (7.5) in both case (F1) and (F2). Unlike the un-regularised setting, this same semigroup is not directly related to the evolution of the sample covariance, in (7.7); for example, in case (F1) the semigroup associated with the evolution of the sample covariance is just \({\widehat{\mathcal {E}}}_{s,t}(Q)\) as given in (5.8) and studied throughout the preceding section.
We can comment on the effect of inflation regularisation on the contraction properties of \({\widehat{\mathcal {E}}}^{\,\varepsilon }_{s,t}(Q)\), as compared, e.g. to \({\widehat{\mathcal {E}}}_{s,t}(Q)\). Firstly, it is worth noting, given the contraction estimates in Sect. 5.2, that,
for any fixed matrix \(P\in \mathbb {S}^0_d\) and \(S\in \mathbb {S}^0_d\). Arguing as in (5.30), when \(S\in \mathbb {S}_d^+\), then up to a change of basis we can always assume that \(S=I\). We then have,
which illustrates the added stabilising effects of \(\varepsilon \,T\) in the extreme case in which \(\widehat{P}^\varepsilon _t\,S\) has no stabilising effect at all. Contrast this with (5.30). Then, one interpretation of the preceding relationship is that \(\varepsilon \,T\) extends the set of signal matrices \(A\in \mathbb {M}_d\) for which one may immediately achieve stabilisation (regardless of the effect of \(\widehat{P}^\varepsilon _t\,S\)). In practice, \(\widehat{P}^\varepsilon _t\,S\) will also act to stabilise the filter, see, e.g. (5.56). Indeed, in the classical Kalman filtering setting (2.2), (2.3) with \(\varepsilon =0\), the time-varying matrix \((A-{P}_tS)\) is stabilising [16] for any \(A\in \mathbb {M}_d\), even A unstable. In the EnKF, we know that \(\widehat{{P}}_{t}\) will fluctuate about \({P}_t\), e.g. see Theorem 5.4. Therefore, the stabilisation properties of \((A-\widehat{{P}}_{t}S)\) are unclear; indeed, the study of \({\widehat{\mathcal {E}}}_{s,t}(Q)\) in the preceding Sect. 5.2 is concerned with precisely this issue. The above implies that the addition of \(\varepsilon \, T\) can act to counter the negative effects of this fluctuation (and directly add a stabilising effect on the state estimation error).
Finally, we have \(\phi _{t}(Q)\le \phi ^\varepsilon _{t}(Q)\) in case (F1) and \(\phi ^\varepsilon _{t}(Q)\le \phi _{t}(Q)\) in case (F2). The semigroup associated with the error flow (7.5) in both cases is the same. The inequality \(\phi _{t}(Q)\le \phi ^\varepsilon _{t}(Q)\) in case (F1) suggests that the diffusion fluctuation in (7.3) or (7.7) will increase. However, we conversely expect that with \(S\in \mathbb {S}^+_d\) we have \(\mu ((A-\varepsilon \,T S) - \phi ^\varepsilon _{t}(Q) S)\le \mu ((A-\varepsilon \,T S) - \phi _{t}(Q) S)\) and thus, we gain a type of stabilising effect. Inflation in case (F1) is then a delicate balancing tradeoff between adding noise to the diffusion coefficients (which may kill the existence of sample covariance moments, for example), and adding a stabilising effect on the sample mean error flow. When \(\varepsilon >0\) is large enough we can achieve added stabilisation in case (F2), as compared to the non inflated case. This is not automatic as in case (F1) because \(\phi ^\varepsilon _{t}(Q)\le \phi _{t}(Q)\). However, the fluctuations are (further) decreased with inflation in case (F2).
7.2 Discretisation matters
The present article is primarily concerned with continuous-time filtering and EnKF models. In practice, the stochastic models and analysis used for the continuous-time EnKF are not applicable without an additional level of time-discretisation approximation. As alluded to earlier, the flow of the sample covariance for the VEnKF has quadratic drift coefficients, while the diffusion term has a polynomial growth of order 3/2. In this particular case, it follows by [73] that a basic Euler time-discretization may blow up, regardless of the boundedness properties of the diffusion.
In contrast with continuous-time models, discrete-time signal and observation models lead to the so-called discrete-time EnKF; e.g. see [34] and [125], respectively, for the corresponding VEnKF and DEnKF methods (also referenced in discrete-time earlier). Convergence of the discrete-time EnKF models to their continuous-time counterparts (studied herein) with appropriate model time-step parameterisations is studied in [92, 94, 95].
The purely discrete-time EnKF is not defined by a single coupled diffusion process, but rather by a coupled two-step prediction-updating process (also known as forecast-analysis steps in the EnKF and data assimilation literature). Moreover, the Gaussian-nature of the diffusion models (e.g. the Riccati diffusion) arising in the analysis of continuous-time EnKF theory is also lost, and an inherent difficulty in discrete-time is the introduction of more sophisticated non-central chi-squared fluctuations.
We emphasize that the discrete-time DEnKF of Sakov and Oke [125] is not consistent; i.e. it does not converge to the optimal filter as the number of particles tends to infinity, even in the linear-Gaussian case. The VEnKF is consistent in discrete-time, see [34]. In discrete-time, another class of EnKF methods, termed square-root EnKF methods [95, 136], are consistent [90, 93]. The discrete-time square-root and deterministic EnKF methods are closely related (see [125]) and in the continuous-time limit they converge to the same object [92, 95], i.e. the continuous-time DEnKF studied here.
Analysis of the discrete-time VEnKF [34] was studied in the linear-Gaussian setting in [50]. That article presents a rather complete analysis of the fluctuations and the long-time behaviour of VEnKF for one-dimensional models, including uniform estimates in the presence of transient and unstable latent signals.
7.3 Particle filter comparisons
We end this section with some theoretical comparisons between the discrete-time VEnKF [34, 50] and the particle filter (abbreviated PF in this section) [45, 52, 57, 63, 83, 84].
We remark that the PF and the EnKF are, in general, built on different prediction/correction mechanisms. The EnKF uses an empirical gain function to weight the observations with the predicted state estimate in a manner akin to the update/correction stage of the classical Kalman filter. This mechanism which involves “moving” the corrected state estimate has the potential to stabilise the state estimate about the, possibly unstable, latent signal. This idea has played a central focus in this article. As shown in Theorem 5.2, the empirical gain depends on an under-biased sampled covariance matrix which may fail to correct the effective unstable dimensions. The EnKF literature abounds with inconsistent but judicious ensemble transformations and regularisation methods like inflation/localisation-type procedures, aimed at addressing this issue. One basic inflation methodology is discussed in Sect. 7.1, see also [24], in the context of continuous-time EnKF methods where its action on the stabilisation properties of the EnKF are shown. Conversely, both the continuous and the discrete-time PF are based on genetic-type mutation-selection transitions: The basic discrete-time PF methods, e.g. see [45, 63, 83], evolve as a Markov chain on a product space. During the mutation transition, particles evolve independently according to the signal transition model. When an observation is delivered by the sensor, particles are selected with a probability proportional to their likelihoods. Importance sampling tricks can also be used to avoid degenerate mutations/predictions.
Next, we provide a detailed comparison of the PF and VEnKF for one-dimensional linear-Gaussian models with a view toward their tracking capability in the event of an unstable latent signal. The one-dimensional discrete-time version of (2.1) has the following form,
where \(t\in \mathbb {N}\) denotes the discrete time index and \((\mathscr {W}_t,\mathscr {V}_{t+1})\) is a sequence of two-dimensional Gaussian random variables with zero-mean and unit variance. The initial condition of the signal \(\mathscr {X}_0\) is Gaussian with mean and variance denoted by \((X^-_0,P_0^-)\) (independent of \((\mathscr {W}_t,\mathscr {V}_{t+1})\)), and \((A,H,R,R_1)\) are the model parameters. Any nonzero values for \((A,H,R,R_1)\) ensure that the model is (discrete-time) detectable and stabilisable.
The discrete-time version of the conditional nonlinear McKean–Vlasov-type diffusion process (F1) discussed in (3.2) is given by,
In the above display, \({\overline{\eta }}_t^-\) denotes the conditional distribution of \(\mathcal {X}_t^-\) given \(\mathcal {Y}_{t}^-:=(\mathscr {Y}_0,\ldots ,\mathscr {Y}_{t-1})\) and \((\mathcal {V}_t,\mathcal {W}_t,\mathcal {X}_0)\) are independent copies of \((\mathscr {V}_t,\mathscr {W}_t,\mathscr {X}_0)\). Using a simple induction argument, it is straightforward to show that,
is Gaussian with mean \(X^-_t\) and variance \(P^-_t\); and,
is also Gaussian with mean \(X_t\) and variance \(P_t\). Moreover, the conditional means \((X_t^-,X_t)\) and the variances \((P_t^-,P_t)\) obey the Kalman filtering (update/correction and prediction) equations,
where in this section \(G_t\) denotes the so-called Kalman gain parameter,
The particle approximation of the nonlinear Markov chain discussed above is given by an interacting particle system defined sequentially for any \(1\le i\le N+1\) by the formulae,
where \(\widehat{P}^-_t\) denotes for the normalised sample variance
The above model coincides with the discrete-time version of the VEnKF (i.e. in case F1) in (4.1), and follows from early results in [34]. The conditional mean \(X_t=\mathbb {E}(\mathscr {X}_t\,|\,\mathcal {Y}_t)\) is approximated by the sample mean,

The next theorem provides uniform mean-error estimates.
Theorem 7.1
For any nonzero values of the model parameters \((A,H,R,R_1)\), any \(n\ge 1\), and for \(N\ge 1\) sufficiently large, we have the uniform estimates

We also have the conditional bias estimate,

The proof of this discrete-time, one-dimensional, version of (6.16) is given in [50]; see also [21] for continuous-time analogues. Contrast this result also with the continuous-time multi-variate result in Theorem 5.9.
Particle filters, e.g. see [45, 46, 49, 52, 56, 57, 63, 83, 84], are a popular method for approximate filtering in nonlinear state space models in relatively low dimensions. The genetic-type particle filter (also referred to as the bootstrap filter) is a Markov chain with a mutation and a selection transition,
The initial configuration \(\left( \xi ^{i-}_0\right) _{1\le i\le N}\) is defined by sampling N independent copies of \(\mathscr {X}_0\). In its simplest form, the selection transition involves sampling N independent random variables \(\left( \xi ^i_t\right) _{1\le i\le N}\) with the weighted distribution
The corresponding mutation transition coincides with prediction stage of the VEnKF above; that is for any \(1\le N\) we set
In this context, the conditional means \(X_t=\mathbb {E}(\mathscr {X}_t~|~\mathcal {Y}_t)\) are approximated by the sample means

A mature literature on the time-uniform contraction/convergence and fluctuation results for the particle filter exists, and a survey of this topic is beyond the scope of this article. However, typically the time-uniform particle filtering estimates discussed in the literature rely on mixing-type or certain contractive conditions on the mutation transitions, e.g. [47,48,49, 55, 113, 141]. In the case of linear-Gaussian state transition models, none of these conditions hold for general unstable transient signals.
A natural question: Can the particle filter track unstable (latent) signals, like the VEnKF can (as per Theorem 7.1), in the simple linear-Gaussian setting of this section? Unfortunately, as we now show (and contrast with the VEnKF and Theorem 7.1) the answer here is rather negative.
Following ideas of Mathieu Gerber (personal communication), whenever \(A>1\) we have
with
This implies that,
Thus, for any given initial conditions \(\xi ^{-i}_0=x^i_0\) with
for some \(\epsilon >0\), we have
Recalling that \(\mathbb {E}[\max _{1\le i\le N} U_i]\le \sqrt{2\log (N)}\) for any sequence of N independent centered Gaussian random variables \(U_i\) with unit variance, we conclude that
This yields the almost sure divergence result

This result is not restricted to proportional selection, but rather holds for any unbiased selection transition. Importantly, we emphasise that this result is true even when the unstable latent signal moves to \(-\infty \); in which case there is very quickly a drastic divergence between the particle filtering estimate and the latent signal (and the optimal filter). This already indicates that the particle filter is not able to track unstable signals.
Theorem 7.2
For any nonzero values of the model parameters \((H,R,R_1)\), and any \(A>1\) and \(P_0^->0\), any \(n\ge 1\), and for any \(N\ge 1\) we find,

Before we proceed to the proof, we contrast the preceding result with the time-uniform bound and error control achievable with the EnKF detailed in Theorem 7.1 above. Theorem 7.2 states that there is no hope in stabilising the particle filtering estimate around an unstable and transient (latent) signal when using the same mutation-prediction (7.24) as the EnKF (and which is common in basic particle filtering implementations, cf. [45, 52, 57, 63, 83, 84]). Increasing the number of particles yields no (long-term) benefits here. More specifically, and in contrast with the EnKF, the selection-correction stage of the above particle filter cannot compensate or correct for an unstable prediction-mutation.
Proof
Following the proof of (7.32), for any \(A>0\), note that
with
Define,
Then, it follows that,
We also then have,
which implies that,
Thus, for any \(A>1\) and \(\epsilon >0\) on the event
we readily check that

Moreover, we have,

In discrete-time, the variance \(P_t=\mathbb {E}[(X_t-\mathscr {X}_t)^2]\) is also uniformly bounded with respect to any time horizon, e.g. see [4, 91] (and similarly to (2.19) in continuous-time), and thus, we have,

for some finite constant \(c<\infty \).
Finally, we confirm the nonzero probability,
This ends the proof of the theorem. \(\square \)
To conclude this discussion, we note briefly that it is possible to stabilise the prediction-mutation step (about an unstable latent signal) at the expense of also changing the selection-correction stage (i.e. via importance sampling). For example, a mutation-prediction step sampled according to the so-called optimal proposal \(\sim \,\textrm{Law}(x_t \,|\,x_{t-1},\mathscr {Y}_t)\), see [57], or earlier in [46, Example 3], [47, Sections 2.4.3 and 12.6.6], is a stable option whenever \(A/(1+H^2R/R_1)<1\). However, in general nonlinear filtering problems these mutation transitions and the corresponding importance selection weights are intractable [57]. The terminology “optimal proposal”, see [57], is somehow confusing as this importance sampling strategy and the one discussed in (7.24) have the same Feynman–Kac-type mathematical structure and sampling according to this proposal does not minimize the asymptotic variance. In this context, following [46, Section 4.2.2], we can use an auxiliary local particle approximation to sample \(\textrm{Law}(x_t \,|\,x_{t-1},\mathscr {Y}_t)\) and compute the corresponding importance weights. Given the topic of this article and this section in particular, we note an interesting approach in [114] employing an ensemble Kalman filter to define a proposal distribution (i.e. in the mutation step) that depends on the observation history [46, 114]. We do not explore this topic in further generality here.
8 Some topics for discussion
8.1 Comments on the results presented
In places, we switch between rather quantitative estimates to those more qualitative in nature. In part this is to simplify presentation, or when the details are (likely) not tight and thus perhaps of little quantitative interest. In some in places, it is because we did not obtain more precise descriptions of the estimates involved. Refining these estimates may be of practical interest in some cases; e.g. when deriving estimates on the required number of particles \(\textsf{N}\) for stability of the sample covariance (or convergence to its invariant measure).
The results presented thus far consisted of constants, e.g. c, \(c_n\), \(c_\tau \), etc., that depend on the model parameters (A, R, S), but importantly not on the ensemble size \((\textsf{N}+1)\) or the time horizon \(t\in [0,\infty [\). Due to the dependence on the model (e.g. (A, R, S)), these constants depend implicitly (via the matrix norms used) on the underlying signal dimension d. It would be of interest to pull this dependence out more explicitly depending on the matrix norm we are using, so as to quantify, at least in some general sense, the tradeoff between \(\textsf{N}\) and d. For example, in Theorem 5.4 or Theorem 5.10 detailing the fluctuation of the sample covariance and sample mean about their limiting covariance and (Kalman–Bucy) state estimate values, it would be of interest to know how this fluctuation scales with dimension d, say, e.g. with fixed \(\textsf{N}\). Unfortunately, the proof tools used in the development of this work do not lend itself naturally to this analysis.
The matrix \(S:=H^{\prime }R_1^{-1}H\) plays a critical role throughout with regards to obtaining time-uniform fluctuation and then subsequently stability/convergence results. In particular, the assumption that \(S\in \mathbb {S}_d^+\) is strictly positive-definite, i.e. Assumption O, is needed in numerous places. This assumption amounts to a type of strong observability result; e.g. a requirement on the “fullness” of the observations and the size and rank of the observation matrix H. It is worth emphasising that this assumption appears in many technical articles discussing the performance properties of the ensemble Kalman filter; e.g. [43, 44, 51, 53, 81, 137]. Typically, the tools used in the proofs in [19, 21, 22, 53] are not sophisticated enough to accommodate zero eigenvalues of S. A basic example of this deficiency is in the proof of time-uniform moment boundedness of \(\widehat{{P}}_{t}\), stated in Theorem 5.3. In that proof, we resort to taking trace or eigenvalue-type reductions of the matrix-valued Riccati diffusion and studying a scalar comparison Riccati equation. This scalar reduction means that we must look at the minimum eigenvalue of S (because it appears with a minus sign in the Riccati equation), and thus, we cannot allow this value to be zero (because we would lose this term completely in the scalar comparison). To obtain uniform-in-time bounds, one needs the stabilising effect of this nonzero S in the scalar comparison. See the proof in [19, Theorem 2.2] for this very transparent example. In this example, one may relax the condition on S to \(S\in \mathbb {S}_d^0\) at the expense of time exponentially growing bounds. Related difficulties in allowing \(S\in \mathbb {S}_d^0\) instead of \(S\in \mathbb {S}_d^+\) arise in numerous other places (and as noted in other related works [43, 44, 51, 53, 81, 137]). One difficulty is related to stability of the (time-varying) matrix \((A-\widehat{{P}}_{t}\,S)\) and the positive-definiteness properties of product \(\widehat{{P}}_{t}\,S\) as discussed subsequently.
We have focused significant effort on relaxing the assumption that the underlying signal is stable. Note that if A is stable, i.e. \(\textrm{Absc}(A)<0\), then the stability of \(\mu (A-\widehat{{P}}_{t}\,S)\), for some log-norm, may be trivially inherited whenever \(S\in \mathbb {S}_d^+\) via a change of coordinates, see [53]. We see here again the use of \(S\in \mathbb {S}_d^+\) as it pertains to the product \(\widehat{{P}}_{t}\,S\). If \(S\in \mathbb {S}_d^0\) is only positive semi-definite, then one can construct counterexamples such that even if \({\widehat{\phi }}_t = (\phi _t + {\widehat{\varphi }}_t/ \sqrt{N})\in \mathbb {S}_d^+\) is positive definite, there exists flows \({\widehat{\varphi }}_t\) such that \(\mu (A-\widehat{{P}}_{t}\,S)=\mu (A-\phi _t\,S-{\widehat{\varphi }}_t\,S/ \sqrt{N})>0\). The fluctuation term \({\widehat{\varphi }}_t/ \sqrt{N}\) might not interact well with the only positive semi-definite \(S\in \mathbb {S}_d^0\). The assumption \(\mu (A)<0\) is made in [53] in the linear-Gaussian setting and follow also in, e.g. [44, 51, 81, 137] when reducing those studies to the linear-Gaussian setting.
If A is allowed to be unstable, then the asymptotic (time-varying) stability of \((A-{{P}}_{t}\,S)\) in the classical Kalman filter follows under so-called detectability (or observability) conditions [89, 115, 139]. Detectability intricately relates the relevant rank deficient directions in \(P_t\) and S in terms of the unstable directions in A (i.e. it basically ensures those directions of A that are unstable are observed (as captured by S) and nonzero weighted in the update Kalman gain via \(P_t\)). The rank of the sample covariance \(\widehat{{P}}_{t}\) is at most \(\textsf{N}\ge 1\). If \(\textsf{N}<d\), then \(\widehat{{P}}_{t}\) is almost surely rank deficient and thus, has zero eigenvalues in some directions. In general, we cannot control the directions in which the random, sub-rank, \(\widehat{{P}}_{t}\) has zero eigenvalues (e.g. to play nicely with S in the sense of detectability). If A is unstable in those directions, the filter is consequently unstable in those directions. Thus, there is a basic, unavoidable, but also transparent tradeoff in requiring either stability of \(\textrm{Absc}(A)<0\) or sufficiently large ensemble sizes \(\textsf{N}\ge d\) in the derivation of uniform-in-time stability results for the EnKF.
In the stability results stated in this work, we emphasised unstable models A but required sufficiently large ensemble sizes \(\textsf{N}\ge d\). Nevertheless, most stability results stated in this work with the hypothesis that “\(\textsf{N}\) is sufficiently large” may be restated with this condition replaced with “\(\textsf{N}\ge 1\) and \(\textrm{Absc}(A)<0\)”, and such results hold time-uniformly over infinite time horizons. In [19, 21, 22], the details on “\(\textsf{N}\) is sufficiently large” are given more explicitly. Note some results that do not consider or rely on the long time stability behaviour of the samples, e.g. the fluctuation size of the sample covariance about its true value, hold with \(\textsf{N}\ge 1\) and any matrix A, e.g. this is true for the DEnKF in Theorem 5.4.
We remark that the assumption that the true Kalman–Bucy filter is stable in the sense \(\mu (A-{{P}}_{\infty }\,S)<0\) is used in a number of the fluctuation (on the sample mean) and long-time behavioural results given in the cited, prior, work [17, 19, 21, 22, 53]. It was originally believed by the authors that this condition was a stronger assumption than the more natural condition \(\textrm{Absc}(A-{{P}}_{\infty }\,S)<0\). The latter follows from the very natural model assumptions of detectability and stabilisability, see (2.11) and the discussion following that equation, e.g. [91, Theorems 9.12, 9.15]. However, the particular logarithmic norm \(\mu (\cdot )\) used throughout the prior work in [17, 19, 21, 22, 53] is unimportant, i.e. the matrix norm defining the log-norm can be chosen arbitrarily. From [131, Theorem 5], it is now known that if \(\textrm{Absc}(A-{{P}}_{\infty }\,S)<0\), then there exists a particular log-norm \(\mu (\cdot )\) such that \(\mu (A-{{P}}_{\infty }\,S)<0\). Thus, the conditions antecedent in much of the prior work, in which we ask for \(\mu (A-{{P}}_{\infty }\,S)<0\) can be replaced with just asking for classical detectability and stabilisability conditions. (In prior work, it was discussed and claimed by the authors that asking for \(\mu (A-{{P}}_{\infty }\,S)<0\) may be viewed as asking for a type of strong observability and controllability. This may be true if one specifies first the log-norm of interest. But if one does not care which log-norm is used, we can significantly relax the setting and simply ask for detectability/stabilisability which leads to \(\textrm{Absc}(A-{{P}}_{\infty }\,S)<0\)). Much of the analysis, as already discussed, requires \(S\in \mathbb {S}_d^+\) which automatically implies detectability (in fact a much stronger condition than observability).
It is worth noting again that all moment boundedness and fluctuation results stated in this work hold with any \(\textsf{N}\ge 1\) and without further assumptions if one replaces the constants \(c,c_{n},c_{n}(Q),c_{n}(z,Q)\ldots \) with functions that depend on (and grow with) the time horizon \(t\ge 0\).
8.2 Bridging the gap to nonlinear ensemble filtering
The focus of this article is ensemble filtering in the linear-Gaussian (continuous-time) setting. The results surveyed herein portray a rather detailed theory of fluctuation and stability/contraction results in that case. In practice, the ensemble Kalman filtering methodology is applied in high-dimensional, nonlinear state-space models [59, 60]. The evolution equations for each ensemble member in the case of nonlinear state-space models are given in (4.10).
In [41, 132, 144], the novel idea of a McKean–Vlasov-type diffusion which has conditional distribution equal to the true Bayesian filter is studied, see also [116]. The mean-field approximation of this McKean–Vlasov-type diffusion in [132, 144], termed the feedback particle filter, resembles somewhat superficially the ensemble filters in (4.10). However, the analogue of the gain function in (4.10) in the feedback particle filter of [132, 144] is derived as the solution of a certain Poisson-type partial differential equation. In the linear-Gaussian case, the filter of [144] coincides with the DEnKF.
In the nonlinear model setting, the ensemble filters in (4.10) are not derived as sampled versions of an equation whose (conditional) distribution is equal to the Bayesian filter. That is, these filters are not derived as sampled versions of the McKean–Vlasov-type diffusion in [132, 144]. Conversely, in the limit (\(\textsf{N}\rightarrow \infty \)) the ensemble filters in (4.10) do not converge to an object with distribution equal to the optimal Bayes filter. In fact, the object these filters converge to has not been rigorously established in general and its properties, as compared to the true Bayesian filter, remain an open topic. Thus, in the nonlinear setting, the ensemble filters discussed in this work, see (4.10), may be viewed as approximations of the feedback particle filter in [132, 144] only in some very weak sense (despite any superficial resemblance to the contrary). Indeed, the gain function approximation in (4.10) is likely a very poor approximation of the solution of the Poisson-type partial differential equation in [144]; except of course in linear-Gaussian models. Rather, we may argue, as we have earlier in this article, that the ensemble filters in (4.10) should be viewed in the context of so-called observer theory, and related not to Bayesian filtering but rather to the more general topic of (dynamic) state estimation [4, 10]. The goal of state estimation in this context is to design an observer that tracks in some suitable (typically point-wise) sense the underlying signal and perhaps provides some usable measure of uncertainty on this estimate. The goal is not to develop an approximation (at each time) of the true conditional (Bayesian) distribution of the signal given the observations. The latter contains significantly more information than is perhaps needed in many practical applications. Nevertheless, we also argue that the filtering ideas in [132, 144], and suitable approximations thereof, are in need of further investigation.
In [51], a class of so-called ensemble extended Kalman filters (En-EKF) is developed that is based on a type of particle approximation of the linearisation-based extended Kalman filter, see [4]. This ensemble filter is interesting because the sample mean is shown to converge (in \(\textsf{N}\rightarrow \infty \)) to the extended Kalman filter state estimate. This extended Kalman state estimator has been widely studied in nonlinear filtering and control theory [4, 10, 25, 80, 123] and may be viewed more as a type of nonlinear state estimator rather than a Bayesian filter [10, 123].
When considering nonlinear signal models, the long time behavioural analysis of various EnKF methods in [51, 81, 137] assumes a strong type of stability property on the signal (which in the linear case would reduce to assuming that A is Hurwitz stable in our model (2.1)). This stability assumption on the true signal is precisely what we aim to relax in our work; albeit limited in our study to linear models. Filter stability without assumptions on the stability of the true signal will ultimately require some control of the fluctuation properties of the sampled observer, e.g. see the discussion in the preceding section on this topic (in the linear-Gaussian model setting). This fluctuation analysis is lacking somewhat in the nonlinear model setting. It is complicated in that case by the absence of any closed-form evolution equations for the sample mean and sample covariance.
Viewing, or even designing, an ensemble filter (or its sample mean for example) as a (dynamic) state estimator (or observer) may have some benefits. In particular, stability may be a larger design consideration if starting from this viewpoint rather than seeking Bayesian probabilistic properties. It may be possible to then also exploit the properties of existing nonlinear state estimators which have traditionally been rigorously analysed, e.g. [10, 25, 80, 123].
This is exemplified in the (En-EKF) in [51] that converges to the extended Kalman filter in the limit \(\textsf{N}\rightarrow \infty \). The stability of the extended Kalman filter as a nonlinear observer has been widely studied, e.g. see [10, 25, 80, 123]. Although strong signal stability assumptions are taken in [51], it would be natural to consider the (En-EKF) in [51] without the underlying signal stability assumption and look at developing the fluctuation type analysis considered herein in the linear-Gaussian setting. We may then also exploit the stability analysis that already exists [10, 25, 80, 123] for the limiting extended Kalman state estimator. This is analogous in many ways to the stability properties and observability/controllability properties used herein in the linear-Gaussian setting.
Inflation is used in [81, 138] in the nonlinear model setting to aid in stability. This is similar to the study considered herein on stability under inflation in linear-Gaussian models. It seems natural that added inflation acts to stabilise the various ensemble filters. In the context of the preceding discussion, inflation-based state estimators may also be viewed in the context of stable nonlinear observers, rather than heuristic adaptions of approximate Bayesian filters.
Finally, we remark that the transport-based ensemble filter DEnTF, see case (NF3) in (4.10), is studied in [43] in a particular nonlinear setting. Non-asymptotic (i.e. finite sample) uniform-in-time accuracy and stability of the DEnTF is studied in [43] under the assumptions of small observation noise, and a square observation matrix, or in other words with linear observations and a change of coordinate so that \(H=I\). Note this latter assumption is made also in [44, 51, 81, 137] which otherwise consider certain classes of nonlinear signals and different EnKF variants. Thus, this strong (and linear) observability assumption seems key to analysis in the ensemble filtering literature even when moving away from the linear signal model.
8.3 Other related literature
The focus of this article is a detailed fluctuation and contraction analysis of the relevant ensemble Kalman filtering terms (e.g. the exponential semigroups, sample mean, and sample covariance) in the linear-Gaussian setting. There is considerable work on the periphery of this rather specific topic and analysis. A broad overview of the literature on filtering is not possible, but we note below some topics and literature for further study.
For example, the introduction of this article was focused primarily on (specific) related literature in ensemble Kalman approximation methods, and so-called data assimilation. The topic of filter stability in the case of the true nonlinear filter (e.g. as given by the Kallianpur-Striebel formula [76]) has been studied widely; see a broad but necessarily incomplete snapshot in [8, 11, 14, 31, 88, 111, 139, 140]. Known results in general suggest that sufficiently informative observation processes and/or sufficiently contractive/ergodic latent signals translate to contractive stability of the nonlinear filter. Emphasis on the continuous-time, linear-Gaussian model setting is studied in [3, 16, 18, 111, 139] where deeply understood observability and controllability model conditions explicitly formalise the properties leading to filter stability. See also [28] for a contraction analysis of a low-rank Kalman–Bucy filter particularly relevant in the application domain of this article.
The fluctuation and stability of other approximations schemes in nonlinear filtering have also been studied; e.g. see [15, 32, 39, 47, 55, 67, 96, 113, 141, 143] for a snapshot of some of these methods. A detailed discussion of these approximation methods and their fluctuation and stability properties is beyond the scope of the ensemble Kalman-type methods studied here. However, the monograph [47] provides a detailed study of the fluctuation and contractive properties of numerous particle filtering methods. We note in passing that in general when studying the stability of filtering approximation schemes it is rather common to assume the latent signal is stable/ergodic and/or the observation sequence is stationary, e.g. see [15, 32, 47, 55, 141]. In this article, and in prior work [19, 21, 22, 53], we relax those assumptions and primarily rely on a strong form of observability (i.e. a strong form of observational informativeness). The results presented here do not rely on any form of latent signal stability in general. This latter fact distinguishes this work, but also the ensemble Kalman approximation method in its ability to handle totally unstable latent signals. The latter point was illustrated above via comparisons with the bootstrap particle filter in one-dimensional unstable linear-Gaussian models.
In the introduction, we list some of the seminal data assimilation and ensemble Kalman methodology articles. Here, we give a by no means complete list of some methodological approaches that in some sense can be considered cousins of
Different particle filtering methods based on evolving particles according to an ordinary differential equation that bridges the prior or predictive distribution with the posterior have been developed, e.g. see [33, 42]. These so-called Bayesian homotopy methods aim to introduce nonlinearities arising from the Bayes update in a tempered fashion. See also [119] for an introduction with connections to ensemble Kalman filtering. Applications of the multilevel Monte Carlo method [62] to ensemble Kalman filtering have been considered in, e.g. [38, 68]. The continuous-time linear-Gaussian case similarly formulated as in this article is considered in detail in [38]. A related extension in multi-index ensemble Kalman filtering was proposed in [69]. The problem of unbiased ensemble Kalman filtering has been considered in [2] with an emphasis and analysis closely related to the formulation considered herein.
The ensemble Kalman filter has been applied to the problem of (log) normalisation constant estimation for continuous-time filtering problems; e.g. see [40, 124]. More generally, ensemble Kalman methods for inverse problems have also been considered in the literature [37, 74] with some related analysis [127, 128]. Particle filtering and ensemble filtering methods have also been applied in optimisation [145]. See these references for further details on the respective topics.
It was noted in the preceding section that certain McKean–Vlasov equations can be derived [144] that superficially resemble the ensemble filters in (4.10), but with gain functions derived as the solution of certain Poisson-type partial differential equations. In general, the (conditional) law of these nonlinear diffusions is equal to the filtering distribution. Applying mean-field particle approximations in the linear-Gaussian case, the filter of [144] coincides with the DEnKF. In the general nonlinear setting, other gain function approximations can be employed such as discussed in [133, 134].
Finally, we remark in passing that different models involving backward matrix Riccati diffusions arise in linear-quadratic optimal control problems with random coefficients; see, e.g. [27, 72, 85]. Another class of random Riccati equations, different from the Riccati (matrix quadratic) diffusion equations studied herein arises in network control and filtering with random observation losses; see, e.g. [130, 135]. The details of these works are beyond the scope of the forward-in-time Riccati diffusions considered herein. The forward-in-time Riccati diffusion of (5.2) is nevertheless of interest on its own, as with \(\kappa =0\) it is a prototypical model of a matrix stochastic differential equation with a quadratic drift term. In the deterministic setting, it is worth noting that the contraction of the Riccati equation, e.g. (2.3), (2.20), can naturally be studied with different metrics, e.g. in the Riemannian space of positive definite matrices, see, e.g. [28, 29, 100, 101], and such contraction results may be of interest and/or practical value in the stochastic setting of the Riccati diffusion describing the flow of sample covariances.
8.4 Some open problems
The stochastic analysis and stability of the EnKF models considered in this article are rather well understood in the linear-Gaussian, continuous-time, setting even with unstable latent signal processes. However, there are still some worthy gaps. In particular, we may contrast the very strong and complete picture in the one-dimensional setting (following from [21] and presented above) with the more general and relevant multivariate setting.
For example, the \(\mathbb {L}_n\) contraction estimates on the Ricatti diffusion flow describing the sample covariance in (6.27) are only available in the scalar case. We know, e.g. see Theorem 5.5, that the Markov semigroup is contractive and that the law of the sample covariance converges to an invariant measure in the multi-dimensional setting, analogously to the convergence of the deterministic Riccati equation to an equilibrium state. However, multi-variate versions of the contraction estimates (6.27) are unknown.
Moreover, multi-variate contraction estimates for the EnKF mean as in (6.28) are known only on certain finite time intervals (with a finite sample size) and a general multi-variate filtering contraction estimate as in (6.28) under mild assumptions would be of interest. There is also a disparity in available results in the multi-variate setting between the VEnKF and DEnKF.
In both (6.27) and (6.28) in the scalar case, we recover in the limit with the ensemble size the deterministic optimal rates of the classical Kalman–Bucy filter. Extensions of these rate estimates to the multi-variate setting would also be of interest.
Finally in reference to the scalar setting, we can explicitly state in closed form the invariant measure of the sample covariance, e.g. see (6.19) for the VEnKF and (6.21) for the DEnKF, and Fig. 3. It is unlikely that closed-form expressions are possible to derive in the multivariate setting; however, it would be of further interest to confirm various properties such as the heavy-tailed nature of the stationary measure in the case of the VEnKF. Such properties as discussed earlier have practical consequences such as the potential to lead to so-called catastrophic divergence and numerical instability.
While not given explicitly, we may crudely introduce the signal dimension into the constants of the results presented in this work. However, a detailed study of the dimension as it pertains to stochastic fluctuation properties of the relevant sample covariance and subsequently ensemble mean is warranted since dimensionality versus computational expense is a primary driver of these methods in practice. Work in this direction with various covariance inflation mechanisms was considered in [24] in the linear-Gaussian setting and more generally in [44] for the transport-inspired ensemble Kalman–Bucy filter DEnTF.
The main assumptions employed throughout are Assumptions O and C. The Assumption C can be relaxed to just stabilisability and is thus completely in line with classical Kalman filtering analysis. It would be of interest to relax Assumption O to observability or even just detectability in line with classical Kalman–Bucy filtering. We have discussed in the preceding sections various issues issues surrounding the need for this stronger observability-type Assumption O, and difficulties with its possible relaxation.
This article focused on the continuous-time linear-Gaussian model case, and the preceding open problems also fall under this setting. Direct extensions of the results presented in this article to the discrete-time linear-Gaussian model setting would be of interest, and some work has been published in this case, particularly in the scalar setting, e.g. see [50] and Theorem 7.1 and the earlier discussion. Finally, without considering specifics and re-discussing the relevant literature, extensions of these results to the nonlinear model setting are of great practical interest, particularly under testable and natural model assumptions (e.g. observability-type assumptions) also accommodating unstable or transient latent signal processes (with the latter relaxation being a major driver of the results presented herein).
References
Allen JI, Eknes M, Evensen G (2003) An ensemble Kalman filter with a complex marine ecosystem model: hindcasting phytoplankton in the Cretan Sea. Ann Geophys 21:399–411
Alvarez M, Chada NK, Jasra A (2022) Unbiased estimation of the vanilla and deterministic ensemble Kalman–Bucy filters. arXiv e-print arXiv:2208.03947
Anderson BDO (1971) Stability properties of Kalman–Bucy filters. J Frankl Inst 291(2):137–144
Anderson BDO, Moore JB (1979) Optimal filtering. Dover Publications, New York
Anderson JL (2001) An ensemble adjustment Kalman filter for data assimilation. Mon Weather Rev 129(12):2884–2903
Anderson JL (2003) A local least squares framework for ensemble filtering. Mon Weather Rev 131(4):634–642
Anderson JL, Anderson SL (1999) A Monte Carlo implementation of the nonlinear filtering problem to produce ensemble assimilations and forecasts. Mon Weather Rev 127(12):2741–2758
Atar R (1998) Exponential stability for nonlinear filtering of diffusion processes in a noncompact domain. Ann Probab 1552–1574
Bain A, Crisan D (2009) Fundamentals of stochastic filtering. Springer, New York
Baras JS, Bensoussan A, James MR (1988) Dynamic observers as asymptotic limits of recursive filters: special cases. SIAM J Appl Math 48(5):1147–1158
Baxendale P, Chigansky P, Liptser R (2004) Asymptotic stability of the Wonham filter: ergodic and nonergodic signals. SIAM J Control Optim 43(2):643–669
Beneš VE (1981) Exact finite-dimensional filters for certain diffusions with nonlinear drift. Stochastics 5(1–2):65–92
Bergemann K, Reich S (2012) An ensemble Kalman–Bucy filter for continuous data assimilation. Meteorol Z 21(3):213–219
Bhatt AG, Budhiraja A, Karandikar RL (2000) Markov property and ergodicity of the nonlinear filter. SIAM J Control Optim 39(3):928–949
Bishop AN, Bonilla EV (2023) Recurrent neural networks and universal approximation of Bayesian filters. In: Proceedings of the 26th international conference on artificial intelligence and statistics, PMLR, vol 206, pp 6956–6967. arXiv e-print arXiv:2211.00335
Bishop AN, Del Moral P (2017) On the stability of Kalman–Bucy diffusion processes. SIAM J Control Optim 55(6):4015–4047 arXiv:1610.04686
Bishop AN, Del Moral P (2019) Stability properties of systems of linear stochastic differential equations with random coefficients. SIAM J Control Optim 57(2):1023–1042 arXiv:1804.09349
Bishop AN, Del Moral P (2021) An explicit Floquet-type representation of Riccati aperiodic exponential semigroups. Int J Control 94(1):258–266 arXiv:1805.02127
Bishop AN, Del Moral P (2019) On the stability of matrix-valued Riccati diffusions. Electr J Probab 24, paper no. 24. arXiv e-print arXiv:1808.00235
Bishop AN, Del Moral P (2018) On the robustness of Riccati flows to complete model misspecification. J Frankl Inst 355(15):7178–7200
Bishop AN, Del Moral P, Kamatani K, Remillard B (2019) On one-dimensional Riccati diffusions. Ann Appl Probab 29(2):1127–1187 arXiv:1711.10065
Bishop AN, Del Moral P, Niclas A (2020) A perturbation analysis of stochastic matrix Riccati diffusions. Annales de l’Institut Henri Poincaré, Probabilités et Statistiques 56(2):884–916 arXiv:1709.05071
Bishop AN, Del Moral P, Niclas A (2018) An introduction to Wishart matrix moments. Found Trends Mach Learn 11(2):97–218 arXiv:1710.10864
Bishop AN, Del Moral P, Pathiraja S (2018) Perturbations and projections of Kalman–Bucy semigroups. Stoch Process Their Appl 128(9):2857–2904
Bishop AN, Jensfelt P (2009) A stochastically stable solution to the problem of robocentric mapping. In: Proceedings of the 2009 IEEE international conference on robotics and automation, Kobe, Japan
Bishop CH, Etherton BJ, Majumdar SJ (2001) Adaptive sampling with the ensemble transform Kalman filter. Part I: theoretical aspects. Mon Weather Rev 129(3):420–436
Bismut JM (1976) Linear quadratic optimal stochastic control with random coefficients. SIAM J Control Optim 14(3):419–444
Bonnabel S, Sepulchre R (2013) The geometry of low-rank Kalman filters. In: Nielsen F, Bhatia R (eds) Matrix information geometry. Springer, New York, pp 53–68 arXiv:1203.4049
Bougerol P (1993) Kalman filtering with random coefficients and contractions. SIAM J Control Optim 31(4):942–959
Bucy RS (1967) Global theory of the Riccati equation. J Comput Syst Sci 1:349–361
Budhiraja A (2003) Asymptotic stability, ergodicity and other asymptotic properties of the nonlinear filter. Annales de l’IHP Probabilites et Statistiques. 39(6):919–941
Budhiraja A, Kushner HJ (1999) Approximation and limit results for nonlinear filters over an infinite time interval. SIAM J Control Optim 37(6):1946–1979
Bunch P, Godsill S (2016) Approximations of the optimal importance density using Gaussian particle flow importance sampling. J Am Stat Assoc 111(514):748–762
Burgers G, van Leeuwen PJ, Evensen G (1998) Analysis scheme in the ensemble Kalman filter. Mon Weather Rev 126(6):1719–1724
Callier FM, Willems JL (1981) Criterion for the convergence of the solution of the Riccati differential equation. IEEE Trans Autom Control 26(6):1232–1242
Callier FM, Winkin J (1995) Convergence of the time-invariant Riccati differential equation towards its strong solution for stabilizable systems. J Math Anal Appl 192(1):230–257
Chada NK, Iglesias MA, Roininen L, Stuart AM (2018) Parameterizations for ensemble Kalman inversion. Inverse Probl 34(5)
Chada NK, Jasra A, Yu F (2022) Multilevel ensemble Kalman–Bucy filters. SIAM/ASA J Uncertain Quantif 10(2):584–618
Chopin N (2004) Central limit theorem for sequential Monte Carlo methods and its application to Bayesian inference. Ann Stat 32(6):2385–2411
Crisan D, Del Moral P, Jasra A, Ruzayqat H (2022) Log-normalization constant estimation using the ensemble Kalman–Bucy filter with application to high-dimensional models. Adv Appl Probab 54(4):1139–1163
Crisan D, Xiong J (2010) Approximate McKean–Vlasov representations for a class of SPDEs. Stochastics 82(1):53–68
Daum F, Huang J, Noushin A (2010) Exact particle flow for nonlinear filters. In: Proceedings of signal processing, sensor fusion, and target recognition XIX, volume 7697 of the international society for optics and photonics (SPIE), pp 92–110
de Wiljes J, Reich S, Stannat W (2018) Long-time stability and accuracy of the ensemble Kalman–Bucy filter for fully observed processes and small measurement noise. SIAM J Appl Dyn Syst 17(2):1152–1181
de Wiljes J, Tong XT (2020) Analysis of a localised nonlinear Ensemble Kalman Bucy Filter with complete and accurate observations. Nonlinearity 33(9):4752 arXiv:1908.10580
Del Moral P (1996) Non linear filtering: interacting particle solution. Markov Process Relat Fields 2(4):555–580
Del Moral P (1998) Measure-valued processes and interacting particle systems. Application to nonlinear filtering problems. Ann Appl Probab 8(2):438–495
Del Moral P (2004) Feynman–Kac formulae. Springer, New York
Del Moral P (2013) Mean field simulation for Monte Carlo integration. Monogr Stat Appl Probab 126(26)
Del Moral P, Guionnet A (1999) On the stability of measure valued processes with applications to filtering. Comptes Rendus de l’Académie des Sciences-Series I-Mathematics 329(5):429–434
Del Moral P, Horton E (2021) A theoretical analysis of one-dimensional discrete generation ensemble Kalman particle filters. arXiv e-print arXiv:2107.01855
Del Moral P, Kurtzmann A, Tugaut J (2017) On the stability and the uniform propagation of chaos of a class of extended ensemble Kalman–Bucy filters. SIAM J Control Optim 55(1):119–155
Del Moral P, Miclo L (2000) Branching and interacting particle systems approximations of Feynman–Kac formulae with applications to non-linear filtering. Séminaire de Probabilités XXXIV:1–145
Del Moral P, Tugaut J (2018) On the stability and the uniform propagation of chaos properties of ensemble Kalman–Bucy filters. Ann Appl Probab 28(2):790–850
Doob JL (1953) Stochastic processes. Wiley, New York
Douc R, Moulines E, Olsson J (2014) Long-term stability of sequential Monte Carlo methods under verifiable conditions. Ann Appl Probab 24(5):1767–1802
Doucet A, de Freitas N, Gordon NJ (eds) (2001) Sequential Monte Carlo methods in practice. Springer, New York
Doucet A, Godsill S, Andrieu C (2000) On sequential Monte Carlo sampling methods for Bayesian filtering. Stat Comput 10(3):197–208
Evensen G (1994) Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics. J Geophys Res Oceans 99(C5):10143–10162
Evensen G (2003) The ensemble Kalman filter: theoretical formulation and practical implementation. Ocean Dyn 53(4):343–367
Evensen G (2009) Data assimilation: the ensemble Kalman filter, 2nd edn. Springer, New York
Evensen G, Hove J, Meisingset HC, Reiso E, Seim KS (2007) Using the EnKF for assisted history matching of a North Sea Reservoir Model. In: Proceedings of the 2007 SPE reservoir simulation symposium, Houston, Texas
Giles MB (2008) Multilevel Monte Carlo path simulation. Oper Res 56(3):607–617
Gordon N, Salmond J, Smith A (1993) A novel approach to non-linear/non-Gaussian Bayesian state estimation. IEE Proc Radar Signal Process 140(2):107–113
Gottwald GA, Majda AJ (2013) A mechanism for catastrophic filter divergence in data assimilation for sparse observation networks. Nonlinear Process Geophys 20(5):705–712
Hamill TM, Whitaker JS, Snyder C (2001) Distance-dependent filtering of background error covariance estimates in an ensemble Kalman filter. Mon Weather Rev 129(11):2776–2790
Harlim J, Majda AJ (2010) Catastrophic filter divergence in filtering nonlinear dissipative systems. Commun Math Sci 8(1):27–43
Heine K, Crisan D (2008) Uniform approximations of discrete-time filters. Adv Appl Probab 40(4):979–1001
Hoel H, Law KJH, Tempone R (2016) Multilevel ensemble Kalman filtering. SIAM J Numer Anal 54(3):1813–1839
Hoel H, Shaimerdenova G, Tempone R (2022) Multi-index ensemble Kalman filtering. J Comput Phys 470
Houtekamer PL, Mitchell HL (1998) Data assimilation using an ensemble Kalman filter technique. Mon Weather Rev 126(3):796–811
Houtekamer PL, Mitchell HL (2001) A sequential ensemble Kalman filter for atmospheric data assimilation. Mon Weather Rev 129(1):123–137
Hu Y, Zhou XY (2003) Indefinite stochastic Riccati equations. SIAM J Control Optim 42(1):123–137
Hutzenthaler M, Jentzen A, Kloeden PE (2011) Strong and weak divergence in finite time of Euler’s method for stochastic differential equations with non-globally Lipschitz continuous coefficients. Proc R Soc Lond A Math Phys Eng Sci 467(2130):1563–1576
Iglesias MA, Law KJH, Stuart AM (2013) Ensemble Kalman methods for inverse problems. Inverse Probl 29(4)
Johns CJ, Mandel J (2008) A two-stage ensemble Kalman filter for smooth data assimilation. Environ Ecol Stat 15(1):101–110
Kallianpur G, Striebel C (1969) Stochastic differential equations occurring in the estimation of continuous parameter stochastic processes. Theory Probab Appl 14(4):567–594
Kalman RE, Bucy RS (1961) New results in linear filtering and prediction theory. J Basic Eng 83(1):95–108
Kalnay E (2003) Atmospheric modelling, data assimilation and predictability. Cambridge University Press, Cambridge
Karatzas I, Shreve SE (1996) Brownian motion and stochastic calculus. Springer, New York
Karvonen T, Bonnabel S, Moulines E, Särkkä S (2018) On stability of a class of filters for non-linear stochastic systems. arXiv e-print arXiv:1809.05667
Kelly D, Law KHJ, Stuart AM (2014) Well-posedness and accuracy of the ensemble Kalman filter in discrete and continuous time. Nonlinearity 27(10):2579–2603
Kelly D, Majda AJ, Tong XT (2015) Concrete ensemble Kalman filters with rigorous catastrophic filter divergence. Proc Natl Acad Sci USA 112(34):10589–10594
Kitagawa G (1993) A Monte Carlo filtering and smoothing method for non-Gaussian nonlinear state space models. In: Proceedings of the 2nd U.S.-Japan joint seminar on statistical time series analysis, pp 110–131
Kitagawa G (1996) Monte Carlo filter and smoother for non-Gaussian nonlinear state space models. J Comput Graph Stat 5(1):1–25
Kohlmann M, Tang S (2003) Multidimensional backward stochastic Riccati equations and applications. SIAM J Control Optim 41(6):1696–1721
Krause GM (1994) Bounds for the variation of matrix eigenvalues and polynomial roots. Linear Algebra Appl 208–209:73–82
Kucera V (1972) A contribution to matrix quadratic equations. IEEE Trans Autom Control 17(3):344–347
Kunita H (1971) Asymptotic behavior of the nonlinear filtering errors of Markov processes. J Multivar Anal 1(4):365–393
Kwakernaak H, Sivan R (1972) Linear optimal control systems. Wiley, New York
Kwiatkowski E, Mandel J (2015) Convergence of the square root ensemble Kalman filter in the large ensemble limit. SIAM/ASA J Uncertain Quantif 3(1):1–17
Lancaster P, Rodman L (1995) Algebraic Riccati equations. Oxford University Press, Oxford
Lange T (2021) Derivation of ensemble Kalman–Bucy filters with unbounded nonlinear coefficients. Nonlinearity 35(2)
Lange T, Stannat W (2021) Mean field limit of Ensemble Square Root Filters-discrete and continuous time. Found Data Sci 3(3):563–588
Lange T, Stannat W (2021) On the continuous time limit of the ensemble Kalman filter. Math Comput 90(327):233–265
Lange T, Stannat W (2021) On the continuous time limit of ensemble square root filters. Commun Math Sci 19(7)
La Scala BF, Bitmead RR, James MR (1995) Conditions for stability of the extended Kalman filter and their application to the frequency tracking problem. Math Control Signals Syst 8(1)
Law KJH, Stuart AM, Zygalakis K (2015) Data assimilation: a mathematical introduction. Springer, New York
Law KJH, Tembine H, Tempone R (2016) Deterministic mean-field ensemble Kalman filtering. SIAM J Sci Comput 38(3):A1251–A1279
Le Gland F, Monbet V, Tran VD (2011) Large sample asymptotics for the ensemble Kalman filter. In: Chapter 22 in the Oxford handbook of nonlinear filtering, pp 598–631
Lee H, Lim Y (2008) Invariant metrics, contractions and nonlinear matrix equations. Nonlinearity 21(4):857
Levy BC, Zorzi M (2016) A contraction analysis of the convergence of risk-sensitive filters. SIAM J Control Optim 54(4):2154–2173
Lisaeter KA, Rosanova J, Evensen G (2003) Assimilation of ice concentration in a coupled ice-ocean model using the Ensemble Kalman Filter. Ocean Dyn 53(4):368–388
Livings DM, Dance SL, Nichols NK (2008) Unbiased ensemble square root filters. Physica D 237(8):1021–1028
Majda AJ, Harlim J (2012) Filtering complex turbulent systems. Cambridge University Press, Cambridge
Majda AJ, Tong XT (2018) Performance of ensemble Kalman filters in large dimensions. Commun Math Sci 71(5):892–937
Mandel J, Cobb L, Beezley JD (2011) On the convergence of the ensemble Kalman filter. Appl Math 56(6):533–541
McKean HP (1966) A class of Markov processes associated with nonlinear parabolic equations. Proc Natl Acad Sci 56(6):1907–1911
Mitchell HL, Houtekamer PL, Pellerin G (2002) Ensemble size, balance, and model-error representation in an ensemble Kalman filter. Mon Weather Rev 130(11):2791–2808
Molinari BP (1977) The time-invariant linear-quadratic optimal control problem. Automatica 13(4):347–357
Naevdal G, Johnsen LM, Aanonsen SI, Vefring EH (2003) Reservoir monitoring and continuous model updating using ensemble Kalman filter. In: Proceedings of the 2003 SPE annual technical conference and exhibition, Denver, Colorado
Ocone D, Pardoux E (1996) Asymptotic stability of the optimal filter with respect to its initial condition. SIAM J Control Optim 34(1):226–243
Ott E, Hunt BR, Szunyogh I, Zimin AV, Kostelich EJ, Corazza M, Kalnay E, Patil D, Yorke JA (2004) A local ensemble Kalman filter for atmospheric data assimilation. Tellus A 56(5):415–428
Oudjane N, Rubenthaler S (2005) Stability and uniform particle approximation of nonlinear filters in case of non ergodic signals. Stoch Anal Appl 23(3):421–448
Papadakis N, Mémin E, Cuzol A, Gengembre N (2010) Data assimilation with the weighted ensemble Kalman filter. Tellus A Dyn Meteorol Oceanogr 62(5):673–697
Park P, Kailath T (1997) Convergence of the DRE solution to the ARE strong solution. IEEE Trans Autom Control 42(4):573–578
Pathiraja S, Reich S, Stannat W (2021) McKean–Vlasov SDEs in nonlinear filtering. SIAM J Control Optim 59(6):4188–4215
Poubelle M-A, Petersen IR, Gevers MR, Bitmead RR (1986) A miscellany of results on an equation of count J. F. Riccati. IEEE Trans Autom Control 31(7):651–654
Rebeschini P, Van Handel R (2015) Can local particle filters beat the curse of dimensionality? Ann Appl Probab 25(5):2809–2866
Reich S (2022) Data assimilation: a dynamic homotopy-based coupling approach. arXiv e-print arXiv:2209.05279
Reich S, Cotter CJ (2012) Ensemble filter techniques for intermittent data assimilation. In: Cullen M, Freitag MA, Kindermann S, Scheichl R (eds) Large scale inverse problems: computational methods and applications in the earth sciences. De Gruyter Publishers, Berlin, pp 91–134 arXiv:1208.6572
Reich S, Cotter CJ (2015) Probabilistic forecasting and Bayesian data assimilation. Cambridge University Press, Cambridge
Reich S, Shin S (2014) On the consistency of ensemble transform filter formulations. J Comput Dyn 1(1):177–189
Reif K, Gunther S, Yaz E, Unbehauen R (2000) Stochastic stability of the continuous-time extended Kalman filter. IEE Proc Control Theory Appl 147(1):45–52
Ruzayqat H, Chada NK, Jasra A (2022) Multilevel estimation of normalization constants using ensemble Kalman–Bucy filters. Stat Comput 32(3):1–25
Sakov P, Oke PR (2008) A deterministic formulation of the ensemble Kalman filter: an alternative to ensemble square root filters. Tellus A 60(2):361–371
Sakov P, Oke PR (2008) Implications of the form of the ensemble transformation in the ensemble square root filters. Mon Weather Rev 136(3):1042–1053
Schillings C, Stuart AM (2017) Convergence analysis of ensemble Kalman inversion: the linear, noisy case. Appl Anal 97(1):107–123
Schillings C, Stuart AM (2017) Analysis of the ensemble Kalman filter for inverse problems. SIAM J Numer Anal 55(3):1264–1290
Seiler A, Evensen G, Skjervheim J-A, Hove J, Vab JG (2010) Using the EnKF for history matching and uncertainty quantification of complex reservoir models. In: Biegler L, Biros G, Ghattas O, Heinkenschloss M, Keyes D, Mallick B, Marzouk Y, Tenorio L, van Bloemen Waanders B, Willcox K (eds) Large-scale inverse problems and quantification of uncertainty. Wiley, New York, pp 247–271
Sinopoli B, Schenato L, Franceschetti M, Poolla K, Jordan MI, Sastry SS (2004) Kalman filtering with intermittent observations. IEEE Trans Autom Control 49(9):1453–1464
Ström T (1975) On logarithmic norms. SIAM J Numer Anal 12(5):741–753
Taghvaei A, Mehta PG (2016) An optimal transport formulation of the linear feedback particle filter. In: Proceedings of the 2016 American control conference (ACC), Boston, USA
Taghvaei A, Mehta PG (2023) A survey of feedback particle filter and related controlled interacting particle systems (CIPS). arXiv e-print arXiv:2301.00935
Taghvaei A, Mehta PG, Meyn SP (2020) Diffusion map-based algorithm for gain function approximation in the feedback particle filter. SIAM/ASA J Uncertain Quantif 8(3):1090–1117
Tanwani A, Yufereva O (2020) Error covariance bounds for suboptimal filters with Lipschitzian drift and Poisson-sampled measurements. Automatica 122
Tippett MK, Anderson JL, Bishop CH, Hamill TM, Whitaker JS (2003) Ensemble square root filters. Mon Weather Rev 131(7):1485–1490
Tong XT, Majda AJ, Kelly D (2016) Nonlinear stability and ergodicity of ensemble based Kalman filters. Nonlinearity 29(2):657–691
Tong XT, Majda AJ, Kelly D (2016) Nonlinear stability of the ensemble Kalman filter with adaptive covariance inflation. Commun Math Sci 14(5):1283–1313
Van Handel R (2009) Observability and nonlinear filtering. Probab Theory Relat Fields 145(1–2):35–74
Van Handel R (2009) The stability of conditional Markov processes and Markov chains in random environments. Ann Probab 37(5):1876–1925
Van Handel R (2009) Uniform time average consistency of Monte Carlo particle filters. Stoch Process Their Appl 119(11):3835–3861
Whitaker JS, Hamill TM (2002) Ensemble data assimilation without perturbed observations. Mon Weather Rev 130(7):1913–1924
Whiteley N (2013) Stability properties of some particle filters. Ann Appl Probab 23(6):2500–2537
Yang T, Laugesen RS, Mehta PG, Meyn SP (2016) Multivariable feedback particle filter. Automatica 71:10–23
Zhang C, Taghvaei A, Mehta PG (2018) A mean-field optimal control formulation for global optimization. IEEE Trans Autom Control 64(1):282–289
Acknowledgements
We want to sincerely thank the editor, associate editor, and the two anonymous reviewers for their handling of the review, and their detailed and thoughtful comments and suggestions which have significantly improved the article.
Funding
Open access funding provided by CSIRO Library Services.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose. The authors declare no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bishop, A.N., Del Moral, P. On the mathematical theory of ensemble (linear-Gaussian) Kalman–Bucy filtering. Math. Control Signals Syst. 35, 835–903 (2023). https://doi.org/10.1007/s00498-023-00357-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00498-023-00357-2