
Abstract
Construction of dams and the resulting water impoundments are one of the most common engineering procedures implemented on river systems globally; yet simulating reservoir operation at the regional and global scales remains a challenge in human–earth system interactions studies. Developing a general reservoir operating scheme suitable for use in large-scale hydrological models can improve our understanding of the broad impacts of dams operation. Here we present a novel use of artificial neural networks to map the general input/output relationships in actual operating rules of real world dams. We developed a new general reservoir operation scheme (GROS) which may be added to daily hydrologic routing models for simulating the releases from dams, in regional and global-scale studies. We show the advantage of our model in distinguishing between dams with various storage capacities by demonstrating how it modifies the reservoir operation in respond to changes in capacity of dams. Embedding GROS in a water balance model, we analyze the hydrological impact of dam size as well as their distribution pattern within a drainage basin and conclude that for large-scale studies it is generally acceptable to aggregate the capacity of smaller dams and instead model a hypothetical larger dam with the same total storage capacity; however we suggest limiting the aggregation area to HUC 8 sub-basins (approximately equal to the area of a 60 km or a 30 arc minute grid cell) to avoid exaggerated results.
Similar content being viewed by others


1 Introduction
Construction of dams and the resulting water impoundments are one of the most common engineering procedures implemented on river systems. Half of the major global river systems are affected by dams (Dynesius and Nilsson 1994). There are over 45,000 operational large dams globally with an estimated aggregate storage capacity of over 6000 km3 (Vörösmarty et al. 1997; WCD 2000; ICOLD 2011; Lehner et al. 2011) trapping over 17 % of global annual runoff (Nilsson et al. 2005; Piao et al. 2007). Dams increase the storage of water in river systems by 700 % and triple the mean residence time of water in the rivers (Vörösmarty et al. 1997). Dams impact ecosystems by flow regulation, upstream flooding, change in sedimentation patterns, draining floodplain wetlands and altering water temperature patterns (Vörösmarty and Sahagian 2000; Kingsford 2000; Syvitski et al. 2005). Overlooking those impacts may significantly affect modelling results and influence decisions addressing water management issues.
In the context of this paper, reservoir or dam operation refers to alteration of the outgoing flow regime via accumulation of the incoming flow and delayed release of water over time. One major problem in dams’ impact studies is the lack of reliable methods for simulating reservoir operation. In reality, dams are regulated in different ways and virtually each dam has a unique operating rule (Simonovic 1992; Wurbs 1993). Actual reservoir operating rules are not available to the public, thus their direct use in models is infeasible, especially for macro-scale applications where hundreds or thousands of dams exist in the study domain.
To address this problem, metrics have been proposed to assess the aggregate hydrologic behavior of dam regulated rivers. For example, Graf (1999) used the total reservoir storage in a watershed as a measure of changes in flow regimes and associated downstream effects. Nilsson et al. (2005) used the percentage of the annual discharge of a river system that can be contained by the reservoirs within that system as a measure to quantify flow regulation by dams (Dynesius and Nilsson 1994). Vörösmarty et al. (1997) used the ratio of aggregated reservoir storage along river networks and the mean annual river discharge to calculate the mean local aging of water and showed how large dams might change the residency time in rivers. They used a similar approach to study the impact of reservoir construction on sediment transport to the ocean (Vörösmarty et al. 2003).
Conceptual or empirical relationships have also been used to model reservoir operation. Meigh et al. (1999) and Döll et al. (2003) used an empirical relationship to simulate the monthly release from dams based on reservoir water storage (\( Q_{out} \sim S^{b} \)). Coe (2000) modelled dam operation by assuming that a reservoir is full in the month of average maximum inflow and is at its minimum storage for the month of average minimum inflow. He calculated the storage for other months assuming a linear relation between those upper and lower limits. Wisser et al. (2010a) used a relationship between daily inflow and average long-term inflow to calculate the daily release from a reservoir. Haddeland et al. (2006) calculated reservoir storage and release to meet monthly irrigation and hydropower demand. Hanasaki et al. (2006) predicted monthly release based on reservoir characteristics, river discharge and water use information. Their model tries to meet the industrial, domestic and irrigation water demand (Yoshikawa et al. 2013). Recent studies have applied remote sensing applications to model dam characteristics like storage, surface area and water level (Coe and Birkett 2004; Peng et al. 2006; Gao et al. 2012).
1.1 Artificial neural networks in hydrology
Artificial neural networks (ANN) have been successfully used in various water resources studies (Hsu et al. 1995; Maier and Dandy 2000; Govindaraju 2000a, b) notably in river flow forecasting (Karunanithi et al. 1994; Zealand et al. 1999; Coulibaly et al. 2000; Coulibaly and Baldwin 2008) and also to solve reservoir operation optimization problems through dynamic programming (Raman and Chandramouli 1996; Fontane et al. 1997; Jain et al. 1999; Rani and Moreira 2010). It has been demonstrated that performances of ANN-based models are similar or superior over conventional statistical and stochastic models for prediction of river flows (Abrahart and See 2000; Cigizoglu 2003; Rani and Moreira 2010).
Here for the first time we use ANN to map the general input/output relationships in actual operating rules of real world reservoirs. Our goal is to parameterize actual dam operation data by using ANN and develop a general reservoir operation scheme (GROS) that is suitable for use in large-scale hydrological models and is sufficiently accurate in simulating the operation of existing reservoirs. GROS enables us to collectively investigate the impact of dams and reservoirs operation on hydrological systems. We seek to limit the input requirements to essential and conveniently calculable data. For regional and global studies, accurate water demand data with applicable resolution is rarely available; therefore, we do not use water demand as an input to GROS. We compare the performance of GROS with a monthly reservoir model developed by Hanasaki et al. (2006) and a daily reservoir model developed by Wisser et al. (2010a).
1.2 Assessment of hydrologic alteration caused by dams
Dams alter the frequency, duration and timing of annual flooding and drought events. While this has beneficiary effects on human water security, aquatic biota is distressed by these changes as they rely on the natural hydrologic cycle for food and reproduction (Pringle et al. 2000; Kingsford 2000). Earlier works have analyzed the impact of dams on natural hydrology by comparing pre and post-dam flow regime from gage station data (Thoms and Sheldon 2000; Magilligan and Nislow 2005). This approach is only valid if no substantial change exists in other factors affecting the hydrologic regime between two periods. Impacts of climate variability and other anthropogenic disturbances such as water use, land cover change, and water transfer projects between the two periods should be accounted for (Yang et al. 2008; Chen et al. 2010). Moreover when comparing data from two periods, it is impossible to see how a different damming strategy could have affected the hydrology of that region.
2 Development of GROS
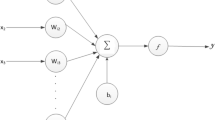
We are using ANN to develop our GROS for use in large-scale hydrological models to simulate the operation of existing reservoirs. The architecture of the ANN used in this study (Fig. 1) is determined by trial and error (Basheer and Hajmeer 2000; Rafiq et al. 2001). Each input set consists of three vectors; if t represents the daily time step, the three input vectors are: Inflow = [I t , I t−1, I t−2], Release = [R t−1, R t−2] and Storage = [S t−1], which are used to calculate the daily release (output) from reservoir [R t ]. Based on our analysis of significance of inputs (discussed in Sect. 2.1), using inflow and release data from previous time steps (i.e. t−3, t−4, etc.) does not have a significant impact on performance of the ANN and since storage levels do not fluctuate substantially every day, we limited the inputs to daily reservoir storage volume, three consecutive days of inflow, and release in past 2 days. Redundant inputs increase the likelihood of overfitting and decrease ANN prediction ability (Tetko et al. 1996; Maier et al. 2010).

Architecture of the artificial neural network used in developing GROS. t stands for daily time step, I for inflow, R for release and S for Storage. W and b represent weights and biases. Rectangles in green are input layers, rectangles in gray are hidden layers, and rectangle in orange is the output layer. Numbers shown for each hidden layer show the number of nodes in that layer
Inflow, release and storage data are each handled by a separate input layer. The three elements of the inflow vector [I t , I t−1, I t−2] are connected to a hidden layer with six nodes. The two elements of the release vector [R t−1, R t−2] are connected to a hidden layer with four nodes, and the storage [S t−1] is connected to a hidden layer with two nodes. Outputs from these layers are connected to the fourth layer with six nodes which are connected to the fifth layer with one node. The sigmoid hyperbolic tangent was selected as the transfer function for all the hidden layers since it provides better accuracy and faster learning speed compared to other sigmoid transfer functions (Adeloye and De Munari 2006; Taormina et al. 2012). The Log-sigmoid transfer function was used in the output layer to ensure that the output is always between 0 and 1. Testing with multiple learning algorithms, the Levenberg–Marquardt algorithm had the best performance (Maier and Dandy 2000; Kişi 2007).
Daily inflow, release and storage data of 12 dams (Table 1) are used in calibration and validation of the ANN. On average each dam has 23 years of daily data. These dams represent a wide range of storage sizes (1.5–32.3 km3), inflows (38.5–2993.5 m3/s), residence time (45–1089 days) and purpose. Two of the 12 dams (Sirikit and Bhumibol) are in Thailand where the climate is different compared to the other sites, which are all in the USA. Data from these two dams were excluded from the ANN training process to be used exclusively as independent validation datasets to ensure that the final ANN has not overfitted to the specific training sites. The input/output pairs from the other 10 dams were randomly divided into three subsets of training (60 %), cross training (20 %) and validation (20 %) (Table 1). In ANN specific terminology, the training set is used for determining the ANN weights and biases to minimize the error function and maximize accuracy in each iteration. The cross training set is used to oversee the training process and improve ANN generalization by minimizing overfitting. An overfitted ANN yields high accuracy on training data but fails to generalize from the training data, thus has poor performance on new, independent input data. The validation dataset provides an unbiased estimate of the generalization error (Govindaraju 2000a).
Data used in this study comes from 12 dams with different operating rules, spanning several orders of magnitude. If the actual data is used directly, the training process will fail as no significant pattern will be detectable between inputs and outputs. To avoid this problem, the data were rescaled to be dimensionless, ranging from 0 to 1. For each dam, flow (m3/s) was converted to daily volume (m3) to be comparable to storage (m3); then all the data for each dam were divided by the maximum capacity of that dam. To use outputs of ANN in a hydrological model, the scaling procedure should be reversed (Appendix 1) by multiplying it by the maximum capacity of the dam to get the daily volume of released water (m3) and then converting it to flow rate (m3/s).
This trained ANN is the core of our GROS. Appendix 1 contains a simplified algorithm that explains how GROS simulates the daily reservoir release. Using GROS in a water balance model (WBMplus) (Wisser et al. 2010b), we isolated reservoir effects from other disturbances (i.e. water withdrawal, flow diversions and climate variability) and studied the impact of dams with various storage sizes and distribution patterns on river system dynamics. We calculated Colwell’s parameters (Colwell 1974) and used the Indicators of hydrological alteration (Richter 1996) and Range of Variability Approach (Richter et al. 1997) to show how dams impact rivers hydrology under different scenarios (Mathews and Richter 2007).
2.1 Significance of ANN inputs
We used an Improved Stepwise method (Gevrey et al. 2003) to identify the importance of inputs used in developing GROS. The change in the sum of square errors (SSE) is calculated when that input and its corresponding weights are removed from the Neural Network. The most important variables are those which cause the largest change in SSE.
Table 2 lists the SSE and coefficient of determination (R2) for 10 experiments that show how eliminating inputs from ANN training affects its performance. From the six single inputs used in this study (I t , I t−1, I t−2, R t−1, R t−2, S t−1), daily storage (S t−1) is the most significant input. S t−1 represents the fraction of dam filled with water in each day. Inputs from older times have a smaller impact on ANN performance. Among the inputs, inflow at time t−2 (I t−2) had the smallest impact on SSE.
2.2 Model performance
We evaluated the performance of GROS against observed time series and compared the outcomes against existing daily and monthly reservoir models (Hanasaki et al. 2006; Wisser et al. 2010a). Wisser et al. (2010a) use a simple relationship linking daily reservoir inflow I t (m3/s) and long-term mean inflow I m (m3/s) to calculate daily reservoir release R t (m3/s) as:
where k and λ are empirical constants set to 0.16 and 0.6, respectively.
Hanasaki et al. (2006) categorized reservoirs as irrigation and non-irrigation and developed a set of rules for monthly release from reservoirs based on their intended purpose and water demand. For a non-irrigation reservoir, monthly release was parameterized as:
where \( r_{m, y}^{\prime} \) is the provisional monthly release (m3/s), and i mean is the mean annual inflow (m3/s).
For an irrigation reservoir, monthly release was parameterized as:
where kalc is an allocation coefficient for grids with more than one reservoir upstream. dirg,m,y is the monthly irrigation water withdrawal (m3/s); ddom is the domestic water withdrawal (m3/s); dind is the industrial water withdrawal (m3/s); and dmean is the mean annual total water demand of the reservoir (m3/s). The subscripts m, y and mean, indicate month, year and annual mean, respectively. The term ∑area indicates integration over the basin downstream reservoir.
The monthly release rm,y (m3/s) was calculated as
where c is the storage capacity to mean total annual inflow ratio (c = C/I mean ); and krls,y is the release coefficient, which reflects water storage at the beginning of the operational year; \( r_{m, y}^{\prime} \) is the provisional monthly release.
We used the observed inflow time series as inputs to GROS and calculated the daily release from the reservoirs (Appendix 1). Based on analysis of observed data, the minimum storage level for reservoirs is set to 10 % of capacity. Nash–Sutcliffe efficiency coefficient (E) (B1), coefficient of determination (R2) (B2) and normalized root mean square error (NRMSE) (B3) are calculated for simulated dam releases (Fig. 2).

Simulation results from GROS are significantly more accurate than the outputs from the other two models. On average, GROS reduces the NRMSE (and RMSE) for simulated daily release by 72 % compared to Wisser et al. (2010a) method. For monthly simulated release, the average NRMSE (and RMSE) for Wisser et al. (2010a) and Hanasaki et al. (2006) models are comparable to each other at around 0.65 but the average NRMSE (and RMSE) for GROS is 0.11, nearly 80 % smaller. The average daily Nash efficiency coefficient is 0.86, and R-squared is 0.85 using GROS.
Accuracy of GROS outputs for simulated release from Bhumibol and Sirikit dams which were excluded from the development of ANN to be used as independent validation datasets, confirms that the ANN used in GROS is not overfitted to its training datasets.
3 Methods for assessing alteration of flow regimes by dams
We used Colwell’s parameters (Colwell 1974), a suite of indicators of hydrological alteration (Richter 1996) and range of variability approach (Richter et al. 1997) to demonstrate how changes in storage size and distribution pattern of dams in a drainage basin alter their hydrological impacts.
Colwell (1974) proposed three parameters of predictability, constancy and contingency to describe patterns of temporal fluctuation in physical and biological phenomena. Predictability is a measure of temporal uncertainty across successive time domains spanning a periodic phenomenon. Maximum predictability occurs when the state of a phenomenon is known with absolute certainty in time. Maximum constancy happens when the state of a phenomenon is always constant. Contingency shows to what degree state of the phenomena depends on time. Values of these parameters range from 0 to 1 (Colwell 1974; Poff and Ward 1989).
Richter (1996) proposed the indicators of hydrologic alteration (IHA) for assessing the degree of hydrologic alteration attributable to human influence within an ecosystem. IHA consists of 32 indices (Table 3) selected to quantitatively describe hydrological alterations caused by anthropogenic disturbances between pre-impact and post-impact time periods (Richter 1996; TNC 2009). The range of variability approach (RVA) defines a range of variation (i.e. mean ± 1SD) for IHA parameters from pre-impact period data (i.e. before dam construction). The degree to which the RVA target range is not attained at the post-impact period (i.e. after dam construction) is a measure of Hydrologic Alteration (Richter et al. 1997).
We implemented GROS in WBMplus and used various scenarios to understand how variation in size and location of dams in a drainage basin changes their hydrological impact. Size and location of dams in each scenario is allocated based on analysis of national inventory of dams (NID) database (USACE 2013) to be representative of real-world conditions (Appendix 4).
Discharges were simulated for a length of 25 years (1986–2010) for each scenario using MERRA precipitation and temperature data (Rienecker et al. 2011) and a gridded 3-min (longitude × latitude) simulated topological network (Vörösmarty et al. 2000) of a large arbitrary drainage basin with 36,450 km2 area (Fig. 3). The average discharge at the mouth of this drainage basin is 690 m3/s and low pulse and high pulse thresholds (mean ± 1SD for IHA and RVA analysis) are at 86.3 and 1293 m3/s.

HUC 8 sub-basins contained in the study domain
3.1 The significance of water storage capacity of a single dam
Analysis of the NID database (USACE 2013) reveals that real world dams, with different purposes and significantly different storage capacities, may be built on rivers with statistically similar flow conditions (Appendix 4). Therefore, storage capacity is a critical input to reservoir models and models that do not use storage values for simulation of release cannot reliably capture the impact of dam operation. For example Wisser et al. (2010a) reservoir operation model (Eq. 1) does not use water storage in its calculations thus simulated release will be identical for dams with significantly different storage capacities. Hanasaki et al. (2006) use ratio of storage capacity to mean total annual inflow (Eq. 4); but the way it is formulated does not enable the model to respond to change in storage capacity properly.
We assumed five scenarios to show the advantage of GROS compared to other models and to quantify how variation in the size of a dam changes its hydrological impact. In the first scenario, flow was simulated without any dams. For the other scenarios, operation of a dam with 5, 10, 15 and 20 km3 storage volume was simulated at the mouth of the drainage basin (Fig. 6, S4).
Figure 4 shows how variation in storage capacity of a dam affects its impact on extreme flow conditions. The IHA and RVA analysis results are presented in Table 7 and Fig. 5. As expected, the impact of dams on natural hydrology increases as storage capacity increases.

Impact of change in storage size of a dam on natural flow

RVA analysis for the 32 IHA parameters using GROS for dams with different storage capacities
Dams decrease the range of fluctuations in the magnitude of monthly flows (IHA parameter 1–12). Magnitude, frequency and duration of extreme water conditions were considerably affected by dams operation (IHA parameter 13–23). Dams shifted the date of the occurrence of the minimum and maximum flows by up to 2 months (IHA parameter 24–25). There were no low pulses and the number of high pulses was reduced (IHA parameter 26–29). Because of the flow regulation by dams, the frequency and rate of daily flow change were also significantly reduced (IHA parameter 30–32).
The Colwell’s parameters also consistently change with the increase in dam capacity (Table 4). Dams reduce the range of flow compared to natural conditions by reducing the magnitude of high flows and increasing the magnitude of low flows (Table 7; Fig. 5). As the storage capacity of dams increases, the standard deviation and coefficient of variation (CV = σ/μ) of flows decrease. Limiting the range of flow variation also results in an increase in the value of Constancy, which respectively increases Predictability (Table 4).
3.2 The significance of distribution patterns of water storage capacity of multiple dams in a basin
Working with incomplete reservoir databases that do not list relatively small reservoirs is a concern in reservoirs impacts studies (ICOLD 2011; Lehner et al. 2011). This is especially important as most of the world’s dams are relatively small structures (Rosenberg et al. 2000). Hydrological impacts of individual small dams may be relatively small, but the aggregate effects of numerous small dams may be substantial.
In regional and global studies it is challenging to match reservoirs with the correct rivers in the model due to inaccurate or missing geo-referencing information in many databases. To address these issues, it is customary to aggregate the storage capacity of multiple reservoirs in a watershed (Graf 1999; Nilsson et al. 2005) or a grid cell (Vörösmarty et al. 1997; Hanasaki et al. 2010) and assume only one larger reservoir exists on the main river of that watershed or grid cell.
By studying the hydrological impact of different distribution patterns of dams in a drainage basin, we show how the hydrological impact of numerous, dispersed, small dams compares to the impact of a few larger ones. We also investigate if this is a valid approach to aggregate the capacity of smaller dams and instead model a hypothetical larger dam with the same total storage capacity.
We used GROS in WBMplus to model river flow and operation of reservoirs under four scenarios (Table 5; Fig. 6). Based on our analysis (Appendix 4) the total storage volume of dams in the basin was set to 20 km3. In scenario S1, 475 relatively small dams are on lower order streams of tributary branches. For scenario S2, there is a single dam in each HUC 12 sub-watersheds with the storage volume equal to aggregated storage volume of smaller dams from scenario S1 in that HUC 12 sub-watershed. Scenario S3 is similar to scenario S2 except that storage volumes are aggregated to HUC 8 sub-basins. In scenario S4 storage volume of all the dams in the basin is aggregated into one 20 km3 dam.

Location of dams in each scenario
Figure 7 illustrates parts of the drainage basin disturbed by reservoirs operation and the accumulated upstream storage volume at each grid cell. Figure 8 shows how variation in the distribution pattern of water storage capacity in a basin impacts some of the extreme flow conditions. Analysis results for IHA and RVA methods are summarized in Table 8 and Fig. 9, and results for the Colwell’s parameters are presented in Table 6. In general, the hydrological impact on the water flow leaving the basin increases from scenario S1 to scenario S4; larger dams have a larger hydrological impact and they are generally located on larger streams, and thus regulate larger amounts of water.

Parts of the basin disturbed by the dams and the accumulated upstream storage volume (km3)

Impact of change in storage distribution pattern of dams on natural flow

RVA analysis for the 32 IHA parameters using GROS for different water storage distribution patterns
Magnitudes of monthly flows (IHA parameter 1–12) are very similar for scenarios S1–S3. From scenario S1–S4, as the number of dams decreases and their capacity increases, they have a larger impact on magnitude, frequency and duration of extreme water conditions (IHA parameter 13–23). Date of the minimum and maximum flows (IHA parameter 24–25) is approximately the same for scenarios S1–S4 and is not sensitive to the distribution pattern of dams. The same is true for low and high pulses (IHA parameter 26–29). The frequency and rate of flow changes (IHA parameter 30–32) do not show a significant difference between different scenarios.
Colwell’s parameters for scenarios S1 and S2 are similar. Generally as the number of dams decreases and their size increases and they move from small streams to larger ones, their impact on Colwell’s parameters increases.
4 Summary of results and discussion
By using ANN, we developed a new general reservoir operation scheme (GROS) which may be added to daily hydrologic routing models for simulating the releases from dams, in regional and global-scale studies. GROS is specifically designed to provide a broad perspective of the general behavior of dams and improve our understanding of the large-scale hydrological impact of dams operation in a relatively easy and efficient way. Comparisons with two other models using a variety of performance metrics verify that using GROS to model the operation of reservoirs can significantly improve the accuracy of the simulation of daily and monthly reservoir release time series.
Analysis of the NID database shows that dams with significantly different storage capacities may be located on rivers with similar flow characteristics. General reservoir models should be tested for their response to changes in storage capacity of dams before being implemented into hydrological models. One advantage of GROS over other models is that it properly responds to changes in storage capacity of dams and therefore can be reasonably used for simulating reservoir releases in regional and global domains where hundreds and thousands of dams with various storage capacities exist.
Using GROS in WBMplus we investigated the practice of aggregating the storage capacity of multiple reservoirs in a watershed and simulating the operation of a hypothetical larger reservoir with the same total storage capacity. For this purpose we aggregated the storage capacity of dams in three scales, HUC 12 sub-watersheds (scenario S2), HUC 8 sub-basins (scenario S3) and basin level (scenario S4) and compared their hydrological impact on the water flow that leaves the basin. Based on our analysis results, hydrological impact of the original condition (scenario S1) is almost identical to scenario S2 (HUC 12 level aggregation) and very similar to scenario S3 (HUC 8 level aggregation). We conclude that for large-scale studies it is generally acceptable to aggregate the capacity of smaller dams and model a hypothetical larger dam with the same total storage capacity; however we suggest limiting the aggregation area to HUC 8 sub-basins (average of 3861 km2 in this experiment) or a grid cell of approximately 60 km or 30 arc minute resolution to avoid exaggerated results.
Based on analysis of significance of capacity and distribution pattern of dams in the way they alter water flow out of a basin, hydrological parameters are mostly affected by the total storage capacity in the basin rather than the pattern in which storage is distributed in the basin. However, it should be noted that a few large dams have a greater impact on hydrological parameters compared to numerous smaller dams with the same total storage capacity. In our experiment, hydrologic alteration of the flow leaving the basin caused by a single large dam was greater than the combined impact of 475 relatively smaller dams with the same cumulative storage. This means that a single large reservoir is a more effective structure to regulate water compared to numerous smaller reservoirs with the same cumulative water storage capacity. Having only one large dam on the main stream of a basin decreases the level of river fragmentation as tributary branches are not affected by the dam operation. These points should be considered for both cases of building new dams and restoration of rivers by dam removal.
References
Abrahart RJ, See L (2000) Comparing neural network and autoregressive moving average techniques for the provision of continuous river flow forecasts in two contrasting catchments. Hydrol Process 14:2157–2172. doi:10.1002/1099-1085(20000815/30)14:11/12<2157:AID-HYP57>3.0.CO;2-S
Adeloye AJ, De Munari A (2006) Artificial neural network based generalized storage-yield-reliability models using the Levenberg–Marquardt algorithm. J Hydrol 326:215–230. doi:10.1016/j.jhydrol.2005.10.033
Basheer IA, Hajmeer M (2000) Artificial neural networks: fundamentals, computing, design, and application. J Microbiol Methods 43:3–31. doi:10.1016/S0167-7012(00)00201-3
Chen YD, Yang T, Xu CY et al (2010) Hydrologic alteration along the middle and upper East River (Dongjiang) basin, South China: a visually enhanced mining on the results of RVA method. Stoch Environ Res Risk Assess 24:9–18. doi:10.1007/s00477-008-0294-7
Cigizoglu HK (2003) Estimation, forecasting and extrapolation of river flows by artificial neural networks. Hydrol Sci J 48:349–361
Coe MT (2000) Modeling terrestrial hydrological systems at the continental scale: testing the accuracy of an atmospheric GCM. J Clim 13:686–704. doi:10.1175/1520-0442(2000)013<0686:MTHSAT>2.0.CO;2
Coe MT, Birkett CM (2004) Calculation of river discharge and prediction of lake height from satellite radar altimetry: example for the Lake Chad basin. Water Resour Res 40:1–12. doi:10.1029/2003WR002543
Colwell RK (1974) Predictability, constancy, and contingency of periodic phenomena. Ecology 55:1148–1153. doi:10.2307/1940366
Coulibaly P, Baldwin CK (2008) Dynamic neural networks for nonstationary hydrological time series modeling. Pract Hydroinf. doi:10.1007/978-3-540-79881-1_6
Coulibaly P, Anctil F, Bobée B (2000) Daily reservoir inflow forecasting using artificial neural networks with stopped training approach. J Hydrol 230:244–257. doi:10.1016/S0022-1694(00)00214-6
Döll P, Kaspar F, Lehner B (2003) A global hydrological model for deriving water availability indicators: model tuning and validation. J Hydrol 270:105–134. doi:10.1016/S0022-1694(02)00283-4
Dynesius M, Nilsson C (1994) Fragmentation and flow regulation of river systems in the northern third of the world. Science 266:753–762. doi:10.1126/science.266.5186.753
Fontane DG, Gates TK, Moncada E (1997) Planning reservoir operations with imprecise objectives. J Water Resour Plan Manag 123:154–162
Gao H, Birkett C, Lettenmaier DP (2012) Global monitoring of large reservoir storage from satellite remote sensing. Water Resour Res. doi:10.1029/2012WR012063
Gevrey M, Dimopoulos I, Lek S (2003) Review and comparison of methods to study the contribution of variables in artificial neural network models. Ecol Model 160:249–264. doi:10.1016/S0304-3800(02)00257-0
Govindaraju RS (2000a) Artificial neural networks in hydrology. I: preliminary concepts. J Hydrol Eng 5:115–123. doi:10.1061/(ASCE)1084-0699(2000)5:2(115)
Govindaraju RS (2000b) Artificial neural networks in hydrology. II: hydrologic applications. J Hydrol Eng 5:124–137. doi:10.1061/(ASCE)1084-0699(2000)5:2(124)
Graf WL (1999) Dam nation: a geographic census of American dams and their large-scale hydrologic impacts. Water Resour Res 35:1305–1311. doi:10.1029/1999WR900016
Haddeland I, Lettenmaier DP, Skaugen T (2006) Effects of irrigation on the water and energy balances of the Colorado and Mekong river basins. J Hydrol 324:210–223. doi:10.1016/j.jhydrol.2005.09.028
Hanasaki N, Kanae S, Oki T (2006) A reservoir operation scheme for global river routing models. J Hydrol 327:22–41. doi:10.1016/j.jhydrol.2005.11.011
Hanasaki N, Inuzuka T, Kanae S, Oki T (2010) An estimation of global virtual water flow and sources of water withdrawal for major crops and livestock products using a global hydrological model. J Hydrol 384:232–244. doi:10.1016/j.jhydrol.2009.09.028
Hsu K, Gupta HV, Sorooshian S (1995) Artificial neural network modeling of the rainfall-runoff process. Water Resour Res 31:2517. doi:10.1029/95WR01955
ICOLD (2011) The world registers of dams. International Commission on Large Dams, Paris
Jain SK, Das A, Srivastava DK (1999) Application of ANN for reservoir inflow prediction and operation. J Water Resour Plan Manag 125:263–271. doi:10.1061/(ASCE)0733-9496(1999)125:5(263)
Karunanithi N, Grenney WJ, Whitley D, Bovee K (1994) Neural networks for river flow prediction. J Comput Civ Eng 8:201–220. doi:10.1061/(ASCE)0887-3801(1994)8:2(201)
Kingsford RTT (2000) Ecological impacts of dams, water diversions and river management on floodplain wetlands in Australia. Austral Ecol 25:109–127. doi:10.1046/j.1442-9993.2000.01036.x
Kişi Ö (2007) Streamflow forecasting using different artificial neural network algorithms. J Hydrol Eng 12:532–539. doi:10.1061/(ASCE)1084-0699(2007)12:5(532)
Lehner B, Liermann CR, Revenga C et al (2011) High-resolution mapping of the world’s reservoirs and dams for sustainable river-flow management. Front Ecol Environ 9:494–502. doi:10.1890/100125
Magilligan FJ, Nislow KH (2005) Changes in hydrologic regime by dams. Geomorphology 71:61–78. doi:10.1016/j.geomorph.2004.08.017
Maier HR, Dandy GC (2000) Neural networks for the prediction and forecasting of water resources variables: a review of modelling issues and applications. Environ Model Softw 15:101–124. doi:10.1016/S1364-8152(99)00007-9
Maier HR, Jain A, Dandy GC, Sudheer KP (2010) Methods used for the development of neural networks for the prediction of water resource variables in river systems: current status and future directions. Environ Model Softw 25:891–909. doi:10.1016/j.envsoft.2010.02.003
Mathews R, Richter BD (2007) Application of the indicators of hydrologic alteration software in environmental flow setting. J Am Water Resour Assoc 43:1400–1413. doi:10.1111/j.1752-1688.2007.00099.x
Meigh JR, McKenzie AA, Sene KJ (1999) A grid-based approach to water scarcity estimates for eastern and southern Africa. Water Resour Manag 13:85–115. doi:10.1023/A:1008025703712
Nilsson C, Reidy CA, Dynesius M, Revenga C (2005) Fragmentation and flow regulation of the world’s large river systems. Science 308:405–408. doi:10.1126/science.1107887
Peng D, Guo S, Liu P, Liu T (2006) Reservoir storage curve estimation based on remote sensing data. J Hydrol Eng 11:165–172. doi:10.1061/(ASCE)1084-0699(2006)11:2(165)
Piao S, Friedlingstein P, Ciais P et al (2007) Changes in climate and land use have a larger direct impact than rising CO2 on global river runoff trends. Proc Natl Acad Sci U S A 104:15242–15247. doi:10.1073/pnas.0707213104
Poff NL, Ward JV (1989) Implications of streamflow variability and predictability for lotic community structure: a regional analysis of streamflow patterns. Can J Fish Aquat Sci 46:1805–1818. doi:10.1139/f89-228
Pringle CM, Freeman MC, Freeman BJ (2000) Regional effects of hydrologic alterations on riverine macrobiota in the new world: tropical-temperate comparisons. Bioscience 50:807. doi:10.1641/0006-3568(2000)050[0807:REOHAO]2.0.CO;2
Rafiq MY, Bugmann G, Easterbrook DJ (2001) Neural network design for engineering applications. Comput Struct 79:1541–1552. doi:10.1016/S0045-7949(01)00039-6
Raman H, Chandramouli V (1996) Deriving a general operating policy for reservoirs using neural network. J Water Resour Plan Manag 122:342–347. doi:10.1061/(ASCE)0733-9496(1996)122:5(342)
Rani D, Moreira MM (2010) Simulation-optimization modeling: a survey and potential application in reservoir systems operation. Water Resour Manag 24:1107–1138. doi:10.1007/s11269-009-9488-0
Richter BD (1996) A method for assessing hydrologic alteration within ecosystems. Conserv Biol 10:1163–1174. doi:10.1046/j.1523-1739.1996.10041163.x
Richter BD, Baumgartner JV, Wigington R, Braun DP (1997) How much water does a river need? Freshw Biol 37:231–249. doi:10.1046/j.1365-2427.1997.00153.x
Rienecker MM, Suarez MJ, Gelaro R et al (2011) MERRA: NASA’s modern-era retrospective analysis for research and applications. J Clim 24:3624–3648. doi:10.1175/JCLI-D-11-00015.1
Rosenberg DM, McCully P, Pringle CM (2000) Global-scale environmental effects of hydrological alterations: introduction. Bioscience 50:746
Simonovic SP (1992) Reservoir systems analysis: closing gap between theory and practice. J Water Resour Plan Manag 118:262–280. doi:10.1061/(ASCE)0733-9496(1992)118:3(262)
Syvitski JPM, Vörösmarty CJ, Kettner AJ, Green P (2005) Impact of humans on the flux of terrestrial sediment to the global coastal ocean. Science 308:376–380. doi:10.1126/science.1109454
Taormina R, Chau K, Sethi R (2012) Artificial neural network simulation of hourly groundwater levels in a coastal aquifer system of the Venice lagoon. Eng Appl Artif Intell 25:1670–1676. doi:10.1016/j.engappai.2012.02.009
Tetko IV, Villa AEP, Livingstone DJ (1996) Neural network studies. 2. variable selection. J Chem Inf Model 36:794–803. doi:10.1021/ci950204c
Thoms MC, Sheldon F (2000) Water resource development and hydrological change in a large dryland river: the Barwon–Darling River, Australia. J Hydrol 228:10–21. doi:10.1016/S0022-1694(99)00191-2
TNC (2009) Indicators of hydrologic alteration version 7.1 user’s manual. The Nature Conservancy, Charlottesville
USACE (2013) National inventory of dams (NID). In: U.S. Army Corps Eng. http://nid.usace.army.mil
Vörösmarty CJ, Sahagian D (2000) Anthropogenic disturbance of the terrestrial water cycle. Bioscience 50:753. doi:10.1641/0006-3568(2000)050[0753:ADOTTW]2.0.CO;2
Vörösmarty CJ, Sharma KP, Fekete BM et al (1997) The storage and aging of continental runoff in large reservoir systems of the world. Ambio 26:210–219
Vörösmarty CJ, Fekete BM, Meybeck M, Lammers RB (2000) Geomorphometric attributes of the global system of rivers at 30-minute spatial resolution. J Hydrol 237:17–39. doi:10.1016/S0022-1694(00)00282-1
Vörösmarty CJ, Meybeck M, Fekete B et al (2003) Anthropogenic sediment retention: major global impact from registered river impoundments. Glob Planet Chang 39:169–190. doi:10.1016/S0921-8181(03)00023-7
WCD (2000) Dams and development: a new framework for decision-making: the report of the world commission on dams. Earthscan Publications Ltd, London and Sterling
Wisser D, Fekete BM, Vörösmarty CJ, Schumann AH (2010a) Reconstructing 20th century global hydrography: a contribution to the global terrestrial network-hydrology (GTN-H). Hydrol Earth Syst Sci 14:1–24. doi:10.5194/hess-14-1-2010
Wisser D, Frolking S, Douglas EM et al (2010b) The significance of local water resources captured in small reservoirs for crop production—a global-scale analysis. J Hydrol 384:264–275. doi:10.1016/j.jhydrol.2009.07.032
Wurbs RA (1993) Reservoir-system simulation and optimization models. J Water Resour Plan Manag 119:455–472. doi:10.1061/(ASCE)0733-9496(1993)119:4(455)
Yang T, Zhang Q, Chen YD et al (2008) A spatial assessment of hydrologic alteration caused by dam construction in the middle and lower Yellow River, China. Hydrol Process 22:3829–3843. doi:10.1002/hyp.6993
Yoshikawa S, Cho J, Yamada HG et al (2013) An assessment of global net irrigation water requirements from various water supply sources to sustain irrigation: rivers and reservoirs (1960–2000 and 2050). Hydrol Earth Syst Sci Discuss 10:1251–1288. doi:10.5194/hessd-10-1251-2013
Zealand CM, Burn DH, Simonovic SP (1999) Short term streamflow forecasting using artificial neural networks. J Hydrol 214:32–48. doi:10.1016/S0022-1694(98)00242-X
Acknowledgments
We are grateful to Naota Hanasaki for sharing datasets and giving us access to results from his previously published work. The authors wish to express their gratitude to Reza Khanbilvardi, Eugene Z. Stakhiv, Michael Piasecki and Matthew C. Larsen for providing valuable insights. We extend our gratitude to Katherine M. Jensen and the anonymous reviewers for their valuable comments that shaped the final form of this article. This work was supported by the National Science Foundation, Award No. 1049181.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: GROS algorithm
This is the simplified algorithm of GROS.

Subscript t represents the daily time step. I o , R o and S o stand for inflow (m3/s), release (m3/s) and storage (m3) of dam in their original form. MaxS stands for maximum storage capacity (m3) of dam. I, R and S, without the subscript o, stand for the values scaled between 0 and 1. The number 86,400 is the number of seconds in a day.
Appendix 2: Equations
Equations of Nash–Sutcliffe efficiency coefficient (B1), coefficient of determination (B2) and normalized root mean square error are (B3) demonstrated here. O stands for observation data, P stands for predicted (simulated) values and N is total number of simulations.
The Hydrologic Alteration in RVA method is defined as:
where “Observed” is the count of years in which observed value of the hydrologic parameter fell within the RVA targeted range and”Expected” is the count of years for which the value is expected to fall within the RVA targeted range.
Appendix 3: Hydrological alteration analysis results
Appendix 4: Analyzing NID for the purpose of scenario development
Size and location of the hypothetical dams in this study are selected based on criteria obtained by analyzing NID dataset (USACE 2013) with reference to a gridded 3-min (longitude × latitude) Simulated Topological Network (Vörösmarty et al. 2000) which we use in WBMplus. Three categories of dams and reservoirs were analyzed; (1) small dams with storage capacity between 5 × 106 and 5 × 107 m3; (2) medium dams with storage capacity between 5 × 107 and 5 × 108 m3; (3) large dams with storage capacity larger than 0.5 km3. To find the appropriate location for each size category we used the middle 50th percentile of average flow, upstream catchment area and residency time (ratio of capacity to average flow) of NID dams. The middle 50th percentile was used to avoid miss match between actual location of dams and their location on simulated network and also to remove outliers.
We defined small dams to be located on rivers with mean flow between 1 and 52 m3/s; upstream catchment area between 58 and 3499 km2; and residency times between 3 and 184 days. Medium dams are located on rivers with mean flow between 3 and 60 m3/s; upstream catchment area between 373 and 4929 km2; and residency time between 61 and 498 days. Large dams are located on rivers with mean flow larger than 9 m3/s; upstream catchment area larger than 2080 km2; and residency time between 140 and 1978 days. Residency time range gives a minimum and maximum limit for storage capacity at each location.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Ehsani, N., Fekete, B.M., Vörösmarty, C.J. et al. A neural network based general reservoir operation scheme. Stoch Environ Res Risk Assess 30, 1151–1166 (2016). https://doi.org/10.1007/s00477-015-1147-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-015-1147-9