
Abstract
This work presents a multi-resolution physics-informed recurrent neural network (MR PI-RNN), for simultaneous prediction of musculoskeletal (MSK) motion and parameter identification of the MSK systems. The MSK application was selected as the model problem due to its challenging nature in mapping the high-frequency surface electromyography (sEMG) signals to the low-frequency body joint motion controlled by the MSK and muscle contraction dynamics. The proposed method utilizes the fast wavelet transform to decompose the mixed frequency input sEMG and output joint motion signals into nested multi-resolution signals. The prediction model is subsequently trained on coarser-scale input–output signals using a gated recurrent unit (GRU), and then the trained parameters are transferred to the next level of training with finer-scale signals. These training processes are repeated recursively under a transfer-learning fashion until the full-scale training (i.e., with unfiltered signals) is achieved, while satisfying the underlying dynamic equilibrium. Numerical examples on recorded subject data demonstrate the effectiveness of the proposed framework in generating a physics-informed forward-dynamics surrogate, which yields higher accuracy in motion predictions of elbow flexion–extension of an MSK system compared to the case with single-scale training. The framework is also capable of identifying muscle parameters that are physiologically consistent with the subject’s kinematics data.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The prediction of the evolution of state variables in dynamical systems has been a vital component to several scientific applications such as biology, geophysics, earthquake engineering, solid mechanics, robotics, computer vision [1,2,3,4,5,6,7] etc. Black-box techniques based on data-driven mapping and development of parameterized multi-physics models describing the progression of the data have been previously utilized for making predictions on the states. This task continues to be an active area of research due to challenges on many fronts, such as, the quality and scarcity of relevant physical data, the dynamics and complexity of the system, and the reliability and accuracy of the prediction model.
On the other hand, the characterization of parameters in the multi-physics models of these dynamical systems is also critical [8,9,10,11,12,13,14]. The task is challenging due in parts to potential noise pollution captured by sensors in the system’s measured data, as well as the potential of the parameter space being high-dimensional, leading to ill-posed problems that pose difficulties in numerical solutions. Standard optimization techniques such as genetic algorithms [15, 16], simulated annealing [17], and non-linear least squares [18, 19] have been employed for parameter identification, but can be computationally expensive and may not converge for ill-posed, non-convex optimization problems that are encountered while solving inverse problems on MSK systems [15, 20].
In recent years, machine learning (ML) or deep-learning-based approaches have gained significant popularity for solving forward and inverse problems, attributed to their capability in effectively extracting complex features and patterns from data [21]. This has been successfully demonstrated in numerous engineering applications such as reduced-order modeling [22,23,24,25,26], and materials modeling [27,28,29], among others. Data-driven computing techniques that enforce constraints of conservation laws in the learning algorithms of a material database, have been developed in the field of computational mechanics [29,30,31,32,33,34,35,36,37]. More recently, physics-informed neural networks (PINNs) have been developed [11, 38, 39] to approximate the solutions of given physical equations by using neural networks (NNs). By minimizing the residuals of the governing partial differential equations (PDEs) and the associated initial and boundary conditions, PINNs have been successfully applied to solve forward problems [11, 40, 41], and inverse problems [11, 38, 42,43,44], where the unknown system characteristics are considered trainable parameters or functions [38, 45]. For biomechanics and biomedical applications [1, 46,47,48,49,50], this method has been applied extensively along with other ML techniques [51, 52]. These attempt to bridge the gap between ML-based data-driven surrogate models and the satisfaction of physical laws.
In this study, we focus on the application to musculoskeletal systems, aiming at utilizing non-invasive muscle activity measurements such as surface electromyography (sEMG) signals to predict joint kinetics or kinematics [1, 18, 19], which is of great significance to health assessment and rehabilitation purposes [15, 16]. These sEMG signals can be used as control inputs to drive the physiological subsystems that are governed by parameterized non-linear differential equations, and thus form the forward dynamics problem. Given information on muscle activations, the joint motion of a subject-specific MSK system can be obtained by solving a forward dynamics problem. Data-driven approaches for motion prediction have also been introduced to directly map the input sEMG signal to joint kinetics/kinematics, bypassing the forward dynamics equations and the need for parameter estimation [26,27,28,29,30]. However, the resulting ML-based surrogate models lack interpretability and may not satisfy the underlying physics. Another challenge is that the sEMG signal usually exhibits a wide range of frequencies that are non-trivial for ML models [1] to map to the joint motion.
In our previous work [1], a physics-informed parameter identification neural network (PI-PINN) was proposed for the simultaneous prediction of motion and parameter identification with application to MSK systems. Using the raw transient sEMG signals obtained from the sensors and the corresponding joint motion data, the PI-PINN learned a forward model to predict the motion with identifying the parameters of the hill-type muscle models representing the contractile muscle–tendon complex. A feature-encoded approach was introduced to enhance the training of the PI-PINN, which yielded high motion prediction accuracy and identified system parameters within a physiological range, with only a limited number of training samples. However, this method relies on mapping in a feature domain constituted by Fourier and polynomial bases, which requires the input sEMG signal to span over the entire duration of the motion. Thus, it prevents real-time predictions as the signal is obtained from the sensor.
To enhance the predictive accuracy of the time-dependent signals, recurrent neural networks (RNNs) such as gated recurrent units (GRUs) [29, 53] are utilized in this study to inform predictions with the history information of the motion. To overcome the limitation of the size of the data and provide more information from the composite frequency bands in the signals, a multi-resolution based (MR) approach is proposed. In this approach, wavelets are used to decompose both the raw sEMG and joint motion signals into coarse-scale components at various frequency scales and the remaining fine-scale details. Using principles of the multi-resolution theory and transfer learning, multi-resolution training processes are repeated recursively from the coarse-scale to the full-scale in order to map the sEMG signal to the joint motion. Furthermore, gaussian noise is introduced to the recorded motion data used for training to enhance the robustness and generalizability of the model [29]. The trained model can be applied for real-time motion predictions given the raw sEMG signal obtained from the sensor.
This manuscript is organized as follows. Section 2 introduces the subsystems and mathematical formulations of MSK forward dynamics, followed by an introduction of the proposed multi-resolution PI-RNN framework for simultaneous motion prediction and system parameter identification in Sect. 3. The following sections verify the proposed framework using synthetic data and validate it by modeling the elbow flexion–extension movement using subject-specific sEMG signals and recorded motion data in Sect. 4 and 5, respectively. Concluding remarks and future work are summarized in Sect. 6.
2 Formulations for muscle mechanics and musculoskeletal forward dynamics
This section provides a brief overview of muscle mechanics and forward dynamics of the human MSK system, with details in “Appendices A and B”. As depicted in Fig. 1, multiple subsystems within the MSK forward dynamics interact hierarchically: 1) the neural excitation \(u\left(t\right)\) transforms into muscle activation \(a\left(t\right)\) (activation dynamics); 2) Muscle activation drives muscle fibers to produce force \({F}^{MT}\) (muscle–tendon (MT) contraction dynamics); 3) the resultant forces produce joint motion q (translation and rotation) of MSK systems, called the MSK forward dynamics [18, 19].

The subsystems involved in the forward dynamics of an MSK system are depicted in this flowchart. Neural excitations are transmitted to muscle fibers (activation dynamics) that contract to produce force (muscle–tendon contraction dynamics). These forces generate torques at the joints (structural level MSK dynamics) leading to joint motion [1, 54]
2.1 Neural excitation-to-activation dynamics
While activations \(a(t)\) in the muscle fibers can be obtained through a non-linear transformation on neural excitations \(u\left(t\right)\), they are difficult to measure in-vivo. Therefore, the excitations are estimated from [15, 16] the raw sEMG signals \(e(t)\) considering an electro-mechanical delay:
where \(d\) measures the delay between the neural excitation originating and reaching the muscle group. The muscle activation signal \(a(t)\) is then expressed as,
where \(A\) is a shape factor. These activations initiate muscle fiber contraction leading to force production from the muscle group (Fig. 2).

A muscle–tendon complex in the arm modelled by a homogenized hill-type model where muscle group’s in a are a homogenized muscle–tendon (MT) complex described by the model shown in b
2.2 Muscle–tendon force generation through contraction dynamics
Forces in the muscle–tendon (MT) complex are generated by the dynamics of MT contractions, where for structural length scale behaviour of the MT complex, homogenized hill-type muscle models are utilized (described in “Appendix B”). Each muscle group can be characterized by a parameter vector,
containing constants such as the maximum isometric force in the muscle (\({f}_{0}^{M}\)), the optimal muscle length (\({l}_{0}^{M}\)) corresponding to the maximum isometric force, the maximum contraction velocity (\({v}_{max}^{M}\)), the slack length of the tendon (\({l}_{s}^{T})\), and the initial pennation angle (\({\vartheta }_{0})\) [18, 19]. The total force produced by the MT complex, \({F}^{MT}\), can be expressed as:
where \(a\) is the activation function in Eq. (2), \({\widetilde{l}}^{M}\) is the normalized muscle length, \({\widetilde{v}}^{M}\) is the normalized velocity of the muscle and \(\vartheta \) is the current pennation angle. In this study, the tendon is assumed to be rigid \(\left({l}^{T}={l}_{s}^{T}\right)\) which simplifies the MT contraction dynamics [57, 58] accounting for the interaction of the activation, force length, and force velocity properties of the MT complex. More details can be found in “Appendices A and B”.
2.3 MSK forward dynamics of motion
Body movement is the result of the force produced by actuators (MT complexes), converted to torques at the joints of the body, leading to rotation and translation of joints, which are considered as the generalized degrees of freedom of an MSK system \(({\varvec{q}})\). The dynamic equilibrium can be expressed as
where \({\varvec{q}},\boldsymbol{ }\dot{{\varvec{q}}},\boldsymbol{ }\ddot{{\varvec{q}}}\) are the vectors of generalized angular motions, angular velocities, and angular accelerations, respectively; \({\varvec{E}}({\varvec{q}})\) is the torque from the external forces acting on the MSK system, e.g., ground reactions, gravitational loads etc.; \({\varvec{I}}\left({\varvec{q}}\right)\) is the inertial matrix; \({{\varvec{T}}}^{MT}\) is the torque from all muscles in the model calculated by \({{\varvec{T}}}^{MT}({\varvec{a}},{\varvec{q}},\dot{{\varvec{q}}};{\varvec{\kappa}})={\varvec{R}}\left({\varvec{q}}\right){{\varvec{F}}}^{MT}({\varvec{a}},{\varvec{q}},\dot{{\varvec{q}}};{\varvec{\kappa}})\), where \({\varvec{R}}\left({\varvec{q}}\right)\) are the moment arm’s and \({{\varvec{F}}}^{MT}({\varvec{a}},{\varvec{q}},\dot{{\varvec{q}}};{\varvec{\kappa}})\) are the forces from the MT complex. Given the muscle activation signals \({\varvec{a}}\), initial conditions and parameters of involved muscle groups \({\varvec{\kappa}}\), the generalized angular motions \({\varvec{q}}\) and angular velocities \(\dot{{\varvec{q}}}\) of the joints can be obtained by solving Eq. (5). An example of these vectors is shown in Sect. 4 and “Appendix D”.
3 Multi-resolution recurrent neural networks for physics-informed parameter identification
This section describes the recurrent neural network algorithms, followed by the physics-informed parameter identification that enables the development of a forward dynamics surrogate and simultaneous parameter identification. The employment of multi-resolution analysis based on fast wavelet transform [59, 60] for training data augmentation is then defined. The computational framework for multi-resolution recurrent neural network for physics-informed parameter identification is also discussed.
3.1 Recurrent neural networks and gated recurrent units
The computational graph of a standard recurrent neural network (RNN) and its unfolded graph is shown in Fig. 3. The hidden state \({\varvec{h}}\) allows for RNNs to learn important history-dependent features from the data in sequential time steps [29, 53]. The unfolded graph shows the sharing of parameters across the architecture of the network, allowing for efficient training. The forward propagation of an RNN starts with an initial hidden state that embeds history-dependent features and propagates through all input steps. Considering an RNN with \(m\) history steps as shown in Fig. 3, the propagation of the hidden state can be expressed as follows [29].

Computational graph of a standard recurrent neural network using ‘m’ history steps for prediction
The hidden state at the final (current) step \(n\) is then used to inform the prediction.
Here, \({a}_{tanh}\) is the hyperbolic tangent function; \({{\varvec{W}}}_{xh}, {{\varvec{W}}}_{hh},\) and \({{\varvec{W}}}_{hq}\) are the trainable weight coefficients; \({{\varvec{b}}}_{h}\) and \({{\varvec{b}}}_{q}\) are the trainable bias coefficients. The trainable parameters are shared across all RNN steps. Let \({{\varvec{x}}}_{n}=\left[{t}_{n},{e}_{n}^{1},\dots ,{e}_{n}^{{N}_{a}}\right]\) be the current time and current sEMG data of the \({N}_{a}\) muscle components and \({\widehat{{\varvec{q}}}}_{n}\) be the predicted joint motions at the current time \({t}_{n}\). Figure 4a illustrates the computational graph of an RNN model trained to predict the motion at step \(n\) by using m history steps of \({\varvec{x}}\) and \({\varvec{q}}\) as well as the \({\varvec{x}}\) at step \(n\). The forward propagation is defined as
with trainable parameters including the weight coefficients \({{\varvec{W}}}_{hh},{{\varvec{W}}}_{xh},{{\varvec{W}}}_{qh}\) and \({{\varvec{W}}}_{h\widehat{q}}\) and bias coefficients \({{\varvec{b}}}_{h}\) and \({{\varvec{b}}}_{q}\). During training, the ‘teacher-forcing’ method is used where the measured motion data is given to the model in the history steps. In test mode, the model is fed back to the previous predictions as input to inform future predictions. The inputs received in this scenario could be quite different from those passed through in the training process, leading the network to make extrapolative predictions and therefore, accumulate errors which will pollute the predictions. To improve the testing performance and enhance model accuracy and robustness, a user-controlled amount of random Gaussian noise is added to the recorded motion data to introduce stochasticity so that the network can learn variable input conditions, resembling those in the test mode, see [29] for details.

An example computational graph of an RNN that uses one history step: a The train mode and b the test mode, where the motion predicted from the previous step is used as part of the input to predict motion at the current step
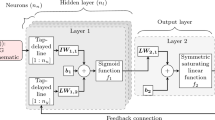
Standard RNNs, however, have difficulties in learning long-term dependencies due to vanishing and exploding gradient issues arising from the recurrent connections. To mitigate these issues, gated recurrent units (GRUs) have been developed [29, 53]. A standard GRU consists of a reset gate\({{\varvec{r}}}_{n}\), that removes irrelevant history information, an update gate \({{\varvec{u}}}_{n}\) that controls the amount of history information that is passed to the next step, and a candidate hidden state \({\widetilde{{\varvec{h}}}}_{n}\) that is used to calculate the current hidden state \({{\varvec{h}}}_{n}\). Considering a GRU with \(m\) history steps, the forward propagation can be expressed as follows [29]:
where \(\odot \) denotes the element-wise (Hadamard) product; \({a}_{\sigma }(\cdot )\) is the sigmoid activation function and \({a}_{tanh}\left(\cdot \right)\) is the hyperbolic tangent function; \({{\varvec{W}}}_{hr},{{\varvec{W}}}_{xr},{{\varvec{W}}}_{qr},{{\varvec{W}}}_{hu},{{\varvec{W}}}_{xu}, {{\varvec{W}}}_{qu},{\boldsymbol{ }\boldsymbol{ }\boldsymbol{ }{\varvec{W}}}_{h\widetilde{h}},{{\varvec{W}}}_{x\widetilde{h}},{{\varvec{W}}}_{q\widetilde{h}}\) and \({{\varvec{W}}}_{h\widehat{q}}\) are the trainable weight coefficients; \({{\varvec{b}}}_{r},{{\varvec{b}}}_{u},{{\varvec{b}}}_{\widetilde{h}},{{\varvec{b}}}_{h}\) and \({{\varvec{b}}}_{\widehat{q}}\) are the trainable bias coefficients. The current hidden state \({{\varvec{h}}}_{n}\) is calculated by a linear interpolation between the previous hidden state \({{\varvec{h}}}_{n-1}\) and the candidate hidden state \({\widetilde{{\varvec{h}}}}_{n}\), based on the update gate \({{\varvec{u}}}_{n}\). The model is trained via the backpropagation through time algorithm applied to RNNs [21]. Training occurs by plugging in the measured motion data in history steps (shown in Fig. 5), known as the teacher forcing procedure [21]. For predictions, the prediction from the previous step is used to predict the current step. The addition of gaussian noise to measured data, as described before, is adopted in GRU models as well.

An example computational graph of a GRU in train mode that uses one history step: a Starting with an initial or previously obtained hidden state \(\left({{\varvec{h}}}_{n-2}\right)\), the main GRU cell takes the input \({{\varvec{x}}}_{n-1}\) and motion \({{\varvec{q}}}_{n-1}\) that are used to obtain the GRU hidden state \({{\varvec{h}}}_{n-1}\) at step \(n-1\) (Eq. (11)) and, b where the hidden state \({{\varvec{h}}}_{n-1}\) is plugged back in to the GRU along with input \({{\varvec{x}}}_{n}\) at step \(n\) to predict the motion \({\widehat{{\varvec{q}}}}_{n}\) (Eq. (12)-(13)). The ‘ + ’ cell produces an output (arrow pointing outwards) that is the summation of the inputs (arrows pointing into the cell)
3.2 Simultaneous forward dynamics learning and parameter identification
With the governing equations for a general MSK forward dynamics (Sect. 2.1), the following parameterized ODE system is defined as.
where the differential operator \({\boldsymbol{\mathcal{L}}}\left[(\cdot );{\varvec{\lambda}}\right]\) is parameterized by a set of parameters \({\varvec{\lambda}}\). The right-hand side \({\varvec{s}}\left(t;{\varvec{\omega}}\right)\) is parameterised by \({\varvec{\omega}}\). \({\boldsymbol{\mathcal{B}}}[(\cdot )]\) is the operator for initial conditions, and \({\varvec{g}}\) is the vector of prescribed initial conditions. To simplify notations, the ODE parameters are denoted by \(\boldsymbol{\Gamma }=\{{\varvec{\lambda}},{\varvec{\omega}}\}\). The solution to the ODE system \({\varvec{q}}:[0,T]\to {\mathbb{R}}\) depends on the choice of parameters \(\boldsymbol{\Gamma }\).
Here, an RNN is used to relate data inputs containing discrete sEMG signals and discrete time from all the \(m\) previous history time-steps of a trial, \({\cup }_{i=n-m}^{n}{{\varvec{x}}}_{i}\in {\mathbb{R}}^{{n}_{in}},m\in {\mathbb{Z}}^{+}\), to discrete joint motion data outputs at the current time-step, \({{\varvec{q}}}_{n}\in {\mathbb{R}}\), approximating the MSK forward dynamics. Let the training input at the \({i}^{th}\) history step be defined as \({{\varvec{x}}}_{i}=\left[{t}_{i},{e}_{i}^{1},\dots ,{e}_{i}^{{N}_{a}}\right]\), where \({t}_{i}\) denotes the time at the \({i}^{th}\) time step, and \({\left\{{e}_{i}^{j}\right\}}_{j=1}^{{N}_{a}}\) denotes the sEMG signals of \({N}_{a}\) muscle groups involved in the MSK joint motion at \({t}_{i}\). The motion at time step \(n\), is then predicted using the training input from all the previous \(m\) steps using the RNN.
where \({f}_{RNN}\) denotes RNN evaluations (depending on model chosen) discussed in Eq. (11)-(13). The optimal RNN parameters \(\widetilde{{\varvec{\theta}}}\) and the ODE parameters \(\widetilde{\boldsymbol{\Gamma }}\) are obtained by minimizing the composite loss function \(J\) as follows,
where \(\beta \) is the parameter to regularize the loss contribution from the ODE residual term in the loss function and can be estimated analytically [1]. The data loss is defined by,
where \({\widehat{{\varvec{q}}}}_{\alpha }\left({\varvec{\theta}}\right)\) is the predicted motion, and \({{\varvec{q}}}_{\alpha }\) is the recorded motion of MSK joints. In addition to training an MSK forward dynamics surrogate, the proposed framework aims to simultaneously identify important MSK parameters from the training data by minimizing residual of the governing equation of MSK system dynamics in Eq. (5).
with
where \({\varvec{r}}\left({\widehat{{\varvec{q}}}}_{\alpha }\left({\varvec{\theta}}\right);\boldsymbol{\Gamma }\right)\) is the residual associated with Eq. (14) for the \({\alpha }^{th}\) sample; \(\boldsymbol{\Gamma }=\{{\varvec{\lambda}},{\varvec{\omega}}\}\) represents the ODE parameters relevant to the MSK system. The gradients of the network outputs with respect to the network parameters \(\left({\varvec{\theta}}\right)\), MSK parameters \(\left(\boldsymbol{\Gamma }\right)\), and inputs are needed in the loss function minimization in Eq. (16), which can be obtained efficiently by automatic differentiation [61]. The formulation in Eq. (15) is general such that more advanced RNN frameworks can be used such as the GRU described in Eq. (11)-(13).
3.3 Multi-resolution training with transfer learning
To improve the training efficiency of RNN for MSK applications with mixed-frequency sEMG input signals and low-frequency output joint motion, a multi-resolution decomposition of the training input–output data is introduced in Sect. 3.3.1, followed by the transfer learning based multi-resolution training protocols to be discussed in Sect. 3.3.2.
3.3.1 Wavelet based multi-resolution analysis
Consider a sequence of nested subspaces \(\dots \subset {V}_{-1}\subset {V}_{0}\subset {V}_{1}\subset \dots \subset {L}^{2}\left({\mathbb{R}}\right)\) where \({\bigcup }_{j\in \mathcal{Z}}{V}_{j}={L}^{2}\left({\mathbb{R}}\right)\), and \({\bigcap }_{j\in \mathcal{Z}}{V}_{j}=\mathrm{\varnothing }\). Each subspace \({V}_{j}\) of scale \([j]\) is spanned by a set of scaling functions \({\phi }_{j,k}(t)\), i.e.,\({V}_{j}=\left\{{\phi }_{j,k}\left(t\right)|{\phi }_{j,k}\left(t\right)={2}^{\frac{j}{2}}\phi \left({2}^{j}t-k\right),k\in \mathcal{Z}\right\}\)
Each subspace is related to the finer subspace through the law of dilation i.e., if \(\phi \left(t\right)\in {V}_{j},\) then \(\phi \left(2t\right)\in {V}_{j+1}, \forall j\in \mathcal{Z}\). Translations of the scaling function span the same subspace, i.e., if \(\phi \left(t\right)\in {V}_{j},\mathrm{ then }\phi \left(t-k\right)\in {V}_{j}, \forall j,k\in \mathcal{Z}\).
A mutually orthogonal complement of \({V}_{j}\) in \({V}_{j+1}\) is \({W}_{j}\), such that,
where \(\oplus \) is a direct sum. This subspace \({W}_{j}\) is spanned by a set of wavelet functions \({\psi }_{j,k}(t)\), i.e.,\({W}_{j}=\left\{{\psi }_{j,k}\left(t\right)|{\psi }_{j,k}\left(t\right)={2}^{\frac{j}{2}}\psi \left({2}^{j}t-k\right), k\in \mathcal{Z}\right\}\)where \(\psi \left(t\right)\) is the mother wavelet. It follows that,
and therefore,
The two-scale dilation and translation relations for the scaling functions can be written as
Orthogonal wavelet functions can be obtained by imposing orthogonality conditions between scaling and wavelet functions in the frequency domain using Fourier transform,
where \({d}_{k}\) is the coefficient.
Orthogonal scaling functions can be constructed by choosing a candidate function \({\phi }^{*}\left(t\right)\) such that \({\phi }^{*}\left(t\right)\) have reasonable decay and a finite support. In addition, \(\int {\phi }^{*}\left(t\right)dt\ne 0\). It should also satisfy the two-scale relation,
With these, an orthogonal scaling function \(\phi \left(t\right)\) can be expressed in terms of \({\phi }^{*}\left(t\right)\) as
It is then possible to define the scaling function at the coarse scale in terms of the scaling function at the fine scale and the wavelet functions at the coarser scale,
Any function can be approximated at scale \([j]\) by using \({\phi }_{j,k}\) as a basis as well as using its coarse scale \([j-1]\) representation and details at the coarse scale, i.e.,
where \({P}_{j}\) and \({H}_{j}\) are the operators projecting \(f\) onto the subspaces \({V}_{j}\) and details of \(f\) at scale \([j]\) in the orthogonal subspace \({W}_{j}\), respectively. \({S}_{k}^{[j]}\) and \({T}_{k}^{[j]}\) are the corresponding basis coefficients at the coarse scale \([j]\). While the example shown here is for a one-dimensional case, this multi-resolution representation can be extended to multi-dimensions.
3.3.2 Multi-resolution data representation and training protocols
In this approach, a given signal \(f\left(t\right)\) is represented using the multi-resolution scaling functions and wavelets. A scale \([j]\) representation of signal \(f\left(t\right)\) can be obtained from the scale \([r] (j>r)\) representation with the addition of wavelet components (high frequency components) of the scales higher than \([r]\), using the discrete wavelet transform modified from Eq. (27),
where \({P}_{r}\) is the projection operator at scale \([r]\) and \({H}_{b}\) are the wavelet projectors of the signal that are added from scale \(\left[r\right]\) to scale \([j-1]\) to reconstruct the signal at scale \([j]\); \({S}_{k}^{[r]}\) and \({T}_{k}^{[b]}\) are the scaling and wavelet function’s coefficients, obtained by the orthogonality condition as given in Sect. 3.3.1.
Using the Wavelet transform to represent a time series under multiple resolutions offers advantages for feature extraction from signals. Compared to the Fourier transform which offers only localization in the frequency domain, the Wavelet transform provides both frequency and time domain localization, making it more suitable for time history (or sequence) learning algorithms such as the standard RNN and its enhanced variant GRU. More specifically, one can enhance training efficiency by using a sequential training strategy for the time-history input (sEMG) and output (joint motion) data. Applying the Fast Wavelet Transform [59, 60] to obtain the input and output data from low to high resolutions results in better generalization performance of the RNN trained to map from sEMG signals to joint motion time history as described below. The second order Daubechies wavelets are used in this work.
Here we consider a general MSK system described in Sect. 2. The original unfiltered data is denoted as scale [0], which will be decomposed into a sequence of lower scales \(\left[-j\right], j\in {\mathbb{Z}}^{+}\) for multi-resolution training.
Let \({{\varvec{D}}}^{[0]}\) be the input training data at the full-scale \(\left(j=0\right)\) of the raw signals i.e.,
and the motion of joints of the MSK system at the \({i}^{th}\) time-step at the full-scale \(\left(j=0\right)\) is \({{\varvec{q}}}_{i}^{\left[0\right]}\) such that the array of the unfiltered motion data for the duration of the motion is \({{\varvec{q}}}^{\left[0\right]}=\left[{{\varvec{q}}}_{1}^{\left[0\right]},{{\varvec{q}}}_{2}^{\left[0\right]},\dots, {{\varvec{q}}}_{{N}_{data}}^{\left[0\right]}\right]\).
From MR theory, subtracting details from the fine scale representations at the full-scale of the signal, i.e., \([0]\), results in a course scale representation of the signal at scale \(\left[-k\right], k=1,\dots j\). The projected training data at coarse scale [-j] is defined as
where \({N}_{data}\) is the total number of data points and
is the input data of scale [-j] at time step \(i\). The motion of the MSK joints at the \({i}^{th}\) time-step at the scale \([-j]\) is \({{\varvec{q}}}_{i}^{\left[-j\right]}.\) The data sets for a representative muscle group ‘\(MT\)’, \({e}_{i}^{MT[-j]}\) and motion \({{\varvec{q}}}_{i}^{\left[-j\right]}\), are obtained from the original raw data \({e}_{i}^{MT[0]}\) and \({{\varvec{q}}}_{i}^{\left[0\right]}\) by wavelet projection using Eq. (27), that is,
where \({{\varvec{P}}}_{j}\) and \({{\varvec{H}}}_{j}\) are the projection operators in multi-dimensions. Hence, datasets that contain lower resolution representations of the original signal at scales \([0]\) can be expressed as:
where \({{\varvec{q}}}^{\left[-j\right]}=\left[{{\varvec{q}}}_{1}^{\left[-j\right]},{{\varvec{q}}}_{2}^{\left[-j\right]},\dots ,{{\varvec{q}}}_{{N}_{data}}^{\left[-j\right]}\right]\).
Instead of learning the signal mapping from input original raw sEMG data \({{\varvec{D}}}^{\left[0\right]}\) to motion data \({{\varvec{q}}}^{\left[0\right]}\), we initiate learning the mapping by starting from a coarse scale representation of the input–output data at scale \([-j]\) and map \({{\varvec{D}}}^{\left[-j\right]}\) to \({{\varvec{q}}}^{\left[-j\right]}\). For multi-resolution RNN, the initial learning starts from the coarsest scale \([-j]\) as follows:
At the next finer scale \([-j+1]\), the weights at scale \([-j]\) (using an early stopping [62]) are used as the initial values for \({{\varvec{W}}}_{hh}^{[-j+1]}\), \({{\varvec{W}}}_{xh}^{[-j+1]}\), \({{\varvec{W}}}_{qh}^{[-j+1]}\), \({{\varvec{W}}}_{h\widehat{q}}^{[-j+1]}{{\varvec{b}}}_{h}^{[-j]}{{\varvec{b}}}_{q}^{[-j]}\), similar to the concept of transfer learning[63].
Similarly, for multi-resolution GRU, the initial learning starts from the coarsest scale \([-j]\) as described in “Appendix C”. The same procedures to transfer the NN parameters in Eq. (34)-(36) are repeated with \([-j]\to [-j+1]\) until it reaches scale [0]. To enhance model accuracy and robustness, variations based on Gaussian noise are added to the motion data in each sequential step, as suggested by [29]. The sequential MR training process is described in Algorithm 1.

4 Verification example
For verification of the proposed MR PI-RNN framework, an elbow flexion–extension model [1] and synthetic sEMG signals with Gaussian noise and associated motion responses were considered. The flowchart of the proposed computational framework for simultaneous forward dynamics prediction and parameter identification of MSK parameters is shown in Fig. 6.

An overview of the application of this framework to the recorded motion data. The location of motion capture markers is circled in red and the sEMG sensors on Biceps and Triceps muscle groups in blue and green, respectively. The simplified rigid body model was used in the forward dynamics equations within the framework with appropriately scaled anthropometric properties (for geometry) and physiological parameters (for muscle–tendon material models). The raw sEMG signals were mapped to the target angular motion of the elbow and used to simultaneously characterize the MSK system using the proposed Multi-Resolution PI-RNN framework
The model contained two rigid links corresponding to the upper arm and forearm with lengths \({l}_{ua}\) and \({l}_{fa}\), respectively. They were connected at a hinge resembling the elbow joint “A”, while the upper arm link was fixed at the top joint “B”, and the biceps (Bi) and triceps (Tri) muscle–tendon complexes (modeled by Hill-type models with parameters \({{\varvec{\kappa}}}_{Bi}\) and \({{\varvec{\kappa}}}_{Tri}\)) were represented by the lines connecting the links, as shown in Fig. 6. The degree of freedom of the model was the elbow flexion angle \(q\). The mass in the forehand was assumed to be concentrated at the wrist location, hence, a mass \({m}_{fa}\) was attached to one end of the forearm link with a moment arm \({l}_{fa}\) from the elbow joint. Tendons were assumed as rigid [58] for ease of computation.
The equation of motion for this rigid body system is given in “Appendix D”. Given the synthetic sEMG signals (\({e}^{Bi}(t),{e}^{Tri}(t)\)), the initial conditions \(q\left(0\right)=\frac{\pi }{6} \mathrm{radians}\) and \(\dot{q}\left(0\right)=0 \; \mathrm{radians}/\mathrm{sec}\) and the parameters in Table 1, the motion of the elbow joint, \(q\), can be obtained by solving the MSK forward dynamics problem using an explicit Runge–Kutta scheme, implemented in Python’s SciPy library [64].
To verify and check the robustness of the MR framework to different levels of noise in the input, the following test was performed. Originally, five synthetic samples i.e., Trial's 1 to 5, of noiseless synthetic muscle sEMG signals are assumed, as shown in Fig. 7. In practical applications, signals obtained from measurement devices such as sEMG sensors contain noise in their content. Therefore, three cases were developed by adding Gaussian noise \(\left(\mathcal{N}\left(\mu ,\sigma \right)\right)\) with zero mean \(\left(\mu =0\right)\) and increasing levels of standard deviations \(\left(\sigma \right)\) to the input synthetic sEMG signals as mentioned in Table 2. As the maximum value of the noiseless sEMG signals is 1, the chosen \(\sigma \)'s were kept within 10%—20% of the signal maximum for a reasonable level of noise. Restricting it between 10%—20% is a choice as having higher noise levels (> 20%) would dominate over the underlying ‘noiseless’ periodic sinusoidal signal, leading to non-physiological synthetic sEMG signals. The corresponding output motions are generated by passing the noisy sEMG as input to the FD equations in Sect. 2. The following training procedures were performed for each of the three cases.

The original ‘noiseless’ input–output data set with the synthetic biceps and triceps sEMG signals having variations in frequency for five trials are shown at the top. Increasing levels of noise are added to develop 3 cases of synthetic mixed frequency input sEMG, from which corresponding output motions are solved, using the forward dynamics equations. To verify the MR framework, these three cases with their respective mixed frequency input data are then mapped to their corresponding motion data
4.1 1-scale training
The mixed frequency input sEMG signals and corresponding output motion data \({\varvec{q}}\) at scale [0], denoted by \({{\varvec{D}}}^{\left[0\right]}\) and \({{\varvec{q}}}^{\left[0\right]}\), respectively, are mapped to get a baseline performance. This is termed as 1-scale training as only the full-scale (i.e., [0]) of the mixed frequency data is used for training.
4.2 2-scale training
-
a.
Initiate learning from a coarse scale representation of the mixed frequency input data at scale \([-1]\) and map \({{\varvec{D}}}^{\left[-1\right]}\) to the corresponding motion data at scale [-1], \({{\varvec{q}}}^{\left[-1\right]}\), of that case.
-
b.
Transfer parameters to the next scale training and finish the learning by mapping \({{\varvec{D}}}^{\left[0\right]}\) to \({{\varvec{q}}}^{\left[0\right]}\).
4.3 3-scale training
-
a.
Start learning from a coarse scale representation of the mixed frequency input data at scale \([-2]\) and map \({{\varvec{D}}}^{\left[-2\right]}\) to the corresponding motion data at scale [-2], \({{\varvec{q}}}^{\left[-2\right]}\), of that case.
-
b.
Transfer parameters to the next scale training and continue learning by mapping \({{\varvec{D}}}^{\left[-1\right]}\) to \({{\varvec{q}}}^{\left[-1\right]}\).
-
c.
Transfer parameters to the next scale training and finish the learning by mapping \({{\varvec{D}}}^{\left[0\right]}\) to \({{\varvec{q}}}^{\left[0\right]}\).
For each case and for each of the training scales in that case, the training data samples contained the data of trial’s 1, 2, 4, 5 while trial 3 was used for testing, each trial with \(n=\) 500 data points. The MSK parameters \(\boldsymbol{\Gamma }={\left\{{\Gamma }_{l}\right\}}_{l=1}^{4}=\left\{{f}_{0,Bi}^{M},{l}_{0,Bi}^{M},{f}_{0,Tri}^{M},{l}_{0,Tri}^{M}\right\}\) were chosen to be identified from the training data using the proposed framework. Due to differences in units and physiological nature of the parameters, the conditioning of the parameter identification system could be affected. To mitigate this issue, normalization [1, 44] was applied to each of the parameters,
where \({\Gamma }_{l}^{\left(0\right)}\) was the initial value of the parameter. Therefore, the parameters to be identified became \(\overline{\boldsymbol{\Gamma } }={\left\{{\overline{\Gamma } }_{l}\right\}}_{l=1}^{4}\).
The proposed framework, as described in Sect. 3, was applied to each case to simultaneously learn the MSK forward dynamics surrogate and identify the MSK parameters \(\overline{\boldsymbol{\Gamma } }\) by optimizing Eq. (16), where the residual of the governing equation for the current time step \(k\), was expressed as
and is included in the residual term \({J}_{res}\) in the loss function in Eq. (16). While the training happens sequentially from coarse to fine-scales of the motion, the final identification of parameters happens at the scale \([0]\), i.e., the full-scale in each of the 1-, 2- and 3-scale MR training types.
A GRU with 2 history steps, 1 hidden layer and 50 neurons in each layer was used. The training was performed after standardizing the data, such that the scale or range of the input and output have minimal influence on model performance [21]. The Adam algorithm [65] was used with an initial learning rate of \(1{\times 10}^{-3}\) and the penalty parameter for the MSK residual term in the loss function, \(\beta \propto \frac{\Delta {t}^{2}}{I}={10}^{-3}\). \(\Delta t\) is the time-step between data points and \(I\) is the moment of inertia in Eq. (38). Five parameter initialization seeds were used for an averaged response of the MR training.
To compare the post-training performance of 1-, 2- and 3-scale MR training’s, the average testing mean squared error (MSE) and testing \({\mathrm{R}}^{2}\) scores were compared, where these measures for a single trial are defined as:
where \({\varvec{q}}\) is the motion data of the trial, \(\widehat{{\varvec{q}}}\) is the trial’s predicted motion from the MR PI-RNN framework, and \(\overline{q }\) is the mean of trial’s motion data with \(n\) being the number of data points in the trial. At each epoch in the MR training, the training loss is calculated by using the scale of the training data used in that training scale, i.e., scale \([-j]\) of the data is used in \(j\)-scale training.
The gradual improvement in these metrics is evident from Fig. 8 where, as further scales of information are added and the training data is augmented, the generalization performance shows improvement from 1-scale to 3-scale. Overall, it is noted that the test metrics such as the MSE reduces, and the \({\mathrm{R}}^{2}\) score gets closer to one, indicating an increase in the generalization accuracy as more training scales are introduced. This can be explained through the theory of bias-variance tradeoff; training on various scales of the data introduces more variance to the training, helping the ML framework to reduce the bias it develops by just training on the full-scale of the data. Together, this reduction in bias and growth in variance leads to a better generalization performance. Computationally, this method improves accuracy in the same amount of training epochs showing the efficiency of this method. As generalization predictions post-training are made using the full-scale of the data, there is no increase in time needed to perform the forward pass for any scale.

The training loss and testing metrics are shown. The zoomed-in plots are included for clarity on the loss evolution for the last 500 epochs. The shaded area indicates one standard deviation from the mean (solid line), in both the loss and average test MSE and \({\mathrm{R}}^{2}\) score figures. As more scales of data are introduced in the MR training, the average Test MSE and \({\mathrm{R}}^{2}\) score calculated post-training improve in each case
Meanwhile, the MSK parameters, \({f}_{0}^{M}\) (maximum isometric force) and \({l}_{0}^{M}\) (optimal muscle length corresponding to the maximum isometric force), of both the biceps and the triceps were accurately identified from the motion data, as shown in Table 3. Compared with the parameter identification from our previous work [1] where in addition to \({f}_{0}^{M}\), the maximum contraction velocity \({v}_{max}^{M}\) was independently identified, due to non-convergence of \({l}_{0}^{M}\) by the time-domain and feature-encoded trainings, the proposed method can accurately identify \({l}_{0}^{M}\). \({v}_{max}^{M}\) can then by obtain by the experimentally observed relationship of \({v}_{max}^{M}/{l}_{0}^{M}=10 {\mathrm {sec}}^{-1}\) [57, 66].
For the identification of optimal muscle length parameters \(\left({l}_{0}^{M}\right)\), the initial points need to be chosen with respect to constraints applied by the geometry of the MSK system. The errors reported in Table 3 are calculated by taking the average of the percentage error of the identified MSK parameters from the 3-scale training with the multiple parameter \(({\varvec{\theta}},\boldsymbol{\Gamma })\) initializations. It was observed that in MSK parameter identification, similar accuracy in characterization was obtained from all training scale approaches used within each case, with errors less than 1%. This indicates that the MR PI-RNN improves the generalization performance of the motion prediction, without loss in parameter identification accuracy. It is noted that this example investigates the predictivity of in-distribution testing data, i.e., testing data that lies within the range of the training data. The effect of MR PI-RNN training on out-of-distribution predictivity is also studied in “Appendix E”.
5 Validation: elbow flexion–extension motion
5.1 Application of MR PI-RNN to subject-specific data
The recorded motion data and sEMG signals were collected and processed as per the data acquisition protocols mentioned in [1]. In brief, three elbow flexion–extension motion trials were performed by the subject for 10 s each, with two Delsys Trigno sEMG sensors placed on the biceps and triceps muscle groups, based on SENIAM recommendations [67]. The processed sEMG signals were transformed as described in Sect. 2.1 to obtain muscle activation signals, used to calculate the MSK forward dynamics ODE residual. The same simplified rigid body model was used as in Sect. 4 and appropriately scaled anthropometric properties (for the geometry of the model) and physiological parameters (for muscle–tendon material models used for the muscle groups) based on the generic upper body model defined in [68, 69] were used. Figure 9 shows the measured data of the three trials, including the transient raw sEMG signals and the corresponding angular motion of the elbow flexion–extension of the subject.

The measured raw sEMG signals and the corresponding angular motion of the elbow flexion–extension of the subject are plotted
In this example, the raw sEMG signals were used as input. A 5-scale MR training procedure as described in Sect. 4 was used on a GRU with 1 hidden layer with 50 neurons. The data of trials 1 and 3 were used for training, while trial 2 was used for testing, where each signal contained 500 temporal data points.
The muscle parameters to be identified by the framework include the maximum isometric force and the optimal muscle length from both muscle groups, which are denoted as \(\boldsymbol{\Gamma }=\left\{{f}_{0,Bi}^{M},{l}_{0,Bi}^{M},{f}_{0,Tri}^{M},{l}_{0,Tri}^{M}\right\}\). It was observed in our tests that despite the normalization process described in Eq. (37) and (38), the parameters obtained at the end of the MR training with motion data either diverged or converged to non-physiological values. To obtain physiologically consistent parameters, we use the values obtained from literature studies and constrain the space of parameter search [44].
Let the parameter to be identified be defined as
where \({\overline{\gamma }}_{r}\) is the value defined in the \({r}^{th}\) literature study and \({\psi }_{r}\) is the parameter to be optimized in the training such that it can be used to evaluate the sigmoid function \(\mathrm{sig}\left({\psi }_{r}\right)\) and \({\varvec{\psi}}\) is the vector of these trainable parameters. Using the optimized \({\varvec{\psi}}\), the desired MSK parameters can be estimated. This formulation constrains the identified parameters to be consistent with parameters obtained through experimental studies [68,69,70].
The proposed framework was then applied to simultaneously learn the MSK forward dynamics surrogate and identify the MSK parameters \(\boldsymbol{\Gamma }\) by optimizing Eq. (16), where the residual of the governing equation for the current time step \(k\), is expressed with a slight correction of Eq. (38) due to parameter space modification as
This is introduced into the residual term \({J}_{res}\) in the loss function and the optimization problem becomes,
As mentioned in the verification example (Sect. 4), the multi-resolution parameter identification is performed starting from the coarsest scale, transferring the learned hyperparameters to the next finer scale parameter identification, and finally completing the parameter identification at the full-scale, i.e., at scale \([0]\).
5.2 Results
To accelerate the training process, the training dataset is standardized to have zero mean and unit variance. The training was performed with the standardized data, using the Adam algorithm [65] with an initial learning rate of \(1{\times 10}^{-3}\) and 4 history steps were considered. Five parameter initialization seeds were used for an averaged response of the MR training. To quantify the error in the testing predictions, a normalized mean squared error (NMSE) was defined,
where \({q}_{i}\) is the \({i}^{th}\) target motion data point, \(\widehat{{q}_{i}}\) is the \({i}^{th}\) predicted motion data point, from the MR PI-RNN framework, and \(\overline{q }\) is the mean of target motion data. The \({\mathrm{R}}^{2}\) score was calculated using the metric defined in Eq. (40). From Fig. 10, Fig. 11 and Table 4, it is clear that addition of training scales leads to improved motion predictions. The multi-resolution training leads to an increase in average test \({\mathrm{R}}^{2}\) score of more than 40% (bringing it closer to one), averaged over the multiple initialization seeds. With the addition of more scales, Fig. 10 clearly shows the progression in improvement of the predictions as more scales are involved in the training.

Comparison of test predictions post-training for each MR training scale performed. The solid dash line is the mean of the predictions post-training when various initialization points are utilized to begin the MR training, with shaded region indicating one standard deviation from the mean

The test normalized mean squared error (NMSE) and test \({\mathrm{R}}^{2}\) score are plot for the testing predictions post-training, averaged over five initialization seeds. The mean of the metric is the solid marker line, the shaded portion being one standard deviation from the mean
The identified MSK parameters from the MR PI-RNN training are summarized in Table 5 with the mean of the final converged values of \({f}_{0}^{M}\) and \({l}_{0}^{M}\) obtained from multiple parameter initializations at 4-scale training, consistent with the physiological estimates of these parameters reported in literature [68,69,70]. \({l}_{0,Bi}^{M}\) is slightly outside the estimated range, which could be attributed to the variance in population. Similar values were obtained across all scales of training hence parameters obtained from a representative 4-scale training are shown here. The results demonstrated the effectiveness of the proposed MR PI-RNN framework and promising potential for real applications.
6 Discussion and conclusions
In this work, we proposed a multi-resolution physics-informed recurrent neural network (MR PI-RNN) for an application to MSK systems, for time-domain motion prediction and parameter identification. A GRU with a physics-informed loss function that minimized the error in the training data and the residual of the MSK forward dynamics equilibrium was used for this purpose. Wavelet based multi-resolution techniques were used to decompose the input sEMG signals and output joint motion data into coarse-scale approximations at different scales and fine-scale details at those scales. The sEMG and joint motion multi-scale components were then mapped to each other starting from a chosen coarse-scale components and then sequentially trained (via transfer learning) to higher scales, completing the training on the full-scale of the data.
By initializing training on the coarse-scale of the training data, the optimization reaches a local minimum that serves as a better initialization state for the training data that includes the sequential fine-scale details. The proposed transfer-learning based sequential training scheme can be used for learning datasets that have high frequency signals as shown in the verification example with synthetic mixed frequency sEMG data. The numerical examples show an improvement in testing prediction and identifying the parameters. We observe from the loss profiles that the testing loss decreased while the training loss increased as more scales of data were brought in. It was also observed that the average test MSE and \({\mathrm{R}}^{2}\) metrics showed a clear improvement in the generalization accuracy. These phenomena can be explained through the theory of bias-variance tradeoff; training on various scales of the data introduces more variance to the training, helping the ML framework to reduce the bias it develops by just training on the full-scale of the data. Computationally, it is noted that the proposed method achieves improved accuracy by using the same amount of training epochs.
The proposed MR framework was validated on recorded sEMG and motion data from a subject [1] and significant improvements were observed in the testing prediction accuracy, with 1-scale training often leading to large errors. The predicted motion at higher training scales showed improvements across all initialization points used, indicating the robustness of the method. The identified parameters were also consistent with the physiological range observed in literature.
This method also has the advantage of operating in the time-domain as compared to the feature-encoded (FE) training [1], where the input sEMG signals were projected on to the frequency domain using the Fourier basis. In the FE training, to make a prediction, the input signal for the entire duration of the movement prediction was needed whereas the physics informed MR training of the RNN enables the trained model to make real-time predictions by using the information of the previous time-steps and the current sEMG signal. In addition, for mixed frequency signals, wavelet resolution can better capture the local frequency information as compared to the Fourier basis which captures the global frequency information. As compared to the NN-based time-domain training performed at the original scale of the data (scale [0]) proposed in [1], the MR PI-RNN training approach described here achieved significant improvements due to the stronger sequence learning capability of the RNN and the ability of the MR training.
This method is presented as a general approach where multi-resolution is applied to both input and output. For some applications, e.g., those that require only data mapping, the MR training can be applied by only considering the decomposition to the input, keeping the output at the full-scale (i.e., scale [0]) throughout, or vice versa. To apply this method to clinical studies, RNN hyperparameters may also be tuned to account for subject variability. The dependence of this method on the number of data points available in a signal can also be studied in the future. To further improve this method, we can consider the use of multi-resolution as activation functions of the ML framework, instead of relying on data filtration processes for better computational efficiency. This method will also be studied on other physics-informed ML techniques to solve forward problems with PDEs having mixed frequency source terms.
Abbreviations
- \(e\) :
-
Raw sEMG signals captured by sensors
- \(u\) :
-
Neural excitations
- \(a\) :
-
Muscle activations
- \(d\) :
-
Electro-mechanical delay between origin of neural excitation from central nervous system and reaching the muscle group
- \(A\) :
-
Shape factor used to relate neural excitation to muscle activation
- \({f}_{0}^{M}\) :
-
Maximum isometric force in the muscle
- \({l}_{0}^{M}\) :
-
Optimal muscle length corresponding to the maximum isometric force
- \({v}_{max}^{M}\) :
-
Maximum contraction velocity
- \({l}_{s}^{T}\) :
-
Slack length of the tendon
- \(\vartheta \) :
-
Pennation angle between muscle and tendon
- \({\boldsymbol{\kappa}}\) :
-
Set of muscle parameters for each muscle group
- \({\widetilde{l}}^{M}\) :
-
Normalized muscle length
- \({\widetilde{v}}^{M}\) :
-
Normalized muscle velocity
- \({l}^{MT}\) :
-
Total length of muscle–tendon complex
- \({f}^{A}\) :
-
Active force component of hill-type muscle model
- \({f}^{A,L}\) :
-
Length dependent active force generation component
- \({f}^{V}\) :
-
Velocity dependent active force generation component
- \({f}^{P}\) :
-
Passive force component of hill-type muscle model
- \({F}^{M}\) :
-
Total muscle force
- \({F}^{MT}\) :
-
Total force produced by muscle–tendon complex
- \({T}^{MT}\) :
-
Torque produced by the muscle–tendon complex
- \(q\) :
-
Generalized angular motion of the MSK system
- \({{\varvec{h}}}_{n}\) :
-
Hidden state after n history steps of the RNN/GRU
- \({{\varvec{W}}}_{XY}\) :
-
Weights connecting the variable \({\varvec{X}}\) to variable \({\varvec{Y}}\)
- \({{\varvec{b}}}_{X}\) :
-
Bias for the RNN to calculate variable \({\varvec{X}}\)
- \({{\varvec{r}}}_{i}\) :
-
Output from the reset gate of the GRU
- \({{\varvec{u}}}_{i}\) :
-
Output from the update gate of the GRU
- \({{\varvec{z}}}_{i},{{\varvec{c}}}_{i},{\widetilde{{\varvec{c}}}}_{i}\) :
-
Intermediate variables in GRU forward pass
- \({\widetilde{{\varvec{h}}}}_{n}\) :
-
Candidate hidden state after n history steps of the GRU
- \({\varvec{\theta}}\) :
-
Set of all weights and biases of the RNN/GRU
- \({\phi }_{j,k}\) :
-
Scaling function in multi-resolution analysis
- \({\psi }_{j,k}\) :
-
Wavelet function in multi-resolution analysis
- \({V}_{j},{W}_{j}\) :
-
The nested and complementary subspaces containing \({\phi }_{j,k}\) and \({\psi }_{j,k}\) respectively
- \({P}_{j},{H}_{j}\) :
-
Projection operators on a function \(f\) projecting it onto subspaces \({V}_{j}\) and \({W}_{j}\) respectively
- \({\Gamma }_{i}\) :
-
\({i}^{th}\) Parameter characterizing the parameterized ODE system
- \({{\varvec{x}}}_{i}^{\left[-j\right]}\) :
-
Input data at scale \([-j]\) to the MR PI-RNN framework at time-step i
- \({{\varvec{D}}}^{\left[-j\right]}\) :
-
Input data set projected to scale \([-j]\)
- \({\widehat{{\varvec{q}}}}_{i}^{\left[-j\right]}\) :
-
Predicted angular motion at scale [-j] from the MR PI-RNN framework at time-step i
- \(J\) :
-
Composite loss function of the PI-PINN minimizing data and ODE residual
- \({l}_{fa}\) :
-
Forearm length
- \({l}_{ua}\) :
-
Upper arm length
- \({m}_{fa}\) :
-
Mass of forearm
References
Taneja K, He X, He Q, Zhao X, Lin Y-A, Loh KJ, Chen J-S (2022) A feature-encoded physics-informed parameter identification neural network for musculoskeletal systems. J Biomech Eng 144(121006):1–16
Costello Z, Martin HG (2018) A machine learning approach to predict metabolic pathway dynamics from time-series multiomics data. npj Syst Biol Appl 4(1):1–14
Damle C, Yalcin A (2007) Flood prediction using time series data mining. J Hydrol 333(2):305–316
Nishino T, Hokugo A (2020) A stochastic model for time series prediction of the number of post-earthquake fire ignitions in buildings based on the ignition record for the 2011 Tohoku earthquake. Earthq Spectra 36(1):232–249
Manevitz L, Bitar A, Givoli D (2005) Neural network time series forecasting of finite-element mesh adaptation. Neurocomputing 63:447–463
Frank RJ, Davey N, Hunt SP (2001) Time Series Prediction and Neural Networks. J Intell Robotic Syst 31:91–103
Längkvist M, Karlsson L, Loutfi A (2014) A review of unsupervised feature learning and deep learning for time-series modeling. Pattern Recogn Lett 42:11–24
Calderón-Macías C, Sen MK, Stoffa PL (2000) Artificial neural networks for parameter estimation in geophysics. Geophys Prospect 48(1):21–47
Hubbard SS, Rubin Y (2000) Hydrogeological parameter estimation using geophysical data: a review of selected techniques. J Contam Hydrol 45(1):3–34
Ebrahimian H, Astroza R, Conte JP (2015) Extended kalman filter for material parameter estimation in nonlinear structural finite element models using direct differentiation method. Earthquake Eng Struct Dynam 44(10):1495–1522
Haghighat E, Raissi M, Moure A, Gomez H, Juanes R (2021) A physics-informed deep learning framework for inversion and surrogate modeling in solid mechanics. Comput Methods Appl Mech Eng 379:113741
Heine CB, Menegaldo LL (2018) Numerical validation of a subject-specific parameter identification approach of a quadriceps femoris EMG-driven model. Med Eng Phys 53:66–74
Hirschvogel M, Bassilious M, Jagschies L, Wildhirt SM, Gee MW (2017) A Monolithic 3D–0D coupled closed-loop model of the heart and the vascular system: experiment-based parameter estimation for patient-specific cardiac mechanics. Int J Numer Methods Biomed Eng 33(8):e2842
Schmid H, Nash MP, Young AA, Hunter PJ (2006) Myocardial material parameter estimation—a comparative study for simple shear. J Biomech Eng 128(5):742–750
Pau JWL, Xie SSQ, Pullan AJ (2012) Neuromuscular interfacing: establishing an EMG-driven model for the human elbow joint. IEEE Trans Biomed Eng 59(9):2586–2593
Zhao Y, Zhang Z, Li Z, Yang Z, Dehghani-Sanij AA, Xie S (2020) An EMG-driven musculoskeletal model for estimating continuous wrist motion. IEEE Trans Neural Syst Rehabil Eng 28(12):3113–3120
Kian A, Pizzolato C, Halaki M, Ginn K, Lloyd D, Reed D, Ackland D (2019) Static optimization underestimates antagonist muscle activity at the glenohumeral joint: a musculoskeletal modeling study. J Biomech 97:109348
Buchanan TS, Lloyd DG, Manal K, Besier TF (2004) Neuromusculoskeletal modeling: estimation of muscle forces and joint moments and movements from measurements of neural command. J Appl Biomech 20(4):367–395
Lloyd DG, Besier TF (2003) An EMG-driven musculoskeletal model to estimate muscle forces and knee joint moments in Vivo. J Biomech 36(6):765–776
Buongiorno D, Barsotti M, Barone F, Bevilacqua V, Frisoli A (2018) A Linear approach to optimize an emg-driven neuromusculoskeletal model for movement intention detection in myo-control: a case study on shoulder and elbow joints. Front Neurorobot 12:74
Goodfellow I, Bengio Y, Courville A (2016) Deep Learning. MIT Press, Cambridge, MA, USA
Kaneko S, Wei H, He Q, Chen J-S, Yoshimura S (2021) A hyper-reduction computational method for accelerated modeling of thermal cycling-induced plastic deformations. J Mech Phys Solids 151:104385
Kim B, Azevedo VC, Thuerey N, Kim T, Gross M, Solenthaler B (2019) Deep fluids: a generative network for parameterized fluid simulations. Comput Graph Forum 38(2):59–70
Xie X, Zhang G, Webster C (2019) Non-intrusive inference reduced order model for fluids using deep multistep neural network. Mathematics 7(8):757
Fries WD, He X, Choi Y (2022) LaSDI: parametric latent space dynamics identification. Comput Methods Appl Mech Eng 399:115436
He X, Choi Y, Fries WD, Belof JL, Chen J-S (2023) GLaSDI: Parametric physics-informed greedy latent space dynamics identification. J Comput Phys 489:112267
Ghaboussi J, Garrett JH, Wu X (1991) Knowledge-based modeling of material behavior with neural networks. J Eng Mech - ASCE 117(1):132–153
Lefik M, Boso DP, Schrefler BA (2009) Artificial neural networks in numerical modelling of composites. Comput Methods Appl Mech Eng 198(21):1785–1804
He X, Chen J-S (2022) Thermodynamically consistent machine-learned internal state variable approach for data-driven modeling of path-dependent materials. Comput Methods Appl Mech Eng 402:115348
Kirchdoerfer T, Ortiz M (2017) Data driven computing with noisy material data sets. Comput Methods Appl Mech Eng 326:622–641
Eggersmann R, Kirchdoerfer T, Reese S, Stainier L, Ortiz M (2019) Model-free data-driven inelasticity. Comput Methods Appl Mech Eng 350:81–99
He Q, Chen J-S (2020) A physics-constrained data-driven approach based on locally convex reconstruction for noisy database. Comput Methods Appl Mech Eng 363:112791
He X, He Q, Chen J-S, Sinha U, Sinha S (2020) Physics-constrained local convexity data-driven modeling of anisotropic nonlinear elastic solids. DCE 1:e19
He Q, Laurence DW, Lee C-H, Chen J-S (2021) Manifold learning based data-driven modeling for soft biological tissues. J Biomech 117:110124
Bahmani B, Sun W (2022) Manifold embedding data-driven mechanics. J Mech Phys Solids 166:104927
Carrara P, De Lorenzis L, Stainier L, Ortiz M (2020) Data-driven fracture mechanics. Comput Methods Appl Mech Eng 372:113390
He X, He Q, Chen J-S (2021) Deep autoencoders for physics-constrained data-driven nonlinear materials modeling. Comput Methods Appl Mech Eng 385:114034
Raissi M, Perdikaris P, Karniadakis GE (2019) Physics-informed neural networks: a deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J Comput Phys 378:686–707
Karniadakis GE, Kevrekidis IG, Lu L, Perdikaris P, Wang S, Yang L (2021) Physics-informed machine learning. Nat Rev Phys 3(6):422–440
He Q, Tartakovsky AM (2021) Physics-informed neural network method for forward and backward advection-dispersion equations. Water Resour Res 57(7):e2020WR029479
Zhu Q, Liu Z, Yan J (2021) Machine learning for metal additive manufacturing: predicting temperature and melt pool fluid dynamics using physics-informed neural networks. Comput Mech 67(2):619–635
Xu K, Tartakovsky AM, Burghardt J, Darve E (2021) Learning viscoelasticity models from indirect data using deep neural networks. Comput Methods Appl Mech Eng 387:114124
Tartakovsky AM, Marrero CO, Perdikaris P, Tartakovsky GD, Barajas-Solano D (2020) Physics-informed deep neural networks for learning parameters and constitutive relationships in subsurface flow problems. Water Resour Res 56(5):e2019WR026731
He Q, Stinis P, Tartakovsky AM (2022) Physics-constrained deep neural network method for estimating parameters in a redox flow battery. J Power Sources 528:231147
He Q, Barajas-Solano D, Tartakovsky G, Tartakovsky AM (2020) Physics-informed neural networks for multiphysics data assimilation with application to subsurface transport. Adv Water Resour 141:103610
Kissas G, Yang Y, Hwuang E, Witschey WR, Detre JA, Perdikaris P (2020) Machine learning in cardiovascular flows modeling: predicting arterial blood pressure from non-invasive 4D flow MRI data using physics-informed neural networks. Comput Methods Appl Mech Eng 358:112623
Sahli Costabal F, Yang Y, Perdikaris P, Hurtado DE, Kuhl E (2020) Physics-informed neural networks for cardiac activation mapping. Front Phys 8:42
Alber M, Buganza Tepole A, Cannon WR, De S, Dura-Bernal S, Garikipati K, Karniadakis G, Lytton WW, Perdikaris P, Petzold L, Kuhl E (2019) “Integrating machine learning and multiscale modeling—perspectives, challenges, and opportunities in the biological, biomedical, and behavioral sciences.” npj Digit Med 2(1):1–11
Yazdani A, Lu L, Raissi M, Karniadakis GE (2020) Systems biology informed deep learning for inferring parameters and hidden dynamics. PLOS Comput Biol 16(11):e1007575
Zhang J, Zhao Y, Bao T, Li Z, Qian K, Frangi AF, Xie SQ, Zhang Z-Q (2023) “Boosting personalized musculoskeletal modeling with physics-informed knowledge transfer.” IEEE Trans Instrum Meas 72:1–11
Bartsoen L, Faes MGR, Andersen MS, Wirix-Speetjens R, Moens D, Jonkers I, Sloten JV (2023) Bayesian parameter estimation of ligament properties based on tibio-femoral kinematics during squatting. Mech Syst Signal Process 182:109525
Linden NJ, Kramer B, Rangamani P (2022) Bayesian parameter estimation for dynamical models in systems biology. PLoS Comput Biol 18(10):e1010651
Lipton, Z. C., Berkowitz, J., and Elkan, C., 2015, “A critical review of recurrent neural networks for sequence learning,” arXiv:1506.00019 [cs].
Hamner SR, Seth A, Delp SL (2010) Muscle contributions to propulsion and support during running. J Biomech 43(14):2709–2716
Zhang Y, Chen J, He Q, He X, Basava RR, Hodgson J, Sinha U, Sinha S (2020) Microstructural analysis of skeletal muscle force generation during aging. Int J Numer Methods Biomed Eng 36(1):e3295
Chen J-S, Basava RR, Zhang Y, Csapo R, Malis V, Sinha U, Hodgson J, Sinha S (2016) Pixel-based meshfree modelling of skeletal muscles. Comput Methods Biomech Biomed Eng Imaging Vis 4(2):73–85
Millard M, Uchida T, Seth A, Delp SL (2013) Flexing computational muscle: modeling and simulation of musculotendon dynamics. J Biomech Eng 135(2):021005
Winters JM (1990) Hill-Based Muscle Models: A Systems Engineering Perspective. Multiple Muscle Systems, Springer, New York, NY, pp 69–93
Mallat SG (1989) Multiresolution approximations and wavelet orthonormal bases of L 2 (R). Trans Am Math Soc 315(1):69
Mallat SG (1989) A theory for multiresolution signal decomposition: the wavelet representation. IEEE Trans Pattern Anal Mach Intell 11(7):674–693
Baydin AG, Pearlmutter BA, Radul AA, Siskind JM (2018) Automatic differentiation in machine learning: a survey. J Mach Learn Res 18:43
Yao Y, Rosasco L, Caponnetto A (2007) On early stopping in gradient descent learning. Constr Approx 26(2):289–315
Weiss K, Khoshgoftaar TM, Wang D (2016) A survey of transfer learning. J Big Data 3(1):9
Virtanen P, Gommers R, Oliphant TE, Haberland M, Reddy T, Cournapeau D, Burovski E, Peterson P, Weckesser W, Bright J, van der Walt SJ, Brett M, Wilson J, Millman KJ, Mayorov N, Nelson ARJ, Jones E, Kern R, Larson E, Carey CJ, Polat İ, Feng Y, Moore EW, VanderPlas J, Laxalde D, Perktold J, Cimrman R, Henriksen I, Quintero EA, Harris CR, Archibald AM, Ribeiro AH, Pedregosa F, van Mulbregt P (2020) SciPy 1.0: fundamental algorithms for scientific computing in python. Nat Methods 17(3):261–272
Kingma, D. P., and Ba, J., 2017, “Adam: A Method for Stochastic Optimization,” arXiv:1412.6980 [cs].
Thelen DG (2003) Adjustment of muscle mechanics model parameters to simulate dynamic contractions in older adults. J Biomech Eng 125(1):70–77
Hermens HJ, Freriks B, Merletti R, Stegeman D, Blok J, Rau G, Disselhorst-Klug C, Hägg G (1999) “European recommendations for surface electromyography. Roessingh Res Dev 8(2):13–54
Garner BA, Pandy MG (2003) Estimation of musculotendon properties in the human upper limb. Ann Biomed Eng 31(2):207–220
Holzbaur KRS, Murray WM, Delp SL (2005) A model of the upper extremity for simulating musculoskeletal surgery and analyzing neuromuscular control. Ann Biomed Eng 33(6):829–840
An KN, Hui FC, Morrey BF, Linscheid RL, Chao EY (1981) Muscles across the Elbow Joint: a biomechanical analysis. J Biomech 14(10):659–669
Acknowledgements
The support of this work by the National Institute of Health under grant number 5R01AG056999-04 to K. Taneja & J. S. Chen are very much appreciated.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Muscle–Tendon Force Generation
The total muscle force \({F}^{M}\) can be expressed as
where \({f}^{P}\left({\widetilde{l}}^{M}\right)\) is the passive muscle length dependent force generation function. The active force \({f}^{A}\) component can be expressed as:
where \(a\) is the activation function in Eq. (2), \({\widetilde{l}}^{M}\) is the normalized muscle length, \({\widetilde{v}}^{M}\) is the normalized velocity of the muscle. The total length of the MT system \({l}^{MT}\) is given by,
Given the current joint angle \(q\) and the angular velocity \(\dot{q}\), the current length, \({l}^{MT}\) of the MT system can be calculated using trigonometric relations.
The \({f}^{A,L}\left({\widetilde{l}}^{M}\right)\) and \({f}^{V}\left({\widetilde{v}}^{M}\right)\) are generic functions of the length and velocity dependent force generation properties of the active muscle, represented by dimensionless quantities. In this study, the tendon is assumed to be rigid \(\left({l}^{T}={l}_{s}^{T}\right)\). The total force produced by the MT complex, \({F}^{MT}\), can be expressed as:
The rigid-tendon model simplifies the MT contraction dynamics [57, 58] which accounts for the interaction of the activation, force length, and force velocity properties of the MT complex.
Appendix B: Hill-Type Muscle Models
For the length dependent muscle force relations, this work uses the equations given in [55]. The active muscle force dependent on variation in length is given as
where \({\gamma }_{1}=0.075\) and \({\gamma }_{2}=6.6\) correspond to parameters in the passive muscle force model related to an adult human. The muscle force velocity relationship \({f}^{V}\left({\widetilde{v}}^{M}\right)\) is used directly from [66].
Appendix C: Multi-Resolution GRU Formulation
For multi-resolution GRU, the initial learning starts from the coarsest scale \([-j]\) as follows with notations according to Sect. 3.3.2,
where the weights \({{\varvec{W}}}_{hr}^{\left[-j\right]},{{\varvec{W}}}_{xr}^{\left[-j\right]},{{\varvec{W}}}_{qr}^{\left[-j\right]},{{\varvec{W}}}_{hu}^{\left[-j\right]},{{\varvec{W}}}_{xu}^{\left[-j\right]},{{\varvec{W}}}_{qu}^{\left[-j\right]},{{\varvec{W}}}_{h\widetilde{h}}^{\left[-j\right]},{{\varvec{W}}}_{x\widetilde{h}}^{\left[-j\right]},{{\varvec{W}}}_{q\widetilde{h}}^{\left[-j\right]}\) and biases \({{\varvec{b}}}_{r}^{\left[-j\right]},{{\varvec{b}}}_{u}^{\left[-j\right]},{{\varvec{b}}}_{\widetilde{h}}^{\left[-j\right]},{{\varvec{b}}}_{h}^{\left[-j\right]},{{\varvec{b}}}_{q}^{\left[-j\right]}\) are trainable parameters.
Appendix D: Equation of Motion of the Simplified MSK Model
The equation of motion for the rigid body system used in Sect. 4 is,
where,
Appendix E: Study on Out-of-Distribution predictivity of the MR PI-RNN training
To investigate the performance of the MR training strategy on predictions made on trials that are out-of-distribution of the training data, two combinations of training and testing trials from the data used in the verification example (Sect. 4) were studied, as shown in Table 6
.
The setting of this study is the same as described in Sect. 4. The MSE and \({\mathrm{R}}^{2}\) scores after applying 1-, 2- and 3-scale MR PI-RNN training are shown in Figs. 12–13. In both tests, the prediction accuracy of the testing trial increases with the number of training scales. Such trend is more apparent when the sEMG signals contain more high-frequency content (from Case 1 to 3). The results demonstrate the effectiveness and the ability for out-of-distribution predictions of the proposed approach.

The average test MSE and \({\mathrm{R}}^{2}\) score post MR training for Set A are shown. The shaded area indicates one standard deviation from the mean (solid line), in both figures

The average test MSE and \({\mathrm{R}}^{2}\) score post MR training for Set B are shown. The shaded area indicates one standard deviation from the mean (solid line), in both figures
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Taneja, K., He, X., He, Q. et al. A multi-resolution physics-informed recurrent neural network: formulation and application to musculoskeletal systems. Comput Mech 73, 1125–1145 (2024). https://doi.org/10.1007/s00466-023-02403-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00466-023-02403-x