
Abstract
Intensity-duration-frequency (IDF) curves are commonly used in engineering practice for the hydraulic design of flood protection infrastructures and flood risk management. IDF curves are simple functions between the rainfall intensity, the timescale at which the rainfall process is studied, and the return period. This work proposes and tests a new methodological framework for the spatial analysis of extreme rainfall depth at different timescales, taking advantage of two different precipitation datasets: local observational and gridded products. On the one hand, the proposed method overcomes or reduces known issues related to observational datasets (missing data and short temporal coverage, outliers, systematic biases and inhomogeneities, etc.). On the other hand, it allows incorporating appropriately terrain dependencies on the spatial distribution of the extreme precipitation regime. Finally, it allows to estimate the IDF curves at regional level overcoming the deficiencies of the classical regional approaches commonly used in practice. The method has been tested to compute IDF curves all over the Basque Country, contrasting results with respect to local analyses. Results show the method robustness against outliers, missing data, systematic biases and short length time series. Moreover, since generalized extreme value (GEV)-parameters from daily gridded dataset are used as covariates, the proposed approach allows coherent spatial interpolation/extrapolation of IDF curves properly accounting for the influence of orographic factors. In addition, due to the current coexistence of local observations and gridded datasets at regional (e.g. The Alps), national (e.g. Spain, France, etc.) or international scale (e.g. E-OBS for Europe or Daymet for the United States of America), the proposed methodology has a wide range of applicability in order to fulfill the known gaps of the observational datasets and reduce the uncertainty related to analysis and characterization of the extreme precipitation regime.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Intensity-duration-frequency (IDF) curves are probably one of the most commonly used tools in engineering practice (Koutsoyiannis et al 1998; Tyralis and Langousis 2019; Emmanouil et al 2020), which are very useful for the hydraulic design of flood protection infrastructures and flood risk management in general, having a great variety of applications. IDF curves are simple functions between the rainfall intensity, the timescale at which the rainfall process is studied, and the return period. Note that rainfall intensity is an instantaneous value which cannot be known. However, the rainfall depth can be measured at consecutive time intervals of duration d each, called timescale, and thus dividing the rainfall depth by the time duration d results in the average rainfall intensity time series. Hereinafter, and for the sake of brevity, instead the term average rainfall intensity the term rainfall intensity will be used (Grimaldi et al 2011). For more information about IDF curves, we recommend the state-of-the-art review by Salas et al (2020) related to probable maximum precipitation (PMP), closely related topic to IDF curves.
This practical interest has encouraged water management administrations to display rain gauges over the watersheds they manage to measure the amount of water that has fallen in real-time, which provide rainfall depths during time intervals of 10/15 min. These records allow the construction of IDF curves for different timescales, which should be updated from time-to-time to include the additional information gathered over time, and/or new methodological developments.
However, a common shortcoming of these datasets is that they do not usually have long enough records all over the area of interest to make return period estimates with confidence. As a result, most IDF curve adjustments are based on daily datasets with longer series (see Yan et al 2021, and references therein). In addition, fitted IDF curves at locations where rain gauges are available provide local information about the extreme precipitation regime, which can not be easily extrapolated to the rest of the target region. In order to solve the spatial coverage problem of the observational networks and due to the known problems of these datasets (missing data, outliers, inhomogeneities due to instrumental and/or location changes, etc.) (Klein Tank et al 2002; Herrera et al 2012, 2019a) a commonly used approach is to build gridded (“regionalized” or “interpolated”) datasets based on quality controlled observational networks, which cover long time periods and the region analyzed. In recent years, many gridded datasets have been developed at regional (Frei and Schär 1998; Bedia et al 2013; Artetxe et al 2019), national (Yatagai et al 2007; Belo-Pereira et al 2011; Herrera et al 2012, 2019a), continental (Haylock et al 2008; Thornton et al 2020) and/or global (Lange 2016, 2019; Dirk N. Karger et al 2021) scale based on different interpolation approaches. Despite the known limitations of the interpolated datasets to reproduce the observed extreme values (Klok and Klein Tank 2009; Herrera et al 2012, 2019a), in general they are able to properly described the spatial dependencies of the variable and, depending on the stations density (Hofstra et al 2010; Herrera et al 2019b), the influence on the rainfall distribution of orographic factors, such as elevation, distance from shoreline, blockages, exposures, curvatures, etc. Based on the advantages and shortcomings of both types of rainfall datasets a question appears: could a gridded dataset be used as a complement of rain gauges for the IDF-curve estimation problem?
In this sense, the combination of different datasets for extreme value analysis is not new. Extreme mixed models have been used to combine reanalysis and instrumental data. Mínguez et al (2013) proposes the mixed extreme value (MEV) climate model for wave analysis. This method allows correcting discrepancies between instrumental and reanalysis records in the upper tail and it is consistent with extreme value theory. However, in order to characterize stochastically the differences between instrumental and reanalysis maxima, it only uses information about annual maxima. In Mínguez and Del Jesus (2015) the method is extended to be applied with alternative models such as Pareto-Poisson(PP, Leadbetter et al 1983) or Peaks-Over-Threshold (POT, Davison and Smith 1990), which are known to be more robust because they use more information during the estimation process.
In addition, recent advances in the extreme value theory (see Coles 2001; Katz et al 2002 as general references) allow modeling the natural variability of extreme events of environmental and geophysical variables based on regression models. These methods introduce time-dependent variations within a certain timescale (year, season or month) and the possibility to construct regression models to show how the variables of interest may depend on other measured covariates. Examples of these kind of models can be found in Carter and Challenor (1981), which proposes a month-to-month distribution assuming that data are identically distributed within a given month. Smith and Shively (1995) constructed a regression model for the frequency of high-level ozone exceedances in which time and meteorology are regressors. Morton et al (1997) apply a seasonal POT model to wind and significant wave height data. Analogous models but applied to different geophysical variables can be found in Coles (2001), Katz et al (2002) or Méndez et al (2007). Méndez et al (2006) developed a time-dependent POT model for extreme significant wave height which considers the parameters of the distribution as functions of time (harmonics within a year, exponential long-term trend, the Southern Oscillation Index (SOI), etc.). Brown et al (2008) studied the global changes in extreme daily temperature since 1950 considering possible trends and the influence of the North Atlantic Oscillation (NAO). Menéndez et al (2009) and Izaguirre et al (2010) developed a time-dependent model based on the Generalized Extreme Value (GEV) distribution that accounts for seasonality and interannual variability of extreme monthly significant wave height. Northrop (2004) proposes a regression model to describe a region-of-influence approach for flood frequency analysis.
Due to the intrinsic spatial and temporal variability of rainfall fields induced by the complex interactions of atmospheric processes with topographic features and the land-sea boundary, fitting extreme type distribution models to maxima series of limited length results in significant parameter estimation uncertainties. For this reason, this problem has been traditionally tackled using regional frequency analysis based on homogeneous regions (M. and Wallis 1997). However, as pointed out by Deidda et al (2021), this approach presents several shortcomings:
-
1.
It results in abrupt quantile estimation shifts along boundaries of homogeneous regions.
-
2.
The effects of topography and local climatology are smeared out by grouping stations associated with homogeneous regions.
-
3.
The extent of homogeneous regions is constrained by the length of the available recordings.
-
4.
The distribution assigned to each homogeneous region is an average of different at-site behaviors, which induces quantile under estimation in some parts of each region and over estimation in other parts.
To overcome those limitations, Deidda et al (2021) proposed a hierarchical boundaryless approach which combines extreme value analysis and geostatistical techniques. In particular, they made a local extreme value analysis at each station, and afterwards the parameter estimates are spatially interpolated using two versions of kriging. In their analysis they compare with the regional approach, and proved how problems related to the application of the regional approach for extreme rainfall estimation can be overcome by implementing the geostatistical analysis of distribution parameters.
The motivation of this work comes, firstly, from the effort that the Basque Country’s Government has made in recent years to improve the knowledge about the climate and water resources of the region, and secondly, as pointed out by Deidda et al (2021) there is still room for improvement in the combination of extreme value analysis and geostatistical interpolation techniques, and we aim to take full advantage of all climatic information available all over the Basque Country, which includes instrumental rain gauges of high temporal frequency (see Fig. 1) and a high spatial resolution gridded dataset of daily precipitation (Artetxe et al 2019). In addition, the Basque Water Agency (Uraren Euskal Agentzia) has promoted and carried out many hydrological and meteorological studies in order to define the average annual rainfall and the regime of extremes, however most of these studies have not collected IDF curves, information of interest to many administrations and individuals, and in those locations where IDF curves have been defined, they have become obsolete and, therefore, it is necessary to update them.
In summary, the aim of this work is to take advantage of the precipitation datasets available for the Basque Country to present a new methodological framework for the spatial analysis of extreme rainfall depth at different timescales with the following features:
-
1.
Can be used to estimate extreme rainfall intensities, i.e. points belonging to IDF curves, just dividing the corresponding rainfall depth by the timescale.
-
2.
Being robust with respect to abnormally high records (outliers). Given the number of available rain gauges, it is advisable to have a methodology that is not sensitive to these anomalous data.
-
3.
Being robust in case the data provided by a rain gauge contains systematic biases due to location, exposure to wind and/or obstacles, among other causes.
-
4.
Being robust with respect to the existence of gaps in time series enabling not to discard records of incomplete years with a high percentage of gaps in the series.
-
5.
Make it robust with respect to the length of the series. There is no doubt that the longer the record, the lower the uncertainty in return period estimations. It would be convenient to have a method that gives more weight to long records than to short ones, without the need to discard short ones from the analysis. Note that it is recognized in the technical literature that when using short records, there is a lack of information on large hydrological events, which is one of main drawbacks in flood frequency analysis and there is a need of “temporal information expansion,” to obtain reliable enough results concerning quantiles of large return periods (Salas et al 2020).
-
6.
Allowing coherent spatial interpolation/extrapolation, i.e. taking into account the influence of orographic factors such as elevation, distance from shoreline, blockages, exposures, curvatures, etc.
In order to achieve these goals, in this paper we propose the combination of instrumental data given by rain gauges and the tail information given by the high-resolution daily precipitation gridded dataset over the Basque Country. We characterise the tail of rainfall depth for different timescales from instrumental records and using the tail behavior of daily precipitations as covariates. Those covariates allows us to interpolate/extrapolate the tail of rainfall depth for different timescales all over the gridded domain, and consequently the tail of rainfall intensities simply dividing by the corresponding timescale. It is precisely in those covariates where the influence of orographic factors such as elevation, distance from shoreline, blockages, exposures, curvatures, etc. is gathered. At this point, it is worth emphasizing the main differences of the approach proposed in this work with respect to the boundaryless approach proposed by Deidda et al (2021):
-
1.
The local extreme value analysis performed in boundaryless approach is based on annual maxima, our approach also models annual maxima but the parameter estimation process is based on Pareto-Poisson model and Peaks-Over-Threshold data.
-
2.
The boundaryless approach starts the estimation process using local analysis, while in this work one unique parameter estimation process, including data associated with all rain gauges, is considered. This strategy allows the estimation process being more robust with respect to possible bias associated with local measurements, and the coexistence of records of different length.
-
3.
In the boundaryless approach, kriging with uncertain data is used to interpolate the shape parameter. These interpolated shape parameters are used again to fit and interpolate the dimensionless scale parameters. Finally, the interpolated shape and scale parameters are used to interpolate the location parameters. In contrast, in our approach we used an existing interpolated gridded product at daily scale. At each location of the grid, we estimated extreme value model parameters, which once interpolated at the rain gauge locations, are used as covariates for the simultaneous fitting of the extreme value analysis model. Once the final model parameter estimates are available, we can get the GEV distribution associated with rainfall depth for a given timescale at each location of the grid using the corresponding covariate information.
The current availability of daily precipitation gridded datasets makes the proposed method highly applicable to perform a coherent and robust spatial analysis of extreme rainfall depth and rainfall intensity for different timescales, i.e. to reconstruct IDF curves. In addition, the positive features of the method and its robustness might justify the effort of developing specific high resolution daily precipitation gridded data sets prior making any extreme value analysis of rainfall depth and/or intensity.
According to Emmanouil et al (2020), we define \(I_d\) to be the (average) rainfall intensity of duration d, \(I_d^{\text{max}}\) the maximum of \(I_d\) in one year and \(i_{d,T}\) the value of \(I_d^\text{max}\) exceeded with probability \(\text{Prob}(I_d^\text{max}>i_{d,T})=1/T\), being T the return period in years. IDF curves represent the relationship of \(i_{d,T}\) with d and T. For temporal scales d above the nominal resolution of rainfall records, and for return periods T below its record length, \(i_{d,T}\) can be obtained directly from the empirical distribution of annual rainfall maxima. However, for return periods T larger than the record lengths we should rely on parametric approaches for the estimation of \(i_{d,T}\). In this study, the selected temporal scales d are always above the resolution of rainfall records, thus our analysis just focuses on the parametric estimation of maximum \(i_{d,T}\) and skip the full IDF curve estimation. Moreover, since rainfall intensity and depth are related through the timescale, we base our model on rainfall depth.
The rest of the manuscript is organized as follows. Section 2 presents the observational (2.1) and gridded (2.2) datasets used, and the proposed extreme value analysis model (2.3). Section 3 shows the performance on real data from Basque Country. Finally, in Sect. 4 relevant conclusions are drawn.
2 Data and methods
In this section, firstly, the observational precipitation data and the gridded dataset are described, including the interpolation method used to build the high resolution daily precipitation gridded dataset for the Basque Country, and secondly, the spatial extreme value model is described in detail.
2.1 Basque water agency rain gauges

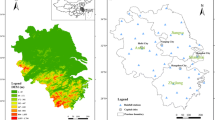
Rain gauge locations all over the Basque Country distributed by watersheds and subwatersheds (left panel) and stations for precipitation and/or temperature associated with the gridded product (right panel)
Left panel of Fig. 1 shows the observational network deployed by the Basque Water Agency (Uraren Euskal Agentzia) covering the different watersheds of the region. This dataset is composed by 131 rain gauges distributed all over the Basque Country covering the period 1989–2020 (see Appendix 1 and Table 2 for a detailed description of the stations network). The average precipitation amount is registered at 10- and 15-minute time intervals, obtaining the values at different timescales (30, 60, 120, 180, 240, 360, 720 and 1440 min) by aggregating the corresponding 10- or 15-minute values using a rolling window.
Note that, despite the large number of rain gauges available, in previous analyses many stations were discarded due to:
-
1.
uncertainties associated with the measurements,
-
2.
the differences in measurement technology among rain gauges, and
-
3.
the disparity in record lengths.
Moreover, precipitation records were brushed up before its use, checking for missing values and outliers. In this sense, filtering anomalous data when dealing with the right tail is complex if you do not have clear indicators that there might be an inconsistency in the data.
An important issue in extreme value analysis is the record length. It is widely acknowledged that larger sample sizes lead to better statistical results in extreme value analysis, increasing confidence in our predictions. Many books and papers on the topic indicate that there are red flags to look out for when working with small samples. However, what constitutes a small sample in this context remains unclear. In a simulation study by Hosking et al (1985), the maximum likelihood and probability moments estimation methods for the GEV distribution were compared, using different sample sizes, with the lowest being 15. This standard may be considered the minimum requirement for good practice in extreme value analysis. In our case, 78% of the records are longer than 15 years, as depicted in Fig. 2. Nevertheless, we included all rain gauges, irrespective of their minimum record length, for two reasons: (a) the minimum of 15 years may be slightly reduced when using the peaks-over-threshold approach, as the average Poisson parameter for all rain gauge locations in the Basque Country is above 2 events per year, and (b) the proposed method’s robustness with respect to short records is one of the manuscript’s aims, avoiding the need to exclude them from the analysis. However, local results linked to records shorter than 15 years should be interpreted with caution.

Cumulative distribution function of record lengths associated with rain gauges in the Basque Country
2.2 Daily precipitation gridded dataset
In the framework of the Basque Climate Change Strategy - KLIMA2050 a high spatial resolution (1 km\(^2\)) gridded dataset for daily precipitation and mean, maximum and minimum daily temperatures was developed covering the period 1971–2016, which was updated until 2019 for this study, by applying the methodology proposed in Artetxe et al (2019).
This grid was developed considering a quality controlled observational dataset that combines stations belonging to the Spanish National Weather Service (AEMET), the Basque Weather Service (EuskalMet) and the Basque Water Agency (URA - Uraren Euskal Agentzia). Only stations with at least 20 consecutive years with at least the 80% of the data were included in the final dataset. In the case of the EuskalMet and URA stations, due to the shorter time coverage, the threshold was reduced to at least 10 years. Moreover, stations with less than 50% of the months with more than 80% of records available were removed from the final dataset. In addition, precipitation values larger than 4 times the 90th percentile of rainy days were considered outliers and removed from the time series. As a result, the final dataset considered for the interpolation contained 244 (164) stations for precipitation (temperature) (see right panel of Fig. 1).
In order to reach the final resolution, a three-step regression-kriging interpolation process was conducted (Hengl et al 2007):
-
First step: monthly rainfall values were obtained. To this aim a two-step approach was applied:
-
1.
A multivariate linear regression model was adjusted to the monthly precipitation considering as regressors a set of variables obtained from a high-resolution (1 km) Digital Elevation Model (DEM) including elevation, distance to coastline and topographic blocking effects by direction (South, North, East, West, South-East, South-West, North-East and South-West). Note that a topographic block for a particular direction is defined if there are any other gridbox with higher altitudes in that direction.
-
2.
The monthly residual obtained from the multivariate linear regression model was then interpolated with ordinary kriging and added to the monthly value obtained with the regression model.
-
1.
-
Second step: the daily anomaly, defined as the quotient between the daily and monthly values, was interpolated by applying ordinary kriging (Atkinson and Lloyd 1998; Biau et al 1999; Haylock et al 2008; Herrera et al 2012).
-
Third step: both the daily anomaly and the monthly values are combined to obtain the final daily estimations.
The high-resolution orography was obtained from the digital elevation model GTOPO30 (Gesch et al 1999) with an spatial resolution of 30" which corresponds to \(\approx 1\)km at these latitudes.
Note that the monthly value for precipitation corresponds to the total precipitation amount for that month and, thus, the daily anomaly is defined as the quotient between the daily precipitation value and the total monthly precipitation amount. This scaling lets us to spatially homogenize the precipitation across the region in order to apply the ordinary kriging (Haylock et al 2008; Cornes et al 2018; Herrera et al 2019a). As a result, the daily value is obtained by multiplying the estimated monthly values and the daily anomalies.
The final result constitutes a high-resolution gridded dataset of daily values of precipitation all over the Basque Country, including the main topographic dependencies given by the observations due to the regression model used in the interpolation process.
2.3 Spatial extreme value analysis model
Before describing the proposed spatial extreme value analysis model for rainfall depth, we provide some insights about extreme value distributions (Castillo 1988; Castillo et al 2005, 2008) required to understand where our model comes from.
2.3.1 Extreme value analysis models
Given any random variable X, the distribution of the maximum of a sample of size n drawn from a population with cumulative probability distribution (CDF) \(F_X(x)\), assuming independent observations, corresponds to \(F_X(x)^n\). However this result does not tell us anything for large samples, i.e. when \(n\rightarrow \infty\), because:
To avoid degeneracy, a linear transformation is looked for such that:
are not degenerate, where \(a_n>0\) and \(b_n\) are constants, which depend on n.
It turns out (Fisher and Tippett (1928); Tiago de Oliveira (1958); Galambos (1987)) that only one parametric family satisfies (2) and it is known as generalized extreme value (GEV) distribution with CDF given by:
where \([a]_+=\max (0,a)\), \(\mu ,\psi ,\xi\) are the location, scale and shape parameters, respectively, and the support is \(x \le \mu - \psi /\xi\) if \(\xi < 0\), \(x \ge \mu - \psi /\xi\) if \(\xi > 0\), or \(-\infty<x<\infty\) if \(\xi = 0\). The GEV distribution includes three distribution families corresponding to the different types of the tail behavior: Gumbel family (\(\xi =0\)) with a light tail decaying exponentially; Fréchet distribution (\(\xi > 0\)) with a heavy tail decaying polinomially; and Weibull family (\(\xi < 0\)) with a bounded tail.
Distribution (3) is useful for analysing maximum rainfall depth and/or intensity for different timescales if annual maxima series (AMS) are considered. The main problem with respect to AMS is that many records belonging to the right tail of the distribution are discarded. That is the reason why we rather using the Peaks-Over-Threshold method (Davison and Smith 1990). The basic idea is that high exceedances occur in clusters associated with single storms. By separating out the peaks within those clusters, they will be approximately independent and can be fitted using the Pareto-Poisson model. The latter relies on the following assumptions:
-
1.
The number of independent storm peaks N exceeding threshold u in any one year follows a Poisson distribution with parameter \(\lambda\).
-
2.
The random variable X associated with independent storm peaks above the threshold u follows a Pareto distribution with cumulative distribution function:
$$\begin{aligned} G(x-u;\sigma ,\xi )=\left\{ \begin{array}{l} 1-\left[ 1+\xi \left( \displaystyle \frac{x-u}{\sigma } \right) \right] _+^{-\displaystyle \frac{1}{\xi }}; \xi \ne 0,\\ \\ 1-\exp \left[ -\left( \displaystyle \frac{x-u}{\sigma }\right) \right] ; \begin{array}{c} \xi =0 \end{array}, \end{array}\right. \end{aligned}$$(4)where \([a]_+=\max (0,a)\), \(\sigma ,\xi\) are the scale and shape parameters, respectively, and the support is \(u<x \le u + \sigma / |\xi |\) if \(\xi < 0\), \(x \ge u\) if \(\xi > 0\), or \(u<x<\infty\) if \(\xi = 0\). The Pareto distribution also includes three distribution families corresponding to the different types of the tail behavior: Exponential family (\(\xi =0\)); Pareto tail distribution (\(\xi > 0\)); and one analogous to the Weibull family (\(\xi < 0\)) and a bounded tail.
Supposing that \(x>u\), this model allows to derive the cumulative distribution function of annual maxima as follows:
Considering the asymptotic relationship between return period (T) and annual maxima given by Beran and Nozdryn-Plotnicki (1977):
the following relationship between Pareto-Poisson model and return period is derived:
Conversely, quantile \(x_T\) associated with given return period T is obtained by solving the following implicit equation:
An advantage of this model is that it is entirely consistent with GEV. In fact, expression (5) is equal to (3) if the following condition holds (Davison and Smith 1990):
which, in the end, allows us to work with GEV distribution for annual maxima but using data associated with the peaks over a threshold. We encourage the use of a PP model because a) it accounts for more than a single data point (i.e., annual maxima) over each year given that more than one exceedances exist, and b) it disregards years for which the maxima deviate significantly (i.e., several order statistics) with respect to other years in record. Besides, contrary to the thought that POT values converge to Pareto distribution given that the threshold tends to infinity (Salas et al 2020), they do converge given that the threshold tends to the upper end of the random variable (Castillo et al 2008). As pointed out by Langousis et al (2016) the proper selection of the threshold u is very important to obtain reliable estimates. In this particular case we chose the graphical method based on the mean-excess plot proposed by Davison and Smith (1990), which according to Langousis et al (2016) provides competitive advantages with respect to alternative methods. The main concerns are: i) the automation, since the method requires visual inspection, and ii) subjective judgement, which might introduce significant bias in case the selection is not appropriate. In this particular case and due to the relevance of the analysis, we did the manual threshold selection for each rain gauge available.
2.3.2 Spatial model
A common practice in modern statistics is building regression models to show how the variable of interest may depend on other covariates. It is usual to include covariates in the location, scale and shape parameters associated with temporal variation such as in Mínguez et al (2010), Izaguirre et al (2012), Yan et al (2021). However, it is also possible to include covariates linked to geographic locations. In this specific case, and for any timescale d, the spatial model we propose has the following parameterization of the GEV location (\(\mu ^{d}\)), scale (\(\psi ^{d}\)) and shape (\(\xi ^{d}\)) parameters, which are functions of the position given by their Universal Transverse Mercator (UTM) coordinates \((x_{\text{UTM}},y_{\text{UTM}})\):
where model parameters correspond to \(\beta ^{d}_0,\beta ^{d}_1, \alpha ^{d}_0, \alpha ^{d}_1, \gamma ^{d}_0\) and \(\gamma ^{d}_1\), while \(\mu _g\), \(\psi _g\) and \(\xi _g\) are the GEV location, scale and shape parameters of the annual maximum distribution associated with daily precipitation records at location \((x_{\text{UTM}},y_{\text{UTM}})\), which are the covariates of the model. Note that subindex g stands for grid, since these parameters are obtained from fitting the GEV distribution to the gridded data set and interpolating the values at the location of interest \((x_{\text{UTM}},y_{\text{UTM}})\).
Once the optimal estimates of model parameters \({\hat{\beta }}^{d}_0,{\hat{\beta }}^{d}_1, {\hat{\alpha }}^{d}_0, {\hat{\alpha }}^{d}_1, {\hat{\gamma }}^{d}_0\) and \({\hat{\gamma }}^{d}_1\) are available, it is possible to get the annual maximum distribution of rainfall depth for timescale d (location, scale and shape parameters) at any geographic location by using expressions (10)–(12) and the interpolated covariates at the location of interest.
2.3.3 Maximum likelihood estimation
For parameter statistical inference the method of maximum likelihood is used. The maximum likelihood estimator \(\hat{{\varvec{\theta }}}^d\) is the value of \({{\varvec{\theta }}}^d\) which maximizes the following log-likelihood function:
where \({{\varvec{x}}}_k^d;\;k=1,\ldots ,n_r\) is the set of rainfall depth records for timescale d associated with peaks over threshold at rain gauge k, being \(n_r\) the number of rain gauges available, \(x_i^k\) the i-th element of the corresponding record, and \(n_k\) is the record length. \({{\varvec{\theta }}}^d\) is the set of parameters for timescale d to be estimated, i.e. \({{\varvec{\theta }}}^d\in \{\beta _0^d,\beta _1^d,\alpha _0^d,\alpha _1^d,\gamma _0^d,\gamma _1^d\}\). Note that index k is associated with a specific geographical location with unique UTM coordinates. The log-likelihood function is composed by the log-likelihood functions for each rain gauge location, i.e. we perform a unique parameter estimation process for the spatial model, which contrast with the traditional individual fitting process usually performed in this type of analyses.
It is worth emphasizing that \(H(x;\mu _k^d,\psi _k^d,\xi _k^d)\) in (13) corresponds to the GEV distribution (3), however we expand the log-likelihood function (13) using the Pareto-Poisson equivalency, which becomes:
where \(T_k\) corresponds to the record length in years at location k, Pareto-scale (\(\sigma _k^d\)) and Poisson (\(\lambda _k^d\)) parameters in terms of GEV parameters correspond to:
being \(u_k^d\) the threshold selection for timescale d at location k.
These expressions are substituted in (14) to express the log-likelihood function as a function of GEV location (\(\mu _k^d\)), scale (\(\psi _k^d\)) and shape (\(\xi _k^d\)) parameters. Finally, expressions (10)–(12) allow to express the log-likelihood function as a function of model parameters \({{\varvec{\theta }}}^d\in \{\beta _0^d,\beta _1^d,\alpha _0^d,\alpha _1^d,\gamma _0^d,\gamma _1^d\}\). Note that we estimate the model parameters for the whole region through the maximization of the log-likelihood function. Once these estimates \(\hat{{\varvec{\theta }}}^d\) are available, it is possible to get the GEV distribution associated with annual maximum rainfall depth for timescale d at any location by just interpolating the covariate information at that location and using regression model (10)–(12).
The maximization of the log-likelihood function is an unconstraint optimization problem, however, there are some practical constraints, such as, the following expressions in (14) and (15):
which must be positive. If during the optimization process any of these expressions become negative the optimization routine might fail. This is the reason why we recommend to use a constrained optimization method including upper and lower bounds for some parameters and practical constraints. In this particular application we used a Trust Region Reflective Algorithm under Matlab (MATLAB 2018) through the function fmincon. For details about the method see Coleman and Li (1994) and Coleman and Li (1996). The trust region reflective algorithm has been chosen because i) analytical first order derivative information can be included and ii) upper and lower bounds on parameters and constraints can be considered easily. Adding these additional constraints makes the estimation process more robust but, in contrast, it could introduce bias if any of these bounds and practical constraints are active at the optimal solution, that is why it is required to check that those bounds and practical constraints are not active at the optimum. In addition, all Newton-type routines require the user to supply starting values. However, the importance of good starting values can be overemphasized and, in this case, simple guesses are enough (Smith 2001).
Parameterizations like (10)–(12) allow constructing complex models that better capture the characteristics of the extreme tail behavior related to rainfall depth for different timescales. However, in order to avoid over fitting, we have to establish a compromise between obtaining a good fit and keeping the model as simple as possible (Akaike 1973; Schwarz 1978; Hurvich and Tsai 1989; George and Foster 1994). In this particular case, this implies the proper selection of parameters from the set \({{\varvec{\theta }}}^d\in \{\beta _0^d,\beta _1^d,\alpha _0^d,\alpha _1^d,\gamma _0^d,\gamma _1^d\}\) which are going to be included in the model. The computational workload of the optimization process is low, so it is possible to run the parameter estimation process for different combinations of parameters, from the simplest model possible \({{\varvec{\theta }}}^d\in \{\beta _0^d,\alpha _0^d\}\) which assumes spatial homogeneity and Gumbel tail behaviour, to the most complex one including all parameters. The final selection of the model could be based on Akaike’s Criteria, Bayesian Information Criteria, or Log-likelihood Ratio Statistic Criteria. Alternatively, the sensitivity based method proposed by Mínguez et al (2010) could be used instead. This method uses a pseudo-steepest descent algorithm, which starting with the simplest model possible \({{\varvec{\theta }}}^d\in \{\beta _0^d,\alpha _0^d\}\) and based on sensitivity analysis (first and second-order derivative) information, selects at every iteration the best parameter to be introduced that maximizes the increment in the log-likelihood function, i.e. the parameter whose score test statistic absolute value is maximum. The algorithm continues including new parameters until the likelihood ratio test rejects the inclusion of new parameters. Alternatively, hypothesis tests based on t-statistics could be used to make sure that we select the most complex model where all parameters are statistically significant for a given significance level (\(\alpha =0.1, 0.05, 0.01\)).
2.3.4 Practical implementation
Once we have described the main ingredients of the method proposed, in this section we enumerate the required steps in order to analyse the rainfall depth for a given timescale or duration d. Prior to this analysis, we need to have the covariate information. This is where the gridded data set comes into play. We fit a GEV distribution for each of the 12, 389 points in our grid domain. In this case, the proper one-by-one selection of peaks over threshold is unrealistic and we decided to use annual maximum data instead. These gridded estimates are used to interpolate the annual maximum daily GEV parameters (covariates \(\mu _ {g}\), \(\psi _ {g}\) and \(\xi _ {g})\) into: i) the rain gauge locations for the spatial model parameter estimation process, or ii) a new location of interest if we want to get the corresponding rainfall depth GEV model parameters for that specific location.
Next, the spatial fitting process is as follows:
-
1.
Let assume we have at our disposal \(n_r\) time series of precipitation at fixed temporal resolution \(t_0\) at \(n_r\) different locations. Typical values are, for instance, \(t_0\in \{5,10,15\}\) minutes.
-
2.
The number of records in each time series are usually different among them and equal to \(n_k^0;\;k=1,\ldots ,n_r\). Note that \(n_k^0\) differs from the previously defined magnitude \(n_k\), being the second the number of peaks over threshold. The total duration in years of each time series is equal to \(T_k=t_0 n_k^0/525,960;k=1,\ldots ,n_r,\) being 525, 960 the average number of minutes in one year.
-
3.
Time series must be aggregated at the desired duration (d) in minutes using a rolling window with length \(d/t_0\). Note that these new time series are highly temporally correlated, however, the selection procedure to determine the peaks over threshold will remove the temporal autocorrelation from the selected peak series.
-
4.
For each time series, a threshold \(u^d_k;k=1,\ldots ,n_r\) must be selected, and then the peaks of clusters above the threshold are taken. We recommend to use a minimum distance in time criteria to ensure that peaks truly belong to independent storms. These data constitutes vectors \({{\varvec{x}}}^d_k;\;k=1,\ldots ,n_r\) to be used in (13). For the threshold selection we used the mean-excess plot proposed by Davison and Smith (1990).
-
5.
Given the UTM coordinates of rain gauges, interpolate covariate information using the gridded parameters. This process results in the obtention of the location, scale and shape covariates \(\mu _g^k,\psi _g^k,\xi _g^k;k=1,\ldots ,n_r\) to be used in the regression model (10)–(12). The interpolation could be done using the nearest neighbour criteria, lineal, bilineal interpolation, or any other spatial interpolation method. It mostly depends on the spatial resolution and how gridded parameters change over space.
-
6.
Next step is the regression model selection. We recommend start fitting the model using the set of parameters \({{\varvec{\theta }}}^{(0)}=\{\beta _0,\alpha _0\}\), which corresponds to the same Gumbel distribution all over the rain gauge domain and using the sequential method proposed by Mínguez et al (2010). Good starting values for the optimization routine correspond to the mean and the logarithm of the standard deviation of all peaks over threshold samples.
-
7.
Once the optimal model and parameter values are achieved, the rainfall depth annual maximum distribution for a given timescale or duration d at any location inside the grid is available.
-
8.
In case we are interested in rainfall intensity annual maximum distributions instead of rainfall depth, we use the relationship between both magnitudes: rainfall intensity is equal to rainfall depth divided by the timescale d. Let remind the reader that the term rainfall intensity in this manuscript truly corresponds to average rainfall intensity.
2.3.5 Leave-one-out cross-validation (LOOCV)
To test the robustness of the proposed method, we also perform a leave-one-out cross-validation to compare the spatial model at each location where data is available. In this particular case, we fit a different spatial model at each location by removing the data associated with the specific location. With this strategy we can estimate how good is the model performance in locations where we have no observations, which would give us a hint about how confidence we could be while using the spatial interpolation proposed by our model. Note that there is not any station in common between the Basque Water Agency rain gauges and the observational network used to build the gridded dataset, ensuring the independence needed in the any cross-validation approach.
2.3.6 Diagnostics
The model proposed in this paper is based on several assumptions. For this reason, once the parameter estimation process is completed, it is very important to make and run different diagnostic plots and statistical hypothesis tests to check whether the selected distributions might be considered appropriate or not. For comparison purposes we make the tests both for the local and spatial analysis. Note that the proposed log-likelihood function based on Pareto-Poisson model allows us to check: i) whether exceedances associated with selected peaks over threshold follow Pareto distribution, and/or ii) whether annual maxima series (which are not used explicitly in the parameter estimation process) follow the GEV distribution. The list of fitting diagnostic tests performed is as follows:
-
Cramer-von Mises and Anderson-Darling tests proposed by Chen and Balakrishnan (1995) to check at each location if Pareto fits (local and spatial) are acceptable. The null hypothesis (\(H_{0}\)) is that the exceedances at each location \({{\varvec{x}}}_k^d-u_k^d\) follow the fitted Pareto distributions. If \(H_{0}\) is not rejected then the original data is accepted to come from the Pareto distribution.
-
Sample autocorrelation and partial autocorrelation functions related to the transformed sample \({{\varvec{z}}}_k^d\) coming from expression:
$$\begin{aligned} G({{\varvec{x}}}_k^d-u_k^d)=\Phi ({{\varvec{z}}}_k^d);\;k=1,\ldots ,n_r, \end{aligned}$$(17)where \(G(\bullet )\) is the cumulative distribution function associated with Pareto given by (4) and \(\Phi (\bullet )\) is the cumulative distribution function of the standard normal random variable. Note that in case exceedances \({{\varvec{x}}}_k^d-u_k^d\) follow a Pareto distribution, transformed values \({{\varvec{z}}}_k^d\) follow standard normal distribution with null mean and unit standard deviation. These sample autocorrelation and partial autocorrelation functions help checking the independence assumption between peaks over threshold, whose values should be within the confidence bounds.
-
To further explore the independence hypothesis, the Ljung-Box (Box and Pierce 1970; Ljung and Box 1978) lack-of-fit hypothesis test (Brockwell and Davis 1991) for model misidentification is applied to the transformed sample \({{\varvec{z}}}_k^d;\forall k\). This test indicates the acceptance or not of the null hypothesis that the model fit is adequate (no serial correlation at the corresponding element of Lags).
-
Cramer-von Mises and Anderson-Darling tests proposed by Chen and Balakrishnan (1995) to check if annual maxima follow the fitted local and/or spatial GEV (using the Pareto-Poisson equivalence). The null hypothesis (\(H_{0}\)) is that the annual maxima at each location \({{\varvec{x}}}_k^{d,AMS}\) follow the fitted GEV distributions. If \(H_{0}\) is not rejected then the original data is accepted to come from the GEV distributions. Note that \({{\varvec{x}}}_k^{d,AMS}\) correspond to the annual maxima series, which are nor used explicitly in the parameter estimation process although most of the annual maxima correspond to selected peaks.
-
Return period diagnostic plot: We also incorporate a graphical method to test the goodness of fit. Due to the relevance for engineers, we show return periods in years versus the corresponding rainfall depths. Suppose we have records \({{\varvec{x}}}_k^{d}\) and \({{\varvec{x}}}_k^{d,AMS}\), we show:
-
1.
Independent peaks plotted using coordinates \(\left( \displaystyle \frac{1}{\lambda _k^d(1-p_{i:n_k})},x_{i:n_k,k}^{d}\right)\), where the first component corresponds to the return period given by expression (7), where \(p_{i:n_k}\) corresponds to the i’th plotting position taken as \((i-1/2)/n_k\), \(n_k\) is the record length (number of peaks over threshold) and \(x_{i:n_k,k}^{d}\) is the peak value at i-th position in the ordered sample.
-
2.
Annual maxima plotted using coordinates \(\left( \displaystyle \frac{1}{(1-p_{i:n_k^{AMS}})},x_{i:n_k^{AMS},k}^{d,AMS}\right)\), where the first component corresponds to the return period, \(p_{i:n_k^{AMS}}\) corresponds to the i’th plotting position taken as \((i-1/2)/n_k^{AMS}\), \(n_k^{AMS}\) is the record length (number of annual maxima) and \(x_{i:n_k^{AMS},k}^{d,AMS}\) is the annual maxima value at i-th position in the ordered sample.
-
3.
For different values of return period \(T_i\), we plot the quantiles associated with Pareto and Pareto-Poisson (GEV) fits as follows:
$$\begin{aligned} \begin{array}{rcl} x^{P}_i &{} = &{} u_k^d+G^{-1}\left( 1-\displaystyle \frac{1}{\lambda _k^d T_i}\right) \\ x^{GEV}_i &{} = &{} H^{-1}\left( 1-\displaystyle \frac{1}{ T_i}\right) , \end{array} \end{aligned}$$(18)where G and H are the cumulative distribution functions of Pareto and GEV given by (4) and (3), respectively. We replace distribution parameters by the corresponding estimates, which could proceed from the local or the spatial analysis.
-
1.
3 Application to the estimation of IDF curves in the Basque Country
This section describes the application of the proposed method with the aim of constructing IDF curves all over the Basque Country based on the 131 rain gauges (see Fig. 1) and the high resolution daily precipitation grid described in Sects. 2.1 and 2.2, respectively. To make the analysis, we follow the steps given in Sect. 2.3.4.
3.1 Annual maxima daily rainfall fitting over the 1 km of spatial resolution grid
The first step consists of analyzing the daily rainfall data from 1971 to 2019 over the grid of 1 km of spatial resolution and fitting annual maxima to an extreme value distribution. Note that in this case we have 49 years of data, for this reason, we use the AMS method using the GEV as shown in the Sect. 2.3.1. We have not used the Pareto-Poisson model because the threshold parameter must be selected carefully, and we have 12,389 points to be fitted, that is the reason to select AMS instead.
We initially make the estimation process using GEV, check the null hypothesis that the shape parameter is null for a 95% confidence level, and in case we do not reject the null hypothesis, we repeat the estimation process using Gumbel distribution (null shape parameter). In all cases, the null hypothesis was not rejected, i.e. annual maxima for daily gridded data set in Basque Country follows a Gumbel distribution. This finding is site specific and can not be a general conclusion for any other region.
Results associated with location (\(\mu _g\)) and scale (\(\psi _g\)) parameters are shown in Fig. 3a and b, respectively. \(\xi _g=0\) all over the domain. Note that units correspond to millimeters of daily precipitation, i.e. daily rainfall depth. These two graphs clearly point out how the orography (see Fig. 4) affects the rainfall behaviour also at the tail of the distribution. Gridded GEV estimated parameters incorporate implicitly the influence of the orography, since the spatial patterns associated with location and scale gridded estimated parameters reproduce the most relevant patterns associated with the digital elevation model. This is precisely the reason why we introduce these quantities as covariates in our spatial model.

GEV fitted parameters associated with daily annual maxima rainfall over the 1 km spatial resolution grid (shape parameters null, i.e. Gumbel distributions)

Digital elevation model in meters over the study area
3.2 Local and spatial extreme value analysis at rain gauge locations
Once the covariates - the gridded GEV parameters - are available for the spatial model, we proceed to the fitting process for different durations. As average durations shorter than 24 h are relevant for hydraulic design of flood protection infrastructures and flood risk management, we are going to consider the following typical timescales d: 10, 20, 30, 60, 120, 180, 240, 360, 720 and 1440 min (Grimaldi et al 2011) with the following considerations:
-
1.
For the 10 and 20 min timescales we only consider in the fitting process rain gauges with a ten minute record frequency.
-
2.
For the rest of timescales, we used the data from all the rain gauges regardless of the recording frequency. However, we take into consideration each recording frequency for appropriate re-scaling.
-
3.
For comparison purposes, besides the spatial analysis we also make local extreme value analysis.
Table 1 provides the optimal parameter estimates of the spatial model (\(\hat{{\varvec{\theta }}}\)) and their corresponding standard deviations for the timescales considered. Note that coefficients related to shape parameter are not included for two reasons: first, the use of regression parameter \(\gamma _1\) is meaningless because the corresponding covariates are null according to gridded GEV fitted parameters, and second, the inclusion of parameter \(\gamma _0\) did not produce a significant change in the log-likelihood ratio statistic. Obviously this finding is site specific and cannot be a general conclusion for any other region. The final model parameterization results from using the sequential sensitivity method proposed by Mínguez et al (2010). According to the values of standard deviations all \(\beta _0^d\) and \(\beta _1^d\) parameters are statistically significant, with values further than two standard deviations away from zero, however this is not the case for \(\alpha _0^{720}\), \(\alpha _0^{1440}\), \(\alpha _1^{10}\), \(\alpha _1^{20}\), \(\alpha _1^{30}\) and \(\alpha _1^{60}\), although their inclusion was statistically significant in terms of the log-likelihood ratio statistic and that is the reason why they are included in the final model selection.
Table 3 in the Appendix provides both local and spatial extreme value fitting information associated with analyzed rain gauges for timescale \(d=10\) minutes, in particular the following information is given:
-
1.
Name of the rain gauge, which is associated with location k.
-
2.
Poisson fitted parameter (\(\lambda _k^d\)) associated with Pareto-Poisson model in events per year.
-
3.
Scale parameter (\(\sigma _k^d\)) from Pareto distribution of rainfall depth exceedances in mm.
-
4.
Selected threshold (\(u_k^d\)) in mm.
-
5.
Location (\(\mu _k^d\)), scale (\(\psi _k^d\)) and shape (\(\xi _k^d\)) parameters related to GEV annual maxima distribution.
-
6.
\(p_{\text{W}}\)-values related to Cramer-von Mises test associated with Pareto fitting. Note that we do not provide the Anderson-Darling test results in this table, however we compare both tests results in next subsections.
-
7.
\(p_1,p_2,p_3,p_4\)-values associated with Ljung-Box lack-of-fit hypothesis test to check whether exceedances over the threshold are temporally independent for time lags 1, 2, 3 and 4, respectively.
-
8.
\(p_{\text{W}}^{\text{max}}\)-values related to Cramer-von Mises test associated with GEV annual maxima fitting.
Note that p-values in Table 3 below significance level α=0.05 are bold faced. From this Table the following considerations are in order:
-
1.
Most of the local fitted distributions correspond to Gumbel, i.e. null shape parameter \(\xi _k^d=0\). However, there are 9 rain gauges (Berriatua, Aixola, Lastur Pluviometro, La Garbea, Mañaria, Orozko (Altube), Oiz, Muxika, Ereñozu) where local tail behaviour corresponds to Frechet \(\xi _k^d>0\), and 2 of them (Bidania, Estanda) correspond to Weibull \(\xi _k^d<0\) (bold faced shape parameter values in Table 3). This contrasts with spatial fitted results, where all rain gauges correspond to Gumbel. Note that in those locations where the local tail is different from Gumbel either the length of the record is short or there exist a very large event with respect to the rest of selected peaks, which results in a Frechet fitted tail. This last effect is observed in Fig. 5 for the fitting process associated with 1440 min timescale in Lastur (LAST), where the precipitation event with rainfall depth above 200 mm results in a Frechet local fitted tail, while the spatial fit corresponds to Gumbel.
-
2.
\(p_W\)-values related to Cramer-von Mises test associated with Pareto local and spatial fitting are simultaneously above significance level \(\alpha =0.05\) in all locations but in 10, being 9 out of 10 above 0.01 and the minimum equal to 0.007, i.e. the hypothesis of exceedances coming from Pareto distribution is rarely rejected. It is worth emphasizing that in Estanda rain gauge the null hypothesis related to the local fitting is accepted (Weibull tail) but the one for spatial fitting (Gumbel tail) is rejected.
-
3.
Regarding the independence assumption for peaks, most p-values from Ljung-Box lack-of-fit hypothesis test are above significance level \(\alpha =0.05\), i.e. independence assumption between peaks is also rarely rejected.
-
4.
If we check the assumption of annual maxima coming from Pareto-Poisson distribution, analogous results are obtained. p-values from Cramer-von Mises test associated with GEV annual maxima fitting are mostly above significance level \(\alpha =0.05\), i.e. the hypothesis of annual maxima coming from Pareto-Poisson or GEV distribution is rarely rejected.
-
5.
In the spatial model, both optimal parameters \(\gamma _0^d\) and \(\gamma _1^d\) from the shape parameterization (12) are equal to zero, i.e. all fitted distributions correspond to Gumbel.
-
6.
Hypothesis tests related to spatial fitting provide the same diagnostics than the local model. The main assumptions required for extreme characterization through Pareto-Poisson distribution are rarely rejected, which also confirms good fitting diagnostics.
-
7.
All results associated with the rest of timescales: 20, 30, 60, 120, 180, 240, 360, 720 and 1440 min are analogous.
Apparently, both local and spatial fittings at locations where rain gauges exist seem to be appropriate. However, we need to define an objective criteria to decide which one is more consistent, and more important, does the spatial model hold the desired characteristics set out previously (see Sect. 1)? Let us analyse results with respect to those features:
-
1.
Being robust with respect to abnormally high records (outliers). In this particular case, there are several locations where one single extreme event results in a Frechet fitted tail. For example, Fig. 5 shows a return period fitting diagnostic plot for precipitation duration of 1440 min at Lastur (LAST) rain gauge. Local fitting corresponds to Frechet type with a positive shape parameter, while the spatial fitting corresponds to Gumbel, which is more consistent with respect to Gumbel fittings around this location. In both cases, the hypothesis of annual maxima coming from the fitted distribution can not be rejected with p-values equal to 0.87 and 0.41, respectively. However, the maximum record of 207.2 mm has less than 100 years of return period for the local fitting, while for the spatial case it corresponds to a return period of about 167 years. Note that the probability of occurrence of a 167-year return period (\(\lambda =1/167\)) over a record of 31 years corresponds to:
$$\begin{aligned} 1-\text{ Prob }(Y=0)^{31}=1-\left( \displaystyle \frac{\lambda ^0}{0!}e^{-\lambda }\right) ^{31}= 0.17 \end{aligned}$$(19)which is likely. This result and the Gumbel fits associated to close locations shows the coherence of spatial fitted model at this specific rain gauge.
-
2.
Being robust in case the data provided by a rain gauge contains systematic biases due to location, exposure to wind, obstacles, or other causes. In this particular case, we know from a previous report about the quality of rain gauges that Matxitxako (C019) rain gauge underestimates precipitation, mainly due to wind exposure. Figure 6 shows a return period fitting diagnostic plot for precipitation duration of 1440 min at this location. Note that even though diagnostic fitting tests do not reject either the local or the spatial fitting with p-values equal to 0.21 and 0.24, respectively. This is probably due to the uncertainty associated with the short record length, return periods related to a particular rainfall depth amount given by the spatial fitting are significantly lower than the local equivalents, i.e. the spatial model makes the model less prone to return period underestimation due to instrumental bias. This correction is induced by the spatial coherence given by the model. Another example about the robustness of the spatial model against instrumental bias corresponds to the fitting at Zaldiaran (Repetidor) rain gauge, where in addition to underestimation induced by wind exposure, the presence of physical obstacles (branch trees) is also confirmed. Note in Fig. 7 how the spatial model pushes up return period estimates clearly above local fitting estimates and empirical data.
-
3.
Being robust with respect to the existence of gaps in the record, enabling not to discard records of incomplete years with a high percentage of gaps in the series. This feature is taken into consideration due to the fact that exceedances over threshold are chosen instead of annual maxima, and exceedances mostly occur uniformly distributed during the year.
-
4.
Make it robust with respect to the length of the series. There is no doubt that the longer the record, the lower the uncertainty in return period estimations. It would be convenient to have a method that gives more weight to long records than to short ones, without the need to discard short ones from the analysis. In this particular case, the spatial model considered allows to make a unique fitting process where the longer the record the higher the influence according to expression (13).
-
5.
Allowing coherent spatial interpolation/extrapolation, i.e. taking into account the influence of orographic factors such as elevation, distance from shoreline, blockages, exposures, curvatures, etc. In this particular case, the spatial coherence and the influence of those factors are taken into consideration though covariates related to GEV parameters from daily gridded data set. If we compare the digital elevation model in Fig. 4 with respect to 100 years return period estimates for different timescales, such as 10 and 1440 min shown in Fig. 8a and b respectively, a clear influence of orographic factors is observed.

Fitted return periods for rainfall depth related to 1440 min timescale at Lastur (LAST) rain gauge

Fitted return periods for rainfall depth related to 1440 min timescale at Matxitxako (C019) rain gauge

Fitted return periods for rainfall depth related to 1440 min timescale at Zaldiaran (Repetidor, C070) rain gauge

100 year return period estimates in mm over the 1 km spatial resolution grid
Previous results show the performance of the method when there are data issues, but there are many locations where both local and spatial fits are very similar, which increase the confidence in the return period estimates at those locations, and the confidence in the proposed model. Figure 9a and b shown return period estimates at Kanpezu and Altzola rain gauges using local and spatial analysis. In both cases the resulting return period estimates are very similar, which shows that when the data quality at rain gauge locations is appropriate, both local and spatial analyses provide consistent results. This behaviour has been observed at many locations and with different timescales.

Estimated return periods for rainfall depth related to 1440 min timescale at Kanpezu and Altzola rain gauges using: i) local and ii) spatial analysis
3.3 Leave-one-out cross validation
We have also performed a leave-one-out cross validation procedure to check the interpolation capabilities associated with the spatial model. Figure 10 shows the scatter plot associated with location and scale spatial fitted parameters for a) all rain gauges data (abscisas axis) and b) leave-one-out process (ordinates axis). Results show that the estimated parameters between both approaches are indistinguishable, with points following almost a perfect straight diagonal. However, numerical results change from the third decimal. We only show results associated with 10 min timescale, but these results are analogous for the rest of timescales and prove the robustness of the proposed method, which makes return period estimations less prone to bias due to difficulties in data gathering.

Scatter plot associated with GEV location (a) and scale (b) spatial fitted parameters for: all rain gauges data (abscisas axis) and leave-one-out process (ordinates axis)
3.4 Model validation using a large high quality rain gauge
The longest record used in the analysis corresponds to Lastur (LAST) rain gauge with 31.875 years, which is relatively short for an extreme value analysis. In order to check the coherence of return period estimations given by the spatial model, we have at our disposal a long record of 85.55 years at San Sebastián-Igeldo (1024E) rain gauge, with UTM coordinates (577907, 4795405) and 259 m heigh, which was not used during the fitting process. Fortunately, we also have another rain gauge (Igeldo DFG) which contains a record length of 24.371 years at 250 m altitude and very close (less than 500 m) to Sebastián-Igeldo (1024E) rain gauge. This proximity allows us to compare results obtained using the proposed method and the local analysis, with the shorter record, with respect to the longest additional record, i.e. validate results.

Estimated return periods for rainfall depth related to 10 min timescale at two close locations in San Sebastián using local and spatial analysis: a medium length record (24.371 years) and b long record (85.55 years)
Note that both local and spatial return periods at Igeldo DFG rain gauge are very similar (see Fig. 11a), and in both cases we can not reject the null hypothesis that data comes from both distributions. On the other hand, the spatial model particularized at Sebastián-Igeldo (1024E) rain gauge location is shown in Fig. 11b. In this particular case, instrumental data is slightly above the spatial return period fitted model, which runs almost parallel to the local fitted model. However, we can not reject the null hypothesis that the data at this location comes from the fitted spatial model. In fact, the spatial model is between local model confidence bands. This result indicates that even though we are using relatively short records, mostly below 30 years, the use of longer series of spatial gridded data products allows getting consistent results.
3.5 Model validation comparing with dimensionless DDF curves

IDF curve Igeldo DFG rain gauge
Going back to the definition rainfall intensity for duration d and return period T (\(i_{d,T}\)) as the value of \(I_d^{\text{max}}\) exceeded with probability \(\text{Prob}(I_d^\text{max}>i_{d,T})=1/T\), being T the return period in years. Figure 12 shows an example of the IDF curve reconstruction associated with rain gauge Igeldo DFG. However, in order to compare results using local and spatial methods all over the study area, we work with dimensionless DDF (Depth-Duration-Frequency) curves, which are analogous to the curves in Fig. 12 but replacing the ordinate axis by the ratio \(x_{d,T}/x_{1440,T}\), being \(x_{d,T}\) the quantile of rainfall depth at timescale d and \(x_{d,1400}\) the corresponding quantile for one day timescale. The ratio between these two magnitudes, i.e. \(x_{d,T}/x_{1440,T}\), is an indication of the degree of torrential rains in a region. Note that in rain gauges with a significant record length, it is an observed fact that these proportions remain approximately constant and independent of the return period considered. This feature is widely used in practice especially when no many records of timescales lower than 6 h are available. In those cases, we use those records to compute those relations and use them all over the study area.
If we make this analysis at all rain gauges locations using return periods associated with local and spatial analysis, we get results shown in Fig. 13a and b, respectively. Note that dashed lines related to “valle”, “monte” and “costa” are the curves used in previous reports to make IDF analyses. Dots corresponds to values related to specific rain gauges and return periods, while we have fitted power curves to those data in an attempt to get representative expressions for each return period considered. Note that data dispersion for the local case is large, clearly contradicting the initial hypothesis that proportions remain approximately constant. The spatial analysis also has dispersion around fitted curves, but considerably lower than the local case. In addition, fitted power curves are almost independent from return period, i.e. spatial analysis seems to be more consistent with this hypothesis of constant proportions.

Dimensionless DDF curves associated with a local and b spatial analysis
3.6 Cramer-von Mises vs Anderson-Darling tests
We performed two validation tests to check the null hypothesis that exceedances and annual maxima follow the fitted distributions respectively. In particular, we used the modification of the Cramer-von Mises and Anderson-Darling distributional fitting tests proposed by Chen and Balakrishnan (1995), which work with the GPD and GEV distributions and where user can provide the distribution parameters. However, we only show the Cramer-von Mises test results. The reason is that very similar results are obtained in both cases, as shown in Fig. 14. The figure shows the scatter plot of p-values related to local and spatial analyses associated with Cramer-von Mises test statistic (left panel) and Anderson-Darling test statistic (right panel). Note that local and spatial analyses present very similar diagnostics, with p-values slightly changing around the diagonal. If we compare the scattet plots for both tests, they are very similar in terms of dispersion and variation range, which justifies why we only present results associated with Cramer-von Mises test.

Scatter plot related to p-values for local and spatial analyses: a Cramer–von Mises test statistic (left panel) and b Anderson–Darling test statistic (right panel)
3.7 Further discussion on the type of tail obtained from the analyses and the selection of extreme model
Koutsoyiannis et al (1998); Koutsoyiannis (1998a, 1998b); Papalexiou and Koutsoyiannis (2013) have done an extensive work in comparing and concluding in the best GEV type for the rainfall extremes. In those studies it is clear that the rainfall extremes follow a GEV type II distribution (with shape parameter values converging at \(0.1{-}0.15\)), and this type of GEV should be preferred mainly for high return periods (\(T>50\) years) because the Gumbel distribution is very conservative and clearly underestimates the rainfall extremes. In those studies, it is pointed out that because of the short time series available (\(20-30\) years available) for the extreme analysis, the Gumbel distribution is falsely chosen as the best fit. Even though the type I error is small and test statistics accept Gumbel as a suitable distribution, the type II error is quite large (up to 80%). Thus, even though here the test statistics are accepting and fitting Gumbel distribution, 30 years (at best case) of observation data may hide the true distribution and cause a severe underestimation of the IDF curves especially at high return periods.
In our analysis most of the fitting models correspond to Gumbel and we accept them, contradicting Koutsoyiannis and coauthors findings. The reason is that we have at our disposal a long record in the area of interest, as shown in Fig. 11b, where the spatial model is validated with a very long record (\(\approx\)85 years); in this particular case, even the local analysis using the Pareto-Poisson model returns the Gumbel distribution as best fit, disregarding the hypothesis that the shape parameter is statistically different from zero. In conclusion, Gumbel seems to be a reasonable choice for the Basque Country, however, this is site specific for the Basque Country and can not be taken as a general advise to disregard heavy tailed distributions. In addition, we also display in our fitting diagnostic plots associated with return periods confidence bands to show long return period estimation uncertainties, which are also relevant for engineering diagnostics.
Another important issue that may be of interest to practitioners is the choice of extreme model, specifically between the peaks-over-threshold (PoT) and annual maxima (AM) methods. In our experience, the advantages of using the PoT approach with a larger sample size outweigh the challenge of selecting an appropriate threshold, provided that the selection process is executed with care (as demonstrated by Mínguez and Del Jesus 2015). However, this is not a universal conclusion, as demonstrated by Emmanouil et al (2020), where the PoT approach was found to be less robust than the AM method in producing IDF curves for datasets with short record lengths. Nevertheless, this issue is more relevant for local analyses, and one of the benefits of the proposed approach is its ability to handle short record lengths effectively.
4 Conclusions
In this work a new methodological framework for the spatial analysis of extreme rainfall depths and/or intensities at different timescales has been described and tested over the Basque Country. The method presents the following positive features:
-
1.
It is aligned with the current trend of climate data availability in which observational and gridded datasets coexist, the former with high temporal frequency and the latest describing the spatial variability and orographic dependencies of the different precipitation regimes over a particular region. In this sense, the proposed framework can be easily adapted to other regions and applied to make a coherent and robust spatial analysis of extreme rainfall depth for different timescales, including DDF and/or IDF curves generation.
-
2.
The proposed approach has proved to be robust with respect to the main issues coming from observational datasets, which includes outliers, systematic biases, missing data and short length time series.
-
3.
Dependencies induced by orographic factors, such as elevation, distance from shoreline, blockages, exposures, curvatures, etc. are properly modelled through the use of covariates coming from the high-resolution gridded dataset.
The methodology has been used to obtain the IDF curves over the Basque Country and tested against local observations, including Sebastián-Igeldo (1024E) rain gauge record, the longest record available, which was not used during the calibration process. The method shows the statistical coherence between the estimated local and spatial return periods, with the latest falling within the confidence intervals of the former.
The positive features of the method and its robustness might justify the effort of developing specific high resolution daily precipitation gridded data sets prior making any extreme value analysis of rainfall intensity.
The method proposed in this work takes advantage of gridded products, also coming from the application of geostatistical techniques, it would be interesting to compare results with respect to those given by the hieralchical boundaryless approach proposed by Deidda et al (2021). This a subject for future research.
Finally, since for some authors, such as Emmanouil et al (2020), the Pareto-Poisson approach has been proved to be less robust than Annual Maxima method, it would be interesting to compare the method performance if we replace the Pareto-Poisson log-likelihood function by the GEV log-likelihood function instead. This is also a topic for further research.
References
Akaike H (1973) Information theory and an extension of the maximum likelihood principle. In: Petrov BN, Csáki F (eds) Proceedings 2nd international symposium on information theory. Akadémia Kiadó, Budapest, pp 267–281
Artetxe A, del Hierro O, Herrera S (2019) Escenarios de cambio climático de alta resolución para el País Vasco. Fase II: Datos diarios con metodologías de corrección de sesgo. Report (in spanish), Ihobe, Ingurumen Jarduketarako Sozietate Publikoa (Sociedad Pública de Gestión Ambiental), Ihobe, Sociedad Pública de Gestión Ambiental. Departamento de Medio Ambiente, Planificación Territorial y Vivienda (Gobierno Vasco) Alda. de Urquijo n.o 36-6.a (Plaza Bizkaia) 48011 Bilbao
Atkinson M, Lloyd C (1998) Mapping precipitation in Switzerland with ordinary and indicator kriging. J Geogr Inf Decision Anal 2:72–86. https://eprints.lancs.ac.uk/id/eprint/77212
Bedia J, Herrera S, Gutiérrez J (2013) Dangers of using global bioclimatic datasets for ecological niche modeling. Limitations for future climate projections. Glob Planet Change 107:1–12. https://doi.org/10.1016/j.gloplacha.2013.04.005
Belo-Pereira M, Dutra E, Viterbo P (2011) Evaluation of global precipitation data sets over the Iberian peninsula. J Geophys Res Atmos. https://doi.org/10.1029/2010JD015481
Beran MA, Nozdryn-Plotnicki MK (1977) Estimation of low return period floods. Bull Int Ass Hydrol Sci 22(2):275–282
Biau G, Zorita E, Von Storch H et al (1999) Estimation of precipitation by kriging in the EOF space of the sea level pressure field. J Clim 12(4):1070–1085. https://doi.org/10.1175/1520-0442(1999)012<1070:EOPBKI>2.0.CO;2
Box GEP, Pierce DA (1970) Distribution of residual autocorrelations in autoregressive-integrated moving average time series models. J Am Stat Assoc 65(332):1509–1526. https://doi.org/10.1080/01621459.1970.10481180
Brockwell PJ, Davis RA (1991) Time series: theory and methods, 2nd edn. Springer, New York, NY
Brown SJ, Caesar J, Ferro AT (2008) Global changes in extreme daily temperature since 1950. J Geophys Res 113:D05115. https://doi.org/10.1029/2006JD008091
Carter DJT, Challenor PG (1981) Estimating return values of environmental variables. Quart J Roy Meteor Soc 107:259–266
Castillo E (1988) Extreme value theory in engineering. Academic Press, New York
Castillo E, Hadi AS, Balakrishnan N et al (2005) Extreme value and related models in engineering and science applications. Wiley, New York
Castillo E, Castillo C, Mínguez R (2008) Use of extreme value theory in engineering design. In: Martorel CS, Guedes Solares, Barnett J (eds) Proceedings of the European safety and reliability conference 2008 (ESREL 2008), safety, reliability and risk analysis: theory, methods and applications, vol 3. Taylor & Francis Group, Valencia, pp 2473–2488
Chen G, Balakrishnan N (1995) A general purpose approximate goodness-of-fit test. J Qual Technol 27(2):154–161. https://doi.org/10.1080/00224065.1995.11979578
Coleman TF, Li Y (1994) On the convergence of reflective newton methods for large-scale nonlinear minimization subject to bounds. Math Program 67(2):189–224
Coleman TF, Li Y (1996) An interior, trust region approach for nonlinear minimization subject to bounds. SIAM J Optim 6:418–445
Coles S (2001) An introduction to statistical modeling of extreme values. Springer Series in Statistics
Cornes R, van der Schrier G, van den Besselaar EJM et al (2018) An ensemble version of the E-OBS temperature and precipitation data sets. J Geophys Res Atmos 123:9391–9409. https://doi.org/10.1029/2017JD028200
Davison AC, Smith RL (1990) Models for exceedances over high thresholds. J Roy Stat Soc: Ser B (Methodol) 52(3):393–442
Deidda R, Hellies M, Langousis A (2021) A critical analysis of the shortcomings in spatial frequency analysis of rainfall extremes based on homogeneous regions and a comparison with a hierarchical boundaryless approach. Stoch Env Res Risk Assess 35(12):2605–2628. https://doi.org/10.1007/s00477-021-02008-x
Dirk N, Karger D, Lange S, Hari C, et al (2021) Chelsa-W5E5 v1.1: W5E5 v1.0 downscaled with chelsa v2.0. Isimip repository. Inter-Sectoral Impact Model Intercomparison Project, https://doi.org/10.48364/ISIMIP.836809.1
Emmanouil S, Langousis A, Nikolopoulos EI et al (2020) Quantitative assessment of annual maxima, peaks-over-threshold and multifractal parametric approaches in estimating intensity-duration-frequency curves from short rainfall records. J Hydrol 589(125):151. https://doi.org/10.1016/j.jhydrol.2020.125151
Fisher RA, Tippett LHC (1928) Limiting forms of the frequency distributions of the largest or smallest member of a sample. J Coastal Res 24:180–190
Frei C, Schär C (1998) A precipitation climatology of the alps from high-resolution rain-gauge observations. Int J Climatol 18(8):873–900. https://doi.org/10.1002/(SICI)1097-0088(19980630)18:8<873::AID-JOC255>3.0.CO;2-9
Galambos J (1987) The asymptotic theory of extreme order statistics. Krieger Publishing Company, Malabar, FL
George EI, Foster DP (1994) The risk inflation criterion for multiple regression. Ann Statist 22:1947–1975
Gesch D, Verdin K, Greenlee S (1999) New land surface digital elevation model covers the earth. Eos 80(6):69–70. https://doi.org/10.1029/99EO00050
Grimaldi S, Kao SC, Castellarin A, et al (2011) 2.18 - Statistical hydrology. In: Wilderer P (ed) Treatise on water science. Elsevier, Oxford, pp 479–517, https://doi.org/10.1016/B978-0-444-53199-5.00046-4
Haylock M, Hofstra N, Klein Tank A et al (2008) A European daily high-resolution gridded data set of surface temperature and precipitation for 1950–2006. J Geophys Res Atmos. https://doi.org/10.1029/2008JD010201
Hengl T, Heuvelink G, Rossiter D (2007) About regression-kriging: From equations to case studies. Comput Geosci 33(10):1301–1315. https://doi.org/10.1016/j.cageo.2007.05.001
Herrera S, Gutiérrez JM, Ancell R et al (2012) Development and analysis of a 50-year high-resolution daily gridded precipitation dataset over Spain (Spain02). Int J Climatol 32(1):74–85. https://doi.org/10.1002/joc.2256
Herrera S, Cardoso RM, Soares PM et al (2019) Iberia01: a new gridded dataset of daily precipitation and temperatures over Iberia. Earth Syst Sci Data 11(4):1947–1956. https://doi.org/10.5194/essd-11-1947-2019
Herrera S, Kotlarski S, Soares P et al (2019) Uncertainty in gridded precipitation products: Influence of station density, interpolation method and grid resolution. Int J Climatol 39(9):3717–3729. https://doi.org/10.1002/joc.5878
Hofstra N, New M, McSweeney C (2010) The influence of interpolation and station network density on the distributions and trends of climate variables in gridded daily data. Clim Dyn 35(5):841–858. https://doi.org/10.1007/s00382-009-0698-1
Hosking JRM, Wallis JR, Wood EF (1985) Estimation of the generalized extreme-value distribution by the method of probability-weighted moments. Technometrics 27(3):251–261
Hurvich CM, Tsai CL (1989) Regression and time series model selection in small samples. Biometrika 76:297–307
Izaguirre C, Méndez FJ, Menéndez M et al (2010) Extreme wave climate variability in Southern Europe using satellite data. J Geophys Res 115(C04009):1–13. https://doi.org/10.1029/2009JC005802
Izaguirre C, Menéndez M, Camus P et al (2012) Exploring the interannual variability of extreme wave climate in the northeast atlantic ocean. Ocean Model 59–60:31–40. https://doi.org/10.1016/j.ocemod.2012.09.007
Katz RW, Parlange MB, Naveau P (2002) Statistics of extremes in hydrology. Adv Water Resour 25:1287–1304
Klein Tank AMG, Wijngaard JB, Können GP et al (2002) Daily dataset of 20th-century surface air temperature and precipitation series for the european climate assessment. Int J Climatol 22(12):1441–1453. https://doi.org/10.1002/joc.773
Klok EJ, Klein Tank AMG (2009) Updated and extended european dataset of daily climate observations. Int J Climatol 29(8):1182–1191. https://doi.org/10.1002/joc.1779
Koutsoyiannis D (1998) Statistics of extremes and estimation of extreme rainfall: I. Theoret Investig Hydrol Sci J 49(4):590. https://doi.org/10.1623/hysj.49.4.575.54430
Koutsoyiannis D (1998) Statistics of extremes and estimation of extreme rainfall: II. Empirical investigation of long rainfall records. Hydrol Sci J 49(4):591–610. https://doi.org/10.1623/hysj.49.4.591.54424
Koutsoyiannis D, Kozonis D, Manetas A (1998) A mathematical framework for studying rainfall intensity-duration-frequency relationships. J Hydrol 206(1–2):118–135
Lange S (2016) EartH2Observe. Report GFZ data services, Potsdam Institute for Climate Impact Research, WFDEI and Era-Interim data merged and bias-corrected for ISIMIP (EWEMBI). https://doi.org/10.5880/pik.2016.004
Lange S (2019) EartH2Observe, WFDEI and Era-Interim data merged and bias-corrected for ISIMIP (EWEMBI) v.1.1. Report GFZ data services, Potsdam Institute for Climate Impact Research, https://doi.org/10.5880/pik.2019.004
Langousis A, Mamalakis A, Puliga M et al (2016) Threshold detection for the generalized Pareto distribution: Review of representative methods and application to the NOAA NCDC daily rainfall database. Water Resour Res 52(4):2659–2681. https://doi.org/10.1002/2015WR018502
Leadbetter M, Lindgren G, Rootzén H (1983) Extremes and related properties of random sequences and processes. Springer, New York
Lehmann EL, Casella G (1998) Theory of point estimation. Springer text in statistics, 2nd edn. Springer, New York
Ljung GM, Box GEP (1978) On a measure of lack of fit in time series models. Biometrika 65(2):297–303. https://doi.org/10.1093/biomet/65.2.297
Hjr M, Wallis JR (1997) Regional frequency analysis. Cambridge University Press, Cambridge
MATLAB (2018) 9.7.0.1190202 (R2019b). The MathWorks Inc., Natick, Massachusetts
Méndez FJ, Menéndez M, Luceño A et al (2006) Estimation of the long term variability of extreme significant wave height using a time-dependent POT model. J Geophys Res. https://doi.org/10.1029/2005JC003344
Méndez FJ, Menéndez M, Luceño A et al (2007) Analyzing monthly extreme sea levels with a time-dependent GEV model. J Atmos Ocean Technol 24:894–911
Menéndez M, Méndez FJ, Izaguirre C et al (2009) The influence of seasonality on estimating return values of significant wave height. Coast Eng 56(3):211–219
Mínguez R, Del Jesus F (2015) Revisited mixed extreme wave climate model for reanalysis databases. Stoch Env Res Risk Assess 29(7):1851–1856. https://doi.org/10.1007/s00477-014-0937-9
Mínguez R, Méndez FJ, Izaguirre C et al (2010) Pseudo-optimal parameter selection of non-stationary generalized extreme value models for environmental variables. Environ Model Softw 25:1592–1607. https://doi.org/10.1016/j.envsoft.2010.05.008
Mínguez R, Tomás A, Méndez FJ et al (2013) Mixed extreme wave climate model for reanalysis databases. Stoch Env Res Risk Assess 27:757–768. https://doi.org/10.1007/s00477-012-0604-y
Morton ID, Bowers J, Mould G (1997) Estimating return period wave heights and wind speeds using a seasonal point process model. Coast Eng 31:305–326
Northrop P (2004) Likelihood-based approaches to flood frequency estimation. J Hydrol 292:96–113
Oehlert GW (1992) A note on the Delta Method. Am Stat 46(1):27–29
Tiago de Oliveira J (1958) Extremal distributions. Revista de la Facultade de Ciencias 7(2A):215–227
Papalexiou SM, Koutsoyiannis D (2013) Battle of extreme value distributions: a global survey on extreme daily rainfall. Water Resour Res 49:187–201. https://doi.org/10.1029/2012WR012557
Salas JD, Am L, Papalexiou SM et al (2020) PMP and climate variability and change: a review. J Hydrol Eng 25(12):03120002
Schwarz G (1978) Estimating the dimension of a model. Ann Stat 6:461–464
Smith RL (2001) Environmental statistics. University of North Carolina, Department of Statistics
Smith RL, Shively TS (1995) A point process approach to modeling trends in tropospheric ozone. Atmos Environ 29:3489–3499
Thornton M, Shrestha R, Wei Y, et al (2020) Daymet: Daily surface weather data on a 1-km grid for north America, version 4. https://doi.org/10.3334/ORNLDAAC/1840
Tyralis H, Langousis A (2019) Estimation of intensity-duration-frequency curves using max-stable processes. Stoch Env Res Risk Assess 33(1):239–252. https://doi.org/10.1007/s00477-018-1577-2
Yan L, Xiong L, Jiang C et al (2021) Updating intensity-duration-frequency curves for urban infrastructure design under a changing environment. WIREs Water 8(3):e1519. https://doi.org/10.1002/wat2.1519
Yatagai A, Xie P, Alpert P (2007) Development of a daily gridded precipitation data set for the middle east. Adv Geosci 12:165–170. https://doi.org/10.5194/adgeo-12-165-2008
Acknowledgements
This research is part of the project “Development of IDF curves in the Basque Country” (URA/41 M/2020), financed by the Basque Water Agency (URA). The authors gratefully acknowledge the financial support from MCIN/AEI/10.13039/501,100,011,033 and project PID2020-116694GB-I00. In addition, we acknowledge funding from the Projects INDECIS (Grant 690,462) and WATExR (https://watexr.eu/), part of European Research Area for Climate Services Consortium (ERA4CS) with co-funding by the European Union. WATExR was partially funded by MINECO-AEI (ES) through the project PCIN-2017-092.
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature. The authors have not disclosed any funding.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interest
The authors have not disclosed any competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1: Information associated with rain gauges
For this study, we have at our disposal the following information about rain gauges given in Table 2:
-
1.
Name of the rain gauge, code and watershed to which it belongs.
-
2.
UTM coordinates and the elevation at which they are located.
-
3.
Start date of the record.
-
4.
End date of the record.
-
5.
Temporal frequency of the records.
-
6.
Total number of data available and number of data without information (not a number).
-
7.
Number of years of record length taking into account the sampling frequency and the number of data available.
Appendix 2: Local and spatial model results
Table 3 provides both local and spatial extreme value fitting information associated with analyzed rain gauges for timescale \(d=10\) min.
Appendix 3: Estimated parameter confidence intervals
Once the optimal estimate \(\hat{{\varvec{\theta }}}\) that maximize the log-likelihood function (13) is available, the estimated parameters \(\hat{{\varvec{\theta }}}\) correspond to mean values, and assuming that observational errors are normally distributed, the estimated parameter vectors are distributed as follows:
where N denotes the multivariate normal distribution, and \(\Sigma _{{{\varvec{\theta }}}}\) is the variance-covariance matrix of the parameter estimates. Using the method of maximum likelihood, if \(\ell (\cdot )\) is twice differentiable with respect to estimated parameters, and under certain regularity conditions which are often satisfied in practice (Lehmann and Casella 1998), then the parameter covariance matrix is equal to the inverse of the Fisher information matrix (\({{\varvec{I}}}_{{{\varvec{\theta }}}}\)). Assuming that the log-likelihood is approximately quadratic in a neighborhood of the maximum, the Fisher information matrix is equal to the Hessian matrix of the log-likelihood functions with the sign changed:
The \((1-\alpha )\) confidence interval for each parameter is equal to:
where \(n_{p}\) is the number of components of vector \({{\varvec{\theta }}}\), \(\Phi ^{-1}(1-\alpha /2)\) is the standard normal distribution \((1-\alpha /2)\) quantile and \({\hat{\sigma }}_{j}\) is the corresponding estimated standard deviation for parameters j (square root of the corresponding diagonal term in \({\varvec{\Sigma }}_{{{\varvec{\theta }}}}\)).
Appendix 4: Quantile confidence intervals
From the practical perspective, the calculation of IDF curves requires computation of quantiles for different return periods (T) (usually in years). These estimated return periods \({\hat{x}}_T\) correspond to those from solving expression (8) from the fitted distribution at the location of interest.
If we are interested in calculating the confidence bands for estimated quantiles \(x_{T_k}\) at location k, and it is known that for large sample sizes the quantile \(x_{T_k}\) is asymptotically normal, and thus, the delta method (Oehlert 1992) can be applied as follows:
where \(\nabla _{{{\varvec{\theta }}}}x_{T_k}\) is the \(n_{p}\) vector of partial derivatives of quantile expressions with respect to \({{\varvec{\theta }}}\).
Note that equation (D4) allows obtaining the estimated variance \({\hat{\sigma }}^2_{x_{T_k}}\) of the quantile, and the confidence intervals then become:
Note that the proposed method fits parameters using information from all local rain gauges simultaneously \(n=\sum _{k=1}^{n_r} n_k\), that is why uncertainty in expression (D5) must be re-scaled to take into consideration the record length at each specific site k. The required derivatives for the return period quantile uncertainty estimation are easily obtained analytically or numerically by finite differences:
where \(\gamma\) represents the corresponding parameter and \(\epsilon =10^{-6}\).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mínguez, R., Herrera, S. Spatial extreme model for rainfall depth: application to the estimation of IDF curves in the Basque country. Stoch Environ Res Risk Assess 37, 3117–3148 (2023). https://doi.org/10.1007/s00477-023-02440-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-023-02440-1